
1
Zagadnienia regresji i
korelacji
Regresja i korelacja dwóch
zmiennych, regresja
wielokrotna i
krzywoliniowa

2
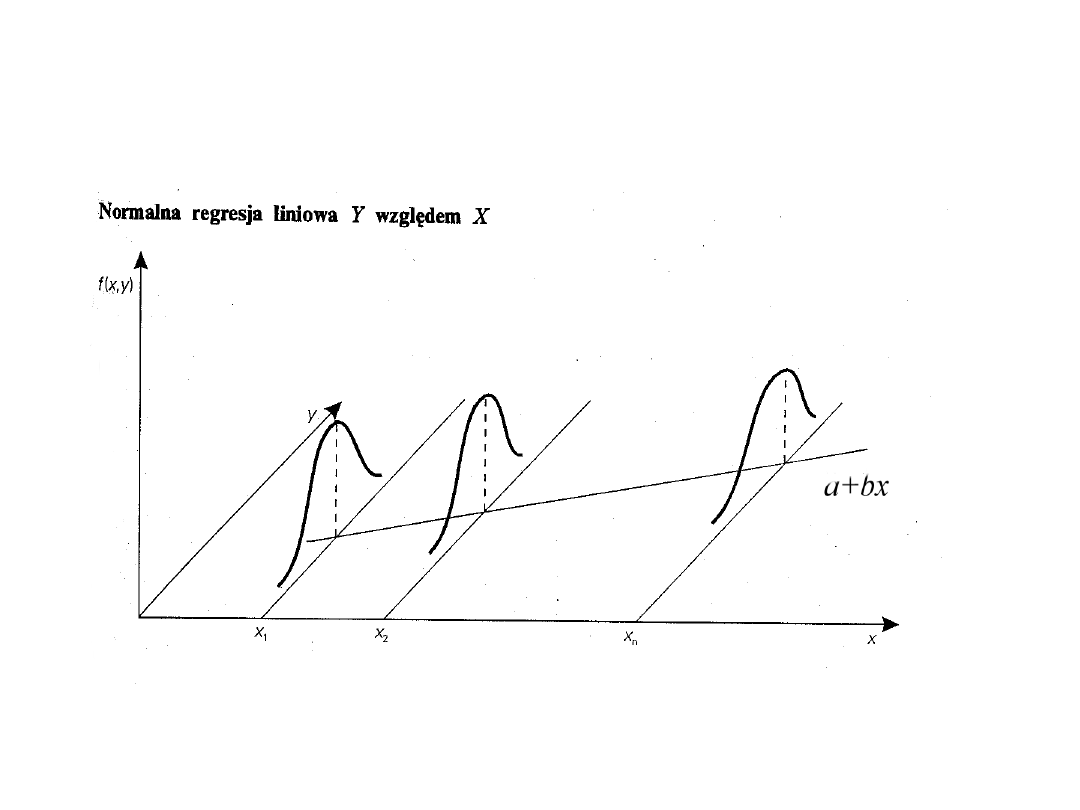
Regresja liniowa
Powiedzmy, że w pewnej populacji generalnej
rozważamy dwie zmienne:
zmienną losową oraz zmienną
rzeczywistą (lub losową) X.
O wartości oczekiwanej zmiennej losowej Y
zakładamy, że jest funkcją liniową zmiennej X
postaci:
Wariancja oznacza, że zmienność cechy
(zmiennej) Y jest niezależna od zmiennej X (jest
stała).
Y N m x
y x
~ ( ( );
)
/
m x
a bx
( )
y x
/
2
3
Regresja liniowa (c.d.)

4
Estymacja parametrów
modelu
Parametry modelu nie są znane i
muszą być estymowane na podstawie odpowiedniej
próby losowej.
Niech oznacza elementy dwucechowej próby
losowej. Wyniki te można zilustrować na wykresie w
układzie OXY uzyskując rozrzut empiryczny punktów.
Zagadnienie estymacji parametrów modelu sprowadza
się do takiego dobrania ich wartości, aby wykres prostej
“jak najlepiej” pasował do punktów empirycznych.
Odpowiednie kryterium można sformułować tak: chcemy
tak poprowadzić prostą regresji, aby suma kwadratów
odległości każdego punktu empirycznego od tej prostej
była jak najmniejsza.
m x
a bx
( )
( , )
y x
i
i

5
Estymacja parametrów
modelu (c.d.)
Zgodnie z modelem każdą obserwację
empiryczną można zapisać jako:
a kryterium estymacji odpowiednio jako:
Problem estymacji sprowadza się więc do
wyznaczenia minium funkcji s.
y
a bx e
i
i
i
s
e
y
a bx
i
i
n
i
i
i
n
2
1
2
1
(
)
min

6
Estymacja parametrów
modelu (c.d.)
Funkcja s jest funkcją dwóch niewiadomych (a i b), aby
znaleźć minimum tej funkcji musimy wyznaczyć
pochodne cząstkowe funkcji s względem obu
niewiadomych:
Przyrównując te pochodne do zera otrzymujemy tzw.
układ równań normalnych (w układzie tym, w miejsce
a i b wstawiamy ich oszacowania z próby, czyli i
).
s
a
y a bx
s
b
x y a bx
i
i
i
n
i
i
i
i
n
2
2
1
1
(
)
(
)
a
b

7
Estymacja parametrów
modelu,
układ równań normalnych
Układ równań normalnych ma postać:
Rozwiązując powyższy układ otrzymujemy:
(
)
(
)
y a bx
x y a bx
i
i
i
n
i
i
i
i
n
1
1
0
0
(
)(
)
(
)
cov
var
b
y y x x
x x
xy
x
i
i
i
n
i
i
n
1
2
1
a y bx

8
Istotność regresji
Istotność wyestymowanego równania regresji
zbadamy weryfikując hipotezę zerową
Przy prawdziwości H
0
statystyka:
ma rozkład t Studenta z liczbą stopni swobody v
= n - 2. Wyrażenie jest oszacowaniem
wariancji odchyleń od regresji z próby:
H b
H b
0
0
0
1
:
:
wobec
t
b
s
b
s
x
b
y x
var
/
2
s
y x
/
2
var
cov
/
/
y x
y x
s
y b
xy
n
2
2
2

9
Istotność regresji i interpretacja
współczynnika regresji
Jeżeli , to H
0
:b = 0 odrzucamy jako zbyt
mało prawdopodobną i wnioskujemy o istotności
wyznaczonego równania regresji postaci:
W sytuacji, gdy wyniki naszej próby nie
przeczą hipotezie zerowej. Tym samym funkcja
regresji ma postać:
Współczynnik regresji mówi nam o tym, o ile zmieni
się zmienna zależna y przy wzroście zmiennej x o
jednostkę.
t
t
emp
n
.
,
2
t
t
emp
n
.
,
2
( )
m x
y
( )
m x
a bx

10
Inne hipotezy związane z
regresją
Korzystając z rozkładu t-Studenta możemy także
weryfikować hipotezy zerowe postaci:
przy alternatywie obustronnej jak i jednostronnej.
Funkcja testowa ma zawsze tę samą postać:
a zmieniać się będą jedynie obszary krytyczne
(zależnie od H
1
) albo krytyczne poziomy istotności
(jeżeli korzystamy z pakietów statystycznych).
H b b
0
0
:
t
b b
s
b
0
11
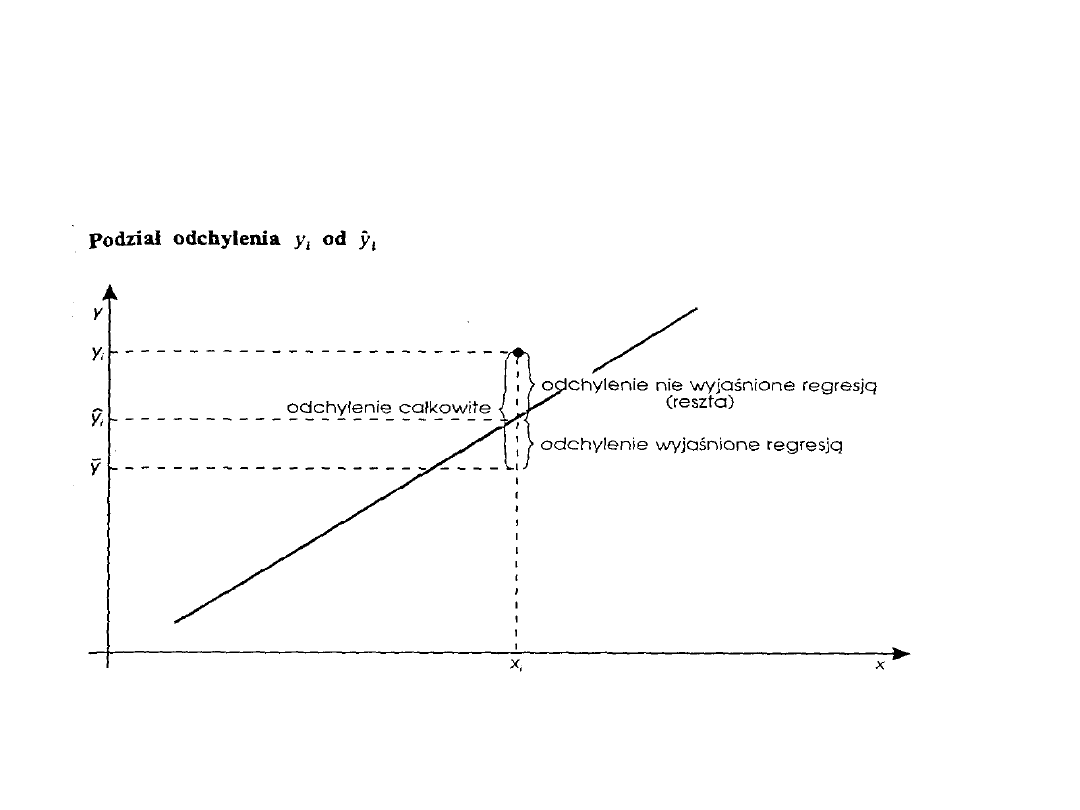
Dokładność dopasowania
prostej regresji
Odchylenie obserwowanej wartości od jej średniej
można zapisać następująco:
Pierwszy składnik można traktować jako tę
część całkowitego odchylenia zmiennej y, która jest
wyjaśniona regresją liniową y względem x.
Drugi zaś składnik jest tą częścią zmienności
całkowitej, która nie została wyjaśniona regresją.
Na kolejnym slajdzie zależność ta jest zilustrowana
graficznie.
y y
y y
y y
i
i
i
i
y y
i
12
Dokładność dopasowania prostej
regresji (c.d.)

13
Dokładność dopasowania prostej
regresji (c.d.)
Podnosząc do kwadratu obie strony równości
i sumując po i = 1, 2,..., n otrzymamy (po
odpowiednich przekształceniach) analogiczną
równość dla sum kwadratów odchyleń:
Równość ta wyraża podział całkowitej sumy
kwadratów odchyleń dla zmiennej y na dwa
składniki:
- sumę kwadratów odchyleń wyjaśnioną regresją,
- resztową sumę kwadratów odchyleń (nie
wyjaśnioną regresją).
y
y
y
y
y
y
i
i
i
i
y y
y y
y y
i
i
n
i
i
n
i
i
i
n
2
1
2
1
2
1

14
Współczynnik determinacji
Równość
można wykorzystać do konstrukcji miary
dopasowania prostej regresji. Wyrażenie:
w którym sumę kwadratów odchyleń wyjaśnioną
regresją odnosimy do całkowitej sumy kwadratów
odchyleń
nazywamy
współczynnikiem
determinacji.
y y
y y
y y
i
i
n
i
i
n
i
i
i
n
2
1
2
1
2
1
r
y y
y y
b
xy
y
i
i
n
i
i
n
2
2
1
2
1
cov
var

15
Współczynnik determinacji
(c.d.)
Wartość współczynnika determinacji zawiera się w
przedziale <0; 1> i informuje nas o tym, jaka część
zmienności całkowitej zmiennej losowej Y
została wyjaśniona regresją liniową względem
X.
Jeżeli między zmiennymi Y i X istnieje pełna
zależność, to wszystkie punkty empiryczne leżą na
prostej, reszty są zerowe, a r
2
= 1.
W przypadku braku zależności ( ) funkcja
regresji jest równa i w
konsekwencji r
2
= 0.
b 0
( )
m x
y y

16
Jeszcze raz o weryfikacji
hipotezy o istotności regresji
Równość daje także
możliwość weryfikacji hipotezy o istotności regresji
testem F Fishera-Snedecora. Analiza wariancji ma
postać:
Zmienność df S.S M.S F
emp
. F
Regresji 1 SS
R
MS
R
F
R
Odchyleń n-2 SS
E
MS
E
Całkowita n-1 SS
T
gdzie:
y y
y y
y y
i
i
n
i
i
n
i
i
i
n
2
1
2
1
2
1
SS
y y
b
xy
R
i
i
n
cov
2
1
SS
y y
y
T
i
i
n
2
1
var
F
n
, ,
1
2

17
Predykcja na podstawie regresji
liniowej
Wyestymowany model regresji można
wykorzystać do przewidywania, jakie wartości
przyjmie zmienna Y przy ustalonych wartościach
zmiennej niezależnej X. Zagadnienie to nosi
nazwę predykcji lub prognozowania.
Niech będzie oszacowaniem
równania regresji z próby, a
oszacowaniem wariancji odchyleń od regresji.
( )
m x
a bx
S
y b
xy
n
y x
/
var
cov
2
2
18
Dokładność predykcji
Wariancja wartości regresyjnej określona jest
wzorem:
Z powyższego wzoru wynika, że wariancja wartości regre-
syjnych (teoretycznych) zależy od wielkości różnicy .
Im wartość x, dla której dokonujemy predykcji jest bardziej
odległa od średniej , tym mniejsza dokładność prognozy.
( )
m x
S
S
n
x x
x
m x
y x
( )
/
(
)
var
2
2
2
1
x x
x

19
Przedział ufności dla
wartości regresyjnej
Przy założeniu, że rozważany model jest
klasycznym modelem normalnej regresji liniowej
statystyka:
ma rozkład t Studenta z liczbą stopni swobody v
= n - 2.
Na tej podstawie możemy wyznaczyć przedział
ufności dla wartości regresyjnych:
t
m x
m x
S
m x
( )
( )
( )
m x
m x t
S
m x t
S
z P
n
m x
n
m x
( )
( )
;
( )
,
( )
,
( )
2
2
1
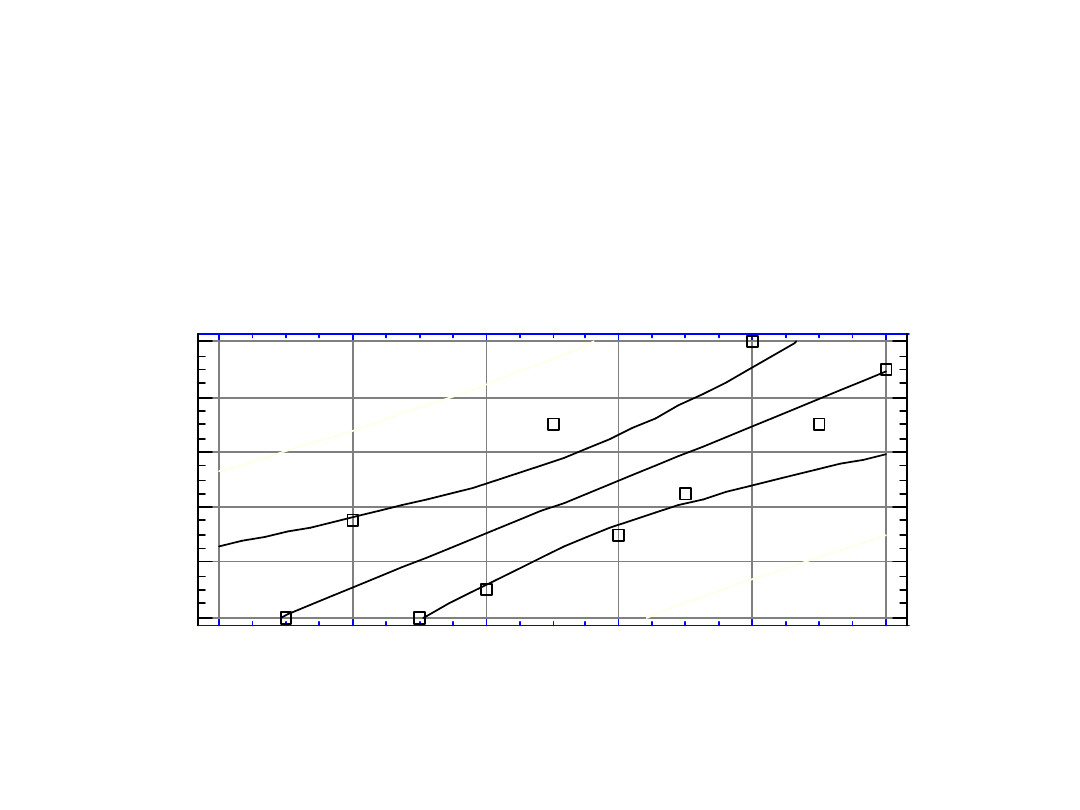
20
Przedział ufności dla
wartości regresyjnej (c.d.)
Plot of Fitted Model
Produkcja
W
o
d
a
0
2
4
6
8
10
8
12
16
20
24
28

21
Współczynnik korelacji
Powiedzmy, że w pewnej populacji generalnej
obserwujemy dwie zmienne losowe Y i X. Miarą siły
związku między zmiennymi losowymi jest współczynnik
korelacji
, a jego oceną w próbie wyrażenie:
Współczynnik korelacji r ma wszystkie własności
określone dla współczynnika korelacji
w populacji:
•
• , jeżeli cechy (zmienne) są liniowo
nieskorelowane
• , jeżeli między zmiennymi zachodzi
zależność
liniowa
(wprost
lub
odwrotnie
proporcjonalna).
cov
var var
r
xy
x
y
r
1 1
;
r 0
r
r
1
1

22
Współczynnik korelacji (c.d.)
Współczynnik korelacji określa, oprócz siły związku
między zmiennymi, także kierunek zależności.
Zależności między wartościami współczynnika
korelacji
r
a
kształtem
rozrzutu
danych
empirycznych pokazane będą na dwóch kolejnych
slajdach.
Kwadrat współczynnika korelacji z próby będziemy
nazywać współczynnikiem determinacji i jest on,
drugim poza współczynnikiem korelacji miernikiem
siły związku między zmiennymi. Interpretacja
współczynnika determinacji jest nam już znana:
podaje, w jakiej części zmienność jednej cechy jest
wyjaśniona przez drugą cechę.
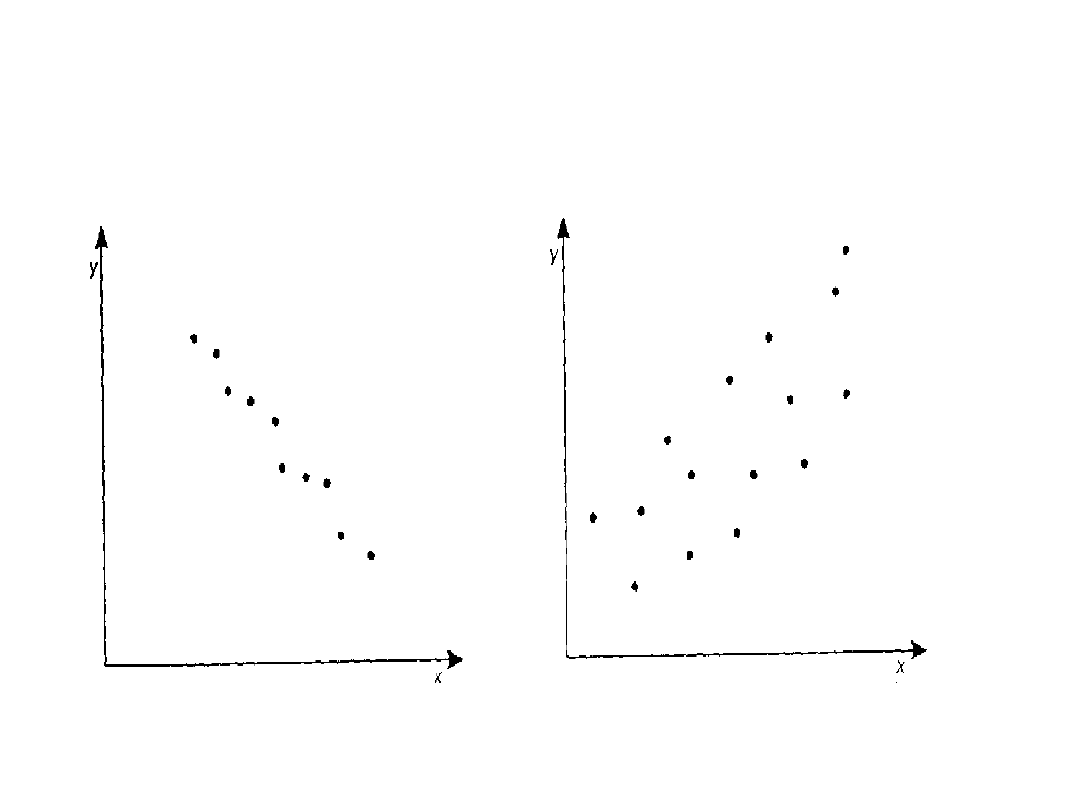
23
Wartości r a rozrzut
empiryczny punktów
r bliskie -1
0
1
r
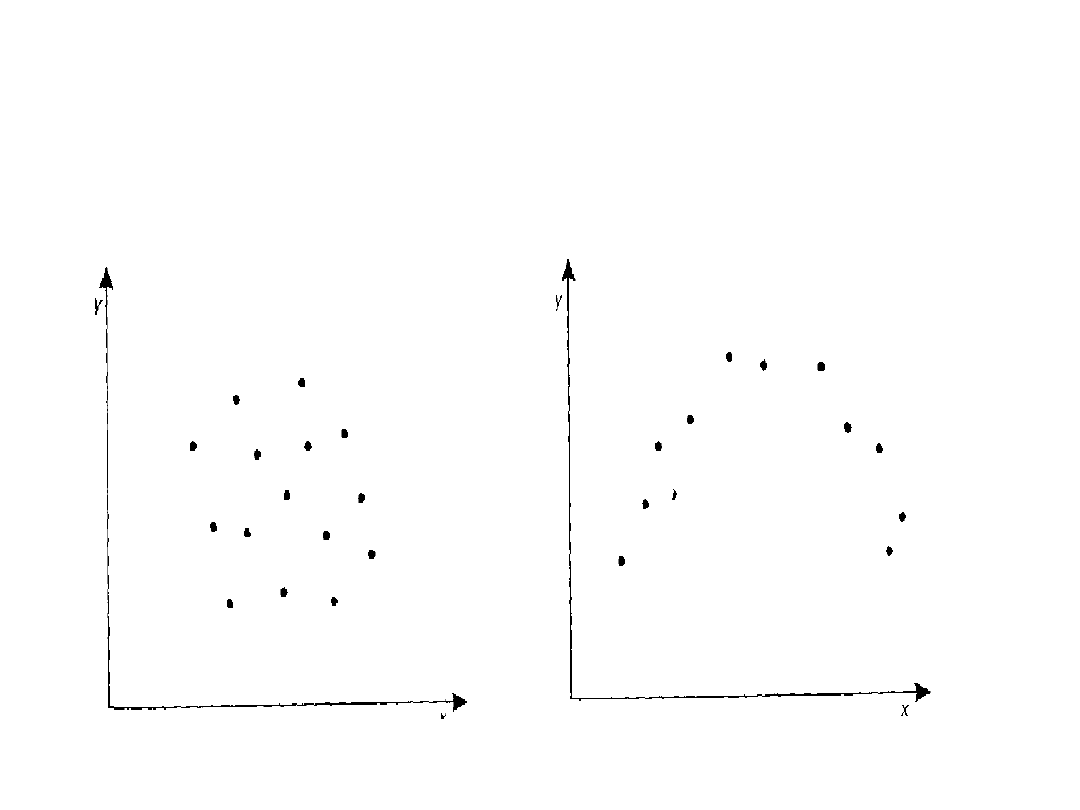
24
Wartości r a rozrzut
empiryczny punktów (c.d.)
r 0
r 0

25
Weryfikacja hipotezy o
istotności korelacji
Załóżymy, że rozkład zmiennych losowych Y i X w
populacji generalnej jest normalny. Na podstawie
n-elementowej
próby
chcemy
zweryfikować
hipotezę, że zmienne te są liniowo niezależne:
wobec
Jeżeli H
0
jest prawdziwa, to statystyka:
ma rozkład t Studenta z liczbą stopni swobody v =
n - 2
Wnioskowanie co do losów H
0
jest standardowe.
H
0
0
:
H
1
0
:
t
r
r
n
1
2
2

26
Istotność regresji a korelacji
Hipoteza o istotności korelacji może być także
zweryfikowana poprzez porównanie
wyznaczonego współczynnika z próby z
wartościami krytycznymi współczynnika
korelacji wielokrotnej Pearsona.
Jeżeli (gdzie k oznacza liczbę
zmiennych niezależnych), to odrzucamy
na korzyść
Hipotezy o istotności regresji i korelacji są
równoważne, tym samym weryfikując jedną z nich
wypowiadamy się jednocześnie o losach drugiej.
r
R
emp
k n k
.
, ,
1
H
0
0
:
H
1
0
:

27
Regresja wielokrotna liniowa
Dotychczas zajmowaliśmy się taką sytuacją, gdzie
w populacji generalnej rozpatrywaliśmy tylko
dwie zmienne: Y i X.
Znacznie częściej będziemy mieć do czynienia z
sytuacjami, gdzie w populacji generalnej
rozpatrywać będziemy k+1 zmiennych: zmienną
losową Y oraz k zmiennych X (stałych lub
losowych).
O zmiennej Y sformułujemy założenie, że jest to
zmienna normalna:
Y N m x
x
k
y x
x
k
~ ( ( ,..., ),
)
/ ,...,
1
1

28
Regresja wielokrotna liniowa
(c.d.)
Załóżmy dalej, że wartość oczekiwana zmiennej
losowej Y jest funkcją liniową zmiennych x
i
(i=1, ...,k):
Zapis wariancji sformułowany w
założeniu oznacza, podobnie jak w przypadku regresji
jednej zmiennej, stałość rozrzutu wartości cechy Y dla
dowolnej kombinacji wartości zmiennych x
i
.
Parametry powyższego modelu liniowego nie są znane
i muszą być oszacowane na podstawie n-elementowej
próby losowej.
Współczynniki modelu b
1
, ..., b
k
będziemy nazywać
cząstkowymi współczynnikami regresji.
m x
x
b bx
b x
k
k k
( ,... )
1
0
1 1
y x
x
k
/
,...,
1
2

29
Regresja wielokrotna liniowa,
estymacja modelu
Oznaczmy elementy próby losowej jako
. Zgodnie z modelem dla j-tej wartości mamy:
Kryterium estymacji sformułujemy analogicznie
jak poprzednio: chcemy tak dobrać parametry
modelu, aby suma kwadratów odchyleń od modelu
była jak najmniejsza:
( ,
,..., )
y x
x
j
j
kj
1
y
b b x
b x
e
j
j
k kj
j
0
1 1
s
e
y b bx
b x
j
j
j
j
k kj
j
2
0
1 1
2
min

30
Regresja wielokrotna liniowa,
estymacja modelu (c.d.)
Minimalizacja funkcji s wymaga rozwiązania
k+1 układów równań. Można częściowo
uprościć obliczenia zapisując model funkcji
regresji w postaci:
gdzie
.
Kryterium estymacji ma teraz postać:
y
y b x
x
b x
x
e
j
j
k
kj
k
j
1
1
1
(
)
(
)
b
y
bx
b x
k k
0
1 1
(
)
s
y
y
b x
x
b x
x
j
j
k
kj
k
j
(
)
(
)
(
)
min
1
1
1
2

31
Regresja wielokrotna liniowa,
estymacja modelu (c.d.)
Minimalizacja funkcji s wymaga teraz rozwiązania
układu k równań normalnych, które otrzymamy
obliczając pochodne cząstkowe funkcji s względem
poszczególnych b
i
i przyrównu-jąc je do zera.
Otrzymany układ równań normalnych można zapisać
macierzowo w postaci:
Macierz V jest macierzą kwadratową współczynników
przy niewiadomych, wektor jest wektorem ocen
cząstkowych współczynników regresji, a wektor C jest
wektorem wyrazów wolnych. Na kolejnym slajdzie
podana jest definicja elementów tych macierzy.
VB C
B

32
Układ równań normalnych
Elementami macierzy V są odpowiednio:
Wektor kolumnowy ocen cząstkowych
współczynników regresji ma postać:
a wektor kolumnowy wyrazów wolnych postać:
v
x
i
j
x x
i
j
ij
i
j
var
dla
cov
dla
i
( , , )
B
T
k
T
b
b
1
C
T
k
T
x y
x y
(cov
, ,cov
)
1

33
Przykład układu równań
normalnych
Dla dwóch zmiennych niezależnych układ
równań normalnych można zapisać w postaci:
W zapisie macierzowym ten sam układ równań
ma postać
gdzie:
var
cov
cov
cov
var
cov
b
x b
x x
x y
b
x x b
x
x y
1
1
2
1 2
1
1
1 2
2
2
2
V
var
cov
cov
var
x
x x
x x
x
1
1 2
1 2
2
B
b
b
1
2
C
cov
cov
x y
x y
1
2
VB C

34
Rozwiązanie układu równań
normalnych
Aby rozwiązać równanie macierzowe
musimy pomnożyć obie strony powyższego
równania przez macierz odwrotną do macierzy V.
Tak więc oceny nieznanych cząstkowych
współczynników regresji są równe
a ocenę wyrazu wolnego znajdziemy z zależności:
VB C
V VB IB B V C
1
1
B V C
1
b
y
bx
i
i
i
0

35
Badanie istotności regresji
wielokrotnej
Hipotezę o istotności regresji wielokrotnej możemy
zapisać jako:
a do jej weryfikacji wykorzystać test F Fishera-
Snedecora.
Tabela analizy wariancji ma postać:
Zmienność d.f SS MS Femp. F
Regresji
k SS
R
MS
R
F
R
Odchyleń n-k-1 SS
E
MS
E
Całkowita n-1 SS
T
H b b
b
k
0
1
2
0
:
F
k n k
, , 1
36
Badanie istotności regresji
wielokrotnej (c.d.)
Sumy kwadratów odchyleń i średnie kwadraty
potrzebne do zweryfikowania hipotezy o
istotności regresji mogą być wyznaczone z niżej
podanych wzorów.
SS
y
T
var
SS
b
x y MS
SS
k
R
i
i
i
R
R
cov
SS
y
b
x y
MS
SS
n k
E
i
i
E
E
i
var
cov
1

37
Badanie istotności regresji
wielokrotnej (c.d.)
Hipotezę będziemy odrzucać
wtedy, gdy
.
Odrzucenie hipotezy H
0
jest równoznaczne z tym, że
co najmniej jeden współczynnik regresji jest
różny od zera.
Tym samym istnieje związek funkcyjny liniowy między
zmienną zależną Y a zmiennymi niezależnymi X
i
.
Problemem statystycznym będzie dalej ustalenie,
które zmienne niezależne powinny pozostać w
modelu regresji.
H b b
b
k
0
1
2
0
:
F
F
R
k n k
, ,
1

38
Weryfikacja hipotez o istotności
cząstkowych współczynników
regresji
Teoretycznie problem sprowadza się do
zweryfikowania serii k hipotez zerowych
mówiących o tym, że i-ty cząstkowy
współczynnik regresji jest równy zero.
Hipotezy te mogą być weryfikowane testem t-
Studenta, a funkcja testowa ma postać:
H b
wobec H b
dla i
k
i
i
0
1
0
0
1 2
:
:
, ,....,
t
b
s
b
s
v
i
i
b
i
y x
x
ii
i
k
/ ,...,
1
2

39
Weryfikacja hipotez
Wyrażenie
jest oszacowaniem średniego kwadratu odchyleń
od regresji, a element v
ii
jest elementem
diagonalnym macierzy odwrotnej do macierzy V.
Przy prawdziwości hipotez zerowych tak
określone statystyki mają rozkład t-Studenta z
liczbą stopni swobody v = n-k-1
H b
i
0
0
:
s
y
b
x y
n k
y x
x
i
i
i
k
/ ,...
var
cov
1
2
1

40
Weryfikacja hipotez ,
wnioskowanie
Hipotezę będziemy więc odrzucać,
jeżeli wartość empiryczna statystyki t znajdzie się w
odpowiednim obszarze krytycznym.
Tym samym zmienna, przy której stoi weryfikowany
cząstkowy współczynnik regresji powinna pozostać
w modelu.
I tu pojawia się pewien trudny problem. Jeżeli
zmienne niezależne są z sobą powiązane (macierz V
nie jest macierzą diagonalną), to oceny istotności
cząstkowych współczynników regresji nie są
niezależne.
H b
i
0
0
:
H b
i
0
0
:

41
Problem doboru zmiennych
W przypadku istnienia silnych współzależności między
zmiennymi niezależnymi X
i
(mierzonymi choćby
współczynnikami korelacji miedzy parami zmiennych)
może to prowadzić do paradoksalnej (z pozoru) sytuacji.
Analizując funkcję regresji wielokrotnej dochodzimy do
wniosku, że jest ona istotna statystycznie (testem F).
Weryfikując dalej hipotezy o istotności cząstkowych
współczynników uzyskujemy takie wartości empiryczne
testu t Studenta, które nie przeczą hipotezom zerowym.
Z jednej strony mamy więc istotną funkcję regresji, a z
drugiej wszystkie zmienne (analizowane oddzielnie) są
nieistotne, powinny więc być usunięte z modelu.

42
Problem doboru zmiennych
(c.d.)
Problem występowania współzależności między
zmiennymi niezależnymi, w aspekcie doboru zmiennych
istotnych, zmusza nas do wypracowania innego
sposobu określania zestawu zmiennych niezależnych.
Można sformułować takie podejście: zaczynamy od
pełnego zestawu potencjalnych zmiennych
niezależnych, a następnie kolejno usuwamy z modelu tę
zmienną niezależną, której rola w opisywaniu
zależności między zmienną Y a zmiennymi niezależnymi
jest najmniejsza. Podejście takie nosi nazwę regresji
krokowej, ale przed jej omówieniem wprowadzimy
jeszcze mierniki dobroci dopasowania modelu.

43
Ocena stopnia dopasowania
modelu
Miarą stopnia dopasowania modelu może być
współczynnik korelacji wielokrotnej R lub jego
kwadrat (współczynnik determinacji D).
Dobierając model funkcji regresji powinniśmy
dążyć do uzyskania jak największego
współczynnika determinacji (korelacji), ale przy
możliwie małym średnim kwadracie odchyleń od
regresji:
R
b
x y
y
i
i
i
cov
var
D R
2
s
y
b
x y
n k
y x
x
i
i
i
k
/ ,...
var
cov
1
2
1

44
Regresja krokowa
W świetle poprzednich rozważań można sformułować
następujący tok postępowania:
1. Zaczynamy od pełnego (potencjalnie) zestawu
zmiennych niezależnych. Estymujemy model i
wyznaczamy
2. Wyznaczamy wektor wartości empirycznych
statystyk t dla hipotez .
3. Usuwamy z modelu tę zmienną, dla której
uzyskaliśmy najmniejszą wartość empiryczną statystyki
t (co do wartości bezwzglednej) i ponownie estymujemy
model.
Postępowanie takie kontynuujemy tak długo, dopóki w
modelu nie pozostaną tylko zmienne istotne.
R
s
y x
x
k
2
2
1
oraz
/ ,...,
H b
i
0
0
:

45
Regresja krokowa (c.d.)
W trakcie wykonywania regresji krokowej powinniśmy
obserwować zmiany wartości współczynnika
determinacji jak i średniego kwadratu błędu.
Usuwanie zmiennych niezależnych będzie oczywiście
zmniejszać wartości współczynnika determinacji, ale
usunięcie zmiennej nieistotnej spowoduje niewielkie
zmniejszenie wartości tego parametru.
Generalnie nasze postępowanie ma doprowadzić do
maksymalizacji wartości współczynnika
determiancji przy jednoczesnej minimalizacji
średniego kwadratu błędu.

46
Regresja krzywoliniowa
W wielu przypadkach interesuje nas nieliniowy
związek między zmienną Y a zmienną X.
Przykładowo może to być związek typu
wielomianu stopnia drugiego:
Problem estymacji tego modelu staje się prosty,
jeżeli dokonamy formalnego podstawienia:
w wyniku którego sprowadzamy model
krzywoliniowy do modelu liniowego postaci:
m x
b bx b x
( )
0
1
2
2
x
x x
x
1
2
2
m x
b bx b x
( )
0
1 1
2 2

47
Regresja krzywoliniowa (c.d.)
Rozważmy jeszcze jeden przykład modelu
nieliniowego z dwoma zmiennymi niezależnymi:
Poprzez formalne podstawienia model ten daje się
sprowadzić do standardowego modelu liniowego.
Postępowanie, które pozwala na sprowadzenie
modelu krzywoliniowego do standardowego
modelu liniowego nosi nazwę linearyzacji
modelu regresji.
y m x x
b bx b x
b x b x
b x x
( , )
1
2
0
1 1
2 1
2
3 2
4 2
2
5 1 2
y b bz b z b z b z b z
0
1 1
2 2
3 3
4 4
5 5

48
Wnioskowanie w regresji
wielokrotnej
Podobnie jak w przypadku regresji liniowej jednej
zmiennej cząstkowe współczynniki regresji mają
następującą interpretację merytoryczną:
i-ty, cząstkowy współczynnik regresji mówi nam o
tym, o ile średnio zmieni się wartość zmiennej Y
przy wzroście i-tej wartości zmiennej X o jednostkę i
przy ustalonych wartościach pozostałych zmiennych
niezależnych.
W przypadku większości modeli regresji
krzywoliniowej taka interpretracja nie jest możliwa.

49
Funkcje przekrojowe
Rozważmy model regresji wielomianowej dwóch
zmiennych niezależnych postaci:
Dość wygodną formą analizowania takiego
modelu jest wyznaczenie funkcji przekrojowych,
czyli takich, gdzie zmienna Y jest funkcją tylko
jednej zmiennej niezależnej. W naszym
przykładzie mamy dwie takie funkcje:
y m x x
b bx b x
b x b x
b x x
( , )
1
2
0
1 1
2 1
2
3 2
4 2
2
5 1 2
y m x x
x
b b x b x
(
)
`
`
1
2
20
0
1 1
2 1
2
y m x x
x
b b x b x
(
)
`
`
2
1
10
0
1 2
4 2
2

50
Problemy związane z
estymacją funkcji regresji
Estymacja funkcji regresji jest trudnym
zagadniem z kilku powodów:
1. Eksperymentator nie ma pewności, że zbiór
analizowanych zmiennych niezależnych jest
pełny.
2. Kształt funkcji regresji z reguły nie jest znany,
stąd pojawia się problem doboru zmiennych.
3. W wielu sytuacjach można uzyskać
porównywalną dobroć dopasowania modelu dla
różnych zestawów zmiennych niezależnych.
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
Wyszukiwarka
Podobne podstrony:
Statystyka #9 Regresja i korelacja
STATYSTYKA-regresja, Statystyka, statystyka
download Statystyka StatystykaZadania4[1]
download Statystyka StatystykaZadania1[1]
6 STATYSTYKA regresja 2 id 4389 Nieznany (2)
download Statystyka StatystykaZadania2[1]
Statystyka #9 Regresja i korelacja
statystyka regresja
download Statystyka StatystykaZadania4[1]
6 STATYSTYKA regresja 2
download Statystyka Stat4
download Statystyka Stat1
6 STATYSTYKA regresja 2
statystyka regresja
zadanie 2- regresja liniowa, Statyst. zadania
06.regresja liniowa, STATYSTYKA
więcej podobnych podstron