Sortowanie B
ą
belkowe
Bubble Sort
Jest to prosty algorytm sortuj
ą
cy o zło
ż
ono
ś
ci obliczeniowej O(n
2
).
Pomimo swojej prostoty nie nadaje si
ę
do sortowania du
ż
ych zbiorów
danych (za górn
ą
granic
ę
przyj
ę
to około 5000 elementów). Algorytm
opiera si
ę
na kolejnych porównaniach dwóch s
ą
siednich elementów za
pomoc
ą
funkcji porównuj
ą
cej. Je
ś
li porównywane elementy s
ą
w dobrej
kolejno
ś
ci, to nast
ę
puje przej
ś
cie do nast
ę
pnego elementu. W przeciwnym
razie elementy s
ą
zamieniane miejscami. Działanie to jest kontynuowane,
a
ż
wszystkie pary s
ą
siednich elementów w zbiorze b
ę
d
ą
uło
ż
one we
wła
ś
ciwej kolejno
ś
ci.
Przykład
Posortujemy metod
ą
b
ą
belkow
ą
zbiór pi
ę
ciu liczb: { 9 5 6 3 1 } w porz
ą
dku
rosn
ą
cym. Porz
ą
dek rosn
ą
cy oznacza, i
ż
element poprzedzaj
ą
cy jest
zawsze mniejszy lub równy od elementu le
żą
cego dalej w zbiorze. Nasza
funkcja porównuj
ą
ca przyjmie zatem posta
ć
relacji mniejszy lub równy.
Algorytm sortowania b
ą
belkowego nie jest zbytnio efektywny dla
nieuporz
ą
dkowanych zbiorów danych. Jednak je
ś
li zbiór jest w wi
ę
kszo
ś
ci
uporz
ą
dkowany (tylko kilka elementów znajduje si
ę
na niewła
ś
ciwym
miejscu), to zło
ż
ono
ść
obliczeniowa zbli
ż
a si
ę
do klasy O(n), a wi
ę
c czas
sortowania zale
ż
y liniowo od liczby elementów, co powoduje, i
ż
wci
ąż
mo
ż
na go zastosowa
ć
w niektórych przypadkach.
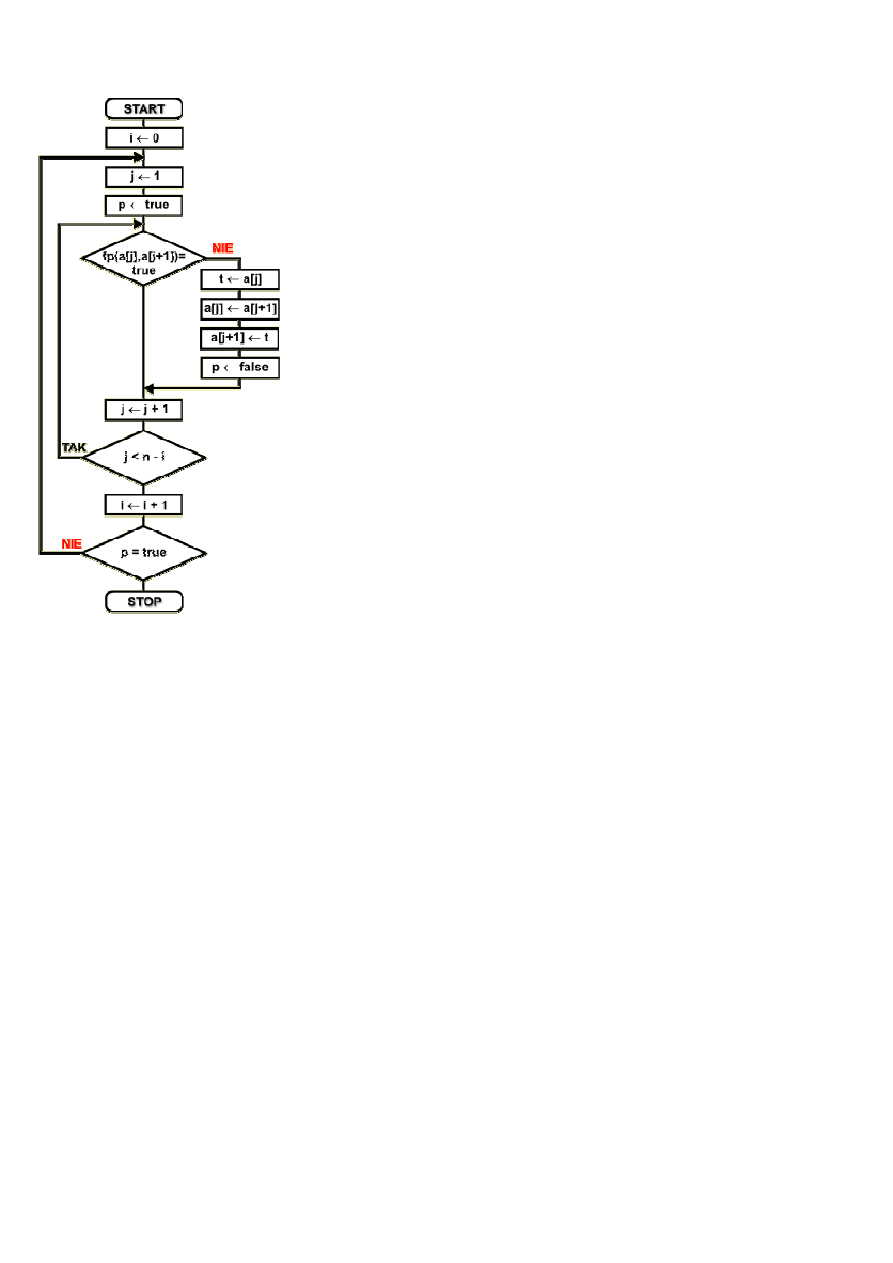
Schemat blokowy
Dany jest zbiór { a
1
a
2
a
3
...a
n-2
a
n-1
a
n
}, który nale
ż
y posortowa
ć
zgodnie z funkcj
ą
porównuj
ą
c
ą
fp(...). W algorytmie zastosowano nast
ę
puj
ą
ce zmienne:
n
liczba elementów w zbiorze
a[...] element zbioru o numerze od 1 do n, podanym w klamrach kwadratowych
i , j
zmienne u
ż
ywane na liczniki p
ę
tli
p
zmienna logiczna u
ż
ywana do sprawdzenia, czy cały zbiór jest ju
ż
posortowany
t
zmienna tymczasowa u
ż
ywana przy wymianie zawarto
ś
ci elementów tablicy
Algorytm rozpoczynamy nadaj
ą
c zmiennej i warto
ść
0. Zmienna ta pełni funkcj
ę
: licznika elementów,
które zostały ju
ż
uporz
ą
dkowane na ko
ń
cu zbioru - patrz przykład. Poniewa
ż
jeszcze nie
uporz
ą
dkowano
ż
adnych elementów, dlatego i przyjmuje warto
ść
0.
W p
ę
tli wewn
ę
trznej porównujemy ze sob
ą
kolejne elementy zbioru z elementem nast
ę
pnym. Zmienna
p jest znacznikiem uporz
ą
dkowania zbioru. Przed wej
ś
ciem do p
ę
tli ustawiana jest na warto
ść
logiczn
ą
true. Je
ś
li wewn
ą
trz p
ę
tli elementy nie s
ą
uporz
ą
dkowane, tzn. funkcja porównuj
ą
ca
fp( a[j] , a[j+1] ) daje w wyniku warto
ść
logiczn
ą
false, porównywane elementy s
ą
ze sob
ą
zamieniane i znacznik p przyjmuje warto
ść
false. Spowoduje to nast
ę
pny obieg p
ę
tli zewn
ę
trznej,
która wykonuje si
ę
do momentu, a
ż
p b
ę
dzie miało warto
ść
logiczn
ą
true, czyli nie wyst
ą
piła
ż
adna
zamiana elementów zbioru, co oznacza jego uporz
ą
dkowanie.
Po porównaniu elementów i ewentualnej zamianie ich miejsc nast
ę
puje zwi
ę
kszenie indeksu j. Je
ś
li w
zbiorze pozostały jeszcze jakie
ś
elementy do porównania, to wykonywany jest nast
ę
pny obieg p
ę
tli
wewn
ę
trznej.

W przeciwnym razie p
ę
tla wewn
ę
trzna jest ko
ń
czona i nast
ę
puje zwi
ę
kszenie o 1 licznika p
ę
tli
zewn
ę
trznej. Powoduje to zmniejszenie o 1 liczby elementów do porównania w zbiorze - ka
ż
dy obieg
p
ę
tli zewn
ę
trznej ustala pozycj
ę
ostatniego elementu zbioru - w nast
ę
pnym obiegu nie musimy go ju
ż
sprawdza
ć
, co przy du
ż
ej liczbie elementów znacznie zmniejsza ilo
ść
wykonywanych porówna
ń
.
Je
ś
li znacznik uporz
ą
dkowania zbioru p ma warto
ść
false, to nast
ę
puje kolejny obieg p
ę
tli
zewn
ę
trznej. Jest to konieczne, poniewa
ż
zbiór mo
ż
e by
ć
nieuporz
ą
dkowany. Sortowanie ko
ń
czymy
dopiero wtedy, gdy wszystkie pary kolejnych elementów s
ą
we wła
ś
ciwym porz
ą
dku i w trakcie
przegl
ą
dania zbioru nie wyst
ą
piło
ż
adne przestawienie elementów. Zwró
ć
my uwag
ę
, i
ż
je
ś
li zbiór jest
w du
ż
ej mierze uporz
ą
dkowany, to algorytm zako
ń
czy si
ę
po kilku obiegach p
ę
tli zewn
ę
trznej, a wi
ę
c
jest dosy
ć
efektywnym rozwi
ą
zaniem.
Poni
ż
ej przedstawiamy realizacj
ę
opisanego algorytmu sortowania w ró
ż
nych j
ę
zykach
programowania. Program tworzy dwie tablice o identycznej zawarto
ś
ci, wypełnione przypadkowymi
liczbami. Nast
ę
pnie jedn
ą
z tych tablic sortuje i wy
ś
wietla obie dla zobrazowania efektu posortowania
danych.
Przykład w C++
#include <stdlib.h>
#include <time.h>
#include <iostream.h>
const int n = 10; // liczba elementów w sortowanym zbiorze
// funkcja porównująca
int fp(int x, int y)
{
return (x <= y);
}
int main()
{
int i,j,t,p,a[n],b[n];
// tworzymy tablicę z przypadkową zawartością.
// tablica b[] służy do zapamiętania stanu a[]
srand( (unsigned)time( NULL ) );
for(i = 0; i < n; i++ )
a[i] = b[i] = 1 + rand() % (n + n);
// sortowanie bąbelkowe
i = 0;
do
{
p = 1;
for(j = 0; j < n - i - 1; j++)
if(!fp(a[j],a[j+1]))

{
t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
p = 0;
};
i++;
}
while(p == 0);
// wyświetlamy wyniki
cout << "Sortowanie babelkowe" << endl
<< "(C)2003 mgr Jerzy Walaszek" << endl << endl
<< " lp przed po" << endl
<< "------------------------" << endl;
for(i = 0; i < n; i++)
{
cout.width(4); cout << i;
cout.width(9); cout << b[i];
cout.width(9); cout << a[i] << endl;
};
cout << endl;
cout.flush();
system("pause");
return 0;
Sortowanie przez Wstawianie
Insertion Sort
Algorytm sortowania przez wstawianie nale
ż
y równie
ż
do klasy
zło
ż
ono
ś
ci obliczeniowej
O(n
2
), lecz w
porównaniu do opisanego wcze
ś
niej algorytmu
sortowania b
ą
belkowego
jest du
ż
o szybszy i bardziej
efektywny, lecz oczywi
ś
cie bardziej zło
ż
ony koncepcyjnie. Zasada działania tego algorytmu
przypomina układanie w r
ę
ce kart pobieranych z talii. W skrócie mo
ż
emy opisa
ć
go tak:
Na ko
ń
cu (lub na pocz
ą
tku) zbioru tworzymy uporz
ą
dkowan
ą
list
ę
elementów. Najpierw lista ta składa
si
ę
z ostatniego elementu. Ze zbioru wyci
ą
gamy przedostatni element. Miejsce, które zajmował staje
si
ę
puste. Sprawdzamy, czy wyci
ą
gni
ę
ty element jest w dobrej kolejno
ś
ci z elementem ostatnim. Je
ś
li
tak, to wstawiamy go z powrotem do zbioru. Je
ś
li nie, to na jego miejsce przesuwamy element ostatni,
a na miejsce elementu ostatniego wstawiamy wyci
ą
gni
ę
ty element. W efekcie na ko
ń
cu zbioru mamy
ju
ż
dwa elementy w dobrej kolejno
ś
ci. Teraz kolejno wybieramy elementy od ko
ń
ca zbioru i
wstawiamy je w odpowiednie miejsce tworzonej na ko
ń
cu listy. Elementy wcze
ś
niejsze s
ą
przesuwane
na li
ś
cie o jedn
ą
pozycj
ę
w lewo. Operacje te s
ą
kontynuowane a
ż
do wstawienia pierwszego
elementu. W efekcie otrzymujemy posortowany zbiór.
Wstawianie elementu do listy uporz
ą
dkowanej
Prezentowany algorytm sortowania przez wstawianie wymaga wstawiania elementu zbioru do listy
uporz
ą
dkowanej. Mamy element wybrany ze zbioru. Naszym zadaniem jest przeszukanie listy
uporz
ą
dkowanej i znalezienie pozycji, na której ma si
ę
znale
źć
wybrany element. Zadanie to
wykonamy najpro
ś
ciej rozpoczynaj
ą
c przegl
ą
danie od pocz
ą
tku listy uporz
ą
dkowanej. Je
ś
li
funkcja
porównuj
ą
ca
przyjmuje warto
ść
false dla elementu wybranego i
elementu z listy, to element z listy uporz
ą
dkowanej przenosimy na
poprzedni
ą
pozycj
ę
i przechodzimy do sprawdzenia kolejnego elementu
na li
ś
cie. Je
ś
li funkcja porównuj
ą
ca przyjmie warto
ść
true, to element
wybrany umieszczamy na poprzednim miejscu na li
ś
cie uporz
ą
dkowanej
(poprzednie miejsce w stosunku do aktualnie testowanego jest zawsze
wolne!).
W przykładzie przedstawionym poni
ż
ej wstawiamy liczb
ę
6 do lity {2 4 5
7 9}. Funkcja porównuj
ą
ca wyznacza porz
ą
dek rosn
ą
cy (ma warto
ść
true, je
ś
li kolejne argumenty s
ą
w porz
ą
dku rosn
ą
cym).
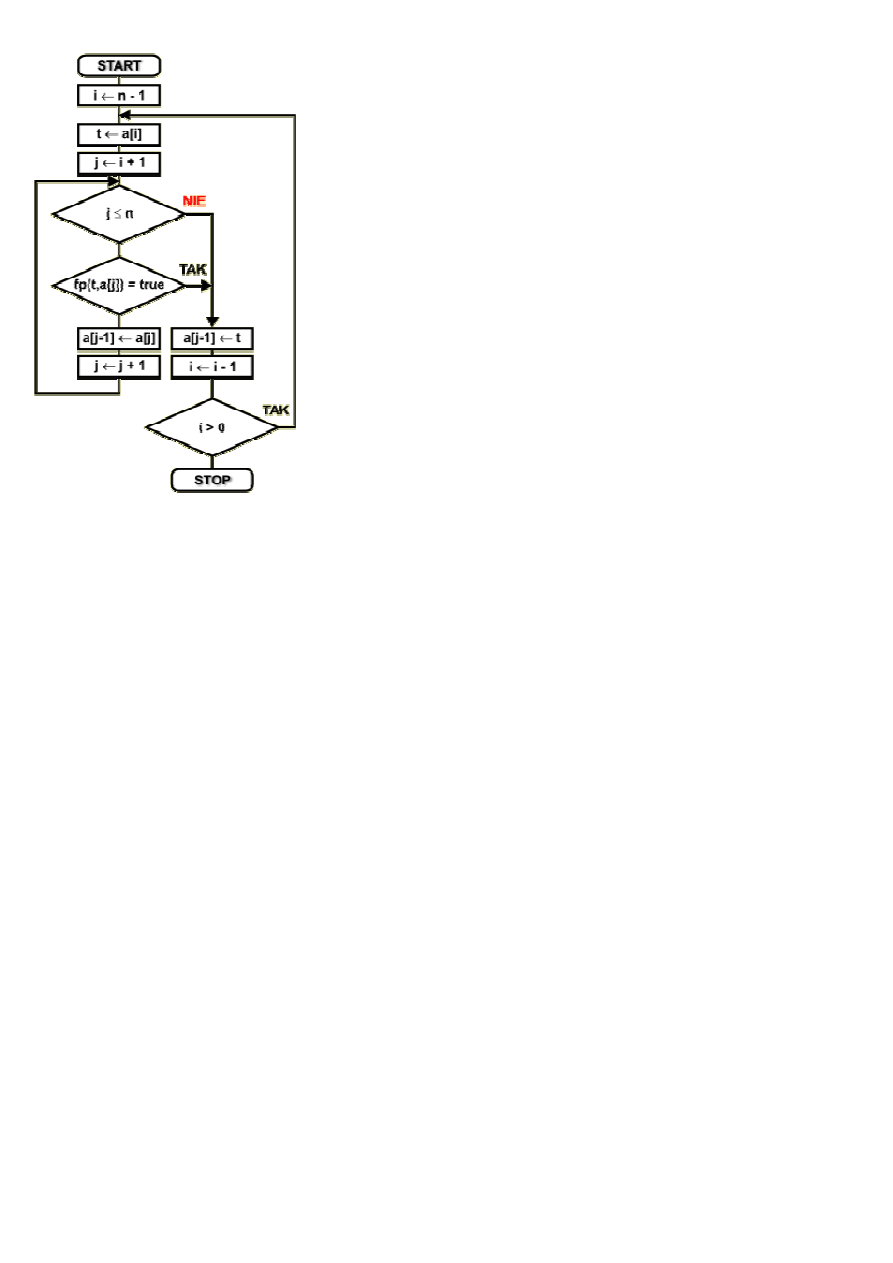
Schemat blokowy
Dany jest zbiór { a
1
a
2
a
3
...a
n-2
a
n-1
a
n
}, który nale
ż
y posortowa
ć
zgodnie
z
funkcj
ą
porównuj
ą
c
ą
fp(...). Do opisu algorytmu stosujemy nast
ę
puj
ą
ce
zmienne:
n
liczba elementów w zbiorze
a[...] element zbioru o numerze od 1 do n, podanym w klamrach kwadratowych
i , j
zmienne u
ż
ywane na liczniki p
ę
tli
t
zmienna tymczasowa u
ż
ywana do przechowania wstawianego elementu
P
ę
tla zewn
ę
trzna wykona n-1 obiegów. Na pocz
ą
tku zmienn
ą
licznikow
ą
tej p
ę
tli ustawiamy na
warto
ść
n-1. Wskazuje ona przedostatni element zbioru. Element ten wybieramy do wstawiania.
Najpierw zapami
ę
tujemy go w zmiennej tymczasowej t. Dzi
ę
ki temu pozycja zajmowana przez ten
element zostaje zwolniona.
W p
ę
tli wewn
ę
trznej sterowanej zmienn
ą
j przeszukujemy tworzon
ą
na ko
ń
cu zbioru list
ę
uporz
ą
dkowan
ą
w poszukiwaniu pozycji wstawienia wybranego wcze
ś
niej elementu. Wszystkie
elementy mniejsze na li
ś
cie uporz
ą
dkowanej s
ą
przesuwane o jedn
ą
pozycj
ę
wstecz. Przeszukiwanie
listy uporz
ą
dkowanej ko
ń
czy si
ę
w dwóch przypadkach:
1. Osi
ą
gni
ę
to koniec listy - wybrany element jest wi
ę
kszy wg funkcji porównuj
ą
cej od wszystkich
elementów
na
li
ś
cie
uporz
ą
dkowanej.
2. Funkcja porównuj
ą
ca przyjmuje warto
ść
true, co oznacza, i
ż
wybrany element powinien by
ć
umieszczony przed testowanym elementem listy uporz
ą
dkowanej.
Gdy p
ę
tla wewn
ę
trzna zako
ń
czy swoje działanie, to w obu mo
ż
liwych przypadkach zmienna j zawiera
pozycj
ę
o 1 wi
ę
ksz
ą
od pozycji wstawiania. Dlatego element wybrany wpisujemy na pozycj
ę
a[j - 1].
Zmniejszamy licznik p
ę
tli zewn
ę
trznej, sprawdzamy, czy nie osi
ą
gn
ą
ł on warto
ś
ci ko
ń
cowej. Je
ś
li nie,
to kontynuujemy z nast
ę
pnym elementem zbioru. W przeciwnym wypadku ko
ń
czymy wykonywanie
algorytmu
sortowania.
Poni
ż
ej przedstawiamy realizacj
ę
opisanego algorytmu sortowania w ró
ż
nych j
ę
zykach
programowania. Program tworzy dwie tablice o identycznej zawarto
ś
ci, wypełnione przypadkowymi
liczbami. Nast
ę
pnie jedn
ą
z tych tablic sortuje i wy
ś
wietla obie dla zobrazowania efektu posortowania
danych.

#include <stdlib.h>
#include <time.h>
#include <iostream.h>
const int n = 10; // liczba elementów w sortowanym zbiorze
// funkcja porównująca
int fp(int x, int y)
{
return (x <= y);
}
int main()
{
int i,j,t,a[n],b[n];
// tworzymy tablicę z przypadkową zawartością.
// tablica b[] służy do zapamiętania stanu a[]
srand( (unsigned)time( NULL ) );
for(i = 0; i < n; i++ )
a[i] = b[i] = 1 + rand() % (n + n);
// sortowanie przez wstawianie
for(i = n - 2; i >= 0; i--)
{
t = a[i];
for(j = i + 1; (j < n) && !fp(t,a[j]); j++) a[j - 1] = a[j];
a[j - 1] = t;
};
// wyświetlamy wyniki
cout << "Sortowanie przez wstawianie\n"
<< "(C)2003 mgr Jerzy Walaszek\n\n"
<< " lp przed po\n"
<< "------------------------\n";
for(i = 0; i < n; i++)
{
cout.width(4); cout << i + 1;
cout.width(9); cout << b[i];
cout.width(9); cout << a[i] << endl;
};
cout << endl;
cout.flush();
system("pause");
return 0;
}

Sortowanie przez Selekcj
ę
Selection Sort
Algorytm sortowania przez selekcj
ę
nale
ż
y do algorytmów sortuj
ą
cych o klasie
zło
ż
ono
ś
ci
obliczeniowej
O(n
2
). Nie jest on cz
ę
sto stosowany, poniewa
ż
opisany w poprzednim rozdziale
algorytm
sortowania przez wstawianie
ma t
ą
sam
ą
zło
ż
ono
ść
, a jest nieco szybszy. Zasada działania
jest bardzo prosta. Najpierw szukamy w zbiorze elementu najmniejszego. Gdy zostanie znaleziony,
wymieniamy
go z pierwszym elementem zbioru. Nast
ę
pnie zbiór pomniejszamy o ten pierwszy
element, który ustawiony został ju
ż
na wła
ś
ciwej pozycji. W tak pomniejszonym zbiorze znów szukamy
elementu najmniejszego i wstawiamy go na drug
ą
pozycj
ę
. Zbiór pomniejszamy i kontynuujemy te
same operacje wyszukiwa
ń
i wstawie
ń
, a
ż
wszystkie elementy zbioru zostan
ą
posortowane.
Przykład
Posortujemy t
ą
metod
ą
zbiór pi
ę
ciu liczb: { 9 5 6 3 1 } w porz
ą
dku rosn
ą
cym. Nasza
funkcja
porównuj
ą
ca
przyjmie wi
ę
c posta
ć
relacji mniejszy lub równy.
{ 9 5 6 3
1
}
W zbiorze szukamy najmniejszego elementu. Jest nim liczba
1
.
{
1
5 6 3
9
}
Poniewa
ż
najmniejszy element nie jest na pierwszej pozycji, wi
ę
c wymieniamy go z
elementem pierwszym, czyli
9
.
1
{ 5 6
3
9 }
W pomniejszonym zbiorze szukamy elementu najmniejszego. Jest nim liczba
3
.
1
{
3
6
5
9 }
Znaleziony element najmniejszy wymieniamy z pierwszym elementem.
1
3
{ 6
5
9 }
Na wła
ś
ciwym miejscu s
ą
ju
ż
dwa elementy zbioru. W
ś
ród pozostałych elementów
znajdujemy element najmniejszy.
1
3
{
5
6
9 }
Wymieniamy go z pierwszym elementem zbioru
1 3 5
{
6
9 }
Na wła
ś
ciwym miejscu s
ą
ju
ż
trzy elementy. Poniewa
ż
pozostały zbiór posiada
wi
ę
cej ni
ż
jeden element, dalej szukamy elementu najmniejszego. Poniewa
ż
element najmniejszy jest ju
ż
na pierwszym miejscu, nie wykonujemy
ż
adnych
przestawie
ń
.
{ 1 3 5 6 9 }
Po wykonaniu ostatniej operacji wszystkie elementy zostały posortowane.
Wyszukanie najmniejszego elementu w zbiorze
W podanym algorytmie wyst
ę
puje problem znalezienia najmniejszego elementu w zbiorze wzgl
ę
dem
zadanej
funkcji porównuj
ą
cej
. Element najmniejszy zdefiniujmy nast
ę
puj
ą
co:
a
∈
∈
∈
∈
D jest najmniejszy, je
ś
li dla ka
ż
dego b
∈
∈
∈
∈
D i a
≠
b zachodzi fp(a,b) = true.
Z definicji tej mo
ż
na wywnioskowa
ć
, i
ż
najmniejszy element nie jest poprzedzony
ż
adnym innym
elementem zbioru, który si
ę
od niego ró
ż
ni. Jest to dosy
ć
istotne spostrze
ż
enie, poniewa
ż
zbiory mog
ą
posiada
ć
elementy o identycznej zawarto
ś
ci. Funkcja porównuj
ą
ca nie okre
ś
la kolejno
ś
ci wzgl
ę
dem
siebie elementów identycznych, tzn. poniewa
ż
elementy te s
ą
sobie równe, wi
ę
c ich kolejno
ść
jest
zwykle nieistotna.
Element najmniejszy znajdujemy nast
ę
puj
ą
co: za tymczasowy element najmniejszy przyjmujemy
pierwszy element zbioru. Nast
ę
pnie porównujemy go kolejno ze wszystkimi pozostałymi elementami
za pomoc
ą
funkcji porównuj
ą
cejj
. Je
ś
li dla jakiego
ś
elementu funkcja ta przyjmie warto
ść
logiczn
ą
false, to element ten b
ę
dzie mniejszy od tymczasowego i zast
ą
pimy nim najmniejszy element
tymczasowy.
Oto odpowiedni przykład: naszym zadaniem jest wyszukanie najmniejszego elementu w zbiorze { 4 7
3 2 5 1 }. Niech funkcja porównuj
ą
ca ustala porz
ą
dek rosn
ą
cy.
{
4
7 3 2 5 1 }
Za tymczasowy najmniejszy element przyjmujemy pierwszy element zbioru, czyli
4
.
{
4
7
3 2 5 1 }
Nast
ę
pnie porównujemy go kolejno z pozostałymi elementami zbioru:
fp(4,7) = true - dobra kolejno
ść
, pozostawiamy element tymczasowy bez zmian
{
4
7
3
2 5 1 }
fp(4,3) = false - znale
ź
li
ś
my element mniejszy, wi
ę
c za nowy element
najmniejszy przyjmujemy warto
ść
3
{ 4 7
3
2
5 1 }
Kontynuujemy przegl
ą
danie
ze
znalezionym
najmniejszym
elementem
tymczasowym:
fp(3,2) = false - nowy element najmniejszy
2
{ 4 7 3
2
5
1 }
fp(2,5) = true - dobra kolejno
ść
, liczba
2
pozostaje elementem najmniejszym
{ 4 7 3
2
5
1
}
fp(2,1) = false - zła kolejno
ść
, znale
ź
li
ś
my nowy element najmniejszy -
1
{ 4 7 3 2 5
1
}
Poniewa
ż
przegl
ą
dn
ę
li
ś
my wszystkie elementy zbioru, to warto
ść
1
jest
najmniejsza wg funkcji porównuj
ą
cej ten zbiór.
Schemat blokowy
Dany jest zbiór { a
1
a
2
a
3
...a
n-2
a
n-1
a
n
}, który nale
ż
y posortowa
ć
zgodnie z
funkcj
ą
porównuj
ą
cej
fp(...). Do opisu algorytmu stosujemy nast
ę
puj
ą
ce zmienne:
n
liczba elementów w zbiorze
a[...]
element zbioru o numerze od 1 do
n
podanym
w
klamrach
kwadratowych
i , j
zmienne u
ż
ywane na liczniki p
ę
tli
t
zmienna przechowuj
ą
ca indeks
elementu najmniejszego
x
zmienna pomocnicza

Zmienna i otrzymuje na pocz
ą
tku warto
ść
1. Pełni ona rol
ę
licznika obiegów p
ę
tli zewn
ę
trznej oraz
elementów posortowanych - znajduj
ą
cych si
ę
na wła
ś
ciwej pozycji.
Zmienna t zawiera indeks najmniejszego elementu. Na pocz
ą
tku p
ę
tli wewn
ę
trznej przyjmuje ona
numer pierwszego elementu w zbiorze, czyli i-ty. Nast
ę
pnie przeszukujemy pozostał
ą
cz
ęść
zbioru w
poszukiwaniu elementów mniejszych. Je
ś
li takie zostan
ą
znalezione, to ich indeksy b
ę
d
ą
wprowadzone do zmiennej t. Kryterium znajdowania elementu najmniejszego ustala funkcja
porównuj
ą
ca dla tego zbioru.
Po przeszukaniu całego zbioru w t mamy indeks najmniejszego elementu. Wymieniamy pierwszy
element zbioru (i-ty) z elementem najmniejszym. Dzi
ę
ki tej operacji na pocz
ą
tek zbioru trafia element
najmniejszy, który znajduje si
ę
ju
ż
na wła
ś
ciwej pozycji.
Zmienna i zostaje zwi
ę
kszona o 1, co powoduje zmniejszenie zbioru do posortowania i przej
ś
cie do
kolejnego elementu. P
ę
tla jest kontynuowana, a
ż
wszystkie elementy zbioru zostan
ą
posortowane.
Poni
ż
ej przedstawiamy realizacj
ę
opisanego algorytmu sortowania w ró
ż
nych j
ę
zykach
programowania. Program tworzy dwie tablice o identycznej zawarto
ś
ci, wypełnione przypadkowymi
liczbami. Nast
ę
pnie jedn
ą
z tych tablic sortuje i wy
ś
wietla obie dla zobrazowania efektu posortowania
danych.
#include <stdlib.h>
#include <time.h>
#include <iostream.h>
const int n = 10; // liczba elementów w sortowanym zbiorze
// funkcja porównuj
ą
ca
int fp(int x, int y)
{
return (x <= y);
}
int main()
{
int i,j,t,x,a[n],b[n];

// tworzymy tablic
ę
z przypadkow
ą
zawarto
ś
ci
ą
.
// tablica b[] słu
ż
y do zapami
ę
tania stanu a[]
srand( (unsigned)time( NULL ) );
for(i = 0; i < n; i++ )
a[i] = b[i] = 1 + rand() % (n + n);
// sortowanie przez wybór
for(i = 0; i < n - 1; i++)
{
t = i;
for(j = i + 1; j < n; j ++)
if(!fp(a[t],a[j])) t = j;
x = a[t]; a[t] = a[i]; a[i] = x;
};
// wy
ś
wietlamy wyniki
cout << "Sortowanie przez wybor" << endl
<< "(C)2003 mgr Jerzy Walaszek" << endl << endl
<< " lp przed po" << endl
<< "------------------------" << endl;
for(i = 0; i < n; i++)
{
cout.width(4); cout << i + 1;
cout.width(9); cout << b[i];
cout.width(9); cout << a[i] << endl;
};
cout << endl;
cout.flush();
system("pause");
return 0;
}
Sortowanie Metod
ą
Shella
Shell Sort
Algorytm ten został zaproponowany przez Donalda Shella w 1959 roku. Jest to najszybszy algorytm
sortuj
ą
cy w klasie O(n
2
). Idea jest nast
ę
puj
ą
ca: Shell zauwa
ż
ył, i
ż
algorytm
sortowania przez
wstawianie
(insertion sort) jest bardzo efektywny, gdy zbiór jest ju
ż
w du
ż
ej cz
ęś
ci uporz
ą
dkowany.
Wtedy zło
ż
ono
ść
obliczeniowa jest prawie liniowa - O(n). Jednak
ż
e algorytm ten nieefektywnie
przestawia elementy w trakcie sortowania - poniewa
ż
porównywane s
ą
kolejne elementy na li
ś
cie
uporz
ą
dkowanej, to ulegaj
ą
one przesuni
ę
ciu tylko o jedn
ą
pozycj
ę
przy ka
ż
dym obiegu p
ę
tli
wewn
ę
trznej. Shell wpadł na pomysł modyfikacji algorytmu sortowania przez wstawianie tak, aby
porównywane były na pocz
ą
tku elementy odległe od siebie, a pó
ź
niej ta odległo
ść
malała i w ko
ń
cowej
fazie powstawałby zwykły algorytm sortowania przez wstawianie, lecz ze zbiorem jest ju
ż
w du
ż
ym
stopniu uporz
ą
dkowanym.
Osi
ą
gn
ą
ł to dziel
ą
c w ka
ż
dym obiegu zbiór na odpowiedni
ą
liczb
ę
podzbiorów, których elementy s
ą
od
siebie odległe o stał
ą
odległo
ść
g. Nast
ę
pnie ka
ż
dy z podzbiorów jest sortowany za pomoc
ą
sortowania przez wstawianie. Powoduje to cz
ęś
ciowe uporz
ą
dkowanie zbioru. Dalej odległo
ść
g jest
zmniejszana (najcz
ęś
ciej o połow
ę
), znów s
ą
tworzone podzbiory (jest ich teraz mniej) i nast
ę
puje
kolejna faza sortowania. Operacje te kontynuujemy a
ż
do momentu, gdy odległo
ść
g osi
ą
gnie warto
ść
0. Wtedy zbiór wyj
ś
ciowy b
ę
dzie uporz
ą
dkowany.
Zasadniczym czynnikiem wpływaj
ą
cym na efektywno
ść
algorytmu sortowania metod
ą
Shella jest
odpowiedni dobór ci
ą
gu kolejnych odst
ę
pów. Shell zaproponował przyj
ę
cie na pocz
ą
tku odst
ę
pu
równego połowie liczby elementów w zbiorze, a nast
ę
pnie zmniejszanie tego odst
ę
pu o połow
ę
przy
ka
ż
dym obiegu p
ę
tli. Nie jest to najbardziej efektywne rozwi
ą
zanie, jednak najprostsze w
implementacji. Dlatego b
ę
dziemy z niego korzysta
ć
.
Przykład
Posortujemy metod
ą
Shella zbiór o
ś
miu liczb: { 4 2 9 5 6 3 8 1 } w porz
ą
dku rosn
ą
cym. Nasza
funkcja
porównuj
ą
ca
przyjmie wi
ę
c posta
ć
relacji mniejszy lub równy. Zbiór posiada osiem elementów, zatem
przyjmiemy na wst
ę
pie odst
ę
p g równy 4. Taki odst
ę
p podzieli zbiór na 4 podzbiory, których elementy
b
ę
d
ą
elementami zbioru wej
ś
ciowego odległymi od siebie o 4 pozycje:
{
4
2
9
5
6
3
8
1
}
-
zbiór
podstawowy
{
5
1
}
-
pierwszy
podzbiór,
elementy
a
4
i
a
8
{
9
8
}
-
drugi
podzbiór,
elementy
a
3
i
a
7
{
2
3
}
-
trzeci
podzbiór,
elementy
a
2
i
a
6
{ 4 6 }
- czwarty podzbiór, elementy a
1
i a
5
Teraz ka
ż
dy z otrzymanych podzbiorów sortujemy algorytmem sortowania przez wstawianie.
Poniewa
ż
zbiory te s
ą
dwuelementowe, to sortowanie p
ę
dzie polegało na porównaniu pierwszego
elementu podzbioru z elementem drugim i ewentualn
ą
zamian
ę
ich miejsc, je
ś
li b
ę
d
ą
w niewła
ś
ciwym
porz
ą
dku okre
ś
lonym
funkcj
ą
porównuj
ą
c
ą
.
{
5 1
}
{ 1 5 }
Podzbiór pierwszy. Niewła
ś
ciwa kolejno
ść
, zamieniamy miejscami
{
9 8
}
{ 8 9 }
Podzbiór drugi. Niewła
ś
ciwa kolejno
ść
, zamieniamy miejscami
{ 2 3 }
Podzbiór trzeci. Kolejno
ść
dobra, pozostawiamy bez zmian.
{ 4 6 }
Podzbiór czwarty. Kolejno
ść
dobra, pozostawiamy bez zmian
Po pierwszym obiegu otrzymujemy nast
ę
puj
ą
cy wynik uporz
ą
dkowania zbioru:
{
1
5
}
-
pierwszy
podzbiór,
elementy
a
4
i
a
8
{
8
9
}
-
drugi
podzbiór,
elementy
a
3
i
a
7
{
2
3
}
-
trzeci
podzbiór,
elementy
a
2
i
a
6
{
4
6
}
-
czwarty
podzbiór,
elementy
a
1
i
a
5
{ 4 2 8 1 6 3 9 5 }
- zbiór podstawowy
Zmniejszamy odst
ę
p g o połow
ę
, wi
ę
c g = 2. Zbiór podstawowy zostanie podzielony na dwa
podzbiory:
{
4
2
9
5
6
3
8
1
}
-
zbiór
podstawowy
{
2
5
3
1
}
-
pierwszy
podzbiór,
elementy
a
2
,
a
4
,
a
6
i
a
8
{
4
9
6
8
}
-
drugi
podzbiór,
elementy
a
1
,
a
3
,
a
5
i
a
7
Ka
ż
dy z tych podzbiorów sortujemy przez wstawianie:
{ 2 5 3 1 }
Na ko
ń
cu tworzymy list
ę
uporz
ą
dkowan
ą
, a kolejne elementy wstawiamy na t
ą
list
ę
pocz
ą
wszy od przedostatniego i sko
ń
czywszy na pierwszym.
3
{ 2 5
1
}
{ 2 5
1 3
}
1 przesuwamy na puste miejsce, a 3 umieszczamy na zwolnionej pozycji. Lista
uporz
ą
dkowana zawiera ju
ż
2 elementy.
5
{ 2
1 3
}
{ 2
1 3 5
}
1 i 3 przesuwamy o jedn
ą
pozycj
ę
w lewo, a 5 umieszczamy na zwolnionej pozycji.
Lista uporz
ą
dkowana ma ju
ż
3 elementy
2
{
1 3 5
}
{
1 2 3 5
}
1 przesuwamy na wolne miejsce, a 2 wstawiamy na zwolnion
ą
pozycj
ę
pomi
ę
dzy 1 a
3. Podzbiór pierwszy został uporz
ą
dkowany
{ 4 9 6 8 }
W taki sam sposób porz
ą
dkujemy podzbiór drugi
6
{ 4 9
8
}
{ 4 9
6 8
}
Poniewa
ż
6 jest w dobrym porz
ą
dku z 8, to nie dokonujemy wymiany elementów.
9
{ 4
6 8
}
{ 4
6 8 9
}
6 i 8 przesuwamy o jedn
ą
pozycj
ę
w lewo, a 9 wstawiamy na koniec listy
uporz
ą
dkowanej.
4
{
6 8 9
}
{
4 6 8 9
}
4 jest w dobrej kolejno
ś
ci, wi
ę
c nie dokonujemy wstawiania wewn
ą
trz listy.
Po drugim obiegu otrzymujemy nast
ę
puj
ą
cy wynik uporz
ą
dkowania zbioru wej
ś
ciowego:

{
1
2
3
5
}
-
pierwszy
podzbiór,
elementy
a
2
,
a
4
,
a
6
i
a
8
{
4
6
8
9
}
-
drugi
podzbiór,
elementy
a
1
,
a
3
,
a
5
i
a
7
{ 4 1 6 2 8 3 9 5 }
- zbiór podstawowy
Zmniejszamy odst
ę
p g o połow
ę
, g = 1. Taki odst
ę
p nie dzieli zbioru wej
ś
ciowego na podzbiory, wi
ę
c
teraz b
ę
dzie sortowany przez wstawianie cały zbiór. Jednak algorytm sortuj
ą
cy ma ułatwion
ą
prac
ę
,
poniewa
ż
dzi
ę
ki poprzednim dwóm obiegom zbiór został cz
ęś
ciowo uporz
ą
dkowany - elementy małe
zbli
ż
yły si
ę
do pocz
ą
tku zbioru, a elementy du
ż
e do ko
ń
ca.
{ 4 1 6 2 8 3 9 5 }
Na ko
ń
cu tworzymy list
ę
uporz
ą
dkowan
ą
, a kolejne elementy wstawiamy
na t
ą
list
ę
pocz
ą
wszy od przedostatniego i sko
ń
czywszy na pierwszym.
9
{ 4 1 6 2 8 3
5
}
{ 4 1 6 2 8 3
5 9
}
5 przesuwamy na woln
ą
pozycj
ę
, a 9 wstawiamy na koniec listy.
3
{ 4 1 6 2 8
5 9
}
{ 4 1 6 2 8
3
5 9
}
3 pozostawiamy na miejscu
8
{ 4 1 6 2
3 5 9
}
{ 4 1 6 2
3
5 8 9
}
3 i 5 przesuwamy o 1 pozycj
ę
w lewo, a 8 wstawiamy na zwolnione miejsce
pomi
ę
dzy 5 i 9
2
{ 4 1 6
3 5 8 9
}
{ 4 1 6
2 3 5 8 9
}
2 pozostawiamy na miejscu.
6
{ 4 1
2 3 5 8 9
}
{ 4 1
2 3 5 6 8 9
}
2, 3 i 5 przesuwamy o 1 pozycj
ę
w lewo. Na zwolnione miejsce wstawiamy
6.
1
{ 4
2 3 5 6 8 9
}
{ 4
1 2 3 5 6 8 9
}
1 pozostawiamy na swoim miejscu.
4
{
1 2 3 5 6 8 9
}
{
1 2 3 4 5 6 8 9
}
1, 2 i 3 przesuwamy o 1 pozycj
ę
w lewo. Na zwolnione miejsce pomi
ę
dzy 3
a 5 wstawiamy 4. Zbiór jest uporz
ą
dkowany.
Zaleta algorytmu sortuj
ą
cego metod
ą
Shella ujawni si
ę
przy du
ż
ej liczbie elementów. W takim
przypadku zbiór zostaje najszybciej posortowany ze wszystkich algorytmów sortuj
ą
cych klasy O(n
2
).
Algorytm mo
ż
na jeszcze bardziej zoptymalizowa
ć
dobieraj
ą
c odpowiednio ci
ą
g odst
ę
pów g, lecz tym
zagadnieniem nie b
ę
dziemy si
ę
tutaj zajmowa
ć
.
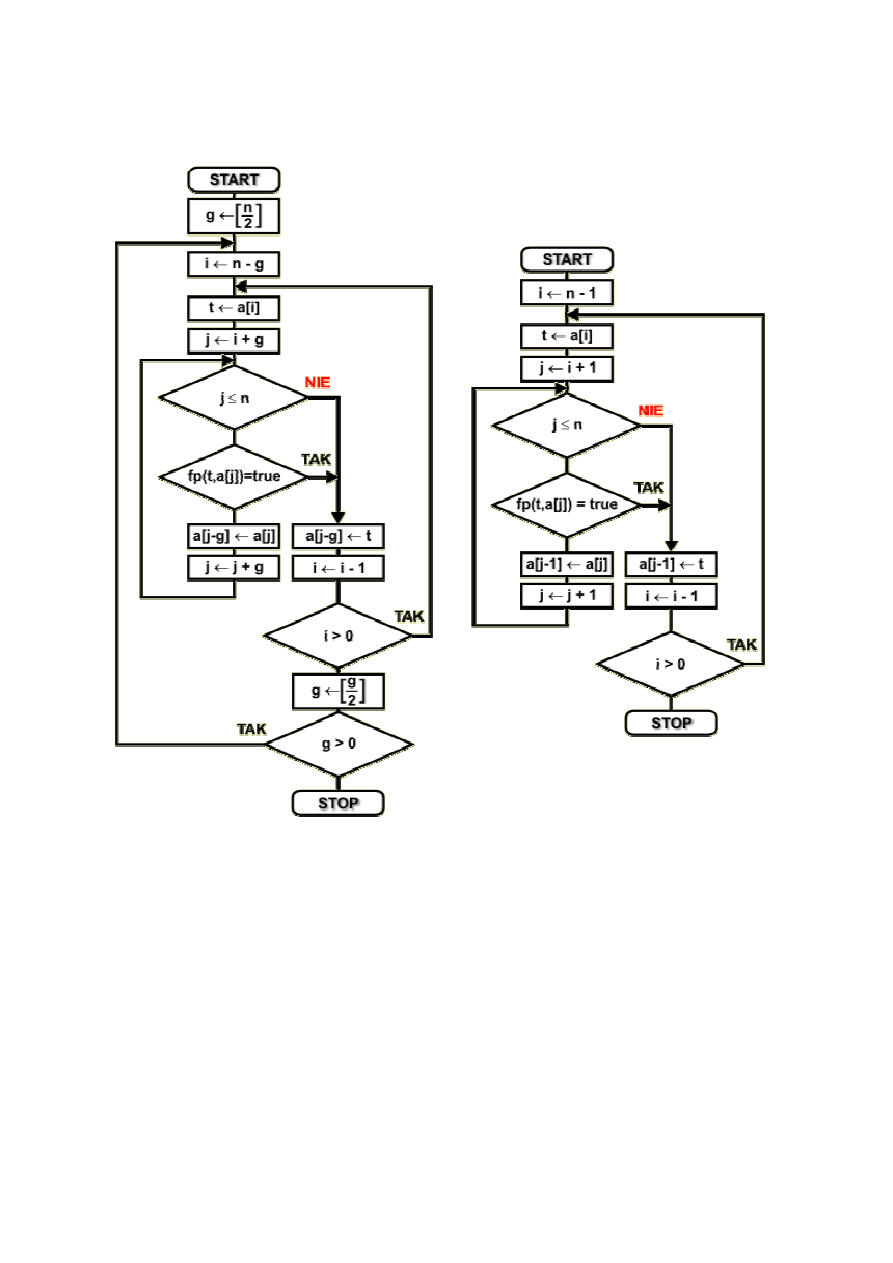
Schemat blokowy
Dany jest zbiór { a
1
a
2
a
3
...a
n-2
a
n-1
a
n
}, który nale
ż
y posortowa
ć
zgodnie z
funkcj
ą
porównuj
ą
c
ą
fp(...). Do opisu algorytmu stosujemy nast
ę
puj
ą
ce zmienne:
n
liczba elementów w zbiorze
a[...] element zbioru o numerze od 1 do n, podanym w klamrach kwadratowych
i , j
zmienne u
ż
ywane na liczniki p
ę
tli
g
zmienna przechowuj
ą
ca odst
ę
p pomi
ę
dzy sortowanymi elementami.
t
zmienna tymczasowa u
ż
ywana przy wymianie zawarto
ś
ci elementów tablicy
Algorytm sortuj
ą
cy Shella
Algorytm sortowania przez wstawianie
W celach porównawczych rozmy
ś
lnie umie
ś
cili
ś
my powy
ż
ej schematy blokowe algorytmu sortowania
metod
ą
Shella oraz
przez wstawianie
. Zwró
ć
cie uwag
ę
na ich podobie
ń
stwo. Algorytm Shella jest
modyfikacj
ą
algorytmu sortowania przez wstawianie polegaj
ą
c
ą
na tym, i
ż
nie jest sortowany od razu
cały zbiór, lecz jego podzbiory. Do tego celu słu
ż
y wła
ś
nie odst
ę
p g, który w algorytmie Shella jest
zmienny, a w sortowaniu przez wstawianie jest stały i wynosi 1. Dodatkowa oprawa algorytmu Shella
zawiera wi
ę
c obsług
ę
zmian odst
ę
pu g. Pozostała cz
ęść
jest praktycznie taka sama jak w algorytmie
sortowania przez wstawianie.
Poni
ż
ej przedstawiamy realizacj
ę
opisanego algorytmu sortowania w ró
ż
nych j
ę
zykach
programowania. Program tworzy dwie tablice o identycznej zawarto
ś
ci, wypełnione przypadkowymi
liczbami. Nast
ę
pnie jedn
ą
z tych tablic sortuje i wy
ś
wietla obie dla zobrazowania efektu posortowania
danych.

#include <stdlib.h>
#include <time.h>
#include <iostream.h>
const int n = 10; // liczba elementów w sortowanym zbiorze
// funkcja porównuj
ą
ca
int fp(int x, int y)
{
return (x <= y);
}
int main()
{
int i,j,t,g,a[n],b[n];
// tworzymy tablic
ę
z przypadkow
ą
zawarto
ś
ci
ą
.
// tablica b[] słu
ż
y do zapami
ę
tania stanu a[]
srand( (unsigned)time( NULL ) );
for(i = 0; i < n; i++ )
a[i] = b[i] = 1 + rand() % (n + n);
// sortowanie metod
ą
Shella
for(g = n / 2; g > 0; g /= 2)
for(i = n - g - 1; i >= 0; i--)

{
t = a[i];
for(j = i + g; (j < n) && !fp(t,a[j]); j += g)
a[j - g] = a[j];
a[j - g] = t;
};
// wy
ś
wietlamy wyniki
cout << "Sortowanie metoda Shella" << endl
<< "(C)2003 mgr Jerzy Walaszek" << endl << endl
<< " lp przed po" << endl
<< "------------------------" << endl;
for(i = 0; i < n; i++)
{
cout.width(4); cout << i + 1;
cout.width(9); cout << b[i];
cout.width(9); cout << a[i] << endl;
};
cout << endl;
cout.flush();
system("pause");
return 0;
}
Sortowanie przez Kopcowanie
Heap Sort
Wszystkie opisane poprzednio algorytmy maj
ą
jedn
ą
podstawow
ą
wad
ę
- nale
żą
do klasy
zło
ż
ono
ś
ci
obliczeniowej
O(n
2
), co oznacza, i
ż
w najgorszym przypadku czas sortowania ro
ś
nie z kwadratem
liczby sortowanych elementów. Przy du
ż
ej ich liczbie (si
ę
gaj
ą
cej dziesi
ą
tków lub setek tysi
ę
cy)
sortowanie mo
ż
e zaj
ąć
nawet najszybszemu komputerowi du
żą
ilo
ść
czasu (nawet wiele wieków!).
Zachodzi wi
ę
c naturalne pytanie, czy nie da si
ę
tego zrobi
ć
szybciej? Odpowied
ź
jest pozytywna.
Wymy
ś
lono wiele algorytmów sortuj
ą
cych, które nale
żą
do klasy zło
ż
ono
ś
ci obliczeniowej O(n log
2
n) -
liniowo logarytmicznej. Poniewa
ż
logarytm z n jest zawsze mniejszy od n (dla n >= 1), to ich iloczyn
jest mniejszy od n
2
, co zapisujemy:
n log
2
n < n
2
Wobec tego algorytm o zło
ż
ono
ś
ci obliczeniowej klasy O(n log
2
n) wykona si
ę
o wiele szybciej od
algorytmu klasy O(n
2
). Ró
ż
nica ta jest szczególnie drastyczna dla du
ż
ych warto
ś
ci n. Dzi
ę
ki temu
algorytmy sortuj
ą
ce klasy O(n log
2
n) nadaj
ą
si
ę
szczególnie do sortowania du
ż
ych ilo
ś
ci elementów,
gdzie wyra
ź
nie korzystamy z ich zalet. Wad
ą
tych algorytmów jest wi
ę
ksza zło
ż
ono
ść
w stosunku do
opisanych metod sortowania zbiorów danych. Z drugiej strony nic nie przychodzi darmo.
Pierwszy z szybkich algorytmów sortuj
ą
cych wykorzystuje specjaln
ą
struktur
ę
danych, zwan
ą
kopcem
(ang. Heap). Przed opisem samego algorytmu zajmiemy si
ę
własno
ś
ciami kopca oraz sposobami jego
tworzenia i pobierania z niego danych.
Drzewo binarne
Drzewo binarne (ang. binary tree - Btree) jest
hierarchiczn
ą
struktur
ą
danych, w której elementy nosz
ą
nazw
ę
w
ę
złów. Ka
ż
dy w
ę
zeł mo
ż
e si
ę
ł
ą
czy
ć
z dwoma
kolejnymi w
ę
złami. Na przykład w
ę
zeł b ł
ą
czy si
ę
z
w
ę
złami d i e. W
ę
zły d i e nosz
ą
nazw
ę
w
ę
złów
potomnych w
ę
zła b lub potomków w
ę
zła b. W
ę
zeł b jest
dla w
ę
złów d i e w
ę
złem rodzicielskim lub przodkiem.
W
ę
zły posiadaj
ą
ce potomków nazywamy gał
ę
ziami - np.
a, b, c, d. W
ę
zły nie posiadaj
ą
ce potomków nosz
ą
nazw
ę
li
ś
ci - e, f, g, h, i. Pierwszy w
ę
zeł, z którego wyrasta całe
drzewo nazywa si
ę
w
ę
złem głównym lub korzeniem - jest
to w
ę
zeł a.
Nazwa drzewa pochodzi od własno
ś
ci posiadania przez
ka
ż
dy w
ę
zeł do dwóch potomków. W j
ę
zyku angielskim słówko binary oznacza dwójkowy -
binary tree - drzewo dwójkowe.
Drzewa binarne da si
ę
w prosty sposób
odwzorowa
ć
w
pami
ę
ci
komputera,
je
ś
li
tworz
ą
ce je elementy b
ę
d
ą
umieszczone w tej
pami
ę
ci obok siebie - tak dzieje si
ę
w tablicach.
Rozwa
ż
my poni
ż
sze drzewo binarne:
W
ę
zeł tworzony przez element a
1
posiada
dwóch potomków - a
2
oraz a
3
. W
ę
zeł a
2
posiada
równie
ż
dwóch potomków - a
4
i a
5
. Je
ś
li
dokładnie przyjrzymy si
ę
indeksom elementów
tworz
ą
cych drzewo binarne, to musimy doj
ść
do
nast
ę
puj
ą
cego wniosku:
Je
ś
li w
ę
zeł utworzony przez element a
i
ma
potomków, to musz
ą
to by
ć
elementy a
2 x i
oraz
a
2 x i + 1
. Innymi słowy indeksy potomków w
ę
zła
i-tego maj
ą
warto
ść
:
2 x i - lewy potomek w
ę
zła i-tego
2 x i + 1 - prawy potomek w
ę
zła i-tego.
Teraz rozwa
ż
my przodków danego w
ę
zła. Tutaj równie
ż
przyjrzenie si
ę
indeksom da nam szybk
ą
odpowied
ź
- przodkiem w
ę
zła i-tego (i musi by
ć
wi
ę
ksze od 1, poniewa
ż
korze
ń
drzewa nie posiada
przodka) jest w
ę
zeł o indeksie równym |i / 2| (cz
ęść
całkowita z dzielenia).
Wzory te pozwalaj
ą
odwzorowa
ć
liniowy ci
ą
g elementów (tablic
ę
) w drzewo binarne i na odwrót. Na
rysunku poni
ż
ej drzewa binarnego widzimy powi
ą
zania poszczególnych elementów w takiej strukturze.
Przykład
Przedstawi
ć
w postaci drzewa binarnego nast
ę
puj
ą
cy ci
ą
g elementów { 3 1 6 8 9 4 }
Tworzenie drzewa rozpoczynamy od korzenia, którym jest pierwszy element ci
ą
gu,
czyli 3.
Do korzenia doł
ą
czamy w
ę
zły potomne, s
ą
to kolejne dwa elementy - 1 i 6
Przechodzimy na nast
ę
pny poziom struktury drzewa i do lewego w
ę
zła [1] doł
ą
czamy
jego w
ę
zły potomne - kolejne dwa elementy ze zbioru, czyli 8 i 9.
Pozostał nam ostatni element, który jest potomkiem w
ę
zła [6].
Kopiec
Kopiec jest drzewem binarnym, w którym istniej
ą
zale
ż
no
ś
ci pomi
ę
dzy w
ę
złami potomnymi a ich
przodkiem wyznaczone przez
funkcj
ę
porównuj
ą
c
ą
w sposób nast
ę
puj
ą
cy:
Dla ka
ż
dego w
ę
zła posiadaj
ą
cego potomków zachodzi
fp(potomek,przodek) = true
Innymi słowy, je
ś
li funkcja porównuj
ą
ca wyznacza porz
ą
dek rosn
ą
cy, to w strukturze kopca ka
ż
dy
przodek ma warto
ść
wi
ę
ksz
ą
lub równ
ą
warto
ś
ci swoich potomków. Korze
ń
kopca ma najwi
ę
ksz
ą
warto
ść
- jest elementem maksymalnym.
To drzewo binarne nie tworzy
struktury kopca, poniewa
ż
np. w
ę
zeł
główny [3] nie jest wi
ę
kszy od w
ę
zła
[6], który jest jego potomkiem.
Równie
ż
warunek kopca nie jest
spełniony dla w
ę
zła [1].
W tym drzewie binarnym wyst
ę
puj
ą
identyczne elementy. Jednak teraz
warunek kopca jest spełniony -
ka
ż
dy w
ę
zeł potomny jest mniejszy
(lub równy) od swojego przodka.
Zwró
ć
uwag
ę
, i
ż
uporz
ą
dkowanie elementów w kopcu nie gwarantuje uporz
ą
dkowania w
odwzorowuj
ą
cym go zbiorze. Przykładowo podany kopiec ma w tablicy reprezentacj
ę
{ 9 8 6 1 3 4 } i
nie jest uporz
ą
dkowany.
Tworzenie kopca
Kopiec tworzymy podobnie jak zwykłe
drzewo binarne
- doł
ą
czamy elementy na ko
ń
cu struktury.
Jednak tutaj musimy sprawdza
ć
, czy po doł
ą
czeniu kolejnego li
ś
cia zostaje zachowana struktura
kopca. Je
ś
li po doł
ą
czeniu elementu jest on wi
ę
kszy od swojego przodka, to musimy elementy te
zamieni
ć
miejscami
. Nast
ę
pnie przenosimy si
ę
na wy
ż
szy poziom struktury drzewa i sprawdzamy, czy
wymieniony przodek jest mniejszy od swojego przodka. Je
ś
li nie, to znów wymieniamy elementy i
przechodzimy na poziom wy
ż
szy. Działanie te kontynuujemy, a
ż
do momentu spełnienia warunku
kopca (przodek wi
ę
kszy od potomka ze wzgl
ę
du na funkcj
ę
porównuj
ą
c
ą
) lub po osi
ą
gni
ę
ciu korzenia
kopca. Poni
ż
ej prezentujemy odpowiedni przykład.
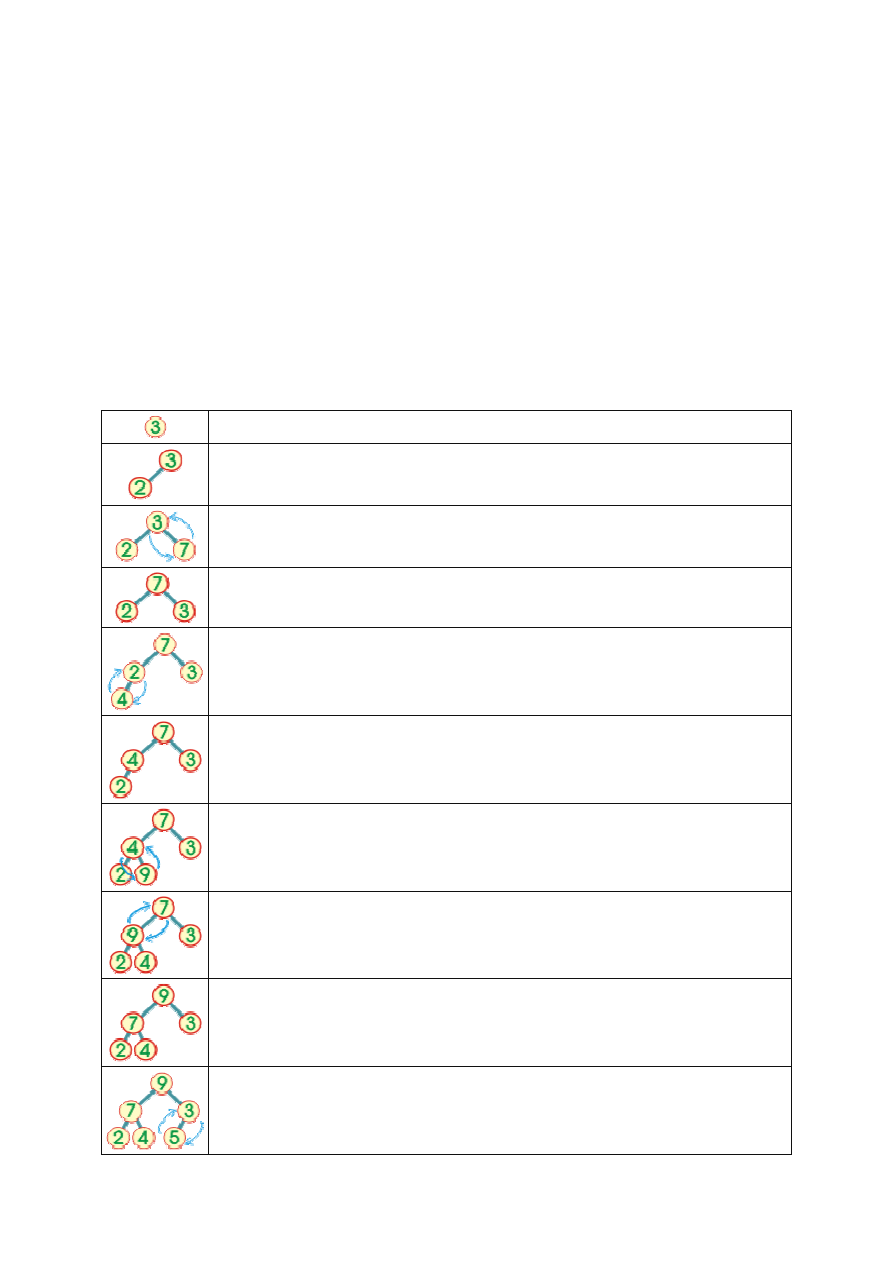
Przykład
Utworzymy kopiec z nast
ę
puj
ą
cego zbioru elementów: { 3 2 7 4 9 5 }. W kopcu okre
ś
limy porz
ą
dek
rosn
ą
cy - przodek ma warto
ść
wi
ę
ksz
ą
lub równ
ą
warto
ś
ci ka
ż
dego ze swoich potomków.
Korzeniem kopca b
ę
dzie pierwszy element zbioru - liczba
3
.
Do korzenia doł
ą
czamy nast
ę
pny element - liczb
ę
2
. Poniewa
ż
potomek jest mniejszy
od swojego przodka, wi
ę
c warunek kopca został zachowany po doł
ą
czeniu i nie
musimy wymienia
ć
elementów.
Pobieramy kolejny element ze zbioru - liczb
ę
7
i doł
ą
czamy go na ko
ń
cu kopca. Po
doł
ą
czeniu warunek kopca nie jest spełniony - potomek wi
ę
kszy od przodka. Musimy
dokona
ć
wymiany elementów
3
i
7
.
Po wymianie otrzymujemy drzewo trójelementowe. w którym spełniony jest warunek
kopca.
Doł
ą
czamy kolejny element - liczb
ę
4
. Warunek kopca nie jest spełniony, wi
ę
c
wymieniamy go z jego przodkiem.
4
i
7
spełnia warunek kopca.
Doł
ą
czamy na spodzie kopca kolejny element zbioru - liczb
ę
9
. Warunek kopca nie
jest spełniony, musimy dokona
ć
wymiany potomka z przodkiem, czyli liczb
4
i
9
.
Po wymianie przesuwamy si
ę
na wy
ż
szy poziom i sprawdzamy warunek kopca. Nie
jest spełniony, wymieniamy potomka z przodkiem, czyli liczby
9
i
7
.
Po tej zamianie warunek kopca jest spełniony we wszystkich w
ę
złach.
Doł
ą
czamy na spodzie kopca nast
ę
pny element ze zbioru - liczb
ę
5
. Warunek kopca
nie jest spełniony, wymieniamy potomka z przodkiem.
Po wymianie warunek kopca jest spełniony dla ka
ż
dego w
ę
zła. Poniewa
ż
wyczerpali
ś
my wszystkie elementy zbioru wej
ś
ciowego, kopiec jest gotowy. Je
ś
li
odwzorujemy go w ci
ą
g elementów, otrzymamy zbiór { 9 7 5 2 4 3 }.
Tworzenie kopca jest operacj
ą
o
zło
ż
ono
ś
ci obliczeniowej
klasy O(n). Oznacza to, i
ż
np.
dziesi
ę
ciokrotny wzrost liczby elementów powoduje dziesi
ę
ciokrotny wzrost czasu budowania kopca.
Zwró
ć
cie uwag
ę
, i
ż
przy wstawianiu nowych elementów wykonujemy niewiele operacji porówna
ń
i
przestawie
ń
- maksymalnie tyle, ile wynosi liczba poziomów drzewa binarnego, która wyra
ż
a si
ę
prostym wzorem:
liczba poziomów = [log
2
(n)], n - liczba elementów-w
ę
złów kopca.
Schemat blokowy tworzenia kopca
Kopiec zostanie utworzony poprzez odpowiednie przegrupowanie elementów zbioru. Taki sposób
działania nazywamy tworzeniem kopca na miejscu - operacja ta nie wymaga dodatkowych zasobów
komputera, wykorzystujemy obszar zaj
ę
ty przez elementy zbioru.
Naszym zadaniem jest utworzenie kopca ze zbioru elementów { a
1
, a
2
, ..., a
n-1
, a
n
}, które nie s
ą
posortowane w
ż
adnym porz
ą
dku. Kolejno
ść
elementów w w
ę
złach kopca definiujemy za pomoc
ą
funkcji porz
ą
dkowej
. Problem mo
ż
na rozwi
ą
za
ć
na dwa sposoby - rekurencyjnie lub iteracyjnie. Ja
wybrałem rozwi
ą
zanie iteracyjne - czytelnik niech zastanowi si
ę
nad sposobem rekurencyjnym.
n
liczba elementów w zbiorze
a[...] element zbioru o numerze od 1 do n, podanym w klamrach kwadratowych
i , j
zmienne u
ż
ywane na liczniki p
ę
tli
t
zmienna tymczasowa u
ż
ywana przy wymianie zawarto
ś
ci elementów tablicy
Tworzenie kopca rozpoczynamy od elementu drugiego. Pierwszy element zbioru
automatycznie jest korzeniem kopca i nie musimy go nigdzie przemieszcza
ć
.
Zmienna i wskazuje kolejne elementy umieszczane w kopcu. Zmienna j
przechowuje indeksy kolejno sprawdzanych w
ę
złów.
Po wstawieniu elementu do kopca na pozycji j-tej,
sprawdzamy, czy w
ę
zeł ten ma przodka. Sytuacja
taka wyst
ą
pi dla wszystkich w
ę
złów o indeksie
wi
ę
kszym od 1. Indeks 1 wskazuje korze
ń
, który nie
posiada przodka i w takim przypadku wychodzimy z
p
ę
tli.
Je
ś
li w
ę
zeł posiada przodka, to sprawdzamy, czy
zachodzi pomi
ę
dzy potomkiem a przodkiem warunek
kopca: fp(potomek,przodek)=true. Je
ś
li tak, to
wychodzimy z p
ę
tli i wstawiamy kolejny element a
ż
do
wyczerpania zbioru. Je
ś
li warunek kopca nie jest
spełniony, to musimy wymieni
ć
ze sob
ą
potomka i
przodka, a nast
ę
pnie przej
ść
na wy
ż
szy poziom
struktury do w
ę
zła przodka i dokona
ć
znów
sprawdzenia warunku kopca. Operacje te wykonuje p
ę
tla
lewa. P
ę
tla prawa wstawia do kopca kolejne elementy.
Rozbiór kopca
W poprzednim rozdziale pokazali
ś
my sposób tworzenia kopca ze zbioru ponumerowanych
elementów. Teraz zajmiemy si
ę
drug
ą
bardzo wa
ż
n
ą
operacj
ą
- rozbiorem kopca. Rozbiór kopca
rozpoczynamy od jego korzenia, który zast
ę
pujemy ostatnim elementem w kopcu. Operacja ta
powoduje zaburzenie struktury kopca, któr
ą
musimy odtworzy
ć
. Dokonujemy tego porównuj
ą
c nowo
utworzony w
ę
zeł z najwi
ę
kszym potomkiem. Je
ś
li warunek kopca nie jest zachowana, to dokonujemy
zamiany przodka z potomkiem. Nast
ę
pnie przechodzimy na miejsce zamienionego potomka i
kontynuujemy porównywanie, a
ż
dojdziemy do spodu kopca lub stwierdzimy zachowanie warunku
kopca. Poni
ż
ej przedstawiamy odpowiedni przykład:
Przykład
Naszym zadaniem jest rozebranie kopca przez kolejne pobieranie korzenia. Po pobraniu struktura
kopca musi by
ć
przywrócona. Oto nasz kopiec do rozbioru:
9
Usuwamy z kopca korze
ń
- liczb
ę
9. Na to miejsce wstawiamy ostatni
element - liczb
ę
3. Technicznie operacj
ą
tak
ą
realizujemy wymieniaj
ą
c
miejscami korze
ń
z ostatnim li
ś
ciem kopca i zmniejszaj
ą
c o 1 jego długo
ść
.
Po wstawieniu do korzenia ostatniego li
ś
cia struktura kopca jest zaburzona
- korze
ń
nie jest ju
ż
najwi
ę
kszym elementem. Musimy wi
ę
c odtworzy
ć
kopiec. Korze
ń
porównujemy z jego potomkami - liczby 7 i 5. Dokonujemy
wymiany z najwi
ę
kszym w
ę
złem potomnym, czyli liczb
ą
7.
Po dokonaniu wymiany przenosimy si
ę
do zmienionego w
ę
zła i dalej
sprawdzamy warunek kopca - nie zachodzi, wi
ę
c wymieniamy przodka
(liczba 3) z najwi
ę
kszym potomkiem (liczba 4).
Po tej operacji kopiec został zrekonstruowany i wszystkie w
ę
zły spełniaj
ą
jego warunek.
7
9
Usuwamy korze
ń
zast
ę
puj
ą
c go najmłodszym li
ś
ciem.
Warunek kopca nie jest spełniony - wymieniamy korze
ń
z najwi
ę
kszym
potomkiem. Poniewa
ż
wymieniony w
ę
zeł nie ma ju
ż
potomków, operacja
odtwarzania warunków kopca została zako
ń
czona.
5
7 9
Usuwamy korze
ń
i zast
ę
pujemy go ostatnim li
ś
ciem kopca.
Warunek kopca nie jest spełniony - wymieniamy przodka z najwi
ę
kszym
potomkiem.
4
5 7 9
Usuwamy korze
ń
, zast
ę
pujemy go ostatnim li
ś
ciem.
3
4 5 7 9 Usuwamy korze
ń
, zast
ę
pujemy go ostatnim li
ś
ciem.
2
3 4 5 7 9 Usuwamy ostatni w
ę
zeł kopca - rozbiór zako
ń
czony.
Zwró
ć
uwag
ę
na usuwane z kopca elementy. Je
ś
li ustawimy je w odwrotnej kolejno
ś
ci, to utworz
ą
ci
ą
g
posortowany zgodnie z kryterium
funkcji porównuj
ą
cej
.
Schemat blokowy rozbioru kopca
Zakładamy, i
ż
kopiec jest utworzony w zbiorze
ponumerowanych elementów { a
1
, ... ,a
n
}. W wyniku
działania algorytmu usuwane z kopca elementy b
ę
d
ą
wstawiane na kolejne od ko
ń
ca pozycje w zbiorze.
Pozycje te s
ą
zajmowane przez najmłodszy li
ść
kopca,
który przenosimy do korzenia, wi
ę
c zajmowane miejsce
ulega zwolnieniu. Po wykonaniu wszystkich operacji
rozbioru elementy zbioru b
ę
d
ą
posortowane rosn
ą
co
zgodnie z kryterium
funkcji porównuj
ą
cej
.

n
liczba elementów w zbiorze
a[...] element zbioru o numerze od 1 do n, podanym w klamrach kwadratowych
i , j, k zmienne u
ż
ywane na liczniki p
ę
tli
t
zmienna tymczasowa u
ż
ywana przy wymianie zawarto
ś
ci elementów tablicy
Zmienna i b
ę
dzie wskazywa
ć
miejsce w zbiorze, do którego wstawiamy pobrany z kopca element.
Dodatkowa funkcja tej zmiennej to okre
ś
lanie długo
ś
ci kopca, która jest zawsze o 1 mniejsza od
aktualnej zawarto
ś
ci zmiennej i.
Rozpoczynamy od ostatniego miejsca w zbiorze. Element z tej pozycji zostaje wymieniony z
korzeniem kopca. Poniewa
ż
korze
ń
kopca zawiera najwi
ę
kszy element, to na ko
ń
cu zbioru b
ę
dzie
tworzony ci
ą
g posortowanych elementów.
Po wymianie sprawdzamy warunek kopca. Najpierw znajdujemy najwi
ę
kszego potomka - wskazuje go
zmienna k. Je
ś
li potomek istnieje i jest wi
ę
kszy od przodka, to zamieniamy ze sob
ą
te w
ę
zły i
przechodzimy do sprawdzania warunku kopca dla wymienionego potomka i jego w
ę
złów potomnych.
Je
ś
li w
ę
zeł nie posiada potomków lub jest dla nich spełniony warunek kopca, to wychodzimy z p
ę
tli
wewn
ę
trznej i przechodzimy do pobrania z kopca kolejnego elementu.
Operacje te s
ą
kontynuowane a
ż
cały kopiec zostanie rozebrany. Wtedy zbiór b
ę
dzie posortowany
rosn
ą
co zgodnie z kryterium
funkcji porównuj
ą
cej
.
Poni
ż
ej przedstawiamy realizacj
ę
opisanego algorytmu sortowania w ró
ż
nych j
ę
zykach
programowania. Program tworzy dwie tablice o identycznej zawarto
ś
ci, wypełnione przypadkowymi
liczbami. Nast
ę
pnie jedn
ą
z tych tablic sortuje i wy
ś
wietla obie dla zobrazowania efektu posortowania
danych.
Sortowanie z wykorzystaniem kopca
Je
ś
li prze
ś
ledzili
ś
cie dokładnie opisane powy
ż
ej rozdziały, to powinni
ś
cie ju
ż
bez trudu poda
ć
zasad
ę
sortowania z wykorzystaniem struktury kopca. Algorytm jest wr
ę
cz banalny i opiszemy go słownie tak:
1.
Utwórz kopiec z elementów zbioru, który chcesz posortowa
ć
.
2.
Rozbierz kopiec wstawiaj
ą
c elementy do sortowanego zbioru
3.
Zbiór jest posortowany.
Algorytm sortowania poprzez kopcowanie (ang. Heap Sort) nale
ż
y do klasy zło
ż
ono
ś
ci obliczeniowej
O(n log
2
n), co oznacza, i
ż
nadaje si
ę
on do porz
ą
dkowania du
ż
ych zbiorów danych. Sortowanie jest
wykonywane nieporównywalnie szybciej w stosunku do opisanych poprzednio algorytmów sortuj
ą
cych
klasy O(n
2
). Drug
ą
jego zalet
ą
jest to, i
ż
jak widzieli
ś
my, nie wymaga on stosowania dodatkowych
struktur danych - kopiec tworzony jest w miejscu zajmowanym przez sortowany zbiór - jest to bardzo
istotna zaleta ze wzgl
ę
du na zaj
ę
to
ść
pami
ę
ci operacyjnej komputera.
Przykład w C++
Wszystkie prezentowane tutaj przykłady zostały uruchomione w
DevC++
, który mo
ż
na darmowo i
legalnie pobra
ć
poprzez sie
ć
Internet.
#include <stdlib.h>
#include <time.h>
#include <iostream.h>

const int n = 10; // liczba elementów w sortowanym zbiorze
// funkcja porównująca
int fp(int x, int y)
{
return (x <= y);
}
int main()
{
int i,j,k,t,a[n],b[n];
// tworzymy tablicę z przypadkową zawartością.
// tablica b[] służy do zapamiętania stanu a[]
srand( (unsigned)time( NULL ) );
for(i = 0; i < n; i++ )
a[i] = b[i] = 1 + rand() % (n + n);
// tworzymy kopiec z elementów tablicy a[]
for(i = 1; i < n; i++)
for(j = i; (j > 0) && !fp(a[j],a[(j-1)/2]); j = (j-1)/2)
{
t = a[j]; a[j] = a[(j-1)/2]; a[(j-1)/2] = t;
};
// rozbieramy kopiec
for(i = n - 1; i >= 0; i--)
{
t = a[0]; a[0] = a[i]; a[i] = t;
j = 0;
while(j != i)
{
k = j + j + 1;
if(k < i)
{
if((k+1 < i) && fp(a[k],a[k+1])) k++;
if(fp(a[k],a[j]))
j = i;
else
{
t = a[k]; a[k] = a[j]; a[j] = t;
j = k;
};
}
else j = i;
};

};
// wyświetlamy wyniki
cout << "Sortowanie przez kopcowanie" << endl
<< "(C)2003 mgr Jerzy Walaszek" << endl << endl
<< " lp przed po" << endl
<< "------------------------" << endl;
for(i = 0; i < n; i++)
{
cout.width(4); cout << i + 1;
cout.width(9); cout << b[i];
cout.width(9); cout << a[i] << endl;
};
cout << endl;
cout.flush();
system("pause");
return 0;
}
Sortowanie Szybkie
Quick Sort
Sortowanie szybkie jest najszybszym z algorytmów sortuj
ą
cych nale
żą
cych do klasy
zło
ż
ono
ś
ci
obliczeniowej
O( n log
2
n), chocia
ż
w pewnych niekorzystnych przypadkach, algorytm ten mo
ż
e sta
ć
si
ę
niestabilny. Zasada jego działania jest bardzo prosta, lecz trudna w implementacji. Ze zbioru
wej
ś
ciowego wybieramy jeden element, który dalej b
ę
dziemy nazywa
ć
elementem
ś
rodkowym.
Nast
ę
pnie reszt
ę
elementów dzielimy na dwa podzbiory - w lewym b
ę
d
ą
wszystkie elementy równe lub
mniejsze od
ś
rodkowego, a w prawym wszystkie elementy wi
ę
ksze od
ś
rodkowego. Kolejno
ść
elementów wyznacza oczywi
ś
cie
funkcja porównuj
ą
ca
wg nast
ę
puj
ą
cej reguły:
D - zbiór sortowany
L - podzbiór lewy
P - podzbiór prawy
p - element
ś
rodkowy nale
żą
cy do D
a - dowolny element zbioru D, ró
ż
ny od p
D = L
∪
∪
∪
∪
{ p }
∪
∪
∪
∪
P
a
∈
∈
∈
∈
L
⇔
⇔
⇔
⇔
fp(a,p) = true
a
∈
∈
∈
∈
P
⇔
⇔
⇔
⇔
fp(p,a) = true
Je
ś
li element a jest równy p (co mo
ż
e si
ę
zdarzy
ć
w zbiorach dopuszczaj
ą
cych identyczne elementy),
to nie ma znaczenia, w którym z podzbiorów go umie
ś
cimy (zwykle b
ę
dzie to lewy podzbiór).
W nast
ę
pnym kroku identycznie sortujemy ka
ż
dy z podzbiorów L i P otrzymuj
ą
c kolejne podzbiory.
Operacj
ę
t
ą
wykonuje si
ę
rekurencyjnie wywołuj
ą
c procedur
ę
szybkiego sortowania z danym
podzbiorem. Sortowanie jest kontynuowane, a
ż
sortowany podzbiór jest pusty lub zawiera tylko jeden
element. Po zło
ż
eniu wszystkich podzbiorów w jeden otrzymujemy zbiór posortowany zgodnie z
kryterium funkcji porównuj
ą
cej.
Przy sortowaniu bardzo istotny jest wybór elementu
ś
rodkowego, który posłu
ż
y do podzielenia zbioru
na dwa podzbiory. Je
ś
li element ten b
ę
dzie wybrany nieprawidłowo, to efektywno
ść
algorytmu

spadnie, nawet do poziomu O(n
2
) dla niektórych typów danych wej
ś
ciowych - nale
ż
y sobie zdawa
ć
z
tego spraw
ę
przy stosowaniu algorytmu szybkiego sortowania. Zwykle zaleca si
ę
przypadkowy wybór
jednego z elementów zbioru, jednak taka implementacja algorytmu jest nieco kłopotliwa dla
pocz
ą
tkuj
ą
cych adeptów sztuk programowania. My zastosujemy inny sposób - jako element
ś
rodkowy
b
ę
dziemy wybiera
ć
ostatni element sortowanego zbioru - jest to dobre rozwi
ą
zanie, o ile zbiór
wej
ś
ciowy nie jest wst
ę
pnie posortowany w kolejno
ś
ci odwrotnej, wtedy mog
ą
by
ć
kłopoty!. Podzbiory
b
ę
d
ą
budowane w zbiorze sortowanym, co znakomicie zaoszcz
ę
dzi wykorzystywan
ą
przez algorytm
pami
ęć
operacyjn
ą
komputera.
Przykład
Posortujemy t
ą
metod
ą
zbiór dziesi
ę
ciu liczb: { 9 7 4 5 0 6 3 2 1 8 } w porz
ą
dku rosn
ą
cym. Nasza
funkcja porównuj
ą
ca
przyjmie wi
ę
c posta
ć
relacji mniejszy lub równy.
{ 9 7 4 5 0 6 3 2 1
8
}
Na element
ś
rodkowy wybieramy ostatni element zbioru
- liczb
ę
8
{ 7 4 5 0 6 3 2 1 }
8
{
9
}
Zbiór
dzielimy
na
dwa
podzbiory
zawieraj
ą
ce
odpowiednio
elementy
mniejsze
i
wi
ę
ksze
od
wybranego elementu
ś
rodkowego. Prawy podzbiór jest
ju
ż
posortowany, poniewa
ż
zawiera tylko jeden element
- liczb
ę
9. Przechodzimy do sortowania lewego zbioru.
{ 7 4 5 0 6 3 2
1
}{
8 9
}
Wybieramy ostatni element - liczb
ę
1.
{
0
}
1
{7 4 5 6 3 2 }{
8 9
}
Dzielimy zbiór wg wybranego elementu
ś
rodkowego na
dwa podzbiory. Podzbiór lewy jest ju
ż
posortowany,
poniewa
ż
zawiera tylko jeden element - liczb
ę
0.
{
0 1
}{7 4 5 6 3
2
}{
8 9
}
Wybieramy w podzbiorze prawym element
ś
rodkowy -
liczb
ę
2.
{
0 1
}{ }
2
{ 7 4 5 6 3 }{
8 9
}
Dokonujemy podziału zbioru na dwa podzbiory
wzgl
ę
dem wybranego elementu. Lewy podzbiór jest
teraz pusty.
{
0 1 2
}{ 7 4 5 6
3
}{
8 9
}
Wybieramy element
ś
rodkowy.
{
0 1 2
}{ }
3
{ 7 4 5 6 }{
8 9
}
Lewy podzbiór znów pusty.
{
0 1 2 3
}{ 7 4 5
6
}{
8 9
}
Wybieramy element
ś
rodkowy
{
0 1 2 3
}{ 4 5 }
6
{
7
}{
8 9
}
Prawy podzbiór jest posortowany, poniewa
ż
zawiera
tylko jeden element.
{
0 1 2 3
}{ 4
5
}{
6 7 8 9
}
Wybieramy element
ś
rodkowy
{
0 1 2 3
}{
4
}
5
{ }{
6 7 8 9
}
Lewy i prawy podzbiór posortowany.
{ 0 1 2 3 4 5 6 7 8 9 }
Poniewa
ż
nie ma wi
ę
cej podzbiorów, zbiór wej
ś
ciowy
został w cało
ś
ci posortowany.
Dzielenie zbioru na dwa podzbiory
Kluczowym elementem szybkiego sortowania jest podział zbioru na dwa podzbiory. Sprecyzujmy
zadanie nast
ę
puj
ą
co:
Mamy zbiór elementów { a
m
, a
m+1
, a
m+2
, ... , a
n-1
, a
n
}, gdzie indeks m okre
ś
la pierwszy element, a
indeks n ostatni i oczywi
ś
cie m < n. Takie okre
ś
lenie elementów pozwoli nam w dalszej cz
ęś
ci
opracowania sortowa
ć
wybran
ą
cz
ęść
zbioru wej
ś
ciowego. Jako element
ś
rodkowy przyjmujemy
pocz
ą
tkowo element ostatni o indeksie n, czyli p = n. Element ten posłu
ż
y do wyznaczenia dwóch

podzbiorów - lewego o indeksach mniejszych od p z elementami mniejszymi od
ś
rodkowego oraz
prawego o indeksach wi
ę
kszych od p z elementami wi
ę
kszymi. Celem naszego algorytmu b
ę
dzie
uzyskanie takiego podziału zbioru wej
ś
ciowego.
Umówmy si
ę
co do sposobu oznaczania tych podzbiorów. Zrobimy to przy pomocy trzech liczb
okre
ś
laj
ą
cych indeksy:
m
-
indeks
pierwszego
elementu
-
warto
ść
stała
n
-
indeks
ostatniego
element
-
warto
ść
stała
p - indeks elementu
ś
rodkowego - warto
ść
zmienna
Przy tej umowie elementy nale
żą
ce do lewego podzbioru (elementy mniejsze od
ś
rodkowego) b
ę
d
ą
miały indeksy od m do p-1. Zbiór ten jest pusty, je
ś
li m = p. Indeksy prawego podzbioru (elementy
wi
ę
ksze od
ś
rodkowego) b
ę
d
ą
miały indeksy od p+1 do n. Zbiór ten jest pusty, gdy p = n:
L
=
{
a
m
,
a
m+1
,
...,
a
p-2
,
a
p-1
},
gdy
m
<
p
L = { }, gdy m = p
P
=
{
a
p+1
,
a
p+2
,
...
,a
n-1
,
a
n
},
gdy
p
<
n
P = { }, gdy p = n
Podział zbioru rozpoczynamy od elementu przedostatniego o indeksie n-1 (element ostatni jest
elementem
ś
rodkowym). Element ten wyjmujemy ze zbioru (zapami
ę
tujemy go w zmiennej
pomocniczej). Jego pozycja jest teraz zwolniona (tzn. mo
ż
e zosta
ć
zapisana bez utraty poprzedniej
zawarto
ś
ci, któr
ą
przechowuje zmienna pomocnicza). Nast
ę
pnie porównujemy wyj
ę
ty element z
elementem
ś
rodkowym. Je
ś
li jest on mniejszy lub równy elementowi
ś
rodkowemu wg
funkcji
porównuj
ą
cej
, to wstawiamy go z powrotem do zbioru (innymi słowy nic z nim nie robimy). W
przeciwnym przypadku przesuwamy w lewo o 1 pozycj
ę
wszystkie elementy pocz
ą
wszy od
nast
ę
pnego i sko
ń
czywszy na elemencie
ś
rodkowym. W wyniku tej operacji po prawej stronie
elementu
ś
rodkowego zwalnia si
ę
miejsce, w którym umieszczamy element wybrany (przepisujemy go
ze zmiennej pomocniczej). Indeks elementu
ś
rodkowego zmniejszamy o 1. Nad kolejnymi w dół
elementami zbioru wykonujemy identyczne operacje a
ż
dojdziemy do elementu o indeksie m. Wtedy
zbiór wej
ś
ciowy zostanie podzielony na dwa podzbiory. Oto odpowiedni przykład:
Przykład
Podzielimy zbiór wej
ś
ciowy { 3 2 8 6 4 7 5 } na dwa podzbiory - lewy z liczbami mniejszymi od
elementu ostatniego - 5 oraz prawego z liczbami wi
ę
kszymi od tej warto
ś
ci.
{ 3 2 8 6 4 7
5
}
p
Elementem
ś
rodkowym podziału jest ostatni element zbioru wej
ś
ciowego -
liczba 5.
7
{ 3 2 8 6 4 ^
5
}
p
Ze zbioru wyjmujemy przedostatni element - liczb
ę
7 i porównujemy j
ą
z
elementem
ś
rodkowym.
7
{ 3 2 8 6 4
5
^ }
p
Poniewa
ż
liczba ta jest wi
ę
ksza od elementu
ś
rodkowego, dokonujemy
przesuni
ę
cia o 1 pozycj
ę
w lewo wszystkich elementów pocz
ą
wszy od
nast
ę
pnego (tutaj nie wyst
ę
puje) a sko
ń
czywszy na elemencie
ś
rodkowym.
Indeks p jest zmniejszany o 1, aby wskazywał now
ą
pozycj
ę
elementu
ś
rodkowego w zbiorze. Po prawej stronie utworzyło si
ę
w wyniku przesuni
ę
cia
puste miejsce.
{ 3 2 8 6 4
5
7
}
p
W miejsce to wstawiamy wybrany poprzednio element - liczb
ę
7.
4
{ 3 2 8 6 ^
5
7
}
p
Wybieramy kolejny w dół element zbioru - liczb
ę
4 i porównujemy j
ą
z
elementem
ś
rodkowym. Poniewa
ż
liczba 4 jest mniejsza od 5, pozostawiamy
j
ą
na swoim miejscu.

6
{ 3 2 8 ^
4
5
7
}
p
Wybieramy kolejny w dół element i porównujemy go z elementem
ś
rodkowym.
6
{ 3 2 8
4
5
^
7
}
p
Poniewa
ż
6 jest wi
ę
ksze od elementu
ś
rodkowego, przesuwamy w lewo o 1
pozycj
ę
wszystkie elementy nast
ę
pne do elementu
ś
rodkowego wł
ą
cznie.
Indeks p jest zmniejszany o 1.
{ 3 2 8
4
5
6 7
}
p
Na zwolnionym miejscu po prawej stronie elementu
ś
rodkowego wstawiamy
liczb
ę
6.
8
{ 3 2 ^
4
5
6 7
}
p
Przechodzimy do nast
ę
pnego w dół elementu zbioru - liczby 8 i porównujemy
j
ą
z elementem
ś
rodkowym - liczb
ą
5.
8
{ 3 2
4
5
^
6 7
}
p
Poniewa
ż
8 jest wi
ę
ksze od 5, przesuwamy w lewo o 1 pozycj
ę
elementy od
nast
ę
pnego do
ś
rodkowego wł
ą
cznie. Indeks p jest zmniejszany o 1.
{ 3 2
4
5
8 6 7
}
p
Na zwolnione miejsce wstawiamy liczb
ę
8.
2
{ 3 ^
4
5
8 6 7
}
p
Liczb
ę
2 pozostawiamy na swojej pozycji, poniewa
ż
jest mniejsza od
elementu
ś
rodkowego.
3
{ ^
2
4
5
8 6 7
}
p
To samo dotyczy liczby 3.
{
3 2 4
5
8 6 7
}
p
Zbiór wej
ś
ciowy został podzielony na dwa podzbiory : L = { 3 2 4 } z
elementami mniejszymi od 5 oraz P = { 8 6 7 } z elementami wi
ę
kszymi od 5.
Z podobnymi operacjami spotkali
ś
my si
ę
ju
ż
w algorytmie
sortowania przez wstawianie
.
Schemat blokowy podziału podziału zbioru na dwa podzbiory
Dany jest zbiór { a
m
a
m+1
a
m+2
...a
n-2
a
n-1
a
n
}, który nale
ż
y podzieli
ć
na dwa podzbiory wzgl
ę
dem
elementu
ś
rodkowego a
n
. Porz
ą
dek wyznacza
funkcja porównuj
ą
ca
fp(...). Do opisu algorytmu
stosujemy nast
ę
puj
ą
ce zmienne:
m
indeks pierwszego elementu zbioru wej
ś
ciowego
n
indeks ostatniego elementu zbioru wej
ś
ciowego
p
indeks elementu
ś
rodkowego
t
zmienna pomocnicza do przechowywania warto
ś
ci tymczasowych
i,j
zmienne liczników p
ę
tli
a[...] element zbioru o podanym indeksie
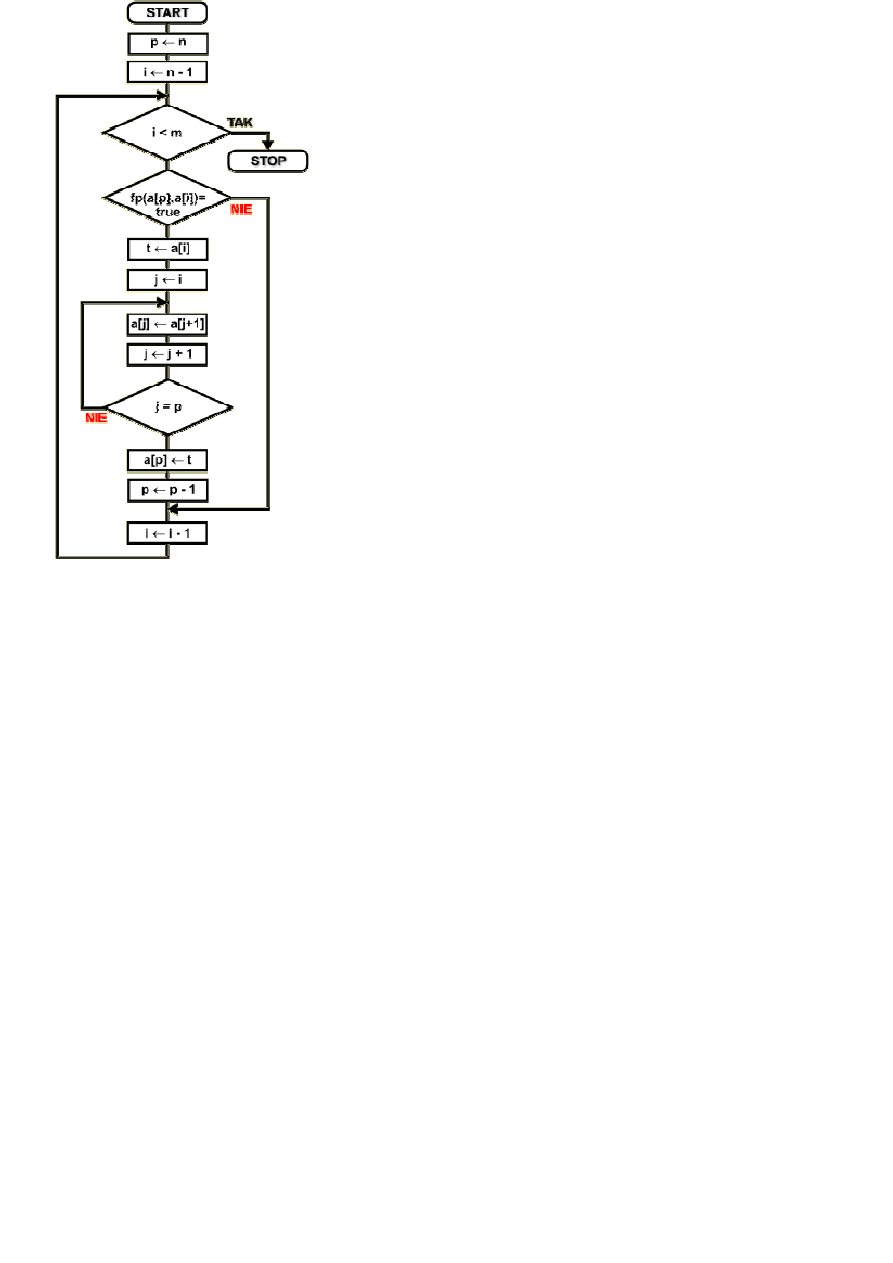
Punkt podziałowy p znajduje si
ę
na ko
ń
cu zbioru. Do zmiennej p
wprowadzamy wi
ę
c indeks ostatniego elementu zbioru. Nast
ę
pnie
b
ę
dziemy przegl
ą
da
ć
kolejno w dół wszystkie elementy o indeksach od
n-1 do m i porównywa
ć
je z elementem
ś
rodkowym a[p]. Je
ś
li b
ę
d
ą
one wi
ę
ksze ze wzgl
ę
du na
funkcj
ę
porównuj
ą
c
ą
, to dokonamy
odpowiedniego przesuni
ę
cia elementów w lewo i wstawienia
porównywanego
elementu
za
element
ś
rodkowy.
Indeks
porównywanych elementów przechowuje zmienna i. Na pocz
ą
tku
wpisujemy do niej indeks przedostatniego elementu, czyli n-1.
Przed wykonaniem kolejnego obiegu p
ę
tli zewn
ę
trznej sprawdzamy,
czy indeks mie
ś
ci si
ę
w zakresie. Je
ś
li nie, to ko
ń
czymy.
Je
ś
li indeks i mie
ś
ci si
ę
w zakresie (jest wi
ę
kszy lub równy m), to
sprawdzamy funkcj
ą
porównuj
ą
c
ą
kolejno
ść
elementów a[i] oraz a[p].
Je
ś
li a[i] ma by
ć
po prawej stronie a[p], to zawarto
ść
elementu a[i]
trafia do zmiennej pomocniczej t, a wszystkie elementy od indeksu i +
1 do p wł
ą
cznie zostaj
ą
przesuni
ę
te o 1 pozycj
ę
w lewo. Dzi
ę
ki tej
operacji element o indeksie p zostaje zwolniony - oryginalny element
ś
rodkowy a[p] jest teraz na pozycji o 1 mniejszej, czyli a[p-1].
Do zwolnionego elementu a[p] wpisujemy zawarto
ść
zmiennej
pomocniczej, czyli oryginalny element a[i].
Indeks p zmniejszamy o 1, aby prawidłowo wskazywał pozycj
ę
elementu
ś
rodkowego.
Przechodzimy do kolejnego w dół elementu zbioru i kontynuujemy p
ę
tl
ę
zewn
ę
trzn
ą
.
Algorytm Sortowania Szybkiego
Procedura sortowania szybkiego jest procedur
ą
rekurencyjn
ą
z parametrami okre
ś
laj
ą
cymi zakres
indeksów sortowanego zbioru. Rekurencja ma to do siebie, i
ż
procedura (lub funkcja) wywołuje sam
ą
siebie. Takie wywołanie powoduje przesłanie na stos wszystkich argumentów procedury podanych w
wywołaniu. Nowy egzemplarz tej procedury b
ę
dzie wi
ę
c pracował z niezale
ż
nym zestawem danych.
Algorytm sortuj
ą
cy mo
ż
emy opisa
ć
słownie tak:
1. Procedura QSrt(ip,ik) - parametry ip i ik okre
ś
laj
ą
indeksy pierwszego i ostatniego
elementu do sortowania w zbiorze wej
ś
ciowym i s
ą
przekazywane poprzez stos.
2. Podziel zadany zbiór wej
ś
ciowy na dwa podzbiory wzgl
ę
dem ostatniego elementu,
który b
ę
dzie elementem
ś
rodkowym podziału. W lewym podzbiorze umie
ść
wszystkie
elementy mniejsze lub równe elementowi
ś
rodkowemu. W prawym podzbiorze umie
ść
wszystkie elementy wi
ę
ksze od elementu
ś
rodkowego.
3. Je
ś
li lewy podzbiór ma wi
ę
cej ni
ż
jeden element, to wywołaj procedur
ę
QSrt(ip,p-1).
Nowy egzemplarz procedury b
ę
dzie pracował z parametrami ip' = ip oraz ik' = p-1
4. Je
ś
li prawy podzbiór ma wi
ę
cej ni
ż
jeden element, to wywołaj procedur
ę
QSrt(p+1,ik).
Nowy egzemplarz procedury b
ę
dzie pracował z parametrami ip' = p + 1 oraz ik' = ik.
5. Zako
ń
cz działanie procedury
Je
ś
li chcemy posortowa
ć
cały zbiór { a
1
a
2
... a
n-1
a
n
}, to w programie nale
ż
y wywoła
ć
procedur
ę
jako
QuickSort(1,n). Wywołanie to zainicjuje kolejne podziały zbioru a
ż
do jego posortowania.
Poni
ż
ej przedstawiamy realizacj
ę
opisanego algorytmu sortowania w ró
ż
nych j
ę
zykach
programowania. Program tworzy dwie tablice o identycznej zawarto
ś
ci, wypełnione przypadkowymi
liczbami. Nast
ę
pnie jedn
ą
z tych tablic sortuje i wy
ś
wietla obie dla zobrazowania efektu posortowania
danych.

Przykład w C++
ź
ródła
Wszystkie prezentowane tutaj przykłady zostały uruchomione w
DevC++
, który mo
ż
na darmowo i
legalnie pobra
ć
poprzez sie
ć
Internet.
#include <stdlib.h>
#include <time.h>
#include <iostream.h>
const int n = 15; // liczba elementów w sortowanym zbiorze
// funkcja porównująca
int fp(int x, int y)
{
return (x <= y);
}
// rekurencyjna funkcja szybkiego sortowania
void qsrt(int ip, int ik, int * a)
{
int i,j,t,p;
p = ik;
for(i = ik - 1; i >= ip; i--)
{
if(fp(a[p],a[i]))
{
t = a[i];
for(j = i; j < p; j++) a[j] = a[j+1];
a[p--] = t;
};
};
if(p - ip > 1) qsrt(ip, p - 1, a);
if(ik - p > 1) qsrt(p + 1, ik, a);
}
// główna funkcja programu
int main()
{
int i,a[n],b[n];
// tworzymy tablicę z przypadkową zawartością.
// tablica b[] służy do zapamiętania stanu a[]
srand( (unsigned)time( NULL ) );

for(i = 0; i < n; i++ ) a[i] = b[i] = 1 + rand() % (n + n);
// wywołujemy funkcję szybkiego sortowania z pełnym zakresem indeksów
qsrt(0,n-1,&a[0]);
// wyświetlamy wyniki
cout << "Sortowanie szybkie" << endl
<< "(C)2003 mgr Jerzy Walaszek" << endl << endl
<< " lp przed po" << endl
<< "------------------------" << endl;
for(i = 0; i < n; i++)
{
cout.width(4); cout << i + 1;
cout.width(9); cout << b[i];
cout.width(9); cout << a[i] << endl;
};
cout << endl;
cout.flush();
system("pause");
return 0;
}
Wyszukiwanie Binarne
Binary Search
Wyszukiwanie danych jest zagadnieniem spokrewnionym z sortowaniem. Je
ś
li zbiór nie jest
posortowany i chcemy w nim znale
źć
element spełniaj
ą
cy okre
ś
lone kryterium, to musimy przegl
ą
da
ć
kolejne elementy a
ż
natrafimy na wła
ś
ciwy. Je
ś
li danego elementu w zbiorze nie ma, odpowied
ź
otrzymamy dopiero po przegl
ą
dni
ę
ciu całego zbioru. Przy du
ż
ym zbiorze mo
ż
e zaj
ąć
to nam sporo
czasu. Taki rodzaj przeszukiwania nosi nazw
ę
liniowego i ma zło
ż
ono
ść
obliczeniow
ą
klasy O(n).
Du
ż
o efektywniejsze jest przeszukiwanie zbiorów posortowanych, gdy
ż
wtedy nie musimy sprawdza
ć
wszystkich elementów, lecz mo
ż
emy skorzysta
ć
z własno
ś
ci tej, i
ż
kolejne elementy zbioru s
ą
umieszczone w nim zgodnie z okre
ś
lonym porz
ą
dkiem (zdefiniowanym np. przez
funkcj
ę
porównuj
ą
c
ą
). Dla takich zbiorów mo
ż
na zastosowa
ć
algorytm wyszukiwania binarnego. Zasada jest
nast
ę
puj
ą
ca. W zbiorze wybieramy element
ś
rodkowy. Poniewa
ż
zbiór jest posortowany, to mamy
pewno
ść
, i
ż
na lewo s
ą
elementy mniejsze (lub równe), a na prawo s
ą
elementy wi
ę
ksze wg funkcji
porównuj
ą
cejj. Sprawdzamy, czy element ten spełnia kryteria poszukiwa
ń
. Je
ś
li tak, to ko
ń
czymy
(tylko jedno porównanie!). Je
ś
li nie, to sprawdzamy, czy element
ś
rodkowy jest wi
ę
kszy lub mniejszy
od poszukiwanego. Je
ś
li jest wi
ę
kszy, to poszukiwany element znajduje si
ę
w lewej połówce.
Analogicznie je
ś
li element
ś
rodkowy jest mniejszy, to poszukiwany element b
ę
dzie si
ę
znajdował w
prawej połówce. Wybieramy wi
ę
c jedn
ą
z połówek za nowy zbiór do przeszukania. Jest on o połow
ę
mniej liczny od zbioru wyj
ś
ciowego. Cał
ą
operacj
ę
powtarzamy z połówk
ą
zbioru. Je
ś
li nie znajdziemy
poszukiwanego elementu, to znów dostaniemy dwie połówki - czterokrotnie mniejsze od zbioru
wyj
ś
ciowego. Wybieramy jedn
ą
z nich zgodnie z podan
ą
reguł
ą
i kontynuujemy a
ż
do znalezienia
elementu lub otrzymania połówek, których ju
ż
dalej nie mo
ż
na dzieli
ć
- wtedy wiemy,
ż
e
poszukiwanego elementu w zbiorze nie ma.
Zwró
ć
uwag
ę
, i
ż
po ka
ż
dym porównaniu liczebno
ść
zbioru maleje o połow
ę
. Umo
ż
liwia to szybkie i
efektywne wyszukanie elementu nawet w olbrzymim zbiorze danych. Oto odpowiedni przykład.

Przykład
Chcemy wyszuka
ć
za pomoc
ą
opisanego algorytmu liczb
ę
14 w zbiorze { 2 3 5 6 7 9 10 14 16 25 30 }.
1 2 3 4 5
6
7 8 9 10 11
{ 2 3 5 6 7
9
10 14 16 25 30 }
Najpierw znajdujemy element
ś
rodkowy. Mo
ż
emy obliczy
ć
jego indeks jako
ś
redni
ą
arytmetyczn
ą
indeksu pierwszego i
ostatniego elementu zbioru. Oczywi
ś
cie wynik zaokr
ą
glamy
do warto
ś
ci całkowitej. (1+11)/2 = 6. Szóstym elementem
jest liczba 9, któr
ą
oznaczyli
ś
my na czerwono.
1 2 3 4 5
6
7 8 9 10 11
{ 2 3 5 6 7
9
10 14 16 25 30 }
14...............
Teraz sprawdzamy, czy element
ś
rodkowy jest równy
poszukiwanemu. U nas nie jest. Skoro nie jest równy, to
musi by
ć
wi
ę
kszy lub mniejszy od poszukiwanego. U nas
jest mniejszy, wi
ę
c dalsze poszukiwania b
ę
dziemy
prowadzi
ć
w prawej połówce.
1 2 3 4 5 6 7 8
9
10 11
{
2 3 5 6 7 9
10 14
16
25 30 }
Obliczamy nowy indeks elementu
ś
rodkowego, który jest
równy: (7+11)/2 = 9. Element
ś
rodkowy zaznaczyli
ś
my na
czerwono. Jest to liczba 16.
1 2 3 4 5 6 7 8
9
10 11
{
2 3 5 6 7 9
10 14
16
25 30 }
.......
14
Sprawdzamy, czy poszukiwany element jest równy
elementowi
ś
rodkowemu. Nie jest. Element
ś
rodkowy jest
wi
ę
kszy, wi
ę
c przenosimy si
ę
do lewej połowy.
1 2 3 4 5 6
7
8 9 10 11
{
2 3 5 6 7 9
10
14
16 25 30
}
Indeks elementu
ś
rodkowego = (7+8)/2 = 7. Jest to liczba
10 zaznaczona na czerwono.
1 2 3 4 5 6
7
8 9 10 11
{
2 3 5 6 7 9
10
14
16 25 30
}
14....
Porównujemy. Element
ś
rodkowy jest mniejszy, przenosimy
si
ę
do prawej połówki.
1 2 3 4 5 6 7
8
9 10 11
{
2 3 5 6 7 9 10
14
16 25 30
}
14
Znajdujemy element
ś
rodkowy - (8+8)/2 = 8. Jest to liczba
14. Porównanie da teraz wynik pozytywny.
Ile operacji porówna
ń
wykonano? Cztery. A wi
ę
c bardzo szybko znale
ź
li
ś
my pozycj
ę
elementu w
zbiorze posortowanym. Teraz zobaczmy, co si
ę
dzieje, gdy poszukiwanego elementu w zbiorze nie
ma. Spróbujemy znale
źć
w tym samym zbiorze danych liczb
ę
4.
1 2 3 4 5 6 7 8 9 10 11
{ 2 3 5 6 7
9
10 14 16 25 30 }
Znajdujemy
element
ś
rodkowy.
Indeks = (1+11)/2 = 6
1 2 3 4 5 6 7 8 9 10 11
{ 2 3 5 6 7
9
10 14 16 25 30 }
...........
4
Element
ś
rodkowy wi
ę
kszy od poszukiwanej liczby,
przenosimy si
ę
do lewej połówki zbioru.
1 2 3 4 5 6 7 8 9 10 11
{ 2 3
5
6 7
9 10 14 16 25 30
}
Znajdujemy
element
ś
rodkowy.
Indeks = (1+ 5)/2 = 3
1 2 3 4 5 6 7 8 9 10 11
{ 2 3
5
6 7
9 10 14 16 25 30
}
.....
4
Element
ś
rodkowy wi
ę
kszy. Wybieramy lew
ą
połówk
ę
.
1 2 3 4 5 6 7 8 9 10 11
{
2
3
5 6 7 9 10 14 16 25 30
}
Znajdujemy
element
ś
rodkowy.
Indeks = (1+2)/2 = 1
1 2 3 4 5 6 7 8 9 10 11
{
2
3
5 6 7 9 10 14 16 25 30
}
4...
Element
ś
rodkowy mniejszy od poszukiwanego. Wybieramy
praw
ą
połówk
ę
.
1 2 3 4 5 6 7 8 9 10 11
{
2
3
5 6 7 9 10 14 16 25 30
}
Znajdujemy
element
ś
rodkowy:
Indeks = (2+2)/2 = 2.
1 2 3 4 5 6 7 8 9 10 11
{
2
3
5 6 7 9 10 14 16 25 30
}
4
Element
ś
rodkowy mniejszy od poszukiwanego. Poniewa
ż
zbiór jest jednoelementowy, to nie mo
ż
na go ju
ż
podzieli
ć
na dwie rozł
ą
czne połowy. Przeszukanie zostaje wi
ę
c
zako
ń
czone z wynikiem negatywnym - poszukiwanego
elementu w zbiorze nie ma.
Ile wykonano porówna
ń
? Cztery. Poniewa
ż
zbiór po ka
ż
dym porównaniu jest dzielony na coraz
mniejsze podzbiory, to maksymalna liczba porówna
ń
w n-elementowym zbiorze posortowanym
wyniesie nie wi
ę
cej ni
ż
|log
2
n|+1. Wobec tego mo
ż
emy oszacowa
ć
zło
ż
ono
ść
obliczeniow
ą
algorytmu
wyszukiwania binarnego na O(log
2
n). Jest to zło
ż
ono
ść
mniejsza od liniowej O(n), a wi
ę
c bardzo
korzystna (np. szesnastokrotny wzrost liczby danych powoduje jedynie czterokrotny wzrost czasu
wyszukiwania).
Schemat blokowy
Dany jest zbiór { a
1
a
2
a
3
...a
n-2
a
n-1
a
n
} oraz element x, który nale
ż
y w zbiorze odszuka
ć
. Zbiór jest
posortowany zgodnie z kryterium zdefiniowanym przez
funkcj
ę
porównuj
ą
c
ą
. Do opisu algorytmu
stosujemy nast
ę
puj
ą
ce zmienne:
n
liczba elementów w zbiorze
a[...] element zbioru o numerze od 1 do n podanym w klamrach kwadratowych
f
zmienna logiczna informuj
ą
ca o wyniku poszukiwa
ń
. Warto
ść
true oznacza znalezienie
elementu, warto
ść
false informuje, i
ż
poszukiwanego elementu w zbiorze nie ma
p
zmienna przechowuj
ą
ca indeks elementu
ś
rodkowego. Po zako
ń
czeniu działania algorytmu w
zmiennej tej znajdzie si
ę
indeks poszukiwanego elementu, je
ś
li f=true
x
poszukiwany element
ip,ik zmienne przechowuj
ą
indeksy elementu pocz
ą
tkowego i ko
ń
cowego przeszukiwanych zbiorów
Zakres poszukiwa
ń
definiuj
ą
dwie zmienne - ip
zawieraj
ą
ca indeks pierwszego elementu oraz ik
zawieraj
ą
ca indeks ostatniego elementu zbioru. Na
pocz
ą
tku algorytmu inicjujemy je odpowiednio na
pierwszy i ostatni element w zbiorze wej
ś
ciowym.
Je
ś
li w trakcie działania algorytmu dojdzie do
sytuacji, gdy indeks pocz
ą
tkowy jest wi
ę
kszy od
ko
ń
cowego, to oznacza to zbiór pusty. W takim
przypadku
ko
ń
czymy
działanie
algorytmu
z
wynikiem negatywnym - poszukiwanego elementu w
zbiorze wej
ś
ciowym nie ma - zmienna f przyjmie
warto
ść
false.
Je
ś
li zakres jest w porz
ą
dku, to obliczamy indeks
elementu
ś
rodkowego, który wyznaczy dwie połówki
zbioru.
Indeks
ten
obliczamy
jako
ś
redni
ą
arytmetyczn
ą
indeksów ip oraz ik, zaokr
ą
glon
ą
do
warto
ś
ci całkowitej.
Sprawdzamy, czy element
ś
rodkowy o indeksie p
jest poszukiwanym elementem. Je
ś
li tak, to

ko
ń
czymy z wynikiem pozytywnym - zmienna p zawiera pozycj
ę
odszukanego elementu.
W przypadku, gdy poszukiwany element nie jest równy elementowi
ś
rodkowemu, musi si
ę
on
znajdowa
ć
w jednej z dwóch połówek, które wyznacza element
ś
rodkowy. Dalsze poszukiwania
b
ę
dziemy prowadzi
ć
w lewej połówce, je
ś
li ze wzgl
ę
du na kolejno
ść
wyznaczon
ą
przez
funkcj
ę
porównuj
ą
c
ą
poszukiwany element jest przed elementem
ś
rodkowym (czyli fp(x,a[p]) = true) lub w
połówce prawej w sytuacji przeciwnej. Przy przej
ś
ciu do połówki lewej indeks ko
ń
cowy ustawiamy na
warto
ść
o jeden mniejsz
ą
od indeksu p, a w prawej połówce indeks pocz
ą
tkowy ip ustawiamy na
warto
ść
o jeden wi
ę
ksz
ą
od p. Eliminuje to z połówek element
ś
rodkowy, który ju
ż
nie musi by
ć
brany
pod uwag
ę
. Równie
ż
w sytuacji, gdy która
ś
z połówek jest zbiorem pustym, powoduje to, i
ż
wyra
ż
enie
ip > ik stanie si
ę
prawdziwe i algorytm zako
ń
czy si
ę
z wynikiem negatywnym.
Poni
ż
ej przedstawiamy realizacj
ę
opisanego algorytmu wyszukiwania binarnego w ró
ż
nych j
ę
zykach
programowania. Przedstawiony program najpierw tworzy tablic
ę
n przypadkowych liczb. Nast
ę
pnie
sortuje j
ą
metod
ą
przez wstawianie. W wyniku posortowania w pierwszym elemencie znajduje si
ę
warto
ść
najmniejsza, a w ostatnim najwi
ę
ksza. Na podstawie tych dwóch warto
ś
ci program generuje
liczb
ę
przypadkow
ą
wpadaj
ą
c
ą
w zakres liczb w tablicy. Za pomoc
ą
algorytmu wyszukiwania
binarnego zostaje znaleziona pozycja wygenerowanej liczby i wyniki s
ą
wy
ś
wietlane na ekranie.
Przykład w C++
Wszystkie prezentowane tutaj przykłady zostały uruchomione w
DevC++
, który mo
ż
na darmowo i
legalnie pobra
ć
poprzez sie
ć
Internet.
#include <stdlib.h>
#include <time.h>
#include <iostream.h>
const int n = 10; // liczba elementów w sortowanym zbiorze
// funkcja porównuj
ą
ca
int fp(int x, int y)
{
return (x <= y);
}
int main()
{
int i,j,ip,ik,p,t,x,a[n];

cout << "Demonstracja przeszukiwania binarnego" << endl
<< " (C)2003 mgr Jerzy Walaszek" << endl << endl;
// tworzymy tablic
ę
z przypadkow
ą
zawarto
ś
ci
ą
.
srand( (unsigned)time( NULL ) );
for(i = 0; i < n; i++ ) a[i] = rand() % n;
// tablic
ę
sortujemy metod
ą
przez wstawianie
for(i = n - 2; i >= 0; i--)
{
t = a[i];
for(j = i + 1; (j < n) && !fp(t,a[j]); j++) a[j - 1] = a[j];
a[j - 1] = t;
};
// wyznaczamy poszukiwany element na podstawie warto
ś
ci
// minimalnej i maksymalnej w tablicy a[]
x = a[0] + rand() % (a[n-1] - a[0] + 1);
cout << "Liczba " << x << " w zbiorze posortowanym" << endl << endl;
for(i = 0; i < n; i++)
cout << "a[" << i << "] = " << a[i] << endl;

// znajdujemy pozycj
ę
elementu x w tablicy a[]
ip = 0; ik = n-1;
while(ip <= ik)
{
p = (ip + ik) / 2;
if(a[p] == x) break;
if(fp(x,a[p]))
ik = p - 1;
else
ip = p + 1;
};
// wy
ś
wietlamy wyniki. Je
ś
li element został znaleziony, to ip <= ik
// i p zawiera jego pozycj
ę
. W przeciwnym razie ip > ik - elementu
// nie znaleziono.
if(ip <= ik)
cout << endl << "znajduje sie na pozycji " << p << endl;
else
cout << endl << "nie wystepuje" << endl;
// czekamy na naci
ś
ni
ę
cie klawisza i ko
ń
czymy program
cout << endl;
cout.flush();
system("pause");
return 0;
}
Wyszukiwarka
Podobne podstrony:
Algorytmy obliczen id 57749 Nieznany
Algorytmy zadania id 51150 Nieznany (2)
algorytmy tekstowe id 57778 Nieznany (2)
3 3 BK Algorytmy parsingu id 34 Nieznany (2)
Algorytmy genetyczne 2 id 57672 Nieznany (2)
Algorytmy wyklad 1 id 57804 Nieznany
algorytmy ewolucyjne id 57660 Nieznany
Algorytm Simplex id 57544 Nieznany (2)
Algorytmy wyklad 6 7 id 57806 Nieznany
Algorytm RSA id 57542 Nieznany
Algorytmy wyklad 4 5 id 57805 Nieznany
algorytm simplex 3 id 57546 Nieznany
algorytm lvq id 57514 Nieznany (2)
ALGORYTM BANKOMATU id 57487 Nieznany (2)
Algorytmy obliczen id 57749 Nieznany
ALGORYTM id 57461 Nieznany
algorytmika id 57568 Nieznany (2)
algorytmy PKI Instrukcja id 577 Nieznany (2)
więcej podobnych podstron