
Mariusz Plich
1
Modele wielorównaniowe - mnożniki i symulacje
Spis treści:
1. Podstawowe pojęcia i klasyfikacje
2. Czynniki modelowania i sposoby wykorzystania modelu
3. Typy i postacie modeli wielorównaniowych
4. Przykłady modeli wielorównaniowych
5. Symulacja jako technika wykorzystania modeli
6. Miary dopasowania modelu do danych empirycznych
7. Wykorzystanie modeli wielorównaniowych
Słowa kluczowe: model wielorównaniowy, symulacja, prognozowanie, analiza
scenariuszowa, mnożniki, metoda Gaussa-Seidela
1. Podstawowe pojęcia i klasyfikacje
Model może pozostawać konstrukcją czysto teoretyczną (model teoretyczny) ―
służy wówczas prezentacji teorii, która legła u podstaw jego konstrukcji. Model
empiryczny (aplikacyjny, stosowany) umożliwia weryfikację teorii (praw) przez ich
konfrontację z rzeczywistością. Może się również przyczynić do sformułowania
nieznanych wcześniej praw rządzących rzeczywistością.
Na każdy model składają się zmienne, parametry strukturalne (parametry modelu)
oraz łącząca je postać funkcyjna. Parametry to pewne stałe (współczynniki)
charakteryzujące związki między zmiennymi w modelu. W przypadku gdy parametry
są nieznane mogą być szacowane na podstawie danych statystycznych, a jakość
oszacowań weryfikowana przy użyciu odpowiednich metod ekonometrycznych.
Parametry mogą być również szacowane na podstawie opinii ekspertów lub ustalane w
oparciu o normy i relacje techniczne. Zdarza się, że parametry znane są na podstawie
założeń teoretycznych, leżących u podstaw konstrukcji modelu.
Zbiór danych statystycznych dotyczących pojedynczej zmiennej określa się mianem
szeregu danych. Szeregi danych mogą występować w następujących postaciach:
−
szeregi czasowe obrazujące wartość zjawiska w kolejnych momentach lub
okresach; mają one określoną częstotliwość, np. szeregi dzienne, miesięczne,
kwartalne czy roczne;
−
szeregi przekrojowe dotyczące stanów różnych obiektów w tym samym
momencie lub okresie, np. wydatki wylosowanych gospodarstw domowych w
listopadzie 2005 r.;
−
szeregi przekrojowo-czasowe zawierające informacje o stanach różnych
obiektów w różnych momentach lub okresach, np. wydatki wylosowanych
gospodarstw domowych w kolejnych miesiącach 2005 r.

Mariusz Plich
2
Model w sensie algebraicznym, to jedno równanie algebraiczne (model
jednorównaniowy) lub układ równań algebraicznych (model wielorównaniowy).
Modele jednorównaniowe zazwyczaj opisują kształtowanie wybranej zmiennej
ekonomicznej (zmienna objaśniana) w zależności od innych zmiennych (zmienne
objaśniające). Uproszczenie rzeczywistości w modelach ekonometrycznych polega na
uwzględnieniu jedynie najważniejszych czynników (zmiennych) mających wpływ na
kształtowanie zmiennej objaśnianej. W zapisie matematycznym związek taki
przyjmuje następującą formę:
(
)
ε
,
...
,
2
1
k
x
x
x
f
y =
co oznacza, że zmienna objaśniana y zależy od zmiennych objaśniających
)
...
1
(
k
i
x
i
=
oraz zmiennej losowej
ε
(składnik losowy). Zmienną losową wprowadza się do
modelu w celu odzwierciedlenia wszystkich czynników przypadkowych i czynników
ubocznych, tj. tych, które nie zostały uwzględnione jawnie w modelu jako zmienne
objaśniające.
Modele w których występuje składnik losowy określane są jako modele
stochastyczne. W praktyce ekonometrycznej znane są również modele
deterministyczne (tożsamościowe), czyli związki typu funkcyjnego, określające ściśle
(bez udziału składnika losowego) zależności między zmiennymi (np. wartość jako
iloczyn ceny i ilości).
O składniku losowym zakłada się, że jego nadzieja matematyczna jest równa 0, co w
praktyce oznacza, że przeciętnie rzecz ujmując nie ma on wpływu na badane zjawisko
(nie wywiera wpływu systematycznego na zmienną objaśnianą). Dlatego prezentując
postać modelu ujmuje się ją czasami na poziomie wartości oczekiwanej, co w praktyce
oznacza pominięcie składnika losowego. Na przykład, związek pomiędzy popytem a
dochodem i ceną, mający charakter stochastyczny można zapisać następująco:
(
)
cena
dochód
f
popyt
,
=
Aby można było dokonać ekonometrycznej analizy takiego związku o stochastycznej
naturze, zmienna objaśniana i zmienne objaśniające muszą być wielkościami
obserwowalnymi, a funkcja
f
musi mieć znaną postać. Jeżeli przyjąć, że funkcja
f
jest
liniowa, model można zapisać w postaci:
ε
α
α
α
α
+
+
+
=
k
k
x
x
x
y
...
2
2
1
1
0
gdzie
(
)
k
i
i
...
0
=
α
są parametrami funkcji. Na przykład:
ε
α
α
α
+
⋅
+
⋅
+
=
cena
dochód
popyt
2
1
0

Mariusz Plich
3
Parametry
1
α
i
2
α
oznaczają siłę reakcji popytu na wysokość dochodu i ceny.
Pozwalają więc poznać bliżej zależność znaną z teorii ekonomii. W przypadku
jednorównaniowych modeli liniowych parametr szacuje się najczęściej za pomocą
metody najmniejszych kwadratów (MNK).
Zmienne użyte modelu odnoszące się do okresu badanego określa się jako zmienne
bieżące. Zmienne opóźnione to takie, które odnoszą się do okresów wcześniejszych
w stosunku do okresu badanego. W modelach wykorzystuje się czasami zmienne
przyspieszone, czyli takie, które odnoszą się do okresów późniejszych w stosunku do
okresu badanego. Aby uwzględnić w zapisie modelu zmienne opóźnione lub
przyspieszone stosuje się zazwyczaj dodatkowy subskrypt czasu przy nazwie
zmiennej. Na przykład,
(
)
ε
,
,
,
t
t
t
t
cena
dochód
dochód
f
popyt
1
−
=
lub
(
)
ε
,
,
,
cena
dochód
dochód
f
popyt
1
−
=
.
Spośród zmiennych modelu wielorównaniowego można wydzielić zmienne
endogeniczne, których wielkości są wyznaczane przez model i zmienne
egzogeniczne, wyznaczane poza modelem, a wpływające na wartości zmiennych
endogenicznych. Opóźnione zmienne modelu wielorównaniowego (endogeniczne i
egzogeniczne) wraz z bieżącymi zmiennymi egzogenicznymi zaliczane są do grupy
zmiennych o wartościach z góry ustalonych (zmienne z góry ustalone).
Jeśli model nie zawiera żadnej zmiennej egzogenicznej to jest to tzw. model
zamknięty. W praktyce modele w pełni zamknięte nie istnieją, albowiem oznaczałoby
to brak wpływu otoczenia na zachowanie modelowanego układu. Z kolei, jeśli model
nie zawiera żadnej zmiennej endogenicznej to jest to modele otwarty. Oczywiście
modele otwarte w tym sensie nie istnieją, bo każdy model powinien zawierać
przynajmniej jedną zmienną endogeniczną. Nie oznacza to jednak, że podział na
modele otwarte i zamknięte nie ma żadnego znaczenia. Można bowiem zdefiniować
stopień otwarcia (zamknięcia) modelu. Poza tym określeń „model otwarty” i „model
zamknięty” używa się na ogół kontekście bloków modeli wielorównaniowych, np.
model gospodarki zamknięty ze względu na popyt finalny oznacza, że popyt finalny w
tym modelu nie jest egzogeniczny.
Ze względu na postać funkcyjną równań modelu wyróżnia się modele liniowe ― jeśli
wszystkie równania modelu są liniowe względem parametrów, oraz modele
nieliniowe ― jeśli występują w nich równania nieliniowe względem parametrów.
Ze względu na ujęcie czynnika czasu, rozróżnia się modele statyczne i modele
dynamiczne. Model statyczny nie jest zależny w żaden sposób od czasu. Model
dynamiczny to taki, w którym wprowadzono czas do równań modelu (może on być
Mariusz Plich
4
wprowadzony bezpośrednio ― w postaci zmiennej czasowej ― lub pośrednio ― przez
zmienne opóźnione, przyrosty zmiennych, ich tempa etc.)
Wreszcie, ze względu na zadania stawiane modelowi wyróżnia się modele
optymalizacyjne oraz modele opisowe. Modele optymalizacyjne ułatwiają podjęcie
najlepszej w danych warunkach decyzji (wybór najlepszego rozwiązania ze zbioru
rozwiązań dopuszczalnych). Modele opisowe służą do opisu rzeczywistości w celu
przedstawienie jej hipotetycznych przeszłych i przyszłych stanów. Model opisowy
zwykle utożsamiany jest z modelem stochastycznym, ponieważ modele opisowe
najczęściej zawierają czynnik losowy. Stochastyczne modele opisowe są często
określane mianem modeli ekonometrycznych.
2. Czynniki modelowania i sposoby wykorzystania modelu
Na rysunku 1 przedstawiono czynniki procesu modelowania i sposoby wykorzystania
(cele) gotowego modelu empirycznego.
Rysunek 1. Czynniki i cele modelowania matematycznego
Źródło: Intriligator 1978: 17
Czynnikami modelowania są: teoria, rzeczywistość i techniki estymacji parametrów.
Aby zbudować model empiryczny należy przedstawić teorię w postaci modelu
teoretycznego. Rzeczywistość związana z badanymi zjawiskami (fakty) ― drugi
składnik służący do budowy modelu ― występuje w postaci zbiorów danych
(obserwacji) dotyczących tych zjawisk. Dane te nie zawsze nadają się do
bezpośredniego zastosowania podczas budowy modelu. Często muszą być
Teoria
Rzeczywistość
(fakty)
Model
teoretyczny
Dane
"oczyszczone"
Dane
Techniki
estymacji
parametrów
Model empiryczny
Analiza struktury
Symulowanie rzeczywistości
(operacyjny)

Mariusz Plich
5
odpowiednio przetworzone (oczyszczone) przez zastosowanie ekstrapolacji,
interpolacji, usunięcie sezonowości, przeliczenia w celu uzgodnienia danych
pochodzących z różnych źródeł etc.
Model teoretyczny przedstawia w sformalizowanej postaci teorie leżące u podstaw
konstrukcji modelu. Teorie te będą później weryfikowane i wykorzystane w modelu
operacyjnym. Konstruując model teoretyczny nie bierze się jednak, na ogół, pod
uwagę możliwości estymacji jego parametrów (dostępności danych czy metod
estymacji).Teoria w postaci modelu teoretycznego i rzeczywistość odwzorowana
poprzez odpowiednio przygotowane dane, w połączeniu z technikami estymacji
umożliwiają oszacowanie nieznanych parametrów modelu. W rezultacie otrzymujemy
model empiryczny (operacyjny) tzn. model przetestowany empirycznie, gotowy do
użycia (symulacji). Jego ostateczna postać jest kompromisem pomiędzy teorią (w
postaci modelu teoretycznego) i praktyką (w postaci dostępnych danych, metod
estymacji i możliwości obliczeniowych komputerów, ograniczeń czasowych i
finansowych).
Model empiryczny jest z jednej strony, podstawą testowania zależności formułowanych
przez teorię (weryfikacja modelu), a z drugiej, może stanowić podstawę do
wnioskowania o rzeczywistości i do jej oceny. Testowanie i wnioskowanie, o których
mowa, to główne cele budowy modelu ekonometrycznego. Realizowane są one
poprzez analizy struktury i symulowanie rzeczywistości.
3. Typy i postacie modeli wielorównaniowych
Model wielorównaniowy to taki model, który zawiera więcej niż jedno równanie. W
sensie matematycznym jest to więc układ równań.
Zapiszmy ogólną postać modelu wielorównaniowego o
M
równaniach:
(
)
it
i
t
k
t
t
t
i
it
U
g
Y
,
,
,...,
,
,
1
Θ
=
−
−
Z
Y
Y
Y
(
) (
)
M
i
T
t
,...,
1
,...,
1
=
=
Ten sam model, zapisany w notacji macierzowej, sprowadza się do następującego
równania:
(
)
t
t
k,
t
1
t
t
t
U
Θ
,
,
Z
Y
,...,
Y
,
Y
G
Y
−
−
=
gdzie:
=
=
=
Nt
t
Mt
t
Mt
t
Z
Z
U
U
Y
Y
...
,
...
,
...
1
1
1
t
t
t
Z
U
Y
k
— maksymalne opóźnienie zmiennych endogenicznych modelu,

Mariusz Plich
6
t
— subskrypt czasu,
i
Y
—
i
-ta zmienna endogeniczna,
i
U
— składnik losowy w
i
-tym równaniu modelu,
Z
— wektor bieżących i opóźnionych zmiennych egzogenicznych,
Θ
— zbiór wszystkich parametrów modelu,
i
Θ
— podzbiór zbioru
Θ
, zawierający parametry
i
-tego równania.
Rozwiązanie modelu wielorównaniowego polega na znalezieniu wartości zmiennych
endogenicznych przy zadanych wartościach zmiennych egzogenicznych. Jako że
zadaniem modeli jest odzwierciedlanie rzeczywistości, rozwiązywanie modeli można
nazwać symulacją rzeczywistych zachowań badanych obiektów i zjawisk przy różnych
założeniach co do zmiennych egzogenicznych.
Równania modeli wielorównaniowych mogą być ze sobą wzajemnie powiązane, gdyż
zmienne endogeniczne opisywane przez poszczególne równania mogą być używane
jako zmienne objaśniające w innych równaniach. Powiązania te charakteryzuje się za
pomocą tzw. macierzy powiązań modelu. Macierz tę oznacza się symbolem
[ ]
ij
r
=
R
. Jest to macierz kwadratowa o wymiarach
MxM
.
Jej elementy przyjmują
wartości 0 lub 1, wg następujących zasad:
1
=
ij
r
gdy zmienna
j
Y
występuje w równaniu objaśniającym zmienną
i
Y
,
1
=
ij
r
w przeciwnym razie.
W zależności od własności macierzy powiązań wyróżnia się następujące typy modeli:
−
modele proste — macierz powiązań jest diagonalna;
−
modele rekurencyjne — macierz powiązań daje się przekształcić do macierzy
trójkątnej poprzez zmianę uporządkowania równań lub zmiennych;
−
modele współzależne — macierz powiązań modelu nie daje się przekształcić do
macierzy trójkątnej.
Powiązania zmiennych endogenicznych modelu można również przedstawić za pomocą
schematów blokowych, na których linie zakończone strzałkami pokazują kierunek
zależności pomiędzy zmiennymi. Prosty przykład takiego schematu pokazano na
rysunku 2. Nawiązuje on do znanego z podręczników ekonomii zagadnienia zwanego
pętlą inflacyjną, w której związki pomiędzy kosztami produkcji, cenami i płacami mają
charakter współzależny.
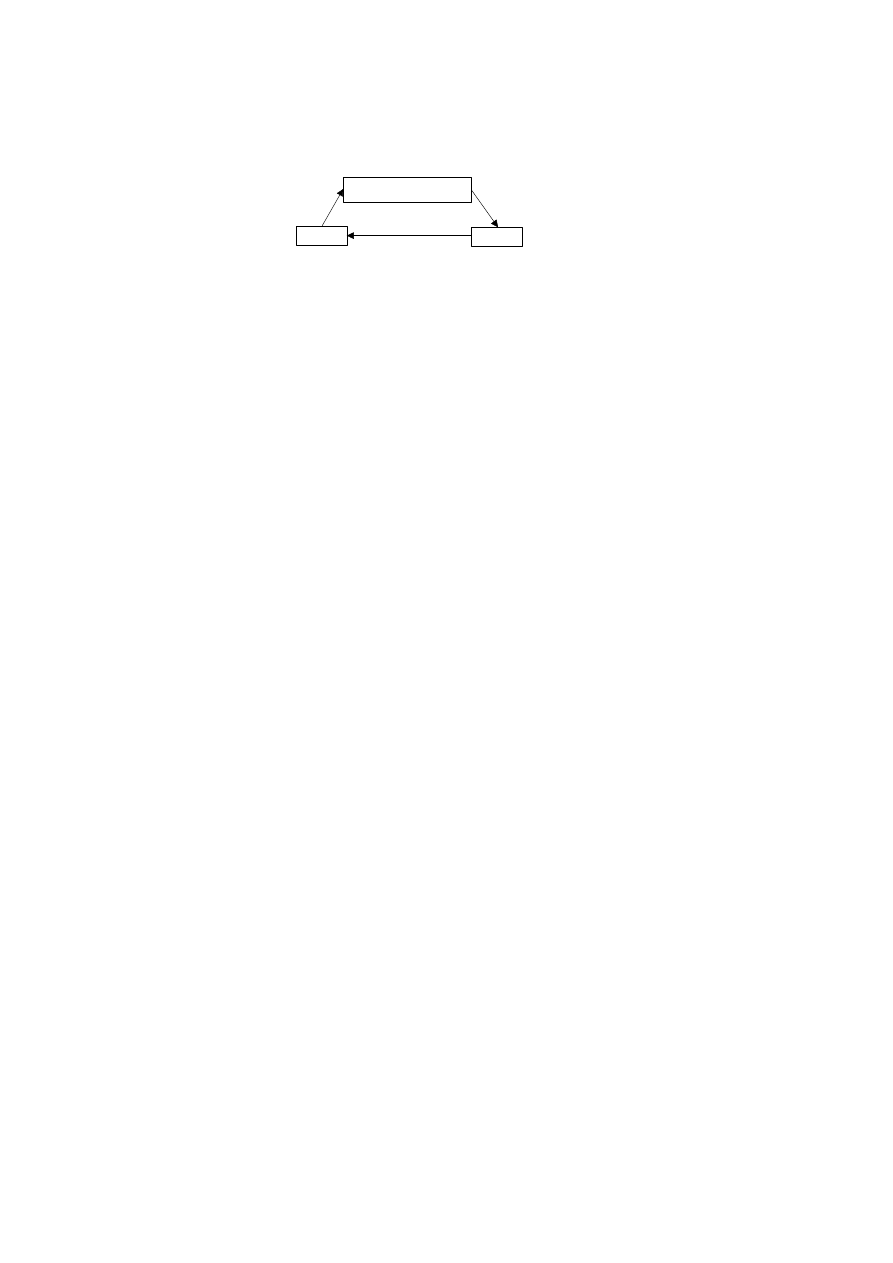
Mariusz Plich
7
Rysunek 2. Przykład powiązań w modelu współzależnym
Schemat pętli inflacyjnej
Przykład powiązań w modelu współzależnym
Płace
Ceny
Koszty produkcji
Źródło: opracowanie własne
Model złożony z równań przedstawionych w postaci, w której były one specyfikowane
w procesie budowy modelu to tzw. postać strukturalna modelu. Używając wcześniej
wprowadzonych oznaczeń model w postaci strukturalnej można zapisać jako:
(
)
t
t
k,
t
1
t
t
U
Θ
,
Z
Y
,...,
Y
,
Y
G
=
−
−
lub
(
)
t
t
k,
t
1
t
t
t
U
Θ
,
,
Z
Y
,...,
Y
,
Y
G
Y
−
−
=
Postać zredukowana powstaje z postaci strukturalnej przez wyeliminowanie wskutek
przekształceń matematycznych sprzężeń jednoczesnych między zmiennymi
endogenicznymi. Oczywiście zmianiu ulec mogą wówczas zarówno parametry
poszczególnych równań, składniki losowe jak również postać analityczna równań:
(
)
t
t
t
k,
t
1
t
t
V
P
,
Z
Y
,...,
Y
H
Y
−
−
=
gdzie:
P — macierz parametrów postaci zredukowanej,
V — wektor składników losowych postaci zredukowanej.
Postać końcowa powstaje w wyniku przekształcenia postaci zredukowanej przez
wyeliminowanie z niej opóźnionych zmiennych endogenicznych. Podobnie jak w
przejściu od postaci strukturalnej do zredukowanej zmianom mogą ulec parametry,
postać analityczna i składniki losowe modelu:
(
)
t
t
t
1,
t
k
t
t
W
F
,
Z
Z
,...,
Z
F
Y
−
−
=
gdzie:
F — macierz parametrów postaci końcowej,
W — wektor składników losowych postaci końcowej.
Znalezienie postaci końcowej jest w zasadzie równoznaczne z rozwiązaniem modelu,
bowiem obliczenie wartości zmiennych endogenicznych przy zadanych wartościach
zmiennych egzogenicznych sprowadza się wówczas do najprostszych podstawień i
działań matematycznych. Parametry postaci końcowej nazywa się mnożnikami.

Mariusz Plich
8
Pokazują one krańcowe przyrosty zmiennych endogenicznych względem zmiennych
egzogenicznych.
4. Przykłady modeli wielorównaniowych
Najważniejsze aspekty badań przy użyciu modeli wielorównaniowych przedstawimy na
znanych z ekonomi przykładach.
Statyczny model Keynesa
Model Keynsa w najprostszej wersji zapisywany jest w postaci dwóch równań:
równania dochodów i równania konsumpcji:
I
C
Y
+
=
( )
Y
f
C =
gdzie:
C
Y
,
— zmienne endogeniczne,
I
— zmienna egzogeniczna.
Równanie konsumpcji często specyfikowane jest w postaci liniowej bez wyrazu
wolnego, tzn.
Y
C
α
=
. Przyjmując taką specyfikację równania konsumpcji możemy
zapisać model Keynesa w postaci strukturalnej:
I
C
Y
+
=
Y
C
α
=
gdzie:
α
— skłonność do konsumpcji.
Chcąc zapisać ten model macierzowo, przekształcimy go do równoważnej postaci:
0
=
−
−
I
C
Y
0
1
=
+
−
C
Y
α
Możemy teraz oddzielić parametry i zmienne, zapisując je w postaci odrębnych
wektorów i macierzy:
=
−
+
−
−
0
0
0
1
1
1
1
1
I
C
Y
α
Wprowadźmy następujące oznaczenia:
−
Macierz parametrów związanych ze zmiennymi endogenicznymi
−
−
=
1
1
1
1
α
A

Mariusz Plich
9
−
Macierz parametrów związanych ze zmiennymi endogenicznymi
−
=
0
1
B
−
Wektor zmiennych endogenicznych
=
C
Y
Y
−
Wektor zmiennych egzogenicznych
[ ]
I
=
X
Stosując powyższe oznaczenia, mamy:
0
BX
AY
=
+
Zapis macierzowy ułatwia rozwiązywanie modeli. Rozwiążmy model Keynesa
względem zmiennych endogenicznych bieżących (model nie zawiera żadnych
zmiennych opóźnionych):
(
)
X
B
AY
−
=
(
)
X
B
A
Y
1
−
=
−
W powyższym zapisie przedstawiliśmy bieżące zmienne endogeniczne w zależności od
pozostałych zmiennych. Oznacza to, że znaleźliśmy postać zredukowaną modelu
Keynesa. Ponieważ model ten nie zawiera w ogóle zmiennych endogenicznych
opóźnionych, więc jest to jednocześnie postać końcowa tego modelu. Przypomnijmy,
że parametry postaci końcowej modelu nazywane są mnożnikami. Przedstawimy ich
znaczenie na następującym przykładzie liczbowym.
Załóżmy, że dochody, spożycie i inwestycje wyrażone są w tysiącach zł., a skłonność
do konsumpcji wynosi 0,6. Wyznaczmy macierz A oraz macierz do niej odwrotną,
którą następnie pomnóżmy przez macierz –B:
(
)
=
−
=
−
−
=
−
−
B
A
A
A
1
1
,
5
,
2
5
,
1
5
,
2
5
,
2
,
1
6
,
0
1
1
5
,
1
5
,
2
Rozwiązanie modelu (postać końcowa) przyjmuje więc postać:
[ ]
I
=
5
,
1
5
,
2
X
albo inaczej
I
C
I
Y
5
,
1
5
,
2
=
=
Powyższy wynik oznacza, że wzrost inwestycji o 1 tysiąc złotych spowoduje wzrost
konsumpcji o 1,5 tys. zł. i wzrost dochodów o 2,5 tys. zł. (konsumpcja 1,5 tys. zł. plus
inwestycje 1 tys. zł.).
Mnożniki modelu Keynesa można oczywiście również wyznaczyć, wykorzystując
metodę podstawiania. Podstawiając równanie konsumpcji do równania dochodów
mamy:

Mariusz Plich
10
I
Y
α
Y
+
=
1
Stąd obliczmy
Y
:
(
)
(
)
I
I
I
α
Y
5
,
2
6
,
0
1
1
1
1
1
=
−
=
−
=
a następnie konsumpcję:
I
C
I
+
=
5
,
2
I
C
5
,
1
=
Jak widać rozwiązanie jest identyczne.
Statyczny model Leontiefa
Przypomnijmy sposób sformułowania modelu Leontiefa.
W układzie gospodarczym wyróżnia się producentów i odbiorców końcowych
(finalnych). Układ gospodarczy podzielono na
n
sektorów (producentów). Każdy sektor
wytwarza jednorodny produkt. Powiązania „technologiczne” pomiędzy sektorami
(przepływy produktów z gałęzi
i
-tej do
j
-tej na przeliczone jednostkę produktu gałęzi
j
-tej) przedstawia macierz
[ ]
j
ai
A =
.
Postać strukturalna modelu Leontifa przybiera następującą formę:
Y
AX
X
+
=
lub
n
1,...,
i
dla
1
=
+
=
∑
=
n
j
i
j
ij
i
Y
X
a
X
gdzie
i
n
X
×
— wektor produktów globalnych,
i
n
Y
×
— wektor produktów finalnych,
n
n
A
×
— macierz współczynników kosztów.
W roli zmiennych endogenicznych tego modelu występuje na ogół wektor produkcji
globalnych
X
. Rozwiążmy ten model względem wektora
X
.
(
)
Y
A
I
X
1
−
−
=
Powyższe równanie stanowi postać zredukowaną modelu Leontiefa. Jest ona
jednocześnie postacią końcową ze względu na statyczny charakter modelu.

Mariusz Plich
11
Dynamiczny model Keynesa
W celu zbudowania dynamicznej wersji modelu Keynesa zmieńmy specyfikację
równania spożycia, wprowadzając do niego opóźnioną wartość zmiennej
Y
. Nowa
wersja postaci strukturalnej modelu Keynesa ma teraz następującą formę:
I
C
Y
+
=
1
2
1
−
+
=
Y
α
Y
α
C
Przedstawimy go teraz w postaci macierzowej. W tym celu wprowadźmy następujące
oznaczenia:
0
-
=
−
I
C
Y
0
1
2
1
=
−
+
−
−
Y
α
C
Y
α
Tak jak poprzednio, przedstawimy parametry i zmienne w postaci oddzielnych
macierzy i wektorów:
[ ]
=
−
+
−
+
−
−
−
−
0
0
0
1
0
0
0
1
1
1
1
1
2
1
I
C
Y
C
Y
α
α
Teraz wprowadźmy następujące oznaczenia:
[ ]
I
C
Y
C
Y
=
−
=
+
−
=
=
−
−
=
−
−
X
B
Y
A
Y
A
1
-
1
,
0
1
,
,
0
0
0
,
,
1
1
1
1
1
2
1
α
α
Zwróćmy uwagę, że w porównaniu z wersją statyczną pojawił się nowy wektor, na
który składają się zmienne endogeniczne opóźnione o 1 okres (tyle wynosi
maksymalne opóźnienie w modelu) oraz nowa macierz złożona ze współczynników
związanych z tym zmiennymi. Model w zapisie macierzowym wygląda następująco:
0
BX
Y
A
AY
1
1
=
+
+
−
Równie łatwo jak poprzednio wyznaczamy postać zredukowaną, wykonując kolejne
przekształcenia:
1
1
Y
A
BX
AY
−
−
−
=
1
1
1
1
Y
A
A
BX
A
Y
−
−
−
−
−
=
W celu uproszczenia zapisu oznaczmy:
B
A
M
A
A
M
1
1
1
1
−
−
−
=
−
=
Ostatecznie postać zredukowana wygląda następująco:
1
1
Y
M
MX
Y
−
−
=
Znalezienie postaci końcowej jest nieco bardziej kłopotliwe. Zacznijmy od zapisania
postaci zredukowanej z opóźnieniem o 1 i 2 okresy:

Mariusz Plich
12
2
1
1
1
Y
M
MX
Y
−
−
−
+
=
3
1
2
2
Y
M
MX
Y
−
−
−
+
=
Podstawiając
1
Y
−
do postaci zredukowanej, mamy:
(
)
2
1
1
2
1
1
1
Y
M
MX
M
MX
Y
M
MX
M
MX
Y
−
−
−
−
+
+
=
+
+
=
2
1
Podstawiając
2
Y
−
do powyższej postaci, mamy:
(
)
3
3
1
2
2
1
1
1
3
1
2
2
1
1
1
Y
M
MX
M
MX
M
MX
Y
M
MX
M
MX
M
MX
Y
−
−
−
−
−
−
+
+
+
=
+
+
+
=
Uogólniając powyższy wzór dla opóźnienia o
s
okresów, mamy:
(
)
s
s
1
1
s
1
s
1
2
2
1
1
1
Y
M
MX
M
...
MX
M
MX
M
MX
Y
−
−
−
−
−
−
+
+
+
+
+
=
Zauważmy, że jeżeli macierz
1
M
ma taką własność, że przy
s
dążącym do
nieskończoności kolejne jej potęgi dążą do macierzy zerowej, to iloczyn kolejnych
potęg macierzy
s
1
M
przez wektor
s
Y
−
dąży do wektora o składowych równych 0, tzn.:
0
Y
M
0
M
s
s
1
s
1
→
⇒
→
−
∞
→
s
W takim razie, suma takich iloczynów jest skończona i postać końcową modelu można
zapisać następująco:
(
)
k
1
s
0
k
k
1
1
s
1
s
1
2
2
1
1
1
MX
M
MX
M
...
MX
M
MX
M
MX
Y
−
−
=
−
−
−
−
−
∑
=
+
+
+
+
=
Pamiętamy, że parametry postaci końcowej nazywa się mnożnikami. W przypadku
modeli dynamicznych mamy do czynienia z następującymi rodzajami mnożników:
−
mnożniki bezpośrednie
B
A
M
1
−
−
=
,
−
mnożniki opóźnione o
k
okresów
M
M
k
1
,
−
mnożniki skumulowane dla okresu
S
∑
=
S
k
0
M
M
k
1
,
−
mnożniki całkowite
∑
∞
=
0
k
M
M
k
1
.
Tak jak poprzednio wyznaczymy mnożniki na konkretnym przykładzie. W tym celu
określmy parametr
1
α
na dotychczasowym poziomie 0,6, natomiast parametr
2
α
przyjmijmy na poziomie 0,18. Przebieg obliczeń mnożników pokazano na rysunku 3.
Podsumowanie obliczeń przedstawione zostało na rysunku 3, zawierającym tabelę i
wykresy mnożników. Mnożniki pokazują siłę reakcji spożycia i inwestycji na
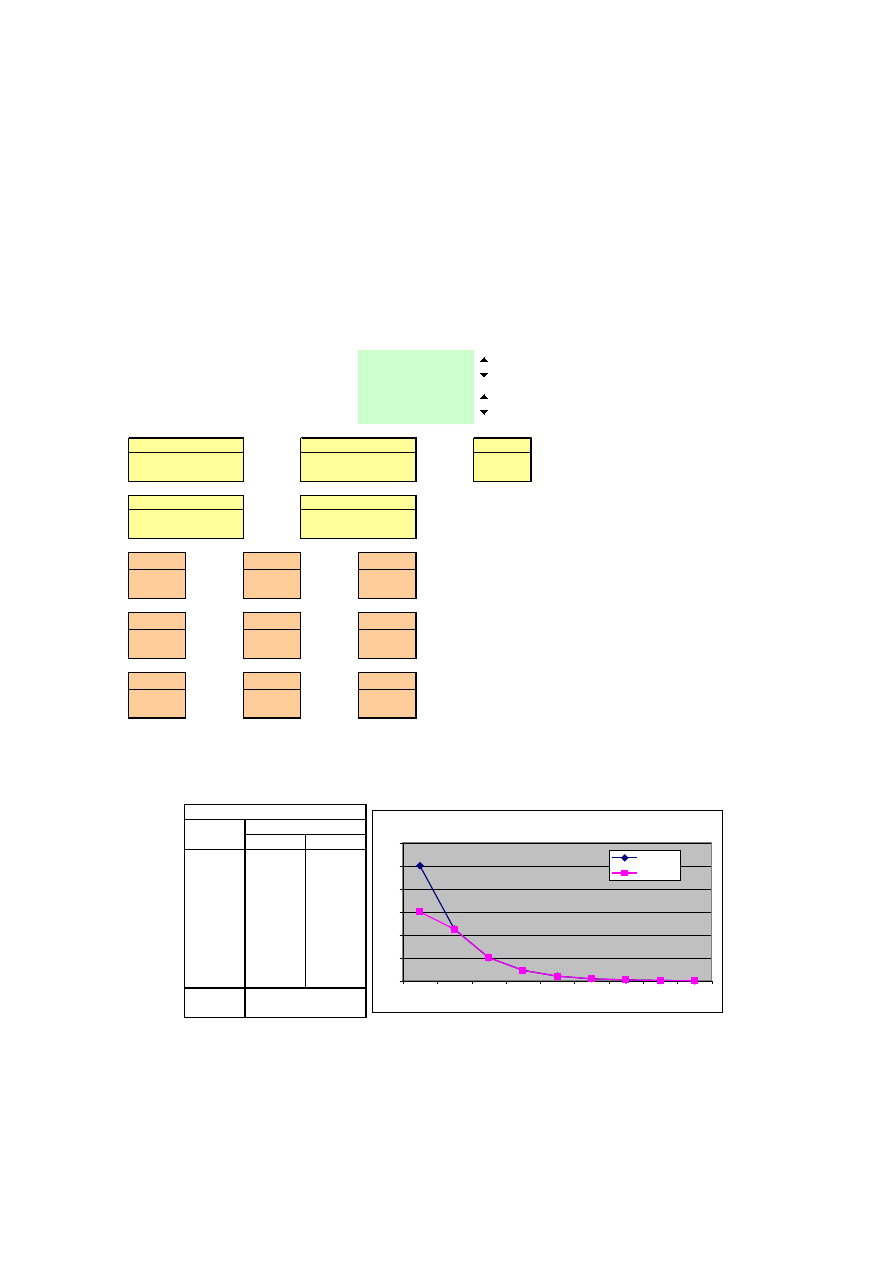
Mariusz Plich
13
początkowy impuls polegający na wzroście inwestycji o 1 tys. zł. Wartości mnożników
maleją wraz ze wzrostem opóźnienia i po 8 okresach są praktycznie równe 0. Łączny
efekt oddziaływania po 8 okresach (mnożniki skumulowane) jest wyraźnie wyższy od
efektu bezpośredniego. W przypadku dochodów efekt bezpośredni wynosi 2,5 tys. zł,
podczas gdy skumulowany ponad wynosi on 4,5 tys. zł., a w przypadku spożycia
mnożniki te wynoszą odpowiednio 1,5 i ponad 3,5 tys zł.
Rysunek3. Wyliczenie i wykres mnożników modelu Keyenesa w wersji dynamicznej
Dynamiczny model Keynesa - mnożniki
Y=C+I
1
0,60
40
C=
1
Y+
2
Y
-1
2
0,18
82
B
1
-1
0
0
-1
-0,6
1
-0,18
0
0
2,5
2,5
0,45
0
1,5
2,5
0,45
0
M
M
1
3
M
M
1
6
M
2,500
0,228
0,021
1,500
0,228
0,021
M
1
1
M
M
1
4
M
M
1
7
M
1,125
0,103
0,009
1,125
0,103
0,009
M
1
2
M
M
1
5
M
M
1
8
M
0,506
0,046
0,004
0,506
0,046
0,004
A
A1
A-1
M1
Źródło: opracowanie własne
Mnożniki modelu Keyenesa w wersji dynamicznej
Źródło: opracowanie własne
5. Symulacja jako technika wykorzystania modeli
Wykorzystanie modeli wielorównaniowych polega na wyznaczeniu mnożników lub
wielokrotnym rozwiązywaniu modeli przy różnych założeniach dotyczących zmiennych
dochody
spożycie
0
2,500
1,500
1
1,125
1,125
2
0,506
0,506
3
0,228
0,228
4
0,103
0,103
5
0,046
0,046
6
0,021
0,021
7
0,009
0,009
8
0,004
0,004
skumu-
lowane
4,542
3,542
Mnożniki
wartość
opóźninie
Mnożniki
0,0
0,5
1,0
1,5
2,0
2,5
3,0
0
1
2
3
4
5
6
7
8
dochody
spożycie

Mariusz Plich
14
egzogenicznych. Przykłady, które były dotychczas prezentowane dotyczyły modeli
liniowych, w przypadku których stosunkowo łatwo można dokonać przekształcenia od
postaci strukturalnej do końcowej. Zastosowanie zapisu macierzowego umożliwia
podanie ogólnych reguł rozwiązywania tych modeli. Reguły te mogą być zastosowane
niezależnie od liczby zmiennych i liczby równań. Znając postać końcową znamy
wszystkie mnożniki modelu. Nie sprawia też problemu znalezienie rozwiązania w
przypadku przyjęcia określonych założeń co do wartości zmiennych egzogenicznych.
W przypadku modeli nieliniowych przejście od postaci strukturalnej do końcowej jest
bardzo trudne (o ile w ogóle możliwe) i najczęściej nieopłacalne. Nie istnieją
uniwersalne wzory umożliwiające wyliczanie mnożników. Dlatego dla modeli
nieliniowych nie poszukuje się postaci zredukowanej i końcowej, operując najczęściej
postacią strukturalną. Mnożniki wyznacza się przez wielokrotne rozwiązywanie modelu
metodami iteracyjnymi. Rozwiązywanie modelu nazywa się symulacją.
Symulacja jest
podstawową techniką badawczą stosowaną na etapie wykorzystania modelu
wielorównaniowego
Metoda Gaussa-Seidela
Jest to podstawowa metoda symulacji. Jest to metoda iteracyjna.
Iteracja 0
Przyjmujemy wartości startowe dla zmiennych z góry ustalonych i zmiennych
endogenicznych występujących w roli zmiennych objaśniających pierwszego równania i
znajdujemy pierwsze „zerowe” rozwiązania równania (obliczamy wartość zmiennej
objaśnianej w iteracji 0).
Obliczenia powtarzamy dla kolejnych równań, wykorzystując już otrzymane,
najnowsze przybliżenia rozwiązań tam gdzie zmienne endogeniczne występują w
charakterze zmiennych objaśniających:
( )
( )
(
)
k
t
k
t
t
t
k
kt
Z
Y
Y
Y
G
Y
Θ
=
−
−
,
'
,...,
,
0
0
0
1
0
0
0
dla
m
k
,...,
2
,
1
=
gdzie
( )
0
0
t
Y
oznacza wektor przybliżeń startowych lub przybliżeń otrzymanych w
iteracji 0 zmiennych endogenicznych występujących w roli zmiennych objaśniających
w
k
-tym równaniu.
Iteracja i+1 (i=1, 2, ...)
Dla kolejnych równań modelu znajdujemy „i plus pierwsze” przybliżenie zmiennych
endogenicznych, wykorzystując „najnowsze” przybliżenia tam, gdzie zmienne
endogeniczne występują w charakterze zmiennych objaśniających:
Mariusz Plich
15
(
)
(
)( )
(
)
k
t
k
t
t
i
i
t
k
i
kt
Z
Y
Y
Y
G
Y
Θ
=
−
−
+
+
,
'
,...,
,
0
0
0
1
1
1
dla
m
k
,...,
2
,
1
=
gdzie
(
)( )
i
i
t
Y
1
+
— wektor przybliżeń zmiennych endogenicznych (z tej lub poprzedniej
iteracji) występujących w roli zmiennych objaśniających w
k
-tym równaniu.
Po obliczeniu przybliżenia dla ostatniego równania sprawdzamy, czy rozbieżność
pomiędzy przybliżeniami z iteracji bieżącej iteracji (iteracja
i+1
) oraz iteracji
poprzedniej (iteracji
i
) są dostatecznie małe. Jeśli nie, to wracamy do punktu 3 i
wykonujemy kolejną iterację). Jeśli tak, to przyjmujemy bieżące przybliżenie jako
rozwiązanie modelu.
Kryterium „stopu”:
(
)
( )
( )
ε
<
−
+
∧
i
kt
i
kt
i
kt
Y
Y
Y
1
k
, gdzie
ε
— żądana dokładność.
Typy symulacji
Symulacje klasyfikuje się wg różnych kryteriów. Poniżej przedstawiamy te kryteria i
związane z nimi rodzaje.
Tabela 1. Klasyfikacja symulacji wg różych kryteriów
Kryterium
Typ symulacji
Założenia o składniku
losowym
deterministyczna
stochastyczna
Okres którego dotyczy
symulacja
ex post
ex ante
Zasób informacji na których
opieramy rozwiązanie
rozwiązanie pojedynczych równań
symulacja statyczna
symulacja dynamiczna
Źródło: opracowanie własne
Symulacja stochastyczna polega na znajdowaniu rozwiązania modelu (najczęściej
wielokrotnym) dla generowanych losowo, zgodnie z założonym rozkładem
prawdopodobieństwa, wartości składników losowych lub wartości estymatorów
parametrów modelu:
(
)
t
k
t
k
t
1
t
R
t
R
t
U
Θ
Z
Y
,...,
Y
,
Y
G
Y
,
,
,
−
−
=
(
)
Γ
−
−
=
Θ
,
Z
'
Y
,...,
Y
,
Y
G
Y
t
k
t
1
t
R
t
R
t

Mariusz Plich
16
gdzie
R
t
Y
to rozwiązanie układu, natomiast
t
U
i
Γ
Θ
oznaczają funkcje rozkładu
prawdopodobieństwa składnika losowego i estymatorów parametrów modelu
(odpowiednio).
Symulacja deterministyczna to rozwiązanie modelu, zakładające realizację
składnika losowego na poziomie wartości oczekiwanej (wynoszącej 0):
(
)
Θ
,
Z
Y
,...,
Y
,
Y
G
Y
t
k
t
1
t
R
t
R
t
,
−
−
=
Wszystkie pozostałe typy symulacji powinny być realizowane w wariancie
deterministycznym lub stochastycznym.
Symulacja ex post oznacza rozwiązanie modelu dotyczące okresu, dla którego znane
są realizacje zmiennych endogenicznych (najczęściej jest to okres, na podstawie
którego szacowano parametry równań modelu):
(
)
(
)
T
t
,...,
1
dla
,
∈
=
−
−
Θ
,
Z
Y
,...,
Y
,
Y
G
Y
t
k
t
1
t
R
t
R
t
Symulacja ex ante to rozwiązanie modelu otrzymane przy nieznajomości
prawdziwych wartości zmiennych endogenicznych:
(
)
(
)
L
T
T
t
+
+
∈
=
−
−
,...,
1
dla
,
Θ
,
Z
Y
,...,
Y
,
Y
G
Y
t
k
t
1
t
R
t
R
t
Rozwiązanie pojedynczych równań polega na wyliczeniu wartości zmiennych
objaśnianych w modelu poprzez podstawienie do kolejnych równań wartości
zmiennych objaśniających bez uwzględnienia powiązań pomiędzy równaniami modelu,
tzn.:
(
)
Θ
,
Z
'
Y
,...,
Y
,
Y
G
Y
t
k
t
1
t
t
R
t
−
−
=
Symulacja statyczna polega na rozwiązaniu modelu względem zadanych wartości
zmiennych z góry ustalonych:
(
)
Θ
,
Z
'
Y
,...,
Y
,
Y
G
Y
t
k
t
1
t
R
t
R
t
−
−
=
Symulację statyczną wykorzystuje się najczęściej do testowania jednoczesnych
sprzężeń zwrotnych modelu.
Symulacja dynamiczna (symulacja) polega na rozwiązaniu modelu na podstawie
zadanych wartości zmiennych egzogenicznych — opóźnione wartości zmiennych
endogenicznych generowane są przez model:
(
)
Θ
,
Z
'
Y
,...,
Y
,
Y
G
Y
t
R
R
R
t
R
t
k
t
1
t
−
−
=
Symulacja dynamiczna jest podstawowym typem symulacji.

Mariusz Plich
17
Weryfikacja reszt to symulacja ex post dla okresu, na podstawie którego szacowano
parametry
Θ
, otrzymana przez rozwiązanie pojedynczych równań, w której wartości
zmiennych objaśniających przyjmujemy na zaobserwowanych historycznie poziomach:
(
)
E
H
t
H
H
H
t
R
t
Θ
,
Z
'
Y
,...,
Y
,
Y
G
Y
k
t
1
t
−
−
=
dla
(
)
T
t
,...,
1
∈
gdzie superskrypt H wprowadzono dla oznaczenia wartości historycznych, natomiast
E
Θ
oznacza oszacowania parametrów modelu otrzymane na podstawie próby.
Weryfikacja reszt wykonywana jest najczęściej jako pierwsza symulacja, po zapisaniu
modelu jako programu komputerowego. Równość reszt otrzymanych przez odjęcie
wyników symulacji od wartości historycznych zmiennych endogenicznych i reszt
otrzymanych na etapie estymacji parametrów, świadczy o poprawności zakodowania
modelu jako procedury komputerowej.
Rozwiązaniem podstawowym modelu nazywa się wynik symulacji dynamicznej ex
post
, przeprowadzonej dla okresu próby, przy założeniu, że wartości zmiennych
egzogenicznych kształtują się na poziomach historycznych:
(
)
E
H
t
R
R
R
t
R
t
Θ
,
Z
'
Y
,...,
Y
,
Y
G
Y
k
t
1
t
−
−
=
dla
(
)
T
t
,...,
1
∈
Rozwiązanie podstawowe stanowi podstawę oceny stopnia dopasowania modelu do
rzeczywistości. Ocenę taką ułatwiają odpowiednie miary stopnia dopasowania.
Symulacją kontrfaktyczną nazywa się rozwiązanie otrzymane w wyniku symulacji
ex post
przy użyciu wartości zmiennych egzogenicznych innych niż dane historyczne
dla
(
)
H
t
Z
Z ≠
lub wartości parametrów różnych od wartości oszacowanych
(
)
E
Θ
≠
Θ
:
(
)
Θ
,
Z
'
Y
,...,
Y
,
Y
G
Y
t
R
R
R
t
R
t
k
t
1
t
−
−
=
dla
(
)
T
t
,...,
1
∈
Symulacją zamrożoną nazywa się symulację przeprowadzoną dla stałych wartości
zmiennych egzogenicznych:
(
)
Θ
,
Z
'
Y
,...,
Y
,
Y
G
Y
0
R
R
R
t
R
t
k
t
1
t
−
−
=
gdzie
0
Z
oznacza wektor stałych w czasie wartości zmiennych egzogenicznych.
Symulacja zamrożona pozwala ocenić „wewnętrzną” dynamikę modelu przez
wyeliminowanie wpływu dynamiki czynników egzogenicznych na wyniki symulacji.
Symulację zamrożoną przeprowadza się zwykle począwszy od okresu następującego
bezpośrednio po ostatniej obserwacji w próbie, przyjmując jako wartości zmiennych
egzogenicznych w okresie symulacji wartości ostatniej obserwacji w próbie
T
0
Z
Z =
(
)
Θ
,
Z
'
Y
,...,
Y
,
Y
G
Y
T
R
R
R
t
R
t
k
t
1
t
−
−
=
dla
(
)
L
T
T
t
+
+
∈
,...,
1
.
Wyniki symulacji zamrożonej służą do testowania własności dynamicznych modelu.
Mariusz Plich
18
Symulacja bazowa (rozwiązanie bazowe, rozwiązanie kontrolne, symulacja
kontrolna) to dowolne rozwiązanie modelu, stanowiące podstawę do porównań z
innymi rozwiązaniami. Rozwiązaniem bazowym dla okresu próby jest najczęściej
rozwiązanie podstawowe, a poza okresem próby — prognoza.
Symulacja zaburzona (zakłócona) polega na wprowadzeniu zmian (zaburzeń) w
stosunku do symulacji bazowej. Zmiany mogą dotyczyć:
−
wartości zmiennych egzogenicznych,
−
specyfikacji równań modelu lub
−
wartości parametrów modelu.
6. Miary dopasowania modelu do danych empirycznych
Przed zastosowaniem modelu wielorównaniowego należy ocenić stopień zgodności
rozwiązania modelu z rzeczywistością. W tym celu wyznacza się i analizuje
następujące miary dopasowania modelu do danych empirycznych.
Średni błąd symulacji (średnia wartość reszt):
(
)
∑
=
−
=
I
t
it
it
Y
Y
T
SB
1
ˆ
1
Średni błąd procentowy symulacji:
(
)
∑
=
×
−
=
T
t
it
it
it
Y
Y
Y
T
SB
1
100
ˆ
1
%
Średni kwadrat błędu symulacji (błąd średniokwadratowy):
(
)
2
1
ˆ
1
∑
=
−
=
T
t
it
it
Y
Y
T
SB
Średni kwadrat błędu procentowego (procentowy błąd średniokwadratowy):
∑
=
×
−
=
T
t
it
it
it
Y
Y
Y
T
SKB
1
2
100
ˆ
1
%
Średni bezwzględny błąd symulacji:
∑
=
−
=
T
t
it
it
Y
Y
T
SBB
1
ˆ
1
Średni bezwzględny błąd procentowy:
∑
=
×
−
=
T
t
it
it
it
Y
Y
Y
T
SKB
1
100
ˆ
1
%
Mariusz Plich
19
7. Wykorzystanie modeli wielorównaniowych
Analiza struktury
Pod pojęciem analizy struktury rozumie się użycie oszacowanego modelu do
ilościowego pomiaru związków zachodzących wewnątrz modelowanego systemu przez
badanie reakcji (wrażliwości) zmiennych endogenicznych modelu na zmiany:
−
wartości zmiennych egzogenicznych,
−
postaci równań (wartości parametrów, specyfikacji, postaci funkcyjnej) oraz
rozkładów prawdopodobieństw składnika losowego).
Siłę tych reakcji przedstawia się najczęściej w postaci mnożników.
Mnożniki klasyczne
Mnożniki mierzą siłę reakcji wybranej zmiennej endogenicznej modelu na jednostkową
zmianę wartości zmiennej egzogenicznej. Mnożnikami są parametry postaci końcowej.
Z matematycznego punktu widzenia mnożniki to pochodne cząstkowe układu równań.
Typy mnożników
Klasyfikację mnożników w modelach liniowych (mnożników klasycznych) przedstawia
tabela 2
Tabela 2. Klasyfikacja mnożników wg różnych kryteriów
Kryterium
Mnożniki
Okres
reakcji
−
mnożniki bezpośrednie, jeśli pokazują reakcje
zmiennych endogenicznych dla okresu, w którym
nastąpiła zmiana zmiennej egzogenicznej,
−
mnożniki pośrednie (opóźnione, dynamiczne), jeśli
dotyczą reakcji w następnych okresach.
Sposób
wprowadz
enia
impulsu
−
mnożniki impulsowe, gdy zmiana dotyczy tylko
jednego, początkowego okresu,
−
mnożniki podtrzymane (skumulowane), gdy
zmiana dotyczy wszystkich okresów, dla których
liczone są mnożniki.
Źródło: opracowanie własne
W przypadku modeli liniowych suma mnożnika bezpośredniego dla wybranej zmiennej
egzogenicznej i mnożników opóźnionych dla tej samej zmiennej daje w wyniku
mnożnik podtrzymany.

Mariusz Plich
20
Mnożniki uogólnione
Mnożnik w sensie uogólnionym jest charakterystyką reakcji rozwiązania modelu na
dowolne zmiany w jego elementach (zmiennych, parametrów, postaci funkcyjnej
równań). Oblicza się je przez znalezienie rozwiązania bazowego oraz zaburzonego:
b
t
z
t
y
y
τ
τ
τ
+
+
−
=
y
t,
m
dla
(
)
L
,...,
2
,
1
,
0
=
τ
gdzie:
y
t,
m
τ
— wartość mnożnika dla zmiennej
y
w okresie
t
, opóźnionego o
τ
okresów,
z
t
y
τ
+
— rozwiązanie zaburzone,
b
t
y
τ
+
— rozwiązanie bazowe,
t
— okres początkowy symulacji zaburzonej.
Mnożnik można przedstawić również w wyrażeniu procentowym:
b
t
b
T
z
t
y
y
y
τ
τ
τ
τ
+
+
+
−
=
y
t,
m
dla
(
)
L
,...,
2
,
1
,
0
=
τ
.
Symulowanie rzeczywistości
Symulowanie rzeczywistości polega na odgadywaniu, na podstawie modelu, przeszłych
lub przyszłych stanów rzeczywistości, przy różnych założeniach dotyczących
elementów modelu (zmiennych, parametrów, postaci funkcyjnej równań).
Scenariusz to zbiór wszystkich założeń przyjętych do symulacji.
Analizy scenariuszowe to wyniki symulacji otrzymanych w oparciu o scenariusze.
Prognoza jest analizą scenariuszową, której scenariusz największe szanse realizacji.
Scenariusz ten nazywa się założeniami prognozy.
Wyszukiwarka
Podobne podstrony:
MP 7 modele wielorównaniowe. rozw, metody prognozowania
modele wielorównaniowe1
MP 7 modele wielorównaniowe(1), metody prognozowania
modele wielorownaniowe
Matlab-kurs, Modele systemow ciaglych, Symulacja:
MP5 modele wielorównaniowe
Pastusiak, Radosław; Plich, Mariusz OJS jako platforma czasopism Wydziału Ekonomiczno Socjologiczne
Kopia MP5 modele wielorównaniowe
Modele symulacyjne trójfazowych przekształtników tyrystorowych
Modele Holta, ● STUDIA EKONOMICZNO-MENEDŻERSKIE (SGH i UW), prognozowanie i symulacje
Modele symulacyjne i symulacja komputerowa
Modele symulacyjne trójfazowych przekształtników tyrystorowych
Trojnar Mariusz 2013 Internetowe symulatory obwodów elektrycznych
w5b modele oswietlenia
więcej podobnych podstron