Obliczone statystyki ![]()
są porównywane z odczytaną z tablic rozkładu ![]()
wartością krytyczną /krytyczna wartość sprawdzianu hipotezy/ ![]()
. Wartość krytyczna ma rozkład ![]()
, gdzie poziom istotności ![]()
jest prawdopodobieństwem popełnienia błędu w rezultacie którego zostaje odrzucona hipoteza prawdziwa, ![]()
jest liczebnością próby statystycznej.
Uwaga: ![]()
oznacza tu nie liczbę zmiennych objaśniających lecz liczbę szacowanych parametrów strukturalnych modelu.
Jeżeli ![]()
nie ma podstaw do odrzucenia hipotezy ![]()
, oznacza to, że zmienna ![]()
nie ma istotnego wpływu na zmiany zmiennej ![]()
. Jeżeli natomiast ![]()
odrzucamy hipotezę ![]()
na rzecz hipotezy alternatywnej ![]()
, co oznacza, że zmienna ![]()
ma znaczący, istotny wpływ na zmiany zmiennej ![]()
.
4. Symetria składnika losowego.
Weryfikacja tej własności modelu dotyczy składnika losowego modelu. Poprzednie odnosiły się do założeń o zmiennych objaśniających modelu.
Cechą charakterystyczną poprawnego rozkładu reszt jest symetria rozkładu, rozumiana jako równość prawdopodobieństw /częstości/ występowania dodatnich i ujemnych reszt, czyli:
![]()
=![]()
.
Sprawdzając własność symetrii składnika losowego, weryfikujemy hipotezę ![]()
, wobec hipotezy alternatywnej ![]()
. Statystykę weryfikującą hipotezę ![]()
w przypadku dużej próby statystycznej definiujemy następująco:
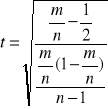
,
gdzie m jest liczbą dodatnich reszt, a n liczbą wszystkich reszt /liczebność próby/. Rozkład statystyki t jest zbliżony do rozkładu normalnego dla dużej próby statystycznej.
Jeżeli przy założonym poziomie istotności ![]()
odczytana z tablic rozkładu normalnego wartość ![]()
spełnia nierówność ![]()
, to nie ma podstaw do przyjęcia hipotezy ![]()
, należy przyjąć hipotezę alternatywną ![]()
co z kolei oznacza brak symetrii rozkładu składnika losowego. Jeśli obliczona wartość ![]()
nie mamy podstaw do odrzucenia hipotezy ![]()
, składnik losowy ma rozkład symetryczny.
W przypadku małej próby statystycznej częstość ![]()
ma rozkład dwumianowy o parametrach (p,q), gdzie ![]()
. Dla sprawdzenia hipotezy symetrii wystarczy sprawdzić czy zachodzi nierówność:
![]()
, gdzie ![]()
odczytujemy z tablic 3.1 rozkładu dla ![]()
.
Tablica 3.1
|
|
|
|
|
|
5 |
1 |
4 |
18 |
5 |
13 |
6 |
1 |
5 |
19 |
5 |
14 |
7 |
1 |
6 |
20 |
6 |
14 |
8 |
2 |
6 |
21 |
6 |
15 |
9 |
2 |
7 |
22 |
7 |
15 |
10 |
2 |
8 |
23 |
7 |
16 |
11 |
3 |
8 |
24 |
7 |
17 |
12 |
3 |
9 |
25 |
8 |
17 |
13 |
3 |
10 |
26 |
8 |
18 |
14 |
4 |
10 |
27 |
9 |
18 |
15 |
4 |
11 |
28 |
9 |
19 |
16 |
4 |
12 |
29 |
9 |
20 |
17 |
4 |
13 |
30 |
10 |
20 |
Jeżeli warunek ![]()
zostaje spełniony, nie ma podstaw do odrzucenia hipotezy ![]()
, w przeciwnym przypadku należy uznać hipotezę alternatywną ![]()
, co oznacza brak symetrii składnika losowego.
5. Losowość składnika losowego.
Symetryczny rozkład składnika losowego nie jest równoznaczny z losowością rozkładu reszt. Przyczyn takiej sytuacji należy upatrywać w zbyt „długich” seriach reszt o takich samych znakach.
Test serii jest sprawdzianem losowości składnika losowego. Niech A oznacza zdarzenie takie, że ![]()
![]()
, natomiast B oznacza zdarzenie, że ![]()
. Zdefiniujmy ciąg tych zdarzeń według następujących zasad:
jeżeli weryfikowany model jest modelem o jednej tylko zmiennej objaśniającej, to:
w porządku odpowiadającym rosnącym wartościom tej zmiennej /dane przekrojowe/,
w porządku odpowiadającym kolejnym momentom czasu/ szeregi czasowe/,
jeżeli weryfikowany model jest modelem o wielu zmiennych objaśniających, a dane stanowią szeregi czasowe, przyjmujemy porządek zdarzeń według kolejnych momentów czasu.
Każdy podciąg ciągu zdarzeń A oraz B, mający tę własność, że zawiera tylko elementy jednego rodzaju A lub B bezpośrednio po sobie następujące, określamy mianem serii. W ciągu może wystąpić kilka serii o jednakowej maksymalnej długości k. Liczbę tych wyróżnionych serii oznaczmy ![]()
. Długość serii i liczba serii są zmiennymi losowymi o znanych rozkładach. Rozkłady te stanowią podstawę opracowania tablicy testu serii. Z tablic tych odczytujemy maksymalną liczbę obserwacji n, przy których prawdopodobieństwo spełnienia nierówności:
![]()
.
Ta wartość prawdopodobieństwa jest poziomem istotności ![]()
przyjętym dla sprawdzenia hipotezy o losowości rozkładu reszt modelu.
Tablica 3.2
Długość serii k |
Największa liczba obserwacji n, dla której |
5 |
10 |
6 |
14 |
7 |
22 |
8 |
34 |
9 |
54 |
10 |
86 |
11 |
140 |
12 |
230 |
Tablica testu serii.
Jeżeli długość serii /maksymalnej/ jest większa od k przy liczebności próby n, to odrzucamy hipotezę ![]()
/![]()
składnik losowy jest losowy}/ i przyjmujemy hipotezę alternatywną ![]()
/![]()
składnik losowy nie jest losowy}/, w przeciwnym przypadku nie ma podstaw do odrzucenia hipotezy o losowości składnika losowego.
Weryfikacji tej własności składnika losowego można przeprowadzić także przy wykorzystaniu tablic liczby serii. Sprawdzianem hipotezy ![]()
jest parametr ![]()
określający liczbę wszystkich serii, niezależnie od długości w ciągu reszt. Z tablic liczby serii, dla parametrów rozkładu ![]()
, gdzie ![]()
oznacza liczbę zdarzeń A, ![]()
oznacza liczbę zdarzeń B a parametr ![]()
poziom istotności, odczytujemy wartość krytyczną ![]()
. Jeżeli ![]()
, to nie ma podstaw by przyjąć hipotezę ![]()
, oznacza to, że liczba serii uzyskana w próbie jest zbyt mała przyjmujemy hipotezę alternatywną![]()
. Jeśli ![]()
, to nie ma podstaw do odrzucenia hipotezy ![]()
, co oznacza losowość składnika losowego.
Wyszukiwarka
Podobne podstrony:
Fuzje i przejęcia - wykłady, WZR UG ZARZĄDZANIE - ZMP I STOPIEŃ, V SEMESTR (zimowy) 2014-2015, FUZJE
Ekonometria wyklad 3.4, Ekonomia UG, 2, Ekonometria
Ekonometria wyklad 1, Ekonomia UG, 2, Ekonometria
Geografia turystyczna wykłady na UG
Geografia turystyczna, wykłady na UG
Finanse - wykład, FiR UG LSN, 5 semestr, Finanse samorządu terytorialnego, Finanse samorządu terytor
Zarządzanie Jakością wykłady, ZARZĄDZANIE - UG, SEMESTR 3, Zarządzanie jakością
Ekonometria wyklad 5, Ekonomia UG, 2, Ekonometria
Podstawy zarządzania wykłady, ZARZĄDZANIE - UG, SEMESTR 2, Podstawy zarządzania
wykład 1-3, wzr UG, OWI
Ekonometria wyklad 2, Ekonomia UG, 2, Ekonometria
Ekonometria wyklad 3.1, Ekonomia UG, 2, Ekonometria
PRODUKTY UBEZEPIECZENIOWE - PIERWSZY WYKŁAD, WZR UG ZARZĄDZANIE - ZMP I STOPIEŃ, V SEMESTR (zimowy)
Ekonometria wyklady 3.3, Ekonomia UG, 2, Ekonometria
Podstawy Zarzadzania - M.Czerska - WYKLADY, ZARZĄDZANIE - UG, SEMESTR 2, Podstawy zarządzania
Ekonometria wyklad 4, Ekonomia UG, 2, Ekonometria
więcej podobnych podstron