Składowe szeregów czasowych
1. Składowa systematyczna:
- tendencja rozwojowa,
- stały (przeciętny) poziom zmiennej
prognozowanej,
- składowa okresowa:
-- wahania cykliczne,
-- wahania sezonowe.
2. Składowa przypadkowa /składnik losowy lub
wahania przypadkowe/.
Tendencja rozwojowa /trend/, to długookresowa skłonność do jednokierunkowych zmian wartości zmiennej.
Stały /przeciętny/ poziom prognozowanej zmiennej występuje wówczas, gdy w szeregu czasowym nie ma tendencji rozwojowej a wartości prognozowanej zmiennej oscylują wokół pewnego stałego poziomu.
Wahania cykliczne wyrażają się w postaci długookresowych, rytmicznych wahań wartości zmiennej wokół tendencji rozwojowej lub stałego (przeciętnego) poziomu zmiennej /związane z cyklami koniunkturalnymi gospodarce/.
Wahania sezonowe są wahaniami wartości obserwowanej zmiennej wokół tendencji rozwojowej lub stałego /przeciętnego/ poziomu tej zmiennej, zwykle nie przekraczają jednego roku.
Składowe /wykres/
Modele szeregów czasowych
Model addytywny:
Yt = f(t) + g(t) + h(t) + ξt
lub
Yt = c + g(t) + h(t) + ξt,
gdzie: f(t) - funkcja czasu charakteryzująca tendencję rozwojową, nazywana funkcja terndu,
g(t) - funkcja czasu, charakteryzująca wahania sezonowe,
h(t) - funkcja czasu, charakteryzująca wahania cykliczne,
c - stały /średni/ poziom zmiennej Yt.
Model multiplikatywny:
Yt = f(t) g(t) h(t) ξt
lub
Yt = c g(t) h(t) ξt,
PROGNOZOWANIE - metody
Metoda „naiwna”
Metoda opiera się na założeniu, że nie nastąpią zmiany w dotychczasowym sposobie oddziaływania czynników określających wartości zmiennej prognozowanej. Przesłanki te umożliwiają /na ogół/ konstrukcję prognoz krótkookresowych tzn. t = n+1.
ypt = yt-1,
Metoda opiera się na znanym w statystyce modelu błądzenia losowego /badania Makridakis S. Wheelwright S.C., Forecasting Methods for Management. New York 1989, J. Wiley and Sons, dotyczyły rynków papierów wartościowych, walut oraz niektórych towarów, wykorzystano w nich tę właściwość, która pozwala zauważyć, iż wahania kursów i cen są na tyle nieprzewidywalne, że czas wystąpienia punktów zwrotnych jest trudno jednoznacznie, więcej w przybliżeniu, oznaczyć/.
Rozwiązanie 1. [Henschel H. Wirtschaftsprognosen., Műnchen 1979. Verlag F. Vahlen].
ypt = yt-1 + (yt-1 - yt-2),
Rozwiązanie 2. [Farnym N.R., Santon W. Quantitative Forecasting Methods. Boston 1989., PWS - Kent Publisching Company].
ypt = (1+c) yt-1,
Rozwiązanie 3. Zakłada się, że prognoza w momencie t jest konstruowana na poziomie zaobserwowanej wartości zmiennej prognozowanej w momencie lub okresie t - 1, powiększonym o średni przyrost wartości zmiennej z przedziału próby statystycznej:
ypt = yt-1 + ![]()
Rozwiązanie 4. Uwzględnia wahania sezonowe np. kwartalne
ypt = yt-4
Rozwiązanie 5. Prognoza korygowana jest wskaźnikiem sezonowości [Hűttner M. Markt und Absatzprognosen. Stuttgart 1982. Verlag W. Kohlhammer]
ypt = yt-1![]()
,
gdzie: ct, ct-1 wskaźniki sezonowości
- Metody naiwne są nieskomplikowane,
- Oparte na obserwacji zmiennej prognozowanej,
- Jakość prognoz jest na ogół niska, szczególnie w sytuacjach kiedy występują duże wahania przypadkowe, ocenę przeprowadza się na podstawie błędów ex post, nie ma możliwości określenia błędów ex ante.
Metoda średniej ruchomej
Występowanie dużych wahań przypadkowych w szeregu czasowym, przekreśla możliwość stosowania metod „naiwnych”. Dokładność konstruowanych prognoz poprawia stosowanie metody opartej na modelu średniej ruchomej [Kohler H., College A., Essentials and Statistics. Glenview 1988, Illinois, Scott, Foresman and Company a także Levin R.I., Quantitative Approaches to Manangement, New York 1989, McGraw - Hill Book Company].
Metoda stosowana jest zarówno do wygładzania szeregu jak i prognozowania.
Wyrównywanie szeregu czasowego polega na zastąpieniu pierwotnych wartości zmiennej prognozowanej, średnimi arytmetycznymi, obliczanymi sekwencyjnie dla wybranej liczby obserwacji. Obliczone wartości średnie przyporządkowuje się na ogół środkowym obserwacjom, rzadziej obserwacjom ostatnim.
Rozwiązanie 1. Średnia ruchoma prosta:
![]()
ypt = ![]()
gdzie: k - stała wygładzania.
Właściwości:
- efekt wyrównywania rośnie wraz ze wzrostem wartości stałej wygładzania,
- wzrost wartości stałej wygładzania powoduje spadek tempa reakcji na zmiany poziomu prognozowanej zmiennej,
- spadek wartości stałej wygładzania powoduje wzrost tempa zmian wartości prognozowanej zmiennej a jednocześnie rośnie wpływ wahań przypadkowych,
- gdy k = 1, model średniej ruchomej prostej jest równoważny modelowi z rozwiązania 1 metody naiwnej.
Do ustalenia wartości stałej wygładzania można wykorzystać średni kwadratowy błąd prognozy ex post.
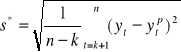
Wybór stałej wygładzania k, powiązany jest z najmniejszą wartością średniego kwadratowego błędu prognozy.
Wady modelu:
- nadawanie tych samych wag jednostkowych wszystkim k wartościom zmiennej prognozowanej /powszechnie podzielany jest pogląd, że bardziej aktualnym informacjom, powinny być nadawane relatywnie większe wagi iż obserwacjom starszym/.
Rozwiązanie 2. Model średniej ruchomej ważonej
ypt = ![]()
,
gdzie: „waga” zmiennej prognozowanej w okresie „i” 0 < w1 <,…,< wk ![]()
1,![]()
= 1.
Warunki stosowalności:
- małe zmiany wartości zmiennej prognozowanej,
- brak wahań cyklicznych oraz sezonowych.
Konstrukcja prognoz:
Uwzględnia się jedynie k ostatnich wartości zmiennej prognozowanej /nie uwzględnia się obserwacji pochodzących z okresów wcześniejszych od t - k z wyjątkiem przypadku, gdy k = n/.
Model wygładzania wykładniczego
3.1 Prosty model wygładzania wykładniczego
Szereg czasowy zmiennej prognozowanej wygładza się metodą ważonej średniej ruchomej, wagi określane są według prawa wykładniczego.
Niech:
ypt - 1 = Ft - 2 = ![]()
Stąd:
ypt = Ft - 1 = ![]()
+ ypt - 1,
niech ponadto: yt-1-k = ypt - 1,
wówczas:
ypt = Ft - 1 = ![]()
yt - 1 +(1- ![]()
) ypt - 1.
Podstawiając α = ![]()
, otrzymamy:
ypt = Ft - 1 = α yt - 1 +(1- α) ypt - 1 a następnie
ypt - 1 = α yt - 2 +(1- α) ypt - 2,
ypt = α yt - 1 +α (1 - α) yt-2 + (1-α)2 ypt - 2.
Kontynuując proces podstawiania otrzymamy:
ypt = α yt - 1 +α (1 - α) yt - 2 + α (1 - α)2 yt - 3 +…+ α (1 - α)t - 2 y2 + (1 - α)t - 1 yp1.
Ponieważ α![]()
[0, 1], przeto dla α![]()
1, wagi α, α (1 - α), α (1 - α)2 … mają wartości wykładniczo malejące. Parametr α, określany jest mianem parametru wygładzania.
Właściwości:
Gdy parametr α ma wartość bliską jedności, budowana prognoza będzie uwzględniała w dużym stopniu błędy ex post prognoz poprzednich. I przeciwnie, jeśli wartość α będzie bliska zeru, to prognoza tylko w niewielkim stopniu będzie uwzględniała błędy poprzednich prognoz,
Jeśli wyznaczona prognoza w okresie t - 1 jest w porównaniu z rzeczywistą wartością zmiennej prognozowanej yt - 1 jest zaniżona, to prognoza konstruowana w okresie następnym t zwiększa się w porównaniu z oszacowaną w okresie poprzednim i przeciwnie, jeśli wyznaczona prognoza na moment t - 1 była, w porównaniu z rzeczywistą wartością zmiennej prognozowanej yt-1 zawyżona, to prognoza konstruowana na okres t zmniejszy się w porównaniu z tą z okresu poprzedniego.
Praktyczny aspekt konstrukcji prognoz
Jako wartość prognozy yp1 przyjmuje się najczęściej wartości początkowe zmiennej prognozowanej y1 lub średnią arytmetyczną rzeczywistych wartości zmiennej prognozowanej z próby statystycznej,
Wartość parametru α określa się zwykle eksperymentalnie, wybierając wartość tak, średni kwadratowy błąd prognoz był najmniejszy. Jeśli α = 1, to jest to równoznaczne z szacowaniem prognoz metodą naiwną.
3.2 Model liniowy Holta
Model Holta rozwiązuje problem wygładzania szeregu czasowego, w którym występują i tendencja rozwojowa i wahania przypadkowe.
Ft-1 = α yt-1 + (1 - α )(Ft-2 + St-2) oraz
St-1 = β (Ft-1 - Ft-2) + (1 - β) St-2 ,
gdzie: Ft-1 - odpowiednik wygładzonej wartości otrzymanej z prostego modelu wygładzania wykładniczego - ocena wartości średniej na moment lub okres t -1,
St-1 - wygładzona wartość przyrostu trendu na moment lub okres t - 1,
α, β - parametry modelu o wartościach z przedziału [0, 1].
Równanie prognozy na moment lub okres t > n :
ypt = Fn + (1 - n) Sn,
gdzie: ypt - prognoza zmiennej Y na moment t,
Fn - odpowiednik wygładzonej wartości otrzymanej z prostego modelu wygładzania wykładniczego w okresie t,
Sn - wygładzona wartość przyrostu trendu szeregu w okresie t,
n - liczba wyrazów szeregu czasowego zmiennej prognozowanej.
Niech Ft-1 = α yt-1 + (1 - α )(Ft-2 + St-2),
Ft-1 = α yt-1 + Ft-2 - α Ft-2 - St-2 - α St-2,
Ft-1 = Ft-2 - St-2 + α yt-1 - α (Ft-2 + St-2),
Ponieważ Ft-1 + St-1 = ypt, stąd Ft-2 + St-2 = ypt-1,
niech yt-1 - ypt-1 = qt-1, wówczas:
Ft-1 = Ft-2 - St-2 + α yt-1 - α ypt-1,
Ft-1 = Ft-2 - St-2 + α ( yt-1 - ypt-1),
Ft-1 = ypt-1 + α qt-1.
Podobnie:
St-1 = β Ft-1 - β Ft-2 + St-2 - β St-2 ,
St-1 = β Ft-1 + St-2 - β (Ft-2 + St-2) ,
St-1 = St-2 + β (Ft-1 - Ft-2 - St-2) ,
St-1 = St-2 + α β qt-1.
Jak oszacować wartości początkowe F oraz S?.
[Makridakis S., Wheelwright S.C. Forecasting Methods for Management New York 1989., J. Wiley and Sons, Zawadzki J. Ekonometryczne metody prognozowania w przedsiębiorstwie. Szczecin 1989., Rozprawy i Studia t.58], uważają, że F1 = y1 oraz S1 = y2 - y1, gdzie y1 jest pierwszą wartością zmiennej prognozowanej Y.
Jak oszacować wartości początkowe α oraz β?.
Zaleca się różne wartości obydwu parametrów, szacuje wartości prognoz i wybiera te wartości, które minimalizują średni kwadratowy błąd prognoz wygasłych.
Model Wintersa
Jest wykorzystywany w przypadku szeregów czasowych zawierających tendencję rozwojową, wahania sezonowe oraz wahania przypadkowe.
Model addytywny:
Ft-1 = α ( yt-1 - Ct-1-r ) + (1 - α)(Ft-2 - St-2),
St-1 = β (Ft-1 - Ft-2) + (1 - β) St-2,
Ct-1 = γ ( yt-1 - Ft-1) + (1 - γ) Ct-1-r .
Model multiplikatywny:
Ft-1 = α (![]()
) + (1 - α)(Ft-2 - St-2),
St-1 = β (Ft-1 - Ft-2) + (1 - β) St-2,
Ct-1 = γ (![]()
) + (1 - γ) Ct-1-r ,
gdzie: Ft-1 - odpowiednik wygładzonej wartości otrzymanej z prostego modelu wygładzania wykładniczego - ocena wartości średniej,
St-1 - ocena przyrostu trendu na moment lub okres t - 1,
Ct-1 - ocena wskaźnika sezonowości na moment lub okres t - 1,
r - długość cyklu sezonowego - liczba faz,
α, β, γ - parametry modelu, przyjmują wartości z przedziału [0, 1].
Równania prognoz na moment lub okres t > n:
Model addytywny: ypt = Fn + Sn (t - n) + Ct+r,
Model multiplikatywny:
ypt = [Fn + Sn (t - n)] Ct+r,
gdzie n jest liczbą wyrazów szeregu czasowego zmiennej prognozowanej.
Jeżeli składowe szeregu czasowego wykazują dużą dynamikę zmian, to wartości parametrów wygładzania α, β, γ należy ustalić na poziomie bliskim jedności, w przeciwnym przypadku - na poziomie bliskim zera. Wartości parametrów można ustalić w drodze eksperymentu, wybierając je tak, by zminimalizować średni błąd kwadratowy prognoz wygasłych, dla prognoz z jedno okresowym wyprzedzeniem,
Wartość F1 - pierwsza wartość zmiennej prognozowanej / Ft = y1 / lub średnia wartość zmiennej w pierwszym cyklu,
Wartość S1 - różnica drugiej i pierwszej wartości zmiennej prognozowanej/y2 - y1/ lub różnica średnich wartości zmiennej wyznaczonych dla drugiego i pierwszego cyklu,
Wartości C1,…,Cr ,wyznaczane na podstawie szeregu czasowego średnią różnic /dla modelu addytywnego/ lub ilorazów /dla modelu multiplikatywnego/, odpowiadających tej samej fazie cyklu sezonowego, wartości zmiennej prognozowanej i wygładzonych wartości trendu.
Modele tendencji rozwojowej
To modele szeregów czasowych, w których występuje tendencja rozwojowa oraz wahania przypadkowe, a jedyną zmienną objaśniającą jest zmienna czasowa:
yt = f (t) +ξt, gdzie: t = 1,2,…,n,
lub
yt = f (t) ξt ,
f (t) - funkcja trendu,
ξt - zmienna losowa, wahania przypadkowe w tendencji rozwojowej szeregu, o wartości oczekiwanej równej zero dla modelu addytywnego lub jedności dla modelu multiplikatywnego i skończonej wartości wariancji.
Modele analityczne
Przyjęcie założenia o postaci analitycznej funkcji trendu metodą analityczną poprzedza przyjęcie kryterium dopasowania modelu do opisu zmian szeregu czasowego zmiennej prognozowanej. Do oceny dopasowania modelu do danych empirycznych kierujemy się wartością współczynnika determinacji R2.
Funkcja liniowa:
yt = α + β t,
Funkcja wykładnicza:
yt = eα + β t, β > 0 lub yt = α β t, β > 1
Wielomian stopnia drugiego:
yt = α0 + α1 t + α2 t2 ,
Wszystkie trzy funkcje „sprawdzają” się przy konstrukcji prognoz krótkookresowych. Ekstrapolacja tych funkcji na zbyt odległe okresy wiąże się najczęściej z dużymi błędami prognoz.
W sytuacjach, w których wzrost wartości zmiennej prognozowanej przebiega wolniej i zdąża do pewnego poziomu „nasycenia”, wykorzystuje się funkcje o malejącym tempie wzrostu.
Funkcja logarytmiczna:
yt = α + β ln t,
Funkcje będące wynikiem transformacji funkcji liniowej oraz wielomianu stopnia drugiego:
yt = α + β ![]()
, yt = α0 + α1 ![]()
+ α2 ![]()
, yt =![]()
, gdzie: α, β >0.
Funkcja logistyczna:
yt = ![]()
, α, δ >0, β >1
Funkcja pozwala na zgodny opis przebiegu prawidłowości rynkowych, szczególnie popytu /na dobra trwałego użytku/, rozwój nowych gałęzi przemysłu, upowszechniania innowacji itp.
Funkcja loglogistyczna:
yt = ![]()
, α, δ >0, β >1
Ekstrapolacja funkcji - konstrukcja prognoz
Prognoza punktowa. Błędy ex ante prognoz punktowych.
Prognoza przedziałowa. Konstrukcja przedziału prognozy, tj. przedziału liczbowego, do którego z góry zadanym prawdopodobieństwem p, zwanym wiarygodnością prognozy, należeć będzie przyszła wartość prognozowanej zmiennej. W praktyce jest to przedział symetryczny wokół wartości oczekiwanej zmiennej prognozowanej E(Yt), na moment lub okres T prognozy ypT:
P(ypT - u vT ![]()
ypT ![]()
ypT + u vT) = p,
gdzie: u - współczynnik zależny od długości szeregu czasowego, rozkładu zmiennej prognozowanej oraz wiarygodności prognozy (u > 0).
Jeżeli w procesie weryfikacji hipotezy o zgodności z rozkładem normalnym składnika losowego, hipoteza nie została odrzucona, to wartość współczynnika u odczytywana jest z tablic rozkładu normalnego (dla n > 30) lub z tablic rozkładu t - Studenta dla n - 2 stopni swobody i prawdopodobieństwa 1 - p.
Jeśli hipotezy o zgodności rozkładu reszt z rozkładem normalnym nie można przyjąć, wówczas wartość współczynnika u może być wyznaczona z nierówności Czebyszewa:
P{|Y - E(Y)| ![]()
u σ } ![]()
1 - ![]()
,
4.2 Modele adaptacyjne. Trend pełzający
Konstrukcja prognoz w oparciu o klasyczne modele tendencji rozwojowej wiąże się brakiem pewności co do aktualności ostatnich znanych obserwacji zmiennej prognozowanej.
Modele adaptacyjne pozwalają odrzucić krępujące założenie o niezmienności mechanizmu rozwojowego badanej prawidłowości.
Dany szereg czasowy {y1,…,yn}. Dla przyjętej wartości stałej wygładzania k <n, na podstawie kolejnych fragmentów szeregu:
{y1,…,yk},
{y2,…,yk+1},
………………
{yn-k+1,…,yn} szacowane są parametry liniowych funkcji trendu:
f1(t) = a1 + b1 t, dla 1![]()
t ![]()
k,
f2(t) = a2 + b2 t, dla 2![]()
t ![]()
k +1,
……………………
fn-k+1(t) = an-k+1 + bn-k+1 t, dla n-k+1 ![]()
t ![]()
n.
Niech:
d(t) = 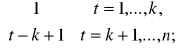
![]()
g(t) = 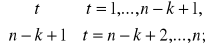
![]()
, d(t) ![]()
j ![]()
g(t),
j=1,…,n - k +1.
Stąd: 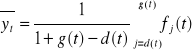
.
Metoda wag harmonicznych
Wyznacza się przyrosty funkcji trendu:
wt+1 = ![]()
- ![]()
, dla t = 1,…,n - 1,
Oblicza wartość średnią przyrostów:
![]()
, gdzie: ![]()
, dla t = 1,…,n - 1,
Wyznacza się odchylenie standardowe przyrostów trendu pełzającego, ważonych wagami harmonicznymi:
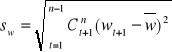
,
Prognoza punktowa: ypt =
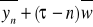
,
Dla założonej wiarygodności prognozy p definiuje się przedział prognozy:
P{ypτ - uτ sτ ![]()
yτ ![]()
ypτ + uτ sτ} = p,
gdzie: ![]()
, u - współczynnik wyznaczany, w zależności od rozkładu przyrostów trendu pełzającego, z nierówności Czebyszewa, z tablic rozkładu normalnego lub z tablic rozkładu
t - Studenta.
4.3 Modele składowej periodycznej
Analiza szeregów czasowych nasuwa w wielu przypadkach oczywiste wnioski - występują wyraźne wahania okresowe o charakterze sezonowym lub cyklicznym. Okres, w którym występują wszystkie fazy wahań określany jest okresem wahań lub cyklem.
Wyodrębnienie wpływu wahań okresowych na kształtowanie wartości prognozowanej zmiennej oraz jego uwzględnienie w procesie predykcji podnosi precyzję prognoz.
4.3.1 Metoda wskaźników
Wymaga wyznaczenia wskaźników sezonowości dla poszczególnych faz cyklu [Zając K., Zarys metod statystycznych, PWE Warszawa 1988].
Wahania bezwzględnie stałe - różnice miedzy rzeczywistymi wartościami zmiennej prognozowanej i wartościami teoretycznymi modelu tendencji rozwojowej stałe, tzw. amplituda wahań.
Wahania względnie stałe - amplituda wahań zmienia się w tym samym stosunku.
Model addytywny:
yti = yTti + ci +ξt, t = 1,…,n oraz i = 1,…,r,
Model multiplikatywny:
yti = yTti ci ξt, t = 1,…,n oraz i = 1,…,r,
gdzie: yti - rzeczywista wartość prognozowanej zmiennej w okresie t oraz i - tej fazie cyklu,
yTti - teoretyczna wartość prognozowanej zmiennej w okresie t oraz i - tej fazie cyklu, wyznaczona z modelu tendencji rozwojowej,
ci - wskaźnik sezonowości dla i- tej fazy cyklu,
ξt - składnik losowy,
r - liczba faz cyklu.
Analiza wahań okresowych wymaga:
Wyodrębnienia tendencji rozwojowej,
Eliminacji tendencji rozwojowej z szeregu czasowego,
Eliminacji wahań przypadkowych,
Obliczenia czystych wskaźników sezonowości.
Eliminacji z szeregu czasowego tendencji rozwojowej dokujemy poprzez wyznaczenie różnic pomiędzy wartościami prognozowanej zmiennej i wartościami teoretycznymi otrzymanymi z modelu tendencji rozwojowej:
dla modelu addytywnego zti = yti - yTti,
dla modelu multiplikatywnego zti = ![]()
.
Wskaźniki zti zawierają wahania sezonowe oraz przypadkowe. Średnie wyznaczone na ich podstawie eliminują oddziaływanie składnika losowego na kształtowanie wartości prognozowanej zmiennej. Średnie tak wyznaczone określane są mianem „surowych wskaźników sezonowości”:
zi = ![]()
,
gdzie k jest liczbą jednoimiennych faz w analizowanym szeregu czasowym /można do ich wyznaczenia wykorzystać także średnią arytmetyczną bądź medianę/.
„Czyste wskaźniki sezonowości”:
ci = zi - q (model addytywny),
ci = ![]()
(model multiplikatywny), gdzie q = ![]()
,
r jest liczbą faz cyklu.
Suma czystych wskaźników sezonowości powinna być równa zero (model addytywny) lub liczbie faz tworzących cykl (model multiplikatywny). Wskaźniki dają informację o bezwzględnych (model addytywny), względnych (model multiplikatywny) odchyleniach wartości prognozowanej zmiennej od tendencji rozwojowej w kolejnych fazach cyklu.
Wartości prognoz:
ypti = ypti(w) + ci, t > n (model addytywny),
ypti = ypti(w) ci, t > n (model multiplikatywny),
gdzie: ypti - prognoza zmiennej Yt wyznaczona na moment lub okres t,
ypti(w) - wstępna prognoza zmiennej Yt na moment lub okres t, wyznaczona na podstawie modelu tendencji rozwojowej,
ci - wskaźnik sezonowości dla i - tej fazy cyklu.
Analiza harmoniczna
Opiera się na uzupełnieniu modelu zmian zmiennej objaśnianej Yt o tzw. harmoniki, tj. funkcje sinusoidalne bądź cosinusoidalne o określonym okresie. Pierwsza harmonika ma okres równy długości okresu badanego, druga - połowie tego okresu, trzecia - jednej trzeciej okresu. Dla n obserwacji liczba wszystkich możliwych harmonik jest równa jednej drugiej n.
Analiza harmoniczna może opierać się na badaniu wahań wokół poziomu średniego /wokół wartości parametru α0 /, bądź w powiązaniu z funkcją trendu.
W pierwszym przypadku po uwzględnieniu składowej periodycznej:
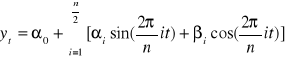
,
w drugim:
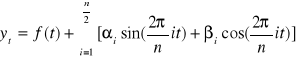
,
gdzie: i - numer i - tej harmoniki,
Parametry {α0, αi, βi} szacowane są metodą najmniejszych kwadratów, stąd:
![]()
,
![]()
,
![]()
, dla i = 1,2, …, ![]()
- 1.
Dla harmoniki ![]()
, parametr ![]()
jest zawsze równy zero, natomiast 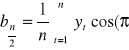
![]()
, stąd amplitudy poszczególnych harmonik Ai:
Ai = ![]()
.
Dla ich zlokalizowania na osi czasu, tj. określenia chwili ich wystąpienia, wyznacza się wartość przesunięcia fazowego ![]()
, gdzie ![]()
, natomiast ![]()
.
W modelu powinno się ujmować harmoniki, których udział w wyjaśnianiu wariancji zmiennej jest największy.
Udział części wariancji zmiennej Yt , która jest uwzględniana przez pierwszych ![]()
- 1 harmonik w ogólnej wariancji, jest ilorazem:
![]()
dla i = 1,…, ![]()
- 1,
a przez harmonikę : ![]()
dla ![]()
,
gdzie: ![]()
dla i = 1,…, ![]()
, s2 - wariancja zmiennej Yt .
Ponieważ harmoniki nie są ze sobą skorelowane, zatem nie mogą odnosić się do tej samej części wariancji. Oznacza to, że części ogólnej zmienności Yt , których dotyczą harmoniki można sumować.
Model Kleina
Uwzględnia jednocześnie tendencję rozwojową oraz wahania okresowe.
yt = f(t) + ![]()
Qi + ξt,
gdzie: f(t) - funkcja trendu,
Qi ; i - ta zmienna zero - jedynkowa, przyjmująca wartość jeden dla fazy o numerze „i” oraz zero dla pozostałych faz cyklu,
r - liczba faz cyklu.
Metoda prognozowania zjawisk okresowych oparta jest na modelu [Zieliński Z. Model szeregu czasowego z periodycznym składnikiem sezonowym. Przegląd Statystyczny nr 2 1967]:
yt = αi + β t + ξt, i = 1,…, r, gdzie r, liczba faz cyklu.
Parametry modelu {αi , β} są szacowane „mnk”. Parametr β na podstawie całego szergu czasowego zmiennej prognozowanej. Parametr α jest różny dla każdej fazy cyklu. Jego estymatorem jest:
ai = yiśr + b tiśr,
gdzie: ai - ocena parametru αi,
b - ocena parametru β,
yiśr - średnia wartość zmiennej prognozowanej w i - tej fazie cyklu,
tiśr - średnia wartość zmiennej czasowej w i - tej fazie cyklu.
Modele autoregresyjne
Liniowy:
yt = α0 + ![]()
+ ξt,
bądź logarytmiczno - liniowy:
ln yt = α0 + ![]()
+ ξt, gdzie p jest rzędem autoregresji.
Jak określić rząd autoregresji p ?.
Podstawę wyboru może stanowić funkcja:
SR(k) = ln s2k + ![]()
ln n, k = 0,1,…,K,
gdzie: s2k - ocena wariancji składnika losowego modelu autoregresji rzędu „k”,
K - maksymalny rząd autoregresji.
Wartość „optymalna” to taka, dla której:
SR(p) = min SR(k).
k
Modele ARMA i ARIMA
Mogą być stosowane do modelowania szeregów stacjonarnych tj. szeregów, w których występują jedynie wahania losowe wokół średniej /możliwe także modelowanie szeregów niestacjonarnych sprowadzalnych do stacjonarnych.
Ich budowa oparta jest na wykorzystaniu korelacji wartości zmiennej prognozowanej z wartościami tej samej zmiennej opóźnionymi w czasie.
Wyróżnia się trzy klasy modeli:
Modele autoregresji,
Modele średniej ruchomej,
Modele mieszane, autoregresji i średniej ruchomej.
4.5.1 Model autoregresji AR:
yt = φ0 + ![]()
+ et,
gdzie: {yt-i} - wartości zmiennej prognozowanej w momencie lub okresie t - i; i = 0,…, p;
{φt-i} - parametry strukturalne modelu,
et - reszty modelu w momencie lub okresie t,
p - wielkość opóźnienia.
Zakładamy, że występuje autokorelacja pomiędzy wartościami zmiennej prognozowanej a jej wartościami opóźnionymi w czasie.
4.5.2 Model średniej ruchomej MA:
yt = θ0 + et - θ1 et-1 - θ2 et-2 -…- θq et-q,
gdzie: yt - wartość zmiennej prognozowanej w okresie t,
{et-j} - reszty modelu, j = 1,…,q,
{θj} - parametry strukturalne modelu,
q - wielkość opóźnienia.
Uwaga: suma „wag” {1, θ0,…,θq} nie musi być równa jedności i nie wymagamy, by wagi były dodatnie.
4.5.3 Model autoregresji i średniej ruchomej
ARMA
yt = φ0 + ![]()
+ θ0 + et - θ1et-1 - θ2et-2 -…- θq et-q
Uwagi: W praktyce dobre wyniki otrzymuje się przyjmując, iż p oraz q nie są większe a często mniejsze od 2, zakłada się jednocześnie, że szereg zmiennej prognozowanej jest stacjonarny. Jeśli założenia tego nie da się spełnić, należy dokonać transformacji szeregu, przekształcając go w szereg stacjonarny, jak? Tę własność można uzyskać poprzez d - krotne obliczanie różnic wartości szeregu zmiennej:
pierwsze różnice: Δ[1] t = yt - yt-1, t = 2,…,n,
drugie różnice: Δ[2]t = Δ[1] t - Δ[1] t-1, t = 3,…,n,
Δ[2]t = yt - 2yt-1 + yt-2,
trzecie różnice: Δ[3]t = Δ[2] t - Δ[2] t-1, t = 4,…,n,
Δ[3]t = yt - 3yy-1 +3yt-2 - yt-3,
…………………………………………………………
Postepujemy tak d - krotnie, dopóki szereg różnic nie będzie stacjonarnym.
Budowane modele w oparciu o tak przekształcone szeregi czasowe, nazywane są zintegrowanymi modelami autoregresji ARI lub modelami średniej ruchomej IMA oraz autoregresji średniej ruchomej ARIMA.
Modele ARIMA definiuje uporządkowany zbiór trzech parametrów (p, d, q), p oznacza rząd autoregresji, d-rząd „różnicowania”, q- wielkość opóźnienia średniej ruchomej.
Wyszukiwarka
Podobne podstrony:
Polityka pieniężna wykłady notatki na podstawie Kazmierczak A Polityka pieniezna w gospodarce otwar
wyklady z GONu na drugiego kolosa, WYKúAD 7a, GOSPODARKA NIERUCHOMOŚCIAMI - sem
MP Wykład 7A Prognozowanie na podstawie modelu ekonometrycznego
Prognozowanie na podstawie modeli autoregresji
2 Prognozowanie na podstawie s Nieznany (2)
8 wnioskowanie na podstawie modelu ekonometrycznego prognozowanie ekonometryczne
Prognozowanie wykład 3, III FiR UMK, prognozowanie gospodarcze
podstawowe pojęcia prognozowania i symulacji na podstawie mo, Ekonometria
3. Prognozowanie na podstawie modeli autoregresyjnych
Prognozowanie na Podstawie Łancuchów Markowa p10x2 scan!!
PG zagadnienia na kolokwium opracowanie, FiR UMK Toruń 2010-2013, III FIR, Prognozowanie gospodarcze
WSZiA prognozowanie zadania na egzamin, PROGNOZOWANIE GOSPODARCZE
podstawowe pojęcia prognozowania i symulacji na podstawie mo
WEiP (6 Prognoza szeregi czasowe 2010)
WEiP (5 Prognozowanie na podstawie modeli ekonometrycznych 2010)
WEiP (4 Prognozowanie na podstawie modeli ekonometrycznych 2011)
teoria na kolokwium, FiR UMK Toruń 2010-2013, III FIR, Prognozowanie gospodarcze
więcej podobnych podstron