1
Autor: mgr inż. Jakub Siwiec
mgr inż. Jakub Siwiec (j.siwiec@utp.edu.pl)
mgr inż. Cezary Graul (cezary.graul@utp.edu.pl)
Katedra Informatyki w Zarządzaniu
Wydział Zarządzania
PODSTAWY ZARZĄDZANIA WIEDZĄ
Ćwiczenia praktyczne nr 3 – Programowanie procesów text-mining’owych
Zadanie:
Na podstawie zdobytej na poprzednich zajęciach bazy tekstów anglojęzycznych (30 artykułów, w 30
plikach tekstowych *.txt, w języku angielskim, o minimalnej długości 1800z znaków bez spacji) oraz
zastosowaniu programu RapidMiner,
zaprogramuj swój pierwszy proces text-mining’owy.
Środowisko pracy:
stwórz „nowy folder” na pulpicie o nazwie Imie_nazwisko,
przekopiuj wszystkie 30 plików tekstowych do nowoutworzonego folderu,
otwórz program RapidMiner (Start Programy RapidMiner) w razie potrzeby ściągnij i zainstaluj
(Strona WZ
– materiały dla studenta),
stwórz nowy proces - „new process” i zapisz go jako 30_imię_i_nazwisko, bez polskich znaków.
Pierwsza kostka:
UWAGA
– pamiętaj o wiązaniach między procesami
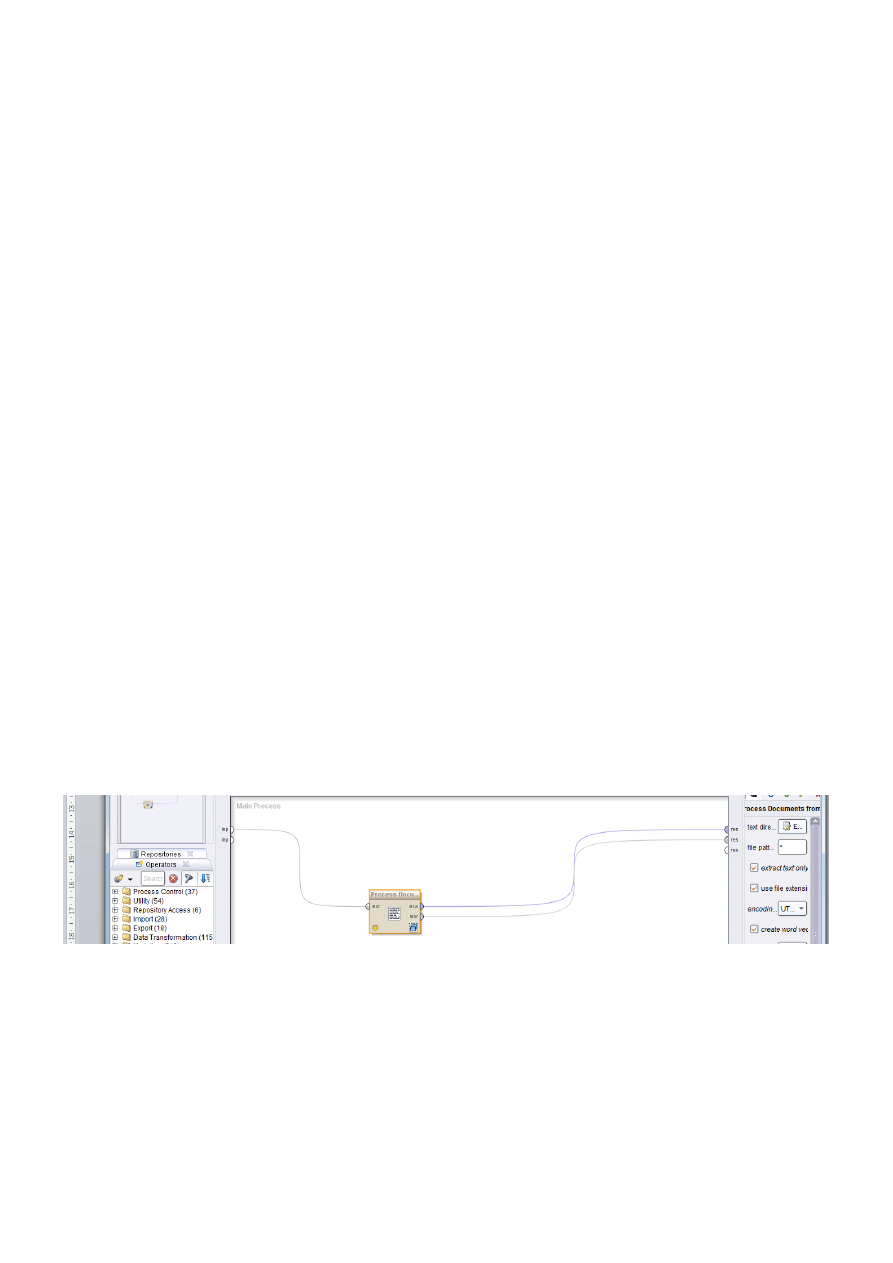
skorzystaj z lewego drzewka procesów – rozwiń „Text Processing”,
przeciągnij proces „Process Documents from Files” na pulpit ekranu projektowego, pamiętaj o
połączeniu wszystkich wiązań związanych z ładowaniem danych (wejściem – input) oraz wynikami
o
klikając na każdej kostce jednokrotnie masz możliwość sformułować założeń,
o w opcji text directories edit list
wskaz folder zawierający Twoje 30 plików tekstowych
(.txt),
o zaznacz opcje:
extract text only
use file extension as type
encoding
– UTF-8
vector creation
– TF-IDF
add meta information
prune method
– none
datamanagement
– double_sparse_array

2
Autor: mgr inż. Jakub Siwiec
Kolejne kostki:
UWAGA
– śledź zmiany w wynikach po każdym dodatkowym procesie!!!
otwórz dodany przez siebie proces „Process Documents from Files” „(podwójne kliknięcie)
dołącz proces tokenizacji, doprowadź go do punktu wynikowego
o mode
– non letters
dołącz proces tranform cases
o opcjonalnie
– lower case (małe litery) lub upper case (wielkie litery)
dołącz proces filter stopwords (English)
dołącz process generate n-Grams (Terms)
o max length - 2
dołącz process filter tokens (by length)
o min chars
– 4
o max chars - 50
Krok końcowy:
zapoznaj się z otrzymanymi wynikami – czyli wykazem wyrazów wraz z ich ilościami wystąpień
(total occurences)
otrzymane wyniki (WordList) przefiltruj
pod względem najczęściej występujących - od najczęściej do
najrzadziej występujących
wykonaj 2 zrzuty ekranu (Print Screen)
o filtr
najczęściej występujących wyrazów
o
filtr najrzadziej występujących wyrazów
zrzuty ekranu wklej do dokumentu WORD i prześlij na adres prowadzącego (
usuń pliki z pulpitu
opróżnij kosz,
wyłącz komputer.
Wyszukiwarka
Podobne podstrony:
cw 2 programowanie procesu id 1 Nieznany
cw 4 programowanie procesu klasteryzacji
cw 4 programowanie procesu klasteryzacji
cw 2 programowanie procesu
konspekt cw 3 1 programowanie liniowe
konspekt cw 4 programowanie sieciowe
Technika Mikroprocesorowa, tup-cw 4, Program 1:
Cw 2 Organizacja Procesu Zaopatrzenia
avt 2502 Programator procesorów 89CX051 INNY
CUDA w przykladach Wprowadzenie do ogolnego programowania procesorow GPU cudawp
Optymalizacja Cw 4 Programowanie nieliniowe z ograniczeniami
programowanie procesorow graficznych GPU denkowski
procesy cw 2, Podstawowe procesy przemysłu chemicznego i aparatura
wykres programowy procesu decyzji
CUDA w przykladach Wprowadzenie do ogolnego programowania procesorow GPU cudawp
programy, procesy
więcej podobnych podstron