
Marek Grajek KURS KRYPTOLOGII
Szyfry podstawieniowe
Przypomnijmy prosty szyfr stanowiący część nomenklatora, z którym zetknęliśmy
się w poprzednim wykładzie. Miał on postać:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
QWERTYUIOPASDFGHJKLZXCVBNM
Zaszyfrujmy nim tekst SZYFRYPODSTAWIENIOWE - otrzymujemy szyfrogram:
LMNYKNHGRLZQVOTFOGVT
Ale przy tym samym tekście jawnym i tym samym, choć wyrażonym w odmiennym
alfabecie szyfrowym kluczu szyfrogram może przybrać formę
*[¢‡9¢41.*$7¶6;861¶;
dla alfabetu szyfrowego użytego w opowiadaniu Allana Edgara Poe “Złoty żuk” lub
dla alfabetu Braille’a, wreszcie
dla alfabetu szyfrowego “tańczących sylwetek” zaczerpniętego z jednego z
opowiadań Conan Doyle’a o Sherlocku Holmesie.
Adept kryptologii nie powinien lekceważyć literatury pięknej. Dowodzi tego
historia ówczesnego porucznika Wojska Polskiego, Jana Kowalewskiego, który w
połowie 1919 roku, w czasie wojny polsko-bolszewickiej, został poproszony przez
swego przyjaciela ze sztabu o zastąpienie go na nocnym dyżurze; siostra kolegi
brała właśnie ślub, a ten, chcąc zatańczyć na jej weselu, musiał znaleźć
zastępcę. Problem w tym, że kolega był pracownikiem sekcji radiowywiadu, a
znajomość szyfrów u Jana Kowalewskiego, jak sam przyznał w spisanych po latach
wspomnieniach, ograniczała się ówcześnie do lektury “Złotego żuka” Allana
Edgara Poe. Wyniesiona z niej wiedza o szyfrach, połączona z dociekliwością i
systematycznością okazały się wystarczające - jeszcze przed rankiem Kowalewski
złamał szyfr bolszewików. Był to początek wielkiego wyczynu polskiego
radiowywiadu, który pod koniec wojny łamał większość używanych przez
przeciwnika szyfrów i kodów w ciągu kilku godzin. Polskie zwycięstwo nad
bolszewikami w sierpniu 1920 roku zyskało później miano “cudu nad Wisłą”.
Jeżeli rzeczywiście był to cud, zdziałali go wyłącznie kryptolodzy polskiej
armii, dostarczając swoim dowódcom precyzyjnej i punktualnej informacji o
wszystkich zamiarach przeciwnika.
Wspólną cechą wszystkich szyfrów, o których będziemy mówić w dzisiejszym
wykładzie, jest ich struktura; w miejsce każdego znaku alfabetu jawnego
podstawia się znak alfabetu szyfrowego. W rezultacie cała rodzina podobnie
©ŁAMACZE SZYFRÓW
1
www.lamaczeszyfrow.pl

Marek Grajek KURS KRYPTOLOGII
skonstruowanych szyfrów zyskała nazwę szyfrów podstawieniowych, lub też, z
łaciny, szyfrów substytucyjnych. Przez kilkaset lat autorzy różnych systemów
szyfrowych usiłowali onieśmielać kryptoanalityków wymyślając coraz bardziej
fantazyjne alfabety szyfrowe, jednak podstawowa zasada ich konstrukcji -
substytucja znaków alfabetu jawnego przez znaki alfabetu szyfrowego -
pozostawała bez zmiany. Zauważyliśmy w poprzednim wykładzie, że elementy dwóch
alfabetów 26-znakowe można przyporządkować sobie wzajemnie na 26! sposobów, co
wydaje się tworzyć bezpieczny system. Wspomnieliśmy jednak także, że dla
większości tradycyjnych systemów kryptologicznych opracowano drogi na skróty, a
szyfr podstawieniowy był bodaj pierwszy na tej liście. Nie wiemy, kto i kiedy
opracował uniwersalny sposób jego łamania. Najstarszy zachowany sygnał tego
wynalazku pochodzi z rękopisu pióra arabskiego uczonego z IX wieku, Al-
Kindiego, który pisał:
“Jeden sposób na odczytanie zaszyfrowanej wiadomości, gdy wiemy w jakim języku
została napisana, polega na znalezieniu innego tekstu w tym samym języku, na
tyle długiego, by zajął mniej więcej jedną stronę, i obliczeniu, ile razy
występuje w nim każda litera. (...) Następnie bierzemy tekst zaszyfrowany i
również znajdujemy najczęściej występującą w nim literę, zastępując go
najczęściej występującą literą innego tekstu (...)”
Abu Jusuf Jakub ibn Ishak al-Kindi i strona z traktatu opisującego łamanie szyfrów przez badanie
częstotliwości występowania liter w tekście.
Resztę przepisu na złamanie szyfru podstawieniowego opiszmy operując
współczesną terminologią. Uczeni arabscy zauważyli, że poszczególne znaki
alfabetu występują w tekstach z charakterystyczną częstotliwością. W tekstach
arabskich najczęściej występuje znak alif, po nim - lam. W innych językach
struktura częstotliwości występowania znaków będzie odmienna, ale pewne cechy
charakterystyczne dla danego języka będą zawsze zachowane. Zauważmy, że ścisłe
wyznaczenie częstotliwości występowania poszczególnych znaków w danym języku
©ŁAMACZE SZYFRÓW
2
www.lamaczeszyfrow.pl
Marek Grajek KURS KRYPTOLOGII
jest niemożliwe; po pierwsze - nikt jeszcze nie opracował słownika obejmującego
wszystkie zwroty języka; po drugie - rzeczywista częstotliwość występowania
znaków jest zależna od wielu czynników, w tym tematu tekstu i indywidualnego
stylu autora. Z pewnością jednak strukturę częstotliwości występowania znaków
można wyznaczyć w sposób wystarczająco precyzyjny, by była użyteczna dla celów
praktycznych. Jeżeli jest to możliwe, zawsze warto próbować wyznaczyć
częstotliwości odniesienia występowania liter w oparciu o próbkę tekstu o takim
samym charakterze, jak podejrzewamy w szyfrogramie.
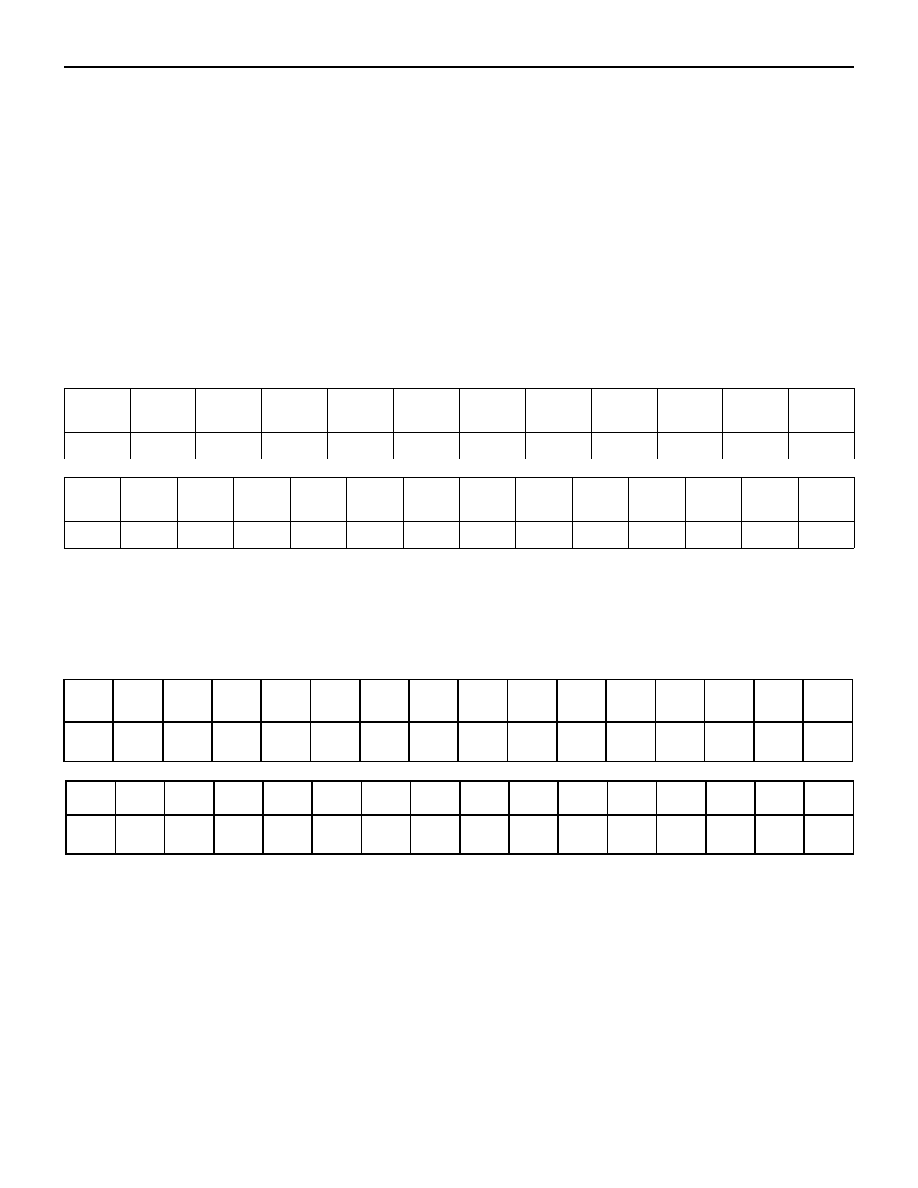
Charakterystyczną częstotliwość występowania znaków w języku angielskim i
polskim (w procentach) wyznaczoną dla długich próbek tekstu przedstawiono w
poniższych tabelach.
a
b
c
d
e
f
g
h
i
j
k
l
8,2
1,5
2,8
4,3
12,7
2,2
2
6,1
7
0,2
0,8
4
m
n
o
p
q
r
s
t
u
v
w
x
y
z
2,4
6,7
7,5
1,9
0,1
6
6,3
9,1
2,8
1
2,4
0,2
2
0,1
język angielski
a
ą
b
c
ć
d
e
ę
f
g
h
i
j
k
l
ł
9,3
1,2
1,8
3,8
0,5
3,2
7,7
1,7
0,2
1,4
1,0
8,8
2,3
3,5
2,2
2,6
m
n
ń
o
ó
p
r
s
ś
t
u
w
y
z
ź
ż
3,3
5,2
0,1
7,0
0,8
3,1
3,8
4,3
0,8
3,4
2,3
4,0
3,7
5,8
0,1
1,1
język polski
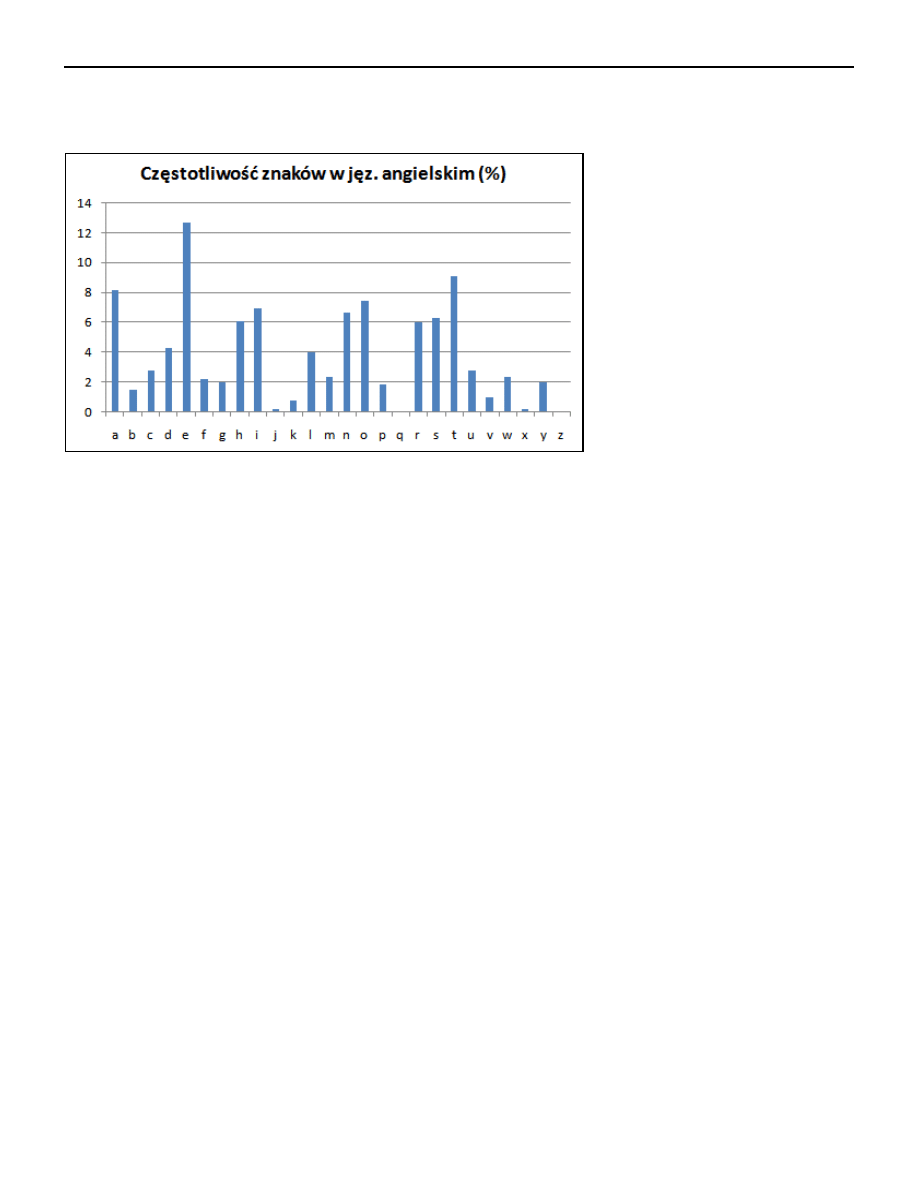
Poniższy wykres przedstawia częstotliwość występowania znaków w języku
angielskim. Warto zwrócić uwagę zarówno na naturalne “szczyty” wykresu,
przypadające na litery E, T, A, O, I, N, jak i widoczne “doliny” pomiędzy
znakami I oraz L jak również O i R.
©ŁAMACZE SZYFRÓW
3
www.lamaczeszyfrow.pl
Marek Grajek KURS KRYPTOLOGII
Przedstawiane dalej przykłady będą zawierać teksty w języku angielskim, co
najmniej z dwóch powodów. Po pierwsze - prawdziwy kryptoanalityk niezwykle
rzadko analizuje szyfry we własnym języku. Po drugie - struktura języka
angielskiego stawia na
drodze
początkującego
kryptologa nieco niższe
przeszkody. Wystarczy rzut
oka
na
tabelę
częstotliwości
występowania znaków w
języku polskim by upewnić
się, że kluczowe dla
łamania szyfru samogłoski
(za wyjątkiem U) są w nim
statystycznie praktycznie
nierozróżnialne.
Załóżmy, że przejęliśmy
szyfrogram, którego źródło
nadania
pozwala
podejrzewać, że został w
oryginale napisany w języku angielskim. Zgodnie z zasadami preparowania tekstów
jawnych szyfrogramów zakładamy, że z tekstu jawnego zostały usunięte wszystkie
odstępy pomiędzy wyrazami oraz znaki interpunkcyjne. Gdyby w tekście jawnym
zachowano odstępy musielibyśmy uwzględnić, że w języku angielskim typowa
częstotliwość występowania spacji jest nieco wyższa od najczęściej występującej
litery E - ale w naszym przykładzie wykluczamy taką możliwość. Zakładamy też,
że treść przejętego szyfrogramu ma związek z kryptologią. Przejęta depesza ma
treść:
HFTHOQGTTKMDATNQETQGHPNSNTPQHYMTKQTYAIGTMNNQMHFLTMQGKFNAEIDTNSRNQAQSQAHFV
KNQHYMTKQTYAIGTMQKRDTNVGAYGGKPEHMTQGKFHFTNSRNQAQSQTOHMTKYGDTQQTMKFPVGAYGG
KPKPPAQAHFKDNSRNQAQSQTNOHMFKETNQGKQVHSDPRTYHEEHFDXSNTPRTYKSNTHOQGTNALFAOA
YKFYTLAUTFQHIMHITMFKETNQGTNTNXNQTENVTMTYKDDTPFHETFYDKQHMNNHETHOQGTTKMDXFH
ETFYDKQHMNVTMTOKAMDXSFNHIGANQAYKQTPQGTNSRNQAQSQTNOHMQGTDTQQTMREALGQRTQGTD
TQQTMEHMQGTPALAQOHSMVMAQQTFAFNTUTMKDPANQAFYQAUTNQXDTNKFPQGTFQGTNSRNQAQSQT
NOHMYEALGQRTQGTDTQQTMFHMQGTPALAQOAUTKLKAFVMAQQTFAFPANQAFYQAUTNQXDTNQGSNKY
MXIQKFKDXNQVADDAFLQHQMXKNAEIDTLSTNNVHSDPHFDXFTTPQHNHDUTKYKTNKMYAIGTMKNAEI
DTNSRNQAQSQAHFVGTMTQGTKDIGKRTQANETMTDXPANIDKYTPAFNQTKPHORTAFLQGHMHSLGDXNY
MKERDTPAFNQTKPHOOKYAFLQGTOSDDIMHRDTEHOOAFPAFLNSRNQAQSQTNOHMQGTOSDDNTQHONX
ERHDNAFPAUAPSKDDXHFTAFLTFAHSNEHPTMFETQGHPHOIMHPSYAFLKGHEHIGHFAYYAIGTMYKDD
TPQGTLMKFPIMTYAIGTMAFUHDUTNYGHHNAFLQTFQTFDTQQTMVHMPNVGAYGYKFRTHMPTMTPNHQG
KQQGTAMOAMNQDTQQTMNOHMEKFTDTUTFQGQTFDTQQTMVHMPKFPVGAYGYHDDTYQAUTDXAFYDSPT
KDDQVHNAWDTQQTMNHOQGTKDIGKRTQQGTYHDSEFNAFIHMQKNPAKLMKEKDDYHFQKAFYGKMKYQTM
NMTDKQTPAFNGKITQGANEKCTNAQTKNATMQHDHHCSIKNXERHDRSQKDNHLAUTNKVKXAFOHMEKQAH
FHFTVKXQHMTQKAFQGTKPUKFQKLTHOTKNADXOAFPAFLKNXERHDRSQVAQGHSQLAUAFLKVKXAFOH
MEKQAHFQHQGTYMXIQKFKDXNQANADDSNQMKQTPAFQGTPAKLMKEKRHUT
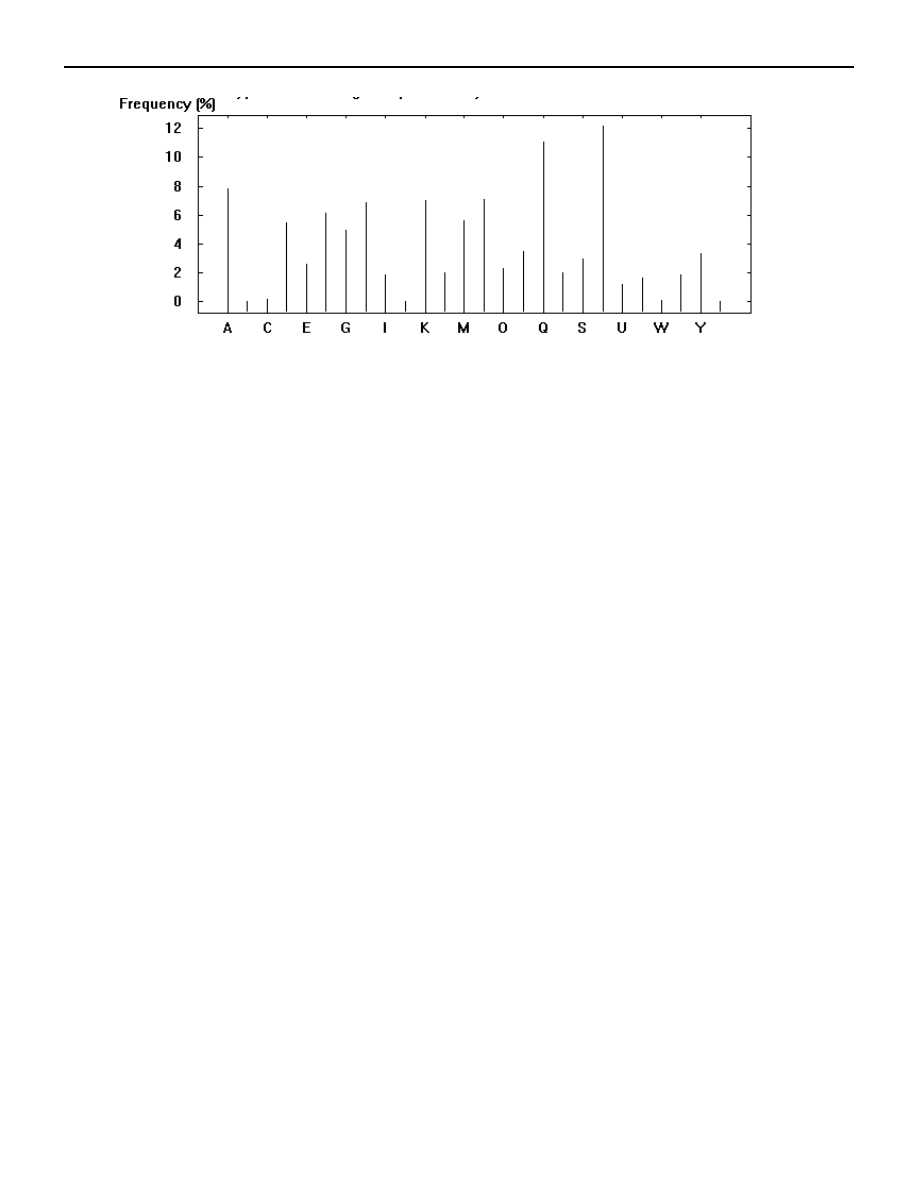
Zaczynamy jej analizę od sporządzenia wykresu częstotliwości występowania
poszczególnych znaków, otrzymując:
©ŁAMACZE SZYFRÓW
4
www.lamaczeszyfrow.pl
Marek Grajek KURS KRYPTOLOGII
Gdyśmy nie wiedzieli, że szyfrogram został zaszyfrowany z użyciem szyfru
monoalfabetycznego, powyższy rozkład częstotliwości dostarcza silnego argumentu
potwierdzającego ten fakt; bardziej złożone szyfry z reguły dają w efekcie
bardziej wyrównany rozkład częstości występowania poszczególnych znaków.
Widzimy, że najczęściej występują znaki T i Q, a ich częstotliwość występowania
odpowiada w przybliżeniu teoretycznym wartościom odpowiednio dla znaków E i T.
W języku angielskim jednym z najczęściej występujących trygramów (trójek liter)
jest trygram THE, korzystamy więc z identyfikacji prawdopodobnych odpowiedników
znaków T oraz E i szukamy w szyfrogramie wystąpień Q i
T
oddzielonych jedną i
zawsze tą samą literą. Znajdujemy liczne wystąpienia trójki QGT, sugerujące, że
literze H tekstu jawnego może odpowiadać litera G w szyfrogramie.
Innym często występującym ciągiem wyrazów języka angielskiego jest THAT, z
którego dysponujemy już trzema elementami; poszukujemy zatem ciągów QG?Q, w
których znakiem zapytania oznaczyliśmy nieznaną literę odpowiadającą A.
Znajdujemy dwa wystąpienia ciągu QGKQ; zaledwie dwa wystąpienia nie są silną
przesłanką, ale z drugiej strony - częstotliwość występowania K w szyfrogramie
jest zbliżona do częstotliwości występowania A w języku angielskim; zaryzykujmy
założenie, że litera K w szyfrogramie odpowiada literze A tekstu jawnego.
Spróbujmy sięgnąć teraz po inną przesłankę; alfabet tekstu jawnego nie zawiera
cyfr. Jeżeli w szyfrogramie występują liczby, zgodnie z często przyjmowaną
konwencją mogły zostać zapisane w postaci podobnej do tej, jaką posługujemy się
podając numer telefoniczny, np. 221 jako “dwadwajeden”. Jeżeli tak się stało,
interesująca z kryptologicznego punktu widzenia jest słowna postać jedynki,
ONE, która zawiera trzy znaki należące do najczęściej występujących. Zakładamy,
że już znamy odpowiednik E. Spośród innych często występujących w szyfrogramie
znaków nie bierzemy pod uwagę litery K, odpowiadającej A w tekście jawnym. Inne
często występujące litery szyfrogramu, to H, N i F. Spróbujmy dopasować do
szyfrogramu ciągi HNT, HFT, NHT, NFT, FHT i FNT. Znajdujemy jedno wystąpienie
trygramu FNT i kilka wystąpień trygramu HFT, co uprawnia nas do założenia, że
HFT odpowiada ONE, zatem O w tekście jawnym jest zastępowane przez H, a N przez
F.
Z diagramu teoretycznej częstości znaków języka angielskiego wnioskujemy, że
ostatnią spośród często występujących liter, której odpowiednika jeszcze nie
zdołaliśmy ustalić, jest litera I o częstotliwości występowania około 7%.
Przeszukując wykres częstości występowania znaków w szyfrogramie zwracamy uwagę
na literę A, której odpowiednika do tej pory nie określiliśmy, lecz ok. 8%
częstotliwość występowania wskazuje na poszukiwaną literę I.
©ŁAMACZE SZYFRÓW
5
www.lamaczeszyfrow.pl

Marek Grajek KURS KRYPTOLOGII
Podsumujmy nasze dotychczasowe ustalenia:
A E H I N O T
w tekście jawnym odpowiadają prawdopodobnie znakom
K T G A F H Q
w szyfrogramie.
Znaleźliśmy już prawdopodobnie szyfrowy odpowiednik frazy
THAT
, jesteśmy też
gotowi do odnalezienia jej bliźniaczej frazy
THIS
. Szukając odpowiadających jej
czwórek o strukturze
QGA?
znajdujemy jedno wystąpienie frazy
QGAN
, które
sugeruje, że odpowiednikiem znaku
S
w tekście jawnym może być
N
. Ponownie -
zaledwie jedno wystąpienie poszukiwanej frazy nie stanowi wystarczającej
przesłanki, ale porównanie częstości występowania obu znaków w tekście jawnym i
szyfrogramie utwierdza hipotezę, że
S
zostało przekształcone w
N
.
Nasza następna hipoteza będzie odważna, ale zgodna z wcześniejszymi
założeniami, zgodnie z którymi treść szyfrogramu ma związek z kryptologią. Może
warto poszukać słowa
CIPHER
(szyfr)? Wydaje się, że znamy trzy spośród
występujących w nim liter:
I
,
H
oraz
E
. Gdyby udało nam się dopasować słowo do
szyfrogramu, otrzymalibyśmy ważną premię - literę
R
o wysokiej częstotliwości
występowania. Poszukując wzorca
?A?GT?
otrzymujemy liczne wystąpienia frazy
YAIGTM, zbyt liczne, by mogło to być wyłącznie wynikiem przypadku. Wydaje
się, że odpowiednikiem litery C tekstu jawnego jest litera Y w
szyfrogramie, a R w tekście jawnym jest zastępowane przez M.
Zważywszy, że zdołaliśmy dotąd zebrać hipotezy dotyczące znaków o
najwyższej częstotliwości występowania, powinniśmy dysponować już
fragmentami obejmującymi znaczącą część tekstu jawnego. Spróbujmy
spojrzeć na efekty naszej dotychczasowej pracy zastępując w szyfrogramie
odpowiednikami litery, dla których sformułowaliśmy już hipotezy, a
pozostałe, nieznane litery - znakiem myślnika.
ONEO-THEEAR-IEST-ETHO-S-SE-TOCREATECI-HERSSTRON-ERTHANSI---ES--STIT-TION-
ASTOCREATECI-HERTA--ES-HICHHA--ORETHANONES--STIT-TE-OREACH-ETTERAN--
HICHHA-A--ITIONA-S--STIT-TES-ORNA-ESTHAT-O----ECO--ON---SE--ECA-SEO-
THESI-NI-ICANCE-I-ENTO-RO-ERNA-ESTHESES-STE-S-ERECA--E-NO-ENC-ATORSSO-EO-
THEEAR--NO-ENC-ATORS-ERE-AIR---NSO-HISTICATE-THES--STIT-TES-ORTHE-ETTER--
I-HT-ETHE-ETTER-ORTHE-I-IT-O-R-RITTENI-ERA--ISTINCTI-EST--ESAN-THENTHES--
STIT-TES-ORC-I-HT-ETHE-ETTERNORTHE-I-IT-I-EA-AIN-RITTENIN-ISTINCTI-EST--
ESTH-SACR--TANA--ST-I--IN-TOTR-ASI---E--ESS-O---ON--NEE-TOSO--EACAESARCI-
HERASI---ES--STIT-TION-HERETHEA--HA-ETIS-ERE---IS--ACE-INSTEA-O--EIN-
THORO--H--SCRA---E-INSTEA-O--ACIN-THE-----RO--E-O--IN-IN-S--STIT-TES-
ORTHE----SETO-S---O-SIN-I-I--A---ONEIN-ENIO-S-O-ERN-ETHO-O--RO--CIN-AHO-
O-HONICCI-HERCA--E-THE-RAN--RECI-HERIN-O--ESCHOOSIN-TENTEN-ETTER-OR-S-
HICHCAN-EOR-ERE-SOTHATTHEIR-IRST-ETTERS-OR-ANE-E-ENTHTEN-ETTER-OR-AN--
HICHCO--ECTI-E--INC---EA--T-OSI--ETTERSO-THEA--HA-ETTHECO---NSIN-ORTAS-
IA-RA-A--CONTAINCHARACTERSRE-ATE-INSHA-ETHIS-A-ESITEASIERTO-OO---AS---
O---TA-SO-I-ESA-A-IN-OR-ATIONONE-A-TORETAINTHEA--ANTA-EO-EASI---IN-IN-
AS---O---T-ITHO-T-I-IN-A-A-IN-OR-ATIONTOTHECR--TANA--STISI---STRATE-
INTHE-IA-RA-A-O-E
©ŁAMACZE SZYFRÓW
6
www.lamaczeszyfrow.pl
Marek Grajek KURS KRYPTOLOGII
Początek otrzymanego tekstu narzuca uzupełnienie do postaci:
ONEOFTHEEARLIESTMETHODSUSEDTOCREATECIPHERSSTRONGERTHANSIMPLE,
a po rozbiciu na poszczególne słowa otrzymujemy:
“One of the earliest methods used to create ciphers stronger than simple…”.
Interesujące, wszystkie hipotezy dotyczące liter tekstu jawnego i ich
szyfrowych odpowiedników potwierdziły się w otrzymanym tekście (pół)jawnym.
Pamiętajmy, że formułowanie hipotez wyłącznie na podstawie częstotliwości
występowania jest rozsądnym rozwiązaniem jedynie dla znaków o najbardziej
charakterystycznych wartościach częstości wystąpień. Jednak połączenie
przesłanek wynikających z częstotliwości występowania i struktury języka z
reguły pozwala na trafne domysły co do zestawienia par znaków. Słuchaczom
biegłym nie tylko w kryptologii, ale i w języku angielskim pozostawiamy
uzupełnienie reszty tekstu oraz odnalezienie słowa kluczowego, użytego przy
generacji alfabetu szyfrowego.
A teraz do rzeczy. Nasz radionasłuch przejął przedstawiony poniżej szyfrogram.
Okoliczności nadania go wskazują, że język angielski jest językiem tekstu
jawnego, a depesza dotyczy kryptologii.
NFMPQCAQQAMPNJMDSHACAVAHQRQAHCAQQAMWJMGSHGWRFEREJCCAEQFVACYFHECUGASCCQWJPFXCAQQ
AMPJNQRASCKRSTAQQRAEJCUDHPFHKJMQSPGFSOMSDSCCEJHQSFHERSMSEQAMPMACSQAGFHPRSKAQRFP
DSBAPFQASPFAMQJCJJBUKSPYDTJCTUQSCPJOFVAPSWSYFHNJMDSQFJHJHAWSYQJMAQSFHQRASGVSHQS
OAJNASPFCYNFHGFHOSPYDTJCTUQWFQRJUQOFVFHOSWSYFHNJMDSQFJHQJQRAEMYKQSHSCYPQFPFCCUP
QMSQAGFHQRAGFSOMSDSTJVARSVAPFDFCSMPYDTJCPSMMSHOAGSCJHOQRAGFSOJHSCPJNQRAGFSOMSDS
HGUPADFXAGSCKRSTAQPSCJHOQRAAGOAPWRFCASGFOMSKRFEPYDTJCEFKRAMFPPJDAQRFHOQRSQFPHQQ
JJKMSEQFESCPFDFCSMQAERHFLUAPRSVATAAHUPAGNJMPDSCCEJGAERSMQPQJDSBAQRADKMSEQFESCSH
GPAEUMAPYPQADSQFEDAQRJGPJNAHEFKRAMFHOPAVAMSCCAQQAMPSQJHEAWFQRJUQPFDKCYUPFHOSVAM
YCSMOAQSTCAWFCCTAJUQCFHAGFHWRSQNJCCJWPNMSEQFJHSQFJHCAHGPFQPACNQJDSHYEJDKCFESQAG
SHGTFZSMMAGAVACJKDAHQPSNAWJNWRFERWFCCTAFCCUPQMSQAGQRAMARJKANUCCYSCCQRAAXSDKCAPQ
RSQWFCCTAEJHQSFHAGFHQRANJCCJWFHOKSOAPWFCCKMJVASPQSMQFHOKJFHQNMJDWRFERYJUESHCAQY
JUMFDSOFHSQFJHMUHWFCGNMSEQFJHSQFJHSCQRJUORSKJWAMNUCQAERHFLUARSPPACGJDTAAHUPAGFH
KSKAMSHGKAHEFCEFKRAMPTAESUPAFQFPQJJEJDKCFESQAGSHGKMJHAQJAMMJM
Poniżej zamieszczamy wykres częstotliwości znaków w szyfrogramie.
©ŁAMACZE SZYFRÓW
7
www.lamaczeszyfrow.pl

Marek Grajek KURS KRYPTOLOGII
Zadanie brzmi:
1. Zaszyfruj szyfrem podstawieniowym o kluczu lamaczeszyfrow kolejno imiona i
nazwiska trzech matematyków - łamaczy szyfrów Enigmy porządkując je
alfabetycznie wg. Nazwisk
2. Przedstawić pierwszych 50 znaków tekstu jawnego szyfrogramu.
3. Przedstawić słowo kluczowe, użyte do wygenerowania alfabetu szyfrowego.
Powodzenia.
©ŁAMACZE SZYFRÓW
8
www.lamaczeszyfrow.pl
Document Outline
Wyszukiwarka
Podobne podstrony:
Kryptologia Wyklad 6
kryptografia Wykład v2
Kryptografia wyklad 04
Kryptografia wyklad 10
PODSTAWY MATEMATYCZNE, MECHANIZMY KRYPTOGRAFICZNE - WYKŁADY
Kryptologia Wyklad 1
Kryptografia wyklad 05
Kryptologia Wyklad 4
Kryptografia wyklad 03
Kryptografia Wyklad z podstaw klasycznej kry
Kryptografia wyklad 08
Kryptografia Wyklad
Kryptografia wyklad 09
Kryptografia wyklad 01
Kryptografia wyklad 07
Kryptologia Wyklad 7a
Kryptografia wyklad 06
Kryptografia wyklad 02
Kryptologia Wyklad 6
więcej podobnych podstron