
Accepted Manuscript
Title: Emotion Recognition and Affective Computing on
Vocal Social Media
Author: Weihui Dai Dongmei Han Yonghui Dai Dongrong Xu
PII:
S0378-7206(15)00018-X
DOI:
http://dx.doi.org/doi:10.1016/j.im.2015.02.003
Reference:
INFMAN 2793
To appear in:
INFMAN
Received date:
7-9-2014
Revised date:
17-12-2014
Accepted date:
14-2-2015
Please cite this article as: W. Dai, D. Han, Y. Dai, D. Xu, Emotion Recognition and
Affective Computing on Vocal Social Media, Information and Management (2015),
http://dx.doi.org/10.1016/j.im.2015.02.003
This is a PDF file of an unedited manuscript that has been accepted for publication.
As a service to our customers we are providing this early version of the manuscript.
The manuscript will undergo copyediting, typesetting, and review of the resulting proof
before it is published in its final form. Please note that during the production process
errors may be discovered which could affect the content, and all legal disclaimers that
apply to the journal pertain.

Page 1 of 18
Accepted Manuscript
Highlights
We examine the complexity of emotion computation on vocal social media.
We propose effective method of for emotion computation on vocal social media.
Extracting 25 acoustic feature parameters from speech signal.
Estimating PAD values of vocal emotion by LV-SVR model.
Analyzing the dynamic propagation of mixed emotions on vocal social media.
Highlights (for review)

Page 2 of 18
Accepted Manuscript
Emotion Recognition and Affective Computing on Vocal
Social Media
Weihui Dai
a,
, Dongmei Han
b,c
, Yonghui Dai
b
, Dongrong Xu
d
a
Department of Information Management and Information Systems, School of Management,
Fudan University, Shanghai 200433, China
b
School of Information Management and Engineering, Shanghai University of Finance and
Economics, Shanghai 200433, China
c
Shanghai Financial Information Technology Key Research Laboratory, Shanghai 200433, China
d
Psychiatry Department, Columbia University/ New York State Psychiatric Institute, New York
City, NY 10032, United States
ABSTRACT: V
ocal media has become a popular way of communication in today’s social networks.
In the meantime of conveying semantic information, vocal message usually also contains abundant
emotional information which has been the new focus of attention in the data-mining of social media
analytics. This paper proposes a computational method for emotion recognition and affective
computing on vocal social media to estimate the complex emotion as well as its dynamic changes in a
three dimensional PAD(Position-Arousal-Dominance) space, and furthermore analyzes the propagation
characteristics of emotions on the vocal social media of Wechat.
Keywords: Social media, Social network, Voice instant messaging, Vocal data-mining, Emotion
recognition, Affective computing
1. Introduction
In today’s social networks, the way of communication is undergoing a new change due to the
emerging vocal social media such as Wechat, QQ(China), ICQ, WhatsApp(U.S.), Line(Japan) and
various tools of instant voice messaging. While facilitating conveying semantic information, vocal
social media can also transmit abundant emotional information. This variation has resulted in
significant influence on not only improving the users’ experiences and senses of belonging to particular
social groups and therefore enhancing their continuance intentions to these groups [31][60], but also
strengthening the interpersonal relationships between the members within these groups as well as the
community’s cohesion and cognitive consistence in the social network [23, 57, 58].
From the relevant literatures, we can find a wide application of social networks due to the rapid
development of social media analytics [1, 2, 53], which provides the effective methodology for
unearthing more business value from social networks [3, 13, 51]. Recently, the great influence of social
networks on psychological cognition and social behaviors has caused the new attention [5, 9, 22, 27,
48]. In our previous research findings [23], the propagation effects of a social network on emergent
events affect the community through an approach that contains five interactional layers and this mostly
depends on its group cognitions: information, emotion, attitude, behavior and culture. Among which,
emotion plays an inducing role on the group’s primary recognitions and easily leads to the consistent
attitude and behavioral reactions in the “small world” because of the member’s close social
relationships, trusts and the empathic effects. Recent neural and behavioral research work has also
indicated the theoretical basis for this phenomenon [32]. The effects of vocal social media on the
interpersonal relationships, group cognitions and especially the emotion propagation, will endow the
social network with some new prominent features and social functions worthy of further research.
In recent years, the emotional impact of social media on the society has been confirmed by more and
more research findings and empirical cases, and thus has drawn great attention to it from a variety of
areas such as Internet marketing research, service comments analysis, social mood monitoring, and
Corresponding author. Tel.: +86 2125011241.
E-mail addresses:
whdai@fudan.edu.cn
(W.H. Dai),
handongmei19610320@gmail.com
(D. M.
Han),
dyh822@163.com
(Y. H. Dai),
dx2013@columbia.edu
(D. R. Xu)
*Manuscript
Page 3 of 18
Accepted Manuscript
emergent event management [5, 8, 9, 22, 27]. Social media has been considered as a sensor to perceive
and predict society’s behaviors in the real world through the data-mining techniques on emotional
information [5, 27]. Since Professor R. W. Picard at Massachusetts Institute of Technology proposed in
his book “Affective Computing” in 1997 that computer can capture, process and reproduce human
emotions [40], this issue of human’s emotion recognition and computing has been explored by the
technology of machine intelligence. Among these efforts, emotion recognition is to identify the
possible types of emotions from the signals, and this can be regarded as a task for pattern recognition,
while the affective computing usually requires, furthermore, a quantitative measurement on that
emotions. It is commonly related to the issue of value estimation based on a trained model.
So far, researchers have proposed a series of computational models for analyzing emotional
information from the data of social media [14, 19, 26, 48]. Due to the widespread application of voice
instant messaging tools, emotion recognition and computing on emerging vocal media has become a
new concerning hot point for research in data-mining of social media analytics. Although the vocal
emotion recognition has made great progress in the past decades, from the speaker-dependent and
template matching recognition based on simple vocabulary to today’s speaker-independent and
statistical model based recognition that can process a continuous speech [19, 29], but there are still
barriers towards dealing with the vocal social media. The speech signal in vocal social media appears
as the human’s conversation using natural language, and in most cases contains the mixed emotions
embedded with dynamic changes. This signal can’t be recognized simply as one of the typical emotions
by the existing methods. Computing such complex and dynamic emotions precisely is actually more
technically difficult. Therefore, this issue had to be studied in more depth. This paper aims at
developing an effective computational method for processing the complex and dynamic emotions from
the speech signals of vocal social media, so that the propagation effects of emotions may be analyzed in
a meticulous and deep-going way.
2. Literature review
2.1. Emotion recognition of vocal signals
Vocal emotion recognition involves the issues of emotion classification, signal pre-processing,
feature extraction, and pattern recognition. How to classify and describe human’s emotions has
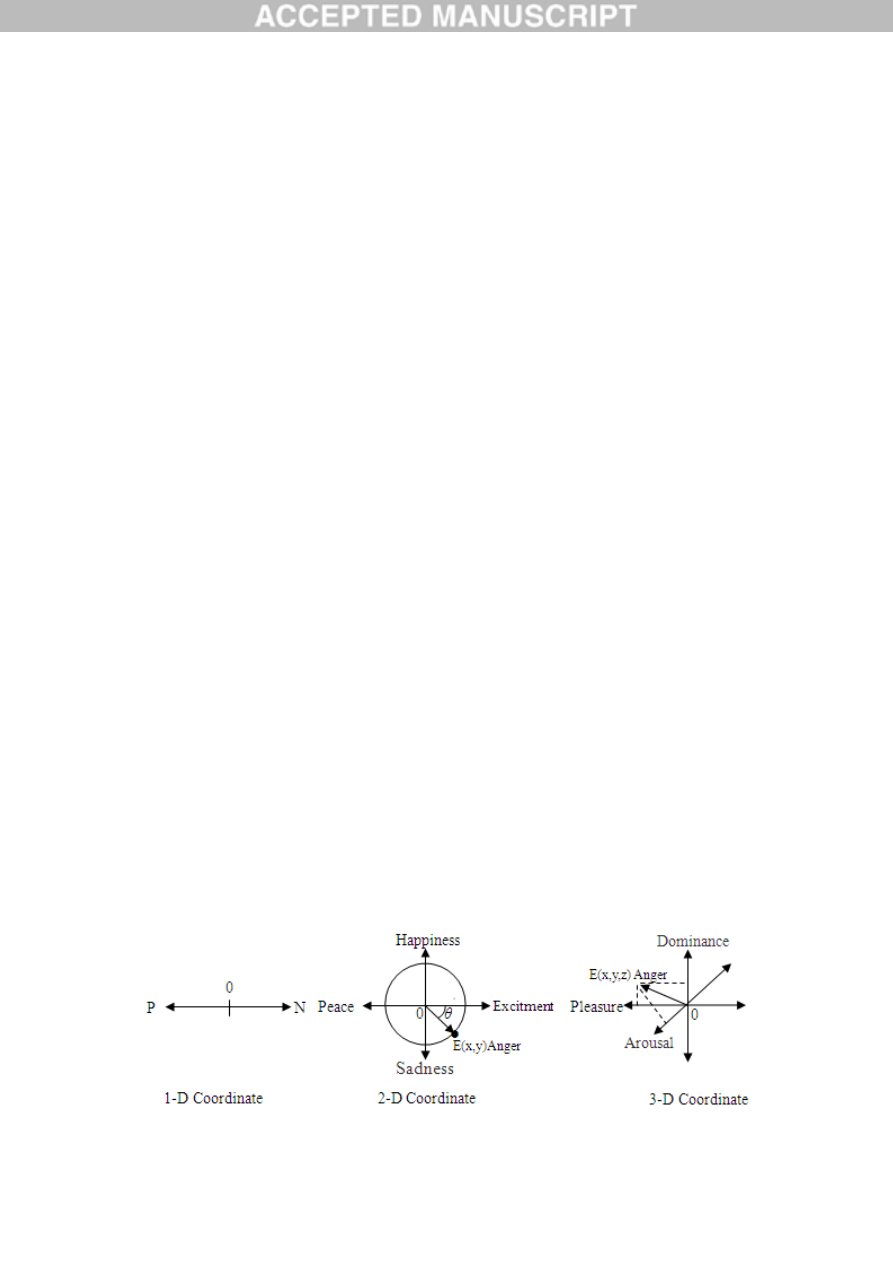
remained to be a controversial issue. The classification of emotions follows into the two categories:
discrete form and continuous form. Discrete form only gives the emotion kinds such as the “six big”:
Anger, Disgust, Fear, Joy, Sadness, and Surprise [12]. Continuous form describes the emotion state in a
continuous space with different dimensions. Among which, the one-dimension only classifies the
positive or negative emotions and determines their strength; the 2-D space are usually based on the H.
Hidenori and T. Fukuda’s Emotional Space
[20], where the emotion state is represented in a unit circle
with two opposite coordinates: Peace vs. Excitement, Happiness vs. Sadness; The 3-D space has
different models presented by W. M. Wundt
[54], H. H. Schlosberg [42], C. E. Izard [24], and C. E.
Osgood [39] respectively. Based on a comprehensive psychological research work, A. Mehrabian
demonstrated that any kind of an emotion state can be well described by the three nearly independent
continuous
dimensions:
Pleasure-Displeasure
(P),
Arousal-Nonarousal
(A),
Dominance-Submissiveness (D), and therefore proposed the famous PAD model [35, 36]. This model
provides an effective means for evaluating the complex emotion, and has been successfully applied to
the subjective measurement by manual manner in a variety of areas [25, 33, 49]. Fig.1. shows the
continuous form of emotions in different dimensions.
Fig.1. Continuous form of emotions in different dimensions
Page 4 of 18
Accepted Manuscript
In the procedure of signal pre-processing, the initial speech signal will be dealt and transformed so
as to be suitable for the extraction of its acoustic feature parameters. Generally speaking, this procedure
includes three steps: signal sampling and quantizing; pre-emphasis, framing and windowing [50]. In
this regard, one of the most important contributions is that Dynamic Time Wap (DTW) and Vector
Quantification (VQ) were presented in 1970s to handle the problems arising from the different lengths
of speech signals
[41]. The feature extraction is to find the appropriate and effective parameters which
can be used to identify the emotions from the vocal signal. The commonly used acoustic parameters are
divided into three categories [19]: (1) Prosody parameters such as the duration, pitch and energy of a
vocal signal; (2) Spectral parameters such as the LPC (Linear Predictor Coefficient), OSALPC
(One-Sided Autocorrelation Linear Predictor Coefficient), LFPC(Log-Frequency Power Coefficient),
LPCC (Linear Predictor Cepstral Coefficient), and MFCC (Mel-Frequency Cepstral Coefficient); (3)
Sound quality parameters such as Format Frequency, Bandwidth, Jitter, Shimmer, and Glottal
Parameter. In the above categories, prosody parameters are the basic parameters for vocal emotion
recognition. Human auditory system is a special nonlinear system so as to respond selectively to the
different frequency signals. MFCC is based on the known variation of the human ear’s bandwidths. It
has the frequency characteristics linearly below 1000 Hz and logarithmically above 1000 Hz, which
match well with the auditory characteristics of human speech signals. Experiences show that the
performance of MFCC parameters is usually better than the other spectral parameters
[17, 37]. Recent
experiments have found that the sound quality parameters play an important role in differentiating the
emotions associated with attitudes and intentions, therefore the combined parameters with all three
categories to be applied to the feature extraction may be the new trend [10, 56].
In the pattern recognition, methods are usually based on Hidden Markov Model (HMM), Artificial
Neural Network (ANN), Gauss Mixture Model (GMM), Support Vector Machine (SVM) and Bayesian
Classification. T. L. Nwe et al. reported that the six typical emotions including anger, distaste, fear, joy,
sadness and surprise can be recognized at the accuracy rate of 78% in their paper Speech Emotion
Recognition Using Hidden Markov Models [38]. In Toward Detecting Emotions in Spoken Dialogs, C.
M Lee and S. S. Narayanan recognized correctly the “positive” and the “negative” emotions from the
dialogues of call voice by using the combined information from the speech and its converted texts
[28]
.
By HMM and GMM, B. Schuller et al. studied the recognition of seven emotional states and obtained
the correct rate of 86.8% [43]. M. W. Bhatti et al. developed a modular neural network to identify the
six typical emotions and reached the rate of 83% [4]. Through the combination of acoustic features and
linguistic information, B. Schuller et al. explored three different methods based on SVM, and achieved
the accuracy rates of 93% (speaker-dependent) and 81% (speaker-independent) [29, 44]. The research
progress on speech emotions were overall summarized by D.Ververidis and C. Kotropoulos in
Emotional Speech Recognition: Resources Features and Methods [50]. Actually, the accuracy rate of
emotion recognition depends mostly on the training samples. Generally speaking, we think that the
reliable rate may be 70%-80% based on the sufficient training samples. Another problem in existing
recognition methods is that the reference emotion states to be taken as the target of the machine
training are all given by people’s subjective evaluation, and thus the evaluation error will obviously
lead to the deviation while compared with the emotion state in a real world.
In recent years, researchers have a more profound understanding on the neural mechanism of
human’s emotions due to the developing experimental technology of fMRI (functional Magnetic
Resonance Imaging), ERPs, (Event-related Potentials) and DTI (Diffusion Tensor Imaging). In
particular, the blood oxygenation level dependent functional magnetic resonance imaging (Bold-fMRI),
with such advantages as being non-invasive, non-traumatic and capable of locating accurately the
activated brain areas, has been applied to the studies the emotions and achieved a number of significant
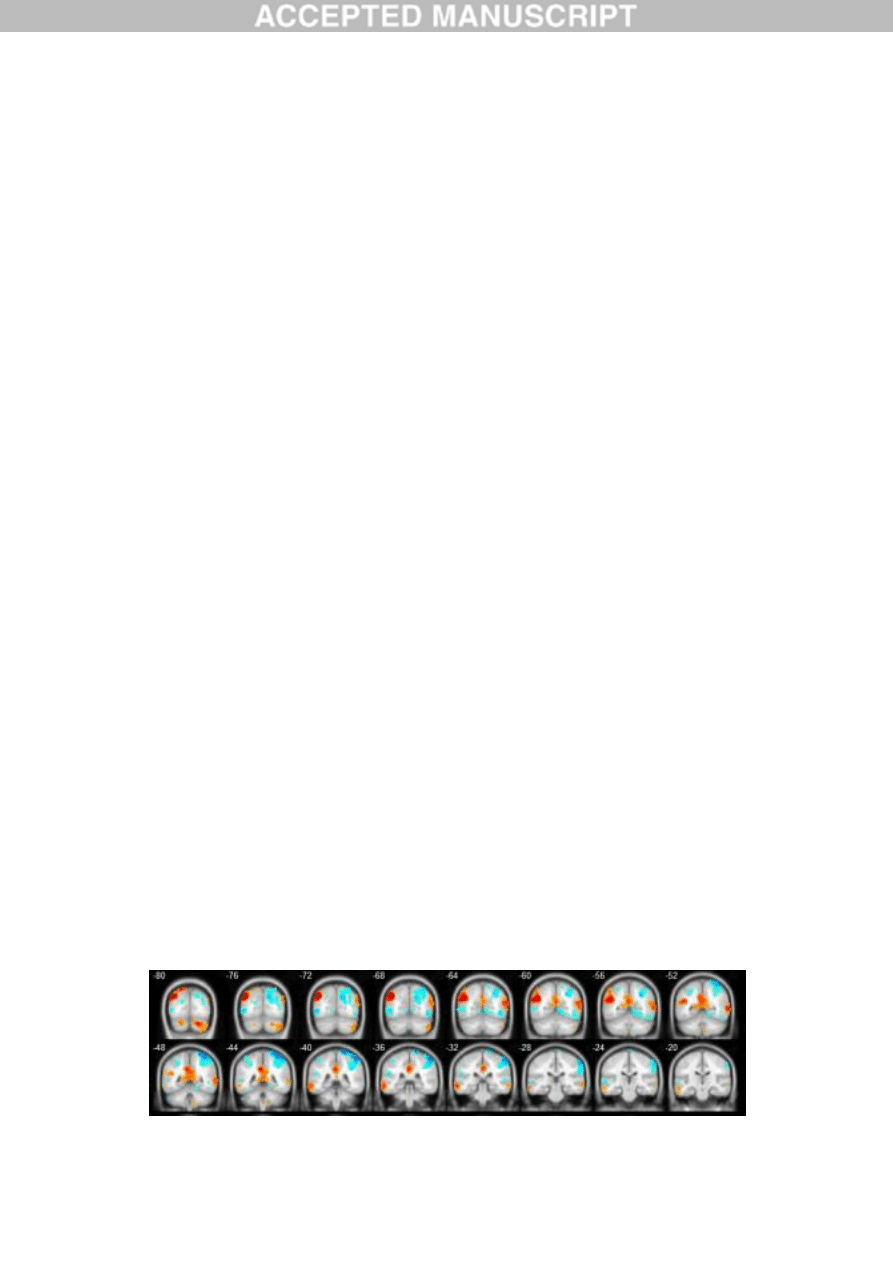
findings [21]. Based on the fMRI technology, we have studied the emotional cognitions on the
information of emergent events [23]. The brain activated characteristics in that cognition are shown as
in Fig.2 by our experimental observation.
Fig. 2. Brain activated characteristics of emotional cognitions on the information of emergent events

Page 5 of 18
Accepted Manuscript
From Fig. 2, we can find that some brain areas are activated when the emotion takes place, and this
will help to establish an objective method for the evaluation of emotion states. Through a further
research work, we have analyzed the brain mechanism of vocal emotion and suggested this mechanism
to be applied to the emotional intelligence design of a humanoid robot [52]. The emotions between the
speaker and listener are different, so we should determine that our recognition target is to identify the
speaker’s emotions from his speech, or to judge the activated emotions of the listener when he hears
the speech. From the view of emotion propagation, the target is usually set up to the later, and thus
we’ll recognize the activated emotions according to the statistical significance of a group of the
possible listeners, and the result may be a statistical distribution of the typical emotions. If the target is
to identify the speaker’s emotion, the more objective judgment may be made with the help of machine
detection due to the limitation and differences in the expressive abilities of the speakers, especially in
the complex emotion states. When the judgment is only possibly made through a subjective evaluation,
our research finding indicates that the speaker’s familiar people can make more accurate judgment. It
seems that this judgment is made based on some more information beyond the speaker’s speeches.
Overall, there are a lot of issues on the recognition of vocal emotions, and this needs the
comprehensive and interdisciplinary research work from the neuroscience, psychology and computer
engineering. At least, the existing method should be improved to recognize the mixed emotions as a
statistical distribution of the typical emotions.
2.2. Affective computing on vocal emotions
Affective computing requires the emotion to be measured quantitatively. This involves the issues of
the descriptive model and computing model of emotions. The descriptive model should not only reflect
the continuous variations in an emotional space with some certain dimensions, but also can calculate
the distance between the different emotions. As previously described in this paper, A. Mehrabian
proposed the famous PAD model [35, 36]. In his model, the emotion state can be described in a
continuous 3-D space. Experiments and statistical studies have shown that all the known emotion states
can be almost described in this space very well [6, 30]. The prominent superiority of this model is that
the complex and mixed emotions as well as their dynamic changes can be described in the three nearly
independent
continuous
dimensions:
Pleasure-Displeasure
(P),
Arousal-Nonarousal
(A),
Dominance-Submissiveness (D). This means that the values in different dimensions may be evaluated
by subjective evaluation or calculated by machine respectively.
In order to achieve a precise and consistent result in subjective evaluation, A. Mehrabian designed
the initial 34-item test questionnaire to conduct a reliable and valid evaluation [35]. But the later
researches and tests showed that the questionnaire should be designed according to the specific
language due to the differences in language understanding and cultural backgrounds. Therefore, Y. Lu
et al. from Psychological Institute, Chinese Academy of Sciences put forward a simplified 12-item
Chinese questionnaire [33]. This questionnaire passed the reliability and validity test [30] and has been
widely accepted to evaluate the emotions in Chinese language. In the measurement of the distance
between two different emotional states, P. H. Sun and L. M. Tao carried out a series of psychology
experiments and found that PAD space is not an isotropic Euclidean space. To solve this problem, they
presented a conversion metric function for calculating the Euclidean distance of emotional states
in
PAD space [46]. So far, PAD model has been successful applied in a variety of areas such as
audio-visual speech synthesis [25], micro-blog sentiment analysis [6], and music emotion comparison
[34].
The research work of affective computing on continuous vocal signal has just got started in the very
recent years. It requests to establish the quantitative relationship between the emotions and the acoustic
feature parameters of a continuous vocal signal, rather than only recognizing one of the typical
emotions from the above acoustic parameters. H. Zhou tested the correlations of PAD values with the
prosody parameters and MFCC, and found no significant correlations between the values of D with the
above parameters [60]. Therefore, she presented a SVR (Support Vector Regression) model for
estimating the values of P and A from a continuous vocal signal based on the parameters of
Hilbert-Huang transformation. Her research findings indicated that more acoustic feature parameters
would be considered in the affective computing on vocal emotions to obtain effective PAD values. In
the speech conversion and synthesis, PAD model has been very successfully used to adjust and produce
the different affective speeches from a neutral speech or text sentence. J. Jia, et al. proposed a unified
model for emotional speech conversion and audio-visual speech synthesis using Boosting-GMM [25].
In their model, the target PAD values were employed as part of the input variables. Y. X. Chen and R.
T. Long discussed the synthesis of emotional speech by taking the PAD values to adjust the parameters
Page 6 of 18
Accepted Manuscript
of a HMM speech synthesis system [7]. S.W. Gilroy, et al. presented a framework for the multimodal
affective fusion in human-machine interface [15]. This framework provided an effective method for the
fusion computing on affective speech, spontaneous behavior, multi-keyword spotting, and interest
aggregation based on PAD model.
From the existing research work, we can conclude that the affective characteristics in a continuous
vocal signal may be determined and adjusted by its PAD values. Therefore, affective computing on
vocal emotions can be explored as the problem of PAD value estimation from the affective acoustic
feature parameters of a vocal signal.
3. Proposed method and research schema
3.1. Proposed method
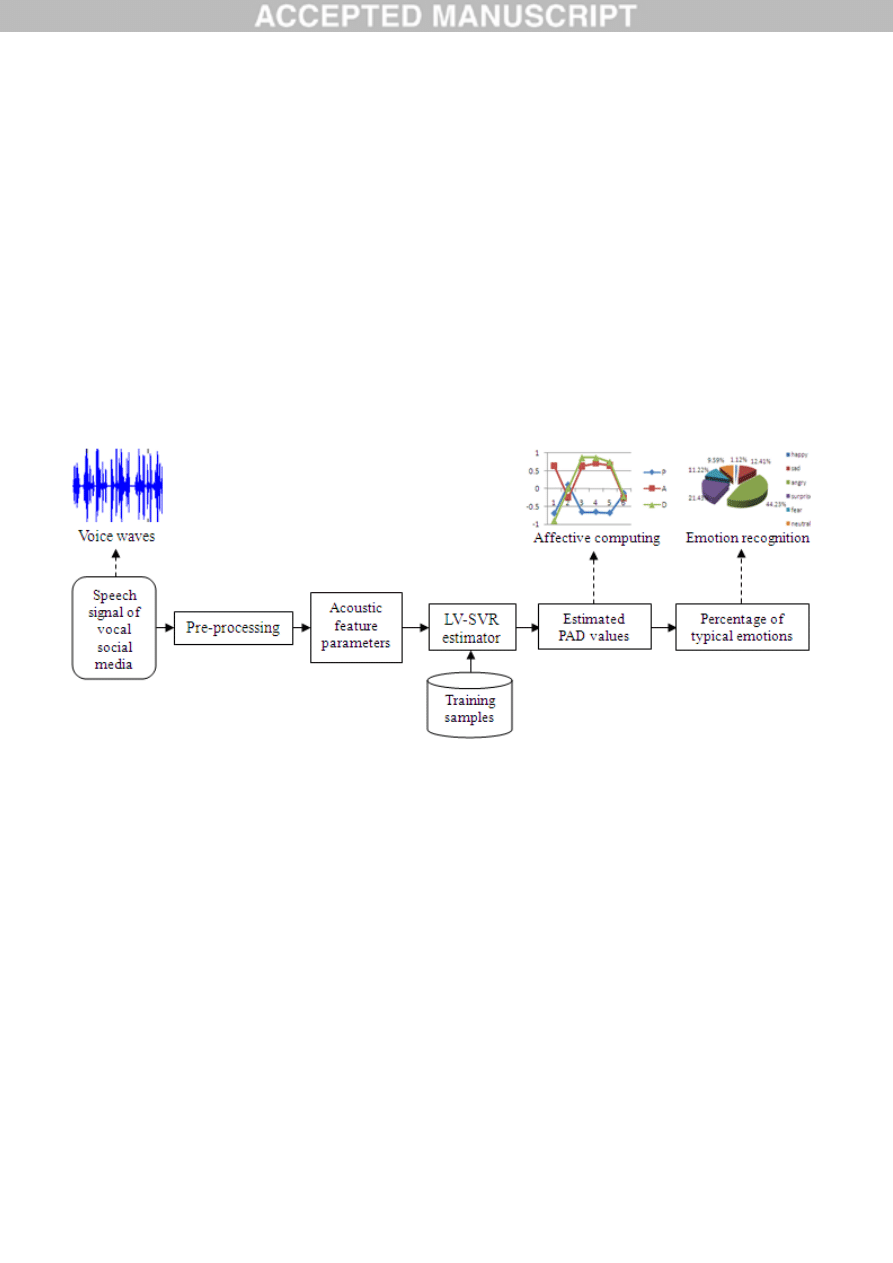
Based on the comprehensive analysis of the previous research work, we hereby turn the emotion
recognition and affective computing on vocal social media into the PAD value estimation from the
extracted acoustic feature parameters of its speech signal, and propose the computational method as
shown in Fig.3.
Fig.3. Proposed computational method
Our proposed computational method includes following 5 steps:
(1)Pre-processing: The speech signal of vocal social media should be firstly dealt by a
pre-processing to satisfy for the acoustic feature parameter extraction. The standard procedure of
pre-processing will experience signal sampling and quantizing, pre-emphasis, framing and windowing
[28, 50, 56]. Speech signal in vocal social media usually exhibits as a sequence of short chats, so the
emotion recognition and affective computing can be estimated for each chat on the average level. In
order to reflect the dynamic changes of emotions in a long chat, a fixed time interval, for example 6
seconds, may be set as the calculation period.
(2)Acoustic feature parameter extraction: The next step is to extract the suitable acoustic feature
parameters from the processed signal data. The acoustic feature parameters should not only represent
the affective characteristics in the vocal signal as precisely as possible, but also be computed effectively.
In our method, we choose 25 parameters from all the three
categories: prosody parameters, spectral
parameters and sound quality parameters. This issue will be discussed in the later.
(3)PAD value estimation: The PAD values will be thereafter estimated from the above acoustic
feature parameters by machine learning. Some commonly used non-linear estimators in the machine
learning, such as HMM, ANN, GMM, and SVR, can be considered in this issue. Among which, the
Least Squares SVR (LS-SVR), presented by J. A. K. Suykens and J. Vandewalle in 1999
[47], has the
advantages of superior stability, good generalization ability, and high efficiency, and is therefore
adopted as the estimator in our method.
(4)Affective computing: Based on the trained LV-SVR estimator by machine learning, the PAD
values of speech signal can be estimated as the affective computing results. The dynamic changes of
Page 7 of 18
Accepted Manuscript
PAD values may be also illustrated according to the sequence of short chats or depending on the fixed
time interval orders in a long chat.
(5)Emotion recognition: Furthermore, the above PAD values in each period can be expressed as the
percentage distributions of the typical emotions based on their converted Euclidean distances in PAD
space [46], and thus get the recognition results of the mixed emotions.
3.2. Research schema
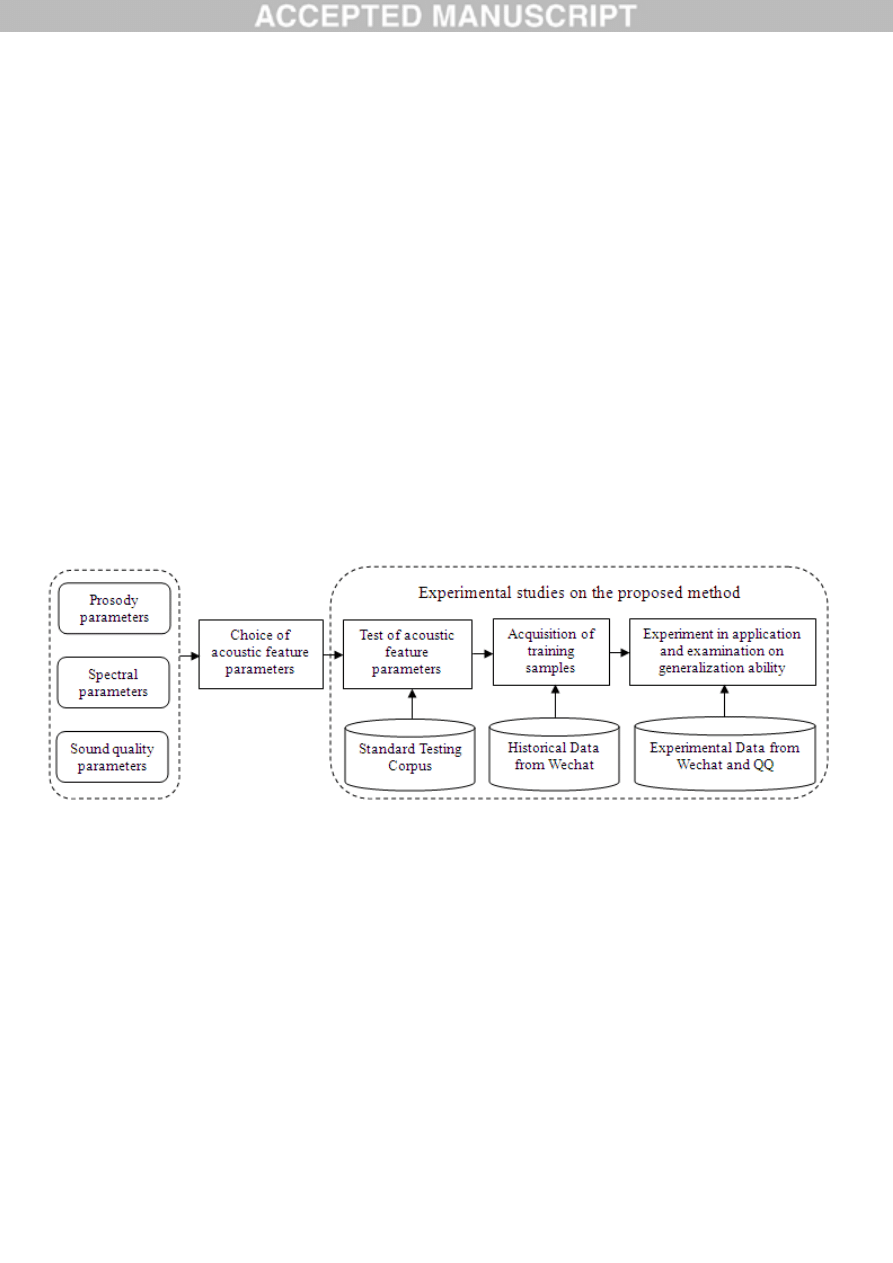
In order to achieve the goal of the proposed method, the following issues need further research
according to the characteristics of vocal social media:
(1) The choice of acoustic feature parameters. Because the emotions may be stimulated either by the
voice or by the semantic information in a speech of vocal social media, so the above parameters require
to be tested to show that they are only related to the vocal emotions and independent of the semantic
information. Besides, those parameters should carry the emotional information sufficiently but
necessarily, and can be computed effectively.
(2) The training samples for LV-SVR estimator. Although researchers have developed various vocal
emotion corpora, 80% of their samples are usually used for the training with the left of 20% for the test,
but so far there has been no one can be suitable for the vocal social media which samples need to be
refined from the real environment at representative significance.
(3) The generalization ability in real application. As the interactive activities on vocal social media
usually take place in the “small world” of a group with familiar members, so the proposed method
should be generally applicable for different groups.
Our researches are focused on the choice of acoustic feature parameters and the experimental studies
of the proposed method associated with the above issues. We hereby draw up our research schema in
accordance with the research paradigm on vocal emotion as Fig.4:
Fig.4. Research schema
Different from the speaker’s recognition and semantic recognition which try to reduce the emotional
effects from the vocal signal [29, 50, 59], emotion recognition on the traditional paradigm will utilize
as much as possible information which is related to emotion and independent of semantic context.
From the previous research findings, the affective characteristics on vocal signal are relevant to all the
three categories of acoustic feature parameters: prosody parameters, spectral parameters and sound
quality parameters. Based on our test experiences, we choose the 25 parameters from the above
categories which can be better to reflect the PAD values in the speech of vocal social media: Short-time
Energy (Max, Min, Mean), Pitch (Max, Min, Mean), Short-time zero crossing rate (Max, Min, Mean),
First Formant, Second Formant, Voice speed, Number of voice breaks, and the 12-order MFCC (12
coefficients).
In the experimental studies, the computational accuracy of proposed method as well as its chosen
acoustic feature parameters should be tested to show that it is only related to the vocal emotions and
independent of the semantic information in a speech. CASIA is the widely used standard testing corpus
in Chinese [18]. There are total 1200 speeches in this corpus which have almost the same structure and
length in each speech. Every speech with the same semantic texts is spoken by 2 men and 2 women in
the six typical emotional tones: happy, sad, angry, surprise, fear, and neutral. So the recognition rates of
the above six emotions can be used to evaluate the reliability and validity which is only related to the
emotions in this proposed method.

Page 8 of 18
Accepted Manuscript
After having passed the test by standard corpus, an experiment with the real data from the vocal
social media will be conducted to verify the
effectiveness of the proposed method in application. The
speech signal on vocal social media is characterized by a series of conversational chats with different
structures and lengths. It is very different from the speech signal in the existing standard testing corpora
such as CASIA. So the training samples for LV-SVR estimator in real application can’t be from the
existing standard testing corpora. The conversational chats on vocal social media usually take place in
the “small world” of a group with familiar members. As discussed before in this paper, the familiar
people can make more accurate judgment on speaker’s emotion information, therefore the training
samples would be better to acquire from the historical data of the members in the same group if
possible. In order to extract the personalized features of the participators for studying the emotion
propagation in the “small world” more precisely, we take 180 real chats from the historical data in the
same group on Wechat as the training samples for machine learning. To ensure the representative
significance, the above chats are from 9 of the most active members with equal 20 chats for each
member. After trained by those samples, the experiment of a discussion is conducted in this group
based on a serious actual incident in food safety to verify the effectiveness of LV-SVR estimator on the
dynamic analysis of emotion propagation.
Generalization ability refers to the machine learning algorithms for the adaptability of new samples.
We here understand it as the applicability for different groups on vocal social media. As discussed
above, the accuracy of LV-SVR estimator in real application is dependent on its trained samples. So the
samples for training and the samples to be estimated in the future should belong to the same statistical
collection in the regular generalization ability examination of a computational method. If the groups on
vocal social media have significant statistical differences in the factors which will affect the estimated
result, the samples for training would be preferably from the historical data of the same group as to be
estimated. However, the historical data are sometimes difficult to obtain when we process with a new
group on vocal social media. In this case, we had to extract the training samples from the historical data
which is close to the new group to be processed. In the generalization ability examination of our
proposed method, we try to use the LV-SVR estimator which has been trained by the historical data of
the group on Wechat to the application of a new group on QQ, and evaluate the influence caused by the
trained samples on the generalization ability.
4. Model and training
4.1. Vector model of acoustic feature parameters
In our proposed computational method, the following 25 parameters are chosen for PAD value
estimation: Short-time Energy (Max, Min, Mean), Pitch (Max, Min, Mean), Short-time zero crossing
rate (Max, Min, Mean), First Formant, Second Formant, Voice speed, Number of voice breaks, and the
12-order MFCC (12 coefficients). Among which, the Short-time Energy, Short-time zero crossing rate,
Pitch, First Formant, Second Formant, Voice speed, Number of voice breaks can be simple calculated
directly in the time domain of the vocal signal [50]. We hereby just discuss the calculation of MFCC.
Let
)
(t
s
represent the original speech signal, and
f
represent the signal’s frequency, therefore the
calculation of MFCC is based on the Mel-frequency scale as the Formula (1):
2595*lg 1
700
Mel
f
f
(1)
After processing by a window function, the speech signal
)
(t
s
will be sampled and turned into the
short time signal
)
(n
x
. Through the FFT (Fast Fourier Transform),
)
(n
x
which be converted from the
time domain into the frequency domain and thus we get the power spectrum
( )
S n
.
Prior to this, it needs to set up a number of band pass filters, such as the Hamming filters described
in Formula (2)
1
2
/
,...,
1
,
0
;
1
,...,
1
,
0
)
(
N
n
M
m
n
H
m
(2)
Here,
M
stands for the number of filters over the frequency spectrum range, which is included in
dynamic Mel filter bank, and is set typically as 24;
N
is the point number of one frame, which is set
Page 9 of 18
Accepted Manuscript
as 256 to be suitable for the speech signal. In frequency domain, the center frequency of filter is
uniformly distributed throughout Mel frequency axis. The extraction algorithm of MFCC parameters
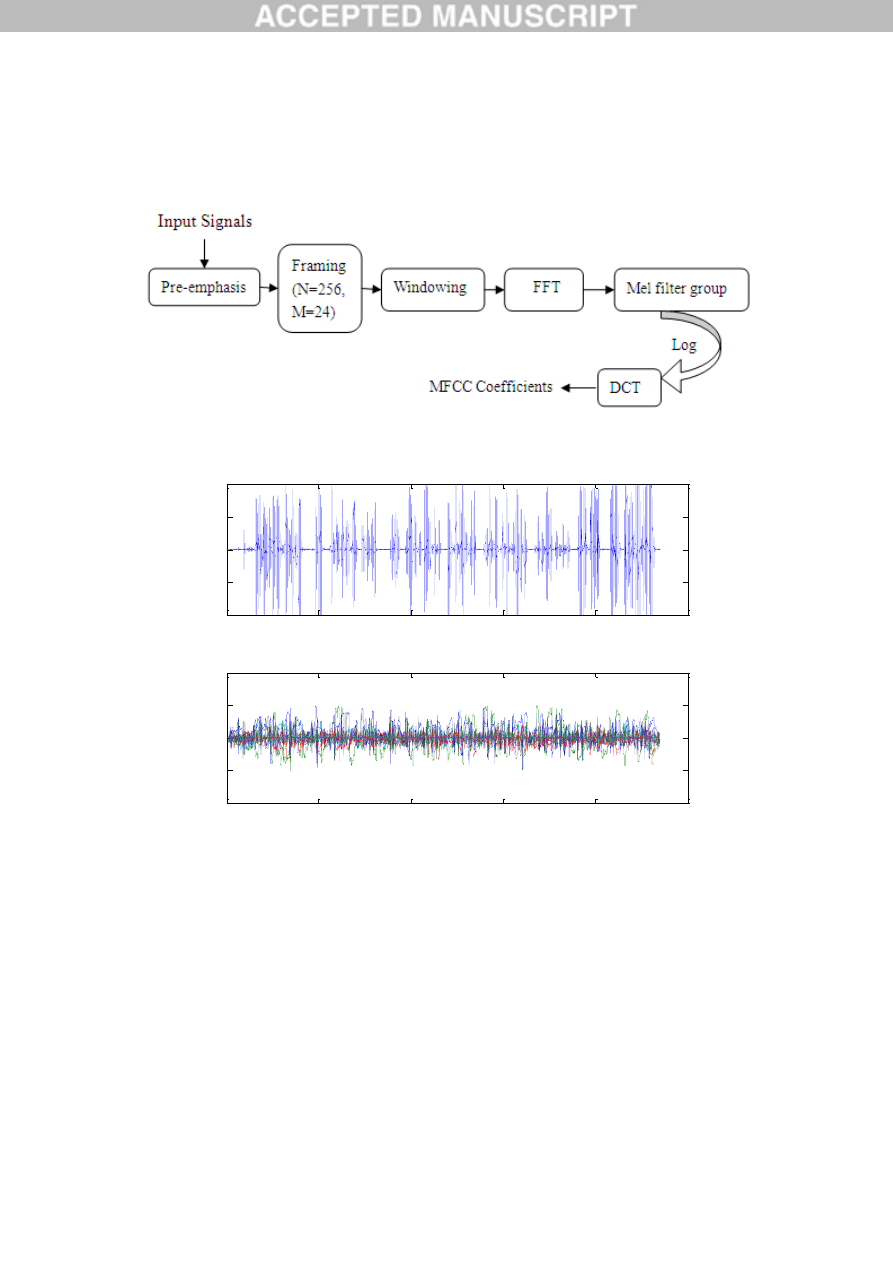
includes the steps as in Fig.5 [17, 37]. Fig. 6 demonstrates the waves of the original speech signal on
Wechat and its MFCC coefficients.
Fig.5. Calculation process of MFCC coefficients
Fig.6. Original speech signal on Wechat and its MFCC coefficients
We hereby take the chosen 25 acoustic parameters to compose a feature vector model as the Formula
(3):
MFCC
NVB
VS
SF
FF
SZC
P
SE
n
F
,
,
,
,
,
,
,
)
(
(3)
Where, SE represents the collection of Max, Min, and Mean values of the Short-time Energy; P
represents the same collection of Pitch; SZC represents the same collection of Short-time zero crossing
rate; FF represents the value of First Formant, Second Formant; SF represents the value of Voice speed;
NVB represents the value of Number of voice breaks; and MFCC represents the collection of the values
of its 12 coefficients. This vector will be used as the input of the LS-SVR for estimating its PAD
values.
4.2. Emotion recognition and affective computing
0
5
10
15
20
25
-1
-0.5
0
0.5
1
Sample of Wechat voice wave
V
a
lu
e
Time (second)
0
500
1000
1500
2000
2500
-40
-20
0
20
40
MFCC
Frame No
V
a
lu
e

Page 10 of 18
Accepted Manuscript
The emotion recognition and affective computing are based on the trained LV-SVR model as
follows [47]:
Set
N
i
i
i
Z
X
1
,
as the collection of the training samples, where the input
n
i
R
x
and the
output
R
z
i
, so the LS-SVR regression model in a high dimensional space can be described as:
b
x
x
z
T
)
(
)
(
(4)
Here,
T
is the vector of the weights, and
)
(x
is the non-linear function for mapping the input
i
x
to that high dimensional space,
b
is the error constant. Therefore the estimation of
)
(x
z
can be
transformed into the following optimization problem:
N
i
i
T
e
e
J
1
2
2
2
1
)
,
(
min
(5)
Subject to:
N
i
e
b
x
x
z
i
i
T
i
,
3
,
2
,
1
)
(
)
(
(6)
Where,
is the normalized constant,
i
e
is the error variable of
i
x
. Set the Lagrangian function as:
N
i
i
i
i
T
i
e
z
b
x
e
b
J
e
b
L
1
)
(
)
,
,
(
)
,
,
,
(
(7)
Where,
i
is the Lagrangian multiplier satisfying
R
i
.
By
solving extreme value point of
)
,
,
,
(
e
b
L
, we get the matrix of the linear equation:
1
0
1
)
,
(
0
i
i
T
b
I
r
x
x
k
Z
Z
(8)
Where,
)
,
,
,
(
2
1
n
z
z
z
Z
,
)
,
(
i
x
x
k
is the core function which must satisfy the Merce condition.
Here, we choose RBF (
Radical Basis Function
) as the core function:
)
2
exp(
)
,
(
2
2
i
i
x
x
x
x
k
(9)
Where,
is the width of RBF,
N
i
,
,
3
,
2
,
1
. Calculating the Lagrangian multiplier
i
and
the constant
b
, we get the LS-SVR estimation model:
N
i
i
i
b
x
x
k
x
f
1
)
,
(
)
(
(10)
Combined with the Formula (9), we get the final LS-SVR model:
N
i
i
i
b
x
x
x
f
1
2
2
)
2
/
exp(
)
(
(11)
In the computation of LS-SVR model, the normalized constant
and the width of RBF
have
major influence on the accuracy of estimated result. To avoid the fitting problem on the training sample,
we adopt the cross validation method [45, 55] to choose the most suitable values of
and
in our
method.
Due to the nearly independent characteristics, the P, A, D values can be estimated by the trained
LV-SVR model respectively. Based on estimated PAD values, the emotion state may be converted to
the percentage distributions of some typical emotions which can describe mixed emotions as well as
their changes. In that conversion, because the PAD space is not an isotropic Euclidean space, so a
conversion metric function presented by P. H. Sun and L. M. Tao [46] should be used to calculate the
converted Euclidean distance to the typical emotions:

Page 11 of 18
Accepted Manuscript
2
2
2
1
2
2
2
1
2
1
)
(
x
x
x
x
D
(12)
Where,
1
and
2
are the squared variances of the two emotion states to be calculated. The
percentage of each typical emotion is a based on its converted Euclidean distance to the estimated
emotion state.
4.3. PAD annotation of training samples
In order to provide the reference for machine training, the PAD values of training samples should be
evaluated as the annotation by a manual manner. Psychologists have design a strict method for
ensuring the reliability and validity of this evaluation [30]. Here, we used the Chinese version of
simplified 12-item questionnaire as in Table 1[33].
Table 1. Chinese version of the simplified 12-item questionnaire
Question
Emotion
-4
-3
-2
-1
0
1
2
3
4
Emotion
Q1
Angry
Activated
Q2:Wide-awake - Sleepy; Q3:Controlled - Controlling; Q4:Friendly - Scornful;
Q5:Calm - Excited; Q6:Dominant - Submissive; Q7:Cruel - Joyful;
Q8:Interested - Relaxed; Q9:Guided - Autonomous; Q10:Excited - Enraged;
Q11:Relaxed - Hopeful; Q12:Influential - Influenced
The scores are assessed based on what kind of feelings is more intense in each item. From the left to
the right, the calibration for scoring records is scaled“- 4” to “4”, and in the middle is “0”.
Finally, the scores will be converted as the normalized values of P, A, D [25]:
16
10
7
4
1
Q
Q
Q
Q
P
(13)
16
11
8
5
2
Q
Q
Q
Q
A
(14)
16
12
9
6
3
Q
Q
Q
Q
D
(15)
As previously described in this paper, our research found that the familiar people can make more
accurate judgment on this evaluation, so the scores are all assessed by the people in the same group on
vocal social media.
5. Test and application
5.1. Test of acoustic feature parameters
The acoustic feature parameters in the vector of Formula (3) require to be tested to show that they
are only related to the vocal emotions and independent of the semantic information in a speech. This
test is carried out with the CASIA, a widely used standard corpus for Chinese language test [18]. In this
corpus, each speech with the same semantic texts is spoken by2 men and 2 women in six different
emotional tones: happy, sad, angry, surprise, fear, and neutral, and therefore the recognition rates of the
above six emotions can be used to evaluate the reliability and validity which is only related to the

Page 12 of 18
Accepted Manuscript
emotions in this proposed method.
Based on the chosen parameters in the vector of Formula (3), we apply our LV-SVR model to
estimate the PAD values of each emotional speech and convert the values into the most possible typical
emotion state by Formula (12). Table 2 shows the test result of the recognition rates.
Table 2. Test result of recognition rates
Emotion type
Recognition rate
happy
81.32%
sad
85.27%
angry
87.72%
surprise
77.69%
fear
79.37%
neutral
83.23%
Average
82.43%
The test result shows that recognition rates of happy, sad, angry, surprise, fear, and neutral are
81.32%, 85.27%,87.72%, 77.69%, 79.37%, 83.23% respectively, and the average rate reaches 82.43%,
which are higher than the existing results reported by the similar tests.
5.2. Training from the historical data
Due to the special characteristics of speech signal on vocal social media, the samples in existing
standard testing corpora such as CASIA are not suitable for the machine training in real application. We
get the training samples of 180 chats from the historical data on Wechat. The above chats are from 9
members in the same group with equal 20 chats for each member.
Table 3 shows the PAD values of the six typical emotions from the 180 chat samples and reflects the
personalized features of the members in this group.
Table 3. PAD values of the six typical emotions
Emotion
Category
Value
P
A
D
Neutral
0.05
-0.22
-0.02
Angry
-0.53
0.43
0.64
Fear
-0.35
0.52
-0.68
Happy
0.49
0.31
0.29
Sad
-0.26
-0.34
-0.52
Surprise
0.21
0.57
0.13
5.3. Experiment and application
The experiment aims to verify the
effectiveness of the proposed method in real application. It is
carried out on the same group with the trained samples. We conduct the discussion about a serious
actual incident in food safety reported by the media on July 20, 2014, Shanghai China. In this
experiment, we collect 52 chat speeches talking about this incident on Wechat from 37 members with
the total duration of 35
minutes and 11seconds.
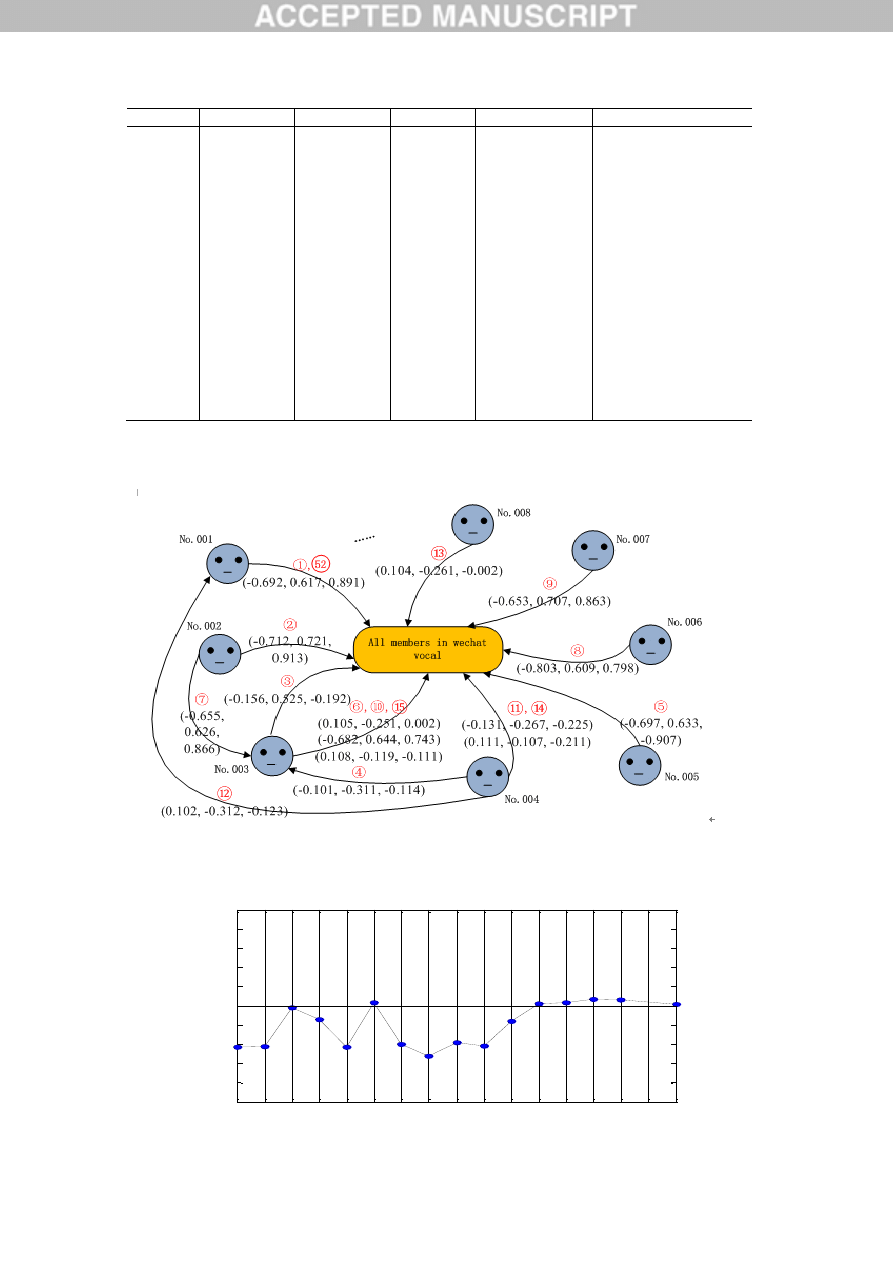
Table 4 shows the information of the chats as well as their estimated PAD values by the trained
LV-SVR model with
01
.
0
. Compared with the subjective evaluation, the averaged relative error
of estimated PAD values is 13.76%, but the converted typical emotions match with the results of
subjective evaluation very well.
Table 4. Chats on Wechat and the estimated PAD values
Chat No.
Start time
End time
Speaker
Referred
Estimated PAD values
Page 13 of 18
Accepted Manuscript
ID
listeners’ ID
by the LV-SRV model
1
00:00:00
00:00:07
NO.001
All
(-0.692, 0.617, 0.891)
2
00:00:11
00:00:29
NO.002
All
(-0.712, 0.721, 0.913)
3
00:00:33
00:00:39
NO.003
All
(-0.156, 0.525, -0.192)
4
00:00:42
00:00:56
NO.004
NO.003
(-0.101, -0.311, -0.114)
5
00:01:00
00:01:18
NO.005
All
(-0.697, 0.633, -0.907)
6
00:01:23
00:01:33
NO.003
All
(0.105, -0.251, 0.002)
7
00:01:45
00:02:02
NO.002
NO.003
(-0.655, 0.626, 0.866)
8
00:02:17
00:02:30
NO.006
All
(-0.803, 0.609, 0.798)
9
00:02:39
00:02:56
NO.007
All
(-0.653, 0.707, 0.863)
10
00:03:10
00:03:45
NO.003
All
(-0.682, 0.644, 0.743)
11
00:03:52
00:04:14
NO.004
All
(-0.131, -0.267, -0.225)
12
00:04:21
00:04:48
NO.004
NO.001
(0.102, -0.312, -0.123)
13
00:04:59
00:05:16
NO.008
All
(0.104, -0.261, -0.002)
14
00:05:26
00:05:46
NO.004
All
(0.111, -0.107, -0.211)
15
00:05:56
00:06:12
NO.003
All
(0.108, -0.119, -0.111)
…
…
…
…
…
…
52
00:35:11
00:35:27
NO.001
All
(0.107, -0.351, 0.022)
We illustrate the chat activities and their PAD changes in the group ordered by the chat number as
Fig.7. It can demonstrate the dynamic process of emotion propagation in this group as well as the
reactions caused by each chat activity.
Fig.7. Dynamic process of emotion propagation in the group
For the purpose of the intuitive observation, we convert the PAD values of chat speeches into the
continuous one-dimension with the positive and negative coordinates as shown in Fig.8:
Fig.8. Dynamic process of emotion propagation in positive and negative coordinates
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
...
52
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
Chat No
sc
ale
o
f e
m
ot
ion
al
po
lar
ity
Emotion of wechat voice
ID:001
ID:002
ID:003
ID:004
ID:005
ID:003
ID:002
ID:006
ID:001
ID:003
ID:004
ID:004
ID:008
ID:004
ID:003
ID:001
Page 14 of 18
Accepted Manuscript
From Fig.8, we can find that this propagation started from No.001 with a strong negative emotion to
this group, hereafter negatively enlarged by No.002, and finally stopped at No.001 in the nearly neutral
emotion. In whole process, No.002 contributed the most negative emotions, No.004 acted as the most
active participant, and No.003 had the most impacts on the group who looked like the opinion leader.
From Fig.7 and Fig.8, we can furthermore study more precisely on the attentions and the roles of
each participant as well as their relationships in the social network, and therefore establish the dynamic
model to describe the emotion propagation quantitatively through a further analysis of the dominant
factors on which. In order to examine the generalization ability of our proposed method, we apply the
LV-SVR estimator which has been trained by the historical data of the group on Wechat to calculate the
following 28 second duration of vocal message from another group on QQ:
“Wow! Even houses can be printed! Really cool! But 3D technology is not fully developed yet, so I
guess people are still playing with the concept. The 3D printing business will be in big trouble if it fails
to meet the increased demands and upgrade the technology, especially when it turns out that the printed
houses are actually not livable.”
This message contains the dynamics changes of different emotions, so we divide it into 5 segments
by the sampling period of 6 seconds. Fig.9 shows the waves of the 5 segments with the duration of 6 s,
6s, 6s, 6s, and the rest 4s
respectively. The acoustic feature parameters and estimated PAD values by
the LV-SVR estimator are listed on Table 5.
Fig.9. Segmental waves of the vocal message
Table 5. Acoustic feature parameters and PAD values of vocal message in 5 segments
Acoustic feature
parameters
Duration time (s)
6
6
6
6
4
Short-time Energy
(Max/Mean /Min)
85.525
77.147
22.003
84.904
74.365
35.990
83.423
74.920
37.884
84.691
75.416
38.181
88.263
81.924
44.101
Pitch
(Max/Mean /Min)
279.762
119.909
90.602
452.043
130.802
95.713
445.153
134.964
47.163
252.689
115.927
49.030
468.043
169.083
98.563
Short-time Zero
Crossing Rate
(Max/Mean /Min)
282
222.627
112
304
231.951
124
302
232.26
122
298
235.42
122
278
208.125
56
12-order MFCC
Coefficients
4.8790
-3.3281
-2.0294
0.5616
4.5146
-1.9265
-1.8245
-0.1242
3.9430
-0.0019
-2.1559
-0.0149
3.7301
0.4819
-2.2706
0.5528
3.4227
-0.3393
-2.8358
-0.7166
0
1
2
3
4
5
6
-1
0
1
wave of state 1
V
al
ue
0
1
2
3
4
5
6
-1
0
1
wave of state 2
V
al
ue
0
1
2
3
4
5
6
-1
0
1
wave of state 3
V
al
ue
0
1
2
3
4
5
6
-1
0
1
wave of state 4
V
al
ue
0
0.5
1
1.5
2
2.5
3
3.5
4
-1
0
1
wave of state 5
V
al
ue
Time(second)
Page 15 of 18
Accepted Manuscript
-1.3772
-0.0616
0.0176
-0.0196
-0.0002
-0.0249
-0.0094
0.0006
-1.2839
-0.1120
-0.0509
0.0324
0.0369
-0.0043
-0.0139
0.0033
-1.2215
-0.0650
0.0240
0.0976
0.0319
-0.0277
-0.0047
-0.0002
-1.6424
-0.0866
-0.0412
-0.0146
-0.0332
-0.0316
0.0365
-0.0044
-1.7581
-0.0686
0.0205
0.0317
0.0345
-0.0073
-0.0281
-0.0033
First Formant
609.567
600.916
569.877
570.547
533.855
Second Formant
1347.997
1462.478
1567.844
1528.431
1523.003
Voice Speed
0.196/s
0.187/s
0.187/s
0.186/s
0.414/s
Number of Voice
Breaks
9
12
15
14
6
P
0.503
0.109
-0.159
-0.255
-0.744
A
0.316
-0.318
-0.338
-0.518
0.434
D
0.312
-0.112
-0.211
-0.213
0.532
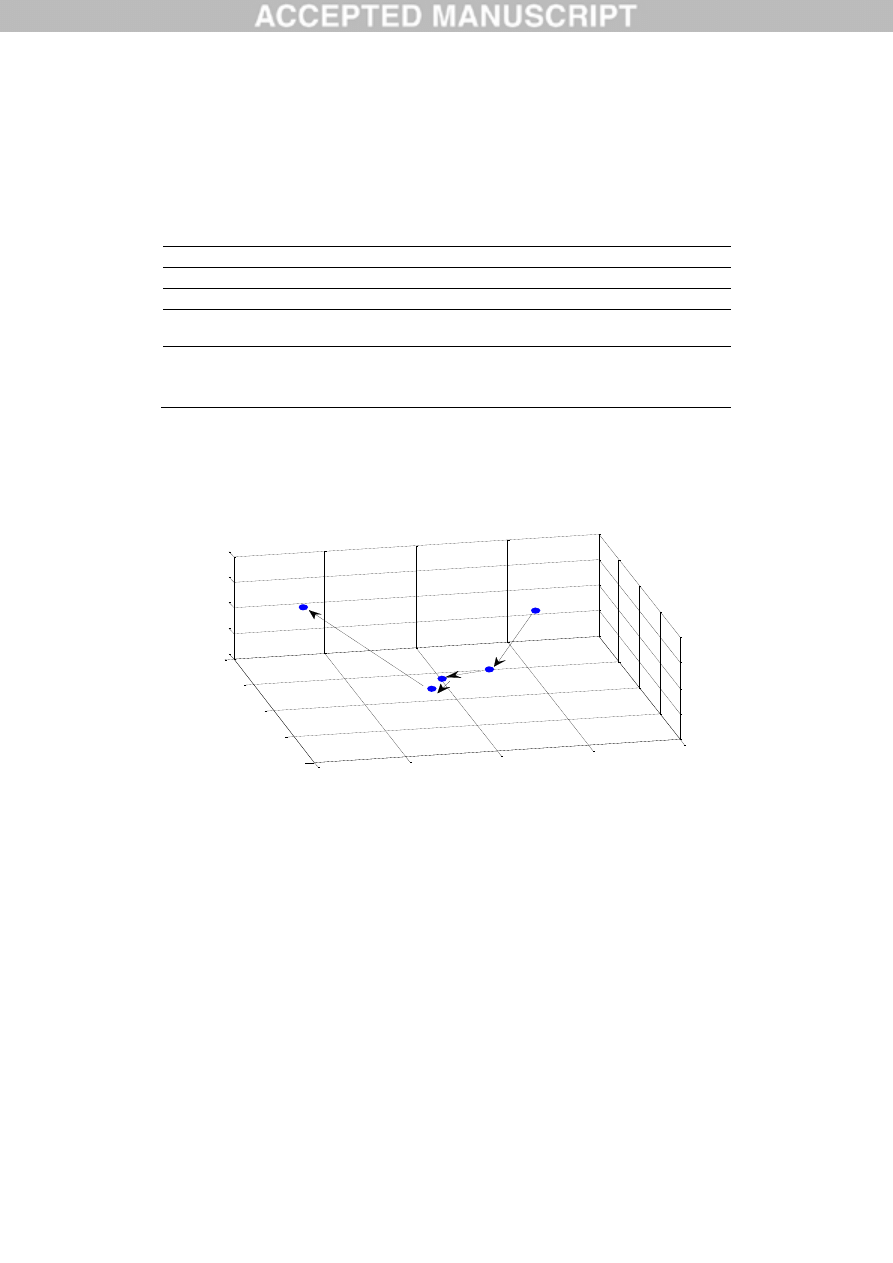
From the estimated PAD values, the dynamic changes of emotion states in each segments of the
vocal message follow the process: State 1(0.503, 0.316, 0.312)-> State 2(0.109, -0.318, -0.112)->
State 3(-0.159, -0.338, -0.211)-> State 4(-0.255, -0.518, -0.213)-> State 5(-0.744, 0.434, 0.532),
as shown in Fig.10.
Fig.10. Dynamic changes of emotion states in vocal message
We hereafter conduct a subjective evaluation on the vocal message by 61 persons of this QQ group
and find the dynamic changes of emotion states can match the evaluation results correctly. It shows that
our proposed method can also be applicable for this group on QQ. However the error of PAD values
between the machine’s estimation and the subjective evaluation has been enlarged by 11.24% than that
of the former group on Wechat. It indicates that the personalized features in the members of different
groups on social media have significant impacts on the estimation of PAD values, so the choice of the
samples for training should consider the similar degree with the group to be applied as much as
possible.
6. Conclusion and discussion
The widespread use of emerging vocal social media has facilitated people’s communication as well
as the emotion propagation on social networks greatly, and is therefore bringing the enormous impacts
on social psychological cognition and group behaviors than ever before. This issue of emotion
recognition and affective computing on emerging vocal media has become a new concerning hot point
in social media analytics. The speech signal in vocal social media appears as the human’s conversation
using natural language, and in most cases contains the mixed emotions embedded with dynamic
changes. Its complexity needs further research on the emotion recognition and computation.
-1
-0.5
0
0.5
1
-1
-0.5
0
0.5
1
-1
-0.5
0
0.5
1
Pleasure Value
Dynamic changes of emotion states
Arousal Value
Do
m
in
an
ce
V
al
ue
State 1
State 2
State 3
State 4
State 5

Page 16 of 18
Accepted Manuscript
Through the comprehensive analysis of previous research work, this paper proposed a computational
method by turning the issue of emotion recognition and affective computing on vocal social media into
the PAD value estimation from the extracted 25 acoustic feature parameters of speech signal based on a
trained LV-SVR model. The choice of acoustic feature parameters, acquisition of training samples, and
the generalization ability in real application were discussed according to the characteristics of vocal
social media under a research schema. Test result by the standard corpus and experiment in real
application showed that the proposed method can reach a high accuracy independent of the semantic
information, and has the good generalization ability for different social media groups. It provides an
effective approach for computing and analyzing the dynamic propagation of mixed emotions on vocal
social media. However, research findings in this paper indicated that trained samples associated with
the personalized features in the members of social media groups have significant impacts on the
accuracy of computational results, so the performance of the proposed method has to be tested and
verified through the large samples and in different social media groups. Besides, the precise
relationship between acoustic feature parameters and PAD values as well as the optimization on the
vector model of acoustic feature parameters are worthy of exploration in the further studies.
Acknowledgements
This research was supported by National Natural Science Foundation of China (No. 91324010,
No.41174007), Shanghai Philosophy and Social Sciences Plan, China (No. 2014BGL022), and
Graduate Innovation Fund Program (No.CXJJ-2013-445) of Shanghai University of Finance and
Economics, China.
References
[1]A. S. Abrahams, J. Jiao, G. A. Wang, W. Fan, Vehicle defect discovery from social media, Decision
Support Systems. 54(1), 2012, pp.87-97.
[2]A. S. Abrahams, J. Jiao, W. Fan, G. A. Wang, Z. Zhang, What is buzzing in the blizzard of buzz:
automotive component isolation in social media postings, Decision Support Systems. 55(4), 2013,
pp.871-882.
[3]A. S. Abrahams, W. Fan, J. Jiao, G. A. Wang, Z. Zhang, An integrated text analytic framework for
product defect discovery, Production and Operations Management. forthcoming, 2014.
[4]M. W. Bhatti, Y. Wang , L. Guan, A neural network approach for human emotion recognition in
speech, Proceedings of ISCAS 2004, 2004, pp..81-184.
[5]J. Bollen, H. Mao, X..J. Zeng, Twitter Mood Predicts the Stock Market, Journal of Computational
Science. (2)1, 2011, pp. 1-8.
[6]H. T. Cao, Chinese Microblog Sentiment Analysis Based on the PAD Model, Dalian, China: Dalian
University of Technology, 2013.
[7]Y. X. Chen, R. T. Long, Trainable emotional speech synthesis based on PAD, Pattern Recognition
& Artificial Intelligence. 26(11), 2013, pp.1019-1025.
[8]W. H. Dai, H. Z. Hu, T. Wu, Y. H. Dai, Information spread of emergency events: Path searching on
social networks. Scientific World Journal. 2014(Article ID 179620), pp. 1-7.
[9]W. H. Dai, X.Q. Wan, X. Y. Liu, Emergency event: Internet spread, psychological impacts and
emergency management, Journal of Computers. 6(8), 2011, pp. 1748-1755.
[10]A. R. Damasio, Descartes Error: Emotion, Reason and the Human Brain. New York, USA:
Gosset/Putnam Press, 1994.
[11]R. J. Davidson, D. C. Jackson, N. H. Kalin, Emotion, plasticity, context, and regulations:
perspectives from affective neuroscience, Psychological Bulletin. (126), 2000, pp. 890–909.
[12]P. Ekman, M. J. Power, Handbook of Cognition and Emotion. Sussex: John Wiley & Sons, 1999.
[13]W. Fan, M. D. Gordon, The power of social media analytic, Communications of the ACM. 57(6),
2014, pp.74-81.
[14]X. L. Fu, L. H. Cai, Y. Liu,J. Jia,W.F. Chen, Z. Yi,G. Z. Zhao, Y. J. Liu, C. X. Wu, A computational
cognition model of perception, memory, and judgment. Science in China Series F: Information
Sciences, 57(3), 2013, pp. 1-15.
[15]S.W. Gilroy, M. Cavazza, M. Niiranen, E. Andre, T. Vogt, J. Urbain, M. Benayoun, H. Seichter, M.
Billinghurst, PAD-based multimodal affective fusion, Proceedings of Affective Computing and
Intelligent Interaction and Workshops, 2009, pp.1-8.

Page 17 of 18
Accepted Manuscript
[16]C. Gobl, A. N. Chasaide, The role of voice quality in communication emotion, mood, and attitude,
Speech Communication, 40, 2003, pp.189-212.
[17]W. Guo, R. H. Wang, L. R. Dai, Mel-Cepstrum integrated with pitch and information of
voiced/unvoiced, Journal of Data Acquisition and Processing. 22(2), 2007, pp. 229–233.
[18]W. J. Han, H. F. Li, A brief review on emotional speech databases, Intelligent Computer and
Applications. 3(1), 2013, pp.5-7.
[19]W. J. Han, H. F. Li, H. B. Ruan, L. Ma, Review on speech emotion recognition, Journal of
Software, 25(1), 2014,pp.37-50.
[20]I. Hidenori, T. Fukuda, Individuality of agent with emotional algorithm, Proceedings of 2001
IEEE/RSJ International Conference on Intelligent Robots and System. 2001, pp.1195-1200.
[21]R. Horlings, Emotion Recognition Using Brain Activity. Delft, Nederland: Delft University of
Technology, 2008.
[22]H. Z. Hu, D. Wang, W.H. Dai, L. H. Huang, Psychology and behavior mechanism of micro-blog
information spreading, African Journal of Business Management . 6(35), 2012, pp. 9797-9807.
[23]L. H. Huang, W. H. Dai, C. Zhou, Z. C. Xu, S. L. Li, Cognitive Model, Propagation Rules and
Early Warning Mechanism of Network Information in Unconventional Emergency Events, National
Natural Science Foundation of China, 2013.
[24]C. E. Izard, The Psychology of Emotions. New York: Plenum press, 1991.
[25]J. Jia, S. Zhang, F. B. Meng, Y. X. Wang, L. H. Cai, Emotional audio-visual speech synthesis
based on PAD, IEEE Transactions on Audio, Speech, and Language Processing. 19( 3), 2011,
pp.570-582.
[26]J. Jia, X. H. Wang, Z. Ren, L. H. Cai, Emotional cognitive computing on the Internet data,
Communications of The CCF . 10(2), 2014, pp.38-43.
[27]I. Kompatsiaris, D. Gatica-Perez, X. Xie, Special section on social media as sensors, IEEE
Transactions on Multimedia. 15(6), 2013, pp.1229-1230.
[28]C. M. Lee, S. S. Narayanan, Toward detecting emotions in spoken dialogs, IEEE Transactions on
Speech and Processing. 13(2), 2005, pp.293-303.
[29]D. D. Li, Y. C. Yang, W. H Dai. 2014. Cost-sensitive learning for emotion robust speaker
recognition, Scientific World Journal. 2014 (Article ID 628516), pp.1-9.
[30]X. M. Li, H. T. Zhou, S. Z. Song, T. Ran, X. L. Fu, The reliability and validity of the Chinese
version of abbreviated PAD emotion scales, Lecture Notes in Computer Science, 3784, 2005,
pp.513-518.
[31] H. Lin, W. G. Fan, Patrick Y. K. Chau, Determinants of users’ continuance of social networking
sites: A self-regulation perspective, Information & Management. 51, 2014, pp.595-603.
[32]Y. Liu, Q. F. Fu, X. L. Fu, The interaction between cognition and emotion, Chinese Sci Bull.
54(18), 2009, pp.2783-2796.
[33]Y. Lu, X. L. Fu, L. M. Tao, Emotion measurement based on PAD 3-D space, Communications of
The CCF 6(5), 2010, pp.9-13.
[34]K. F. MacDorman, S. Ough, C. G. Ho, Automatic emotion prediction of song excerpts: index
construction, algorithm design, and empirical comparison, Journal of New Music Research. 36(4),
2007, pp.283–301.
[35]A. Mehrabian, Framework for a comprehensive description and measurement of emotional states,
Genetic, Social, and General Psychology Monographs, 121, 1995, pp.339-361.
[36]A. Mehrabian, Pleasure-arousal-dominance: A general framework for describing and measuring
individual differences in temperament, Current Psychology: Developmental, Learning, Personality,
Social, 14, 1996, pp.261-292.
[37]L. Muda, M. Begam and I. Elamvazuthi, Voice recognition algorithms using mel frequency cepstral
coefficient (MFCC) and dynamic time warping (DTW) techniques, Journal of computing. 2(3),
2010, pp.138-143.
[38]T. L. Nwe, S.W. Foo, L.C. De Silva, Speech emotion recognition using hidden Markov models,
Speech Communication, 41(4), 2003, pp.603–623.
[39]C. E. Osgood, Dimensionality of the semantic space for communication via facial expressions,
Scandinavian Journal of Psychology. 17(1), 1996, pp.1-30.
[40]R. W. Picard, Affective Computing. Cambridge, USA: MIT Press, 1997.
[41]S. C. Sajjan, C. Vijaya, Comparison of DTW and HMM for isolated word recognition,
Proceedings of the International Conference on Pattern Recognition, Informatics and Medical
Engineering of the IEEE, 2012, pp.466-470.
[42]H. H. Schlosberg, Three dimensions of emotion, Psychological Review. 61(2), 1954, pp.81-88.
[43]B. Schuller, G. Rigoll, M. Lang, Hidden Markov Model-Based Speech Emotion Recognition,
Proceedings of ISCAS 2003, 2003, pp.1-4.

Page 18 of 18
Accepted Manuscript
[44]B. Schuller, G. Rigoll, M. Lang, Speech emotion recognition combining acoustic features and
linguistic information in a hybrid support vector machine-belief network architecture, Proceedings
of ICASSP 2004. 2004, pp. 577-580.
[45]H. Shi, N. Li, Z. X. Tian, W. L. Zhang, N. Zhu, Multivariate wear trend prediction based on cross
validation of optimization SVR, Lubrication Engineering. 38(11), 2013, pp. 22-25.
[46]P. H. Sun, L. M. Tao, Emotion measuring method in PAD emotional space, Proceedings of The
Fourth Harmonious Man-machine Environment Joint Academic Conference, 2008, pp.638-645.
[47]J. A. K. Suykens, J. Vandewalle, Least squares support vector machine classifiers, Neural Process
Letters. 9(3), 1999, pp.293–300.
[48]J. Tang, Y. Zhang, J. M. Sun, J. H. Rao, W. J. Yu, Y. R. Chen, A. C. M. Fong, Quantitative study
of individual emotional states in social networks, IEEE Transactions on Affective computing. 3(2),
2012, pp. 132-144.
[49]L. M. Tao, Y. Liu, X.L. Fu, L.H. Cai, A computational study on PAD based emotional state model.
Proceedings of the 26th Computer-Human Interaction Conference, 2008.
[50]D.Ververidis, C. Kotropoulos, Emotional speech recognition: resources, features, and methods,
Speech Communication. 48(9), 2006, pp.1162–1181.
[51]G. A. Wang, J. Jiao, A. S. Abrahams, W. Fan, Z. Zhang, ExpertRank: A topic-aware expert finding
algorithm for online knowledge communities, Decision Support Systems. 54(3), 2013,
pp.1442-1451.
[52]Y. H. Wang, X. H. Hu, W. H. Dai, J. Zhou, T. Z. Kuo, Vocal emotion of humanoid robots: A study
from brain mechanism, Scientific World Journal. 2014(Article ID 216341), pp.1-7.
[53]Y. W. Wang, W. H. Dai, Y. F. Yuan. Website Browsing Aid: A Navigation Graph-Based
Recommendation System, Decision Support Systems. 45(3), 2008, pp.387-400.
[54]W. M. Wundt, Outlines of Psychology. Oxford, England: Engelmann, 1897.
[55]Q. Zhang, Y. Q. Yang, Research on the kernel function of support vector machine, Electric Power
Science and Engineering. 28( 5), 2012, pp.42-46..
[56]S. Q. Zhang, Z. J. Zhao, B. C. Lei, G. Y. Yang, Speech emotion recognition by combining voice
quality and prosody features, Journal of Circuits and Systems. 14(4), 2009, pp.120-123.
[57]Y. Zhang, Exploration of the new interpersonal communication pattern by Wechat in the mobile
Internet era, News Research, (2), 2014, pp.19-21.
[58]Q. Zhao, A survey of group spread effects on vocal social networks: the example of Wechat,
Science & Technology for China’s Mass Media, (6b), 2013, pp.155-156.
[59]H. Zhou, Emotional Speech Conversion and Recognition Based on the Three-dimensional PAD
Model, Lanzhou, China: Northwest Normal University, 2009.
[60]M. Zhou, L. Lei, J. Wang, A. G. A. Wang, W. Fan, Social media adoption and corporate disclosure,
Journal of Information Systems. forthcoming, 2014.
Wyszukiwarka
Podobne podstrony:
1 s2 0 S0009254115002983 mainid Nieznany
1 s2 0 S0261561413001040 mainid Nieznany (2)
1 s2 0 S0009254115002983 mainid Nieznany
Proz S2 id 402992 Nieznany
ppg s2 id 381339 Nieznany
Proz S2 id 402992 Nieznany
jpolski lu s2 pk3 id 228816 Nieznany
jpolski lu s2 pk1 id 228814 Nieznany
Digit S2 CD Digit CD Black id 1 Nieznany
Gor±czka o nieznanej etiologii
s2 1
02 VIC 10 Days Cumulative A D O Nieznany (2)
Abolicja podatkowa id 50334 Nieznany (2)
45 sekundowa prezentacja w 4 ro Nieznany (2)
4 LIDER MENEDZER id 37733 Nieznany (2)
Mechanika Plynow Lab, Sitka Pro Nieznany
katechezy MB id 233498 Nieznany
2012 styczen OPEXid 27724 Nieznany
więcej podobnych podstron