
SQL jest językiem obsługi baz danych implementowanym przez praktycznie
wszystkie systemy zarządzania bazami danych (SZBD) przeznaczone dla wielu
użytkowników, częściowo ze względu na fakt, iż uzyskał on akceptację ANSI
(Amerykańskiego Narodowego Instytutu Normalizacji) oraz ISO
(Międzynarodowej Organizacji Normalizacyjnej) jako standardowy język
zapytań dla relacyjnych baz danych.
Język SQL został opracowany przez korporację IBM w laboratorium
badawczym w San Jose, we wczesnych latach 70. Prototyp SQL-a,
zaprezentowany na konferencji ACM w 1974 roku nosił początkowo miano
SEQUEL (Strukturalny Angielski Język Zapytań; ang. Structured English
Query Language). Nazwa ta została później skrócona do SQL.
Znacznie ulepszona wersja SQL pojawiła się w 1989 roku pod nazwą SQL-
89. Znaczna większość stosowanych dziś relacyjnych systemów SZBD obsługuje
przynajmniej tę wersję języka.
W 1992 roku istniejący standard poddano kolejnemu unowocześnieniu
(SQL-92), dzięki czemu SQL zyskał szereg nowych możliwości. Ponieważ SQL-92
jest rozszerzeniem SQL-89, starsze systemy zarządzania bazami danych mogły
po niewielkich modyfikacjach pracować w nowym standardzie.
Aż do października 1996, producenci oprogramowania SZBD mogli
przedstawiać swoje produkty instytutowi NIST (Narodowy Instytut Standardów
i Technologii) w celu określenia ich zgodności ze standardami SQL. Proces
testowania i certyfikacji stanowił silny bodziec do trzymania się obowiązujących
norm –wynikiem standard SQL:1999. W 2003 przedstawiono SQL:2003 – nowy
standard języka SQL. Został on opublikowany w Sigmod Record Vol. 33 No. 1
Marzec 2004. Jest to w zasadzie poprawione SQL:1999 z wyjątkiem części
SQL/XML oraz kilku dodatkowych właściwości.
W takiej czy innej postaci, SQL jest niezwykle przydatnym narzędziem.
Można go stosować do modyfikowania i wczytywania danych oraz do tworzenia i
obsługi struktur bazodanowych. Nie jest to jednak język samodzielny. Pisząc
aplikację obsługującą twoją bazę danych trzeba osadzać polecenia SQL w innym
języku programowania.
Mówienie o zapytaniach przed utworzeniem bazy i wprowadzeniem do niej
przykładowych danych może wydawać się dziwne, ale większość poleceń SQL-a
wykorzystywanych do modyfikowania tabel wymaga wpierw odszukania danych,
które należy podać modyfikacjom. Załóżmy więc, że dysponujemy gotową bazą
danych, wypełnioną odpowiednimi informacjami.

SQL ma tylko jedno polecenie służące do odszukiwania danych: SELECT.
Wbrew pozorom fakt ten nie stanowi ograniczenia. SELECT umożliwia
wybieranie kolumn oraz wierszy, łączenie tabel, grupowanie danych i
przeprowadzanie na nich prostych obliczeń. Pojedyncze wyrażenie SELECT
wystarczy do wykonania dowolnej kombinacji działań algebry relacyjnej.
Oto podstawowa składnia polecenia SELECT:
SELECT kolumna1, kolumna2, ...
FROM tabela1, tabela2, ...
WHERE kryteria_wyboru
Klauzula SELECT określa kolumny, które chcemy ujrzeć w tabeli
wynikowej. W klauzuli FROM podajemy nazwy tabel, które mają zostać
przeszukane. Klauzula WHERE jest opcjonalna i zawiera kryteria, które mają
być spełnione przez wszystkie zwracane wiersze.
Wyświetlanie wszystkich kolumn
Aby wyświetlić wszystkie kolumny z danej tabeli w kolejności, w której
zostały one zdefiniowane, można skorzystać z gwiazdki (*). Eliminuje to
konieczność wpisywania kolejnych nazw kolumn w wyrażeniu SELECT.
Załóżmy, że chcemy wyświetlić wszystkich dostawców, u których nasza
księgarnia zamawia książki. Wpisz:
SELECT *
FROM dostawcy
Wyświetlanie wybranych kolumn
Większość zapytań SQL-owych polega na wybraniu niektórych kolumny z
analizowanych tabel i wyświetleniu ich w odpowiedniej kolejności. Należy w tym
celu wypisać nazwy interesujących nas kolumn po słowie kluczowym SELECT w
kolejności, w jakiej chcemy je ujrzeć na wydruku. Przyjrzyjmy się zapytaniu
wybierającemu numery telefonów i nazwy dostawców z naszej przykładowej
bazy danych:
SELECT TelefonDost, NazwaDost
FROM Dostawcy
Usuwanie duplikatów

Unikatowe wartości kluczy podstawowych uniemożliwiają wprowadzenie
dwóch identycznych wierszy do danej tabeli bazowej. Jeśli jednak wybierasz z
analizowanej tabeli tylko niektóre kolumny, może się zdarzyć, że tabela
wynikowa będzie zawierać duplikaty.
Aby usunąć duplikaty z tabeli wynikowej, należy po słowie kluczowym
SELECT dopisać DISTINCT:
SELECT DISTINCT NumerKli, NumerKartyKred
FROM Zamówienia
Operacja rzutowania
Wybierając z tabeli interesujące nas kolumny, żądamy od SZBD dokonania
operacji rzutowania. Rzutowanie polega na wyodrębnieniu wartości wskazanych
kolumn ze wszystkich wierszy w tabeli. Ponieważ system zarządzania nie musi
analizować wybieranych wartości, rzutowanie należy do operacji szybkich.
Mówiąc o rzutowaniu należy zwrócić uwagę na pewien problem: SZBD
wybierze z podsuniętej mu tabeli żądane kolumny nie zwracając uwagi czy
wybór ten jest logiczny, czy nie. Przyjrzyj się następującemu zapytaniu:
SELECT NumerZam, Suma
FROM ZamówioneKsiążki
Sortowanie tabeli wynikowej
O ile nie zdecydujesz inaczej, wiersze w tabeli wynikowej będą miały taką
samą kolejność jak w tabeli źródłowej. Jeśli chcesz zmienić porządek wierszy,
musisz dodać klauzulę ORDER BY do wyrażenia SELECT.
Dopisanie klauzuli ORDER BY spowoduje posortowanie tabeli wynikowej
w kolejności alfabetycznej:
SELECT *
FROM Wydawcy
ORDER BY NazwaWydawcy
Po słowach kluczowych ORDER BY następuje nazwa kolumny lub
kolumn, względem których ma zostać posortowana tabela wynikowa. Jeśli
podasz nazwę więcej niż jednej kolumny, wówczas pierwsza kolumna zostanie

wzięta pod uwagę przy sortowaniu zewnętrznym, następna – przy sortowaniu
wewnętrznym pierwszego stopnia itp.
Weźmy dla przykładu następujące wyrażenie:
SELECT NazwiskoKli, KodPocztowyKli
FROM Klienci
ORDER BY NazwiskoKli, KodPocztowyKli
Wynik został posortowany według nazwisk klientów, a wewnętrznie – według
numerów kodów pocztowych.
Jeśli odwrócimy kolejność kolumn, według których nasza tabela ma zostać
posortowana:
SELECT NazwiskoKli, KodPocztowyKli
FROM Klienci
ORDER BY KodPocztowyKli, NazwiskoKli
ASC, DESC!!!!
Otrzymamy listę posortowaną według numerów kodów pocztowych, a
wewnętrznie – według nazwisk klientów.
Podobnie jak w przypadku kolumn, można ograniczać zawartość zwracanej
tabeli przez wyrażenie SELECT do interesujących nas wierszy. Kryteria wyboru
wierszy wpisujemy w klauzuli WHERE. Wyrażenie logiczne następujące po
WHERE określane jest mianem predykatu. Jeśli dany wiersz spełnia kryteria
wyboru (innymi słowy, wartość logiczna predykatu dla zawartych w tym wierszu
danych jest równa 1), wówczas zostaje on włączony do tabeli wynikowej.
Poniższe operatory porównania są wykorzystywane w wyrażeniach i warunkach
do porównywania dwóch wyrażeń. Wynikiem działania operatorów porównania
jest zawsze wartość logiczna (TRUE lub FALSE).
Operator Opis
Przykład
( )
Zmienia normalną kolejność
wykonywania działań
... NOT (A=1 OR B=1)
=
Sprawdza, czy dwa wyrażenia
są równe
... WHERE PLACA = 1000
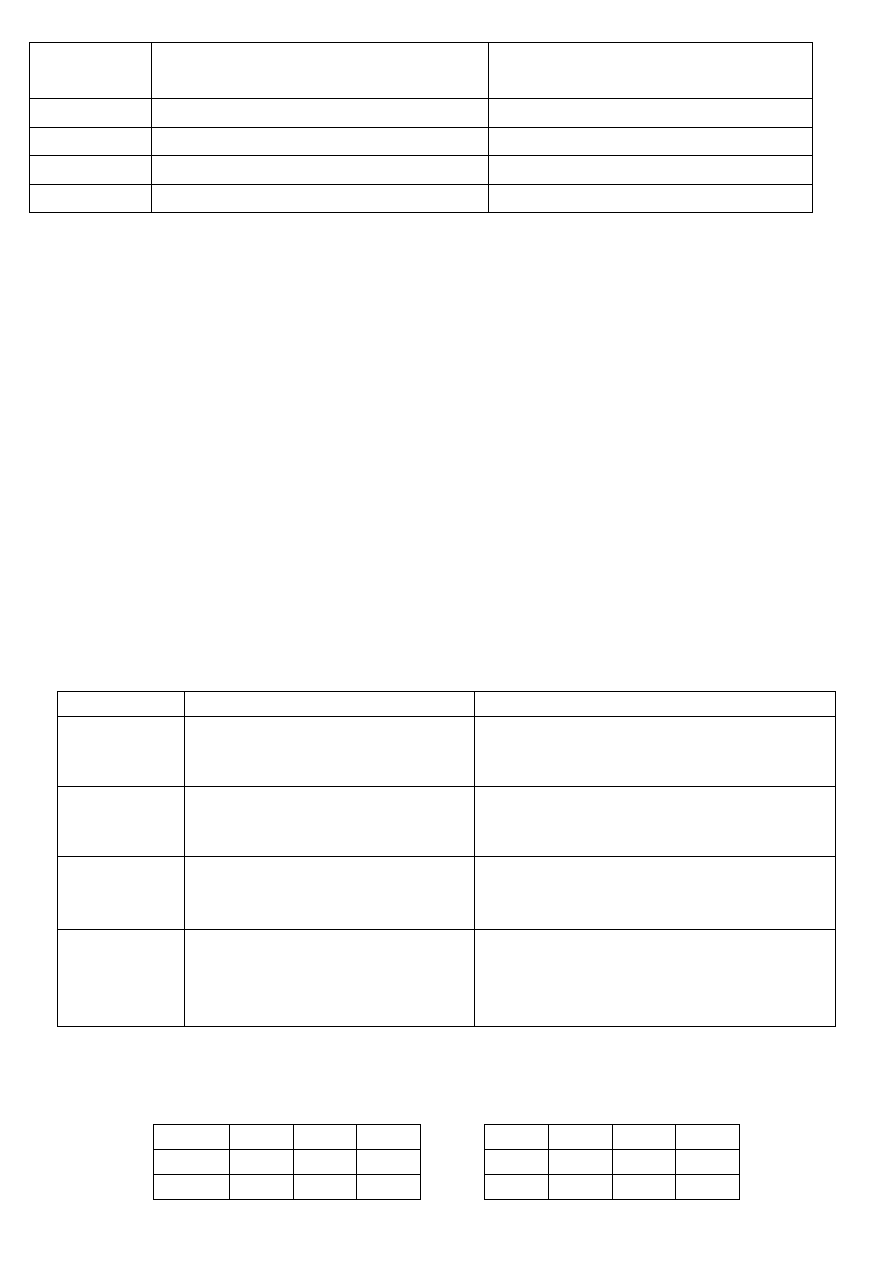
!=, ^=, <> Sprawdza, czy dwa wyrażenia
są różne
... WHERE PLACA != 1000
>
Większe niż
... WHERE PLACA > 1000
<
Mniejsze niż
... WHERE PLACA < 1000
>=
Większe lub równe niż
... WHERE PLACA >= 1000
<=
Mniejsze lub równe niż
... WHERE PLACA <= 1000
Wpisując z obu stron wyrażenia nazwy kolumn należy pamiętać, że predykat
stosuje się oddzielnie do każdego wiersza tabeli. Można więc porównywać
wartości przechowywane w dwóch różnych kolumnach tego samego wiersza, ale
nie można w ten sposób porównywać wartości tej samej kolumny w dwóch
różnych wierszach.
SZBD opiera ocenę wartości logicznej na typie porównywanych danych
Dane liczbowe – na zwykłej kolejności liczb
Dane tekstowe – na kolejności alfabetycznej
Dane daty, godziny – na kolejności chronologicznej.
Do konstrukcji złożonych warunków służą operatory logiczne. Wykonują one
obliczenia na wartościach typu logicznego (w szczególności będących wynikiem
obliczania warunków).
Operator
Opis
Przykład
( )
Zmienia normalną kolejność
wykonywania działań
SELECT ...
WHERE x = y AND (a = b OR p = q)
NOT
Zaprzeczenie
wyrażenia
logicznego
...WHERE NOT (zawod IS NULL)
...WHERE NOT (A=1)
AND
Logiczne 'i'. Wynik jest równy
TRUE, jeśli wartości obu
operandów są równe TRUE
... WHERE A = 1 AND B = 2
OR
Logiczne 'lub'. Wynik jest
równy TRUE, jeśli wartość
przynajmniej
jednego
operandu jest równa TRUE
... WHERE A = 1 OR B = 3
Poniższe tabele przedstawiają wynik działania operatora AND i OR dla różnych
wartości:
AND
true
false null
OR
true
false null
True
true
false null
True true
true true
False
false false false
False true
false null

Null
null
false null
Null
true
null null
Jeśli utworzymy wyrażenie zawierające więcej niż jeden operator logiczny,
system zarządzania będzie musiał zdecydować, w jakiej kolejności należy
analizować poszczególne wyrażenia proste. O ile nie zarządzimy inaczej, SZBD
zastosuje się do tzw. hierarchii operatorów. Zgodnie z tą hierarchą, najpierw
ustalone są wartości logiczne wyrażeń prostych, a następnie bierze się pod uwagę
operatory. Tam gdzie znajduje się więcej niż jeden operator logiczny tego samego
typu, analiza postępuje od lewej do prawej. System zarządzania przyznaje
wyższy priorytet wyrażeniom znajdującym się wewnątrz nawiasów.
SQL udostępnia szereg operatorów specjalnych, ułatwiających konstruowanie
wyrażeń logicznych. Operatory te to między innymi BETWEEN, LIKE, IN ,
ALL, ANY, EXISTS oraz IS NULL.
ANY
Porównuje wartość z każdą wartością ze
zbioru po prawej stronie. Musi być
poprzedzony jednym z operatorów: =, !=,
>, <, <=, >=. Zwraca TRUE, jeśli
przynajmniej jeden z elementów spełnia
podany warunek.
... WHERE PLACA = ANY
(SELECT
PLACA
FROM
PRAC
WHERE WYDZIAL=30)
IN
Równy dowolnemu elementowi. Synonim
do " = ANY"
...
WHERE
ZAWOD
IN
('URZEDNIK',
'INFORMATYK')
...
WHERE
PLACA
IN
(SELECT
PLACA
FROM
PRAC
WHERE
WYDZIAL=30)
ALL
Porównuje wartość z każdą wartością ze
zbioru po prawej stronie. Musi być
poprzedzony jednym z operatorów: =, !=,
>, <, <=, >=. Zwraca TRUE, jeśli każdy z
elementów spełnia podany warunek.
...WHERE
(PLACA,
PREMIA) >= ALL ((14900,
300), (3000, 0))
BETWEE
N x AND y
większy lub równy x i mniejszy lub
równy y.
... WHERE A BETWEEN 1
AND 9
EXISTS
Zwraca TRUE jeśli zapytanie zwraca
przynajmniej jeden wiersz.
...
WHERE
EXISTS
(SELECT PLACA
FROM
PRAC
WHERE
WYDZIAL= 30)
LIKE
spełnia podany wzorzec. Litera '%' jest
używana do zapisywania dowolnego ciągu
znaków (0 lub więcej), który nie jest
równy NULL. Litera '_' zastępuje
... WHERE STAN LIKE 'T%'

dowolną pojedynczą literę.
IS NULL jest równe NULL.
...
WHERE
ZAWOD
IS
NULL
WYBIERANIE DANYCH Z WIELU TABEL (ZŁĄCZENIA).
ZŁĄCZENIE TRADYCYJNE.
Do tej pory zapytania SQL-owe adresowane były do jednej tabeli. SQL zezwala
na odwołanie się do wielu tabel – należy wymienić ich nazwy po klauzuli FROM.
Wynikiem zapytania SQL-owego odwołującego się do dwóch tabel bez warunku
łączenia jest iloczyn kartezjański relacji (tabel).
SELECT *
FROM samochody, wypozyczenia
Najprostsze złączenie uzyskamy uzupełniając powyższe zapytanie o warunek
złączenia czyli :
SELECT *
FROM samochody, wypozyczenia
WHERE samochody.nr_samochodu=wypozyczenia.nr_samochodu
Przeanalizować w jakich kolorach samochody najchętniej są wypożyczane. Do
tego celu zastosujemy złączenie tradycyjne
SELECT count(kolor),kolor
FROM wypozyczenia , samochody
WHERE wypozyczenia.nr_samochodu=samochody.nr_samochodu
GROUP BY kolor
Złączenia wewnętrzne (INNER JOIN)
W przypadku SQL spełniającego standard 92 złączenie tradycyjne może być
realizowane za pomocą złączenia wewnętrznego (INNER JOIN).
Wówczas składnia złączenia tradycyjnego może być zastąpiona następującym
poleceniem :
SELECT *
FROM
wypozyczenia
INNER
JOIN
samochody
ON
samochody.nr_samochodu=wypozyczenia.nr_samochodu
W ogólności składnia z użyciem (INNER) JOIN przedstawia się następująco :
SELECT lista_pól
FROM tabelaA INNER JOIN tabelaB ON warunek_złączenia
WHERE dodatkowe_ograniczenia

Złączenia zewnętrzne (OUTER JOIN)
Wyróżnione zostały trzy rodzaje złączenia zewnętrznego : LEFT, RIGHT, FULL
OUTER JOIN
Złączenie LEFT OUTER JOIN charakteryzuje się tym iż z pierwszej tabeli (z
lewej strony join) wypisywane są wszystkie wiersze i dopisywane ich
odpowiedniki z drugiej tabeli zaś w przypadku gdy brak odpowiednika w
brakujące miejsca wpisywana jest wartość null.
Analogicznie działa złączenie prawostronne zewnętrzne.
Złączenie zewnętrzne pełne (FULL) uwzględnia wszystkie wiersze z obu tabel
składowych, wypełniając odpowiednie kolumny wartościami null.
Domyślnym rodzajem złączenia zewnętrznego jest złączenie pełne. Składnia
złączenia zewnętrznego jest analogiczna do składni złączenia wewnętrznego :
SELECT lista_pól
FROM tabela_1 LEFT OUTER JOIN tabela_2 ON warunek_złączenia
WHERE dodatkowe_ograniczenia
Złączenie (tradycyjne, wewnętrzne, zewnętrzne) mogą być dokonywane również
dla wielu tabel. Przykładowa składnia dla złączenia tradycyjnego trzech tabel
wygląda następująco:
SELECT lista_pól
FROM tabela_1, tabela_2, tabela_3
WHERE warunki_złączenia
Przykładowa składnia dla złączenia wewnętrznego trzech tabel wygląda
następująco:
SELECT lista_pól
FROM tabela_1 INNER JOIN tabela_2 ON warunek_1_złączenia INNER JOIN
tabela_3 ON warunek_2_złączenia
WHERE dodatkowe_ograniczenia
Obliczenia i grupowanie.
Wprawdzie SQL nie jest samodzielnym językiem programowania ale można za
jego pomocą prowadzić proste obliczenia i operacje agregujące. SQL potrafi
prowadzić proste operacje arytmetyczne na wartościach kolumn i na stałych
(jeśli używamy osadzonego SQL-a, możemy korzystać ze zmiennych języka

bazowego). Przykładowo jeśli tabela zawiera pola ilość, cena_jednostkowa_netto
, stawka_vatu to możemy przy pomocy polecenia SELECT uzyskać nową
kolumnę będącą wartością brutto.
SELECT
ilość,
cena_jednostkowa_netto
,
stawka_vatu,
(ilość*cena_jednostkowa_netto)*(1+stawka_vatu/100) as wartość_brutto
FROM ZAKUPY
Jeżeli kolumnie wyliczeniowej nie nadamy nazwy to kolumna ta otrzyma
domyślną nazwę najczęściej wygenerowaną z formuły wyliczającej.
Operatory arytmetyczne
Standardowo SQL rozpoznaje podstawowe operatory arytmetyczne:
mnożenie *
dzielenie /
dodawanie
+
odejmowanie -
dzielenie modulo - % (MS SQL Server)
Powyższe uporządkowanie związane jest z hierarchią operatorów. Najwyższy
priorytet mają mnożenie i dzielenie, zaś najniższy dodawanie i odejmowanie.
Jeśli dane wyrażenie zawiera kilka operatorów o tym samym priorytecie,
wówczas będą one analizowane od lewej do prawej.
Standardowe Typy Danych Liczbowych w Sql.
INTEGER (skrót INT): liczba całkowita (dodatnia lub ujemna). Ilość bitów
poświęconych na przechowanie takiej liczy zależy od implementacji. ( standard w
komp. typu desktop to 16-32 bity)

SMALLINT: krótka liczba całkowita – zazwyczaj o połowę krótsza od zwykłej
liczby całkowitej.
NUMERIC: stałoprzecinkowa liczba rzeczywista. Przykład NUMERIC(6,2)
3456,73
DECIMAL: stałoprzecinkowa liczba rzeczywista, podobna do typu NUERIC ale
w przypadku DECIMAL system zarządzania może przechowywać więcej cyfr po
przecinku niż zostało to ustalone i może to poprawiać dokładność obliczeń.
REAL: zmiennoprzecinkowa liczba o „ pojedynczej precyzji”
DOUBLE PRECISION (DOUBLE): zmiennoprzecinkowa liczba o „ podwójnej
precyzji”
FLOAT: zmiennoprzecinkowa liczba o wybieralnej precyzji
Typy Danych Liczbowych W Ms Sql Sever 2005
Liczby całkowite.
Istnieją cztery rodzaje danych typu całkowitego (integer), które mogą
przechowywać dokładne, skalarne wartości : bigint, int, smallint, tinyint. Różnica
pomiędzy typami tych danych całkowitych występuje w ilości przestrzeni
pamięci, której wymagają, oraz w zakresie wartości jakie mogą przechowywać.
Poniższa tabela pokazuje typy danych i ich zakresy.
Typ danych
Długość (w bajtach)
Zakres
tinyint
1
0-255
smallint
2
-32767 do +32767

int
4
- + 2147483657
bigint
8
- + 2^63
Przybliżone i dokładne liczbowe typy danych
MS SQL Server zezwala na dwa typy przybliżonych danych (float i real), jak i na
dwa dokładne typy danych liczbowych (decimal i numeric).
Przybliżonymi typami danych są float i real. Liczby przechowywane za pomocą
tych typów danych zapisywane są w postaci pary : mantysy i wykładnika.
Algorytm, używany do określania takiej pary może okazać się mało precyzyjny
dla liczb z górnego zakresu precyzji. Liczby zmiennoprzecinkowe i rzeczywiste są
przydatne do danych naukowych i statystycznych, dla których absolutna
dokładność nie jest niezbędna ale potrzebny jest zakres wartości od bardzo
małych do bardzo dużych.
Liczby rzeczywiste mają precyzję 7 cyfr i wymagają 4 bajtów. Jeżeli
zadeklarowany będzie typ float o precyzji mniejszej niż 7, to tak naprawdę
zostanie utworzony kolumna typu rzeczywistego (real).
Przykład
Liczby 23487,23 45,98763 można przechować w kolumnie typu real, ale
8,4557987 już nie.
Typy float mogą mieć dokładność od 1 do 38. Domyślna precyzja dla typu float to
15 cyfr.
( na danych typy float, real nie można wykonywać dzielenia modulo; generalnie
unikamy typów float, real gdyż wyniki obliczeń mogą być zaskakujące)
Dokładne typy danych liczbowych to decimal i numeric. Dokładność jest
utrzymywana do najmniej znaczącej cyfry. Jeżeli deklarujemy dokładny typ

danych numerycznych, należy określić dwa składniki : precyzję i skalę. Jeśli nie
zostaną określone to przyjmowane są wartości domyślne 18 i 0.
Funkcje Matematyczne (W Ms Sql Sever 2005)
Oto niektóre dostępne funkcje matematyczne:
ABS(X)
Moduł z X.
CEILING(X)
Zaokrąglenie w górę (do całkowitej) X-a.
FLOOR(X)
Zaokrąglenie w dół (do całkowitej) X-a.
EXP()
funkcja wykładnicza o podstawie E
POWER(X,Y)
Zwraca X do potęgi Y.
ROUND(X,Y) Zaokrągla X do Y miejsc po przecinku
SIGN(X)
-1 gdy X<0, +1 gdy X>0, 0 gdy X=0
SQRT(X)
Pierwiastek kwadratowy z X.
LOG()
funkcja logarytm naturalny
LOG10()
funkcja logarytm dziesiętny
COS, SIN, COT, TAN() funkcje trygonometryczne
ACOS, ASIN, ATAN()
funkcje cyklometryczne
PI()
liczba Pi
RAND()
losowa liczba z przedziału [0,1]
Typy DANYCH TEKSTOWYCH
CHARACTER (skrót CHAR): łańcuch tekstowy o stałej długości. Deklarując
ten typ należy wskazać długość łańcucha (w MS SQL maksymalnie 8000 znaków
brakujące znaki zastępowane są spacjami). ---- CHAR(25)
CHARACTER VARYING (skrót VARCHAR) : ): łańcuch tekstowy o zmiennej
długości. Deklarując ten typ należy wskazać dopuszczalną długość łańcucha. -----
VARCHAR(25)
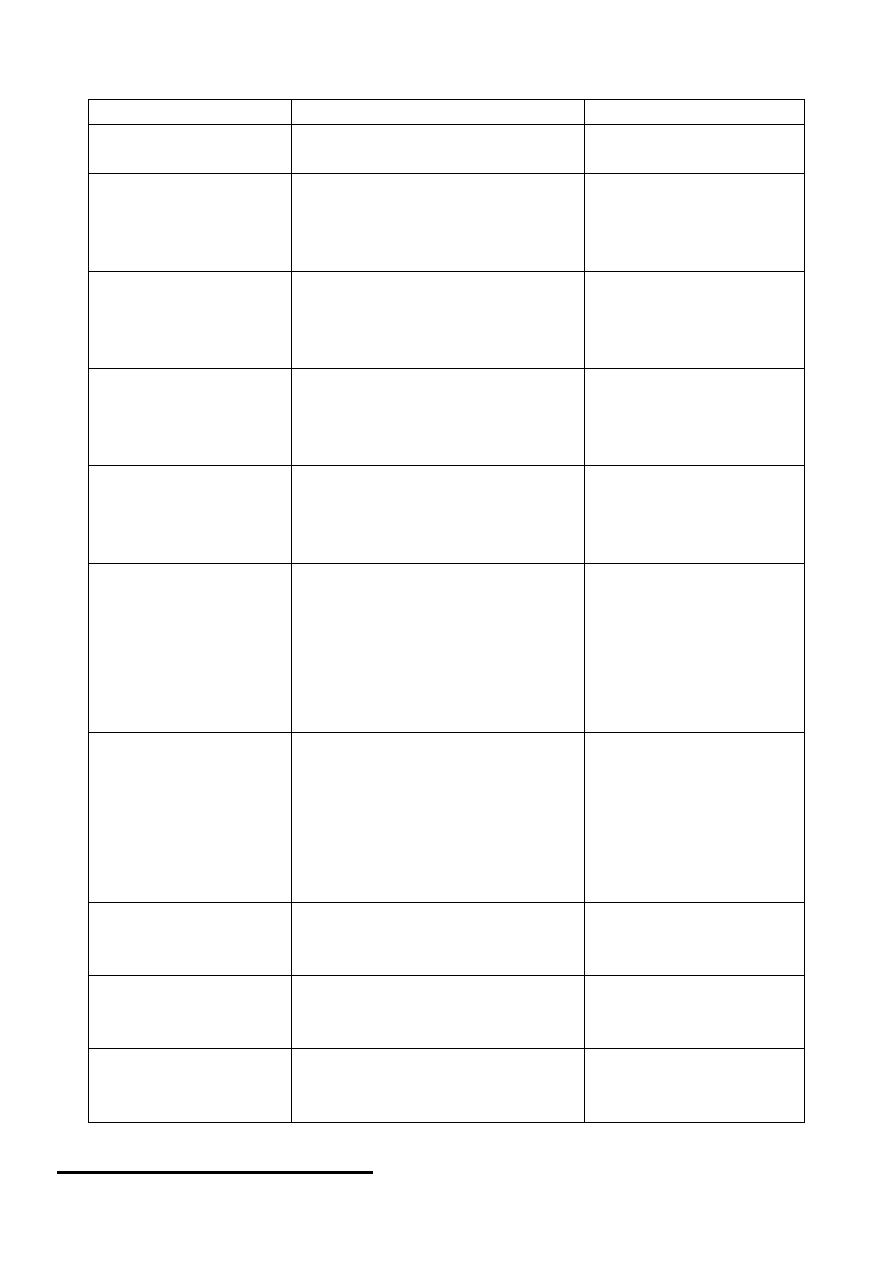
Funkcje znakowe
Składnia
Przeznaczenie
Przykład
CHR(n)
Zwraca znak o podanym
kodzie
CHR(65)
Wynik: "A"
LOWER(string)
Zamienia wszystkie litery w
podanym stringu na małe.
LOWER('PAN JAN
NOWAK')
Wynik: "pan jan
nowak"
LTRIM(string )
Zwraca dane bez spacji na
początku
LTRIM(' Ostatnie
słowo')
Wynik: ”Ostatnie
słowo"
REPLACE(string1,
string2 , string3 )
Zastępuje wszelkie wystąpienia
łańcucha string2 w łańcuchu
string1 przez string3
REPLACE('Jack &
Jue', 'J', Bl')
Wynik: "Black &
Blue"
RTRIM(string)
Zwraca dane bez spacji na
końcu
RTRIM('Ostatnie
słowo ‘)
Wynik: "Ostatnie
słowo”
SOUNDEX(string)
Zwraca ciąg znaków
reprezentujący wymowę słów
wchodzących w skład string.
Funkcja SOUNDEX może być
użyta do porównywania słów
zapisywanych w różny sposób,
ale wymawianych tak samo.
SELECT nazwisko
FROM bibl
WHERE
SOUNDEX(nazwisko)
=
SOUNDEX('Mickiewic
z');
SUBSTRING(string,
m , n)
Zwraca podciąg z ciągu
znaków string zaczynający się
na znaku m i o długości n. Jeśli
n nie jest podane, to zwracany
jest podciąg od znaku m do
ostatniego w string. Pierwszy
znak w ciągu ma numer 1.
SUBSTR('ABCDE',2,
3)
Wynik: "BCD"
UPPER(string)
Zamienia wszystkie znaki z
ciągu string na duże litery.
UPPER('Jan Nowak')
Wynik: "JAN
NOWAK"
ASCII(string)
Zwraca kod ASCII pierwszej
litery w podanym ciągu
znaków
ASCII('A')
Wynik: 65
|| +
Funkcja dwu argumentowa
dodawania łańcuchów,
konkatencja
Typy Danych Dla Daty i Czasu
DATE – data
TIME – godzina
DATETIME – data i godzina (typ dla MS SQL)
Funkcje daty
Przy pomocy funkcji daty można operować na danych typu datetime. Można
również używać funkcji daty w liście kolumn (column_list), w klauzuli WHERE
lub innych wyrażeniach. Składnia jest następująca:
SELECT date_function(parameters)
Należy umieszczać wartości datetime jako parametry w pojedynczym lub
podwójnym cudzysłowiu. Niektóre funkcje korzystają z parametru datepart. W
tabeli została przedstawiona lista wartości datepart i ich skrótów.
datepart
Skrót
Wartości
day
dd
1–31
day of year
dy
1–366
hour
hh
0–23
milisecond
ms
0–999
minute
mi
0–59
month
mm
1–12
quarter
1–4
second
ss
0–59
week
wk
0–53
weekday
dw
1–7 (Sun–Sat)
year
yy
1753–9999
Poniższa tabela pokazuje funkcje daty, parametry tych funkcji i wyniki ich działania.
Funkcja
Wynik
DATEADD(datepart, number,
date)
Dodaje ilość (number) jednostek czasu
datepart do date
DATEDIFF(datepart, date1, date2) Zwraca ilość jednostek datepart pomiędzy
dwoma datami
DATENAME(datepart, date)
Zwraca wartość ASCII dla określonej
jednostki datepart dla określonej daty (date)
DATEPART(datepart, date)
Zwraca wartość całkowitą dla określonej
datepart dla daty (date)
DAY(date)
Zwraca wartość całkowitą reprezentującą
ilość dni

GETDATE()
Zwraca bieżącą datę i czas w wewnętrznym
formacie
MONTH(date)
Zwraca wartość całkowitą reprezentującą
miesiąc
YEAR(date)
Zwraca wartość całkowitą reprezentującą rok
SQL udostępnia szereg funkcji (agregujących) do przetwarzania zbiorów danych, umożliwiających prowadzenie operacji na wartościach tej samej kolumny w
wybranych wierszach. Rezultatem zastosowania każdej z nich jest kolumna obliczona pojawiająca się w tabeli wynikowej.
Składnia
Przeznaczenie
Przykład
AVG( num)
Zwraca wartość średnią
ignorując wartości puste
SELECT AVG(placa)
"Srednia"
FROM pracownicy
COUNT( expr)
Zwraca liczbę wierszy, w
których expr nie jest równe
NULL
SELECT
COUNT(nazwisko)
"Liczba"
FROM pracownicy
COUNT(*)
Zwraca liczbę wierszy w
tabeli włączając
powtarzające się i równe
NULL
SELECT COUNT(*)
"Wszystko"
FROM pracownicy
MAX( expr)
Zwraca maksymalną
wartość wyrażenia
SELECT MAX(Placa)
"Max"
FROM pracownicy
MIN( expr)
Zwraca minimalną wartość
wyrażenia
SELECT MIN(Placa)
"Min"
FROM pracownicy
STDEV( num)
Zwraca odchylenie
standardowe wartości num
ignorując wartości NULL.
SELECT STDEV(Placa)
"Odchylenie" FROM
pracownicy
SUM( num)
Zwraca sumę wartości num. SELECT SUM(Placa)
"Koszty osobowe"
FROM pracownicy
VAR(num)
Zwraca wariancję wartości
num ignorując wartości
NULL
SELECT VAR(Placa)
"Wariancja" FROM
pracownicy
Tworzenie grup.
Aby utworzyć grupę należy do wyrażenia SELECT dodać klauzulę GROUP BY,
zawierającą nazwy kolumn, których wartości mają być użyte przy formatowaniu
grup.
SELECT COUNT(*), NR_SAMOCHODU
FROM WYPOZYCZENIA

GROUP BY NR_SAMOCHODU
Można również zagnieżdżać grupowanie, podając więcej niż jedną nazwę
kolumny w klauzuli GROUP BY.
Wiersze poddawane grupowaniu mogą być ograniczone poprzez wykorzystanie
klauzuli WHERE. Możemy również ograniczyć utworzyć grupy a następnie
ograniczyć ich wyświetlanie poprzez użycie klauzuli HAVING.
SELECT COUNT(*), NR_SAMOCHODU
FROM WYPOZYCZENIA
GROUP BY NR_SAMOCHODU
HAVING NR_SAMOCHODU>00003
ZAGNIEśDśANIE ZAPYTAŃ.
Zapytania w SQL mogą operować na wynikach innych zapytań; możliwe jest
więc tzw. zagnieżdżanie zapytań. Podzapytanie (lub podwybór) to pełne
wyrażenie SELECT zagnieżdżone w innym wyrażeniu SELECT. Rezultat
wewnętrznego SELECT staje się tabelą wyjściową dla zapytania zewnętrznego.
Typowy schemat zagnieżdżania:
SELECT lista kolumn
FROM tabela
WHERE kolumna IN (SELECT kolumna FROM tabela WHERE warunek)
SELECT *
FROM samochody
WHERE nr_samochodu in
(SELECT wypozyczenia.nr_samochodu from wypozyczenia where data_odd is
null)
Istnieją dwa typy podzapytań. W podzapytaniu nieskorelowanym interpretator
poleceń SQL-a potrafi zakończyć przetwarzanie wewnętrznego SELECT przed
przystąpieniem do analizy zewnętrznego. Z kolei w podzapytaniu skorelowanym
, interpretator nie jest w stanie wykonać zapytania wewnętrznego bez informacji
pochodzących z zewnętrznego. Zapytania skorelowane wymagają zazwyczaj
wielokrotnego obliczania wewnętrznego SELECT i są w związku z tym mało
wydajne.

Zagnieżdżanie zapytań może zostać wykorzystane do wyznaczenia różnicy dwóch
zgodnych relacji (tabel).
W tym przypadku schemat postępowania można przedstawić w postaci:
SELECT *
FROM tabelaA
WHERE (lista_kolumn) NOT IN (SELECT (lista_klumn) FROM tabelaB)
SELECT *
FROM tabelaA
WHERE (nr_samochodu||rok_prod) not in (SELECT nr_samochodu||rok_prod
from tabelaB)
Suma relacji zgodnych – operator UNION wewnątrz klauzuli SELECT
Klauzula UNION łączy dwa lub więcej polecenia SELECT w jedną tabelę
wynikową. Klauzule SELECT muszą zwracać tę samą liczbę kolumn, kolumny
pokrywające się muszą mieć tę samą szerokość i typ danych. Nazwy kolumn
mogą być różne. Klauzula UNION łączy dwa zestawy wyników w jeden i
jednocześnie usuwa duplikaty.
Podstawową składnię można przedstawić w następujący sposób:
SELECT lista_kolumn_z_A
FROM TabelaA
WHERE warunek_dla_A
UNION
SELECT lista_kolumn_z_B
FROM TabelaB
WHERE warunek_dla_B
Można używać klauzuli UNION z parametrem ALL, wówczas wynik może
zawierać powtarzające się wiersze. Klauzula UNION ALL działa szybciej niż
UNION. Wynik dodawania relacji (tabel) może być porządkowany z użyciem
ORDER BY.
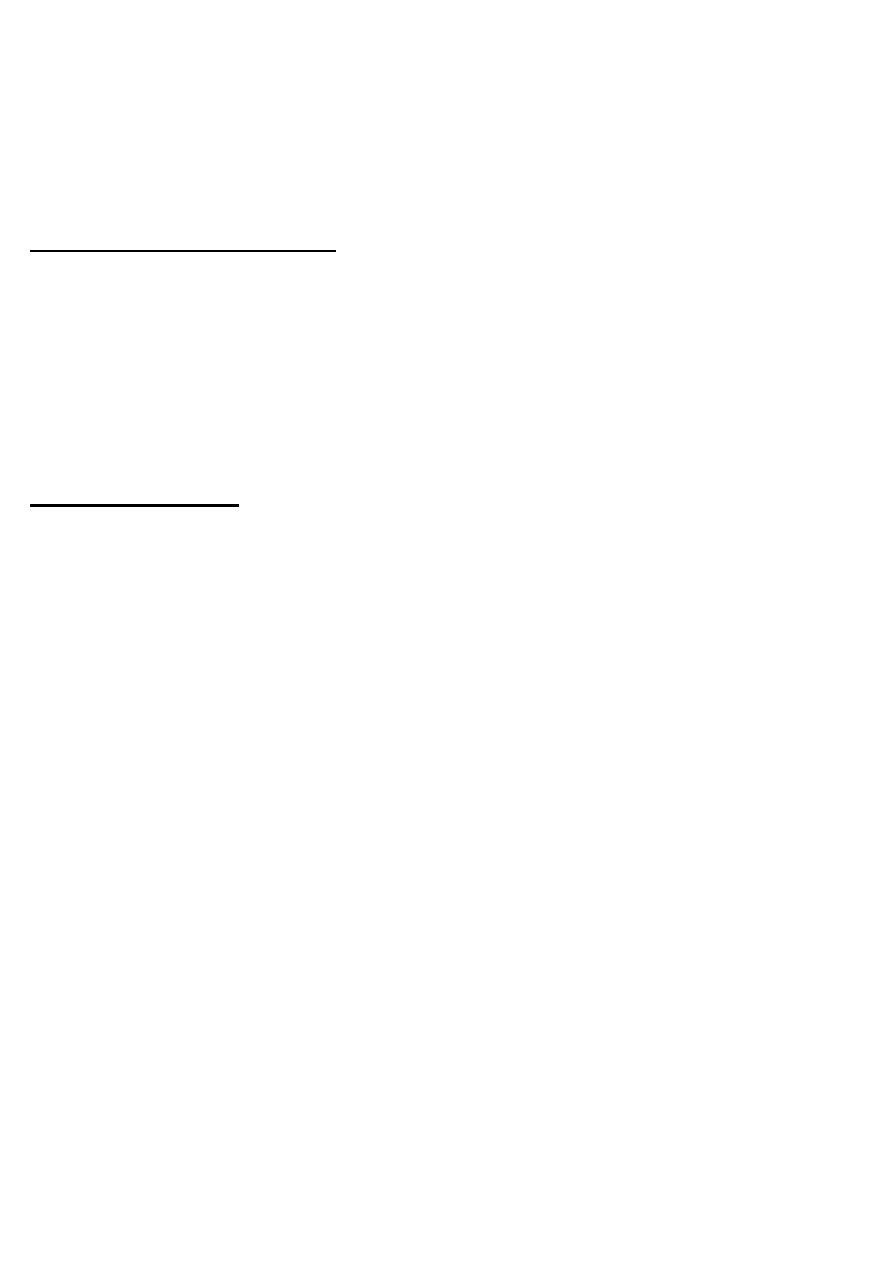
SELECT *
FROM TabelaA
UNION
SELECT *
FROM TabelaB
ORDER BY 1 ASC
MODYFIKOWANIE DANYCH.
Istnieją trzy czynności dotyczące wierszy, jakie możemy wykonać na tabeli:
wstawić wiersz do tabeli, usunąć wiersz z tabeli lub dokonać zmiany wartości
zawartych w wierszu. SQL zawiera trzy polecenia służące do modyfikowania
danych przechowywanych w tabelach. Są to: INSERT, UPDATE i DELETE.
Większość aplikacji bazodanowych udostępnia swoim użytkownikom formularze
służące do wprowadzania i zmiany danych w tabelach bazowych co eliminuje
konieczność bezpośredniego wydawania poleceń SQL-owych.
Wstawianie wierszy.
SQL-owe polecenie INSERT posiada dwa zastosowania: po pierwsze umożliwia
dopisanie pojedynczego wiersza do tabeli bazowej, a po drugie można za jego
pomocą skopiować jeden lub więcej wierszy z innej tabeli.
Aby dopisać jeden wiersz do wybranej tabeli, wykorzystujemy następującą
składnię:
INSERT INTO nazwa_tabeli
VALUES (lista_wartości)
Lista wartości powinna zawierać wartości dla wszystkich kolumn w tabeli (w
kolejności określonej w schemacie), wpisywane dane winny być zgodne z typami
poszczególnych kolumn. Dla przykładu, aby dodać rekord do tabeli Klienci
wydamy polecenie:
INSERT INTO Klienci
VALUES
(121,’Tadeusz’,’Poreda’,NULL,’Sofomat’,’Gospodarcza’,’11/10’,’Łódź’,’93-
335’,NULL, ‘042666768’)
Podczas dopisywania nowego wiersza do tabeli , system zarządzania sprawdza
czy dopisanie tych danych nie naruszy reguł integralności.
Jeżeli dodając rekord nie zamierzamy umieszczać wartości we wszystkich
kolumnach tabeli możemy w poleceniu INSERT po nazwie tabeli podać listę
kolumn do których wstawiane będą wartości. Kolumny pominięte w liście
kolumn wypełnione zostaną wartością null. Pamiętać przy tym należy o tym, że
kolumny klucza podstawowego nie mogą przyjmować wartości null.

Drugim zastosowaniem polecenia INSERT jest kopiowanie dowolnej liczby
wierszy z jednej tabeli do drugiej. Kopiowane wiersze muszą zostać wskazane za
pomocą polecenia SELECT.
Składnia wówczas przedstawia się następująco:
INSERT INTO nazwa_tabeli
SELECT pełna_składnia_do_select
(kolumny zwracane przez polecenie SELECT muszą odpowiadać tym, z których
składa się tabela docelowa)
INSERT INTO tabelaA
SELECT * FROM tabelaB
Polecenie wstawienia wyniku zapytania powoduje wykonanie zapytania oraz
utworzenie tabeli roboczej, która jest wstawiana od razu w całości do tabeli
docelowej. Wstawienie nie jest wykonane pomyślnie, jeśli chociaż jeden wiersz
narusza ograniczenia na tabelą docelowa.
Poleceniem INSERT możemy dodawać rekordy nie tylko do tabel ale również do
perspektyw (widoków) tworzonych poleceniem Create View.
Nowo wstawianym wierszom najczęściej system zarządzania przypisuje
wewnętrzny identyfikator (będący zazwyczaj połączeniem numeru wiersza i
identyfikatora tabeli) który określa fizyczne położenie wiersza w pliku
zawierającym bazę danych. Jeżeli skasujemy któryś z wierszy jego numer na ogół
nie jest wykorzystywany w początkowym etapie. Stąd odwoływanie się do
fizycznego adresu wiersza jest niewłaściwe.
Kasowanie wierszy
Instrukcja DELETE w SQL-u powoduje usunięcie zero lub większej liczby
wierszy jednej tabeli. Większość interaktywnych narzędzi SQL-a powiadamia
użytkownika o liczbie wierzy przeznaczonych do skasowania (aktualizacji).
Wyrażenie DELETE odnosi się do jednego lub większej ilości wierszy wybranych
z tabeli na podstawie określonych kryteriów. Ogólna składnia instrukcji
DELETE przedstawia się następująco:
DELETE FROM nazwa_tabeli
WHERE kryterium_wyboru;
Przykład dotyczący tabeli Wyp (kasujący wszystkie rekordy z datą wypożyczenia
wcześniejszą niż 2004-12-31).
Delete from wyp
Where data_wyp<’12/31/2004’
Polecenie COMMIT potwierdza zaś polecenie ROLLBACK anuluje zmiany i
zamyka aktywną transakcję. DELETE jest operacją potencjalnie niebezpieczną.

Opuszczenie klauzuli WHERE spowoduje skasowanie wszystkich wierszy tabeli.
Sama tabela pozostaje w bazie danych ale jest pusta. Klauzula WHERE w
instrukcji może być złożona, jak tylko chcemy (np. może zawierać podzapytanie
czy też odwoływać się do innej tabeli lub jej samej).
Większość implementacji SQL-a wykonuje usuwanie wierszy w dwóch
przejściach tabeli. W pierwszym zostają zaznaczone wszystkie kandydujące
wiersze, które spełniają kryterium podane w klauzuli WHERE. W drugim
przejściu następuje ich usunięcie bądź natychmiast, bądź oznaczenie ich w taki
sposób, by program porządkujący mógł później odzyskać zajmowaną przez nie
przestrzeń.
Przykład: Dokonać usunięcia tych pracowników których pensja jest większa od
średniej płacy wszystkich pracowników:
Delete from pracownicy
Where pensja>(Select avg(pensja) from pracownicy);
Gdyby dane przetwarzane były po jednym wierszu a pracownicy byliby
uporządkowani malejąco wg pensji to praktycznie wszyscy byliby skasowani.
Pracownik Pensja
P1
4000
P2
3000
P3
2000
P4
2000
P5
1000
Problem usuwania duplikatów. Nadmiarowymi duplikatami są niepotrzebne
kopie wierszy w tabeli. Jeżeli wiersze stanowią ścisłe duplikaty, nie możemy ich
usunąć za pomocą zwykłej instrukcji Delete.
Szereg problemów może sprawić usuwanie wierszy w tabeli zależnej od innej
tabeli ze względu na integralność referencyjną.
Zmiana (modyfikowanie) danych
SQL-owe polecenie UPDATE operuje na wartościach jednego lub większej ilości
wierszy, w zależności od kryteriów wyboru zawartych w klauzuli WHERE.
Update ma następującą składnię;
UPDATE nazwa_tabeli
SET kolumna1=nowa_wartość,
Kolumna2=nowa_wartość
WHERE kryteria_wyboru_wierszy
Przykład: Zbudować zapytanie podnoszące pensję wszystkim pracownikom
działu obsługa techniczna o 10%

Update pracownicy
Set pensja=pensja+pensja*0.1
Where dzial=’TECHNICZNY’
Możemy modyfikować zawartość kolumny wykorzystywanej do odszukania
interesujących nas wierszy. System zarządzania bazą danych najpierw sporządzi
listę wierszy do modyfikacji, a dopiero potem przystąpi do wprowadzania zmian.
Ta równoległość działania nie jest podobna do postępowania w klasycznych
językach programowania
Uwaga Poniższe polecenie zamieni dane w kolumnach pensja, dodatek
Update pracownicy ab
Set dodatek=(Select abc.pensja from pracownicy abc where
ab.nr_pracownika=abc.nr_pracownika),
pensja=(Select abc.dodatek from pracownicy abc where
ab.nr_pracownika=abc.nr_pracownika)
Przykład: Zbudować zapytanie podnoszące pensję o 20% wszystkim
pracownikom którzy aktualnie mają pensję poniżej 1400.
Update pracownicy
Set pensja=pensja+pensja*0.2
Where pensja<1400
Modyfikacja danych w jednej z tabel może odbywać się z wykorzystaniem
danych pochodzących z innej tabeli.
Przykład:
Update pracownicy
set pensja=pensja*(1+(select podwyzka from dzialy where
pracownicy.dzial=dzialy.dzial))
Wyszukiwarka
Podobne podstrony:
jawa podr Podstawy programowaniaT-SQL
CBS podr pl 2010
podr niem0020
CBS podr przyk pl 2010
(OTWP wiadomosci podstwowe)id 1 Nieznany
podr niem0004
I TEST chorby z podr
Kolor na kulturowe podstwy
Obsługa i naprawa motocykla Jawa TS50
Analiza podr czników szkolnych
Co to jest prÄdkoÅÄ podróż1
Kurs - Podstawy SQLa, TYTAN 5
PODSTWTO, Data
Wykład II Podstwowe pojęcia, WYKŁAD II
ćw 5 podr Rozwój aktywności i zabawy
więcej podobnych podstron