
1
1.
Wymień cechy algorytmu i sposoby jego reprezentacji.
Cechy algorytmu:
• poprawność (algorytm daje dobre wyniki, odzwierciedlające rzeczywistość)
• jednoznaczność (brak rozbieżności wyników przy takich samych danych,
jednoznaczne opisanie każdego kroku)
• skończoność (wykonuje się w skończonej ilości kroków)
• sprawność (czasowa - szybkość działania i pamięciowa - "zasobożerność")
• prostota wykonania(operacje powinny być jak najprostsze)
Sposoby reprezentacji algorytmu:
• w postaci słownej
• pseudokodu
• schematu blokowego
• języka programowania
2.
Omówić zagadnienie asymptotycznej złożoności obliczeniowej algorytmów. Podać
standardowe notacje rzędu złożoności.
Złożoność asymptotyczna mówi o tym, jak złożoność kształtuje się dla bardzo dużych,
granicznych rozmiarów danych wejściowych. Są trzy rodzaje złożoności asymptotycznej:
• notacja O (omikron) – ma największe znaczenie w teorii złożoności obliczeniowej.
Zapis f(n) = O(g(n)) czytamy: funkcja f jest co najwyżej rzędu g, jeśli istnieje taka
stała rzeczywista c i liczba naturalna n0, iż dla każdego n większego lub równego
n0 funkcja f(n) jest niewiększa od iloczynu cxg(n)
• notacja W (omega) – gdy funkcja g(n) ogranicza funkcję f(n) od dołu
• notacja Q (theta) – gdy funkcja g(n) ogranicza funkcje f(n) od góry i od dołu
3.
Algorytmy sortowania oraz charakterystyka ich złożoności obliczeniowej.
• Sortowanie bąbelkowe – złożoność O(n2) – porównywanie kolejnych par
elementów, za każdym razem jedną parę mniej
• Sortowanie przez wstawianie - złożoność O(n2) – każdy od drugiego sprawdzany
gdzie pasuje na liście
• Sortowanie przez scalanie – złożoność O(nlogn), wymaga O(n) dodatkowej
pamięci, podział listy na podlisty, sortowanie podlist, łączenie posortowanych
podlist
• Sortowanie szybkie – złożoność optymistyczna O(nlogn), pesymistyczna O(n2),
wyszukanie elementu średniego, mniejsze na lewo większe na prawo itd. Aż do
pojedynczych elementów (rekurencja)
2
4.
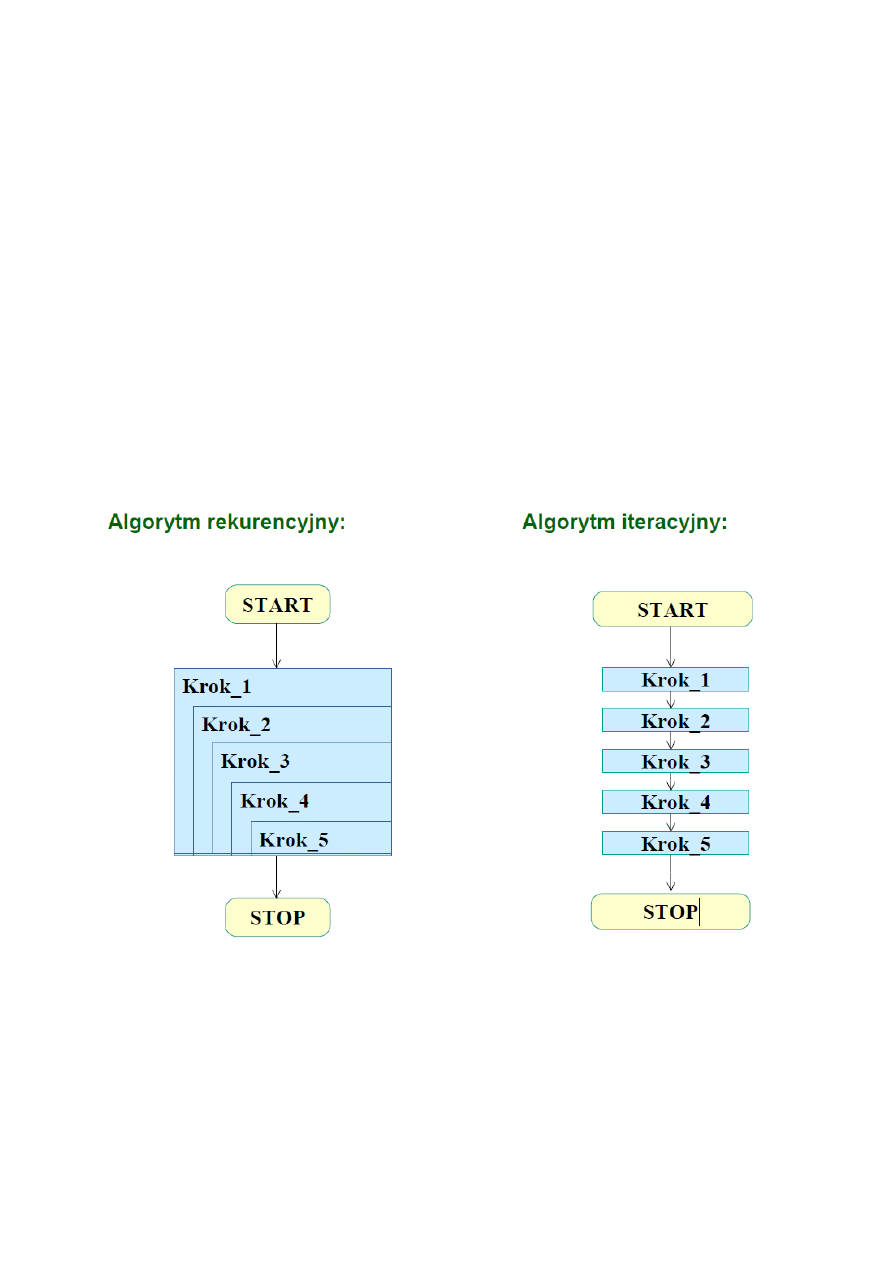
Przedstawić iteracyjne oraz rekurencyjne struktury algorytmiczne. Dokonać
porównania.
Rekurencja – technika pozwalająca opisać problem za pomocą jego składowych.
W algorytmie rekurencyjnym mamy przypadek bazowy (obiekty podstawowe) i ogólny
(obiekty zbudowane z podstawowych). Podstawowymi elementami przy układaniu
algorytmów rekurencyjnych są: warunek stopu i dekompozycja problemu. Rekurencja
pozwalana na przejrzysty i zwarty opis algorytmu, kosztem złożoności wykonania.
Implementacja rekurencyjnej definicji funkcji wymaga tłumaczenia na język programowania
– rekord aktywacji (w stosie programu; parametry wywołania, wartość zwracana, zmienne
lokalne, dynamiczne dowiązanie do rekordu wywołania procesu wywołującego, adres
powrotu do procesu wywołania)
Algorytm iteracyjny - algorytm, który uzyskuje wynik przez powtarzanie danej operacji początkowo
określoną liczbę razy lub aż do spełnienia określonego warunku.
5.
Struktury drzewiaste, charakterystyka podstawowych typów drzew oraz przykłady
ich zastosowań.
Drzewa- kolekcja węzłów, z których 1 wyróżniany jest jako korzeń.
3
Podstawowe pojęcia:
- węzły powiązane są ze sobą relacją rodzicielstwa
- węzły mające tego samego rodzica nazywamy węzłami
siostrzanymi
- wysokość węzła- liczba krawędzi na najdłuższej, prostej ścieżce
prowadzącej od tego węzła do liścia
- wysokość drzewa= wysokość korzenia
- głębokość (poziom) drzewa- długość ścieżki łączącej węzeł z korzeniem
Zastosowanie drzew, których węzły mogą mieć więcej niż 2 potomków:
- Drzewo genealogiczne
Drzewo binarne- drzewo w którym każdy z węzłów:
- posiada lewe i prawe poddrzewo
- posiada jedno z nich
- nie posiada poddrzew
Zastosowanie drzew binarnych:
- Zapis historii turnieju tenisowego (nie tylko), gdzie każdej grze
przypisuje się zwycięzcę a dwie poprzednie gry zawodników oznaczają
jej potomków.
- Wyrażenie arytmetyczne z dwuargumentowymi operatorami, gdzie
każdy operator jest węzłem, a jego argumenty poddrzewami
Drzewo BST (Binary Search Tree)- dowolne drzewo binarne, którego wierzchołki są ułożone
zgodnie z porządkiem symetrycznym. Elementy z kluczami większymi są zawsze na prawo, a
elementy z kluczami mniejszymi na prawo od węzła.
Podstawowe operacje na drzewach BST:
- wyszukiwanie
- wstawianie
- usuwanie
- wyszukiwanie min
- wyszukiwanie max
- predecessor, successor
Binarne drzewa wyszukiwań często stosuje się w zadaniach, w których wymagane jest
względnie szybkie sortowanie lub wyszukiwanie elementów, na przykład różnego rodzaju
słowniki, kolejki priorytetowe
Zrównoważone drzewa BST:
- złożoność obliczeniowa na drzewach BST jest
proporcjonalna do wysokości drzewa
- zrównoważone drzewa binarne- różnica wysokości obu
podddrzew każdego węzła wynosi 0 lub 1
- drzewo w pełni zrównoważone- jeśli jest zrównoważone a wszystkie liście znajdują się na 1
lub 2 poziomach
- drzewa w pełni zrównoważone są drzewami BST gwarantującymi wysokość O(logn)
4
Drzewa zrównoważone AVL:
- drzewa zrównoważone lokalnie
- dla każdego węzła różnica poziomów różni się nie więcej niż o 1 poziom
- współczynnik zrównoważenia (różnica wysokości lewego i prawego poddrzewa) -1, 0, 1
Własności:
- dla każdego wierzchołka wysokość 2 jego poddrzew różni się co najwyżej o 1 poziom
- search, min, max, successor, predecessor- nie zmieniają drzewa
- insert, delete- zmieniają drzewo
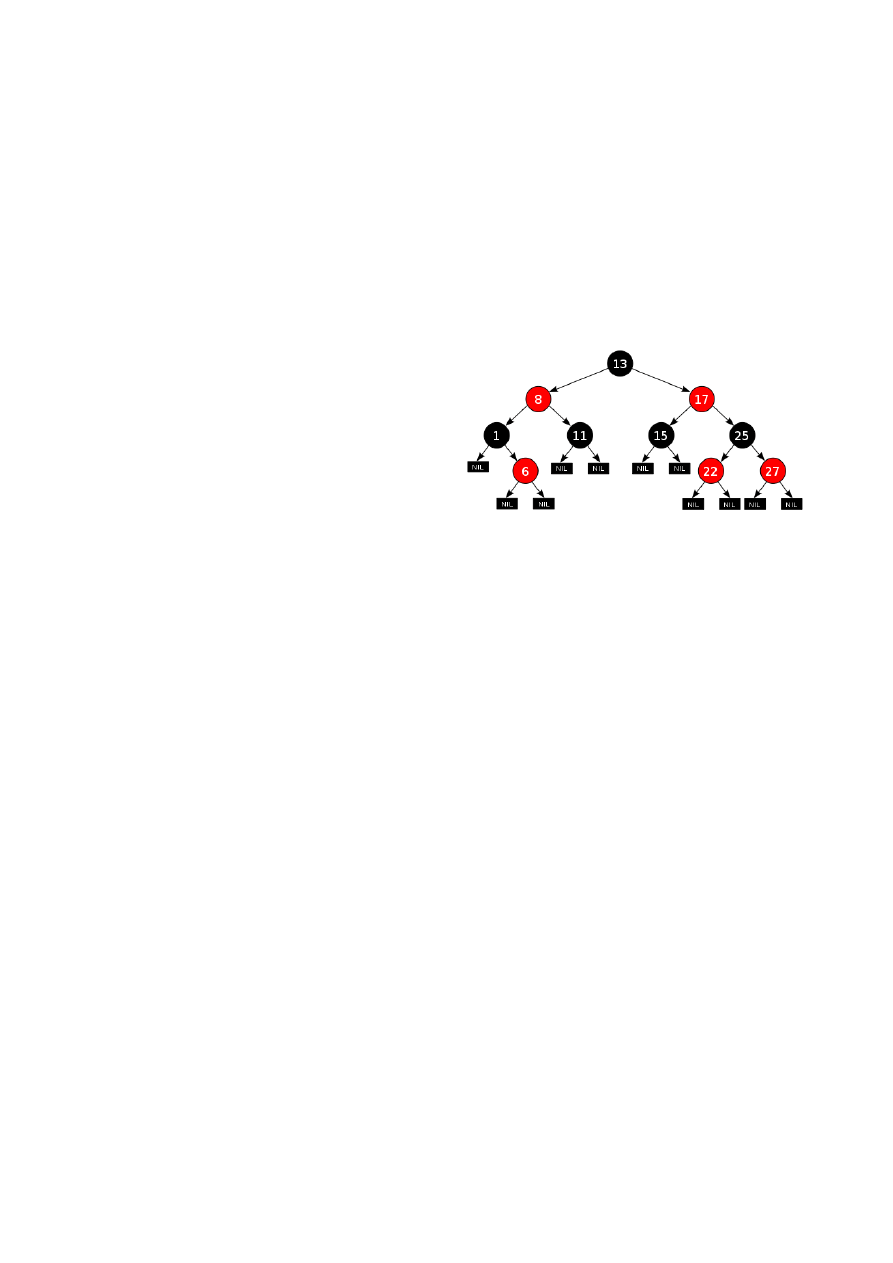
Drzewa Czerwono-Czarne (RB)
Własności:
- każdy węzeł jest czerwony lub czarny
- każdy liść jest czarny
- jeśli węzeł jest czerwony to obaj jego synowie
są czarni
- każda ścieżka z ustalonego węzła do liścia ma
tyle samo czarnych węzłów
- każdy węzeł drzewa zawiera pola: color, key,
left, right, parent
- search, min, max, successor, predecessor- nie zmieniają drzewa
- insert, delete- zmieniają drzewo
- pesymistyczna złożoność operacji O(logn)
6.
Omówić sposoby implementacji list jednokierunkowej oraz dwukierunkowej. Podać
zestaw operacji wchodzących w skład interfejsu listy.
Lista - struktura danych służąca do reprezentacji zbiorów dynamicznych, w której elementy
ułożone są w liniowym porządku. Rozróżniane są dwa podstawowe rodzaje list: lista
jednokierunkowa w której z każdego elementu możliwe jest przejście do jego następnika
oraz lista dwukierunkowa w której z każdego elementu możliwe jest przejście do jego
poprzednika i następnika. Istnieją dwie popularne implementacje struktury listy: tablicowa i
wskaźnikowa.
Wskaźnikowa
W przypadku tej implementacji każdy element listy składa się z co najmniej dwóch pól:
klucza oraz pola wskazującego na następny element listy. W przypadku list
dwukierunkowych każdy element listy zawiera także pole wskazujące na poprzedni element
listy. Pole wskazujące poprzedni i następny element listy są najczęściej wskaźnikami.
Dopisanie elementu (dla prostej listy jednostronnej):
- jeśli ma ono nastąpić na końcu listy, to wskaźnik wiążący w obiekcie ostatnim ustawia się na
nowy obiekt danego typu;
- jeśli ma ono nastąpić wewnątrz listy, to najpierw tworzy się nowy obiekt danego typu i jego
wskaźnik wiążący ustawia się na następnik elementu, za którym ma być wstawiany. Później
wskaźnik poprzednika przestawia się na ten nowy obiekt. W tym przypadku bardzo ważna
jest kolejność, której zachwianie jest częstą przyczyną błędów. Np. można najpierw
przestawić wskaźnik poprzednika na nowy obiekt, co spowoduje bezpowrotną utratę

5
dostępu do dalszych elementów listy, na które już nie będzie pokazywał żaden wskaźnik.
Ustawienie wskaźnika nowego elementu na następnik nie będzie możliwe, bo nie będzie
znany jego adres.
Usunięcie elementu jest odwrotne do wstawiania: w pewnym miejscu zapisuje się wskaźnik
do usuwanego elementu (aby nie "zgubić" jego adresu), następnie wskaźnik wiążący
poprzednika przestawia się na następnik. Dopiero w tym momencie zwalnia się pamięć po
obiekcie usuwanym (do tego potrzebny jest ten wskaźnik tymczasowy). Zalety i wady tej
implementacji są komplementarne w stosunku do implementacji tablicowej.
Tablicowa
Jak wskazuje nazwa, lista zaimplementowana w ten sposób opiera się na tablicy obiektów
(lub rekordów) danego typu.
Dopisanie elementu do listy to wstawienie elementu do tablicy:
- jeśli ma ono nastąpić na końcu listy, będzie to kolejny element w tablicy;
- jeśli nowy element ma znaleźć się między innymi elementami, należy przesunąć o jedno
pole w prawo wszystkie elementy o indeksie wyższym niż pole, na które będzie wstawiany
obiekt; następnie w powstałą lukę wpisuje się nowy element.
Usunięcie elementu znajdującego się pod danym indeksem tablicy to przesunięcie o jedno
pole w lewo wszystkich elementów o indeksie wyższym. Zalety tej implementacji: prosta
nawigacja wewnątrz listy, korzystanie z gotowej struktury tablicy, szybki dostęp do elementu
o konkretnym numerze, większa odporność na błędy. Wady: niska elastyczność, szczególnie
dotycząca rozmiaru tablicy, liniowa złożoność operacji wstawiania i usuwania.
Implementację tablicową stosuje się tam, gdzie elastyczność nie odgrywa istotnej roli, a
wymagana jest szybka i prosta nawigacja.
7.
Omówić algorytmy efektywnego poszukiwania najkrótszej ścieżki w grafie.
Problem najkrótszej ścieżki jest zagadnieniem szczególnie istotnym w informatyce. Polega on
na znalezieniu w grafie ważonym najkrótszego połączenia pomiędzy danymi wierzchołkami.
Szczególnymi przypadkami tego problemu są problem najkrótszej ścieżki od jednego
wierzchołka do wszystkich innych oraz problem najkrótszej ścieżki pomiędzy wszystkimi
parami wierzchołków.
Algorytm Dijkstry
Algorytm Dijkstry działa zarówno dla grafów skierowanych jak i nieskierowanych. Znajduje
najkrótszą drogę z wierzchołka p (zwanego źródłem lub początkiem) do wszystkich
pozostałych wierzchołków grafu lub do wybranego wierzchołka k (zwanego ujściem lub
końcem) w grafie, w którym wszystkim krawędziom nadano nieujemne wagi. Polega na
przypisaniu wierzchołkom pewnych wartości liczbowych. Taką liczbę nazwijmy cechą
wierzchołka. Cechę wierzchołka v nazwiemy stałą (gdy jest równa długości najkrótszej drogi z
p do v) albo, w przeciwnym przypadku, tymczasową. Na początku wszystkie wierzchołki,
oprócz p, otrzymują tymczasowe cechy ∞. źródło p otrzymuje cechę stałą równą 0.
Następnie wszystkie wierzchołki połączone krawędzią z wierzchołkiem p otrzymują cechy

6
tymczasowe równe odległości od p. Potem wybierany jest spośród nich wierzchołek o
najmniejszej cesze tymczasowej. Oznaczmy go v. Cechę tego wierzchołka zamieniamy na
stałą oraz przeglądamy wszystkie wierzchołki połączone z v. Jeśli droga z p do któregoś z
nich, przechodząca przez v ma mniejszą długość od tymczasowej cechy tego wierzchołka, to
zmniejszamy tą cechę. Ponownie znajdujemy wierzchołek o najmniejszej cesze tymczasowej i
zamieniamy cechę tego wierzchołka na stałą. Kontynuujemy to postępowanie aż do
momentu zamiany cechy wierzchołka k na stałą (czyli obliczenia długości najkrótszej drogi z p
do k). Bardzo ważnym założeniem w algorytmie Dijkstry są nieujemne wagi krawędzi. Jeśli
krawędzie mogą przyjmować wagi ujemne, to NIE WOLNO stosować algorytmu Dijkstry. W
tym wypadku używa się wolniejszego, lecz bardziej ogólnego algorytmu Bellmana-Forda. Jeśli
graf nie jest ważony (wszystkie wagi mają wielkość 1), zamiast algorytmu Dijkstry wystarczy
algorytm przeszukiwania grafu wszerz. Algorytm Dijkstry jest przykładem algorytmu
zachłannego.
Algorytm zachłanny
Algorytm zachłanny (greedy algorithm) to taki algorytm, który w celu wyznaczenia
rozwiązania w każdym kroku dokonuje najlepiej rokującego w danym momencie wyboru
rozwiązania częściowego, tzw. zachłannego. Innymi słowy mówiąc algorytm zachłanny nie
patrzy czy w kolejnych krokach jest sens wykonywać dane działanie, dokonuje lokalnie
optymalną decyzję, dokonuje on wyboru wydającego się w danej chwili najlepszym,
kontynuując rozwiązanie podproblemu wynikającego z podjętej decyzji.
Złożoność
Złożoność obliczeniowa algorytmu Dijkstry zależy od liczby V wierzchołków i E krawędzi
grafu. O rzędzie złożoności decyduje implementacja kolejki priorytetowej:
- wykorzystując “naiwną” implementację poprzez zwykłą tablicę, otrzymujemy algorytm o
złożoności O(V^2)
- w implementacji kolejki poprzez kopiec, złożoność wynosi O(ElogV)
- po zastąpieniu zwykłego kopca kopcem Fibonacciego, złożoność zmniejsza się do O(E +
VlogV)
Algorytm Bellmana-Forda
Algorytm ten służy do wyznaczania najmniejszej odległości od ustalonego wierzchołka s do
wszystkich pozostałych w skierowanym grafie bez cykli o ujemnej długości. Warunek
nieujemności cyklu jest spowodowany faktem, że w grafie o ujemnych cyklach najmniejsza
odległość między niektórymi wierzchołkami jest nieokreślona, ponieważ zależy od liczby
przejść w cyklu.
Niech ustalonym wierzchołkiem źródłowym będzie wierzchołek 1. Przed d(i, j) oznaczamy
koszt krawędzi (i, j), jeśli krawędź taka nie istnieje to przyjmujemy, że jej koszt jest
nieskończony. Wówczas można przyjąć, że minimalny koszt dojścia D(j) od wierzchołka 1 do
wierzchołka j jest równy d(1, j).
Niech v będzie dowolnym wierzchołkiem grafu różnym od wierzchołka źródłowego 1. Jeśli
istnieje krawędź (1, v), to koszt dojścia do wierzchołka v równy D(v) posiada już przypisaną
wartość d(1, v), która wcale nie musi być najmniejszym kosztem dojścia, ale jest określona,
tzn. różna od nieskończoności.
Stawiamy pytanie, czy do wierzchołka v można dojść ścieżką długości 2, przechodzącą przez
pewnien inny wierzchołek u, czyli ścieżką postaci 1-i-v. Możemy to sprawdzić pisząc pętlę,

7
która oszacuje koszty wszystkich możliwych ścieżek długości 2 postaci 1-i-v, pamiętając o
tym, że nawet jeśli nie istnieją krawędzie (1, i) lub (i, v) to niczemu to nie przeszkadza - koszt
takiej ścieżki będzie równy nieskończoności:
For i:=1 To n Do If D(i)+d[i, v] Po wykonaniu takiej pętli koszt dojścia do wierzchołka v, czyli
D(v), będzie równy albo kosztowi krawędzi d[1, v], albo kosztowi pewnej znalezionej ścieżki
długości 2 o mniejszym koszcie. Można zatem powiedzieć, że wyznaczony został najmniejszy
możliwy koszt dojścia do wierzchołka v po ścieżce o maksymalnej długości 2. Nie musi to być
ścieżka najtańsza, ale na pewno jest najtańszą ścieżką z wszystkich ścieżek o długości nie
większej niż 2.
Algorytm Bellmana-Forda wyznacza minimalne koszty dojścia do wszystkich wierzchołków po
ścieżkach o maksymalnej długości 2, co uzyskamy dopisując jedną pętlę For: Dla wszystkich
węzłów j od 2 do n: znajdź najtańszą ścieżkę długości 2 prowadzącą do wierzchołka j For j:=2
To n Do For i:=2 To n Do If D(i)+d[i, j]
Pozostaje teraz postawić pytanie co wykonałby taki kod: For j:=2 To n Do For i:=2 To n Do If
D(i)+d[i, j] For j:=2 To n Do For i:=2 To n Do If D(i)+d[i, j]
Pierwsze dwie pętle wyznaczą minimalne koszty dojścia do wierzchołków po ścieżkach o
maksymalnej długości 2. Jeśli graf zawiera ścieżkę 1-u-v-z to podczas wykonywania drugich
pętli For dla j=z i i=v będą określone wartości D(v) oraz d[v, z], a tym samym znalezione
zostanie mniejsze oszacowanie kosztu dojścia do wierzchołka z. Powtórne wykonanie
wyznaczy minimalne koszty dojścia do wszystkich wierzchołków po ścieżkach o maksymalnej
długości 3.
Ponieważ każda prosta ścieżka w grafie ma długość co najwyżej n-1 powtarzając obie pętle n-
1 razy znajdziemy minimalne koszty dojścia do wszystkich wierzchołków grafu.
For k:=1 To n-1 Do For j:=2 To n Do For i:=2 To n Do If D(i)+d[i, j]
Ciężko jest go krótko opisać, dokładniejszy przystępny opis tutaj.
Złożoność
Złożoność obliczeniowa Przy reprezentacji grafu za pomocą macierzy sąsiedztwa całość
algorytmu tworzą trzy pętle For, co daje złożoność rzędu O(n^3). Jeśli graf zapamiętamy za
pomocą listy krawędzi, to dwie pętle For przebiegające po wszystkich wierzchołkach zastąpić
można jedną przebiegająca po wszystkich krawędziach. Złożoność obliczeniowa będzie
wówczas rzędu O(V*E).
Algorytm Floyda-Warshalla
Algorytm Floyda-Warshalla służy do znajdowania najkrótszych ścieżek pomiędzy wszystkimi
parami wierzchołków w grafie ważonym. Algorytm Floyda-Warshalla korzysta z tego, że jeśli
najkrótsza ścieżka pomiędzy wierzchołkami v1 i v2 prowadzi przez wierzchołek u, to jest ona
połączeniem najkrótszych ścieżek pomiędzy wierzchołkami v1 i u oraz u i v2. Na początku
działania algorytmu inicjowana jest tablica długości najkrótszych ścieżek, tak że dla każdej
pary wierzchołków (v1,v2) ich odległość wynosi:
- d[v1, v2] = 0 gdy v1 = v2
- d[v1, v2] = w(v1, v2) gdy (v1, v2) należy do E
- d[v1, v2] = +∞ gdy (v1, v2) nie należy do E
Algorytm jest dynamiczny i w kolejnych krokach włącza do swoich obliczeń ścieżki
przechodzące przez kolejne wierzchołki. Tak więc w k-tym kroku algorytm zajmie się

8
sprawdzaniem dla każdej pary wierzchołków, czy nie da się skrócić (lub utworzyć) ścieżki
pomiędzy nimi przechodzącej przez wierzchołek numer k (kolejność wierzchołków jest
obojętna, ważne tylko, żeby nie zmieniała się w trakcie działania programu). Po wykonaniu
|V| takich kroków długości najkrótszych ścieżek są już wyliczone.
Złożoność obliczeniowa: O(|V|^3) Złożoność pamięciowa: O(|V|^2)
8.
Procesy kompilacji i interpretacji w różnych językach programowania. Omów ich
przebieg, porównaj wady i zalety, wskaż przykłady implementacji w popularnych językach.
Translator
program, który umożliwia przetłumaczenie na kod maszynowy i wykonanie
programów napisanych w języku różnym od języka komputera.
Kompilator jest programem (translatorem), który przetwarza kod napisany w jednym
języku (tzw. języku źródłowym) na równoważny kod w drugim języku (tzw. języku
wynikowym).
Istnieją kompilatory dla tysięcy języków źródłowych od tradycyjnych uniwersalnych
języków programowania takich jak wciąż używany Fortran, Pascal czy C aż do języków
wyspecjalizowanych do konkretnych zastosowań.
Alternatywnym typem translatora jest interpreter.
Interpreter jest programem, który nie generuje programu wynikowego tylko od razu
wykonuje instrukcje zawarte w programie źródłowym.
Interpretery są wykorzystywane do wykonywania języków poleceń powłok systemów
operacyjnych oraz języków bardzo wysokiego poziomu takich, jak APL czy Prolog.
W chwili obecnej interpretery są rzadziej wykorzystywane niż kompilatory przede
wszystkim ze względu na małą wydajność aplikacji
mają pewne istotne zalety – ich implementacja bywa szybsza i prostsza, można
uruchamiać częściowo napisane systemy, pozwalają na szybkie i częste modyfikacje
oprogramowania.
Interpretery czasami bywają wykorzystywane również dla języków zwykle
kompilowanych (takich, jak np. C), czasami dostępne są podejścia hybrydowe – język
Prolog może być kompilowany albo interpretowany.
Ważną dziedziną zastosowań interpreterów są maszyny wirtualne, choć także i tutaj
ze względu na wydajność są wypierane przez kompilatory lub mechanizmy sprzętowe
(np. koprocesory bezpośrednio wykonujące kod Javy).
Kompilacja - podstawowe cechy
Program źródłowy jest napisany w języku źródłowym, a program wynikowy należy do
języka wynikowego.
Wykonanie programu kompilatora następuje w czasie tłumaczenia.
Program po przetłumaczeniu nie da się zmienić, jest statyczny.
Kompilator jako dane wejściowe otrzymuje “cały” program źródłowy i przekształca go
na postać wynikową.
Skompilowane moduły są zazwyczaj łączone przez linker w jeden program
wykonywalny. Interpretacja - podstawowe cechy
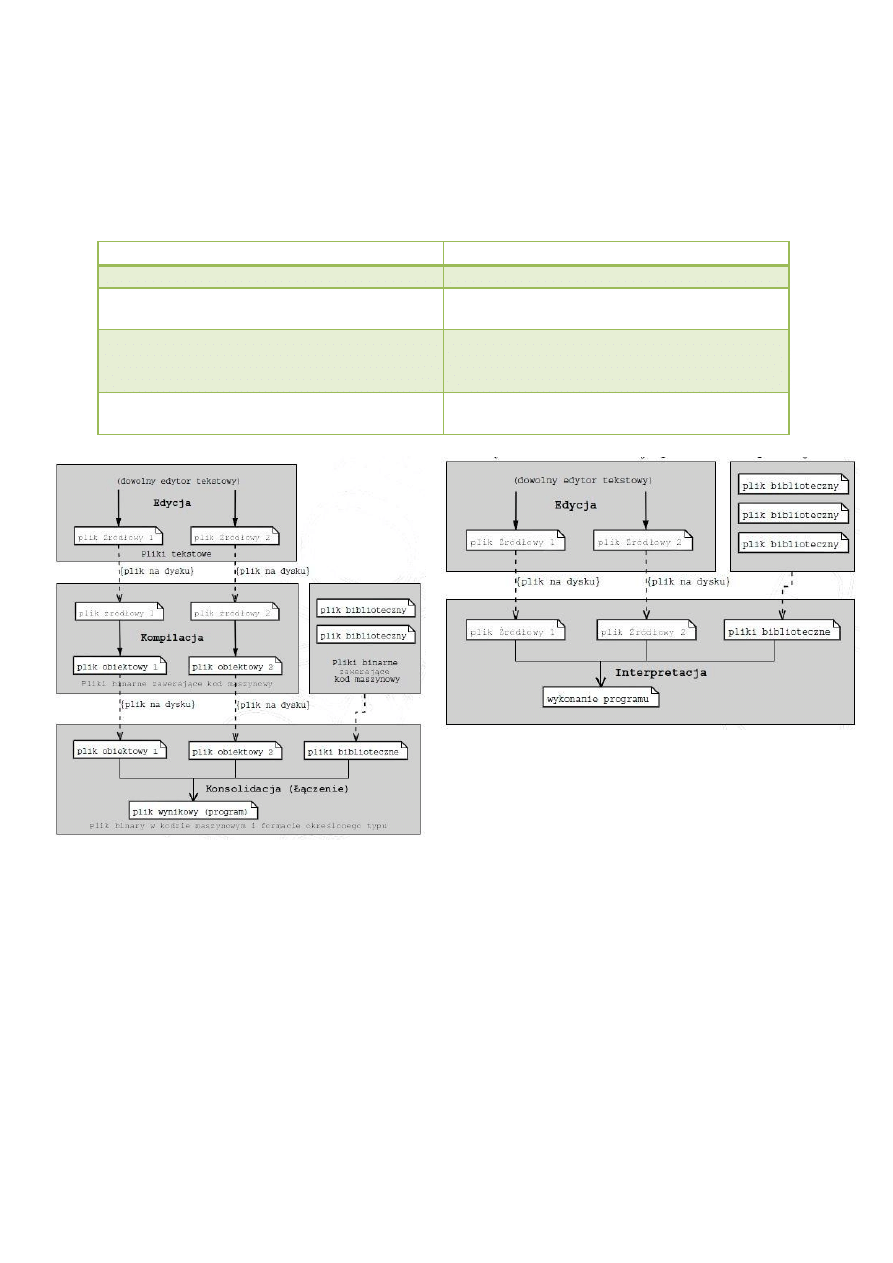
9
Działanie interpretera polega na: wyodrębnieniu niewielkich jednostek programu
źródłowego, tłumaczeniu ich na pewną postać wynikową oraz natychmiastowym ich
wykonywaniu.
Proces interpretacji jest cykliczny.
W czasie interpretacji przechowywany jest program źródłowy.
Kompilacja
Interpretacja
Program wynikowy wykonuje się szybciej.
Łatwość zmian programu.
Do wykonania programu wynikowego nie jest
potrzebny kompilator.
Mniejsza zajętość pamięci zewnętrznej (tylko
tekst źródłowy).
Lepsza optymalizacja kodu (optymalizacja
dedykowana pod daną architekturę).
Możliwość pracy konwersacyjnej (zatrzymanie
wyk., zmiana wartości zmiennych, kontynuacja
wyk.).
Przenośność, wykorzystanie w zastosowaniach
sieciowych.
Języki programowania
Kompilowane
Napisane w nich kody po kompilacji to samodzielne programy:
Delphi (Pascal),
C, C++.
Częściowo kompilowane
Powstaje kod bajtowy (postać pośrednia) wymagający platformy uruchomieniowej:
Java - JVM (Java VirtualMachine, Java RuntimeEnvironment),
C# -.NET Framework. Interpretowane
10
Wymagają interpretera:
JavaScript (interpreterem jest przeglądarka),
Perl (Practical Extraction and Report Language, praktyczny język ekstrakcji i
raportowania),
PHP (obecnie PHP HypertextPreprocessor(akronim rekurencyjny), pierwotnie
PersonalHome Page) stosowany głównie do dynamicznego tworzenia stron
internetowych,
Python,
Ruby,
VBA (Visual Basic for Aplications), interpretatorem jest pakiet MS Office.
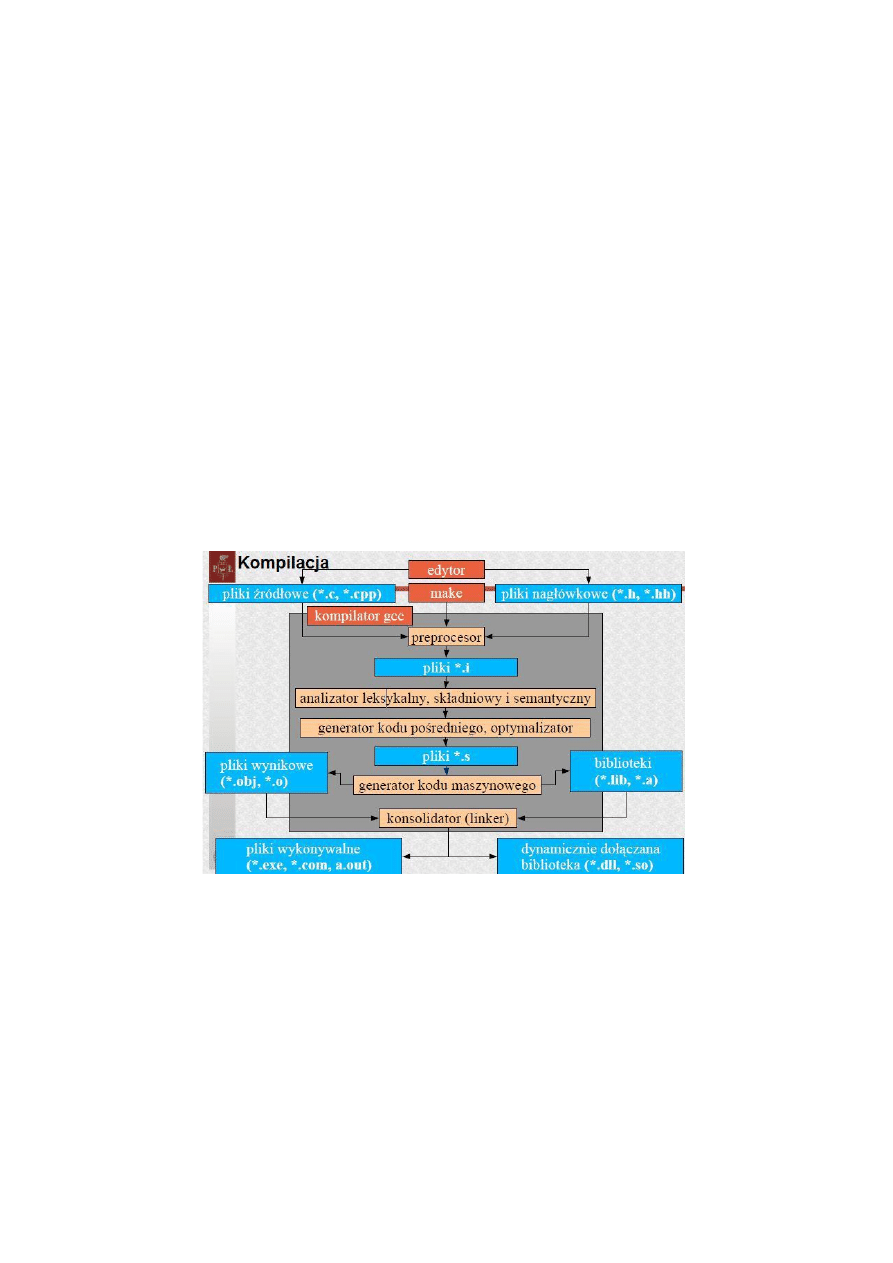
Omówienie procesu kompilacji
Każda kompilacja jest dwuetapowym procesem. Najpierw następuje etap analizy, w
trakcie którego program źródłowy jest rozkładany na części składowe i generowana jest
jego reprezentacja pośrednia. Ważnym elementem tego etapu kompilacji jest
wykrywanie i zgłaszanie użytkownikowi informacji o ewentualnych błędach w programie
źródłowym. W drugim etapie – syntezie – na podstawie reprezentacji pośredniej
generowany jest program wynikowy. Program wynikowy może być programem w innym
języku źródłowym albo jakąś postacią kodu wykonywalnego.
9.
Mechanizm przeładowanie operatorów w językach obiektowych. Podaj przykład
praktycznego zastosowania.
Przeciążanie operatorów (ang. operator overloading, przeładowanie operatorów)
to rodzaj polimorfizmu występującego w niektórych językach programowania,
polegający na tym, że operator może mieć różne implementacje w zależności od
typów użytych argumentów (operandów).
Przeciążanie operatorów to typowy lukier składniowy.
Potencjalnie znacznie poprawia czytelność kodu i umożliwia zdefiniowanie większej
części biblioteki standardowej na poziomie języka, bez uciekania się do trików.

11
Z drugiej strony, ta technika programistyczna może spowodować powstawanie
niejasnych konstrukcji, gdzie operatory wykonują kompletnie różne czynności w
zależności od ich operandów.
Przykład:
W C++ przeładowanie operatora wyjścia << dzięki czemu możemy drukować na wyjściu nasz
obiek oraz określić jak będzie wydruk wyglądał, np. dla klasy Student wypisujemy Imie
Nazwisko, nr indeksu. Przeładowanie operatora == abyśmy mogli porównywać nasze
obiekty, np. dla klasy Student wystarczyłoby porównywać nr. indeksu, aby wiedzieć czy to ta
sama osoba.
10.
Mechanizm dziedziczenia. Dziedziczenie jedno i wielokrotne. Podaj przykład
wykorzystania.
Dziedziczeniem (ang. inheritance) w programowaniu obiektowym nazywamy mechanizm
współdzielenia funkcjonalności między klasami. Klasa może dziedziczyć po innej klasie, co
oznacza, że oprócz swoich własnych atrybutów oraz zachowań, uzyskuje także te
pochodzące z klasy, z której dziedziczy. Klasa dziedzicząca jest nazywana klasą pochodną lub
potomną (w j. angielskim: subclass lub derived class), zaś klasa, z której następuje
dziedziczenie — klasą bazową (w ang. superclass). Z jednej klasy bazowej można uzyskać
dowolną liczbę klas pochodnych. Klasy pochodne posiadają obok swoich własnych metod i
pól, również kompletny interfejs klasy bazowej.
W programowaniu obiektowym wyróżniane jest dziedziczenie pojedyncze oraz dziedziczenie
wielokrotne. Z dziedziczeniem pojedynczym mamy do czynienia, gdy klasa pochodna
dziedziczy po dokładnie jednej klasie bazowej (oczywiście klasa bazowa wciąż może
dziedziczyć z jakiejś innej klasy), natomiast w dziedziczeniu wielokrotnym klas bazowych
może być więcej.
Dziedziczenie wielokrotne stanowi właściwość niektórych obiektowych języków
programowania w których klasa może dziedziczyć metody i pola z więcej niż jednej klasy
bazowej. Języki wspierające dziedziczenie wielokrotne to: Eiffel, C++, Python, Perl, Curl,
Common Lisp (via CLOS).
11.
Klasy abstrakcyjne i funkcje wirtualne w językach obiektowych. Podaj przykład
zastosowania.
Klasa abstrakcyjna w programowaniu obiektowym jest to klasa, która nie może mieć swoich
reprezentantów pod postacią obiektów. Zależnie od użytego języka programowania klasy
abstrakcyjne tworzy się na różne sposoby.
Klasa abstrakcyjna jest pewnym uogólnieniem innych klas (na przykład dla występujących w
rzeczywistości obiektów), lecz sama jako taka nie istnieje. Ustalmy, że przez "figurę"
będziemy rozumieć "koło", "kwadrat" lub "trójkąt". Te obiekty matematyczne mogą być
reprezentowane przez pewne klasy. Obiekty te posiadają już konkretne właściwości takie jak
promień (dla konkretnego koła) czy długość boku (dla konkretnego kwadratu). Klasy tych
obiektów wywodzą się z pewnej uogólnionej klasy określanej jako po prostu figura. Jednak
nie jesteśmy w stanie określić jaką konstrukcję miałby obiekt klasy figura, ponieważ figura

12
geometryczna jako taka nie istnieje. Istnieją natomiast wywodzące się od niej klasy koło czy
kwadrat. Dodatkowo oczywistym jest, że figura nie posiada konkretnej wartości pola czy
obwodu, jednak już na tym etapie wiemy, że każda figura tak zdefiniowana (koło, kwadrat
czy trójkąt) posiada pole i obwód, które będzie różnie obliczane dla różnych figur. Dzięki
temu figura definiuje pewien interfejs dla klas wywodzących się od niej.
C++
W C++ klasą abstrakcyjną jest klasa, która posiada zadeklarowaną co najmniej jedną metodę
czysto wirtualną. Każda klasa, która dziedziczy po klasie abstrakcyjnej i sama nie chce być
abstrakcyjną, musi implementować wszystkie odziedziczone metody czysto wirtualne.
Java
W Javie klasę abstrakcyjną możemy stworzyć na dwa sposoby: za pomocą słowa kluczowego
abstract, które tworzy klasyczną klasę abstrakcyjną lub za pomocą słowa kluczowego
interfacetworzącego abstrakcyjny interfejs
C#
W C# klasą abstrakcyjną jest klasa, która została zadeklarowana jako abstrakcyjna za pomocą
słowa kluczowego abstract.
Właściwości:
- Klasa abstrakcyjna w Javie nie musi posiadać metod czysto wirtualnych aby być
abstrakcyjną, jednak takie użycie klasy abstrakcyjnej określa klasę jako nieinstancjowalną i
jest rzadziej spotykane.
- Jeśli co najmniej jedna metoda w klasie zostanie zadeklarowana jako czysto wirtualna
(abstrakcyjna), to ta klasa musi zostać zadeklarowana jako abstrakcyjna.
- Jeżeli wszystkie metody klasy są czysto wirtualne, zaleca się, aby taką klasę zadeklarować
jako interfejs klasy.
Funkcje wirtualne
To specjalne funkcje składowe, które przydają się szczególnie, gdy używamy obiektów
posługując się wskaźnikami lub referencjami do nich. Dla zwykłych funkcji z identycznymi
nazwami to, czy zostanie wywołana funkcja z klasy podstawowej, czy pochodnej, zależy od
typu wskaźnika, a nie tego, na co faktycznie on wskazuje. Dysponując funkcjami wirtualnymi
będziemy mogli użyć prawdziwego polimorfizmu - używać metod klasy pochodnej wszędzie
tam, gdzie spodziewana jest klasa podstawowa. W ten sposób będziemy mogli korzystać z
metod klasy pochodnej korzystając ze wskaźnika, którego typ odnosi się do klasy
podstawowej. W tej chwili może się to wydawać niepraktyczne, lecz za chwilę przekonasz
się, że funkcje wirtualne niosą naprawdę sporo nowych możliwości.
12.
Obsługa sytuacji wyjątkowych w językach obiektowych (np. C++, Java).
Jeżeli w jakimś miejscu programu zajdzie nieoczekiwana sytuacja, programista piszący ten
kod powinien zasygnalizować o tym. Dawniej polegało to na zwróceniu specyficznej wartości,
co nie było zbyt szczęśliwym rozwiązaniem, bo sygnał musiał być taki jak wartość zwracana
przez funkcję. W przypadku obsługi sytuacji wyjątkowej mówi się o obiekcie sytuacji
wyjątkowej, co często zastępowane jest słowem "wyjątek". W C++ wyjątki się "rzuca", służy
13
do tego instrukcja throw. Tam gdzie spodziewamy się wyjątku umieszczamy blok try, w
którym umieszczamy "podejrzane" instrukcje. Za tym blokiem muszą (tzn. musi przynajmniej
jedna) pojawić się bloki catch.
13.
Organizacja pamięci pomocniczej - metody przydziału miejsca na dysku
Ciągły - Każdy plik zajmuje jeden spójny obszar na dysku, metoda całkowicie niefektywna w
wyniku zmian wielkości plików i konieczności ciągłego "przemeblowywania" dysku.
Listowy - Bloki dyskowe tworzące jeden plik połączone są w listę jednokierunkową, tzn.
każdy blok zawiera numer następnego bloku tworzącego listę. Plik identyfikowany jest przez
numer swojego pierwszego bloku.
Indeksowy - Numery wszystkich bloków tworzących plik (właściwą treść pliku) zebrane są w
jednym bloku, tzw. bloku indeksowym. Plik jest na dysku reprezentowany przez numer tego
bloku indeksowego. Jeżeli więc np. bloki mają po 4 kB, a numer bloku jest 32-bitowy, to
maksymalny rozmiar pliku wynosi 1024 * 4 KB = 4 MB.
14.
Omów i porównaj najczęściej stosowane systemy plików.
FAT32
● brak mechanizmu zarządzania wolnymi sektorami na dysku
● pliki porozrzucane na dysku
● częste fragmentacje
● obliczanie wolnego miejsca jest czasochłonne
● obsługiwany (chyba) przez wszystkie systemy operacyjne, dlatego stosowany na
przenośnych nośnikach danych
● brak kontroli praw dostępu do danych
NTFS
● ulepszony względem FAT32
● przechowuje znacznie więcej metadanych (np. prawa dostępu)
● dziennik systemowy plików
● wprowadzona quota
● kompresja woluminów
● obsługa rzadkich plików (dużo zer)
● możliw- przechowuje archiwalne wersje plików i katalogów
● Windows Vista wprowadza linki symboliczne
ext2
● hierarcha za pomocą i-węzłów
● każdy plik ma swój i-węzeł
● i-węzeł ma unikatowy numer
● katalog - specjalny plik
● przeciwdziałanie fragmentacji (bliskie bloki, prealokacja)
● stabilny i dobrze przetestowany

14
● automatyczne sprawdzanie systemu po każdym niepoprawnym odmontowaniu oraz co
jakiś czas
● wolne sprawdzanie systemu plików
● niska wydajność dla bardzo małych plików
ext3
● kompatybilny z ext2
● nowe cechy:
■ journaling - zwiększenie bezpieczeństwa danych, skraca do minimum czas sprawdzania
systemu plików po awarii
■ indeksowane katalogi przy dużej liczbie plików, większa wydajność
Journaling
● dodatkowe miejsce na dysku przechowuje informacje na temat zmian danych i
metadanych
● wprowadzenie atomowych operacji - albo wszystkie, albo żadna
● skraca sprawdzanie systemu plikowego - czas przestaje zależeć od rozmiaru systemu
plików
Journaling Block Device
● jest przechowywane w i-węźle
● do właściwego journalingu służy interfejs JBD
● wadą takiego rozwiązania jest większe zapotrzebowanie na powierzchnię dyskową
● zaletą jest znaczne uproszczenie systemu oraz ograniczenie wymuszeń na moc
obliczeniową
● data=ordered - zapełnia tylko meta-dane
● łączy modyfikacje danych i odpowiadające im meta-dane w logiczną całość w transakcje
● dopiero po zapisaniu danych na dysku
15.
Metody zarządzania wolną przestrzenią pamięci dyskowej.
Wektor bitowy – Mapa bitowa: Każdy blok dyskowy jest reprezentowany przez 1 bit
w wektorze, jeśli jest 1 to blok jest wolny, jeśli 0 to blok jest zajęty, mało wydajne,
nadaje się jedynie dla małych dysków
Lista powiązana – Powiązanie wszystkich wolnych bloków w ten sposób, że w bloku
poprzednim znajduje się indeks bloku następnego, metoda niewydajna
Grupowanie – pierwszy wolny blok zawiera indeksy n innych wolnych bloków, z
których n-1 wolnych bloków służy do alokacji, a n-ty blok zawiera znowu n-1
indeksów kolejnych wolnych bloków, umożliwia szybkie odnajdywanie większej liczby
wolnych bloków
Zliczanie – W przypadku kilku kolejnych (przylegających do siebie) wolnych bloków
pamiętany jest tylko indeks pierwszego z nich oraz liczba wolnych bloków
znajdujących się bezpośrednio za nim. Wykazy wolnych obszarów jest ciągiem
wpisów składających się z indeksu bloku oraz licznika

15
16.
Algorytmy planowania przydziału procesora.
FCFS -(first come first served)
• Jest on najprostszym ze znanych algorytmów planowania procesora.
• Według tego schematu proces, który pierwszy zamówi procesor, pierwszy go
otrzyma.
• Implementację tego algorytmu otrzymuje się przez zastosowanie kolejki FIFO.
• Blok kontrolny procesu wchodzącego dokolejki jest umieszczany na jej końcu. J
• est to algorytm niewywłaszczający.
• Po objęciu kontroli nad procesorem proces utrzymuje ją do czasu, aż sam zwolni
procesor wskuteg zakończenia swego działania lub zamówienia operacji wejścia-
wyjścia.
• W algorytmie FCFS, średni czas oczekiwania bywa przeważniedługi.
SJF - (shortest job first)
• Algorytm ten wiąże z każdym procesem długość jego najbliższej z przyszłych faz
procesora.
• Gdy procesor staje się dostępny, wówczas zostaje przydzelony procesorowi proces o
najkrótszej następnej fazieprocesora.
• Algortm SJF może być wywłaszczający lub niewywłaszczający.
• Konieczność wyboru powstaje wówczas, gdy w kolejce procesów gotowych, podczas,
gdy procesor jest zajęty innym procesem, pojawia się proces o krótszej fazie
procesora, niż to co jeszcze zostało do wykonania w procesie bieżącym.
• Algorytm SJF - wywłaszczający usunie wówczas, bierzący proces do kolejki procesów
gotowych i przydzieli mu proces o krótszej fazie z kolejki.
• Algorytm SJF jest optymalny, tzn daje minimalny średni czas oczekiwania dla danego
zbioru procesów. Jednak poważną trudność sprawia określenie długości następnej
fazy procesora.
Planowanie priorytetowe
• Każdemu procesowi przypisuje się priorytet, po czym przydziela się procesor temu
procesowi, którego priorytet jest najwyższy.
• Procesy o równych priorytetach planuje się wg. schematu FCFS. (Algorytm SJF jest
szczególnym przypadkiem planowania priorytetowego, w którym priorytet jest
odwrotnością następnej przewidywanej fazy procesora).
• Planowanie priorytetowe może być wywłaszczające lub niewywłaszczające.
• Priorytet procesu dołączonego do kolejki procesów gotowych jest porównywany z
priorytetem procesu aktualnie przetwarzanego.
• Algorytm wywłaszczający wywłaszczy proces aktualnie przetwarzany, jeżeli nowo
przybyły proces charakteryzuje się wyższym priorytetem, natomiast algorytm
niewywłaszczający ustawi nowo przybyły proces z wyższym priorytetem na czole
kolejki.
• Należy pamiętać też o tym, że w mocno obciążonym systemie komputerowym, przy
użyciu planowania priorytetowego z wywłaszczeniem, stały dopływ napływ
procesów o wysokich priorytetach może nigdy nie dopuścić do wykonania się
procesu o priorytecie niskim. Rozwiązaniem tego problemu jest postarzanie

16
priorytetów. Polega ono na podnoszeniu priorytetów procesów długo oczekujących
na przydział procesora.
Planowanie rotacyjne (RR - round robin)
• Algorytm ten zaprojektowano specjalnie do systemów z podziałem czasu.
• Jest on podobny do FCFS, z tym, że w celu przełączania procesów dodano do niego
wywłaszczenie.
• Ustala się małą jednostkę czasu (kwant czasu), kolejka procesów gotowych jest
traktowana jako kolejka cykliczna.
• Planista przegląda tę kolejkę i każdemu procesowi przydziela odcinek czasu nie
dłuższy niż kwant czasu.
• Wydajność algorytmu rotacyjnego w dużym stopniu zależy od rozmiaru kwantu
czasu. Gdy kwant czasu jest bardzo długi, metoda rotacyjna sprowadza się do
planowania FCFS, natomiast jeśli kwant czasu jest bardzo mały to planowanie
rotacyjne nazywa się dzieleniem procesora i sprawia ono wrażenie, że każdy z n
procesów ma własny procesor działający z 1/n szybkości rzeczywistego procesora.
17.
Algorytmy zastępowania stron.
• algorytm FIFO - ofiarą staje się strona, która najdłużej przebywa w pamięci, gorszy niż
LRU, nie jest wolny od anomalii Belady’ego
• algorytm drugiej szansy
• algorytm zegarowy
• algorytm optymalny - ofiarą staje się strona, która przez najdłuższy okres będzie
nieużywana – jest to algorytm teoretyczny, służy do oceny jakości innych
algorytmów, nie da się go zaimplementować, gdyż nie da się przewidzieć przyszłym
odwołań do pamięci, maksymalne obniżenie braków stron, wolny od anomalii
Belady’ego
• LRU - ofiarą staje się strona , która nie była używana przez najdłuższy okres, uzyskuje
mniejszą ilość braków stron niż FIFO. Trudny w zaimplementowaniu, można
zastosować dla strony pole znacznika czasu ostatniego dostępu do strony(ofiara to ta
z najmniejszą wartością znacznika) lub skorzystać ze stosu, wolny od anomalii
Belady’ego
• MFU - ofiarą staje się strona, do której było najwięcej odwołań (najczęściej używana
strona)
18.
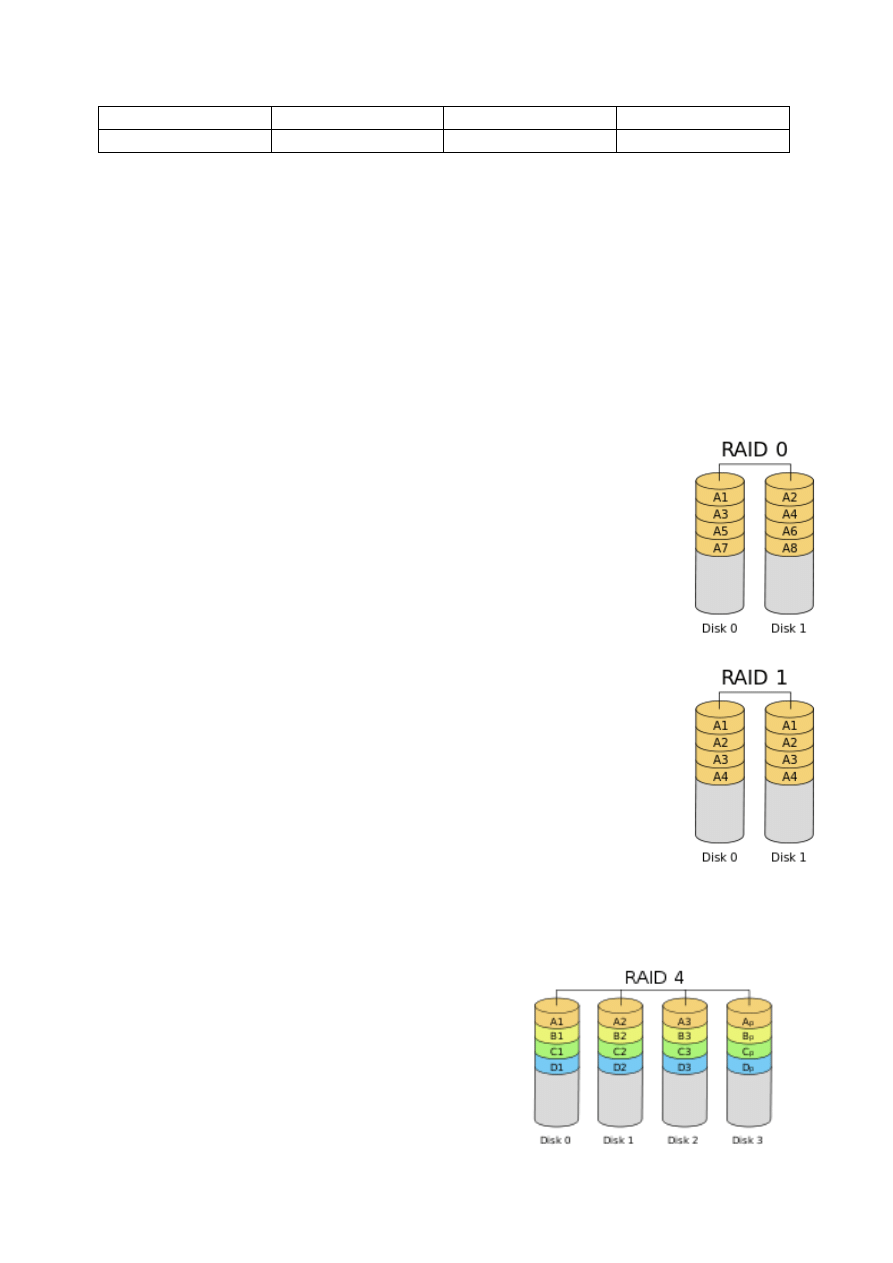
Schematy RAID (Redundant Array of Independent Disks). Porównanie pod kątem
niezawodności i wydajności.
POZIOM
MIN LICZBA
DYSKÓW
DOSTĘPNA
PRZESTRZEŃ
MAX LICZBA
DYSKÓW, KTÓRE
MOGĄ ULEC AWARII
RAID 0
2
N
0
RAID 1
2
1
N-1
RAID 4
3
N-1
1
17
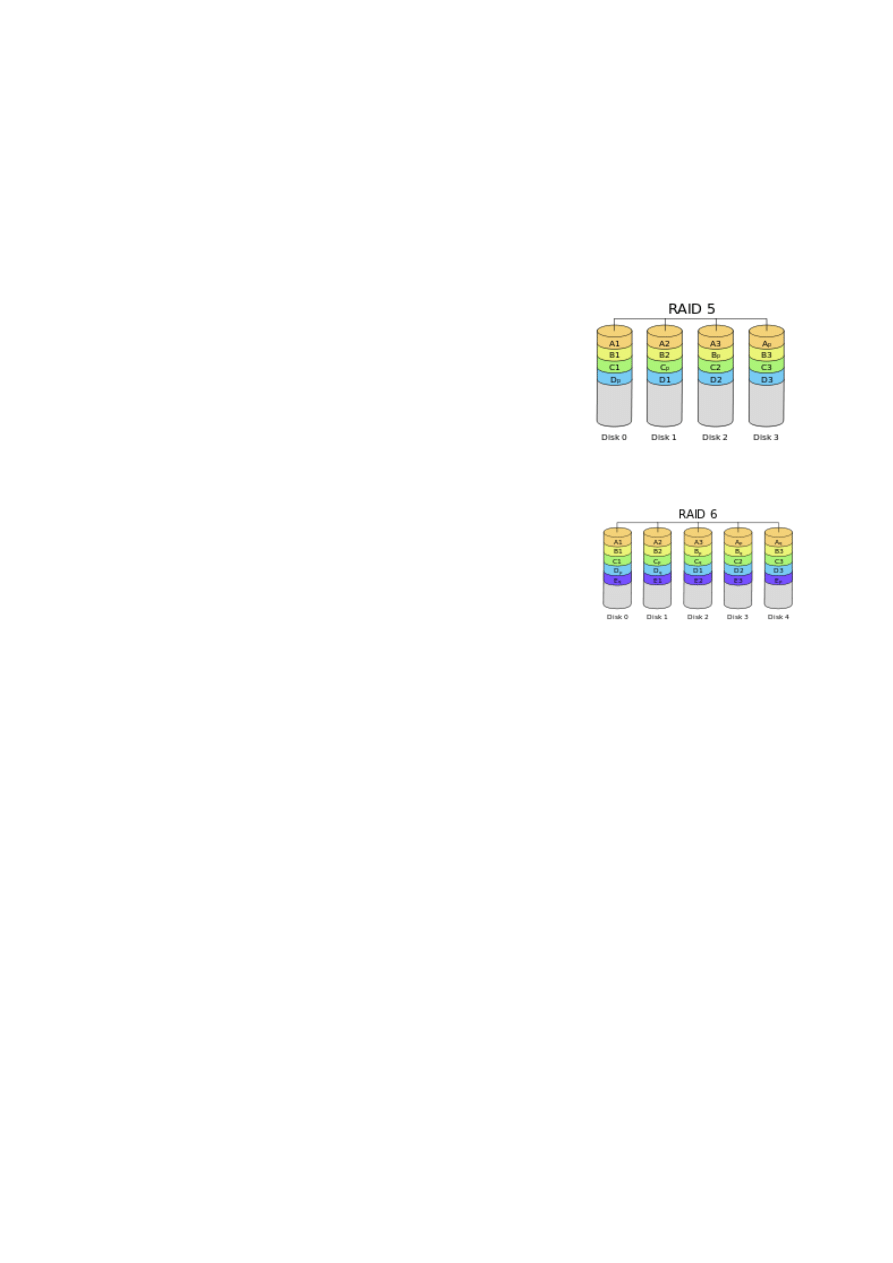
RAID 5
3
N-1
1
RAID 6
4
N-2
2
RAID - linear
● pojemność dysków w macierzy zsumowana
● zapis liniowy, po przepełnieniu jednego dysku zapis na następnym
● zalety:
■ duża pojemność
■ łączenie dysków o dużych pojemnościach
● wady:
■ brak zabezpieczonych danych
■ czas odczytu i zapisu nie zmienia się
RAID-0 (stripping)
● dane są dzielone na paski (stripe) o rozmiarze 4-128KB i przenoszone
kolejno naprzemiennie na poszczególne dyski
● pojemność dyskowa macierzy = ilość dysków * pojemność najmniejszego
dysku
● zalety:
■ duża pojemność
■ duża szybkość odczytu/zapisu
● wady:
■ brak zabezpieczenia danych, awaria jednego dysku prowadzi do utraty
wszystkich danych
RAID-1
● zalety:
■ duża niezawodność, przy awarii jednego działa drugi
■ możliwy równoległy odczyt z dwóch dysków
● wady:
■ zmniejszona szybkość zapisu - konieczność zapisu na dwóch
dyskach jednocześnie
■ utrata połączonej pojemności macierzy
RAID-4
● dane dzielone są na paski
● “w locie” obliczane są kody parzystości i zapisywane na dodatkowym dedykowanym
dysku
● zalety:
■ zwiększona niezawodność
■ lepsze wykorzystanie przestrzeni
● wady:
■ ciągłe obciążenie jednego dysku
■ minimum 3 dyski
● obliczanie parzystości
■ A xor B xor C xor D = P
18
■ P xor B xor C xor D = A
RAID-5
● dane dzielone na paski o rozmiarze 4-128KB i przenoszone kolejno naprzemiennie na
poszczególne dyski
● “w locie” obliczane są kody parzystości i zapisywane kolejno na każdym z dysków
● zalety:
■ zwiększenie niezawodności
■ równomierne wykorzystanie wszystkich dysków
● wady:
■ skomplikowany i długotrwały proces odbudowania
■ minumum 3 dyski
RAID-6
● jak w RAID-5, ale namiarowe są 2 dyski
● zalety:
■ zwiekszenie niezawodności
■ ochrona systemu w momencie uszkodzenia jednego
dysku podobna do RAID-5, z Hot Spare ale ochrona w
trakcie odbudowania systemu
● wady:
■ skomplikowany i długotrwały proces odbudowy
■ minimum 4 dyski
19.
Omów metody zarządzania pamięcią.
Metody przydziału pamięci operacyjnej procesom użytkowym:
1. brak podziału, wolna przestrzeń adresowa w danej chwili przydzielana jednemu procesowi
użytkowemu. Wieloprogramowanie można realizować przez wymiatanie.
2. podział pamięci, wolna przestrzeń adresowa podzielona na części przydzielane
pojedynczym procesom użytkowym.
- podział statyczny- dzieli pamięć na stałe partycje o różnej długości lub na bloki o stałej
długości zwane ramami (ang. frames)
- podział dynamiczny- realizacja z wykorzystaniem struktur opisujących wolne bloki pamięci
o różnych długościach oraz mechanizm wymiatania.
3. wykorzystanie pamięci wirtualnej, istnieje jedna lub wiele wirtualnych przestrzeni
adresowych przydzielanych procesom użytkowym, a mających w niewielkim stopniu
pokrycie w pamięci operacyjnej.
20.
Mechanizmy komunikacji międzyprocesowej IPC (Inter Process Communication).

19
Komunikacja międzyprocesowa (ang. Inter-Process Communication — IPC) – umowna nazwa
zbioru sposobów komunikacji pomiędzy procesami systemu operacyjnego.
Procesy mogą używać różnych sposobów komunikacji, a najpowszechniejsze z nich to:
• pliki i blokady – najprostsza i najstarsza forma IPC
• sygnały (ang. signals) – w niektórych systemach (jak np. DOS) znane jako przerwania
programowe
• semafory (ang. semaphores) - Używane są do kontroli dostepu do zasobów systemu
dzielonych przez kilka procesów. Zapobiegają one sytuacją w którym dwa procesy
jednocześnie mają dostęp do modyfikacji danego zasobu systemowego. Semafor jest
implementowany w jądrze, a używające go procesy otrzymują identyfikator semafora
, dzięki któremu mogą się do niego odwoływać.
• łącza nienazwane (ang. pipes) – znane też jako łącza komunikacyjne. Są to łącza do
których dostęp maja jedynie procesy pokrewne, czyli proces oraz jego potomkowie.
Dzieje się tak dlatego, że procesy potomne dziedziczą deskryptory plików. Łącza
nienazwane oparte są właśnie na deskryptorach. Jądro systemu, na żądanie procesu,
tworzy łącze bez nazwy i umieszcza jego deskryptor w tablicy deskryptorów plików
otwartych w procesie. Z deskryptorół tych korzysta najpierw proces, a następnie jego
potomkowie. Kiedy ostatni proces zostaje zrealizowany, zamyka on koniec łącza.
• łącza nazwane (ang. named pipes) – znane też jako nazwane łącza komunikacyjne.
Działają one w oparciu o algorytm FIFO (ang. First In First Out). Łącze nazwane jest
identyfikowane przez nazwę. Dzięki temu procesy niespokrewnione mogą przesyłać
między sobą dane. Łącze to ma dowiązanie w systemie plików, oznacza to że istnieje
w systemie jako plik w jakimś katalogu. Łącze to ma to do siebie, że pozostaje w
systemie nawet po zakończeniu ostatniego używającego je procesu.
• kolejki komunikatów (ang. message queues) - Kolejki służą do komunikacji między
procesami. Działają one na zasadzie algorytmu FIFO, to znaczy, że jeżeli proces chce
wysłać komunikat umieszcza go na końcu kolejki. Komunikaty zawarte w kolejce są w
kolejności nadesłania wysyłane do swoich odbiorców. W momencie kiedy proces
będzie na pierwszym miejscu w kolejce, zostaje pobrany przez swojego odbiorce. W
tym momencie komunikat jest automatycznie usuwany z kolejki.
• pamięć dzieloną (ang. shared memory) – znane też jako segmenty pamięci dzielonej
(ang. shared memory segments). Jest to obszar pamięci dzielony pomiędzy kilkoma
procesami. Dane umieszczane są przez proces w tzw. segmentach, w obszarze
adresowym procesu wywołującego. Może z nich korzystać wiele procesów. Pamięć
dzielona jest najszybszym sposobem komunikacji pomiędzy procesami.
• gniazda dziedziny Uniksa (ang. Unix domain sockets) - Gniazda wykorzystywane są do
komunikacji przez sieć w ramach komunikacji międzyprocesowej. Umożliwiają
komunikacje dwukierunkową, czyli wysyłanie i przyjmowanie danych. Gniazda są
pojęciem abstrakcyjnym i oznaczają dwukierunkowy punkt końcowy połączenia.

20
Gniazda posiadają takie właściwości jak: swój typ, lokalny adres, oraz opcjonalnie
port. Typ gniazda określa sposób wymiany danych, adres IP określa węzeł w sieci a
numer portu określa proces w węźle.
21.
Układy elektroniczne jako filtry. Klasyfikacja i przykłady zastosowań.
Filtr jest to fragment obwodu elektrycznego lub obwodu elektronicznego odpowiedzialny za
przepuszczanie lub blokowanie sygnałów o określonym zakresie częstotliwości lub
zawierającego określone harmoniczne.
Podział filtrów
Ze względu na przeznaczenie filtry można podzielić na cztery podstawowe rodzaje
- dolnoprzepustowe
- górnoprzepustowe
- środkowoprzepustowe
- środkowozaporowe
Ze względu na konstrukcję i rodzaj działania filtry można podzielić na:
- pasywne – nie zawierają elementów dostarczających energii do obwodu drgającego,
zawierają tylko elementy RLC
* jednostopniowe
* wielostopniowe
- aktywne – zawierają zarówno elementy RLC, jak również i elementy dostarczające energię
do filtrowanego układu np. wzmacniacze, układy nieliniowe.
Filtry można również podzielić na typy obwodów w jakich są używane:
- analogowe
- cyfrowe
Najprostszym rodzajem filtra pasywnego, szeroko stosowanego w elektronice, jest filtr
dolnoprzepustowy w postaci kondensatora o dużej pojemności połączonego równolegle do
filtrowanego napięcia (z ewentualnym szeregowym opornikiem).
Filtry aktywne najczęściej są stosowane przy układach scalonych do zastąpienia filtrów LC
przy niskich częstotliwościach.
22.
Wzmacniacz operacyjny. Parametry charakterystyczne, zastosowania.
Wzmacniacz operacyjny to
wielostopniowy, wzmacniacz różnicowy prądu stałego,
charakteryzujący się bardzo dużym różnicowym wzmocnieniem napięciowym rzędu
stu kilkudziesięciu decybeli
przeznaczony zwykle do pracy z zewnętrznym obwodem sprzężenia zwrotnego, który
decyduje o głównych właściwościach całego układu
PARAMETRY:

21
Różnicowe wzmocnienie napięciowe - to stosunek zmiany napięcia wyjściowego
do zmiany różnicowego napięcia wejściowego.
Wejściowe napięcie niezrównoważenia. W idealnym wzmacniaczu operacyjnym
jeżeli na obu wejściach jest napięcie równe 0, to na wyjściu też powinno być
napięcie równe 0. Ale w rzeczywistych wzmacniaczach tak nie jest. Wejściowym
napięciem niezrównoważenia określa się napięcie między wejściami
wzmacniacza, gdy na wyjściu panuje napięcie równe 0.
Wzmocnienie sygnału współbieżnego Napięcie wyjściowe wzmacniacza może
zależeć też od sumy napięć na wejściach wzmacniacza.
Współczynnik tłumienia sygnału współbieżnego - w miejsce wzmocnienia sygnału
współbieżnego często podawany jest współczynnik tłumienia sygnału
współbieżnego (ang. Common Mode Rejection Ratio, CMRR), który lepiej określa
własności wzmacniacza.
Wyjściowe napięcie niezrównoważenia Napięcie na wyjściu wzmacniacza, gdy na
obu wejściach napięcie jest równe zero.
Rezystancja wejściowa
Określa się:
- Rezystancję sygnału różnicowego, określoną jako rezystancję między wejściami
wzmacniacza przy podawaniu napięcia między wejścia.
- Rezystancję sygnału współbieżnego, określoną między jednym z wejść a masą.
Rezystancję wyjściową określa się jako rezystancję wyjścia przy obu sygnałach
wejściowych równych zero.
Współczynnik tłumienia wpływu zasilania (ang. Power Supply Rejection Ratio, PSRR),
określa się jako stosunek zmiany napięcia zasilania do wywoływanej przezeń zmiany
napięcia wyjściowego. Współczynnik PSRR wyrażany jest zazwyczaj w decybelach.
Zakres zmian napięcia wejściowego Zakres zmian napięcia na każdym z wejść
względem masy, przy których wzmacniacz pracuje poprawnie.
Maksymalne napięcie wyjściowe - to maksymalne napięcie jakie można uzyskać na
wyjściu bez nasycenia wzmacniacza.
Maksymalny prąd wyjściowy - to maksymalny prąd jaki może przepływać przez
wyjście wzmacniacza przy jego prawidłowej pracy.
Wejściowy prąd polaryzujący - wymagane jest pewne minimalne natężenie prądu na
wejściach wzmacniacza, aby prawidłowo pracował. Jest ono rzędu nA lub uA.
22
Szybkość zmian napięcia wyjściowego - to maksymalna szybkość zmiany napięcia na
wyjściu wzmacniacza po pobudzeniu wejścia jednostkowym skokiem napięcia.
Zazwyczaj podawana jest to wartość w woltach na mikrosekundę.
Pasmo pętli otwartej to pasmo przenoszenia wzmacniacza przy otwartej pętli
sprzężenia zwrotnego.
Wzmacniacze operacyjne są stosowane np. w sumatorach.
23.
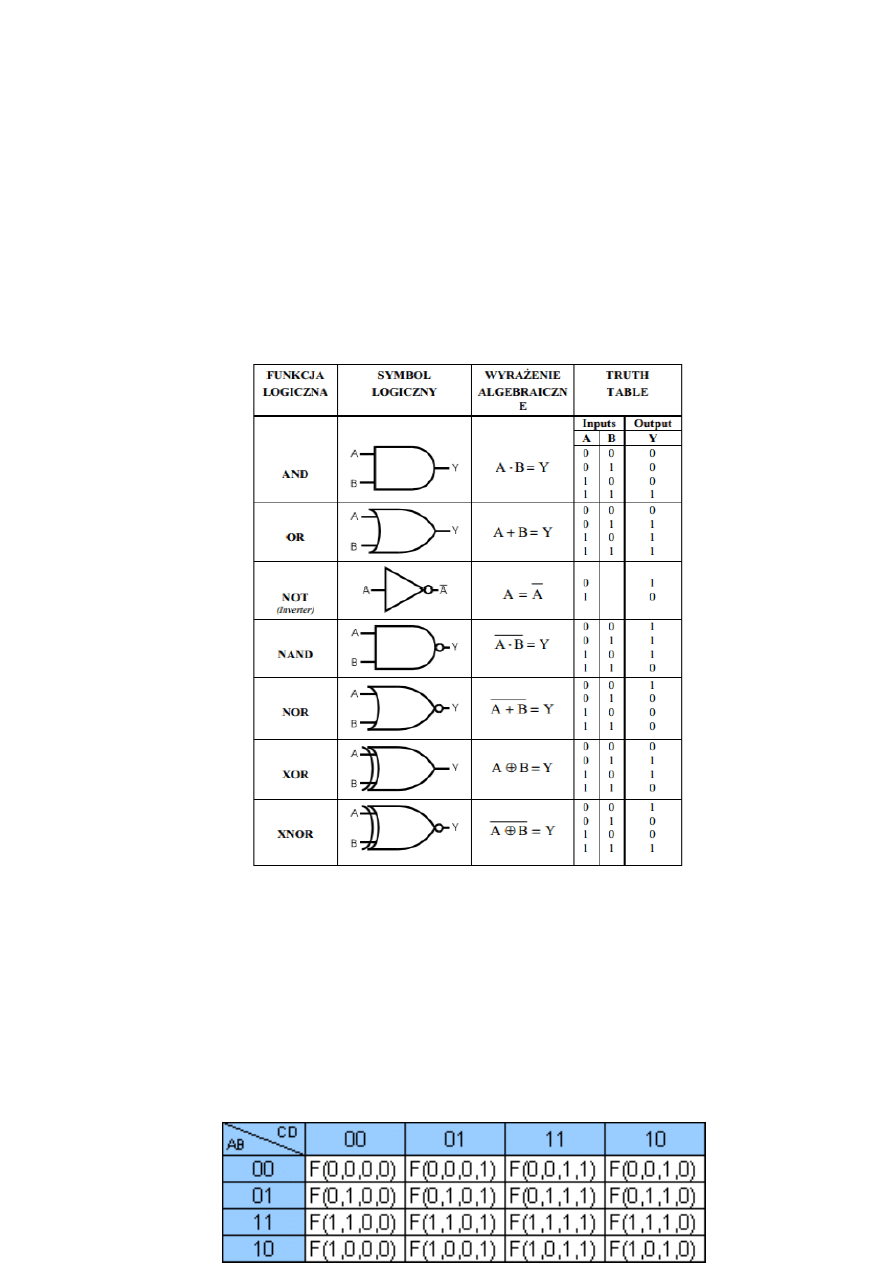
Bramki i funktory logiczne. Tabele prawdy. Minimalizacja funkcji.
Minimalizacja funkcji metodą Karnaugh’a. Tablica Karnaugha (mapa Karnaugha), to:
• uporządkowany w specyficzny sposób zapis wartości funkcji logicznej.
• Struktura mapy jest prostokątna, złożona z elementarnych pól, gdzie każde pole
reprezentuje iloczyn pełny w odniesieniu do zmiennych wejściowych, czyli
argumentów danej funkcji. Stąd też tablica ta zawiera wszystkie możliwe kombinacje
wartości argumentów.
• Na marginesach tablicy wpisuje się w określonym porządku (wg kodu Graya)
wartości argumentów.
• Przy parzystej liczbie argumentów połowa z nich umieszczona jest na marginesie
poziomym, a druga połowa na marginesie pionowym.

23
24.
Układy sekwencyjne. Przykłady realizacji i obszary zastosowań.
Układ sekwencyjny jest jednym z rodzajów układów cyfrowych. Charakteryzuje się tym, że
stan wyjść y zależy od stanu wejść x oraz od poprzedniego stanu, zwanego stanem
wewnętrznym, pamiętanego w zespole rejestrów (pamięci).
Układy asynchroniczne
W układach asynchronicznych zmiana sygnałów wejściowych X natychmiast powoduje
zmianę wyjść Y. W związku z tym układy te są szybkie, ale jednocześnie podatne na zjawisko
hazardu i wyścigu. Zjawisko wyścigu występuje, gdy co najmniej dwa sygnały wejściowe
zmieniają swój stan w jednej chwili czasu (np. ). Jednak, ze względu na niezerowe czasy
przełączania bramek i przerzutników, zmiana jednego z sygnałów może nastąpić [trochę]
wcześniej niż innych, powodując trudne do wykrycia błędy. Dlatego też w analizie układów
asynchronicznych uznaje się, że jednoczesna zmiana kilku sygnałów jest niemożliwa.
Układy synchroniczne
W układach synchronicznych zmiana stanu wewnętrznego następuje wyłącznie w
określonych chwilach, które wyznacza sygnał zegarowy (ang. clock). Każdy układ
synchroniczny posiada wejście zegarowe oznaczane zwyczajowo symbolami C, CLK lub
CLOCK. Charakterystyczne dla układów synchronicznych, jest to, iż nawet gdy stan wejść się
nie zmienia, to stan wewnętrzny - w kolejnych taktach zegara - może ulec zmianie.
Ponieważ w przypadku układu synchronicznego zrealizowanego jako automat Moore'a
wyjście układu jest funkcją stanu wewnętrznego, może ono zmieniać się tylko w chwili
nadejścia taktu, co daje gwarancję, że odpowiedni stan wyjść utrzyma się przez cały takt. W
przypadku automatu Mealy'ego zmiana wyjścia układu może nastąpić także w momencie
zmiany wejścia.
Jeśli układ reaguje na określony stan (logiczny) zegara, to mówi się że układ jest statyczny
(wyzwalany poziomem), jeśli zaś układ reaguje na zmianę sygnału zegarowego jest
dynamiczny(wyzwalany zboczem). Układ dynamiczny może być wyzwalany zboczem (ang.
edge) opadającym lub narastającym, albo impulsem.
Jeśli układ synchroniczny nie ma wejść, a jedynie charakteryzuje go stan wewnętrzny, to taki
układ nazywany jest autonomicznym (dobrym przykładem takich układów są liczniki
stosowane w popularnych zegarkach elektronicznych).
25.
Sumator równoległy. Sumator a jednostka arytmetyczno- logiczna.
Sumator – cyfrowy układ kombinacyjny, który wykonuje operacje dodawania dwóch (lub
więcej) liczb dwójkowych.
Sumatory równoległe- wielopozycyjne, dodają do siebie jednocześnie bity ze wszystkich
pozycji, a przeniesienie realizowane jest w zależności od sposobu połączenia sumatorów
jednobitowych

24
Są dwa główne rodzaje sumatorów równoległych:
• z przeniesieniami szeregowymi (ang. ripple-carry adder)
Sumator ten zbudowany jest z bloków funkcjonalnych, które realizują funkcje i Bloki są
połączone kaskadowo (ripple), tzn. wyjście jest łączone z wejściem
bloku następnego.
Aby np. otrzymać bit sumy uprzednio muszą zostać wyznaczone sygnały przeniesień ,
oraz
(
zależy od
, a ten zależy od ). Czas otrzymania ostatecznego wyniku jest więc
ograniczony do dołu przez × czas generacji przeniesienia , gdzie to liczba elementarnych
bloków z których zbudowanych jest sumator.
• z przeniesieniami równoległymi (ang. carry look-ahead adder)
W sumatorze z przeniesieniami równoległymi bity przeniesień są wyznaczane równolegle.
Wyrażenia opisujące są [rekursywnie] rozwijane, tzn. występujący w nich składnik
jest
zastępowany stosownym wyrażeniem, np.:
Układ buduje się z dwóch głównych części:
1.
bloków wyznaczających sumę oraz grupy generacyjne i propagacyjne
(które są liczone niezależnie!)
2.
bloku generującego przeniesienia, zgodnie z rozwiniętymi wyrażeniami
W praktyce buduje się 4-bitowe sumatory tego typu, ze względu na znaczne skomplikowanie
wyrażeń (a więc obwodów elektrycznych bloku nr 2).
Sumator z przeniesieniami równoległymi jest ok. 20-40% szybszy niż sumator z
przeniesieniami szeregowymi.
Często jako sumator wykorzystywany jest układ jednostki arytmetyczno-logicznej (ang.
arithmetic logic unit - ALU). W rzeczywistości układ ten potrafi realizować wiele innych
funkcji. Na przykład 4-bitowe ALU '181 (z możliwością zwiększenia długości słowa) może
dodawać, odejmować, przesuwać bity, porównywać wartości bezwzględne liczb oraz
wykonywać kilka innych funkcji. Sumatory i ALU wykonują funkcje arytmetyczne w czasie od
pojedynczych nanosekund do dziesiątków nanosekund, w zależności od rodziny układów
scalonych.
26.
Budowa i zasada działania procesorów: potokowy, wektorowy, CISC, RISC.
RISC
- stosunkowo niewiele rozkazów wykonywanych w pojedynczym cyklu rozkazowym,
- stosunkowo niewiele trybów adresowania,

25
- łatwe do zdekodowania, stałej długości formaty rozkazów
- dostęp do pamięci ograniczony do rozkazów LOAD i STORE
- stosunkowo obszerny zbiór uniwersalnych rejestrów
- rozkazy działające zazwyczaj na argumentach zapisanych w rejestrach, a nie w pamięci
operacyjnej,
- układowo zrealizowana jednostka sterująca
Inne cechy charakteryzujace nie tylko procesory RISC:
- intensywne wykorzystanie przetwarzania potokowego, w tym potokowe wykonywanie
rozkazow
- kompilatory o dużych możliwościach optymalizacji kodu wykorzystujące architekturę
potokową,
- skompilowane funkcje zaimplementowane częściej programowo niż sprzętowo.
Procesor CISC:
- występowanie złożonych, specjalistycznych rozkazów (instrukcji) - które do wykonania
wymagają od kilku do kilkunastu cykli zegara
- szeroka gama trybów adresowania,
- przeciwne niż w architekturze RISC rozkazy mogą operować bezpośrednio na pamięci
(zamiast przesyłania wartości do rejestrów i operowania na nich)
- powyższe założenia powodują iż dekoder rozkazów jest skomplikowany
Istotą architektury CISC jest to, iż pojedynczy rozkaz mikroprocesora wykonuje kilka operacji
niskiego poziomu, jak na przykład pobranie z pamięci, operację arytmetyczną i zapisane do
pamięci.
Procesor wektorowy
- w przeciwieństwie do skalarnego, pozwala na przetwarzanie w pojedynczych cyklach całych
wektorów danych.
- Operandami instrukcji są wieloelementowe zbiory liczb. Dzięki temu można przyspieszyć
niektóre obliczenia.
- Procesory wektorowe stosowane są także we współczesnych superkomputerach.
Procesor potokowy
- technika budowy procesorów polegająca na podziale logiki procesora odpowiedzialnej za
proces wykonywania programu (instrukcji procesora) na specjalizowane grupy w taki sposób,
aby każda z grup wykonywała część pracy związanej z wykonaniem rozkazu.
- Grupy te są połączone sekwencyjnie – potok (ang. pipe) – i wykonują pracę równocześnie,
pobierając dane od poprzedniego elementu w sekwencji. W każdej z tych grup rozkaz jest na
innym stadium wykonania. Można to porównać do taśmy produkcyjnej.
- Podstawowym mankamentem techniki potoku są rozkazy skoku, powodujące w najgorszym
wypadku potrzebę przeczyszczenia całego potoku i wycofania rozkazów, które następowały
zaraz po instrukcji skoku i rozpoczęcie zapełniania potoku od początku od adresu, do którego
następował skok. Taki rozkaz skoku może powodować ogromne opóźnienia w wykonywaniu
programu – tym większe, im większa jest długość potoku. Dodatkowo szacuje się, że dla
modelu programowego x86 taki skok występuje co kilkanaście rozkazów. Z tego powodu
niektóre architektury programowe (np. SPARC) zakładały zawsze wykonanie jednego lub
większej ilości rozkazów następujących po rozkazie skoku, tzw. skok opóźniony. Stosuje się

26
także skomplikowane metody predykcji skoku lub metody programowania bez użycia
skoków.
27.
Klasyfikacja architektur komputerowych.
Taksonomia Flynna jest klasyfikacją architektur komputerowych, zaproponowaną w latach
sześćdziesiątych XX wieku przez Michaela Flynna, opierająca się na liczbie przetwarzanych
strumieni danych i strumieni rozkazów. W taksonomii tej wyróżnia się cztery grupy:
- SISD (Single Instruction, Single Data) - przetwarzany jest jeden strumień danych przez jeden
wykonywany program - komputery skalarne (sekwencyjne).
- SIMD (Single Instruction, Multiple Data) - przetwarzanych jest wiele strumieni danych przez
jeden wykonywany program - tzw. komputery wektorowe.
- MISD (Multiple Instruction, Single Data) - wiele równolegle wykonywanych programów
przetwarza jednocześnie jeden wspólny strumień danych. W zasadzie jedynym
zastosowaniem są systemy wykorzystujące redundancję (wielokrotne wykonywanie tych
samych obliczeń) do minimalizacji błędów.
- MIMD (Multiple Instruction, Multiple Data) - równolegle wykonywanych jest wiele
programów, z których każdy przetwarza własne strumienie danych - przykładem mogą być
komputery wieloprocesorowe, a także klastry i gridy.
28.
Systemy przerwań. Aspekty sprzętowe i programowe.
Przerwanie (ang. interrupt) lub żądanie przerwania (IRQ – Interrupt ReQuest) – sygnał
powodujący zmianę przepływu sterowania, niezależnie od aktualnie wykonywanego
programu. Pojawienie się przerwania powoduje wstrzymanie aktualnie wykonywanego
programu i wykonanie przez procesor kodu procedury obsługi przerwania (ang. interrupt
handler).
Przerwania dzielą się na dwie grupy:
Sprzętowe:
Zewnętrzne – sygnał przerwania pochodzi z zewnętrznego układu obsługującego
przerwania sprzętowe; przerwania te służą do komunikacji z urządzeniami
zewnętrznymi, np. z klawiaturą, napędami dysków itp.
Wewnętrzne, nazywane wyjątkami (ang. exceptions) – zgłaszane przez procesor dla
sygnalizowania sytuacji wyjątkowych (np. dzielenie przez zero); dzielą się na trzy
grupy:
o faults (niepowodzenie) – sytuacje, w których aktualnie wykonywana instrukcja
powoduje błąd; gdy procesor powraca do wykonywania przerwanego kodu
wykonuje tę samą instrukcję która wywołała wyjątek;
o traps (pułapki) – sytuacja, która nie jest błędem, jej wystąpienie ma na celu
wykonanie określonego kodu; wykorzystywane przede wszystkim w debugerach;
gdy procesor powraca do wykonywania przerwanego kodu, wykonuje następną,
po tej która wywołała wyjątek, instrukcję;

27
o aborts (nienaprawialne) – błędy, których nie można naprawić.
Programowe – z kodu programu wywoływana jest procedura obsługi
przerwania; najczęściej wykorzystywane do komunikacji z systemem
operacyjnym, który w procedurze obsługi przerwania (np. w DOS 21h, 2fh,
Windows 2fh, Linux x86 przerwanie 80h) umieszcza kod wywołujący
odpowiednie funkcje systemowe w zależności od zawartości rejestrów
ustawionych przez program wywołujący, lub oprogramowaniem
wbudowanym jak procedury BIOS lub firmware.
29.
Omówić podstawowe tryby adresowania
Tryby adresowania:
Tryb prosty- W trybie adresowania prostego (inherent addressing mode) wszystkie
informacje wymagane dla wykonania operacji są już z "natury" znane jednostce
centralnej i żaden zewnętrzny argument z pamięci lub z programu nie jest potrzebny.
Argumenty, jeżeli występują, są jedynie wartościami rejestru indeksowego i
akumulatora. Rozkazy w tym trybie są zawsze jednobajtowe.
Tryb natychmiastowy - pole adresowe zawiera bezpośrednio operand (argument)
czyli daną dla rozkazu. Długość operandu zależy od kodu operacji lub od kodu
operacji i dodatkowego pola sterującego w rozkazie. Ten tryb adresowania
stosujemy, gdy np. chcemy bezpośrednio z rozkazu ( bez odwolywania się do
pamięci) załadować do rejestru prostą daną - bajt lub parę bajtów.
Adresowanie bezpośrednie - jest najbardziej podstawowym trybem adresowania. W
tym trybie zawartość pola adresowego stanowi już finalny adres argumentu rozkazu
w pamięci operacyjnej i nie podlega przekształceniu. Ten tryb stosujemy, gdy nie
zależy nam na tym, aby nasz program był przesuwalny w pamięci operacyjnej, lecz
jest przeznaczony do wykonania przy zapisie w ściśle określone miejsce w pamięci.
Adresowanie pośrednie - rozkaz zawiera adres komórki pamięci operacyjnej, w której
zawarty jest finalny adres operandu rozkazu. W tym przypadku komórka pamięci
wskazana przez adres rozkazu pośredniczy w określeniu finalnego adresu. Ten tryb
stosujemy, gdy chcemy, aby finalny adres operandu rozkazu mógł być dynamicznie
wstawiony do komórki pośredniczącej w adresowaniu w czasie wykonywania
programu. Może tak być, gdy ten adres zależy od jakichś testów na wyniku operacji
poprzedzającego rozkazu.
Adresowanie względne - polega na modyfikacji adresu zawartego w rozkazie przez
aktualną zawartość licznika rozkazów. Ten tryb adresowania dostarcza innego
sposobu osiągnięcia dynamicznej przesuwalności adresów dostępu do danych, tj. gdy
nie chcemy lub nie możemy znać przesunięcia całości programu w stosunku do
adresu zerowego. Przy tym trybie adresowania, finalny adres danej jest wyliczany
względem bieżącej zawartości licznika rozkazów, a więc do rozkazu wstawiamy
przesunięcie danej w programie względem adresu następnego rozkazu, np. n

28
komórek w przód lub w tył. Musimy tylko zapewnić, aby dana została umieszczona w
spodziewanym miejscu pamięci, a ściślej w spodziewanej odległości od rozkazu, który
z tej danej korzysta. Można to osiągnąć przez zaplanowanie w jakiej odległości od
danego rozkazu, będzie umieszczony obszar danych programu.
Adresowanie indeksowe - jest inaczej nazywane modyfikacją adresu przez
indeksowanie. W tym trybie wykorzystuje się specjalne rejestry procesora tzw.
rejestry indeksowe, które zawierają przesunięcie, które trzeba dodać do adresu
istniejącego w rozkazie aby wyliczyć adres finalny operandu. Ten tryb adresowania
pozwala przesunąć adres zawarty w rozkazie o wartości rejestru indeksowego.
Używając tego trybu we wszystkich rozkazach programu, można osiągnąć możliwość
wykonania programu przy załadowaniu w dowolne miejsce pamięci.
Adresowanie rejestrowe - stosuje się, gdy dana dla rozkazu jest przechowywana w
rejestrze. Część adresowa rejestru zawiera wtedy jedno lub więcej pól, w których
znajdują się identyfikatory rejestrów. Adresowanie rejestrowe jest często stosowane
w tym samym rozkazie razem z innymi trybami adresowania dotyczącymi pamięci
operacyjnej. Wówczas rozkaz dotyczy zarówno pamięci operacyjnej jak i rejestrów
procesora.
Adresowanie pośrednie rejestrowe - polega na tym, że jako miejsce pobrania
finalnego adresu operandu rozkazu stosuje się rejestr procesora, którego
identyfikator umieszczony jest w polu adresowym rozkazu. Przy pomocy tego trybu
adresowania można dynamicznie określić finalny adres operandu poprzez
odpowiednie załadowanie zawartości rejestru, w zależności od przebiegu obliczeń w
programie.
30.
Formaty i typy rozkazów procesora, wpływ długości rozkazów procesora na
wielkość zajmowanej pamięci przez program oraz na jego czas wykonania.
Rozkazem (instrukcją maszynową) nazywamy najprostszą operację, której wykonania
programista może zażądać od procesora.
Sposób realizacji rozkazu nie jest istotny dla użytkownika systemu i z reguły nie jest znany.
Został on po prostu wyznaczony przez projektanta mikroprocesora.
Rozkazy tworzące listę rozkazów możemy podzielić na grupy w zależności od ich
przeznaczenia:
rozkazy przesłań - są najczęściej wykonywanymi rozkazami. Nie zmieniają one
wartości informacji, natomiast przenoszą ją z miejsca na miejsce.
rozkazy arytmetyczne i logiczne - służą do przetwarzania informacji, czyli w wyniku
ich wykonania jest ona zmieniana.
rozkazy sterujące - rozkazy te pozwalają zmieniać kolejność wykonywania instrukcji
programu np. rozkazy skoku, bezwarunkowe i warunkowe wywołania programów czy
też instrukcje pętli.

29
pozostałe instrukcje to instrukcje charakterystyczne dla danego typu procesora np.
sterowanie pracą koprocesora, rozkazy testujące, operacje w trybie chronionym.
Długość rozkazu
Im krótszy rozkaz, tym zajmuje mniej pamięci i może być szybciej wczytany.
Dłuższe rozkazy pozwalają na umieszczenie większej ilości informacji lub dłuższych
adresów.
Długość rozkazu powinna być wielokrotnością jednostki transferu (najczęściej słowa),
choć możliwe są wyjątki od tej reguły.
Słowo powinno być wielokrotnością długości znaku, jeśli operacje na znakach są
brane pod uwagę (w maszynach do obliczeń numerycznych to może nie mieć dużego
znaczenia)
31.
Typy i hierarchia pamięci w systemie komputerowym.
Hierarchia pamięci:
pamięć rejestru (pamięć najbliżej procesora),
pamięć kieszeniowa (podręczna lub cache)
pamieć operacyjna (pamięć RAM)
pamięć masowa (dyski)
pamięć zewnętrzna (CD, taśmy)
Pod względem trwałości długoterminowej zapisu pamięci dzielimy na:
Stałe - w których zapis nie ulega zniszczeniu po wyłączeniu zasilania w systemie
komputerowym (np. pamięci półprzewodnikowe ROM zaprogramowane przez
producenta, lub programowane przez użytkownika UVPROM, EEPROM, pamięci
dyskowe, itp. )
Ulotne - w których zapis ulega zniszczeniu po wyłączeniu zasilania (np. pamięci
operacyjne, podręczne, rejestrowe, itp.).
Pod względem sposobu pamięci dzielimy na:
Pamięć o dostępie swobodnym (ang. Random Access Memory - RAM) - do której
dostęp odbywa się przez adres i jest równie szybki do każdej komórki pamięci (np.
pamięć operacyjna).
Pamięć o dostępie cyklicznym - do której dostęp możliwy jest okresowo w pewnych
odstępach czasu (np. pamięć dyskowa)
Pamięć o dostępie sekwencyjnym - do której dostęp do kolejnych komórek odbywa
się w pewnej stałej kolejności (np. pamięć taśmowa).
Pamięć asocjacyjna - do której dostęp odbywa się w sposób kierowany
wewnętrznymi adresami ustalającymi kolejność przeszukiwania komórek.
Pod względem trwałości krótkoterminowej zapisu pamięci dzielimy na:
Pamięć statyczną - zrealizowaną na układach przerzutnikowych bistabilnych, w której
zawartość istnieje dopóki włączone jest zasilanie; pamięć tą charakteryzuje duża
szybkość działania, znaczny pobór mocy, stopień złożoności komórki i koszt.

30
Pamięć dynamiczną - zrealizowana na dynamicznych układach pamiętających MOS,
gdzie czynnikiem pamiętającym jest naładowanie pojemności bramkowe tranzystora
MOS, zapis ten zanika po kilkudziesięciu milisekundach na skutek rozładowywania się
tej pojemności; w porównaniu z pamięciami statycznymi charakteryzuje ją większa od
pamięci statycznych skala opakowania (ilość powierzchni układu scalonego
zajmowana przez jednostkę pojemności), mniejszy pobór mocy i koszt jednostki
pojemności, ale jednocześnie mniejsza szybkość działania.
Pamięć podręczna - Cache to mechanizm w którym ostatnio pobierane dane
dostępne ze źródła o wysokiej latencji i niższej przepustowości są przechowywane w
pamięci o lepszych parametrach.
Pamięć cache składa się z 3 elementów:
banku danych pamięci cache (pamięć danych)
katalogu pamięci cache (często nazywanego TAG-RAMEM)
sterownika pamięci cache
Wyróżniamy 3 główne typy pamięci podręcznych:
Pamięć podręczną całkowicie asocjacyjną (fully associative)
Pamięć podręczną z odwzorowaniem bezpośrednim (direct mapped)
Wielodrożną pamięć podręczną (set associative)
32.
Omów metody projektowania baz danych.
Metody projektowania bazy danych:
wstępująca – rozpoczyna się od podstawowego poziomu zawierającego atrybuty, a
następnie poprzez analizę powiązań łączy się je w encje i związki między nimi;
metodę tę stosuje się do projektowania prostych baz danych zawierających małą
liczbę atrybutów;
zstępująca – rozpoczyna się od stworzenia modeli danych zawierających niewielką
liczbę ogólnych encji, atrybutów i związków między nimi; stosując metodę kolejnych
uściśleń wprowadza się encje, związki i atrybuty niższych poziomów; metoda ta jest
właściwą strategią projektowania złożonych baz danych;
strategii mieszanej – łączy w sobie powyższe dwie metody.
33.
Omów relacyjny model danych.
Model relacyjny - podstawowe założenia:
Baza danych składa się z prostokątnych tablic, każda o określonej liczbie kolumn i
dowolnej liczbie wierszy. Takie tablice sa okreslane jako relacje. Wiersz relacji jest
nazywany krotką.
Elementy krotek są atomowe (niepodzielne) i są bezpośrednio wartościami.
Niedozwolone jest tworzenie wskaźników prowadzących do innych krotek.

31
Niedozwolone jest, aby element krotki był zbiorem wartości. Jest to tzw pierwsza
forma normalna (1NF).
Porządek krotek nie ma znaczenia. Porządek kolumn również nie ma znaczenia.
Jakiekolwiek cechy odnoszące się do reprezentacji relacji lub usprawnienia dostępu
do relacji są ukryte przed użytkownikiem
Relacje i ich kolumny posiadają nazwy. Nazwy kolumn są określane jako atrybuty.
Każda relacja posiada wyróżniony atrybut lub grupę atrybutów określną jako klucz.
Wartość klucza w unikalny sposób identyfikuje krotkę relacji. Jakakolwiek inna
identyfikacja krotki (np. wewnętrzny identyfikator) jest niewidoczna dla użytkownika.
Manipulacja relacjami odbywa się w sposób makroskopowy przy pomocy operatorów
algebry relacji lub innego tego rodzaju języka. Przetwarzanie “krotka po krotce” jest
niedozwolone.
34.
Na czym polega proces normalizacji baz danych
Normalizacja bazy danych jest to
proces mający na celu eliminację powtarzających się danych w relacyjnej bazie
danych.
Główna idea polega na trzymaniu danych w jednym miejscu, a w razie potrzeby
linkowania do danych. Taki sposób tworzenia bazy danych zwiększa bezpieczeństwo
danych i zmniejsza ryzyko powstania niespójności (w szczególności
problemów anomalii).
Normalizacja nie usuwa danych, tylko zmienia schemat bazy danych.
Normalizacja przeprowadza bazę danych z jednego stanu spójnego (przed
normalizacją) w inny stan spójny (po normalizacji). Jedyna różnica polega na innym
układzie danych i relacji pomiędzy nimi, ale bez utraty danych (ewentualnie
dodawane są nowe klucze główne)
Postacie normalne:
1sza wszystkie pola elementarne
2ga wszystkie atrybuty w tabeli funkcyjnie zależne od klucz głównego
3cia wszystkie atrybuty w tabeli bezpośrednio zależne od klucz głównego
35.
Przedstawić koncepcję transakcyjności w relacyjnych bazach danych.
Transakcja to ciąg operacji do wspólnego niepodzielnego wykonania. Współbieżne
wykonywanie transakcji wymaga zachowania własności ACID (Atomicity, Consistency,
Isolation, Durability):
- niepodzielności: ,,wszystko-lub-nic”, transakcja nie może być wykonana częściowo;
- integralności: po zatwierdzeniu transakcji muszą być spełnione wszystkie warunki
poprawności nałożone na bazę danych;
- izolacji: efekt równoległego wykonania dwu lub więcej transakcji musi być szeregowalny;
- trwałości: po udanym zakończeniu transakcji jej efekty na stałe pozostają w bazie danych.
Przykładem transakcji może być transakcja bankowa jaką jest przelew. Muszą tu zostać
dokonane 2 operacje - zabranie pieniędzy z jednego konta oraz dopisanie ich do drugiego. W
przypadku niepowodzenia żadna z tych operacji nie powinna być zatwierdzona, gdyż zajście

32
tylko jednej powodowałoby nieprawidłowości w bazie danych (pojawienie się lub zniknięcie
pieniędzy).
Transakcja składa się zawsze z 3 etapów:
·
rozpoczęcia
·
wykonania
·
zamknięcia
W systemach bazodanowych istotne jest, aby transakcja trwała jak najkrócej, ponieważ
równolegle może być dokonywanych wiele transakcji i część operacji musi zostać wykonana
w pewnej kolejności. Każdy etap transakcji jest logowany, dzięki czemu w razie awarii
systemu (dzięki zawartości logów), można odtworzyć stan bazy danych sprzed transakcji,
która nie została zamknięta.
Część systemów baz danych umożliwia używanie punktów pośrednich (ang. save point), są to
zapamiętane w systemie etapy transakcji, do których w razie wystąpienia błędu można się
wycofać, bez konieczności anulowania wszystkich wykonanych działań.
36.
Techniki modelowania bazy danych, diagramy E/R i UML, narzędzia do
modelowania.
Diagram związków encji lub Diagram ERD (od ang. Entity-Relationship Diagram) – rodzaj
graficznego przedstawienia związków pomiędzy encjami używany w projektowaniu
systemów informacyjnych do przedstawienia konceptualnych modeli danych używanych w
systemie.
Systemy CASE, które wspierają tworzenia tych diagramów, mogą na ich podstawie
automatycznie tworzyć bazy danych odpowiadające relacjom na diagramie.
Diagram pokazuje logiczne związki pomiędzy różnymi encjami, związki te mają dwie cechy:
Opcjonalność – która mówi o tym, czy każda encja musi, czy też może wystąpić
równocześnie z inną. Np. TOWAR musi zostać zakupiony przez co najmniej
jednego KLIENTA, ale KLIENT może być nabywcą TOWARU. W reprezentacji
graficznej linia przerywana oznacza opcjonalność związku, natomiast ciągła
wymóg związku.
Krotność – określającą ile encji wchodzi w skład związku:
∙ 1:1 ("jeden do jeden") – encji odpowiada dokładnie jedna encja,
∙ 1:N ("jeden do wielu") – encji odpowiada jedna lub więcej encji,
∙ M:N ("wiele do wielu") – jednej lub więcej encjom odpowiada jedna lub więcej
encji.W przypadku związków M:N często stosuje się normalizację diagramu, która
polega na dodaniu encji pośredniczącej i zastąpienie związku M:N dwoma związkami
1:N z nową encją.
Diagram stanów – diagram używany przy analizie i projektowaniu oprogramowania.
Pokazuje przede wszystkim możliwe stany obiektu oraz przejścia, które powodują zmianę
tego stanu. Można też z niego odczytać, jakie sekwencje sygnałów (danych) wejściowych
powodują przejście systemu w dany stan, a także jakie akcje są podejmowane w odpowiedzi
na pojawienie się określonych stanów wejściowych. Tym samym tworzony jest cykl życia

33
obiektu, który może być tym istotniejszy w procesie wytwarzania oprogramowania, im
więcej jest możliwych stanów obiektu.
Diagram stanów to diagram UML
37.
Problemy współbieżności i wielodostępu w SZBD.
Anomalie współbieżnego dostępu:
poważne zagrożenia, nie do zaakceptowania:
- Brudny odczyt (ang. Dirty read) - kiedy pozwalamy na odczyt danych modyfikowanych przez
transakcje jeszcze nie zatwierdzoną
- Utracona modyfikacja (ang. Lost update) - kiedy dwie transakcje modyfikują te same dane
mniej poważne, tolerowane:
- Niepowtarzalny odczyt (ang. Non-repeatable read) - gdy transakcja składa się z poleceńm
które wielokrotnie odczytują ten sam rekord z bazy, a my odczytujemy inne dane; na 1
komórce; niby odczytujemy jedną wartość a tak naprawdę wiele
- Fantomy (ang. Phantoms) - wykonujemy polecenie select na bazie danych, za każdym
razem wykonujemy coraz więcej, za każdym razem select coraz więcej wyświetla
38.
Model ISO OSI. Model TCP/IP. Krótka charakterystyka warstw modelu.
Model ISO/OSI
Model TCP/IP
Model ISO/OSI
Model
OSI zbiera w logicznie ułożone
warstwy
funkcje potrzebne do
zdefiniowania, nawiązania i utrzymania komunikacji między dwoma (lub więcej)
urządzeniami niezależnie od ich producenta i architektury. Procesy zachodzące podczas
komunikacji dzielone są na siedem warstw funkcjonalnych, które zbudowane są w oparciu o
naturalny ciąg zdarzeń zachodzących w czasie sesji komunikacyjnej.
Warstwy modelu ISO/OSI:
fizyczna: (physical layer)
Jest odpowiedzialna za transmisję strumienia bitów między węzłami sieci. Definiuje
protokoły opisujące interfejsy fizyczne, to jest ich aspekty: mechaniczny, elektryczny,
funkcjonalny i proceduralny. Do funkcji tej warstwy należą: sprzęgniecie z medium transmisji

34
danych, dekodowanie sygnałów, określanie zakresu amplitudy prądu lub napięcia i
określanie parametrów mechanicznych łączówek (kształtu, wymiarów i liczby styków) oraz
inne kwestie związane z transmisją bitów.
łącza danych: (data link layer)
Zapewnia niezawodne łącze pomiędzy sąsiednimi węzłami. Nadzoruje przepływ informacji
przez łącze i w związku z podatnością warstwy fizycznej na zakłócenia i wynikające stąd błędy
oferuje własne mechanizmy kontroli błędów w przesyłanych ramkach lub pakietach (CRC -
Cyclic Redundancy Check).
sieciowa: (network layer)
Dostarcza środków do ustanawiania, utrzymania i rozłączania połączeń sieciowych miedzy
systemami otwartymi, w których rezydują komunikujące się aplikacje, i odpowiada, za
obsługę błędów komunikacji. Ponadto warstwa sieciowa jest odpowiedzialna za funkcje
routingu, który wyznacza optymalną pod względem liczby połączeń drogę przesyłania
pakietu przez sieć.
transportowa: (transport layer)
Zapewnia przezroczysty transfer danych między stacjami sesyjnymi, odciąża je od
zajmowania się problemami niezawodnego i efektywnego pod względem kosztów transferu
danych. Warstwa ta zapewnia usługi połączeniowe. Wszystkie protokoły w warstwie
transportowej są typu “od końca do końca”(end-to-end). Oznacza to, że działają one tylko
między końcowymi systemami otwartymi.
sesji: (session layer)
Umożliwia aplikacjom organizację dialogu oraz wymianę danych między nimi. Do
najważniejszych usług warstwy sesji należą: sterowanie wymianą danych, ustalanie punktów
synchronizacji danych (dla celów retransmisji w wypadku przemijających przekłamań na
łączach) oraz umożliwienie odzyskania danych (utraconych w wyniku przerwy w łączności)
przez ponowne ich przesłanie.
prezentacji: (presentation layer)
Zapewnia możliwość reprezentowania informacji, którą się posługują stacje aplikacyjne
podczas komunikacji Zapewnia tłumaczenie danych, definiowanie ich formatu oraz
odpowiednią składnię.
aplikacji: (application layer)
Dostarcza procesom aplikacyjnym metod dostępu do środowiska OSI, pełni rolę okna między
współdziałającymi procesami aplikacyjnymi.
Model TCP/IP
Podstawowym założeniem modelu TCP/IP jest podział całego zagadnienia komunikacji
sieciowej na szereg współpracujących ze sobą warstw. Każda z nich może być tworzona przez
programistów zupełnie niezależnie, jeżeli narzucimy pewne protokoły według których

35
wymieniają się one informacjami. Założenia modelu TCP/IP są pod względem organizacji
warstw zbliżone do modelu OSI. Jednak liczba warstw jest mniejsza i bardziej odzwierciedla
prawdziwą strukturę Internetu. Model TCP/IP składa się z czterech warstw.
Warstwy modelu TCP/IP:
aplikacji
to najwyższy poziom, w którym pracują użyteczne dla człowieka aplikacje takie jak np.
serwer WWW czy przeglądarka internetowa. Obejmuje ona zestaw gotowych protokołów,
które aplikacje wykorzystują do przesyłania różnego typu informacji w sieci.
transportowa
gwarantuje pewność przesyłania danych oraz kieruje właściwe informacje do odpowiednich
aplikacji. Opiera się to na wykorzystaniu portów określonych dla każdego połączenia. W
jednym komputerze może istnieć wiele aplikacji wymieniających dane z tym samym
komputerem w sieci i nie nastąpi wymieszanie się przesyłanych przez nie danych. To właśnie
ta warstwa nawiązuje i zrywa połączenia między komputerami oraz zapewnia pewność
transmisji.
Internetu
to sedno działania Internetu. W tej warstwie przetwarzane są datagramy posiadające adresy
IP. Ustalana jest odpowiednia droga do docelowego komputera w sieci. Niektóre urządzenia
sieciowe posiadają tę warstwę jako najwyższą. Są to routery, które zajmują się kierowaniem
ruchu w Internecie, bo znają topologię sieci. Proces odnajdywania przez routery właściwej
drogi określa się jako trasowanie.
dostępu do sieci
jest najniższą warstwą i to ona zajmuje się przekazywaniem danych przez fizyczne połączenia
między urządzeniami sieciowymi. Najczęściej są to karty sieciowe lub modemy. Dodatkowo
warstwa ta jest czasami wyposażona w protokoły do dynamicznego określania adresów IP.
39.
Metody dostępu do medium. Protokół CSMA/CD.
Transmisja danych pomiędzy dwiema stacjami w sieci poprzedza realizacja dostępu do
medium transmisyjnego.
Przykładami metod wyłączania pojedynczego nadajnika do medium transmisyjnego sieci
lokalnej są:
1. metody dostępu do magistrali przez badanie obecności nośnika na linii transmisyjnej
(CSMA/CD)
2. metody dostępu do magistrali za pomocą wędrującego żetonu/znacznika (token passing
bus)
3. metoda dostępu do pierścienia za pomocą wędrującego żetonu (token passing bus)
CSMA / CD
Carrier Sense Multiple Access with Collision Detection
określa prawa dostępu komputera do medium transmisyjnego

36
Carrier Sense oznacza, że zanim komputer rozpocznie nadawanie musi sprawdzić czy iny
komputer nie nadaje.
Multiple Access oznacza, że komputer po zakońćzeniu “nadawania” może natychmiast
rozpocząć nową sesję nadawania - uzyskać następny dostęp do medium.
Collision Detection odnosi się do zdolności interfejsu wykrywania kolizji sygnałów
elektrycznych na kablu oraz odpowiedniego reagowania na to zdarzenie i może się zdarzyć,
że dwie stacje równocześnie zaczną nadawać (kolizja)
1. Karta sieciowa (węzeł) sprawdza stan linii i podejmuje transmisję tylko wtedy wtedy, gdy
inna stacja nie nadaje.
2. Przypadkowe rozpoczęcie nadawania przez więcej niż jeden z węzłów jest sygnalizowanie
przez układ detekcji kolizji.
3. Nadawanie zostaje przerwana i po losowo wybranym czasie opóźnienia następuje
powtórzenie próby włączenia się do linii.
4. W schemacie wykorzystującym CSMA/CD każde niepowodzenie transmisji powoduje
obniżenie efektywności systemu przekazywania danych.
5. CSMA/CD stosowany jest dla różnych mediów transmisyjnych z szybkością od 1 Mb/s do
100 Mb/s.
40.
Adresowanie IP, podsieci i maski podsieci zmiennej długości.
Maska sieci składa się podobnie jak adres IP z 4 bajtów, używana jest do wydzielenia
części adresu odpowiadającej za identyfikację sieci i części odpowiadającej za
identyfikację komputera z adresu IP.
Adres sieci tworzymy przepisując niezmienione wszystkie bity adresu IP, dla których
odpowiednie bity maski mają wartość jeden. Resztę uzupełniamy zerami. Adres
broadcast jest adresem rozgłoszeniowym sieci. Używa się go do jednoczesnego
zaadresowania wszystkich komputerów w danej sieci (jest przetwarzany przez wszystkie
komputery w sieci). Tworzymy go podobnie do adresu sieci, jednak dopełniamy
jedynkami zamiast zerami.
Typ adresu
Domyślna wartość maski
Klasa A
255.0.0.0
Klasa B
255.255.0.0
Klasa C i Klasa B z podsiecią
255.255.255.0
Podsieci poszerzają pole adresu sieci poza granicę zdefiniowana przez schemat dla
typów A, B, C. Zapewnia to możliwość hierarchizacji poszczególnych podsieci wewnątrz
sieci.
Typ
Część opisująca sieci
Część opisująca hosty
A
1-126
0.0.1-255.255.254
B
128.1-191.254
0.1-255.254
C
192.0.1-223.255.254
1-254

37
41.
Routing w sieciach komputerowych, metody routingu, porównanie.
Metody Routingu:
Rozproszony - gdy w dowolnym momencie jedna stacja posiada uprawnienie do
nadawania, a uprawnienie przekazywane jest miedzy kolejnymi stacjami w sieci.
Wykorzystywany jest w metodach z przekazywaniem znacznika.
Scentralizowany - gdy jedna stacja kontroluje działanie sieci i przyznaje innym
stacjom prawo do nadawania (przepytywanie - poling, komutacja łączy)
Statyczne - protokół ten jest stosowany w małych sieciach lokalnych polega na tym że
jest ręcznie ustawiany przez administratora sieci
Dynamiczne - stosowane są w większych sieciach. Protokół taki sam modyfikuje trasę.
42.
Metody dostępu do sieci w technologii bezprzewodowej WiFi.
Metody dostępu do łącza w sieciach radiowych.
W sieciach bezprzewodowych bez przeszkód stosuje się protokoły dostępu sterowanego
jak np.
Odpytywanie (gdy stacja centralna posiada łączność z każdą ze stacji pozostałych)
przekazywanie żetonu (w pierścieniu sieci Token Ring krąży mała ramka zwana
token „żeton”) — gdy wszystkie stacje sieci posiadają wzajemną łączność.
Wykorzystuje się także wiele protokołów rywalizacyjnych dostępu do łącza.
Nowsze z nich wyposażono w odpowiednie mechanizmy eliminacji kolizji
wynikających ze zjawisk ukrytej bądź odkrytej stacji.
43.
Podstawowe i złożone topologie sieci komputerowych.
Topologie fizyczne:
- Topologia liniowa (ang. Line) – wszystkie elementy sieci oprócz granicznych połączone
są z dwoma sąsiadującymi
- Topologia magistrali (szyny, liniowa) (ang. Bus) – wszystkie elementy sieci podłączone
do jednej magistrali
- Topologia pierścienia (ang. Ring) – poszczególne elementy są połączone pomiędzy sobą
odcinkami kabla tworząc zamknięty pierścień
- Topologia podwójnego pierścienia – poszczególne elementy są połączone pomiędzy
sobą odcinkami tworząc dwa zamknięte pierścienie

38
- Topologia gwiazdy (ang. Star) – komputery są podłączone do jednego punktu
centralnego, koncentratora (koncentrator tworzy fizyczną topologię gwiazdy, ale
logiczną magistralę) lub przełącznika
- Topologia gwiazdy rozszerzonej – posiada punkt centralny (podobnie do topologii
gwiazdy) i punkty poboczne (jedna z częstszych topologii fizycznych Ethernetu)
- Topologia hierarchiczna – zwana także topologią drzewa, jest kombinacją topologii
gwiazdy i magistrali, budowa podobna do drzewa binarnego
- Topologia siatki – oprócz koniecznych połączeń sieć zawiera połączenia nadmiarowe;
rozwiązanie często stosowane w sieciach, w których jest wymagana wysoka
bezawaryjność
44.
Charakterystyka systemów rozproszonych - zalety i wady.
System rozproszony (ang. distributed system)
to zbiór niezależnych urządzeń technicznych połączonych w jedną, spójną
logicznie całość.
Zwykle łączonymi urządzeniami są komputery, rzadziej – systemy automatyki.
Połączenie najczęściej realizowane jest przez sieć komputerową, jednak można
wykorzystać również inne – prostsze – magistrale komunikacyjne.
Urządzenia są wyposażone w oprogramowanie umożliwiające współdzielenie
zasobów systemowych.
Jedną z podstawowych cech systemu rozproszonego jest jego przezroczystość (
ang. transparency), tj. tworzenie na użytkownikach systemu rozproszonego
wrażenie pojedynczego i zintegrowanego systemu.
ZALETY
- Dzielenie zasobów (dane, urządzenia sprzętowe, jak np. drukarki, dyski).
- Przyśpieszenie obliczeń (dzielenie obciążenia).
- Niezawodność (awaria jednego urządzenia nie powinna uniemożliwiać działania
systemu, lecz co najwyżej pogorszyć jego wydajność).
- Komunikacja (np. poczta elektroniczna).
- Ekonomiczność (system rozproszony może być tańszy niż odpowiadający mu mocą
obliczeniową system scentralizowany)
- Wewnętrzne rozproszenie (niektóre aplikacje są z natury rozproszone i wymagają
rozproszonych komputerów).
- Stopniowy wzrost (można stopniowo zwiększać moc obliczeniową systemu;
skalowalność to zdolność systemu do adaptowania się do wzrastających
zapotrzebowań).
WADY
- Oprogramowanie (zdecydowanie bardziej złożone; wymaga opracowania wspólnych
standardów).
- Sieć (może ulec awarii lub zostać przeciążona).
- Bezpieczeństwo (komputer podłączony do sieci jest mniej bezpieczny).

39
45.
Modele programowania równoległego.
Modele programowania równoległego:
Pamięć współdzielona (ang. Shared memory )
jest specjalnie utworzonym segmentem wirtualnej przestrzeni adresowej,
do którego dostęp może mieć wiele procesów.
Jest to najszybszy sposób komunikacji pomiędzy procesami.
Podstawowy schemat korzystania z pamięci współdzielonej wygląda
następująco:
- jeden z procesów tworzy segment pamięci współdzielonej, dowiązuje go
powodując jego odwzorowanie w bieżący obszar danych procesu,
opcjonalnie zapisuje w stworzonym segmencie dane.
- Następnie, w zależności od praw dostępu inne procesy mogą
odczytywać i/lub zapisywać wartości w pamięci współdzielonej. Każdy
proces uzyskuje dostęp do pamięci współdzielonej względem miejsca
wyznaczonego przez jego adres dowiązania, stąd każdy proces korzystając
z tych samych danych używa innego adresu dowiązania.
- W przypadku współbieżnie działających procesów konieczne jest
najczęściej synchronizowanie dostępu np. za pomocą semaforów. –
- Kończąc korzystanie z segmentu pamięci proces może ten segment
odwiązać, czyli usunąć jego dowiązanie.
- Kiedy wszystkie procesy zakończą korzystanie z segmentu pamięci
współdzielonej, za jego usunięcie najczęściej odpowiedzialny jest proces,
który segment utworzył.
Wątki - część programu wykonywana współbieżnie w obrębie jednego procesu;
w jednym procesie może istnieć wiele wątków.
Różnica między zwykłym procesem a wątkiem polega na współdzieleniu przez wszystkie
wątki działające w danym procesie przestrzeni adresowej oraz wszystkich innych
struktur systemowych (np. listy otwartych plików, gniazd itp.) – z kolei procesy
posiadają niezależne zasoby.
Ta cecha ma dwie ważne konsekwencje:
1. Wątki wymagają mniej zasobów do działania i też mniejszy jest czas ich tworzenia.
2. Dzięki współdzieleniu przestrzeni adresowej (pamięci) wątki jednego zadania mogą
się między sobą komunikować w bardzo łatwy sposób, niewymagający pomocy ze
strony systemu operacyjnego. Przekazanie dowolnie dużej ilości danych wymaga
przesłania jedynie wskaźnika, zaś odczyt (a niekiedy zapis) danych o rozmiarze nie
większym od słowa maszynowego nie wymaga synchronizacji (procesor gwarantuje
atomowość takiej operacji).

40
Przekazywanie komunikatów (ang. Message Passing )- w dziedzinie informatyki
jest formą komunikacji wykorzystywaną w przetwarzaniu równoległym,
programowaniu obiektowym i komunikacji międzyprocesowej. W tym modelu,
procesy lub obiekty mogą wysyłać i odbierać wiadomości (zawierające zero lub
więcej bajtów, złożone struktury danych, a nawet części kodu) do innych
procesów. Czekając na wiadomości, procesy mogą się również synchronizować.
Równoległe dane (ang. Data Parallel )- jest formą zrównoleglenia przetwarzania
na wielu procesorach w równoległych środowiskach obliczeniowych.
Równoległość danych skupia się na rozpowszechnianiu danych między różnymi
równoległymi węzłami obliczeniowymi.
Hybrydowy (ang. Hybrid )- Połączenie różnych modeli programowania
równoległego
Model programowania równoległego stanowi ujęcie abstrakcyjne zasłaniające
architekturę sprzętu i pamięci.
Modele te nie są przypisane do żadnych konkretnych architektur i w zasadzie mogą być
realizowane na dowolnym sprzęcie.
46.
Miary efektywności obliczeń równoległych.
Miary wydajności obliczeń równoległych:
- przyspieszenie obliczeń: S(p) = Ts / T||(p)
- Ts – czas rozwiązania zadania najlepszym algorytmem sekwencyjnym na pojedynczym
procesorze
- T||(p) – czas rozwiązania zadania rozważanym algorytmem równoległym na p
procesorach
- (w praktyce często zamiast Ts używa się T||(1) )
- efektywność zrównoleglenia: E(p) = S(p) / p
- ideałem jest uzyskanie liniowego przyspieszenia i 100% efektywności (jak musi się
zachowywać narzut obliczeń,
T||narz(p) = T||(p) – T||(1)/p , aby uzyskać przyspieszenie liniowe?)
47.
Środowiska programowania równoległego.
OpenMP (ang. Open Multi-Processing) – wieloplatformowy interfejs programowania
aplikacji (API) umożliwiający tworzenie programów komputerowych dla systemów
wieloprocesorowych z pamięcią dzieloną. Może być wykorzystywany w językach
programowania C, C++ i Fortran na wielu architekturach, m.in. Unix i Microsoft
Windows. Składa się ze zbioru dyrektyw kompilatora, bibliotek oraz zmiennych
środowiskowych mających wpływ na sposób wykonywania się programu. Dzięki temu,
że standard OpenMP został uzgodniony przez głównych producentów sprzętu i
oprogramowania komputerowego, charakteryzuje się on przenośnością,
skalowalnością, elastycznością i prostotą użycia. Dlatego może być stosowany do
tworzenia aplikacji równoległych dla różnych platform, od komputerów klasy PC po

41
superkomputery. OpenMP można stosować do tworzenia aplikacji równoległych na
klastrach komputerów wieloprocesorowych.).
RPC ( Remote Procedure Call )
1. mechanizm RPC został opracowany przez firmę Sun; obecnie znormalizowany przez
ISO/IEC
2. nie przystosowany do programowania obiektowego
3. powszechnie stosowany w systemach Unix
4. wspólny sposób reprezentowania podstawowych typów danych eXternal Data
Representation
OGRANICZENIA
1. zdalna procedura przyjmuje tylko jeden argument może on być strukturą
2. wszelkie zmiany dokonywane przez procedurę w obrębie jej argumentu pozostają
lokalne i nie są przekazywane z powrotem do klienta
3. do klienta przekazywany jest wynik procedury jako dowolny typ XDR
RMI ( Remote Method Invocation )
1. jest częścią języka Java
2. umożliwia wywoływanie metod obiektów istniejących w maszynie wirtualnej Javy
przez obiekty znajdujące się na innej maszynie wirtualnej
3. obiekty zdalne jak i lokalne identyfikowane przez referencje
OGRANICZENIA
1. problemy rozproszonego bezpieczeństwa danych, synchronizacji, odśmiecania
pamięci
2. możliwe jest tylko wykonywanie metod zdalnego obiektu a nie dostęp do jego pól
3. metody RMI muszą być zdeklarowane w interfejsie rozszerzającym interfejs
java.rmi.Remote
CORBA ( Common Object Request Broker Architecture )
1. standard komunikacji aplikacji w środowisku rozproszonym realizowanej za
pośrednictwem wspólnego brokera ORB
2. opracowany przez Object Managment Group
Interfejsy Corby
1. moduły programowe komunikują się z innymi za pośrednictwem własnych brokerów
2. wszyscy brokerzy komunikują się ze sobą w jednakowy sposób
3. moduł poznaje charakterystykę interfejsu innego modułu
4. umożliwia komunikowanie się modułów w różnych językach programowania
5. umożliwia komunikowanie się modułów działających w maszynach o rożnych
architekturach
6. w tym celu CORBA wprowadza własny język do definicji interfejsów IDL
48.
Prawo Amdahla.

42
Przy liczbie procesorów zmierzającej do nieskończoności czas rozwiązania określonego
zadania nie może zmaleć poniżej czasu wykonania części sekwencyjnej programu,
przyspieszenie nie może przekroczyć wartości wyznaczonej przez udział części
sekwencyjnej, a efektywność zrównoleglenia zmierza do zera.
PRAWO AMDAHLA
Sp=T1/Tp=1/(F+(1-F)/p)
T - czas wykonania algorytmu
F - udział części nierównoległej
przy użyciu dowolnej liczby procesorów, obliczeń nie da się przyśpieszyć bardziej, niż
odwrotność części sekwencyjnej w programie
49.
Obrazy rastrowe i wektorowe: budowa, właściwości, różnice.
Grafika rastrowa
prezentacja obrazu za pomocą pionowo-poziomej siatki odpowiednio
kolorowanych pikseli na monitorze komputera, drukarce lub innym urządzeniu
wyjściowym.
Bez zastosowania kompresji kolor każdego piksela jest definiowany pojedynczo.
Obrazki z głębią kolorów RGB często składają się z kolorowych kwadratów
zdefiniowanych przez trzy bajty – jeden bajt (czyli 8 bitów) na kolor czerwony,
jeden na zielony i jeden na kolor niebieski.
Mniej kolorowe obrazki potrzebują mniej informacji na piksel, np. obrazek w
kolorach czarnym i białym wymaga tylko jednego bitu na każdy piksel (bitmapa).
Grafika rastrowa różni się od wektorowej tym, że grafika wektorowa pokazuje
obraz używając obiektów geometrycznych, takich jakkrzywe czy wielokąty.
Pixmapę charakteryzują dwie podstawowe liczby - wysokość i szerokość pixmapy
liczone w pikselach.
Wielkość obrazka rastrowego nie może zostać zwiększona bez zmniejszenia jego
ostrości. Jest to przeciwne grafice wektorowej, którą łatwo można skalować,
dostosowując jej wielkość do urządzenia, na którym jest wyświetlany obraz.
Grafika rastrowa jest bardziej użyteczna od wektorowej do zapisywania zdjęć i
realistycznych obrazów, podczas gdy grafika wektorowa jest częściej używana do
obrazów tworzonych z figur geometrycznych oraz prezentacji tekstu (w tym tabel
i wzorów).
Grafika wektorowa (obiektowa)
jeden z dwóch podstawowych rodzajów grafiki komputerowej, w której obraz
opisany jest za pomocą figur geometrycznych (w przypadku grafiki
dwuwymiarowej) lub brył geometrycznych (w przypadku grafiki trójwymiarowej),
umiejscowionych w matematycznie zdefiniowanym układzie współrzędnych,
odpowiednio dwu- lub trójwymiarowym.
W przeciwieństwie do grafiki rastrowej grafika wektorowa jest grafiką w pełni
skalowalną, co oznacza, iż obrazy wektorowe można nieograniczenie powiększać
oraz zmieniać ich proporcje bez uszczerbku na jakości.

43
W przypadku grafiki rastrowej obrót obrazu może zniekształcić go powodując
utratę jakości (w szczególności, jeśli nie jest to obrót o wielokrotność kąta
prostego).
Typowe edytory grafiki wektorowej pozwalają oprócz zmiany parametrów i
atrybutów prymitywów także na przekształcenia na obiektach, np.: obrót,
przesunięcie, odbicie lustrzane, rozciąganie, pochylanie, czy zmiana kolejności
obiektów na osi głębokości.
Do zalet należą przede wszystkim:
- skalowalność, prostota opisu, a przez możliwość modyfikacji poprzez
zmianę parametrów obrazu,
- mniejszy rozmiar w przypadku zastosowań niefotorealistycznych
(schematy techniczne, loga, flagi i herby, wykresy itp.),
- opis przestrzeni trójwymiarowych,
- możliwość użycia ploterów zgodnie z metodą ich pracy,
- bardzo dobre możliwości konwersji do grafiki rastrowej.
Wśród głównych wad wymieniane są:
- ogromna złożoność pamięciowa dla obrazów fotorealistycznych,
- przy skomplikowanych obrazach rastrowych nieopłacalność obliczeniowa
konwersji (poprzez wektoryzację) do formy wektorowej.
Grafika wektorowa sprawdza się najlepiej, gdy zachodzi potrzeba
stworzenia grafiki, czyli mającego stosunkowo małą ilość szczegółów, nie
zaś zachowaniu fotorealizmu obecnego w obrazach. Odpowiednimi
przykładami użycia grafiki wektorowej są:
- schematy naukowe i techniczne
- mapy i plany,
- logo, herby, flagi, godła,
- różnego typu znaki, np. drogowe,
- część graficznej twórczości artystycznej (np. komiksy),
50.
Grafika rastrowa - prymitywy graficzne 2D: kreślenie odcinków, okręgów,
wypełnianie obszarów.
51.
Algorytmy poprawy jakości obrazu rastrowego.
52.
Metody skalowania obrazów rastrowych.
53.
Modele barw stosowane w grafice komputerowej (RGB, CMY, HSV, LAB).
RGB
jeden z modeli przestrzeni barw, opisywanej współrzędnymi RGB. Jego nazwa
powstała ze złożenia pierwszych liter angielskich nazw barw: R – red
(czerwonej), G – green (zielonej) i B – blue(niebieskiej), z których model ten się
składa.
Jest to model wynikający z właściwości odbiorczych ludzkiego oka, w którym
wrażenie widzenia dowolnej barwy można wywołać przez zmieszanie w ustalonych
proporcjach trzech wiązek światła o barwie czerwonej, zielonej i niebieskiej (zob.
promieniowanie elektromagnetyczne).

44
Z połączenia barw RGB w dowolnych kombinacjach ilościowych można
otrzymać szeroki zakres barw pochodnych, np. z połączenia barwy zielonej i
czerwonej powstaje barwa żółta.
Do przestrzeni RGB ma zastosowanie synteza addytywna, w której wartości
najniższe oznaczają barwę czarną, najwyższe zaś białą.
Model RGB jest jednak modelem teoretycznym a jego odwzorowanie zależy
od urządzenia (ang. device dependent), co oznacza, że w każdym urządzeniu każda
ze składowych RGB może posiadać nieco inną charakterystykę widmową, a co za
tym idzie, każde z urządzeń może posiadać własny zakres barw możliwych do
uzyskania.
CMYK
zestaw czterech podstawowych kolorów farb drukarskich stosowanych
powszechnie w druku wielobarwnym w poligrafii i metodach pokrewnych
(atramenty, tonery i inne materiały barwiące w drukarkach komputerowych,
kserokopiarkach itp.).
Na zestaw tych kolorów mówi się również barwy procesowe[1] lub kolory
triadowe (kolor i barwa w jęz. polskim to synonimy).
CMYK to jednocześnie jedna z przestrzeni barw w pracy z grafiką komputerową.
Skrót CMYK powstał jako złożenie pierwszych liter angielskich nazw kolorów.
- Cyjan – odcień niebieskiego, ale trochę bledszy i bardziej spłowiały, można go określić
jako szarobłękitny lub sinoniebieski. Najbardziej podobne kolory to błękit, szafir i
turkus. Nazywanie koloru cyjanowego kolorem "zielononiebieskim" jest błędem
wynikającym z niezrozumienia różnic pomiędzy addytywną i subtraktywną metodą
mieszania barw. W syntezie addytywnej kolor uzyskany w wyniku połączenia zielonego
i niebieskiego.
- Magenta – w syntezie addytywnej kolor uzyskany w wyniku połączenia czerwieni i
niebieskiego. Najbardziej podobne kolory to fuksja, karmazyn i amarant.
- Yellow – kolor bardzo podobny do żółtego, jednak trochę bledszy od typowej nasyconej
żółcieni. W syntezie addytywnej kolor uzyskany w wyniku połączenia czerwieni i
zielonego.
- Black – kolor czarny, jednak o niezbyt głębokiej czerni.
HSV (ang. Hue Saturation Value)
model opisu przestrzeni barw zaproponowany w 1978 roku przez Alveya Raya
Smitha.
Model HSV nawiązuje do sposobu, w jakim widzi ludzki narząd wzroku, gdzie
wszystkie barwy postrzegane są jako światło pochodzące z oświetlenia.
Według tego modelu wszelkie barwy wywodzą się ze światła białego, gdzie część
widma zostaje wchłonięta a część odbita od oświetlanych przedmiotów.
Symbole w nazwie modelu to pierwsze litery nazw angielskich dla składowych
opisu barwy: H – odcień światła , S – nasycenie koloru (ang. Saturation) jako
promień podstawy oraz składowa V – (ang. Value) równoważna nazwie B – moc
światła białego (ang. Brightness) jako wysokość stożka.

45
54.
Cykl życia oprogramowania.
1. Planowanie systemu (w tym specyfikacja wymagań)
2. Analiza systemu (w tym Analiza wymagań i studium wykonalności)
3. Projekt systemu (poszczególnych struktur itp.)
4. Implementacja (wytworzenie kodu)
5. Testowanie (poszczególnych elementów systemu oraz elementów połączonych w
całość)
6. Wdrożenie i pielęgnacja powstałego systemu.
55.
Model kaskadowy i spiralny, charakterystyka i porównanie.
Kaskadowy:
Nie można przejść do następnej fazy przed zakończeniem poprzedniej
Model ten posiada bardzo nieelastyczny podział na kolejne fazy
Iteracje są bardzo kosztowne - powtarzamy wiele czynności
Spiralny:
Każda pętla spirali podzielona jest na cztery sektory:
Ustalanie celów - Definiowanie konkretnych celów wymaganych w tej fazie
przedsięwzięcia. Identyfikacja ograniczeń i zagrożeń. Ustalanie planów realizacji.
Rozpoznanie i redukcja zagrożeń - Przeprowadzenie szczegółowej analizy rozpoznanych
zagrożeń, ich źródeł i sposobów zapobiegania. Podejmuje się odpowiednie kroki
zapobiegawcze.
Tworzenie i zatwierdzanie - Tworzenia oprogramowania w oparciu o najbardziej
odpowiedni model, wybrany na podstawie oceny zagrożeń.
Ocena i planowanie - Recenzja postępu prac i planowanie kolejnej fazy przedsięwzięcia
bądź zakończenie projektu.
56.
Metryki oprogramowania, przykłady i obszary zastosowań.
Metryka oprogramowania – miara pewnej własności oprogramowania lub jego specyfikacji.
Termin ten nie ma precyzyjnej definicji i może oznaczać właściwie dowolną wartość liczbową
charakteryzującą oprogramowanie.
Metryki statyczne - pozwalają na ocenę jakości kodu źródłowego i łączą się ściśle z analizą
statyczną, dziedziną inżynierii oprogramowania zajmującą się badaniem struktury kodu
źródłowego. Metryki te najbardziej przydatne są dla samych programistów i innych osób
bezpośrednio zaangażowanych w proces powstawania oprogramowania. Pozwalają na
bieżące śledzenie jakości kodu i zwrócenie uwagi na miejsca, które wymagają uproszczenia
bądź szczególnie uważnego testowania.

46
57.
Specyfikacja wymagań funkcjonalnych i niefunkcjonalnych, rola UML w procesie
specyfikowania wymagań.
Wymagania funkcjonalne – opisuja funkcje (czynności, operacje, usługi) wykonywane
przez system. Specyfikacja wymagań funkcjonalnych powinna być kompletna i spójna
(bez sprzecznosci).
Wymagania niefunkcjonalne – opisuja ograniczenia, przy zachowaniu których system
powinien realizowac swe funkcje. Wynikaja z: potrzeb uzytkownika,ograniczen
budzetowych, strategii firmy,koniecznosci współpracy z innymi systemami (sprzetu lub
programowania), czynników zewnetrznych jak przepisy o bezpieczenstwie, ustawy
chroniace prywatnosc, itd.
Istotną rolę w specyfikowaniu wymagań pełnią diagramy przypadków użycia,
dokumentacja scenariuszy przypadków użycia – a także modele procesów biznesowych
i analityczne.
Specyfikacja w notacji UML powinna zawierac:
- diagramy klas modelu dziedziny,
- diagramy czynnosci do algorytmów metod obiektów,
- diagramy maszyny stanowej, opisujace zachowanie obiektów stanowych,
- inne diagramy, jesli sa konieczne.
58.
Model logiczny a model fizyczny systemu – rola w procesie tworzenia oprogramowania.
Model fizyczny to propozycja konkretnej realizacji (implementacji) modelu logicznego,
czyli projekt techniczny oprogramowania i rozwiązań sprzętowych.
Model logiczny to zbiór informacji określający zachowanie się systemu.
Podstawowe elementy modelu logicznego
- lista funkcji systemu
- określenie obiektów zewnętrznych systemu
- określenie współzależności między funkcjami systemu
Ten etap prac można określić mianem "inwentaryzacji stanu obecnego". Celem prac w
tej fazie projektowania jest przede wszystkim stworzenie możliwości:
- wyodrębnienia przepływów ze zbyt dużym zagregowaniem danych (optymalizacja
wielkości przepływów danych) oraz przepływów rozdrobnionych;
- określenia niezbędnych porcji przesyłanych danych do realizacji poszczególnych funkcji
- połączenia identycznych funkcji wykonywanych w różnych miejscach i przez różne
osoby
- wyeliminowania zbędnych przepływów i zasobów danych
Informacje o takim charakterze stanowią zarówno podstawę do prac analitycznych i
projektowych nowego systemu informatycznego, a także pozwalają na określenie

47
sposobów wdrożenia nowego systemu, czyli metody przejścia z jednego (aktualnego)
systemu zarządzania firmą do systemu nowego.
59.
UML w analizie i projektowaniu – omówienie podstawowych cech notacji.
Unified Modeling Language (UML)
język formalny wykorzystywany do modelowania różnego rodzaju systemów.
Służy do modelowania dziedziny problemu (opisywania-modelowania fragmentu
istniejącej rzeczywistości – np. modelowanie tego, czym zajmuje się jakiś dział w
firmie)
w przypadku stosowania go do analizy oraz do modelowania rzeczywistości,
która ma dopiero powstać – tworzy się w nim głównie modele systemów
informatycznych.
UML jest głównie używany wraz z jego reprezentacją graficzną – jego elementom
przypisane są symbole, które wiązane są ze sobą na diagramach.
UML jest notacją pośrednią, pomostem pomiędzy ludzkim rozumieniem
struktury i działania programów, a kodem programów.
Taka notacja jest niezbędna do specyfikacji, konstrukcji, wizualizacji i
dokumentacji wytworów związanych z systemami intensywnie wykorzystującymi
oprogramowanie.
Diagramy UML ustanawiają bezpośrednie powiązanie elementów modelu
pojęciowego z wykonywalnymi programami.
Jednocześnie umożliwiają one objęcie zagadnień związanych ze skalą problemu,
towarzyszących złożonym systemom o krytycznej misji.
60.
Diagramy stanu oraz diagramy sekwencji, porównanie obszarów stosowania.
Diagram stanów – diagram używany przy analizie i projektowaniu oprogramowania.
Pokazuje przede wszystkim możliwe stany obiektu oraz przejścia, które powodują
zmianę tego stanu. Można też z niego odczytać, jakie sekwencje sygnałów (danych)
wejściowych powodują przejście systemu w dany stan, a także jakie akcje są
podejmowane w odpowiedzi na pojawienie się określonych stanów wejściowych
Diagram sekwencji - służy do prezentowania interakcji pomiędzy obiektami wraz z
uwzględnieniem w czasie komunikatów, jakie są przesyłane pomiędzy nimi. Na
diagramie sekwencji obiekty ułożone są wzdłuż osi X, a komunikaty przesyłane są
wzdłuż osi Y. Zasadniczym zastosowaniem diagramów sekwencji jest modelowanie
zachowania systemu w kontekście scenariuszy przypadków użycia. Diagramy sekwencji
pozwalają uzyskać odpowiedź na pytanie, jak w czasie przebiega komunikacja
pomiędzy obiektami. Dodatkowo diagramy sekwencji stanowią podstawową technikę
modelowania zachowania systemu, które składa się na realizację przypadku użycia.
61.
Testowanie oprogramowania, omówić model V.
Jak powstaje model V?
Pierwszym stadium tworzenia oprogramowania jest Idea. Kiedy podejmiemy decyzję, że
koncepcja znajdzie swoją realizację "wchodzimy" w Model V i fazę projektową. Analizę

48
modelu dokonamy na przykładzie programu „Przypominacz”. Jego podstawowym
założeniem będzie, jak nie trudno się domyślić, przypominanie o wydarzeniach.
Musimy zacząć od wymagań: O czym ma nam przypominać? Jak ma przypominać?
Jakie parametry można w nim nastawić? Itd. Stworzone wymagania są podstawą do
rozpoczęcia definiowania weryfikacji. Mając wiedzę, co chcemy osiągnąć, możemy
określić, jak chcemy to sprawdzić i czy będzie to działać. Pierwszy i podstawowy test
końcowy to, jeśli program się uruchomi, czy przypominacz przypomina?!
Wymagania podlegają analizie, podczas której zespoły architektów, programistów,
testerów itp.,
decydują czy dana Idea jest realizowalna. Czy da się zaimplementować wszystkie
wstępne założenia?
Ważne jest, choć niestety rzadko stosowane, by w procesie analizy uczestniczyli
testerzy, którzy na poziomie weryfikacji mogliby zacząć tworzyć podwaliny testowania
systemowego.
Następnie do gry wchodzą architekci projektu dzieląc go na poszczególne komponenty
(architektura komponentu). Tworzą oni specyfikację, będącą informacjami
wejściowymi dla programistów oraz testerów. Każdy projekt ma swoje interfejsy, które
pozwolą mu na przykład współpracować z systemem operacyjnym. Z kolei każdy
komponent może być poddany osobnemu sprawdzeniu zanim zostanie zintegrowany w
całość. Tu pojawiają się pojęcia testowania interfejsów i komponentów.
Implementacja jest teoretycznym końcem lewego ramienia.
Prawe ramię, czyli weryfikacja ,to najprościej rzecz ujmując, sprawdzanie, czy założenia
wstępne
zostały wypełnione; poczynając od sprawdzania najmniejszych komponentów na całym
zintegrowanym systemie kończąc. Testy końcowe to zazwyczaj tzw. testy akceptacyjne,
odpowiadające na pytanie, czy dany produkt spełnia wymagania klienta. W naszym
przypadku byłoby to sprawdzenie, czy przypominacz zachowuje się tak, jak
zakładaliśmy to sobie na początku.
Zalety
Model V precyzyjnie pokazuje zależności, jakie powinny łączyć kolejne etapy projektu.
Każdy etap projektowania kończy się stworzeniem danych wejściowych dla następnej
fazy oraz do korespondującej z nim fazy weryfikacji.
Zachęca do jak najwcześniejszego rozpoczęcia procesu tworzenia planów testów,
specyfikacji
testowej i samego testowania.
Dzięki analizie grafu możemy łatwo zidentyfikować obszary, gdzie stworzona
dokumentacja powinna
być sprawdzona.
Model V a teraźniejszość
Model V ciągle jest jednym z najważniejszych modeli tworzenia oprogramowania. Choć
mało
szczegółowy i mało wydajny, daje przykład idealnego świata kooperacji między
architektami, a

49
programistami, testerami i klientami. Jest niedoścignionym wzorcem, o którym każdy
człowiek chcący zajmować się oprogramowaniem, powinien przynajmniej wiedzieć.
62.
Podstawowe pojęcia niezawodności systemów technicznych, niezawodność systemów
oprogramowania, miary niezawodności.
Niezawodność- Stopień odporności programu na błędy, jego poprawność formalna oraz
sposoby reakcji na błędne sytuacje
Miarami niezawodności oprogramowania są np.:
prawdopodobieństwo wystąpienia awarii
częstotliwość występowania awarii (lub średni czas pomiędzy awariami, MTBF)
dostępność – procent czasu w jakim system pozostaje do dyspozycji użytkownika
63. Proces zarządzania bezpieczeństwem systemów informatycznych, polityka
bezpieczeństwa.
Cele strategie i polityki bezpieczeństwa
Cele, strategie i polityki bezpieczeństwa instytucji powinny być opracowane hierarchicznie
od poziomu instytucji do poziomu eksploatacyjnego. Powinny odzwierciedlać potrzeby
instytucji i uwzględniać wszelkie występujące w instytucji ograniczenia.
Bezpieczeństwo wchodzi w skład odpowiedzialności na każdym poziomie kierowniczym
instytucji i w każdej fazie cyklu życia systemów.
Cele, strategie i polityki powinny być utrzymywane i aktualizowane w oparciu o wyniki
cyklicznych przeglądów bezpieczeństwa (na przykład analizy ryzyka, audytów
bezpieczeństwa) oraz zmian w celach działania instytucji.
Pojęcia i stosowane definicje
Bezpieczeństwo systemu informatycznego (IT security): wszystkie aspekty związane z
definiowaniem, osiąganiem i utrzymywaniem poufności, integralności, dostępności,
rozliczalności, autentyczności oraz niezawodności.
Polityka bezpieczeństwa instytucji w zakresie systemów informatycznych (IT security policy):
zasady, zarządzenia i procedury, które określają jak zasoby – włącznie z informacjami
wrażliwymi – są zarządzane, chronione i dystrybuowane w instytucji i jej systemach
informatycznych.
Polityka bezpieczeństwa instytucji
Na politykę bezpieczeństwa instytucji składają się podstawowe zasady bezpieczeństwa i
wytyczne dla całej instytucji dot. bezpieczeństwa
Polityka bezpieczeństwa instytucji powinna odzwierciedlać polityki o szerszym zakresie w
instytucji, w tym te, które obejmują prawa jednostki, wymagania prawne i normy.
Polityka bezpieczeństwa systemów informatycznych
Polityka bezpieczeństwa systemów informatycznych powinna odzwierciedlać podstawowe
zasady bezpieczeństwa i zarządzenia wynikające z polityki bezpieczeństwa instytucji oraz
ogólne zasady korzystania z systemów informatycznych w instytucji.

50
64. Kryptosystemy symetryczne oraz metody dystrybucji kluczy w systemach
symetrycznych.
Kryptosystem DES
System DES (Data Encryption Standard) opracowany przez IBM jest najbardziej znanym
symetrycznym systemem kryptograficznym, który w 1977 r. został przyjęty przez Narodowe
Biuro Standardów USA (NBS, National Bureau of Standards) jako amerykańska norma
szyfrowania danych. Algorytm DES jest przeznaczony do szyfrowania 64-bitowych bloków
danych. Blok wyjściowy (zaszyfrowany) ma taką samą długość jak blok wejściowy
(poddawany szyfrowaniu), równą 64. Przekształcenia szyfrujące i odszyfrowujące są
wyznaczane przez 64-bitowy klucz. 8 bitów stanowią tzw. bity parzystości. Aktualnie DES nie
jest już uważany za dostatecznie silny.
Istotą trudności kryptoanalizy algorytmu DES metodą przeszukiwania wyczerpującego jest
złożoność obliczeniowa procesu dopasowania kolejnych możliwych wartości klucza.
Kryptosystem 3DES
Z uwagi na zbyt małą jak na obecne możliwości obliczeniowe przestrzeń kluczy algorytmu
DES (w czerwcu 1997 r. publicznie zakończono sukcesem atak na zaszyfrowaną algorytmem
DES wiadomość), nie zaleca się stosowania tego algorytmu w jego podstawowej postaci.
W jego miejsce najczęściej używa się potrójnego DES-a (3DES), polegającego na trzykrotnym
zaszyfrowaniu wiadomości algorytmem DES za pomocą trzech różnych kluczy (co skutecznie
chroni przed atakiem metodą przeszukiwania przestrzeni kluczy).
Kryptosystem IDEA
W USA uważano DES za produkt o znaczeniu militarnym (ograniczenia eksportowe) jak
również panowało przekonanie iż DES używa zbyt krótkich kluczy szyfrowania (64-bitowy, a
właściwie 56 bitów). Prace w Europie nad stworzeniem alternatywy dal DES-a zaowocowało
produktem znanym pod nazwą IDEA (International Data Encryption Algorithm). IDEA jest
algorytmem stosunkowo nowym, wprowadzonym w latach dziewięćdziesiątych.
• Algorytm RC4
Symetryczny algorytm szyfrowania strumieniowego oparty o ciąg pseudolosowych
permutacji
generowanych z klucza. Jeden z częściej stosowanych algorytmów szyfrujących.
• RC5
Symetryczny, blokowy algorytm szyfrujący. Dane szyfrowane w 16-, 32- lub 64-bitowych
blokach; długość klucza jest parametrem. RC5, mimo prostej budowy, uważany jest za
algorytm bardzo bezpieczny. Z RC4 łączy go tylko nazwisko autora – Rona Rivesta.
• RC6
RC6 jest następcą RC5. Jest to symetryczny blokowy algorytm szyfrujący o
nieskomplikowanej konstrukcji wywodzącej się z RC5. Dane szyfrowane są 128-bitowym
kluczem.
• Rijndael , Advanced Encryption Standard

51
Symetryczny , blokowy algorytm szyfrujący. Dane szyfrowane są 128-, 192- lub 256- bitowym
kluczem w 128-bitowych blokach. Algorytm w 2000 roku zwyciężył konkurs AES i stał się
nowym standardowym algorytmem szyfrowania symetrycznego.
• Serpent
Symetryczny, blokowy algorytm szyfrujący. Dane szyfrowane są 256- bitowym […]
• Twofish
Symetryczny, blokowy algorytm szyfrujący. Dane szyfrowane są 128-, 192- lub 256-bitowym
kluczem w 128-bitowych blokach. W 2000 roku algorytm zakwalifikował się do finału
konkursu AES.
• Mars
Symetryczny, blokowy algorytm szyfrujący zaproponowany przez firmę IBM. Dane
szyfrowane są kluczem w 128-bitowych blokach, za pomocą klucza o długości od 128 do 400
bitów. Finalista w konkursie AES.
• Blowfish
Stworzony przez Bruce'a Schneiera. Opiera się na kluczach o zmiennej długości (do 448
bitów). Uważany jest za bardzo bezpieczny (dotychczas nie udowodniono, iż istnieje
skuteczny sposób łamania szyfrów wygenerowanych przez ten algorytm),. Wykorzystywany
w wielu programach, m.in. PGP.
65. Kryptografia asymetrycznej w zagadnieniach bezpieczeństwa sieciowych systemów
komputerowych – przykłady zastosowań.
Kryptografia asymetryczna jest to kryptografia, w której do szyfrowania używamy jednego
klucza (tzw. Klucz publiczny) natomiast do odszyfrowywania używamy innego klucza
(tzw. Klucz prywatny).
Algorytmy asymetryczne
Istnieje wiele różnych algorytmów asymetrycznych, jednakże wszystkie działają w w taki
sposób, że w publicznym katalogu każdy użytkownik umieszcza procedurę szyfrowania i
deszyfrowania (ang. Encryption and decryption procedure). W katalogu zawarty jest również
publiczny klucz E tego użytkownika. Klucz prywatny D jest przechowywany przez
użytkownika i nikomu pod żadnym względem nie powinien być udostępniony. Metody
szyfrowania i deszyfrowania są jawne, ponieważ bezpieczeństwo systemów z kluczem
publicznych jest zapewnione dzięki trudności i ilości wymaganych obliczeń, a nie tajności
zastosowanego sposobu zaszyfrowania wiadomości.
Procedury E i D muszą spełniać następujące cztery warunki:
a) Odszyfrowując zaszyfrowaną wiadomość musimy dostać oryginalną
wiadomość:
D(E(M))=M dla każdej wiadomości M;
b) Zarówno E jaki i D nie są obliczeniowo skomplikowane (są to funkcje
o złożoności wielomianowej);
c) Publikując E użytkownik nie zmniejsza bezpieczeństwa wiadomości tj.

52
nie istnieje prosta metoda wyznaczenia D za pomocą E. Oznacza to, że 12
użytkownik D jest jedyną osobą mogącą odszyfrować wiadomość
zaszyfrowaną za pomocą E;
d) Jeśli wiadomość M zostanie najpierw „odszyfrowana”, a następnie
zaszyfrowana to powinniśmy otrzymać M:
E(D(M))=M dla każdej wiadomości M.
Zastosowanie:
Podpis cyfrowy (Podpisu cyfrowy umożliwia potwierdzenie autentyczności
dokumentu, weryfikację sygnatariusza, zapewnienie niezmienności treści od
momentu podpisania oraz uniemożliwienia wyparcie się faktu podpisania
dokumentu. Podpis cyfrowy wykonywany jest przy pomocy klucza prywatnego, a
weryfikowany za pomocą klucza publicznego. Oznacza to, że tylko jedna osoba może
dokonać podpisu, właściciel klucza prywatnego, natomiast weryfikacji dokumentu
może dokonać każdy, wystarczy, że z ogólnodostępnego katalogu pobierze klucz
publiczny.)
Certyfikaty (Certyfikat klucza publicznego jest ochroniony przez podpis cyfrowy
wydawcy. Użytkownicy certyfikatów wiedzą, że jego zawartość nie została
sfałszowana od momentu, gdy została podpisana, jeśli tylko podpis może zostać
zweryfikowany.)
Protokół SSL
66. Podpis elektroniczny a podpis cyfrowy, definicje, przykłady zastosowań.
Podpis elektroniczny
Technologia podpisu elektronicznego to powiązanie dokumentu (poddanego digitalizacji) z
daną osobą, poprzez cechy jednoznacznie go charakteryzujące (np. biometryczne).
Przy dzisiejszym stanie technologii jedynie nagranie dokumentu przekazywanego głosem
człowieka spełnia wymagania stawiane podpisowi elektronicznemu (np. zlecenia bankowe
lub maklerskie przekazywane przez telefon).
Odcisk linii papilarnych, obraz tęczówki oka, kształt twarzy, itp. są doskonałymi sposobami
identyfikacji, ale nie mogą być jeszcze stosowane do podpisu elektronicznego ze względów
technicznych.
Podpis elektroniczny a podpis cyfrowy
Pojęcia podpisu elektronicznego oraz podpisu cyfrowego nie są tożsame – podpis
elektroniczny to pojęcie szersze znaczeniowo niż podpis cyfrowy, ten drugi tanowi jeden z
rodzajów podpisu elektronicznego.
Podpis cyfrowy różni się od innych podpisów elektronicznych tym, że został wykonany przy
pomocy kryptografii asymetrycznej z parą kluczy prywatny – publiczny (gdyby wykorzystano
inną technikę kryptograficzną przy tworzeniu podpisu elektronicznego – taki podpis nie byłby
już podpisem cyfrowym).
67. Zapory ogniowe – pojęcia podstawowe, obszary zastosowań.
Zapora sieciowa (ang. firewall – ściana przeciwogniowa) – jeden ze sposobów zabezpieczania
sieci i systemów przed intruzami.

53
Termin ten może odnosić się zarówno do dedykowanego sprzętu komputerowego
wraz ze specjalnym oprogramowaniem, jak i do samego oprogramowania
blokującego niepowołany dostęp do komputera, na którego straży stoi.
Pełni rolę połączenia ochrony sprzętowej i programowej sieci wewnętrznej LAN przed
dostępem z zewnątrz tzn. sieci publicznych, Internetu,
chroni też przed nieuprawnionym wypływem danych z sieci lokalnej na zewnątrz.
Często jest to komputer wyposażony w system operacyjny (np. Linux, BSD) z
odpowiednim oprogramowaniem.
Do jego podstawowych zadań należy filtrowanie połączeń wchodzących i
wychodzących oraz tym samym odmawianie żądań dostępu uznanych za
niebezpieczne.
Najczęściej używanymi technikami obrony są:
Filtrowanie pakietów, czyli sprawdzanie pochodzenia pakietów i akceptowanie
pożądanych (np. SPI).
Stosowanie algorytmów identyfikacji użytkownika (hasła, cyfrowe certyfikaty).
Zabezpieczanie programów obsługujących niektóre protokoły (np. FTP, TELNET).
Bardzo ważną funkcją zapory sieciowej jest monitorowanie ruchu sieciowego i zapisywanie
najważniejszych zdarzeń do dziennika (logu). Umożliwia to administratorowi wczesne
dokonywanie zmian konfiguracji. Poprawnie skonfigurowany firewall powinien odeprzeć
wszelkie znane typy ataków. Na zaporze można zdefiniować strefę ograniczonego zaufania –
podsieć, która izoluje od wewnętrznej sieci lokalne serwery udostępniające usługi na
zewnątrz.
Typy zapór sieciowych:
Zapory filtrujące
Translacja adresów sieciowych (NAT) - (ang. network address translation)
Zapory pośredniczące
68. Systemy wykrywania zagrożeń (IDS) – koncepcja, zasady lokalizacji sondy.
IDS ( Intrusion Detection System)
systemy wykrywania i zapobiegania włamaniom – urządzenia sieciowe zwiększające
bezpieczeństwo sieci komputerowych przez wykrywanie (IDS) lub wykrywanie i blokowanie
ataków (IPS) w czasie rzeczywistym.
Systemy wykrywania włamań działają przez analizę ruchu sieciowego za pomocą dwóch
metod:
Analiza heurystyczna – polegająca na defragmentacji, łączeniu pakietów w strumienie
danych, analizie nagłówków pakietów oraz analizie protokołów aplikacyjnych.
Pozwala wytypować pakiety mogące doprowadzić do zdestabilizowania docelowej
aplikacji w razie obecności w niej błędów implementacyjnych. Stosowane są różne
nazwy handlowe – np. protocol analysis (np. IBM ISS) czy preprocessing (Snort). W
większości systemów IDS analiza heurystyczna odbywa się równocześnie z
normalizacją danych przed poddaniem ich analizie sygnaturowej.

54
Analiza sygnaturowa – polegająca na wyszukiwaniu w pakietach ciągów danych
charakterystycznych dla znanych ataków sieciowych. Kluczowym elementem jest
baza sygnatur, budowana wraz z pojawianiem się nowych ataków i odpowiednio
często aktualizowana.
Typowe elementy systemu IDS/IPS to:
sonda (ang. sensor) – element analizujący ruch sieciowy i wykrywający ataki,
baza danych – zbierająca informacje o atakach z grupy sensorów,
analizator logów – umożliwiający wizualizację i analizę logów z grupy sensorów.
Architektura
W zależności od lokalizacji sensora oraz zakresu analizowanych zdarzeń wyróżnia się
następujące rodzaje systemów IDS:
hostowe – HIDS (ang. Host-based IDS) – działają jako aplikacja w jednym,
ochranianym systemie operacyjnym analizując zdarzenia pochodzące z logu
systemowego oraz z lokalnych interfejsów sieciowych.
sieciowe – NIDS (ang. Network IDS) – analizujące ruch sieciowy dla wszystkich
systemów w segmencie sieci, do którego są podłączone. NIDS potrafi rozpoznawać
ataki skierowane przeciwko systemom, które nie mają zainstalowanych HIDS.
Równocześnie jednak ma ograniczone zdolności analizowania ruchu przesyłanego w
kanałach SSL lub zdarzeń zachodzących lokalnie w systemie (np. brak pamięci, ataki
lokalne z konsoli).
69. Wirtualne sieci prywatne (VPN) - koncepcja, przykłady zastosowań, stosowane
protokoły.
VPN (ang. Virtual Private Network, Wirtualna Sieć Prywatna)
Tunel, przez który płynie ruch w ramach sieci prywatnej pomiędzy klientami
końcowymi za pośrednictwem publicznej sieci (takiej jak Internet) w taki sposób, że
węzły tej sieci są przezroczyste dla przesyłanych w ten sposób pakietów.
Można opcjonalnie kompresować lub szyfrować przesyłane dane w celu zapewnienia
lepszej jakości lub większego poziomu bezpieczeństwa.
Określenie "Wirtualna" oznacza, że sieć ta istnieje jedynie jako struktura logiczna
działająca w rzeczywistości w ramach sieci publicznej, w odróżnieniu od sieci
prywatnej, która powstaje na bazie specjalnie dzierżawionych w tym celu łącz.
Pomimo takiego mechanizmu działania stacje końcowe mogą korzystać z VPN
dokładnie tak jak gdyby istniało pomiędzy nimi fizyczne łącze prywatne.
Rozwiązania oparte na VPN stosowane są np. w sieciach korporacyjnych firm, których
zdalni użytkownicy pracują ze swoich domów na niezabezpieczonych łączach.
Wirtualne Sieci Prywatne charakteryzują się dość dużą efektywnością, nawet na
słabych łączach (dzięki kompresji danych) oraz wysokim poziomem bezpieczeństwa
(ze względu na szyfrowanie). Rozwiązanie to sprawdza się w firmach, których
pracownicy często podróżują lub korzystają z możliwości telepracy.
Protokoły
IPSec (Internet Protocol Security)

55
Protokół najbardziej uniwersalny a zarazem mający największe ograniczenia. Nadaje
się do tworzenia wszystkich w/w rodzajów VPNów. W wersji podstawowej nie radzi
sobie z NATem i musi znać konfigurację zdalnej sieci.
IPsec to zbiór protokołów służących implementacji bezpiecznych połączeń oraz
wymiany kluczy szyfrowania pomiędzy komputerami. Protokoły tej grupy mogą być
wykorzystywane do tworzenia Wirtualnej Sieci Prywatnej (ang. VPN).
VPN oparta na IPsec składa się z dwóch kanałów komunikacyjnych pomiędzy
połączonymi komputerami: kanał wymiany kluczy za pośrednictwem którego
przekazywane są dane związane z uwierzytelnianiem i szyfrowaniem (klucze) oraz
kanału (jednego lub więcej), który niesie pakiety transmitowane poprzez sieć
prywatną. Kanał wymiany kluczy jest standardowym protokołem UDP (port 500).
L2TP
Czyli Layer 2 Tunneling Protocol - opcjonalnie wykorzystuje IPSec do zapewnienia
poufności (szyfrowania). Zazwyczaj Client-to-Site, prosta konfiguracja i autoryzacja na
podstawie loginu i hasła. Wyraźny podział na serwer (router) i klienta (zdalny
komputer). Serwer musi mieć publiczny (routowalny) adres IP, klient może być za
NATem, pod warunkiem, że router dostępowy w jego sieci obsługuje (i ma aktywną)
funkcję L2TP Pass-Through. Ten sam problem co z IPSec - protokół ESP.
PPTP
Najmniej konfliktowy ale i zapewniający najniższy poziom bezpieczeństwa.
Wykorzystuje protokół GRE do transmisji danych. Autoryzacja na podstawie loginu i
hasła. Autoryzacja przez MS-CHAP, opcjonalne szyfrowanie przez MPPE. Reszta zasad
jak w L2TP. Zabezpieczenia tego protokołu zostały złamane już dawno temu i nie jest
uważany za bezpieczny, mimo to wciąż bardzo popularny.
70. Wyjaśnij określenie "exploitation-exploration trade-off" w kontekście próby definicji
sztucznej inteligencji.
Z uwagi na trudność sformułowania definicji sztucznej inteligencji. Wskazuje się na wspólne
cechy, które są mianownikiem systemów inteligentnych.
Prawdziwy inteligentny system, powinien w odpowiednim stopniu, wykorzystywać
informacje i wiedzę na temat problemu(exploitation)[wykorzystanie tego co już wiemy o
problemie i metodzie jego rozwiązania]. Jednak system taki nie powinien się zawężać tylko
do wykorzystania tego co już umiemy, ale również dążyć do poznania nowego[exploration].
Dobrze skonstruowany system, powinien odpowiednio wyważyć ile zasobów poświęcić na
exploitation i exploration zarazem [ang. exploitation-exploration trade off].
71. Na czym polega uczenie sieci neuronowej algorytmem typu backpropagation.
Metoda wstecznej propagacji błędów została wyprowadzona przez J. Werbos'a i
ponownie odkryta przez E. Rumelhart'a i J.L. McCelland'a.
Obecnie pozostaje nadal jedną z najpopularniejszych metod uczenia sieci
neuronowych wielowarstwowych.

56
Algorytm wstecznej propagacji - BP (ang. BackPropagation) określa strategię doboru
wag w sieci wielowarstwowej przy wykorzystaniu gradientowych metod
optymalizacji.
Podczas procesu uczenia sieci dokonuje się prezentacji pewnej ilości zestawów
uczących (tzn. wektorów wejściowych oraz odpowiadających im wektorów sygnałów
wzorcowych (wyjściowych)).
Uczenie polega na takim doborze wag neuronów by w efekcie końcowym błąd
popełniany przez sieć był mniejszy od zadanego.
Nazwa "wsteczna propagacja" pochodzi od sposobu obliczania błędów w
poszczególnych warstwach sieci.
Najpierw obliczane są błędy w warstwie ostatniej (na podstawie sygnałów
wyjściowych i wzorcowych.
Błąd dla neuronów w dowolnej warstwie wcześniejszej obliczany jest jako pewna
funkcja błędów neuronów warstwy poprzedzającej. Sygnał błędu rozprzestrzenia się
od warstwy ostatniej, aż do warstwy wejściowej, a więc wstecz.
Korekcja wektora wag sieci oparta jest na minimalizacji funkcji miary błędu, która
określona jest jako suma kwadratów błędów na wyjściach sieci.
72. Omów podstawowe metody bezstratnej i stratnej kompresji danych
Kompresja stratna
metoda zmniejszania liczby bitów potrzebnych do wyrażenia danej informacji, które
nie dają gwarancji, że odtworzona informacja będzie identyczna z oryginałem
Dla niektórych danych algorytm kompresji stratnej może odtworzyć informację w
sposób identyczny.
Kompresja stratna jest możliwa ze względu na sposób działania ludzkich zmysłów, tj.
wyższą wartość pewnych części danych nad innymi.
Algorytmy kompresji stratnej zazwyczaj posługują się modelami psychoakustycznymi,
psychowizualnymi itd., aby odrzucić najmniej istotne dane o dźwięku, obrazie,
pozostawiając dane o wyższej wartości dla rozpoznawania tej informacji (akustycznej,
wizualnej) przez zmysły.
Ilość odrzucanych danych jest zazwyczaj określana przez stopień kompresji. Z tego też
względu nie istnieją algorytmy kompresji stratnej, które można stosować do
dowolnego typu danych. Np. kompresja stratna plików wykonywalnych byłaby
praktycznie niemożliwa do zastosowania, gdyż nie jest to informacja odczytywana
przez zmysły, a przez maszynę.
Zwykle kompresję stratną stosuje się do: obrazków, dźwięków, ruchomych obrazów,
np. w filmie. Przy danych audiowizualnych zazwyczaj kompresuje się osobno dźwięk,
a osobno obraz.
Prostym przykładem kompresji stratnej jest np. zachowanie tylko co drugiego piksela,
lub odrzucenie 2 najmniej istotnych bitów. Takie metody jednak nie dają zazwyczaj
tak zadowalających rezultatów jak oparte na modelach psychozmysłowych.
Kompresja bezstratna (ang. lossless compression) – ogólna nazwa metod kompresji
informacji do postaci zawierającej zmniejszoną liczbę bitów, pod warunkiem że metoda ta
gwarantuje możliwość odtworzenia informacji z postaci skompresowanej do identycznej
postaci pierwotnej. Algorytmy kompresji bezstratnej dobrze kompresują "typowe" dane,

57
czyli takie w których występuje znaczna nadmiarowość informacji (redundancja). Pewne
rodzaje danych są bardzo trudne lub niemożliwe do skompresowania:
strumienie liczb losowych (niemożliwe do skompresowania)
strumienie liczb pseudolosowych (trudne do skompresowania, choć teoretycznie
łatwe)
dane skompresowane za pomocą tego samego lub innego algorytmu (w praktyce
trudne)
Najczęściej używane metody kompresji bezstratnej można podzielić na słownikowe i
statystyczne, choć wiele metod lokuje się pośrodku:
metody słownikowe poszukują dokładnych wystąpień danego ciągu znaków, np.
zastępują 'the ' krótszą ilością bitów niż jest potrzebna na zakodowanie 4
niezwiązanych znaków. Jednak znajomość symbolu 'the ' nie pociąga za sobą
usprawnień w kompresowaniu 'they' czy 'then'.
metody statystyczne używają mniejszej ilości bitów dla częściej występujących
symboli, w przypadku praktycznie wszystkich oprócz najprostszych metod,
prawdopodobieństwa zależą od kontekstu. A więc np. dla 'h' występującego po 't'
używają mniejszej ilości bitów niż dla innych znaków w tym kontekście.
73. Wymień standardowe metody kompresji sygnałów multimedialnych: obrazów
nieruchomych, dźwięku, video. Omów dokładniej jedną z nich.
Kompresja obrazków JPEG
Najbardziej powszechnym algorytmem kompresji obrazów jest JPEG. Wiele rozwiązań
użytych w JPEG jest używanych także w innych algorytmach, więc warto je tutaj omówić.
Kolejne kroki algorytmu JPEG to:
zamiana przestrzeni kolorów z RGB na kanał jasności i dwa kanały koloru. Ludzie
znacznie dokładniej postrzegają drobne różnice jasności od drobnych różnic barwy, a więc
użyteczne jest tutaj użycie różnych parametrów kompresji. Krok nie jest obowiązkowy.
obniżenie rozdzielczości kanałów koloru, zwykle odrzuca się co drugą wartość wzdłuż
osi poziomej i każdą na pionowej, choć możliwe są też inne ustawienia. Tak radykalne cięcie
danych nieznacznie wpływa na jakość, ponieważ rozdzielczość postrzegania kolorów przez
ludzkie oko jest słaba. Krok nie jest obowiązkowy.
podzielenie każdego kanału obrazka na bloki 8x8. W przypadku kanałów kolorów, jest
to 8x8 aktualnych danych, a więc zwykle 16x8.
transformata kosinusowa każdego z bloków. Zamiast wartości pikseli mamy teraz
średnią wartość wewnątrz bloku oraz częstotliwości zmian wewnątrz bloku, obie wyrażone
przez liczby zmiennoprzecinkowe. Transformata DCT jest odwracalna, więc na razie nie
tracimy żadnych danych.
Zastąpienie średnich wartości bloków przez różnice wobec wartości poprzedniej.
Poprawia to w pewnym stopniu współczynnik kompresji.
Kwantyzacja, czyli zastąpienie danych zmiennoprzecinkowych przez liczby całkowite.
To właśnie tutaj występują straty danych. Zależnie od parametrów kompresora, odrzuca się
mniej lub więcej danych. Zasadniczo większa dokładność jest stosowana do danych
dotyczących niskich częstotliwości niż wysokich kodowanych algorytmem Huffmana. Użyta
transformata powoduje efekty blokowe w przypadku mocno skompresowanych obrazków.

58
Inne metody
Inne algorytmy kompresji obrazków opierają się głównie na:
użyciu innej transformaty o zmodyfikowanej transformaty kosinusowej, która nie
powoduje efektu bloków, a więc jest korzystniejsza w przypadku mocno skompresowanych
obrazków. Nie odbiega ona wynikami znacząco od DCT w przypadku obrazów o średniej i
niskiej kompresji. o transformat falkowych - mogą one dać znacznie lepsze wyniki. Zazwyczaj
kompresji wszystkich kanałów naraz, w szczególności ich wspólnej kwantyzacji. Daje
lepsze wyniki jeśli wartości w różnych kanałach są mocno skorelowane. Kompresja fraktalna
Zupełnie inną metodą jest kompresja fraktalna. Opisuje ona obraz w postaci parametrów
funkcji fraktalnej, która daje w efekcie przybliżoną postać obrazu. Dotychczas kompresja
fraktalna daje znacznie słabszą jakość w przypadku obrazów o niskim i średnim stopniu
kompresji. Dla obrazów silnie skompresowanych może dawać lepsze rezultaty niż JPEG,
przede wszystkim nie powoduje efektu bloków, jednak są one słabsze od znacznie prostszych
metod opartych na MDCT czy falkach. Nic nie wskazuje na to, że kompresja fraktalna
znajdzie szersze zastosowanie.
Kompresja ruchomych obrazów
Najprostsze systemy kompresji ruchomych obrazów po prostu kompresują wszystkie klatki
osobno. Jest to bardzo nieefektywne, ponieważ kolejne klatki są zazwyczaj do siebie bardzo
podobne. Zazwyczaj używa się zestawu klatek kluczowych, które kompresuje się tak samo jak
samodzielne obrazki. Pozostałe klatki kompresuje się natomiast korzystając z danych z klatek
poprzednich. Lepsze wyniki dałoby wykorzystanie danych o poprzednich klatkach przy
kompresji każdej klatki, jednak utrudniało by to znacznie przewijanie. Prostym sposobem
wykorzystania danych o poprzednich klatkach jest kodowanie różnicy wartości pikseli o tym
samym położeniu zamiast samych wartości. Tym sposobem można dobrze skompresować
sceny w których kamera jest nieruchoma, jednak nie da to znaczących efektów w scenach z
ruchomą kamerą. Zwykle wykorzystuje się więc różne rodzaje kompensacji ruchu. Np. dla
każdego bloku podaje się który niewielki wektor przesunięcia, np. [2,-1], czyli zamiast tego
samego bloku klatki poprzedniej używamy bloku o 2 piksele w prawo i jeden w górę (czy też
w lewo i w dół).
Inną ważną techniką wykorzystywaną przy kompresji ruchomych obrazów jest zmienna
przepływność (variable bitrate), czyli używanie różnej dokładności dla różnych klatek. Jest
wiele sposobów dobierania takich różnic, algorytmy wyboru jakości zwykle są cechą bardziej
enkodera niż formatu. Często enkodery stosują metody dwu-przejazdowe, pierwszy przejazd
po danych zbiera informacje potrzebne algorytmowi zmiennej przepływności, a dopiero
drugi kompresuje dane. Ruchome obrazy są zazwyczaj mocno skompresowane, a więc dla
kodeka MPEG, który używa podobnie jak JPEG transformaty kosinusowej, efekty blokowe
mogą być bardzo uciążliwe.
Kompresja dźwięku
Dwa najpopularniejsze publicznie dostępne algorytmy - MP3 i Vorbis, używają podobnych
technik. Warto tu omówić algorytm Vorbis, ponieważ używa on bardziej efektywnych
rozwiązań.
Strumień jest dzielony na okna. Okna występują w dwóch rozmiarach - duże (zwykle
2048 próbek) i małe (zwykle 256 próbek). Małe służą do przedstawienia szybko

59
zmieniającego się dźwięku oraz nagłego wzrostu intensywności dźwięku w danej
częstotliwości. Nie używa się ich w przypadku spadków intensywności, ponieważ ludzkie
ucho jest na nie znacznie mniej czułe. Okna nie są po prostu grupą kolejnych wartości
natężenia dźwięku. Okna częściowo się nakrywają i jedna wartość należy w tych obszarach
częściowo do kilku okien. Dla obszarów zachodzenia na siebie okien, dana wartość należy do
lewego okna w stopniu sin(pi/2 × sin2(pi/2 × t)), gdzie t=0 dla początku obszaru i t=1 dla jego
końca.
Na każdym oknie jest przeprowadzana zmodyfikowana transformata kosinusowa.
Zamiast poszczególnych wartości mamy teraz w bloku widmo parametrów MDCT czyli
(pomijając szczegóły) częstotliwości.
Dane z MDCT są upraszczane zależnie od parametrów kompresji zgodnie z modelem
psychoakustycznym.
Dane o energii przypadającej na daną częstotliwość są skalowane, co umożliwia
równie dobrą kompresje głośnych jak i cichych dźwięków.
Dane są kwantyfikowane i kompresowane bezstratnie.
Wyszukiwarka
Podobne podstrony:
Lista do opracowania pytań na obronę z nazwiskami
Lista do opracowania pytań na obronę
opracowanie pytań na obronę
Maszyny Elektryczne Opracowanie Pytań Na Egzamin
pytania egz ekonimak II, OPRACOWANIE PYTAŃ NA EGZAMIN
opracowane zestawy, OPRACOWANIE PYTAŃ NA EGZAMIN
Opracowanie pytań na zaliczenie Opto
Opracowania pytań na analizę instrumentalną
instalacje i oświetlenie elektryczne opracowanie pytań na egzamin
Pytania na egz z Ekonomiki, OPRACOWANIE PYTAŃ NA EGZAMIN
Opracowanie pytań na surowce cz. 7, Technologia Chemiczna, sem V, surowce, opracowania do egzaminu
Opracowanie pytań na biurowe, Cosinus Technik Informatyk, semestr 1
opracowanie pytań na kolokwium, SOCJOLOGIA UJ, Współczesne teorie socjologiczne
OPRACOWANIE PYTAŃ NA KLINIKIE EGZAMIN SEM IV
opracowanie pytan na ekologie
Opracowanie pytań na egzamin z Systemów Sterowania Maszyn i Robotów u Salamandry
Pytania z egzaminu ekonomika KTZ ORO 2010, OPRACOWANIE PYTAŃ NA EGZAMIN
więcej podobnych podstron