Literatura:
„Prognozowanie gospodarcze” M Cieślak, PWN III wydanie
„Prognozowanie gospodarcze” Dittman AE Wrocław
„Predykcja ekonometryczna” A. Zewiasz
Wykład 1 - 13.10.2001
Wyznaczanie prognoz
Prognozowanie ilościowe czyli predykcja pozwala wyznaczać prognozy za pomocą przesłanek z modeli ekonometrycznych. Nie dotyczy ono tylko przyszłości ale może także dotyczyć przeszłości lub teraźniejszości. Prognozowanie ma ścisłe powiązania z demografią.
Prognozowanie wykorzystywane jest między innymi w Głównym Urzędzie Statystycznym oraz w dużych przedsiębiorstwach czy centralach gdzie za pomocą prognozowania ocenia się perspektywy planowanej produkcji.
Podstawowe pojęcia:
model ekonometryczny
(wg Z. Czerwińskiego) - może być rozumiany ogólnie, intuicyjnie jako obraz, odbicie, odwzorowanie określonego obiektu w określonym języku.
Model ekonometryczny - również będzie układem równań odwzorowującym wyróżnione zależności między zjawiskami ekonomiczno - społecznymi.
Część związków można mierzyć a niektóre nie.
Związki mierzalne nazywane są korelacyjnymi.
Y = f (x1, x2 ......xkၖ)
y - zjawisko badane
x1,x2-zjawiska, czynniki
ၖ- składnik losowy (psi,) - jest to łączny efekt oddziaływania na zmienną y, oddziałuje na te i inne czynniki, które nie zostały uwzględnione bezpośrednio w zbiorze x.
Jest to zmienna losowa o określonym rozkładzie.
E(ၖ) = 0; D2(ၖ) = ၤ2 = const. (ၤ2 - wariancja)
liniowy model ekonometryczny
Yt = ၡ0 + ၡ1xt + ၸt t = 1,2,………….,n
gdzie:
ၸt - składnik losowy
ၡ0 - współczynnik kierunkowy funkcji regresji
Aby przedłużyć prognozę od 1,2,.............,n należy wykonać estymację parametrów ၡ0 i ၡ1.
Do estymacji parametrów wykorzystuje się metodę najmniejszych kwadratów.
MNK polega na znajdowaniu takich wartości ocen parametrów strukturalnych modelu, by suma kwadratów odchyleń zaobserwowanych (empirycznych) wartości i zmiennej y, od jej wartości teoretycznych wyznaczonych przez model była najmniejsza w przypadku jednej zmiennej objaśniającej.
MNK polega na znajdowaniu takiej prostej , która jest najlepiej dopasowana, do wszystkich punktów empirycznych, czyli minimalizowana jest sumą kwadratów reszt (ut).
Klasyczne założenia MNK
Zmienne objaśniające x są nielosowe i niewspółliniowe k<n;
Istnieje n populacji składników losowych, o nadziejach matematycznych E(ၖt)=0 i stałych wariancjach o skończonych wartościach ၤ2 =D2(ၖt) = const, t= 1, 2, 3, ...... n.
Realizacje zmiennych tworzą proces czysto losowy tzn., że następuje po sobie realizacja składnika losowego , są nieskorelowane, czyli ρ(ၖt; ၖts)= 0 dla t ≠ s
składniki losowe są nieskorelowane ze zmiennymi objaśniajacymi.
Jeżeli ww. założenia są spełnione to estymator ma dobre własności tzn.
jest nieobciążony;
zgodny;
najbardziej efektywny;
f (0, 1) = ![]()
(Yt - 0 - 1xt)2 = ![]()
et2 ![]()
et2 = Yt - (0 - 1xt)
^ ^
f (0, 1) = minimum
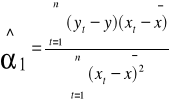
gdy wartość zmiennej objaśniającej zależy od więcej niż jednej zmiennej objaśnianej
Yt = ၡ0 + ၡ1xt1 + ၡ2xt2 + …………. + ၡkxtk + ၸt
t = 1,2,……………,n
parametr „ၡ1” wskazuje o ile przeciętnie zmieni się wartość „y” jeśli „x1” zmieni się o jedną jednostkę w pewnym okresie czasu.
szeregi czasowe - są realizacją procesu stochastycznego który możemy zapisać ciągiem zmiennych losowych.
ၻytၽ= ၻy1, y2, ................., ynၽ szeregi czasowe
gdy „t” jest okresem miesiąca to:
„y1” to np. styczeń
„y2” to luty itd.
gdy zaobserwujemy już jakiś proces wówczas oznaczamy dane małymi literami.
momenty czasu
ၻYtၽ= ၻY1, Y2, ................., Ynၽ
zmienna “Y” jest pewną funkcją która może
przybierać różne wartości „y”
0,3 dla y = 0
PၻY=yၽ = 0,5 dla y = 1
0,2 dla y = 2
PၻY=yၽ = 0 < p < 1
realizacja procesu to ciąg: ၻ0,0,1,1,0,0,0,1ၽ
^
oceniając p wyznaczamy prognozę
![]()
„p” zmienia się jednak z czasem
P ၻYt=yၽ = 0 < p < 1
Rachunek macierzowy
Y = ![]()
x = 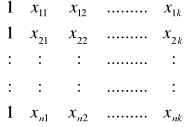
n x 1 n x (k+1)
Składnik losowy - ၸ (ksi)
ၸ = 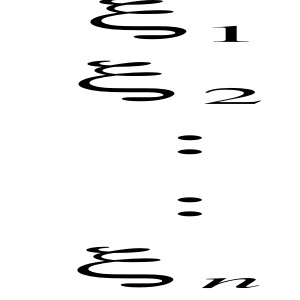
ၡ = ![]()
n x 1 (k + 1) x 1
f (α0, α1, ................... αk) = ![]()
lub w formie macierzowej:
Y = Xα + ξ Y* = Xα ; Y* - wartość teoretyczna funkcji regresji
f(α) = (Y - Yt)T(Y - Y*) = (Y - Xd)T(Y - Xα)
![]()
![]()
gdy, chcemy obliczyć średni błąd szacunku stawiamy hipotezę, że α0 = 0 i próbujemy ją zweryfikować.
Główne klasyczne założenia regresji liniowej.
zakładamy, że dla każdego „t” nadzieja matematyczna równa się 0.
![]()
2. zakładamy, że dla każdego „t” wariancja składnika losowego jest równa δ2 - jest stała
![]()
składnik losowy ma rozkład homostechastyczny
![]()
3. gdy w czasie są nieskorelowane macierze składników losowych
4. zakładamy, że wartości zmiennych objaśniających są nie losowe to znaczy są
ustalone z góry.
R(X) = k+1 ⇒ det (XTX) > 0 R(X) - rząd macierzy
5. czasami wprowadzamy założenie, że wektor składników losowych ma
n-wymiarowy rozkład normalny z nadzieją matematyczną równą 0.
ξ ∼ N(0, In δ2) ⇒ Y ∼ N(Xαi, In δ2)
wektor wartości funkcji regresji (wartości teoretyczne funkcji regresji)
![]()
![]()
![]()
wariancja resztowa
![]()
współczynnik zbieżności
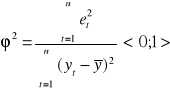
![]()
![]()
Macierz wariancji i dewariancji estymatorów.
D2(α) = (XTX)-1δ2 Se2 ⇒ δ2
![]()
![]()
![]()
![]()
![]()
; ![]()
Hipotezy:
a) H0 αj = 0
b) H1 αj ≠ 0
j-oty parametr funkcji jest równy 0, nie ma wpływu ma zmienną objaśniającą.
Sprawdzian testu Studenta
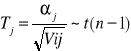
![]()
0
![]()
a → ta → K = (-∞; -ta > ∪ < ta; ∞)
za „a” przyjmujemy małą liczbę np. 0,01; 0,05
Poziom istotności:
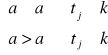
prognoza czy wartość symulowana
![]()
XT - wartości hipotetyczne
![]()
Wykład 2 - 28.10.2001
Model potęgowy
![]()
t = 1,2, ........., n
najczęściej rozważany natomiast jest model:
![]()
gdzie:
Zt - poziom zatrudnienia,
Wt - poziom środków trwałych,
α1- elastyczność produkcji względem zatrudnienia.
model ten jest modelem nieliniowym
- estymacja modelu:
![]()
- logarytm modelu:
![]()
Ut, Rt, Vt - są nowymi zmiennymi
po obliczeniu otrzymujemy:
![]()
natomiast ![]()
]
Szczególne modele regresji (trendy).
a) model addytywny jest jednym z modeli szeregu czasowego
Yt,h = f(t) + a(h) + ξt
trend wahania wahania
sezonowe losowe
trend f(t) jest funkcją kolejnych numerów czasów (generalnie obrazuje przyrost).
b) model multiplikatywny.
![]()
rozwój zjawiska obrazuje trend ale wahania sezonowe są coraz większe (brak stabilności)
Najprostszą formą trendu jest funkcja liniowa:
f1(t) = β0 + tβ1 + ξt
Wyliczenie parametrów na podstawie wzorów analitycznych:
wzór 1:
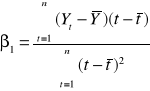
wzór 2:
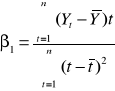
wzór 3:
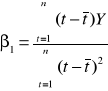
wzór na β0:
![]()
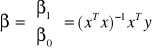
Zadanie:
W miesiącach od stycznia do kwietnia zaobserwowano następujące wydatki: 4, 6, 10, 8.
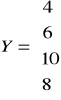
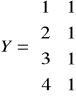
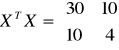
![]()
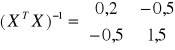
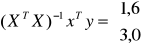
![]()
Interpretacja wyniku: Średnio z miesiąca na miesiąc wartość wydatków rosła o 1,6 jednostki.
t |
|
Yt |
Yt- |
|
1 |
4,6 |
4 |
-0,6 |
0,36 |
2 |
6,2 |
6 |
-0,2 |
0,04 |
3 |
7,8 |
10 |
2,2 |
4,84 |
4 |
9,4 |
8 |
-1,4 |
1,96 |
Σ |
|
|
0,0 |
7,2 |
suma reszt
jest to pośredni test sprawdzający poprawność wykonania zadania, gdy otrzymamy 0 zadanie uważa się za wykonane poprawnie.
obliczamy odchylenia wydatków od trendu:
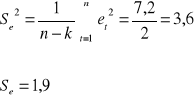
Interpretacja wyniku: Wydatki rzeczywiste odchylają się od trendu o 1,9 jednostki.
oceniamy błąd obliczeń:
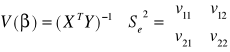
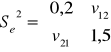
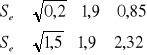
Interpretacja wyniku: Średni błąd szacunku czyli odchylenie standardowe estymatora pierwszego β1 jest równe 0,85 jednostki (wskazuje to rząd błędu jakim szacowany jest parametr)
oceniamy względny błąd szacunku (błąd średni)
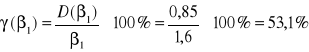
Interpretacja wyniku: Względny błąd szacunku stanowi 53,1% oceny całego szacunku.
Wyznaczamy prognozę na podstawie trendu:
![]()
![]()
Interpretacja wyniku: Prognoza równa jest 11 jednostek.
Obliczamy możliwy błąd prognozy:
![]()
czyli: ![]()
- średni błąd prognozowania czyli predykcji.
Interpretacja wyniku: Rzeczywiste prognozowania które występują w przyszłości mogą się odchylać o 5,2 jednostki.
Obliczamy odchylenie średniego błędu predykcji:
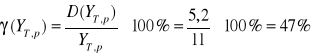
Rodzaje trendów liniowych.
a) ![]()
![]()
przyrost trendu liniowego
b) aby opisać krzywą z wykresu należy:
![]()
funkcja trendu zapisana jest w postaci funkcji regresji, do obliczenia jej używamy wzorów macierzowych.
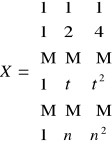
c) krzywą tą możemy również modelować za pomocą funkcji wykładniczej:
![]()
![]()
i wyznaczamy logarytm:
![]()
![]()
; ![]()
d) inna postać trendu to:
![]()
model szeregu czasowego wygląda wtedy następująco:
![]()
i wyznaczamy logarytm:
![]()
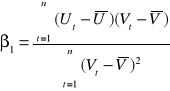
![]()
e) funkcja logarytmiczna:
![]()
![]()
f) funkcja logistyczna:
![]()
f(t) punkt nasycenia rynku
t
Zadanie:
Rozważamy wahania sezonowe o cyklu rocznym, obserwowane będą wartości cechy w poszczególnych miesiącach:
gdzie: t = 1,2 - bieżący numer miesiąca
h = 1,2,3,.......,12- miesiąc w cyklu wahań
k = 1,2,.... - numer roku .
np. obserwacja z piątego roku z marca
to: k=5; h=3
t = (5-1) x 12 + 3 = 48+3 = 51
z obliczenia wynika, że jest to 51 miesiąc z kolei w cyklu który obserwujemy.
cykl dwuokresowy:
![]()
![]()
określa amplitudę
wahania sezonowego
gdzie:
„t” - przyjmujemy jako bieżące półrocze
„h” - numer półrocza (0 - pierwsze półrocze, 1 - drugie półrocze)
„k” - numer roku
macierz danych przyjmuje następującą postać:
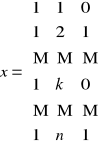
cykl kwartalny - wprowadzamy dwie zmienne zero - jedynkowe.
![]()
suma dwóch zmiennych
zero jedynkowych
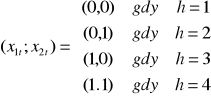
aby obliczyć cykl miesięczny musimy wprowadzić cztery zmienne zero jedynkowe
numer bieżący miesiąca:
t = (k-1)c+h
wahania sezonowe wprowadzają składnik losowy ηt (eta).
![]()
![]()
![]()
![]()
m - liczba wszystkich lat
![]()
np.
![]()
gdzie: t - numer bieżący kwartału
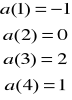
prognozy kwartalne
wyznacz prognozę na trzeci kwartał piątego roku:
k=5, H=3
T = (k-1)c+H
T = (5-1) 4+3 = 19
badany kwartał jest 19 z kolei badanym kwartałem
obliczamy prognozę:
![]()
Wykład 3 - 10.11.2001
Wyznaczanie tendencji rozwojowych zwanych trendami.
Metody adaptacyjne:
a) metoda średnich ruchomych - metoda wygładzania średnich czasowych.
t |
Yt |
|
|
|
1 |
2 |
- |
- |
- |
2 |
4 |
3,3 |
- |
3,5 |
3 |
4 |
5,3 |
4,0 |
5,0 |
4 |
8 |
4,7 |
4,8 |
5,5 |
5 |
2 |
5,3 |
4,4 |
4,5 |
6 |
6 |
3,3 |
4,4 |
4,0 |
7 |
2 |
4 |
- |
3,5 |
8 |
4 |
- |
- |
- |
obliczeń w tabeli dla średniej ruchomej scentrowanej trzyokresowej dokonano z wzoru:
![]()
a dla średniej ruchomej scentrowanej pięciookresowej z wzoru:
![]()
wykres szeregu ![]()
(3) oraz ![]()
(5) przedstawia się w sposób następujący:
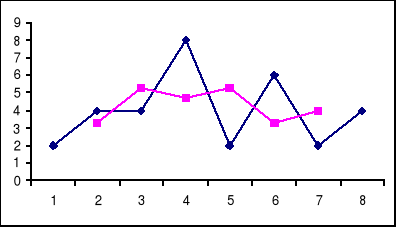
Im więcej składowych tym przebieg jest bardziej łagodny. Zazwyczaj rozważamy średnie 5, 10, 30 i 100 okresowe.
Uogólnienie wzoru na dowolną liczbę składników:
gdy k jest liczbą nieparzystą:
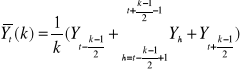
gdy k jest liczbą parzystą:
dla k = 2
![]()
dla k = 4
![]()
dla dowolnej liczby parzystej:
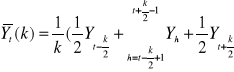
b) średnie ruchome uprzednie:
wzór ogólny:
![]()
w szczególności:
![]()
![]()
Im większe „k” tym prognoza wyznaczona na podstawie tendencji długookresowej a im mniejsze „k” prognoza zależna od czynników bieżących.
przykład:
t |
Yt |
|
|
Ut(2) |
Ut(4) |
Ut2(2) |
Ut2(4) |
1 |
2 |
- |
- |
- |
- |
- |
- |
2 |
4 |
- |
- |
- |
- |
- |
- |
3 |
4 |
3 |
- |
1 |
- |
1 |
- |
4 |
8 |
4 |
- |
4 |
- |
16 |
- |
5 |
2 |
6 |
4,5 |
- 4 |
-2,5 |
16 |
6,25 |
6 |
6 |
5 |
4,5 |
1 |
-1,5 |
1 |
2,25 |
7 |
2 |
4 |
5,0 |
- 2 |
-3,0 |
4 |
9 |
8 |
4 |
4 |
4,5 |
0 |
-0,5 |
0 |
0,25 |
Σ |
|
|
|
0 |
-4,5 |
38 |
17,75 |
wyznaczanie prognozy na okres 9:
wyliczamy błędy prognoz ex - post na podstawie wzoru:
![]()
średnie wartości błędów prognoz obliczamy z wzoru:
![]()
dla badanego przykładu:
![]()
![]()
prognoza przeszacowana
wyznaczenie wariancji predykcji ex - post obliczamy z wzoru:
![]()
dla badanego przykładu:
![]()
⇒ Sp(2) = 2,52
![]()
⇒ Sp(4) = 2,11
wyniki obrazują odchylenia prognoz, ze względu na mniejszy błąd należy wybrać prognozę o parametrze 2,11.
uprzednia mediana ruchoma.
![]()
k = 1,2 ⇒ Met(k) = ![]()
przykład:
t |
Yt |
Met+1(3) |
Met+1(4) |
1 |
2 |
- |
- |
2 |
4 |
4 |
- |
3 |
4 |
4 |
- |
4 |
8 |
4 |
4 |
5 |
2 |
6 |
4 |
6 |
6 |
2 |
5 |
7 |
2 |
4 |
4 |
8 |
4 |
- |
3 |
obliczenie do tabeli:
Met+1(3) - kolejność składników do obliczeń wpisywać rosnąco (od najmniejszej do największej).
mediana dla nieparzystej liczby składników jest składnikiem środkowym.
2,4,4 środkowa 4 czyli mediana
4,4,8 środkowa 4 czyli mediana
2,4,8 środkowa 4 czyli mediana
2,6,8 środkowa 6 czyli mediana
2,2,6 środkowa 2 czyli mediana
2,4,6 środkowa 4 czyli mediana
Met+1(4) - kolejność składników do obliczeń wpisywać rosnąco (od najmniejszej do największej).
mediana dla parzystej liczby składników jest średnią arytmetyczną środkowych dwóch operacji.
2,4,4,8 suma dwóch środkowych cyfr dzielona przez dwa 8:2 = 4
2,4,4,8 suma dwóch środkowych cyfr dzielona przez dwa 8:2 = 4
2,4,6,8 suma dwóch środkowych cyfr dzielona przez dwa 10:2 = 5
2,2,6,8 suma dwóch środkowych cyfr dzielona przez dwa 8:2 = 4
2,2,4,6 suma dwóch środkowych cyfr dzielona przez dwa 6:2 = 3
![]()
![]()
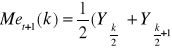
wyznaczanie kwantyli - gdy „k” jest duże:
![]()
![]()
Wykład 4 - 12.01.2002
Metody adaptacyjne cd.
wyrównywanie wykładnicze ma postać:
![]()
![]()
ocena trendów w okresie ![]()
jest równa:
![]()
![]()
ocena ta równa jest średniej wartości dwóch ważonych
prognoza na okres t+1 ma postać:
![]()
prognozę tę możemy również zapisać jako:
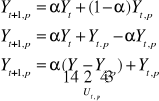
Ut - błąd prognozy
![]()
![]()
błąd prognozy okresu t+1
Sposoby wyznaczania parametru α.
W praktyce wykonujemy to w sposób arbitralny - jeśli szereg który mamy analizować przebiega w sposób stacjonarny.
Aby wyznaczyć α przyjmuje się, że:
α = 0; 0,1; 0,2; 0,3; 0,4; ........................1,0
i dla każdego α wylicza się wartości trendu np.
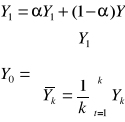
k = 1,2 ............n
następnie obliczamy błędy prognozowania Ut,p(α)
następnie wyliczamy sumy kwadratów błędów prognozowania
![]()
![]()
przykład:
Cena akcji w poszczególnych pięciu notowaniach tworzy następujący szereg.
Wyznaczyć prognozę na okres szósty.
t |
Yt |
|
|
|
|
1 |
2 |
2,0 |
- |
- |
- |
2 |
4 |
3,6 |
2,0 |
2 |
4,0 |
3 |
1 |
1,52 |
3,6 |
-2,6 |
6,76 |
4 |
5 |
4,3 |
1,52 |
3,5 |
12,25 |
5 |
5 |
4,86 |
4,3 |
0,7 |
0,49 |
6 |
- |
- |
4,86 |
- |
|
Σ |
|
|
|
|
23,50 |
dla obliczeń założono, że
Y0 = Y1 a α = 0,8
sposób obliczania ![]()

suma kwadratów Q(α) wynosi Q(0,8) = 23,5
możemy teraz obliczyć wariancję predykcji ex - post
![]()
![]()
metoda autoregresyjna
rozważamy ciąg obserwacji od Y1 do Yn
współczynnik autokorelacji rzędu „k”
(ro) ![]()
i należy do przedziału <-1,1>
![]()
![]()
estymator współczynnika:
![]()
![]()
![]()
modele autoregresyjne:
funkcja autoregresyjna rzędu „g”
![]()
![]()
model autoregresyjny rzędu pierwszego zachodzi gdy:
Rk > Rk+1 k = 1,2 ................. n
i ma postać:
![]()
Współczynnik autokorelacji rzędu pierwszego mierzy następujące współzależności:
B(Yt,Yt-1) > 0
B(Yt, Yk) = 0
dla k = 2,3 .................n
http://otior.w.interia.pl Prognozowanie i symulacje
______________________________________________________________________________
1
Pt, gdy y = 1
1 - pt, gdy y = 0
rozkład Studenta
P, gdy y = 1
1 - p, gdy y = 0
rozkład normalny
Wyszukiwarka