
Wprowadzenie
do ekonometrii
i prognozowania
(6)
Prognozowanie na podstawie
szeregów czasowych

GK (WEiP(6) - 2010)
Pojęcie szeregu czasowego
Przebieg wielu zjawisk o charakterze społecznym,
ekonomicznym itp. jest ewidencjonowany jako ciąg
następujących po sobie obserwacji tego poziomu tego zjawiska
w ustalonych chwilach (momentach) bądź przedziałach
(okresach) czasu. Ciąg taki jest powszechnie nazywany
szeregiem czasowym
. Dalej będą rozpatrywane szeregi czasowe
momentów lub okresów, których poszczególne wartości są
pomiarem badanego zjawiska w jednakowych odstępach czasu,
np. dniach, tygodniach, miesiącach itp.
Analiza szeregów czasowych ma na celu wykrycie
prawidłowości, którym podlega badane zjawisko i zakłada, że
szereg czasowy
y
t
= [y
1
, y
2
, …, y
n
]
(
t
– moment lub okres czasu, w
którym dokonano pomiaru poziomu zjawiska,
y
t
– poziom
zjawiska w momencie lub okresie
t
) jest jedną z możliwych
realizacji pewnego dyskretnego procesu stochastycznego postaci
{Y
t
}
t=1,2,…
, przy czym
Y
t
oznacza zmienną losową dla ustalonego
t
.
2

GK (WEiP(6) - 2010)
Pojęcie szeregu czasowego
O procesie stochastycznym
{Y
t
}
t=1,2,…
generującym szereg
czasowy zakłada się, że:
•jest stacjonarny
, co oznacza niezmienność w czasie ani modelu
przyjętego do formalnego opisu zjawiska oraz także jego
parametrów,
•jest ergodyczny
, co oznacza, że wartości procesu odległe w
czasie nie są ze sobą skorelowane.
W dalej prezentowanym procesie analizy szeregów
czasowych przyjmuje się, że w szeregu czasowym będzie się
wyróżniać dwie składowe:
•składową systematyczną
, która może przyjąć postać stałego
poziomu zjawiska, trendu (tendencji rozwojowej zjawiska) oraz
składowej periodycznej w postaci wahań cyklicznych lub wahań
sezonowych,
•
składową przypadkową
(składnik losowy, wahania
przypadkowe) odzwierciedlającą losowy wpływ nieznanych
czynników na kształtowanie się poziomu zjawiska.
3
GK (WEiP(6) - 2010)
Pojęcie szeregu czasowego
4
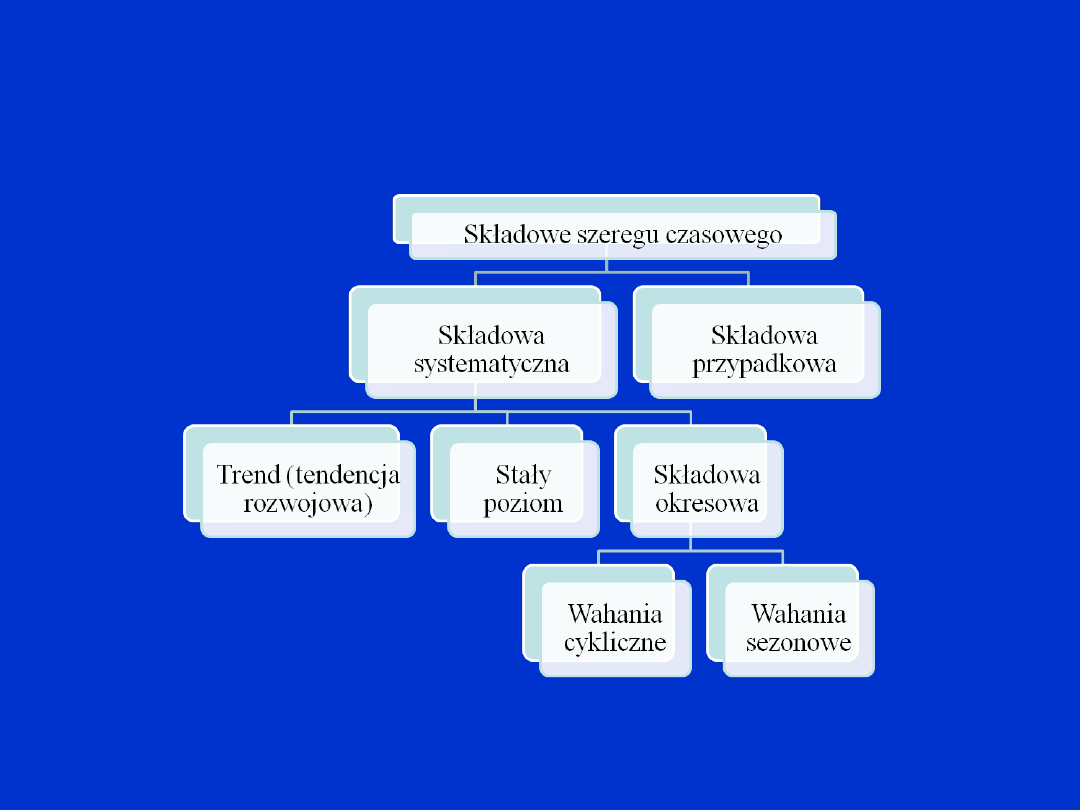
Składowe szeregu czasowego
Źródło: A. Zeliaś i inni: „Prognozowanie ekonomiczne”. PWN, Warszawa, 2004.

GK (WEiP(6) - 2010)
Pojęcie szeregu czasowego
Trend (tendencja rozwojowa)
– długookresowa skłonność
do jednokierunkowych zmian poziomu obserwowanego zjawiska
pod wpływem oddziaływania stałych czynników na to zjawisko.
Stały (średni) poziom
oznacza brak trendu i oscylowanie
poziomu obserwowanego zjawiska wokół pewnego stałego
poziomu.
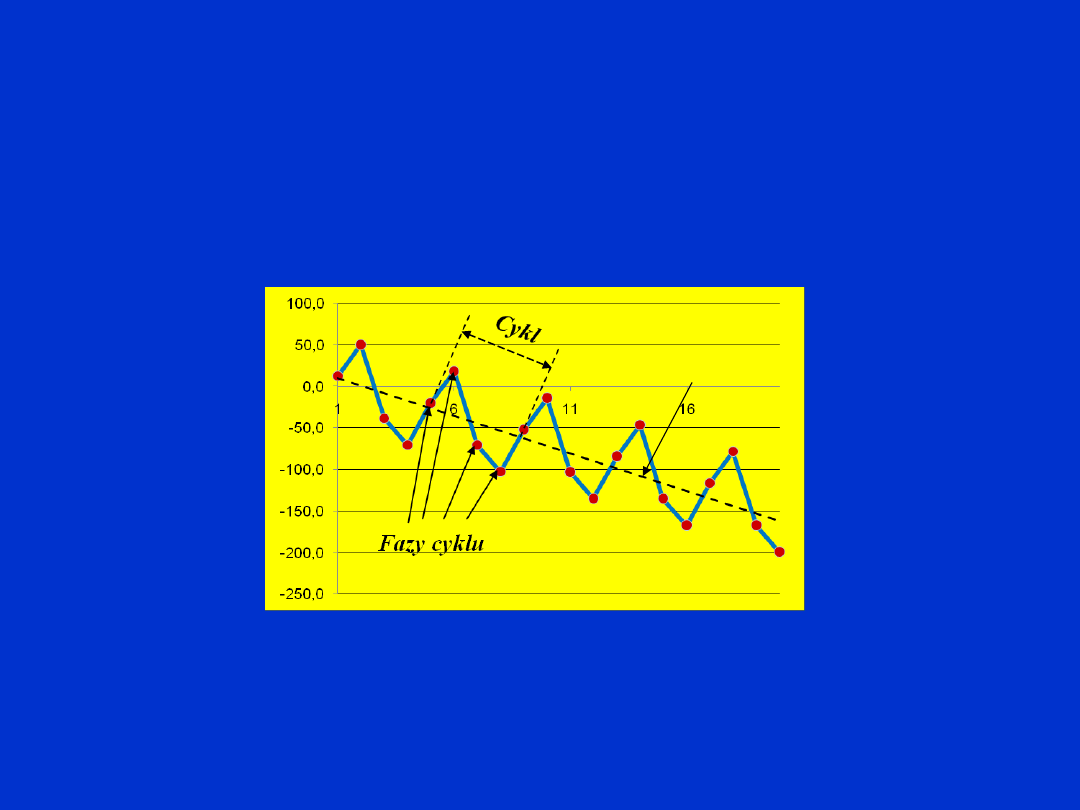
Wahania cykliczne
– długookresowe rytmiczne oscylacje
poziomu obserwowanego zjawiska wokół trendu lub stałego
poziomu. Wahania cykliczne zwykle dotyczą zmian
koniunkturalnych.
Wahania sezonowe
– krótkookresowe rytmiczne oscylacje
poziomu obserwowanego zjawiska wokół trendu lub stałego
poziomu, powtarzające się w przybliżeniu w tych samych
rozmiarach (bezwzględnych lub względnych) co pewien stały (w
przybliżeniu) okres, nieprzekraczający jednego roku.
5

6
Przy założeniu, że w modelu jedyną zmienną
objaśniającą będzie zmienna czasowa
t
wyróżnia się dwa
następujące rodzaje modeli z trendem lub stałym poziomem
f(t)
, wahaniami sezonowymi
g(t)
i cyklicznymi
h(t)
oraz
składnikiem losowym
t
:
•model addytywny:
•model multiplikatywny:
Szczegółowe postacie modeli
f(t)
,
g(t)
i
h(t)
składników szeregu
czasowego zależą od sposobu modelowania.
t
t
y
f(t) g(t) h(t)
,
e
=
+
+
+
t
t
y
f(t) g(t) h(t)
.
e
=
�
�
�
GK (WEiP(6) - 2010)
Pojęcie szeregu czasowego
Modelowanie ekonometryczne szeregu czasowego
wymaga jego uprzedniej dekompozycji , tj. zidentyfikowania i
wyodrębnienia wszystkich tworzących go składowych
systematycznych, a następnie określenia ich wpływu na
kształtowanie poziomu zjawiska reprezentowanego przez ten
szereg.
GK (WEiP(6) - 2010)
7
Składowe szeregu czasowego wahań seznowych:
Pojęcie szeregu czasowego
Trend

GK (WEiP(6) - 2010)
8
W prognozowaniu według szeregów czasowych
można wyróżnić dwa podstawowe nurty:
•prognozowanie na podstawie klasycznych modeli trendu,
•prognozowanie na podstawie modeli adaptacyjnych.
Metody wykorzystywane w pierwszym z tych nurtów
są takie same jak dla metod prognozowania na podstawie
liniowych modeli ekonometrycznych, gdyż ich podstawę
stanowią regresyjne (ekonometryczne) modele trendu. Jak
wiadomo, stosowanie tych metod jest uwarunkowane
spełnieniem rygorystycznych założeń co do stabilności
relacji wiążących zmienną prognozowaną z innymi
zmiennymi (w przypadku szeregów czasowych – tylko z
czasem) zarówno w przeszłości, jak i w okresie
prognozowania.
Prognozowanie na podstawie
szeregu czasowego

GK (WEiP(6) - 2010)
9
Metody należące do drugiego nurtu opierają się na
mniej rygorystycznych założeniach dotyczących stabilności
ww. relacji, a nawet dopuszczają brak ich stabilności w
czasie, zatem mogą one być stosowane w przypadkach
nieregularnych zmian kierunku i prędkości trendu
(funkcja trendu nie musi być stała w badanym przedziale
czasu i w okresie prognozowania, a nawet może być
segmentowa, tj. przedziałami stała) czy też różnego
rodzaju zniekształceń i przesunięć wahań periodycznych
(sezonowych i cyklicznych). W praktyce metody
prognozowania na podstawie modeli adaptacyjnych stosuje
się głównie wówczas, gdy zmienna prognozowana ma
względnie labilny przebieg w czasie, a wnioskowanie w
przyszłość będzie opierane na modelu trendu, a nie na
modelu przyczynowo-skutkowym.
Jedynym zasadniczym założeniem, determinującym
poprawność stosowania modeli adaptacyjnych jako
podstawy prognozowania, jest założenie o stałości w czasie
błędów prognozowania (predykcji).
Prognozowanie na podstawie
szeregu czasowego

Niech ciąg postaci
oznacza szereg czasowy.
Dalej będzie rozważany szereg czasowy, w którym
występuje tylko składowa systematyczna w postaci trendu
oraz składowa przypadkowa
t
, przy czym trend będzie
opisywany tylko funkcją liniową lub nieliniową
f(t)
,
sprowadzalną do liniowej. Zatem będzie rozpatrywany
szereg czasowy, którego model addytywny lub
multiplikatywny przyjmuje następującą postać formalną:
.
...
n
2
1
,y
,
,y
y
t
t
t
t
t=1,2,...,n
(model addytywny)
(model multiplikatywny)
,
,
y
f (t)
,
y
f (t)
.
e
e
=
+
=
�
GK (WEiP(6) - 2010)
10
Prognozowanie na podstawie
modeli trendu
GK (WEiP(6) - 2010)
11
Prognozowanie na podstawie
modeli trendu
Trend liniowy.
Funkcja trendu:
Model szeregu czasowego:
Wariancja resztowa:
Prognoza punktowa w okresie prognozy
T
:
Średni i względny błąd (predykcji) prognozy
ex ante
:
0
1
f (t)
t.
a
a
= + �
t
t
0
1
t
t=1,2,...,n
y
f(t)
t
,
.
e a
a
e
=
+ = + �+
(
)
n
2
2
e
t
t
t 1
1
ˆ
S
y
y .
n 2
=
=
-
-
�
p
T
0
1
y
a
a T.
= + �
(
)
(
)
2
p
e
n
2
t 1
T t
1
S
S 1
,
n
t t
=
-
=
+ +
-
�
(
)
(
)
2
e
n
2
p
t 1
p
p
0
1
T
T t
1
S 1
n
t t
S
v
.
a
a T
y
=
-
+ +
-
=
=
+ �
�
GK (WEiP(6) - 2010)
12
Prognozowanie na podstawie
modeli trendu
Trend kwadratowy (paraboliczny).
Funkcja trendu:
Model szeregu czasowego:
Wariancja resztowa:
Prognoza punktowa w okresie prognozy
T
:
Średni i względny błąd (predykcji) prognozy
ex ante
:
2
0
1
2
f(t)
t
t .
a
a
a
=
+ �+ �
2
t
t
0
1
2
t
t=1,2,...,n
y
f (t)
t
t
,
.
e a
a
a
e
=
+ =
+ �+ � +
(
)
n
2
2
e
t
t
t 1
1
ˆ
S
y
y .
n 3
=
=
-
-
�
p
2
T
0
1
2
y
a
a T a T .
= + � + �
(
)
1
2
T
p
e
2
1
S
S 1 1 T T
X X
T ,
T
-
� �
� �
�
�
=
+�
�
� �
� �
� �
(
)
1
2
T
e
2
p
p
p
2
T
0
1
2
1
S 1 1 T T
X X
T
T
S
v
.
y
a
a T a T
-
� �
� �
�
�
+�
�
� �
� �
� �
=
=
+ � + �

GK (WEiP(6) - 2010)
13
Prognozowanie na podstawie
modeli trendu
Trend wykładniczy.
Funkcja trendu:
Model szeregu czasowego:
Zlinearyzowany model szeregu czasowego:
Wariancja resztowa modelu zlinearyzowanego:
Prognoza punktowa w okresie prognozy
T
dla modelu
zlinearyzowanego:
0
1
t
0
1
f(t) e
,
0,
1.
a a
a
a
+ �
=
>
�
t
0
1
t
t
t
t=1,2,...,n
y
f(t) e
e
e ,
.
e
a a
e
+ �
=
� =
�
t
0
1
t
t
0
1
t
t=1,2,...,n
lny
t
y
t
,
.
a
a
e
a
a
e
= + �+
�
= + �+
)
(
)
n
2
2
e
t
t
t 1
1
ˆ
S
y
y .
n 2
=
=
-
-
�
)
)
)
p
T
0
1
y
a
a T.
= + �
)
GK (WEiP(6) - 2010)
14
Prognozowanie na podstawie
modeli trendu
Prognoza punktowa w okresie prognozy
T
dla modelu
pierwotnego:
Średni błąd (predykcji) prognozy
ex ante
dla modelu
zlinearyzowanego:
Średni i względny błąd (predykcji) prognozy
ex ante
dla
modelu pierwotnego:
[
]
(
)
p
T
p
t
T
1
p
ˆy
T
p
e
t
t y y
S
1
S
e
S 1 1 T X X
,
T
dy
dy
-
=
��
=
=
�
+
��
��
)
)
)
[
]
(
)
1
p
T
p
e
p
T
S
1
v
S 1 1 T X X
.
T
y
-
��
=
=
+
��
��
)
p
0
1
T
y
a a T
p
T
y
e
e
.
+ �
=
=
)
[
]
(
)
1
T
p
e
1
S
S 1 1 T X X
,
T
-
��
=
+
��
��
)
)

GK (WEiP(6) - 2010)
15
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
Prognozowanie zachowania szeregów czasowych na
podstawie modelu trendu z wahaniami sezonowymi, tj.
szeregów postaci:
• szereg czasowy z trendem
f(t)
i addytywnymi wahaniami
sezonowymi
g(t)
:
• szereg czasowy z trendem
f(t)
i multiplikatywnymi
wahaniami sezonowymi
g(t)
:
zależy od przyjętego modelu. Jeżeli modelem szeregu
czasowego będzie model ekonometryczny uzyskany np.
według metody Kleina (wahania okresowe są modelowane
za pomocą sztucznych zmiennych zero-jedynkowych) lub
z wykorzystaniem analizy harmonicznej, to
prognozowanie tego szeregu przebiega identycznie jak
prognozowanie dla modeli przyczynowo-skutkowych.
t
t
y
f(t) g(t) e
=
+
+
t
t
y
f(t) g(t) e
=
�
�

GK (WEiP(6) - 2010)
16
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
W przypadku, gdy występuje szereg czasowy z
trendem i wahaniami sezonowymi stosuje się uprzednie
modelowanie ekonometryczne tego szeregu, a następnie
prognozowanie na podstawie uzyskanego modelu. Dalej
zostanie rozpatrzony przypadek modelowania szeregu
czasowego według metody Kleina. Podstawowe etapy
metody:
•identyfikacja trendu,
•identyfikacja wahań sezonowych,
•budowa i estymacja modelu,
•weryfikacja modelu.
Prognozowanie może odbywać się na podstawie modelu
zweryfikowanego oraz po ocenie stabilności jego postaci
analitycznej (poprawności specyfikacji postaci
funkcyjnej) i stabilności parametrów.

GK (WEiP(6) - 2010)
Wyodrębnianie trendu szeregu czasowego.
Spośród wielu metod identyfikacji trendu w szeregu
czasowym najczęściej wymienianymi są:
•analiza wzrokowa,
•test współczynnika korelacji Pearsona,
•test Danielsa,
•test Coxa-Stuarta,
•test funkcji autokorelacji.
Wzrokowa analiza
graficznej prezentacji szeregu czasowego
umożliwia często wstępne określenie prawidłowości
występujących w szeregu czasowym, co pozwala na wstępne
wyróżnienie tworzących go składowych systematycznych. Oceny
wynikające z analizy wzrokowej należy starać się zawsze
potwierdzić metodami formalnymi (w tym przypadku –
statystycznymi).
17
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
18
Test współczynnika korelacji Pearsona
polega na wyznaczeniu
wartości tego współczynnika dla szeregu czasowego i zmiennej
czasowej
t
z zależności:
a następnie na zweryfikowaniu hipotezy zerowej
o niewystępowaniu korelacji wobec hipotezy alternatywnej
że taka korelacja występuje.
n
t
t 1
n
n
2
2
t
t 1
t 1
(y
y)(t t)
r
(y
y)
(t t)
=
=
=
-
-
=
-
-
�
�
�
0
H :
0
r =
1
H :
0,
r �
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
19
Sprawdzianem jest statystyka
która w przypadku prawdziwości tej hipotezy ma rozkład t-
Studenta z
n-2
stopniami swobody.
Jeżeli dla przyjętego poziomu istotności
pomiędzy
wartością krytyczną
t
,n-2
spełniona jest nierówność
t
emp
t
,n-2
,
to nie ma podstaw do odrzucenia hipotezy zerowej, co oznacza,
że trend w szeregu czasowym nie występuje. W przeciwnym
przypadku, tj. gdy
t
emp
>
t
,n-2
hipoteza zerowa jest odrzucana, co
oznacza, że trend w szeregu czasowym występuje.
Omawiany test jest przeznaczony przede wszystkim do
wykrywania trendu liniowego, ale często za jego pomocą można
wykryć także trend nieliniowy.
emp
2
r
n 2
t
,
1 r
� -
=
-
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
20
Test Danielsa
polega na wyznaczeniu wartości współczynnika
korelacji Spearmana dla szeregu czasowego i zmiennej
czasowej
t
z zależności:
gdzie
d
i
oznacza różnicę rang obliczonych dla zmiennej
czasowej
t
oraz szeregu czasowego
y
t
, a następnie na
zweryfikowaniu hipotezy zerowej
o niewystępowaniu korelacji wobec hipotezy alternatywnej
że taka korelacja występuje.
(
)
n
2
i
t 1
s
2
6
d
r
1
,
n n
1
=
�
= -
� -
�
0
s
H :
0
r =
1
s
H :
0,
r �
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
21
Jeżeli dla przyjętego poziomu istotności
oraz liczności
n
szeregu czasowego i odczytaną dla nich z tablicy krytycznych
wartości współczynnika korelacji rang Spearmana wartością
krytyczną
r
,n
zachodzi
r
s
< r
,n
, to nie ma podstaw do odrzucenia
hipotezy zerowej, co oznacza, że trend w szeregu czasowym nie
występuje. W przeciwnym przypadku, tj. gdy
r
s
r
,n
hipoteza
zerowa jest odrzucana, co oznacza, że trend w szeregu
czasowym występuje.
W przypadku, gdy
n > 10
do weryfikacji prawdziwości
hipotezy zerowej można zastosować test oparty również na
współczynniku korelacji rang Spearmana, w którym
sprawdzianem jest statystyka postaci
która w przypadku prawdziwości tej hipotezy ma rozkład
normalny
N(m,
)
, gdzie:
n
2
n
i
i 1
S
d ,
=
=
�
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
(
)
(
)
2
n n 1
m
,
6
n n 1
n 1.
6
s
� -
=
� +
=
� -

GK (WEiP(6) - 2010)
22
Dla przyjętego poziomu istotności
wartością krytyczną testu
jest
u
1-
/2
kwantyl rozkładu normalnego
N(0,1)
. Jeżeli zachodzi
to nie ma podstaw do odrzucenia hipotezy zerowej, co oznacza,
że trend w szeregu
czasowym nie występuje. W przeciwnym przypadku hipoteza
zerowa jest odrzucana, co oznacza, że trend w szeregu
czasowym występuje.
Omawiany test, podobnie jak test współczynnika
korelacji Pearsona, jest przeznaczony przede wszystkim do
wykrywania trendu liniowego, ale często za jego pomocą można
wykryć także trend nieliniowy.
n
1
2
S m
u
,
g
s
-
-
<
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
23
Test Coxa-Stuarta (test znaków)
.
Realizacja testu polega na:
•podzieleniu szeregu czasowego na dwa równoliczne
podszeregi; w przypadku nieparzystej liczby obserwacji
usuwana jest obserwacja środkowa,
•porównywaniu kolejnych odpowiadających sobie obserwacji z
obydwu podszeregów i oznaczaniu znakiem „+” sytuacji, gdy
obserwacja z pierwszego podszeregu ma większą wartość od
wartości odpowiadającej jej obserwacji z drugiego podszeregu
oraz oznaczanie znakiem „-” sytuacji odwrotnej; przypadek, gdy
porównywane sobie obserwacje są równe jest opuszczany.
Weryfikacji podlega hipoteza zerowa postaci
wobec hipotezy alternatywnej
przy czym
p
oznacza prawdopodobieństwo wystąpienia znaku
„
+
”.
0
H : p 0,5,
=
1
H : p 0,5,
�
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
GK (WEiP(6) - 2010)
24
Sprawdzianem jest statystyka
która w przypadku prawdziwości hipotezy zerowej ma rozkład
dwumianowy.
Niech
m
oznacza sumę znaków „
+
” i „
-
” łącznie. Dla
przyjętego poziomu istotności
i liczby
m
wyznacza się taką
liczbę całkowitą
C
/2,m
, aby odpowiadająca jej wartość
dystrybuanty rozkładu dwumianowego z parametrami
p = 0,5
i
m
była najbardziej zbliżona do wartości
/2
. Jeżeli
T
C
/2,m
lub
T
(m-C
/2,m
)
, hipoteza zerowa jest odrzucana, co
oznacza, że w szeregu czasowym występuje trend.
W przypadku dużej próby (np. gdy
m·p > 5
) jako
sprawdzian hipotezy zerowej można zastosować statystykę
postaci
która w przypadku prawdziwości tej hipotezy ma rozkład
N(0,1).
T liczba znaków "+" ,
=
2 T m
z
m
�-
=
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
Test funkcji autokorelacji
polega na wyznaczeniu z szeregu
czasowego współczynników autokorelacji rzędu
τ
postaci
które zostaną wykorzystane do oceny występowania trendu w
tym szeregu. Na występowanie trendu wskazują duże i
statystycznie istotne wartości współczynników autokorelacji
pierwszych kilku rzędów oraz stopniowo malejące następnych
rzędów.
Oprócz występowania trendu, powtarzające się co stałą
liczbę (stały odstęp) rzędów istotne wartości współczynników
autokorelacji sygnalizują istnienie wahań sezonowych o cyklu
równym temu stałemu odstępowi.
Do oceny istotności
współczynników autokorelacji stosuje się test Ljunga-Boxa.
nτ
t
tτ
t 1
τ
n
2
t
t 1
(y
y)(y
y)
n
r
,τ 1,2,...,
,
2
(y
y)
-
+
=
=
-
-
��
=
=
��
��
-
�
�
25
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
26
Test Ljunga-Boxa polega na weryfikowaniu hipotezy zerowej
o nieistotności współczynnika autokorelacji rzędu
wobec
hipotezy alternatywnej
że ten współczynnik autokorelacji jest istotny.
Sprawdzianem jest statystyka Ljunga-Boxa postaci:
która w przypadku prawdziwości hipotezy zerowej ma rozkład
2
o
stopniach swobody. Jeżeli dla przyjętego poziomu istotności
oraz rzędu
zachodzi
Q(
)
2
,
(wartość krytyczna testu), to hipoteza zerowa jest
odrzucana, co oznacza istotność testowanego współczynnika
autokorelacji. W przypadku przeciwnym, tzn. gdy
Q(
) <
2
,
nie
ma podstaw do odrzucenia hipotezy zerowej, co oznacza, że
testowany współczynnik autokorelacji nie jest istotny.
0
H :
0
t
r =
1
H :
0,
t
r �
( )
(
)
2
i
i 1
r
Q
n n 1
,
n i
t
t
=
= � -
�
-
�
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
Najczęściej spotykaną metodą wyodrębniania tendencji
rozwojowej z szeregów czasowych jest jej wyrażenie w postaci
analitycznej za pomocą np. jednego z wcześniej
przedstawionych
modeli trendu
, który w sensie matematycznym
jest
funkcją czasu
(zmiennej czasowej)
f(t)
. Model trendu
f(t)
może przyjmować dowolną postać funkcji liniowych i
nieliniowych.
Ze względu na łatwość estymowania parametrów
strukturalnych modelu trendu, dąży się w praktyce do
konstruowania tego modelu w postaci wielomianu. Jest to
postępowanie dopuszczalne nawet w przypadkach, gdy
tendencja rozwojowa badanego szeregu czasowego,
reprezentowanego w modelu przez zmienną objaśnianą,
opisywana jest w rzeczywistości inną funkcją ciągłą niż
wielomian. Uzasadnieniem takiego podejścia jest twierdzenie
Weierstrassa, które mówi, że dowolną funkcję ciągłą można
aproksymować wielomianem.
27
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
Postać analityczną modelu trendu
f(t)
można ustalić
łatwo w przypadku, gdy tendencję rozwojową badanego zjawiska
da się zidentyfikować, co w przypadkach rzeczywistych jest
trudne, bowiem tendencja rozwojowa może podlegać różnym
zmianom z upływem czasu. Z tego względu do identyfikacji
trendu szeregu czasowego najczęściej służą adaptacyjne modele
trendu. Są one stosowane w przypadku, gdy:
•
nie można zaobserwować wyraźnej tendencji rozwojowej w
szeregu czasowym (metoda wzrokowa i metody statystyczne nie
dają jednoznacznie pozytywnego rezultatu) ,
•
nie można jednoznacznie określić typu krzywej mającej
stanowić analityczną reprezentację trendu,
•
tendencja ulega w miarę upływu czasu dynamicznym i
nieregularnym zmianom.
28
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
Spośród adaptacyjnych metod wygładzania szeregów
czasowych (wyodrębniania trendu) najczęściej stosowana jest
metoda
średniej ruchomej
. Idea tej metody polega na
wyznaczaniu z kolejnych
p
wartości empirycznych szeregu
czasowego (zmiennej objaśnianej) średnich arytmetycznych. W
zależności od liczby
p
wyróżnia się
średnią ruchomą
nieparzystą
(zwykłą) i
parzystą
. Wyrażają się one następującymi
zależnościami:
•
nieparzysta (zwykła) średnia ruchoma
•
parzysta średnia ruchoma
,
~
p
1
i
2
i
t
t
y
p
1
y
.
~
1
p
1
i
2
p
i
t
2
p
t
2
p
t
t
y
y
y
2
1
p
1
y
29
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
Otrzymane wartości średnich ruchomych są
przyporządkowywane chwili
t
odpowiadającej środkowej
wartości szeregu czasowego spośród wartości tego szeregu
wziętych do obliczeń. Zatem stosowanie
średniej ruchomej
do
wygładzania szeregu czasowego powoduje utratę danych
proporcjonalną do kroku
p
tej średniej, co oznacza, że trend
uzyskany za jej pomocą ma mniej wartości niż wyjściowy szereg
czasowy. Traci się odpowiednio
(p-1)/2
wartości początkowych
i końcowych w przypadku
nieparzystej średniej ruchomej
oraz
p/2
wartości początkowych i końcowych w przypadku
parzystej
średniej ruchomej
. Z powyższego wynika, że wartości
nieparzystej średniej ruchomej
będą wyznaczane tylko dla chwil
a
parzystej średniej ruchomej
– tylko dla chwil
,
...
2
1
p
,n
1,
2
1
p
,
2
1
p
t
.
...
2
p
,n
2,
2
p
1,
2
p
t
30
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
W metodzie
średniej ruchomej
istotnym problemem jest
wyznaczenie właściwego jej kroku
p
, ponieważ średnia ruchoma
o kroku
p
eliminuje z szeregu czasowego wahania okresowe,
dla których długość cyklu mieści się bez reszty w
p
. Z tego
względu przy ustalaniu kroku
p
należy brać pod uwagę rodzaj
wahań występujących w wygładzanym szeregu czasowym. Na
ogół przyjmuje się, że do wyeliminowania z szeregu czasowego
wahań przypadkowych wystarczające są zwykle średnie
ruchome o
p = 2
lub
3
. Do wyeliminowania wahań sezonowych
o cyklu np. kwartalnym stosuje się średnią ruchomą o
p = 4
lub
8
.
Ustalanie postaci analitycznej modelu trendu odbywa się
na podstawie wartości wygładzonego szeregu czasowego
i może
być dokonywane dowolną metodą, np. za pomocą estymacji
ekonometrycznej, na podstawie oceny stałości przyrostów
wygładzonych wartości szeregu czasowego (zmiennej
objaśnianej) itp.
31
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
W przypadku, gdy trend można zamodelować za pomocą
wielomianu z parametrem
t
, konieczne jest ustalenie jego
stopnia
k
. W tym celu można stosować wiele różnych metod
praktycznych wśród, których często wykorzystywane są metody
oparte na:
• teście F-Fiszera,
• badaniu stałości przyrostów szeregu.
Metoda oparta na teście F-Fiszera
. Analizie może być
poddawany zarówno wygładzony, jak i niewygładzony szereg
czasowy. Procedura ustalania stopnia wielomianu opisującego
trend polega na badaniu, czy zwiększenie stopnia wielomianu
wyraźnie obniża wariancję resztową szeregu. Weryfikuje się
prawdziwość hipotezy zerowej postaci
gdzie oznaczają wariancje resztowe dla wielomianu
trendu stopnia
k
i
k+1
odpowiednio.
32
2
2
0
k
k 1
H : s
s
+
=
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
2
2
k
k 1
,
s s
+
GK (WEiP(6) - 2010)
33
Hipotezą alternatywną jest hipoteza postaci
Sprawdzianem jest statystyka
która przy prawdziwości hipotezy zerowej ma rozkład F-
Snedecora o
1
= n-k-1
i
2
= n-k
stopniach swobody
odpowiednio.
Wariancje resztowe są wyznaczane z zależności:
gdzie oznaczają reszty uzyskane w przypadku
estymowania modelu trendu wyrażonego wielomianem
k
i
k+1
stopnia odpowiednio.
2
2
1
k
k 1
H :
.
s
s
+
>
2
e,k
2
e,k 1
S
F
S
+
=
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
n
n
2
2
k
k 1
2
2
i 1
i 1
e,k
e,k 1
e
e
S
, S
,
n k 1
n k
+
=
=
+
=
=
- -
-
�
�
k
k 1
e ,e
+

GK (WEiP(6) - 2010)
34
Jeżeli dla poziomu istotności
zachodzi
F < F
,
1,
2
, to nie ma
podstaw do odrzucenia hipotezy
H
0
, zatem model trendu
będzie oparty na wielomianie stopnia
k
. Na tym zostaje
zakończona procedura ustalania stopnia wielomianu trendu.
Jeżeli
F ≥ F
,
1,
2
, to hipotez
H
0
jest odrzucana na korzyść
H
1
, co
oznacza, że opisany sposób postępowania zostaje powtórzony,
ale z wielomianami stopnia wyższego o
1
, zatem w kolejnym
kroku sprawdzany jest następny stopień wielomianu trendu.
Wybrany wielomian (model trendu) musi mieć istotny
parametr stojący przy najwyższej potędze zmiennej czasowej.
Metoda oparta na badaniu stałości przyrostów
.
Metoda ta
umożliwia określenie stopnia wielomianu opisującego trend na
podstawie badania przyrostów wartości wygładzonego szeregu
czasowego. Metoda jest oparta na spostrzeżeniu, że dla
wielomianu stopnia
k
stałe powinny być
k
-te
przyrosty tego
szeregu, obliczane z następującej zależności rekurencyjnej:
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
n
2,...,
i
1,
i
t
k;
1,2,...,
i
,
Δ
Δ
Δ
1
i
1
t
1
i
t
i
t
GK (WEiP(6) - 2010)
przy czym
gdzie oznaczają wartości wygładzonego szeregu czasowego
(wygładzone wartości zmiennej objaśnianej).
Decyzja o stałości przyrostów określonego stopnia
szeregu jest podejmowana zwykle na podstawie badania
istotności współczynnika korelacji ze zmienną czasową
t
.
Proces decyzyjny przybiera postać postępowania
weryfikującego hipotezę zerową
względem alternatywnej
przy przyjętym poziomie istotności
γ
.
n
2,3,...,
t
,
y
~
y
~
Δ
1
t
t
1
t
t
y
~
35
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
0
r
:
H
k
t
Δ
0
0
r
:
H
k
t
Δ
1

GK (WEiP(6) - 2010)
Sprawdzianem jest statystyka postaci:
która w przypadku prawdziwości hipotezy ma rozkład t-
Studenta o
ν = n-2-k
stopniach swobody (
k
– stopień
przyrostu).
Jeżeli brak jest podstaw do odrzucenia hipotezy
zerowej dla przyrostów rzędu
k
, przyjmuje się, że występuje
trend wielomianowy, którego modelem ekonometrycznym
będzie wielomian rzędu
k
.
k
2
n
r
1
r
t
k
t
k
t
Δ
Δ
Δ
r
2
36
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
Identyfikacja wahań sezonowych.
Analiza wahań sezonowych jest
przeprowadzana na podstawie szeregu czasowego pozbawionego
trendu.
W przypadku
addytywnych wahań sezonowych
usuwanie
trendu z szeregu oryginalnego następuje przez
odjęcie
wartości
trendu
f(t)
od wartości
y
t
tego szeregu, tj.
a w przypadku
multiplikatywnych wahań sezonowych
– przez
podzielenie
wartości
y
t
szeregu oryginalnego przez wartości
trendu
f(t)
, tj.
t
t
t
t 1,2,...,n,
Sε
y
f(t),
=
+ = -
t
t
t
t 1,2,...,n
.
y
Sε
,
f(t)
=
+ =
37
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
Właściwe zamodelowanie szeregu czasowego wymaga
ustalenia parametrów wahań sezonowych, tj. ich
cyklu
oraz
amplitudy
.
Cykl wahań sezonowych
S
t
zwykle wyznacza się na
podstawie
funkcji autokorelacyjnej
, której wartościami są
współczynniki autokorelacji szeregu wahań sezonowych,
wyznaczane dla poszczególnych momentów lub okresów czasu z
następującego wyrażenia:
Ocenę okresu wahań sezonowych przeprowadza się na podstawie
analizy wykresu funkcji autokorelacyjnej (najlepiej wykresu
kolumnowego), poprzez określanie odstępu między
jednoimiennymi kolejnymi istotnymi wartościami tej funkcji.
.
...,
2
n
0,1,2,
τ
,
)
S
(S
)
S
)(S
S
(S
r
n
1
t
2
t
τ
n
1
t
τ
t
t
τ
38
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
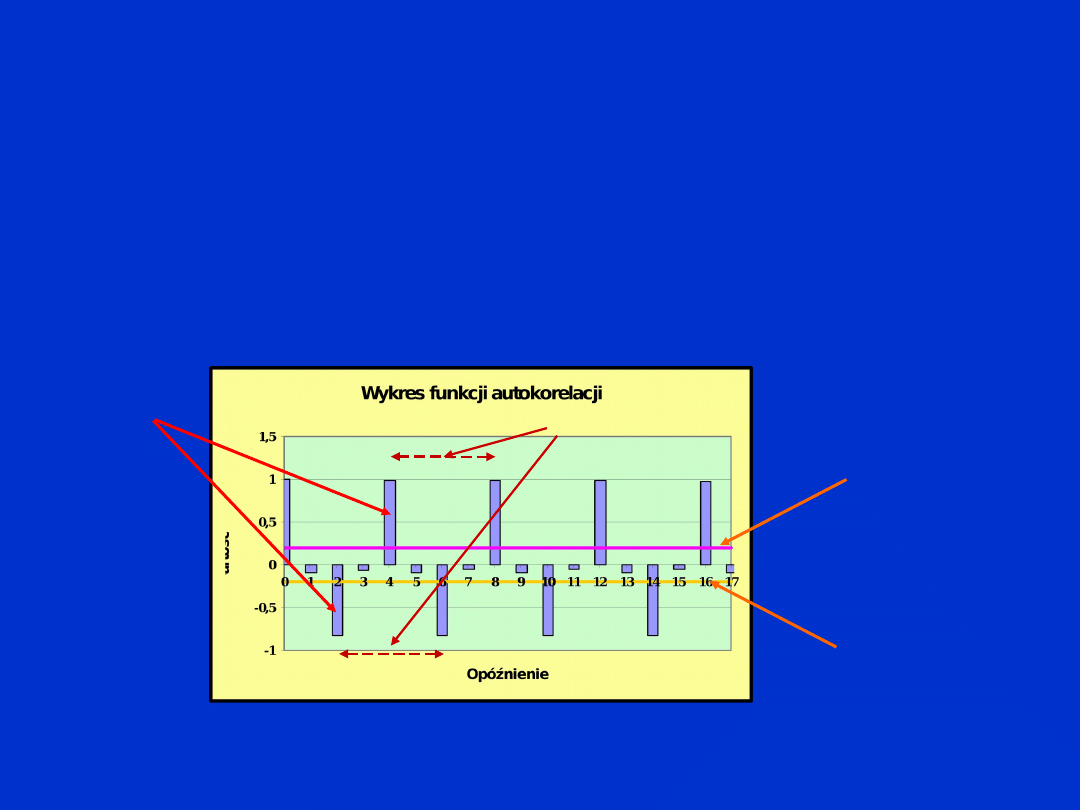
GK (WEiP(6) - 2010)
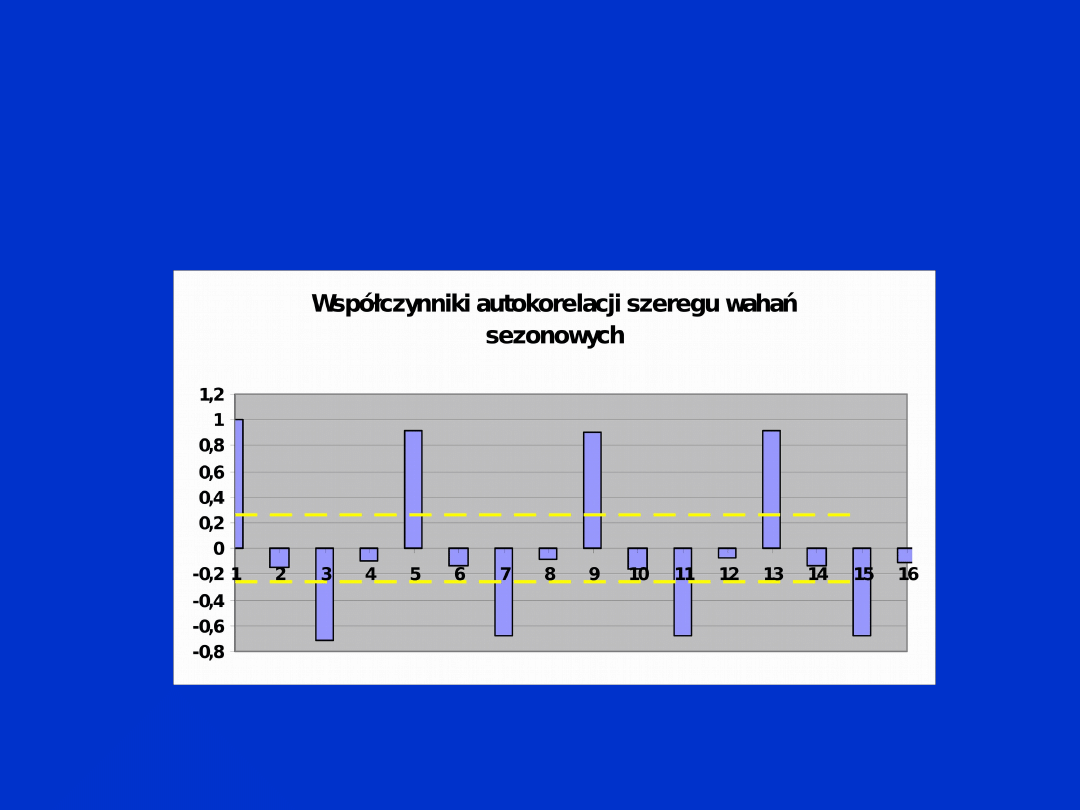
Na przedstawionym wykresie funkcji autokorelacyjnej
zaznaczono liniami poziomymi granice ufności dla tej funkcji. Za
istotne uznaje się te wartości współczynników autokorelacji, które
są większe od górnej granicy przedziału ufności, bądź mniejsze od
dolnej granicy przedziału ufności.
Górna granica
przedziału
ufności
Dolna granica
przedziału
ufności
Istotna
wartość
współczyn
nika
autokorela
cji
39
Cykl wahań
sezonowych
(4)
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
Dla dostatecznie dużej liczebności
n
szeregu wahań sezonowych
S
t
granice ufności dla funkcji autokorelacyjnej tego szeregu
wyznacza się przyjmując, że funkcja ta ma asymptotyczny rozkład
normalny postaci Stąd granice ufności dla funkcji
autokorelacyjnej na poziomie ufności
1-
wyznacza się z
zależności:
przy czym
u
1-
/2
oznacza kwantyl rozkładu normalnego
N(0,1)
rzędu
1-
/2
.
.
n
1
0,
N
2
γ
1
τ
u
n
1
r
40
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
t
y
t
t
y
t
t
y
t
t
y
t
1
86,7
16
99,5
31
-
142,
0
46
-
380,
8
2
133,
3
17
-9,5
32
-
125,
4
47
-
333,
6
3
167,
8
18
13,8
33
-
234,
2
48
-
291,
2
4
204,
9
19
46,9
34
-
244,
9
49
-
405,
7
5
111,
2
20
76,7
35
-
186,
9
50
-
358,
1
6
153,
9
21
-76,9
36
-
192,
0
51
-
306,
6
7
151,
8
22
-66,5
37
-
306,
2
52
-
297,
9
8
190,
1
23
-20,9
38
-
262,
0
53
-
428,
4
9
83,4
24
-2,8
39
-
255,
3
54
-
376,
2
10
103,
7
25
-
115,
2
40
-
242,
7
55
-
289,
8
11
115,
3
26
-
117,
7
41
-
355,
1
56
-
273,
5
12
168,
0
27
-82,6
42
-
316,
9
57
-
379,
2
13
41,4
28
-80,1
43
-
284,
6
58
-
329,
2
14
58,1
29
-
188,
3
44
-
247,
9
59
-
290,
2
15
132,
1
30
-
165,
5
45
-
361,
7
60
-
254,
5
41
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
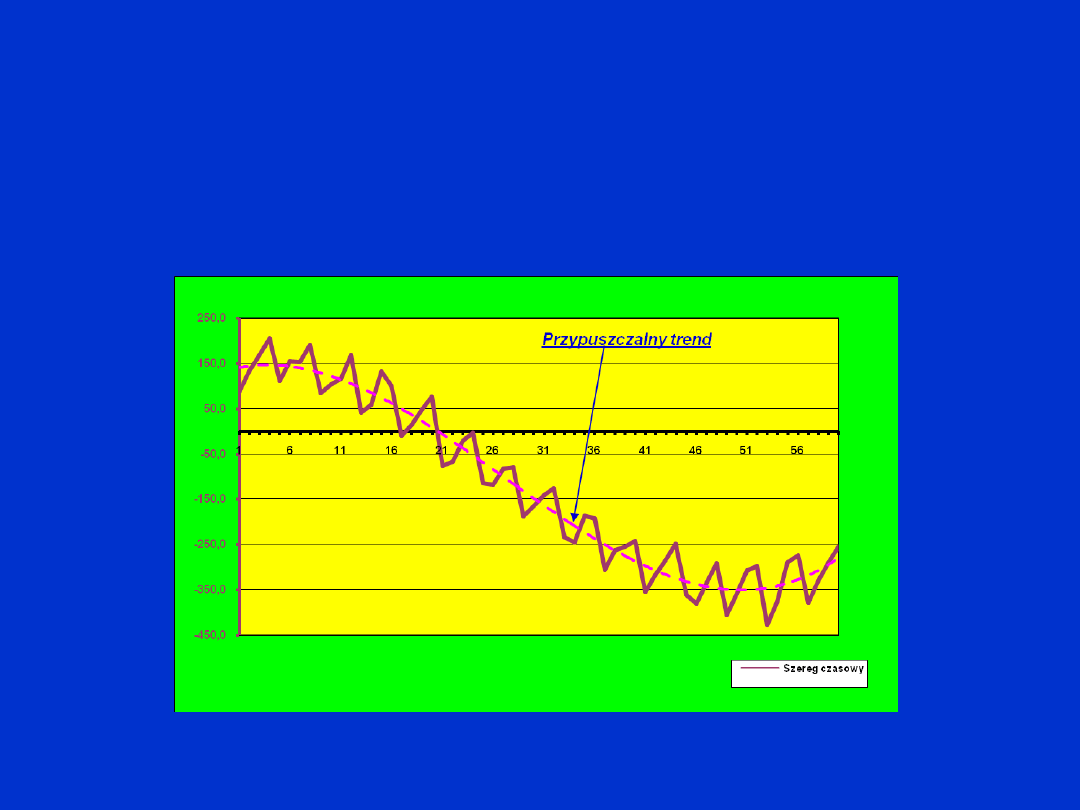
Przykład.
Rozpatruje się
szereg czasowy
o danych jak w
tabeli:
GK (WEiP(6) - 2010)
42
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
Graficzna prezentacja
badanego szeregu
czasowego:

GK (WEiP(6) - 2010)
43
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
Statystyczna identyfikacja występowania trendu:
•Test współczynnika korelacji Pearsona:
• wartość współczynnika korelacji Pearsona:
r = -0,94111
,
• wartość sprawdzianu hipotezy zerowej:
t = 21,19884
,
• wartość krytyczna testu:
t
0,05;58
= 2,001717
,
Ponieważ
t > t
0,05;58
, odrzucana jest hipoteza zerowa o
nieistnieniu trendu –
przyjmuje się hipotezę alternatywną o
istnieniu trendu,
•Test Danielsa:
• wartość współczynnika korelacji rangowej Spearmana:
r
s
=
0,931759,
• wartość krytyczna współczynnika korelacji Spearmana:
r
0,05;60
= 0,236802,
Ponieważ
r > r
0,05;60
, odrzucana jest hipoteza zerowa o
nieistnieniu trendu –
przyjmuje się hipotezę alternatywną o
istnieniu trendu,

GK (WEiP(6) - 2010)
44
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
Statystyczna identyfikacja występowania trendu:
•Test Coxa-Stuarta (dwustronny):
• liczba porównywanych par:
m = 30,
• wartość sprawdzianu hipotezy zerowej:
T = 30,
• wartość krytyczna testu:
C
0,025;30
= 10,
Ponieważ
T > m - C
0,025;30
, odrzucana jest hipoteza zerowa o
nieistnieniu trendu –
przyjmuje się hipotezę alternatywną o
istnieniu trendu,
•Test Coxa-Stuarta (dwustronny) dla dużych liczb:
• liczba porównywanych par:
m = 30,
• liczba znaków „+”:
T = 30,
• wartość sprawdzianu hipotezy zerowej:
z = 5,477226,
• wartość krytyczna testu:
u
0,975
= 1,959964,
Ponieważ
|z| > u
0,975
, odrzucana jest hipoteza zerowa o
nieistnieniu trendu –
przyjmuje się hipotezę alternatywną o
istnieniu trendu.
GK (WEiP(6) - 2010)
45
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
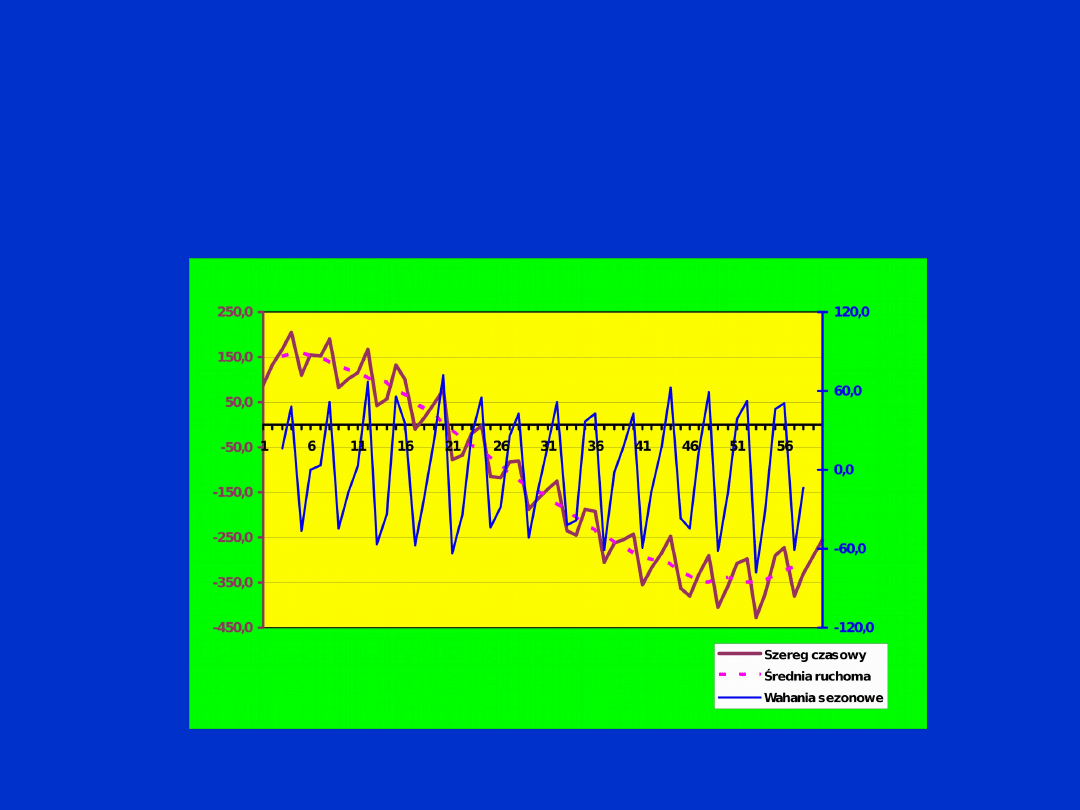
Po wygładzeniu szeregu czasowego średnią ruchomą i
wyodrębnieniu z niego addytywnych wahań sezonowych otrzymuje
się następujące wykresy:

GK (WEiP(6) - 2010)
t
s
t
t
s
t
t
s
t
t
s
t
1
16,
6
16
-
21,
0
31
-
42,
0
46
58,
8
2
48,
0
17
23,
4
32
-
38,
7
47
-
61,
9
3
-
46,
3
18
71,
6
33
36,
6
48
-
16,
9
4
0,3
19
-
63,
5
34
42,
6
49
38,
3
5
3,5
20
-
34,
7
35
-
60,
9
50
52,
1
6
51,
6
21
25,
7
36
-1,8
51
-
78,
2
7
-
44,
3
22
55,
0
37
17,
4
52
-
31,
2
8
-
16,
7
23
-
43,
3
38
42,
9
53
46,
0
9
3,0
24
-
28,
5
39
-
58,
9
54
50,
3
10
66,
6
25
25,
4
40
-
16,
4
55
-
61,
2
11
-
56,
4
26
43,
1
41
17,
4
56
-
13,
6
12
-
33,
2
27
-
51,
8
42
62,
9
57
13
55,
7
28
-
15,
9
43
-
36,
8
58
14
35,
0
29
19,
0
44
-
44,
4
59
15
-
57,
8
30
51,
3
45
13,
7
60
46
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
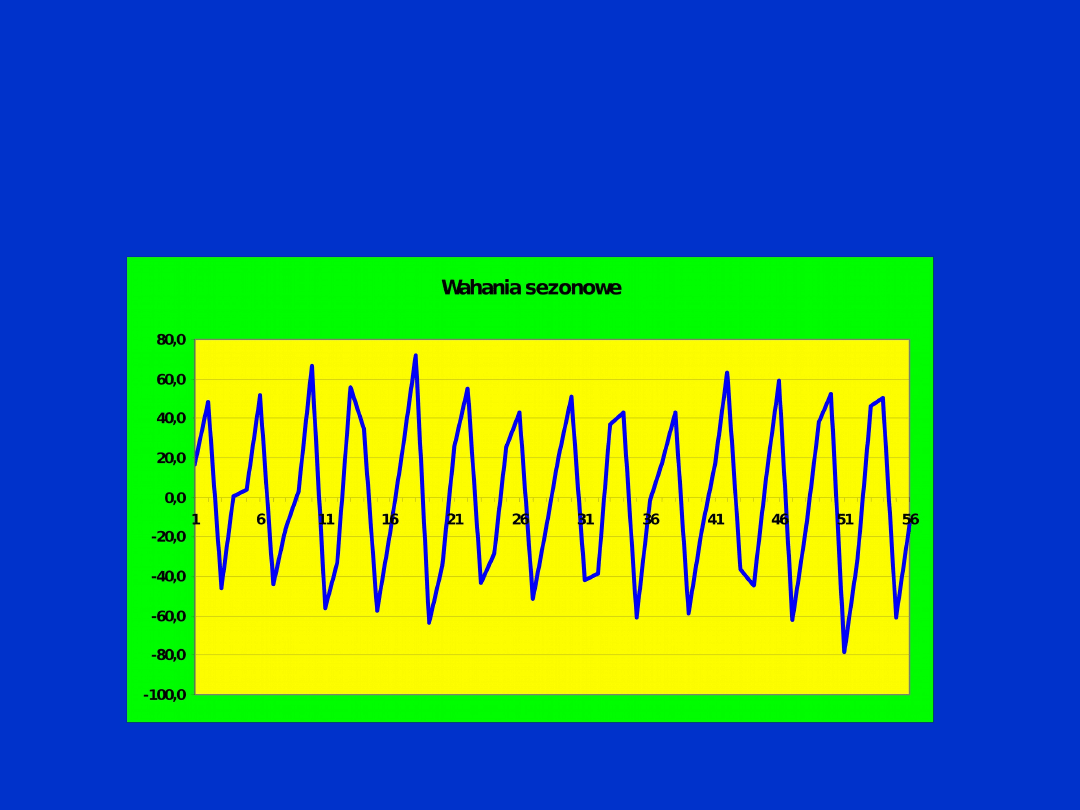
Analizie jest
poddawany szereg
czasowy wahań
sezonowych postaci:
GK (WEiP(6) - 2010)
47
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
Przebieg badanego szeregu czasowego wahań sezonowych
GK (WEiP(6) - 2010)
48
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
Wykres funkcji autokorelacyjnej:

GK (WEiP(6) - 2010)
Modelowanie szeregu czasowego.
Metoda Kleina
modelowania
szeregów czasowych zakłada możliwość modelowania
wahań
sezonowych
za pomocą sztucznych zmiennych
zero-
jedynkowych
. Służy ona do modelowania addytywnych szeregów
czasowych, tj. takich, w których kształtowanie się zmiennej
objaśnianej powstaje w wyniku
sumarycznego
nakładania się
zmian wnoszonych przez wszystkie składowe szeregu . Stąd w
metodzie Kleina wykorzystywany jest następujący model
szeregu czasowego:
•f(t)
– model trendu,
•m
– liczba faz w okresie (rok) wahań roku (np.
l = 4
–
wahania kwartalne),
•π
j
– parametr strukturalny modelu związany z sezonową
zmienną
zero-jedynkową, odpowiadającą
j
-tej fazie,
•Q
j
– sezonowa zmienna zero-jedynkowa odpowiadająca
j
-tej
fazie w okresie.
49
( )
m
t
j
j
t
j 1
(t 1,2,...,n)
y
f tπ Q ε ,
,
=
=
=
+
+
�
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
Sezonowe zmienne zero-jedynkowe
są takimi zmiennymi
objaśniającymi w modelu Kleina, które przyjmują wartość
1
cyklicznie, wskazując fazę, której zostały przypisane. W
przypadku sezonowości występuje sytuacja, gdy zjawisko
jakościowe w postaci efektu sezonowego ( np. tygodniowe,
miesięczne, kwartalne,
półroczne) pojawia się tyle razy, ile cykli obejmuje szereg
czasowy. Przy założeniu, że efekt sezonowości jest stały w
całym szeregu, zmienne
zero-jedynkowe
przeznaczone w
modelu do opisywania efektów poszczególnych faz każdego z
tych cykli będą przyjmowały wartości równe
1
(jedynki) tylko w
przypadku reprezentowania danej fazy. W pozostałych
przypadkach takie zmienne będą przyjmowały wartości równe
0
(zeru), co oznacza że:
50
[
]
[
]
j
gdy
t mod m
j
j 1,2,...,m; t 1,2,...,n
gdy
t mod m
j
1,
Q
,
.
0,
=
=
=
�
�
=�
�
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
W modelu z wyrazem wolnym (taki jest rozpatrywany) nie
można uwzględnić wszystkich sezonowych zmiennych zero-
jedynkowych, gdyż spowoduje to ścisłą współliniowość zmiennych
objaśniających (suma zmiennych sezonowych jest identyczna ze
zmienną związaną z wyrazem wolnym), co wyklucza zastosowanie
KMNK do szacowania parametrów strukturalnych modelu. Drogą
do rozwiązania tego problemu jest przyjęcie założenia, że w
ramach każdego cyklu efekty sezonowe równoważą się (sumują
się do zera), tzn. zachodzi:
Przyjęte założenie umożliwia usunięcie współliniowości z modelu
poprzez następującą transformację:
m
j
j 1
π
0
=
=
�
51
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
( )
(
)
m 1
t
j
j
m
t
j 1
(t 1,2,...,n)
y
f tπ Q Q
ε ,
.
-
=
=
=
+
-
+
�
GK (WEiP(6) - 2010)
52
Oszacowanie wartości parametrów strukturalnych
rozpatrywanego modelu otrzymuje się z następującej
zależności:
gdzie:
a
– oszacowania parametrów trendu,
p
– oszacowania parametrów zmiennych sezonowych.
Macierz
X
wartości empirycznych zmiennych objaśniających
jest postaci:
gdzie oznaczają odpowiednio macierz jedynkową
n
× 1
, macierz
n × k
, której kolumny zawierają wartości kolejnych zmiennych
objaśniających trendu,
(i=1,2,…,k)
, macierz o wymiarach
n ×
(m-1)
, której kolumny zawierają wartości kolejnych zmiennych
objaśniających
Q
j
-Q
m
.
y
X
X)
(X
q
T
1
T
(k m) 1
a
q
p
+ �
��
=��
��
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
,
...
...
Q
t
X
X
X
1
Q
t
X
X ,
,
1

Macierz wariancji i kowariancji ocen parametrów
strukturalnych modelu jest postaci:
przy czym wariancję odchyleń losowych (wariancja reszt)
wyznacza się z zależności:
Oszacowanie
p
m
parametru
π
m
wyznacza się z zależności:
gdzie
p
j
oznacza oszacowanie parametru strukturalnego
π
j
,
związanego z
j
-tą
zmienną sezonową.
GK (WEiP(6) - 2010)
n
2
T
t
2
t 1
e
e
e e
S
n k m n k m
=
=
=
- -
- -
�
1
T
2
e
2
X)
(X
S
)
q
(
D
53
m 1
m
j
j 1
p
p
-
=
=-
�
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych

GK (WEiP(6) - 2010)
54
Wariancja oszacowania
p
m
parametru
π
m
wyraża się następującą
zależnością:
gdzie elementy
d
js
są elementami macierzy
D
2
(q)
.
Po oszacowaniu parametrów strukturalnych metodą
KMNK model przyjmie ostateczną postać:
Prognoza punktowa w okresie prognozy
T
dla modelu Kleina:
k m
k m k m
2
m
jj
js
j k 2
j k 2 s k 2
s j
S (p )
d
d
+
+
+
= +
= + = +
�
=
+
�
� �
( )
m 1
m 1
t
j
j
m
j
j 1
j 1
(t 1,2,...,n).
ˆ
ˆy
f t
p Q Q
p ,
-
-
=
=
=
=
+
� -
�
�
�
Prognozowanie na podstawie
modeli trendu i wahań
sezonowych
.
ˆ
m
j
j
j
p
T
Q
p
T
f
y
1

GK (WEiP(6) - 2010)
55
Prognozowanie na podstawie
modeli adaptacyjnych
Prognozowanie z wykorzystaniem modeli
adaptacyjnych jest właściwie prognozowaniem przebiegu
zjawiska tylko na podstawie opisującego je szeregu
czasowego. Prognostyk ma więc do dyspozycji tylko
wartości empiryczne zmiennej objaśnianej związane z
czasem, tj. ma do dyspozycji ciąg postaci:
Wśród metod wykorzystywanych w prognozowaniu
szeregów czasowych na podstawie modeli adaptacyjnych
najczęściej są wykorzystywane metody należące do
następujących podstawowych klas:
•metody naiwne,
•metody oparte na średnich,
•metody wyrównywania wykładniczego.
.
...
n
2
1
,y
,
,y
y

GK (WEiP(6) - 2010)
56
Metody należące do wymienionych klas są
stosowane do prognozowania krótkookresowego,
obejmującego zwykle okres prognozowania
T=n+1
, tj. czas
następujący zaraz po czasie, w którym została
zaobserwowana ostatnia wartość zmiennej objaśnianej,
tzn.
y
n
.
Omawiane metody prognozowania są stosowane w
przypadkach, gdy nie ma się pewności co do stabilności w
czasie modelu ekonometrycznego opisującego zmiany
zjawiska reprezentowanego przez zmienną objaśnianą. Tak
więc modele adaptacyjne nie zakładają stałości w czasie
analitycznej postaci funkcji trendu ani parametrów w niej
występujących. W procesie prognozowania opartym na
tych modelach przyjmuje się, że rozwój obserwowanego
zjawiska w czasie może być segmentowy, tj. gładki tylko w
pewnych przedziałach czasu. Istotnym założeniem
koniecznym do poprawnego zastosowania modeli
adaptacyjnych opartych na omawianych metodach jest
założenie stacjonarności w czasie błędów predykcji.
Prognozowanie na podstawie
modeli adaptacyjnych

GK (WEiP(6) - 2010)
57
Prognozowanie na podstawie
modeli adaptacyjnych
(metody naiwne)
Metody naiwne
należą do najprostszych metod
prognozowania. Prognozowanie naiwne opiera się na
założeniu, że najlepszą informacją przy tworzeniu
prognozy na okres
T=n+1
jest informacja o wartości lub
zmianie wartości zmiennej objaśnianej w chwili
n
, tj.
wartości
y
n
.
Omawiane metody w praktyce występują w wielu
odmianach (wariantach):
metoda oparta na błądzeniu losowym
wokół pewnego
stałego poziomu, a szereg czasowy opisujący zmiany
zmiennej objaśnianej nie wykazuje żadnej wyraźnej
tendencji rozwojowej (trendu) ani wahań sezonowych. W
tym przypadku za prognozę zjawiska przyjmuje się
ostatnią wartość empiryczną, tj.
,
n
p
T
y
y

GK (WEiP(6) - 2010)
58
metoda dla szeregu czasowego z trendem
- szereg
czasowy opisujący zmiany zmiennej objaśnianej oprócz
wahań przypadkowych wykazuje wyraźną tendencję
rozwojową (trend), natomiast nie wykazuje wahań
sezonowych. W tym przypadku za prognozę zjawiska
przyjmuje się nie tylko ostatnią wartość empiryczną
zmiennej objaśnianej, ale również ostatnio
zaobserwowaną tendencję zmian, tj.:
•
dla zmian zmiennej objaśnianej wyrażanych w sposób
bezwzględny:
•
dla zmian zmiennej objaśnianej wyrażanych w sposób
względny:
,
y
y
y
y
1
n
n
n
p
T
,
y
y
y
y
1
n
n
n
p
T
Prognozowanie na podstawie
modeli adaptacyjnych
(metody naiwne)

GK (WEiP(6) - 2010)
59
metoda dla szeregu czasowego z wahaniami sezonowymi
- szereg czasowy opisujący zmiany zmiennej objaśnianej
oprócz wahań przypadkowych wykazuje wahania
sezonowe wokół pewnego stałego poziomu bez wyraźnej
tendencji rozwojowej (trendu). W tym przypadku za
prognozę zjawiska przyjmuje się ostatnią wartość
empiryczną zmiennej objaśnianej dla sezonu o numerze
m
, odpowiadającemu sezonowi w okresie
prognozowanym
T=n+1
, tj.:
W przypadku, gdy oszacowane zostały wskaźniki
sezonowości prognoza jest tworzona według zależności:
przy czym
a)
oznacza wahania multiplikatywne, a
b)
–
addytywne.
,
y
y
m
1
n
p
T
,m
1,2,
j
,
n
g
T
g
y
y
b
n
w
T
w
y
y
a
j
j
n
p
T
j
j
n
p
T
lub
...
Prognozowanie na podstawie
modeli adaptacyjnych
(metody naiwne)

GK (WEiP(6) - 2010)
60
Prognozowanie na podstawie
modeli
adaptacyjnych
(metody oparte na
średnich)
W
metodach opartych na średnich
prognozowanie
wartości zmiennej objaśnianej odbywa się na podstawie
większej liczby obserwacji niż w metodach naiwnych.
Omawiane metody mogą być wykorzystywane w
przypadkach, gdy szereg czasowy wykazywał w
przeszłości wahania losowe wokół pewnego stałego
poziomu
. Dokładność prognoz może być tylko oceniania
na podstawie błędów
ex post
dla prognoz wygasłych
(podobnie jak dla metod naiwnych).
Do najczęściej stosowanych nalezą metody
prognozowania na podstawie:
zwykłych średnich,
średnich ruchomych,
średnich ważonych.

GK (WEiP(6) - 2010)
61
Charakterystyka poszczególnych metod:
metoda prognozowania na podstawie średnich zwykłych
– uwzględnia się wszystkie dane empiryczne występujące
w szeregu czasowym tj.:
Zaletą rozpatrywanej metody jest jej prostota, ale wadą
jest uwzględnianie w prognozie wszystkich obserwacji
niezależnie od ich „wieku” jako jednakowo ważnych,
chociaż w wielu przypadkach dane starsze często nie
odzwierciedlają najnowszej tendencji rozwoju zmiennej
objaśnianej, zawartej w jej „najmłodszych” danych
empirycznych.
,
...
n
2
1
,y
,
,y
y
,
y
n
1
y
y
n
1
t
t
p
T
Prognozowanie na podstawie
modeli
adaptacyjnych
(metody oparte na
średnich)

GK (WEiP(6) - 2010)
62
metoda prognozowania na podstawie średnich
ruchomych
– średnia ruchoma uwzględnia starzenie się
informacji poprzez okresową wymianę najstarszej
danej empirycznej na nową. Prognoza jest wyznaczana
z zależności:
przy czym
h
oznacza rząd średniej ruchomej.
Ponieważ wszystkie dane wykorzystywane do obliczania
średniej ruchomej wywierają taki sam wpływ na
prognozę, najważniejszym problemem, który należy
rozwiązać jest kompromisowe ustalenie rzędu średniej
ruchomej, bowiem rząd wysoki oznacza lepsze
wygładzanie szeregu, a rząd niski – mniejszy wpływ na
prognozę starzejących się danych.
n
p
T
t
t n h 1
1
y
y ,
h
= - +
=
�
Prognozowanie na podstawie
modeli
adaptacyjnych
(metody oparte na
średnich)

GK (WEiP(6) - 2010)
63
metoda prognozowania na podstawie średnich
ważonych
– średnia ważona uwzględnia starzenie się
informacji poprzez zmniejszenie ich wpływu na
prognozowana wartość zmiennej objaśnianej. Osiąga
się to poprzez przyporządkowanie zróżnicowanych wag
poszczególnym danym, wykorzystywanym do obliczania
średniej. Wagi
w
t
uwzględniające starzenie się
informacji powinny spełniać następujące wymagania:
przy czym
h
oznacza rząd średniej ruchomej.
[ ]
t
h
t
t 1
t 1
t
t 1
t
t
t 1
t 1,2,...,h,
t 1,2,...,h 1,
t 1,2,...,h 1,
w
0,1 ,
w 1,
w
w ,
w
w
w w ,
=
+
+
-
=
=
-
=
-
�
=
>
-
� -
�
Prognozowanie na podstawie
modeli
adaptacyjnych
(metody oparte na
średnich)

GK (WEiP(6) - 2010)
64
Prognoza jest ustalana z następującej zależności:
Wagi
w
t
mogą być ustalane według różnych zasad, ale
najczęściej spotykanymi są wagi:
•
liniowe opisane zależnością:
•
harmoniczne opisane zależnością:
n
p
T
t
t
t n h 1
y
w y .
= - +
=
�
�
(
)
t
t 1,2,...,h,
2t
w
,
h h 1
=
=
+
(
)
t
t 1
0
t 1,2,...,h,
1
w
w
,
w
0.
h h 1 t
-
=
=
+
=
+ -
Prognozowanie na podstawie
modeli
adaptacyjnych
(metody oparte na
średnich)

GK (WEiP(6) - 2010)
65
Przykład:
Przyjęte parametry: rząd średniej ruchomej
p = 3
,
wagi harmoniczne:
w
1
= 0,111111
,
w
2
= 0,277778
,
w
3
=
0,611111
.
t
Dane
Średnia
zwykła
Błąd
bezwzględn
y
Średnia
ruchom
a
Błąd
bezwzględn
y
Średnia
ważona
Błąd
bezwzględ
ny
1
199,9
-
-
-
-
-
-
2
200,2
199,90
0,30
-
-
-
-
3
200,7
200,05
0,65
-
-
-
-
4
198,9
200,27
1,37
200,27
1,37
200,47
1,57
5
200,1
199,93
0,18
199,93
0,17
199,54
0,56
6
201,2
199,96
1,24
199,90
1,30
199,83
1,37
7
200,0
200,17
0,17
200,07
0,07
200,64
0,64
8
199,5
200,14
0,64
200,43
0,93
200,34
0,84
9
201,1
200,06
1,04
200,23
0,87
199,83
1,27
10
200,1
8
0,70
200,2
0
0,78
200,5
3
1,04
Prognozowanie na podstawie
modeli
adaptacyjnych
(metody oparte na
średnich)

GK (WEiP(6) - 2010)
66
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)
Wyrównywanie (wygładzanie ) wykładnicze
jest
metodą prognozowania wykorzystywaną do ustalania
prognoz krótkookresowych. Prognozowanie opiera się na
ciągłej aktualizacji prognoz wraz z napływem nowych
obserwacji o wartościach prognozowanej zmiennej
objaśnianej oraz o trafności wcześniejszych prognoz.
Przyszłe wartości zmiennej objaśnianej są ustalane na
podstawie średniej ważonej wszystkich dotychczasowych
obserwacji, przy czym wagi przyporządkowane
poszczególnym zaobserwowanym wartościom zmiennej
objaśnianej maleją wraz z ich wiekiem co powoduje, że
obserwacje starsze mają mniejszy wpływ na prognozę.
Mankamentem omawianych metod jest to, że
dokładność prognoz uzyskiwanych za ich pomocą może
być określana jedynie na podstawie błędu
ex post
,
szacowanego na podstawie prognoz wygasłych.

GK (WEiP(6) - 2010)
67
Podstawowym założeniem warunkującym
stosowanie metod wyrównywania wykładniczego jest
założenie o tym, że przyrosty wartości trendu zmiennej
objaśnianej są w przybliżeniu stałe lub zmieniają w
regularny sposób.
Omawiane metody w praktyce występują w wielu
odmianach (wariantach):
metoda oparta na błądzeniu losowym
wokół pewnego
stałego poziomu, a szereg czasowy opisujący zmiany
zmiennej objaśnianej nie wykazuje żadnej wyraźnej
tendencji rozwojowej (trendu) ani wahań sezonowych.
Równanie rekurencyjne, stanowiące podstawę
prognozowania wartości zmiennej objaśnianej
y
n
w okresie
T
, tj.
.
,
y
y
α
y
y
α
1
αy
y
0,1
α
1;
n
T
p
n
n
p
n
p
n
n
p
T
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
68
Z przedstawionej zależności wynika, że
prognozowanie z wykorzystaniem omawianej metody
polega na powtarzającym się co okres korygowaniu
ostatniej prognozy, poprzez uwzględnienie najświeższej
informacji o odchyleniu rzeczywistej (zaobserwowanej)
wartości zmiennej objaśnianej od postawionej wcześniej
prognozy. Prognoza w okresie
T
zmiennej objaśnianej
jest więc średnią ważoną rzeczywistej (zaobserwowanej)
wartości zmiennej objaśnianej na okres o 1 wcześniejszy
od prognozowanego oraz sporządzonej na tenże okres jej
prognozy. Rolę wag pełni
stała wygładzania
(wyznaczana doświadczalnie) oraz jej dopełnienie do
1
.
Małe wartości
preferują prognozy w
interesującym okresie zbliżone do prognoz z okresu
bezpośrednio poprzedzającego okres prognozowania.
Takie rozwiązanie stosuje się w przypadku oczekiwanych
rzadkich i niewielkich odchyleń wartości zmiennej
objaśnianej od trendu. W przeciwnym przypadku
powinno się dobierać
zbliżone do
1
.
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
69
Przykład.
Stosując metodę wyrównywania wykładniczego
ustalić prognozę na 2003 rok liczby nowelizowanych
ustaw gospodarczych (dane w tabeli).
Rozwiązanie.
Obliczenia zestawiono w tabeli. Jako
wartości początkowe przyjęto . Przyjęto stałą
wygładzania
= 0,8
.
1
p
1
y
y
Rok
t
Liczba
nowelizacji
ustaw gosp.
Prognoza
y
p
t
Błąd
bezwzględ
ny
prognozy
1995
1
10
10
-
1996
2
11
10
1,00
1997
3
35
11
24,00
1998
4
19
30
-11,00
1999
5
9
21
-12,00
2000
6
16
11
5,00
2001
7
24
15
9,00
2002
8
26
22
4,00
2003
9
-
25
2,86
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
70
metoda dla szeregu czasowego z wahaniami sezonowymi
- szereg czasowy opisujący zmiany zmiennej objaśnianej
oprócz wahań przypadkowych wykazuje wahania
sezonowe wokół pewnego stałego poziomu bez wyraźnej
tendencji rozwojowej (trendu). W tym przypadku tworzy
się nowe zmienne
objaśniane postaci:
gdzie
g
j
(t)
oraz
w
j
(t)
oznaczają wskaźniki sezonowe
(addytywne i multiplikatywne odpowiednio) dla sezonów
j=1,2,…,m
,
dla których wyznacza się prognozy z wykorzystaniem
wygładzania wykładniczego, a następnie prognozy dla
pierwotnych zmiennych prognozowanych według
następujących zależności:
,m
1,2,
j
,
t
w
y
z
t
g
y
z
j
j
j
j
j
j
lub
...
p
T
z
.
...,m
1,2,
j
,
T
w
z
y
T
g
z
y
j
p
T
p
T
j
p
T
p
T
lub
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
71
metoda dla szeregu czasowego z trendem
- szereg
czasowy opisujący zmiany zmiennej objaśnianej nie jest
stacjonarny, tzn., że oprócz wahań przypadkowych
wykazuje wyraźny trend i nie wykazuje wahań
sezonowych. W tym przypadku, aby pozbyć się
systematycznych błędów prognozy, stosuje się
model
Holta (metoda podwójnego wygładzania wykładniczego)
,
uwzględniający długookresową tendencję rozwojową w
szeregu czasowym, o której zakłada się, że ma charakter
liniowy.
Model Holta
składa się z następujących trzech
równań:
•
równanie wygładzające część stałą szeregu
czasowego:
,
,
y
y
α
y
y
α
1
αy
d
c
α
1
αy
c
0,1
α
;
,n,
2,3,
t
p
t
t
p
t
p
t
t
1
t
1
t
t
t
...
...
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
72
•
równanie wygładzające przyrost szeregu czasowego:
•
równania prognozy:
gdzie
i
oznaczają stałe wygładzania odpowiednio
części stałej szeregu czasowego oraz jego trendu.
,
t
,
y
y
αβ
d
d
β
1
c
c
β
d
0,1
β
;
,n,
2,3,
p
t
t
1
t
1
t
1
t
t
t
...
...
,...
...
,
,n
2,3,
t
1
t
1
t
p
t
d
c
y
W przypadku, gdy prognozowanie będzie dotyczyć nie
jednego, ale
k
okresów naprzód, prognozę, przy
założeniu stałości przyrostu trendu, można wyznaczyć z
zależności:
.
d
k
c
y
n
n
p
k
T
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
73
Przed rozpoczęciem procedury podwójnego
wyrównywania wykładniczego konieczne jest ustalenie
wartości początkowych dla
c
1
oraz
d
1
. Najczęściej
przyjmuje się
oraz
y
c
y
c
1
1
1
lub
.
0
d
y
y
d
1
1
2
1
lub
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)
GK (WEiP(6) - 2010)
74
Przykład.
Stosując metodę podwójnego wyrównywania
wykładniczego uwzględniającego trend ustalić prognozę
na 2003 rok poziom finansowy inwestycji francuskich w
Polsce (dane w tabeli).
Rozwiązanie.
Obliczenia zestawiono w tabeli. Jako
wartości początkowe przyjęto
c
1
= y
1
,
d
1
= 0
. Przyjęto
stałe wygładzania:
= 0,4
oraz
= 0,9
.
Rok
t
Inwestyc
je [tys.
USD]
c
t
d
t
Prognoz
a y
p
t
Błąd
bezwzględn
y prognozy
1995
1
737,30
737,30
0,00
-
-
1996
2
973,40
831,74
85,00
737,30
236,10
1997
3
1088,99
985,64
147,01
916,74
172,25
1998
4
1402,60
1240,63
244,19
1132,65
269,95
1999
5
1546,60
1509,53
266,43
1484,82
61,78
2000
6
1707,80
1748,70
241,90
1775,96
-68,16
2001
7
1975,50
1984,56
236,46
1990,60
-15,10
2002
8
2261,20
2237,09
250,92
2221,02
40,18
2003
9
-
-
-
2488,0
1
99,57
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
75
Przykładowe obliczenia:
.
1484,82
244,19
1240,63
d
c
y
244,19
147,01
0,9
1
985,64
1240,63
0,9
d
β
1
c
c
β
d
1240,63
147,01
985,64
0,4
1
1402,60
0,4
d
c
α
1
y
α
c
4
4
p
5
3
3
4
4
3
3
4
4
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
76
metoda dla szeregu czasowego z trendem i wahaniami
sezonowymi
- szereg czasowy opisujący zmiany zmiennej
objaśnianej nie jest stacjonarny, tzn., że oprócz wahań
przypadkowych wykazuje wyraźny trend oraz wahania
sezonowe. W tym przypadku, aby pozbyć się
systematycznych błędów prognozy, stosuje się
model
Wintersa (metoda potrójnego wygładzania
wykładniczego – rozszerzenie metody Holta)
,
uwzględniający długookresową tendencję rozwojową w
szeregu czasowym, o której zakłada się, że ma charakter
liniowy oraz wahania sezonowe. Prognoza jest
wyznaczana sekwencyjnie.
Model występuje w dwóch wariantach:
model multiplikatywny – wahania sezonowe mają
charakter multiplikatywny,
model addytywny - wahania sezonowe mają charakter
addytywny.
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
77
Model multiplikatywny
obejmuje następujące równania:
i.
równanie wygładzające część stałą szeregu czasowego,
ii.
równanie wygładzające przyrost (trend) szeregu czasowego,
iii.
równanie wygładzające wskaźnik sezonowości,
iv.
równanie prognozy bieżącej,
v.
równanie prognozy na następny okres jednoimienny:
gdzie
m
oznacza długość cyklu sezonowego (liczba faz cyklu).
)
(
)
(
)
(
]
)
(
)
(
)
)
(
)
)
(
)
)
(
)
(
)
t
t
t 1
t 1
t m
t
t
t 1
t 1
t
t
t m
t
p
t
t 1
t 1
t m
p
T
n
n
T m
t 1,2,3,...,n,...;α,β,γ
0,1
y
Fα
1 α
F
S
,
,
C
Sβ F F
1 β S ,
y
Cγ
1 γ C
,
F
iv y
F
S
C
,
y
F
T n S C
.
i
ii
iii
v
-
-
-
-
-
-
-
-
-
-
=
�
=
+ -
�
+
=
-
+ -
�
=
+ -
�
=
+
�
=
+
-
�
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
78
Potrójne wygładzanie (wyrównywanie) wykładnicze wymaga
ustalenia
m+2
wartości początkowych, tj.
F
0
,
S
0
oraz wskaźników
sezonowości
C
1
, C
2
, …, C
m
. Jako wartości początkowe
F
0
oraz
S
0
przyjmuje się:
Początkowe wartości dla wskaźników sezonowości przyjmuje się
równe:
a przyporządkowuje się je sezonom z roku poprzedniego,
poprzedzającego ten, z którego pochodzą pierwsze obserwacje.
0
1
0
2m
m
t
t
t m 1
t 1
0
0
2
lub
lub
F
y
F
y,
y
y
S
0
S
.
m
= +
=
=
=
-
=
=
� �
( )
( )
( )
( )
( )
1 0
2 0
m 0
m
j 0
j 1
j
m
j 0
i
i 1
lub
przy czym
j 1,2,...,m
C
C
... C
1
C
m
y
C
,
1
y
m
=
=
=
�
�
�
=
= =
=
�
�
=
�
�
�
=
�
�
�
�
�
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
79
Przykład.
Jest dany szereg czasowy obrazujący sprzedaż
wybranego produktu na przestrzeni 4 kolejnych lat. Należy
wyznaczyć prognozę sprzedaży tego produktu na następny
rok.
Rozwiązanie.
Z analizy szeregu czasowego wynika, że
charakteryzuje się on zarówno trendem, jak i kwartalną
sezonowością multiplikatywną. Prognozowanie zostanie
oparte na modelu wygładzania wykładniczego Wintersa.
Jako wartości początkowe przyjęto:
dla części stałej
F
0
= 13237,50
,
dla trendu
S
0
= 0,0000
,
dla wskaźników sezonowości
C
1(0)
= C
2(0)
= C
3(0)
= C
4(0)
= 1
,
parametry:
= 0,2,
= 0,1,
= 0,3
.
Wyniki obliczeń są zamieszczone w tabeli na kolejny
slajdzie.
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)
GK (WEiP(6) - 2010)
80
Rok
Kwartał
t
Sprzedaż
F
t
S
t
C
t
Prognoza
Błąd ex post
na podstawie
prognoz
wygasłych
0
I
-3
1,0000
-
II
-2
1,0000
-
III
-1
1,0000
-
IV
0
13237,50
0,0000
1,0000
-
1
I
1
5100
11610,00
-162,7500
0,8318
13237,50
-8137,50
II
2
9800
11117,80
-195,6950
0,9644
11447,25
-1647,25
III
3
15200
11777,68
-110,1371
1,0872
10922,11
4277,90
IV
4
11300
11594,04
-117,4880
0,9924
11667,55
-367,55
2
I
5
6100
10647,97
-200,3461
0,7541
9546,00
-3446,00
II
6
12300
10908,80
-154,2285
1,0134
10076,11
2223,89
III
7
18400
11988,58
-30,8273
1,2215
11692,08
6707,92
IV
8
13200
12226,44
-3,9584
1,0186
11866,78
1333,22
3
I
9
7200
11687,52
-57,4550
0,7127
9217,12
-2017,12
II
10
14100
12086,85
-11,7762
1,0593
11785,53
2314,47
III
11
20700
13049,45
85,6611
1,3309
14749,21
5950,79
IV
12
14800
13414,15
113,5646
1,0440
13378,93
1421,07
4
I
13
8600
13235,56
84,3493
0,6938
9641,07
-1041,07
II
14
15700
13620,08
114,3665
1,0873
14110,10
1589,90
III
15
22800
14413,80
182,3020
1,4062
18279,22
4520,78
IV
16
16500
14837,84
206,4757
1,0644
15238,15
1261,85
Prognoza 5
I
17
10437,94
II
18
16582,80
III
19
21735,66
IV
20
16672,45

GK (WEiP(6) - 2010)
81
Model addytywny
obejmuje następujące cztery równania:
i.
równanie wygładzające część stałą szeregu czasowego,
ii.
równanie wygładzające przyrost (trend) szeregu czasowego,
iii.
równanie wygładzające wskaźnik sezonowości,
iv.
równanie prognozy bieżącej,
v.
równanie prognozy na następny okres jednoimienny:
gdzie
m
oznacza długość cyklu sezonowego (liczba faz cyklu).
)
(
)
(
)
(
)
(
]
)
(
)
(
)
)
(
)
(
)
)
)
(
)
t
t
t m
t 1
t 1
t
t
t 1
t 1
t
t
t
t m
p
t
t 1
t 1
t m
p
T
n
n
T m
t 1,2,3,...,n,...;α,β,γ
0,1
Fα y C
1 α
F
S
,
,
Sβ F F
1 β S ,
Cγ y F
1 γ C ,
y
F
S
C
,
y
F
T n S
C
.
i
ii
iii
iv
v
-
-
-
-
-
-
-
-
-
-
=
�
=
-
+ -
�
+
=
-
+ -
�
=
-
+ -
�
=
+
+
=
+
-
� +
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)

GK (WEiP(6) - 2010)
82
Wartości początkowe
F
0
,
S
0
są ustalane tak, jak dla modelu
multiplikatywnego, tj.:
natomiast początkowe wartości dla wskaźników sezonowości
przyjmuje się równe:
a przyporządkowuje się je sezonom z roku poprzedniego,
poprzedzającego ten, z którego pochodzą pierwsze obserwacje,
bowiem one posłużą do utworzenia pierwszej prognozy.
0
1
0
0
0
m 1
1
lub
lub
F
y
F
y,
S
0
S
y
y .
+
=
=
=
=
-
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)
( )
( )
( )
( )
( )
1 0
2 0
m 0
m
j 0
j 1
m
j
i
j 0
i 1
lub
przy czym
j 1,2,...,m
C
C
... C
0
C
0
1
C
y
y ,
m
=
=
=
�
�
=
= =
=
�
�
=
�
�
�
= -
�
�
�
�

GK (WEiP(6) - 2010)
83
Stałe
,
i
są dobierane doświadczalnie, np. na
podstawie kryterium najmniejszego błędu średniego
prognoz wygasłych, tj.
Większe wartości tych stałych powodują, że na prognozę
wywierają większy wpływ dane najnowsze, a mniejsze
wartości stałych dają lepsze wygładzenie wahań
występujących w szeregu czasowym.
Prognozowanie na podstawie
modeli adaptacyjnych
(wyrównywanie wykładnicze)
(
)
(
)
s
2
p
t
t
, ,
t 1
, ,
1
min
y
y
.
s
a b g
a b g
=
-
�

GK (WEiP(6) - 2010)
84
Rozpatrywany dalej model jest
modelem
autoregresyjnym AR(p) rzędu p
postaci:
W praktyce najczęściej rozpatruje się modele liniowe lub
logarytmiczno-liniowe. W przypadku pierwszym model jest
postaci:
a w przypadku drugim:
gdzie:
y
t
- zmienna objaśniana w chwili (okresie)
t
;
y
t-i
–
zmienna objaśniana opóźniona w czasie
(i=1,2,…,p)
;
p
– rząd
autoregresji.
(
)
t
t 1
t 2
t p
t
t 1,2,...,n
.
y
f y ,y ,...,y ,ε ,
-
-
-
=
=
p
t
0
i
t i
t
i 1
t 1,2,...,n
.
lnyα
αlny
ε ,
-
=
=
= +
+
�
,n
1,2,
t
,
ε
y
α
α
y
t
p
1
i
i
t
i
0
t
...
Prognozowanie na podstawie
modeli autoregresyjnych

GK (WEiP(6) - 2010)
85
Parametry strukturalne modelu autoregresyjnego
AR(p)
można estymować wykorzystując KMNK lub układ
równań Yule’-Walkera postaci:
Zamieniając w nim teoretyczne wartości współczynników
autokorelacji
k
(k=1,2…,p)
na wartości tych
współczynników
r
k
oszacowane z szeregu czasowego,
otrzymuje się tzw. oszacowania Yule’-Walkera dla
parametrów strukturalnych modelu
AR(p)
.
1
1
2 1
p p 1
2
1 1
2
p p 2
p
1 p 1
2 p 2
p
ρ
α
α ρ
...
α ρ
ρ
α ρ
α
...
α ρ
.
... ...
...
...
...
ρ
α ρ
α ρ
...
α
-
-
-
-
=
+
+
+
�
�
=
+
+
+
�
�
�
�
=
+
+
+
�
Prognozowanie na podstawie
modeli autoregresyjnych

GK (WEiP(6) - 2010)
86
Najbardziej zadawalającym estymatorem funkcji
autokorelacji
k
jest estymator postaci:
W praktyce przyjmuje się, że rząd
p
autokorelacji nie
powinien przekraczać
n/4
, tj
25%
liczebności szeregu
czasowego.
n k
t
t k
t 1
k
n
2
t
t 1
k 1,2,..., p.
(y
y)(y
y)
r
,
(y
y)
-
+
=
=
=
-
-
=
-
�
�
Prognozowanie na podstawie
modeli autoregresyjnych

GK (WEiP(6) - 2010)
87
Model autoregresji
AR(p)
w zapisie macierzowym
przyjmuje postać:
gdzie:
ε
Xα
y
n
2
p
1
p
p
1
0
p
n
2
n
1
n
2
p
1
p
1
1
p
p
n
2
p
1
p
ε
ε
ε
ε
,
α
α
α
α
,
y
y
y
1
y
y
y
1
y
y
y
1
X
,
y
y
y
y
...
...
...
...
...
...
...
...
...
...
...
Prognozowanie na podstawie
modeli autoregresyjnych

GK (WEiP(6) - 2010)
88
Estymując model
AR(p)
za pomocą KMNK
otrzymuje się następujące estymatory parametrów
strukturalnych, wariancji resztowej oraz macierzy
dokładności oszacowania parametrów strukturalnych
modelu:
y
X
X
X
a
T
1
T
1
T
2
e
2
X
X
S
a
D
n
1
p
t
2
t
2
e
e
1
p
p
n
1
S
Prognozowanie na podstawie
modeli autoregresyjnych
GK (WEiP(6) - 2010)
89
Współczynniki determinacji
R
2
określający
dopasowanie modelu do danych empirycznych wyznacza
się z zależności:
gdzie:
.
n
1
p
t
2
t
n
1
p
t
2
t
2
y
y
e
1
R
n
1
p
t
t
y
p
n
1
y
Prognozowanie na podstawie
modeli autoregresyjnych

GK (WEiP(6) - 2010)
90
Przy budowaniu modeli
AR(p)
występuje problem
określenia rzędu autoregresji, czyli parametru
p
. Jedną z
często wykorzystywanych metod do wyznaczania tego
parametru jest metoda oparta na szacowaniu parametrów
modelu dla różnych opóźnień. Podstawą wyboru
optymalnej wartości parametru
p
jest kryterium w postaci
funkcji:
gdzie:
k
– rząd autoregresji; - oszacowanie
wariancji składnika losowego modelu
AR(k)
;
K
–
maksymalny rząd autoregresji (nie większy niż
n/4
).
,K
0,1,2,
k
lnn,
n
k
(k)
lnS
SR(k)
2
e
...
(k)
S
2
e
Prognozowanie na podstawie
modeli autoregresyjnych

GK (WEiP(6) - 2010)
91
Parametr
p
wybiera się tak, aby:
.
Model
AR(p)
pozwala na wykonywanie sekwencyjne
prognoz, tzn. prognozę na okres
n+h
opiera się na
prognozie wykonanej dla okresu bezpośrednio
wcześniejszego
n+h-1
. Stąd prognoza na okres
T
jest
równa:
a jej dokładność
ex ante
szacuje się z wyrażenia
SR(k)
min
SR(p)
,K}
{0,1,2,
k
...
0
1
p
T
p
p
p
T
*
T 1
T 2
T p
p
α
α
y
x a
1 y
y
... y
,
...
α
-
-
-
� �
� �
� �
�
�
=
=�
�� �
� �
� �
� �
(
)
(
)
p
T
1
2
2
T
T
e
*
*
y
S
S 1 x X X
x .
-
=
+
Prognozowanie na podstawie
modeli autoregresyjnych

GK (WEiP(6) - 2010)
92
Przykład.
W poniższej tabeli zestawiono kwartalną wartość
sprzedaży sprzętu RTV (w tys. zł.) w specjalistycznym
sklepie w latach 1997-2006.
Kw
1
Kw
2
Kw
3
Kw
4
1997
267,3
318,6
357,0
383,5
1998
369,4
448,6
373,0
374,1
1999
379,5
414,9
464,4
544,1
2000
563,9
625,8
698,6
696,1
2001
650,5
739,7
807,7
775,8
2002
693,7
791,0
841,1
791,0
2003
810,4
933,3
988,2
888,5
2004
785,9
917,1
1105,0
1071,5
2005
888,2
989,6
1044,7
974,0
2006
1052,3
1043,3
1030,9
1057,4
Prognozowanie na podstawie
modeli autoregresyjnych

GK (WEiP(6) - 2010)
93
Tabela z wynikami obliczeń do określenia rzędu
autoregresji.
p
1
5391,735
8,68484
5
2
5695,186
8,83182
1
3
3365,241
8,39792
1
4
3480,88
8,52392
8
5
3680,09
8,67180
2
6
3837,161
8,80582
7
3518,077
8,81122
4
8
3721,546
8,95967
9
3274,773
8,92400
2
10
3268,236
9,01422
5
p
S
2
e
SR(p)
Prognozowanie na podstawie
modeli autoregresyjnych

GK (WEiP(6) - 2010)
94
Parametr
struktural
ny
Wartość
(oszacowa
na)
a
0
66,33122
a
1
0,897229
a
2
-0,59576
a
3
0,654433
Parametry strukturalne wybranego modelu
oszacowane KMNK
t
3
t
3
2
t
2
1
t
1
0
t
ε
y
α
y
α
y
α
α
y
Prognozowanie na podstawie
modeli autoregresyjnych

GK (WEiP(6) - 2010)
95
Prognozy na okresy
T+1, T+2, T+3
i
T+4
:
1103,3
1083,7
0,654433
1083,3
9576
1084,7-0,5
0,897229
66,33122
y
α
y
α
y
α
α
y
1084,7
1057,4
0,654433
1083,7
9576
1083,3-0,5
0,897229
66,33122
y
α
y
α
y
α
α
y
1083,3
1030,9
0,654433
1057,4
9576
1083,7-0,5
0,897229
66,33122
y
α
y
α
y
α
α
y
1083,7
1043,3
0,654433
1030,9
9576
1057,4-0,5
0,897229
66,33122
y
α
y
α
y
α
α
y
p
1
T
3
p
2
T
2
p
3
T
1
0
p
4
T
T
3
p
1
T
2
p
2
T
1
0
p
3
T
1
T
3
T
2
p
1
T
1
0
p
2
T
2
T
3
1
T
2
T
1
0
p
1
T
Prognozowanie na podstawie
modeli autoregresyjnych

96
GK (WEiP(6) - 2010)
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
- Slide 56
- Slide 57
- Slide 58
- Slide 59
- Slide 60
- Slide 61
- Slide 62
- Slide 63
- Slide 64
- Slide 65
- Slide 66
- Slide 67
- Slide 68
- Slide 69
- Slide 70
- Slide 71
- Slide 72
- Slide 73
- Slide 74
- Slide 75
- Slide 76
- Slide 77
- Slide 78
- Slide 79
- Slide 80
- Slide 81
- Slide 82
- Slide 83
- Slide 84
- Slide 85
- Slide 86
- Slide 87
- Slide 88
- Slide 89
- Slide 90
- Slide 91
- Slide 92
- Slide 93
- Slide 94
- Slide 95
- Slide 96
Wyszukiwarka
Podobne podstrony:
WEiP (5 Prognozowanie na podstawie modeli ekonometrycznych 2010)
Wyklad 4 - Prognozowanie na podstawie szeregow czasowych, PROGNOZOWANIE GOSPODARCZE
Prognozowanie finansowych szeregów czasowych z wykorzystaniem SN
Prognozowanie i symulacje wykład 1 2010
szeregi czasowe sciagawka, Ekonometria szeregów czasowych, Welfe, eszcz
11 Analiza Szeregów Czasowych z rozwiązaniami
Ekonometria szeregow czasowych Nieznany
Analiza szeregów czasowych wzory
11 Analiza Szeregów Czasowych
WEiP (8 Prognoza zjawiska jakosciowe 2014)
pist 8 (szeregi czasowe sezonowe arima + interwencje)
Dekompozycja szeregu czasowego - Zadania, Marketing, Badania operacyjne
Analiza szeregów czasowych
sylabus ekonometria i prognozowanie SSE2 UWr 2010 11, Ekonometria(1)
więcej podobnych podstron