
1
Metody Analizy Danych
(MAD)
Wiesław Szczesny
KATEDRA INFORMATYKI SGGW
tel. 601 810 996
Wieslaw_Szczesny@SGGW.pl

2
Warunki „zaliczenia”
przedmiotu:
• Zaliczenie ćwiczeń (
według wymagań prowadzącego
ćwiczenia
- czyli ogólnie rzecz biorąc weryfikacja hipotezy
H0(student nie opanował materiału)
na poziomie istotności 0.05- metodę weryfikacji ustala
prowadzący
)
•
Pozytywna ocena przez prowadzącego ćwiczenia pracy
okresowej (
dwa projekty:
(i)
indywidualny
wykonana analiza
na własnym zbiorze danych rzeczywistych, (ii) zespołowy
dopuszcza się prace indywidualne lub w grupach 1-3 osobowych
)
•
Test sprawdzający wiedzę z przedmiotu obejmującą
zagadnienia omawiane na wykładzie i ćwiczeniach.
•
Zaliczenie finalne przedmiotu średnia z projektów i
testu z wagami 0.3, 0.4, 0.3

3
Diagram ilustrujący graficznie zmiany w kierunkach badania
danych wielowymiarowych

4
Harmonogram wykładu
Metody analizy danych
• 1. Zagadnienia wstępne. Schemat analizy danych
wielowymiarowych
(punkt ciężkości badań dawniej – dzisiaj)
.
• 2-9. Klasyczne metody analizy danych: wielowymiarowa
analiza porównawcza (WAP), analiza regresji, analiza
klasyfikacyjna (z nauczycielem i bez)
• 10-11 Wybrane informacje dotyczące metod: składowych
głównych, analizy odpowiedniości i analizy czynnikowej,
• 12-13. Wybrane informacje dotyczące niestandardowych
metod
analizy
danych:
GCCA
(
gradacyjna
analiza
odpowiedniości i skupień
), GAP (
Generalized Association Plots
),
wizualizacja
wyników
,
uzupełnianie
braków
danych
i
wyszukiwanie elementów odstających.
• 14. Studium przypadku:
porównanie wyników uzyskanych przy
wykorzystaniu klasycznych i nowo-proponowanych technik analizy
i wizualizacji danych wielowymiarowych oraz przegląd pakietów
komputerowych (komercyjnych i bezpłatnych dostępnych przez
Internet) pod tym kątem.
• 15. Wykorzystanie technik symulacji komputerowej do
badania użyteczności omówionych metod.

5
schemat złożony z trzech bloków:
A B C,
gdzie
A:
ustalenia dotyczące badań wstępnych (określenie
tematyki badawczej i typu badań, dokonanie
wyboru obiektów i cech, które je opisują;
B:
utworzenie macierzy danych i jej analiza,
połączona z oczyszczeniem danych z grubych
błędów i elementów odstających od „głównego
trendu” oraz uzupełnieniem brakujących danych;
wyznaczenie struktury danych;
C:
synteza, wizualizacja, weryfikacja i interpretacja
praktyczna uzyskanych informacji.
Wspólny rdzeń statystyki matematycznej
i analizy danych w przypadku danych
wielowymiarowych:
6
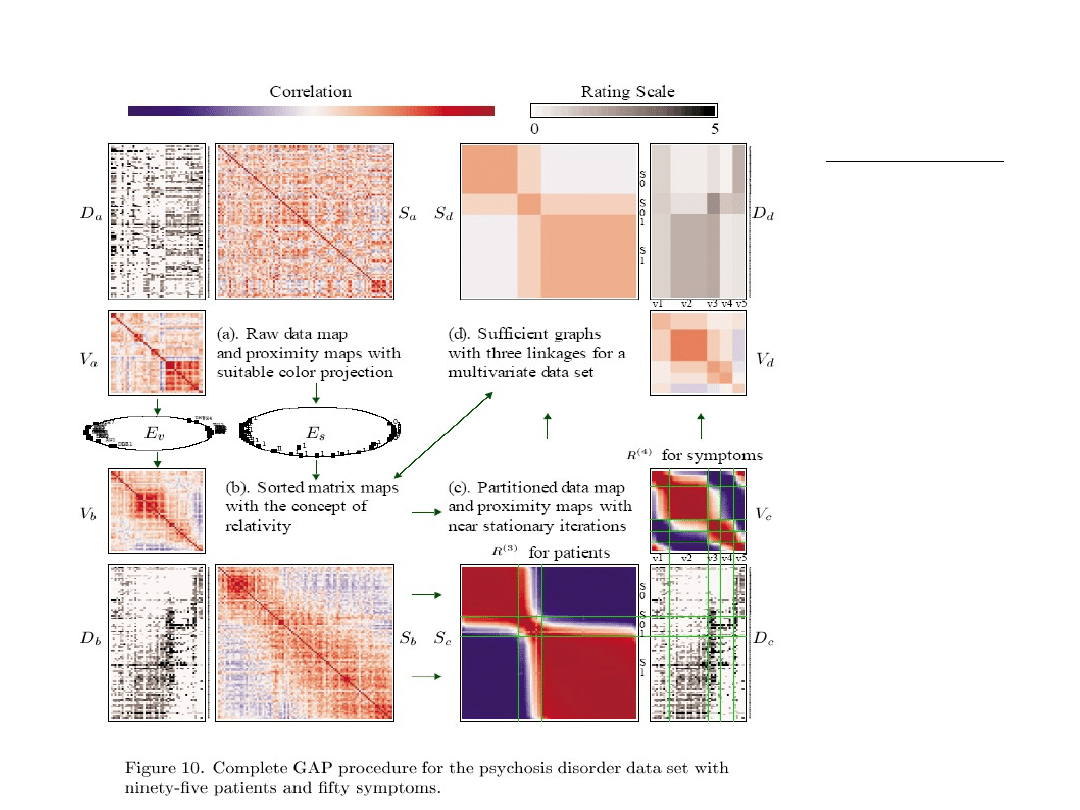
Przykład z pracy: Chun Houh Chen, Generalized Assoctiation Plots: Information
Visualization
Via Iteratively Generated Correlation Matrices, Statistica
Sinica 12 (2002) 7-29
Przykład 0.
danych do
analizy:
Wybrane
symptomy
chorobowe.

7
Porządkowanie obiektów wielo-
cechowych (na razie tylko skala
przedziałowa)
• Wybór wskaźników (jak z danych powstają cechy)
• Podział na stymulanty, destymulanty i nominanty
• Zamiana na stymulanty (zmiana zwrotu)
• Normalizacja cech (wskaźników)
• Budowa wskaźnika syntetycznego (m. in. wagi,)
• Podział na grupy według wartości wskaźnika
syntetycznego
• Informacja nt innych sposobów podziału wartości
wskaźnika na jednorodne grupy
• Porządkowanie obiektów w oparciu o odległość
(niepodobieństwo) od wzorca (lub dwu wzorców)
8
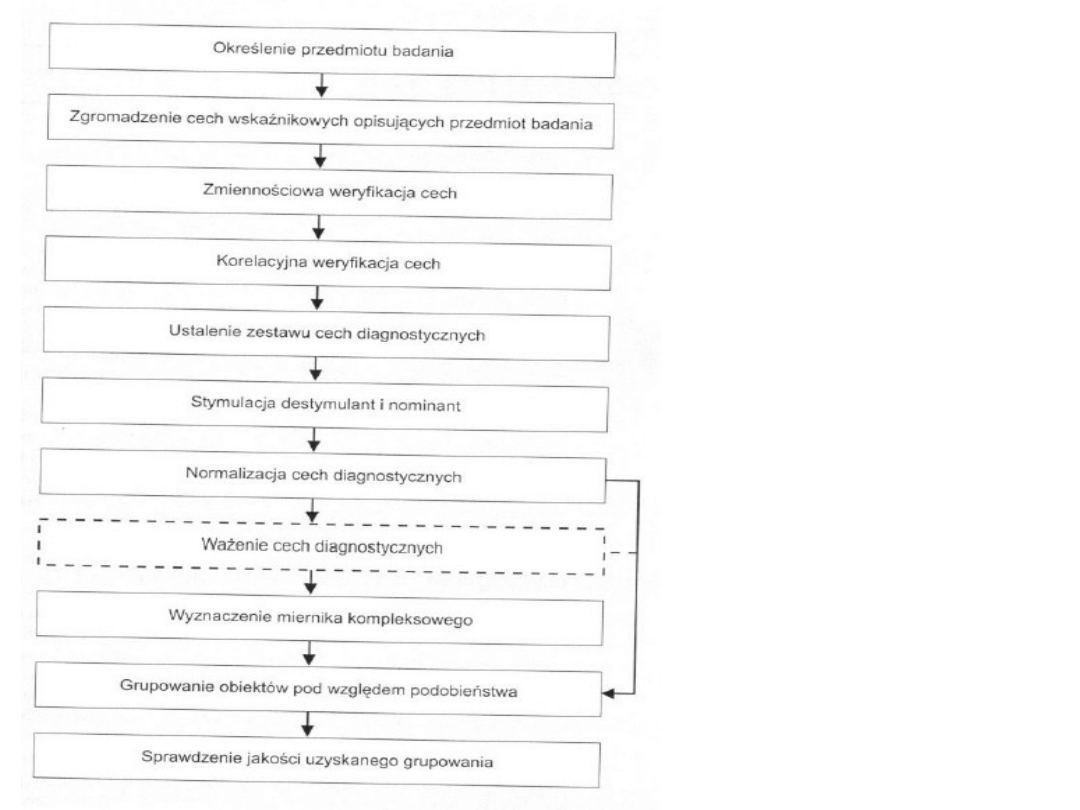
Klasyczny schemat
analizy danych
prowadzącej do
porządkowania
obiektów na
podstawie
utworzonego miernika
syntetycznego i
podziału badanego
zbioru na podzbiory -
ten schemat często
oznacza się symbolem
WAP
Schemat ten nie
obejmuje elementów
wstępnej danych – w
szczególności
elementów
odstających.
Ani
schematu sprawdzania
skuteczności uzytej
metody (metod)
9
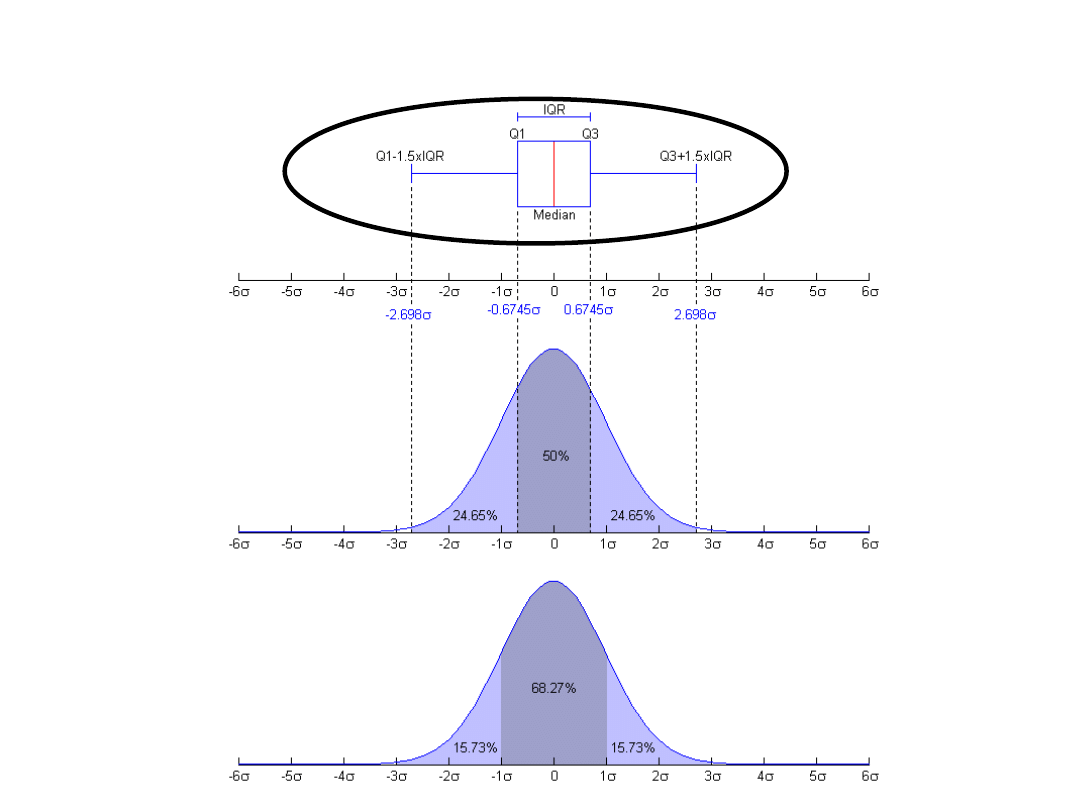
Wykres pudełkowy jako narzędzie wstępnego wyszukiwania elementów
odstających
10
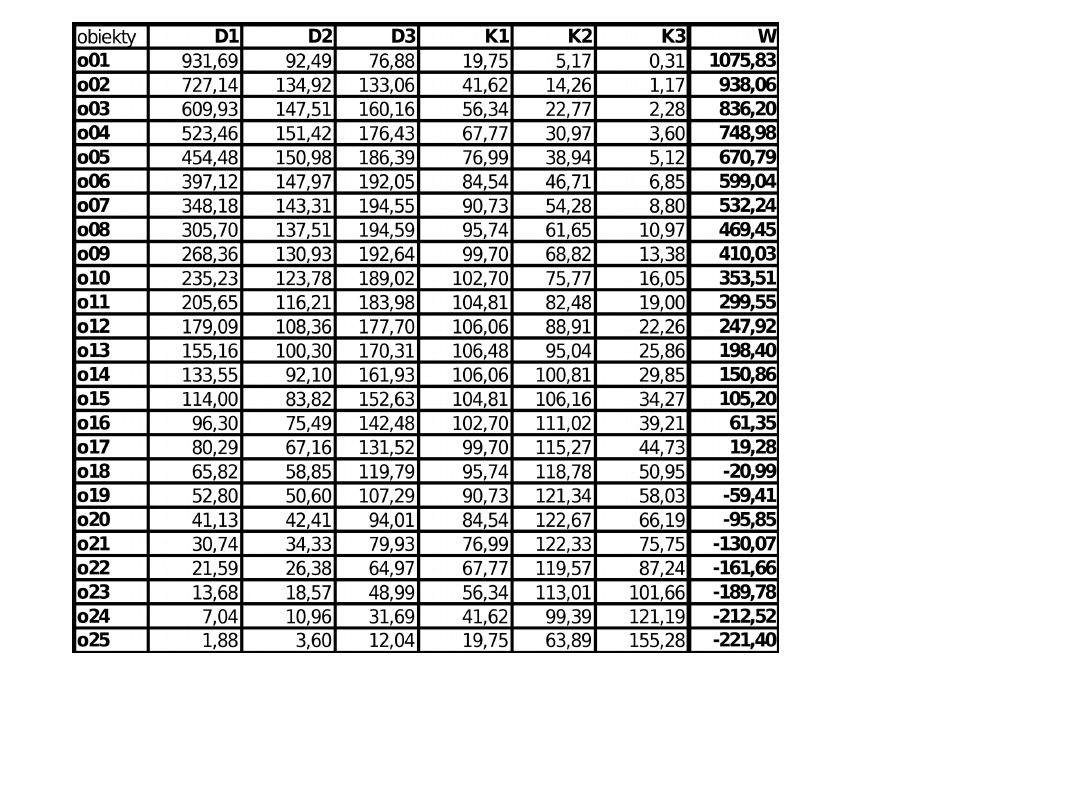
Przyjęliśmy, że cechy te odnoszą się do oddziałów pewnego banku, gdzie D1 –
D3 są to dochody poszczególnych dziedzin działalności z uwzględnieniem
kosztów transferu funduszy, K1 – K3 to kategorie kosztów działalności a W –
wynik ekonomiczny (finansowy) oddziału.
Przykład 1.
danych do
analizy:
Wyniki
oddziałów
pewnego
Banku
11
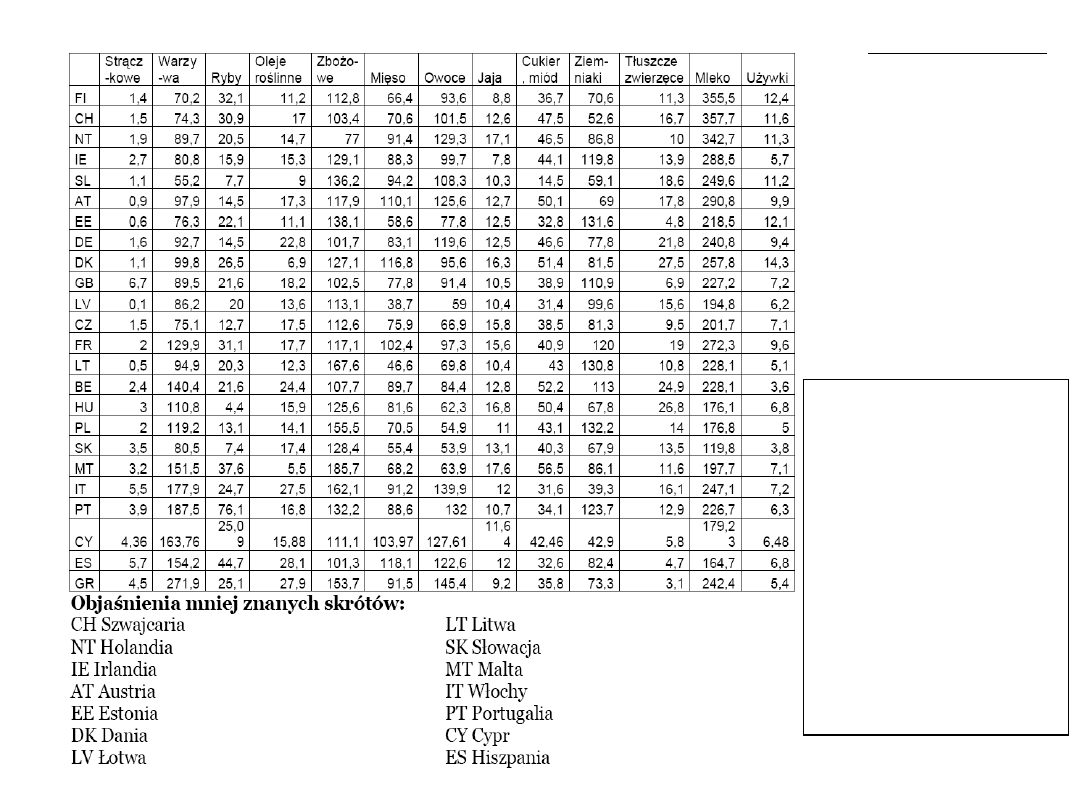
Przykład 2.
danych do
analizy:
Spożycie
produktów
żywnościowy
ch w kg w
ciągu roku w
Europie.
Problem:
DOKONAĆ
PODZIAŁU
KRAJÓW NA
PODOBNE
GRUPY pod
względem
profilu spożycia
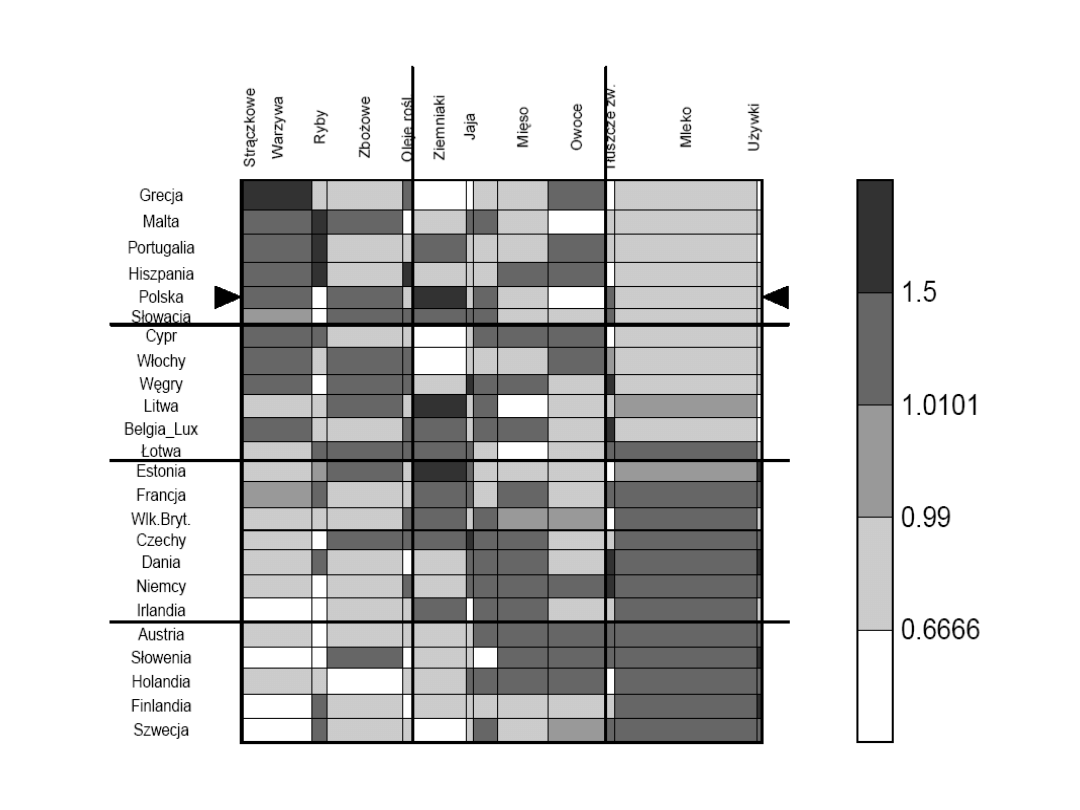
12
13
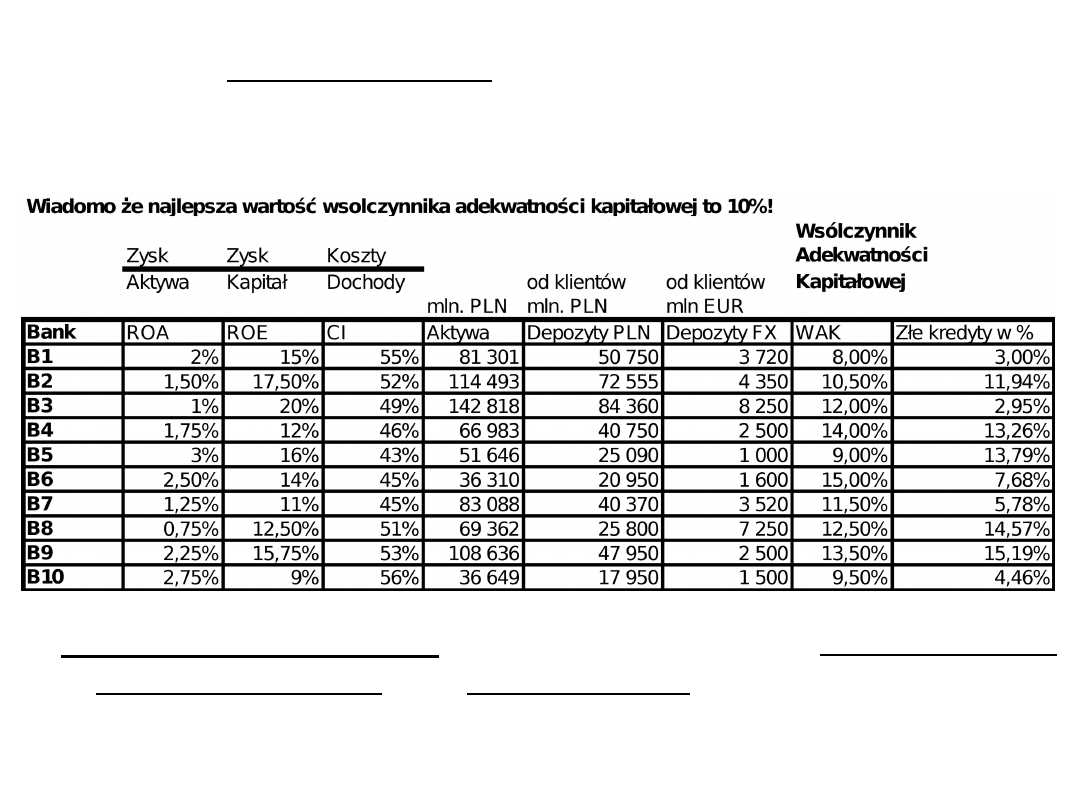
Przykład 3.
Wyniki 10 Banków.
Problem:
uporządkować pod względem atrakcyjności dla
inwestora i podzielić na 4 grupy
Na ćwiczeniach:
ustalimy które cechy są Stymulantami
destymulantami. oraz nominantami oraz przeprowadzimy
normowania tego zbioru danych oraz konstrukcję miernika
syntetycznego. Podział dopiero na kolejnych zajęciach.

14
Uwagi na temat modeli regresji II-go
rodzaju
(
czyli rozszerzenie wiadomości z rachunku prawdopodobieństwa i
statystyki
)
Wykorzystanie cech o wartościach na różnych skalach
• Skala porządkowa - rangowanie
• Skala nominalna – zamiana na zestaw cech dychotomicznych
Uwagi dot. szacowania parametrów w regresyjnych
modelach nieliniowych
• Przybliżone rozwiązywanie – przykłady (model potęgowy itp.)
• Rozwiązania techniką iteracyjną (EXCEL i dedykowane pakiety
programowe)
Techniki wyboru najlepszego modelu regresji w przypadku
dużej liczby cech oraz interpretacja wyników
• Regresja krokowa
• Interpretacje: współczynników regresji, współczynnika
determinacji przyrost marginalny itp
• O czym mówią reszty itp
Inne uwagi dotyczące problematyki regresji
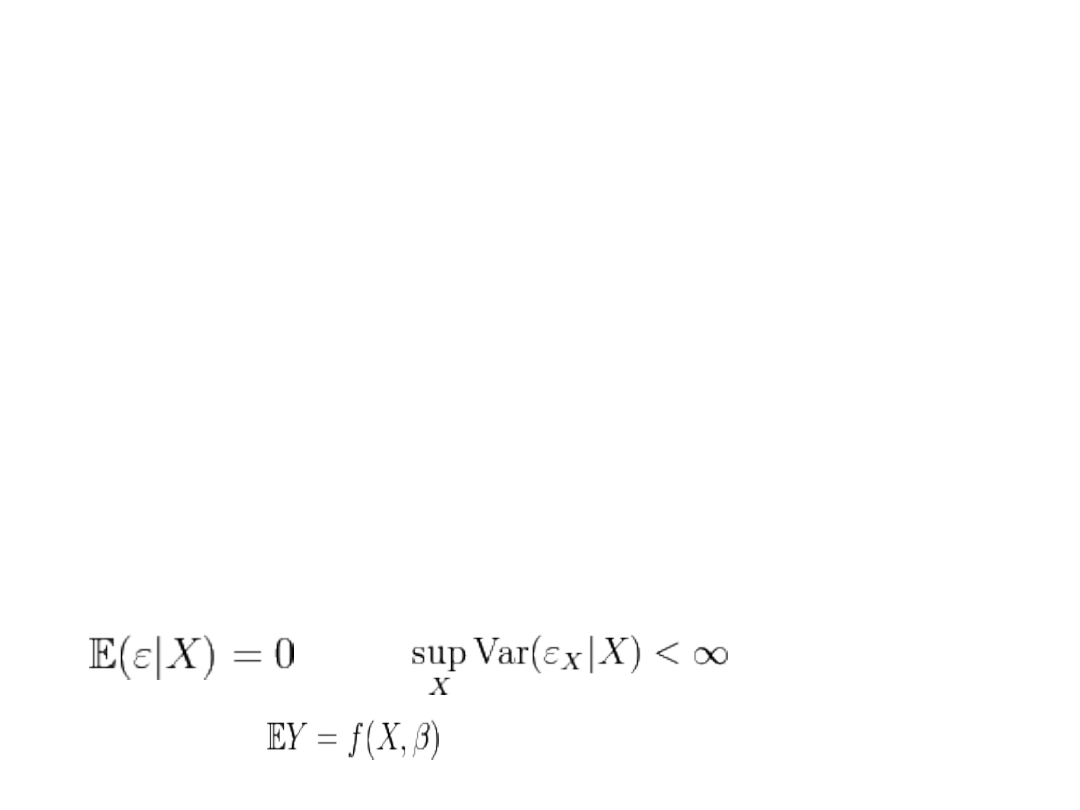
15
Globalne modele
parametryczne
W modelach parametrycznych ogólna postać modelu jest założona z góry,
a celem procedury regresji jest dobranie takich jej parametrów, które
definiowałyby funkcję możliwie dobrze odpowiadającą próbie uczącej.
Zwykle stosuje się tzw. globalne modele parametryczne, gdzie wartości
współczynników są takie same dla dowolnych wartości zmiennych
objaśniających.
Ogólna postać modelu
W zapisie formalnym model przybiera zwykle postać:
Y = f(X,β) + ε
gdzie:
X – wektor zmiennych objaśniających, Y – zmienna objaśniana,
β - wektor współczynników regresji (zwykle będących
)
f(X,β) – funkcja regresji o wartościach w liczbach rzeczywistych,
ε – błąd losowy, o rozkładzie być może zależnym od X, przy czym
oraz
Dzięki temu

16
Dysponujemy więc zmiennymi losowymi, o określonej liczbie przypadków lub danymi
empirycznymi pochodzących z szeregów czasowych. Zmienne objaśniane tworzą macierz
natomiast wartości zmiennej objaśnianej tworzą wektor Y. Dysponując macierzą X, w
której znajdują się wartości zmiennych objaśniających oraz wektorem Y zmiennej
objaśnianej. Przy czym warto zaznaczyć, że wektor jedynkowy w macierzy X jest
pomyślany jako wyraz wolny.
Aby dokonać estymacji metodą najmniejszych kwadratów należy pamiętać, iż ilość
wyznaczanych parametrów musi być równa lub mniejsza ilości okresów, z jakich
pochodzą dane.
Zmienne ze zbioru X={X1, ..., Xm} traktujemy jako ustalone na podstawie analizy
merytorycznej. Zależność zmiennej Y od zmiennych X1, ..., Xm przedstawia się za
pomocą (równania regresji II - ego rodzaju) równania:
gdzie: X1, ..., Xm to zmienne regresyjne, objaśniające, natomiast e - element losowy modelu.
Zatem ogólny model regresji liniowej, funkcja teoretyczna - ma postać równania:
gdzie: - to parametry strukturalne populacji oraz element losowy modelu.
Rozwiązanie:
e
m
,
,...,
,
1
0

17
Trudniejsze przykłady WAD.
• Wybór dostawcy oprogramowania wspomagającego
kompleksowo zarządzanie w firmie finansowej (banku,
towarzystwie ubezpieczeniowym)
• Wybór dostawcy konkretnego oprogramowania
realizującego postawione zadania przed pewnym
obszarem dużej firmy (np. Data Mining, Integracja
Danych, Bussines Intelligence, ERP itp.)
• Wybór kredytu konsumpcyjnego lub hipotecznego z
punktu widzenia interesu klienta
• Wybór Banku z którym wiążemy się na dłużej….
• Wybór portfela inwestycyjnego na GPW lub w innym
kraju
• Ranking Uczelni ….

18
Typowe dylematy analityka danych i
współpracujących z nim przedstawicieli
IT:
(
występujące w centrali dużej instytucji
)
• jakie dane są potrzebne aby odpowiedzieć na
postawione pytanie i jak „mocne” należy przygotować
uzasadnienie do przygotowanej odpowiedzi;
• jak zdobyć i jak przygotować do analizy zdobyte dane;
• jakich narzędzi analitycznych użyć do zebranych
danych;
• przy
pomocy
jakich
narzędzi
(programów)
obliczeniowych zrealizować zadanie analityczne;
• jak szybko dokonać syntezy podstawowych informacji
zawartych w danych;
• jak w prosty sposób przekonać odbiorcę, że wnioski
przedstawione
przez
niego
wynikają
ze
zgromadzonego materiału liczbowego;

19
Literatura
Borkowski B, Dudek H., Szczesny W. : Ekonometria. Wybrane zagadnienia, PWN, Warszawa 2003.
Cun Houh Chen: Generalized Assoctiation Plots: Information Visualization Via Iteratively Generated
Correlation Matrices. Statistica Sinica 12 (2002), 7-29. (Dostępny w Internecie:
http://gap.stat.sinica.edu.tw/index.html
)
Charemza W., Deadman D. : Nowa Ekonometria, PWE 1997.
Frączak E. (red): Wielowymiarowa Analiza Statystyczna,Teorai – przykłady z zastosowań z
systemem SAS , Szkoła Główna Handlowa, Warszawa 2009
Kowalczyk T., Pleszczyńska E., Ruland F. (Eds), Grade Models and Methods for Data Analysis, Studies in
Fuzziness and Soft Computing No 151, Springer, Berlin-Heidelberg-New York 2004, 1-477.
Kukuła K.: Metoda unitaryzacji zerowej, PWN 2000.
Koronacki J., Ćwik J.: Statystyczne systemy uczące się. WNT Warszawa 2005.
Koronacki J., Mielniczuk J.: Statystyka dla kierunków technicznych i przyrodniczych WNT Warszawa 2001.
Malina A. : Wielowymiarowa analiza przestrzennego zróżnicowania struktury gospodarki Polski
według województw, AE, Seria Monografie nr 162, Kraków 2004.
Młodak A.: Analiza taksonomiczna w statystyce regionalnej, Warszawa 2006.
Mardia K. V. , Kent J. T., Bibby J.,M.: Mutlivariate Analysis, Academic Press, London, New York, Toronto
1979
Morison D. F.: Wielowymiarowa Analiza Statystyczna, PWN Warszawa 1990.
Ostasiewicz W (red): Statystyczne metody analizy danych. Wydawnictwo Akademii Ekonomicznej
im. Oskara Lanego we Wrocławiu, Wrocław 1999.
Panek T. :Statystyczne Metody Analizy Wielowymiarowej, Szkoła Główna Handlowa, Warszawa 2009
Szczesny W.: Grade correspondence analysis applied to contingency tables and questionnaire data.
Intelligent Data Analysis 6 (2002), No 1, 17-51.
Tadeusz Marek: Analiza skupień w badaniach empirycznych, M. Metody SAHN, PWN Warszawa 1989.
Zeliaś A. (red): Taksonomiczna analiza przestrzennego zróżnicowania poziomu życia w Polsce w ujęciu
dynamicznym, Wydawnictwo Akademii Ekonomicznej w Krakowie, Kraków 2000.
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
Wyszukiwarka
Podobne podstrony:
Metody analizy danych
Metody zbierania danych w psychologii osobowości, psychologia osobowości
Metody zbierania danych w psychologii osobowości, WSFiZ, V, Psychologia osobowości, ćwiczenia
Metody opracowania danych I
Metody analizy danych
Metody gromadzenia danych, WSFiZ - Psychologia, V semestr, Psychologia Osobowości - ćwiczenia
4. Graficzne i tabelaryczne metody prezentacji danych statystycznych, licencjat(1)
Metody Metody prezentacji danych statystycznych, BHP Ula
Braki danych, Informatyka SGGW, Semestr 4, Metody analizy danych
metody analizy danych dane ilosciowe
Wymagania pierwszego projektu, Informatyka SGGW, Semestr 4, Metody analizy danych
praca semestralna - metody prezentacji danych statystycznych, SPIS TREŚCI
LOTS, Metody zbierania danych w psychologii osobowości, Zasadniczo całość metod stosowanych w psycho
METODY PRZEDSTAWIANIA DANYCH
METODY ZBIERANIA DANYCH W NAUKACH PEDAGOGICZNYCH. WPROWADZENIE, Pedagogika ogólna
Prof Kukuła tekst HD, Informatyka SGGW, Semestr 4, Metody analizy danych
więcej podobnych podstron