Bazy danych – wykład ósmy
Indeksy
Konrad Zdanowski
Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
1 / 34
Outline
1
Podstawowe typy organizacji plików
2
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
2 / 34
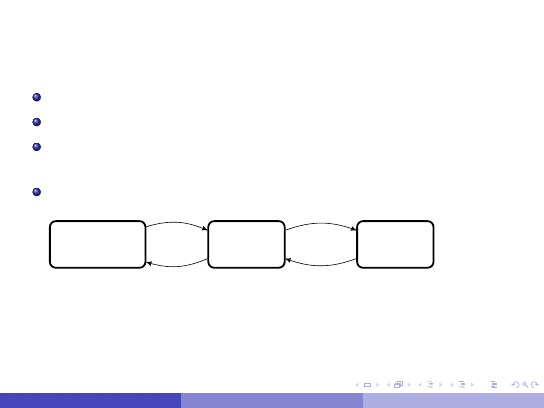
Rekordy tabeli przechowujemy w blokach na dysku.
W jednym bloku mo˙zemy przechowywa´c wiele rekordów.
Nie zakładamy ˙zadnej zale˙zno´sci mi ˛edzy warto´sci ˛
a atrybutów
rekordu i jego miejscem na dysku.
Bloki pliku mo˙zemy traktowa´c jako list ˛e dwukierunkow ˛
a.
Nagłówek
pliku
Blok
danych
Blok
danych
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
3 / 34
Nagłówek
pliku
Blok
danych
Blok
danych
Je´sli N to liczba rekordów w tabeli, R rozmiar rekordu, B rozmiar
bloku na dysku to liczba zaj ˛etych bloków dyskowych D wynosi
przynajmniej:
dN/k e,
gdzie k = bB/Rc – ilo´s´c rekordów, które zmieszcz ˛
a si ˛e w jednym
bloku.
W praktyce trudno osi ˛
agn ˛
a´c takie maksymalne wykorzystanie
bloków na dysku.
Mniejsze wykorzystanie pojedy ´nczych bloków zwi ˛eksza liczb ˛e
operacji I/O podczas pracy BD.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
4 / 34
Outline
1
Podstawowe typy organizacji plików
2
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
5 / 34
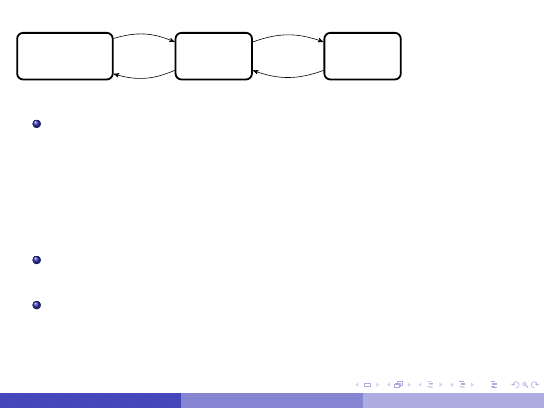
Plik nieuporz ˛
adkowany
Nagłówek
pliku
Blok
danych
Blok
danych
Nie zakładamy ˙zadnej zale˙zno´sci mi ˛edzy warto´sci ˛
a atrybutów
rekordu i jego miejscem na dysku.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
6 / 34
Operacje na pliku nieuporz ˛
adkowanym
Nagłówek
pliku
Blok
danych
Blok
danych
Wstawianie mo˙zemy wykona´c w czasie stałym, je´sli wstawiamy do
ostatniego bloku.
Wyszukiwanie mo˙ze wymaga´c, pesymistycznie, wczytania
wszystkich bloków, ´srednio – połowy bloków.
Usuwanie wymaga wyszukania odpowiedniego rekordu a potem
usuni ˛ecia go z danego bloku. Mo˙zliwe, ˙ze musimy wtedy
przeorganizowa´c bloki, je´sli wymagamy ich minimalnego
zapełnienia (np. na poziomie 50%).
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
7 / 34
Outline
1
Podstawowe typy organizacji plików
2
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
8 / 34
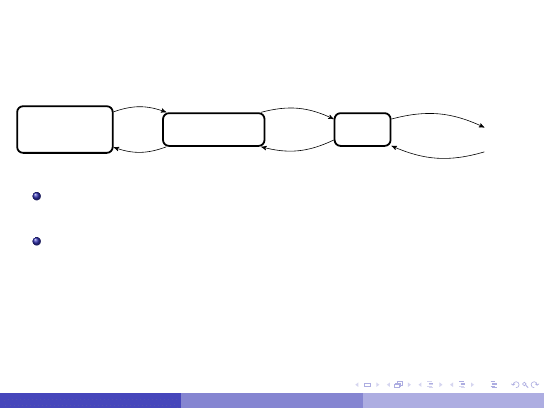
Pliki uporz ˛
adkowane
Nagłówek
pliku
1, 1, 1, 2, 2,3
3,4,4,5
Pliki w kolejnych blokach uporz ˛
adkowane s ˛
a zgodnie z
warto´sciami ustalonego zbioru atrybutów.
Je´sli interesuj ˛
a nas inne atrybuty to plik taki musimy traktowa´c jak
plik nieuporz ˛
adkowany.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
9 / 34
Pliki uporz ˛
adkowane
Je´sli nasz plik zawiera s ˛
asiednie bloki lub stosujemy dodatkowe
struktury danych, to wyszukanie rekordu o zadanej warto´sci
atrybutu, po którym plik jest posortowany kosztuje log
2
(
D), gdzie
D to liczba zaj ˛etych bloków (wyszukiwanie binarne).
Wstawienie kosztuje nas ´srednio D/2 gdy˙z wstawiaj ˛
ac rekord w
´srodku pliku musimy zrobi´c dla niego miejsce czyli przesun ˛
a´c do
przodu rekordy wyst ˛epuj ˛
ace po nim.
Podobny problem wyst ˛epuje przy usuwaniu lub modyfikacji pola,
po którym plik jest posortowany.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
10 / 34
Pliki uporz ˛
adkowane
Wysokie koszty operacji wstawiania sprawia, ˙ze stosuje si ˛e
dodatkowy plik, do którego wstawia si ˛e nowe rekordy.
Co jaki´s czas plik ten jest scalany z plikiem głównym.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
11 / 34
Outline
1
Podstawowe typy organizacji plików
2
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
12 / 34
Pliki haszowe
Blok, w którym umieszczony b ˛edzie rekord wyznaczany jest na
podstawie warto´sci funkcji haszuj ˛
acej.
Pozwala to na efektywne wyszukiwanie, wstawianie i usuwanie
rekordów.
Problemy powstaj ˛
a, gdy nast ˛epuje przepełnienie bloku
przeznaczonego dla rekordów o danej warto´sci funkcji haszuj ˛
acej.
Mo˙zliwe rozwi ˛
azania to np. druga funkcja haszuj ˛
aca,
umieszczenie nadmiarowych rekordów w dodatkowych blokach
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
13 / 34
Outline
1
Podstawowe typy organizacji plików
2
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
14 / 34
Indeksy
Indeksy s ˛
a dodatkow ˛
a struktur ˛
a przechowuj ˛
aca informacje o pliku
z tabel ˛
a.
Dzi ˛eki tej informacji mo˙zemy efektywniej wyszukiwa´c rekordy w
pliku nie zwi ˛ekszaj ˛
ac kosztów utrzymania pliku w zało˙zonej formie
(np. uporz ˛
adkowanej).
Musimy wtedy dba´c o aktualizawonie pliku z indeksem – indeks
jest jednak mniejszy ni˙z cały rekord i mo˙zemy efektywnie
zaprojektowa´c struktur ˛e danych dla pliku z indeksem (B drzewa).
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
15 / 34
Indeksy
Najbardziej czasochłonn ˛
a operacj ˛
a w bazie danych jest dost ˛epo
do dysku.
Wyszukiwanie krotki wymaga przej˙zenia ´srednio połowy tabeli.
Indeksy zakładane s ˛
a na tabel ˛e w celu przy´spieszenia
wyszukiwania.
Implementowane przez B-drzewa pozwalaj ˛
a ławiej znale´z´c adres
na dysku, pod którym znajduje si ˛e interesuj ˛
aca nas krotka.
Indeks nakłada dodatkowy koszt na operacje wstawiania do tabeli
i modyfikacji.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
16 / 34
Indeksy – przykład
select * from Przelewy where data=’2011-11-11’ and
nadawca=’Kowalski’;
Zbiór wyników takiego zapytania jest istotnie mniejszy ni˙z cała
tabela.
Nie posiadaj ˛
ac indeksu musieliby´smy jednak przej˙ze´c cał ˛
a tabel ˛e
aby odnale´z´c odpowiednie krotki (albo trzyma´c dane w pliku
uporz ˛
adkowanym).
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
17 / 34
Indeksy – przykład
Indeks pozwala nam efektywniej wyszukiwa´c krotki o danych
warto´sciach atrybutów. Mo˙ze przy´spieszy´c obliczanie zł ˛
acze ´n.
Utrzymanie struktury indeksu nakłada dodatkowe koszty na
operacje modyfikacji tabeli.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
18 / 34
Indeks oparty na kluczu
Cz ˛esto wyszukujemy krotki w oparciu o klucz relacji.
Indeks na kluczu relacji pozwala odnale´z´c jedn ˛
a krotk˛e zamiast
przegl ˛
adania całej relacji – koszt dost ˛epu wynosi wtedy: koszt
przejrzenia indeksu + O(1).
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
19 / 34
Indeks na kluczu – przykład
select data_urodzenia from Ksiazki, Autorzy where tytul=’Cyberiada’
and Ksiazki.author_id = Autorzy.id;
Je˙zeli mamy zało˙zony indeks na atrybut tytul w tabeli Ksiazki, to
mo˙zemy szybko wyszuka´c rekord ksi ˛
a˙zki Cyberiada.
Nast ˛epnie, je´sli mamy indeks na id w tabeli Autorzy, to łatwo
znajdziemy rekord z autorem Cyberiady.
Sprawdzenie jego wieku wykona sie w czasie stałym plus koszt
przej˙zenia indeksu.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
20 / 34
Kiedy indeks na kluczu jest nieprzydatny – przykład
Załó˙zmy, ˙ze mamy nieposortowany plik z tabel ˛
a Ksiazki z
zało˙zonym indeksem na pola (tytul, rok_wydania).
Wykonujemy zapytanie:
select * from Ksiazki where rok_wydania = 2000;
Je´sli w wi ˛ekszo´sci bloków znajduj ˛
a si ˛e ksi ˛
azki wydane w roku
2000 to oczywi´scie i tak musimy odczyta´c wszystkie bloki w pliku.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
21 / 34
Rodzaje indeksów
Ze wzgl ˛edu na rodzaj atrybutu, na którym zało˙zony jest indeks
dzielimy indeksy na:
indeks podstawowy – zało˙zony na atrybucie porz ˛
adkuj ˛
acym plik i
unikalnym,
indeks zgrupowany – zało˙zony na atrybucie porz ˛
adkuj ˛
acym plik
lecz nie unikalnym,
indeks wtórny – zało˙zony na atrybucie nieporz ˛
adkuj ˛
acym.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
22 / 34
Rodzaje indeksów
Ze wzgl ˛edu na rodzaj atrybutu, na którym zało˙zony jest indeks
dzielimy indeksy na:
indeks podstawowy – zało˙zony na atrybucie porz ˛
adkuj ˛
acym plik i
unikalnym,
indeks zgrupowany – zało˙zony na atrybucie porz ˛
adkuj ˛
acym plik
lecz nie unikalnym,
indeks wtórny – zało˙zony na atrybucie nieporz ˛
adkuj ˛
acym.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
23 / 34
Rodzaje indeksów
Ze wzgl ˛edu na wskazywane przez indeks rekordy, mo˙zemy podzieli´c je
na:
indeks g ˛esty – posiada wska´zniki do ka˙zdego rekordu w tabeli,
indeks rzadki – posiada wska´zniki tylko do niektórych rekordów.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
24 / 34
Indeks o kluczu zło˙zonym
Indeks mo˙zemy nało˙zy´c na par ˛e (lub wi ˛ecej atrybutów).
Indeks nało˙zony na atrybuty (A,B) pozwala wyszukiwa´c rekordy o
danej warto´sci obu atrbybutów ale pozwala tak˙ze wyszuka´c
rekordy o danej warto´sci atrybutu A.
Indeks nało˙zony na par ˛e atrybutów jest efektywniejszy przy
wyszukiwaniu po obu atrybutach ale mniej elastyczny jak dwa
indeksy pojedy ´ncze.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
25 / 34
Indeks o kluczu zło˙zonym – przykład
Indeks nało˙zony na pare (nazwisko, imie) pozwoli efektywnie
wyszuka´c krotki dla (Kowalski, Jan) pozwoli tak˙ze wyszuka´c
wszystkich Kowalskich.
O rekordach takiego indeksu mo˙zemy my´sle´c jako o trójkach
(nazwisko, imie, adres) i uporz ˛
adkowanych według pary atrybutów
(nazwisko, imie).
Indeks ten nie pozwoli wyszuka´c wszystkich Janów.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
26 / 34
Outline
1
Podstawowe typy organizacji plików
2
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
27 / 34
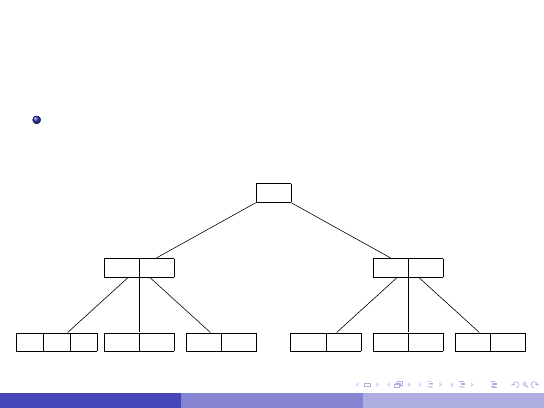
Struktura pliku indeksu
Rekordy pliku indeksu zawieraj ˛
a dwa atrybuty:
I
pole z warto´sci ˛
a indeksowanego atrybutu,
I
pole z adresem bloku na dysku, w którym znajduje si ˛e dana krotka
(lub krotki).
Poniewa˙z rekordy indeksu s ˛
a (z reguły) mniejsze ni˙z rekordy
tabeli, dla której go zakładamy dost ˛ep do nich wymaga mniej
operacji I/O. Mamy te˙z wi ˛eksze szanse, ˙ze indeks bedziemy mogli
trzyma´c w cało´sci w pami ˛eci operacyjnej.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
28 / 34
Indeks jako plik uporz ˛
adkowany
Najprostsz ˛
a realizacj ˛
a jest indeks jako plik uporz ˛
adkowany według
atrybutów, dla których stworzyli´smy indeks.
Plik taki ma posta´c:
(klucz1, adr1), (klucz2, adr2), ...., (kluczN, adrN),
gdzie klucz1< klucz2 < ... < kluczN a plik zajmuje spójny fragment
dysku.
Poniewa˙z rekordy indeksu s ˛
a mniejsze od rekordów tabeli, dla
której tworzymy indeks przechowanie pliku indeksu w jednym,
spójnym fragmencie dysku jest mniej kłopotliwe.
Podobnie jeden blok na dysku zawiera wiecej rekordów indeksu
ni˙z zawierałby rekordów oryginalnej tabeli – szybciej mo˙zemy
wczyta´c cały indeks.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
29 / 34
Indeks jako plik uporz ˛
adkowany
Wyszukanie rekordu o zadanej warto´sci na polu indeksowanym
trwa wtedy O(log
2
(
N)), gdzie N to liczba rekordów w tabeli
(wyszukiwanie binarne).
Koszt wstawienia rekordu do tabeli jest zwi ˛ekszony o koszt
uaktualnienia indeksu. Ten koszt to O(N) ale poniewa˙z plik
indeksu zajmuje mniej bloków ni˙z plik tabeli i tak jest on mniejszy
ni˙z koszt utrzymawania jako uporz ˛
adkowanego całego pliku.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
30 / 34
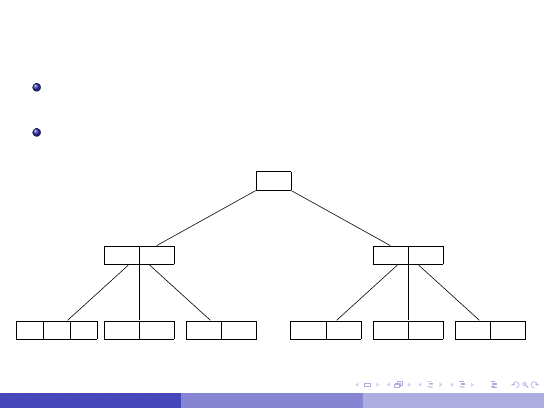
B drzewa
B-drzewa i ich warianty s ˛
a najbardziej efektywna struktur ˛
a
implementacji indeksu.
Zapewniaj ˛
a niski koszt operacji wstawiania do indeksu oraz
wyszukiwania w indeksie - rz ˛edu O(log
C
(
N)), gdzie N to liczba
rekordów w tabeli a C jest „du˙z ˛
a” stał ˛
a.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
31 / 34
B drzewa
Załó˙zmy, ˙ze mamy indeks zało˙zony na atrybucie, którego warto´sciami
s ˛
a liczby naturalne.x
Jeden w ˛ezeł (rekord) B–drzewa zawiera tablic ˛e o postaci
(wska´znik0, warto´s´c1, wska´znik1, warto´s´c2, ...., warto´s´cN,
wska´znikN)
51
12
46
1
5
7
38
45
47
48
62
91
53
55
68
78
92
97
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
32 / 34
B drzewa
Ka˙zdy w ˛ezeł drzewa jest wypełniony w przynajmniej 50% (z
wyj ˛
atkiem korzenia).
Na ostatnim poziomie drzewa w ˛ezły zawieraj ˛
a adresy miejsc na
dysku rekordów z odpowienimi warto´sciami.
Wyszukiwanie kosztuj ˛e tyle co przej´scie ´scie˙zki od korzenia do
li´scia.
Podobny jest koszt implementacji wstawiania i usuwania z B
drzewa – musimy dba´c, ˙zeby struktura drzewa była
zrównowa˙zona.
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
33 / 34
B
+
drzewa
W B
+
drzewach li´scie tworz ˛
a list ˛e dwukierunkow ˛
a (poł ˛
aczenia te
nie s ˛
a narysowane).
Ułatwia to wyszukanie rekordów o warto´sciach z zadanego
przedziału.
51
12
46
1
5
7
38
45
47
48
62
91
53
55
68
78
92
97
Konrad Zdanowski ( Uniwersytet Kardynała Stefana Wyszy ´nskiego, Warszawa)
Bazy danych – wykład ósmy Indeksy
34 / 34
Document Outline
Wyszukiwarka
Podobne podstrony:
KZ BD w09 id 256667 Nieznany
KZ BD w04
KZ BD w05
KZ BD w02
KZ BD w07 id 256666 Nieznany
KZ BD w14 2 id 256670 Nieznany
KZ BD w12 id 256669 Nieznany
KZ BD w03 2 id 256664 Nieznany
KZ BD w11 2 id 256668 Nieznany
KZ BD w06
KZ BD w09 id 256667 Nieznany
więcej podobnych podstron