PRZETWARZANIE WYNIKÓW ZAPYTAŃ
1. Instrukcja DISTINCT
2. Funkcje agregujące
3. Instrukcja GROUP BY
4. Filtrowanie instrukcją HAVING
Instrukcja SELECT, prócz możliwości jakie zostały pokazane w rozdziale jej poświęconej, pozwala
także na przeprowadzanie różnego rodzaju wyliczeń i grupowań danych, co daje możliwość na
uzyskanie bardziej globalnego widoku na dane.
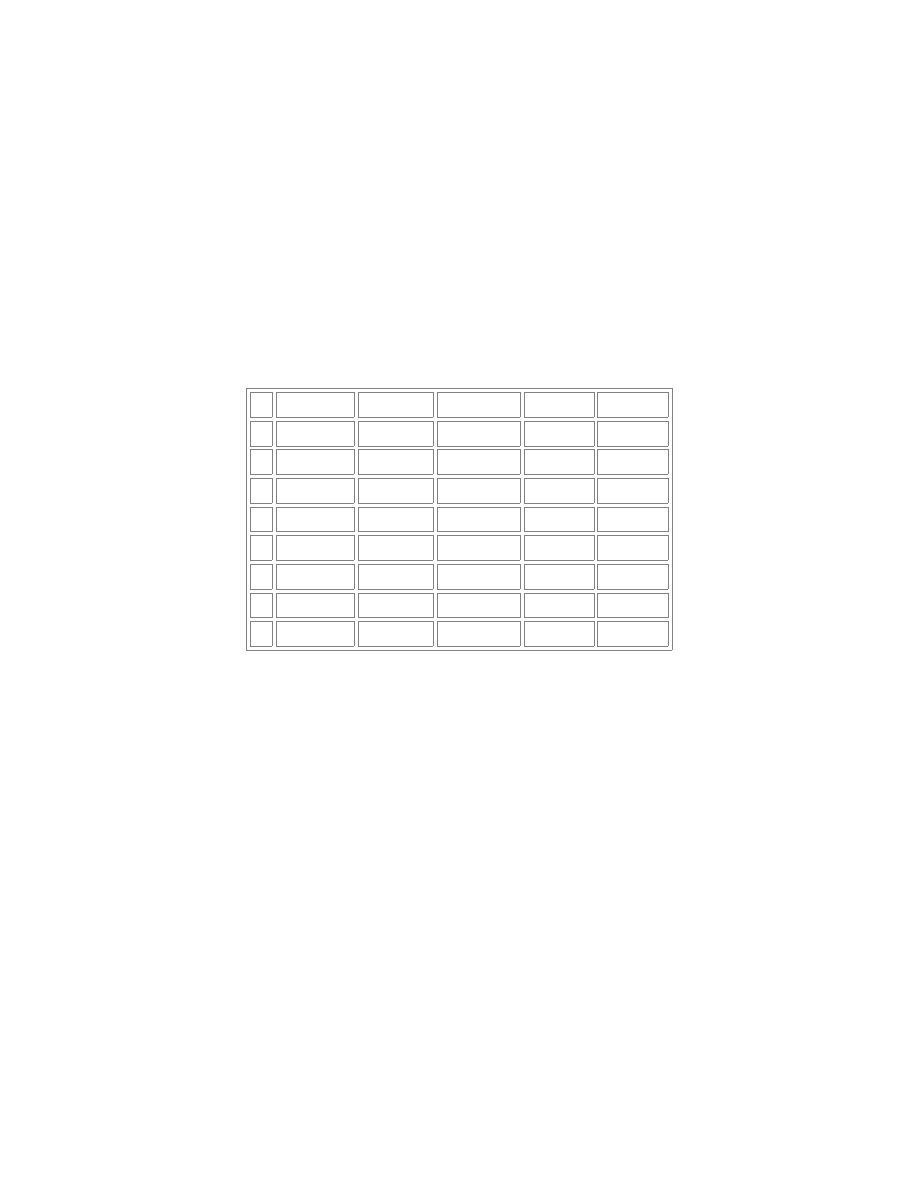
Tabela Osoby "popsuta" celowo.
Id Imię
Zarobki
Dochody
Kod
Praca
1 Rafał
100
200
50-500
Gniezno
2 Marek
200
250
Gniezno
3 Kamil
50
500
Gniezno
4 Zdzisław 300
120
40-400
Kraków
5 Rafał
100
200
60-600
Kraków
6 Kamil
150
300
80-800
Poznań
7 Rafał
130
60
Poznań
8 Zdzisław 300
200
Kraków
INSTRUKCJA DISTINCT
Instrukcja DISTINCT eliminuje powtarzające się rekordy. Składnia zapytania z tą instrukcją wygląda
następująco:
SELECT [DISTINCT] lista_kolumn
FROM nazwa_tabeli [lista_tabel]
[WHERE wyrażenie]
[ORDER BY wyrażenie];
Zwykłe zapytanie do naszej tabeli dałoby wynik, który nie za bardzo nas zadawala:
SELECT Imię FROM Osoby;
Copyright© mgr inż. Rafał Mikołajczak – Kopiowanie i rozpowszechnianie zabronione
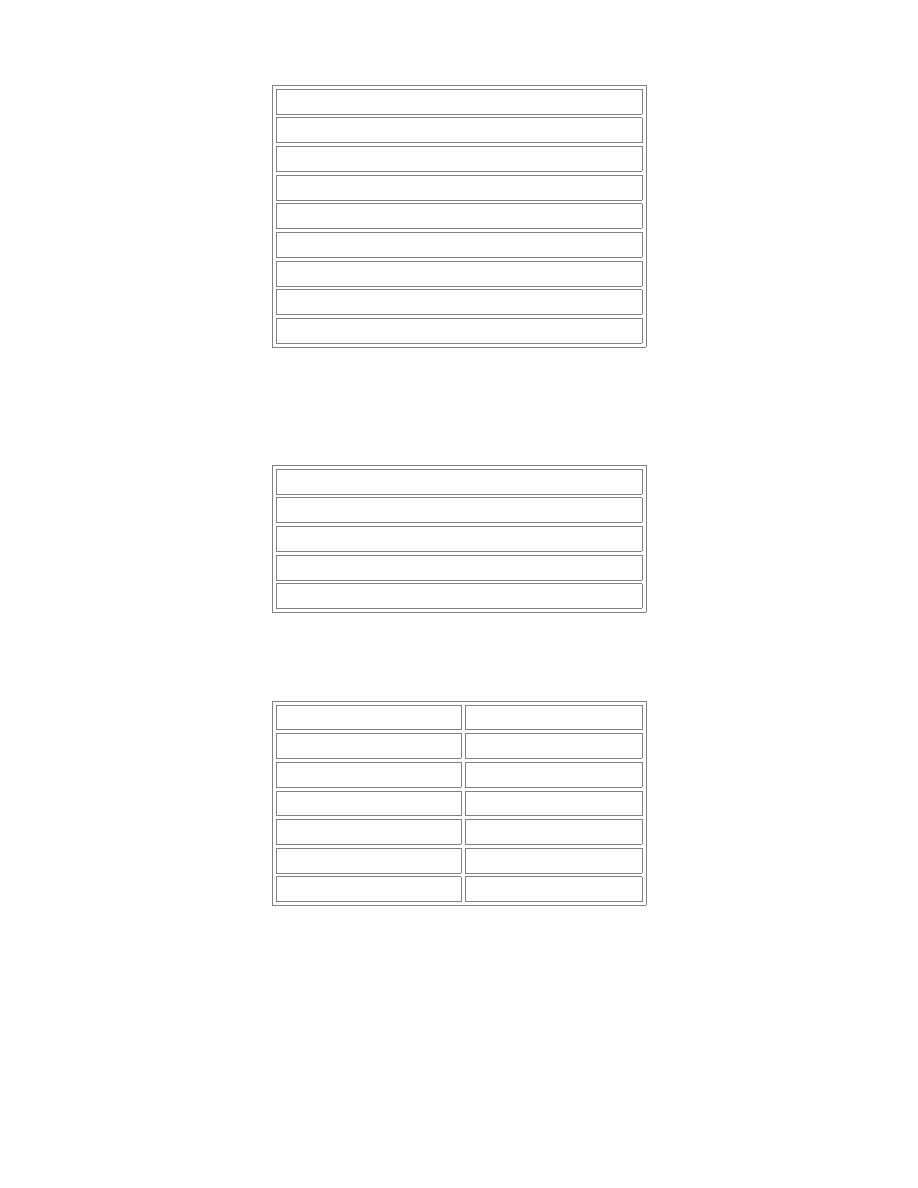
Imię
Rafał
Marek
Kamil
Zdzisław
Rafał
Kamil
Rafał
Zdzisław
,ale z użyciem instrukcji DISTINCT będzie o wiele lepiej:
SELECT DISTINCT Imię FROM Osoby;
Imię
Rafał
Marek
Kamil
Zdzisław
,proste i oczywiste. Teraz zmieńmy trochę pytanie:
SELECT DISTINCT Imię, Zarobki FROM Osoby;
Imię
Zarobki
Rafał
100
Marek
200
Kamil
50
Zdzisław
300
Kamil
150
Rafał
130
,coś się Rafałów i Kamili namnożyło - Prawda? No tak, bo jeżeli po instrukcji DISTINCT podamy
kilka kolumn, to zostanie zwrócony wynik, gdzie nie będzie się powtarzała kombinacja wierszy.
Oznacza to, że dane w każdej z kolumn mogą powtórzyć. Oczywiście TEORETYCZNIE (my jako
najlepsi na świecie projektanci baz danych) nigdy nie spotkamy się z taką sytuacją, ponieważ będziemy
tworzyli bazy danych zgodnie z teorią (klucze, unikaty, normalizacja itd.) i nie będziemy mieli w
żadnej tabeli powtarzających się danych. Mimo wszystko jednak, gdyby ktoś się zapomniał i popełnił
Copyright© mgr inż. Rafał Mikołajczak – Kopiowanie i rozpowszechnianie zabronione

"drobne przeoczenie" w fazie projektowania bazy danych, radzę dobrze się przyjrzeć, co zwraca nam
zapytanie z eliminacją powtarzających się rekordów.
No tak - teraz czas na coś, co jest nie wiadomo czym - NULL. A właśnie, że nie - właśnie, że wiadomo!
Instrukcja DISTINCT traktuje NULL jako wartość (teoretycznie) określoną. Oznacza to, że podczas
eliminacji powtarzających się danych z kolumny, w której znajdują się wartości NULL, instrukcja
DISTINCT potraktuje ją jako konkretną wartość i wybierze tylko raz.
Przykład:
SELECT DISTINCT Kod FROM Osoby;
Kod
50-500
40-400
60-600
80-800
Wszystko zgodnie z zasadą działania operatora DISTINCT.
FUNKCJE AGREGUJĄCE
Język SQL dysponuje dużą ilością funkcji agregujących. Funkcje takie mogą działać na całej tabeli,
wybranych wierszach, za pomocą WHERE lub na grupie wierszy wybranej klauzulą GROUP BY.
Użycie funkcji agregującej wymaga wywołania zapytania w następującej formie:
SELECT funkcja (lista_kolumn)
FROM nazwa_tabeli [lista_tabel]
[WHERE wyrażenie];
Funkcja COUNT( )
Count znaczy po polsku Licz. No to spróbujmy:
SELECT COUNT(*) FROM Osoby;
COUNT (*)
8
Funkcja COUNT(*) zlicza więc rekordy w tabeli. O ile w klauzuli
SELECT * FROM..., użycie znaku "*" zdecydowanie spowalnia pracę, użycie tego znaku w klauzuli
COUNT znacznie przyspiesza otrzymanie odpowiedzi, ponieważ optymalizator bazy danych sam
wybiera kolumnę, po której zlicza rekordy.
Możemy oczywiście zadać także warunek:
Copyright© mgr inż. Rafał Mikołajczak – Kopiowanie i rozpowszechnianie zabronione

SELECT COUNT(*) FROM Osoby WHERE Praca = 'Krakow';
COUNT (*)
3
Możemy także wymusić zliczanie po konkretnej kolumnie (może tylko trwać trochę dłużej). Trzeba
jednak pamiętać, że jeżeli zadamy zliczanie po kolumnie, w której znajdują się wartości NULL - te nie
będą brane pod uwagę:
SELECT COUNT (Kod) FROM Osoby;
COUNT (Kod)
4
Do operatora COUNT możemy także użyć klauzuli DISTINCT:
SELECT COUNT (DISTINCT Imię) FROM Osoby;
COUNT (DISTINCT
Imię)
4
Funkcja SUM( ) i AVG( )
Funkcja SUM() i AVG() działają tylko na typach liczbowych i zwracają pojedynczy wynik - SUM( ) -
sumuje wartości, AVG( ) – zlicza wartość średnią.
SELECT SUM (Dochody) FROM Osoby;
SUM
(Dochody)
1830
SELECT AVG (Dochody) FROM Osoby;
AVG
(Dochody)
228,75
Obie funkcje mogą używać operatora DISTINCT wg schematu:
SELECT [SUM / AVG] (DISTINCT nazwa_kolumny) FROM nazwa_tabeli;
Copyright© mgr inż. Rafał Mikołajczak – Kopiowanie i rozpowszechnianie zabronione
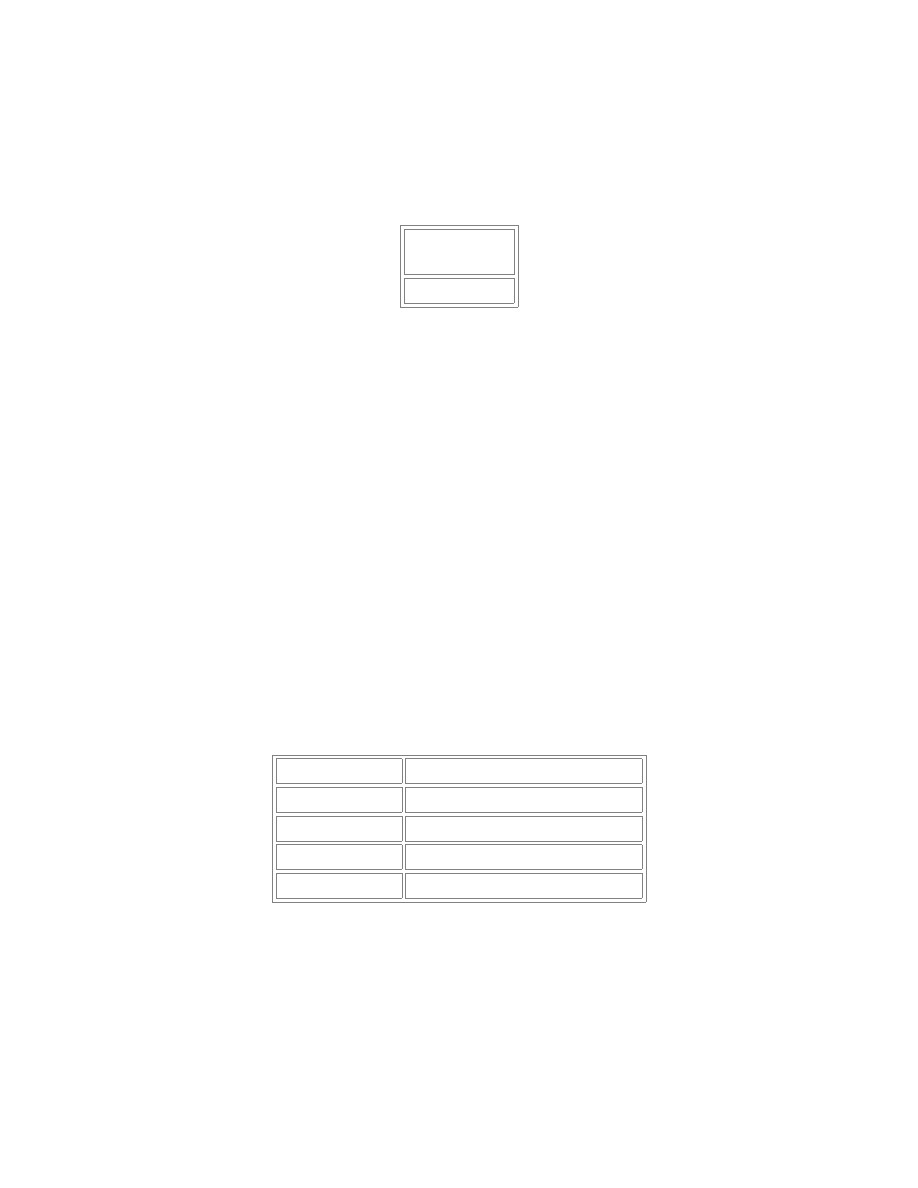
Funkcja MIN( ) i MAX(
)
Funkcje odpowiednio zawracają najmniejszą i największą wartość w zadanym zbiorze - zarówno na
typach liczbowych, łańcuchach znaków (zgodnie z opisywanymi wcześniej prawami), jak i na datach.
Przykład
SELECT MIN(Zarobki) FROM Osoby;
MIN
(Zarobki)
50
Obie funkcje mogą współdziałać z operatorem DISTINCT.
INSTRUKCA GROUP BY
Instrukcja GROUP BY umożliwia grupowanie wyników względem zawartości wybranej kolumny.
Jeżeli dodamy do tej instrukcji funkcję agregującą dla innej kolumny, to otrzymamy wynik funkcji
agregującej, która zadziała tylko na pewnej części (grupie) rekordów. Składnia instrukcji GROUP BY
przedstawia się następująco:
SELECT nazwa_kolumny [lista_kolumn]
[Funkcja agregująca]
FROM nazwa_tabeli [lista_tabel]
[WHERE warunek]
[GROUP BY opcja_grupowania]
[ORDER BY warunek_kolejności];
Przykład
SELECT Imię SUM(Dochody) FROM Osoby GROUP BY Imię;
Imię
SUM (Dochody)
Rafał
460
Marek
250
Kamil
800
Zdzisław
320
Jeżeli nie użyjemy funkcji agregującej, to pytanie:
SELECT Imię FROM Osoby GROUP BY Imię;
będzie równoważne z pytaniem:
SELECT Imię FROM Osoby DISTINCT (Imię);
Copyright© mgr inż. Rafał Mikołajczak – Kopiowanie i rozpowszechnianie zabronione
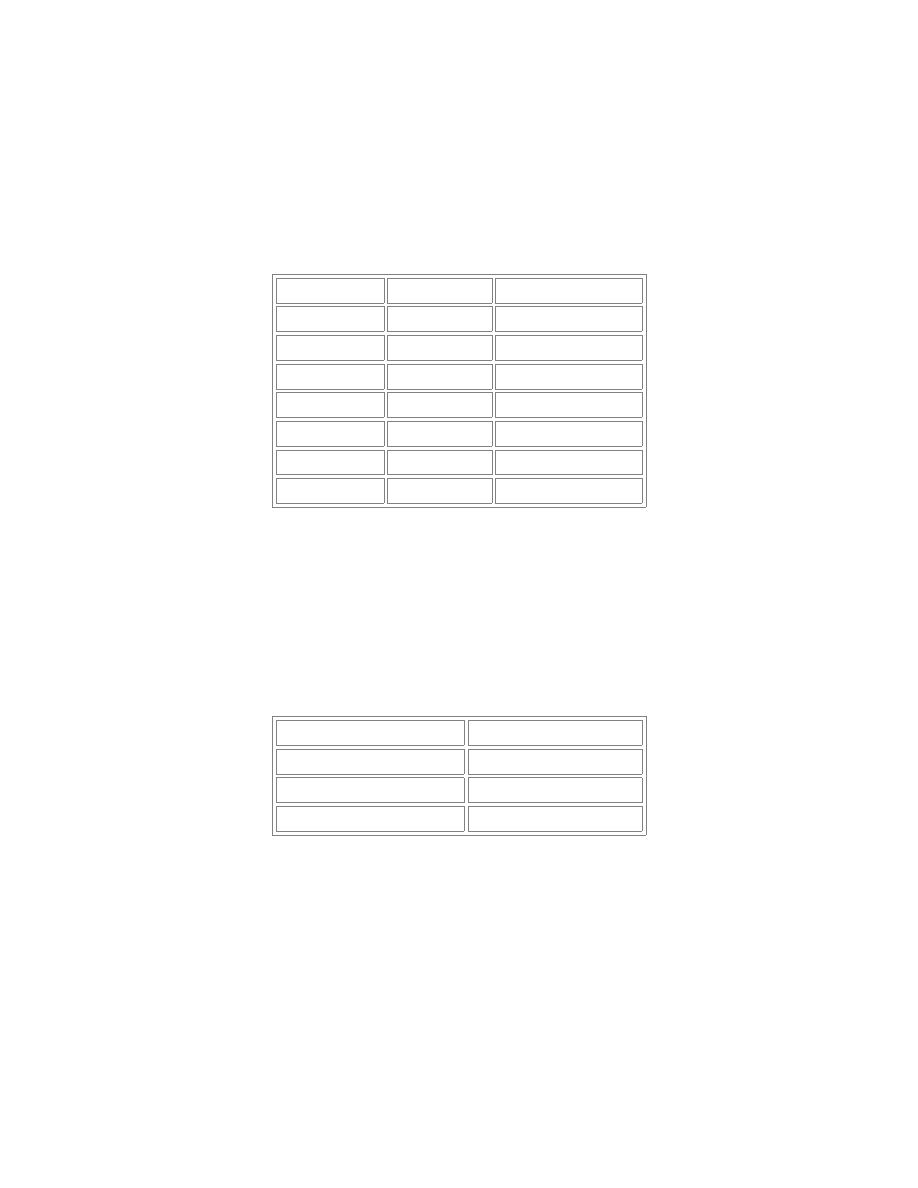
Instrukcja GROUP BY jest także podobna do DISTINCT w sensie selekcji kolumn z wartościami
NULL. Oznacza to, że wszystkie pozycje z tą wartością są zaliczane do tej samej kategorii.
W przypadku, gdy w klauzuli GROUP BY wybranych zostanie kilka kolumn, tworzone są grupy i
podgrupy (analogia do sortowania wewnątrz kategorii - wielu kolumn - w instrukcji ORDER BY).
Przykład:
SELECT Imię, Praca COUNT(*) FROM Osoby GROUP BY Imię, Praca ORDER BY Imię;
Imię
Praca
COUNT(*)
Kamil
Gniezno
1
Kamil
Poznań
1
Marek
Gniezno
1
Rafał
Gniezno
1
Rafał
Poznań
1
Rafał
Kraków
1
Zdzisław
Kraków
2
Zdzisław posiada dwa miejsca zatrudnienia i oba znajdują się w Krakowie. Tak jak to było w
przypadku DISTINCT – nie występują dwie takie same kombinacje kolumn.
UWAGA - Klauzula GROUP BY nie może zawierać nazwy kolumny nieuwzględnionej na liście
SELECT.
Do klauzuli GROUP BY możemy również dołączać klauzule WHERE np.:
SELECT Imię, COUNT(*) FROM Osoby WHERE Praca='Gniezno' OR Praca='Poznań' GROUP BY
Imię;
Imię
Praca
Rafał
2
Marek
1
Kamil
2
FILTROWANIE INSTRUKCJĄ HAVING
Instrukcja HAVING pozwala na filtrowanie wyników zapytań już po procesie grupowania (inaczej niż
WHERE, która filtruje wyniki przed grupowaniem).
Spróbujmy wybrać osoby, których łączny dochód we wszystkich miejscach pracy przekracza 300. Nie
da się stworzyć jednego pytania wykorzystującego tylko instrukcje WHERE, które przeprowadziłoby
Copyright© mgr inż. Rafał Mikołajczak – Kopiowanie i rozpowszechnianie zabronione
poprawnie taki proces. Musimy najpierw pogrupować osoby, a następnie przefiltrować ich dochody
instrukcją HAVING:
SELECT Imię, SUM(Dochody) FROM Osoby GROUP By Imię HAVING SUM (Dochody)>300;
Imię
SUM (Dochody)
Rafał
460
Kamil
800
Zdzisław
320
Bez HAVING na liście znalazłby się jeszcze Marek z zarobkiem 250.
Można oczywiście bardziej rozbudować filtr:
SELECT Imię, SUM(Dochody), Praca
FROM Osoby
GROUP By Imię
HAVING SUM(Dochody)<350 And Praca IN( 'Gniezno', 'Poznań')
ORDER BY Imię;
Cała tabela przedstawia się tak:
Id Imię
Zarobki Dochody Kod
Praca
1 Rafał
100
200
50-500 Gniezno
2 Marek
200
250
Gniezno
3 Kamil
50
500
Gniezno
4
Zdzisła
w
300
120
40-400 Kraków
5 Rafał
100
200
60-600 Kraków
6 Kamil
150
300
80-800 Poznań
7 Rafał
130
60
Poznań
8
Zdzisła
w
300
200
Kraków
,a wynik pytania tak:
Imię
SUM (Dochody)
Praca
Marek
250
Gniezno
Możemy także łączyć WHERE i HAVING.
Przykład
SELECT Imię, SUM(Dochody), Praca
FROM Osoby WHERE Praca IN ( 'Gniezno', 'Poznań')
GROUP By Imię
Copyright© mgr inż. Rafał Mikołajczak – Kopiowanie i rozpowszechnianie zabronione

HAVING SUM(Dochody)<350
ORDER BY Imię
Imię
SUM (Dochody)
Praca
Marek
250
Gniezno
Rafał
260
Gniezno
Powstaje pytanie - skąd ta różnica?
W pytaniu, które wykorzystuje WHERE najpierw wybierane są osoby z Gniezna i Poznania. Zdzisław
„odpada” od razu. Kamil ma dochody w Gnieźnie i Poznaniu 800, więc też „odpada”. Na listę zawsze
wejdzie Marek, bo pracuje tylko w Gnieźnie i ma dochody = 250. Pozostaje więc tylko problem z
Rafałem.
Imię
Dochody
Praca
Rafał
200
Gniezno
Rafał
200
Kraków
Rafał
60
Poznań
Jeżeli zadamy warunek WHERE Praca IN ('Gniezno', 'Poznań') przed grupowaniem, to Rafał wejdzie
na listę, bo w tych miastach ma dochody na poziomie 260. Jeżeli potraktujemy go jako grupę, to już
jego dochody będą na poziomie 460, a więc nie zostanie spełniony lewy warunek instrukcji AND,
przez co automatycznie nie załapie się na listę.
Copyright© mgr inż. Rafał Mikołajczak – Kopiowanie i rozpowszechnianie zabronione
Wyszukiwarka
Podobne podstrony:
fpr-wyk3, FIR UE Katowice, SEMESTR IV, Finanse przedsiębiorstw, Finanse Przedsiębiorstwa
Część1
Fot wyk3 int
isd wyk3
Monitoring środowiska część1 - Notatki, Nauka, Ochrona środowiska
mb-wyk3, UE Katowice FiR, marketing bankowy
gitg-wyk3, FIR UE Katowice, SEMESTR VI, gieldy, gieldy 1, gieldy
Alfabet.Mafii.czesc10.Korek.Szykuje.sie.do.Wystrzalu.UoM, Mafia w Polsce
Ceny usług turystycznych wyk3, Geografia 2 rok, Ekonomiczne podstawy turystyki, Wykłady
czesc1
PIR zestaw pytań czesc1B
CZEŚĆ1
wyk3, studia, semestr V, zarzadzanie produkcja i uslugami, Wykład
egzamin czesc1
metro - część1, 1
więcej podobnych podstron