Wprowadzenie do baz danych
1/31
Wprowadzenie do baz danych
Każde przedsiębiorstwo przechwuje jakieś dane. Zajmijmy się przykładowo linią lotniczą. Firma taka
musi zbierać informacje o pasażerach, rejsach, samolotach i personelu. Pomiędzy tymi danymi zachodzą jakieś
związki, które także należy przechowywać w komputerze. Związki te to np. rezerwacje (kórzy pasażerowie
zarezerwowali miejsca na które rejsy) lub załogi samolotów (kto ma być pierwszym pilotem, w których rejsach).
Tego rodzaju dane, przechowywane w komputerze stale lub czasowo, nazywamy bazą danych (BD).
Baza danych może być traktowana na wiele sposobów, np. jako:
1.
model świata rzeczywistego
2.
zbiór struktur danych
3.
uniwersum interpretacji języka danych – czyli zbiór wartości wyrażeń pewnego języka danych
4.
zasób systemu informatycznego – zasób o którego przydział współzawodniczą ze sobą procesy współbieżne
5.
element składowy systemu informatycznego – o ustalonych związkach między systemem zarządzania bazą
danych a systemem operacyjnym komputera oraz o określonych środkach sprzętowych i programowych do
przechowywania danych, transmisji, komunikacji z człowiekiem
W bazie danych odwzorowana jest wiedza odnosząca się do pewnego wydzielonego fragmentu świata
rzeczywistego. Powstają dwa pytania:
1.
Jaki zakres wiedzy może być odwzorowany w bazie danych?
2.
W jaki sposób odwzorowanie to może być zrealizowane?
W przypadku sformatowanych baz danych (takimi się tu zajmujemy), tj. w których można podać
skończony zbiór wzorców służących do wyrażania pewnych informacji o stanie świata rzeczywistego – zakres
odwzorowywanej wiedzy nie może być szeroki. O wiele szerszy zakres wiedzy można odwzorować stosując np.
pewne metody opracowane w dziedzinie sztucznej inteligencji, takie jak sieci semantyczne, specjalne języki
oparte na rachunku predykatów lub wyspecjalizowane języki opisu wiedzy.
MODEL ŚWIATA
ZASÓB SYSTEMU
RZECZYWISTEGO
INFORMATYCZNEGO
ELEMENT
ZBIÓR
SKŁADOWY
STRUKTUR
SYSTEMU
DANYCH
INFORMATYCZNEGO
UNIWERSUM
INTERPRETACJI
JĘZYKA
DANYCH
BAZA
DANYCH
Wprowadzenie do baz danych
2/31
Ustalenie związków między danymi w BD a faktami w świecie rzeczywistym (czyli ustalenie
semantyki danych) nie odbywa się bezpośrednio. Pomostem umożliwiającym określenie tych związków jest tzw.
schemat konceptualnej bazy danych.
Fizyczna baza danych jest stale przechowywana w pamięci pomocniczej np. na dyskach, taśmach. W
fizycznej BD można wyróżnić kilka poziomów abstrakcji, poczynając od poziomu rekordów i plików w
językach programowania (np. Pascal, C) przez poziom rekordów logicznych w systemie operacyjnym, na
którym opiera się system zarządzania bazą danych, aż do poziomu bitów i adresów fizycznych w pamięci.
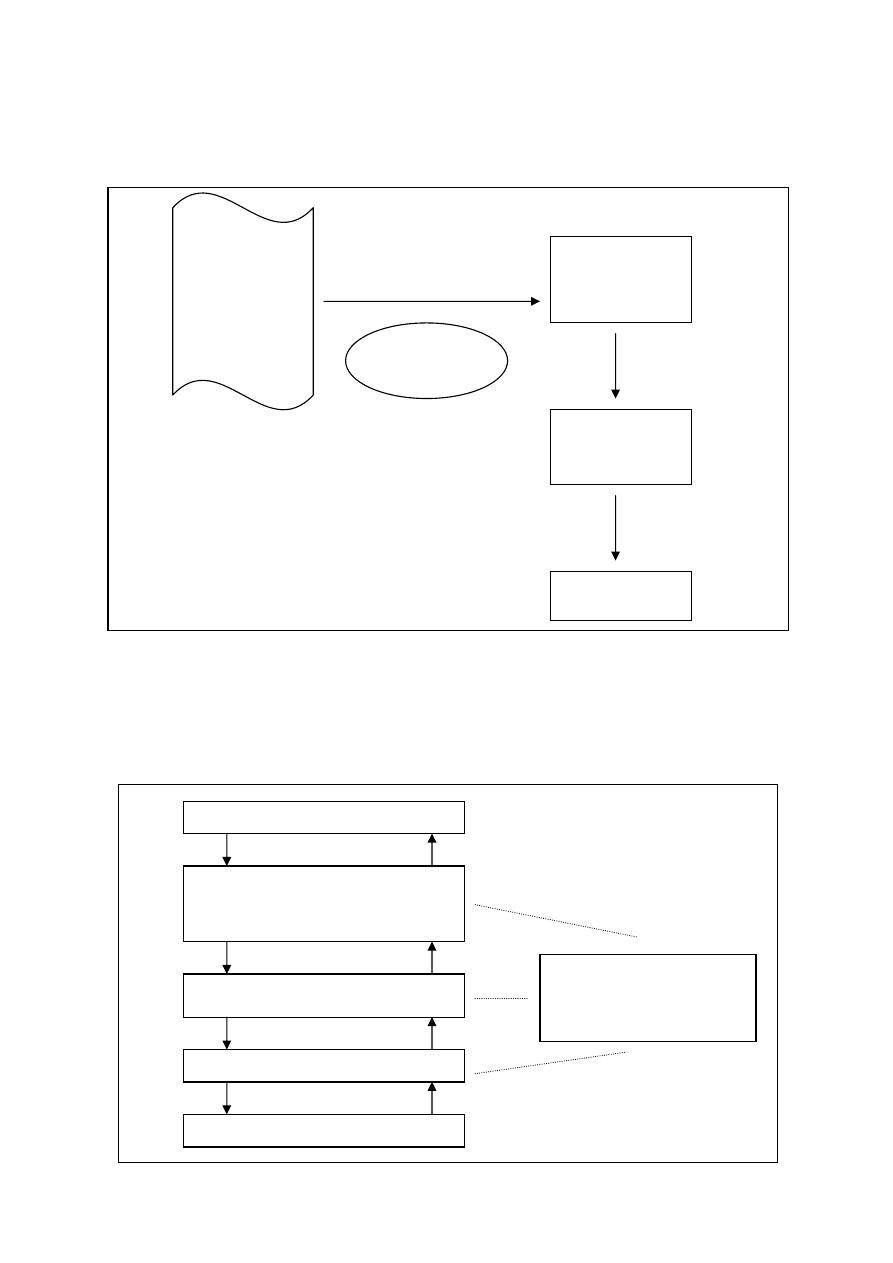
Proces przejścia od faktów w świecie rzeczywistym do danych w BD podzielono poniżej na pięć
etapów:
(1)
(2)
(3)
(4)
(5)
FAKTY W ŚWIECIE RZECZYWISTYM
PODZBIÓR JĘZYKA NATURALNEGO
DO FORMUŁOWANIA WYPOWIEDZI
O FAKTACH W ŚWIECIE
RZECZYWISTYM
ABSTRAKCYJNY MODEL
Ś
WIATA RZECZYWISTEGO
KONCEPTUALNA BAZA DANYCH
LOGICZNA BAZA DANYCH
SYSTEMATYZACJA
FRAGMENTU ŚWIATA
IMPLEMENTACJA
W JĘZYKU DML I DDL
IMPLEMENTACJA
NISKIEGO POZIOMU
(NP. W C)
Ś
WIAT
MODEL
KONCEPCYJNY
MODEL
LOGICZNY
DANYCH
REALIZACJA
FIZYCZNA
ANALIZA
SYSTEMOWA
PRZEDSTAWIENIE
ABSTRAKCYJNEGO
MODELU ZA POMOCĄ
DIAGRAMU O-Z

Wprowadzenie do baz danych
3/31
Zakładamy, że istnieje pewien obiektywny i poznawalny świat rzeczywisty (1), który chcemy
odwzorować w bazie danych (5). Możliwe jest (jak to zaznaczono strzałkami) przejście zarówno od świata
rzeczywistego do baz danych jak i odwrotne (5)
→
(1). Zakres wiedzy podlegającej odwzorowaniu wyznacza nam
zasób wyrażeń języka naturalnego, w którym wiedza ta ma być formułowana. W ten sposób wyznaczany jest
pewien podzbiór języka naturalnego (2). Etap (3) to tworzenie abstrakcyjnego modelu świata rzeczywistego,
który zawiera pojęcia ściśle związane z wyrażeniami wybranego podzbioru języka naturalnego, a jednocześnie
umożliwia formalne sformułowanie pewnych niezmienniczych praw istniejących w świecie rzeczywistym.
Kolejnym etapem jest przedstawienie języka służącego do opisu modelu abstrakcyjnego. Zbiór wyrażeń tego
języka nazywamy schematem konceptualnej bazy danych (4).
Formułowanie i przekazywanie wiedzy o świecie rzeczywistym możliwe jest tylko za pomocą
specjalnego języka. Mamy wówczas do czynienia z trzema procesami: nazywaniem, selekcją i klasyfikowaniem
pewnych interesującyh faktów występujących w świecie. W dalszym ciągu zajmować się będziemy jedynie
sformatowaną wiedzą opisową (deskryptywną, sytuacyjną), a więc dotyczącą faktów odnoszących się do
ustalonych stanów świata rzeczywistego, nie będziemy rozważać wiedzy operacyjnej, proceduralnej – opisującej
zjawiska przyczynowo skutkowe. Skorzystamy dalej z metodyki zaproponowanej przez Chena, szeroko przyjętej
w teorii i praktyce baz danych.
Do podstawowych faktów rozpatrywanych w świecie rzeczywistym, o których wiedza reprezentowana
jest w bazie danych, zaliczamy: występowanie obiektów, encji (entity), pozostawanie tych obiektów we
wzajemnych powiązaniach (relationship) między sobą oraz posiadanie przez obiekty powiązania określonych
wartości (value) atrybutów (attribute).
Obiekt (encja) jest przedmiotem (materialnym lub abstrakcyjnym), który może być wyróżniony i
określony w świecie rzeczywistym i o którym chcemy pamiętać informacje. Informacjami tymi jest to, że ma on
określone wartości swoich atrybutów oraz że pozostaje w pewnych powiązaniach z innymi obiektami. Jest to byt
konceptualny (pojęciowy). Np. mrówki w mrowisku nie mogą być encjami, bo nie można ich odróżnić.
Atrybut określony jest jako funkcja częściowa ze zbioru obiektów lub zbioru powiązań w zbiór
wartości:
A: ENT
n
→
VAL
Formalnie rzecz biorąc opis świata rzeczywistego jest pewną teorią w sensie logiki matematycznej,
natomiast model stanu świata rzeczywistego jest modelem tej teorii. Dla celów baz danych wymagane jest
formalne określenie pewnego podzbioru języka naturalnego. Podzbiór ten nazwiemy językiem opisu stanu JOS.
JOS=<X,P>
Alfabet języka JOS składa się ze zbiorów: nazw jednostkowych X i predykatów P.
Modelem abstrakcyjnym stanu świata rzeczywistego generowanym przez język JOS nazywamy
następującą strukturę matematyczną:
MAS=<X,R>
gdzie R = W
∪
O
∪
Z
∪
A
, przy czym:
X – zbiór wartości (nazw jednostkowych język JOS)
W – rodzina zbiorów wartości
O – rodzina zbiorów obiektów
Z – rodzina relacji wyrażających powiązania
A – rodzina relacji wyrażających wartości atrybutów obiektów i powiązań
Wprowadzenie do baz danych
4/31
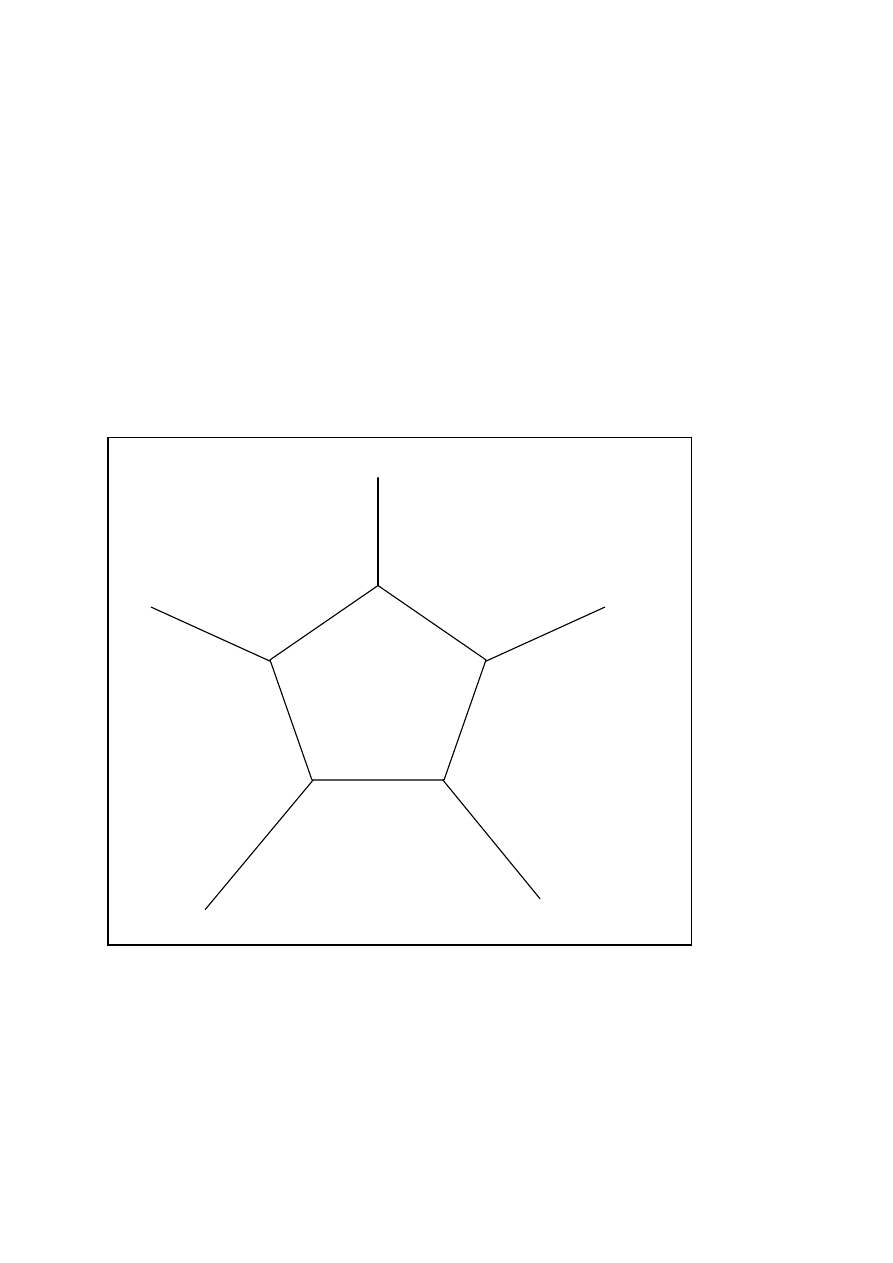
Przykład:
Na rysunku został określony zbiór obiektów PRACOWNIK. Atrybuty: NR_PRACOWNIKA, NAZWISKO i
WIEK przyporządkowują każdemu obiektowi ze zbioru PRACOWNIK wartości w zbiorach wartości,
odpowiednio NR_PRACOWNIKA, NAZWISKO i LICZBA_LAT.
1.
Zbiór wartości:
Nr_Pracownika={1001,1002,...,5000}
Nr_Wydziału={W1,W2}
Liczba_Lat={0,1,...,70}
Procent={0.1, 0.2, 1,... ,100}
Nr_Projektu={101,102,...,200}
2.
Zbiory obiektów:
Pracownik={1001,1002,1003,1004}
Wydział={W1,W2}
Projekt={101,102,103,104}
3.
Zbiory powiązań (relacje wyrażające powiązania):
Pr_Wydz={(1001,W1), (1002,W1), (1003,W2)}
Pr_Proj={(1001,101), (1001,102), (1002,101), (1003,103)}
4.
Relacje wyrażające wartości atrybutów:
Nazwisko={(1001,Kowalski), (1002,Rysiuk), (1003,Janicki)}
Udział={(1001,101,10), (1001,102,50), (1002,101,41)}
Staż={(1001,W1,5), (1002,W1,15), (1003,W2,1)}
Bazy danych są przedmiotem intensywnych badań w informatyce co najmniej od początku lat
siedemdziesiątych. Wówczas to szybko wzrastała liczba komputerów i ich moc obliczeniowa. Łączyło się to ze
zmniejszeniem kosztów przechowywania i przetwarzania informacji co pociągnęło za sobą szybki rozwój metod
tworzenia systemów informatycznych w tym i systemów zarządzania danymi.
ZBIÓR OBIEKTÓW
ATRYBUTY
ZBIORY WARTOŚCI
NR_PRACOWNIKA
NR_PRACOWNIKA
PRACOWNIK
NAZWISKO
NAZWISKO (np. Kowalski)
WIEK
LICZBA_LAT
C1
101
38
Wprowadzenie do baz danych
5/31
Poniżej przedstawiono etapy rozwoju komputerów prowadzące do powstania systemów
informatycznych.
Rozwój sieci komputerowych doprowadził do możliwości terytorialnego rozproszenia bazy danych na
różne stanowiska komputerowe. Przy czym celowe stało się duplikowanie niektórych danych na kilku
stanowiskach. Wszystko to spowodowało, że efektywna obsługa wielu współbieżnych procesów stała się
zadaniem złożonym. Stąd też pojawiła się konieczność tworzenia oprogramowania niezbędnego do zarządzania
wielowymiarowymi danymi - programów, które umożliwiłyby różnym osobom korzystanie lub zmienianie
danych. Powstały więc systemy zarządzania bazami danych - SZBD (Data Base Managment System – DBMS).
Głównym zadaniem takiego systemu jest zapewnienie użytkownikowi możliwości operowania danymi
za pomocą pojęć abstrakcyjnych w możliwie niewielkim stopniu odwołujących się do sposobu przechowywania
danych przez komputer. Tak rozumiany system działa jak interpreter języka programowania wysokiego
poziomu.
Oprogramowanie DBMS stanowi najważniejsze zastosowanie komputerów w przedsiębiorstwach, a
jednocześnie jest jednym z najbardziej skomplikowanych systemów wśród istniejących rodzajów
oprogramowania. Wykorzystywane jest m.in. w gospodarce materiałowej i magazynowej, obsłudze kadrowej,
finansowo-księgowej, bibliotecznej, dokumentacyjnej.
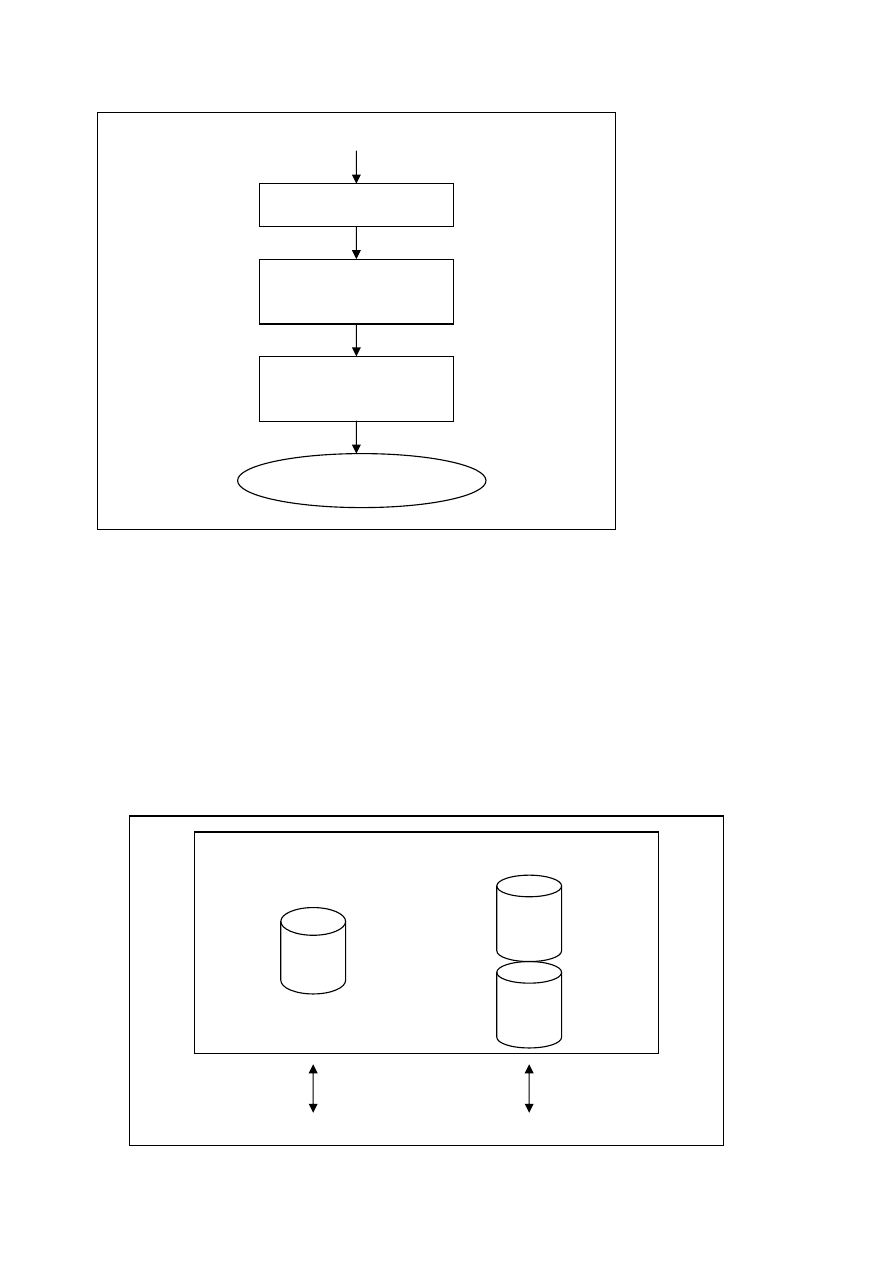
Poniżej przedstawiono schemat systemu bazy danych.
ZMIANY ILOŚCIOWE
BIERNA ROLA
W ZAKRESIE SPRZĘTU
W ŚRODOWISKU
OPROGRAMOWANIA I
METOD UŻYTKOWANIA
ZMIANY JAKOŚCIOWE
ROZWÓJ BAZ DANYCH
I SYSTEMÓW
ZARZĄDZANIA NIMI
AKTYWNA ROLA
W ŚRODOWISKU
KOMPUTER
SYSTEM
KOMPUTEROWY
SYSTEM
INFORMATYCZNY
Wprowadzenie do baz danych
6/31
Procesor zapytań jest czymś w rodzaju kompilaora zapytań. Wyniki uzyskuje się w postaci ciągu
rozkazów przekazywanych do innych części systemu.
Programy zarządzania bazą danych często realizują jeszcze kilka innych zadań. Należą do nich:
1.
Ochrona. Nie każdy użytkownik powinien mieć dostęp do wszystkich danych dlatego stosuje się hasła.
2.
Integralność. System zarządzający może sprawdzić niektóre rodzaje więzów spójności (consistency
constraints), tj. wymaganych własności danych.
3.
Synchronizacja. Często zdarza się, że wielu użytkowników korzysta z BD w tym samym czasie. System
powinien chronić przed niespójnością powstającą w wyniku wykonania na jednostce danych dwóch prawie
równoczesnych operacji.
W BD naturalne jest rozdzielenie funkcji deklaracji i obliczania między dwa różne języki. Wynika to stąd,
iż zmienne zwyczajnego programu istnieją tylko w czasie jego wykonywania, podczas gdy w systemach BD
dana istnieje „wiecznie” i może być deklarowana raz na zawsze.
ZAPYTANIE UŻYTKOWNIKA - KWERENDA
PROCESOR
ZAPYTAŃ
PROGRAMY
ZARZĄDZAJĄCE
BAZĄ DANYH
PROGRAMY
ZARZĄDZAJĄCE
PLIKAMI
FIZYCZNA
BAZA DANYCH
DDL
DML
DANE
OPIS DANYCH

Wprowadzenie do baz danych
7/31
Opis BD wyraża się w secjalnym języku zwanym językiem definicji danych (data definition language
DDL). Nadaje mu się postać tablic używanych przez pozostałe częsci systemu DBMS.
Natomiast działanie na BD wymaga specjalnego języka, zwanego językiem manipulacji danymi (data
monipulation language DML) lub językiem zapytań. W języku tym można wyrażać m.in. takie polecenia jak:
-
Wyszukaj w BD liczbę wolnych miejsc w rejsie 123 w dniu 20 lipca
-
Znajdź wszystkie rejsy do Nowego Jorku
Przetłumaczenie zapytania na operacje na plikach nie jest zadaniem łatwym, gdyż bazy danych mogą
reprezentować skomplikowne struktury plików. Te struktury tworzy się po to, aby w możliwie największym
stopniu przyspieszyć dostęp do bazy danych i działanie na niej.
Z baz danych korzysta kilka rodzajów użytkowników mających określone funkcje i różniących się
„stopniem wtajemniczenia” w problematykę BD:
1.
Naiwny użytkownik, np. szef lub słabo wyszkolona sekretarka. Pracują oni z wykorzystaniem
makropoleceń, formularzy itd.
2.
Dobrze wyszkolony użytkownik. Potrafi tworzyć zapytania, raporty itd.
3.
Programista użytkowy. Tworzy programy użytkowe, makra itd.
4.
Administrator baz danych. Jest odpowiedzialny za sprawy dotyczące BD jako całości. Do jego obowiązków
należą m.in.:
-
Tworzenie pierwotnego opisu struktury BD i sposobu odwzorowywania go w plikach fizycznej BD.
-
Udzielanie rozmaitych zezwoleń na korzystanie z BD lub jej fragmentów.
-
Modyfikacja opisu BD lub jego związków z fizyczną organizacją BD, gdy wnioski z jej eksploatacji
wskazują, że inna organizacja błaby bardziej efektywna.
-
Wykonywanie archiwalnych kopii BD i przywracanie jej poprawnego stanu po uszkodzeniach
powstałych na skutek awarii lub niewłaściwego użycia sprzętu bądź oprogramowania
Kierunki rozwoju baz danych:
1.
Rozproszone bazy danych
2.
Obiektowo zorientowane bazy danych
Bazy relacyjno-obiektowe
3.
Aktywne bazy danych
4.
Database legacy
5.
Database mining
Wprowadzenie do baz danych
8/31
Modele koncepcyjne
Związki encji
Bazy danych (BD) zajmują się modelowaniem otaczającego nas świata. Dowolny fragment
rzeczywistości możemy próbować opisać. Dane w bazie traktowane są więc jako reprezentacja faktów, wiedzy
ze świata rzeczywistego. Mamy zatem pewien model za pomocą którego przedstawiamy w komputerze wycinek
ś
wiata. Każda dziedzina może być objęta bazą danych pod warunkiem, że da się dobrze ustruktualizować czyli,
ż
e uda się opisać jej elementy, znaleźć między nimi związki itd.
W BD przechowujemy wypowiedziane przez człowieka zdania, słowa o jakichś obiektach. Ludzkie
zdania w komputerze przechowujemy za pomocą rekordów.
Czy BD to dobra metoda reprezentacji świata? Świat zewnętrzny lepiej można reprezentować za
pomocą sztucznej inteligencji. Metody sztucznej inteligencji lepiej wykorzystują wiedzę.
Rozróżniamy dwie metody reprezentacji wiedzy:
1.
Baza danych
2.
Baza wiedzy
W bazach danych informacje o obiektach przedstawiane są tylko w postaci faktów (wyjątkiem są
aktywne bazy danych). Możemy np. stworzyć BD dotyczącą studentów. Mogą się w niej znajdować rekordy
zawierające np. takie pola:
-
nazwisko studenta
-
data urodzenia
-
miejsce zamieszkania
-
itd.
Znajdują się tu wyłącznie informacje o studentach.
Natomiast w bazach wiedzy oprucz faktów przekazywane są mechanizmy wnioskowania. Mamy tu
zatem:
-
bazę faktów
-
bazę regół
Czyli z jednych faktów dzięki regułom możemy wnioskować o innych faktach.
Terminologia używana w BD pochodzi od Chena. Chen wprowadził pojęcie encji (ang. entity). Encja
mówi o jakimś obiekcie: o czymś co istnieje i co możemy rozróżnić. Jeśli nie potrafimy rozróżnić jakichś
obiektów to nie są to encje. Przykładami obiektów nie dających się rozróżnić są np. cząsteczki wody, mrówki
itd. – czyli obiekty przeważnie małe, występujące w dużych ilościach. W sensie BD obiekty takie nas nie
interesują.
Każda encja opisana jest zestawem atrybutów, a każdy atrybut należy do jakiejś dziedziny (np. miesiąc
ma dni). Atrybuty mogą być różnego typu np. tekstowe, liczbowe itd.
Ś
WIAT
MODEL
KOMPUTER
OBIEKTY
Wprowadzenie do baz danych
9/31
Gdyby interesowały nas same obiekty to taka baza byłaby bazą płaską, kartotekową. Przykładem są
chociażby katalogi biblioteczne. W takiej bazie kartotekowej mamy w zasadzie informacje tylko o obiektach.
Pomiędzy elementami w zbiorach mogą zachodzić pewne zależności. Zależnościami w BD nazywamy
wszystkie możliwe rodzaje powiązań między rekordami. Z matematycznego punktu widzenia są równoważne
pojęciu odwzorowania jednego zbioru encji w inny. Wyróżniamy trzy rodzaje związków:
1.
jednoznaczne 1:1
2.
jednoznaczne 1:N
3.
wieloznaczne N:M
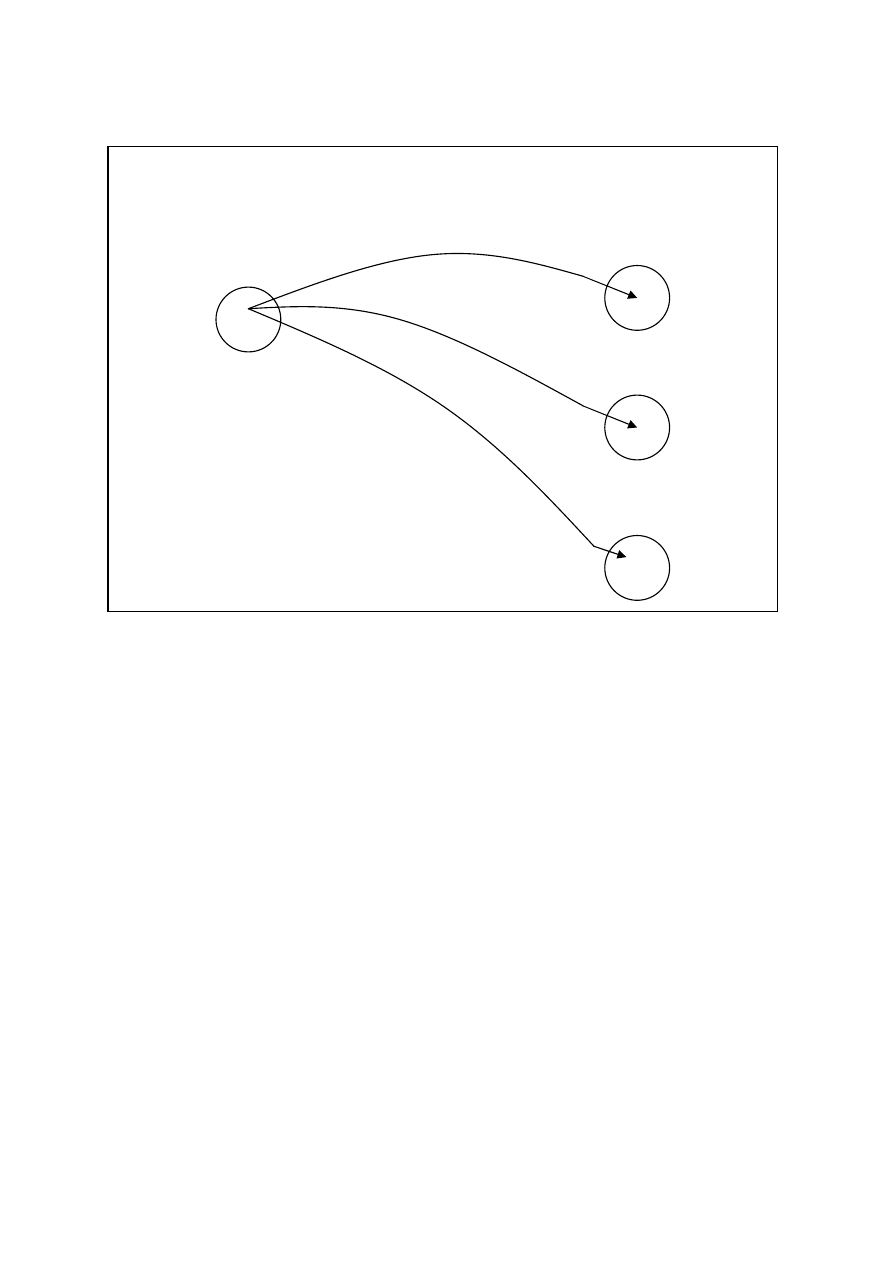
Przykład związku jednoznacznego 1:1 przedstawiony jest na poniższym rysunku:
Każdemu elementowi ze zbioru A przyporządkowany jest jeden element ze zbioru B i odwrotnie. Elementami
zbioru A mogą być np. nazwiska i PESEL w dowodzie osobistym. Nie mogą dwie osoby mieć tego samego
numeru i odwrotnie – każdy numer przyporządkowany jest tylko jednej osobie.
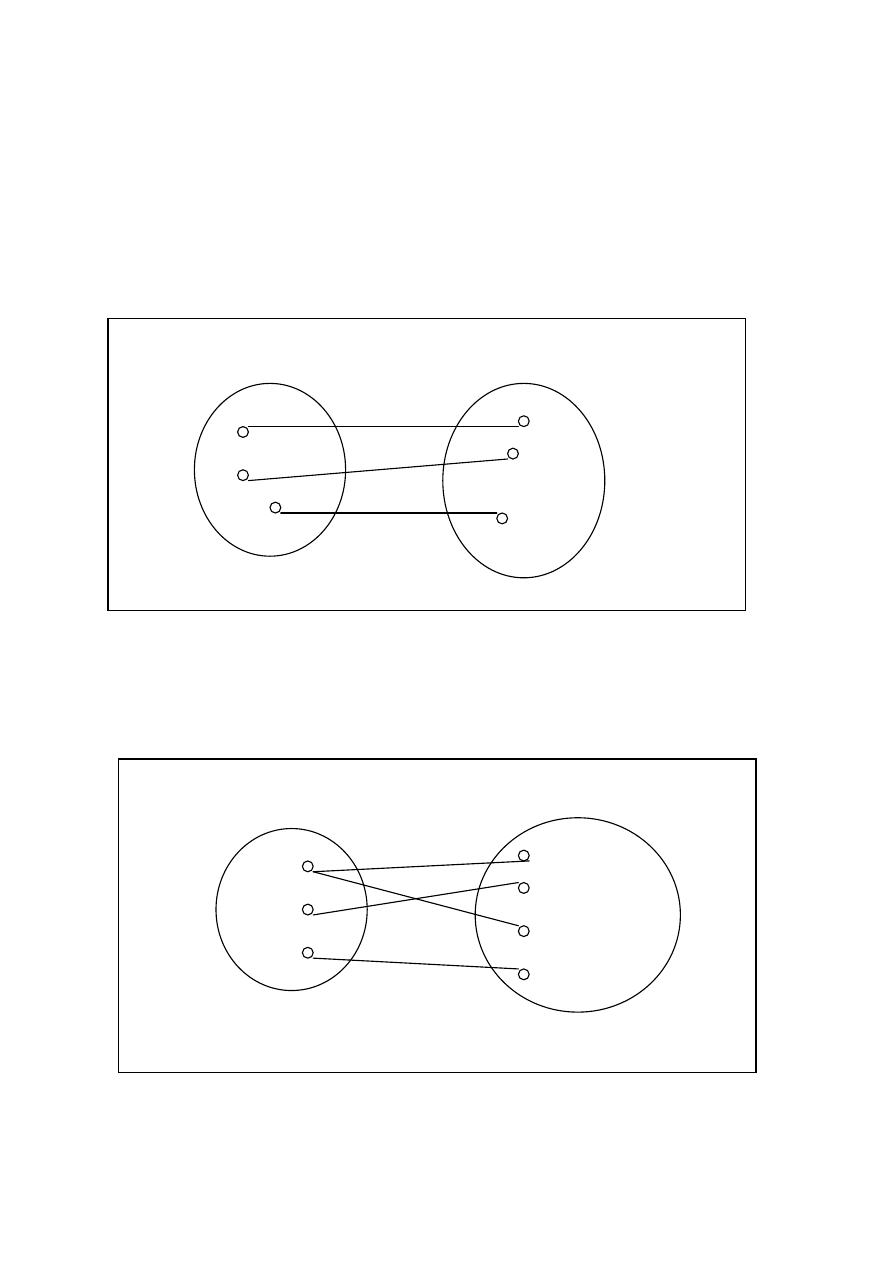
Najczęściej stosuje się zależności jednoznaczne 1:N (rysunek poniżej).
Klient może złożyć kilka zamówień (na rysunku Klient 1 składa Zamówienie 1 i 3). Natomiast każde
zamówienie przyporządkowane jest tylko jednemu klientowi.
ZBIÓR A
ZBIÓR B
Klient 1
Klient 2
Klient 3
Zamówienie 1
Zamówienie 2
Zamówienie 3
Zamówienie 4
Wprowadzenie do baz danych
10/31
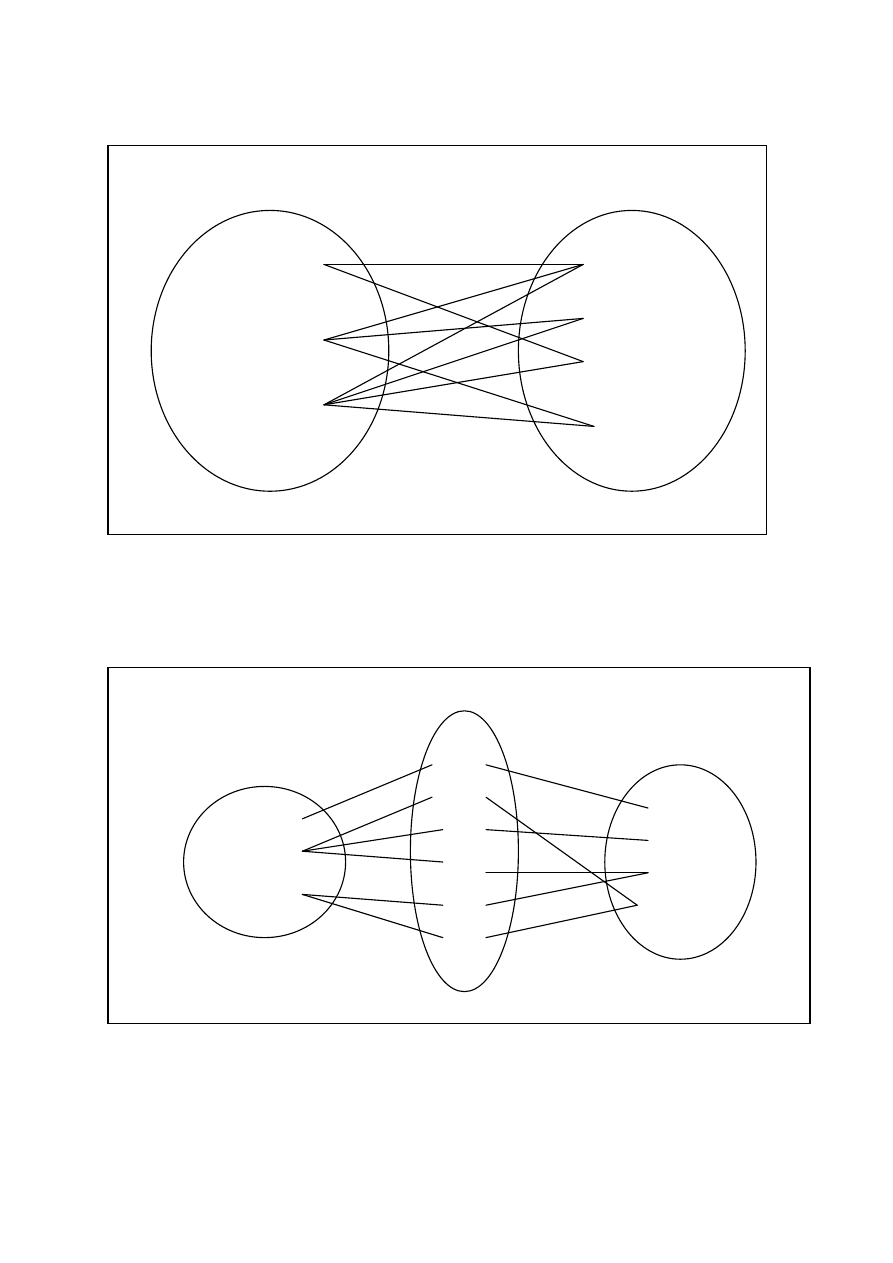
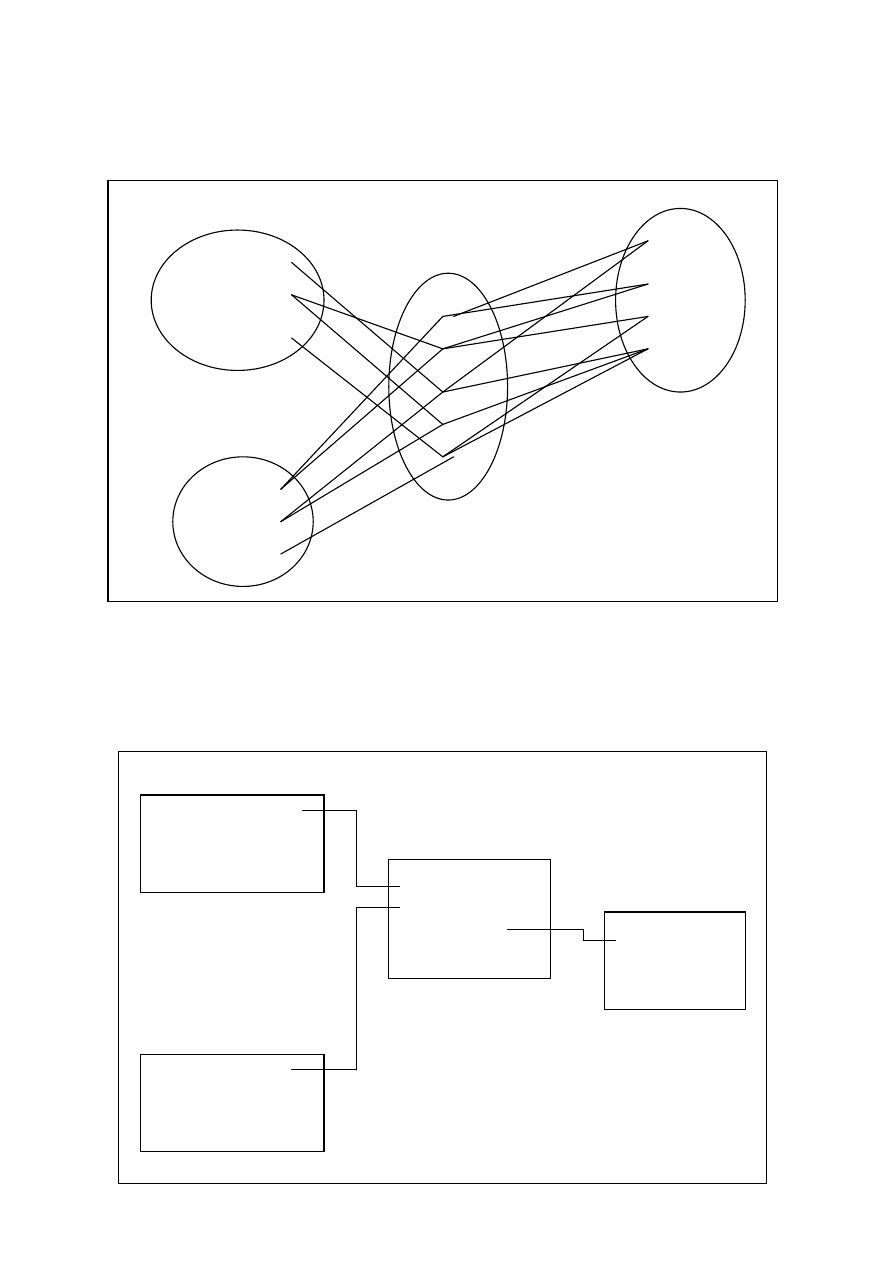
Trzecim rodzajem związków są związki wieloznaczne N:M.
Każda dostawa może składać się z wielu towarów, a każdy towar może znaleźć się w różnych dostawach.
W rzeczywistości bazy wieloznaczne zamieniane są na jednoznaczne typu 1:N poprzez wprowadzenie
dodatkowego obiektu. Na poniższym rysunku zastąpiono zależność N-M dwiema zależnościami 1-N poprzez
wstawienie dodatkowego obiektu FAKTURA.
Każda dostawa może być wpisana na wiele faktur, ale faktura może dotyczyć tylko jednej dostawy. Tak samo
każda faktura może odnosić się tylko do jednego towaru, ale „Towar 3” został wpisany do dwóch faktur: „Fak. 4
i 5”. Zatem otrzymaliśmy związki jednoznaczne.
DOSTAWA
TOWAR
DOSTAWA 1
DOSTAWA 2
DOSTAWA 3
TOWAR 1
TOWAR 2
TOWAR 3
TOWAR 4
DOSTAWA
FAKTURA
TOWAR
DOSTAWA 1
DOSTAWA 2
DOSTAWA 3
FAK.1
FAK.2
FAK.3
FAK.4
FAK.5
FAK.6
TOWAR 1
TOWAR 2
TOWAR 3
TOWAR 4
Wprowadzenie do baz danych
11/31
Poprzednio pokazywaliśmy związki zachodzące między dwoma zbiorami encji. Takich zbiorów może
być więcej, a więc zależności mogą być bardziej skomplikowane. Mówimy wówczas o stopniu zależności. Na
poniższym rysunku stopień zależności k=3.
Z istnienia trzech zależności w rodzaju (Producent1,Towar1), (Producent1,Sklep1), (Towar1,Sklep1)
nie wynika bezpośrednio, iż istnieje zależność (Producent1,Towar1,Sklep1).
Zależności dowolnego stopnia można sprowadzić do kilku zależności binarnych, wprowadzając nową
tabelę. W naszym przykładzie może to być tabela o nazwie Dostawa zawierająca co najmniej trzy atrybuty:
identyfikator producenta, towaru oraz sklepu. Zależność trzeciego stopnia (Producent,Towar,Skep) zastąpimy
wówczas trzema zależnościami binarnymi: (Producent,Dostawa), (Towar,Dostawa) oraz (Sklep,Dostawa):
SKLEP
PRODUCENT
DOSTARCZA
TOWAR
PRODUCENT 1
PRODUCENT 2
PRODUCENT 3
O
O
O
O
O
SKLEP 1
SKLEP 2
SKLEP 3
SKLEP 4
TOWAR 1
TOWAR 2
TOWAR 3
PRODUCENT
DOSTAWA
SKLEP
TOWAR
NR PRODUCENTA
. . .
. . .
. . .
NR TOWARU
. . .
. . .
. . .
NR DOSTAWY
NR PRODUCENTA
NR TOWARU
NR SKLEPU
. . .
. . .
NR SKLEPU
. . .
. . .
. . .
Wprowadzenie do baz danych
12/31
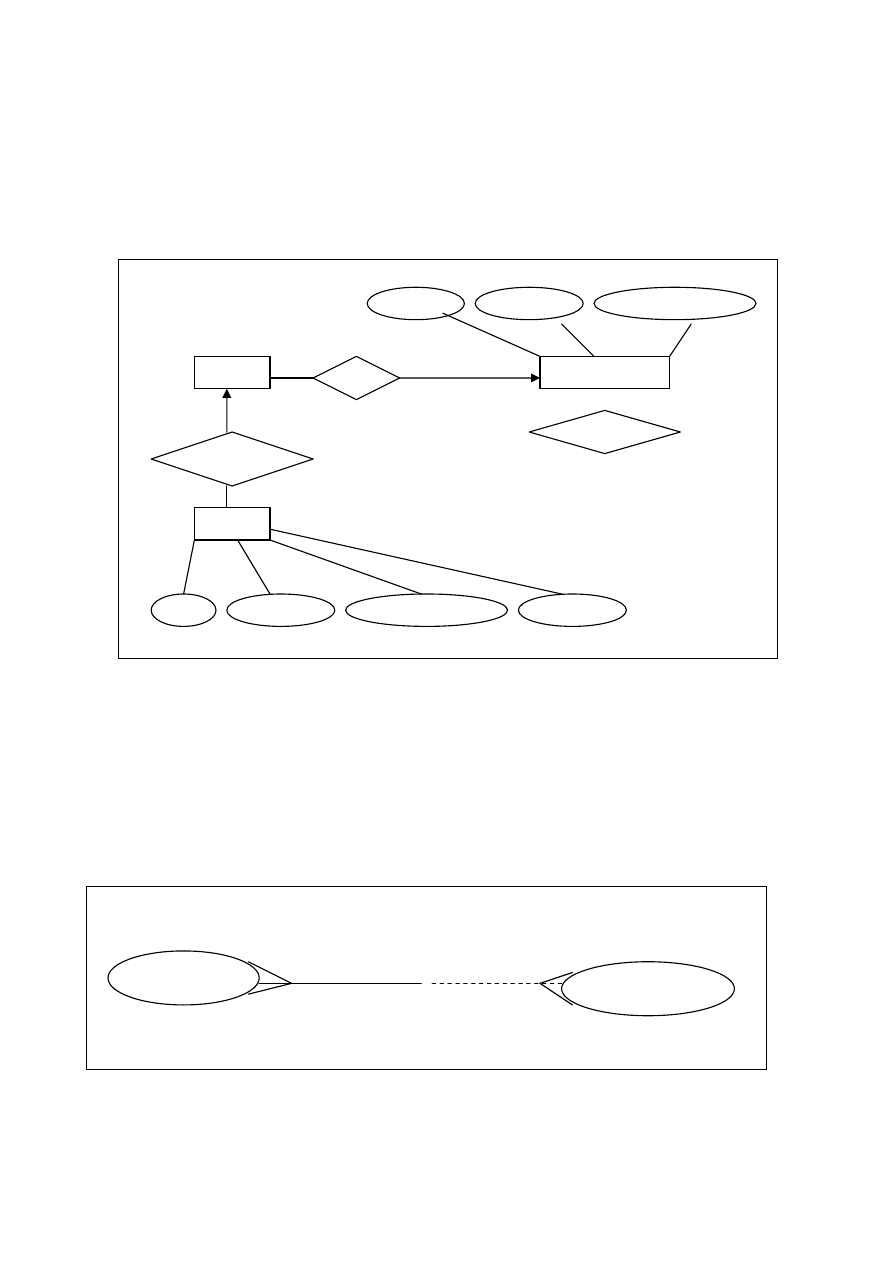
Podstawowym narzędziem do modelowania zależności między zbiorami encji jest model ERD (ang.
Entity Relationship Diagram).
Model zależności ERD to pewnego rodzaju graf, w którym występuje kilka rodzajów elementów. W
prostokątach występują encje, w owalach (elipsach) atrybuty opisujące te encje, romby oznaczają zależności
miedzy encjami. Linie (łuki, gałęzie) łączą poszczególne elementy ze sobą, przy czym połączenia mogą być
skierowane (strzałki) tzn że zależności występują w kierunku strzałki, ale w drugą stronę nie. Poniżej podany
został przykład bazy danych Towarzystwa Ubezpieczeniowego.
Każdy pracownik opisany jest trzema atrybutami: #PRAC, NAZWISKO, WYNAGRODZENIE. Wśród
pracowników mogą być KIEROWNICY. Podobnie polisy mają swoje atrybuty: P#, NAZWA, BENEFICIANT,
KWOTA. Możemy poruszać się po tym modelu i wypowiadać pewne zdania np.:
„Każdy pracownik ma swój numer”
„Agent jest pracownikiem”
W ten sposób dostajemy sieć, która pozwala nam wnioskować co z czego wynika.
Jeśli rzeczywistość jest bardziej skomplikowana to i model ulega komplikacji i składa się z większej
liczby elementów.
Z biegiem lat modele Chena zaczęto udoskonalać. Do grafu dodano nowe elementy:
Nowe elementy to:
-
różne rodzaje linii:
>linia przerywana wskazuje na związek opcjonalny: „coś może być”
>linia ciągła oznacza że „coś musi być”
KUPIONY PRZEZ
TOWAR
KLIENT
PRAC#
Nazwisko
Wynagrodzenie
PRACOWNICY
KIERUJE
AGENT
jest
Sprzedane
POLISY
P#
NAZWA
BENEFICIANT
KWOTA

Wprowadzenie do baz danych
13/31
-
zakończenie linii:
>„kurza łapka” oznacza „jeden albo wiele”
> normalne zakończenie oznacza „dla jednego”
Zatem można tworzyć nowe zdania:
„Każdy klient może być nabywcą jednego lub wielu towarów”
„Każdy towar musi być kupiony przez jednego lub wielu klientów”
Zatem diagramy związków encji służą do modelowania danych i podają sposób widzenia ich struktury.
W zależnościach takich też mogą występować związki wieloznaczne, które należy wyeliminować dążąc
do jednoznaczności. Wieloznaczność komplikuje BD. Powoduje, że poruszanie się (nawigowanie) po bazie jest
utrudnione. Zatem należy dążyć do jednoznaczności, aby bez nieporozumień dojść do poszukiwanej informacji
(istnieją specjalne języki ułatwiające nawigacje).
Do reprezentacji zadań jakiejś organizacji, które reprezentujemy w BD służą hierarchie funkcji. Funkcje
najwyższego poziomu określają nam cel organizacji (czyli do czego dana firma jest powołana). Funkcje niższego
poziomu zawierają zadania, które są potrzebne do spełnienia jakichś przedsięwzięć.
Diagramy przepływu danych (inaczej diagramy DFD) jest to model pokazujący w jaki sposób dane
przepływają między funkcjami i jak są przez nie używane. Model ten przedstawiany jest w postaci grafu.
W grafie DFD mamy następujące elementy:
-
procesy odpowiadające funkcjom hierarchi – za ich pomocą przedstawia się sposób przetwarzania danych
wejściowych na wyjściowe
-
encje zewnętrzne – dostarczają systemowi danych wejściowych i odbierają dane wyjściowe (czasami
nazywane źródłami lub odpływami)
-
magazyny danych – służą one do czasowego przechowywania informacji (krótkotrwałe pamięci)
-
przepływy (połączenia) czyli łuki gałęzie rysowane w postaci strzałek – pokazują ruch danych
Diagramy DFD buduje się poziomami. Najwyższy poziom zwany poziomem kontekstu mówi do czego
służą
Rozbicie procesu DFD odpowiada dekompozycji funkcji w hierarchii funkcji.
Istnieje oprogramowanie, które służy do zautomatyzowania tworzenia BD. Tworzy się model zasadniczy,
który składa się z czterech modeli:
-
model środowiska
-
model danych (ERD)
-
model zachowań (DFD)
-
hierarchia funkcji.
Podstawowe wzorce modelu środowiska, danych i zachowań obejmują następujące czynności:
-
analiza i specyfikacja potrzeb użytkownika
-
szacowanie wielkości BD
-
dobór BD do potrzeb użytkownika
Pomiędzy ludźmi, którzy projektują a kierownictwem, które ma wiedzę i żądania o BD wytwarza się
współpraca. Mamy zatem sześć etapów projektowania i wdrażania systemu BD.
-
strategia
-
analiza
-
projektowanie
-
budowa – dokumentacja
-
wdrożenie
-
utrzymanie i rozwój.
Wprowadzenie do baz danych
14/31
Modele logiczne baz danych
Trzy najważniejsze modele danych używane w większości systemów baz danych to modele: relacyjny,
sieciowy i hierarchiczny. Są pod wieloma względami podobne do modelu związków encji. Mają jednak pewne
właściwości, dzięki którym są lepiej dopasowane do fizycznych struktór używanych przy implementacji baz
danych.
Relacyjny model baz danych
Model ten został stworzony na początku lat siedemdziesiątych przez Codda.
Do reprezentacji danych wykorzystuje się dwuwymiarowe tabele inaczej zwane relacjami. Każda tabela
opatrzona jest nazwą i posiada określoną liczbę kolumn. Z kolei każda kolumna ma swój nagłówek czyli atrybut.
Atrybut danej kolumny charakteryzuje się określonym typem. Przykłady typów: liczbowe, tekstowe, typ czasu,
daty, waluty, typ wyliczeniowy, logiczny itd. Zatem w każdej kolumnie dopuszczalne są tylko ściśle określone
wartości zgodne z jej typem.
Nazwa
Atrybut_1 Atrybut_2 Atrybut_3 ...
Atrybut_n
Pierwszy etap projektowania relacyjnej BD polega na określeniu liczby atrybutów w wierszu. Każdy
wiersz tabeli może składać się z wielu pól dlatego inaczej wiersz nazywamy rekordem. Tabela przedstawia więc
sobą zbiór rekordów.
Poniżej stworzona została tabela o nazwie „student”. Zawiera ona następujące atrybuty: „nazwisko”,
„inię”, „rok_urodzenia”, „miejsce_urodzenia”.
Student
Nazwisko Imie
rok_urodzenia
miejsce_urodzenia
...
...
...
...
Kowalski
Jan
1980
Warszawa
...
...
...
...
Patrząc na taką tabelę można wypowiadać pewne zdania np.
„Pan Kowalski ma na imię Jan, urodził się w Warszawie”
Baza taka zawiera więc najbardziej zwięzłe informacje, pomija się w niej czasowniki niezbędne do
wypowiedzenia zdania.
Rekord możemy interpretować jako encję, wynika z tego, że tabela to zbiór encji. W relacyjnych BD
stosuje się też inne określenia w miejsce rekordów: krotki, entki.
Zatem rzeczywisty świat widziany jest w postaci tabelek, ale pomimo zwięzłości mamy tu pewien
nadmiar informacji. Aby tabelki można było powiązać ze sobą to nie można ustrzec się powielania niektórych
atrybutów w różnych tabelkach. Z jednej strony jest to niekorzystne bo informacje się powtarzają, ale z drugiej
daje nam to łatwość powiązania, sklejenia ze sobą różnych zbiorów danych bez używania wskaźników.
Inną zaletą relacyjnej BD jest to, że potrafimy wyciągnąć z niej każdą informację. Nie ma tu „czarnych
dziur” tzn informację wprowadzoną bez problemu możemy odzyskać. Podobnych twierdzeń nie można
sformułować już chociażby dla modelu sieciowych BD.
Ważnym pojęciem w modelach relacyjnych jest klucz. Wyróżniamy dwa rodzaje kluczy: główny i
obcy.
Wprowadzenie do baz danych
15/31
Klucz główny jest atrybutem lub zestawem atrybutów, który w sposób jednoznaczny identyfikuje
rekordy w tabeli. Jest niezbędny do jednoznaczności nawigowania po BD. Przykładowo w powyższej tabeli
„student” dla uzyskania jednoznaczności klucz musi składać się z wielu atrybutów gdyż może istnieć kilku
studentów o tym samym nazwisku. Pamiętać należy jednak, że klucz powinien być jak najmniejszym zestawem
atrybutów. Rozwiązaniem byłoby tu zastosowanie dodatkowej kolumny „numer indeksu”, która jednoznacznie
określiłaby studenta w danej uczelni. Na skalę kraju lepiej aby kluczem był numer dowodu osobistego, gdyż
istnieje szansa, że na innej uczelni inny student ma ten sam numer indeksu.
Zate klucz główny musi mieć unikalne, niepowtarzalne wartości, a jednocześnie nie może mieć
wartości nieokreślonych (jak nieskończonośc). Poza tym musi zostać zapewniona łatwość w wyznaczaniu jego
wartości, a także powinien być łatwo przewidywalny. W BD cechy te spełnia specjalny typ – wyliczeniowy.
Kolejne liczby naturalne są najlepszym kluczem.
Klucz obcy służy do robienia powiązań między tabelkami. Zastosowano tu rozwiązania wachlarzowe:
Model relacyjny ma solidne podstawy matematyczne. Zaczerpnięty jest z teorii mnogości i opiera się na
pojęciu relacji.
Relacja jest to pewien podzbiór iloczynu kartezjańskiego dla pewnych dziedzin. Dziedziną może być
zbiór liczb całkowitych, zbiór studentów itd.
Załóżmy, że mamy dziedziny: D1,D2,...,Dk. Wówczas iloczyn kartezjański to: D1
×
D2
×
...
×
Dk. Taki
iloczyn kartezjański jest zbiorem wszystkich k-krotek (v1,v2,...,vk) takich, że: v1
∈
D1, v2
∈
D2,...,vk
∈
Dk.
Przykład:
Przyjmijmy, że k=2 (dwukrotka) i D1={0,1}, D2={a,b,c}. Wówczas iloczyn kartezjański jest zbiorem:
D1
×
D2={ (0,a) , (0,b) , (0,c) , (1,a) , (1,b) , (1,c) }
Jeżeli z tego iloczynu wybierzemy podzbiór np.: { (0,a) , (1,b) } to będzie to pewna relacja.
Zatem relacja jest dowolnym podzbiorem iloczynu kartezjańskiego jednej lub więcej dziedzin.
Elementy relacji nazywamy krotkami. Każda krotka składa się z wartości atrybutów.
Stąd widzimy, że relacje łatwo wyobrazić sobie jako tabelkę, w której wiersze to krotki, a kolumny
(czyli atrybuty) to dziedzina.
Zbiór nazw atrybutów relacji nazywa się schematem relacji. Jeżeli relacje nazywają się REL, a jej
schemat zawiera atrybuty A1,A2,..,Ak to taki schemat określimy: REL(A1,A2,...,Ak).
Dane diagramów związków encji reprezentują dwa rodzaje tabelek:
-
Zbiór encji reprezentuje relacje, której schemat składa się ze wszystkich atrybutów tego zbioru. Każda
krotka to jedna encja w zbiorze encji.
-
Związek między zbiorami encji reprezentuje relacja (tabela), której schemat składa się z atrybutów kluczy
do każdego zbioru encji.
POWIĄZANIE
Wprowadzenie do baz danych
16/31
Model sieciowy
Cechy:
-
struktura danych przypomina graf
-
wierzchołki grafu – typy obiektów
-
łuki w grafie – wiązania między typami
-
opis obiektu zbudowany z pól zawierających dane opisujące obiekt
-
reprezentacja wiązań (wskaźniki): odesłanie bezpośrednie, odesłanie inwersyjne, wiązania codasylowe
Sieciowy model danych jest w pewnym uproszczeniu reprezentacją diagramów związków encji, w
którym wszystkie związki muszą być binarne oraz jednoznaczne co pozwala na tworzenie stosunkowo prostego
grafu.
Binarne tzn każdy związek jest między dwoma rekordami.
Jednoznaczne tzn związki są w jedną stronę, informacja przechodzi w jednym kierunku.
W modelu sieciowym zamiast o zbiorach encji mówi się o typach rekordów logicznych. Pojęcie krotki z
modelu relacyjnego zastąpiono rekordem logicznym, a zamiast schematu relacji mamy format rekordu
logicznego. Podstawową różnicą między modelem relacyjnym a sieciowym jest to, że w tym drugim istnieją
wskaźniki.
Związki binarne nazywamy powiązaniami (links). Do reprezentowania rekordów czyli sieci służy graf,
który jest uproszczonym diagramem związków encji.
Wierzchołki odpowiadają typom rekordów, krawędzie reprezentują powiązania. Wierzchołki i
krawędzie są oznaczane nazwami odpowiadającymi typom powiązań.
Zatem model ten ma bardziej naturalną reprezejtacje rzeczywistości, ale za to jest trudniejszy w
implementacji. Manipulowanie na takiej bazie jest bardziej skomplikowane, gdyż podczas poszukiwania
informacji trzeba „chodzić” po rekordach, a to może doprowadzić do zapętlenia.
Modele hierarchiczne
Hierarchia jest to pewne uporządkowanie przypominające drzewo. Jeżeli przyjmiemy węzeł główny-
korzeń to będziemy mieli jego następniki, które będą się rozgałęziać aż dojdziemy do liści (rozwidlenia nie
muszą być binarne). Wszystkie powiązania wyznaczają kierunek od poprzednika do następnika. Sprawia to, że
nawigacja po takiej bazie jest stosunkowo prosta.
Za pomocą modelu hierarchicznego można przedstawić każdy diagram związków encji, który
reprezentowany jest tu przez zbiory drzew, czyli las.
KORZEŃ
LIŚCIE

Wprowadzenie do baz danych
17/31
Drzewo składa się z dwóch elementów: łuków i węzłów. Łuki reprezentują związki typy ojciec-syn,
węzły natomiast są typami opisywanych obiektów. Drzewo ma uporządkowaną strukture tj. na każdym poziomie
kolejność węzłów jest określona.
Terminologia jest podobna jak w modelu sieciowym bo i są to właściwie bazy sieciowe, które mają
specyficzne grafy.
Istnieją tu pewne ograniczenia:
-
nie ma związków n-m
-
związki realizowane są jako wskaźniki
-
tylko jeden rodzaj związku między dwoma typami obiektów
-
dodawanie związków wymusz tworzenie z dodatkowych drzew hierarchii lub odsyłaczy do rekordów
oryginału.

Wprowadzenie do baz danych
18/31
Język SQL
Relacyjna baza danych jest zbiorem tabel. Tabele są dwuwymiarowe, zawierają określoną liczbę
kolumn i zmienną liczbę nie uporządkowanych wierszy. Każdy wiersz jest określony za pomocą pewnej liczby
atrybutów zwanych kolumnami. W przecięciu kolumny i wiersza znajduje się pojedyncza wartość.
Same dane, nawet poukładane w tabelach, to jeszcze bardzo niewiele. Są jedynie podstawą do
przetwarzania informacji ze świata rzeczywistego, tworem statycznym i nieożywionym. Aby móc z nich
korzystać, trzeba zdefiniować przede wszystkim sposób dostępu do nich oraz pewne procedury umożliwiające
podstawowe operacje. W systemach relacyjnych baz danych czynności te wykonywane są za pomocą procedur
zwanych zapytaniami lub inaczej kwerendami (query).
Język zapytań jest niezbędnym elementem w każdym systemie bazodanowym. Przy jego pomocy
użytkownik może określić warunki, które mają spełniać poszukiwane dane, system zaś, na tej podstawie,
wyszuka potrzebne informacje. W założeniu język taki nie powinien być uzależniony od konkretnych aplikacji,
tj. powinien działać dla dowolnego schematu bazy danych i nie powinien być uzależniony od platformy, czyli
powinien działać zarówno na PC-tach, minikomputerach jak i dużych stacjach roboczych.
Do formułowania zapytań stworzono kilka języków, początkowo bardzo sformalizowanych. Wiązało
się to z matematycznymi podstawami teorii relacyjnych baz danych.. Dopiero później opracowano języki
wyższego poziomu, bliższe językowi naturalnemu, których współczesnym przedstawicielem jest język SQL.
Język SQL (Structured Query Language – strukturalny język zapytań). Powstał pod koniec lat
siedemdziesiątych w firmie IBM. Jest obecnie światowym standardem przeznaczonym do operowania i
sterowania relacyjnymi bazami danych. Występuje w produktach większości liczących się firm, sprzedających
oprogramowanie dla baz danych. Zaliczany jest do języków czwartej generacji (fourth-generation language)
Oznacza to, że umożliwia użytkownikowi określenie tego co ma być wykonane bez podania konkretnych
kroków jak to osiągnąć.
SQL i relacyjna baza danych są nieproceduralne, dlatego nie ma potrzeby, aby z góry definiować
ś
cieżkę dostępu do rekordu w bazie. System SQL sam znajdzie ścieżkę do rekordów. Tę właściwość określa się
mianem automatycznej nawigacji. Dzięki temu zwiększa się wydajność programisty, a system jest łatwy w
obsłudze dla przeciętnego użytkownika. Inną korzyścią wynikającą ze stosowania SQL jest możliwość wymiany
danych pomiędzy oprogramowaniem różnego typu takim jak procesory tekstów czy arkusze kalkulacyjne.
Pondto bezpośrednia modyfikacja schematu bazy danych nie zaburza istniejących aplikacji.
SQL jest językiem strukturalnym, zdefiniowanym za pomocą reguł składniowych. Zawiera trzy rodzaje
poleceń:
-
polecenia języka definiowania danych (DDL), które umożliwiają tworzenie obiektów bazy danych, takich
jak np. tabele
-
polecenia języka operowania danymi (DML), które są używane do np. modyfikowania, kasowania,
wydobywania informacji z bazy danych.
-
Polecenia języka administrowania danymi, które służą np. do przyznawania i odwoływania uprawnienia
dostępu do bazy danych
Poniżej podane zostaną podstawowe polecenia języka SQL.
Klauzula SELECT
Jest to podstawowa instrukcja w SQL używana do wyszukiwania danych w tabeli. Składa się z co
najmniej dwóch klauzul: SELECT i FROM.Składnia:
SELECT nazwa(y)_kolumn(y) / *
FROM nazwa_tabeli;
Konstrukcja ta mówi systemowi zarządzania relacyjną bazą danych, które kolumny należy wyszukać w
tabeli wymienionej w klauzuli FROM. Nazwę lub nazwy kolumn możemy opcjonalnie zastąpić znakiem *
który informuje system, że należy wyszukać wszystkie kolumny tabeli.

Wprowadzenie do baz danych
19/31
System w odpowiedzi wyświetli tabelkę o żądanej nazwie, która będzie zawierała kolumny
wyspecyfikowane po klauzuli SELECT. Jeśli nie znajdzie żadnych rekordów to tabelka będzie pusta. Po słowie
kluczowym SELECT (FROM) może wystąpić nazwa jednej jak i wielu kolumn (tabel). W przypadku podania
listy nazw tabel nastąpi połączenie danych z różnych tabel i umieszczenie ich w jednej, wspólnej tabeli.
Należy zauważyć, iż każda instrukcja SQL kończy się średnikiem.
Przykład:
SELECT *
FROM nazwa_tabeli
Stworzenie takiego zapytania wyświetli całą zawartość tabeli o podanej nazwie.
W kolejnych przykładach posługiwać będziemy się tabelką dotyczącą pracowników o atrybutach
podanych poniżej:
PRAC
NUMP
NAZWISKO STANOWISKO TELEFON
ZATRUD ZAROB
PROWIZJA NUMDZ
Obliczenia
W poleceniach SQL mogą występować wyrażenia arytmetyczne. Wyrażenie takie składa się z nazw
kolumn o liczbowych wartościach i liczb połączonych operatorami: + , - , * , / . Aby wyświetlić wynik
obliczenia, trzeba zamieścić wyrażenia arytmetyczne w klauzuli SELECT tak jak poprzednio nazwę kolumny.
Wprowadzenie do baz danych
20/31
Zależności funkcyjne.
Poniżej podane zostaną definicje operacji relacyjnych:
(1) Relację T typu X nazywamy projekcją relacji R na zbiór X
T=R[X]
gdy
T={t
∈
KROTKA(X): (
∃
r
∈
R) t=r[X]}
Przykład:
Mamy tabelkę o trzech kolumnach:
A
B
C
a
X
1
b
X
1
a
X
2
c
Y
2
Wyznaczyć projekcję na zbiory: {A,C} i {B,C}.
Zgodnie z definicją należy wyrzucić kolumny, których nie ma w zbiorze na jaki rzutowana jest tabela. W wyniku
otrzymujemy:
A
C
a
1
b
1
a
2
c
2
B
C
x
1
x
2
y
2
(2) Relację T(U) nazywamy selekcją relacji R(U) względem warunku selekcji E
T=R/E/
wtw gdy
T={t
∈
R: E(t)=true}
Selekcja wiąże się z wyborem odpowiednich krotek za pomocą warunków selekcji (oznaczanych przez E) czyli z
wykorzystaniem:
-
operacji : =,
≠
, <,
≤
, >,
≥
,
∈
-
spójników logicznych:
¬
,
∧
,
∨
,
∼
Przykład:
Dana jest relacja:
A
B
C
D
a
X
1
3
a
Y
4
2
c
X
3
3
Wprowadzenie do baz danych
21/31
b
X
2
1
Wyznaczyć selekcję: T=R / C
≥
D
∧
(A=a
∨
A=b) /
Odpowiedź:
A
B
C
D
a
Y
4
2
b
X
2
1
(3) Niech będą dane relacje R typu X i S typu Y. Relację typu X
∪
Y nazywamy złączeniem tych relacji
T=R S
wtw gdy
T={t
∈
KROTKA(X
∪
Y): t[X]
∈
R
∧
t[Y]
∈
S}
Przykład:
Dane są dwie tabele R i S:
R
A
B
C
a
X
1
a
X
2
a
Y
2
b
Y
3
S
A
B
D
a
X
f
a
Y
g
b
X
h
Wyznaczyć złączenie R i S.
W obu tabelach powtarzają się wartości ax i ay w kolumnach AB. Łączymy tylko to co jest wspólne, gdybyśmy
połączyli wszystkie kolumny w wyniku otrzymalibyśmy iloczyn kartezjański a więc o wiele więcej wierszy.
A
B
C
D
a
X
1 f
a
X
2 f
a
Y
2 g
Wyznaczenie złączenia relacji polega na utworzeniu takiej tabeli, której krotki powstają z połączenia tych krotek
z odpowiednich relacji, które mają jednakowe wartości na tych samych atrybutach (czyli każdy atrybut może
wystąpić tylko raz).
(4) Relację T(U-X) nazywamy podzieleniem relacji R przez zbiór X
T=R/X
wtw gdy
T={t
∈
KROTKA(U-X): dla każdego s
∈
KROTKA(X) t s
∈
R}
Przykład:
Wprowadzenie do baz danych
22/31
Dane są zbiory atrybutów relacji: U={S,P} i X={S} i ich dziedziny: DOM(S)={1,2,3} i DOM(P)={a,b,c} oraz
relacja R(U):
S
P
1 A
2 B
1 B
1 C
3 C
Wówczas krotki są wektorami:
KROTKA(S)
1
2
3
KROTKA(P)
a
b
c
Zatem T=R/{P}
S
1
Zależności funkcyjne
Mając relacje będziemy teraz poszukiwać prawidłowości jakie w nich występują czyli interesować nas
będą semantyczne właściwości relacji.
Przykład:
Egzamin
I
N
P
O
10 F
a
3
10 F
b
4
11 G
a
3
12 H
a
3
Dana jest tabela o nazwie Egzamin, w której poszczególne pola mają następujące znaczenie:
I – numer indeksu
N – nazwisko
P – przedmiot
O – ocena z egzaminu
W tabeli tej możemy zauważyć pewien związek: numer indeksu i nazwisko wskazują na tę samą osobę. Mamy
tu zależność między atrybutami I oraz N co można zapisać:
I
→
N
Inna zależność: ocena zależy od przedmiotu i od studenta:
IP
→
O
Należy podkreślić, że nie są to funkcje a jedynie zależności funkcyjne. Funkcja oznacza istnienie stałego
przyporządkowania między elementami zbioru, natomiast zależność funkcyjna nie reprezentuje tej stałości.

Wprowadzenie do baz danych
23/31
Zależność funkcyjna między zbiorem atrybutów X i Y istnieje wtedy gdy w każdym stanie istnieje pewna
funkcja ze zbioru krotek typu X w zbiór krotek typu Y. W różnych stanach funkcje te mogą być różne.
Zależnością funkcyjną nazywamy każdy zapis postaci: X
→
Y gdzie X,Y
⊆
U. Mówimy wówczas, że X
determinuje funkcyjnie Y lub że Y zależy funkcyjnie od X.
Mówimy, że w tabeli R spełniona nest zależność funkcyjna X
→
Y jeżeli dla dwóch krotek r1,r2
∈
R :
(r1[X]=r2[X]) ⇒ (r1[Y]=r2[Y])
Istnieją pewne zasady pozwalające w sposób formalny manipulować na atrybutach i dzięki temu można
wydedukować jedne zależności funkcyjne z innych.
Niech będą dane trzy podzbiory: X,Y,X
⊆
U.
Oznaczmy przez F
+
najmniejszy zbiór zależności funkcyjnych, który zawiera zbiór F i jest zamknięty ze
względy na następujące reguły wyprowadzeń:
F1: Y
⊆
X ⇒ X
→
Y
⊆
F
+
(zwrotność)
F2: X
→
Y
∈
F
+
⇒ XZ
→
YZ
∈
F
+
(poszerzalność)
F3: X
→
Y
∈
F
+
∧
Y
→
Z
∈
F
+
⇒
X
→
Z
∈
F
+
(przechodniość)
Zbiór F
+
nazywamy najmniejszym domknięciem zbioru F. Zależności F1-F3 to tzw aksjomaty Armstronga.
Zbiór tych aksjomatów jest niesprzeczny. Korzystając z nich można wyprowadzić kolejne aksjomaty:
F4: X
→
Y
∈
F
+
∧
YW
→
Z
∈
F
+
⇒ XW
→
Z
∈
F
+
(pseudoprzechodniość)
F5: X
→
Y
∈
F
+
∧
X
→
Z
∈
F
+
⇒ X
→
YZ
∈
F
+
(addytywność)
F6: X
→
YZ
∈
F
+
⇒
X
→
Y
∈
F
+
∧
X
→
Z
∈
F
+
(dekompozycyjność)
Minimalny zredukowany generator zbioru F
+
jest to najmniejszy podzbiór F
0
zbioru F dla którego F
0
+
=F
+
.
Przykład:
Dany jest zbiór zależności funkcyjnych:
F={ P
→
GS, GS
→
P, PI
→
O, GI
→
PS, PGS
→
E }
Zbiór U składa się więc z atrybutów: U={ P, I, O, E, G, S } gdzie
P – przedmiot egzaminacyjny
I – numer indeksu
O – ocena z egzaminu
E – numer ewidencyjny egzaminatora
G – godzina egzaminu
S – sala egzaminacyjna
Spróbujmy wyprowadzić minimalny zredukowany generator dla tego zbioru.
F
0
1
={ P
→
G, P
→
S, GS
→
P, PI
→
O, GI
→
P, P
→
E }
bo
P
→
GS ⇒ P
→
G i P
→
S
GI
→
PS ⇒ GI
→
P i GI
→
S
w zależnościach P
→
GS i PGS
→
E powtarza się GS zatem
P
→
GS
∧
PGS
→
E ⇒ P
→
E

Wprowadzenie do baz danych
24/31
F
0
2
={ P
→
G, P
→
S, GS
→
P, PI
→
O, GI
→
S, P
→
E }
Prawe strony zależności funkcyjnych są pojedynczymi atrybutami zatem jest to minimalny zredukowany
generator rodziny zależności F
+
.
Badanie związków między rozkładalnością relacji na relacje bardziej elementarne będziemy nazywać
rozkładalnością schematów relacyjnych. Wyróżniamy trzy rodzaje takiej rozkładalności:
1)
rozkładalność bez straty danych – jeśli mamy tabelę o wielu kolumnach i rozłożymy ją na mniejsze tabelki,
to po złączeniu danych stracimy zależności funkcyjne
2)
rozkładalność bez straty zależności funkcyjnych – po złączeniu nie mamy gwarancji zachowania danych
3)
rozkładalność na składowe niezależne – nie tracimy ani danych, ani zależności
Teoria ta potrzebna jest do normalizacji a więc projektowania baz danych.
Proces normalizacji schematów relacyjnych
Dokonamy teraz formalizacji pojęcia klucza. Niech będzie dany schemat relacyjny:
R=(U,F)
gdzie
U – cały zbiór atrybutów
F – zbiów wszystkich zależności funkcyjnych
Zbiór atrybutów K
⊆
U nazywamy kluczem (key) schematu R wtw gdy zbiór ten spełnia następujące warunki:
a) K
→
U
∈
F
+
(jednoznaczna identyfikowalność)
Od klucza muszą być uzależnione funkcyjnie wszystkie atrybuty należące do zbioru U.
b) X
→
U
∈
F
+
⇒
¬
(X
⊂
K) (minimalność)
Kluczem może być tylko taki zbiór atrybutów, którego żaden podzbiór nie ma cechy jednoznacznej
identyfikowalności, czyli klucz musi być najmniejszym zbiorem.
Kryteria wyboru klucza:
-
minimalna liczba atrybutów
-
możliwość przewidzenia zakresu wartości klucza (najlepiej typ wyliczeniowy)
-
niewystępowanie wśród wartości klucza wartości nieokreślonych
Przykład:
Niech będzie dany schemat relacji E (tabela znajduje się niżej):
E=( {I, N, A, K, P, O}, {I
→
NAK, IP
→
O} )
gdzie:
P – przedmiot egzaminacyjny
I – numer indeksu
N – nazwisko
O – ocena z egzaminu
A - adres zamieszkania studenta
K – kierunek studiów
Pytanie: co będzie kluczem relacji?
Odpowiedź: kolumny I oraz P.
Klucz relacji podkreślamy zatem należy napisać:
E=( {I, N, A, K, P, O}, {I
→
NAK, IP
→
O} )
W schematach relacyjnych mogą występować różne anomalie. Anomalie te mogą być usuwane przez
rozkładanie schematów relacyjnych na bardziej elementarne. Proces taki (zaproponowany przez Codd’a)
nazywamy procesem normalizacji.
1PN (pierwsza postać normalna)
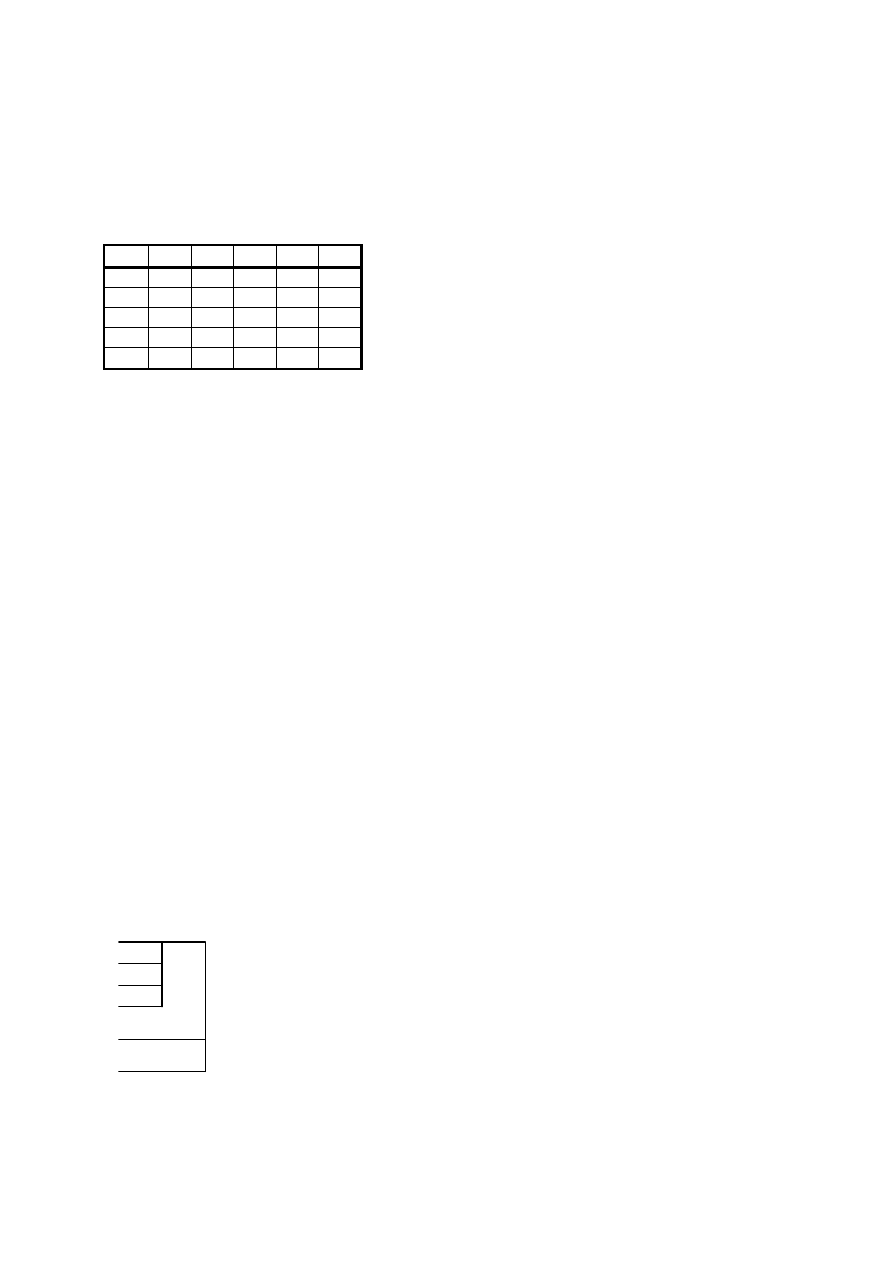
Wprowadzenie do baz danych
25/31
Schemat relacyjny jest w 1PN jeżeli wszystkie atrybuty występujące w tym schemacie są o wartościach
prostych. Wartości proste to takie, które nie są podzielne np.:
-
liczby: 58, 34
-
napisy: „Kowalski”
W dalszych przykładach posłużymy się poniższą tabelą:
I
N
A
K
P
O
10
F
x
100 a
3
10
F
x
100 b
4
11
G
y
200 a
3
12
H
x
200 a
3
10
F
x
100 c
5
Wyróżniamy trzy rodzaje anomalii:
1)
anomalia dołączania
Powyższa tabela dotyczy tylko tych studentów, którzy zdali egzamin, nie obejmuje natomiast tych, którzy do
egzaminu nie przystąpili. A zatem wielu studentów nie moglibyśmy w niej umieścić, gdyż wtedy klucz IP nie
byłby pełny. Trudność tę można by przezwyciężyć w sposób sztuczny dopuszczając wartości nieokreślone lub
zerowe. Ale klucz nie może mieć takiej wartości.
2)
anomalia aktualizacji
Przypuśćmy, że student „10” zmienił adres zamieszkania z „x” na „w”. Ponieważ student ten występuje w trzech
krotkach musielibyśmy dokonać trzech poprawek. Jednak należy pamiętać, że przeglądanie dużej tablicy jest
czasochłonne.
Często przy większych bazach zawartość rekordów może się zmieniać w czasie. Może się wówczas zdarzyć, że
przed zakończeniem procesu aktualizacji baza danych mogła zostać zmieniona. Wypływa z tego oczywisty
wniosek: w aktualizacji powinno uczestniczyć jak najmniej elementów.
3)
anomalia usuwania
Ten rodzaj anomalii polega na tym, że usuwając jakieś krotki możemy zgubić cenne informacje potrzebne do
innych celów. Przypuśćmy, że student o numerze „12” ściągał i jego egzamin zostaje unieważniony. Jeśli
skasujemy cały jego rekord, to stracimy informacje o adresie zamieszkania, nazwisku itd.
Podsumowując: pod wieloma względami baza danych składająca się z jednej tabeli jest niekorzystna,.poza tym
zajmuje dużo pamięci. Lepiej jeśli składa się z kilku mniejszych tabelek. Powinno się dążyć do wyeliminowania
anomalii. Robi się to przez normalizację bazy. Pierwszym etapem jest doprowadzenie jej do 2PN.
2PN (druga postać normalna)
Schemat relacyjny R=(U,F) jest w 2PN jeśli każdy niekluczowy atrybut A
∈
U jest w pełni funkcyjnie
zależny od klucza. W pełni tzn. zależy od całego klucza a nie jego części.
I
N
A
K
P
O
Atrybuty IP stanowią klucz. Atrybut O zależy od całego klucza IP. Z kolei trzy atrybuty NAK zależą tylko od I,
a nie zależą od P. A więc te trzy atrybuty nie zależą od całego klucza. Wobec tego ten schemat relacyjny nie jest
w 2PN.
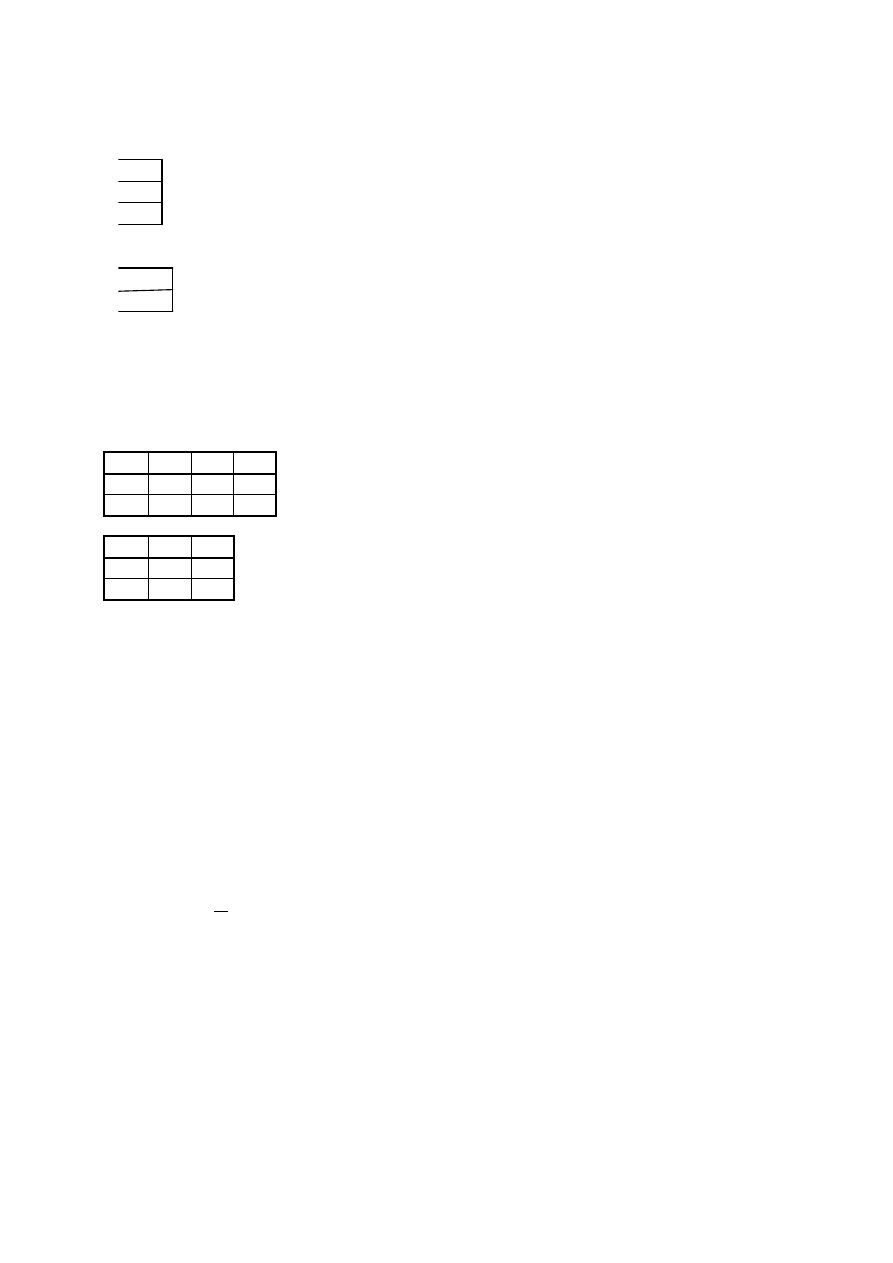
Wprowadzenie do baz danych
26/31
Aby doprowadzić go do 2PN należy dokonać rozbicia na dwa schematy:
I
N
A
K
I
P
O
Czyli dużą tabelę rozbić na dwie mniejsze: w jednej zawarte będą informacje o studentach, a w drugiej o
egzaminach:
I
N
A
K
I
P
O
Tak wygląda projektowanie relacyjnych baz danych. Tabelki powinny być tworzone z przeznaczeniem
tematycznym, żeby nie było mieszania (redundancji) informacji. Cana jaką płacimy to powtarzanie się
niektórych kolumn.
Dekompozycja na tabelki mniejsze nie jest w ogólnym przypadku jednoznaczna tzn. można porozbijać
ją na wiele sposobów.
Jeżeli klucz składa się z jednego atrybutu to dany schemat jest już w 2PN.
3PN (trzecia postać normalna)
Posiadanie przez jakiś schemat relacyjny właściwości 2PN nie jest wystarczające do tego aby nie
wystąpiły anomalia (choć w wielu przypadkach jest). Wówczas należy dalej normalizować schemat
doprowadzając do 3PN.
Przykład:
Niech będzie dany schemat relacyjny:
R=({W,A,P,D}, {W
→
APD, P
→
D}
gdzie:
W – wykonawca
A – adres wykonawcy
P – projekt zlecony wykonawcy do realizacji
D – data zakończenia projektu
Podany zbiór zależności funkcyjnych ma następującą interpretację semantyczną:
1) W
→
APD – każdy wykonawca ma jednoznacznie określony adres i może realizować tylko jeden projekt.
Natomiast jeden projekt może być wykonywany przez wielu wykonawców. Każdy wykonawca ma określony
termin zakończenia projektu.
2) P
→
D – termin ukończenia projektu jest taki sam dla wszystkich wykonawców (bo przecież kiedyś trzeba
projekt zakończyć)
Wprowadzenie do baz danych
27/31
Kluczem jest atrybut „W”. Ten schemat jest w 2PN ponieważ ma jednoelementowy klucz, ale anomalie mogą
jeszcze wystąpić:
1) anomalia dołączenia – nie można zapamiętać informacji o projekcie i dacie jego zakończenia;
2) anomalia aktualizacji – jeżeli będzie wymagana zmiana daty ukończenia któregoś z projektów, to spowoduje
to wiele zmian w różnych krotkach;
3) anomalia usuwania – jeżeli zaniechamy realizacji jakiegoś projektu to usuwając krotkę tracimy informacje o
wykonawcy. Albo jeśli jest jeden wykonawca jakiegoś projektu to jeśli się wycofa – stracimy informacje o
projekcie.
Z 3PN związane jest pojęcie zależności tranzytywnej.
Zbiór atrybutów Z jest tranzytywnie zależny od zbioru atrybutów X w schemacie relacyjnym R=(U,F) jeżeli:
a)
X i Z są rozłączne
b)
Istnieje Y
⊂
U rozłączne z X iż oraz takie, że:
X
→
Y
∈
F
+
Y
→
X
∉
F
+
Y
→
Z
∈
F
+
Czyli jest to taka zależność pośrednia – mamy tu tranzyt przez Y:
X
→
Y
→
Z
Schemat relacyjny R=(U,F) jest w 3PN jeśli jest w 2PN i żaden zbiór niekluczowych atrybutów Z
⊂
U nie jest
tranzytywnie zależny od klucza tego schematu.
W rozpatrywanym przykładzie mamy:
W
A
P
D
Musimy wyeliminować taką zależność na dwie mniejsze (z jednej tabeli stworzyć dwie):
W
A
P
P
D

Wprowadzenie do baz danych
28/31
Bezpieczeństwo danych
Istnieje uzasadniona konieczność ochrony danych zarówno przed osobami, które nie powinny mieć do
nich dostępu (istnieją specjalne ustawy chroniące dane osobowe) jak i przed wypadkami losowymi, w których
dane mogą ulec zniszczeniu. Można wyróżnić kilka przypadków podczas których istnieje zagrożenie utraty
danych:
1)
błąd działania transakcji aktualizującej obiekty – jeśli tylko część danych zostanie zapisana to może powstać
niespójność
2)
błąd pracy systemu operacyjnego komputera lub systemu zarządzania bazą danych
3)
spadek napięcia
4)
błędy sprzętowe, czyli uszkodzenia niektórych elementów komputera (np. pamięci dyskowej)
5)
błędy powstałe w bazie ze względu na uruchamianie błędnych, wadliwie skonstruowanych transakcji
Błędy tego typu powstają najczęściej w środowiskach wielodostępnych czyli takich w których wielu
użytkowników ma jednoczesny dostęp do danych. Utrzymanie spójności BD jest jednym z podstawowych
zagadnień bezpieczeństwa danych i należy do obowiązków administratora.
Podstawowe elementy ochrony BD:
1)
kopie bezpieczeństwa – jest to podstawowa metoda ochrony ważnych danych, ale jest kosztowna ze
względu na ilość zapisywanych nośników. W czasie tworzenia kopi nie powinny być uruchamiane żadne
transakcje. W przypadku BD o szybko zmieniających się wartościach często zabezpiecza się tylko
fragmenty danych.
2)
dziennik transakcji.
W dzienniku transakcji przechowywane są informacje o wszystkich transakcjach, które miały miejsce
od czasu utworzenia ostatniej kopii bezpieczeństwa. Zwykle zapisuje się w nim informacje takie jak:
-
unikalny identyfikator transakcji
-
adresy wszystkich obiektów aktualizowanych przez transakcję
-
stan obiektu przed i po modyfikacji
-
informacje dotyczące przebiegu transakcji (np. czasy rozpoczęcia i zakończenia)
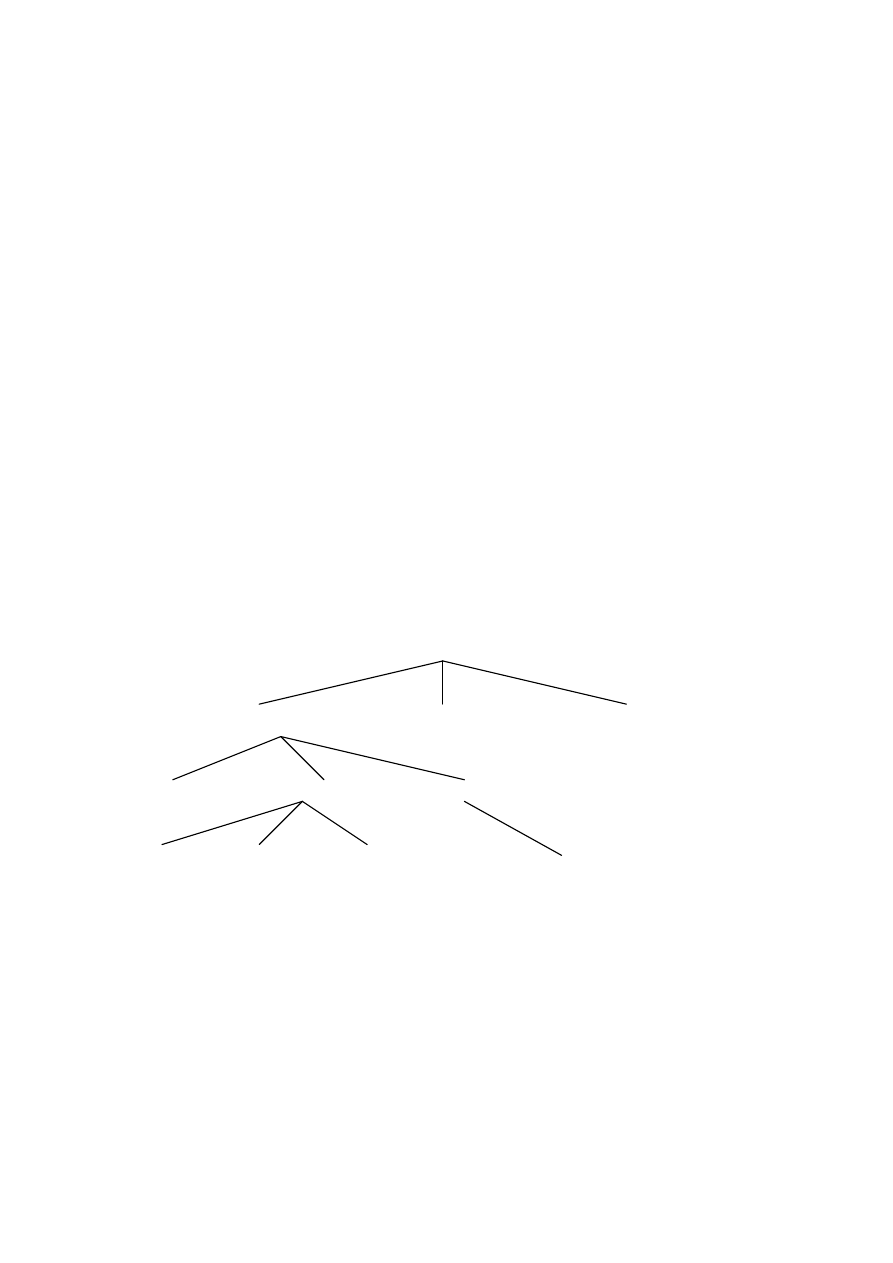
Aby ułatwić ewentualne odzyskiwanie danych transakcje zwykle najpierw zapisują zmiany w dzienniku a
dopiero potem do właściwej bazy danych. Ułatwia to odzyskanie danych w przypadku awarii.
Zmiany zapisywane
Operacja
dopiero po
Aktualizacji
zatwierdzeniu
transakcji
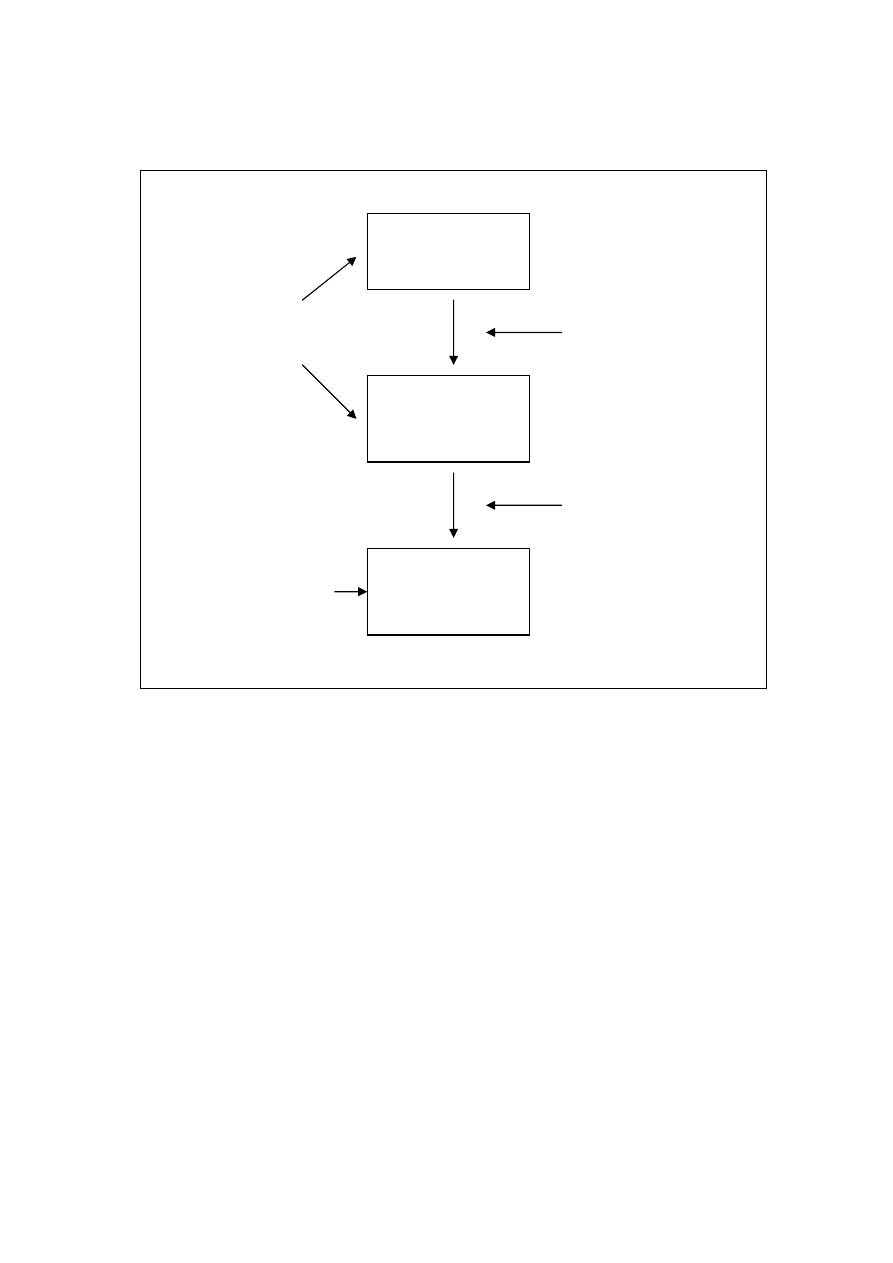
Przywracanie niespójności BD sprowadza się albo do cofania zmian dokonanych przez aktywne (czyli
nie zatwierdzone) w momencie awarii transakcje (roll-back) albo do powtórnego zapisania zmian dokonanych
przez transakcje, które zdążyły się zakończyć i były zatwierdzone przed awarią (roll-forward).
Do przywracania spójności wykorzystuje się tzw punkty kontroli prazy systemu (check points), które są
przechowywane w dzienniku transakcji. Są to informacje o tych stanach działania systemu do których możemy
wrócić mając pewność, że w tym momencie stan bazy był spójny i poprawny.
W przypadku awarii niekrytycznej (soft crash) dzięki punktom kontrolnym poprawności pracy systemu
musimy określić, które transakcje muszą być cofnięte (lista UNDO), a które ponownie zatwierdzone (lista
REDO). Ostatecznie transakcje z listy transakcji do cofnięcia powinny być usunięte z dziennika a następnie
uruchomione ponownie. Rezultaty transakcji z listy REDO są powtórnie zapisywane do właściwej bazy danych.
Dziennik transakcji
(LOG FILE)
Transakcja
Baza Danych
Wprowadzenie do baz danych
29/31
Istnieją także awarie krytyczne. W takich przypadkach prawdopodobnie konieczne będzie odtworzenie
całej bazy z ostatniej kopii bezpieczeństwa i ponowne zapisanie efektów transakcji , które były zatwierdzone do
momentu katastrofy.
Mechanizmy ochrony dostępu do danych
Model ochrony dostępu do danych dla baz danych wywodzi się w prostej linii z modelu ochrony
zasobów stosowanego w systemach operacyjnych. W skład mechanizmu ochrony dostępu wchodzą trzy
podstawowe czynniki:
-
zbiór obiektów O – jest to zbiór encji, do których będzie przyznawane różnego typu prawo dostępu
-
zbiór podmitów S – jest to zbiór aktywnych encji, które będą żądały dostępu do obiektów
-
zbiór typów dostępu A – typy dostępu zależą od rodzaju akcji, która ma być wykonana na żądanie jakiegoś
podmiotu w stosunku do obiektu. Podstawowe typy to: czytania, usuwania i modyfikacja.
Powstaje pytanie: komu jakie dać prawo dostępu do której części BD? Rodzaj dostępu może być zdefiniowany
poniższą regułą dostępu (s,o,a), gdzie s
∈
S, o
∈
O, a
∈
A:
F: S
×
O
×
A
→
(True, False)
która może przyjmować dwie wartości. Jeżeli wartość funkcji wynosi True znaczy to, że podmit s może uzyskać
dostęp typu a do obiektu o, w przeciwnym przypadku dostęp ten jest niemożliwy. Przykładem reguły dostępu
może być trójka (Robert, Dokument[i], R). Regua ta informuje, że użytkownik Robert może odczytać (R-read)
obiekt Dokument[i].
Zamiast magazynować wszystkie wartości dostępu, czyli informacje o tym na którym obiekcie
użytkownik może wykonać operacje a na którym nie, tworzy się grafy i dopiero na ich podstawie przeprowadza
się wnioskowanie. Stosuje się trzy typy grafów. Pierwszy reprezentuje hierarchię obiektów.
System [Politechnika]
database [Nauka]
database [Administracja]
database [Studenci]
class[Pracownicy]
class[Publikacje]
class[Projekty]
Publikacja[1]
Publikacja[2]... ...Publikacja[100]
Projekt[10]
Hierarchia taka definiuje sposób w jaki w systemie jedne obiekty są przedstawiane przy pomocy innych. Prawo
dostępu może być przyznawane na każdym poziomie. Podstawą funkcjonowania takiego modelu jest niejawne
propagowanie praw dostępu w stosunku do obiektów stojącuch niżej w hierarchii niż obiekt, dla którego jawnie
określono prawa dostępu. Jeżeli przyznano prawo dostępu typu a użytkownikowi s do obiektu o to użytkownik
zyskuje też prawo do wszystkich obiektów, które stoją niżej w hierarchii niż o.
Istnieje rozróżnienie pomiędzy silnym (modyfikacja) i słabym (czytanie) prawem dostępu oraz
pozytywnym i negatywnym a także jawnym i pochodnym (czyli wywnioskowanym z grafu) prawem dostępu.
Dla przykładu jeśli użytkownikowi przyznano słabe prawo dostępu typu „czytanie” do klasy Publikacja a
następnie negatywne prawo dostępu do czytania obiektu Publikacja[2] klasy Publikacja będzie miało to taki
efekt, że użytkownik będzie mógł czytać wszystkie obiekty klasy Publikacja z wyjątkiem obiektu Publikacja[2].
Wprowadzenie do baz danych
30/31
Aby zmniejszyćliczbę podmiotów ubiegających się o prawa dostępu do danych wprowadzono pojęcie
roli. Użytkownicy są gromadzen w jedną grupę ze względu na role, które są im przypisywane w procesie
ubiegania się o prawa dostępu do danych. Użytkownik może przynależeć do kilku ról istniejących w systemie.
Role można przedstawić za pomocą kraty RL (role lattice).
super-user
Projekt 93/E/II
Projekt Omega
Dyrektor jednostki
Projekt 94/A/I
Projekt Alfa
Dyrektor Techniczny
Szef personelu
Pracownik
Węzeł reprezentuje tutaj poszczególną rolę. Można sformułować zasadę, że jeśli danej roli są przyznawane
określone prawa dostępu to dla wszystkich ról, które poprzedzają daną rolę ze względu na porządek częściowy
określony przez kratę RL, są przyznane te same prawa dostępu co dla danej roli.
W podobnej postaci można przedstawić typy dostępu, mamy wtedy do czynienia z kratą typów dostępu
ATL (authorization type lattice).
W
R
C
SC
RD
Każdy węzeł reprezentuje tu jakiś typ dostępu. Strzałka od węzła A do węzła B oznacza, że jeśli występuje typ
dostępu A to występuje również typ dostępu B. Można na tej podstawie sformułować zasadę, na podstawie
której niejawne prawa dostępu mogą być przyznane ze względu na dziedzinęA funkcji f. Dla baz relacyjnych
podstawowe typy praw dostępu to R(read), W(write - modify), C(create) i RD(read definition). Dla baz
obiektowych można jeszcze wyróżnić typ dodatkowy ze względu na typ dziedziczenia, a mianowicie
S.C.(subclass create), który pozwala zdefiniować podklasę danej klasy. Zatem zbiór A można opisać jako
A = (R,W,C,S.C.,RD)

Wprowadzenie do baz danych
31/31
Przykład
Załóżmy, że mamy silne prawo dostępu opisane przez (Projekt_94/A/I, database[Nauka], +W) i chcemy
sprawdzić czy możliwy jest dostęp opisany jako (Projekt_93/E/II, Publikacja[2], +R), gdzie +W oznacza
pozytywne prawo dostępu do modyfikacji, zaś +R prawo do czytania.
Aby tego dokonać trzeba predsięwziąć następujące kroki:
1)
dla dziedziny S: ‘Projekt_93/E/II’ > ‘Projekt_94/A/I’, zatem (Projekt_94/A/I, database[Nauka], +W)
→
(Projekt_93/E/II, database[Nauka], +W),
2)
dla dziedziny O: ‘database[Nauka]’ > ‘class[Publikacja]’ > ‘Publikacja[2]’ i WI A.down, zatem
(Projekt_93/E/II,database[Nauka],+W)
→
(Projekt_93/E/II,Publikacja[2],+W),
3)
dla dziedziny A: W>R, zatem (Prijekt_93/E/II,Publikacja[2],+W)
→
(Projekt_93/E/II,Publikacja[2],+R).
Ponieważ prawo dostępu (Projekt_93/E/II,Publikacja[2],+R) może być wywnioskowane na podstawie
założonego silnego prawa dostępu (Projekt_94/A/I,database[Nauka],+W) funkcja f ma wartość:
F(Projekt_93/E/II,Publikacja[2],+R)=True.
Przykład
Można również zastosować negatywne prawa dostępu: załóżmy, że mamy silne prawo dostępu
(Projekt_93/E/II,class[Publikacja],-RD) i musimy sprawdzić prawo dostępu (Pracownik,Publikacja[2],W). W
tym celu należy wykonać następujące kroki:
1)
dla dziedziny S: ‘Projekt_93/E/II’ > ‘Projekt_94/A/I’ > ‘Pracownik’, zatem (Projekt_93/E/II,
class[Publikacja],-RD]
→
(Pracownik,class[Publikacja],-RD),
2)
dla dziedziny O: ‘class[Publikacja]’ > ‘Publikacja[2]’ i RDI A.up, zatem (Pracownik,class[Pracownik],-RD)
→
(Pracownik, Publikacja[2], -RD),
3)
dla dziedziny A: W > R > RD, zatem (Pracownik, Publikacja[2],-RD)
→
(Pracownik,Publikacja[2],-W).
Stąd: f(Pracownik,Publikacja[2],W)=False.
Jednoczesny dostęp do danych
Każda transakcja musi zachowywać poprawność i spójność bazy danych. Komputery często łączone są
w sieć, tworzy się więc sieć abonentów, z których każdy może nie tylko odczytywać ale i zmieniać dane. Przez
stan poprawny BD rozumiemy taki stan, w którym wszystkie wartości atrybutów obiektów występujących w BD
mają wartość zgodną z oczekiwaniami. Przez spójność BD rozumiemy taki stan, w którym wszelkie powiązania
między obiektami tworzą logiczną całść np. nie ma odwołań do obiektów nie istniejących w BD.
Ż
eby dało się sprawnie zarządzać takimi BD wprowadza się pewne ograniczenia: nie każdy użytkownik
ma w danej chwili dostęp do wszystkich danych. Poprawną pracę zapewnia się poprzez synchronizowanie
dostępu do BD – pesymistyczne i optymistyczne.
Przy synchronizowaniu pesymistycznym korzysta się z mechanizmów tzw. zamków. Przy
jednoczesnym dostępie do danych wyróżniamy dwa rodzaje zamków:
1)
zamknięcie do czytania – żadna transakcja nie może aktualizować obiektu, który został zamknięty do
czytania przez jakąkolwiek transakcję. Natomiast możliwa jest sytuacja, że wiele transakcji czyta dane z
tego samego obiektu
2)
zamknięcie do aktualizacji – żadna inna transakcja z wyjątkiem tej, która dokonała zamknięcia nie ma
dostępu (zarówno do czytania jak i aktualizacji) do danego obiektu
Wyszukiwarka
Podobne podstrony:
bazy danych wyk id 81390 Nieznany (2)
bazy danych druga id 81754 Nieznany (2)
Bazy danych kolo 2 1 id 81756 Nieznany
Bazy Danych1 secret id 81733 Nieznany (2)
bazy danych kol 2 id 81577 Nieznany (2)
bazy danych wyk2 id 81712 Nieznany (2)
bazy danych wyklad1 id 81713 Nieznany (2)
Bazy Danych bd4 id 633777 Nieznany (2)
Bazy danych 07 id 81462 Nieznany (2)
bazy danych sql id 81694 Nieznany
Bazy Danych kolokwium1 id 81578 Nieznany (2)
bazy danych wyklady id 81711 Nieznany (2)
Bazy danych egzamin(1) id 81477 Nieznany
Bazy Danych bd5 id 633778 Nieznany (2)
bazy danych druga id 81754 Nieznany (2)
Bazy danych kolo 2 1 id 81756 Nieznany
Bazy Danych1 secret id 81733 Nieznany (2)
bazy danych kol 2 id 81577 Nieznany (2)
Podstawy logistyki wyk 3 id 367 Nieznany
więcej podobnych podstron