Statystyka
Rodzaje błędów w analizie ilościowej
Błędy występujące w analizie ilościowej są bardzo ważne. Podstawową zasadą analizy ilościowej jest to, każdy wynik analizy ilościowej powinien być podany wraz z wartością błędu w nim zawartym. Zasada ta dotyczy nie tylko chemii analitycznej, ale każdego rodzaju badań, w których jako rezultat końcowy otrzymujemy wynik liczbowy.
Podstawową rzeczą jest rozróżnienie trzech podstawowych rodzajów błędów: grubych, systematycznych i przypadkowych. Błędy grube są najłatwiej rozpoznawalne i są to błędy tak poważne, że nie ma innej alternatywy niż wykonanie danego eksperymentu od początku. Błędy te zdarzają się nawet w najlepszych laboratoriach, ale są bardzo szybko wykrywane. Błędy przypadkowe powodują, iż poszczególne wyniki powtórzeń danej analizy różnią się między sobą i układają się po obu stronach względem wartości średniej. Błędy przypadkowe wpływają na precyzję i powtarzalność danego eksperymentu. Błędy systematyczne powodują, iż otrzymane wyniki są jednokierunkowe (czyli wszystkie za duże lub za małe). Całkowity błąd systematyczny jest nazywany biasem albo przesunięciem danego eksperymentu.
Błędy przypadkowe |
Błędy systematyczne |
Wpływają na precyzję - powtarzalność i odtwarzalność
Powodują, iż wyniki układają się po obu stronach wartości średniej Mogą być oszacowane przez wykonanie powtórzeń danego eksperymentu Mogą być zmniejszone przez dobrą technikę lab., ale nigdy nie będą wyeliminowane
Spowodowane są zarówno przez czynniki ludzkie i aparaturowe |
Powodują powstanie biasu - całkowitego odchylenia wyników od wartości prawdziwej nawet, jeżeli błędy przypadkowe są bardzo małe Powodują, że wyniki obarczone tym błędem są wszystkie za duże lub za małe Nie mogą być prosto wykryte przez wykonanie powtórzeń Mogą być skorygowane, np. przez stosowanie materiałów i metod standardowych Spowodowane są zarówno przez czynniki ludzkie i aparaturowe |
W większości eksperymentów analitycznych najbardziej istotne jest stwierdzenie jak daleko otrzymany wynik jest oddalony od wartości prawdziwej. Dokładność jest zdefiniowana przez ISO jako zgodność pomiędzy wynikiem a odpowiednią wartością referencyjną dla danego analitu. Według tej definicji dokładność pojedynczego wyniku jest uzależniona od wielkości błędu systematycznego i przypadkowego. Dokładność średniej wyników również jest uzależniona od obu rodzajów błędów i nawet, jeżeli nie występuje błąd systematyczny to wartość średnia nie będzie równa wartości referencyjnej, ze względu na występowanie błędu przypadkowego. Podsumowując, precyzja opisuje błąd przypadkowy, bias opisuje błąd systematyczny, natomiast dokładność opisująca zgodność pomiędzy wartością rzeczywistą a pojedynczym wynikiem lub średnią wartością, zawiera w sobie oba rodzaje błędów.
Innym ważnym terminami są powtarzalność i odtwarzalność, a szczególnie ich rozróżnienie. Powtarzalność opisuje precyzję zawartą w poszczególnych powtórzeniach, natomiast odtwarzalność precyzję pomiędzy powtórzeniami. Zatem powtarzalność danej metody jest słabsza niż jej odtwarzalność ( z dużym błędem przypadkowym).
Błąd systematyczny powoduje, iż średnia otrzymana dla danego zbioru wyników dla powtórzonych pomiarów różni się od wartości rzeczywistej. W przeciwieństwie do błędu przypadkowego, błędu systematycznego nie można ujawnić przez wykonanie serii powtórzeń i jeżeli wartość prawdziwa nie jest znana, (co jest bardzo częste) nawet bardzo duże błędy systematyczne mogą pozostać nie wykryte, jeżeli odpowiednie środki ostrożności nie zostaną zastosowane. Zatem bardzo łatwo przeoczyć źródło błędów systematycznych.
Sposoby wyeliminowania błędu systematycznego:
Uważne planowanie eksperymentu, np. stosowanie metod kalibracyjnych
Dokładne sprawdzenie aparatu
Stosowanie materiałów referencyjnych
Porównanie z inną metodą dla tego samego analitu
Przewidywanie i identyfikacja problemów przed rozpoczęciem eksperymentu
Statystyka powtarzanych eksperymentów
2.1 Średnia i odchylenie standardowe
Średnia arytmetyczna jest sumą wartości wszystkich wyników podzieloną przez ich liczbę.
Średnią oznaczoną jako ![]()
obliczamy ze wzoru: ![]()
Miarą rozrzutu wyników jest rozstęp, czyli różnica między największą i najmniejszą zaobserwowaną wartością, jednak częściej używaną miarą rozrzutu jest odchylenie standardowe s obliczane ze wzoru: 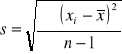
Kwadrat odchylenia standardowego jest powszechnie używaną wielkością zwaną wariancją, s2.
Inną szeroko stosowaną miarą rozrzutu wyników jest współczynnik zmienności (CV), znany także jako względne odchylenie standardowe (RSD) obliczany ze wzoru: ![]()
Zarówno współczynnik zmienności jak i względne odchylenie standardowe są wyrażane w procentach (podobnie jak błąd względny) i dlatego są bardzo często stosowane do porównania precyzji otrzymanych wyników, zwłaszcza jak wyniki te są wyrażane w różnych jednostkach czy wielkościach.
Zadanie 1.
2.2. Rozkłady wyników
Pomimo iż odchylenie standardowe jest miarą rozrzutu wyników wokół wartości średniej to jednak nie informuje nas o kształcie rozkładu tych wyników. Aby to przedstawić potrzebujemy dużej liczby pomiarów, tak jak np. w Tab.2. Przedstawiono w niej 50 powtórzeń oznaczania stężenia jonów azotanowych w próbce wody.
Tab.2

Wyniki te zostały zsumowane i przedstawione w tabeli częstości (Tab.3). Rozkład tych wyników najłatwiej ocenić przez narysowanie histogramu, tak jak na Ryc.1. Widać na nim, że rozkład jest mniej więcej symetryczny wokół średniej arytmetycznej, a poszczególne wyniki są zgrupowane wokół środkowej wartości.
Tab.3 Tabela częstości dla wyników oznaczenia jonów azotanowych.
Stężenie jonów azotanowych |
Częstość |
0.46 |
1 |
0.47 |
3 |
0.48 |
5 |
0.49 |
10 |
0.5 |
10 |
0.51 |
13 |
0.52 |
5 |
0.53 |
3 |
Fig.1. Histogram wyników oznaczania jonów azotanowych
Zbiór 50 wyników oznaczenia jest próbą pochodzącą z bardzo dużej (teoretycznie nieskończonej) liczby pomiarów. Zbiór zawierający wszystkie możliwe pomiary jest nazwany populacją. Jeżeli nie występuje błąd systematyczny to średnia wyników dla tej populacji oznaczona jako µ jest jednocześnie wartością rzeczywistą dla pomiarów danego oznaczenia. Średnia wyników z próby pozwala na oszacowanie wartości µ. Podobnie jest z wartością odchylenia standardowego. Odchylenie standardowe populacji oznaczone jako σ może być oszacowane na podstawie odchylenia standardowego próby oznaczonego jako s.
Na podstawie równania 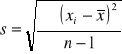
można oszacować wartość σ.
Wyniki pomiarów stężenia jonów azotanowych przedstawione w Tab.2 przyjmują tylko pewne określone wartości z powodu ograniczenia danej metody. Teoretycznie stężenie może przyjmować każdą wartość, dlatego do opisu rozkładu próby, która pochodzi z danej populacji, potrzebna jest ciągła krzywa. Najczęściej stosowanym modelem matematycznym jest rozkład normalny lub inaczej rozkład Gaussa, który jest opisany za pomocą równania:
![]()
Kształt tego rozkładu jest pokazany na Ryc.2
Ryc.2. Krzywa przedstawiająca rozkład normalny.
Krzywa ta jest symetryczna względem wartości µ. Im większa jest wartość µ tym większy jest `rozrzut' krzywej. Bardziej szczegółowa analiza tej krzywej, bez względu na wartości µ oraz σ, wykazała, iż posiada ona następujące własności:
Dla rozkładu normalnego ze średnią µ i odchyleniem standardowym σ, około 68% wyników populacji zawiera się w przedziale µ ± 1 σ; około 95% wyników zawiera się w przedziale µ±2σ i około 99,7% wyników jest w przedziale µ±3σ.
2.3 Rozkład z próby dla średniej
Rozkład wszystkich możliwych średnich próby jest nazywany rozkładem średniej. Średnia ta jest taka sama jak średnia oryginalnej populacji. Jej odchylenie standardowe jest nazwane odchyleniem standardowym średniej (s.e.m.). Bezpośredni związek pomiędzy tą średnią a odchyleniem standardowym σ dla rozkładu poszczególnych wyników przedstawia równanie:
Błąd standardowy średniej (s.e.m.) = ![]()
dla próby z n wynikami (pomiarami).
Im większa wartość n tym mniejsza jest wartość s.e.m. i w konsekwencji mniejszy rozrzut średnich z próby wokół wartości µ.
Inną właściwością rozkładu średniej jest fakt, iż nawet, jeżeli rozkład oryginalnej populacji nie jest normalny, to rozkład średniej jest tym bardziej zbliżony do rozkładu normalnego, jeżeli wartość n rośnie. Ta teoria ma ogromne znaczenie w wielu statystycznych testach wykonywanych właśnie dla średniej przy założeniu normalności rozkładu.
2.4 Przedział ufności dla średniej dużych prób
Jeżeli już znamy rozkład średniej próby możemy rozwiązać problem zdefiniowania dla próby przedziału, w którym możemy zakładać, że mieści się w nim wartość prawdziwą. Przedział ten jest nazwany przedziałem ufności a wartości graniczne tego przedziału są zwane granicami przedziału ufności. Z przedziałem tym jest związana miara ufności (pewności), że przedział ten naprawdę zawiera wartość prawdziwą, zwana poziomem ufności. Wielkość tego przedziału zależy od tego, jaką pewność chcemy mieć, że zawiera on wartość prawdziwą.
Ryc.3 przedstawia rozkład z próby dla średniej dla prób o wielkości n. Jeżeli założymy, że rozkład ten jest normalny wtedy 95% średnich próby będzie mieściła się w przedziale:
![]()
W praktyce najczęściej mamy do czynienia z jedną próbą ze znaną średnią i do niezbędna jest do określenia przedziału wartość prawdziwa µ. Ponieważ nie zawsze jest to możliwe, dlatego przekształcono powyższe równanie do postaci:
![]()
Przedział podany posiada 95% miarę pewności dla średniej. Granice ufności dla tego przedziału można obliczyć ze wzoru:
![]()
Fig.3. Rozkład z próby dla średniej z zaznaczony przedziałem ufności dla średniej z miarą pewności 95%
Zadanie 2.
2.5 Przedział ufności dla średniej z małych prób
Jeżeli wielkość próby maleje to jednocześnie szacowanie wartości σ jest mniej wiarygodne. Dlatego też dla małych prób przedział ufności dla średniej obliczamy ze wzoru:
![]()
Jak widać ze wzoru wartość t zależy od wartości indeksu dolnego (n-1), który jest nazwany stopniami swobody - df. Termin stopni swobody odnosi się do liczby niezależnych odchyleń ![]()
, które zostały użyte do obliczenia wartości s. W tym przypadku stosujemy wartość (n-1), ponieważ znanych jest (n-1), jeżeli ![]()
. Wartość t zależy także od zakładanego poziomu istotności.
Zadanie 3.
Testy istotności
Jedną z najważniejszych cech metody analitycznej jest to, iż powinna ona być pozbawiona błędu systematycznego. Oznacza to, że otrzymana wartość - ilość analitu - powinna być wartością prawdziwą. Jednak nawet, jeżeli nie występuje błąd systematyczny, to bardzo prawdopodobne, że błąd przypadkowy spowoduje, że mierzona wartość nie będzie równa standardowej wartości. Należy zatem zdecydować, czy różnica pomiędzy otrzymaną wartością a wartością standardową jest spowodowana błędem przypadkowym. W tym celu stosuje się testy istotności. Testy istotności są powszechnie stosowane do oceny otrzymanych wyników eksperymentalnych. Poniżej zostaną omówione testy, które są szczególnie użyteczne w chemii analitycznej.
3.1 Porównanie doświadczalnej średniej z wartością prawdziwą
W testach istotności testujemy hipotezę prawdziwą zwaną hipotezą zerową oznaczaną H0. Hipoteza zerowa zakłada, że wartość średniej eksperymentalnej i wartość prawdziwa nie różnią się z wyjątkiem tych różnic, które są spowodowane błędem przypadkowym. Zakładając, że hipoteza zerowa jest prawdziwa zastosowano statystyczną teorię do obliczenia prawdopodobieństwa, że obserwowane różnice pomiędzy wartością średniej ![]()
a wartością prawdziwą µ spowodowane są wyłącznie błędem przypadkowym. Im mniejsze prawdopodobieństwo, że obserwowane różnice występują przypadkowo, tym mniej prawdopodobne jest, że hipoteza zerowa jest prawdziwa. Najczęściej hipoteza zerowa zostaje odrzucona, jeżeli prawdopodobieństwo wystąpienia tych różnic przez przypadek jest mniejsze niż 1 na 20 (tj. 0,05 lub 5%). W tym przypadku różnica jest statystycznie istotna na poziomie istotności 0,05 (lub 5%). Stosując ten poziom istotności w 1 na 20 przypadków odrzucimy hipotezę zerowa, która w rzeczywistości jest prawdziwa. Jeżeli chcemy być bardziej pewni podjęcia prawidłowej decyzji można podwyższyć poziom istotności, najczęściej na 0,01 lub 0,001. Poziom istotności jest zaznaczony przez podanie wartości P (tj. prawdopodobieństwo) = 0,05 i oznacza ona prawdopodobieństwo odrzucenia hipotezy zerowej w przypadku, gdy jest ona w rzeczywistości prawdziwa. Należy również zauważyć, że zatrzymanie hipotezy zerowej nie świadczy o tym, że jest ona prawdziwa, ale że udowodniono, iż jest ona fałszywa.
W celu zdecydowania czy różnica pomiędzy wartością ![]()
a µ jest znacząca, czyli
H0: średnia populacji = µ, statystyka t jest obliczana wg wzoru:
![]()
gdzie: ![]()
jest średnią próby, s odchyleniem standardowym próby a n ilością prób
Jeżeli ![]()
przekracza wartość krytyczną wówczas hipoteza zerowa zostaje odrzucona. Wartość krytyczna t dla konkretnego poziomu istotności jest odczytywana z tablic rozkładu t. Oprogramowania statystyczne podają najczęściej wartość prawdopodobieństwa jako wynik testu istotności. Jest to oczywiście dużą zaletą tych programów, ponieważ nie trzeba znajdować wartości krytycznych w tabelach statystycznych.![]()
Zadanie 4.
3.2. Porównanie dwóch średnich eksperymentalnych
W celu zdecydowania zypadku, gdy jest ona w rzeczywistości prawdziwa. ,001. ści jest prawdziwa. przypadek są mniejsze niż 1 na 20 (tj. czy różnica pomiędzy dwoma średnimi z prób ![]()
i ![]()
jest znacząca testowana jest hipoteza zerowa postaci H0: ![]()
. Statystyka t jest obliczana ze wzoru:
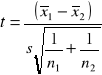
natomiast s jest obliczane ze wzoru:
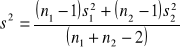
oraz t posiada n1+n2-2 stopni swobody.
Metoda ta zakłada, że obie próbki pochodzą z populacji o równym odchyleniu standardowym.
W celu sprawdzenia hipotezy zerowej H0: ![]()
w przypadku, gdy nie możemy założyć, że próbki pochodzą z tej samej populacji o równych odchyleniach standardowych, statystykę t należy obliczyć ze wzoru:
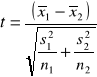
gdzie liczbę stopni swobody obliczmy ze wzoru:
df = 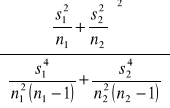
Zadanie 5.
3.3 Test sparowany
Bardzo często zdarza się, że porównywane są dwie metody oznaczeń przez badanie próbek zawierających różną ilość analitu. Test do porównywania dwóch średnich nie jest odpowiedni, ponieważ nie możliwe jest oddzielenie odchyleń spowodowanych zastosowaniem dwóch różnych metod od odchyleń pomiędzy dwoma grupami próbek. Ta trudność jest pokonana przez zastosowanie wartości d, która jest różnicą pomiędzy parami wyników otrzymanych za pomocą obu metod.
W celu sprawdzenia czy n sparowane wyniki pochodzą z tej samej populacji, czyli H0: ![]()
, obliczana jest statystyka t ze wzoru:
![]()
gdzie ![]()
i ![]()
jest to średnia I odchylenie standardowe odpowiednich wartości d, czyli różnicy pomiędzy parami wyników. Liczba stopni swobody dla t wynosi n-1.
Zadanie 6.
3.4 Testy jednostronne i dwustronne
Opisywane dotąd metody były stosowane do rozważania różnic pomiędzy średnimi w jednym i drugim kierunku. W większości sytuacji tego rodzaju badań osoba wykonująca eksperyment nie ma wiedzy a priori czy interesująca nas różnica przybierze wartość dodatnią czy ujemną. Dlatego test musi pokrywać obie możliwości. Takie testy są nazywane dwustronnymi. W nielicznych przypadkach tylko inne testy będą bardziej właściwe. Rozważmy na przykład eksperyment, gdy badany jest wzrost szybkości reakcji po dodaniu katalizatora. W tym przypadku już przed rozpoczęciem eksperymentu możemy zakładać wzrost szybkości reakcji, więc tak naprawdę interesuje nas tylko fakt, czy wzrost szybkości reakcji będzie znaczący statystycznie. Taki rodzaj testu jest nazwany jednostronnym. Dla danej wartości n przy założonym poziomie prawdopodobieństwa wartości krytyczne dla testów jednostronnych różnią się od wartości dla testów dwustronnych. W testach jednostronnych wartość krytyczna t dla P=0,05 jest to wartość, która została przekroczona przy prawdopodobieństwie 5%. Jeżeli zakładamy, że rozkład z próby jest symetryczny to prawdopodobieństwo jest dwukrotnie większe niż w odpowiednich testach dwustronnych. Odpowiednia wartość dla testu jednostronnego jest ta znaleziona dla P=0,1 w odpowiedniej kolumnie. Podobnie, dla testu jednostronnego przy P=0,01 kolumna 0,002 jest używana.
Zadanie 7.
3.5 Test F do porównania odchyleń standardowych
Wszystkie testy opisane powyżej są stosowane do porównania średnich, a więc do wykrycia błędu systematycznego. W wielu przypadkach istotne jest również porównanie odchyleń standardowych, czyli błędów przypadkowych dla dwóch zbiorów danych. W celu sprawdzenia czy różnica pomiędzy wariancjami dwóch prób jest znacząca, czyli H0: ![]()
, statystyka F jest obliczana ze wzoru:
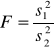
przy czym w liczniku zawsze jest wariancja większa, a w mianowniku wariancja mniejsza. Dzięki temu wartość F jest zawsze ≥1.
Liczba stopni swobody dla licznika i mianownika wynosi odpowiednio n1-1 i n2-1.
Zakłada się, że rozkład populacji, z której pochodzą próby jest normalny.
Jeżeli hipoteza zerowa jest prawdziwa wówczas iloraz obu wariancji jest zbliżony do 1. Jeżeli wartość F odbiega nieznacznie od 1to jest to spowodowane przypadkowym odchyleniem. Natomiast, jeżeli różnica ta jest zbyt duża to nie można tego już przypisywać przypadkowi. Jeżeli obliczona wartość F ze wzoru przekracza wartość tabelaryczną hipotezę zerową należy odrzucić.
Zadanie 8.
3.6 Wyniki odbiegające - Outliers
Każdy analityk dobrze zna sytuację, kiedy to w zbiorze otrzymanych wyników pojawiają się wyniki znacznie odbiegające od pozostałych, tzw. outliers. ISO poleca test Grubbego do testowania wyników wątpliwych. W teście tym w celu sprawdzenia czy dany wynik jest wynikiem wątpliwym, czyli H0: wszystkie wyniki pochodzą z tej samej populacji, statystyka G jest obliczana ze wzoru:
![]()
gdzie ![]()
i s są obliczane włączając do zbioru wyników wartość, którą podejrzewamy, że jest odbiegająca czyli outlier.
Test ten zakłada normalny rozkład populacji.
Test Dixona (Q test) jest innym testem stosowanym w tym samym celu i jest on bardzo popularny ze względu na prostotę obliczenia. W tym teście (hipoteza zerowa jest identyczna jak poprzednio), obliczana jest statystyka Q według wzoru:
![]()
Test ten jest uzasadniony dla ilości prób od 3 do 7 i zakłada normalny rozkład populacji.
Zadanie 9.
Metody kalibracji w analizie instrumentalnej: regresja i korelacja
Metody klasyczne takie jak miareczkowanie czy metody grawimetryczne są nadal stosowane w laboratoriach. Zwłaszcza kiedy mamy do czynienia z niewielką ilością próbek, a czasami są konieczne do wykonania analizy dla substancji wzorcowych. Jednak bez wątpienia największa ilość analiz jest wykonywana za pomocą metod instrumentalnych. W ponad 90% praca analityczna jest wykonywana za pomocą technik spektrofotometrycznych, elektrochemicznych, masowej spektrometrii i chromatograficznych. Metody instrumentalne są bardziej czułe, pozwalają na jednoczesne oznaczanie wielu substancji na bardzo niskich poziomach stężeń, są ponadto szybsze i tańsze.
Metody instrumentalne wymagają jednak kalibracji z zastosowaniem substancji wzorcowych w celu oznaczenia danego analitu. Jakość wykonanej przez nas kalibracji zależy w dużym stopniu od użytej substancji wzorcowej oraz od dopasowania zastosowanej procedury obliczeniowej. Większość stosowanych metod opiera się na względnej kalibracji substancji wzorcowych o znanej zawartości lub stężeniu oznaczanej substancji za pomocą odpowiedniego detektora. Oznaczanie analitu w próbkach przeprowadza się w analogicznych warunkach jak substancje wzorcowe i następnie oblicza stężenie lub zawartość analitu na podstawie krzywej kalibracyjnej otrzymanej dla substancji wzorcowej.
4.1 Współczynnik korelacji
Powszechnie stosowaną metodą oszacowania jak dobrze punkty eksperymentalne są dopasowane do linii prostej jest obliczenie współczynnika korelacji r. Współczynnik korelacji mierzy zatem siłę korelacji pomiędzy zmiennymi.
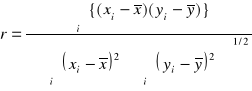
Współczynnik korelacji może przyjmować wartości z zakresu ![]()
. Wartość -1 opisuje ścisły ujemny związek pomiędzy zmiennymi. Wartość 1 oznacza ścisły dodatni związek pomiędzy zmiennymi. W praktyce analitycznej dla krzywych kalibracyjnych współczynnik ten przyjmuje wartości większe niż 0,99. Wartości poniżej 0,90 praktycznie nie występują.
Fig. Współczynnik korelacji r
Zadanie 10.
4.2 Prosta regresji liniowej y od x
Jeżeli istnieje liniowa zależność pomiędzy sygnałem analitycznym (y) i stężeniem (x) możemy obliczyć parametry dla najlepszej linii prostej przechodzącej przez punkty eksperymentalne dla krzywej kalibracyjnej, przy czym każdy z tych punktów jest obarczony błędem eksperymentalnym. Ponieważ zakładamy, że wszystkie błędy występują w kierunku y szukamy takiej prostej, która minimalizuje odchylenia w kierunku y pomiędzy punktami eksperymentalnymi a punktami obliczanej prostej. Niektóre z tych odchyleń (y-reszty) mogą być dodatnie, a inne ujemne. To tłumaczy częste stosowanie metody najmniejszych kwadratów dla tej procedury, ponieważ chcemy znaleźć linię prostą minimalizującą sumę kwadratów reszt, czyli sumę kwadratów odchyleń od tej linii. Linię prostą dopasowaną metodą najmniejszych kwadratów nazwiemy linią najmniejszych kwadratów.
Współczynnik kierunkowy prostej: 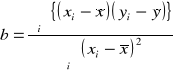
Parametr przecięcia, czyli wyraz wolny: ![]()
Zadanie 11.
4.3 Błędy nachylenia i przecięcia linii regresji
Krzywa regresji jest stosowana do szacowania stężenia badanych związków przez interpolację i do szacowania limitu detekcji w procedurze analitycznej. Dlatego musimy obliczyć statystykę ![]()
, która szacuje wartości błędów w kierunku y.
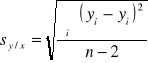
![]()
są to punkty na obliczonej linii regresji odpowiadające poszczególnym wartościom x; tzw. „dopasowane” wartości y;
Fig.5. y-reszty dla linii regresji
Na podstawie wartości ![]()
możemy obliczyć sb i sa czyli standardowe odchylenia dla nachylenia (b) oraz wyrazu wolnego (a):
Odchylenie standardowe nachylenia: 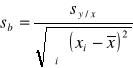
Odchylenie standardowe wyrazu wolnego: 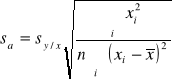
Zadanie 12.
4.4 Obliczenia stężenia i jego błędu przypadkowego
Na podstawie wartości nachylenia i wyrazu wolnego czyli przecięcia (z osią x) możemy obliczyć wartość stężenia (wartość x) odpowiadającą mierzonej wartości sygnału aparatu (wartość y). Jednak konieczne jest także znalezienie błędu związanego z szacowaniem wartości stężenia. Obliczenie wartości x na podstawie danej wartości y wymaga użycia obu wartości: i nachylenia (b) i wyrazu wolnego (a), a obydwie te wartości zawierają w sobie błąd. Ponadto, zawiera go także wartość sygnału aparatu pochodząca od każdej badanej substancji. W rezultacie całkowity błąd oznaczenia przyjmuje bardzo skomplikowaną postać:
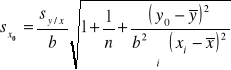
gdzie y0 jest wartością eksperymentalną dla y na podstawie której wartość x0 została oznaczona, ![]()
jest szacowanym odchyleniem standardowym dla wartości x0;
W niektórych przypadkach dokonuje się kilku odczytów w celu otrzymania wartości y0; jeżeli jest m takich odczytów wówczas równanie to przyjmuje postać:
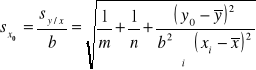
Przedział ufności można obliczyć jako ![]()
, z n-2 stopniami swobody.
Zadanie 13.
4.5 Limit detekcji
Podstawową zaletą stosowania metod analitycznych jest możliwość detekcji i oznaczenia śladowych ilości analitu. Limit detekcji analitu może być opisany jako ta wartość stężenia, która daje sygnał aparatu znacząco różny od sygnału próby ślepej (blanku) lub sygnału tła. Definicja ta jak widać nie daje konkretnej interpretacji wyrażenia `znacząco różny', przez co analityk może sam decydować w dużym stopniu o tej wartości. Jednak najczęściej uznaje się za limit detekcji stężenie analitu dające sygnał równy sygnałowi próby ślepej yB plus trzy odchylenia standardowe próby ślepej sB.
Limit detekcji = yB+3sB
Fig.6 Limit detekcji
Zadanie 14.
4.6 Metoda wzorca wewnętrznego
W wielu metodach instrumentalnych założenie, że nie ma wpływu tzw. matrycy spowodowany przez obecność innych związków jest błędne. Bardzo często otrzymanie próbki z matrycy niezawierającej analitu w celach eliminacji wpływu matrycy jest niemożliwe. Dlatego koniecznie jest w wielu pomiarach analitycznych, włączając wykonie krzywej kalibracyjnej, wykonanie oznaczenia dla całej próbki. W tym celu stosuje się metodę wzorca wewnętrznego. Metoda ta jest szeroko stosowana w absorpcji atomowej, spektrometrii emisyjnej i metodach elektrochemicznych. Do badań użyte są jednakowe objętości próbki i każda z nich jest obciążona znaną, ale różną ilością agalitu, a następnie rozcieńczone do tej samej objętości. Dla wszystkich roztworów zmierzony jest sygnał aparatu i wyniki przedstawione na wykresie (Ryc.7). Wartość sygnału jest odłożona na osi y, a na osi x ilość dodanego analitu (albo masa absolutna albo stężenie). Linia regresji jest obliczana jak zwykle, ale jest ona ekstrapolowana do punktu na osi x, dla którego wartość y=0. Wartość ujemnego przecięcia (wyrazu wolnego) odpowiada ilości analitu w próbce. Wartość tajesz określona jako iloraz a/b wyrazu wolnego i nachylenia linii regresji. Jeżeli obie te wartości posiadają błąd to ten iloraz również go posiada.
Wzór na odchylenie standardowe ![]()
dla ekstrapolowanej wartości x (xE) jest następujący:
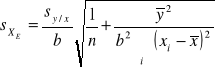
Wzrost wartości n poprawia precyzję szacowanego stężenia. Generalnie przynajmniej sześć punktów powinno być użytych do metody wzorca wewnętrznego. Ponadto, precyzja jest poprawiana przez zwiększenie wartości wyrażenia ![]()
, dlatego kalibracja jeżeli jest to możliwe powinna pokrywać rozważany przedział. Przedział ufności dla xE może być obliczony jak poprzednio jako ![]()
.
Ryc. 7 Metoda wzorca wewnętrznego
Zadanie 15.
4.7 Wyniki odbiegające (outliers) w regresji
Identyfikacja wyników odbiegających w metodach kalibracyjnych jest bardzo ważna. Po pierwsze, w przypadkach gdzie błędy oczywiste zostały popełnione jak np. transkrypcja lub niesprawność aparatu dopuszczalne jest odrzucenie wyników (lub, jeżeli to jest możliwe powtórzenie ich). Jeżeli natomiast nie znamy źródła błędu a wyniki pomiaru są dla nas podejrzane wtedy należy wykonać analizę reszt. Programy komputerowe przeprowadzają takie diagnostyki rutynowo. Są one proste, jak np. wykres poszczególnych x względem wartości yi (Ryc.8). W przypadku prawidłowego modelu kalibracyjnego na wykresie tym reszty powinny być mniej więcej jednakowej wielkości przy wzroście wartości yi oraz posiadać rozkład normalny względem 0.
Ryc.8 Wykres rozrzutu reszt:
(a) wykres sugeruje prawidłowy rozkład reszt
(b) wykres sugeruje, że ważona regresja raczej będzie konieczna, ponieważ wraz ze wzrostem yi rosną również wartości reszt
wykres (c) pokazuje, że badane reszty posiadają jakiś `trend', co sugeruje, iż Inna funkcja powinna być zastosowana
wykres (d) wskazuje na prawidłowy rozkład reszt z wyjątkiem jednej wartości odbiegającej (outlier) y6;
Wykresy te wskazują wartości podejrzane bardzo jasne, ale nie wskazują kryterium do odrzucenia lub pozostawienia danych wartości. Ponadto w wielu metodach analitycznych ograniczeniem jest liczba punktów stosowanych do kalibracji, często jest ich za mało do przeprowadzenia takiej diagnostyki. Z tego względu zaproponowano wiele innych, bardziej zaawansowanych metod, np. szacowanie dla każdego punktu dystansu Cooka. Ta statystyka jest używana rutynowo przez niektóre oprogramowania statystyczne, ale jej interpretacja wymaga znajomości algebry macierzy. Dystans Cooka jest przykładem funkcji wpływów, tzn. mierzy efekty odrzucenia punktu kalibracyjnego na współczynniki regresji a i b.
ZADANIA
Zadanie 1.
Oblicz średnią i odchylenie standardowe podanych wyników:
xi (10,08; 10,11; 10,09; 10,10; 10,12)
Zadanie 2.
Podaj przedziały ufności dla średniej dla oznaczania jonów azotanowych z 95% i 99% miarą pewności. Wartość ![]()
; s=0,0165; n=50. Podaj również granice ufności dla obu przedziałów.
Zadanie 3.
Oznaczono zawartość jonów sodu w próbce moczu za pomocą selektywnych elektrod. Otrzymano następujące wyniki: 102, 97, 99, 98, 101, 106 Mm. Jakie są 95% i 99% przedziały ufności dla stężenia jonów sodu?
Zadanie 4.
Stosując nową metodę oznaczania selenomocznika w wodzie otrzymano następujące wartości dla próbek wody z kranu obciążonych 50ng ml-1 selenomocznika: 50,4; 50,7; 49,1; 49,0; 51,1 ng ml-1. Czy metoda ta jest obciążona błędem systematycznym?
Zadanie 5.
Stosując dwie metody oznaczania chromu w życie otrzymano następujące wyniki (w mg kg-1Cr):
Metoda 1: średnia=1,48; odchylenie standardowe: 0,28
Metoda 2: średnia: 2,33; odchylenie standardowe: 0,31
Dla każdej metody 5 oznaczeń było wykonanych. Czy średnie otrzymane z obu metod różnią się znacząco?
Wykonano serie oznaczeń cyny w artykułach żywnościowych. Próbki ogrzewano z kwasem solnym w różnych czasach. Niektóre wyniki to:
Czas (min) cyna (mg kg-1)
55; 57; 59; 56; 56; 59;
57; 55; 58; 59; 59; 59;
Czy średnie zawartości cyny przy dwóch różnych czasach ogrzewania różnią się znacząco?
Otrzymano podane poniżej wyniki oznaczania tiolu (Mm) w osoczu krwi dla dwóch grup wolontariuszy. Pierwsza grupa była tzw. normalną grupą a drugą stanowiły osoby cierpiące na reumatoidalne zapalenie stawów:
Normalna grupa: 1,84 1,92 1,94 1,92 1,85 1,91 2,07
Reumatoidalna grupa: 2,81 4,06 3,62 3,27 3,27 3,76
Hipoteza zerowa zakłada, iż średnie stężenie tiolu w obu grupach jest jednakowe.
Zadanie 6.
Przykład sparowanych danych:
Partia spektroskopia UV spektroskopia NIR IR
84.63 83.15
84.38 83.72
84.08 83.84
84.41 84.20
83.82 83.92
83.55 84.16
83.92 84.02
83.69 83.60
84.06 84.13
84.03 84.24
Sprawdź czy jest statystyczna różnica pomiędzy wynikami otrzymanymi za pomocą obu metod.
Zadanie 7.
Podejrzewa się, iż metoda miareczkowania kwas-zasada jest obciążona błędem wskaźnika i przez to ma tendencję do otrzymywania zawyżonych wyników. W celu sprawdzenia zastosowano mianowany 0,1M kwas do miareczkowania 25,00 ml zasady 0,1M. Otrzymano następujące wyniki (ml): 25,06; 25,18; 24,87; 25,51; 25,34; 25,41. Sprawdź czy wyniki te są obciążone pozytywnym biasem.
Zadanie 8.
Zaproponowano nową metodę oznaczania tlenu w ściekach wodnych i porównano otrzymane wyniki z wynikami uzyskanymi za pomocą standardowej metody (soli rtęci). Otrzymano następujące wyniki:
Średnia (mg L-1) Odchylenie standardowe (mg L-1)
Metoda standardowa 72 3,31
Zaproponowana metoda 72 1,51
Dla każdej metody wykonano 8 oznaczeń. Czy precyzja nowej zaproponowanej metody różni się znacząco od metody standardowej?
Zadanie 9.
A. Otrzymano następujące wyniki dla oznaczania stężenia jonów azotanowych w próbce wody (mg L-1): 0,403; 0,401; 0,410; 0,380;
Sprawdź czy ostatnia wartość jest odbiegająca i czy należy ją odrzucić.
B. Wykonano więcej pomiarów do przykładu podanego powyżej i w ten sposób otrzymane wyniki to: 0,403; 0,401; 0,410; 0,380; 0,400; 0,413; 0,411;
Czy wynik 0,380 nadal powinien być odrzucony? Zastosuj test Grubego i Dixona.
Zadanie 10.
Dla wodnych roztworów fluoresceiny zmierzono intensywność fluorescencji za pomocą i otrzymano następujące wyniki:
Intensywność fluorescencji: 2,1 5,0 9,0 12,6 17,3 21,0 24,7
Stężenie, pg ml-1 0 2 4 6 8 10 12
Oblicz współczynnik korelacji.
Zadanie 11.
Dla przykładu z zadania 9 oblicz współczynnik kierunkowy prostej oraz wyraz wolny.
Zadanie 12.
Oblicz odchylenie standardowe i przedział ufności dla nachylenia i wyrazu wolnego linii regresji z zadania 10.
Zadanie 13.
Używając danych z zadania 10 oblicz wartości x0 i![]()
oraz przedziały ufności dla roztworów o wartości fluorescencji: 2,9; 13,5; 23,0;
Zadanie 14.
Oblicz limit detekcji dla badania fluoresceiny w poprzednich zadaniach.
Zadanie 15.
Oznaczono stężenie srebra w próbkach fotograficznych za pomocą atomowej spektrometrii absorpcyjnej i otrzymano następujące wyniki:
Ilość dodanego srebra w μg
na ml badanej próbki 0 5 10 15 20 25 30
Absorbancja 0.32 0.41 0.52 0.60 0.70 0.77 0.89
Oblicz stężenie srebra w badanej próbce oraz przedział ufności z 95% poziomem ufności.

Wyszukiwarka
Podobne podstrony:
egzaminy9pyt), analityka medyczna UMP II ROK 2015, BIOCHEMIA, EGZAMIN
epid, analityka medyczna UMP II ROK 2015, higiena z epidemiologią
opr bioch Piotrek, analityka medyczna UMP II ROK 2015, BIOCHEMIA, EGZAMIN
TECHNIKI HISTOLOGICZNE, analityka medyczna UMP II ROK 2015, HISTOLOGIA, WYKŁADY
synteza vs rozkład KT, analityka medyczna UMP II ROK 2015, BIOCHEMIA, EGZAMIN
MATEUSZ ROGACKI- opracowanie na egzamin z biochemii, analityka medyczna UMP II ROK 2015, BIOCHEMIA,
KWALIFIKOWANA PIERWSZA POMOC, analityka medyczna UMP II ROK 2015, kwalifikowana pierwsza pomoc
tomek pytania, analityka medyczna UMP II ROK 2015, BIOCHEMIA, EGZAMIN
Jola, analityka medyczna UMP II ROK 2015, BIOCHEMIA, EGZAMIN
Test rok II[2], analityka medyczna UMP II ROK 2015, higiena z epidemiologią
Właściwości fizyczne, analityka medyczna UMP II ROK 2015, BIOCHEMIA, ĆWICZENIA, LIPIDY
biochem-egzam-moje opr, analityka medyczna UMP II ROK 2015, BIOCHEMIA, EGZAMIN
ula, analityka medyczna UMP II ROK 2015, BIOCHEMIA, EGZAMIN
Techniki Histologiczne 2, analityka medyczna UMP II ROK 2015, HISTOLOGIA, WYKŁADY
Okulistyka giełda 2 opracowana, Ratownictwo Medyczne UMED - II rok, okulistyka
Pytania z wejściówek, analityka medyczna UMP 2014, chemia fizyczna, ćwiczenia
pediatria 2014, Ratownictwo Medyczne UMED - II rok, pediatria
II Rok Przedsiębiorczość Analiza procesu przedsiebiorczosci na przykladzie przedsiebiorstwa
wnioski OŚ, Studia, II rok, IIIsem, analiza kumulacj metali ciezkich w organizmach
więcej podobnych podstron