SAS Enterprise Miner Klasyfikacja za regresji logistycznej – laboratorium nr 5 - klucz
Wczytać z pliku SPAMBASE.DATA do zbioru SPAMBASE dane opisujące e-maile pod kątem
częstości występowania słów i znaków, oraz zaklasyfikowanych jako spam lub normalna
poczta.
W pliku SPAMBASE.DESC oraz SPAMBASE.NAMES znajduje się opis zmiennych
zawartości pliku i interpretacji zmiennych.
Zbudować model predykcyjny dla klasyfikowania e-maila jako spam w oparciu o
zaproponowane w modelu zmienne predykcyjne, przyjmując założenia opisane poniżej.
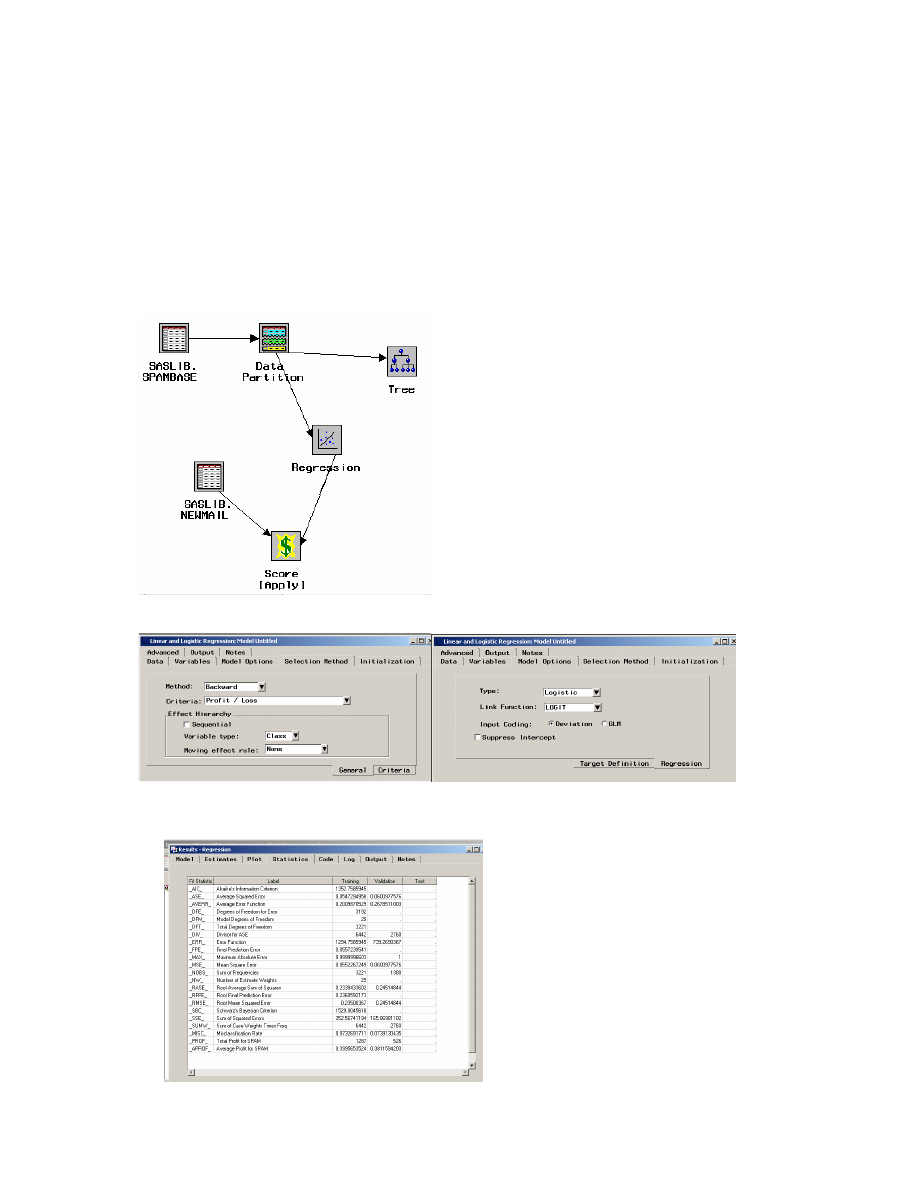
Wykorzystać diagram budowany dla drzewa decyzyjnego.
Przyjąć metodę Backward doboru zmiennych do modelu. Pozostałe parametry pozostawić
domyślne.
a)
Podaj proporcję błędnych klasyfikacji wyznaczoną w oparciu o ciąg walidujący
Odp. 0.0739130435
b)
Porównać proporcję błędnych klasyfikacji w porównaniu z modelem opartym o
drzewo decyzyjne.
Dla drzewa decyzyjnego proporcja błędnych klasyfikacji wynosiła 0,1072, a więc
model predykcyjny oparty na regresji logistycznej jest lepiej dopasowany.
c)
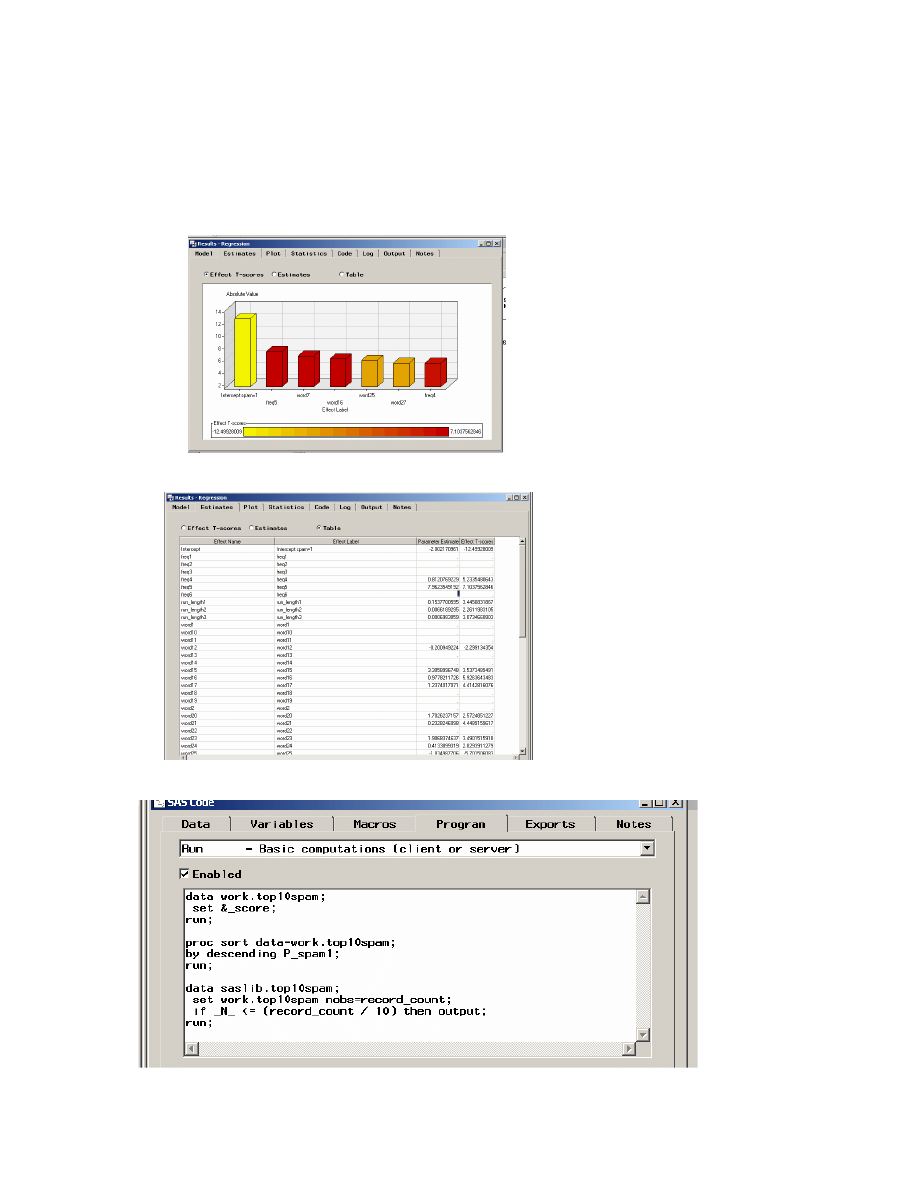
Podaj trzy najistotniejsze zmienne dla prognozowania charakteru maila ?
Odp. FREQ5, WORD7, WORD16.
d)
Podaj przykładowe trzy zmienne, które nie są istotne ?
Odp. FREQ1, WORD1, WORD18
e)
Wyszukiwarka
Podobne podstrony:
L5, regresja logistyczna
L5 regresja logistyczna (2)
regresja logistyczna w R
L4 regresja liniowa klucz (2)
L4, regresja liniowa -klucz
cw 04 regresja logistyczna
regresja logistyczna w R
L4 regresja liniowa klucz (2)
logistyka transportu towarowego w europie klucz do zrównoważonej mobilności
3 SYSTEMY LOGISTYCZNE
Magazyny i centra logistyczne
Logistyczny łańcuch dostaw
więcej podobnych podstron