
Prognozowanie na podstawie
modeli ekonometrycznych

Prognozowanie na podstawie modelu
ekonometrycznego (prognozowanie
ekonometryczne)
polega na budowaniu
prognozy, dotyczącej przyszłej wartości
zmiennej objaśnianej (zmiennej
prognozowanej) na podstawie modelu
ekonometrycznego, opisującego w sposób
formalny kształtowanie się zmiennej
prognozowanej w zależności od zmiennych
objaśniających to kształtowanie się.
2
GK (WEiP(4) - 2011)
Wstęp

Podstawowa reguła prognozowania ekonometrycznego
to ekstrapolacja modelu ekonometrycznego na okres
prognozowania poza zakres obserwacji (danych
empirycznych) wykorzystanych do oszacowania parametrów
strukturalnych modelu. Prognoza według reguły podstawowej
określana jest zależnością:
gdzie:
y
p
- wartość zmiennej objaśnianej w okresie prognozy
(prognoza),
x
*
- wektor znanych wartości zmiennych objaśniających w
okresie prognozy,
f
– postać analityczna modelu ekonometrycznego,
a
– oszacowania parametrów strukturalnych modelu
ekonometrycznego.
Różnica pomiędzy
estymacją
parametrów
strukturalnych modelu a
prognozowaniem
wartości zmiennej
objaśnianej polega na tym, że estymowanie odbywa się na
podstawie znanych wartości zmiennej objaśnianej i zmiennych
objaśniających (dane empiryczne), natomiast prognozowanie
odbywa się przy braku możliwości zaobserwowania
rzeczywistych wartości zmiennej objaśnianej i niekiedy
zmiennych objaśniających w okresie prognozy, a wynik
prognozowania (prognoza) jest zawsze weryfikowany
rozwojem wydarzeń.
(
)
p
*
y
f x ,a
=
3
GK (WEiP(4) - 2011)
Wstęp

Warunki predykcji
Dokonywanie predykcji jest możliwe wtedy, gdy:
jest znany model ekonometryczny wyjaśniający kształtowanie
się zmiennej objaśnianej,
model ekonometryczny został wszechstronnie i pozytywnie
zweryfikowany,
relacje między zmiennymi uwzględnionymi w modelu są
stabilne, co oznacza:
•
stałość postaci analitycznej modelu ekonometrycznego,
•
stabilność wartości parametrów strukturalnych
(parametry strukturalne nie zmieniają swoich wartości
przy zmianie wartości zmiennych objaśniających),
•
spełnienie założeń dotyczących składnika losowego
modelu dla okresu prognozy,
zasadna i dopuszczalna jest ekstrapolacja wartości zmiennej
objaśnianej i zmiennych objaśniających poza zakres
obserwacji wykorzystanych do oszacowania parametrów
strukturalnych modelu,
są dostępne wartości zmiennych objaśniających w okresie
prognozy, tj. w okresie, dla którego jest budowana prognoza
(wielkości założone, planowane lub kreowane w
scenariuszach rozwoju zjawiska opisywanego modelem
ekonometrycznym).
4
GK (WEiP(4) - 2011)

Model ekonometryczny stanowiący podstawę
prognozowania musi cechować się stabilnością postaci
analitycznej (poprawnością specyfikacji postaci funkcyjnej) i
stabilnością parametrów. Stabilność postaci analitycznej
modelu zwykle jest rozpatrywana na etapie weryfikacji
modelu
(test RESET, test Walda).
Do weryfikacji hipotezy o stabilności parametrów
strukturalnych modelu ekonometrycznego jest najczęściej
wykorzystany
test Chowa
, tzw.
I test Chowa
. Stabilność parametrów strukturalnych modelu
oznacza stałość w czasie (także poza obszarem objętym
danymi empirycznymi) relacji, na których opiera się
weryfikowany model liniowy. Niezmienność (dopuszczalna w
praktyce) parametrów strukturalnych modelu jest
warunkiem trafności uzyskiwanych prognoz na jego
podstawie.
I test
Chowa wymaga przeprowadzenia trzech
estymacji parametrów strukturalnych za pomocą KMNK: dla
całej próby, tj. dla wszystkich danych empirycznych
(y, X)
oraz dla dwóch rozłącznych podprób
(y
1
, X
1
)
i
(y
2
, X
2
)
.
Pierwsza estymacja jest estymacją warunkową przy
założeniu, że wartości parametrów strukturalnych są stałe
dla całej próby, co oznacza, że wartości odpowiadających
sobie parametrów strukturalnych uzyskane z estymacji dla
podprób są sobie równe.
5
GK (WEiP(4) - 2011)
Warunki predykcji

Niech I, II i III oznaczają odpowiednio modele dla
całej próby, dla podpróby pierwszej i dla podpróby drugiej:
Niech wektory
a
I
,
a
II
,
a
III
oznaczają odpowiednio oszacowania
parametrów strukturalnych modeli I, II i III uzyskane za
pomocą KMNK, a wektory
e
I
,
e
II
,
e
III
– reszty tych modeli.
Wartość
m
może być przyjęta w sposób arbitralny lub
ze względu na model I:
jeżeli wartości bezwzględne reszt są monotoniczne lub nie
wykazują żadnej prawidłowości przyjmuje się
m = n/2
,
jeżeli wartości reszt wykazują początkowo tendencję rosnącą,
a następnie malejącą (lub odwrotnie), za wartość
m
przyjmuje
się numer (największej (najmniejszej) co do wartości
bezwzględnej reszty.
Wybrana wartość
m
musi spełniać następujące nierówności:
m > k+1
i
n-m > k+1
.
.
,
,
)
(
...
...
...
k
1
i
t
it
III
i
III
0
t
k
1
i
t
it
II
i
II
0
t
k
1
i
t
it
I
i
I
t
,n
2,
1,m
m
t
,m
1,2,
t
,n
1,2,
t
,
ε
x
α
α
y
(III)
,
ε
x
α
α
y
(II)
,
ε
x
α
α
y
I
0
6
GK (WEiP(4) - 2011)
Warunki predykcji

Weryfikowaną hipotezą (zerową) jest hipoteza postaci:
H
0
: a
I
= a
II
= a
III
wobec hipotezy alternatywnej postaci
H
1
: a
I
= a
II
= a
III
.
Sprawdzianem prawdziwości hipotezy
zerowej jest statystyka postaci:
która w przypadku prawdziwości hipotezy zerowej ma
rozkład F-Snedecora o
ν
1
=k+1
i
ν
2
=n-2(k+1)
stopniach
swobody.
Jeżeli wartość statystyki
F
obliczona z próby jest
nie większa od wartości krytycznej
F
*
, odczytanej z tablic
rozkładu F-Snedekora dla przyjętego poziomu istotności
γ
i
stopni swobody
ν
1
i
ν
2
(
F
F
*
),
to nie ma podstaw do odrzucenia hipotezy zerowej,
co oznacza, że parametry strukturalne weryfikowanego
modelu są stabilne i co oznacza dalej, że model może być
wykorzystywany w procesie prognozowania. W przeciwnym
przypadku, tj. gdy
F
>F
*
, hipoteza zerowa jest odrzucana.
Rozpatrywany
test Chowa
może być stosowany tylko
w przypadku homoskedastyczności reszt modeli
, wyrażającej
się równością wariancji reszt modeli I, II i III. W przypadku
niespełnienia tego warunku może być zastosowany albo
test
Walda
, albo nadal
test Chowa
, ale dla skorygowanych
danych empirycznych w jednej z podprób.
,
1
k
1)
2(k
n
e
e
e
e
e
e
e
e
e
e
F
III
T
III
II
T
II
III
T
III
II
T
II
I
T
I
7
GK (WEiP(4) - 2011)
Warunki predykcji

8
GK (WEiP(4) - 2011)
Warunki predykcji
Korekcja danych empirycznych przed ponownym
zastosowaniem
testu Chowa
polega na następującej
transformacji danych np. dla modelu III:
W wyniku estymacji parametrów strukturalnych modelu III
dla tak skorygowanych danych uzyskuje się wektor oszacowań
parametrów
strukturalnych
a
*
III
oraz reszt
e
*
III
.
W rozpatrywanym przypadku weryfikowaną hipotezą
jest hipoteza zerowa postaci:
H
0
: a
I
= a
II
= a
*
III
wobec
alternatywnej
H
1
: a
I
= a
II
= a
*
III
.
Teraz sprawdzianem prawdziwości hipotezy zerowej jest
statystyka postaci:
która w przypadku prawdziwości hipotezy zerowej statystyka
F
ma rozkład
F-Snedecora o
ν
1
=k+1
i
ν
2
. Weryfikacja prawdziwości hipotezy
zerowej jest prowadzona tak samo jak poprzednio.
.
,
,
:
gdzie
,
...
n
1
m
t
2
III
e
1
k
m)
(n
1
2
III
S
m
1
t
2
II
e
1
k
m
1
2
II
S
III
S
II
S
,n
1,
m
t
,
t
ε
*
t
ε
,
it
x
*
it
x
,
t
y
*
t
y
.
,
*
*
*
*
1
k
1)
2(k
n
e
e
e
e
e
e
e
e
e
e
F
III
T
III
II
T
II
III
T
III
II
T
II
I
T
I

9
GK (WEiP(4) - 2011)
Prognoza punktowa
Wartości zmiennej prognozowanej, tj. zmiennej
objaśnianej w okresie prognozowania (prognozy) mogą być
określane za pomocą jednej liczby lub za pomocą przedziału
liczbowego, który z określonym prawdopodobieństwem
zawiera rzeczywistą wartość zmiennej prognozowanej. W
pierwszym przypadku mówi się o
prognozie punktowej
, a w
drugim – o
prognozie
przedziałowej
.
Niech oszacowany model ekonometryczny, który
będzie wykorzystywany do prognozowania ma postać:
oraz niech wektor
oznacza wektor wartości zmiennych objaśniających w okresie
prognozy.
Prognozę punktową
y
p
wyznacza się z zależności:
co w zapisie wektorowym oznacza się jako:
k
1
i
it
i
0
t
,n
1,2,
t
,
x
a
a
y
...
ˆ
*
k
*
2
*
1
T
*
x
,
,
x
,
x
1,
x
...
k
1
i
i
i
0
p
,n
1,2,
t
,
x
a
a
y
,
...
*
p
T
*
y
x a.
=

10
GK (WEiP(4) - 2011)
Prognoza punktowa
W przypadku
autokorelacji składnika
losowego parametry
strukturalne modelu muszą być estymowane z zastosowaniem
jednej z dostępnych metod, najlepiej za pomocą Uogólnionej
Metody Najmniejszych Kwadratów Aitkena. Niech
a
oznacza
wektor oszacowań parametrów strukturalnych modelu uzyskany
metodą odpowiednią dla przypadku występowania autokorelacji
składnika losowego. Ze względu na autokorelację, między
składnikami losowymi zachodzi relacja:
gdzie
oznacza rząd autokorelacji, a
t
– proces czysto losowy.
Parametry
i
,
(
i=0,1,2,…,
) można oszacować za pomocą
KMNK, używając zamiast nieznanych wielkości
t
, reszt modelu
e
t
. Prognozę wartości składnika losowego w okresie prognozy
T
otrzymuje się z zależności:
gdzie
b
i
są ocenami parametrów strukturalnych
i
.
Prognozę
y
T
p
w okresie prognozy
T
wyznaczana się z
zastosowaniem prostej reguła prognozy z poprawką, co wyraża się
zależnością:
t
0
s
t s
t
s 1
t
1,
2,...,n
.
,
t
t
t
e
b
b e
x
-
=
= +
+
=
+
� +
�
p
T
0
s
T s
s 1
T n,
b
b e ,
t
e
-
=
>
= +
�
�
k
p
*
p
T
0
i it
T
i 1
T n
y
a
a x
,
.
e
=
>
= +
+
�
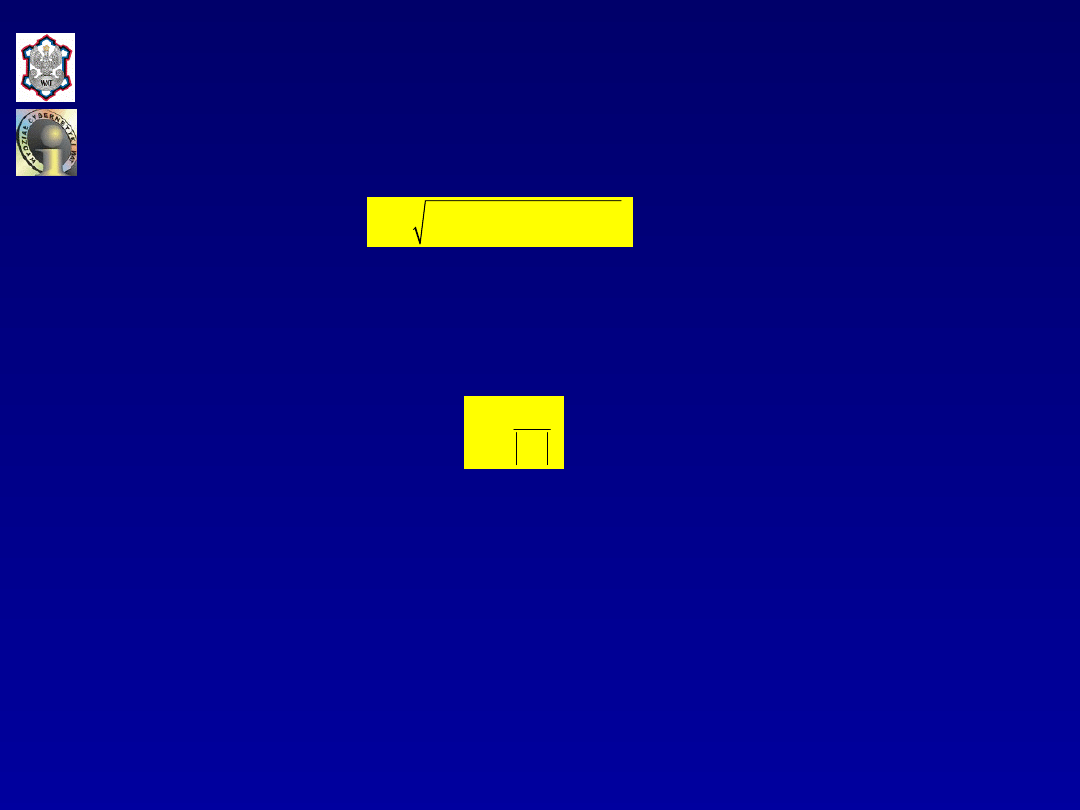
Średniokwadratowy błąd prognozy
ex ante
dla
rozpatrywanego przypadku wyznacza się z zależności:
gdzie:
x
*
- wektor wartości zmiennych objaśniających w okresie
prognozowania,
S
e
2
- estymator wariancji składnika losowego modelu.
Średni względny błąd
predykcji (prognozy)
ex ante
wyraża się zależnością:
Błędy ex post
(np. ME, MAE, Thiela) wyznacza się ze znanych
zależności.
Zbyt wielkie różnice pomiędzy prognozami a rzeczywistymi
wartościami zmiennej prognozowanej, stwierdzone na
podstawie analiz błędów
ex post
sugerują małą przydatność
modelu do prognozowania ze względu na niestabilność
parametrów strukturalnych w odniesieniu do okresów
prognozowania. Do zweryfikowania tej oceny może być
zastosowany rozpatrywany wcześniej
test Chowa
. W przypadku
odrzucenia hipotezy o stabilności parametrów strukturalnych
modelu prognostycznego, stosuje się następujące
postępowanie.
(
)
(
)
1
2
T
T
p
e
*
*
S
S 1 x
X X
x ,
-
=
+
p
p
p
S
v
.
y
=
11
GK (WEiP(4) - 2011)
Prognoza punktowa

Przyjmuje się, że parametry strukturalne modelu
wykorzystywanego do prognozowania zostały oszacowane na
podstawie
n
danych empirycznych oraz dla niego zostały
obliczone reszty
e
n
(wektor). Na podstawie tego modelu
wykonano prognozy dla
m
,
(
m > 1
) okresów prognozowania,
a po zaobserwowaniu ich realizacji, jeszcze raz zostały
oszacowane parametry strukturalne tego modelu, teraz już
na podstawie
n+m
danych empirycznych oraz obliczane
reszty
e
n+m
(wektor).
Weryfikowaną hipotezą (zerową) jest hipoteza postaci:
H
0
: a
m+n
= a
n
wobec hipotezy alternatywnej
H
1
: a
m+n
a
n
.
Sprawdzianem prawdziwości hipotezy zerowej jest statystyka
postaci:
która w przypadku prawdziwości hipotezy zerowej ma
rozkład F-Snedecora o
ν
1
=m
i
ν
2
=n-(k+1)
stopniach swobody.
Jeżeli zachodzi nierówność
F
F*
(
F*
wartość krytyczna dla
przyjętego poziomu istotności
γ
i stopni swobody
ν
1
ioraz
ν
2
),
to nie ma podstaw do odrzucenia hipotezy zerowej, co
oznacza, że różnice pomiędzy prognozami a rzeczywistymi
realizacjami zmiennej prognozowanej nie wynikają z
niestabilności parametrów strukturalnych modelu.
,
m
1)
(k
n
e
e
e
e
e
e
F
n
T
n
n
T
n
m
n
T
m
n
12
GK (WEiP(4) - 2011)
Prognoza punktowa

Prognoza przedziałowa
może być wyznaczana na
podstawie modelu ekonometrycznego, dla którego została
pozytywnie zweryfikowana hipoteza o rozkładzie normalnym
składnika losowego. Do wyznaczania prognozy przedziałowej
jest wykorzystywany
średni błąd predykcji
ex ante
, a
przedział
predykcji
dla nieznanej wartości
y
*
na poziomie ufności
1-γ
(wiarygodność prognozy) wyraża się zależnością:
gdzie
t
γ,n-k-1
jest kwantylem rzędu
γ
o
ν=n-k-1
stopniach
swobody rozkładu
t-Studenta.
W praktyce często jest również wykorzystywana
prognoza
przedziałowa dla wartości oczekiwanej prognozy
E(y
*
)
, która wyraża się zależnością:
gdzie
,
p
1
k
γ,n
p
p
1
k
γ,n
p
S
t
y
,
S
t
y
.
*
1
T
T
*
e
y
x
X
X
x
S
S
p
,
p
p
y
1
k
γ,n
1
p
y
1
k
γ,n
1
p
S
t
y
,
S
t
y
13
GK (WEiP(4) - 2011)
Prognoza przedziałowa

Należy sporządzić prognozę zmiennej
y
na okres
T =
13 (T=n+2) z wykorzystaniem prostej (podstawowej) reguły
prognozowania
przyjmując, że zmienna prognozowana zależy
od dwóch zmiennych objaśniających
x
1
oraz
x
2
i zależność ta
jest modelowana za pomocą jednorównaniowego liniowego
modelu ekonometrycznego, estymowanego za pomocą
KMNK. Oszacować błąd prognozy:
•ex ante
,
•
jako średnią z modułów błędów prognoz wygasłych (błędów
ex post
).
Dane empiryczne charakteryzujące tę zależność są podane w
poniższej tabeli:
t
y
x
1
x
2
1
64
22
9,2
2
73
19
10,5
3
76
18
11,0
4
81
16
11,7
5
90
14
13,4
6
98
13
14,5
7
105
11
15,3
8
110
11
17,8
9
116
10
18,5
10
127
9
20,5
11
135
6
21,7
Przykład
14
GK (WEiP(4) - 2011)

Rozwiązanie.
Zasada:
Prognozy wygasłe używane do oszacowania błędu
prognozy (autentycznej, tj. poszukiwanej w zadaniu) muszą
być sporządzane według takiej samej reguły i na taką samą
odległość jak prognoza autentyczna.
Spełnienie powyższej zasady wymaga, aby prognozy wygasłe
były sporządzane w okresie równym 2 (zgodnie z założeniami
zadania).
1.Estymacja modelu liniowego
na podstawie wszystkich danych empirycznych:
t
0
1 1t
2 2t
t
t=1,2,...,11
y
x
x
,
a
a
a
e
= +
+
+
t
1t
2t
t=1,2,...,11
ˆy 65,890136 1,645323x
3,662131x ,
=
-
+
15
GK (WEiP(4) - 2011)
Przykład

2. Prognoza jest obliczana jako zwykła ekstrapolacja zmiennej
prognozowanej na okres
T=13 (n+2)
. Ze względu na brak
informacji o wartościach zmiennych objaśnianych w okresie
prognozowania, ustalono je na drodze liniowej ekstrapolacji
na okres prognozowania i otrzymano:
Stąd prognoza:
3. Średniokwadratowy błąd prognozy
ex ante
:
*
*
1T
2T
T n 2 11 2 13.
x
4,0, x
23,8,
= + =
+ =
=
=
p
T
T
T=13.
ˆ
y
y
65,890136 1,645323 4,0 3,662131 23,8 146,4676,
+�-==
(
)
[
]
1
2
T
T
S
S
1 x
X X
x
p
e
*
*
60,826099
1,986105
2,226719
1
1 1 4,0 23,8
1,986105 0,0663063 0,0715544
4,0
2,226719 0,0715544 0,0828094 23,8
1,9325297
1,7234.
-
=
+
=
-
-
=
� +
-
�
-
�
�
�
�
�
�
�
�
�
��
�
�
�
�
��
�
�
�
�
��
�
�
�
�
��
�
�
��
�
�
�
16
GK (WEiP(4) - 2011)
Przykład

4. Prognozy wygasłe i ich błędy.
W celu uzyskania możliwie największej liczby ocen błędów
prognoz wygasłych o okresie prognozowania podanym w
treści zadania
(T=n+2)
przy zachowaniu warunków
KMNK, przyjmuje się, że pod uwagę będą brane kolejne
„początkowe” podzbiory danych empirycznych. Przyjmuje
się także, iż pierwszy taki podzbiór będzie liczył
5
obserwacji, drugi –
6
itd., a ostatni
9
obserwacji.
Poszczególne podzbiory danych empirycznych,
wyestymowane na ich podstawie kolejne modele oraz
odpowiadające im prognozy zostały zestawione poniżej:
t
y
x
1
x
2
1
64
22
9,2
2
73
19
10,5
3
76
18
11,0
4
81
16
11,7
5
90
14
13,4
t
1t
2t
p
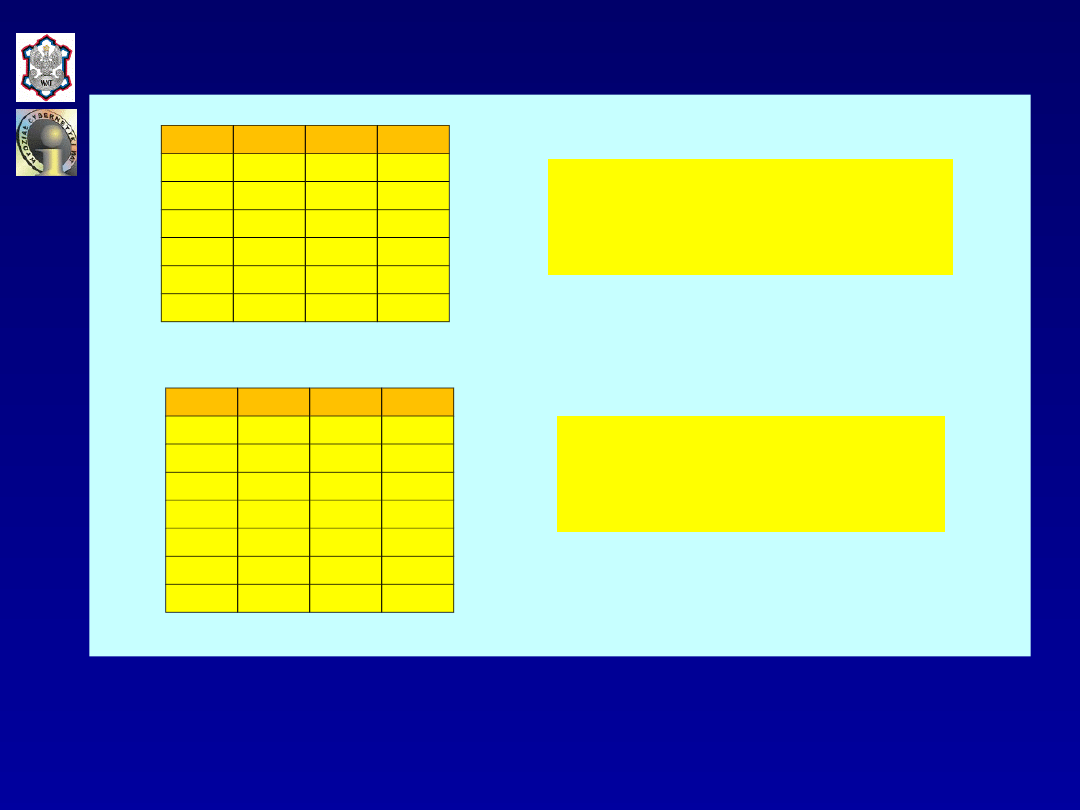
7
7
t=1,2,...,5,
ˆy
51,5376 1,16209x
4,15466x ,
ˆ
y
y
102,0885.
=
-
+
=
=
17
GK (WEiP(4) - 2011)
Przykład
t
y
x
1
x
2
1
64
22
9,2
2
73
19
10,5
3
76
18
11,0
4
81
16
11,7
5
90
14
13,4
6
98
13
14,5
t
y
x
1
x
2
1
64
22
9,2
2
73
19
10,5
3
76
18
11,0
4
81
16
11,7
5
90
14
13,4
6
98
13
14,5
7
105
11
15,3
2t
t
1t
p
8
8
t=1,2,...,6,
ˆy
39,13688 0,88026x
4,81579x ,
ˆy
115,1750.
y
=
-
+
= =
2t
t
1t
p
9
9
t=1,2,...,7,
ˆy
41,9332 1,01771x
4,79562x ,
ˆy 120,0679.
y
=
=
-
+
=
18
GK (WEiP(4) - 2011)
Przykład
t
y
x
1
x
2
1
64
22
9,2
2
73
19
10,5
3
76
18
11,0
4
81
16
11,7
5
90
14
13,4
6
98
13
14,5
7
105
11
15,3
8
110
11
17,8
t
y
x
1
x
2
1
64
22
9,2
2
73
19
10,5
3
76
18
11,0
4
81
16
11,7
5
90
14
13,4
6
98
13
14,5
7
105
11
15,3
8
110
11
17,8
9
116
10
18,5
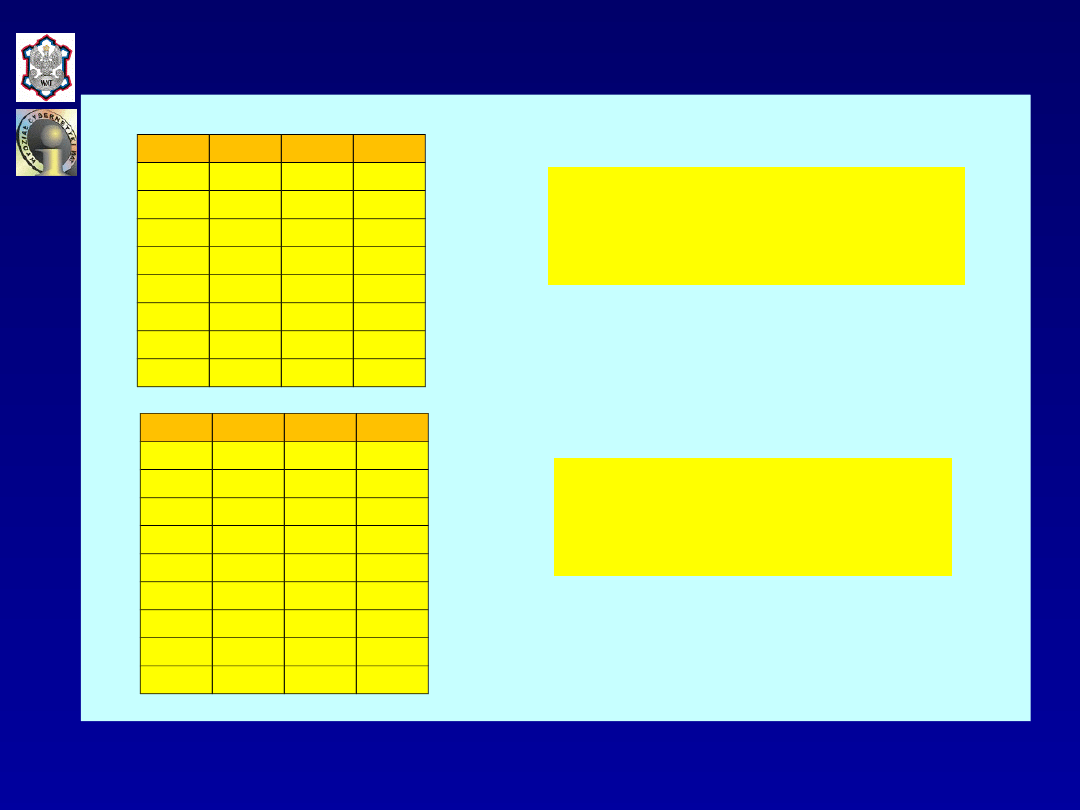
t
1t
2t
p
10
10
t=1,2,...,8,
ˆy
90,96074 2,31996x
2,53026x ,
ˆ
y
y
121,2554.
=
=
-
+
=
1t
t
2t
p
11
11
t=1,2,...,9,
ˆy
80,7798 2,04876x
2,99781x ,
ˆ
y
y
132,1056.
=
-
+
=
=
19
GK (WEiP(4) - 2011)
Przykład

5. Zestawienie błędów prognozy
ex post
dla prognoz
wygasłych:
6. Zestawienie błędów
ex ante
i
ex post
:
• Błąd
ex ante
:
1,7234
,
• Błąd
ex post
na podstawie prognoz wygasłych:
4,1587
.
t
y
x
1
x
2
Progno
za
Błąd
prognozy
Moduł błędu
7
105 11,2 15,3
102,088
5
2,9115
2,9115
8
110 11,0 17,8
115,175
0
-5,1750
5,1750
9
116 10,4 18,5
120,067
9
-4,0679
4,0679
10
127
9,3
20,5 121,255
4
5,7446
5,7446
11
135
6,7
21,7
132,105
6
2,8944
2,8944
Błąd ex post
(MAE)
4,1587
20
GK (WEiP(4) - 2011)
Przykład

21
GK (WEiP(4) - 2011)
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
Wyszukiwarka
Podobne podstrony:
WEiP (5 Prognozowanie na podstawie modeli ekonometrycznych 2010)
Prognozowanie na podstawie modeli autoregresji
MP Wykład 7A Prognozowanie na podstawie modelu ekonometrycznego
3. Prognozowanie na podstawie modeli autoregresyjnych
Prognozowanie na podstawie modeli autoregresji
J Ossowski Prognozowanie Na Podstawie Modeli Multiplikatywnych Względne Błędy Prognoz
Prognozowanie na podstawie modelu ekonometrycznego
5 Prognozowanie na podstawie modelu ekonometrycznego zadaniaid 26868
8 wnioskowanie na podstawie modelu ekonometrycznego prognozowanie ekonometryczne
podstawowe pojęcia prognozowania i symulacji na podstawie mo, Ekonometria
8 wnioskowanie na podstawie modelu ekonometrycznego prognozowanie ekonometryczne
2 Prognozowanie na podstawie s Nieznany (2)
Prognozowanie na Podstawie Łancuchów Markowa p10x2 scan!!
Wyklad 4 - Prognozowanie na podstawie szeregow czasowych, PROGNOZOWANIE GOSPODARCZE
2 Prognozowanie na podstawie s Nieznany (2)
Prognozowanie na Podstawie Łancuchów Markowa p10x2 scan!!
więcej podobnych podstron