2013-05-28
1
1
Metody probabilistyczne
Analiza współzależności zjawisk
Analiza regresji
2
Funkcje w Excelu
SUMA.KWADRATÓW(liczba1;liczba2;..)
SUMA.ILOCZYNÓW((tablica1;tablica2;…)
POZYCJA(liczba,lista,lp)
gdzie: liczba
– to liczba, dla której pozycję chcemy znaleźć,
lista
– lista z liczbami,
lp
– lp>0 sortowanie rosnąco, lp=0 lub brak – sortowanie malejąco,
MODUŁ.LICZBY(liczba)
KOWARIANCJA(tablica1,tablica2)
WSP.KORELACJI(tablica1;tablica2)
gdzie: tablica1
– wartości zmiennej objaśnianej,
tablica2
– wartości zmiennej objaśniającej ,
2013-05-28
2
3
Regresja prosta
Ważnym uzupełnieniem zagadnienia badania kierunku i siły zależności
pomiędzy cechami X i Y jest analiza regresji.
Przez
analizę regresji rozumiemy metodę badania wpływu
zmiennych uznanych za niezależne (przyczyny) na zmienną uznaną
za zależną (skutek).
Jeżeli w analizie uwzględnimy tylko 1 zmienną niezależną, to
mówimy o regresji prostej.
Cecha X (zmienna niezależna) - przyczyna,
Cecha Y (zmienna zależna) - skutek.
Jeżeli w analizie uwzględnimy więcej zmiennych niezależnych, to
mówimy o regresji wielokrotnej (wielorakiej).
4
Funkcja regresji
Podstawowe narzędzie badania
Rozważany jest przypadek zależności liniowej dla regresji prostej.
Narzędziem będzie zatem funkcja regresji postaci:
gdzie:
ŷ
i
-
teoretyczna wartość zmiennej zależnej (Y)
x
i
-
empiryczna wartość zmiennej niezależnej (X)
b
ax
y
i
i
ˆ
a
– współczynnik regresji
(współczynnik kierunkowy)
Interpretacja:
jeżeli wartość zmiennej niezależnej X
wzrośnie o jednostkę, to wartość
zmiennej zależnej Y:
•wzrośnie (jeżeli a>0) o |a| jednostek lub
•zmaleje (jeżeli a<0) o |a| jednostek
b
– wyraz wolny
Interpretacja:
stały poziom wartości zmiennej
zależnej Y niezależny od zmian
wartości zmiennej niezależnej X.
Uwaga! Interpretacja wyrazu
wolnego nie zawsze ma sens
ekonomiczny
2013-05-28
3
5
Liniowa funkcja trendu
może być również traktowana jako liniowa funkcja regresji prostej.
Zmienna zależna Y opisuje wówczas poziom badanego zjawiska Y.
Zmienna niezależna X jest czasem (zmienna czasowa t).
W efekcie podstawiając x zamiast t oraz zmieniając wskaźnik t
na wskaźnik i otrzymamy funkcję regresji:
W nowym układzie funkcja trendu może być traktowana jako funkcja
regresji Y względem czasu t.
b
at
y
t
ˆ
b
ax
y
i
i
ˆ
6
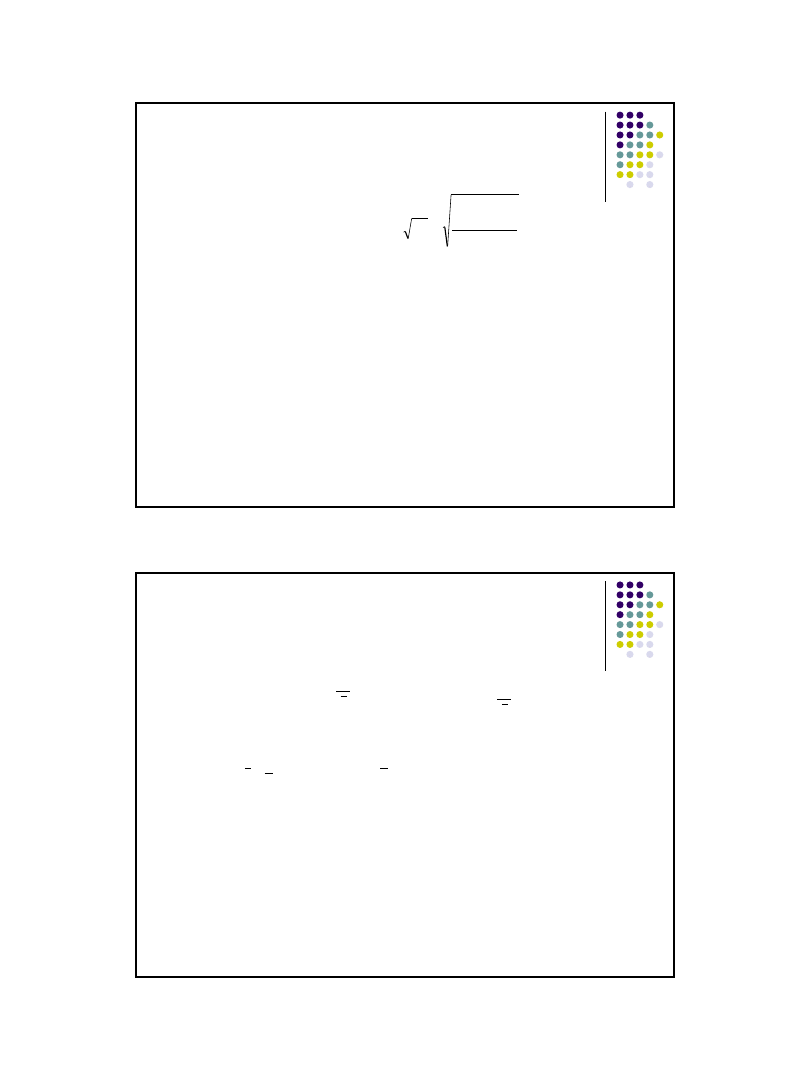
Szacowanie parametrów a i b funkcji regresji
Metoda
– najmniejszych kwadratów
współczynnik regresji a
wyraz wolny b
k
i
i
k
i
i
i
x
x
x
y
y
x
x
s
Y
X
C
a
1
2
1
2
,
x
a
y
b
k
i
k
i
i
i
k
i
k
i
i
k
i
i
i
i
x
x
x
n
y
x
y
x
n
s
Y
X
C
a
1
2
1
2
1
1
1
2
,
2013-05-28
4
7
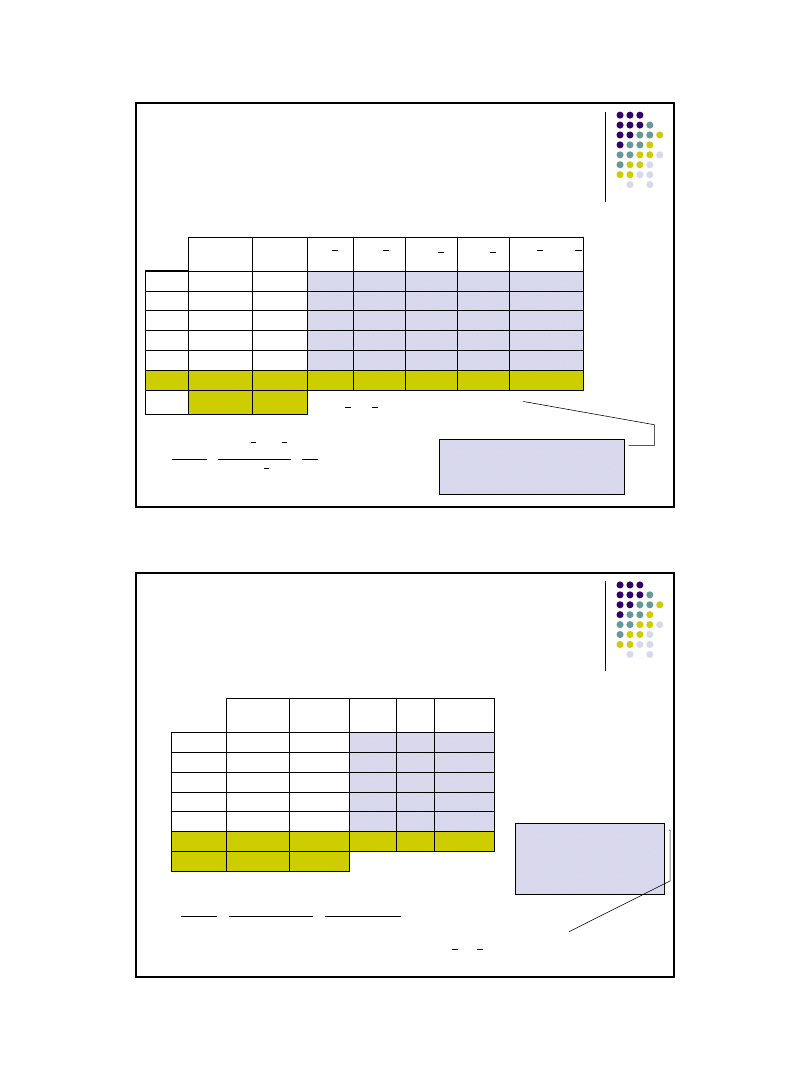
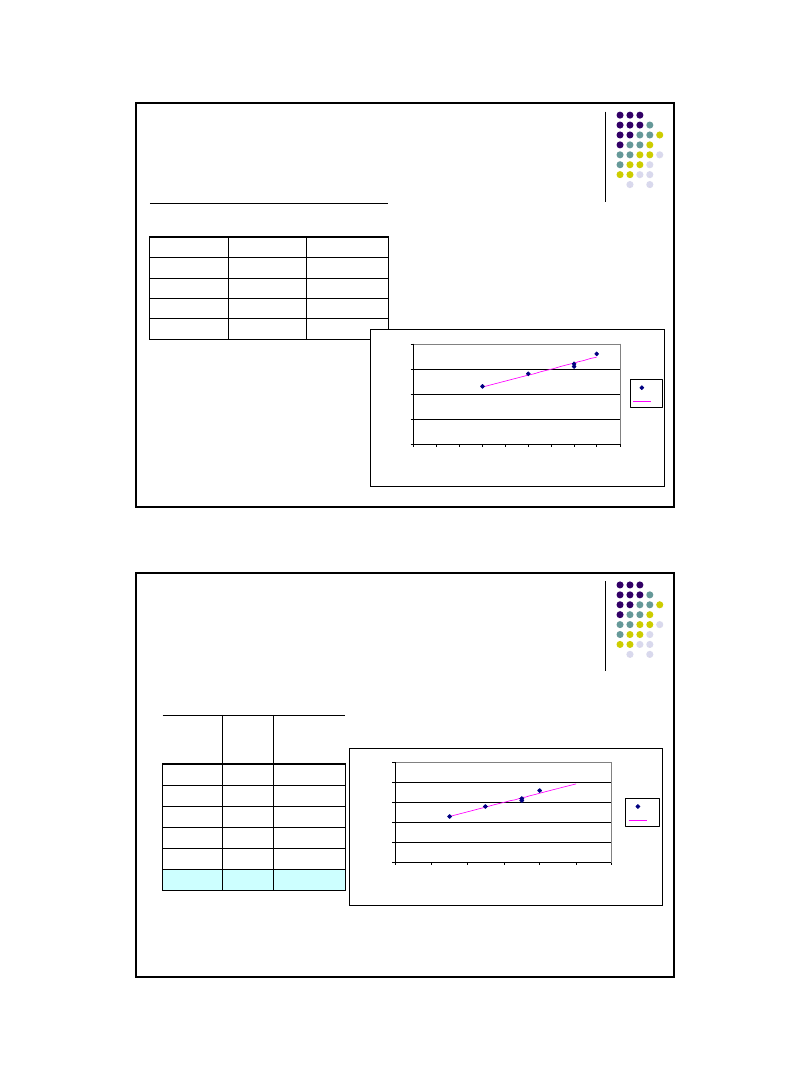
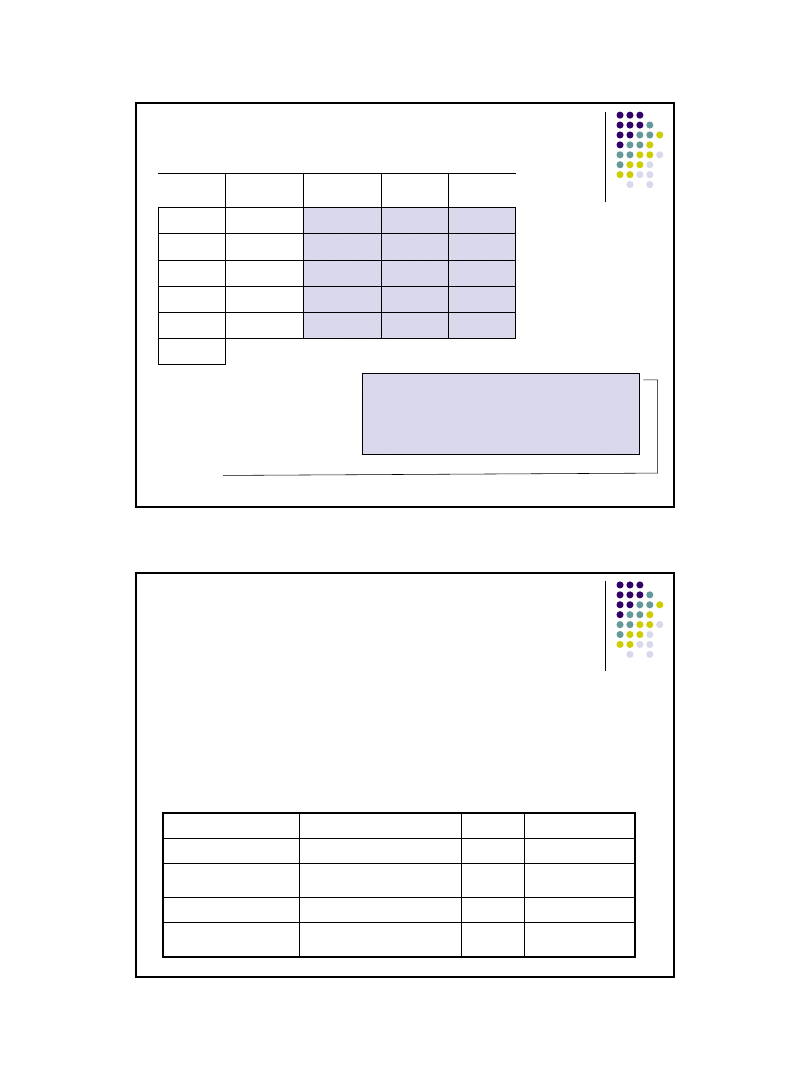
Szacowanie parametrów a i b funkcji regresji - przykład
Liczba emitowanych tygodniowo reklam usługi przewoźnika i wysokość
obrotów w (tys zł) są zestawione w tabeli. Czy istnieje zależność między
badanymi zmiennymi:
Wniosek:
Funkcja regresji ma postać
ŷ
i
=11,875*x
i
+78,75
Liczba
reklam x
i
Obroty
y
i
1
3
115
-3
-35
9
1225
105
2
5
140
-1
-10
1
100
10
3
7
155
1
5
1
25
5
4
7
160
1
10
1
100
10
5
8
180
2
30
4
900
60
Suma
30
750
0
0
16
2350
190
Śr.
6
150
x
x
i
y
y
i
2
i
x
x
2
i
y
y
y
y
x
x
i
i
875
,
11
16
190
,
1
2
1
2
k
i
i
k
i
i
i
x
x
x
y
y
x
x
s
Y
X
C
a
75
,
78
6
875
,
11
150
x
a
y
b
8
Szacowanie parametrów a i b funkcji regresji - przykład
Liczba emitowanych tygodniowo reklam usługi przewoźnika i wysokość
obrotów w (tys zł) są zestawione w tabeli. Czy istnieje zależność między
badanymi zmiennymi:
Liczba
reklam x
i
Obroty
y
i
x*y
x
2
y
2
1
3
115
345
9
13225
2
5
140
700
25
19600
3
7
155
1085
49
24025
4
7
160
1120
49
25600
5
8
180
1440
64
32400
Suma
30
750
4690
196
114850
Średnia
6
150
Wniosek:
Funkcja regresji ma
postać
ŷ
i
=11,875*x
i
+78,75
875
,
11
30
196
5
750
30
4690
5
,
2
1
2
1
2
1
1
1
2
k
i
k
i
i
i
k
i
k
i
i
k
i
i
i
i
x
x
x
n
y
x
y
x
n
s
Y
X
C
a
75
,
78
6
875
,
11
150
x
a
y
b
2013-05-28
5
9
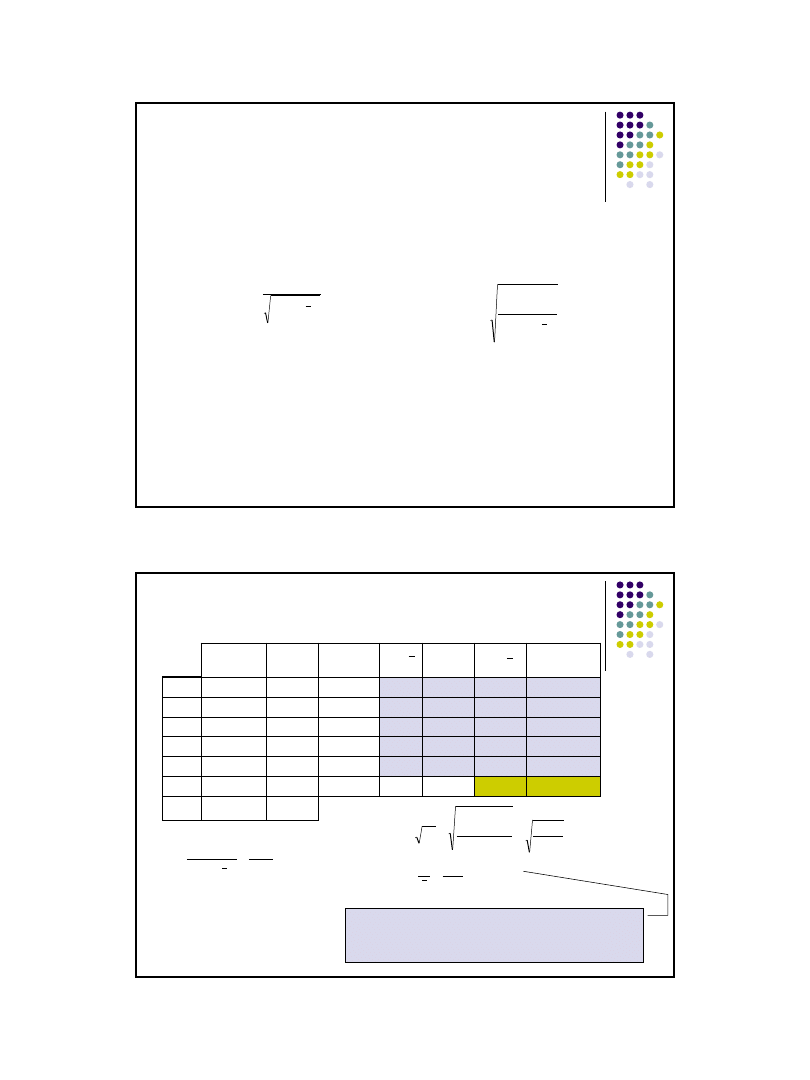
Szacowanie parametrów a i b funkcji regresji –
interpretacja przykładu
Liczba emitowanych tygodniowo reklam usługi przewoźnika i wysokość
obrotów w (tys zł) są zestawione w tabeli:
Liczba
reklam x
i
Obroty
y
i
Funkcja
regresji
ŷ
i
3
115
114,375
5
140
138,125
7
155
161,875
7
160
161,875
8
180
173,75
0
50
100
150
200
0
1
2
3
4
5
6
7
8
9
liczba emitowanych reklam (X)
w
ie
lk
o
ść
o
b
ro
tu
(
Y
)
y
y^
ŷ=11,875*x+78,75
R
2
=0,96
ŷ
i
=11,875*x
i
+78,75
10
Wykorzystanie funkcji regresji do prognozowania
Jakich obrotów można się spodziewać przy zwiększonej liczbie
emitowanych reklam?
ŷ
6
= 11,875*x
6
+78,75 = 11,875*9+78,75 = 185,625
0
50
100
150
200
250
0
2
4
6
8
10
12
liczba emitowanych reklam (X)
w
ie
lk
o
ść
o
b
ro
tu
(
Y
)
y
y^
ŷ=11,875*x+78,75
R
2
=0,96
Liczba
reklam
x
i
Obroty
y
i
Funkcja
regresji
ŷ
i
3
115
114,375
5
140
138,125
7
155
161,875
7
160
161,875
8
180
173,75
9
185,625
2013-05-28
6
11
Ocena dopasowania funkcji regresji do danych
empirycznych
Podstawowe
miary „dobroci” dopasowania linii regresji do danych
empirycznych:
współczynnik zbieżności (φ
2
),
współczynnik determinacji (R
2
),
średni błąd szacunku S
e
(pierwiastek z tzw. wariancji resztowej S
e
2
),
współczynnik zmienności resztowej V
e
Współczynnik zbieżności (φ
2
):
gdzie: 0 ≤ φ
2
≤ 1
mierzy zgodność
między danymi empirycznymi i danymi
oszacowanymi na podstawie modelu
Im φ
2
jest bliższy 0, tym dopasowanie jest lepsze.
n
i
i
n
i
i
i
y
y
y
y
1
2
1
2
2
ˆ
12
Ocena dopasowania funkcji regresji do danych
empirycznych
Współczynnik determinacji (R
2
):
gdzie:
0 ≤ R
2
≤ 1
Przy zależności liniowej można go wyznaczyć również jako:
lub
Ocenia jakość dopasowania modelu do danych empirycznych.
Im R
2
jest bliższy 1, tym dopasowanie jest lepsze.
2
2
1
R
2
2
xy
r
R
2
2
yx
r
R
2013-05-28
7
13
Ocena dopasowania funkcji regresji do danych
empirycznych
Średni błąd szacunku (S
e
):
gdzie:
k
– liczba szacowanych parametrów funkcji regresji
(tutaj k=2; szacujemy dwa parametry: a i b )
Jest to pierwiastek z wariancji resztowej (S
e
2
) -
informuje, jakie są
przeciętne odchylenia rzeczywistych wartości zmiennej
objaśniającej od wartości teoretycznych,
Nazwa bierze się od reszty (e
i
), którą definiuje się jako:
różnicę pomiędzy wartością empiryczną a wartością
teoretyczną cechy zależnej Y:
k
n
y
y
S
S
n
i
i
i
e
e
1
2
2
ˆ
i
i
i
y
y
e
ˆ
14
Ocena dopasowania funkcji regresji do danych
empirycznych
Współczynnik zmienności resztowej (wyrazistości) V
e
:
lub
gdzie:
i
Wyraża on, jaką częścią średniej wartości zmiennej objaśnianej jest
odchylenie standardowe reszt S
e
,
Gdy V
e
>0,1
– uznajemy, że zmienna objaśniana jest nieprzewidywalna,
a model nie powinien być wykorzystany do prognozowania.
y
S
V
e
e
n
i
i
y
n
y
1
1
0
y
%
*100
y
S
V
e
e
2013-05-28
8
15
Błędy w ocenie poszczególnych parametrów
funkcji regresji
Estymacji parametrów funkcji regresji dokonuje się na podstawie
próby losowej – stąd możliwe jest popełnianie błędów w ocenie
poszczególnych parametrów funkcji,
Standardowe błędy szacunku parametrów (średnie błędy):
współczynnika regresji a
Informują: na ile – przeciętnie biorąc mylimy się (in plus lub in
minus) szacując parametry a i b,
Przyczyny błędów:
Mała liczebność próby losowej,
Niewłaściwa metoda estymacji parametrów funkcji regresji,
Przyjęcie niewłaściwej zmiennej objaśniającej do funkcji regresji.
n
i
i
e
x
x
S
a
D
1
2
n
i
i
n
i
i
e
x
x
n
x
S
b
D
1
2
1
2
2
wyrazu wolnego b
16
Ocena dopasowania funkcji regresji do danych
empirycznych -
przykład
Wniosek: wszystkie obliczone miary dopasowania
potwierdzają bardzo dobre dopasowanie funkcji
regresji do danych empirycznych
Liczba
reklam x
i
Obroty
y
i
ŷ
i
y
i
-
ŷ
(y
i
-
ŷ)
2
1
3
115
114,375
-35
0,625
1225
0,391
2
5
140
138,125
-10
1,8751
100
3,516
3
7
155
161,875
5
-6,8751
25
47,266
4
7
160
161,875
10
-1,8751
100
3,516
5
8
180
173,75
30
6,254
900
39,063
Σ
2350
93,75
Śr.
6
150
y
y
i
2
i
y
y
0399
,
0
2350
75
,
93
ˆ
1
2
1
2
2
n
i
i
n
i
i
i
y
y
y
y
96
,
0
0399
,
0
1
1
2
2
R
96
,
0
979
,
0
2
2
2
xy
r
R
59
,
5
2
5
75
,
93
ˆ
1
2
2
k
n
y
y
S
S
n
i
i
i
e
e
n= 5
k= 2
037
,
0
150
59
,
5
y
S
V
e
e
2013-05-28
9
17
Ocena dopasowania funkcji regresji do danych
empirycznych -
przykład
Interpretacja współczynników – miar dopasowania:
współczynnik zbieżności φ
2
= 0,0399
mierzy zgodność między danymi empirycznymi i danymi oszacowanymi
na podstawie modelu. Jeżeli φ
2
= 0 wówczas składnik losowy nie
występuje
współczynnik determinacji R
2
= 0,96
duża wartość R
2
świadczy o dobrym dopasowaniu modelu do danych
empirycznych i oznacza, żę zmienność ta została w 96% wytłumaczona
przez model
średni błąd szacunku S
e
= 5,59
wielkość obrotów różni się przeciętnie o 5,59 od wartości uzyskanych z
funkcji trendu liniowego,
współczynnik zmienności resztowej V
e
= 0,037
udział odchylenia standardowego składnika resztowego w przeciętnej
wartości obrotów wynosi ponad 3,7 %,
18
Hipotezy o istotności współczynnika regresji
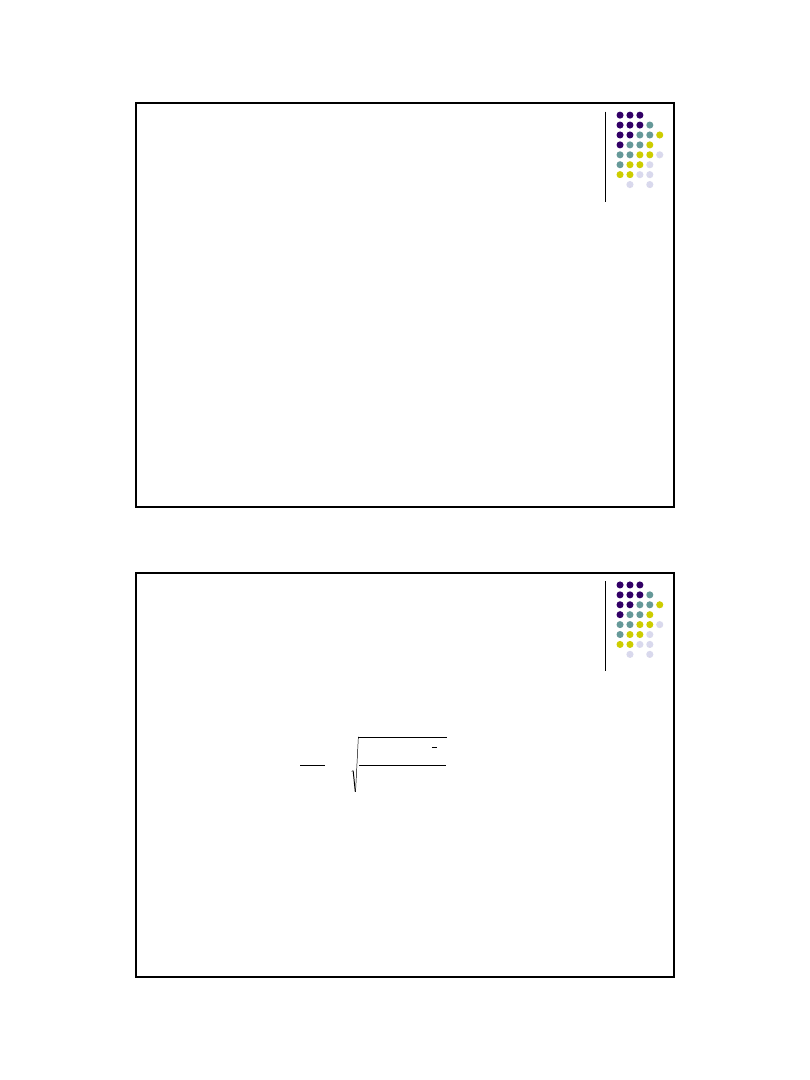
Weryfikacja hipotezy o istotności współczynnika regresji a
Hipoteza H
0
: α
1
= 0 wobec H
1
: α
1
≠ 0 (H
1
: α
1
≥ 0 lub H
1
: α
1
≤ 0 )
Statystyka:
ma rozkład t-Studenta o s=n-2 stopniach swobody
Weryfikacja hipotezy
jeżeli | t | ≥ t
α,n-2
to hipotezę H
0
należy odrzucić,
jeżeli | t | < t
α,n-2
to nie ma podstaw do odrzucenia hipotezę H
0
,
n
i
i
i
n
i
i
y
y
x
x
k
n
a
a
D
a
t
1
2
1
2
ˆ
*
*
)
(
2013-05-28
10
19
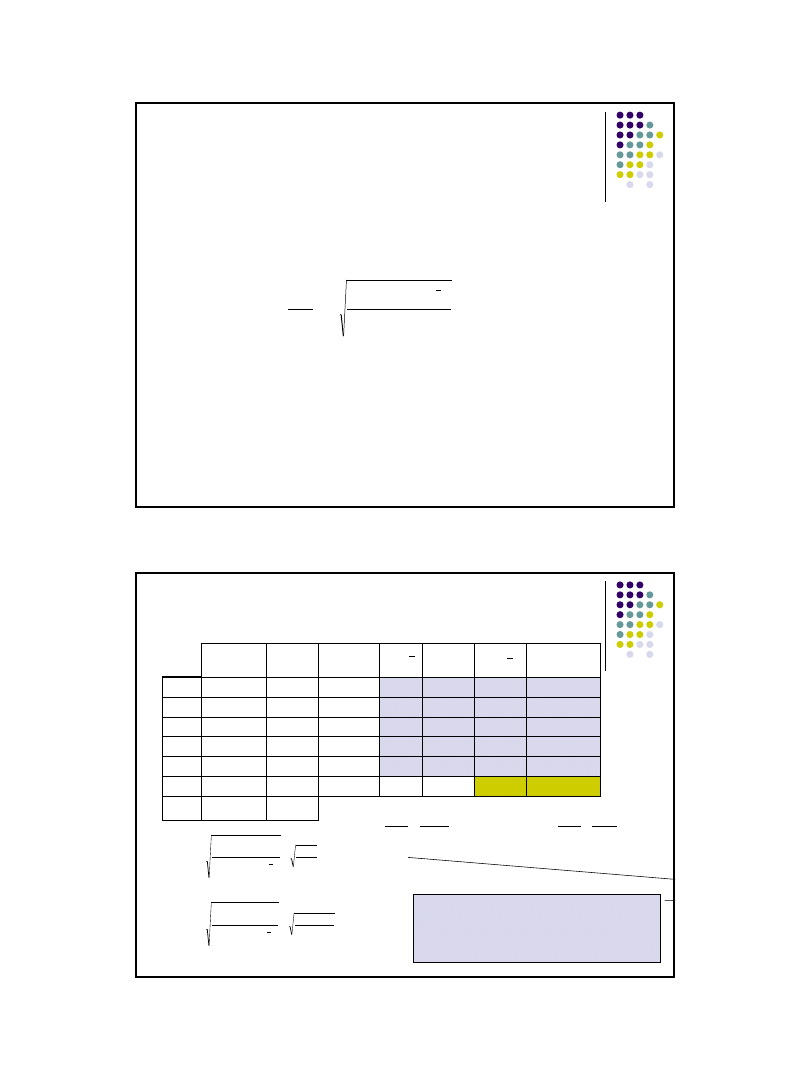
Hipotezy o istotności współczynnika regresji
Weryfikacja hipotezy o istotności wyrazu wolnego
Hipoteza H
0
:
β
1
= 0 wobec H
1
:
β
1
≠ 0 (H
1
:
β
1
≥ 0 lub H
1
:
β
1
≤ 0 )
Statystyka:
ma rozkład t-Studenta o s=n-2 stopniach swobody
Weryfikacja hipotezy
jeżeli | t | ≥ t
α,n-2
to hipotezę H
0
należy odrzucić,
jeżeli | t | < t
α,n-2
to nie ma podstaw do odrzucenia hipotezę H
0
,
n
i
i
i
n
i
i
n
i
i
y
y
x
x
x
k
n
n
b
b
D
b
t
1
2
1
1
2
ˆ
*
*
*
*
)
(
20
Istotność parametrów funkcji regresji - przykład
Wniosek:
Zarówno parametr a jak i parametr b
wywierają statystycznie istotny wpływ na
zmienną objaśnianą,
Liczba
reklam x
i
Obroty
y
i
ŷ
i
y
i
-
ŷ
(y
i
-
ŷ)
2
1
3
115
114,375
-35
0,625
1225
,0391
2
5
140
138,125
-10
1,8751
100
3,516
3
7
155
161,875
5
-6,8751
25
47,266
4
7
160
161,875
10
-1,8751
100
3,516
5
8
180
173,75
30
6,254
900
39,063
Σ
2350
93,75
Śr.
6
150
y
y
i
2
i
y
y
n= 5
k= 2
397
,
1
16
*
3
75
,
93
*
ˆ
)
(
1
2
1
2
n
i
i
n
i
i
i
x
x
k
n
y
y
a
D
75
,
8
16
*
3
*
5
196
*
75
,
93
ˆ
)
(
1
2
1
1
2
2
n
i
i
n
i
n
i
i
i
i
x
x
k
n
n
x
y
y
b
D
T
α,n-2
= 3,182
0
,
9
75
,
8
75
,
78
)
(
b
D
b
t
b
49
,
8
397
,
1
875
,
11
)
(
a
D
a
t
a
2013-05-28
11
21
Badanie losowości odchyleń losowych
Założenia:
daną populację generalną bada się ze względu na dwie cechy X i Y,
wylosowano n
elementów otrzymując wyniki (x
i
, y
i
),
należy zweryfikować hipotezę, że funkcja regresji cechy Y względem X w
populacji jest liniowa, tzn. jest postaci y =
αx + β.
Hipoteza:
H
0
:rozkład składnika losowego jest losowy wobec
H
1
:rozkład składnika losowego nie jest losowy
Sposób postępowania:
Określić liczbę reszt dodatnich n
1
i ujemnych n
2
(reszty =0 pomija się),
Określić liczbę serii s reszt dodatnich i ujemnych
Statystyka:
Dla n ≤ 20 – liczba serii s
wartość krytyczna – tablice serii
Dla n ≤ 20 – statystyka u - rozkład N(0,1)
1
1
2
2
1
2
2
2
1
2
1
2
1
n
n
n
n
n
n
n
n
n
n
s
u
22
Hipoteza o istnieniu związku liniowego między zmienną
X i Y
Hipoteza:
H
0
: R
2
= 0 wobec H
1
: R
2
≠ 0
Statystyka:
ma rozkład F Fishera-Snedecora o m
1
= 1 i m
2
= n-2 stopniach swobody
Weryfikacja hipotezy:
Jeżeli F < F
α
– to nie ma podstaw do odrzucenia hipotezy H
0
2
ˆ
ˆ
1
2
1
2
n
y
y
y
y
F
n
i
i
i
n
i
i
2013-05-28
12
23
Badanie normalności rozkładu składnika losowego
Stosuje się testy nieparametryczne, które określają stopień
zgodności rozkładu reszt z rozkładem normalnym
Hipoteza:
H
0
: rozkład reszt jest normalny wobec
H
1
: rozkład reszt nie jest rozkładem normalnym
Stosowane testy:
dla małych prób – test Hellwiga
dla dużych prób – test λ-Kołmogorowa
24
Test Hellwiga
Sposób postępowania:
Uporządkować reszty e
t
(t = 1, … , n) w ciąg niemalejący,
Standaryzować reszty wg wzoru:
gdzie: s
– odchylenie standardowe reszt
Każdej wartości e
i
’ przypisać wartość dystrybuanty rozkładu normalnego F
i
,
Odcinek [ 0 ,1 ] podzielić na n równych części, tzw. cel (tzn.obliczyć d=1/n
i utworzyć n przedziałów o długości d),
Statystyka:
Wyznaczyć liczbę k cel, do których nie trafiła żadna wartość F
i
(liczbę cel
pustych),
Weryfikacja hipotezy:
Odczytać z tablic testu Hellwiga dla zadanego poziomu istotności α wartości
krytyczne k
1
i k
2
,
Jeżeli k
1
< k < k
2
to nie ma podstaw do odrzucenia H
0
s
e
e
i
i
'
2013-05-28
13
25
Test Hellwiga -
przykład
e
i
=y
i
-
ŷ
i
e
i
'
F
i
(e
i
’)
d=1/n
Cela
0-pusta
-6,875
-1,420
0,078
0,2
1
-1,875
-0,387
0,349
0,4
1
0,625
0,129
0,551
0,6
1
1,875
0,387
0,651
0,8
1
6,25
1,291
0,902
1
1
s = 4,84
Liczba cel pustych k = 0
Dla n = 5 k
1
= 0 k
2
= 3
Wniosek:
Ponieważ k
1
<k<k
2
nie ma podstaw do
odrzucenia hipotezy, że rozkład przyrostów
trendu jest rozkładem normalnym
26
Funkcje Excela
CZĘSTOŚĆ(lista_zakres;lista przedziały) – formuła tablicowa,
REGLINP
(znane_y;znane_x;stała,statystyka) – formuła tablicowa
gdzie:
znane_y
– wartości zmiennej objaśnianej Y,
znane_x -
wartości zmiennej objaśniającej X,
stała – wartość logiczna, czy ma być szacowany model z wyrazem
wolnym (jeśli tak, to argument można pominąć),
statystyka
– wartość logiczna określająca czy mają być zwracane
statystyki regresji,
Formuła tablicowa - zaznaczony obszar akceptować (Shift+Crlt+Enter)
Ocena a
k
Ocena a
k+1
……
Ocena a
0
Błąd oceny a
k
= D(a
k
)
Błąd oceny a
k+1
=d(a
k+1
)
Błąd oceny a
0
Współczynnik
determinacji R
2
Odchylenie standardowe
składnika resztowego S
e
Statystyka Fishera F
Liczba stopni swobody
Regresyjna suma
kwadratów Σ(ŷ
i
-y
śri
)
2
Resztowa suma kwadratów
Σ(y
i
-
ŷ
i
)
2
2013-05-28
14
27
Oznaczenia sum i błędów
całkowita suma kwadratów SS
Y
suma kwadratów błędów SSE
suma kwadratów odchyleń
regresyjnych SSR
współczynnik determinacji R
2
statystyka F
n
i
i
y
y
SSE
1
2
n
i
i
y
y
SSR
1
2
n
i
i
Y
y
y
SS
1
2
Y
Y
SS
SSE
SS
SSR
R
1
2
2
1
1
n
SSE
SSR
MSE
MSR
F
Wyszukiwarka
Podobne podstrony:
10 regresja
MP 10
MP 10-11 Z dz w0. Istota MP
10 regresja
test MP 10 2003, medycyna, Testy do egzaminu z chorób wewnętrznych, Testy MP
test MP 10 2001, medycyna, Testy do egzaminu z chorób wewnętrznych, Testy MP
MP 10 Z inz dz s3 cw Wyt z3 Nieznany
MP 10 Z dz inz s3 w 3 Marketing zakupów
MP 10 Z inz dz s3 cw progr Nieznany
10 Regresso
MP 10-11 Z dz cw karta przedmiotu
MP 10 Z inz dz s3 cw Z1 prez Nieznany
mp 4 10 wykres
MP 10 Z dz inz s3 w 2 Otoczenie rynkowe
10 regresja liniowa prim, Parametry dwuwymiarowych zmiennych losowych
mp 4 10
więcej podobnych podstron