Wstęp
Pomimo, że poniższe materiały mają za zadanie w jak największym stopniu ułatwić naukę ekonometrii, nie obejdzie się bez wprowadzenia formalnych określeń i definicji. Dlaczego? Otóż wbrew pozorom służy to ułatwieniu, a nie komplikowaniu wykładu. Czy wyobrażacie sobie na przykład lekarza, który w czasie operacji mówi do instrumentariuszki: podaj mi ów mały nóż o ostrzu jednostronnym lub na końcu dwustronnym? Zanim pielęgniarka zorientuje się, że chodzi o skalpel, pacjent może umrzeć. A co z prawnikiem, który mówi do kolegi idąc do sądu, że idzie do państwowego organu wymiaru sprawiedliwości myśląc o sądzie. Albo meteorologa, który mówi, że wzrośnie wielkość fizyczna równa stosunkowi siły działającej prostopadle na daną powierzchnię - do wielkości tej powierzchni zamiast powiedzieć, że wzrośnie ciśnienie. A możecie sobie wyobrazić definicję użytych powyżej słów: instrumentariuszka, prawnik, meteorolog?. Zajrzyjcie do słownika, i nie zdziwcie się, gdy wyjaśnienie będzie nie miej zrozumiałe niż samo słowo, jak w przypadku ciśnienia (bo o to chodziło w tym stosunku powierzchni).
Każda dziedzina wytwarza swój specyficzny język; inżynierowie, prawnicy, lekarze, ekonomiści mają swój własny kod porozumiewania. Dlaczego?. Żeby było krócej i precyzyjniej. Czasami brak tej precyzji może tylko śmieszyć, jak w przypadku meteorologa, lecz czasem może mieć wagę ludzkiego życia, jak w przypadku niedouczonego lekarza.
W ekonometrii nie podejmujemy na szczęście decyzji na taką miarę, lecz posługiwanie się pewnymi określeniami po prostu ułatwia sprawę. Początkowo te określenia takie jak składnik losowy, zmienna endogeniczna itd. będą dla nas trudne, ale to tylko dlatego, że są nowe. Czy trzeba wam teraz dokładnie wyjaśniać pojęcia takie jak substytut, dobro komplementarne, czy popyt? Nie, a przecież są to bardzo specjalistyczne nazwy. To że nie trzeba ich wyjaśniać wynika z „obycia” się z nimi, podobnie jak będzie po pewnym czasie z ekonometrią. A zatem kontynuujemy formalny wykład, na razie nie przejmując się za bardzo tymi formalnymi określeniami.
1. Informacje początkowe
1.1 Definicje ekonometrii
Chow (1995): „Ekonometria jest nauką i sztuką stosowania metod statystycznych do mierzenia relacji ekonomicznych”.
Pawłowski (1978): „Ekonometria jest nauką o metodach badania ilościowych prawidłowości występujących w zjawiskach ekonomicznych za pomocą odpowiednio wyspecjalizowanego aparatu matematyczno-statystycznego”.
Maddala (2001): Ekonometria to zastosowanie metod statystycznych i matematycznych do analizy danych ekonomicznych w celu nadania teoriom ekonomicznym kontekstu empirycznego oraz ich potwierdzenia lub odrzucenia”.
Ostateczna (nasza) definicja: „Ekonometria jest obszarem ekonomii zajmującym się zastosowaniem narzędzi statystycznych i matematycznych do empirycznego mierzenia i weryfikacji teorii postulowanych przez teorię ekonomii”.
1.2. Dziedziny pokrewne Ekonometrii
Ekonomia matematyczna - zajmuje się matematycznym zapisem teorii ekonomicznych oraz tworzeniem modeli ekonomicznych, na podstawie których wyprowadzane są twierdzenia ekonomiczne. Ekonomia matematyczna nie zajmuje się empiryczną weryfikacją swoich twierdzeń - formułuje tylko pewne hipotezy dotyczące funkcji opisującej powiązania między badanymi zmiennymi ekonomicznymi.
Badania operacyjne - to szereg metod wykorzystywanych do podejmowania decyzji optymalnych z punktu widzenia określonego celu, przy uwzględnieniu dających się zdefiniować ograniczeń technicznych, ekonomicznych.
1.3. Warunki stosowania ekonometrii:
Znajomość teorii ekonomicznych.
Jakie teorie ekonomiczne mogą być testowane w ramach ekonometrii?. Przykłady:
Popytu - prawo popytu,
Stopy procentowe - teoria podaży pieniądza,
Inflacja - krzywa Phillipsa,
Dochód - krzywe Engela,
Produkcja -funkcja Cobb-Douglasa.
Uwzględniane zjawiska ekonomiczne i pozaekonomiczne muszą być mierzalne lub sprowadzalne do mierzalnej postaci.
Dostępne są dane statystyczne dotyczące badanych czynników, które posłużą do budowy zmiennych modelu.
1.4. Rodzaje danych statystycznych
1. Szeregi czasowe (time series data TSD): xt for t=1,2,…,T.
Przykład szeregu czasowego:
Liczba zatrudnionych w Polsce w okresie 1. kwartał 1995 - 4. kwartał 2006
2. Dane przekrojowe lub przestrzenne (cross-section or spatial data CSD): xi for i=1,2,…,N.
Przykład danych przekrojowych (przestrzennych):
Liczba zatrudnionych w 4. kwartale 2006 w 16 województwach Polski
3. Dane panelowe lub przestrzenno-czasowe (panel data or cross-section time PD): xit for i=1,2,…,N; t=1,2,…,T.
Przykład danych panelowych: Liczba zatrudnionych w 6 województwach Polski mierzona w 4 kolejnych kwartałach 2006 r
.
2. Mierzenie zależności pomiędzy zjawiskami ekonomicznymi za pomocą korelacji
Wygodnym sposobem opisu siły i kierunku wpływu jednej zmiennej na drugą jest współczynnik korelacji.
Dodatnia korelacja (dokładnie dodatni współczynnik korelacji) oznacza, że wzrostowi (spadkowi) wartości pierwszej cechy np. X towarzyszy wzrost (spadek) wartości drugiej cechy Y. W przyrodzie, życiu i gospodarce znajdujemy szereg przykładów na dodatnią korelację, np. pomiędzy:
ilością spożywanego jedzenia (X) i wagą ciała (Y) - choć niektórych chudzielców to nie dotyczy;
ilością wypalanych papierosów (X) i prawdopodobieństwem zachorowania na raka płuc (Y), lub choroby układu krążenia (Y);
wilgotnością powietrza (X) i ilością komarów w lecie (Y);
żyznością gleby (X) i wzrostem roślin (Y);
dochodem (X) i popytem na dobra wyższego rzędu (Y);
reklamą (X) i popytem (Y).
Gdy zależność pomiędzy dwoma cechami jest odwrotnie proporcjonalna mówimy, że są one ujemnie skorelowane. Ujemna korelacja (dokładnie ujemny współczynnik korelacji) oznacza, że wzrostowi (spadkowi) wartości pierwszej cechy (X) towarzyszy spadek (wzrost) wartości drugiej cechy (Y). Ujemną korelację możemy zaobserwować na przykład pomiędzy:
ilością spożywanego jedzenia (X) i sprawnością fizyczną (Y);
ilością wypalanych papierosów (X) i długością życia (Y);
wilgotnością powietrza (X) i ilością wypijanych napojów (Y);
żyznością gleby (X) i nieurodzajem (Y);
dochodem (X) i popytem na dobra niższego rzędu
reklamą dobra (X) i popytem na dobro konkurencyjne (Y);
cena dobra (X) i popyt na to dobro (Y).
Możemy również mówić o braku korelacji, czy inaczej mówiąc o korelacji zerowej, która oznacza, że wzrost (spadek) wartości cechy X nie towarzyszą zmiany wartości cechy Y. Korelacją zerową, czyli brakiem korelacji charakteryzuje się większość przypadkowo dobranych zjawisk. Brak korelacji, czyli zależności występuje na przykład pomiędzy:
ilością spożywanego jedzenia (X) i ilością komarów w lecie (Y);
ilością wypalanych papierosów (X) i wilgotnością powietrza (Y);
żyznością gleby (X) i ilością wypalanych papierosów;
dochodem (X) i popytem na dobra pierwszej potrzeby (Y).
2.1. Korelogramy (scatter diagram)
Graficzną interpretacją siły i kierunku związku pomiędzy zmiennymi jest wykres zależności tych zmiennych. Taki wykres nazywamy korelogramem, lub wykresem skaterowym (ang. scatter diagram).
Przykład: cena i popyt na produkt A (dane do przykładu znajdują się w pliku example1.xls)
cena |
popyt |
2,40 |
136 |
2,30 |
151 |
2,20 |
157 |
2,20 |
157 |
2,10 |
185 |
2,00 |
199 |
1,90 |
235 |
1,80 |
246 |
1,70 |
271 |
1,60 |
294 |
Korelogram: wykres zależności pomiędzy ceną i popytem na produkt A
Co nam mówi korelogram (o zależnościach liniowych):
Mówi nam o kierunku zależności.
Rosnąca linia: dodatnia korelacja.
Malejąca linia: ujemna korelacja.
Mówi nam o sile zależności.
Im bardziej prostą linię formują punkty korelogramu tym silniejsza zależność.
Im bardziej „okrągły” kształt formują punkty korelogramu, tym słabsza zależność.
Prosta linia, lecz równoległa do którejkolwiek osi oznacza brak korelacji.
2.2. Definicja współczynnika koralacji
Formuła na wyliczenie współcznynnika korelacji pomiędzy dwiema zmiennymi jest następująca:
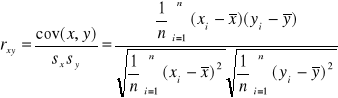
2.3. Właściwości współczynnika korelacji
rxy jest miarą z przedziału (-1;1).
Moduł z rxy oznacza siłę związku.
Znak rxy oznacza kierunek powiązań pomiędzy x i y.
Znak współczynnika korelacji (kierunek powiązań pomiędzy x i y)
rxy <0 - ujemna korelacja: jeśli x rośnie (spada), to y spada (rośnie).
rxy >0 - dodatnia korelacja: jeśli x rośnie (spada), to y rośnie (spada).
Siła korelacji
Moduł z rxy, którego wartość jest z przedział (0;1) informuje nas o sile związku pomiędzy dwoma zmiennymi.
rxy = 0 - zmienne nie są powiązane, czyli nie są skorelowane.
rxy =1 - bardzo silna korelacja pomiędzy zmiennymi.
Przykład „ręcznego” obliczenia współczynnika korelacji
(przykład ten znajduje się w pliku correlation_for_demand_A.xls)
3. Model ekonometryczny
3.1. Definicje
Model ekonometryczny - jest podstawowym narzędziem w ekonometrii, służącym do analizy zależności zachodzących między różnymi zjawiskami.
Model - jest uproszczonym odwzorowaniem rzeczywistości, uproszczoną reprezentacją realnego obiektu, realnej sytuacji lub realnego procesu. Jego cechą charakterystyczną jest, że:
- uwzględnia tylko istotne cechy, najważniejsze z punktu widzenia określonego celu,
- nie jest dokładną reprezentacją rzeczywistości.
Pawłowski [1978]: „Model ekonometryczny jest to konstrukcja formalna, która za pomocą jednego równania lub układu równań przedstawia zasadnicze powiązania występujące pomiędzy rozpatrywanymi zjawiskami ekonomicznymi”.
3.2. Etapy budowy modelu ekonometrycznego
Sformułowanie hipotezy ekonomicznej: Y=f(X1,X2,…,Xk)
Zebranie danych
Ustalenie postaci analitycznej równania (równań)
Estymacja
Interpretacja i/lub prognozowanie (przed interpretacją modelu należy go poddać weryfikacji statystycznej)
3.2.1. ETAP 1: Sformułowanie hipotezy ekonomicznej
Zależność pomiędzy interesującym nas zjawiskiem - y- a czynnikami go kształtującymi x1, x2, x3 itd. możemy zapisać jako:
(3.2.1) y=f(x1, x2, ..., xk,…)
Równanie (3.2.1) opisuje hipotezę ekonomiczną, która określa zjawisko ekonomiczne będące przedmiotem naszego zainteresowania (np. popyt jak w przypadku case study w rozdziale 8) i czynniki go kształtujące (w case study z rozdziału 8 są to: cena, dochody,...).
Powiązania pomiędzy zmiennymi x1, x2, ..., xk a zmienną y znajdują swój formalny zapis w modelu ekonometrycznym, który jest równaniem (lub grupą równań) w którym rolę zmiennej objaśnianej (zwanej też engogeniczną lub i) pełni interesujące nas zjawisko ekonomiczne -y, a rolę zmiennych objaśniających (egzogenicznych, niezależnych)- czynniki go kształtujące, czyli iksy. Dla takiego równania charakterystyczne są zatem: zmienna objaśniana i objaśniające, postać analityczna związku który pomiędzy nimi zachodzi (funkcja liniowa, potęgowa i.t.d.- por. 1.2), parametry strukturalne (współczynniki funkcji), które mierzą siłę i kierunek wpływu poszczególnych zmiennych objaśniających na zmienną objaśnianą.
Zwróćmy uwagę na trzykropek, który pojawił się w powyższym równaniu. Zamknięcie nawiasu bez jego uwzględnienia oznaczałoby, że wymieniliśmy wszystkie czynniki wpływające na na badane zjawisko y. Czy taka sytuacja jest możliwa?. Czy w przypadku jakiegokolwiek zjawiska będziemy mogli stwierdzić, że wyróżniliśmy wszystkie czynniki go kształtujące? Raczej nie, ze względu na czynniki nieprzewidywalne (pogoda, wojna) lub takie, których wpływ jest mało istotny (na przykład reklama rękawiczek skórzanych, pomocnych w prowadzeniu samochodu, może mieć wpływ na popyt na ten samochód, lecz jest to wpływ mało istotny).Trzykropek reprezentuje wpływ zjawisk nieuwglęnionych w modelu, który w modelach ekonometrycznych jest reprezentowany przez składnik losowy.
3.2.2. ETAP 2: Zebranie danych
Dane statystyczne do modelu ekonometrycznego mogą pochodzić z wielorakich źródeł. Poniżej wymieniono kilka z nich:
dane zbierane przez GUS (Główny Urząd Statystyczny, w Łodzi na ul. Suwalskiej) powstające w wyniku ankietowania przedsiębiorców, zbierane w postaci miesięcznych lub kwartalnych szeregów i publikowane w Biuletynach Statystycznych. Błędy z tego rodzaju danych pochodzą od pracodawców, którzy z różnych powodów zawyżają lub zaniżają wartość różnych zmiennych (liczba i wynagrodzenie pracowników, obroty i zyski firmy i.t.p). dane pochodzące z badania budżetu gospodarstw domowych, których użyteczność jest ograniczona rzadkością przeprowadzonego badania (co kilka lat);
dane pochodzące z Urzędów Pracy;
dane z Badania Aktywności Ekonomicznej Ludności (mają postać szeregów kwartalnych i uznaje się je za jedne z bardziej reprezentatywnych);
dane pochodzące z ankiet przeprowadzanych na zamówienie konkretnego klienta. Błąd w tego rodzaju danych może wynikać z niereprezentatywnośći próby i nieprawdomówności respondentów.
Bardzo często dzieje się tak, że zestaw zmiennych zaproponowanych w hipotezie ekonomicznej jest znacznie zredukowany ze względu na brak danych statystycznych. Brak ten może wynikać z faktu, że dane te nie istnieją, np. nie robiono wcześniej podobnych badań i posiadać dane na ten temat należy przeprowadzić własne badania ankietowe. Może się również zdarzyć, że dane istnieją, ale są dla badacza nie dostępne - jak w przypadku informacji o dobrach substytucyjnych wytwarzanych przez konkurencyjną firmę.
3.2.3. ETAP 3: Ustalenie postaci analitycznej równania
Przypomnijmy, że równanie (3.2.1) opisuje zjawisko Y jako funkcję czynników go określających. Nie wiadomo natomiast jaki rodzaj funkcji należy zastosować: liniową, potęgową, wykładniczą i.t.d. Postać funkcyjna modelu powinna odzwierciedlać rzeczywiste interakcje pomiędzy zmiennymi, tzn. jeżeli zależność jest liniowa należy użyć funkcji liniowej, jeśli jest nieliniowa, należy użyć funkcji nieliniowej.
Zależności liniowe, to inaczej mówiąc zależności proporcjonalne, czyli takie, dla których taka sama zmiana jednego czynnika powoduje taką samą zmianę drugiego. Mogą one być wprost proporcjonalne, gdy wzrost (spadek) jednej zmiennej powoduje wzrost (spadek) drugiej, oraz odwrotnie proporcjonalne, gdy wzrost (spadek) jednej zmiennej powoduje spadek (wzrost) drugiej.
Można zastanowić się, czy typowe czynniki kształtujące popyt obrazują zależności liniowe, czy nieliniowe. Czy możemy założyć, że podobne przyrosty dochodów i reklamy będą powodować zawsze takie same przyrosty popytu. Gdyby tak było, to w przypadku reklamy moglibyśmy mówić o superecepcie na sukces, bo oznaczałoby to, że ciągły wrost wydatków na reklamę powoduje nieskończony przyrost popytu - a tak niestety nie jest. W przypadku dochodu, proporcjonalny wzrost popytu na jakieś dobro i usługę w porównaniu do wzrostu dochodu spowodowałoby, że bogaci ludzie byliby „zalani” potokiem dóbr, na które popyt powinien nieprzerwanie wzrastać. Czy kupimy bowiem następną suszarkę, telewizor tylko dlatego, że nas na to stać? Czy będziemy wychodzić codziennie do kina, fryzjera, kosmetyczki, tylko dlatego, że rosnący dochód, zgodnie z relacją liniową, powinien się przełożyć na proporcjonalny wzrost popytu na te usługi?
Odpowiedź na powyższe pytania jest negatywna: zarówno wpływ reklamy jak i dochodu nie wpływa liniowo na popyt, lecz po osiągnięciu pewnego pułapu popyt stabilizuje się na pewnym poziomie (jest to punkt nasycenia, stabilizacji wydatków, lub w przypadku reklamy punkt nasycenia rynku). Matematycznie rzecz ujmując do opisania zależności pomiędzy dochodem, reklamą i popytem powinniśmy użyć funkcji, która posiada asymptotę poziomą, która będzie odzwierciedlała stabilizację popytu na pewnym poziomie.
Funkcjami takimi są funkcje wymierne, które w przypadku, gdy opisują relacje pomiędzy dochodami i wydatkami na określone grupy dóbr, opisywane w teorii Engle'a. Szersze omówienie tej kwestii znajduje się w rozdziale 8 dotyczącym Modeli Törnquista.
W praktyce, na szczęście dla większości studentów, głównym zadaniem w przypadku doboru postaci funkcyjnej modelu, jest stwierdzenie, czy dana zależność ma postać liniową czy krzywoliniową. W pierwszym wypadku używamy naturalnie funkcji liniowej, w drugim zaś używamy najczęściej funkcji potęgowej, której pewne własności predysponują ją do opisu nieliniowych zależności.
Funkcja liniowa (jednorównaniowy model liniowy) ma postać:
(3.2.3a) y=α0+α1x1+α2x2+...+αk+ξ
Funkcja potęgowa (jednorównaniowy model potęgowy) ma postać:
(3.2.3b) y=α0 x1α1x2α2… xkαkeξ
gdzie:
α0 - wyraz wolny równania,
α1,...,αk - parametry strukturalne,
ξ - składnik losowy.
W ten sposób - po odrzuceniu zmiennych na temat których nie udało się zebrać danych i po ustaleniu postaci funkcyjnej - hipoteza ekonomiczna (3.2.1) zamienia się w model ekonometryczny. Zwróćmy uwagę, że miejsce trzykropka zajął teraz tzw. składnik losowy. Powody występowania składnika losowego ξ w równaniach ekonometrycznych można wyjaśnić następującymi przyczynami:
1. Nieuwzględnieniu wszystkich zmiennych. Należy tu rozróżnić jednakże różne przyczyny nieuwzględniania zmiennych:
z powodu braku danych statystycznych na temat badanej zmiennej (np. w badaniach rynkowych potrzebne są dane dotyczące badanego produktu. Są one na tyle szczegółowe, że nie występują w oficjalnych publikacjach - por. p. 2, a brak jest środków do zebrania materiału statystycznego, lub jest to niemożliwe, bowiem potrzebne są dane historyczne);
z powodu braku dostępu do danych statystycznych (dane na temat konkurencyjnego produktu zapewne istnieją, ale u konkurencji);
z powodu trudności w kwantyfikacji tych zmiennych (np. zmienne takie jak jakość, moda, które mają istotny wpływ na kształtowanie się zjawisk rynkowych, lecz są trudno mierzalne);
z powodu ich mało istotnego wpływu na badane zjawisko. Ten powód występowania składnika losowego wynika z założenia, że model ekonometryczny powinien być uproszczonym schematem kształtowania się badanego zjawiska. Oznacza to, że w modelu powinniśmy uwzględniać zmienne „najważniejsze”, tak aby postronny badacz patrząc na wyrażone przez nas czynniki mógł rozeznać się od czego przede wszystkim zależy dane zjawisko. Na przykład nie można wprawdzie dowieść ze 100% pewnością, że liczba plam na słońcu nie wpływa na popyt na komputery, ale nie jest to powód , aby uwzględniać tą zmienną jako jeden z czynników ten popyt kształtujących. Nawet jeśli liczba plam na słońcu wpływa na popyt na komputery, to jest to wpływ na pewno mniej istotny niż wpływ innych czynników kształtujących popyt (cena, dochody, itp.), a zatem wpływ takiej zmiennej (jeśli on istnieje) będzie przejawiał się w składniku losowym , bo jej dołączenie z pewnością nie uprości, a wręcz skomplikuje zależności leżące u podstaw popytu na komputery.
Etap 4: Estymacja
Estymacja (ang. estimate = szacować) to inaczej szacowanie parametrów, w wyniku którego otrzymujemy liczbowe wartości parametrów α0, α1, ..., αk , które nazywamy estymatorami lub oszacowanymi parametrami. Estymacji można dokonać różnymi metodami. Dość powszechnie stosowaną jest metoda najmniejszych kwadratów - MNK. Ma ona tę wadę, że można ją zastosować do modeli liniowych względem parametrów. Czyli można nią oszacować model (3.2.3a), ale już nie (3.2.3b) - w każdym razie nie bezpośrednio.
Jak już powiedziano oszacowane parametry strukturalne noszą nazwę estymatorów. Estymatory często zapisuje się z „daszkiem” nad parametrem. Szczegóły szacowania parametrów modeli ekonometrycznych podajemy w rozdziale 4, tutaj zaś podamy sposób ich oszacowania w Excelu.
Do szacowania parametrów równań ekonometrycznych w Excelu służy dodatek Analiza Danych, który znajduje się w menu Narzędzia. Jeżeli nie używano wcześniej tego dodatku należy go zainstalować poprzez wykonanie następujących czynności:
W menu Narzędzia kliknij polecenie Dodatki i włącz dodatek AnalisisToolPak (odpowiedzialny za Analizę Danych). Jeśli nie został on umieszczony w oknie dialogowym Dodatki, kliknij przycisk Przeglądaj i znajdź stację dysków i folder, gdzie znajduje się plik dodatku AnalisisToolPak o nazwie analys32.xla - zwykle jest to folder ProgramFiles\MicrosoftOffice\Office\Analysis. Jeżeli nie możesz odnaleźć pliku, uruchom program instalacyjny.
W oknie dialogowym Dodatki zaznacz pole wyboru AnalisisToolPak. Uwaga - dodatki, których pola wyboru zaznaczono w oknie dialogowym Dodatki, są aktywne do czasu ich usunięcia.
Aby oszacować liniowy model ekonometryczny należy:
W menu Narzędzia wybrać polecenie Analiza Danych, a następnie Regresja.
W pole „Zakres Wejściowy Y” wskazać myszką lub wpisać zakres zmiennej objaśnianej modelu (jest to jeden szereg) z tytułem lub bez.
W polu „Zakres Wejściowy X” wskać myszką lub wpisać zakres zmiennych objaśnianych modelu (jest to jeden szereg w przypadku jednej zmiennej objaśniającej, lub macierz, tzn. kilka kolumn z danymi, w przypadku kilku zmiennych objaśniających) z tytułem lub bez.
Jeżeli wpisane zakresy zawierają tytuły, zaznaczyć to w polu „Tytuły”
Wcisnac OK.
Pokażemy to na przykładzie
Przykład 1 (źródło: Borkowski, [2003], s. 103)
Dane są wartości średniego spożycia owoców, dochody i płeć 12 losowo wybranych osób:
Nr |
Spożycie owocó (kg) |
Dochody (tys. Zł) |
Płeć |
1 |
3,8 |
2,0 |
Mężczyzna |
2 |
4,7 |
2,1 |
Kobieta |
3 |
4,4 |
1,8 |
Kobieta |
4 |
5,0 |
2,7 |
Kobieta |
5 |
4,1 |
3,0 |
Mężczyzna |
6 |
3,7 |
3,5 |
Mężczyzna |
7 |
4,9 |
5,0 |
Kobieta |
8 |
5,4 |
4,5 |
Mężczyzna |
9 |
5,2 |
4,2 |
Kobieta |
10 |
4,6 |
3,8 |
Mężczyzna |
11 |
4,0 |
2,4 |
Mężczyzna |
12 |
3,6 |
1,4 |
Mężczyzna |
Oznaczmy:
Y - miesięczne spożycie owoców w kg;
X - miesięczne dochody w tys. zł
Z - zmienna zero jedynkowa przyjmująca wartość jeden jeśli badana osoba jest kobietą i zero w pozostałych przypadkach.
Model, który należy oszacować ma postać: Y=α0+α1X+α2Z+ξ
W Excelu wpisujemy dane i uzupełniamy tabelę regresji, tak jak to pokazano na rysunku 1.3.1
Rys. 3.2.4a: Wpisywanie danych do okna dialogowego Regresji
Po naciśnięciu OK. w okienku regresji pojawi się następująca ramka z wynikami:
Rys. 3.2.4b: Wyniki działania opcji Regresja - oszacowania modelu ekonometrycznego
W kolumnie zatytułowanej Współczynniki (komórka B16 na rys. 3.2.4b) znajdują się oszacowane parametry strukturalne, pozwalające nam zapisać model następująco:
Y=3,27+0,31X+0,60Z
Wynika z tego, że oszacowane parametry strukturalne są następujące: α0=+3,27, α1=+0,31, α2=+0,60.
Etap 5: Interpretacja i/lub prognozowanie (przed interpretacją modelu należy go poddać weryfikacji statystycznej)
Przy założeniu, że model jest poprawny (co sprawdzimy za pomocą szeregu statystyk omawianych w rozdziale 5), a parametry istotne statystycznie (co później sprawdzimy za pomocą statystyki t-Studenta-por. p. 5.2.3) możemy je zinterpretować jako:
α1=0,31 oznacza, że wzrost miesięcznych dochodów o 1 tys. zł powoduje wzrost miesięcznego spożycia owoców o 0,31 kg.
α2=0,60 oznacza, że kobiety spożywają średnio o 0,60 kg owoców więcej od mężczyzn
Wyrazu wolnego α0=3,27 najczęściej nie interpretuje się.
Ogólnie, interpretacja parametrów liniowego modelu ekonometrycznego postaci (3.2.3a) mówi na o ile zmieni się y wskutek zmiany x o jednostkę, czyli parametr αj stojący przy zmiennej xj mówi nam o ile zmienia się y (wzrośnie lub spadnie w zależności od znaku αj) jeżeli xj wzrośnie o jednostkę. Na tej podstawie można również rozważać, jak zmieni się y wskutek zmian xj o wielokrotność lub część jednostki, a mianowicie jeśli xj wzrośnie o część jednostki (np.,0.5, 0.3 itp.) to y zmieni się o odpowiednią część parametru αj, ( np.0.5αj, 0.3αj, itd.). Jeśli xj zmieni się o odpowiednią wielokrotność swojej jednostki ( np. o 1.5; 2; 3 itd.) to y zmieni się o odpowiednią wielokrotność parametru αj (np.1.5αj , 2αj, 3αj itd.). Podstawową zatem sprawą w interpretacji parametrów jest ustalenie czy podana zmiana xj stanowi część, czy wielokrotność jego jednostki.
Poniżej podano kilka przykładów interpretacji estymatorów modeli ekonometrycznych
Przykład 2
Funkcja popytu na ryby ma postać:
PA = 3 - 4CA + 5CB
gdzie:
PA- oznacza popyt na ryby bałtyckie w tonach;
CA- cena ryb bałtyckich w złotych;
CB- cena ryb importowanych w dolarach.
Zgodnie z podstawową interpretacją, wzrost (spadek) ceny ryb bałtyckich o 1 zł spowoduje spadek popytu na nie o 4 tony, zaś wzrost ceny ryb importowanych o 1 zł spowoduje wzrost popytu na ryby bałtyckie o 5 ton. Gdyby cena ryb bałtyckich wzrosła o 10 groszy, to jest o 0.1 część jednostki, którą jest złotówka (10 gr stanowi 0,1 zł), to zmiana spowoduje spadek popytu o 4 x 0,1 (a nie o 4x10!) co daje 0,4 tony czyli 400 kg.
Weryfikacja statystyczna modelu
Głównym zadaniem analizy ekonometrycznej jest właściwe oszacowanie parametrów, bowiem dzięki temu możemy zrealizować główne cele szacowania modelu ekonometrycznego jakimi są:
Analiza zjawisk ekonomicznych - czynimy to poprzez interpretację oszacowanych parametrów modelu.
Prognozowanie zjawisk ekonomicznych, o czym będzie mowa później
Zanim jednak dokonamy analiz i prognoz na podstawie modelu ekonometrycznego należy sprawdzić na ile jest on „dobry”. Temu służą różnorakie statystyki obliczane w ramach weryfikacji statystycznej modelu. Ogólnie, weryfikacja (sprawdzanie) modelu polega na jego weryfikacji:
merytorycznej
statystycznej.
Weryfikacja merytoryczna modelu - polega na stwierdzeniu, czy oszacowane znaki parametrów są zgodne z naszymi oczekiwaniami i przesłankami ekonomicznymi. Jeśli tak jest to mówimy, że parametr jest merytorycznie poprawny, jeśli nie, to mówimy, że parametr jest merytorycznie niepoprawny . Np. w funkcji popytu postaci PA = α0 + α1 CA + α2 RA + ξ spodziewamy się następujących znaków:
przy zmiennej CA (cena badanego produktu) spodziewamy się, że α1 < 0, bo taki znak sugeruje typowy wpływ ceny na popyt, a mianowicie, że wzrost ceny powoduje spadek popytu;
przy zmiennej RA (reklama badanego produktu) spodziewamy się, że α2 > 0, bo taki znak sugeruje, że wzrost nakładów na reklamę powoduje wzrost popytu.
Oszacowanie powyższej funkcji daje następujące rezultaty PA = -15,4 + 3,14 CA + 1,5 RA, co oznacza, że:
α0 po oszacowaniu wynosi -15,4 (inaczej mówiąc estymator parametru α0 wynosi -15,4);
α1 po oszacowaniu wynosi +3,14 (inaczej mówiąc estymator parametru α1 wynosi +3,14);
α2 po oszacowaniu wynosi +1,5 (inaczej mówiąc estymator parametru α2 wynosi +1,5);
Porównanie znaków oszacowanych parametrów z ich spodziewanymi znakami pozwala stwierdzić, że parametr α1 jest merytorycznie niepoprawny (bo wbrew temu czego oczekiwaliśmy jest dodatni), a parametr α2 jest merytorycznie poprawny (bo zgodnie z tym czego oczekiwaliśmy jest ujemny).
Analiza merytoryczna jest wstępem do analizy statystycznej w tym sensie, że dopiero wtedy, gdy współczynniki pozytywnie przejdą etap analizy merytorycznej jest sens do przestąpienia do analizy statystycznej modelu. W przypadku, gdy jeden lub więcej współczynników jest merytorycznie niepoprawny model należy zdyskwalifikować, a przynajmniej usunąć daną zmienną lub zmienne i ponownie oszacować parametry. W bardzo rzadkich przypadkach uzyskanie niezgodnego z naszymi oczekiwaniami współczynnika jest wynikiem natrafienia na pewną nietypowość ekonomiczną, a nie jego merytoryczną niepoprawność wynikającą najczęściej ze złej jakości danych statystycznych.
Rolę badania merytorycznej poprawności znaków parametrów pokażemy na przykładzie funkcji popytu na ryby bałtyckie rozważanej w przykładzie 2. Przypomnijmy, że funkcja ta ma postać: PA = 3 - 4CA + 5CB, gdzie: PA- oznacza popyt na ryby bałtyckie w tonach, CA- cena ryb bałtyckich w złotych, CB- cena ryb importowanych w dolarach.
Załóżmy dodatkowo, że ze względu na możliwość zepsucia się ryb bałtyckich należy natychmiast sprzedać ich 2 tony. Z interpretacji parametrów funkcji wynika, że aby zwiększyć popyt na ryby o 2 tony należy zmniejszyć ich cenę o 50 groszy. Gdyby powyższa funkcja była źle oszacowana, a mianowicie otrzymalibyśmy na przykład PA = 3 + 1,5CA + 5CB, to w celu zwiększenia popytu na 2 tony poradzilibyśmy zwiększenie ceny o 1,5 złotego. Podejmujemy zatem błędną decyzję skutkującą najprawdopodobniej zepsuciem się 2 ton ryb. Aby takich sytuacji uniknąć, należy poddać model weryfikacji merytorycznej i statystycznej. W powyższym przypadku zastosowanie analizy merytorycznej wskazuje na niepoprawność parametru α1 i jest wystarczający do zakwestionowania modelu.
Weryfikacja statystyczna modelu
W ramach weryfikacji statystycznej interpretowane są dwie grupy statystyk. Pierwsza jest to grupa statystyk mierzących „kondycję” modelu jako całości, np.: R2, czyli współczynnik determinacji oraz Se, czyli błędy średnie równania. Następna grupa statystyk mierzy „kondycję” poszczególnych parametrów i zmiennych. Należą do nich: S(άj), czyli błędy średnie estymatorów (oszacowanych parametrów), statystyki t-studenta mierzące istotność parametru i zmiennych oraz przedziały ufności dla parametrów mówiące nam o tym, z jakim prawdopodobieństwem przedział o podanych krańcach pokrywa prawdziwą wartość parametru. Szczegółowy opis tych miar znajduje się w rozdziale 5.
Definicja przytoczona za Słownikiem języka polskiego, [1981], PWN, Warszawa, tom III, s.223
tamże, s 183
tamże, tom I, s 309
W istocie pojęcie dane przekrojowe jest nieco szersze niż dane przestrzenne, bowiem uwzględnia fakt, że analizowane dane pochodzą nie tylko z poszczególnych punktów przestrzeni (jak w podanym przykładzie), ale mogą oznaczać dowolny obiekt, jak np. grupę gospodarstw domowych, lub grupę przedsiębiorstw.
Od tej reguły są pewne wyjątki o których piszemy przy okazji korelacji Ca - Pa
W praktyce nie otrzymujemy współczynników korelacji, które są dokładnie równe 0. O braku korelacji mówimy więc, gdy współczynnik korelacji można ocenić jako nieistotny statystycznie, o czym będzie szerzej mowa w paragrafie poświęconym badaniu istotności zmiennych i parametrów.
W tym przypadku mielibyśmy do czynienia ze słabą korelacją.
Jeżeli możemy założyć, że poziom wydatków na dane dobre jest daleki od stabilizacji możemy zastosować funkcję liniową. Szersze omówienie tej kwestii znajduje się w załączniku pt. Model Allena-Bowleya.
Nawiasem mówiąc, fakt, że wiele zjawisk ekonomicznych “układa się” w znane z matematyki wykresy funkcji, jest fundamentem ekonometrii, bo skłonił naukowców do próby opisu tych zjawisk za pomocą tych funkcji.
Pełny zestaw nieliniowych funkcji trendu znajduje się w rozdziale 7.
Mowa tu o dogodnej interpretacji parametrów tej funkcji w kategoriach elastyczności. O ile jednak w przypadku nieliniowych zależności przyczynowo-skutkowych najwygodniej jest używać funkcji potęgowej, to w takim samym przypadku używamy funkcji wykładniczej dla modeli trendu.
14
Wykłady z Ekonometrii dr Ewa Kusideł
14
Wyszukiwarka
Podobne podstrony:
model ekonometryczny, Studia ZiIP GiG AGH, Magisterskie, Ekonometria
egzamin - opracowanie pytań, Studia ZiIP GiG AGH, Magisterskie, Zarządzanie strategiczne
zarzadzanie strategiczne!!!, Studia ZiIP GiG AGH, Magisterskie, Zarządzanie strategiczne
egzamin - zagadnienia, Studia ZiIP GiG AGH, Magisterskie, Zarządzanie strategiczne
ekonimika-1wyklad, Studia ZiIP GiG AGH, Inżynierskie, Makroekonomia, ekonomika
KOSZTY PRODUKCJI GORNICZEJ I PROG RENTOWNOSCI, Studia ZiIP GiG AGH, Inżynierskie, Makroekonomia, eko
Prawo Gospodarcze - pojecia, Studia ZiIP GiG AGH, Inżynierskie, Prawo
TEST Z BHP 2, Studia ZiIP GiG AGH, Inżynierskie, BHP i ergonomia
Analiza wyklady, Studia ZiIP GiG AGH, Inżynierskie, Analiza finansowa
Skutki wdrożenia pakietu 3x20 - praca pisemna, Studia ZiIP GiG AGH, Inżynierskie, Ekologia
stezenia zadania, Studia ZiIP GiG AGH, Inżynierskie, Chemia
Prawo Gospodarcze - pojecia, Studia ZiIP GiG AGH, Inżynierskie, Prawo
egz ekonomika z poprzedniego roku, ZiIP - GIG AGH, Semestr 3, Ekonomika przedsiębiorstwa
kolokwium 1 2012, ZiIP - GIG AGH, Semestr 3, Statystyka
kolokwium 1 2012 v2, ZiIP - GIG AGH, Semestr 3, Statystyka
Model mechanistyczny cechuje, Studia, ZiIP, SEMESTR IV, semestr IV zaoczny, Podstawy zarządzania
więcej podobnych podstron