Ilość przedziałów klasowych :
k=5logN, R=Xmax-Xmin
Rozpiętość przedziałów klasowych ![]()
a) wskaźnik struktury ![]()
b) wskaźnik natężenia ![]()
Dominanta
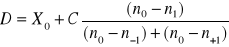
pozycja mediany ![]()
![]()
dla N nieparzystych
![]()
Kwartyle szeregów rozdzielczych przedziałowych:
![]()
; ![]()
;![]()
Średnie klasyczne
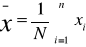
, dla szeregu szczegółowego (wyliczającego)
![]()
, dla szeregu rozdzielczego punktowego
![]()
, dla szeregu rozdzielczego przedziałowego
a) suma odchyleń średniej arytmetycznej ![]()
b) średnia geometryczna ![]()
dla szeregu prostego
![]()
dla szeregu rozdzielczego
średnią chronologiczną
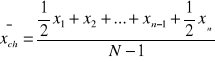
średnią harmoniczną
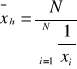
dla szeregu szczegółowego
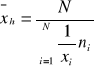
dla szeregu rozdzielczego punktowego
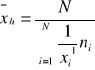
dla szeregu rozdzielczego wielowariantowego
POZYCYJNE MIARY ZMIANNOŚCI
odchylenie ćwiartkowe
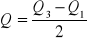
współczynnik zmienności
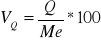
KLASYCZNE MIARY ZMIENNOŚCI (DYSPERSJI)
odchylenie przeciętne
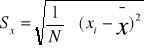
dla szeregów prostych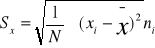
dla szeregów rozdzielczych punktowych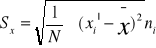
dla szeregów rozdzielczych przedziałowych
współczynnik zmienności : 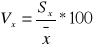
współczynniki koncentracji
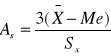
,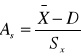
,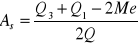
,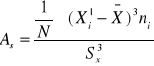
współczynnik koncentracji 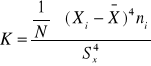
- k=3 dla rozkładu normalnego, k<3 dla rozkładu spłaszczonego
Do pomiaru nierównomierności podziału cechy w szeregu statystycznym wykorzystujemy współczynnik koncentracji Pearsona oraz krzywą Lorentza:
![]()
, gdzie ![]()
Fwi i Fzi - dystrybuanty empiryczne
k=0 rozkład równomierny, k=1 pełna koncentracja
Momenty centralne
![]()
- suma odchyleń od średniej arytmetycznej
![]()
- wariancja
![]()
- wykorzystywany do obliczeń współczynnika asymetrii
![]()
- wykorzystywany do obliczeń współczynnika koncentracji
momenty zwykłe ![]()
![]()
, ![]()
itd.
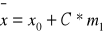
- średni poziom badanej cechy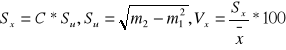
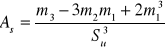
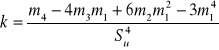
Rozkład dwumianowy:
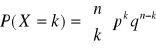
dla k całkowitych
wartość oczekiwana (średnia) M.(X)=n*p
wariancja D2(x)=n*p*q
odchylenie standardowe
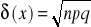
współczynnik asymetrii

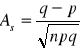
współczynnik ekscesu (koncentracji)
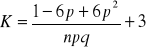
dystrybuanta
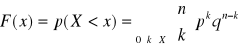
Estymator
Zgodny estymator limz'=z
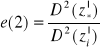
, D2=b2
Szacowanie średniej populacji na podstawie średniej z próby
1-a=0,90 to 2a=1,64
1-a=0,95 to 2a=1,96
1-a=0,99 to 2a=2,58
nieznane odchylenie standardowe populacji, duża próba (N>30)
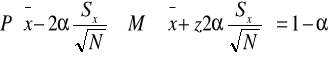
nieznane odchylenie standardowe populacji, mała próba (N<30)
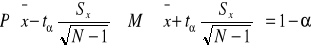
lub 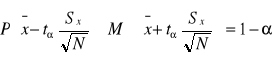
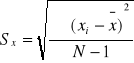
Ustalenia względnej precyzji szacunku danego parametru dokonujemy za pomocą następujących form:
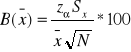
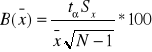
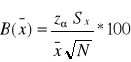
2. Szacowanie odchylenia standardowego populacji na podstawie próby
nieznane odchylenie standardowe, duża próba (N>30)
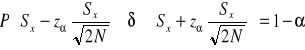
![]()
nieznane odchylenie standardowe, mała próba (N<30)
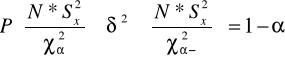
lub 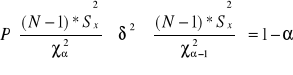
3. Szacowanie wskaźnika struktury (frakcji) populacji na podstawie próby - dokonujemy tylko gry N jest bardzo duże N>122.
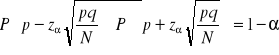
, gdzie ![]()
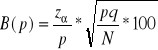
4. Ustalanie minimalnej liczebności próby: 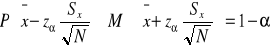
![]()
![]()
, gdzie d - zakładany błąd szacunku
![]()
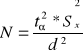
![]()
WERYFIKACJA
Test na zgodność średniej z próby ze średnią z populacji (zgodność średniej z populacji z wartością hipotetyczną):
N>30
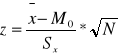
N<30
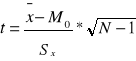
lub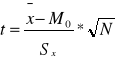
TEST DLA 2 ŚREDNICH
test na zgodność średnich z 2 populacji przy nieznanych odchyleniach standardowych populacji (N>30)
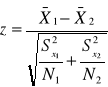
N<30
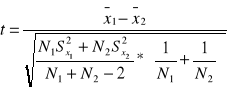
ta statystyka ma N1+N2-2 stopni swobody
2 pomiary na tej samej próbie populacji Wyniki z próby losowej traktujemy jako różnicę pomiędzy parą obserwacji:
di=xi-yi
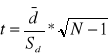
lub 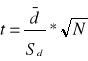
![]()
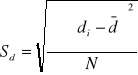
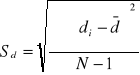
TEST ISTOTNOŚCI DLA WSKAŹNIKA STRUKTURY
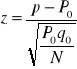
, ![]()
, P0 - hipotetyczny wskaźnik struktury w populacji generalnej.
WERYFIKACJA HIPOTEZ STATYSTYCZNYCH TESTAMI NIEPARAMETRYCZNYMI
Test zgodności X2 o postaci :
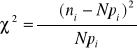
, gdzie pi - częstość teoretyczna (prawdopodobieństwo odpowiadające wartości podanej cechy w poszczególnym przedziale klasowym)
Uwaga! Test X2 ma tylko prawostronny obszar odrzucania!
Test X2 wykorzystany jako test niezależności :
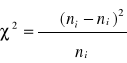
, ![]()
- liczebność teoretyczna
statystyka ta ma (k-1)(r-1)
TESTY ISTOTNOŚCI DLA WARIANCJI
n<30
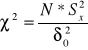
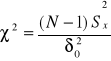
n>30
![]()
TESTY WERYFIKUJĄCE HIPOTEZĘ O LOSOWOŚCI PRÓBY
Jeżeli xi>Me a
Xi<Me b
Xi=Me pomijamy
Wyszukiwarka