
Krzysztof Pancerz
Algorytmy i struktury danych
Algorytmy
i
struktury danych
WYKŁAD 3
Dr inż. Krzysztof Pancerz
Krzysztof Pancerz
Algorytmy i struktury danych
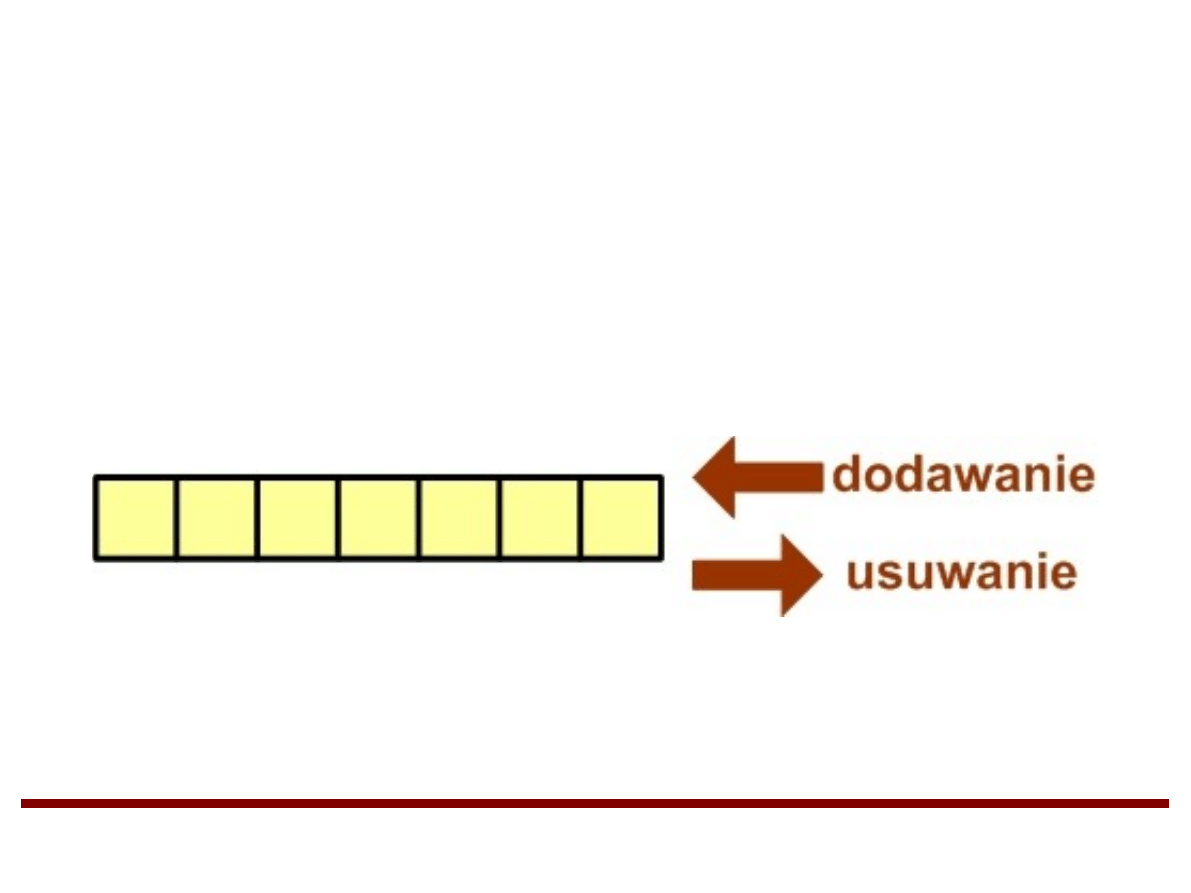
Stos
●
Stos jest strukturą danych, do której dostęp jest
możliwy tylko z jednej strony
●
Zasada działania stosu określana jest regułą
“Last In First Out” (LIFO)

Krzysztof Pancerz
Algorytmy i struktury danych
Stos (cd.)
●
Operacje na stosie:
–
stack_init( ) - utworzenie pustego stosu.
–
empty( ) - sprawdzanie czy stos jest pusty.
–
push(element) – dodanie elementu na stos.
–
pop( ) - usunięcie elementu ze stosu.
–
top( ) - pobranie elementu ze stosu bez jego
usuwania.

Krzysztof Pancerz
Algorytmy i struktury danych
Stos (cd.)
●
Stos może być implementowany na różne
sposoby.
●
Jedną z możliwych implementacji jest
implementacja przy użyciu tablicy.
Przyjmujemy:
●
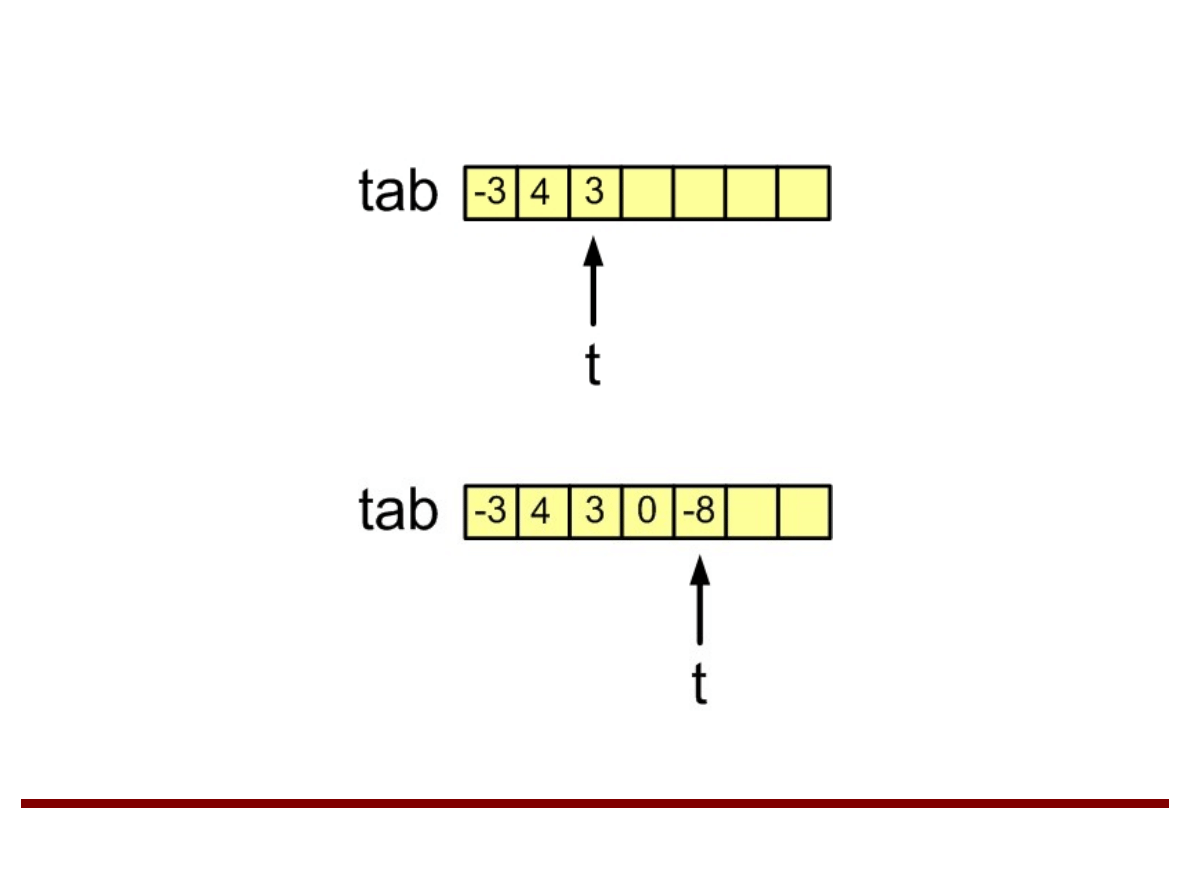
Tablica:
int tab[n];
n - rozmiar tablicy.
●
t – zmienna używana do indeksowania
wierzchołka stosu.
Krzysztof Pancerz
Algorytmy i struktury danych
Stos (cd.)

Krzysztof Pancerz
Algorytmy i struktury danych
Stos (cd.)
void stack_init( )
{
t=-1;
}
int empty( )
{
if(t==-1) return 1;
else return 0;
}

Krzysztof Pancerz
Algorytmy i struktury danych
Stos (cd.)
●
Przy dodawaniu elementu na stos
inkrementujemy zmienną t i umieszczamy
element w komórce o indeksie t.
●
Zakładamy, że tablica nie jest pełna.
void push(int element)
{
t=t+1;
tab[t]=element;
}

Krzysztof Pancerz
Algorytmy i struktury danych
Stos (cd.)
●
Przy usuwaniu elementu ze stosu
dekrementujemy zmienną t.
●
Zakładamy, że stos nie jest pusty.
void pop()
{
t=t-1;
}

Krzysztof Pancerz
Algorytmy i struktury danych
Stos (cd.)
●
Zakładamy, że stos nie jest pusty.
int top()
{
return tab[t];
}
Krzysztof Pancerz
Algorytmy i struktury danych
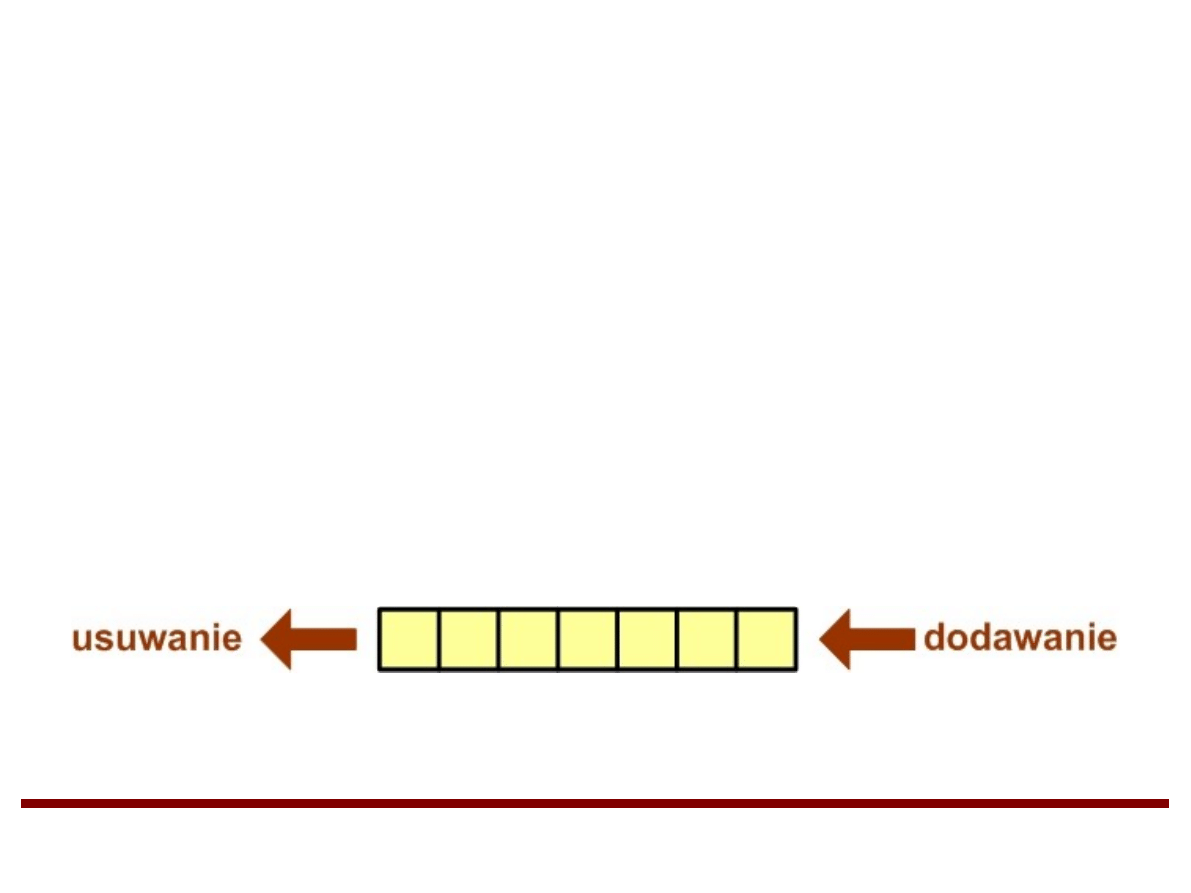
Kolejki
●
Kolejka jest strukturą danych o ograniczonym
dostępie.
●
Elementy mogą być dodawane tylko na koniec
kolejki. Elementy mogą być usuwane
(pobierane) tylko z początku kolejki.
●
Zasada działania kolejki określana jest regułą:
“First In First Out” (FIFO)

Krzysztof Pancerz
Algorytmy i struktury danych
Kolejki (cd.)
●
Operacje na kolejce:
–
queue_init( ) - utworzenie pustej kolejki.
–
empty( ) - sprawdzenie czy kolejka jest pusta.
–
enqueue(element) – dodanie elementu do
kolejki.
–
dequeue( ) - usunięcie elementu z kolejki.
–
front( ) - pobranie pierwszego elementu z
kolejki bez jego usuwania.

Krzysztof Pancerz
Algorytmy i struktury danych
Kolejki (cd.)
●
Kolejka może być implementowana na różne
sposoby.
●
Jedną z możliwych implementacji jest
implementacja przy użyciu tablicy.
Przyjmujemy:
●
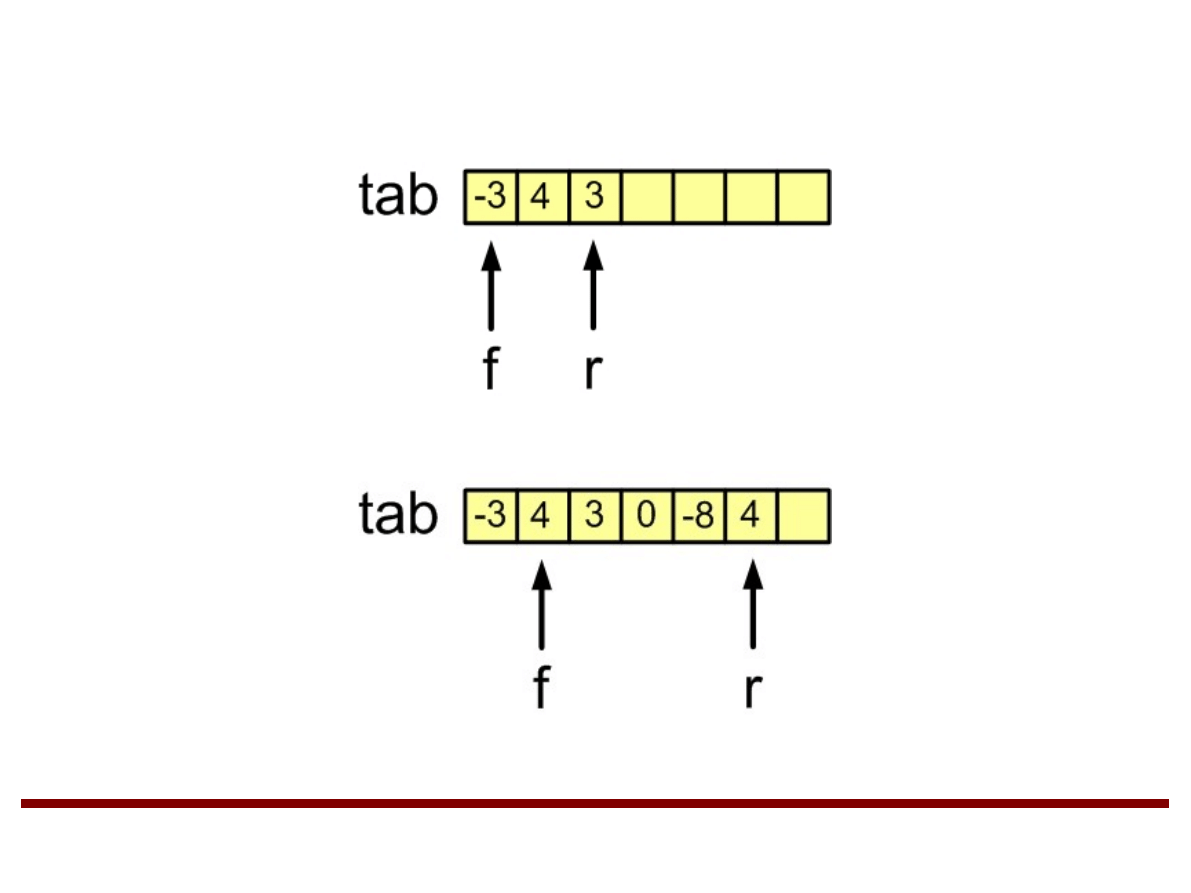
Tablica:
int tab[n];
n – rozmiar tablicy.
●
r – zmienna używana do indeksowania końca
kolejki, f - zmienna używana do indeksowania
początku kolejki.
Krzysztof Pancerz
Algorytmy i struktury danych
Kolejki (cd.)

Krzysztof Pancerz
Algorytmy i struktury danych
Kolejki (cd.)
void queue_init( )
{
r=-1; f=-1;
}
int empty( )
{
if(r==-1) return 1;
else return 0;
}

Krzysztof Pancerz
Algorytmy i struktury danych
Kolejki (cd.)
void enqueue(int element)
{
if(r=-1)
{ r=0; f=0; }
else
{ r=r+1; }
tab[r]=element;
}

Krzysztof Pancerz
Algorytmy i struktury danych
Kolejki (cd.)
●
Zakładamy, że kolejka nie jest pusta.
void dequeue()
{
f=f+1;
}

Krzysztof Pancerz
Algorytmy i struktury danych
Kolejki (cd.)
●
Zakładamy, że kolejka nie jest pusta.
int front()
{
return tab[f];
}
Krzysztof Pancerz
Algorytmy i struktury danych
Listy powiązane
●
Lista powiązana jest strukturą danych z
dynamiczną alokacją pamięci.
●
Lista składa się z obiektów nazywanych
węzłami.

Krzysztof Pancerz
Algorytmy i struktury danych
Listy powiązane (cd.)
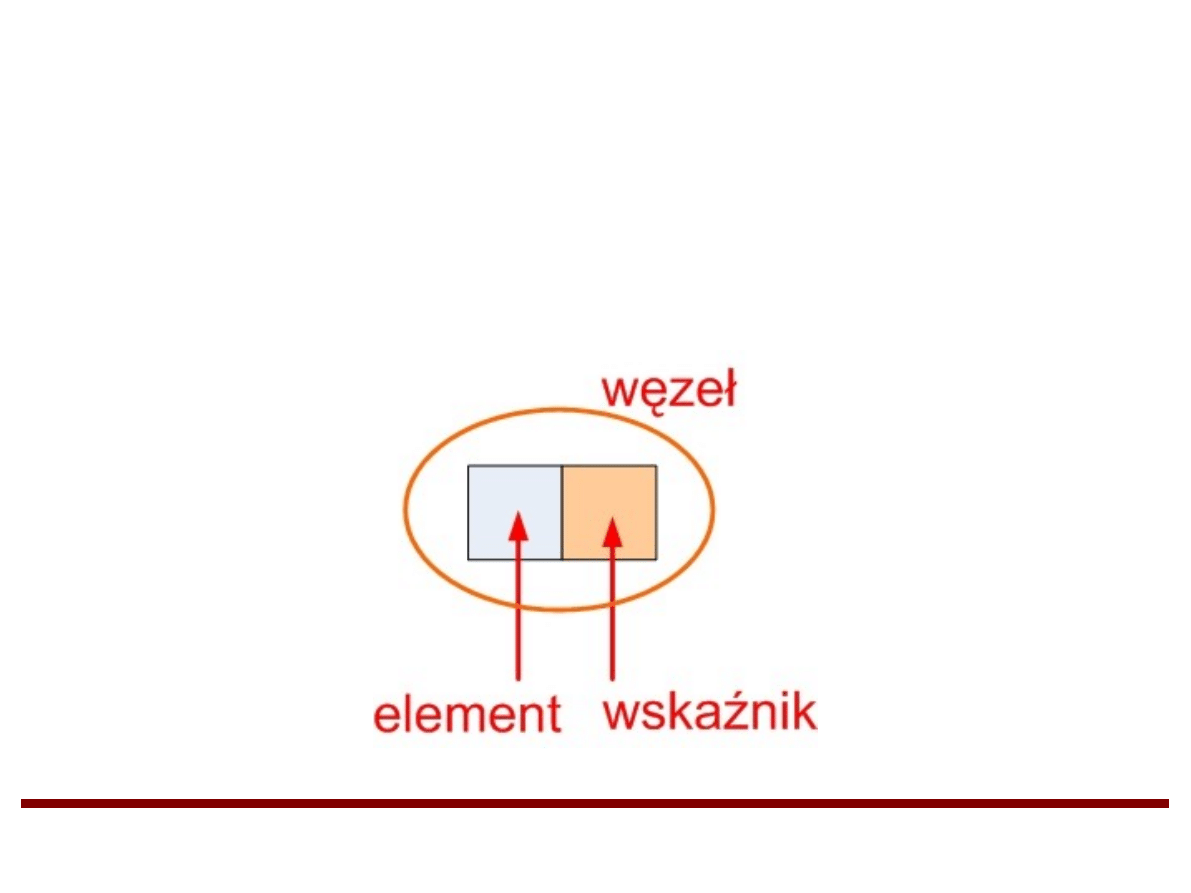
●
Każdy węzeł listy powiązanej zawiera element
oraz wskaźnik na następny węzeł. W tym
przypadku lista jest nazywana listą
jednokierunkową.
●
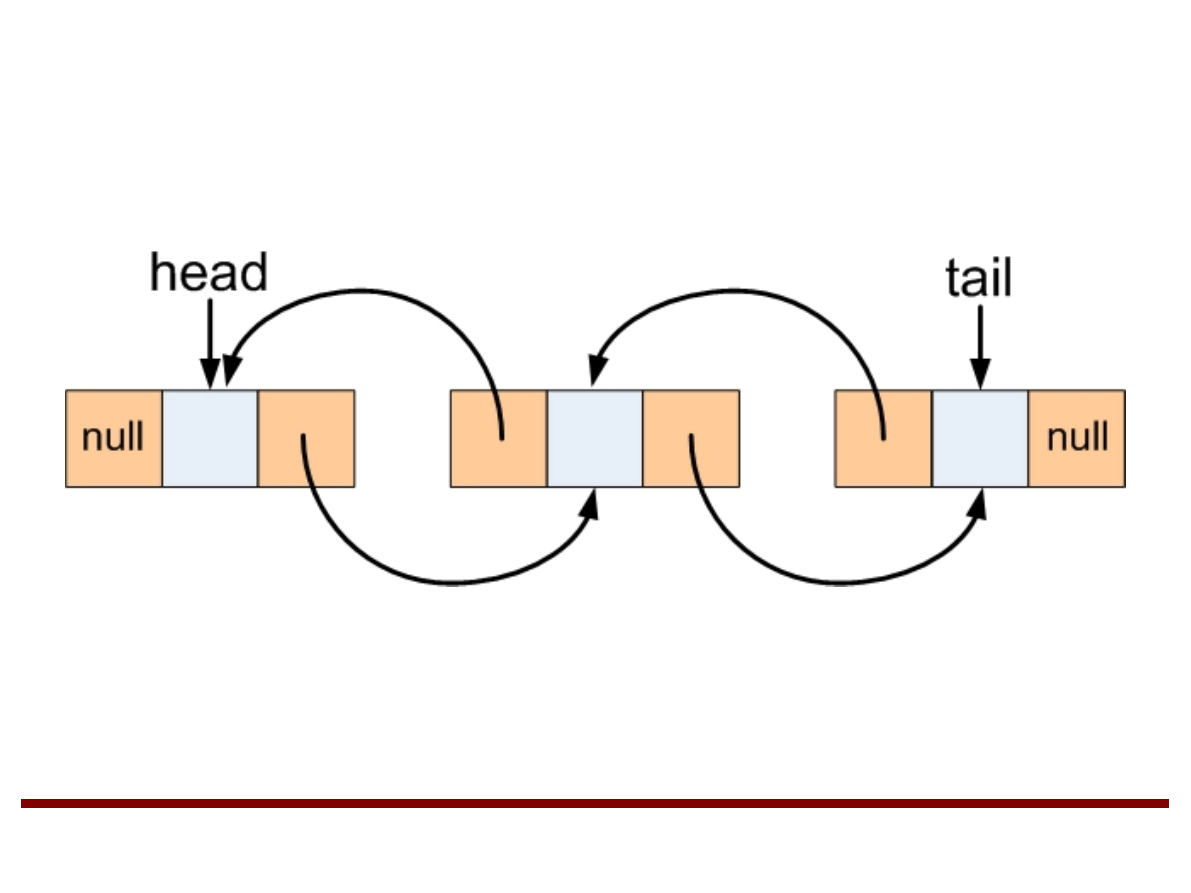
Pierwszy węzeł listy jest dostępny za pomocą
wskaźnika head.
●
Ostatni węzeł listy jest dostępny za pomocą
wskaźnika tail.
Krzysztof Pancerz
Algorytmy i struktury danych
Listy powiązane (cd.)

Krzysztof Pancerz
Algorytmy i struktury danych
Listy powiązane (cd.)
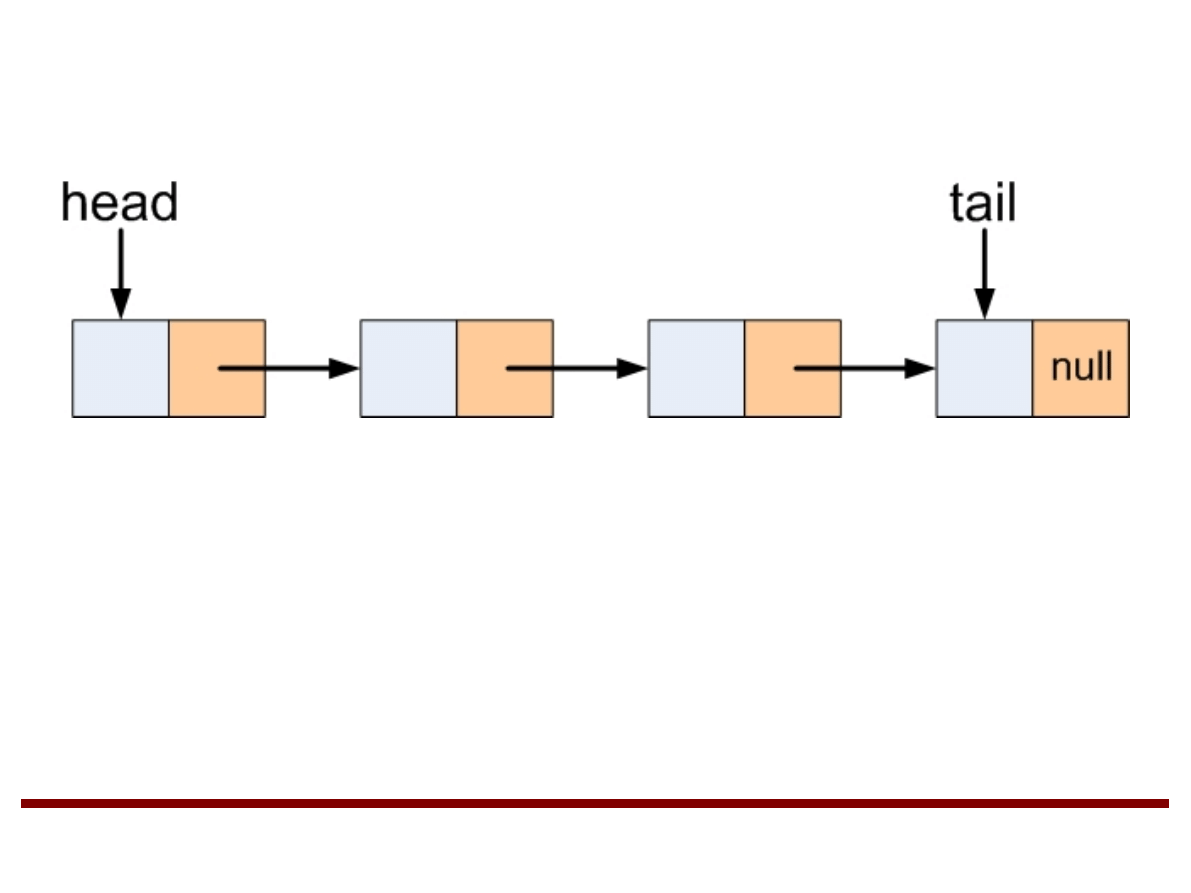
●
W najgorszym wypadku dostęp do elementu na
liście realizowany jest w czasie liniowym θ(n).
Krzysztof Pancerz
Algorytmy i struktury danych
Listy powiązane (cd.)
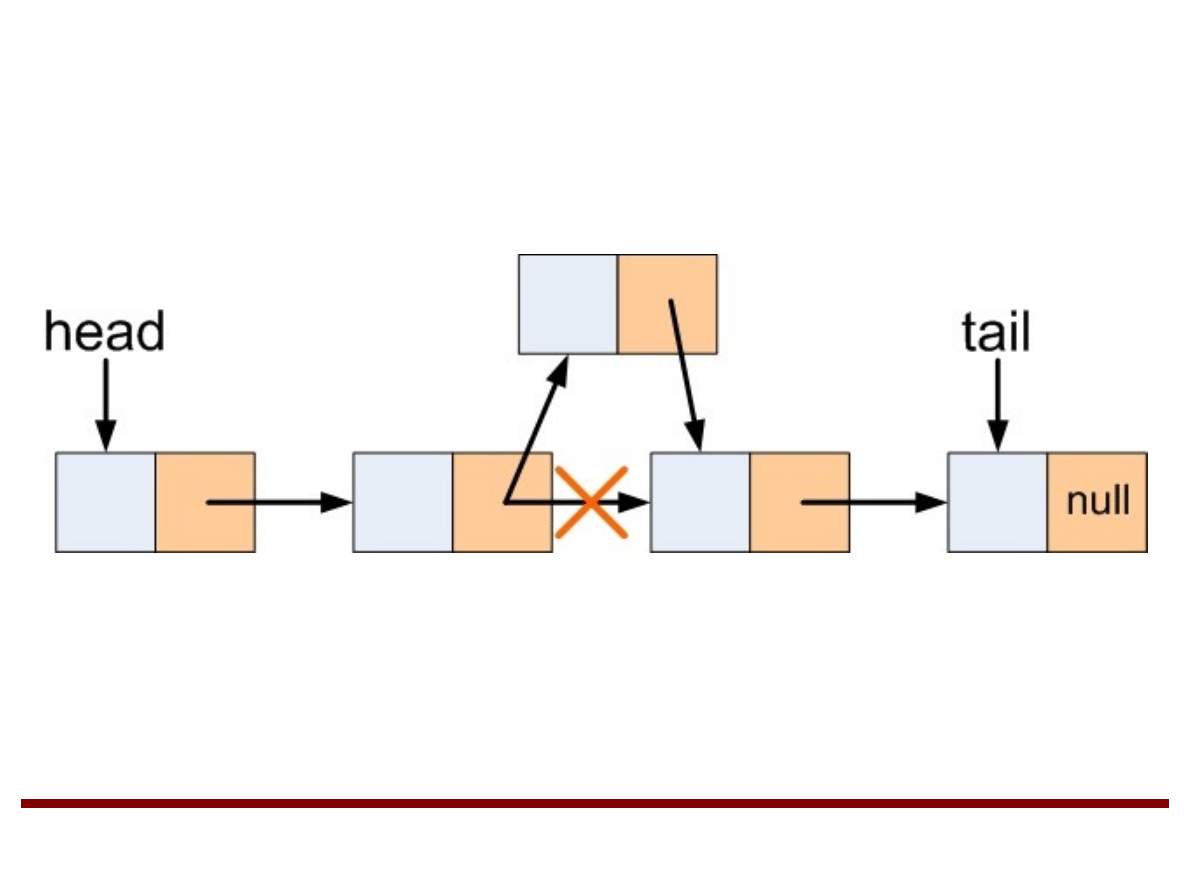
●
Wstawienie nowego elementu na liście:
Krzysztof Pancerz
Algorytmy i struktury danych
Listy powiązane (cd.)
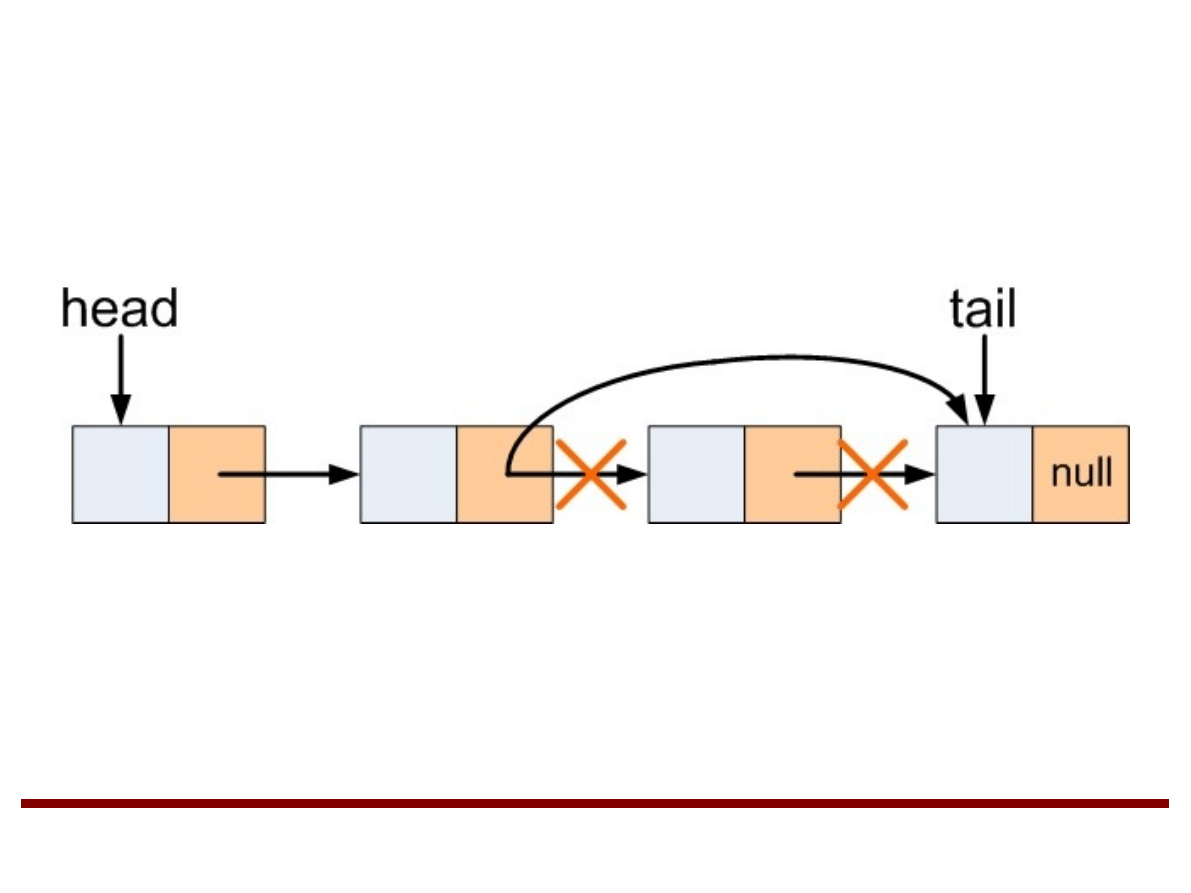
●
Usunięcie elementu z listy:

Krzysztof Pancerz
Algorytmy i struktury danych
Listy powiązane dwukierunkowe
●
W liście powiązanej dwukierunkowej każdy
węzeł zawiera element oraz dwa wskaźniki:
–
wskaźnik na następny węzeł,
–
wskaźnik na poprzedni węzeł.
Krzysztof Pancerz
Algorytmy i struktury danych
Listy powiązane dwukierunkowe (cd.)
Wyszukiwarka
Podobne podstrony:
AiSD Wyklad4 dzienne id 53497 Nieznany (2)
AiSD Wyklad9 dzienne id 53501 Nieznany
AiSD Wyklad2 dzienne
AiSD Wyklad1 dzienne
AiSD wyklad 1 id 53489 Nieznany
AiSD Wyklad11 dzienne id 53494 Nieznany
AiSD wykład drzewa (procedury)
Algorytmy i struktury danych AiSD-C-Wyklad05
AiSD wyklad 5
AiSD Wyklad1 dzienne
AiSD Wyklad6 dzienne id 53499 Nieznany (2)
AiSD Wyklad7 dzienne id 53500 Nieznany (2)
AiSD wyklad 9 id 53492 Nieznany (2)
AiSD Wyklad3 dzienne id 53496 Nieznany (2)
Algorytmy i struktury danych, AiSD C Wyklad04 2
Algorytmy i struktury danych AiSD-C-Wyklad04
AiSD wyklad 2
AiSD Wyklad2 dzienne
więcej podobnych podstron