
Bazy danych
3. Zależności funkcyjne
Postaci normalne
P. F. Góra
http://th-www.if.uj.edu.pl/zfs/gora/
semestr letni 2007/08

Bazy danych - wykład 3
2
• W bardzo sformalizowanych wykładach
baz danych jest to jedno z
najważniejszych zagadnień.
• W wykładach (kursach) pisania kodu w
SQL jest to zagadnienie całkowicie
pomijane.
• Proste (kilkutabelowe) bazy można z
powodzeniem projektować (i
optymalizować) bez znajomości tego
tematu.
Złożonych baz bez tego
zaprojektować się praktycznie nie da.

Bazy danych - wykład 3
3
Definicja
zależności funkcyjnej
Jeśli dwie krotki pewnej tabeli
(relacji) są zgodne w atrybutach A
1
,
A
2
, …A
n
, to muszą być zgodne w
pewnym innym atrybucie B.
Zapisujemy to
A
1
, A
2
, …A
n
B
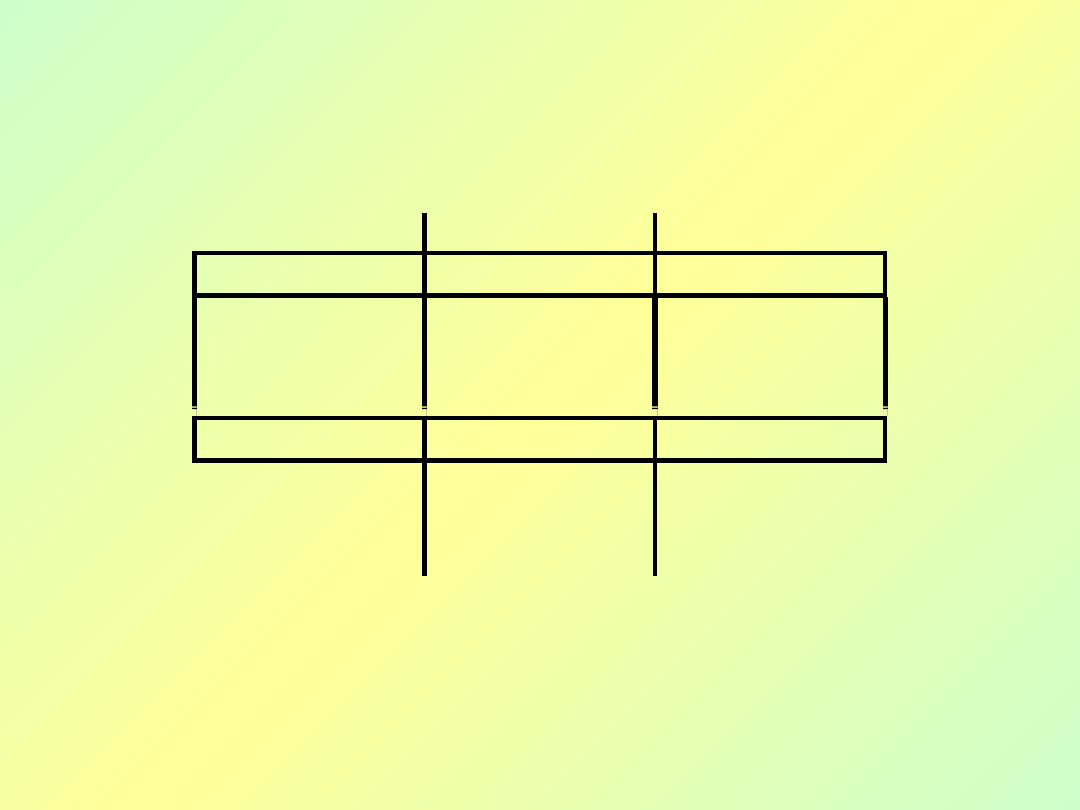
Bazy danych - wykład 3
4
A
B
Jeśli są zgodne
tutaj…
…to muszą być
zgodne także
tutaj
A B
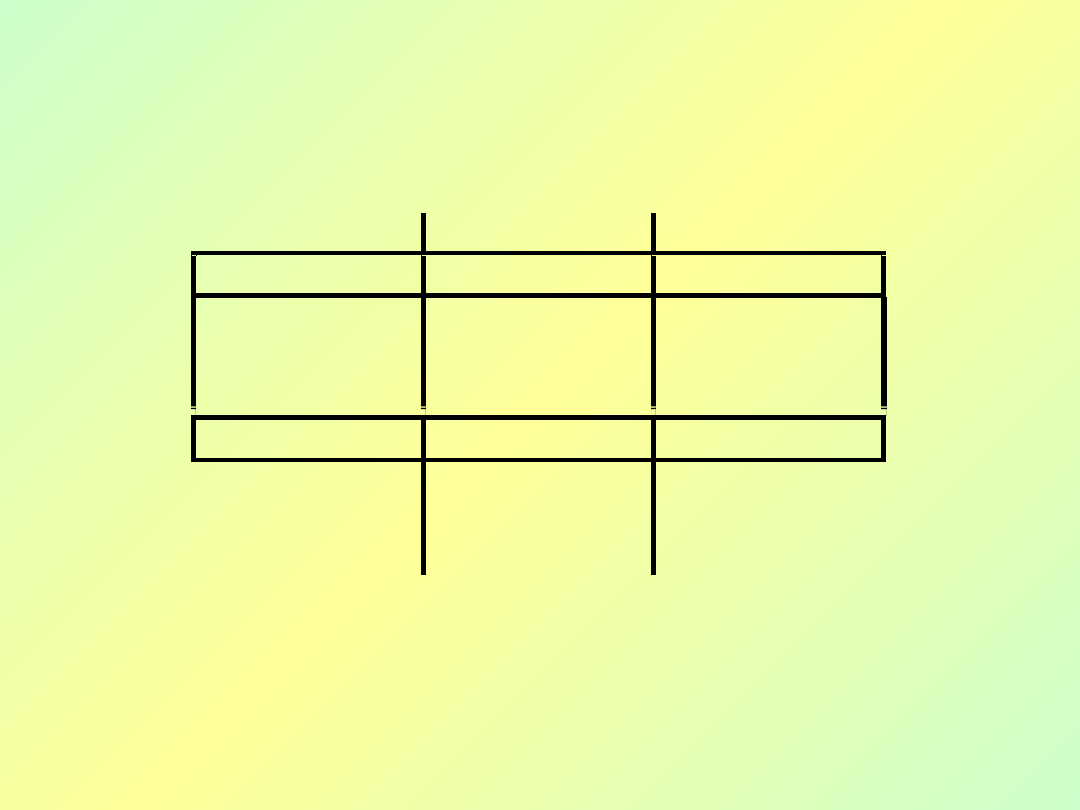
Bazy danych - wykład 3
5
PESEL
Nazwisko
Jeśli są zgodne
tutaj…
…to muszą być
zgodne także
tutaj
PESEL Nazwisko

Bazy danych - wykład 3
6
• Zależności funkcyjne są matematycznym
modelem więzów jednoznaczności w
modelu relacyjnym baz danych.
• Zależności funkcyjne należą do schematu
bazy. Nie można o nich wnioskować
jedynie na podstawie instancji
(faktycznych wystąpień) tabel.
Jeżeli zachodzi
A
1
, A
2
,…,A
n
B
1
,…,
A
1
, A
2
,…, A
n
B
m
piszemy w skrócie
A
1
, A
2
,…, A
n
B
1
,…,
B
m

Bazy danych - wykład 3
7
Przykład
W używanym w podręczniku przykładzie tabeli
Filmy występują następujące zależności
funkcyjne:
tytuł rok długość
tytuł rok TypFilmu
tytuł rok NazwaStudia
Jednak na przykład zdanie
tytuł rok NazwiskoGwiazdy
jest fałszywe: w jedym filmie, identyfikowanym
przez zbiór atrybutów {tytuł, rok}, może
występować wiele gwiazd.

Bazy danych - wykład 3
8
Reguły dotyczące zależności
funkcyjnych
Przykład: Załóżmy, że w pewnej tabeli z atrybutami A, B, C
zachodzą zależności funkcyjne A B, B C. Wnioskujemy
sąd, iż zachodz także A C.
Dowód: Niech dwie krotki zgodne dla A mają postać
(a,b
1
,c
1
), (a,b
2
,c
2
). Ponieważ zachodzi A B, krotki zgodne
dla A muszą być też zgodne dla B, a zatem b
1
=
b
2
. Krotki
mają więc postać (a,b,c
1
), (a,b,c
2
). Ponieważ zachodzi B
C, musi być spełnione c
1
=
c
2
, co kończy dowód.
Jest to przykład
reguły przechodniości
.

Bazy danych - wykład 3
9
Zależności trywialne
• Zależność nazywam trywialną, jeśli atrybut B
jest równy któremuś atrybutowi A.
• Jeśli przyjmiemy „skrótowy” zapis zależności z
wieloczłonową prawą stroną, zależność jest
– Trywialna, jeśli zbiór złożony z atrybutów B
jest podzbiorem zbioru złożonego z
atrybutów A
– Nietrywialna, jeśli co najmniej jeden B nie
jest A
– Całkowicie nietrywialna, jeśli żadnen B nie
jest A.

Bazy danych - wykład 3
10
Reguły wnioskowania
(aksjomaty Armstronga)
1. Zwrotność: Jeżeli {B
1
,B
2
,…,B
m
} {A
1
,A
2
,…
A
n
}, to A
1
A
2
…A
n
B
1
B
2
…B
m
2. Rozszerzenie: Jeżeli A
1
A
2
…A
n
B
1
B
2
…B
m
, to
A
1
A
2
…A
n
C
1
C
2
…C
k
B
1
B
2
…B
m
C
1
C
2
…C
k
dla
dowolnych C
1
C
2
…C
k
.
3. Przechodniość: Jeżeli A
1
A
2
…A
n
B
1
B
2
…B
m
oraz
B
1
B
2
…B
m
C
1
C
2
…C
k
, to A
1
A
2
…A
n
C
1
C
2
…C
k
.
Zależności
trywialne

Bazy danych - wykład 3
11
Domknięcia
Niech {A
1
, A
2
, …A
n
} będzie pewnym zbiorem
atrybutów, S niech będzie zbiorem zależności
funkcyjnych.
Domknięciem zbioru {A
1
, A
2
, …A
n
}
nad S
nazywamy taki zbiór atrybutów B, że jeśli
jego elementy spełniają wszystkie zależności
funkcyjne z S, to spełniają także zależność A
1
A
2
…
A
n
B, a zatem zależność A
1
A
2
…A
n
B wynika z
S.
Domknięcie oznaczam cl {A
1
, A
2
, …A
n
}.

Bazy danych - wykład 3
12
Mówiąc niezbyt ściśle,
domknięcie
to
zbiór wszystkich atrybutów
determinowanych, w sensie
zależności funkcyjnych, przez
atrybuty zbioru wyjściowego.
Ściśle było na poprzednim
ekranie

Bazy danych - wykład 3
13
Algorytm obliczania domknięcia
1.
Na początku X oznacza zbiór {A
1
,A
2
,…,A
n
}.
2.
Znajdujemy wszystkie zależności funkcyjne
postaci B
1
B
2
…B
m
C, gdzie B
i
należą do X, a C
nie należy. Dołączamy C do X.
3.
Powtarzamy krok 2 tak długo, jak długo do X
nie można dołączyć żadnego nowego atrybutu.
Ponieważ X może się tylko rozszerzać, zaś
zbiór atrybutów jest skończony, po skończonej
ilości kroków nastąpi moment, w którym do X
nie da się niczego dołączyć.
4.
X=cl {A
1
,A
2
,…,A
n
}.

Bazy danych - wykład 3
14
Przykład (najprostszy)
Dane mamy atrybuty A, B, C, D i zbiór zależności
funkcyjnych (zbiór S) następującej postaci: B C, AB
D. Ile wynosi cl({B}) nad podanym zbiorem
zależności funkcyjnych?
Na początku X ={B}.
Na podstawie zależności B C, do zbioru X dołączam
atrybut C. X={B,C}.
W podanym zbiorze zależności funkcyjnych nie ma
żadnej innej zależności, której poprzednik
obejmowałby elementy zbioru X, a więc nie ma
sposobu, aby do X coś jeszcze dołączyć.
Ostatecznie cl({B})={B,C}.

Bazy danych - wykład 3
15
Caveat emptor!
Powyżej przedstawiony algorytm jest poprawny i
intuicyjnie prosty, ale nie jest efektywny – może być
algorytmem kwadratowym (w czasie) w najgorszym
przypadku.
Znacznie rozsądniej jest tak uporządkować
zależności funkcyjne, aby każda była używana
(„odpalana”) dokładnie w tym momencie, w którym
wszystkie atrybuty jej lewej strony znajdą się w
„kandydacie” X.
Dla dużych baz (i tabel) domknięć nie oblicza się
ręcznie, ale komputerowo!

Bazy danych - wykład 3
16
Przykład:
Rozważmy zbiór atrybutów {A, B, C, D, E, F}. Załóżmy, że w
tym zbiorze zachodzą zależności AB C, BC AD,D E, CF
B. Obliczmy cl{A,B}.
X={A,B}. Wszystkie atrybuty zależności AB C są w X, więc
do X dołączamy C. X={A,B,C}.
Lewa strona zależności BC AD jest w X, A jest już w X, więc
do X dołączamy D. X={A,B,C,D}.
Na mocy zależności D E, dołączamy do X atrybut E.
X={A,B,C,D,E}.
Zleżności CF B nie możemy zastosować, ponieważ FX i nie
ma jak F do X dołożyć.
Ostatecznie cl{A,B} = {A,B,C,D,E}.

Bazy danych - wykład 3
17
Bazy relacji
Każdy zbiór zależności funkcyjnych pewnego zbioru
atrybutów, z którego można wyprowadzić wszystkie inne
zależności funkcyjne zachodzące pomiędzy elementami
tego zbioru, nazywam
bazą
relacji. Jeśli żaden podzbiór
bazy nie jest bazą (nie umożliwia wyprowadzenia
wszystkich relacji), bazę tę nazywam
bazą minimalną
.
Przykład: Mam atrybuty A,B,C i zależności A B, A C, B
A, B C, C A, C B. Można teraz wyprowadzić
zależności nietrywialne AB C, AC B, BC A (oraz
zależności trywialne). Bazą minimalną jest zbiór
{A B, B A, B C, C B}
Inną bazą minimalną jest
{A B, B C, C A}

Bazy danych - wykład 3
18
Po co jemy tę
żabę?!

Bazy danych - wykład 3
19
Klucze relacji (tabeli)
Mówimy, że zbiór atrybutów {A
1
,A
2
,…,A
n
}
tworzy
klucz
tabeli, jeśli
1.
Wszystkie pozostałe atrybuty są
funkcyjnie zależne od tych atrybutów, a
zatem
dwie różne
krotki nie mogą być
zgodne dla atrybutów A
1
,A
2
,…,A
n
.
2.
Nie istnieje taki podzbiów właściwy
zbioru {A
1
,A
2
,…,A
n
} , od którego
pozostałe atrybuty są zależne
funkcyjnie.

Bazy danych - wykład 3
20
Nadzbiór klucza nazywa się nadkluczem.
Terminologia alternatywna:
„Nadklucz” nazywa się kluczem.
To, co na poprzednim ekranie było nazwane
„kluczem”, nazywa się „kluczem
minimalnym”.

Bazy danych - wykład 3
21
Zauważmy, że zbiór cl{A
1
,A
2
,…,A
n
} zawiera
wszystkie atrybuty pewnej tabeli R wtedy i
tylko wtedy, gdy elementy A
1
,A
2
,…,A
n
są
nadkluczem R.
Stwierdzenie, czy zbiór {A
1
,A
2
,…,A
n
} stanowi
klucz tabeli
(klucz minimalny w terminologii
alternatywnej),
polega na
1. Sprawdzeniu, czy wszystkie atrybuty R należą
do cl {A
1
,A
2
,…,A
n
}.
2. Sprawdzenie, czy domknięcie zbioru
powstałego przez usunięcie choćby jednego
elementu A
i
nie zawiera wszystkich atrybutów
R.

Bazy danych - wykład 3
22
„Żaba” służy zatem jako formalne
narzędzie do identyfikowania kluczy.
Identyfikacja kluczy jest elementem
niezbędnym przy normalizacji bazy
danych.
Bez formalnego zastosowania
mechanizmu relacji funkcyjnych i
domknięć,
normalizacja
dużych baz jest
praktycznie niemożliwa.

Bazy danych - wykład 3
23
Cel
normalizacji baz danych
–
unikanie anomalii
Rodzaje anomalii
1. Redundancja
2. Anomalie modyfikacji
3. Anomalie usuwania
Te same dane niepotrzebnie
powtarzają się w kilku
krotkach
Wartość tej samej danej
zostanie zmodyfikowana w
jednej krotce, w innej zaś
nie. Która wartość jest
wówczas poprawna?
Utrata części danych, gdy dla pewnego
atrybutu zacznie obowiązywać wartość pusta
(null)
Odwrotność:
anomalie
dołączania
Bazy danych - wykład 3
24
Pierwsza postać normalna:
Tabele zawierają wyłącznie
dane atomowe.
Każda tabela ma klucz.
Zakaz duplikowania wierszy.
Tabela jest zbiorem wierszy.
Bazy danych - wykład 3
25
Nr
zamówienia
Id dostawcy Nazwa
dostawcy
Adres
dostawcy
Id części Nazwa części
ilość
054
Dysk twardy
30
001
010
Seagate
Borsucza 8
055
Sterownik I/O
50
002
020
Toshiba
Wilcza 3
070
Napęd CD
10
054
Dysk twardy
40
003
010
Seagate
Borsucza 8
070
Napęd CD
15
Problem: Jednemu numerowi zamówienia odpowiada
zbiór identyfikatorów części
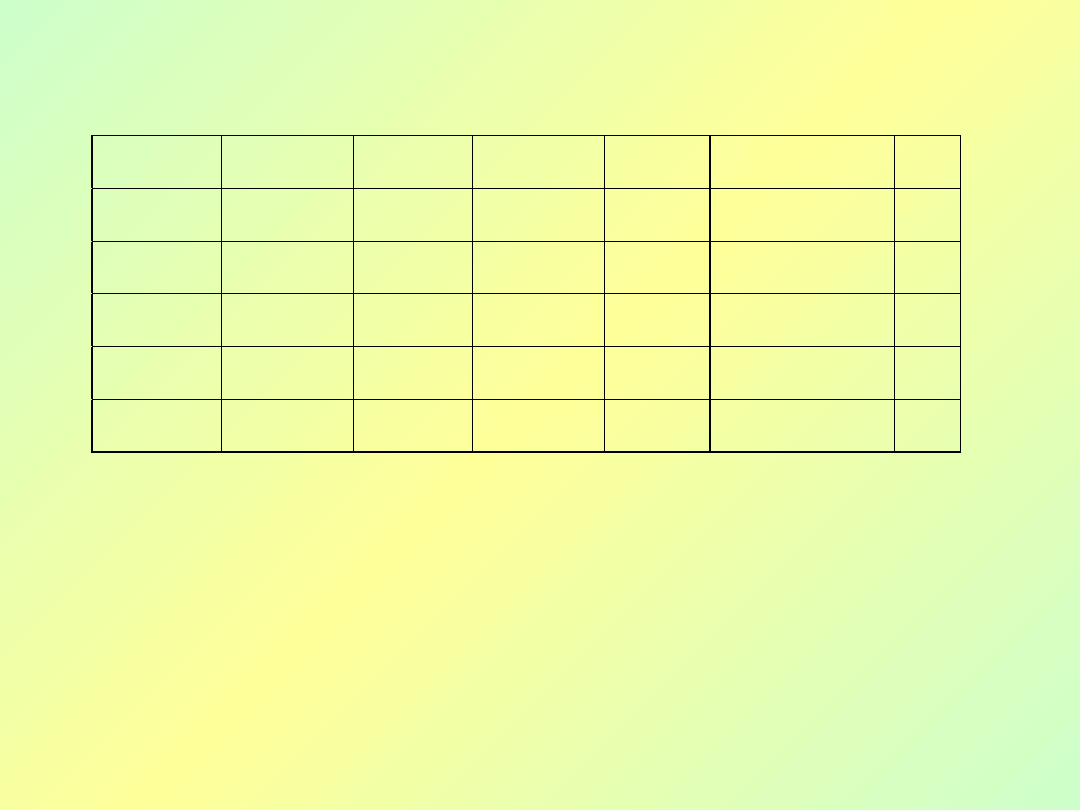
Bazy danych - wykład 3
26
Nr
zamówienia
Id dostawcy Nazwa
dostawcy
Adres
dostawcy
Id części Nazwa części
ilość
001
010
Seagate
Borsucza 8 054
Dysk twardy
30
001
010
Seagate
Borsucza 8 055
Sterownik I/O
50
002
020
Toshiba
Wilcza 3
070
Napęd CD
10
003
010
Seagate
Borsucza 8 054
Dysk twardy
40
003
010
Seagate
Borsucza 8 070
Napęd CD
15
Tabela w 1PN — „podzielone” niektóre wiersze.
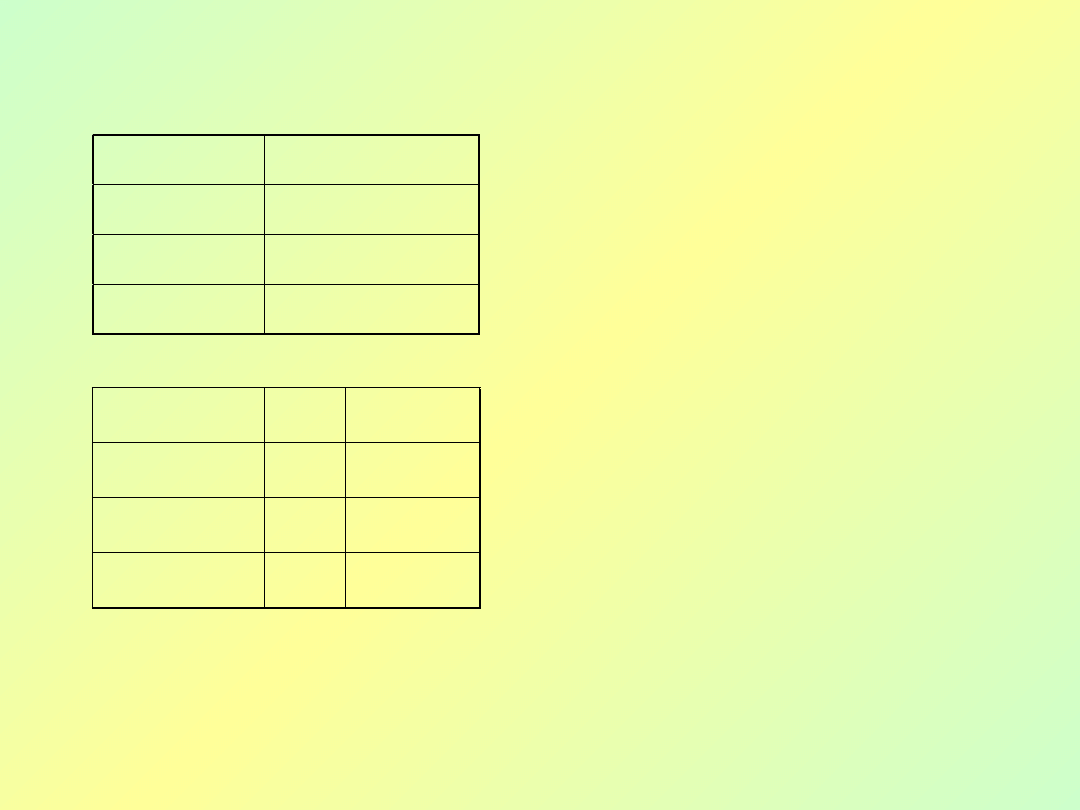
Bazy danych - wykład 3
27
PESEL
Imię Nazwisko
7908195528
Jan Kowalski
80011100921
Ewa Nowak
79092442133
Marta Król
Nie jest w
1PN
PESEL
Imię Nazwisko
7908195528
Jan
Kowalski
80011100921
Ewa
Nowak
79092442133
Marta Król
Jest w 1PN — podzielone
niektóre kolumny

Bazy danych - wykład 3
28
Druga postać normalna:
Tabela jest w 1PN.
Każdy atrybut niekluczowy zależy
funkcyjnie od pełnego klucza.
•Od pełnego klucza, a nie tylko od podzbioru
właściwego klucza.
•Każda tabela, której wszystkie klucze są
jednokolumnowe, jest w 2PN.
Kontynuujemy konsumpcję płazów
Bazy danych - wykład 3
29
Nr
zamówienia
Id dostawcy
Nazwa
dostawcy
Adres
dostawcy
Id części
Nazwa części
ilość
001
010
Seagate
Borsucza 8 054
Dysk twardy
30
001
010
Seagate
Borsucza 8 055
Sterownik I/O
50
002
020
Toshiba
Wilcza 3
070
Napęd CD
10
003
010
Seagate
Borsucza 8 054
Dysk twardy
40
003
010
Seagate
Borsucza 8 070
Napęd CD
15
Nie jest w 2PN: nazwa dostawcy adres, id dostawcy; nazwa części id części
Anomalie:
1.
Redundancja: adres Seagate w czterech (sic!) krotkach.
2.
Anomalia modyfikacji: Jeśli Seagate zmieni siedzibę, czy na pewno
poprawimy to we wszystkich miejscach?
3.
Anomalia usuwania: Jeśli usuniemy zamówienie nr 002, stracimy
informacjęo siedzibie Toshiby.
4.
Anomalia dołączania: Nie da się dołączyć nowej firmy, dopóki nie
złożymy w niej zamówienia.
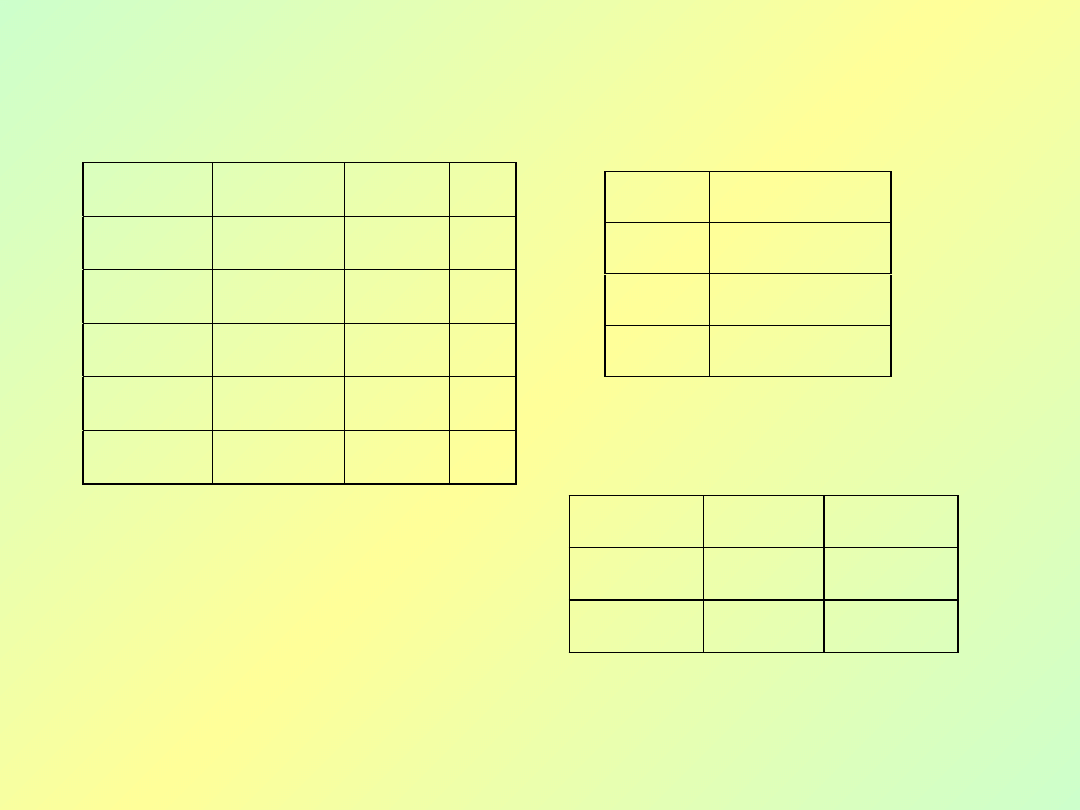
Bazy danych - wykład 3
30
Sprowadzenie do 2PN: podział tabeli
Nr
zamówienia
Id dostawcy Id części ilość
001
010
054
30
001
010
055
50
002
020
070
10
003
010
054
40
003
010
070
15
Id dostawcy Nazwa
dostawcy
Adres
dostawcy
010
Seagate
Borsucza 8
020
Toshiba
Wilcza 3
Id części Nazwa części
054
Dysk twardy
055
Sterownik I/O
070
Napęd CD
Bazy danych - wykład 3
31
Trzecia postać normalna:
Tabela jest w 2PN.
Jeśli A
1
A
2
…A
n
B, to albo {A
1
,A
2
,
…,A
n
} jest nadkluczem, albo B jest
elementem pewnego klucza.
Dotyczy tylko zależności
nietrywialnych!

Bazy danych - wykład 3
32
Trzecia postać normalna jest
postacią najczęściej występującą w
praktyce.
Istnieją specjalne algorytmy i specjalne
narzędzia CASE do
„przeprojektowywania” bazy do 3PN.
W specjalistycznych zastosowaniach (np.
hurtownie danych
) niekiedy korzystnie
jest pozostawić bazę w 2PN lub nawet
1PN.

Bazy danych - wykład 3
33
Często mówi się, że
3PN wyklucza zależności przechodnie
(typu AB, BC, zatem AC). Jeśli jednak C jest elementem
klucza (być może obejmującego jakieś atrybuty A), to dalej
jest 3PN.
Przykład: Tabela z trzema atrybutami i zależnościami
kino miasto
tytuł miasto kino
Kluczem jest {tytuł, miasto}. Innym kluczem jest
{kino, tytuł}. Tabela jest w 3PN: chociaż samo kino nie
jest nadkluczem, miasto jest elementem klucza.
Zwanego
„kluczem
kandydującym”.
Bo każde kino jest w jakimś
mieście.
Bo dystrybutor ogranicza
rozpowszechnianie do
jednego kina w danym
mieście.

Bazy danych - wykład 3
34
Procedura postępowania:
1. Dany jest zbiór atrybutów, które chcemy
reprezentować, i zbiór zależności
funkcyjnych pomiędzy atrybutami.
2. Znajdujemy bazę minimalną (bazy
minimalne) zbioru zależności funkcyjnych.
Eliminujemy symetryczne zależności funkcyjne.
3. Dla (pewnej) bazy minimalnej sumujemy
zależności funkcyjne o takich samych lewych
stronach i dla każdej wysumowanej
zależności tworzymy tabelę z odpowiednią
lewą stroną zależności jako kluczem.

Bazy danych - wykład 3
35
Procedura szukania bazy
minimalnej:
1. Każdy atrybut musi występować z lewej lub z
prawej strony jednej zależności funkcyjnej w
zbiorze.
2. Jeśli jakaś zależność funkcyjna jest włączona
do zbioru, nie wszystkie zależności funkcyjne
potrzebne do jej wyprowadzenia mogą
występować w tym zbiorze.
3. Jeśli jakaś zależność funkcyjna zostaje
wyłączona ze zbioru, zależności funkcyjne
potrzebne do jej wyprowadzenia muszą
zostać doń dołączone.

Bazy danych - wykład 3
36
Jeśli mamy wiele atrybutów i wiele
zależności, normalizacji „ręcznie”
przeprowadzić się nie da.
Powyższa procedura jest dostosowana
do projektowania „od zera”.
Jeśli mamy wstępny projekt w postaci
diagramu E/R, projektowanie jest
znacznie prostsze.

Bazy danych - wykład 3
37
Przykład
Firma transportowa posiada bazę danych, w której zachodzą
następujące zależności funkcyjne:
NrRejestracyjny Data Kierowca
NrRejestracyjny Data Odbiorca
Odbiorca Odległość
Kierowca Stawka
Odległość Stawka Koszt
Odbiorca Kierowca Koszt
NrRejestracyjny Data Koszt
Bazy danych - wykład 3
38
Tabele:
(NrRejestracyjny, Data, Kierowca, Odbiorca)
(Kierowca, Stawka)
(Odbiorca, Odległość)
(Odległość, Stawka, Koszt)

Bazy danych - wykład 3
39
Postać normalna Boyce’a-
Coda
(BCNF, PNBC)
Tabela jest w BCNF wtedy i tylko
wtedy, gdy dla każdej zależności
nietrywialnej A
1
A
2
…A
n
B, zbiór
{A
1
,A
2
,…,A
n
} jest nadkluczem

Bazy danych - wykład 3
40
Używa się także wyższych postaci
normalnych (czwartej, piątej i szóstej),
ale nie będą one omawiane na tym
wykładzie.
Wyższe postaci normalne
są
potrzebne, ale do bardzo wielu
zastosowań praktycznych postaci
trzecia i BCNF wystarczają.
Niekiedy wygodniej jest używać niższych postaci
normalnych, drugiej i pierwszej.

Bazy danych - wykład 3
41
Bezstratne złączenia
Normalizacja ma na celu unikanie
redundancji i innych anomalii. Trzeba
jednak być ostrożnym: Powstające tabele
muszą zapewniać
bezstratność złączeń
–
tak, aby informacja nie została utracona.

Bazy danych - wykład 3
42
Dekompozycję tabeli R na tabele R
1
, R
2
, …,
R
n
nazywamy
dekompozycją bezstratnego
złączenia
(ze względu na pewien zbiór
relacji funkcyjnych), jeśli naturalne
złączenie R
1
, R
2
, …, R
n
jest równe tabeli R.
Formalną definicję
złączenia poznamy
później

Bazy danych - wykład 3
43
Dekompozycja tabeli R na dwie tabele
R
1
, R
2
jest dekompozycją bezstratnego
złączenia, jeśli spełniony jest jeden z
dwu warunków:
(R
1
R
2
) (R
1
-R
2
)
lub
(R
1
R
2
) (R
2
-R
1
)
Innymi słowy,
wspólna część
atrybutów R
1
, R
2
musi zawierać klucz
kandydujący R
1
lub R
2
Bazy danych - wykład 3
44
Przykład negatywny
Dana jest tabela
Zapisy(NrStudenta,NrKursu,DataZapisu,Sala,Prowadzący)
Przykładowa instancja może wyglądać tak:
NrStude
nta
NrKurs
u
DataZapi
su
Sala Prowadzą
cy
830057
K202
1.10.05
A1
Góra
830057
K203
1.10.05
A1
Oramus
820159
K202
1.02.06
A1
Góra
825678
K204
1.10.05
C1
Oramus
826789
K205
12.02.06
C2
Bogacz
Bazy danych - wykład 3
45
Rozbijamy tabelę Zapisy na dwie tabele:
Z1(NrStudenta,NrKursu,DataZapisu)
Z2(DataZapisu,Sala,Prowadzący)
NrStuden
ta
NrKurs
u
DataZapis
u
830057
K202
1.10.05
830057
K203
1.10.05
820159
K202
1.02.06
825678
K204
1.10.05
826789
K205
12.02.06
DataZapis
u
Sal
a
Prowadząc
y
1.10.05
A1
Góra
1.10.05
A1
Oramus
1.02.06
A1
Góra
1.10.05
C1
Oramus
12.02.06
C2
Bogacz
To jest dość kiepski podział: DataZapisu nie
jest kluczem kandydującym
Instancje tych tabel wyglądają tak:

Bazy danych - wykład 3
46
Chcemy się dowiedzieć jakich studentów naucza Góra.
W tym celu robimy złączenie Z1 Z2
Wspólną kolumną obu tabel jest DataZapisu
Dostajemy
NrStuden
ta
NrKur
su
DataZapi
su
Sal
a
Prowadzący
830057
K202
1.10.05
A1
Góra
830057
K203
1.10.05
A1
Góra
825678
K204
1.10.05
C1
Góra
etc
Zaznaczone krotki są fałszywe – nie występują w pierwotnej
tabeli. Zaproponowana dekompozycja spowodowała, że po
wykonaniu złączenia tracimy informację o tym, kto kogo
naucza.

Bazy danych - wykład 3
47
Uwaga!
Przeprowadzając normalizację,
staramy się
zachować
trzy
warunki:
1. BCNF
2. Zachowanie zależności funkcyjnych
3. Bezstratne złączenia
Czy zawsze da się to zrobić?

Bazy danych - wykład 3
48
Rozważmy tabelę T(A, B, C) z
następującymi relacjami funkcyjnymi:
C A
AB C
Tabela ta nie jest w postaci BCNF, gdyż C nie
jest nadkluczem.
Na przykład:
A – nazwa banku
B – nazwisko klienta
C – nazwisko bankiera

Bazy danych - wykład 3
49
Próbujemy następującej dekompozycji:
T
1
(A,C)
T
2
(B,C)
Ta dekompozycja nie zachowuje relacji
AB C
i
nie jest
dekompozycją bezstratnego
złączenia
W naszym przykładzie byłoby to
T
1
(NazwaBanku,NazwiskoBankiera)
T
2
(NazwiskoKlienta,NazwiskoBankiera)

Bazy danych - wykład 3
50
Jak widać, nie zawsze udaje się przeprowadzić
normalizację do postaci BCNF tak, aby zachować
komplet relacji funkcyjnych i aby dekompozycja
pozwalała na bezstratne złączenia.
W takiej sytuacji rezygnujemy z postaci
BCNF, zadowalając się jakąś „niższą”
postacią normalną i dopuszczając pewne
anomalie.
Zachowanie kompletu zależności
funkcyjnych oraz bezstratność złączeń
muszą mieć priorytet!
Document Outline
- Slide 1
- Slide 2
- Slide 3
- Slide 4
- Slide 5
- Slide 6
- Slide 7
- Slide 8
- Slide 9
- Slide 10
- Slide 11
- Slide 12
- Slide 13
- Slide 14
- Slide 15
- Slide 16
- Slide 17
- Slide 18
- Slide 19
- Slide 20
- Slide 21
- Slide 22
- Slide 23
- Slide 24
- Slide 25
- Slide 26
- Slide 27
- Slide 28
- Slide 29
- Slide 30
- Slide 31
- Slide 32
- Slide 33
- Slide 34
- Slide 35
- Slide 36
- Slide 37
- Slide 38
- Slide 39
- Slide 40
- Slide 41
- Slide 42
- Slide 43
- Slide 44
- Slide 45
- Slide 46
- Slide 47
- Slide 48
- Slide 49
- Slide 50
Wyszukiwarka
Podobne podstrony:
ssciaga, Studia PŚK informatyka, Semestr 4, Bazy Danych 2, Bazy Danych Zaliczenie Wykladu, Bazy Dany
Podstawy Informatyki Wykład XIX Bazy danych
13 Bazy danych obiektowość wykładid 14617
Bazy Danych, STUDIA, SEMESTR III, Bazy Danych, Wykład
2 Bazy danych projektowanie wykład
bazy danych wyklad1 id 81713 Nieznany (2)
WYKLAD I - wprowadzenie modele baz danych, Uczelnia, sem V, bazy danych, wyklad Rudnik
BAZY DANYCH Streszczenie z wykładów (2)
3 Bazy danych SQL cz 1 wykład
więcej podobnych podstron