
Bazy Danych
Bazą danych (ang. database) będziemy nazywać trwały, zamknięty i dobrze zorganizowany magazyn
danych
Tak więc baza danych charakteryzuje się trzema ważnymi cechami: trwałością, ograniczonością
(zamkniętością) i dobrą organizacją (co dla kogo jest dobre, jest rzeczą dyskusyjną - postaramy się jednak
sprecyzować, co dla nas będzie oznaczać dobra organizacja magazynu).
Trwałość bazy danych
Trwałość oznacza, że dane zapisane w bazie danych są w niej zapisane w sposób nieulotny. Nie
można więc zbudować bazy danych w pamięci operacyjnej komputera, gdyż po dołączeniu zasilania dane
w niej zapisane są tracone. Na trwały magazyn danych dobrze natomiast nadaje się kamień (zapisy
dokonane w kamieniu przetrwały tysiące lat), papier (ten nie jest już tak trwały) czy dyski magnetyczne lub
inne nośniki magnetooptyczne. Trwałość danych zapisanych w bazie danych jest bardzo ważnym
postulatem. Wszystkie współczesne systemy baz danych muszą go spełniać.
Ograniczoność bazy danych
Ograniczoność oznacza, że w bazie danych nie można zapisać zupełnie dowolnych danych. Baza
oparta jest na pewnym modelu rzeczywistości (modelu danych). Modele te mogą być bardzo różne i
niektóre z nich pokrótce omówimy w dalszej części. Model danych definiowany jest przez projektanta bazy
danych. Określa on, w jaki sposób dane występujące w rzeczywistości (np. dane adresowe studentów) będą
reprezentowane w bazie. Przyjęty model ogranicza więc (determinuje) dane, które możemy trwale
przechowywać w bazie.
Dobra organizacja bazy danych
Aby zbiór danych można było uważać za bazę danych, musi on być odpowiednio zorganizowany.
Organizacja ta musi zapewniać możliwość nie tylko sprawnego umieszczania danych w bazie, ale również
możliwość odszukiwania i odczytywania danych już w niej zapisanych. Jeśli więc znalezienie danych
zapisanych w magazynie wymaga od nas miesiąca przeglądania zapisanych danych, to taki magazyn nie
może być uznany za bazę danych.
Baza danych to oczywiście każdy magazyn danych spełniający powyższe warunki. Ludzkość
dostrzegła potrzebę tworzenia baz danych już bardzo dawno. J. Diamond w swojej książce "Guns, Germs
and Steel: The Fastest of Human Societies" twierdzi, że bazy danych istniały od czasów, kiedy cywilizacja
umeryjska i egipska zaczęły korzystać z pisma klinowego i hieroglifów do zapisu informacji w formie
trwałej i możliwej do odczytania na każde żądanie. Stosowane w tamtych czasach nośniki danych były
mało wygodne. Nasza cywilizacja przez całe wieki budowała swoje bazy danych wykorzystując jako
trwały nośnik danych papier. Bazy "papierowe" mają jednak bardzo wiele wad takich jak duże rozmiary
magazynu, trudności w wyszukiwaniu danych, brak wielodostępu itd. Do budowy i obsługi baz danych
nadają się natomiast znakomicie maszyny cyfrowe. Dzisiaj mówiąc baza danych mamy w zasadzie na
myśli komputerowe bazy danych. W dalszej części naszych wykładów pod pojęciem bazy danych
będziemy więc rozumieli bazę zorganizowaną i zarządzaną z wykorzystaniem komputera.
Gdzie i w jakim celu stosuje się bazy danych
Bazy danych spotykamy właściwie na każdym kroku. Każdy na pewno korzystał z bazy
papierowej takiej jak encyklopedia, książka telefoniczna czy kartoteka w bibliotece. Bazy danych są też

powszechne w świecie informatyki. Większość systemów informatycznych współpracuje z bazami danych,
gdyż muszą one przechowywać dane. Są aplikacje, których głównym zadaniem jest przechowywanie,
zarządzanie i udostępnianie danych. Potocznie są one nazywane bazami danych lub, dla podkreślenia faktu
istnienia odpowiednich dodatków ułatwiających pracę, aplikacjami bazodanowymi. Należy jednak mieć
świadomość, że znakomita większość aplikacji, to aplikacje które współpracują z bazami danych mniej lub
bardziej skomplikowanymi
Najważniejsze cechy bazy danych
Zastanowimy się teraz nad najważniejszymi cechami bazy danych, które powinna ona spełniać,
aby mogła sprostać stawianym przed nią dzisiaj wymaganiom.
Zgodność z rzeczywistością
Postulat zgodności danych zapisanych w bazie z rzeczywistością jest jednym z ważniejszych
postulatów stawianych bazom danych. Na przykład, jeśli baza opisuje dane osobowe pracowników, takie
jak ich imię, nazwisko, telefon, adres zamieszkania, stanowisko itd., to postulat zgodności
z rzeczywistością oznacza, że w chwili gdy pracownik zmienia stanowisko pracy (a tym samym również
telefon), to również w bazie danych dokonywane są odpowiednie zmiany danych.
Postulat zgodności z rzeczywistością oznacza więc, że dane zgromadzone w bazie są danymi
prawdziwymi, odpowiadającymi faktycznemu stanowi świata, którego dotyczą. Na pewno każdy z nas
spotkał się z bazą, która nie spełniała tego postulatu i przechowywała dane dawne już nie aktualne.
Z takimi bazami często spotykam się dzisiaj zaglądając do oferty sklepów i firm internetowych. Niezwykle
rzadko zdarza mi się, aby dane podawane w bazach udostępnianych przez te podmioty były prawdziwe.
Najczęściej nie zgadzają się ani ceny towarów ani ich dostępność w magazynie.
Powoduje to nie tylko stratę mojego czasu (bo i tak trzeba zadzwonić do "żywego człowieka"), ale również
utratę zaufania do firmy, która udostępnia bazę z danymi niezgodnymi z rzeczywistością.
Spełnienie postulatu zgodności z rzeczywistością nie jest łatwe. Trudności nie leżą w zasadzie po stronie
technicznej, ale po stronie ludzkiej. Nie można bowiem (jak na razie) całkowicie zautomatyzować
procesów biznesowych i w każdym z nich niezbędnym ogniwem jest człowiek. Aby zapewnić zgodność
danych przechowywanych w bazie z danymi rzeczywistymi, trzeba opracować i stosować w firmie
odpowiednie procedury.
Na przykład w wypadku zmiany stanowiska przez pracownika, dział kadr mógłby (obowiązkowo)
przesyłać odpowiednie zgłoszenie do operatora bazy (albo wprowadzać samodzielnie) z informacją o
zaistniałych zmianach. Sposób przesyłania takiego zgłoszenia, jego zawartość, określenie
odpowiedzialności itd. powinien być właśnie określony w takiej procedurze.
Problem aktualności danych w bazie jest jednym z trudniejszych problemów do rozwiązania, szczególnie
kiedy w przedsiębiorstwie działa wiele różnych systemów i baz danych. Dlatego też obserwuje się dzisiaj
silną tendencję do integracji różnych systemów w jeden spójny system, który potrafiłby automatycznie
wymieniać dane między swymi modułami (częściami). Rozwiązania tego typu noszą nazwę rozwiązań EAI
(ang. Enterprise Architecture Integration) i są oferowane i rozwijane przez wiodących dostawców
systemów bazodanowych.
Ilustracja fragmentu rzeczywistości
Projektując bazę danych należy pamiętać, że stanowi ona pewien model otaczającego nas świata.
Aby baza spełniała swoje zadania, musi być ilustracją kompletnego i dobrze zdefiniowanego fragmentu
rzeczywistości. Można oczywiście zbudować działającą bazę danych, która będzie pozwalała na poprawne

wprowadzanie, usuwanie i modyfikację danych, ale która nie będzie związana ze światem rzeczywistym.
Przydatność takiej bazy stoi oczywiście pod znakiem zapytania.
Aby spełnić ten postulat, należy prawidłowo zdefiniować dziedzinę problemową, która będzie modelowana
za pomocą bazy oraz wykonać odpowiadający tej rzeczywistość model logiczny bazy. Określaniem
wymagań i budową modelu logicznego bazy danych będziemy się zajmować w module 2
Kontrola replikacji danych
Replikacja danych oznacza reprezentowanie w bazie tego samego faktu w wielu jej miejscach lub
w różnych formach. Na przykład baza danych zawierająca informacje o dostawach towarów może
przechowywać nazwę i adres dostawcy w specjalnej liście dostawców współpracujących z naszą firmą oraz
te same dane w wykazie zamówień. Taka sytuacja jest zazwyczaj niepożądana.
Może ona prowadzić:
• do niepotrzebnego zwiększenia miejsca zajmowanego przez bazę,
• do niepotrzebnego angażowania mocy obliczeniowych w przeprowadzanie operacji w wielu
miejscach (np. zmiana adresu dostawcy będzie musiała być wykonana i na liście dostawcy i przy
każdym zamówieniu),
• do powstania błędów i niezgodności danych gromadzonych w bazie z danymi rzeczywistymi (np.
zapomnimy o zmianie adresu dostawcy przy zamówieniach z lipca).
Więcej miejsca temu problemowi oraz sposobowi radzenia sobie z nim poświęcimy w module 2
poświęconym normalizacji bazy danych.
Czasem jednak zachodzi potrzeba replikacji danych. Może ona wynikać ze względów wydajnościowych
lub ze względów bezpieczeństwa. Trzeba jednak zawsze pamiętać, że jeśli decydujemy się na zastosowanie
(dopuszczenie) replikacji, to zawsze należy poświęcić jej szczególną uwagę, aby pozostawała pod kontrolą.
Spójny model danych
Baza danych powinna być zbudowana na podstawie spójnego modelu. Spójny model danych
oznacza, że fragment rzeczywistości, którego dotyczy baza został zamodelowany w jednym z możliwych
modeli oraz że dane i pojęcia (np. pojęcie: faktura) reprezentowane w bazie będą ze sobą połączone
tworząc jedną, spójną logicznie całość.
Spójny model należy zapewnić na etapie projektowania logicznego bazy, a jego wyegzekwowanie w czasie
eksploatacji bazy jest możliwe dzięki narzuceniu na bazę odpowiednich warunków i więzów (np.
związków, o których więcej w module 2
Współbieżny dostęp do danych
Można sobie oczywiście wyobrazić bazę (a nawet znaleźć takie działające bazy), która będzie
umożliwiać dostęp w danej chwili tylko jednemu użytkownikowi. Taka cecha nie powinna nikogo z nas
dziwić, gdyż wiele baz papierowych, z których korzystamy działa w ten właśnie sposób.
Nie jest to jednak wygodne, w szczególności jeśli baza ma służyć wielu użytkownikom. Problem ten
zauważono już dawno i radzono sobie z nim powielając zbiory danych. Na przykład książka telefoniczna
jest drukowana w wielu tysiącach egzemplarzy, dzięki czemu z danych w niej zawartych może
jednocześnie korzystać wielu użytkowników. Nikogo jednak nie trzeba przekonywać, jak wiele wad ma to
rozwiązanie.
Systemy komputerowe pozwalają na dostęp do danych wielu użytkownikom jednocześnie. Oczywiście
udostępnienie danych wielu osobom na raz stwarza dodatkowe problemy związane z zarządzaniem
dostępem do tych danych i wymaga odpowiedniego zaprojektowania i organizacji bazy danych.
Bezpieczeństwo danych
Bazy danych są dzisiaj obecne w bardzo wielu miejscach i instytucjach, wspomagają nasze życie
codzienne i biorą udział w licznych procesach biznesowych. Są w nich gromadzone informacje finansowe,
księgowe, dane osobowe, transakcje bankowe itp. Z oczywistych więc powodów wymagają one ochrony.
Dobra baza danych musi zapewniać odpowiednie mechanizmy identyfikacji, uwierzytelnienia, autoryzacji,
poufności, integralności i dostępności.
Więcej na temat bezpieczeństwa systemów bazodanowych znajdziesz w module 11.
Systemy Zarządzania Bazami Danych
Rodzaje, klasyfikacja i przykłady SZBD
Sprostanie wymaganiom stawianym dzisiaj bazom danych nie jest łatwe. Dlatego budowane są
złożone systemy zawierające zbiór gotowych narzędzi zapewniających odpowiedni dostęp, manipulację i
aktualizację do danych gromadzonych w systemach komputerowych. Narzędzia te to Systemy
Zarządzania Bazą Danych - w skrócie SZBD (ang. Database Management Systems - DBMS).
Do najważniejszych cech charakteryzujących SZBD możemy zaliczyć:
• operowanie na dużych i bardzo dużych zbiorach danych,
• zarządzanie złożonymi strukturami,
• działanie w długim cyklu życia.
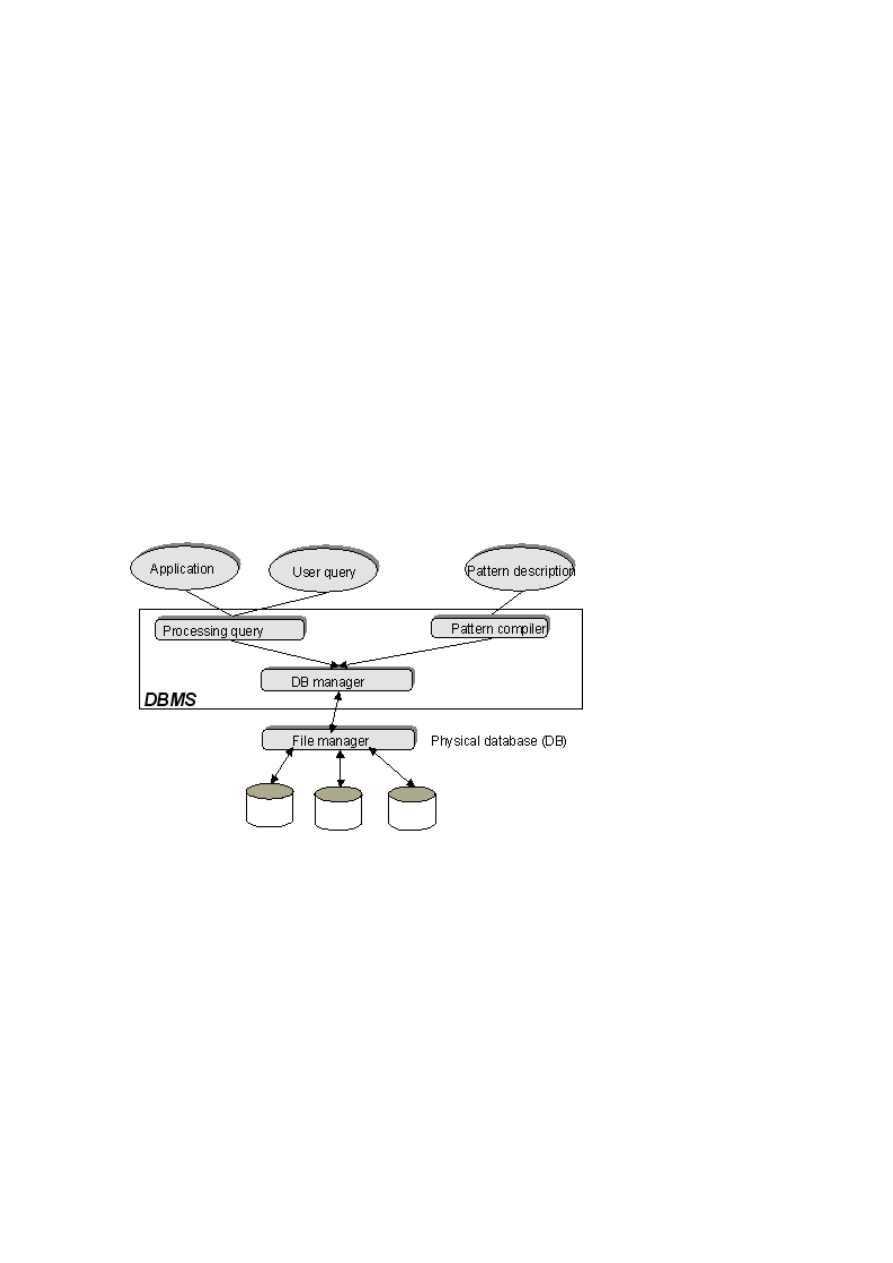
Schemat SZBD wraz z otaczającym go środowiskiem pokazuje poniższy rysunek.
Rys 1.1 System Zarządzania Bazami Danych
SZBD składa się z:
• managera bazy danych (ang. DB manager) - jego rola polega na zarządzaniu obiektami bazy
danych,
• procesora zapytań (ang. processing query) - jego rola polega na przetwarzaniu zapytań (poleceń)
kierowanych do bazy danych,
• kompilatora definicji schematu (ang. pattern compiler) - jego rola polega na przetwarzaniu
definicji obiektów znajdujących się w bazie na postać zrozumiałą dla managera bazy.
Jak widać na rys. 1.1, SZBD komunikuje się jednej strony z managerem plików (ang. file manager), a z
drugiej z warstwą wyższego poziomu. Manager plików jest odpowiedzialny za obsługę fizycznych
nośników danych, zna i rozumie sposób organizacji tych nośników (systemu plików).
W warstwie wyższego poziomu mogą natomiast znajdować się aplikacje użytkownika (ang. application),
zapytania formułowane przez użytkownika (ang. user query), narzędzia do definiowania schematu bazy
danych (ang. pattern description) itp.

Na rynku dostępnych jest wiele Systemów Zarządzania Bazami Danych dostarczanych przez różnych
producentów. Do najważniejszych należą:
Oracle,
MS SQL Server,
DB2,
Sybase,
Informix,
Adabase,
ObjectStore,
MS Access
oraz wiele innych.
Kryteria doboru SZBD
Wybór odpowiedniego systemu SZBD nie jest łatwy. Przed podjęciem decyzji warto jest rozważyć
wiele aspektów związanych zarówno z tym co baza danych ma robić, jak i innymi uwarunkowaniami po
stronie dostawcy systemu i jego użytkownika.
Do najważniejszych kryteriów doboru SZBD należą:
• Wydajność (ang. performance)
Wydajność określa, jak szybko system będzie reagował na wydawane mu polecenia, ile jednocześnie
będzie potrafił obsłużyć zleceń czy użytkowników.
• Skalowalność (ang. scalability)
Skalowalność określa, jak zmieni się działanie systemu (jego wydajność) jeśli wzrośnie liczba
użytkowników lub danych. Cecha ta określa również możliwość adaptacji systemu do nowych warunków
obciążenia i możliwość jego rozbudowy w celu sprostania nowym, większym obciążeniom.
• Funkcjonalność (ang. functionality)
Funkcjonalność określa, jakie funkcje są dostępne w systemie. Warto zwrócić uwagę zarówno na funkcje
wykorzystywane przez użytkownika, jak i administratora czy projektanta takiego systemu. Najczęściej brak
odpowiednich funkcji - szczególnie potrzebnych projektantom i administratorom pociąga za sobą
konieczność dokupienia dodatkowych narzędzi i zwiększa koszty systemu.
• Zgodność ze standardami
Zgodność ze standardami oznacza spełnienie przez system pewnych zasad i reguł uznanych za
powszechne, czyli standardów (np. standard języka, standard protokołu, itp.). Spełnienie powszechnie
stosowanych standardów uniezależnia nas od dostawcy systemu i pozwala na dokładanie do niego innych
elementów proponowanych przez różnych dostawców (oczywiście jeśli są godne ze standardem).
• Łatwość użycia (ang. usability)
Łatwość użycia jest ważną cechą systemu. Zdarzają się systemy o bardzo dobrych parametrach
wydajnościowych lub dużej niezawodności, które jednak są tak trudne w obsłudze, że użytkownicy z nich
rezygnują. Ocena tej cechy zależy od użytkownika systemu, jego przygotowania i doświadczenia. Jest więc
cechą subiektywną i ten sam system przez różnych użytkowników może być zakwalifikowany jako łatwy
lub trudny w użyciu.
• Niezawodność (ang. reliability)
Niezawodność oznacza, jak często system przestaje działać. Oczywiście, im większa niezawodność
systemu, tym większe są jego koszty wytworzenia. Trzeba więc wyważyć odpowiednią proporcję między
niezawodnością systemu a potrzebami użytkownika. Choć każdy chciałby, aby jego system działał bez
błędnie (był niezawodny) w jak największym stopniu, to jednak często jesteśmy gotowi zaakceptować
przestój systemu trwający godzinę w zamian za przystępną cenę.
• Wspomaganie (ang. support)
Wspomaganie oznacza zapewnienie odpowiedniej pomocy przez dostawcę systemu. Z całą pewnością jest
to bardzo ważna cecha systemu. Z pewnością warto zapłacić wyższą cenę za produkt, którego producent
zapewnia dobry i stabilny serwis. Nie ma przecież systemów niezawodnych w stu procentach ani
systemów, które nie kryją tajemnic o sposobie ich użytkowania.
• Środowisko (ang. environment)
Środowisko określa, na jakim sprzęcie czy systemie operacyjnym będzie działać nasz system.
• Cena (ang. price)
Cena oznacza nie tylko koszt zakupu systemu, ale również wszystkie pozostałe koszty związane z
wdrożeniem tego systemu oraz przewidywanymi kosztami jego eksploatacji. Koszt zakupu jest często tylko
elementem składowym ogólnej ceny systemu.
Użytkownicy baz danych i ich rola w systemie
Wśród najważniejszych grup użytkowników systemów SZBD możemy wyróżnić następujące grupy:
Administrator systemu (ang. system administrator)
Zadaniem administratora systemu jest nadzór nad całym systemem. To on definiuje bazy danych w
systemie, zakłada użytkowników o charakterze globalnym itp.
Administrator bazy danych (ang. database administrator)
Administrator bazy danych administruje jedynie bazą, którą ma pod swoją opieką. Ma on uprawnienia do
zakładania i administrowania obiektami bazy ale tylko w obrębie danej bazy danych.
Programista aplikacji (ang. application programmer)
Rolą programisty jest pisanie kodu, który będzie wspomagał użytkowanie bazy (np. procedur
składowanych).
Operator
Operator czuwa nad codzienną eksploatacją bazy. Czuwa nad wykonaniem kopii bezpieczeństwa i
wykonuje inne proste, codzienne czynności admnistracyjne.
Użytkownik (ang. user)
Użytkownik to ktoś wykonujący czynności nie wchodzące w zakres obowiązków pozostałych grup.
Modele baz danych
Modele struktury logicznej bazy danych mogą być bardzo różne. Modele te starają się
odzwierciedlić rzeczywistość, której baza dotyczy oraz mają zasadniczy wpływ na implementacje i
działanie bazy. Dzisiaj najpopularniejszym modelem stosowanym w SZBD jest model relacyjny. Obok
niego funkcjonują też inne modele - starszy model hierarchiczny i zyskujący sobie powoli popularność
model obiektowy
Model hierarchiczny
Model hierarchiczny przypomina odwrócone drzewo. Jeden z elementów pełni role korzenia, a
pozostałe tworzą gałęzie i liście. W modelu tym występują związki między obiektami zwane związkami
"ojciec-syn".
Związki takie charakteryzują się tym, że obiekt nadrzędny (ojciec) może pozostawać w związku z wieloma
innymi obiektami podrzędnymi (synowie), natomiast tylko z jednym obiektem nadrzędnym w stosunku do
niego (jego ojcem).
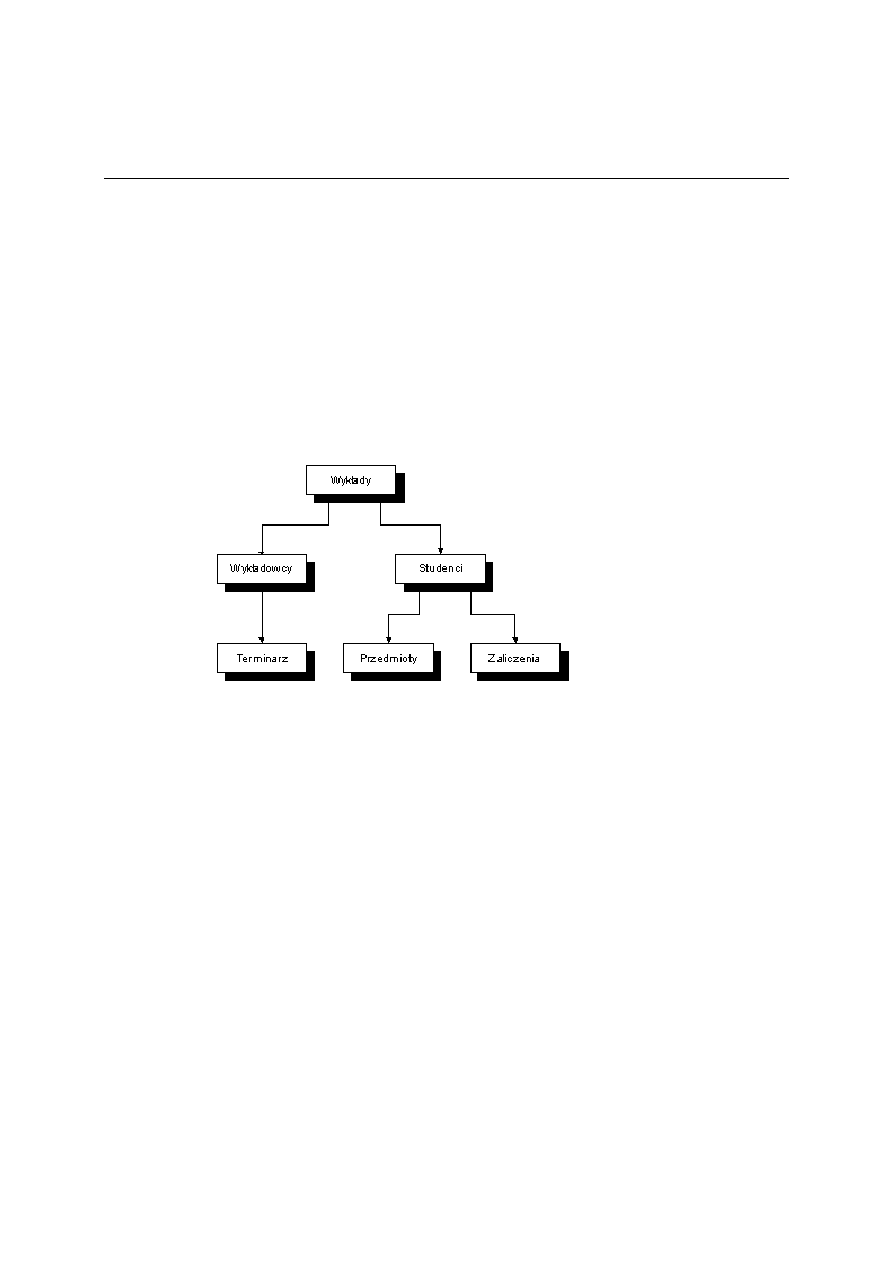
Rys. 1.2 Model hierarchiczny
Na rys. 1.2 przedstawiono przykład modelu hierarchicznego dla bazy przechowującej informacje o
wykładach, wykładowcach oraz studentach uczęszczających na te wykłady.
Model hierarchiczny ma jednak wiele wad. Do najważniejszych należą:
• niemożność zapisania w bazie danych, które nie mają ojca (np. wykładowcy, który w danym roku
nie prowadzi wykładów),
• nadmiarowość danych (np. dane o przedmiocie są wpisane w bazie dwa razy - w wykładach i
przedmiotach),
• brak możliwości obsługi bardziej złożonych związków między obiektami (np. związków "wiele do
wiele").
Zaletą tego modelu jest łatwość (a co za tym idzie szybkość) dojścia do szukanych danych (idziemy od
korzenia wzdłuż gałęzi aż do celu), ale pod warunkiem, że znamy strukturę tego modelu.
Model hierarchiczny stosowany jest dziś w systemach plików (struktura katalogów ma strukturę
drzewiastą) oraz w wielu popularnych aplikacjach (np. MS Outlook, Lotus Notes).
Model relacyjny
W celu wyeliminowania wad modelu hierarchicznego opracowano na początku lat
siedemdziesiątych nowy model zwany modelem relacyjnym. Podstawy teoretyczne dla modelu relacyjnego
opracował dr E. Codd pracując w firmie IBM i opublikował w roku 1970 w książce pod tytułem "Relacyjny
model logiczny dla dużych banków danych". Model ten oparty jest na silnych podstawach matematycznych
głownie teorii mnogości.
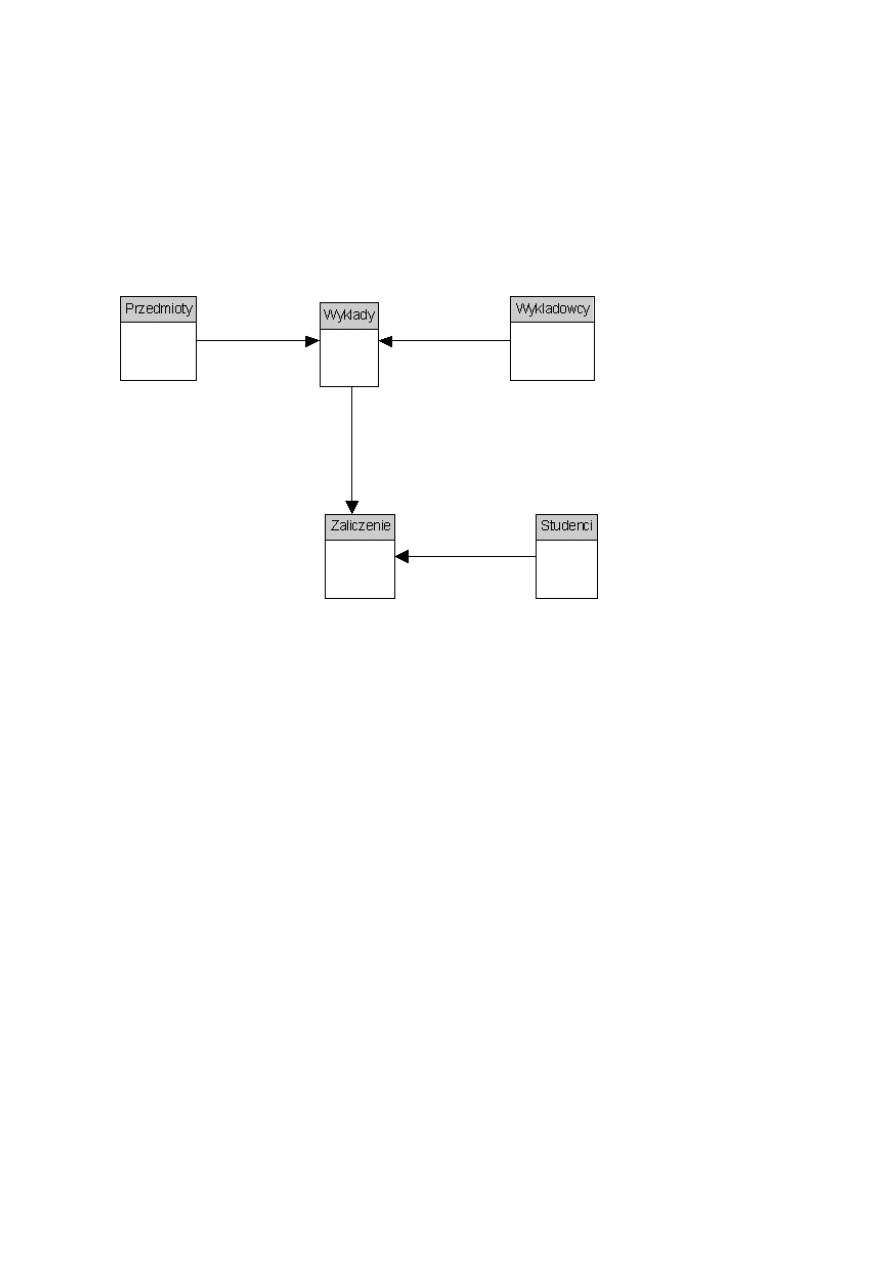
Idea modelu relacyjnego bazuje na pojęciu relacji - czyli tabeli. Wszystkie dane w tym modelu są
przechowywane w tabelach (relacjach). Tabele te mogą być ze sobą powiązane tak zwanymi związkami.
Rysunek rys. 1.3 przedstawia przykład modelu relacyjnego. Zasadniczą wadą modeli relacyjnych jest ich
znaczna rozbieżność w stosunku do świata rzeczywistego, który mają modelować. Pozwalają za to na
efektywne przechowywanie danych, obniżają redundancję danych (powtarzalność) i pozwalają na łatwe
wyszukiwanie danych.
Rys. 1.3 Model relacyjny
Bazy danych oparte na modelu relacyjnym są obecnie najbardziej rozpowszechnionym rodzajem baz
danych.
Model obiektowy
Obecnie technologią, która pozwala najlepiej odwzorowywać świat rzeczywisty w projektowaniu
oprogramowania, jest technologia obiektowa. O jej sukcesie świadczy popularność takich języków
programowania jak C++ czy Java. Technologia obiektowa jest obecnie dominującym narzędziem przy
tworzeniu dużych i złożonych projektów.
Obiektowość nie ogranicza się jedynie do nowego sposobu organizacji kodu w językach programowania.
Jest ona pewną ideologią w informatyce, której cechą jest chęć dopasowania modeli pojęciowych
stosowanych w informatyce do modelu świata postrzeganego przez człowieka. Jest to kolejny krok
w ewolucji kontaktów człowiek-maszyna (a ściślej programista-komputer).
Śledząc, nawet pobieżnie, rozwój języków programowania widzimy, że ewolucja ta przebiega ciągle w
stronę ułatwiania życia człowiekowi. Wynika to z rozwoju technologii i związanego z tym zwiększania
złożoności modelowanych procesów. Bez wprowadzania nowych metod, wyższych poziomów abstrakcji w
projektowaniu i programowaniu , człowiek szybko staje się najsłabszym ogniwem w procesie tworzenia
oprogramowania.
Większość producentów systemów relacyjnych baz danych wyposaża obecnie swoje produkty w
rozszerzenia obiektowe. Są one implementowane w różnym stopniu i zakresie. Obejmują takie funkcje jak
obsługa abstrakcyjnych typów danych, klas, przechowywanie obiektów, wyzwalacze, procedury
składowane. Podstawą takiego systemu jest najczęściej ten sam 'silniczek' jaki był stosowany w wersji
relacyjnej - dobry i sprawdzony, ale pisany z myślą o modelu relacyjnym a nie obiektowym. Systemy tego
typu nie spełniają w pełni paradygmatu obiektowości, mogą być traktowane raczej jako rozszerzenie
systemów relacyjnych o pewne atrakcyjne cechy umożliwiające efektywne tworzenie aplikacji, a nie jako
pełnowartościowe systemy obiektowe.

Systemy w pełni obiektowe zrywają natomiast z założeniami modelu relacyjnego i opierają się w całości na
technologii obiektowej. Zapewniają tradycyjną funkcjonalność bazy danych (trwałość, integralność
danych, obsługę wielodostępu, odtwarzanie danych) przy zastosowaniu obiektowego modelu danych.
Wiele tego typu systemów obsługuje również bardziej zaawansowane funkcje jak np. obsługa
rozproszonych baz danych.
Systemy obiektowych baz danych są najlepiej dopasowane do potrzeb zorientowanych obiektowo aplikacji
przetwarzających duże ilości danych oraz obsługujących wielu użytkowników. Istniejące rozwiązania
obejmują różne zakresy funkcjonalności - od prostych systemów przeznaczonych do obsługi małej liczby
użytkowników, dostosowanych do jednego języka programowania aż do bardzo zaawansowanych
rozwiązań w których wydajny serwer obiektowej bazy danych jest sercem całego systemu serwera
aplikacji.
Należy jednak zwrócić uwagę, że systemy obiektowe ciągle stanowią przedmiot badań i nie osiągnęły
jeszcze pełnej dojrzałości.
Podsumowanie
Współczesne systemy informatyczne wykorzystują bazy danych od małych baz budowanych
specjalnie na ich potrzeby aż po duże i bardzo duże uniwersalne bazy i systemy baz danych. W zasadzie
trudno byłoby znaleźć program komputerowy, który nie korzystał by z baz danych.
Nie każdą strukturę przechowującą dane możemy jednak uznać za bazę danych. Baza danych musi
charakteryzować się odpowiednimi cechami. Ponieważ dzisiaj przed bazami danych stawia się coraz
większe wymagania związane z wydajnością, bezpieczeństwem itd. Wymaganiom tym mogą sprostać
dopiero Systemy Zarządzania Bazami Danych, które są wyposażone w odpowiednie mechanizmy
zapewniające bezpieczeństwo, spójność, wydajność i łatwość obsługi.
Modele baz danych są różne. Do najpopularniejszych należą model hierarchiczny, relacyjny i obiektowy.
Każdy z nich nadaje się do innych celów, a najbardziej rozpowszechnionym modelem w bazach
spotykanych w rozwiązaniach przemysłowych jest model relacyjnym. Nasz wykład poświęcony jest
właśnie temu modelowi.
Wyszukiwarka
Podobne podstrony:
Materia dodatkowy nt encji encr
Cw 5 Struktury Danych Materiały dodatkowe
Analiza baz danych na temat materiałów betonopodobnych
Projektowanie baz danych [ prof dr hab inz Zbyszko Krolikowski], Transformacja EER material dydaktyc
Cw 5 Struktury Danych Materiały dodatkowe
Analiza baz danych na temat materiałów betonopodobnych
więcej podobnych podstron