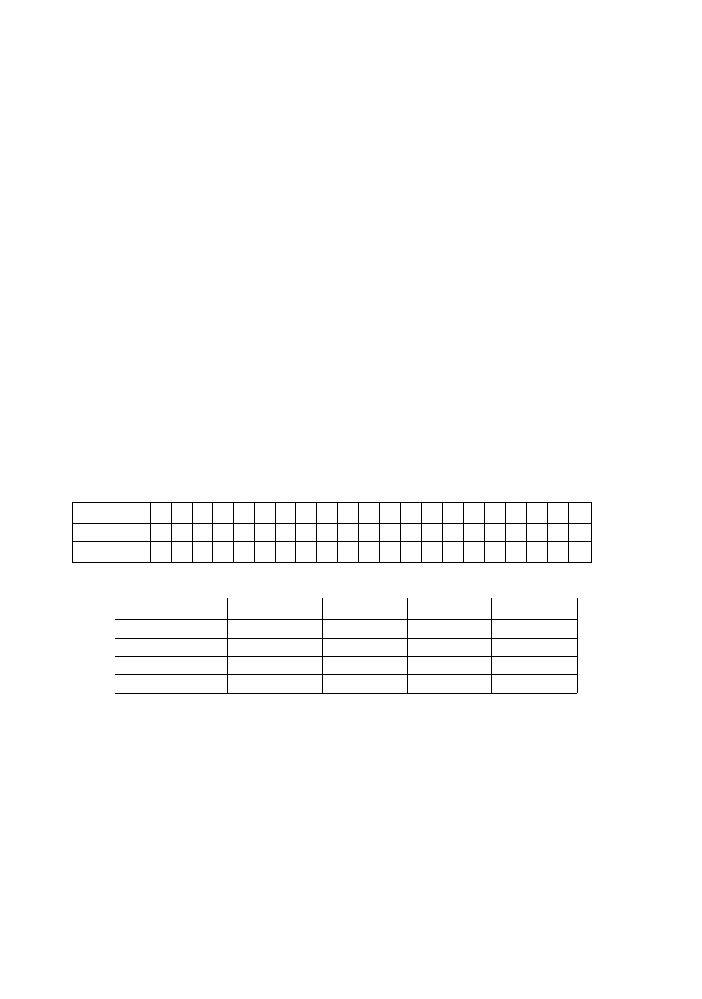
ROZDZIAŁ 6
SZEREGI ROZDZIELCZE
I. Pojęcia wstępne
Tablice liczebności (freąuence tables) stanowią najprostsze i najczęściej używane
narzędzie do wstępnej analizy danych jakościowych (danych w skali nominalnej).
Umożliwiają one pogrupowanie danych według przyjętych kategorii dla ich
uporządkowania i znalezienia interesujących różnic. Można też pogrupowane dane
przedstawić graficznie w postaci histogramu. Tablice liczebności informują o tym, jak
często pojawiają się określone warianty analizowanej cechy w całym zbiorze danych.
Oczywiście wszystkie metody grupowania można zastosować też do zmiennych
ilościowych.
Przykład 1
Wysunięto przypuszczenie, że palenie papierosów i picie kawy wpływa na ostrzejszy
przebieg pewnej choroby.
Z populacji chorych na tę chorobę wylosowano więc 21 pacjentów (10 kobiet, 11
mężczyzn) i przeprowadzono wśród nich ankietę na temat palenia papierosów i picia kawy.
Dla każdej używki (papierosy, kawa) wprowadzono następującą skalę:
duże ilości (1), średnio (2), małe ilości (3), nigdy nie używano (4). Wyniki były
następujące:
Płeć
M M K M K M M K M K K M K M M K K K K M M
Papierosy
1 1 4 1 3 1 1 1 1 2 1 1 1 1 1 4 4 1 1 1 2
Kawa
1 1 1 1 1 1 2 1 3 4 4 1 2 1 1 1 1 1 3 2 2
Tablica liczebności dla naszego przykładu przyjmuje postać:
Papierosy
Procenty
Kawa
Procenty
Duże ilości
15
71,4
13
62
Średnio
2
9,5
4
19
Małe ilości
1
4,8
2
9,5
Nigdy
3
14,3
2
9,5
Histogramy liczebności (dla pijących kawę i palących papierosy) utworzone przy pomocy
powyższej tablicy przedstawiają poniższe rysunki:
109

Przystępny kurs statystyki
Rys. 6.1 Histogram liczebności palaczy Rys. 6.2 Histogram liczebności dla pijących kawę
Można też narysować histogramy osobno dla mężczyzn i kobiet, podpowiadające
wystąpienie zależności od płci w rozważanym problemie. Tak jest w naszym przykładzie.
Histogramy dla mężczyzn i kobiet wykazują interesujące różnice warte dalszej analizy
statystycznej.
Histogram: PAPIEROS
Rys. 6.3 Histogram dla palaczy w zależności od płci
Konstrukcja powyższej tablicy nie nastręczała praktycznie żadnych trudności. Inaczej
przedstawia się sprawa, gdy liczba wariantów cechy jest duża lub cecha jest mierzalna.
W takim przypadku tworząc tablicę liczebności dla zmiennej, musimy ustalić wiele
parametrów - liczbę przedziałów (klas), rozpiętość przedziałów oraz ustalić granicę dolną
pierwszego przedziału lub granice klas. Wymaga to zastanowienia - jak wyglądają nasze
dane i co chcemy osiągnąć. Przy różnych parametrach bowiem otrzymamy różne
wynikowe tabele i histogramy.
110
Szeregi rozdzielcze
Przykład 2
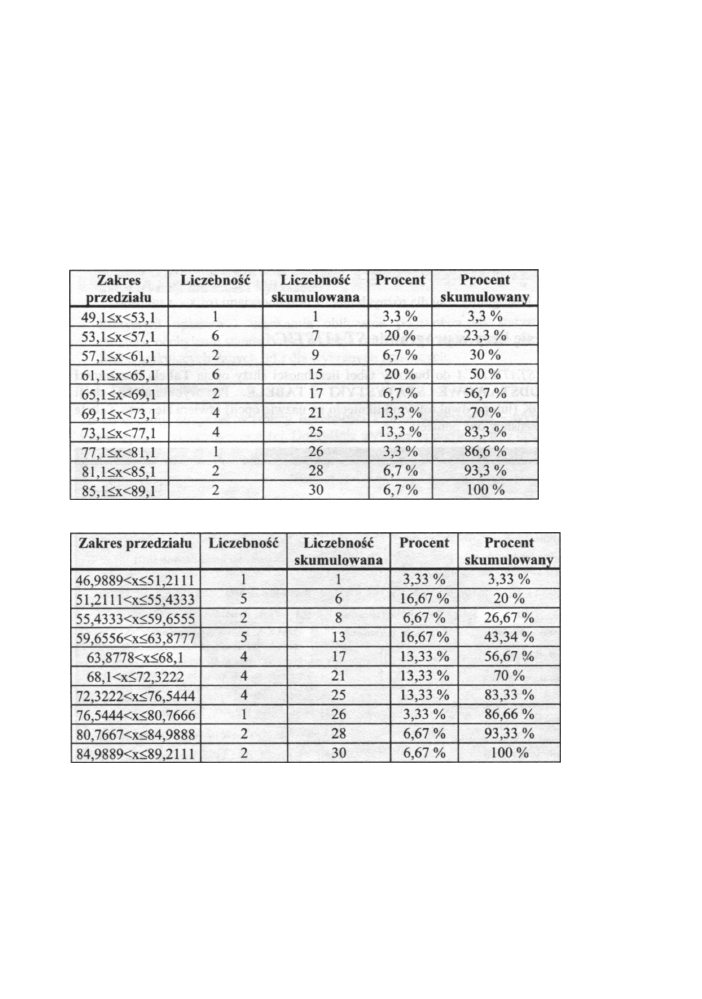
Z populacji mężczyzn pewnego województwa wybrano losowo 30 osób i określono ich
wagę z dokładnością do 0,1 kg Otrzymano następujące dane liczbowe: 49,10; 54,50; 63,00;
64,60; 69,50; 74,40; 79,40; 85,80; 53,20; 55,40; 61,50; 65,00; 70,00; 75,00; 82,10; 87,10;
54,00; 54,10; 62,20; 65,60; 70,40; 75,90; 83,80; 56,30; 63,40; 66,70; 71,60; 75,20; 58,40;
60,90.
Otrzymane dane możemy na szereg sposobów przedstawić w postaci tablicy
liczebności. Poniżej przedstawiamy, dla rozpatrywanych danych, dwie różne tablice
liczebności oraz odpowiadające im histogramy.
Pierwsza tabela liczebności
Druga tabela liczebności
111
Przystępny kurs statystyki
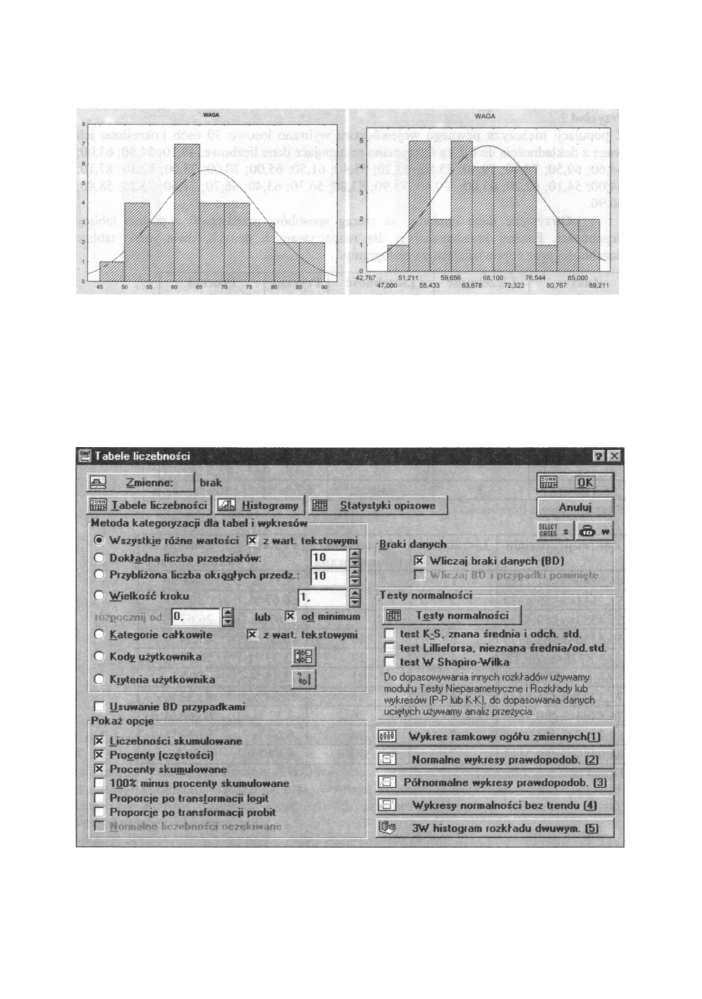
Rys. 6.5 Histogramy wag dla różnych tabel z liczebnościami (oś x - wagi osób)
II. A jak to się liczy w programie STATISTICA
W programie STATISTICA do budowy tabel liczebności służy opcja Tabele liczebności
w module PODSTAWOWE STATYSTYKI I TABELE. Po wybraniu tej opcji
i naciśnięciu OK (lub po dwukrotnym kliknięciu na nazwie opcji) otwiera się okno Tabele
liczebności przedstawione poniżej:
Rys. 6.6 Okno dialogowe Tabele liczebności
112

Szeregi rozdzielcze
Na górze okna mamy przycisk Zmienne, otwierający okno dialogowe wyboru zmiennych
do analizy. Dokładne opisanie sposobu wyboru zmiennych do analizy znajdziemy
w rozdziale trzecim.
Poniżej mamy trzy przyciski uruchamiające (po wyborze zmiennych) interesującą
nas procedurę obliczeniową:
• Tabele liczebności - uruchamia procedurę tworzenia tabel liczebności dla wybranych
zmiennych według wybranego przez nas sposobu.
• Histogramy - uruchamia procedurę rysowania histogramów dla wybranych zmiennych.
Umożliwia ona graficzną prezentację szeregu rozdzielczego wraz z jego klasami za
pomocą zbioru słupków. Postać histogramu zależy od opcji wybranych w polu Metoda
kategoryzacji dla tabel i wykresów.
• Statystyki opisowe - uruchamia obliczanie podstawowych statystyk opisowych
(średnia, odchylenie standardowe, wartość minimalna i maksymalna, liczebność próby,
liczba brakujących danych itd.) dla wybranych zmiennych.
II.1. Tabele liczebności
To co chcemy otrzymać w tablicy liczebności - poza liczebnością - wybieramy w polu
Pokaż opcje - widocznym poniżej. Domyślnie wybrane są pierwsze trzy opcje.
113
Poszczególne opcje w tym polu umożliwiają (po ich wybraniu):
• Liczebności skumulowane - wyliczenie liczebności skumulowanych (liczebność danej
klasy i wszystkich wcześniejszych).
• Procenty - obliczenie procentów względem wszystkich przypadków (uwzględniając
lub nie brakujące dane w zależności od ustawień w polu Braki danych).
• Procenty skumulowane - wyliczenie procentów skumulowanych.
• 1 0 0 % minus procenty skumulowane - odejmuje od 100% poprzednio obliczone
procenty skumulowane.
• Proporcje po transformacji logit - wyliczenie logitowej transformacji skumulowanej
proporcji. Oznaczmy przez p
i
wartość skumulowanej proporcji dla i-tej klasy. Wówczas
przekształcenie logitowe definiujemy jako:
Przystępny kurs statystyki
• Proporcje po transformacji probit - wyliczenie probitowej transformacji
skumulowanej proporcji. Przekształcenie probitowe jest definiowane jako normalna
wartość skojarzona z prawdopodobieństwem równym skumulowanej proporcji
obserwacji. Innymi słowy: dla dowolnego procentu p wartość transformacji probitowej
to taka liczba, że na lewo od niej znajduje się p - ta część powierzchni zawartej pod
krzywą standaryzowanego rozkładu normalnego.
• Normalne liczebności oczekiwane - wyliczenie oczekiwanych frekwencji bazujące na
normalnym rozkładzie.
Przykład 3
Dla wielu zbiorów danych można z kontekstu domyślić się, jaką metodę analizy trzeba
zastosować. Zagadnienie komplikuje się, gdy obserwacjami podstawowymi są frakcje
(procenty, częstość). W wielu medyczno-biologicznych badaniach (skuteczność leków,
szkodliwość środków trujących) uzyskujemy dane w postaci frakcji. Frakcje te wypełniają
cały przedział od 0 do 1.
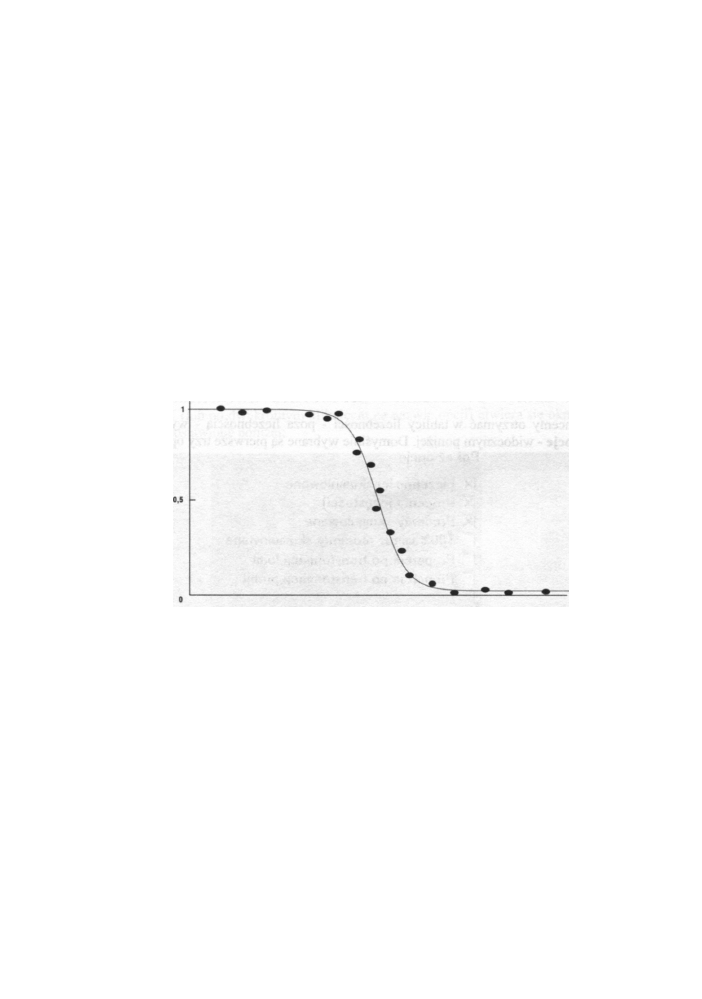
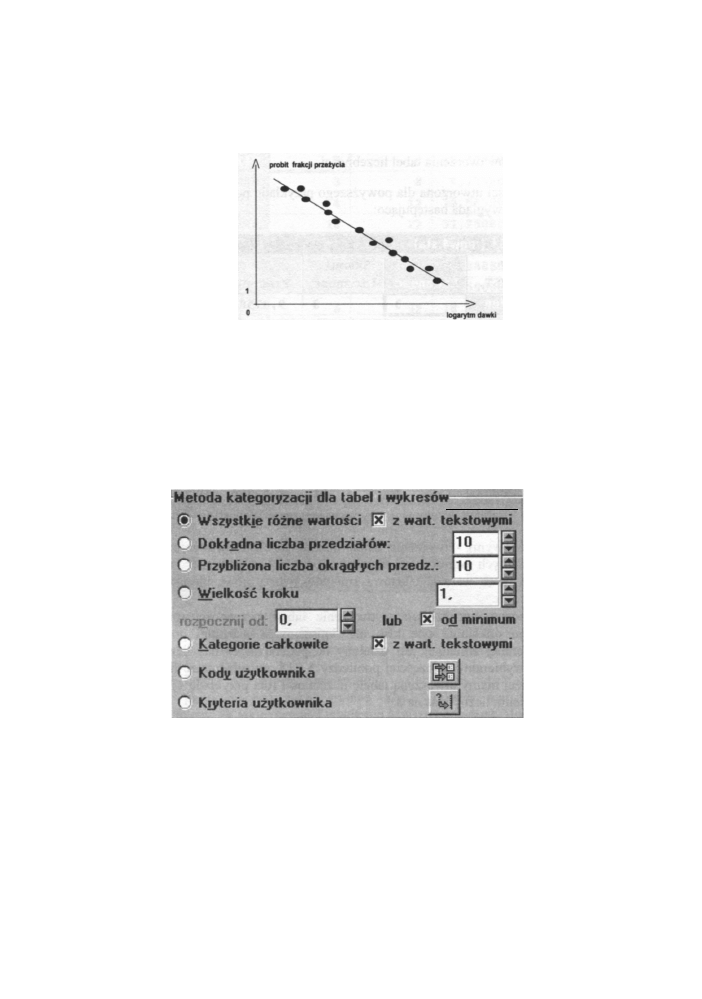
Rys. 6.8 Skuteczność pewnej trutki wraz z dopasowaną sigmoidalną krzywą regresji
Przykładowo, chcemy obliczyć pięćdziesięcioprocentowa dawkę śmiertelną pewnej
trucizny na szkodniki. W tym celu zwierzęta doświadczalne podzielono na równoliczne
grupy, a następnie każdej grupie podano truciznę w innym stężeniu. Po upływie pewnego
czasu oznaczono w każdej grupie frakcję zwierząt, które przeżyły. Dla małych stężeń
częstość ta wynosiła 1, a dla dużych 0. Przy stężeniach pośrednich frakcje układają się
w przybliżeniu wzdłuż tzw. krzywej sigmoidalnej (rysunek 6.8).
Dalsze badania danych przeprowadza się po wstępnym przekształceniu frakcji w celu
linearyzacji zależności i stabilizacji wariancji. Najbardziej popularne są dwa
przekształcenia - logitowe i probitowe. Dają one podobne wyniki.
Przekształcenie logitowe dobrze linearyzuje krzywe sigmoidalne, ale nie stabilizuje
wariancji.
Przekształcenie probitowe, mimo że bardziej skomplikowane, cieszy się większą
popularnością wśród medyków i biologów. Przekształcenie to również dobrze linearyzuje
krzywe sigmoidalne, przy czym końce skali są rozciągnięte bardziej niż jej środek. Gdy
114
Szeregi rozdzielcze
pjest 0 lub 1 wartość przekształcenia przyjmuje wartości nieskończone. Wynik
przekształcenia probitowego dla naszego przykładu (trutka na szkodniki) wygląda jak na
rysunku poniżej.
/ \ probit frakcji przeżycia
0
logarytm dawki
Rys. 6.9 Przekształcenie probitowe dla wyznaczenia „50 % - owej dawki śmiertelnej"
Wykorzystując następnie analizę regresji, można znaleźć 50 % dawkę śmiertelną.
11.2. Sposób tworzenia tabel
Sposób tworzenia tabel liczebności i histogramu wybieramy w polu Metoda kategoryzacji
dla tabel i wykresów. Domyślnie ustawiona jest pierwsza opcja. Pozostałe widzimy na
poniższym rysunku:
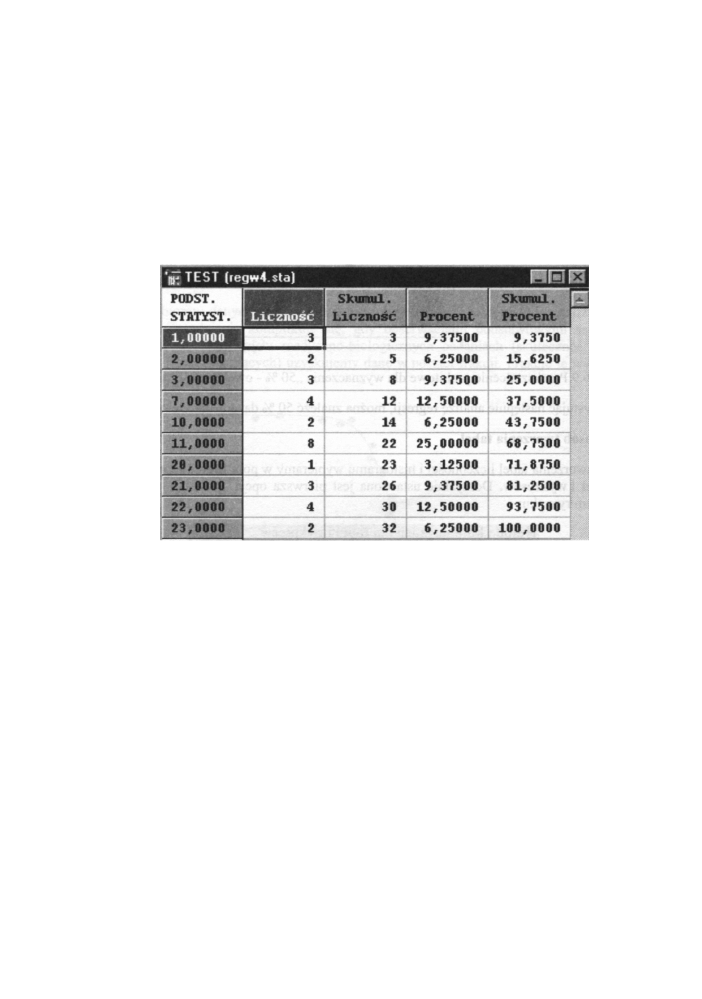
Metoda kategoryzacji dla tabel i wykresów ^
(i
W s z y s t k i e różne wartości [x z wart. tekstowymi
O
D o k ł a d n a l i c z b a przedziałów:
C
Przybliżona liczba o k r ą g ł y c h przędz.
C
W i e l k o ś ć kroku
Rys. 6.10 Pole dialogowe metoda kategoryzacji dla tabel i wykresów
Poszczególne opcje tego pola umożliwiają (po ich wybraniu):
• Wszystkie różne wartości - tworzenie tabeli liczebności (oraz histogramu) bazującej
na wszystkich różnych wartościach dla każdej wybranej zmiennej. Innymi słowy, każda
nowa wartość zmiennej tworzy nową klasę w konstruowanej tabeli liczebności. Klasy
utworzą wszystkie warianty cechy (wybranej zmiennej). Ta metoda kategoryzacji jest
domyślnie wybrana.
115
Przystępny kurs statystyki
Przykład 4
Przeprowadzono pewien tekst psychologiczny w grupie 32 osób. Wyniki tego testu
(w punktach) są następujące: 7, 1, 11, 11, 7, 11, 3, 1, 2, 21, 1, 11, 10, 7, 22, 21, 10, 22,
2, 20, 11, 3, 22, 23, 11,3, 11, 23, 7, 21, 11, 22. Dane te posłużą nam do zobrazowania
różnych sposobów tworzenia tabel liczebności.
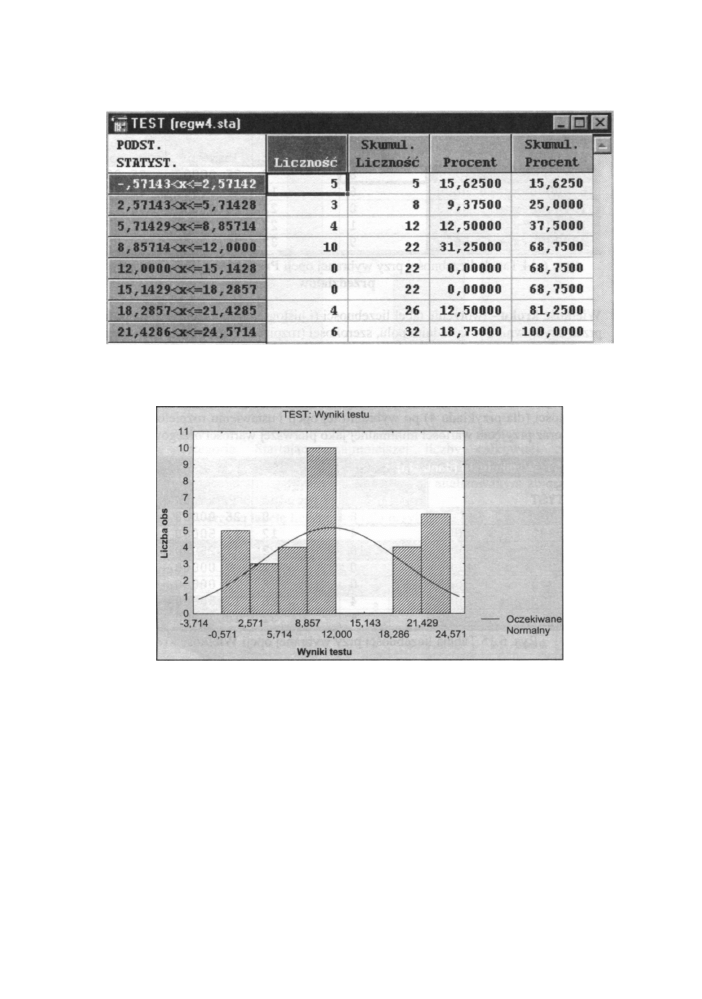
Tabela liczebności utworzona dla powyższego przykładu po wybraniu opcji Wszystkie
różne wartości wygląda następująco:
Rys. 6.11 Tablica liczebności przy wybranej opcji Wszystkie różne wartości
• Z wart. tekstowymi - tworzenie tabeli liczebności (oraz histogramu) bazującej na
wszystkich różnych wartościach tekstowych dla każdej wybranej zmiennej. Innymi
słowy, każda nowa wartość tekstowa zmiennej tworzy nową klasę w konstruowanej
tabeli liczebności.
• Dokładna liczba przedziałów - tworzenie tabeli liczebności (oraz histogramu)
przyjmującego dokładnie tyle klas, ile wpiszemy w sąsiednim polu. Cały zakres
wartości wybranej zmiennej jest dzielony na podaną przez nas liczbę przedziałów.
Liczbę klas wybieramy najczęściej pomiędzy 5 i 15, uwzględniając liczebność zbioru
danych. Poniżej mamy utworzoną tabelę liczebności (dla przykładu 4) po wybraniu tej
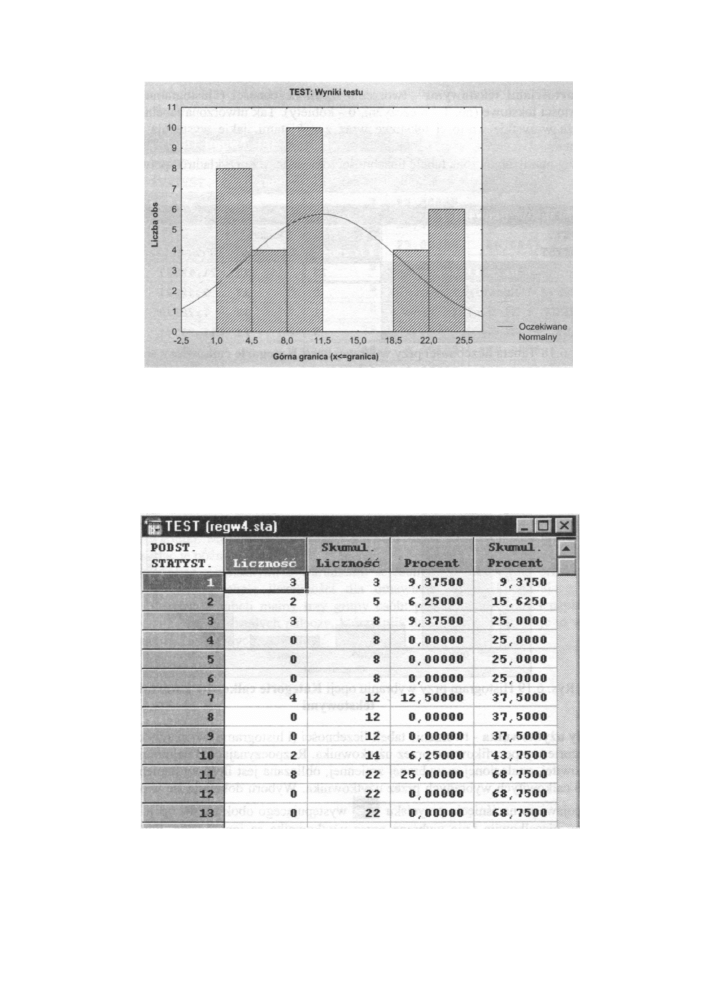
opcji i ustawieniu liczby klas na 8.
116
Szeregi rozdzielcze
Rys. 6.12 Tabela liczebności przy wybranej opcji Dokładna liczba przedziałów
A tak wygląda histogram (dla naszego przykładu) utworzony po wybraniu tej opcji:
Wyniki testu
Rys. 6.13 Histogram przy wybraniu opcji Dokładna liczba przedziałów
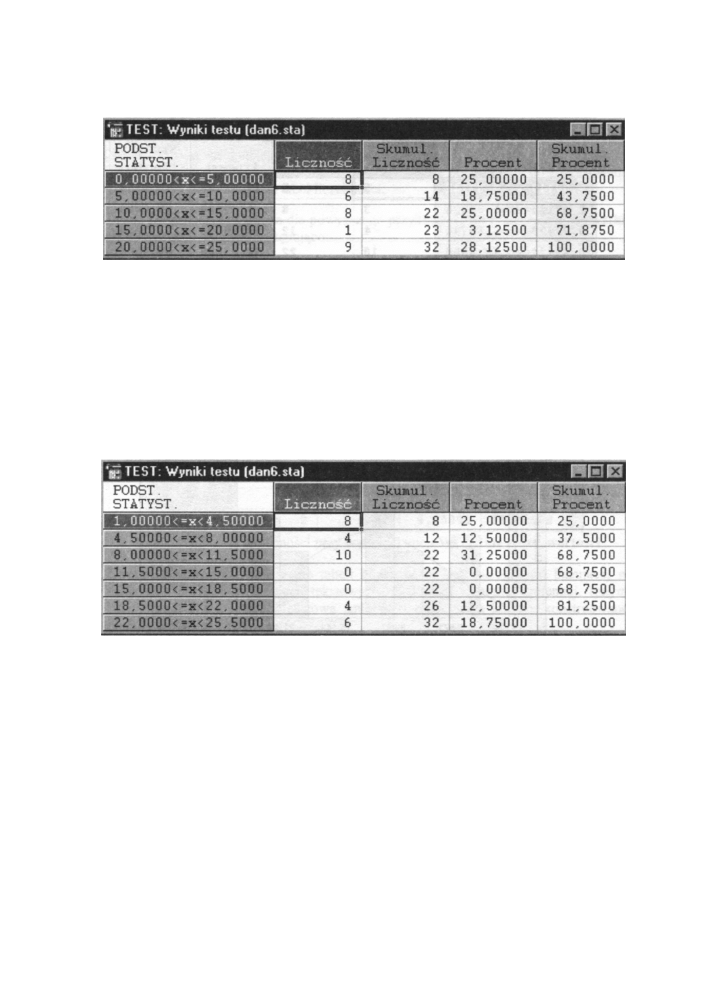
• Przybliżona liczba okrągłych przedziałów - tworzenie tabeli liczebności (oraz
histogramu) przyjmującego jako granice klas i zakresy przedziałów prostsze
zaokrąglone liczby. W takiej sytuacji tabele nie zawsze będą miały dokładnie taką ilość
przedziałów, jaką podaliśmy w sąsiednim polu. Poniżej mamy utworzoną tabelę
liczebności (dla przykładu 4) po wybraniu tej opcji i ustawieniu liczby klas na 8
(w tabeli otrzymaliśmy tylko 5 klas).
117
Przystępny kurs statystyki
Rys. 6.14 Tabela liczebności przy wybranej opcji Przybliżona liczba okrągłych
przedziałów
• Wielkość kroku - tworzenie tabel liczebności (i histogramów) bazujących na podanym
przez użytkownika w sąsiednim polu, szerokości (rozpiętości) przedziału klasowego.
• Rozpocznij od minimum - jeśli ta opcja będzie wybrana, wówczas pierwszą wartością
brzegową w tworzonej tabeli liczebności będzie najmniejsza wartość wybranej
zmiennej. Jeśli ta opcja nie jest wybrana, wówczas użytkownik ma możliwość podania
pierwszej wartości brzegowej w okienku obok. Poniżej mamy utworzoną tabelę
liczebności (dla przykładu 4) po wybraniu tej opcji i ustawieniu rozpiętości przedziału
na 3,5 oraz przyjęciu wartości minimalnej jako pierwszej wartości brzegowej.
Rys. 6.15 Tabela liczebności przy wybranej opcji Wielkość kroku
A tak wygląda histogram (dla naszego przykładu) utworzony po wybraniu tej opcji:
118
Szeregi rozdzielcze
Rys. 6.16 Histogram przy wybraniu opcji Wielkość kroku
• Kategorie całkowite - tworzenie tabeli liczebności (i histogramu) w oparciu
o całkowite kategorie. Startując z najmniejszej liczby całkowitej znalezionej
w wybranej zmiennej obliczana jest ilość wystąpień kolejnych liczb całkowitych. Klasy
utworzą wszystkie całkowite wartości znajdujące się w analizowanym zbiorze danych.
Wszystkie liczby niecałkowite są ignorowane.
Poniżej mamy utworzoną tabelę liczebności (dla przykładu 4) po wybraniu tej opcji.
Rys. 6.17 Tabela liczebności przy wybranej opcji Kategorie całkowite
119
Przystępny kurs statystyki
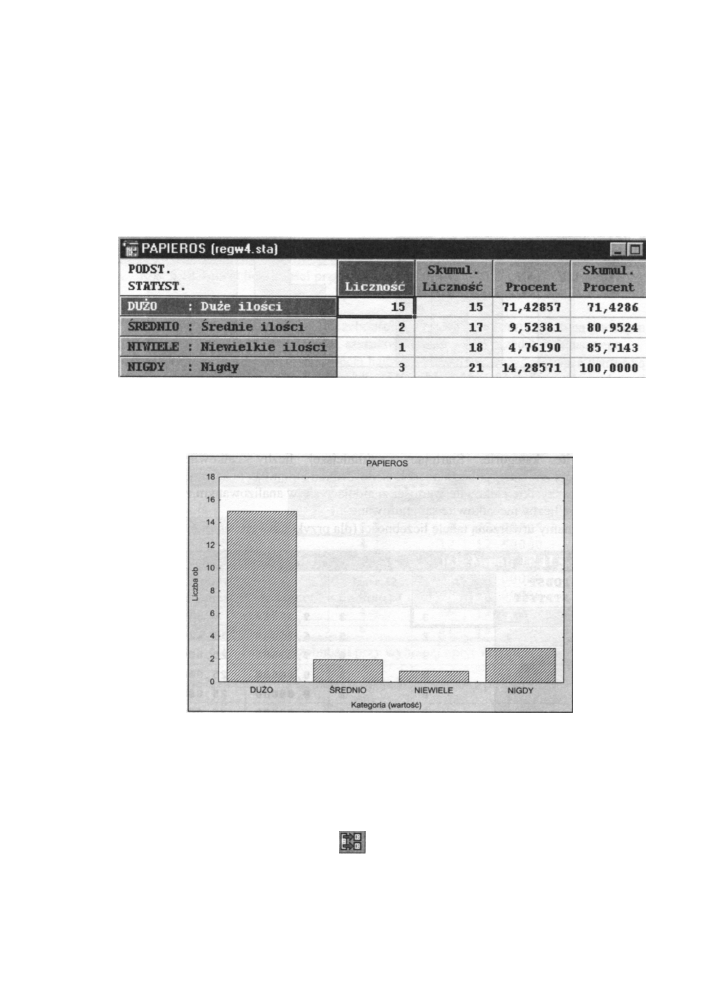
• Z wartościami tekstowymi - tworzenie tabeli liczebności (i histogramu) w oparciu
o wartości tekstowe (np. 1 - mężczyźni, 0 - kobiety). Tak utworzona tabela liczebności
pokaże wszystkie wartości tekstowe wraz z etykietami, jakie występują w wybranej
zmiennej.
Poniżej mamy utworzoną tabelę liczebności (dla palaczy z przykładu 1) po wybraniu tej
opcji.
Rys. 6.18 Tabela liczebności przy wybranej opcji Kategorie całkowite z wartościami
tekstowymi
A tak wygląda histogram (dla naszego przykładu) utworzony po wybraniu tej opcji:
Rys. 6.19 Histogram przy wybraniu opcji Kategorie całkowite z wartościami
tekstowymi
• Kody użytkownika - tworzenie tabeli liczebności (i histogramu) w oparciu o całkowite
kategorie wyspecyfikowane przez użytkownika. Rozpoczynając od najmniejszej liczby
całkowitej, znalezionej w wybranej zmiennej, obliczana jest ilość wystąpień kolejnych
liczb całkowitych wybranych przez użytkownika. Wyboru dokonuje się w oknie, które
120
się pojawi po naciśnięciu przycisku
występującego obok nazwy opcji. Wszystkie
liczby niecałkowite i nie wybrane przez użytkownika są ignorowane. Poniżej mamy
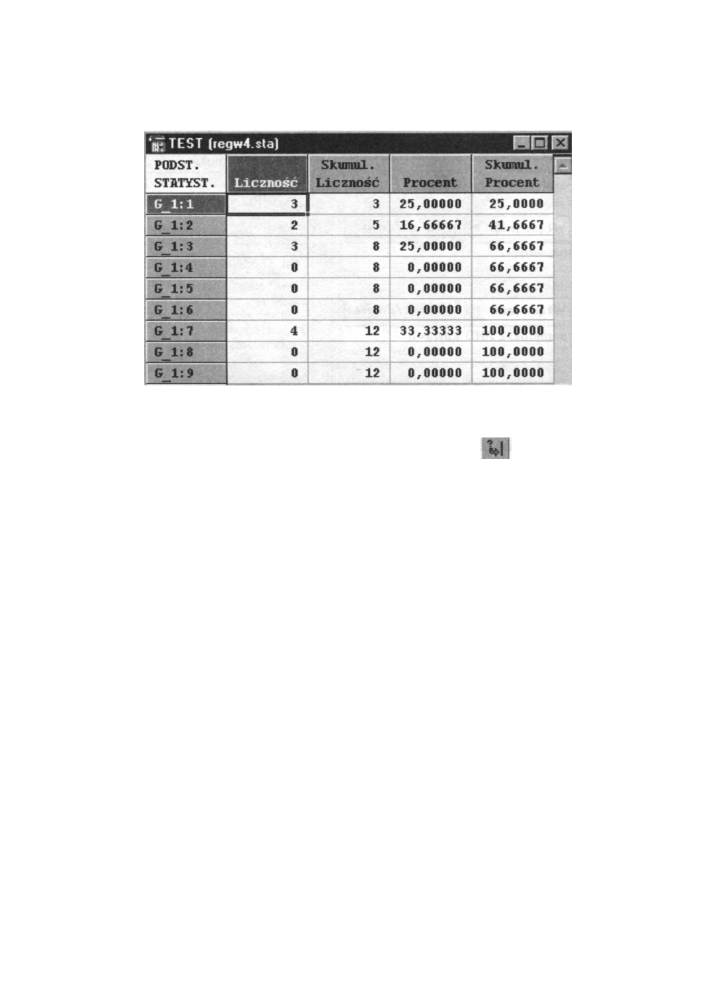
Szeregi rozdzielcze
utworzoną tabelę liczebności (dla przykładu 4) po wybraniu tej opcji (wybrane zostały
kody od 1 do 9).
Rys. 6.20 Tabela liczebności przy wybranej opcji Kody użytkownika
aż 16 logicznych warunków selekcji przypadków definiujących 16 kategorii w tabeli
liczebności. Warunki te mogą być złożone i odwoływać się do kilku zmiennych. Dla
każdego przypadku w pliku danych warunki selekcji wykonywane są sekwencyjnie
i przypadek ten jest przyporządkowywany do pierwszej kategorii w której spełnia
logiczne warunki. Możemy także podane warunki zapamiętać na dysku lub dyskietce
i wykorzystać je później.
Poniżej mamy okno z wpisanymi 3 warunkami selekcji przypadków (dla przykładu 1),
a następnie utworzoną tabelę liczebności dla omawianej opcji (korzystającej z tych
warunków selekcji). W tabeli mamy trzy grupy osób: palących duże ilości papierosów,
palących średnio oraz pozostałych palaczy, którzy piją duże ilości kawy. Daje to w sumie
liczbę wszystkich testowanych pacjentów.
121
• Kryteria użytkownika - tworzenie tabeli liczebności (oraz histogramu) w oparciu
o kategorie wyspecyfikowane przez użytkownika. Możemy dokonać selekcji
przypadków w oknie wywołanym przez naciśnięcie przycisku
Możemy wybrać
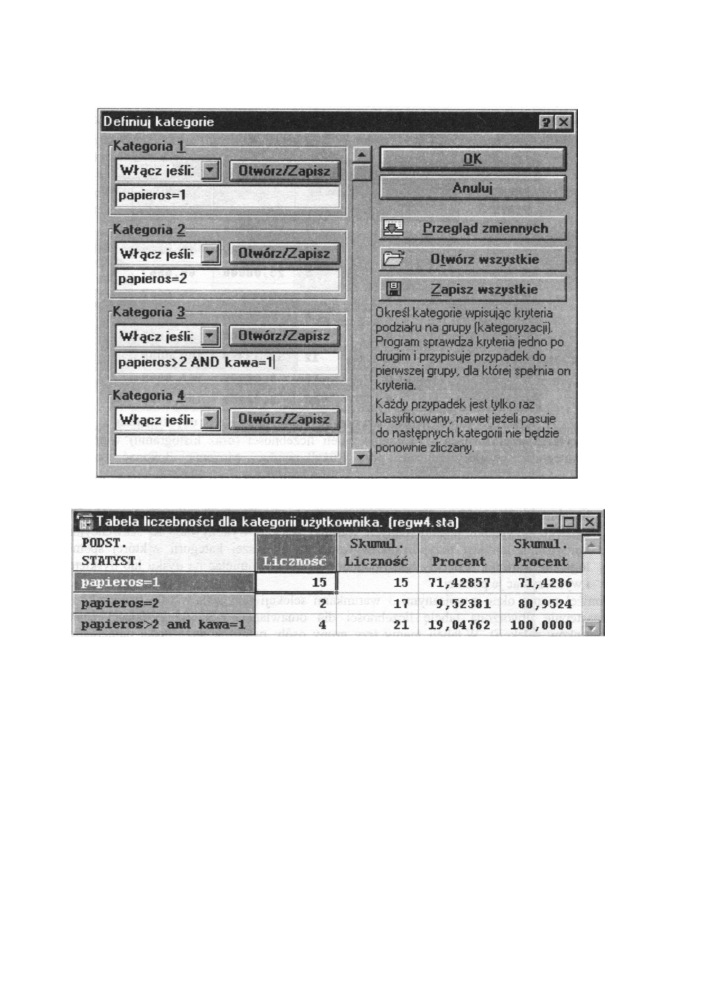
Przystępny kurs statystyki
Rys. 6.21 Okno do definiowania kategorii
Rys. 6.22 Tabela liczebności przy wybranej opcji K r y t e r i a u ż y t k o w n i k a
I I . 3 . S p r a w d z i a n n o r m a l n o ś c i
W oknie Tabele liczebności mamy też możliwość sprawdzenia normalności rozkładu
wybranych zmiennych. Dokonujemy tego w polu T e s t y n o r m a l n o ś c i widocznym na
rysunku 6.23.
122

Szeregi rozdzielcze
Rys. 6.24 Okna z wynikami testu normalności
II. 4. Brakujące dane
O brakujących danych mówią nam trzy opcje:
• Usuwanie BD przypadkami - jeśli ta opcja jest włączona, wówczas z obliczeń są
wyłączone wszystkie przypadki z brakującymi danymi dla jakiejkolwiek wybranej
zmiennej. Wszystkie tabele liczebności dla różnych wybranych zmiennych tworzone są
dla takiej samej ilości przypadków. W przeciwnym wypadku z obliczeń wyłączane są
123
Rys. 6.23 Pole sprawdzianu normalności
Jeśli naciśniemy przycisk
wyświetlone zostaną dodatkowe okna
wynikowe z wynikami testów normalności rozkładu zmiennej. Możemy skorzystać
z trzech rodzajów testów: test Kołmogorowa-Smirnowa, test Lilieforsa oraz test Shapiro-
Wilka (ich dokładniejsze omówienie znajduje się w rozdziale Statystyka opisowa). Wyboru
dokonujemy przez wybranie nazwy testu lub zaznaczenie kwadracika obok nazwy.
Domyślnie wybierany jest test Lilieforsa. Poniższe okna przedstawiają wyniki testu
Lilieforsa i Shapiro-Wilka dla wartości zmiennej z przykładu 4. Obydwa testy
potwierdzają, że omawiana zmienna nie ma rozkładu normalnego (hipotezę normalności
można odrzucić nawet na poziomie istotności równym 0,0007).

Przystępny kurs statystyki
tylko te przypadki, w których brakuje danych dla konkretnej liczonej zmiennej
(otrzymane tabele mogą mieć różne liczebności dla różnych zmiennych).
• Wliczaj braki danych w polu Braki danych - po wybraniu tej opcji w wynikowej
tabeli liczebności pojawi się nowy wiersz (na końcu) z danymi dotyczącymi
brakujących przypadków. W takiej tabeli procenty i skumulowane procenty liczone są
z całkowitej liczby przypadków (łącznie z przypadkami z brakującymi danymi). Na
rysunku 6.18 mamy przykład takiej tabeli liczebności.
• Wliczaj BD i przypadki pominięte w polu Braki danych - po wybraniu tej opcji
w wynikowej tabeli liczebności pojawią się nowe wiersze (na końcu) z danymi
dotyczącymi brakujących przypadków i nie wybranych przypadków. W takiej tabeli
procenty i skumulowane procenty liczone są z całkowitej liczby przypadków (łącznie
z przypadkami niewybranymi i brakującymi danymi).
II. 5. Grafika
Przyciski - związane z graficzną interpretacją - umieszczone w prawej dolnej części okna
Frequency Tables umożliwiają:
124
- wywołanie okna do rysowania wykresów
ramkowych (skrzynek z wąsami - box and whisker) dla wybranych zmiennych;
- rysowanie wykresu normalnego dla wybranych
zmiennych;
- rysowanie wykresu półnormalnego dla wybranych
zmiennych;
- rysowanie wykresu normalności z eliminacją
trendu dla wybranych zmiennych;
- rysowanie trójwymiarowych histogramów dla
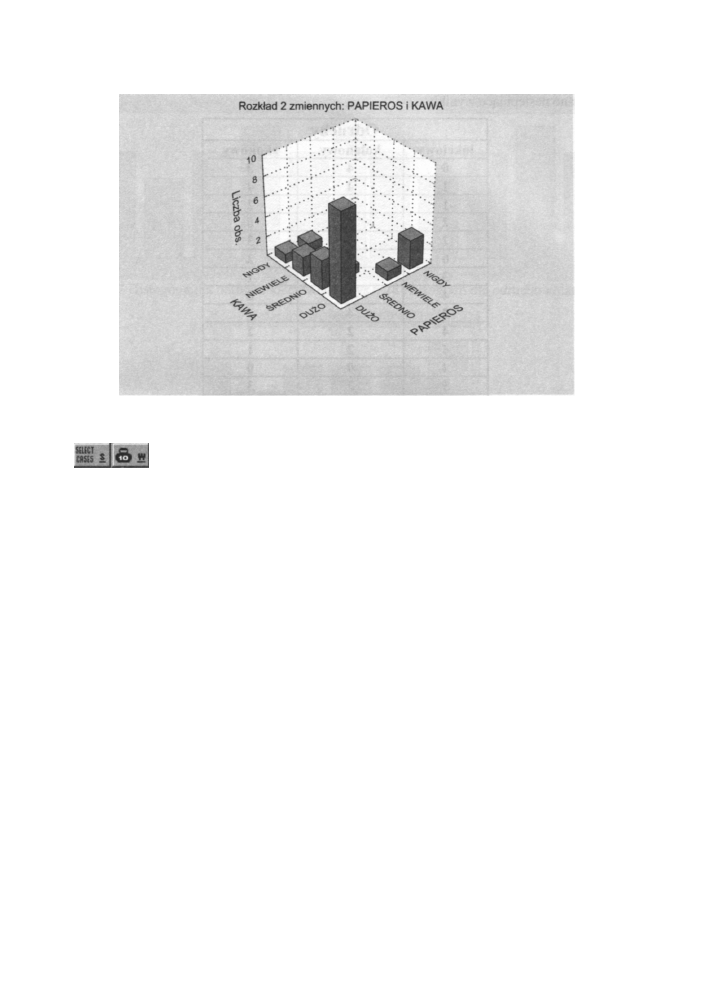
wybranych par zmiennych. Po naciśnięciu tego przycisku pokazuje się okno, w którym
wybieramy pary zmiennych. Poniższy rysunek pokazuje histogram dla zmiennych kawa
i papierosy z przykładu 1.
Szeregi rozdzielcze
szczegółowo wcześniej.
Po wybraniu zmiennych do analizy i ustawieniu odpowiednich opcji procedurę
obliczeniową uruchamiamy wykorzystując przycisk Tabele liczebności lub OK. Przycisk
Anuluj zamyka okno bez wykonania jakichkolwiek obliczeń.
Na zakończenie przeanalizujmy jeszcze jeden medyczny przykład tworzenia szeregu
rozdzielczego i histogramu.
Przykład 5
Wykonano badania neurologiczne dotyczące odruchów w grupie 20 chorych. W trakcie
oceniania przyjęto następującą skalę:
0 - brak, 1 - osłabiony, 2 - prawidłowy, 3 - wyraźny, 4 - wygórowany
125
Rys. 6.25 Trójwymiarowy histogram dla zmiennych papierosy i kawa
Podobnie jak w każdym z okien w programie
S T A T I S T I C A ,
tak i tutaj mamy przyciski
do ustawiania wag i selekcji przypadków. Okna te zostały omówione
Przystępny kurs statystyki
Otrzymano następujące wyniki:
Odruchy
łokciowy
kolanowy
skokowy
0
4
3
1
4
4
1
2
2
2
0
0
2
3
3
0
3
2
3
1
1
4
1
0
2
4
4
4
2
2
4
2
1
4
0
0
3
3
3
3
3
3
0
4
4
3
0
3
0
2
2
2
4
4
1
1
0
3
1
1
Wybierając w oknie Tabele liczebności opcję Wszystkie różne wartości z opcją
z wartościami tekstowymi otrzymujemy przykładowo dla odruchu łokciowego
następujący histogram:
Rys. 6.26 Szereg rozdzielczy dla 1 zmiennej z przykładu 5
A tak wyglądają histogramy dla opisywanych powyżej zmiennych (otrzymane po
naciśnięciu przycisku Histogramy):
126

Szeregi rozdzielcze
Rys.6.27 Histogram dla odruchu łokciowego Rys.6.28 Histogram dla odruchu kolanowego
Rys.6.29 Histogram dla odruchu skokowego
Zauważamy dużą zbieżność odpowiedzi dla odruchów „kolanowego" i „skokowego".
Potwierdza to trójwymiarowy histogram (rysunek poniżej), zachęcając do dalsze głębszej
analizy (np. zbadanie siły tej zależności i wynikających stąd konsekwencji).
127

Przystępny kurs statystyki
Wyszukiwarka
Podobne podstrony:
więcej podobnych podstron