SKALOWALNOŚĆ:
-czyli zdolność automatycznego dostosowania pracy aplikacji do liczby dostępnych procesorów
obliczeniowych. Dane i sekwencje sterujące wysyłane są przez proces sterujący do takiej liczby
procesów obliczeniowych jaka jest dostępna.
Skalowalność (ang. scalability) — zdolność systemu informatycznego do sprawnego działania w
warunkach rosnącej liczby użytkowników, zwiększającej się wielkości przetwarzanych danych lub
powiększającej się mocy obliczeniowej. Dotyczy również zawężania funkcjonowania systemu.
Skalowalność (ang. scalability) - zapewnienie coraz wydajniejszej pracy w miarę zwiększania liczby
elementów składowych. Jest to np. cecha sieci komputerowych polegająca na zdolności do dalszej
rozbudowy.
Jeszcze do tego dostałem pytanie: „jaki warunek musi spełniać aplikacja aby można było powiedzieć że
jest skalowalna?”
odpowiedzi nie ma
X. Model PRAM
W modelu przetwarzania sekwencyjnego kluczowa role pełni model maszyny RAM (random access
machine). Kazda taka maszyna składa sie z ustalonego programu, jednostki obliczeniowej, tasmy (tylko
do odczytu) z danymi wejsciowymi, tasmy (tylko do zapisu) na wynik działania programu oraz
nieograniczonej pamieci o dostepie swobodnym. Ponadto kazda komórka pamieci jest w stanie
zapamietac liczbe całkowita o nieograniczonym zakresie. Jednostka obliczeniowa nie jest
skomplikowana – pozwala na wykonywanie najprostszych instrukcji takich jak: kopiowanie komórek
pamieci, porównania i skoki
warunkowe, podstawowe operacje arytmetyczne itp. Ustalony program uzytkownika składa sie z ciagu
takich instrukcji. Miara złozonosci programów dla maszyny RAM sa typowo
czas działania mierzony liczba wykonanych instrukcji i zuzycie pamieci mierzone liczba
wykorzystywanych komórek. Zeby uchronic ten model przed zniekształceniami zabronione jest
generowanie bardzo duzych liczb w krótkim czasie. Np. zabrania sie generowania
liczb o niewielowmianowej długosci zapisu w wielomianowym czasie. Mozna to osiagnac albo przez
uwazny dobór zestawu instrukcji, albo przerzucajac odpowiedzialnosc na „twórców algorytmów” dla
danego modelu. W ten sposób otrzymujemy game równowaznych modeli dla obliczen sekwencyjnych.
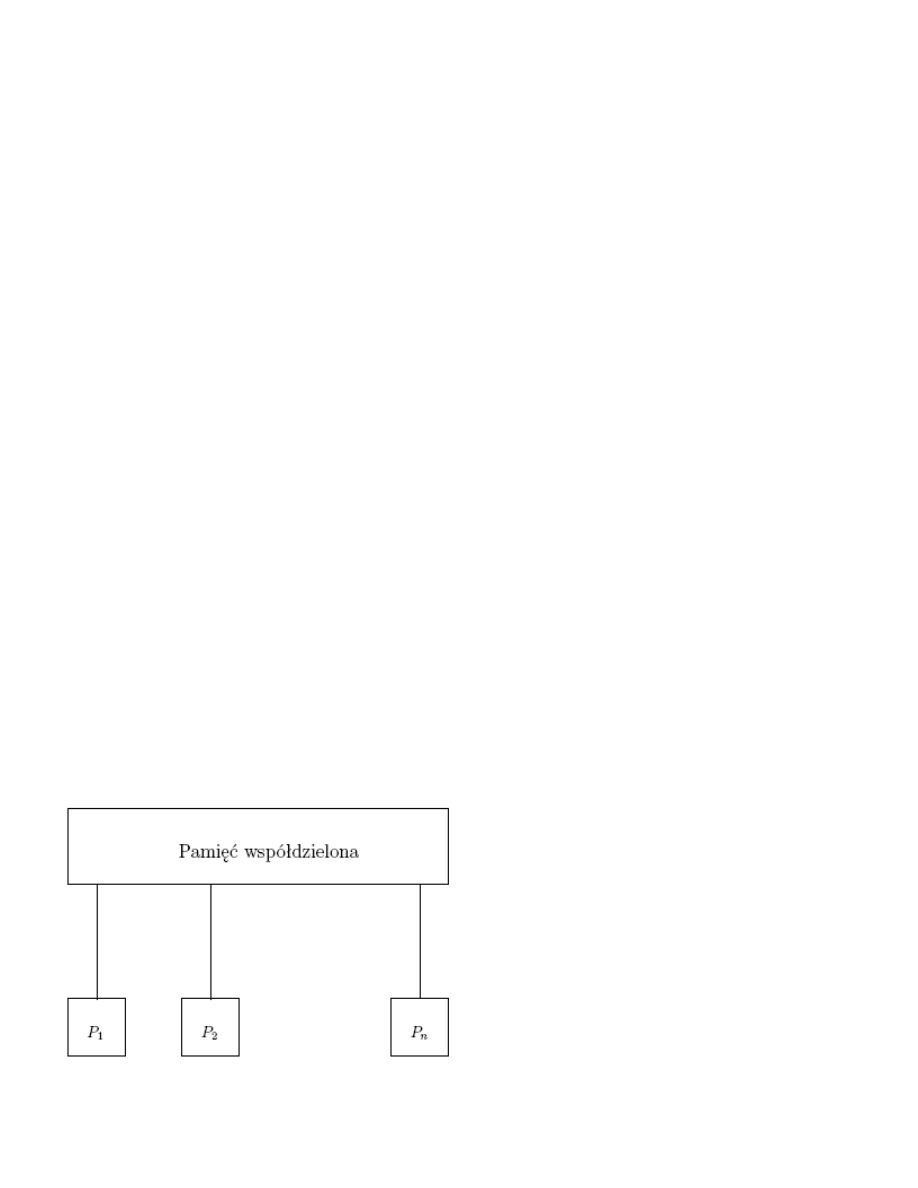
Naturalnym uogólnieniem modelu RAM jest dodanie
wiekszej liczby jednostek obliczeniowych. Idee maszyny PRAM moze ilustrowac ponizszy schemat:

PRAM - załozenia
• Pamiec jest wspólna dla wszystkich procesorów.
• Kazdy procesor jest maszyna typu RAM.
• Wszystkie procesory działaja synchronicznie.
• Czas działania mierzymy liczba dostepów do pamieci współdzielonej.
• Zuzycie pamieci liczymy liczba uzytych komórek.
• Dodatkowym parametrem jest liczba uzytych procesorów. Tu zakładamy, ze w wielomianowym czasie
mozna uzyc „tylko” wielomianowej liczby procesorów.
Uwagi do załozen
• Ostatni punkt załozen mozna rozwiazac np. w taki sposób, ze procesor P
1
oblicza potrzebna
liczbe procesorów, a nastepnie włacza je wpisujac liczbe do odpowiedniego rejestru.
• Liczenie dostępów do pamięci ma taki sens praktyczny, ze zwykle wszelkie operacje typu
komunikacyjnego zabierają znacznie wiecej czasu niz obliczenia lokalne.
• Wada założenia o jednostkowym czasie dostepu jest, wystepowanie w rzeczywistych systemach
równoległych mechanizmów komunikacji o bardzo zróznicowanej wydajnosci.
Dostep do pamieci
Istniej kilka sposobów modelowania równoległego dostepu do pamieci współdzielonej.We wszystkich
modelach zakładamy oddzielenie operacji zapisu i odczytu. Przyjmujemy, ze maszyna PRAM działa w
cyklu składajacym sie z:
• (jesli potrzeba) czytaj z pamieci współdzielonej,
• (jesli potrzeba) wykonaj obliczenia lokalne,
• (jesli potrzeba) pisz do pamieci współdzielonej.
W ten sposób zakładamy, ze nie ma konfliktów typu:
jednoczesny zapis/odczyt.
Pozostaja jednak konflikty typu: jednoczesny zapis/zapis i odczyt/odczyt. Generalnie mozliwosci sa
nastepujace:
• maszyna EREW-PRAM: nie dopuszcza sie konfliktów zadnego rodzaju,
• maszyna CREW-PRAM: dopuszcza sie konflikty typu jednoczesny odczyt,
• maszyna ERCW-PRAM: dopuszcza sie konflikty typu jednoczesny zapis,
• maszyna CRCW-PRAM: dopuszcza sie zarówno konflikty typu jednoczesny odczyt jak i jednoczesny
zapis.
Przy czym w przypadku dopuszczenia jednoczesnego odczytu (CREW, CRCW) zakładamy, ze
wszystkie procesory przeczytaja zadana komórke pamieci. W przypadku dopuszczenia jednoczesnego
zapisu sytuacja jest bardziej złozona.
Rozwiazywanie konfliktów typu jednoczesny zapis
• ECR (equality conflict resolution) – jednoczesny zapis sie powiedzie, jesli wszystkie procesory próbuja
zapisac to samo.
• PCR (priority conflict resolution) - zapis udaje sie tylko procesorowi o najwyzszym priorytecie.
• ACR (arbitrary conflict resolution) - jednemu z procesorów zapis sie powiedzie.
x. Lista kontrolna w projektowaniu podziału
1. Liczba zadań powinna być co najmniej o jeden rząd większa niż liczba procesorów.
2. Ma być skalowalny (liczba zadań rośnie ze wzrostem rozmiaru problemu)
3. Czy nie jest zbyt duża liczba powieleń obliczeń i danych?
4. Czy zadania mają podobny rozmiar?

x. Lista kontrolna w projektowaniu komunikacji
1. Czy wszystkie zadania wykonują taką samą liczbę komunikacji?
2. Komunikacja powinna zapewnić równoległe wykonywanie komunikatów.
3. Czy każde zadanie komunikuje się tylko z niewielką ilością zadań sąsiadujących? Jeżeli nie to czas
komunikacji może być większy od czasu obliczeń.
x. Lista kontrolna w projektowaniu aglomeracji
1. Ilość zadań nie mniejsza niż ilość procesorów.
Algorytm wciąż ma być skalowalny (odp: zad18)
x. Planowanie statyczne i dynamiczne, przykład zastosowania
Statyczne – dokonujemy mapowania przed wykonaniem programu
Dynamiczne – mapowanie następuje podczas wykonania programu
Gdy dane są niedokładne lub ich brak to stosujemy alg. dynamiczne w sys. scentralizowanych - kontrola
wykorzystania mocy obliczeniowej (obciżenie) - ilość zadań wykonywanych na 1 komputerze
x. Planowanie dokładne i heurystyczne, przykład zastosowania
Planowanie dokładne - korzystamy z funkcji celu z określeniem ekstremów (?) Planowanie heurystyczne
- przybliża wynik. Stosowane najczęsciej.
x. Planowane scentralizowane i rozproszone, przykład zastosowania
Podział stosowany dla planowania dynamicznego(tylko) Zcentralizowane – procesor - koordynator jest
odpowiedzialny za podział zadań na procesory Zdecentralizowane – brak koordynatora
Scentralizowane – 1komp. podejmuje decyzje o mapowaniu. + prostota, - wąskie gardło (ogranicza
skalowalność) Ropzroszone – wszystkie komputery podejmują decyzję wspólnie. + duża skalowalność, -
duży czas planowania.
x. Algorytmy planowania zadań
FCFS (ang. First Come, First Served)
Według tego schematu, ten z procesów, który pierwszy zgłosi zapotrzebowanie na procesor, otrzyma go
jako pierwszy. Implementacja tego algorytmu jest wykonywana przy pomocy kolejki FIFO. Algorytm
ten dokonuje najsprawiedliwszego przydziału czasu (każdemu według potrzeb), jednak powoduje bardzo
słabą interakcyjność systemu - pojedynczy długi proces całkowicie blokuje system na czas swojego
wykonania, gdyż nie ma priorytetów zgodnie z którymi mógłby zostać wywłaszczony. Algorytm ten
stosuje się jednak z powodzeniem w systemach wsadowych, gdzie operator ładuje zadania do
wykonania, a one wykonują się do skutku
SJF (Shortest Job First) - Najpierw najkrótsze zadanie
Jest algorytmem optymalnym ze względu na najkrótszy średni czas oczekiwania. W wersji z
wywłaszczaniem, stosowana jest metoda: najpierw najkrótszy czas pracy pozostałej do wykonania.
Problemem tego algorytmu jest głodzenie długich procesów - może się zdarzyć, że cały czas będą
nadchodzić krótsze procesy, a wtedy proces dłuższy nigdy nie zostanie wykonany.
Kolejki priorytetowe
Wybierany jest proces o najwyższym priorytecie. W tej metodzie występuje problem nieskończonego
blokowania (procesu o niskim priorytecie przez procesy o wysokim priorytecie). Stosuje się tu
postarzanie procesów, polegające na powolnym podnoszeniu priorytetu procesów zbyt długo
oczekujących

Rotacja (Round Robin)
Każde z zadań otrzymuje kwant czasu; po spożytkowaniu swojego kwantu zostaje wywłaszczone i
ustawione na końcu kolejki
Planowanie z wykorzystaniem wielu kolejek
Opiera się na podziale procesów pomiędzy poszczególne grupy, procesy są na stałe przypisywane od
jednej z kategorii. Każda z kolejek może stosować swój własny algorytm kolejkowania, ponadto
pomiędzy kolejkami powinno następować jakieś wybrane planowanie. Dodatkowo można przydzielać
procentowe wartości czasu różnym kolejkom z uwzględnieniem ich ważności.
Planowanie z wykorzystaniem wielu kolejek ze sprzężeniem zwrotnym
Ten rodzaj planowania umożliwia przemieszczanie się procesów pomiędzy kolejkami, występują tu
dodatkowe koszty związane z planowaniem, ale zyskujemy na elastyczności.
Planowanie zadań dla wielu procesorów
Należy rozróżnić systemy z identycznymi procesorami (homogeniczne) i różnymi procesorami
(heterogeniczne). Dla środowiska heterogenicznego jest konieczne pisanie różnych programów na każdy
z procesorów, natomiast w przypadku procesorów homogenicznych mamy do czynienia z planowaniem
zadań bardzo zbliżonego do tego w systemie z jednym procesorem, jednak z dodatkowymi
utrudnieniami. Można zastosować metodę ładowania dzielonego polegającą na przydzieleniu każdemu
procesorowi oddzielnej kolejki zadań. Można również stosować wspólną kolejkę dla wszystkich
procesorów. Należy wtedy jednak zapewnić, aby wszystkie procesy zostały prawidłowo wykonane
(proces nie może być wykonywany przez dwa procesory, proces nie może zostać „zgubiony”). Należy
część czasu jednego z procesorów przeznaczyć na planowanie zadań dla siebie i pozostałych
procesorów. Takie podejście nazywane jest wieloprzetwarzaniem asymetrycznym.
x. Definicja i sposoby modelowania wydajności
Przez wydajność aplikacji rozumie się wiele aspektów,czas wykonania, przyspieszenie, efektywność,
skalowalność, zasoby systemu, kosz, projektowanie i konserwacja aplikacji
ekstrapolacja z obserwacje
T=N + M
2
/ P
T = (M + M
2
) / P
podejscie oparte o prawo Amdala
analiza asymptotyczna O (N log N) O(P) istnieje N
0
, że N>=N
0
, to koszt obliczeń <=N log N na P
procesorów
x. Czas wykonania programu rozproszonego
T jest funkcja zależna od T=F(N,P,Moc), Ts=Tobliczen+Tkomunikacji+Tprzestoju. Czas wykonywania
aplikacji rozproszonej to czas, który upływa od chwili, gdy pierwszy procesor zaczyna obliczenia a
ostatni kończy.T=1/P*(To+Tk+Tp)-jest to Tsumaryczny TsObliczen można obliczyć korzystająć z
aplikacji sekwencyjnej(brak Tk i Tp) TsKomunikacji = ts+l*tw [ts-czas starotowy;tw-czas przekazania
jednego słowa,jednostki;l-ilość jednostek] T=(Tobl-Tkom)/P
x. Czas obliczeń
Czas obliczen jest to czas ktory procesy poswiecaja na obliczenia, czyli na wykonywanie operacji
arytmetycznych i logicznych. Wraz ze wzrostem ilosci procesorow problem mozemy podzielic na coraz
wiecej podproblemow i laczny czas obliczen dla problemu maleje. TsObliczen można obliczyć
korzystająć z aplikacji sekwencyjnej(brak Tk i Tp) Innym problemem jest to, ze wraz ze wzrostem ilosci
procesow rozsnie czas komunikacji pomiedzy nimi (o tym w punkcie nastepnym).
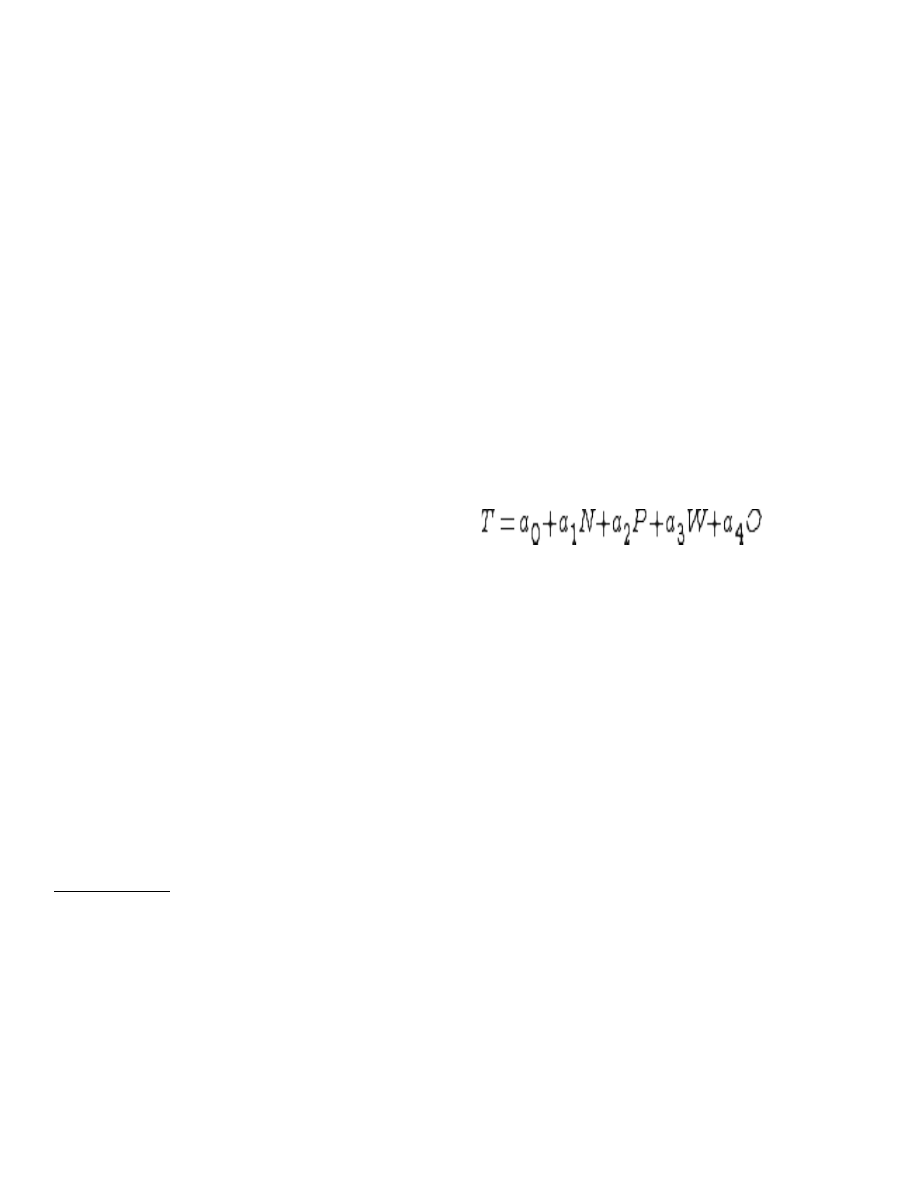
x. Czas komunikacji
Czas komunikacji to czas, który procesy poświęcają na komunikowanie się między sobą. Wraz ze
wzrostem ilości procesów czas potrzebny na komunikację wzrasta. Komunikacja ma na celu np.
przekazanie wyników obliczeń jednego procesu do drugiego procesu. Optymalny czas wykonania
programu uzyskujemy dla takiej liczby procesów, przy której suma czasów komunikacji i obliczeń jest
minimalna (a nie jakby się mogło wydawać im więcej procesorów tym lepiej). Aby zmniejszyć czasy
komunikacji w niektórych przypadkach możemy zastosować powielenie obliczeń (jeśli jest to
korzystniejsze czasowo niż komunikacja).
x. Czas oczekiwania
Czas oczekiwania to czas, w którym procesy nie robią nic ze względu na to, że oczekują na zakończenie
obliczeń przez inne procesy - na przykład gdy występuje synchronizacja barierowa lub gdy oczekują na
dostęp do zasobów dzielonych (stoją pod semaforem). Czas oczekiwania może wynikać z braku danych
luz z braku obliczeń
x. Model oparty na danych eksperymentalnych
a) określić wszystkie czynniki, które mogą mieć wpływ na T i dla których da się oszacować wartości:
T=(N, P, W, O) - N wielkość prblemu, P - ilość procesorów, W - ilość wątków, O - pamięc
operacyjna
b) wybrać strukturę modelu (liniowy, nieliniowy, etc.), np:
c)badanie eksperymentalne:
/---|---|---|---|---|---
| T | N | P | W | O | ...
|---+---+---+---+---+---
| x | x | x | x | x | - x - jakaś dana
|---+---+---+---+---+---
| x | x | x | x | x |
|---+---+---+---+---+---
| x | x | x | x | x |
|---+---+---+---+---+---
. . . . . .
d) z analizy wyników badania wygenerowane zostają współczynniki
e) wykorzystanie modelu
x. Komunikacja i synchronizacja w OpenMP
Synchronizacja:
W przypadku gdy wymagane jest sekwencyjne wykonanie pewnego fragmentu kodu w sekcji
równoległej, możliwa jest jego serializacja. Przykładem jest synchronizowana sekwencja OMP
CRITICAL, do której w danym momencie może wejść jeden wątek, sekcja OMP MASTER –
wykonywana jedynie przez wątek główny oraz OMP SINGLE – wykonywana przez dowolny wątek (nie
można z góry określić który).

Przykład:
#pragma omp paralel for
for(int i=0; i<100; i++)
{
#omp single
printf(„START”);
operations(i);
#omp critical
synchronizacja(i);
#omp master
printf(„Master dziala”);
}
Ponieważ wątki mogą działać na wspólnych danych, potrzebne są mechanizmy synchronizacji
zapewniające uzyskanie poprawnych wyników. OpenMP dostarcza konstrukcji, które umożliwiają
prawidłową współpracę wątków. Są to:
a) Synchronizacja domyślna
b) Synchronizacja jawna
Synchronizacja domyślna występuje na końcu bloku kodu wybranych dyrektyw: OMP PARALLEL,
OMP FOR, OMP SECTIONS, OMP SINGLE;
chyba że użyto klauzuli NOWAIT, która nakazuje brak synchronizacji wątków. Każdy wątek, który
wykona swoją pracę i dojdzie do punktu synchronizacji, czeka na wszystkie pozostałe wątki. W chwili,
gdy wszystkie wątki dojdą do punktu synchronizacji, każdy z nich wykonuje dalszą część programu lub
następuje ich zniszczenie.
W synchronizacji jawnej programista może sam wskazać miejsce synchronizacji poprzez użycie
dyrektywy OMP BARRIER.
Dodatkowo OpenMP udostępnia mechanizm sekcji krytycznej. Fragment kodu, który może być
wykonany tylko przez jeden wątek w danym czasie, należy umieścić w bloku po dyrektywie OMP
CRITICAL.
Można wskazać także operację atomową, czyli polegającą na modyfikacji jednej komórki pamięci,
podczas której tylko jeden proces może te komórkę modyfikować (odczytywać). Operacją taką może
być inkrementacja, dekrementacja i przypisanie wartości (pod warunkiem, że do obliczenia
przypisywanej wartości nie wykorzystuje się modyfikowanej zmiennej). Wskazanie operacji atomowej
odbywa się poprzez użycie dyrektywy OMP ATOMIC. Operacja atomowa często jest wspomagana
sprzętowo, dlatego wykonywana jest efektywniej niż sekcja krytyczna. Jednak obecnie kompilatory
przeważnie wykonują operację oznaczoną jako atomową, zamieniając ją na sekcję krytyczną.
Do sterowania synchronizacją w OpenMP dostępne są także funkcje zarządzające ryglami (ang. lock), za
pomocą których można zatrzymać aktywność wątku, aż do zwolnienia rygla.
Komunikacja pomiędzy wątkami:
Komunikacja między wątkami odbywa się z wykorzystaniem pamięci dzielonej.
Każdy wątek w sekcji równoległej posiada zmienne prywatne i zmienne dzielone – wspólne dla każdego
wątku. Poprzez zmienne dzielone wątki mogą komunikować się, gdy znajdują się w tej samej sekcji
równoległej. Zmienne dzielone deklarowane są przy wejściu do sekcji równoległej jako PRIVATE,
natomiast zmienne współdzielone jako SHARED.
Istnieje także możliwość komunikacji między wątkami, gdy działają one w ramach innych grup w
innych sekcjach równoległych, jednak tylko w przypadku, gdy w kolejnych sekcjach liczba wątków się
nie zmienia. Wówczas wątki tworzone w kolejnych obszarach równoległych operują na tym samym
zestawie zmiennych. Deklaracji zmiennych dla wielu sekcji równoległych w jednym programie
dokonuje się za pomocą klauzuli THREAD-PRIVATE.

x. Model wykonywania programu w OpenMP
x. Szeregowanie iteracji w OpenMP(statyczne, dynamiczne, GSS)
Składnia:
schedule(type [, chunk])
Sposoby szeregowania operacji w pętli:
•
simple, static
•
dynamic
•
guided
•
runtime
•
Domyślnie kompilator przyjmuje zawsze szeregowanie statyczne
•
Dynamic – czas wykonywania się nieznacznie waha w poszczególnych iteracjach (np. gdy w pętli
stosujemy if-else, gdzie instrukcje w „if” wykonują się w podobnym czasie jak w „else”)
•
Guided – czas wykonywania poszczególnych iteracjach waha się znacząco
•
Runtime – stosujemy jeżeli nie wiemy jak pętle będą się zachowywać
Przykład:
#pragma omp for schedule(dynamic)
for(i=0;i<j;i++)
sum++;
DYNAMI
STATIC
GUIDED
t
(czas)
N
(liczba iteracji)

x. Zmienne "threadprivate", klauzula "copyin", przykłady zastosowania
•
Private obowiązuje tylko w zakresie statycznym. Natomiast zmienna taka w zakresie dynamicznym
będzie Shared. Po to właśnie warto stosować threadprivate.
•
Copyin powiązana jest z threadprivate. Ma taką rolę jak firstprivate.
Threadprivate
Dyrektywa threadprivate oznacza, że wszystkie zmienne podane jako parametry w lista będą
prywatne dla wątków w całej przestrzeni programu. Składnia:
#pragma omp threadprivate (lista)
Każda z kopii zmiennej jest inicjowana raz, w nieokreślonym punkcie programu, przed
pierwszym odwołaniem do niej.
Copyin
Każda kopia zmiennej zadeklarowanej jako threadprivate i wymienionej w klauzuli copyin jest
przy wejściu do bloku równoległego inicjowana wartością zmiennej z wątku głównego. Skłądnia
klauzuli.
copyin (lista)
x. Wątki dynamiczne w OpenMP, przykłady zastosowania
OpenMP udostępnia mechanizm wątków dynamicznych. Dzięki niemu aplikacja może
dynamicznie decydować ile wątków ma być utworzonych w regionie równoległym aby uzyskać
możliwie jak największą wydajność. Konsekwencją uruchomienia wątków dynamicznych jest to,
że użytkownik ustawiając ilość wątków w regionie równoległym, ustawia ich maksymalną, a nie
dokładną ilość. Mechanizm wątków dynamicznych w OpenMP uruchamiany jest za pomocą
zmiennej środowiskowej OMP_DYNAMIC. Zmienna ta przyjmuje wartości TRUE oraz FALSE.
Dodatkowo mechanizm ten można uruchomić za pomocą funkcji z biblioteki OpenMP:
omp_set_dynamic(). Aby dowiedzieć się czy uruchomiony został mechanizm wątków
dynamicznych należy użyć funkcji omp_get_dynamic(). Wątki dynamiczne można w systemach
w których wykonywanych jest wiele prac przez wielu użytkowników i użycie zasobów zmienia
się dynamicznie.
Przykład:
//z dupy przykład
omp_set_dynamic(true);
omp_set_num_threads(4);
#pragma omp parallel
{
for(int i = 0; i < 4; i++)
std::cout << „Iteracja „ << i << std::endl;
}
Document Outline
Wyszukiwarka
Podobne podstrony:
Opracowanie07v2 id 338680 Nieznany
chemia opracowanie id 112613 Nieznany
ginexy opracowanie id 191652 Nieznany
Najlepsze opracowanie id 313141 Nieznany
Promethidion Opracowanie id 40 Nieznany
ZFHi tech Opracowanie id 932670 Nieznany
Opracowanie 3 id 338046 Nieznany
PE opracowanie id 353179 Nieznany
zmk opracowanie id 591480 Nieznany
Opracowanie1 id 338664 Nieznany
lab2 Opracowanie02 id 750512 Nieznany
opracowanie 7 id 338056 Nieznany
Opracowanie 6 id 338054 Nieznany
Inne opracowanie id 214648 Nieznany
Baryleczka opracowanie id 80468 Nieznany (2)
więcej podobnych podstron