SPIS TREŚCI
1.Wstęp ................................................................................................................. 3
1.1. Cel pracy .................................................................................................. 4
2.Opis środowiska pracy........................................................................................ 5
2.1. Charakterystyka firmy .............................................................................. 5
2.2. Opis organizacji......................................................................................... 6
2.3. Struktura zatrudnienia w ZE Legnica S.A................................................. 6
3. Metoda projektowania....................................................................................... 8
3.1. DFD.......................................................................................................... 8
3.2. ERD.......................................................................................................... 9
4. Pojęcia z zakresu baz danych............................................................................ 11
4.1. Wprowadzenie w temat baz danych ....................................................... 11
4.2. Modele baz danych .................................................................................. 13
4.2.1. Model hierarchiczny .................................................................... 13
4.2.2. Model sieciowy ........................................................................... 14
4.2.3. Model relacyjny ........................................................................... 14
4.2.4. Model obiektowy.......................................................................... 15
4.3. Relacyjny model danych ........................................................................... 17
4.3.1. Projektowanie relacyjnej bazy danych .......................................... 17
4.3.2. Własności relacyjnej bazy danych ................................................. 18
4.4. System zarządzania bazą danych ............................................................... 22
4.5. Język SQL .................................................................................................. 24
4.5.1. Historia SQL .................................................................................. 24
4.5.2. Główne elementy składni SQL ...................................................... 26
4.5.3. Definicja danych............................................................................. 27
5.Projekt systemu.................................................................................................... 33
6.Opis implementacji.............................................................................................. 42
6.1. Wybór narzędzia......................................................................................... 42
6.2. ASP (Active Server Pages)......................................................................... 46
6.3. Relacje występujące w systemie ............................................................... 49
6.4. Zabezpieczenia systemu ............................................................................ 49
7. Wnioski .............................................................................................................. 62
Literatura ................................................................................................................. 63
Załączniki.................................................................................................................64
1.Wstęp
„ Prawdą jest tylko to,
że wszystko wokół ulega zmianom.”
Heraklit z Efezu
Żeglując wśród zmian.... .Rzeczywistość jest z natury dynamiczna i zmienna.
Zmienność to cecha wszystkiego, co nas otacza.
Zmienia się przyroda, sztuka, architektura, technologia, zmieniają się także systemy informatyczne i ludzie. Dzięki temu świat stale idzie do przodu.
Można pozostać biernym wobec zmian, co bywa wygodne, ale sprawia, że zostaje się w tyle. Można też im dotrzymywać kroku i akceptować je. Sukces , poczucie spełnienia i jakość życia coraz częściej zależą od umiejętności odpowiedniego wykorzystania zmian oraz zachowania wobec nich koniecznej elastyczności. Czasem trzeba starać się je wyprzedzić, a kiedy indziej umieć im się poddać. Kształt rzeczywistości dnia jutrzejszego podlega zmianom i to szybkim zmianom. Coraz szybsze tempo zmian oznacza, że długość każdego modelu świata ulega skróceniu.
Środowisko zmian... .Transformacja gospodarcza w Polsce stworzyła nowe możliwości rozwoju dla wielu gałęzi produkcji i usług. W procesie dojrzewania przedsiębiorstw następują jednak zawsze takie okresy, kiedy dla kontynuacji wzrostu niezbędne stają się zmiany strukturalne.
Oznaczają one często zmianę w sposobie zarządzania, organizacji oraz konieczności wprowadzenia nowego systemu informatycznego [14].
1.1. Cel pracy
Celem pracy jest stworzenie projektu oraz komputerowej implementacji systemu umożliwiającego obsługę odbiorcy energii elektrycznej.
Pomysł niniejszej pracy dyplomowej narodził się podczas pracy jednego ze współautorów w Zakładzie Energetycznym Legnica S.A.
Część posterunków energetycznych nie posiada komputerów, wszystkie dane na temat zawartych umów są zapisane w „księdze umów ”, dlatego wyszukanie odbiorcy w księdze jest dość czasochłonne i pracochłonne.
W kolejnych rozdziałach zostanie przedstawiona:
Charakterystyka Zakładu Energetycznego - przedsiębiorstwo, dla którego tworzony jest system informatyczny,
Wybrana metodologia projektowania systemu informatycznego,
Podstawowe pojęcia z zakresu baz danych, ze szczególnym uwzględnieniem relacyjnego modelu danych i języka SQL,
Projekt systemu,
Opis implementacji,
Wnioski z realizacji projektu systemu informatycznego.
2.Opis środowiska pracy
2.1. Charakterystyka firmy
Zakład Energetyczny Legnica S.A. utworzony został w dniu 1 sierpnia 1993 roku w wyniku przekształcenia przedsiębiorstwa państwowego. Założycielem Spółki jest Skarb Państwa , w imieniu którego aktualnie działa minister właściwy do spraw Skarbu Państwa. Spółka wpisana jest pod numerem 969 do Rejestru Handlowego prowadzonego przez Wydział V Gospodarczy Sądu Rejonowego w Legnicy .
Spółka działa na obszarze Rzeczpospolitej Polskiej i za granicą . Praktycznie do końca 1999 roku zakres działania Zakładu Energetycznego ( ZE ) Legnica S.A. w Legnicy ograniczał się do terenu byłego województwa legnickiego obejmującego powierzchnię 4073 km2 .
Kapitał akcyjny Spółki wynosi : 36.866.400 zł i dzieli się na 368.664 akcji zwykłych o wartości nominalnej 100 zł każda .Właścicielem wszystkich akcji jest Skarb Państwa .
Zgodnie z wymogami ustawy - Prawo energetyczne ( Dziennik Ustaw z 1997 roku nr 54 , poz. 348 ) i wydanych na jej podstawie rozporządzeń wykonawczych , ZE Legnica S.A. uzyskał , na podstawie decyzji Prezesa Urzędu Regulacji Energetyki z dnia 16.11.1998 r. , stosowne koncesje do dnia 30.11.2008 r. na :
Przesyłanie i dystrybucje energii elektrycznej,
Obrót energią elektryczną.
2.2. Opis organizacji
Zakład Energetyczny Legnica S.A. jest nowoczesną firmą sieciową, której zadaniem jest dostarczenie klientom energii elektrycznej w każdej ilości i wszędzie tam gdzie jej potrzebują. Odbywać się to ma w bezpieczny sposób, po konkurencyjnych cenach, przy zapewnieniu właściwych parametrów, dbając o należyty rozwój Firmy oraz jej pracowników.
Ponad 50 lat pracy firmy dało wiele doświadczeń sprawdzalności stosowanych technologii w ekstremalnych warunkach na terenach nizinnych i górzystych, miejskich i wiejskich, obszarach przemysłowych i osiedlach mieszkaniowych.
Nowy styl działania firmy nakierowany jest przede wszystkim na doskonalenie jej struktur do potrzeb i wymagań klientów, na unowocześnienie infrastruktury technicznej i organizacji Spółki.
Następuje sukcesywna wymiana i modernizacja sieci oraz stacji elektroenergetycznych, wprowadzane są nowoczesne technologie zabezpieczeń dostaw energii, dzięki którym zdecydowanie poprawia się także bezpieczeństwo. Wdrożono nowoczesne środki łączności zarówno pomiędzy jednostkami organizacyjnymi, służbami i pracownikami, jak i do transmisji danych.
2.3. Struktura zatrudnienia w ZE Legnica S.A.
Struktura kadry ZE Legnica S.A. wskazuje na przewagę ludzi młodych . Przy 1036 osobach zatrudnionych na dzień 31.12.1999 r. ponad 59 % to ludzie młodzi w wieku do 40 lat . Korzystnie przedstawia się również struktura zatrudnienia wg stażu pracy . Przy 1036 zatrudnionych większość , bo aż 56,95 % pracowników posiada łączny staż pracy od 11 do 25 lat . Wśród ogółu zatrudnionych, 221 etatów przypada kobietom . Ponad połowa pracowników posiada wykształcenie średnie lub wyższe (rys.1.). Spółka przyjęła iż podstawowym warunkiem powodzenia restrukturyzacji Spółki , a także dostosowania do gospodarki rynkowej jest odpowiedni poziom umiejętności i kwalifikacji kadry pracowniczej. Podnoszenie kwalifikacji i umiejętności pracowników odbywa się w formach szkolnych oraz pozaszkolnych , do których należą kursy , seminaria , treningi i warsztaty . Potrzeby szkoleniowe są definiowane na podstawie strategii firmy i sytuacji w jej otoczeniu oraz na podstawie potrzeb pracowników . W roku 1999 na szkolenia pracowników przeznaczono 101849 zł . Przeszkolono łącznie 507 osób . W podziale na poszczególne dziedziny szkoleń , przeznaczono na nie następujące kwoty : szkolenia techniczne ponad 39 tyś. zł , szkolenia ekonomiczne - 40 tyś. zł , szkolenia z zakresu administracji , zarządzania i marketingu ponad 22 tyś. zł .
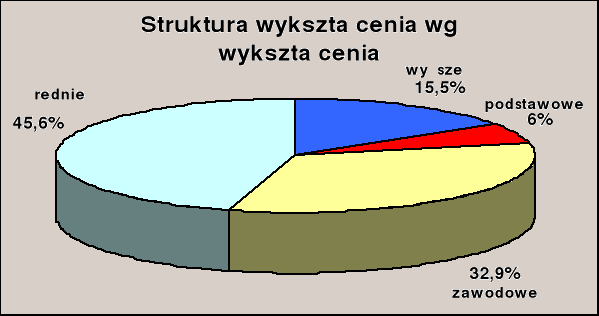
Rys. 1. Sytuacja kadrowa w Spółce
Warunkiem powodzenia restrukturyzacji Spółki, a także dostosowania do gospodarki rynkowej jest odpowiedni poziom umiejętności i kwalifikacji kadry pracowniczej. Potrzeby szkoleniowe są definiowane na podstawie strategii firmy i sytuacji w jej otoczeniu oraz na podstawie potrzeb pracowników .
Struktura organizacyjna Spółki składa się z trzech pionów wyodrębnionych i zróżnicowanych zakresem działania poszczególnych dyrektorów operacyjnych .Wprowadzone w 1999 roku zmiany organizacyjne odzwierciedlają istniejący w Spółce podział zadań poprzez podporządkowanie każdej komórce organizacyjnej właściwego zakresu obowiązków , uprawnień i odpowiedzialności .
3. Metoda projektowania
Analiza systemu jest pierwszą fazą projektowania systemu informatycznego. Na tę fazę składają się:
Sformalizowanie zbioru wymagań stawianych przed systemem,
Zdefiniowanie funkcjonalnego modelu systemu opisującego:
Interakcję systemu ze światem zewnętrznym,
Strukturę systemu,
Przepływ danych i sterowania między elementami systemu,
Abstrakcyjne struktury danych,
Dynamikę systemu.
Produktem tej fazy jest model logiczny systemu.
3.1. DFD
Diagramy przepływu danych DFD(ang.data flow diagrams) są podstawowym narzędziem reprezentacji modelu funkcjonalnego systemu. Są zbudowane z czterech podstawowych składników :
procesów (ang.processes), przepływów danych (ang.data flows), zbiorów danych (ang.stores) i obiektów zewnętrznych (ang.terminators), których oznaczenia są na poniższym rysunku.
Proces, akcja,
Przepływ danych,
Połączenie,
Pamięć,
zbiór danych,
Obiekt zewnętrzny,
element terminalny,
Rys. 2.Składniki diagramów DFD (Yourdon, DeMarco)
Proces jest podstawowym składnikiem diagramów reprezentującym element systemu przetwarzający dane wejściowe na dane wyjściowe.
Przemieszczanie się tych danych między poszczególnymi częściami systemu jest ilustrowane za pomocą przepływów danych.
Z kolei te dane, które są zebrane i zdeponowane w pewnym miejscu systemu, są przedstawiane jako zbiory danych.
Obiekty zewnętrzne reprezentują obiekty znajdujące się poza modelowanym systemem, z którymi system musi się komunikować.
Główne właściwości dotyczące diagramów DFD:
Podstawowe narzędzie opisu funkcjonalnego systemu,
Diagramy pozwalają zidentyfikować i zdefiniować przepływ danych,
Definiują miejsca przechowywania danych,
Definiują niezbędny dostęp do danych jaki jest realizowany przez użytkownika.
3.2. ERD
Diagramy relacyjne danych (ang.entity-relationship diagrams,ERD) służą do modelowania danych o złożonej strukturze, przetwarzanych przez procesy zdefiniowane za pomocą diagramów przepływu danych. Zostały one przejęte z modelu relacyjnego danych, wprowadzonego w 1976 przez Chena
i zasymilowane przez metodę Yourdona. Istnieje bardzo wiele odmian konwencji zdefiniowanych na bazie ERD.
Składniki diagramów ERD:
Rys.3. Typ obiektu
Rys.4.Symbole związków (relacji) stosowane w modelu konceptualnym (ERD)
Symbole związków (relacji) stosowane w modelu konceptualnym (ERD):
jeden do jednego (po stronie docelowej musi wystąpić element zależny);
jeden do wielu (po stronie źródłowej i docelowej nie muszą wystąpić elementy);
wiele do jednego (po stronie docelowej musi wystąpić dokładnie jeden element zależny);
- wiele do wielu (po stronie źródłowej i docelowej nie muszą wystąpić odpowiadające sobie elementy).
Typ obiektu jest klasą abstrakcji zbioru pewnych obiektów, tzn. definiuje zbiór cech charakterystycznych, wspólnych dla zbioru tych obiektów.
Relacje są używane do definiowania powiązań między typami. Bardzo często na diagramach relacyjnych zaznaczane również tzw. stopień relacji, określający, ile obiektów należących do każdego z typów wchodzi w daną relację [2]
4. Pojęcia z zakresu baz danych
4.1. Wprowadzenie w temat baz danych
Baza danych to model pewnego aspektu rzeczywistości danej organizacji.
Tę rzeczywistość nazywamy obszarem analizy (OA). Obiekty istotne dla obszaru analizy nazywamy klasami lub encjami. Klasy mają właściwości lub atrybuty.
Bazę danych możemy uważać za zbiór danych, których zadaniem jest reprezentowanie pewnego OA. Dane to fakty. Dana, jednostka danych, jest jednym symbolem lub zbiorem symbol, którego używamy, aby reprezentować jakąś rzecz. Fakty same w sobie nie mają znaczenia. Aby były użyteczne, muszą być zinterpretowane. Zinterpretowane dane to informacje. Informacje to dane umieszczone w kontekście nadającym im znaczenie. Informacja to dane z przypisaną im semantyką - znaczeniem.
Bazę danych możemy uważać za zbiór faktów lub pozytywnych asercji na temat obszaru analizy. Zazwyczaj fakty negatywne nie są przechowywane. Dlatego bazy danych stanowią „zamknięte światy”, w których tylko to, co jest jawnie reprezentowane, jest uważane za prawdziwe.
Mówimy, że w określonej chwili baza danych znajduje się w pewnym stanie. Stan oznacza zbiór faktów, które są prawdziwe w danej chwili. W związku z tym system baz danych możemy uważać za bazę faktów, która zmienia się w czasie.
Dane w bazie danych są traktowane jako trwałe. Przez trwałość rozumiemy, że dane są przechowywane przez pewien czas. Ten czas nie musi być bardzo długi. Termin trwałość jest używany do rozróżnienia bardziej trwałych danych od danych które są tymczasowe.
Baza danych składa się z dwóch części: intensjonalnej i ekstensjonalnej. Część intensjonalna bazy danych jest zbiorem definicji, które opisują strukturę danych bazy danych. Część ekstensjonalna bazy danych jest łącznym zbiorem danych w bazie danych. Część intensjonalną bazy danych nazywamy schematem bazy danych. Tworzenie schematu bazy danych nazywamy projektowaniem bazy danych.
Właściwość integralności bazy danych oznacza, że jest ona dokładnym odbiciem swojego obszaru analizy. Proces zapewnienia integralności jest główną cechą nowoczesnych systemów informacyjnych. Integralność jest ważną sprawą ponieważ większość baz danych jest projektowana z myślą o zmianach zachodzących w trakcie ich używania. Baza danych przechodzi przez ciąg zmian stanów, spowodowanych zarówno przez zdarzenia zewnętrzne jak i wewnętrzne. W zbiorze możliwych, przyszłych stanów bazy danych niektóre są poprawne, a niektóre nie. Każdy poprawny stan stanowi zawartość bazy danych w danej chwili. Integralność jest procesem zapewniającym, że baza danych zmienia się w przestrzeni, określonej przez stany poprawne. Integralność jest związana z określeniem, czy przejście do kolejnego stanu jest poprawne.
Bazy danych są projektowane tak, aby zminimalizować powtarzanie się danych. W bazie danych staramy się przechowywać tylko jeden element danych na temat obiektów lub związków między obiektami z naszego obszaru analizy. Idealna baza danych powinna być magazynem bez powtarzających się faktów.
Zdarzenia, które powodują zmianę stanu są w terminologii baz danych nazywane transakcjami. Nowy stan jest wprowadzany przez stwierdzenie faktów, które stają się prawdziwe, i/lub przez zaprzeczenie faktów, które przestają być prawdziwe.
Integralność bazy danych jest realizowana przez więzy integralności. Więzy integralności to reguła, która określa, w jaki sposób baza danych ma pozostać dokładnym odbiciem swojego obszaru analizy. Więzy dzielimy na dwa główne typy: więzy statyczne i więzy przejść. Więzów statycznych, nazywanych także „niezmiennikiem stanów”, używamy do sprawdzania, czy wykonana transakcja nie zmienia stanu bazy danych w stan niepoprawny. Więzy statyczne to ograniczenie określone na bazie danych. Więzy przejść są to reguły, które wiążą ze sobą stany bazy danych. Przejście jest zmianą stanu i dlatego może być reprezentowane przez parę stanów. Więzy przejść są ograniczeniem nałożonym na przejście.
Większość danych jest przechowywana w bazie danych po to, aby spełnić pewne potrzeby związane z organizacją firmy. Do wykonania operacji na bazie danych są potrzebne dwa rodzaje funkcji: aktualizujące i zapytań. Funkcje aktualizujące dokonują zmian na danych. Funkcje zapytań wydobywają dane z bazy danych.
Transakcja jest funkcją aktualizującą. Zmienia ona bazę danych z jednego stanu w drugi. Pojęcia funkcji aktualizującej i więzów integralności są ze sobą powiązane. Z funkcją aktualizującą jest zwykle związany ciąg warunków. Warunki te reprezentują więzy integralności. Z funkcją aktualizującą jest także związany ciąg akcji. Określają one, co powinno się zdarzyć, jeśli warunki będą prawdziwe.
Drugim podstawowym typem funkcji bazy danych jest funkcja zapytania. Nie modyfikuje ona w żaden sposób bazy danych, ale jest używana głównie do sprawdzania, czy pewien fakt lub grupa faktów jest spełniona w danym stanie bazy danych. Najprostsza postać funkcji zapytania jest wewnętrznie powiązana z danym faktem. Używamy takiej funkcji, aby sprawdzić, czy dany fakt zachodzi w naszej bazie danych. Większość jednak używanych zapytań do baz danych zwraca zakres lub zbiór wartości, a nie tylko prawdę lub fałsz [4,5,9].
4.2. Modele baz danych
Każdy system bazy danych musi używać jakiegoś formalizmu reprezentacji („zbiór składniowych i semantycznych konwencji, które umożliwiają opisywanie rzeczy”). Składnia reprezentacji określa zbiór reguł łączenia symboli i układów symboli w celu tworzenia wyrażeń w formalizmie reprezentacji. Semantyka reprezentacji określa, w jaki sposób takie wyrażenia mają być interpretowane, to znaczy, w jaki sposób wyprowadza się ich znaczenie. W terminologii baz danych idea formalizmu reprezentacji odpowiada pojęciu modelu danych. Model danych dostarcza twórcom baz danych zbioru reguł, za pomocą których mogą skonstruować system bazy danych.
4.2.1. Model hierarchiczny
Cechy podstawowe:
struktura danych ma postać drzewa,
węzły -- typy opisywanych obiektów,
łuki -- związki typu ojciec-syn,
drzewo jest uporządkowane, tj. na każdym poziomie kolejność węzłów jest określona,
opis obiektu (rekord) zbudowany z pól zawierających dane opisujące obiekt,
związki zrealizowane jako wskaźniki.
Ograniczenia:
nie ma związków typu n-m ,
tylko jeden rodzaj związku między dwoma typami obiektów,
dodatkowe związki,
dodatkowe drzewa hierarchii,
odsyłacze do rekordów "oryginału".
Znaczenie praktyczne:
system IBM IMS (1978) ,
bardzo wielkie dane zgromadzone,
poprzednik użyty w programie Apollo,
nowych projektów nie robi się.
4.2.2. Model sieciowy
Cechy podstawowe:
struktura danych ma postać grafu (sieci),
wierzchołki grafu -- typy obiektów,
łuki w grafie -- wiązania między typami,
opis obiektu (rekord) zbudowany z pól zawierających dane opisujące obiekt,
reprezentacja wiązań (wskaźniki):
odesłanie bezpośrednie (jednowart.),
odesłanie inwersyjne (wielowart.),
wiązanie codasylowe.
4.2.3. Model relacyjny
Cechy podstawowe:
dane zawarte w tabelach,
tabele składają się z kolumn,
liczba kolumn i typy - stałe,
liczba wierszy zmienna,
wiersze nie mają tożsamości innej niż wynikająca z zawartości kolumn,
związki pomiędzy wierszami tabel -- zdefiniowane poprzez zależności między wartościami wybranych kolumn, tzw. kluczy (nie ma wskaźników),
z punktu widzenia teorii model można opisać algebrą relacji między zbiorami atrybutów.
Języki obsługi:
nieproceduralne: SQL, Sequel, QUEL, QBE,
proceduralne: xBase.
Znaczenie praktyczne:
model dominujący w zastosowaniach komercyjnych,
przykłady SZBD: Oracle, Informix, Sybase, Ingres, DB2, Progress, Gupta, Access, dBase, Paradox.
Ograniczenia:
brak bezpośredniej reprezentacji związków n-m,
dla trudniejszych problemów -- bardzo wiele tabel,
mało naturalna reprezentacja danych,
ograniczona podatność na zmiany,
trudne operowanie na złożonych obiektach -- dane rozproszone w wielu tabelach,
brak złożonych typów danych,
model mało wygodny dla zastosowań CAD, GIS itp.
4.2.4. Model obiektowy
Cechy podstawowe:
obiekt w bazie reprezentuje obiekt w świecie zewnętrznym,
typ obiektowy (klasa):
definicja złożonego typu danych (może zawierać inne typy obiektowe lub ich kolekcje),
procedury (metody) i operatory do manipulowania tymi danymi,
tożsamość obiektu jest niezależna od zawartości danych,
dziedziczenie (ang.inheritance):
strukturalne: potomek dziedziczy strukturę danych,
behawioralne: potomek dziedziczy metody i operatory.
Cechy dodatkowe:
enkapsulacja: wnętrze obiektu dostępne jedynie w sposób w nim zdefiniowany,
polimorfizm: tak samo nazwane metody i operatory działają swoiście w zależności od klasy obiektu.
Zalety modelu:
dość naturalna reprezentacja świata,
łatwość działania na złożonych obiektach,
duża podatność na zmiany.
Znaczenie praktyczne:
w zastosowaniach naukowych lub eksperymentalnych,
przykłady systemów: GemStone, O2,
przewidywana ewolucja baz relacyjnych w kierunku obiektowo-relacyjnych[11].
4.3. Relacyjny model danych
Do realizacji naszego projektu wybraliśmy relacyjny model danych.
Relacyjny model danych jest najpopularniejszym z modeli używanych do organizowania i zarządzania elementami danych. Większość oprogramowania mikrokomputerowego przeznaczonego do zarządzania bazami danych jest zaprojektowana zgodnie z tym modelem. Jednym z powodów popularności tego modelu jest to że, jest on łatwy do zrozumienia i prosty do zastosowania. Może on być stosowany do strukturalizacji relacji typu jedno-jedno, jedno-wiele oraz wiele-wiele. Mając poprawnie określoną strukturę bazy danych, można z łatwością operować elementami danych. Odnajdywanie pożądanych informacji staje się bardzo szybkie, jeśli wszystkie powiązania i relacje pomiędzy obiektami danych zostały uwzględnione.
4.3.1. Projektowanie relacyjnej bazy danych
Użyteczność i siła bazy danych zależy w znacznej mierze od tego, w jaki sposób zdefiniowano tabele danych opisujące obiekty danych i ich wzajemne relacje. Poprawnie zrestrukturalizowana baza danych pozwala na szybki i łatwy dostęp do wszelkich potrzebnych informacji poprzez odtwarzanie powiązanych elementów danych z bazy danych. Lecz jeśli nie zdefiniuje się poprawnie struktury bazy, to okaże się, że zarządzanie bazą danych jest bardzo trudne, jeśli nie niemożliwe. Zatem, zawsze opłaca się poświęcić trochę czasu na zaplanowanie sposobu organizacji tablic danych i określenie powiązań koniecznych do opisu relacji pomiędzy elementami danych w przyszłości.
Projektowanie bazy danych należy zacząć od przestudiowania istoty przedmiotu bazy danych i przemyślenia, jakiego typu elementy danych składają się na opis organizacji tego przedmiotu. Przewidywanie potrzebnych typów informacji pomaga określić postać elementów danych, które mają być przechowywane w bazie danych. Pracując nad naszym przykładem, należy rozważyć, czy w pewnym momencie może okazać się potrzebne utworzenie raportu uzupełniającego na temat wynagrodzeń osób zatrudnionych przy sprzedaży w danym regionie sprzedaży. Do tego celu potrzebne będą elementy danych opisujące stawki wynagrodzeń oraz regiony, do których są one przypisane. Z drugiej strony, do wygenerowania faktur potrzebne są elementy danych opisujące każdą z transakcji sprzedaży: numer faktury, nazwisko i adres klienta, któremu sprzedano towar, opis towaru, jego cena, jakość itp.
Kiedy już określono, jakie elementy danych będą potrzebne, kolejnym krokiem jest ich logiczne zorganizowanie. Aby to zrobić, należy spróbować pogrupować elementy związane z poszczególnymi obiektami danych w pojedyncze tabele danych. Należy uwzględnić wszystkie elementy danych opisujące, na przykład, sprzedawców w tabeli Sprzedawcy. Każda z własności jest z kolei opisywana przez pojedynczy element danych w polu danych.
Po utworzeniu wszystkich potrzebnych tablic danych do przechowywania elementów danych związanych z obiektami danych, należy utworzyć tabele relacji opisujące powiązania pomiędzy elementami danych z różnych tablic danych. Liczba relacyjnych tablic danych jest określona przez złożoność relacji pomiędzy tablicami danych. Na ogół nie jest konieczne tworzenie żadnych tablic relacyjnych do opisu relacji jedno-jedno i jedno-wiele; są one niezbędne do operowania relacjami wiele-wiele.
4.3.2. Własności relacyjnej bazy danych
Projektowanie bazy danych może być procesem złożonym, szczególnie, jeśli ma ona wiele tablic danych i uwzględnia dużą liczbę relacji wiele-wiele. Wiele użytecznych baz danych ma jednak małą liczbę prostych tablic danych z kilkoma tylko relacyjnymi tablicami danych opisującymi powiązania. Jeśli zrozumiałe są podstawowe zasady relacyjnej bazy danych, to rozumienie bardziej złożonych baz danych przyjdzie samo wraz z doświadczeniem.
Niezależnie od wielkości i złożoności relacyjnej bazy danych, musi ona cechować się pewnymi własnościami. Implementacja tych własności ma kluczowe znaczenie dla uniknięcia powtórzeń elementów danych i poprawnego ich powiązania. Te istotne własności mogą być sformułowane w następujący sposób:
-wszystkie elementy danych muszą być zorganizowane w tabele;
-elementy danych w pojedynczej tabeli muszą pozostawać w relacji jedno-jedno;
-w tabeli danych nie mogą występować powtórzenia tych samych wierszy;
-w tabeli danych nie mogą występować powtórzenia tych samych kolumn;
-w każdej komórce danych może być przechowywany tylko jeden element danych.
Pierwszą i podstawową cechą relacyjnej bazy danych jest to, że elementy danych związane z unikalnym obiektem danych muszą być zorganizowane w formie tablic, jak to miało miejsce we wcześniejszych przykładach. Tablica danych jest podstawową jednostką relacyjnej bazy danych. Każda tablica może zawierać dowolną liczbę wierszy (rekordów) i kolumn (pól). Liczba i kolejność kolumn, jak również wierszy, nie jest istotna.
Brak powtarzających się wierszy
W poprawnie zrestrukturalizowanej bazie danych nie może występować dwa lub więcej wierszy z identycznymi elementami danych. Powtarzające się wiersze nie tylko stanowią marnotrawstwo przestrzeni przechowywania danych, lecz przede wszystkim zwalniają proces przetwarzania danych poprzez nieuzasadnioną rozbudowę tablicy.
Inne pożądane cechy
Wspomnieliśmy o kilku podstawowych wymogach, jakie muszą zostać spełnione przy poprawnym projektowaniu relacyjnej bazy danych. Można je podsumować następująco:
-planuj dobrze i z wyprzedzeniem potrzeby związane z danymi ; -wyprzedzaj potrzeby informacyjne i przechowuj jedynie niezbędne dane; -grupuj elementy danych logicznie w kolumny; wykorzystuj tablice do przechowywania elementów danych i relacji pomiędzy nimi; -nie pozwalaj na dublowanie się wierszy w żadnej z tablic;
-umieszczaj tylko jedną wartość danych w jednej komórce;
-unikaj pustych komórek, jeśli to tylko możliwe.
Dodatkowo, istnieją jeszcze inne pożądane cechy, które dobrze jest wbudować w swoją bazę danych. Można je ująć następująco:
-twórz elastyczne struktury baz danych, aby móc wprowadzać zmiany; -utrzymuj minimalną liczbę powtórzeń w danych;
-utrzymuj tablice w stanie logicznie poindeksowanym; -utrzymuj tablice danych w stanie maksymalnej prostoty.
Relacyjne bazy danych są obecnie najczęściej używanymi bazami danych, których opracowanie rozwiązało wiele problemów występujących wcześniej w nierelacyjnych bazach danych takich jak wymaganie od programistów i administratorów szczegółowej wiedzy na temat rozmieszczenia danych i struktury bazy co znacznie utrudniało rozbudowę i modyfikację aplikacji. Natomiast relacyjne bazy danych pozwalają na pracę z danymi na wyższym poziomie, gdyż wszystkie operacje na danych są wykonywane za pomocą programu Systemu Zarządzania Bazą Danych DBMS (ang.Database Managment System)[9].
Model relacyjnej bazy danych został opracowany na początku lat siedemdziesiątych przez Amerykanina E.F. Codda, który przy jego tworzeniu oparł się na matematycznej teorii relacji i zbiorów. Na podstawie modelu opracowanego przez siebie E.F. Codd zdefiniował 12 reguł, które od jego nazwiska zostały nazwane Dwunastoma Regułami Codda. Reguły te służą jako wytyczne i podstawa do oceny relacyjności danej bazy danych [11].
A o to dwanaście Reguł Codda:
1. Reguła Informacyjna. Wszystkie informacje znajdujące się w bazie danych muszą być przedstawione w postaci tabel, które zorganizowane są w wiersze i kolumny.
2. Reguła Gwarantowanego Dostępu. Wszystkie rekordy w tabeli muszą być zdolne do wyszukiwania za pomocą unikalnego klucza. Reguła ta jest wynikiem własności klucza głównego, która mówi, że każdy rekord musi mieć unikalny klucz główny.
3. Reguła Systematycznego Traktowania Wartości Pustych. System bazy danych musi rozpoznać wartość pustą jako "wartość nieznana" albo "nieodpowiednia informacja". Wartość pusta jest różna od zera albo spacji i jest manipulowana przez System Zarządzania Bazą Danych w sposób systematyczny.
4. Reguła Organizacji Dostępu w Modelu Relacyjnym. System bazy danych musi wykorzystywać bezpośredni, wbudowany, katalog relacji, który jest dostępny do autoryzacji użytkowników za pomocą ich regularnego języka zapytań.
5. Reguła Danych Zbiorczych Podjęzyka. System musi wspierać co najmniej jeden język relacyjny, który ma następującą charakterystykę :
a) Używa linearnej składni.
b) Może być używany zarówno interaktywnie jak i w stosowanych programach.
c) Popiera definicje danych działania, manipulacji, bezpieczeństwa, i integralności kontroli.
6. Reguła Przeglądania Modyfikacji. Wszystkie modyfikacje działające na widokach muszą być zdolne do wykonania przez System Zarządzania Bazą Danych.
7. Reguła Wysokiego Poziomu Wstawiania, Aktualizacji i Usuwania. System musi wspierać zespół jednoczesnych działań takich jak wstawianie, aktualizacja i usuwanie danych.
8. Reguła Fizycznej Niezależności Danych. System Zarządzania Bazą Danych musi działać niezależnie od fizycznego systemu zarządzania danymi. Użytkownik nie musi posiadać wiedzy na temat fizycznej organizacji systemu plików.
9. Reguła Logicznej Niezależności Danych. Modyfikacje w logicznej strukturze bazy danych mogą być wykonywane bez wylogowywania istniejących użytkowników czy zamykania istniejących programów.
10. Reguła Niezależności Integralności. Ograniczenie integralność musi być określone oddzielnie dla programów i dla przechowywanych danych. Musi być możliwe zachowanie tych ograniczeń bez naruszania integralności aplikacji tzn. integralność musi być cechą bazy danych, a nie aplikacji.
11. Reguła Niezależności Dystrybucji. Istniejące programy powinny kontynuować pomyślne działanie w następujących okolicznościach :
a) Zastąpienia rozproszonego Systemu Zarządzania Bazą Danych,
b) Dokonywana jest dystrybucja danych po całej sieci.
12. Reguła Braku Podwersji. Dostęp na niskim poziomie albo na poziomie rekordu nie może być zdolny do obalenia system przez ominięcie relacyjnego bezpieczeństwa lub ograniczenie integralności.
4.4. System zarządzania bazą danych
System zarządzania bazą danych (SZBD) jest zorganizowanym zbiorem narzędzi umożliwiającym dostęp i zarządzanie jedną lub więcej bazami danych. SZBD jest powłoką, która otacza bazę danych i za pomocą której dokonują się wszystkie operacje na bazie danych. Funkcje realizowane przez większość SZBD zaliczamy do trzech grup:
1.Zarządzanie plikami:
dodawanie nowych plików do bazy danych,
usuwanie plików z bazy danych,
modyfikowanie struktury istniejących plików,
wstawianie nowych danych do istniejących plików,
aktualizowanie danych w istniejących plikach,
usuwanie danych z istniejących plików.
2.Wyszukiwanie informacji:
wydobywanie danych z istniejących plików do stosowania przez użytkowników,
wydobywanie danych do stosowania przez programy użytkowe.
3.Zarządzanie bazą danych:
tworzenie i monitorowanie użytkowników bazy danych,
ograniczanie dostępu do plików w bazie danych,
monitorowania działania bazy danych.
W kontekście SZBD (rys.5) należy rozróżnić pojęcie jądra systemu i zestawu narzędzi. Przez jądro SZBD rozumiemy centralną część systemu, która realizuje funkcje wymienione powyżej, jak również zarządza innymi, podstawowymi operacjami, takimi jak współdzielenie danych między wieloma użytkownikami. Przez zestaw narzędzi SZBD rozumiemy duży zestaw narzędzi, które albo są wbudowane jako część SZBD, albo są dostarczane przez producentów, na przykład arkusze kalkulacyjne, języki czwartej generacji, programy monitorowania działania itp. Między jądrem a zestawem narzędzi musi być określony specjalny interfejs. Interfejs jest językiem, który łączy narzędzie z funkcjami jądra.
Rys.5. System zarządzania bazą danych [1]
System zarządzania bazami danych jest systemem umożliwiającym przechowywanie i wyszukiwanie informacji w bazie danych.
Skomputeryzowany system zarządzania bazą danych można wykorzystać do gromadzenia i wyszukiwania danych w komputerze[1].
.4.5. Język SQL
SQL (strukturalny język zapytań - ang.Structured Query Language) był pierwotnie zaprojektowany jako język zapytań, mający podstawę w rachunku relacyjnym. Obecna specyfikacja SQL jest jednak czymś więcej niż tylko językiem zapytań. Język baz danych to o wiele trafniejsze określenie tego języka. Jako język baz danych SQL staje się standardowym interfejsem dla relacyjnych i nie relacyjnych SZBD.
4.5.1. Historia SQL
Koncepcja leżąca u podstaw języka SQL powstała w wyniku prac prowadzonych w laboratorium badawczym IBM w San Jose w Kalifornii w latach siedemdziesiątych. Tam też została zbudowana implementacja prototypowa relacyjnych pojęć o nazwie System/R. Ten wczesny relacyjny SZBD używał języka znanego wówczas jako SEQUEL. Dlatego właśnie wiele osób wciąż wymawia nazwę SQL jak SEQUEL.
W latach 1973-1979 badacze z IBM opublikowali w akademickich czasopismach dużo materiałów na temat budowy System/R. W tym czasie zarówno w USA, jak i w Europie na konferencjach i seminariach prowadzono ożywione dyskusje na temat poprawności relacyjnego SZBD. IBM okazał się niewątpliwie nadzwyczaj powolny w dostrzeżeniu komercyjnego znaczenia systemów relacyjnych. Pierwsze pomyślne, komercyjne wykorzystanie idei związanych z relacyjnym modelem danych przypadło korporacji ORACLE, założonej w 1977 r.
System ORACLE był i jest relacyjnym SZBD opartym na SQL. Wielu innych producentów również wyprodukowało systemy używające SQL. Z tego powodu w 1982 r. organizacja ANSI (ang.American National Standards Committee) przekazała swojemu komitetowi baz danych (X3H2) sprawę utworzenia standardu języka relacyjnych baz danych (RDL). Komitet ten opublikował definicję składni standardu SQL w 1986 r., opartą głównie na dwóch dialektach SQL IBM i ORACLE (ANSI, 1986). W 1987 r. organizacja ISO (ang.International Standards Organization) opublikowała bardzo podobny standard (ISO, 1987). Ten standard jest również znany pod nazwą SQLI. Oryginalny dokument ANSI określa dwa poziomy dla SQLl: poziom pierwszy i poziom drugi. Poziom drugi jest pełnym językiem SQL. Poziom pierwszy, którego pierwotnym założeniem było pełnienie funkcji przecięcia dla istniejących implementacji, jest podzbiorem poziomu drugiego.
W następstwie powyższych publikacji pojawiło się wiele krytycznych uwag na temat standardu ANSI/ISO, zwłaszcza ze strony specjalistów w dziedzinie baz danych, takich jak E. F. Codd (1988a, 1988b) i C. Dale (1987). Wiele osób uważało, że wadą standardu jest fakt, że jest on częścią wspólną istniejących aplikacji. Inni uważali, że język ma poważniejsze wady, zwłaszcza w zakresie relacyjnych konstrukcji.
W 1989 r. w odpowiedzi na krytykę ANSI opublikowała dodatek do standardu, zawierający głównie ulepszenia cech integralności (ANSI, 1989a). Duża część tego dodatku została włączona do roboczej wersji proponowanej drugiej wersji standardu, również wydanego przez ANSI w 1989 r. (ANSI, 1989b). ISO, blisko współpracując z ANSI, wydała w tym samym roku dokument zatytułowany "Database Language SQL with Integrity Enhancement" (ISO, 1989).
W 1992 r. ANSI i ISO wydały pełną specyfikację rozszerzonej wersji SQL, znanej jako SQL2. Dla tego standardu określono dwa podzbiory: poziom minimalny i poziom pośredni. Poziom minimalny SQL2 jest w zasadzie taki sam jak SQL1 z udoskonalonymi cechami integralności. Uzgodniono już kolejne istotne rozszerzenia standardu SQL2 i oczekując na pojawienia się wersji standardu o nazwie SQL3 pod koniec lat dziewięćdziesiątych.
Nie ma zatem jednego standardu, a przynajmniej trzy. Oznacza to, że jakakolwiek implementacja SQL może realizować wszystkie lub część z tych trzech wersji standardu. Jest to jeden z powodów, dla których większość implementacji komercyjnych uważa się w najlepszym razie za dialekty standardu SQL. Innymi słowy, pod wieloma względami znajdują one wspólny grunt wokół definicji podstaw lub poziomu jeden standardu SQLl. Pod innymi względami różnią się one nie dostosowując się ani do SQLI, ani do późniejszych standardów (typy danych są tu dobrym przykładem). Niektóre implementacje oferują dodatkowe konstrukcje nie uwzględnione w standardzie.
Funkcjonowanie współczesnych systemów relacyjnych baz danych oparte jest głównie na języku SQL (ang.Structured Query Language, strukturalny język zapytań). SQL został pierwotnie zaprojektowany jako język do formułowania zapytań, oparty na rachunku relacyjnym. Obecnie jest on jednak uniwersalnym interfejsem do większości systemów zarządzania bazami danych, tj. wszelkie operacje dotyczące definicji danych, dostępu do danych i ich modyfikacji, jak również zazwyczaj czynności administracyjne, odbywają się poprzez komendy i programy zapisywane w SQL.
Istnieje szereg standardów normujących postać języka SQL: m. in. normy ANSI i ISO (1986-87) z uzupełnieniami z 1989 r. (tzw. SQL1), specyfikacja SQL2 z 1992 r.; kolejna specyfikacja (SQL3) znajduje się obecnie w opracowaniu. Co gorsza, większość implementacji nie trzyma się ściśle żadnej z tych norm, zarazem pomijając pewne elementy specyfikacji, jak i oferując niestandardowe rozszerzenia. Inny obecnie popularny ,,standard'' to ODBC (ang.Open DataBase Connectivity), propagowany przez Microsoft. Jego praktyczne znaczenie polega głównie na umożliwianiu wykorzystywania programu Access jako interfejsu do RDBMS, za pośrednictwem tzw. sterowników (ang.drivers) ODBC, pośredniczących w komunikacji pomiędzy Access'em a RDBMS. Sterowniki takie istnieją prawdopodobnie dla wszystkich popularniejszych RDBMS.
4.5.2. Główne elementy składni SQL
Zasady ogólne
Każda komenda SQL kończy się średnikiem (;) i może składać się z wielu linii tekstu;
Wartości napisowe podaje się tak: "napis", lub tak: 'napis'. Znaki "%" i "_" są metaznakami, służącymi do tworzenia wzorców do porównań; oznaczają odpowiednio dowolny ciąg znaków i dowolny jeden znak. Aby zostały przekazane dosłownie, należy je poprzedzać metaznakiem "\". Dotyczy to również szeregu znaków kontrolnych;
Wartości liczbowe zapisuje się w ,,zwykły'' sposób, ew. z kropką dziesiętną lub w notacji wykładniczej (np. -32032.6809e+10) gdy chodzi o wartości zmiennoprzecinkowe.
4.5.3. Definicja danych
Do utworzenia tabeli służy instrukcja CREATE TABLE, wymagająca podania nazwy tworzonej tabeli, nazwy każdej kolumny w tej tabeli, typu danych kolumn oraz maksymalnej długości danych w kolumnie.
W MySQL większość typów danych ma domyślne lub ustalone (DATE, TIME, YEAR, ...) długości lub długości maksymalne (TEXT, BLOB, ...), parametr długości można więc często pominąć.
Składnia polecenia (w uproszczeniu) jest następująca:
CREATE TABLE nazwa_tabeli
(nazwa_kolumny typ_danych[(długość) opcje],
... nazwa_kolumny typ_danych[(długość) opcje]) [opcje_tabeli]
(nawiasami kwadratowymi obejmujemy elementy opcjonalne).
Opcje które mogą wystąpić po określeniu typu i długości danych to np. NULL, NOT NULL, PRIMARY KEY, UNIQUE, DEFAULT wartość_domyślna.
Typy danych
Standard ISO SQL (1992) przewiduje około piętnastu typów danych, podzielonych na grupy:
Typy napisowe (String): np. CHAR(N), VARCHAR(N). CHAR(N) definiuje pole napisowe o stałej długości (ew. uzupełniane spacjami), podczas gdy VARCHAR(N) jest polem o zmiennej długości nie przekraczającej N.
Typy liczbowe (Numeric): np. INT, BIGINT, FLOAT, DECIMAL. Na ogół dostępnych jest wiele różnych typów liczbowych, różniących się możliwym zakresem wartości (INT, BIGINT, SMALLINT, ...) i precyzją (FLOAT, DOUBLE PRECISION, ...). Typ DECIMAL(M,D) to liczba (ułamek) dziesiętny o ustalonej liczbie cyfr dziesiętnych w części całkowitej i ułamkowej.
Typy daty i godziny (Datetime): np. DATE, TIME, TIMESTAMP.
Interval: typ opisujący przedział czasu. W MySQL nie występuje.
Brak precyzji w powyższym opisie jest poniekąd celowy: poszczególne DBMS różnią się dość znacznie co do realizowanych typów danych (choć wymienione jako przykłady pojawiają się chyba zawsze). Większość implementacji (w tym MySQL) oferuje ponadto typy w rodzaju TEXT i BLOB, służące do przechowywania danych odp. tekstowych i binarnych o zmiennej długości (która może być całkiem duża), oraz ich odmiany (TINYTEXT, MEDIUMTEXT, LONGTEXT, TINYBLOB, MEDIUMBLOB, LONGBLOB) różniące się limitem długości (nie dopuszczają one dodatkowego określenia długości i przechowują informację o długości faktycznie wprowadzonych danych; typ VARCHAR jest w MySQL ograniczony do maksymalnej długości 255). Innym częstym rozszerzeniem repertuaru typów są (np. w MySQL) ENUM i SET; są to typy napisowe przyjmujące jedną lub odpowiednio kilka spośród z góry określonych (w definicji typu kolumny) wartości.
Bogactwo dostępnych typów danych i możliwość określania długości należy wykorzystywać do optymalizowania definicji tabeli pod kątem zużycia miejsca i do kontroli integralności wprowadzanych (bądź wynikających z operacji na danych) wartości.
Ogólnie można powiedzieć, że we wcześniejszych Systemach Zarządzania Bazami Danych często były stosowane różne języki do obsługi bazy danych, a język SQL łączy je w jedno dzięki czemu dobrze zaprojektowana baza danych zapewnia szybki i wygodny dostęp do potrzebnych informacji z bazy danych. Język SQL oparty jest na wyrażeniach języka angielskiego i dlatego w rozkazach SQL-a występują takie słowa angielskie jak : select (wybierz), insert (wstaw), delete (usuń). SQL jest językiem deklaratywnym wymagającym określenia co należy wykonać, a nie w jaki sposób. Innymi słowy w SQL-u nie trzeba podawać metody dostępu do danych, a optymalizator zapytań będący częścią Systemu Zarządzania Bazą Danych wybiera najefektywniejszą drogę realizacji polecenia przez co umożliwia skoncentrowanie się na sformułowaniu celu polecenia i sprawia, że programowanie jest łatwiejsze. SQL pracuje na zbiorach wierszy, a nie na indywidualnych rekordach. Najczęściej spotykanym zbiorem rekordów jest tabela. SQL jest językiem używanym zarówno przez administratorów bazy danych jak i przez programistów aplikacji, kierownictwo czy końcowych użytkowników.
SQL jest językiem poleceń służącym do :
wybierania danych,
wstawiania, modyfikowania, usuwania wierszy z tabel,
tworzenia modyfikowania, usuwania obiektów bazy danych,
zarządzania prawami dostępu do bazy danych i do obiektów bazy danych,
zagwarantowania spójności danych.
Język SQL jest używany na trzy sposoby :
Interaktywny lub samodzielny SQL jest używany do wprowadzania danych do bazy danych albo wyszukiwania danych w bazie danych. Na przykład użytkownik może poprosić o listę aktywnych kont w bieżącym miesiącu, a wynik może być wysłany na ekran, skierowany do pliku albo wydrukowany.
Statyczny SQL jest to stały kod SQL-a napisany przed wykonaniem programu. Są dwie wersje statycznego SQL-a. Pierwsza wersja to zanurzony SQL, w którym kod SQL-a znajduje się w źródłowym programie innego języka. Większość tych aplikacji jest napisana w językach C lub COBOL, natomiast odwoływania do bazy danych są w SQL-u. Druga wersja statycznego SQL-a to język modułowy.
Dynamiczny SQL jest to kod SQL-a generowany przez aplikację w czasie jej wykonywania się. Jest używany zamiast statycznego SQL-a, gdy potrzebny kod nie może być określony podczas pisania programu, ponieważ zależy on od wyboru użytkownika. Ten rodzaj kodu SQL-a jest często generowany w odpowiedzi na działania użytkownika za pomocą takich narzędzi jak np. graficzne języki zapytań.
Komendy SQL-a można podzielić według funkcji na :
Queries (Zapytania) - w skład tej grupy wchodzi tylko jedna komenda : SELECT. Pozwala ona wybierać informacje z bazy danych i nie ma wpływu na przebieg transakcji.
DML - Data Manipulation Language (Język Manipulacji Danymi) - w skład tej grupy wchodzą komendy : INSERT, UPDATE, DELETE, które pozwalaj wstawiać nowe dane oraz poprawiać i usuwać istniejące informacje.
DDL - Data Definition Language (Język Definicji Danych) - w skład tej grupy wchodzą komendy : CREATE, ALTER, DROP, TRUNCATE, które pozwalają definiować obiekty bazy danych (struktury danych), tworzą transakcje jednoelementowe .
DCL - Data Control Language (Język Kontroli Danych) - w skład tej grupy wchodzą komendy : GRANT, REVOKE, AUDIT, które służą do nadawania, odbierania i kontrolowania praw dostępu do danych, tworzą transakcje jednoelementowe.
Transaction Control (Kontrola Transakcji) - w skład tej grupy wchodzą komendy : COMMIT, ROLLBACK, SAVEPOINT, które sterują transakcją złożoną z poleceń DML.
Relacyjne bazy danych i standard SQL-a oparte są na kilku prostych zasadach :
Wszystkie wartości danych są typów prostych. W przeciwieństwie do innych znanych języków programowania, w SQL-u nie ma tablic, wskaźników, wektorów i innych złożonych typów.
Wszystkie dane są zapisane w dwuwymiarowej tablicy (ang.table), która składa się z wierszy (ang.rows) oraz z kolumn (ang.columns). Tablica może nie mieć wierszy (czyli danych), ale musi zawierać przynajmniej jedną kolumnę. Wszystkie wiersze w tablicy mają taką samą kolejność kolumn, w których zazwyczaj znajdują się różne wartości.
Po wprowadzeniu danych do bazy danych można porównać wartości z różnych kolumn, także znajdujących się w różnych tablicach oraz łączyć odpowiadające sobie wiersze. Umożliwia to wykonywanie skomplikowanych operacji na danych znajdujących się w całej bazie.
Operacje są definiowane logicznie, a nie poprzez pozycje wiersza w tablicy. Wiersze w relacyjnej bazie danych są dowolnie uporządkowane, a porządek w jakim się pojawiają, niekoniecznie odzwierciedla kolejność ich wprowadzenia do bazy, bądź przechowywania na dysku.
Ponieważ nie można identyfikować wierszy za pomocą ich pozycji, rozróżnia się je poprzez jedną lub więcej unikalnych kolumn, nazywanych kluczem głównym (ang.primary key).
Znaczenie języka SQL
Język zapytań - deklaratywny dostęp do danych,
Składnia dosyć łatwa i naturalna (choć daleka od doskonałości),
Możny protektor (IBM),
Standardowe narzędzie dostępu do wielu różnych SZRBD: DB2, Oracle, Informix, Rdb, Ingres, Gupta, Progress, Access...,
Normy ANSI i ISO oraz wiele dialektów,
Szczególna rola w systemach klient-serwer i heterogenicznych.
Części języka:
DQL (ang.Data Query Language),
DML (ang.Data Manipulation Language),
DDL (ang.Data Definition Language).
SQL realizuje:
1 Proste zapytania.
2 Wyszukanie wszystkich kolumn i wierszy.
3Wyszukanie niektórych kolumn i wierszy (projekcja + selekcja).
4 Złącznie zewnętrzne (ang.outer join).
5 Wyszukanie wierszy bez odpowiedników.
6 Wyszukiwanie niejednakowych wierszy.
Narzędzia 4GL do tworzenia aplikacji
Formularze (np. Oracle Forms),
Raporty (np. Oracle Reports),
Uniwersalne (np. MS Access, Oracle PowerObjects).
Języki 3GL
Call Level Interfaces,
ODBC (ang.Open Data Base Conectivity) - łącznik do programów biurowych [3,6,10,11].
5.Projekt systemu
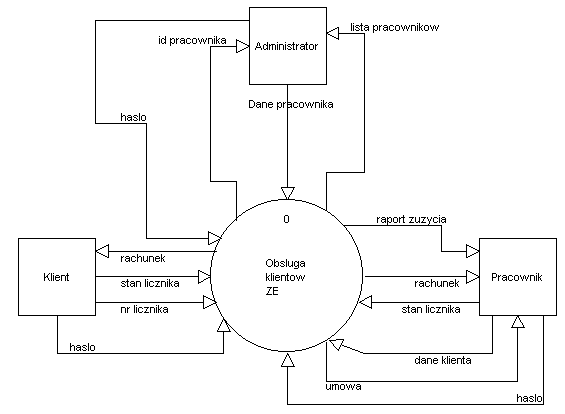
Rys.6. Diagram kontekstowy systemu
Projektowany system ma za zadanie umożliwić zawarcie umowy na dostawę energii elektrycznej z klientem zakładu energetycznego.
Następnym etapem obsługi klienta ma być prowadzenie ewidencji zużycia energii elektrycznej na podstawie rzeczywistych wskazań urządzeń pomiarowych, oraz prognoz przez poszczególnych klientów, oraz wystawianie rachunków za dostawę energii elektrycznej.
1.Przechowywanie informacji o odbiorcach, urządzeniach pomiarowych, stanie sald, odczytach wystawianych faktur i dokonanych wpłatach. Informacje zawarte w słownikach wykorzystywane są przez dział techniczny i handlowy.
2.Rejestracja danych całego cyklu obsługi odbiorcy :
warunki techniczne zasilania,
umowę na licznik,
rozliczenie zużycia energii rewindykację należności,
obsługę techniczną licznika przez cały okres eksploatacji,
zamknięcie rozliczeń i rozliczenie końcowe odbiorcy.
3. Analizy i raporty w dowolnych przekrojach, w rozbiciu na rejony i centrale,
4. Dostęp do pełnej informacji o kliencie i możliwości obsługi klienta w dowolnym punkcie obsługi:
w dyrekcji,
rejonie,
posterunku.
5. Wspólny system obejmujący wielki i drobny odbiór.
6. Rozliczanie zgodnie z prawem energetycznym z rozbiciem opłat na przesył i dystrybucję.
7. Rejestrowanie i generowanie umów z odbiorcami.
8. Wspomaganie tworzenia taryf.
9. Bezdyskusyjna jest zgodność systemu z obowiązującymi przepisami, ale konieczna jest także możliwość i pewność łatwej adaptacji systemu do zmieniających się przepisów, np. do nowych taryf dzięki wsparciu ze strony producenta oprogramowania.
10. Umożliwia planowanie wpływów ze sprzedaży.
11. System powinien być niezawodny i pracować na niezawodnych (zdublowanych) urządzeniach.
DFD diagram przepływu danych - pierwszy poziom
Rys.7. Diagram przepływu danych
Proces przetwarzania umów realizuje wszystkie czynności niezbędne do zawarcia nowej umowy lub zmodyfikowania wprowadzonej poprzednio umowy.
Dane klienta wprowadzone przez pracownika są przetwarzane i zapisywane do składnicy danych - UMOWY. gotową umowa jest drukowana i dostarczana klientowi.
Proces wystawiania rachunków umożliwia rejestrację zużycia energii na podstawie danych wprowadzonych przez klienta lub pracownika Zakładu Energetycznego.
Na podstawie podanych danych generowany jest rachunek za dostawę energii elektrycznej.
Proces obsługi słowników dba o prawidłowe funkcjonowanie wszystkich niezbędnych tabel, z których dane wykorzystywane są przy zawieraniu nowych umów i wystawieniu rachunków.
Dane przetworzone przez ten proces wykorzystywane są przez proces przetwarzania umów i proces wystawiania rachunków.
Rys.8. ERD - Wg. metodologii Martina [2]
Tabela 1. Adresy zawiera wykaz miejscowości i ulic, które obsługuje Zakład Energetyczny w Legnicy
Nazwa pola |
Typ pola |
Długość pola |
Opis |
id adresu |
Liczba (Długa) |
4 |
unikalne pole jednoznacznie idenyfikujące adres wykorzystywane w tabeli 'UMOWY' |
miasto |
Tekst |
30 |
nazwa miasta |
ulica |
Tekst |
50 |
nazwa ulicy |
Tabela 2.Liczniki przechowuje istniejące typy liczników energii elektrycznej
Nazwa pola |
Typ pola |
Długość pola |
Opis |
typ licznika |
Tekst |
50 |
Typ licznika energii elektrycznej |
Tabela 3.Obiekty zawiera wykaz obiektów do których może być doprowadzona energia elektryczna
Nazwa pola |
Typ pola |
Długość pola |
Opis |
id obiektu |
Tekst |
1 |
Identyfikator obiektu wykorzystywany w tabeli 'UMOWY' |
Typ obiektu |
Tekst |
10 |
Typ obiektu do którego doprowadzona jest energia elektryczna |
Tabela 4.Pozycje zawiera wykaz poszczególnych pozycji każdego rachunku
Nazwa pola |
Typ pola |
Długość pola |
Opis |
nr rachunku |
Liczba (Długa) |
4 |
Numer wystawionej faktury za dostawę energii elektrycznej |
Rodzaj |
Tekst |
2 |
|
Zużycie |
Liczba (Długa) |
4 |
stan poprzedni licznika |
cena za 1kw |
Walutowy |
8 |
cena za 1 kW energii elektrycznej pobrana z tabeli 'TARYFY' na podstawie [id taryfy] |
Cena |
Walutowy |
8 |
koszt zużytej energii elektrycznej |
Tabela 5.Rachunki zawiera wykaz wystawionych rachunkow za dostawe energii elektrycznej
Nazwa pola |
Typ pola |
Długość pola |
Opis |
nr rachunku |
Liczba (Długa) |
4 |
Numer wystawionej faktury za dostawę energii elektrycznej |
stan poprzedni |
Liczba (Długa) |
4 |
stan poprzedni licznika |
stan bieżący |
Liczba (Długa) |
4 |
stan bieżący licznika |
id umowy |
Liczba (Długa) |
4 |
identyfikator umowy na dostawę energii z tabeli 'UMOWY' |
data od |
Data/Godzina |
8 |
data poprzedniego odczytu licznika energii elektrycznej |
data do |
Data/Godzina |
8 |
data bieżącego odczytu energii elektrycznej |
id pracownika |
Liczba (Długa) |
4 |
identyfikator pracownika wystawiającego fakturę z tabeli 'PRACOWNICY' |
Tabela 6.Obiekty zawiera wykaz obiektów do których może być doprowadzona energia elektryczna
Nazwa pola |
Typ pola |
Długość pola |
Opis |
id |
Tekst |
2 |
|
rodzaj |
Tekst |
20 |
|
Tabela 7.Taryfy zawiera wykaz uzywanych taryf wg których dostarczana jest energia elektryczna
Nazwa pola |
Typ pola |
Długość pola |
Opis |
id |
Tekst |
2 |
|
taryfa |
Tekst |
20 |
|
Tabela 8. Umowy przechowująca informacje o zawartych umowach na dostawę energii
Nazwa pola |
Typ pola |
Długość pola |
Opis |
id umowy |
Liczba (Długa) |
4 |
Identyfikator umowy wykorzystywany w tabeli 'RACHUNKI' |
Nazwisko |
Tekst |
35 |
Nazwisko osoby zawierającej umowę |
Imię |
Tekst |
20 |
Imię osoby zawierającej umowę |
PESEL |
Tekst |
11 |
PESEL osoby zawierającej umowę |
nr dowodu |
Tekst |
9 |
numer dowodu |
adres |
Liczba (Długa) |
4 |
lokalizacja obiektu (kod adresu z tabeli 'ADRESY' : ulica + miasto) |
numer bramy |
Tekst |
10 |
lokalizacja : numer bramy |
numer mieszkania |
Tekst |
10 |
lokalizacja : numer mieszkania |
nr licznika |
Tekst |
10 |
numer licznika energii elektrycznej |
amperarz |
Liczba (Całkowita) |
2 |
zabezpieczenie przedlicznikowe [A] |
moc przyłączeniowa |
Liczba (Całkowita) |
2 |
doprowadzona moc przyłączeniowa [kW] |
liczba faz |
Liczba (Bajt) |
1 |
liczba przyłączonych faz |
obiekt |
Tekst |
1 |
rodzaj obiektu podłączonego do sieci energetycznej |
taryfa |
Tekst |
2 |
rodzaj taryfy rozliczeniowej za energie elektryczna |
id pracownika |
Liczba (Długa) |
4 |
identyfikator pracownika podpisującego umowę na dostawę energii elektrycznej |
data zawarcia |
Data/Godzina |
8 |
Data zawarcia umowy |
licznik |
Tak/Nie |
1 |
umiejscowienie licznika wewnątrz nieruchomości |
rodzaj licznika |
Tekst |
5 |
symbol licznika energii elektrycznej |
hasło |
Tekst |
10 |
hasło dostępu użytkownika do systemu |
Powiązania pomiędzy tabelami używanymi w systemie
Rys.9. powiązania pomiędzy tabelami używanymi w systemie
Rys.9. .Powiązania pomiędzy tabelami używanymi w systemie (c.d.)
6.Opis implementacji
6.1. Wybór narzędzia
Access 2000 jako narzędzie naszej pracy wybraliśmy dlatego, że jest prosty w obsłudze i posiada wiele różnych mechanizmów ułatwiających pracę. Microsoft Access jest prawdziwie zaawansowanym i profesjonalnym programem baz danych. Microsoft Access jest systemem zarządzającym bazą danych DBMS ( ang.Database Managment System), za pomocą którego można tworzyć i administrować bazy danych. Access należy przy tym do systemów zarządzania relacyjnymi bazami danych. Oznacza to, że poszczególne tabele mogą być ze sobą powiązane.
Access umożliwia definiowanie kluczy podstawowych i obcych, a także ma zaimplementowane wszystkie mechanizmy ułatwiające wymuszanie integralności referencyjnej za pomocą samego aparatu bazy danych, co skutecznie eliminuje operacje aktualizacji i usuwania danych, które prowadziłyby do powstawania niespójności. Dodatkowo w tabelach Accessa można definiować reguły poprawności eliminujące nieprawidłowe dane niezależnie od sposobu ich wprowadzenia. Każde pole tabeli ma swój format i definicje domyślne, ułatwiające bardziej produktywne wprowadzanie danych. Pakiet obsługuje wszystkie niezbędne typy danych, w tym tekst, liczby, automatyczne numerowanie rekordów, waluty, daty i czas, pola memo, wartości logiczne, hiperłącza i obiekty OLE. W przypadku brakujących danych program zapewnia osobne traktowanie wartości pustych (null).
Przetwarzanie relacyjne w Accessie zaspokaja wiele różnorodnych potrzeb użytkowników dzięki swej elastycznej architekturze. Program może być używany jako samodzielny system zarządzania bazami danych, w konfiguracji serwera plików lub jako klient serwera SQL. System umożliwia korzystanie z protokołu ODBC, dzięki któremu można tworzyć połączenia z wieloma zewnętrznymi systemami danych, takimi jak SQL Server, Oracle, Sybase.
Program zapewnia pełną obsługę przetwarzania transakcyjnego i gwarantuje pełną integralność transakcji. Dodatkowo zawiera system ochrony na poziomie użytkownika, za pomocą którego możliwa jest kontrola nad sposobem nadawania użytkownikom i grupom użytkowników uprawnień do odczytu i modyfikowania obiektów baz danych.
Access jest zestawem narzędzi pozwalających użytkownikowi końcowemu zarządzać bazami danych. Access umożliwia importowanie i eksportowanie danych przy użyciu wielu różnych formatów danych, takich jak dBase, FoxPro, Excel, SQL Server, Oracle, Btrieve, a także wielu formatów tekstowych (w tym o ustalonej długości pól i z separatorami) oraz w formacie HTML.
Access zawiera zestaw wbudowanych funkcji, które wykonują różnorodne czynności należące do wielu kategorii. Są to funkcje bazodanowe, matematyczne, finansowe, operacji na datach, godzinach i napisach. Można ich używać w formularzach, raportach i kwerendach.
Makra umożliwiają wykonywanie typowych czynności bez interwencji użytkownika, pozwalają one na manipulowanie danymi, tworzenie menu i okien dialogowych, otwieranie formularzy i raportów oraz na automatyzowanie dowolnej czynności, którą wykonujemy obsługując bazę danych.
Access jest poważnym środowiskiem programistycznym z pełnowartościowym językiem programowania. Visual Basic for Applications (VBA) służy do kodowania modelu programowego opartego na sterowaniu zdarzeniami. Pozwala na korzystanie z wywołań API do procedur obecnych w dowolnej dynamicznie skonsolidowanej bibliotece (DLL) systemu Windows. To pełnowartościowe środowisko programowe umożliwia edycję w wielu oknach, umożliwia debugowanie oraz automatyczne sprawdzanie składni podczas programowania, obsługuje czujki, punkty przerwań oraz krokowe wykonywanie programów.
Microsoft Access jest systemem zarządzania relacyjnymi bazami danych (RDBMS), umożliwiającym przechowywanie i wyszukiwanie informacji zgodnie z relacjami. Za pomocą programu Microsoft Access można zarządzać wszystkimi niezbędnymi informacjami używając jednego pliku bazy danych. W pliku takim można dzielić dane na odrębne części zwane tabelami. Za pomocą formularzy elektronicznych można oglądać, dodawać i aktualizować dane w tabelach; za pomocą kwerend można znajdować i pobierać tylko te dane, które są rzeczywiście aktualnie niezbędne; za pomocą raportów można analizować i drukować dane w określonym przez siebie układzie. Pomimo tego że wszystkie obiekty bazy danych znajdują się w jednym pliku istnieje możliwość importowania/eksportowania pojedynczych tabel.
Najlepiej jest przechowywać dane tworząc po jednej tabeli dla każdego typu informacji, które mają być analizowane. Dane z różnych tabel można później łączyć razem w kwerendach, formularzach lub raportach - należy w tym celu zdefiniować relacje między tabelami [7,8].
Architektura pakietu
Access - program główny: łączy funkcje:
programu dla projektanta,
interakcyjnego narzędzia do operowania danymi,
interpretera wykonującego gotowe aplikacje,
runtime i generator dyskietek instalacyjnych (w pakiecie Access Developer's Kit).
W MS Access istnieje możliwość korzystania z serwerów SQL przez ODBC (ang.Open Database Connectivity) oraz możliwość udostępniania własnych danych przez ODBC(np.dla Visual Basica, Visual C++).
Programowanie w Visual Basic for Application jest niezwykle proste co nierzadko zachęca projektantów do tworzenia za pomocą Accessa małych systemów baz danych: do użytku prywatnego lub dla małych biur.
Access 2000
Zdolność łączenia z serwerem SQL. Z Access 2000 i serwerem SQL, użytkownicy mogą tworzyć nowe bazy danych serwera SQL lub bezpośrednio otwierać i edytować istniejącą już bazę danych SQL, a nawet przeprowadzać działania administracyjne jak replikacja, kopia zapasowa i przywrócenie. Formularze i raporty Access 2000 mogą być użyte zamiast danych SQL.
Podarkusze danych. Nowy hierarchiczny widok wyświetla kilka tabel, ułatwiając rozpoznanie pokrewieństwa.
"Gotowy do pracy". Kiedy nowa baza danych jest zaznaczona, Access 2000 prezentuje tabelę w widoku arkusza danych tak, by użytkownik mógł bez trudu wpisywać dane.
Autonaprawa nazwy. Access 2000 będzie przekazywał zmiany nazw w każdym polu bazy automatycznie.
Grupowanie kontrolek. Kontrolki mogą być przetwarzane jako jedna całość.
Formatowanie warunkowe. Wartość danych w bazie Access 2000 może zdeterminować wygląd danych w formularzu.
Zgodny interfejs użytkownika. Interfejs Access 2000 zmienił się nieznacznie by polepszyć użyteczność i zgodność z innymi aplikacjami Office. Również zawiera taki pasek jak w Outlook.
8.Autokompresowanie. Access 2000 automatycznie kompresuje bazę danych, gdy plik jest zamykany jeśli zmniejszenie miejsca wolnego na dysku jest znaczne. Bazy Access są dlatego tak małe jak to tylko możliwe, by nie marnować miejsca na dysku i uczynić przesyłanie danych za pomocą poczty elektronicznej bardziej efektywnym[12,13].
6.2. ASP (Active Server Pages)
W związku z planowanym w przyszłości wprowadzeniem płatności przez Internet oraz szerokiego asortymentu innych usług związanych z siecią należy uwzględnić technologię umożliwiającą realizację tych idei.
Active Server Pages, czyli aktywne strony serwera są technologią firmy Microsoft stanowiącą część programu serwera WWW. ASP mogą być zaimplementowane w większości serwerów Microsoftu pracujących w systemach Windows 95/98/NT. Może to być zarówno Internet Information Server, Peer Web Serwer jak i Personal Web Serwer. ASP jest technologią alternatywną dla CGI, charakteryzuje ją łatwość programowania oraz większa szybkość działania. Jak zapewnia producent, dobrze napisany w ASP program może być do czterech razy szybszy od programu napisanego przy użyciu CGI. Aplikacje ASP wykonywane są po stronie serwera, czyli do przeglądarki dochodzi "gotowy" kod taki jak w plikach typu HTML. Źródło skryptu jest niewidoczne dla odbiorcy, odwrotnie niż w HTML czy JavaScript(JS). Co pozytywnie wpływa na ochronę naszych pomysłów przed plagiatem. Strona ASP może składać się z elementów pisanych w kilku językach, np. HTML, VB Script(VBS) czy JS przeplatających się ze sobą. Kody poszczególnych języków oddzielane są odpowiednimi dla nich znacznikami, program wykonuje się liniowo, najpierw wykonywane są instrukcje na początku pliku później linia po linii kolejne komendy niezależnie od języka w którym zostały napisane. Przy czym wyższy priorytet mają instrukcje napisane w VBS. Wybór języka programowania za pomocą którego chcemy zrealizować dane zadanie zależy przede wszystkim od tego czy dany język posiada odpowiednie narzędzia. Zdarza się jednak, że ten sam efekt końcowy możemy uzyskać na wiele sposobów, trzeba wtedy wybrać metodę zapewniającą największą szybkość. Jeżeli zadanie można zrealizować bez konieczności odwoływania się do serwera należy skorzystać z metod JS a do utworzenia szaty graficznej wykorzystać np. HTML.
Technologia pozwalająca na tworzenie dynamicznych stron WWW (z dynamicznie zmieniającą się zawartością). Wchodzi w skład rozwijanej przez Microsoft technologii Active Platform i przeznaczona jest do pracy pod kontrolą serwerów WWW tej firmy - komercyjnego IIS (Internet Information Server) lub darmowego Personal Web Server. Dokumenty ASP mogą odwoływać się do programów uruchomionych na serwerze WWW w celu podjęcia określonych działań, np. przeszukania bazy danych, włączenia do strony innego dokumentu lub udostępnienia strony w wersji przeznaczonej dla określonej przeglądarki.
Strona WWW, w której wykorzystano elementy ASP jest zwykłym plikiem tekstowym zawierającym polecenia HTML-a, skrypty oraz właściwą treść dokumentu. W chwili wystąpienia żądania pobrania pliku z rozszerzeniem .asp serwer analizuje znajdujące się w nim skrypty ASP, przetwarza polecenia i wygenerowaną w ten sposób stronę WWW przesyła do przeglądarki. Ponieważ wynikowy plik zawiera wyłączenie "czysty" HTML, nie ma znaczenia, pod kontrolą jakiego systemu operacyjnego pracuje przeglądarka użytkownika. Zależność ASP od systemu Windows dotyczy bowiem wyłącznie serwera. W rzeczywistości ASP nakłada na oprogramowanie klienckie znacznie mniejsze wymagania niż chociażby popularne skrypty JavaScript, które przez część starszych przeglądarek mogą nie być wykonywane poprawnie lub - gdy w przeglądarce wyłączono obsługę JavaScript - wręcz w ogóle.Ogólna zasada działania ASP (server-side scripting, czyli wykonanie określonego kodu przez serwer) jest podobna do aplikacji komunikujących się z klientem przez interfejs CGI. Podstawowa różnica między tymi dwiema technikami polega na tym, że o ile w przypadku CGI każde odwołanie do skryptu lub programu wykonywanego na serwerze wiąże się z koniecznością utworzenia na nim nowego procesu (co pochłania znaczącą część zasobów systemowych), to program ASP przetwarzany jest przez wyznaczony moduł serwera WWW obecny przez cały czas w pamięci. Fakt ten ma niebagatelny wpływ nie tylko na stopień obciążenie serwera, ale również na szybkość działania programów (oczywiście z korzyścią dla tych napisanych pod kątem ASP).
Możliwości ASP
Z pomocą ASP tworzyć można równie dobrze nieskomplikowane, generowane "w locie" strony WWW jak i duże, złożone aplikacje operujące na wewnętrznych bazach danych. Oto kilka przykładów wykorzystania możliwości ASP:
odciążenie przeglądarki poprzez wykonywanie przez serwer zadań wymagających dużej mocy obliczeniowej,
odczytywanie i przetwarzanie danych z formularzy,
włączanie do stron informacji z innych dokumentów,
przeszukiwanie, pobieranie i składowanie informacji w bazach danych,
obsługa mechanizmu cookie,
identyfikacja i śledzenie poczynań osób odwiedzających witrynę (mechanizm sesji),
uruchamianie zewnętrznych modułów programowych napisanych w technologii ActiveX,
obsługa popularnych elementów stron WWW (liczniki i księgi gości).
Skryptowe środowisko programistyczne, jakie oferuje ASP jest praktycznie niezależne od języka programowania. Najczęściej używa się odmian popularnych języków. Dla Visual Basic jest to VBScript, dla C, C++ i Javy - JScript. Gotowe skrypty umieszcza się w dokumencie HTML, obejmując bloki instrukcji VBScriptu lub JScriptu znakami . Ostatnią czynnością przed umieszczeniem strony na serwerze jest przemianowanie rozszerzenia pliku z .html na .asp.
6.3. Relacje występujące w systemie
Konsekwencją diagramu relacyjnego danych rys.8. są następujące relacje między tabelami, zawarte na rys.10.
Rys.10. Relacje między tabelami
6.4. Zabezpieczenia systemu
System zabezpieczony jest przed nieautoryzowanym dostępem poprzez formularz Identyfikacja, który sprawdza uprawnienia osoby próbującej z niego skorzystać (rys. 11).
Rys. 11.Formularz identyfikacyjny użytkownika sytemu
W celu potwierdzenia uprawnień system pyta o identyfikator użytkownika oraz o jego hasło. W przypadku podania nieprawidłowego hasła system nie zezwala na dostęp do opcji użytkowych programu (rys.13). Podanie poprawnego hasła gwarantuje dostęp do programu (rys.12).
Rys. 12. Okno komunikatu po uzyskaniu dostępu do bazy
Rys. 13 Komunikat w przypadku odmowy dostępu do systemu
Identyfikatory służące do rozpoznania użytkowników podzielone są na dwie grupy:
identyfikatory klientów,
identyfikatory pracowników.
Za identyfikator klienta przyjęty został unikatowy numer licznika jaki posiada abonent. Hasło dla klienta ustalane jest z góry przez Zakład Energetyczny.
Jako identyfikator pracownika stosowany jest jego unikatowy numer w systemie. Swoje hasło pracownik może zmienić.
W zależności do której grupy użytkowników (klient czy pracownik) należy osoba logująca się do systemu ma ona do dyspozycji różne opcje programu.
Pracownik podając swój identyfikator i prawidłowe hasło ma dyspozycji menu główne programu (rys.14).
Może on zawrzeć z klientem nową umowę, sprawdzić rachunki, wystawić nowy rachunek. Może on również jeżeli ma do tego odpowiednie uprawnienia dopisać nowego pracownika do systemu lub zmodyfikować słownik adresów.
Rys. 14. Menu główne programu
Wybierając przycisk Umowy otrzymujemy formularz służący do zawierania i przeglądania „Umów na dostawę energii elektrycznej” (rys.15)
Rys. 15. Formularz Umowy na dostawę energii elektryczej
Formularz ten umożliwia wydruk zawartej umowy (załącznik nr 1), jest również zabezpieczony przed przypadkowym usunięciem umowy (rys.16).
Rys. 16. Okno dialogowe - Potwierdzenie usunięcia umowy
Formularz posiada funkcje wyszukiwania umów po nazwisku klienta lub jego numerze PESEL (rys.17).
Zawierając nową umowę system umożliwia korzystanie ze zbiorów-słowników, które usprawniają pracę i zapobiegają wprowadzeniu błędnych danych (rys.18). Głównym słownikiem systemu jest tabela z adresami (miasta i ulica), która zawiera wykaz wszystkich ulic, które obsługuje Zakład Energetyczny. Nie ma możliwości zawarcia umowy dla lokalu położonym przy ulicy, której nie ma w spisie.
Wprowadzając rodzaj obiektu z którym podpisywana jest umowa wykorzystywana jest tabela Obiekty i z niej czerpane są dane (rys.19). Dane pola rodzaj licznika również czerpane są z tabeli słownika Liczniki (rys.21).Pole pracownik jest automatycznie wypełniane na podstawie identyfikatora osoby logującej się do systemu i nie może być zmienione na inne (rys.22). Wartością domyślną dla pola Data zawarcia jest data bieżąca.
Rys. 17 - Formularz zawarcia umowy - wyszukiwanie klientów
Rys. 18 Pole kombi służące do wprowadzania adresów
Rys. 19 Pole kombi służące do wprowadzaniarodzaju obiektu
Rys. 20 Pole kombi służące do wyboru taryfy
Rys. 21 Pole kombi do wyboru rodzaju licznika
Rys. 22 Pole zawierające dane pracownika
Wybierając kolejną pozycję Menu-Rachunki pracownik ma możliwość przeglądania i wydruku zarejestrowanych rachunków oraz wystawiania nowych rachunków (rys.23).
Rys. 23 Menu służące do przeglądania i wystawiania rachunków.
Klienta można odnaleźć poruszając się po kolejnych rekordach za pomocą przycisków nawigacyjnych lub wybrać osobę z pola kombi uruchamiając przycisk znajdź (rys.24)
Rys. 24 Wyszukiwanie klientów
Wybierając przycisk Nowy rachunek system automatycznie odnajduje poprzedni stan licznika oraz końcową datę okresu za który rozliczone już zostało zużycie energii elektrycznej (rys.25).
Rys.25 Formularz wystawiania nowego rachunku
Jako data końcowa okresu za który dokonywane jest rozliczenie proponowana jest data bieżąca, którą w razie potrzeby można zmodyfikować. System kontroluje czy stan końcowy > stan początkowy i w przypadku błędu generuje komunikat i nie pozwala na opuszczenie pola stan końcowy (rys.26).
Rys. 26 Komunikat w przypadku nieprawidłowych stanów licznika
Również kontrolowane jest czy pole data końcowa jest większa od daty początkowej i w przypadku nieprawidłowości jest generowany odpowiedni komunikat błędu (rys. 27).
Rys. 27 Komunikat w przypadku nieprawidłowych dat rozliczanego okresu
Po wypełnieniu pól charakteryzujących okres rozliczeniowy (stan końcowy licznika i datę końcową) system automatycznie wylicza i dodaje do rachunku odpowiednie pozycje (rys.28) :
Koszt zużytej energii.
Opłata abonamentowa.
Opłata przesyłowa stała.
Opłata przesyłowa zmienna.
Zaakceptowany rachunek można wydrukować (Załącznik 2).
Rys.28 Formularz przedsatwiający poszczególne pozycje rachunku
W przypadku gdy okres rozliczeniowy obejmuje dwie taryfy tzn. w tym okresie nastąpiła zmiana ceny za 1kW energii elektrycznej system automatycznie dokonuje proporcjonalnego podziału zużytej energii na okresy w których obowiązywały różne stawki i na tej podstawie generuje odpowiedni rachunek
Pracownik z uprawnieniami Administratora może modyfikować dane innych pracowników, ma możliwość zakładania nowych kont dla pracowników w systemie (rys.29).
Rys. 29 Formularz Dane pracowników
Może on również modyfikować tabele-słowniki systemu, w tym tabelę adresy (rys.30).
Rys. 30 Formularz Adresy
Klient po podaniu swojego identyfikatora (numer licznika) i po wprowadzeniu prawidłowego hasła ma możliwość podania swojego stanu licznika oraz może otrzymać rachunek za rozliczany okres (rys. 25) [12,13].
Rys. 31. Przykładowy wykres zużycia energii w kWh przez odbiorcę w ciągu roku.
Na podstawie tego wykresu odbiorca mógłby w sposób szczegółowy przeanalizować swoje zużycie energii. Każdy za pośrednictwem Internetu będzie mógł porównać zużycie energii w poszczególnych miesiącach. Taki wykres dawałby możliwość wstępnego przewidzenia opłaty za energię elektryczną przez wszystkie miesiące w roku.
7. Wnioski
Zaprezentowany system bazodanowy do obsługi posterunków energetycznych spełnia założenia postawione przed przystąpieniem do jego realizacji. Jest on więc funkcjonalny, efektywny i przyjazny dla użytkownika umożliwia przechowywanie i uporządkowanie danych odbiorców, a przez to szybki do nich dostęp.
Baza danych posiada liczne zabezpieczenia przed wprowadzeniem nieprawidłowych danych. Jej interface jest czytelny i łatwy w obsłudze.
Użytkownicy mają zróżnicowane prawa dostępu do bazy - nad czym czuwa administrator. Głównym niebezpieczeństwem jest możliwość dostępu do bazy danych osób nieuprawnionych i zniszczenie lub wykradzenie danych. System został więc zabezpieczony przed niekontrolowanym dostępem przez wprowadzenie hasła dostępu do bazy.
Program z pewnością usprawnił uzyskanie informacji o odbiorcach energii elektrycznej.
Ułatwił pracownikom posterunków energetycznych wprowadzanie, gromadzenie i przechowywanie danych dotyczących klientów. System bazodanowy po przyjęciu przez Zakład Energetyczny może mieć zastosowanie we wszystkich posterunkach energetycznych. Ważną zaletą tego systemu jest także fakt, że dane o odbiorcach, drukowanie rachunków, analiza zużycia energii elektrycznej i podawanie stanu licznika może odbywać się, po drobnej modyfikacji, przez Internet. Umożliwi to natychmiastowy dostęp do wszystkich informacji. Strona nie została jeszcze umieszczona ze względów ekonomicznych, oraz ze względu na fakt, że bardzo mało osób w tych małych miejscowościach, gdzie są posterunki energetyczne ma dostęp do Internetu.
System bazodanowy po zaakceptowaniu przez Zakład Energetyczny Legnica S.A. może mieć zastosowanie we wszystkich posterunkach energetycznych. System po niewielkiej modyfikacji może zostać integralną częścią całej bazy danych znajdującej się w Rejonie Energetycznym Legnica.
Literatura
[1] Paul Beynon-Davies „Systemy baz danych” Wydawnictwo Naukowo-Techniczne Warszawa 1998
[2] Mariusz Flasiński Wstęp do analitycznych metod projektowania systemów informatycznych Wydawnictwo Naukowo -Techniczne Warszawa 1997
[3] Bowman J.S., Emerson S.L., Darnovsky M. -Podręcznik języka SQL , Wydawnictwo NT, Warszawa, 2001
[4] Date C.J. Wprowadzenie do systemów baz danych, WNT, Warszawa, 2000
[5] Ullman Jeffrey D., Widom Jennifer Podstawowy wykład z systemów baz danych, WNT, Warszawa, 2000
[6] Date C. J., Darwen Hugh - SQL. Omówienie standardu języka ("A Guide to the SQL Standard"), WNT, 2000
[7] Cary n. Prague, Michael R. Irwin, ACCESS 97 Biblia, Wydawnictwo RM
sp. z o.o., Warszawa 1998
[8] D. Boratyn, Ms Access 2.0. System. Oblicze ku aplikacjom, Wydawnictwo Croma, Wrocław 1997
[9] W. Wierzyński, Bazy danych, Poznań 1994
[10] Martin Gruber, SQL, Wydawnictwo Helion Gliwice 1996
[11] www.bazydanych.w.pl (wiadomości z zakresu baz danych)
[12] Paul Cassel, Pamela Palmer Access 2000 PL dla każdego Helion Gliwice 2000
[13] Peter Norton i inni Access 2000 PL Programowanie według Petera Nortona MIKOM Warszawa 2000
[14] Liz Clarke Zarządzanie zmianą Gebethner&S-ka, Warszawa 1997
6
___________________________________________________________________________
Wstęp
Opis środowiska pracy
Metoda projektowania
Pojęcia z zakresu baz danych
Projekt systemu
Opis implementacji
Wnioski
Literatura
Interface QBE
(zapytanie przez przykład)
Interface programowania
aplikacji
Jądro SZBD
SQL
Interface języka
naturalnego
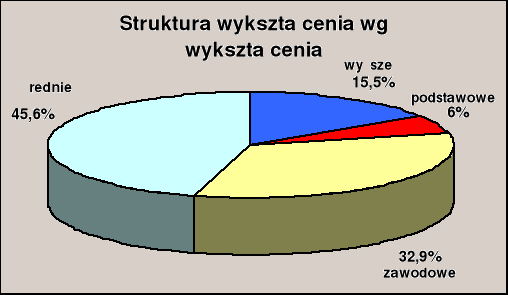
Proces
Interface linii
poleceń
Graficzny Inerface
użytkownika
Zestaw narzędzi SZBD
Typ
Wyszukiwarka
Podobne podstrony:
Praca Magisterska-rachunkowość(1), PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!!!!
Praca Licencjacka - Karty płatnicze w ofercie banku pko bp, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA
praca licencjacka(9)Bankowość Internetowa jako nowa forma usługi bankowej, PRACA MAGISTERSKA INŻYNIE
Praca licencjacka- faszyzm(1), PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!!!!
Praca Fundusze Strukturalne, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!!!!
Praca Dyplomowa-KOBIETY W PROZIE OLGI TOKARCZUK, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !
Praca Socjalna Dyplomowa, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!!!!
Lęk - praca dyplomowa, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!!!!
Komunikacja niewerbalna - SPRAWOZDAWCZOŚĆ I ANALIZA FINANSOWA, PRACA MAGISTERSKA INŻYNIERSKA DYPLOM
PROCES DOBORU PRACOWNIKÓW NA WYBRANE STANOWISKA, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !
Praca dyplomowa - Medycyna - Kręgosłup(3), PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!!!!
Praca MEDYCYNA NIEKONWENCJONALNA, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!!!!
Praca magisterska-REKLAMA W PRZEDSIĘBIORSTWIE, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!
Praca Magisterska Socjologia MEDYCYNA NIEKONWENCJONALNA, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!!
Praca licencjacka- gotowa, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!!!!
Negocjacje - Praca Magisterska, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!!!!
Praca (tajne technologie III Rzeszy), PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!!!!
Unia Europejska - praca, PRACA MAGISTERSKA INŻYNIERSKA DYPLOMOWA !!! PRACE !!!!!!
więcej podobnych podstron