Wydział Zarządzania
Temat: Konwersja głos - tekst
Konwersja to, zmiana organizacji danych dostępnych w pewnym formacie na inny format.
W telekomunikacji konwersja tekst - głos to zmiana komend wydawanych komputerowi za pomocą głosu na język umożliwiający wykonywanie poszczególnych poleceń.
Najprościej mówiąc konwersja głos text to po prostu rozpoznawanie głosu ludzkiego (mowy) przez komputer.
Pierwotne dla dialogu jest słowo i od niego wszystko się zaczęło, bo pierwsze programy (pamiętające jeszcze komputery z procesorem i486) umiały rozpoznawać tylko pojedyncze wyrazy i to z niewielkiej puli komend typu Yes, No albo Run command. Ich działanie przypominało dzisiejsze portale głosowe albo aplikacje typu Call Center, gdzie manipulując klawiszami z wybieraniem tonowym i czasami pomagając sobie głosem, możemy uzyskać interesujące nas informacje, zarezerwować bilet do kina albo wykonać przelew bankowy. Od strony technicznej taki model jest dość prosty: po wstępnej obróbce sygnału stosuje się analizę słownikową, czyli porównywanie przetwarzanego głosu z określonymi wzorcami. Gdy program stwierdzi, że fraza pasuje do jednej z komend, wykonuje ją; gdy nie uda się znaleźć dopasowania, generowany jest komunikat o błędzie lub prośba o zawężenie wypowiedzi do jednego z rozpoznawanych przez automat rozkazów (patrz ramka).
Następne lata przyniosły niewiele nowego i mimo że pod koniec lat 90. Programy ASR rozpowszechniły się, to korzystanie z nich wymagało samozaparcia - dyktując należało robić przerwę po każdym wypowiedzianym słowie. Amerykańska firma Dragon Systems pod koniec 1998 roku wypuściła rewolucyjny program Dragon Naturally Speaking, po raz pierwszy umożliwiający przechwytywanie przez system pełnych zdań. Od strony technicznej takie podejście wymagało bardzo dużych zmian. Przede wszystkim koniec i początek wyrazu nie był już określany przez ciszę, lecz wynikał z kontekstu wypowiedzi. Oznaczało to zastosowanie HMM (Hidden Markov Model), modelu matematycznego, który wykonując mnóstwo obliczeń szukał najbardziej prawdopodobnego łańcucha słów, mogącego reprezentować określony ciąg fonemów (ekran).
ROZPOZNAWANIE MOWY
Rozpoznawanie mowy przez komputer nie ma na razie nic wspólnego z jej rozumieniem. Polega raczej na wyliczaniu najbardziej prawdopodobnego układu wyrazów i znaków interpunkcyjnych na podstawie: predefiniowanych zależności kontekstowych pomiędzy fonemami w danym języku oraz informacji treningowych dostosowujących parametry Speech Engine do konkretnego użytkownika. Mianem Speech Engine określa się pracujący w tle proces, na którego wejście kieruje się spróbkowany dźwięk i na którego wyjściu pojawiają się rozpoznane frazy - patrz ramka.
Ze względu na powszechność pakietu Office, omawiając cechy typowej aplikacji Speech Recognition, będziemy odwoływać się do programu Microsoft Word 2002 zainstalowanego na platformie Windows XP. Zanim wypowiemy pierwsze zdanie do komputera, musimy uruchomić silnik mowy. Czynimy to poprzez zaznaczenie w menu Tools ŕ Speech. Gdy robimy to po raz pierwszy, menedżer instalacyjny pakietu Office poprosi nas o włożenie dysku z zasobami do napędu CD-ROM, po czym skopiuje odpowiednie pliki. Następnie musimy dostosować Speech Engine do naszego głosu, czyli stworzyć nowy profil.
Najpierw system sprawdza mikrofon i dobiera poziom sygnału. Następnie jesteśmy proszeni o podanie płci i przybliżonego wieku. Później musimy przeczytać na głos kilkanaście zdań. Poprawnie rozpoznane frazy program podświetla. W każdej chwili możemy zrobić przerwę i opuścić słowo, którego nie możemy poprawnie przeczytać. Ostatnia cecha jest bardzo przydatna osobom, dla których angielski nie jest językiem ojczystym (kto nie wierzy, niech spróbuje podyktować systemowi słowo "alias" albo "alliance").Po zakończeniu tych procedur mówimy "Hello World" i... nic. Niestety, języka polskiego Speech Engine nie obsługuje. Aby mówić do komputera, musimy wcześniej w Panelu sterowania systemu dodać co najmniej język angielski, a później, będąc już w Wordzie, wybrać go na pasku zadań. Pojawi się charakterystyczne pyknięcie w głośnikach i maszyna jest gotowa do dyktowania. Warto wiedzieć, że zainstalowanie pakietu Office XP sprawia, iż zmienia się opcja "Ustawienia regionalne" w panelu sterowania. Przy wyborze języka automatycznie, jeśli system znajdzie odpowiednie komponenty, dodaje zakładki niezbędne do prawidłowego działania systemów ASR oraz OCR (rozpoznawanie pisma odręcznego).
Rozpoznawanie mowy znacznie przyspiesza wprowadzanie tekstów pod warunkiem uzyskiwania wysokiej dokładności. Nie dajmy się nabrać na zapewnienia producentów. Dokładność 95 procent oznacza, że średnio co dwadzieścia słów, czyli praktycznie w co drugim zdaniu, musimy robić przerwę na poprawkę źle zrozumianego wyrazu. Rozsądne minimum wynosi 98 procent, czyli średnio jeden wyraz na akapit. ASR w działaniu gdy ustawimy w Wordzie język wprowadzania jako angielski, niepozorny do tej pory pasek językowy (na ekranie widoczny jako zielona belka tuż pod tekstem) zmienia się we wskaźnik odzwierciedlający stan przetwarzania dźwięków. I tak ikona mikrofonu, która znajduje się zaraz za oznaczeniem języka, określa, czy pętla nasłuchowa jest aktywna. Jeśli mikrofon jest podniesiony, aplikacja słucha co do niej mówimy. Program pracuje w dwóch trybach. W Dictation wybieranym ikoną z dymkiem, wtedy możemy czytać, a komputer posłusznie wypisuje zrozumiany tekst na ekranie. Natomiast Voice Command umożliwia sterowanie zachowaniem całej aplikacji.
CO TO JEST INTERFEJS I DO CZEGO SŁUŻY
Maszyny nie umieją mówić, albo, patrząc na to z innej perspektywy, używają języka niezrozumiałego dla ludzi. Wzajemną komunikację umożliwia system operacyjny. Gdy tylko komputery zawitały pod strzechy, wyposażono je w klawiatury i monitory, dzięki którym można było porozumiewać się z jądrem systemu za pomocą komend, a wyniki oglądać w postaci ciągu symboli. Z czasem pojawiły się myszki i środowisko graficzne, a dominującą formą dialogu stała się operacja "przeciągnij i upuść". System rozumie nasze polecenia dzięki nakładce, która pozwala mu interpretować grafikę i zamieniać ją na ciąg zrozumiałych dla niego komend. Polecenia te to najczęściej zawarte w jądrze OS funkcje API (Application Program Interface), albo rozkazy języka skryptowego obsługującego rozszerzenia powłoki. Aby maszyna mogła komunikować się z człowiekiem za pomocą głosu, potrzebne są jej procedury, które zapewnią translację poleceń języka potocznego na API. To coś znacznie bardziej złożonego niż popularne ostatnio na świecie aplikacje do rozpoznawania mowy. Newralgiczne punkty w tym schemacie to procedury odpowiedzialne za rozpoznawanie mowy (ASR), rozumienie języka naturalnego (NLU) oraz syntezę głosu (TTS). Reprezentacja znaczeń to po prostu matryca kojarząca wyekstrahowany z polecenia sens z ciągiem kolejnych, zrozumiałych dla maszyny instrukcji, a układ generowania wypowiedzi to zbiór zdań, które maszyna serwuje przy odpowiednim pobudzeniu. Każdy język ma unikalne, charakterystyczne tylko dla siebie układy głosek i na tym bazuje blok odpowiedzialny za jego rozpoznawanie, który wspomaga procedury NLU. Innymi słowy, zanim system spróbuje rozłożyć nasze polecenie na czynniki pierwsze, wie już, jakim posługujemy się narzeczem. Identyfikacja rozmówcy polega na analizie widmowej barwy głosu, porównaniu jej z zapisanymi w jądrze systemu próbkami autoryzowanych użytkowników i ma na celu wstępne rozpoznanie rozmówcy. Oczywiście gdy chcemy wykonać przelew albo sprawdzić stan naszego konta, to nie wystarczy, ale dobrym odzwierciedleniem funkcjonalności tego typu jest zwrot voice cookie.
JAK FUNKCJONUJE ROZPOZNAWANIE MOWY
CZY KOMPUTER MYŚLI, CZY TEŻ NIE?
W przeciwieństwie do sposobu postępowania z danymi wprowadzanymi poprzez klawiaturę, komputer odczytujący informacje głosowe musi przeprowadzić złożone procesy analityczne. Na podstawie rozkładu prawdopodobieństwa ustala on wówczas, co użytkownik przypuszczalnie powiedział.
W pierwszym etapie analizy komputer rejestruje dźwięk w postaci cyfrowej sekwencji audio i dzieli go na fragmenty o milisekundowej długości. Następnie działające w tle oprogramowanie porównuje te sekwencje z zapisanymi wzorcami mowy. Odpowiednia jakość wzorcowej bazy danych jest najważniejszym warunkiem sprawnego działania mechanizmu rozpoznawania mowy. Baza ta zawiera fragmenty głosu wielu osób mających zróżnicowane właściwości mowy: intonację, dialekt, akcentowanie głosek i wymowę. Ten element techniki rozpoznawania mowy określany jest mianem systemu niezależnego od mówcy.
Systemy rozpoznawania mowy korzystają dodatkowo z techniki identyfikacji fonemów, czyli najmniejszych dźwiękowych jednostek mowy. Tę samą literę wypowiada się bowiem w różnych wyrazach inaczej. Podczas fazy treningowej oprogramowanie poznaje najważniejsze cechy fonemów wymawianych przez użytkownika i zapisuje te dane w indywidualnym profilu mówcy. Jest więc bardzo ważne, aby w trakcie późniejszego dyktowania użytkownik utrzymywał na możliwie niezmiennym poziomie melodię i sposób wymowy.
Uzupełnienie mechanizmu rozpoznawania mowy stanowią podstawowe reguły zależności kontekstowych. Istnieje wysokie prawdopodobieństwo, że po określonym wyrazie użyta zostanie tylko pewna liczba innych słów, aby zdanie miało jakiś sens. Posiadacze nowszych modeli telefonów komórkowych znają tę technikę z wiadomości SMS, gdzie podczas wprowadzania tekstu aparat automatycznie proponuje odpowiednie słowo.
Dzięki połączeniu różnych metod rozpoznawania mowy możemy zatem odnieść wrażenie, że programy analizujące głos naprawdę rozumieją słowa wypowiedziane przez użytkownika.
UPROSZCZONE ROZPOZNAWANIE MOWY
Fonemy to najmniejsze części języka mówionego. Około pięćdziesięciu pięciu z nich wystarcza, aby wypowiedzieć zdanie w dowolnym ziemskim narzeczu, a rzadko który język operuje więcej niż trzydziestoma naraz. Aby komputer mógł je wyekstrahować, musi najpierw przekształcić analogowe kontinuum informacji w liczby. W pececie dokonuje tego karta dźwiękowa, która pracując niezależnie od procesora, przetwarza sygnał dochodzący do niej z mikrofonu w ciąg próbek opisujących natężenie sygnału mowy w funkcji czasu. Dane te są następnie dzielone na tak zwane okna czasowe, czyli milisekundowe wycinki, na których prowadzona jest szybka transformata Fouriera (FFT Fast Fourier Transformation), przenosząca przebiegi do dziedziny częstotliwości. Połączenie FFT z przebiegiem czasowym tworzy tak zwane pasmo dynamiczne sygnału, na podstawie którego wyodrębnia się kolejne czynniki. Są nimi momenty oraz formanty widma określające maksima obwiedni sygnału dla określonych częstotliwości. Ostatecznie okno czasowe zostaje określone przez najważniejsze cechy sygnału w postaci zbioru od dziesięciu do dwudziestu parametrów opisujących niezmienniki języka mówionego niezależne od konkretnej osoby. Tworzą one wektor cech, który jest punktem wyjścia dla następnego etapu, czyli klasyfikacji. Wszystkie wymienione obliczenia przeprowadza się głównie ze względu na kompresję (po przekształceniach transfer informacji zmniejsza się około sto razy), bez niej poprawna klasyfikacja była niemożliwa ze względu na zbyt duże obciążenie procesora. Proces klasyfikacji polega na próbie dopasowania fonemów do napływającego strumienia wektorów cech. Na początku historii rozpoznawania mowy wektory zawierały pięć parametrów, więc problem sprowadzał się do policzenia odległości wzorca od każdego z fonemów w pięciowymiarowej przestrzeni i wyborze tego, który leżał najbliżej aktualnego sygnału. Dziś, gdy wektory cech są opisane przez znacznie większą liczbę parametrów (nawet do dwudziestu), takie podejście jest niemożliwe i często używa się metod heurystycznych, takich jak klasyfikator neuronowy. Dwa omówione etapy są identyczne dla większości metod rozpoznawania mowy. Ostatni - poszukiwania - w przypadku rozpoznawania komend jest wyjątkowo prosty i polega na próbie dopasowania znanego polecenia do łańcucha rozpoznanych fonemów.
AUTOMATYCZNE ROZPOZNAWANIE MOWY ASR
Prowadzenie dialogu za pomocą klawiatury tonowej, zarówno z tradycyjnym systemem telefonii komputerowej CTI, jak i w internetowych formach komunikacji - za pomocą klawiatury komputerowej, jest co najmniej uciążliwe. Pokonywanie wielu proponowanych przez systemy komputerowe rozgałęzień algorytmicznych czy zawiłych opcji telefonii komputerowej CTI niewątpliwie zmniejsza komfort korzystania z usług teleinformatycznych za pomocą klawiatury.
Aby rozwiązać ten problem, szereg dużych firm teleinformatycznych podjęło badania podstawowe, eliminujące korzystanie z klawiatury przyciskowej lub komputerowej i zastąpienie jej wyłącznie mową, przetwarzaną za pośrednictwem nowej generacji technologii automatycznego rozpoznawania mowy - ASR (Automatic Speech Recognition).
Nawet teoretycznie proces komputerowego rozpoznawania i syntezy mowy nie należy do zagadnień łatwych. Podstawowym wyróżnikiem systemu automatycznego rozpoznawania mowy jest przyjęcie jednego z dwóch kryteriów poszukiwań: albo interpretacja izolowanych, pojedynczych słów, albo bardziej zaawansowany sposób rozpoznawania mowy ciągłej. W systemach z rozpoznawaniem izolowanych słów poszczególne interpretowane słowa muszą być rozdzielone pauzą, a ich niewielki zbiór zwykle nie przekracza kilkunastu lub najwyżej kilkudziesięciu. Najczęściej reprezentują one cyfry, pojedyncze rozkazy, hasła czy operacje (matematyczne, handlowe, produkcyjne, inne). Dotychczas stosowane proste metody rozpoznawania (ASR) interpretują jedynie pojedyncze słowa bądź niektóre zwroty językowe (frazy) wypowiadane przez człowieka. Do często używanych należą komunikaty zawierające poszczególne cyfry, krótkie polecenia albo ciągi izolowanych cyfr i słów, związanych z numerem karty kredytowej, hasłem czy kodem klienta. W rozpoznawaniu ciągłym dochodzi dodatkowo trudność w określaniu początku i końca zdania, kontekstu słów, fraz językowych, rozpoznawania ciągu słów izolowanych, pojedynczych słów lub innych, jeszcze mniejszych jednostek elementarnych języka mówionego. W celu bardziej kompleksowego rozwiązania tego problemu przez komputery opracowano statystyczne metody rozpoznawania głosu - oparte na podstawach matematycznych - dające się w prosty sposób adaptować do aplikacji użytkowych. Statystyczna koncepcja takiego rozpoznawania polega na wyszukaniu określonych, wcześniej zarejestrowanych i wyizolowanych, elementarnych składników mowy, których ciągi z największym prawdopodobieństwem odpowiadają odbieranym (odsłuchanym) przez odbiorcę słowom.
Trudności te powodują, że jedynie najbardziej nowoczesne rozwiązania pozwalają na rozpoznawanie mowy ciągłej, oparte na uprzednio zdefiniowanych elementarnych jednostkach językowych, takich jak alofony, fonemy, diafony, sylaby lub nawet krótkie kompletne słowa. Takie podejście do problemu umożliwia kontekstowe rozpoznawanie mowy bądź syntetyczne tworzenie na tej podstawie nowych wyrazów, fraz i zwrotów, także pełnych poleceń sterujących.
STEROWANIE GŁOSEM
Sterowanie może odbywać się na cztery sposoby. Używając SAPI, możemy głosem symulować naciskanie klawiszy, ruchy myszki, rozwijanie menu systemowych, obsługę okien dialogowych itp. Wszystkie testowane aplikacje umożliwiają sterowanie poprzez SAPI, jednak jest to rozwiązanie niewygodne i mało wydajne, a przy tym, w wydaniu polskim niedopracowane. Drugim sposobem jest wykorzystywanie napisanych przez producenta globalnych komend typu "Go to desktop", "Open <program>", "Close". Sterują one systemem operacyjnym i są dostępne w każdej chwili. Komendy kontekstowe to trzeci sposób komunikacji. Jest to zbiór poleceń, które reagują na kontekst - pewne komendy są dostępne, gdy aktywny jest Internet Explorer, a inne, gdy widzimy przed sobą Worda. W każdej aplikacji istnieje również rozkaz "What Can I Say", wyświetlający okienko z dostępnymi w danym momencie komendami. Czwarty i ostatni sposób sterowania głosem polega na definiowaniu własnych komend i przypisywaniu im poleceń systemowych albo makr wykonywanych w danym programie użytkowym. Zakres integracji komend głosowych z systemem operacyjnym i popularnymi aplikacjami jest różny w testowanych programach (patrz tabela "Sterowanie głosem").
CZYTANIE I ODTWARZANIE
Ostatnią porównywaną kategorią jest synteza dźwięku - proces niejako odwrotny do rozpoznawania mowy. Na podstawie zapisu symbolicznego aplikacja syntetyzuje w czasie rzeczywistym dźwięk i przesyła go do urządzenia audio. Jakość tej syntezy ma dość duży wpływ na komfort korzystania z programu, Odtwarzanie, czyli playback polega na możliwości odsłuchu nagranych przy dyktowaniu dźwięków. Nie jest to nic odkrywczego, a jedyna sztuczka polega na synchronizacji tekstu w edytorze z pamiętanymi nagraniami. Doskonałą jakość syntezy zaimplementowano w Voice Xpress. Po zaznaczeniu tekstu i wydaniu komendy "Read it" w głośniku słyszymy przyjemny kobiecy głos, odczytujący tekst i zmieniający tempo i barwę w sposób bardzo zbliżony do ludzkiego. Proces idealnie interpretuje wszystkie znaki interpunkcyjne i jako jedyny implementuje zawiłości angielskiej intonacji. Dragon Naturally Speaking wyróżnia się z kolei na minus. Głos jest blaszany i reaguje tylko na kropki (w sztuczny sposób robi wtedy krótkie przerwy), a w dodatku czyta w tak zawrotnym tempie, że zrozumienie tekstu jest praktycznie niemożliwe. Porównanie testowanych programów pod względem zdolności do czytania i odgrywania znajduje się w tabeli "Synteza i odtwarzanie
KRÓTKA HISTORIA KONWERSJII
Rozwój rozpoznawania mowy
1958
Cyfrowy system konwersacyjny Davida, Mathewsa i McDonalda.
1962
Pierwszy komercyjny generator mowy - model 7772 firmy IBM.
1984
Pierwszy system do rozpoznawania mowy na dużej maszynie. Analiza każdego wyrazu trwa wiele minut. Urządzenie rozpoznawało około 5000 pojedynczych słów angielskich.
1986
Prototyp systemu Tangora 4: dzięki specjalizowanym mikroprocesorom po raz pierwszy przetwarzanie mowy może odbywać się na stacji roboczej i w czasie rzeczywistym. System zawiera już mechanizm kontroli kontekstowej.
1990
Dragon Systems przedstawia pierwszą amerykańską wersję systemu Dragon Dictate.
1992
Technologia Tangora jako model klient-serwer: niezbędny jest system IBM RS/6000 z systemem operacyjnym AIX. Rejestracja głosu odbywa się na pecetach pracujących pod kontrolą OS/2.
1993
Personal Dictation firmy IBM jest pierwszym typowo pecetowym systemem przetwarzającym głos. Jego cenę ustalono na 1000 dolarów. Philips Dictation Systems przedstawia pierwszą wersję pakietu do ciągłego rozpoznawania mowy.
1996
IBM OS/2 Warp 4 - pierwszy komercyjny system operacyjny z wbudowanymi funkcjami rozpoznawania mowy i nawigacji głosem.
1997
Speech Magic Philipsa - rozwiązanie klasy klient-serwer. Spółka Lernout & Hauspie prezentuje pierwszy anglojęzyczny pakiet do rozpoznawania mowy.
1998
IBM, Dragon, Lernout & Hauspie oraz Philips opracowują komercyjne wersje swoich produktów.
2001
Rozpoznawanie mowy dla mas: premiera korzystających z mechanizmów analizy głosu MS Office XP i Corel WordPerfect Office 2002.
GŁOSOWA KONWERSJA TEKSTU TTS
Nowym elementem w automatycznym rozpoznawaniu informacji, stanowiącym rozszerzenie procedur IVR, jest funkcja komputerowego czytania tekstów TTS (Text to Speech), coraz częściej stosowana do szybkiej interpretacji informacji tekstowych i drukowanych.
Wprowadzenie technologii konwersji TTS podczas dialogu użytkownika z interaktywnym systemem (Call Center, Contact Center, Data Center, Internet Data Center) czy przeglądania i czytania portali znacznie skraca czas uzyskiwania potrzebnej informacji, a sam dialog staje się bardziej naturalny.
Funkcja komputerowego czytania tekstów staje się przydatna w systemach bankowych, w sektorze telekomunikacyjnym i w transporcie, a także podczas przeszukiwania portali internetowych. Dobrym przykładem aplikacji tej usługi jest możliwość odczytywania poczty elektronicznej przez telefon, gdy użytkownik jest pozbawiony w danym momencie możliwości przeglądania zawartości swojej skrzynki pocztowej.
KONWERSACJA OGRANICZONA
Technika rozpoznawania mowy nie jest tylko domeną pecetów, ale powoli opanowuje również inne obszary codziennego życia. Dzwoniąc na Zachodzie np. do firmy wysyłkowej, na numer infolinii lub bankowego teleserwisu, czasami można się zetknąć ze sterowanym głosowo komputerem telefonicznym. System ów pobierze od nas automatycznie takie dane, jak nazwisko i hasło dostępu. W przeciwieństwie do rzeczywistego, dynamicznego rozpoznawania mowy systemy takie pracują jednak zgodnie z wcześniej ustalonym drzewem decyzyjnym i ściśle określonymi procedurami. Osoba dzwoniąca musi więc zawsze posłużyć się jednym z dostępnych poleceń. Z reguły te aplikacje nie potrafią obsługiwać języka naturalnego.
Część dostępnych od pewnego czasu na rynku telefonów komórkowych również jest wyposażona w mechanizm rozpoznawania mowy, służący do wyboru zapamiętanych wcześniej numerów. W tym przypadku urządzenia nie rozumieją jednak faktycznych słów wypowiedzianych przez użytkownika. Odpowiednie nazwy i imiona są zapamiętywane przez aparat w postaci pliku audio wraz z numerem abonenta. Gdy w celu wybrania numeru użytkownik wypowiada nazwę, telefon porównuje oba wzorce. Jeśli są one ze sobą zgodne, aparat wybiera odpowiedni numer.
Systemy sterowania głosem wykorzystuje się nawet w tzw. komputerach ubraniowych (ang. body-worn computers). Zajmuje się tym m.in. firma Xybernaut we współpracy z amerykańskimi siłami zbrojnymi.
POJEDYNEK GIGANTÓW
Prawdopodobnie producenci oprogramowania zrobią wszystko, żeby upowszechnić technologie ASR z dwóch powodów: komunikacja za pomocą głosu jest najbardziej naturalnym dla człowieka sposobem porozumiewania się, a rosnący stopień skomplikowania obsługi programów i urządzeń elektronicznych sprawia, że klienci chętnie, zamiast uczyć się setek nowych opcji, powiedzieliby programowi bądź gadżetowi, co ma zrobić. Z uwagi na szacowaną skalę zjawiska, analitycy rynkowi są przekonani, że technologie głosowe wkrótce staną się jedną z bardziej lukratywnych branż w sektorze IT. O powadze, z jaką traktowany jest ten sposób komunikacji z maszyną świadczą firmy, które inwestują w technologię ASR. Kilka lat temu, zaraz po premierze Dragon Naturally Speaking, widzieliśmy wyścig największych producentów działających w branży IT, którzy próbowali zdobyć przyczółek na dziewiczym wtedy obszarze. I tak: IBM opracował doskonały produkt ViaVoice, którego Speech Engine zakupiła między innymi polska firma YDP, wyspecjalizowana w tworzeniu interaktywnych słowników i edukacyjnych aplikacji multimedialnych; Philips ruszył z serią produktów FreeSpeech, które jako jedyne bardzo łatwo radziły sobie z wielojęzykowym środowiskiem, a wspomniany już Dragon Systems prowadził prace mające na celu daleko idącą integrację technik SR z systemem Windows.
Efekt zainteresowania Microsoftu technikami SR był nietrudny do przewidzenia i potwierdza prognozy analityków. Ich zdaniem, techniki SR podzielą los przeglądarek. Gdy trwała wojna o dominację na rynku internetowym, Microsoft zdecydował się udostępnić Internet Explorer za darmo, jako standardowe wyposażenie Windows. W efekcie Netscape, Opera, czy Mozaik przestały się liczyć. Na podobnej zasadzie Office XP wzbogaca system operacyjny Windows o moduł rozpoznawania mowy. Zastosowano w nim Speech Engine autorstwa nieistniejącej już firmy L&H. Dzięki temu, że jest pozornie udostępniana za darmo oraz integruje się z systemem, wyraźnie przyblokowała silniejszą technologicznie konkurencję, która powoli zwraca się w kierunku rozwiązań instytucjonalnych, tworząc moduły software'owe dla programistów (SDK - Software Development Kit) oraz rozumiejące mowę ludzką gadżety. Philips, producent wielojęzykowego pakietu do rozpoznawania mowy ciągłej, FreeSpeech, już go nie rozwija. Zamiast tego oferuje SDK SpeechMagic, narzędzie programistyczne wspomagające rozpoznawanie mowy w aplikacjach prawniczych, medycznych i ubezpieczeniowych. Dla masowego rynku przeznaczono przenośne urządzenie do dyktowania, potrafiące rozpoznawać nagrane słowa. Digital Pocket Memo 9300 umożliwia mówienie bez przerwy przez prawie dwie godziny oraz zapewnia transfer rozpoznanego tekstu na peceta. IBM nadal sprzedaje ViaVoice, ale od chwili pojawienia się Office XP produkt zatrzymał się w rozwoju. Dla przykładu, nowa wersja, oznaczona symbolem 10, rozpoznaje mniej języków niż jej poprzednik sprzed dwóch lat. Jedyne intensywnie rozwijane obecnie produkty typu Speech Recognition, których przeznaczeniem jest rynek masowy, to seria aplikacji Dragon Naturally Speaking. Microsoft poprzez alians z L&H jest w dużej mierze właścicielem smoka, który notabene występuje teraz w barwach firmy Synapse Adaptive. Szkoda, że w Office XP zamiast bardzo dobrej Speech Engine Dragona użyto przestarzałej L&H. Rozpoznawanie mowy ma nowe dziecko firmy Corel, WordPerfect 2002. Zastosowana w nim Speech Engine jest autorstwa Dragon Systems. Sam Corel został kiedyś dofinansowany przez giganta z Redmond, ale nie udało nam się ustalić w polskim oddziale firmy, czy wybór technologii wynika z praw rynkowych, czy też wpływ na to miały inne czynniki. Od niedawna można mówić też do komputerów korporacji Apple. Ostatnia wersja Mac OS X zapewnia rozpoznawanie mowy ciągłej oraz potrafi odczytywać na głos zawartość przeglądanych stron WWW. Mimo dość znacznego postępu w aplikacjach typu ASR wydaje się, że znacznie bliżej realizacji jest dziś IVR czyli Interactive Voice Recognition - system używany do zbierania i dostarczania informacji przez telefon.
IDEAŁ CALL CENTER
Jak działa system call center? Zdawałoby się, że najprostszym rozwiązaniem będzie zorganizowanie tylu stanowisk telefonicznych, ilu spodziewamy się rozmów jednocześnie i zatrudnienie takiej samej liczby pracowników obsługi. Każda przychodząca rozmowa jest wtedy odbierana przez pierwszą wolną osobę w call center. Wadą takiego rozwiązania jest duży koszt, związany z utrzymaniem wielu stanowisk, pracowników i linii telefonicznych, a także jego nieelastyczność. Co się stanie, gdy na przykład po wykryciu serii wad w produktach zacznie dzwonić dużo więcej klientów niż dotychczas? Z drugiej strony, można spodziewać się nieefektywnego wykorzystania czasu pracy telemarketerów w okresie zmniejszonego zainteresowania klientów. Jest kilka sposobów na ominięcie tego problemu. Przede wszystkim zatrudnienie mniejszej liczby telemarketerów i usprawnienie procedury obsługi klienta. Służą temu m.in. specjalnie przygotowane bazy danych, które zawierają odpowiedzi na najczęściej zadawane pytania. Inną metodą jest zapewnienie właściwego systemu łączenia rozmów. Dobrze skonstruowany system call center potrafi bez angażowania obsługi rozpoznać, jaki produkt lub usługa interesuje klienta oraz wybrać telemarketera, z którym klient powinien rozmawiać. Czynności te wykonywane są na podstawie odpowiedzi udzielanych przez klienta (wciskaniem odpowiednich klawiszy aparatu telefonicznego) na samoczynnie zadawane pytania; bazują także na informacjach zapisanych w systemie i identyfikowanych według numeru telefonu petenta. Pracownik obsługujący linię otrzymuje na ekranie komputera wszystkie informacje zdobyte podczas pierwszego kontaktu dane, np. numer telefonu, z którego dzwoni klient, nazwa usługi, która go interesuje itd. System powinien oceniać, kogo łączyć z którym operatorem, uwzględniając przy tym długość oczekiwania na połączenie przez klienta, wielkość potencjalnego zamówienia itp.
Call center w Polsce |
|
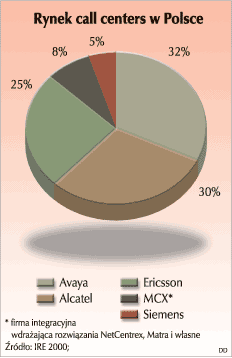
{kind=link}
SYSTEM OD ŚRODKA
Z technicznego punktu widzenia call center to miejsce, w którym obsługuje się wchodzące i wychodzące rozmowy telefoniczne prowadzone z klientami w celu rozwiązania ich problemów związanych z działalnością firmy. Z call center można się łączyć przez telefon (firma udostępnia numery telefonów dla klientów, pod którymi oczekują telemarketerzy) lub przez Internet (firma zapewnia interaktywne usługi przez Internet służące do kontaktu z agentem). Wykorzystywane są również takie media, jak faks, pod który klienci przesyłają zapytania, krótkie wiadomości tekstowe SMS (służące z reguły jako element kontaktu zwrotnego z klientem), czy np. interaktywne kioski montowane w miejscach publicznych.
CIEKAWOSTKI I ZASTOSOWANIA SYSTEMU ROZPOAZNAWANIA MOWY
[1] Rozpoznawanie mowy przekazywanej przez telefon wykorzystywane w:
* poczcie głosowej
* prowadzeniu operacji bankowych przez telefon
* odczytywaniu pomiarów
* połączeniach, w których płaci strona odbierająca rozmowę
* monitorowaniu pomieszczeń i zakupach przez telefon (ang. home shopping).
[2] Pierwsze komercyjne systemy automatycznego rozpoznawania mowy, niezależne od osoby, której polecenia miały być rozpoznawane, pojawiły się na początku lat dziewięćdziesiątych. Początkowo były to systemy bardzo proste. Nie wymagały już specjalnego szkolenia dla osób, których głos miał być rozpoznawany, ale były w stanie rozpoznawać jedynie 16 słów.
[3] Podstawowy zestaw szesnastu słów składa się z:
* cyfr od zera do dziewięć
* zera wymawianego jako 'oh'
* komend: tak, nie, stop, pomoc, zlikwiduj (cancel).
[4] Współczesne systemy rozpoznawania mowy są o wiele bardziej skomplikowane. Technologie w nich używane pozwalają stosować wiele udogodnień:
* Zdolność do rozpoznawania zarówno osobno wymawianych cyfr lub liter, jak i zdań mówionych w sposób zupełnie naturalny, czyli ciągły.
* Wcinanie się głosem (voice cut thru), czyli możliwość rozpoznawania tego, co jest mówione w czasie nadawania nagranej wiadomości. To udogodnienie jest szczególnie cenne w poczcie głosowej. Wcinanie się pozwala dzwoniącemu podać komendę głosem bez konieczności wysłuchiwania całego opisu opcji.
* Punktowanie słów (word spotting), czyli zdolność do rozpoznawania ograniczonej liczby słów wypowiadanych w czasie naturalnego mówienia.
* Weryfikacja głosu (voice verification), czyli umiejętność stwierdzania, czy rozmówca jest tym, za kogo się podaje, na podstawie tego jak mówi. Każda osoba, której głos ma być rozpoznany, musi pozostawić w systemie nagranie wielocyfrowego hasła. Gdy następnie dzwoni, jej sposób wymowy tego hasła jest porównywany z nagraniem.
* Rozpoznawanie mowy konkretnej osoby (speaker dependent recognition), dzięki której użytkownik telefonu może stworzyć własną listę osób, do których najczęściej dzwoni, a następnie - po wprowadzeniu tej listy do systemu i po skojarzeniu jej z numerami telefonów tych osób - łączyć się z nimi wymawiając ich imiona lub nazwiska.
[5] Preferred Telecom Inc., jako pierwszy na świecie, wprowadził kartę do międzymiastowych i międzynarodowych rozmów telefonicznych, której użytkownik może wybierać numer rozmówcy głosem.
[6] Rozpoznawanie mowy konkretnej osoby znajduje zastosowanie w telefonii komórkowej
Wbrew zapewnieniom producentów o nadejściu ery komunikacji werbalnej, komputery jeszcze przez długi czas będą miały problemy z rozumieniem języka naturalnego. Używając myszy i klawiatury, działamy szybciej niż wydając polecenia głosem. Wyjątek stanowi dyktowanie. Stąd, moim zdaniem, właściwym polem zastosowań tego typu oprogramowania na obecnym etapie rozwoju systemów operacyjnych są aplikacje, których głównym celem jest wprowadzanie tekstu. Będą to przede wszystkim edytory, ale również popularne programy komunikacyjne, takie jak ICQ, Instant Messanger czy IRC. Znacznie bardziej skuteczne są technologie stosowane tam, gdzie w grę wchodzi tylko ściśle ograniczone słownictwo fachowe. Na przykład programy dla radiologów przekształcają ustne diagnozy lekarskie bezpośrednio w tekst pisany. Nawet jednak w przypadku drogich systemów dla lekarzy i prawników ręczna korekta automatycznie wczytanych dokumentów jest wciąż na porządku dziennym.
Zakłócenia uboczne (np. hałas uliczny czy rozmowy telefoniczne innych pracowników biura) mogą powodować poważne błędy w rozpoznawaniu wyrazów. Czasochłonna i irytująca faza intensywnego uczenia systemów jest nadal niezbędna ze względu na różnice w dialektach, sposobie akcentowania czy nawykach językowych danego użytkownika.
Literatura:
www.telenetforum.pl
Słownik informatyki dla ekonomistów. Adamczewski, E. Danecka, W. Fliegner, M. Fonfara, H. Romanow, E. Szajba
Wstęp do informatyki - Praca zbiorowa pod redakcją E. Niedzielskiej PWE Warszawa 1993
2
Wyszukiwarka
Podobne podstrony:
Rozdział-17-propagandowe i inne, Szkolenie Szybowcowe, Procedury operacyjne
TRYBUNA KONSTYTUYJNY 3 ST, Inne
OG LNE POJ CIA PRAWNE 5 ST, Inne
RACHUNKOWO BANKOWA 10 ST, Inne
ANKITA HERBATY LIPTON 3 ST, Inne
OG LNE POJ CIA PRAWNE 4 ST, Inne
METODOLOGIA WG PILCHA 4 ST, Inne
Pytanie 17, st. Pedagogika ćwiczenia, pedagogika U P tematy do egzaminów 46 tematów
OCHOTA SERCE WARSZAWY 9 ST, Inne
POWSTANIE WARSZAWSKIE 2 ST, Inne
ANALIZA STRATEGICZNA 40 ST, Inne
OG LNE ZASADY BUD ETU PA ST, Inne
PRAWO ADMINISTRACYJNE 3 ST, Inne
ELEMENTY BIZNES PLANU 4 ST, Inne
więcej podobnych podstron