
56. Podprogramy. Przekazywanie parametrów podprogramu.
Podprogram
(inaczej funkcja lub procedura) - termin związany z programowaniem
proceduralnym. Podprogram to wydzielona część programu wykonująca jakieś
operacje. Według „Słownika informatycznego” podprogram to wydzielony logicznie
fragment programu, realizujący określone zadanie.
Jedną z zasad praktyki dobrego programowania jest modularność kodu,
oznaczająca, że różne części programu są w miarę możliwości wyodrębnione i
niezależne od siebie. Podprogramy stosuje się, aby uprościć program główny i
zwiększyć czytelność kodu. Bez względu na wykorzystywane przez program
podprogramy, realizacja programu zawsze rozpoczyna się od programu głównego.
O podprogramie można myśleć jako o osobnym programie, który może zostać
uaktywniony (wywołany) w odpowiednim momencie. Jest niezależny od programu
głównego i nic nie wie o zmiennych przez ten program wykorzystywanych. I
odwrotnie, program główny nic nie wie o zmiennych wykorzystywanych przez
podprogram. Pomimo tej niezależności i autonomii podprogram jest jednostką
niesamodzielną i może być uaktywniony tylko przez segment nadrzędny. Podprogramy
umożliwiają wydzielenie określonego ciągu instrukcji i nadanie im postaci
podprogramu. Z formalnego punktu widzenia można dosyć dowolnie dzielić program
na mniejsze fragmenty podprogramów, Najczęściej uzasadnieniem i motywacją
wykorzystania podprogramów jest zwiększenie czytelności programu w wyniku jego
rozbicia na mniejsze podzadania opisywane za pomocą kolejnych segmentów lub
sytuacja, w której określony ciąg czynności powinien być wielokrotnie realizowany w
toku wykonania programu, i co więcej, w odniesieniu do różnych wartości. Innym
ważnym aspektem jest wykorzystanie gotowych podprogramów dostępnych w postaci
bibliotek.
Zalety podprogramów :
możliwość wykonania tego samego algorytmu dla różnych danych
uproszczenie zapisu większych algorytmów
znaczne uproszczenie czytania i analizowania algorytmów
podprogram jest rozszerzeniem istniejącej listy instrukcji elementarnych
łatwiejszy proces projektowania algorytmów – poprzez zbliżanie się do celu
stopniowo , za pośrednictwem podprogramów jeszcze nieistniejących
Rodzaje podprogramów
W pewnych językach programowania dzieli się podprogramy na funkcje i procedury:
Funkcja ma wykonywać obliczenia i zwracać jakąś wartość, nie powinna
natomiast mieć żadnego innego wpływu na działanie programu (np. funkcja
obliczająca pierwiastek kwadratowy)
Procedura natomiast nie zwraca żadnej wartości, zamiast tego wykonuje pewne
działania (np. procedura czyszcząca ekran)

Przez zwracanie wartości należy rozumieć możliwość użycia wywołania funkcji
wewnątrz wyrażenia. Procedury często też zwracają wartości, ale poprzez odpowiednie
parametry.
Podział ten występuje w językach takich jak Pascal i Ada. W pozostałych językach (m.
in. w C i C++) nie ma już takiego rozróżnienia i funkcją jest każdy podprogram,
niezależnie od tego czy zwraca jakieś wartości i czy ma wpływ na program.
Oprócz powyższego podziału, wyróżnić także należy podprogram główny, tj. taki od
którego rozpoczyna się wykonywanie skompilowanego programu. W językach
programowania zastosowano zasadniczo kilka różnych rozwiązań. Albo zdefiniowana
jest w składni odrębna jednostka (np. program w Pascalu), albo stosuje się
specjalną frazę, dyrektywę języka,
informującą
aby
program łączący
dany
podprogram wybrał jako podprogram główny (np. OPTIONS(MAIN) w jęzuku PL/1). W
języku C i pokrewnych definiuje się zwykłą funkcję lecz o specjalnym
identyfikatorze main.
Podprogram może być identyfikowany:
przez nazwę - identyfikator przypisany do podprogramu w jego deklaracji
jest to najczęściej spotykany przypadek w językach wysokiego poziomu
języki programowania: np. C++ itp.
przez etykietę
języki programowania:Basic, Visual Basic,
przez liczbę - literał całkowity
języki programowania:Basic, Visual Basic, Jean, JOSS
przez adres/referencję
w językach wysokiego poziomu takie wskaźniki do podprogramów
przechowywane są w zmiennych typu proceduralnego/funkcyjnego lub
wskaźnikowego.

Przekazywanie parametrów :
Podprogram nie będący metodą ma dostęp do danych na dwa sposoby: przez zmienne
nielokalne (zgodnie z zasadami zakresu widoczności) oraz przez przekazane
parametry. Oczywiście drugi sposób jest znacznie lepszy, gdyż pozwala na jasne
zdefiniowanie sprzężenia podprogramu z otoczeniem, bez polegania na trudnych
często do uchwycenia efektach ubocznych. Metoda ma dodatkowo dostęp do danych
obiektu, z którego jest wołana.
Podstawowe definicje dotyczące przekazywania parametrów:
Parametry w nagłówku nazywane są parametrami formalnymi.
Parametry w instrukcji wywołania podprogramu, które zostaną przypisane
parametrom formalnym, nazywane są parametrami aktualnymi.
W większości języków, odpowiedniość pomiędzy parametrami formalnymi a
aktualnymi ustalana jest poprzez zestawienie ich położenia w liście. Mówi się,
że są to parametry pozycyjne.
Stosuje się też wiązanie parametrów formalnych z aktualnymi na podstawie
nazw podanych wraz z parametrami aktualnymi. Są to parametry z kluczem.
Niektóre języki pozwalają na użycie parametrów z wartością domyślną, np.
Ada, C++, PHP. Wówczas liczba parametrów aktualnych może być mniejsza
niż liczba parametrów formalnych.
Niektóre języki programowania posiadają mechanizmy przekazywania
zmiennej liczby parametrów, np. params w C++.
Różnice pomiędzy procedurami a funkcjami.
Pod względem technicznym, procedury i funkcje różnią się jedynie zwracaniem
wartości, tzn. procedury jej nie zwracają. Semantycznie jednak różnica jest istotna.
Procedury są zestawem instrukcji, które definiują sparametryzowane obliczenia. Są
one uruchamiane poprzez pojedyncze wywołanie. Można zatem powiedzieć, że
procedury definiują nowe instrukcje. Funkcje natomiast przypominają funkcje
matematyczne. Są wywoływane poprzez użycie ich nazwy w wyrażeniu. Nie powinny
dawać żadnych efektów ubocznych (typowych w przypadku procedur). Funkcje
definiują zatem nowe operatory. Języki programowania oparte na języku C formalnie
nie posiadają procedur, ale funkcje typu void zachowują się tak jak procedury.
Tryby przekazywania parametrów:
Wejściowy (IN) – parametr zawiera wartość stałej, zmiennej , bądź wyrażenia
Wyjściowy (OUT) – program zwraca za pośrednictwem wyrażenia wartość
Wejściowo-wyjściowy (IN-OUT) – program zarówno otrzymuje , jak i zwraca
wartość za pośrednictwem parametru

Przekazanie danych może następować na dwa sposoby:
o
Kopiowana jest faktyczna wartość (do wywoływanego podprogramu, do
programu wołającego lub w obie strony).
o
Dostęp do danych przekazywany jest pośrednio (np. przez wskaźnik).
Modele przekazywania parametrów można implementować jako:
Przekazywanie przez wartość.
Przekazywanie przez wynik.
Przekazywanie przez wartość i wynik.
Przekazywanie przez referencję.
Przekazywanie przez nazwę.
Przekazywanie przez wartość
Wartość parametru aktualnego jest używana do zainicjowania
odpowiadającego mu parametru formalnego.
Parametr formalny funkcjonuje następnie w podprogramie jako zmienna
lokalna.
Tak implementujemy semantykę trybu wejściowego.
Dane przekazuje się zwykle przez kopiowanie wartości, ale można też użyć
dostępu pośredniego (z dodatkowym zabezpieczeniem przed zmianą wartości
parametru aktualnego).
Przekazywanie przez wartość jest kosztowne, gdy trzeba przekazać duże
struktury danych.
Przekazywanie przez wynik
Nie przekazujemy wartości do podprogramu.
Parametr formalny działa jak zmienna lokalna.
Tuż przez przekazaniem sterowania z powrotem do wywołującego, wartość
parametru formalnego jest przesyłana do parametru aktualnego w programie
wywołującym.
Parametr aktualny musi zatem być zmienną (a nie np. wyrażeniem
arytmetycznym).
Tak implementujemy semantykę trybu wyjściowego.
Dane przekazuje się zwykle przez kopiowanie.
Przy przekazywaniu przez wynik może dojść do kolizji parametrów
aktualnych.
Przekazywanie przez wartość i wynik
Jest to kombinacja dwóch wcześniejszych sposobów implementacji, dająca
semantykę trybu wejściowo-wyjściowego.
Zwane niekiedy przekazywaniem przez kopiowanie, jako że parametr aktualny
jest kopiowany do parametru formalnego, a następnie kopiowany z powrotem
przy zakończeniu podprogramu.

Przekazywanie przez referencję
Jest to alternatywna implementacja semantyki trybu wejściowo-wyjściowego.
Dostęp do danych przekazywany jest pośrednio, czyli przekazywany jest w
istocie wskaźnik do wartości a nie sama wartość.
Podprogram zyskuje więc faktyczny dostęp do parametru aktualnego.
Taki sposób przekazania jest efektywny.
Przekazywanie przez referencję może powodować aliasowanie, np. w
przypadku wywołań subp(x, x) lub subp(T[i], T[j]) przy i = j.
Aliasowanie może również się pojawić na skutek kolizji między parametrami
formalnymi a zmiennymi nielokalnymi.
Przekazywanie przez nazwę
Ten sposób implementuje semantykę trybu wejściowo-wyjściowego.
Parametr aktualny jest wstawiany (tekstowo) w miejsce odpowiadającego mu
parametru formalnego, we wszystkich wystąpieniach w podprogramie.
W poprzednio omówionych sposobach było inaczej — parametry formalne były
wiązane z aktualnymi wartościami (lub adresami) w chwili wywołania
podprogramu.
Przy przekazywaniu przez nazwę parametr formalny jest wiązany z metodą
dostępu do danych w chwili wywołania podprogramu, ale właściwe wiązanie z
wartością lub adresem następuje dopiero w momencie odwołania lub
przypisania do owego parametru formalnego.
Jest to „późne wiązanie” — kosztowne...
57. Porównanie programowania obiektowego i strukturalnego.
Programowanie obiektowe
(ang. object-oriented programming) jest
obecnie najpopularniejszą techniką tworzenia programów komputerowych.
Program komputerowy wyraża się jako zbiór obiektów będących bytami
łączącymi stan (czyli dane) i zachowanie (czyli metody, które są procedurami
operującymi na danych obiektu). W celu realizacji zadania obiekty wywołują
nawzajem
swoje
metody,
zlecając
w
ten
sposób
innym
obiektom
odpowiedzialność za pewne czynności.
W porównaniu z tradycyjnym programowaniem proceduralnym, w którym dane i
procedury nie są ze sobą powiązane, programowanie obiektowe ułatwia
tworzenie dużych systemów, współpracę wielu programistów ,ponowne
wykorzystywanie istniejącego kodu i jego konserwacje.
Podstawowe założenia paradygmatu obiektowego:
Abstrakcja
Dziedziczenie
Hermetyzacja
Polimorfizm
Można wyróżnić dwa zasadnicze podtypy programowania obiektowego
Programowanie oparte na klasach
Definiowane są klasy, czyli typy zmiennych, a następnie tworzone są
obiekty, czyli zmienne (w uproszczeniu) tych typów.
Programowanie oparte na prototypach
W tym podejściu nie istnieje pojęcie klasy. Nowe obiekty tworzy się w
oparciu o istniejący już obiekt - prototyp, po którym dziedziczone są pola i
metody i można go rozszerzać o nowe. Spotykany raczej w językach
interpretowanych np. JavaScript.
Programowanie
strukturalne
to
paradygmat
programowania
zalecający hierarchiczne dzielenie kodu na moduły, które komunikują się jedynie
poprzez
dobrze
określone
interfejsy.
Jest
to
rozszerzenie
koncepcji
programowania proceduralnego. Jest to programowanie zalecająca stosowanie
konstrukcji języka takich jak pętle i instrukcje warunkowe, oraz unikanie
instrukcji goto i wielokrotnych punktów wejścia i wyjścia z kodu danego
podbloku programu.
Dane mogą być zmiennymi typów prostych, ale najczęściej są grupowane do
postaci typów złożonych - encji (struktur, rekordów, krotek, unii - zależnie od
przyjętej implementacji i nomenklatury). Cechą charakterystyczną jest mniejsza,
niż w programowaniu proceduralnym, ilość zmiennych oraz częste wykorzystanie
tablic o elementach typu złożonego. Znamiennym jest też przekazywanie do
podprogramów danych w postaci pojedynczej zmiennej typu złożonego, zamiast
wielu
parametrów
o
typach
prostych.
Programowanie strukturalne jest często stosowane w ramach implementacji
interfejsu programowania aplikacji systemów operacyjnych (tak Linux jak
Windows), gdzie nie jest wykorzystywane programowanie zorientowane
obiektowo. Jest podstawowym paradygmatem języków Pascal, C oraz wielu
innych.
Tabela porównawcza
Programowanie obiektowe
Programowanie
strukturalne
Zalety
Przejrzystość
Łatwa modyfikacja
stworzonego kodu
Łatwa konserwacja,
rozbudowa i optymalizacja
kodu
Wygoda
Małe ryzyko utraty
funkcjonalności i błędów przy
zmianach
Ułatwia współpracę wielu
programistów
Szybsze
wykonywanie
skryptów
Podobieństwo formy
kodu maszynowego
i źródłowego.
Mała ilość
zmiennych
Prostota
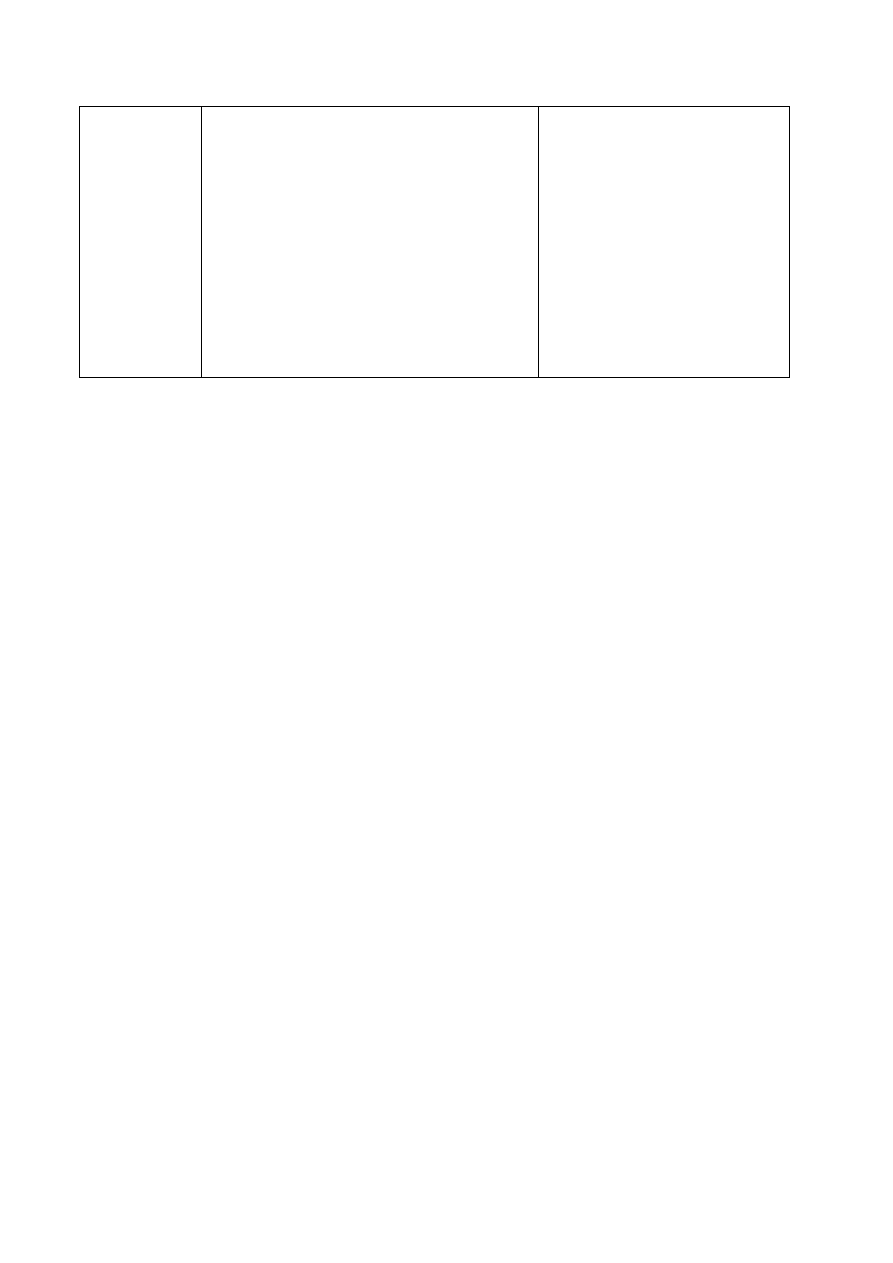
Wady
Częsta potrzeba
wykorzystania dużej ilości
nadmiarowego kodu do
zdefiniowania klas
W porównaniu z kodem
strukturalnym, wykonuje się
wolniej
Potrzeba przeprowadzenia
szczegółowej analizy i
projektowania budowy klas z
uwzględnieniem widoczności
metod
Rozdzielenie
danych i operacji
na nich
wykonywanych
Nieporządek,
chaos. Brak
logicznego
powiązania
Trudna modyfikacja
i stworzenie API
58. Hermetyzacja danych – cechy klas obiektowych (pola,
metody, poziomy prywatności danych).
Do podstawowych pojęć paradygmatu obiektowego należą klasa, obiekt,
metoda,
pole (zwane
też
właściwością), enkapsulacja,
dziedziczenie,
polimorfizm.
Klasa to definicja obiektu, łącząca zarówno stan obiektu, określony
wartościami pól, jak możliwe zachowanie obiektu, określone dostępnymi
metodami.
Obiekt to utworzony egzemplarz określonej klasy, który posiada własny,
indywidualny stan i zbiór zachowań.
Metoda to funkcja lub procedura, skojarzona z ogółem klasy lub
poszczególnymi jej obiektami; określa możliwe zachowania danego obiektu
pewnej klasy.
Pole/Właściwość to zmienna, skojarzona z ogółem klasy lub poszczególnymi
jej obiektami; określa aktualny stan danego obiektu pewnej klasy.
Dziedziczenie to mechanizm definiowania nowej klasy na bazie już
istniejącej, wzbogacając ją o nowe pola, metody lub zmieniając zakres ich
widoczności.
Polimorfizm to mechanizm wywołania metody obiektu, dla którego ją
wywołano, bez względu na typ referencji lub wskaźnika, użytego do
wywołania.

Hermetyzacja
(z ang. encapsulation, kapsułkowanie, enkapsulacja lub
inaczej ukrywanie informacji) to jedno z założeń paradygmatu programowania
obiektowego. Polega ono na ukrywaniu pewnych danych składowych lub metod
obiektów danej klasy tak, aby były one (i ich modyfikacja) dostępne tylko metodom
wewnętrznym danej klasy lub funkcjom z nią zaprzyjaźnionym. Z pełną hermetyzacją
mamy do czynienia wtedy gdy dostęp do wszystkich pól w klasie jest możliwy tylko i
wyłącznie poprzez metody, lub inaczej: gdy wszystkie pola w klasie znajdują się w
sekcji prywatnej (lub chronionej).
Przyczyny stosowania hermetyzacji:
· Uodparnia tworzony model na błędy polegające np. na błędnym przypisywaniu
wartości oraz umożliwia wykonanie czynności pomocniczych
· Lepiej oddaje rzeczywistość.
· Umożliwia rozbicie modelu na mniejsze elementy.
Dzięki stosowaniu hermetyzacji można budować modele rzeczywistości jako
struktury składające z mniejszych modułów, z których każdy ma pewne określone
dane i określone metody wpływania na ich stan i sprawdzania go. Ukrywanie
wewnętrznej struktury obiektu jest bardzo ważne z kilku powodów. Po pierwsze,
obiekt taki jest odizolowany, a więc nie jest narażony na celowe, bądź niezamierzone
działanie ze strony użytkownika. Po drugie, obiekt ten na pewno jest chroniony od
niepożądanych referencji ze strony innych obiektów. Po trzecie, obiekt taki – jeśli jest
to tylko możliwe, nie wpływa na zmiany, czy jakieś małe korekty wprowadzone w
implementacji. Po prostu obie strony nie kolidują wówczas ze sobą. I po czwarte,
dzięki ukryciu wewnętrznej struktury obiektu, można uzyskać jego przenośność.
Innymi słowy, zastosować definiującą go klasę w innym fragmencie kodu, czy też
programie.
Poziomy prywatności danych
Zmienna składowa lub metoda może mieć trzy różne poziomy dostępności: publiczny,
prywatny i chroniony. Składowe publiczne są dostępne z poziomu dowolnego kodu, a
składowe prywatne dostępne są tylko z poziomu klasy. Te ostatnie to zwykle elementy
o zastosowaniu wewnętrznym, takie jak uchwyt połączenia z baza danych czy
informacje konfiguracyjne. Składowe chronione są dostępne dla samej klasy oraz dla
klas jej potomnych.
Dzięki stworzeniu metod dostępowych dla wszystkich właściwości o wiele łatwiej dodać
testowanie prawidłowości danych, nowa logikę obszaru zastosowania lub inne przyszłe
zmiany w obiektach. Nawet jeżeli bieżące wymogi wobec aplikacji nie narzucają
konieczności sprawdzania prawidłowości danych dla pewnej właściwości, należy mimo
to zaimplementować ją, posługując się funkcjami get i set, aby możliwe było dodanie
takiego sprawdzania, albo zmianę logiki obszaru zastosowania w przyszłości.
Wyszukiwarka
Podobne podstrony:
57 58
57 58
56 57
57 58 607 pol ed01 2007
56 57
Cwiczenie 56-57 f, Sprawozdanie z laboratorium
F 56 57C, sprawozdanie z cw 56,57
F 56 57C, sprawozdanie z cw 56,57
56 57
5-56-57
57 58
57 58
56 57 (2)
56 i 57, Uczelnia, Administracja publiczna, Jan Boć 'Administracja publiczna'
milosc zycie smierc STR 56 57
Cwiczenie 56-57 i
Cwiczenie 56-57 d, Sprawozdanie z laboratorium
więcej podobnych podstron