
Wykład 1: Wstępne
przetwarzanie danych
Biometria i
Biostatystyka

Statystyka – cóż to jest?
Naukowa analiza
danych opisujących
naturalną zmienność.
Naukowa analiza:
Zbieranie danych dokonywane jest z
uwzględnieniem ogólnie akceptowanych
kryteriów przeprowadzania
eksperymentów naukowych.
Prezentacja danych oraz wyników analiz
musi być przeprowadzana obiektywnie,
zgodnie z zasadami ‘kodu etycznego
naukowca’.
„Liczby nigdy nie kłamią, wszystkiemu
winni są statystycy”

Dane:
Statystyka to analiza zjawisk, które
dotyczą populacji lub grupy
osobników; opiera się na analizie
zbioru informacji, a nie pojedynczego
pomiaru. Oznacza to, że nie będzie
nas interesować pojedynczy osobnik.
Dane stanowią pomiary bądź
zliczenia.

Naturalna zmienność:
Analizować będziemy jedynie takie
zdarzenia, które w naturze nie
podlegają bezpośrednie naszej kontroli
(np. liczba ziaren grochu w strąku).
Czasami dopuszczalne jest częściowe
kontrolowanie czynników przez badacza
(np. mierząc krzywą cukrową u osób z
podejrzeniem cukrzycy podaje się im
wcześniej odpowiednią dawkę cukru).

Podstawowym celem analizy
statystycznej jest wnioskowanie o
cechach dużej grupy osobników na
podstawie informacji uzyskanej z
relatywnie małolicznej grupy badanej.
Takie podejście wymaga
sprecyzowania pojęć populacji i próbki.

Podstawowe definicje
Dane składają się z pojedynczych
obserwacji
, które są pomiarami
dokonanymi na pojedynczej
jednostce.
Jeśli mierzymy wzrost u 100 osób,
wówczas wzrost każdej z osób stanowi
pojedynczą obserwację.

Podstawowe definicje
Próba
jest zbiorem pojedynczych
obserwacji wybranych z
zastosowaniem specyficznych
kryteriów selekcji.
Zebranych 100 pomiarów wzrostu
stanowi próbę.

Podstawowe definicje
Cecha, którą mierzymy w
pojedynczych obserwacjach
nazywana jest
zmienną
.
Więcej niż jedna zmienna może być
mierzona u pojedynczej jednostki.
Możemy mierzyć u każdej z osób jej wzrost
oraz np. masę ciała i wiek.

Podstawowe definicje
Populacja
to całość pojedynczych
obserwacji, o których przeprowadzane
jest wnioskowanie statystyczne,
istniejąca gdziekolwiek na świecie,
albo przynajmniej w dokładnie
zdefiniowanym w dziedzinie czasu i
przestrzeniu obszarze próbkowania.
Przykładowo:
1. Wszyscy ludzie w wieku 18-25 lat
2. Wszyscy ludzie w wieku 18-25 w
Gliwicach

Trochę więcej o zmiennych
...
Możemy zatem powiedzieć, że zmienna
to cecha, która zmienia się u osobników
w jakiś określony sposób.
Cecha, która nie jest różnorodna nie
podlega zainteresowaniu statystyków.

Trochę więcej o zmiennych
...
Stałocieplność u ssaków nie jest
zmienną ponieważ wszystkie one
są stałocieplne.
Temperatura ciała poszczególnych
ssaków może być zmienną.
Trochę więcej o zmiennych
...
Zmienne
Zmienne
pomiarowe
Zmienn
e
rangow
e
Atrybut
y
Zmienne
ciągłe
Zmienne
dyskretne

Zmienne pomiarowe
(mierzalne)
Zmienne pomiarowe
to takie,
których różne wartości mogą być
uporządkowane numerycznie .
Mogą być wyrażone w skali
ilorazowej bądź przedziałowej.

Zmienne pomiarowe
Są dwie najważniejsze cechy
skali
ilorazowej
:
W całym zakresie skali jest ustalona, niezmienna
jednostka.
Zdefiniowany jest punkt zerowy, który ma
znaczenie fizyczne.

Cóż to oznacza?
Stała jednostka
:
Przykładowo, różnica wzrostu pomiędzy
osobąmi o wzrostach 166 cm i 167 cm
jst taka sama jak różnica pomiędzy
osobami 180 cm i 181 cm
.
Punkt zerowy
:
Pozwala na określenie stosunku dwóch
pomiarów. Możemy zatem powiedzieć, że 90
cm to połowa 180 cm.

Zmienne pomiarowe
Niektóre skale spełniają warunek stałej
jednostki, ale nie posiadają zera
fizycznego. Takie skale nazywamy
skalami przedziałowymi
.
Książkowym przykładem są skale temperatury: Celsius (ºC)
i Fahrenheit (ºF). Różnica temperatur pomiędzy 20ºC a
25ºC jest taka sama w sensie energetycznym jak różnica
pomiędzy 5ºC 10ºC. Jednak nie można powiedzieć, że
temperatura 40ºC jest dwukrotnością temperatury 20ºC;
punkt zerowy został zdefiniowany arbitralnie. (Takiego
problemu nie ma w przypadku stosowania skali Kelvina)

Zmienne pomiarowe
Niektóre skale, często stosowane w
biologii i medycynie, to skale
przedziałowe zwane
skalami
cyklicznymi.
Pora dnia, pora roku to przykłady takich skal. Okres
czasu pomiędzy 14:00 a 15:30 jest taki sam jak
pomiędzy 8:00 a 9:30. Nie możemy nic powiedzieć
o stosunku pór dnia.

Zmienne pomiarowe
Występują dwa typy zmiennych pomiarowych:
Zmienne ciągłe
teoretycznie przyjmujące
nieskończoną liczbę wartości pomiędzy dwoma
ustalonymi wielkościami.
Zmienne dyskretne
to zmienne, które
przyjmują wartości ze ściśle określonego,
skończonego zbioru wartości dopuszczalnych.

Ciągłe versus dyskretne
Ciągłe:
długość (cm, in), waga (mg, lb), powierzchnia
(sq cm, sq ft), objętość (ml, qt), prędkość
(cm/sec, mph, mg/min), czas trwania (hr, yr),
kąt (grad, rad), temperatura (º), procenty
Dyskretne:
Liczność (liści, fragmentów, zębów), liczba
potomków, liczba białych krwinek w 1mm
3
krwi, liczba żyraf u wodopoju, liczba jajeczke
złożonych przez konika polnego

Zmienne rangowe
Niektóre zmienne nie mogą być
dokładnie zmierzone, ale można
uporządkować ich poziomy rosnąco
lub malejąco. O takich danych mówi
się, że są przedstawione w
skali
porządkowej (rangowej)
, opisującej
bardziej relacje aniżeli ilościowe
różnice .

Zmienne rangowe
Wyrażając jakąś zmienną w skali rangowej,
jako ciąg wielkości 1, 2, 3, 4, 5 my nie
zakładamy, iż różnica pomiędzy rangami 1 i
2 jest taka sama (bądź proporcjonalna do)
jak różnica pomiędzy rangami 2 i 3.
Zmienne przedstawione w skali porządkowej
wnoszą znaczniej mniej informacji aniżeli
zmienne w skali ilorazowej bądź
przedziałowej.

Atrybuty
Zmienne, które nie mogą być
zmierzone, a jedynie wyrażone są
jakościowo nazywa się
atrybutami
a
skalę, w której są wyrażone nazywamy
skalą nominalną
(od słowa „name”).
Atrybuty to przykładowo takie cechy
jak: żywy/martwy, prawo-/leworęczny,
mężczyzna/kobieta, kolor oczu (zielony,
niebieski, szary, brązowy), kolor włosów
(czarne, brązowe, blond czy rude)
.

Wstępne przetwarzanie
danych
Kiedy dane zostały już zebrane w
konkretnym eksperymencie badawczym,
powinne być najpierw przedstawione w
postaci, któa jest użyteczna dla dalszych
obliczeń i interpretacji.
W pierwszym kroku najczęściej wykreśla się
wykresy częstościowe (histogramy)
oraz
wyznacza się tzw.
statystyki opisowe
.

Wykresy częstościowe
Ilościowe
Są to reprezentacje graficzne realizacji
zmiennych pomiarowych, zarówno
ciągłych jak i dyskretnych, oraz
zmiennych rangowych.
Jakościowe
Dotyczą tylko zmiennych typu atrybut.

Przykład
U 462 dzieci z terenu Górnego Śląska
została rozpoznana cukrzyca typu 1 na
przestrzeni lat 1989-1996.
Zebrano następujące dane:
Płeć dziecka (chłopiec/dziewczynka)
Numer kolejny dziecka w rodzinie
Rok urodzenia
Waga urodzeniowa
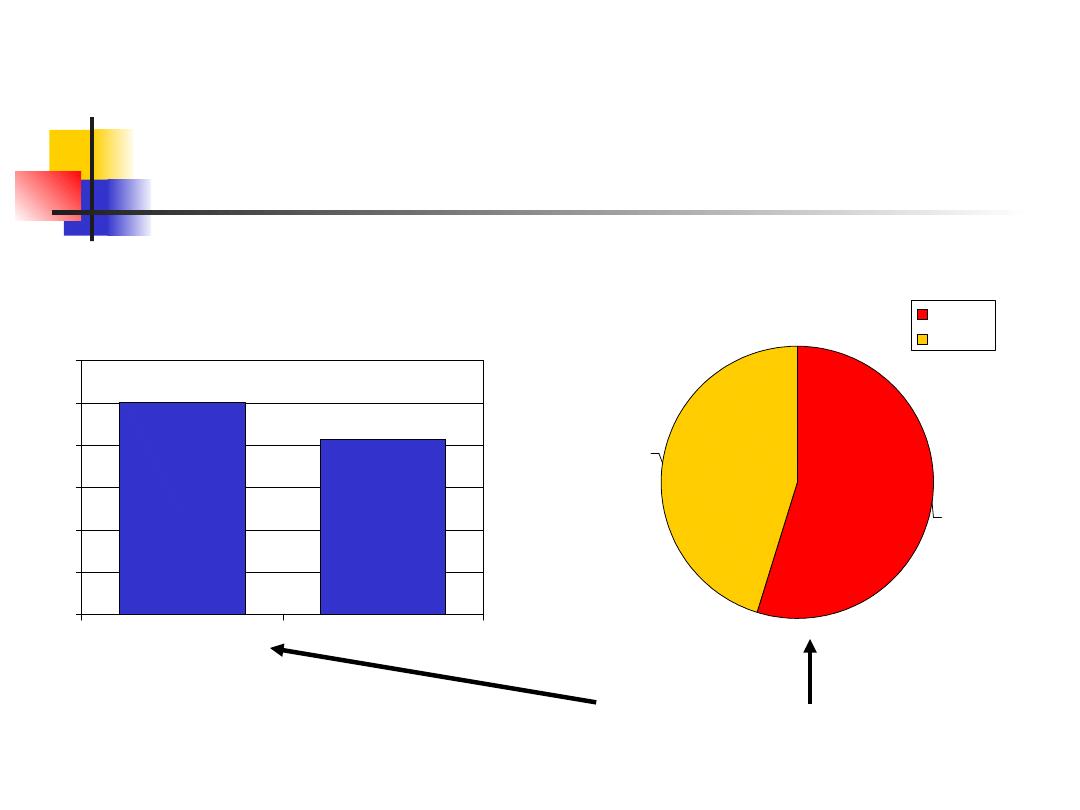
Przykład – Płeć
251
207
0
50
100
150
200
250
300
Female
Male
N
o
of
c
as
es
54.8
45.2
Female
Male
Można przedstawić dane w postaci zliczeń bądź
procentów
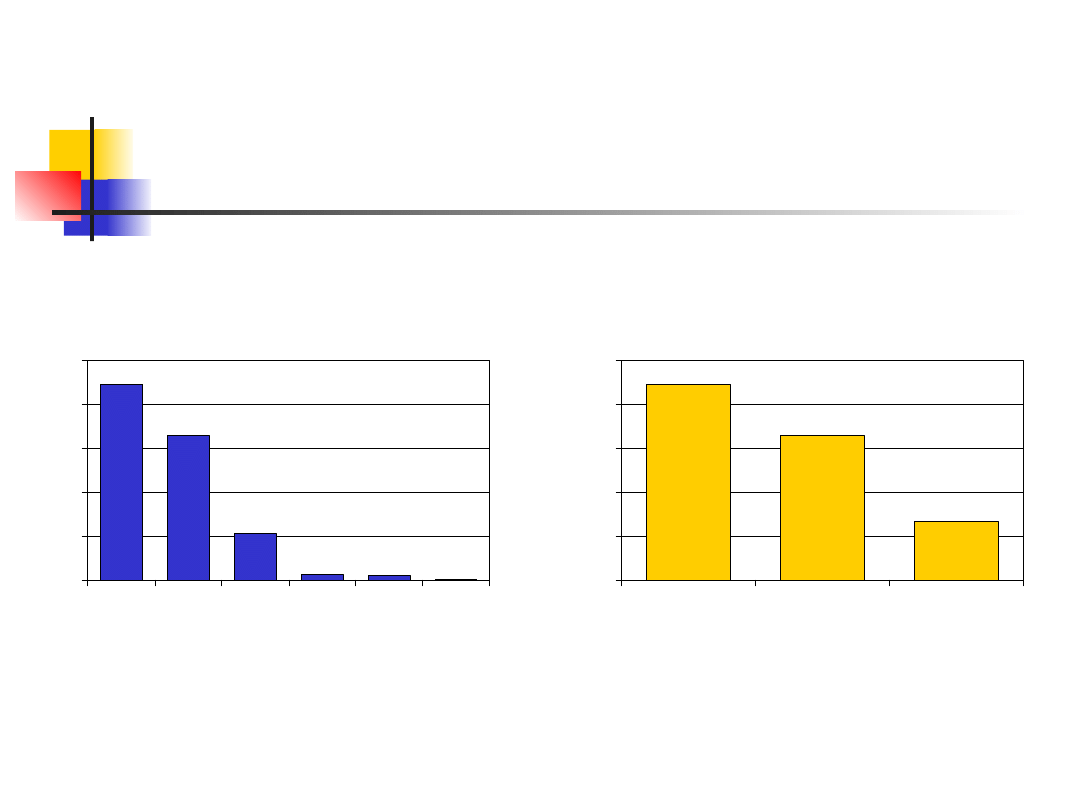
Przykład – numer dziecka
165
54
7
5
1
223
0
50
100
150
200
250
1st
2nd
3rd
4th
5th
6th
Child number in a family
N
o
of
c
as
es
165
67
223
0
50
100
150
200
250
1st
2nd
3rd or later
Child number in a family
N
o
of
c
as
es
Czasami zachodzi potrzeba przekodowania
danych
Zmienna dyskretna
Zmienna rangowa
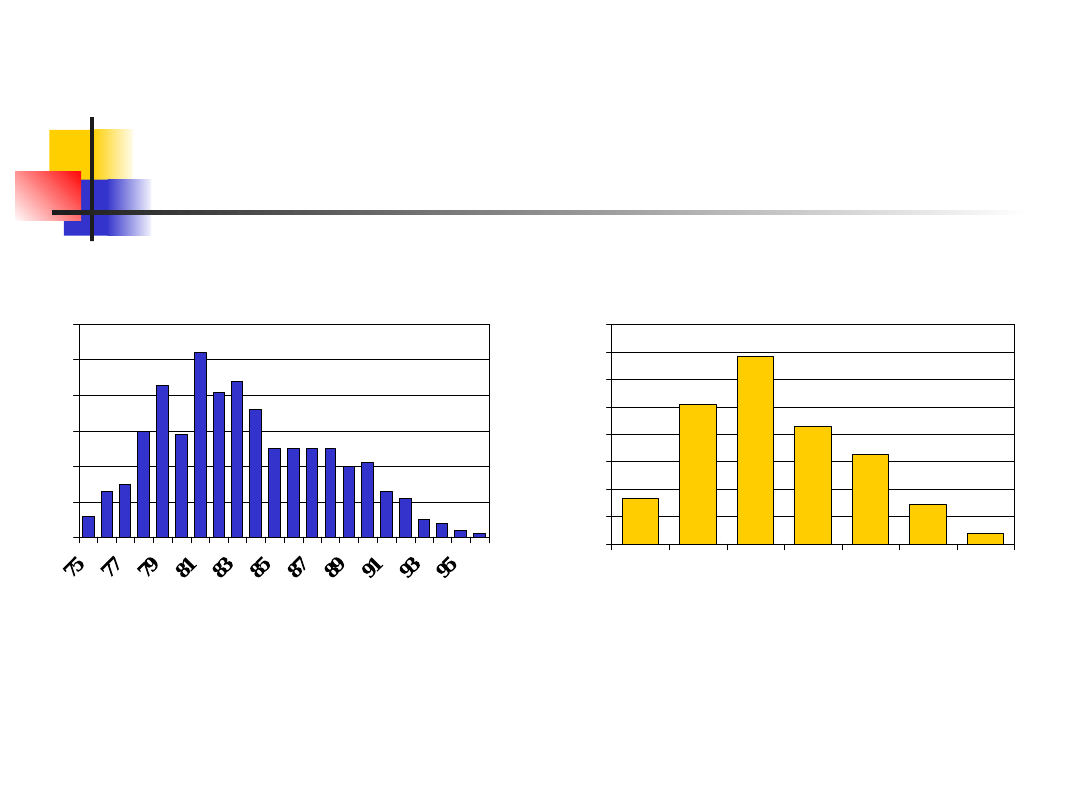
Przykład – rok urodzenia
1315
30
43
29
52
4144
36
25252525
2021
1311
5 4 2 1
6
0
10
20
30
40
50
60
Birth year
N
o
of
c
as
es
102
137
86
66
29
8
34
0
20
40
60
80
100
120
140
160
75-77 78-80 81-83 84-86 87-89 90-92 93-96
Birth year
N
o
of
c
as
es
Grupowanie klas często pozwala uzyskać
bardziej spójny i regularny kształt wykresu.

Statystyki opisowe
Istnieje potrzeba zwięzłego podsumowania
danych w takiej postaci, która pozwoli na
ocenę i łatwą prezentację ich własności.
Wykresy częstościowe są taką formą.
Jednakże potrzebujemy również opisu w
formie liczb, które pozwoliłyby na zwięzły i
dokładny ilościowy opis własności
obserwowanego rozkładu częstości.
Nazywamy je
statystykami opisowymi
.

Statystyki opisowe
Definiuje się dwie podstawowe grupy
statystyk opisowych:
Statystyki położenia
(miary centralnej
tendencji) – określają położenie próbki w
przestrzeni reprezentującej analizowaną
zmienną losową.
Statystyki rozrzutu
(miary zmienności) –
oceniają rozrzut pomiarów wokół środka
dystrybucji.

Średnia arytmetyczna
Najszerzej używaną statystyką
położenia jest
średnia arytmetyczna
,
powszechnie nazywana średnią.
Każdy pomiar (realizacja zmiennej
lsowej) wchodzący w skłąd próby
oznaczamy jako X
i
. Indeks i jest liczbą
całkowitą przyjmującą wartości od 1
do N – całkowitej liczby osobników w
próbie.

Średnia arytmetyczna
Średnia arytmetyczna najczęściej oznaczana jest jako
N
X
X
N
i
i
1
X

Średnia ważona
Często występuje potrzeba wyznaczenia
wartości średniej średnich bądź innych
statystyk, których wiarygodność jest
różna z powodu np. różnych liczności
próbek. W takim przypadku trzeba
wyznaczyć
średnią ważoną
.
N
i
i
N
i
i
i
w
w
X
w
X
1
1

Przykład
W tym przypadku trzy wartości
średnie wyznaczono na
podstawie trzech prób o różnych
licznościach, ich średnia ważona
wynosi:
n
i
3.85 12
5.21 25
4.70
8
i
X
76
.
4
8
25
12
70
.
4
8
21
.
5
25
85
.
3
12
w
X
i różni się od standardowej
średniej arytmetycznej
59
.
4
3
70
.
4
21
.
5
85
.
3
X

Średnia geometryczna
Często dokonuje się transformacji
zmiennej losowej wyliczając logarytmy
ich wartości. Jeśli wyliczymy średnią
arytmetyczną pomiarów po
transformacji i dokonamy transformacji
odwrotnej, to uzyskana liczba będzie
inna niż średnia arytmetyczna danych w
surowej postaci. Nazywa się ją
średnią
geometryczną
.

Średnia geometryczna
Ponieważ sumowanie logarytmów jest równoważne
logarytmowaniu iloczynu argumentów możemy tę
wielkość przedstawić jako
N
X
X
N
i
i
GM
1
log
log
N
N
i
i
GM
X
X
1

Średnia harmoniczna
Odwrotność średniej arytmetycznej
odwrotności pomiarów nazywana
jest
średnią harmoniczną
i
oznaczana jest najczęściej
symbolem H
N
i
i
H
X
N
X
1
1
1
1

Mediana
Mediana
M definiowana jest jako taka
wartość zmiennej (po uporządkowaniu
danych w szereg rosnący), że taka
sama liczba pomiarów jest od niej
większa i mniejsza.
Jeśli liczność próbki jest liczbą
nieparzystą, wówczas
2
/
)
1
(
N
X
M

Mediana
Gdy N jest liczbą parzystą wtedy
wyrażenie (N+1)/2 nie jest liczbą
całkowitą – nie ma po prostu liczby
środkowej. Miast niej są dwie liczby
najbliższe środka, a mediana jest
wyznaczana jako średnia z nich:
2
/
)
(
1
2
2
N
N
X
X
M

Pozostałe kwartyle
Mediana jest jedną ze statystyk
porządkowych, dzielących dystrybucję
zmiennej losowej na równoliczne części.
Mediana dzieli ją na dwie połowy.
Kwartyle
, definiują przez analogię do
mediany punkty 25%, 50%, i 75%, tzn. są
to punkty dzielące dystrybucję na
pierwsza, drugą, trzecią i czwartą ćwiartkę
jej powierzchni. Zazwyczaj oznacza się je
jako Q
1
(dolny kwartyl), M (mediana), Q
3
(górny kwartyl).

Mode
Modę
zazwyczaj definiuje się jako pomiar
występujący najczęściej w analizowanym
zbiorze danych. Jednakże czasami lepiej
zdefiniować ją jako pomiar o istotnie
większej koncentracji/częstości
występowania od pozostałych.
W niektórych przypadkach może
występować więcej niż jeden punkt
koncentracji.
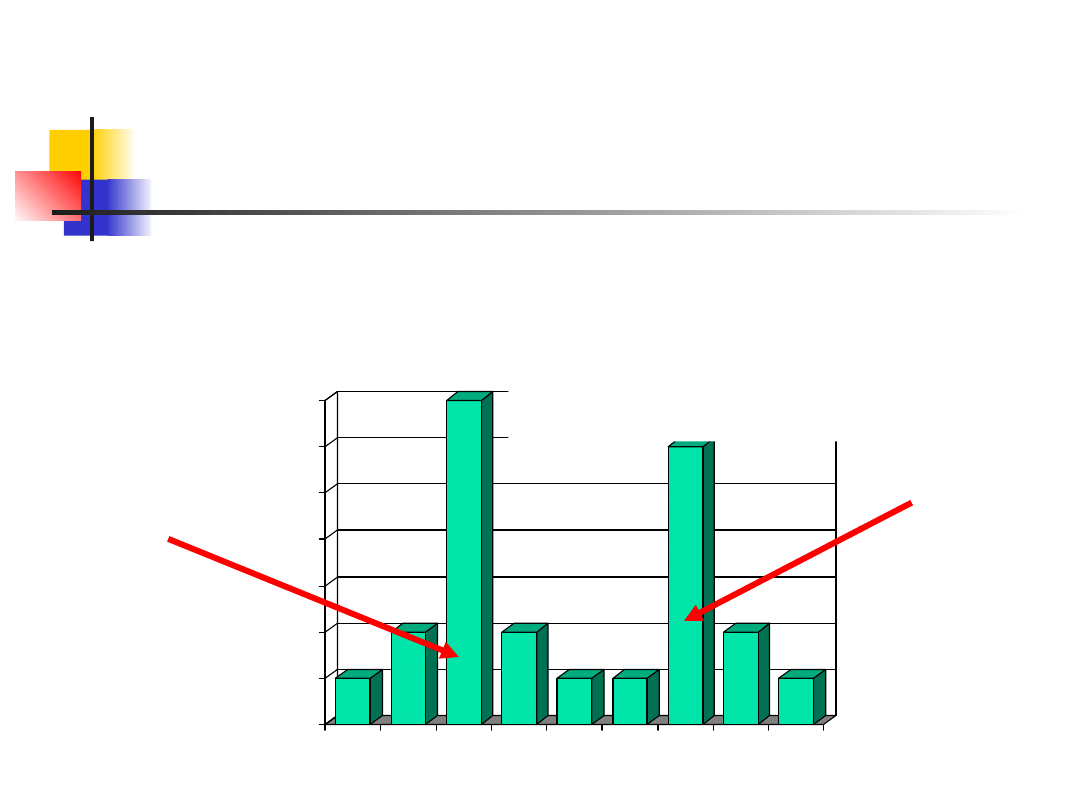
Przykład
Załóżmy, iż próba składa się z następujących
pomiarów: 6, 7, 7, 8, 8, 8, 8, 8, 8, 8, 9, 9, 10,
11, 12, 12, 12, 12, 12, 12, 13, 13, i 14 mm.
0
1
2
3
4
5
6
7
N
o
o
f
in
d
iv
id
u
a
ls
6
7
8
9 10 11 12 13 14
length [mm]
Główna moda
Moda oboczna
Rozkład dwumodalny
Uwagi

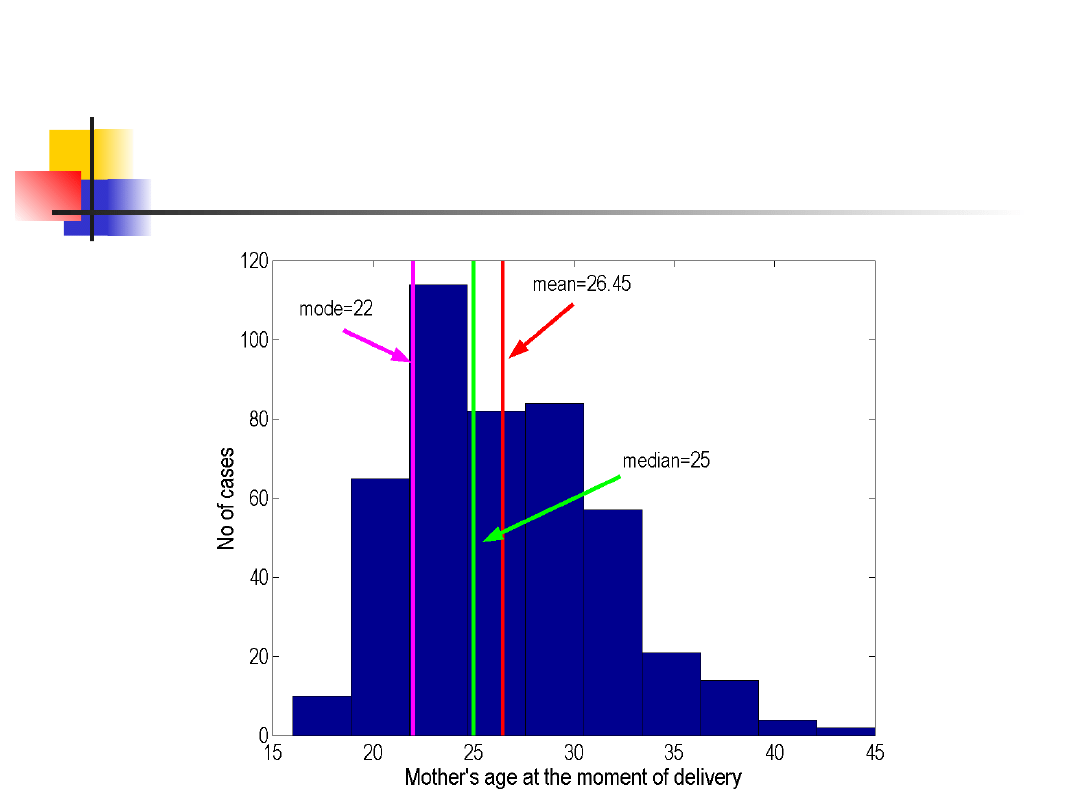
Uwagi
Średnia arytmetyczna jest najczęściej
stosowaną statystyką położenia, jednak
jest bardzo wrażliwa na wartości odstające
(istotnie różne od pozostałych), podczas
gdy mediana i moda są nań odporne.
W przypadku symetrycznego i
jednomodalnego rozkładu zmiennej
losowej średnia arytmetyczna, mediana i
moda są sobie równe.

Miary rozrzutu - zakres
Zakres
jest miarą, która ukazuje
zmienność/rozrzut pomiarów zmiennej.
i
N
i
i
N
i
X
X
Range
,...,
1
,...,
1
min
max
Jest silnie wrażliwy na pojedyncze
wielkości odstające i z tego
powodu może być traktowany
jedynie jako zgrubna ocena
zmienności pomiarów.

Przedział
międzykwartylowy
Odległość pomiędzy Q
1
a Q
3
, pierwszym
i trzecim kwartylem (inaczej 25-tym i
75-tym percentylem) jest nazywana
przedziałem międzykwartylowym
albo
odchyleniem kwartylowym.
1
3
Q
Q
IQR

Średnie odchylenie
Ponieważ średnia jest użyteczną miarą
położenia, wielkość mierząca odchyłki od
średniej wyrażać będzie zmienność
pomiarów w próbie.
Suma wartości absolutnych odchyłek od
wartości średniej podzielona przez liczność
próby N daje w wyniku statystykę
nazywaną
średnim odchyleniem (AD)
N
X
X
AD
N
i
i
1

Wariancja
Alternatywnym sposobem pomiaru odchyleń
od wartości średniej jest posługiwanie się
kwadratem odległości a nie wartością
absolutną. Ich suma jest bardzo ważną
wielkością w statystyce, nazywaną
sumą
kwadratów
(SS).
Wariancja
jest średnią
kwadratów odchyleń.
1
1
1
1
2
1
2
1
2
N
X
N
X
N
X
X
Var
N
i
N
i
i
i
N
i
i

Odchylenie standardowe
Odchylenie standardowe
jest dodatnim
pierwiastkiem wariancji; dzięki temu
wyrażany jest w oryginalnych
jednostkach zmiennej losowej.
1
1
2
N
X
X
s
N
i
i
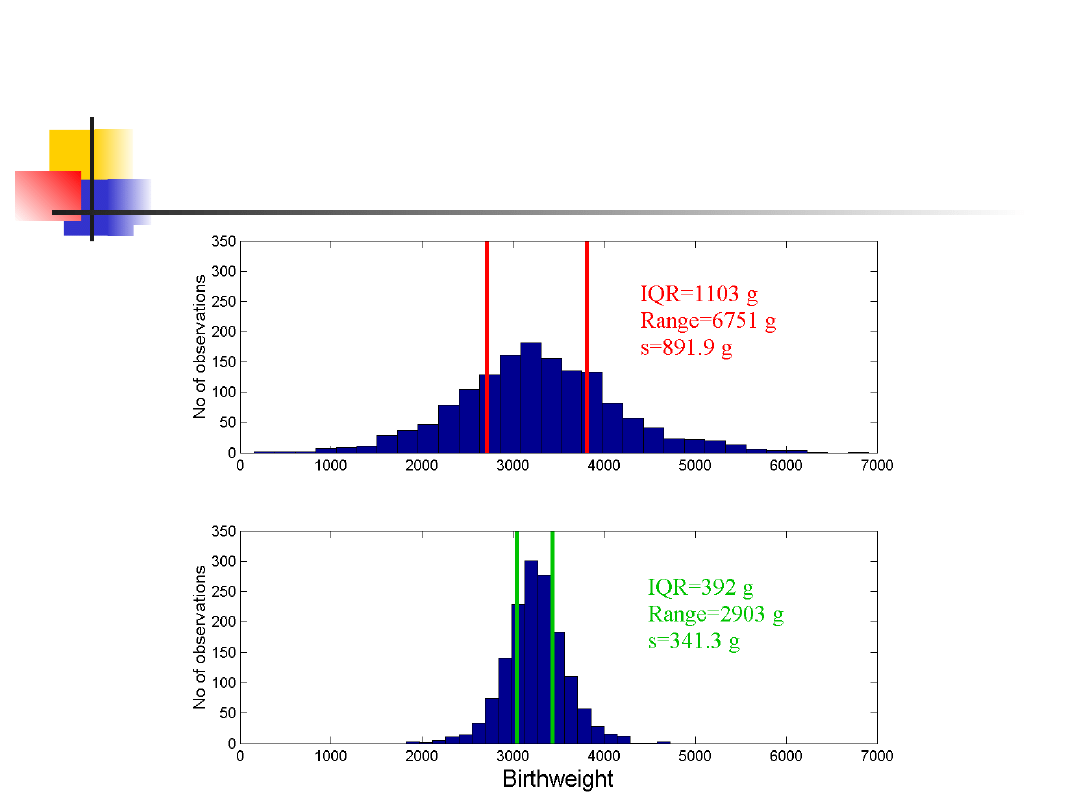
Przykład

Współczynnik zmienności
Zarówno wariancja jak i odchylenie
standardowe przyjmują wartości ściśle
zależne od poziomu pomiarów.
Słonie mają uszy, których wielkość jest
około stukrotnie większa od uszu myszy.
Tym samym odchylenie standardowe będzie
(zakładając podobną zmienność osobniczą
w grupie słoni i myszy) liczbowo stukrotnie
większe w grupie słoni w odniesieniu do
myszy. A ich wariancja będzie 100
2
razy
większa.

Współczynnik zmienności
Współczynnik zmienności (CV)
wyraża
zmienność pomiarów w ramach próbki
odniesioną do średniej arytmetycznej
próbki
%
100
X
s
CV

Wskaźniki różnorodności
Dla zmiennych wyrażanych w skali
nominalnej (atrybuty) nie istnieje
pojęcie średniej czy mediany, które
byłby odniesieniem dla pomiaru
rozrzutu. Możemy jednak przenieść
ideę różnorodności dla dystrybucji
obserwacji w ramach
poszczególnych kategorii.

Wskaźniki różnorodności
Najczęściej stosowanym wskaźnikiem
różnorodności jest entropia
Shannona-
Wienera
definiowana jako:
gdzie k jest liczbą kategorii,
natomiast p
i
jest częścią
obserwacji zakwalifikowanych do
kategorii i.
k
i
i
i
p
p
H
1
log

Wskaźniki różnorodności
Jeśli N jest licznością próby, a f
i
liczbą obserwacji dla kategorii i, to
N
f
p
i
i
więc
N
f
f
N
N
H
k
i
i
i
1
log
log
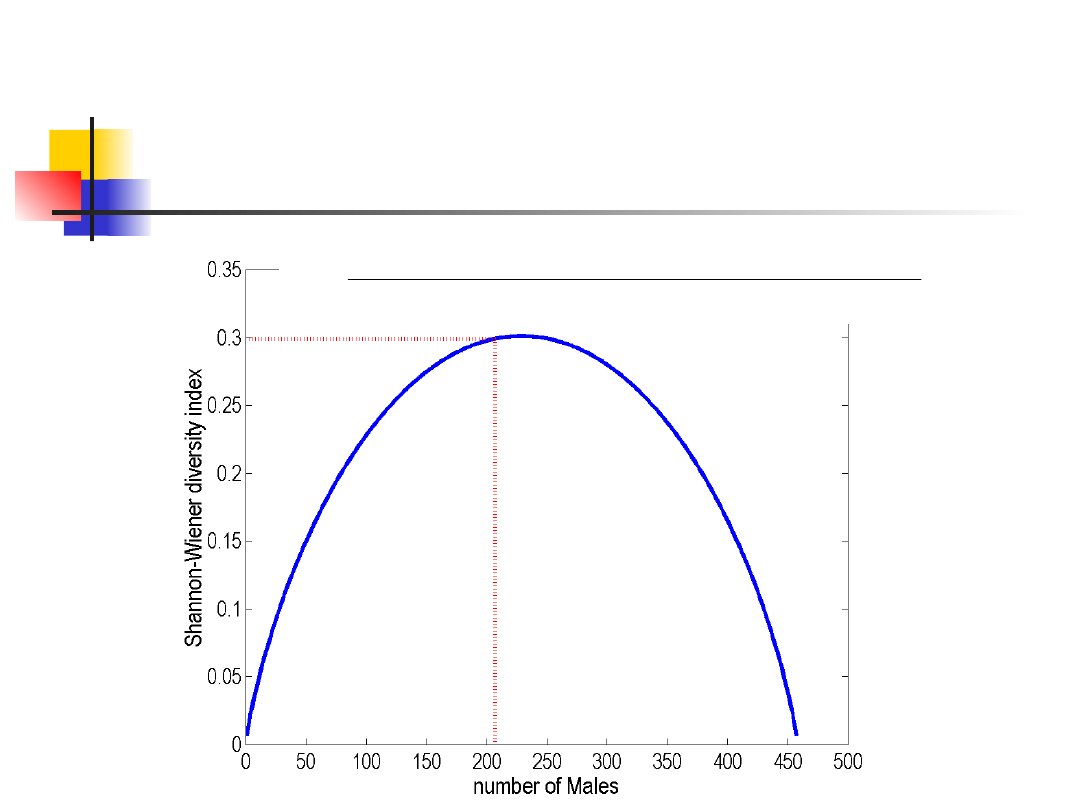
Przykład
2990
.
0
458
)
207
log
207
251
log
251
(
458
log
458
H

Wskaźniki różnorodności
Zdefiniujmy maksymalną entropię jako
k
N
f
i
i
k
H
log
max
Możemy zatem wyrazić
obserwowaną entropię jako część
maksymalnej możliwej – nazywa
się ją wówczas
relatywnym
wskaźnikiem różnorodności
.
max
H
H
J
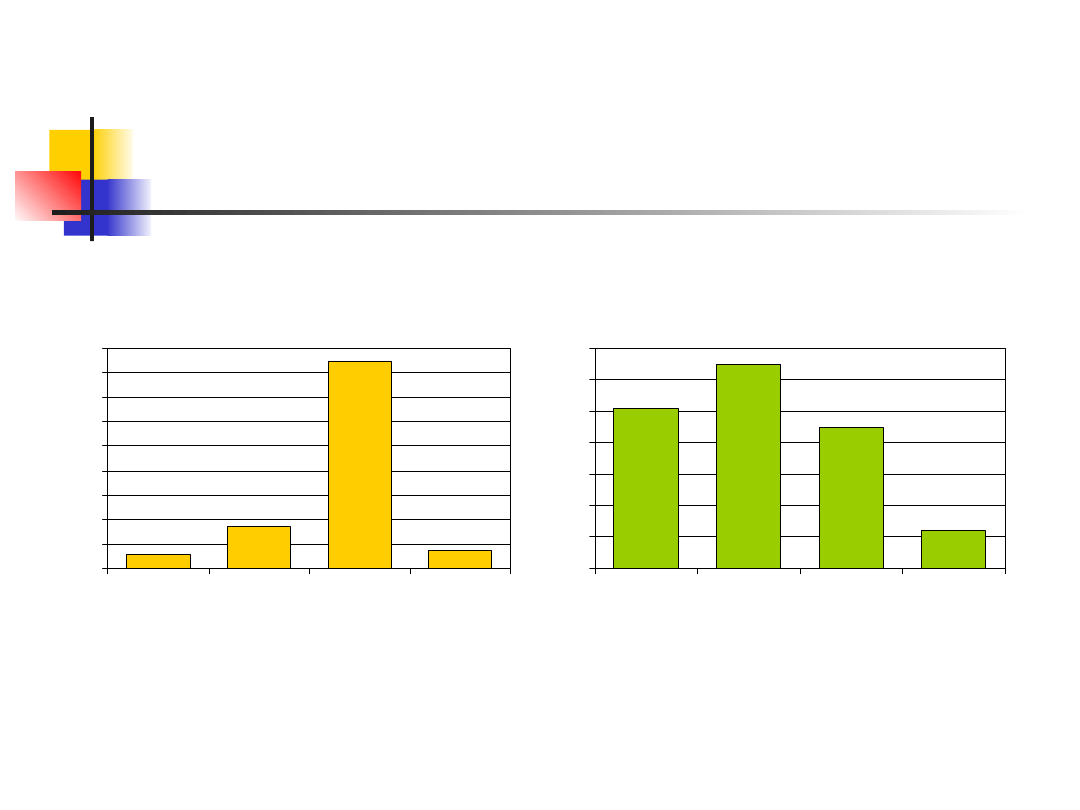
Przykład
65
45
12
51
0
10
20
30
40
50
60
70
Black
Brown
Blonde
Red
Hair color - Italian
N
o
of
c
as
es
34
169
15
11
0
20
40
60
80
100
120
140
160
180
Black
Brown
Blonde
Red
Hair color - Swedish
N
o
of
c
as
es
5486
.
0
H
60
.
0
J
9112
.
0
J
3612
.
0
H
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
- Slide 51
- Slide 52
- Slide 53
- Slide 54
- Slide 55
- Slide 56
- Slide 57
- Slide 58
- Slide 59
Wyszukiwarka
Podobne podstrony:
Wyklad 1 Wstepne przetwarzania danych
1a, UŁ Sieci komputerowe i przetwarzanie danych, Semestr II, Systemy operacyjne, Wykład, Systemy, Sy
22 Bazy danych wyklad wstepny Nieznany
TAM GDZIE PLUS TO ODPOWIEDŹ POPRAWNA, UŁ Sieci komputerowe i przetwarzanie danych, Semestr II, Syste
Podstawy Informatyki Wykład XIX Bazy danych
upowaznienie-do-przetwarzania-danych-osobowych, Prawo Pracy, Druki
PHP i Oracle Tworzenie aplikacji webowych od przetwarzania danych po Ajaksa
prawo ustrojowe ue wyklad wstepny rozwoj 2014
Akwizycja i wstępne przetwarzanie (preprocessing) obrazów cyfrowych
fotka, ĆWICZENIE 5, ĆWICZENIE 5-6: WSTEPNE PRZETWARZANIE OBRAZU CYFROWEGO
Wzor-upowaznienia-do-przetwarzania-danych-osobowych, Prawo Pracy, Druki
Upoważnienie do przetwarzania danych osobowych
wyklad4 cpp, Baza danych studentów
Bazy danych - podstawowe kroki w projektowaniu cz 2 - wyklady, Zajęcia z Baz Danych - MS Access, cz
więcej podobnych podstron