Opisowe miary siły korelacji dwóch zmiennych
Siłę współzależności dwóch zmiennych można wyrazić liczbowo za pomocą wielu mierników. Ich wybór jest uzależniony m.in. od rodzaju cech, między którymi badana jest zależność (mierzalne, niemierzalne, mieszane); liczby obserwacji (tablica korelacyjna, szeregi korelacyjne), kształtu zależności (regresja, prostoliniowa, krzywoliniowa).
Zakładając, że współzależność badanych zmiennych losowych X i Y jest statystycznie istotna, możemy wyróżnić cztery rodzaje podstawowych miar sił korelacji tych zmiennych:
współczynnik zbieżności Czuprowa;
wskaźniki (stosunki) korelacyjne Pearsona;
współczynnik korelacji liniowej Pearsona;
współczynnik rang (korelacji kolejnościowej) Spearmana.
Współczynnik zbieżności Czuprowa
Miernik ten oparty jest na teście chi - kwadrat (χ2). Wielkość χ2 jest podstawą do określenia unormowanej funkcji zależności cech zwanej współczynnikiem zbieżności Czuprowa. Określa go wzór:
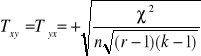
Współczynnik ten przyjmuje wartość z przedziału ![]()
, gdy badane zmienne są stochastycznie niezależne. Przy zależności funkcyjnej zmiennych, T = 0.
Im bardziej współczynnik zbieżności jest bliższy zeru, tym słabsza jest zależność między zmiennymi.
Przy wyznaczaniu współczynnika zbieżności nie jest ważne, którą z cech traktuje się jako zależną a którą jako niezależną - co jest istotne przy badaniu zależności w sensie korelacyjnym. Własność tę określa się mianem symetryczności:
![]()
Zaletą współczynnika zbieżności jest to, że może być stosowany do mierzenia współzależności zarówno cech mierzalnych jak i niemierzalnych. Jego wadą jest natomiast to, że nie wskazuje kierunku korelacji (jest zawsze dodatni).
Do oceny natężenia korelacji między zmiennymi X i Y wykorzystuje się również współczynnik determinacji.
![]()
Miara ta wskazuje, w ilu procentach zmienność zmiennej zależnej jest określona zmiennością zmiennej niezależnej. Tak więc o ile z rachunkowego punktu widzenia T ocenia zarówno zależność cechy X od cechy Y jak i cechy Y od X , o tyle interpretacja współczynnika zbieżności musi jednoznacznie określać charakter zmiennych, tzn. która z nich jest zmienną zależną, a która niezależną.
Z uwagi na to, że przy obliczaniu współczynnika zbieżności brane są pod uwagę jedynie liczebności odpowiednich rozkładów, a nie ich parametry, współczynnik zależności jest przede wszystkim miarą zależności stochastycznej dwóch zmiennych. Ponieważ zależność korelacyjna jest pojęciem węższym od zależności stochastycznej można go wykorzystać jako miarę siły związku korelacyjnego.
Wskaźniki korelacyjne Pearsona
Konstrukcja stosunków korelacyjnych opiera się na równości wariancyjnej (której istotą, jak wszyscy pamiętają z czasów gdy zgłębialiśmy miary zmienności, jest rozłożenie wariancji ogólnej na dwa składniki: średnią z wariancji wewnątrzgrupowych i wariancję średnich warunkowych).
Stosunki korelacyjne stosowane są do badania współzależności między zmiennymi X i Y w przypadku dużej liczby obserwacji ujętych w formie tablicy korelacyjnej. Stąd też należy rozpatrywać dwie równości wariancyjne: jedną dla cechy X, drugą dla cechy Y. Równości te wyglądają następująco:
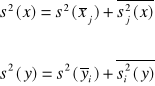
Gdzie:
s2(x) oraz s2(y) są wariancjami ogólnymi odpowiednich zmiennych;
![]()
oraz ![]()
są wariancjami średnich warunkowych (wariancjami międzygrupowymi) odpowiednich zmiennych;
![]()
oraz ![]()
są średnimi z wariancji warunkowych (wariancjami wewnątrzgrupowymi) odpowiednich zmiennych.
Wariancje międzygrupowe zmiennych X i Y są obliczane ze wzorów:
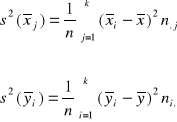
Gdzie ![]()
są odpowiednio średnimi warunkowymi zmiennych X i Y a ![]()
są średnimi ogólnymi obliczonymi z rozkładów brzegowych.
Wariancje wewnątrzgrupowe zmiennych X i Y są obliczane ze wzoru:
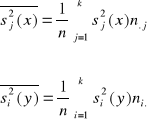
Wskaźnik korelacyjny zmiennej X względem zmiennej Y określa zatem wzór:
![]()
Z czego wynika, że wskaźnik korelacyjny zmiennej Y względem zmiennej X określa wzór:
![]()
Stosunki (wskaźniki) korelacyjne są miarami niemianowanymi, przyjmującymi wartości z przedziału ![]()
. Są one równe 0, gdy cechy są nieskorelowane, 1 - gdy między badanymi zmiennymi zachodzi zależność funkcyjna.
Im wartość wskaźnika korelacyjnego jest bliższa 1, tym zależność korelacyjna jest silniejsza.
Stosunki korelacyjne są niesymetryczne ![]()
, z wyjątkiem dwóch przypadków:
1. gdy zmienne X i Y są niezależne stochastycznie;
2. gdy między zmiennymi X i Y zachodzi związek funkcyjny ![]()
Z powyższego wynika, że przy obliczaniu wskaźników korelacyjnych ważne jest ustalenie, która z cech jest zależna, a która niezależna.
Wskaźniki korelacyjne nie wskazują kierunku korelacji badanych zmiennych, zawsze są dodatnie.
Ich zaletą jest fakt, że nie zależą od kształtu regresji. Dzięki temu mogą być stosowane zarówno w przypadku zależności prostoliniowych, jak i krzywoliniowych. Dodatkowo wskaźniki korelacyjne mogą być wykorzystywane dwóch cech, z których jedna jest niemierzalna.
Równolegle do wskaźników korelacyjnych ![]()
korzysta się ze współczynników determinacji: ![]()
, wyrażonych w procentach. Współczynnik determinacji informuje o tym, w ilu procentach zmiany zmiennej zależnej są spowodowane (zdeterminowane) zmianami zmiennej niezależnej.
Przykład 1
Wylosowano 100 rodzin i zbadano je pod względem liczby dzieci pozostających na całkowitym utrzymaniu i standardu ekonomicznego rodziny, określonego przez średni miesięczny dochód przypadający na członka rodziny.
Za pomocą stosunku korelacyjnego określić siłę związku korelacyjnego standardu ekonomicznego względem liczny dzieci w rodzinie. [Sobczyk str. 205-207 wyd. z 1991 r.]
Liczba dzieci |
Standard ekonomiczny |
Razem |
|||
|
1 |
2 |
3 |
4 |
|
0 1 2 3 4 |
- - - 6 4 |
- - 11 3 1 |
5 30 14 1 - |
15 10 - - - |
20 40 25 10 5 |
Razem |
10 |
15 |
50 |
25 |
100 |
W pierwszej kolejności obliczamy średnią ogólną i wariancję ogólną cechy Y:
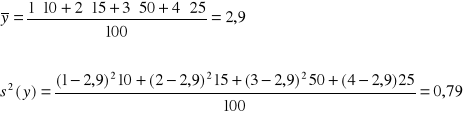
Następnie obliczamy wartości średnich warunkowych rozkładów cechy Y:
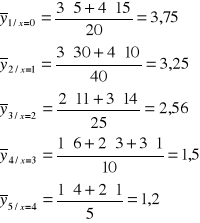
Po zakończeniu kalkulacji obliczamy wariancję średnich warunkowych:
![]()
Podstawiając obliczone wartości do wzoru na wskaźnik korelacyjny otrzymujemy:
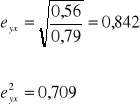
Uzyskany wynik świadczy o silnej zależności standardu ekonomicznego rodziny od liczby dzieci. W niemal 71% przypadków zmiany standardu ekonomicznego rodziny mogą być wyjaśnione zmianami liczby posiadanych dzieci.
Jest to zależność jednostronna - liczba dzieci nie zależy od standardu ekonomicznego.
Współczynnik korelacji liniowej Pearsona
Współczynnik ten (rxy) jest miernikiem siły związku prostoliniowego między dwoma cechami mierzalnymi.
Związkiem prostoliniowym nazywamy taką zależność, w której jednostkowym przyrostom jednej zmiennej (przyczyny) towarzyszy, średnio biorąc, stały przyrost drugiej zmiennej (skutku).
Wzór na współczynnik korelacji liniowej Pearsona jest wyznaczany poprzez standaryzację kowariancji. Kowariancja jest średnią arytmetyczną iloczynu odchyleń wartości zmiennych X i Y od ich średnich arytmetycznych:

Kowariancja przekazuje następujące informacje o związku korelacyjnym:
cov(x,y) = 0 - brak zależności korelacyjnej;
cov(x,y) < 0 - ujemna zależność korelacyjna;
cov(x,y) > 0 - dodatnia zależność korelacyjna.
Kowariancja przyjmuje wartości liczbowe z przedziału: [-s(x)s(y), +s s(x)s(y)], gdzie s(x) i s(y) są odchyleniami standardowymi odpowiednich zmiennych.
Jeżeli cov(x,y) = -s(x)s(y), to między zmiennymi istnieje ujemny związek funkcyjny. Przy dodatnim związku funkcyjnym cov(x,y) = +s(x)s(y).
Kowariancja charakteryzuje współzmienność badanych zmiennych, ale jej wartość zależy od rzędu wielkości, w jakich wyrażone są obydwie cechy, co powoduje, że nie można jej wykorzystać w sposób bezpośredni do porównań.
Unormowanym miernikiem natężenia i kierunku współzależności liniowej dwóch zmiennych mierzalnych X i Y jest współczynnik korelacji linowej Pearsona, wyznaczony przez standaryzację kowariancji:
![]()
Współczynnik korelacji liniowej Pearsona jest miarą unormowaną, przyjmującą wartości z przedziału: -1 < rxy <+1.
Dodatni znak współczynnika korelacji wskazuje na istnienie współzależności pozytywnej (dodatniej), ujemny zaś oznacza współzależność negatywną (ujemną). Im wartość bezwzględna współczynnika korelacji jest bliższa jedności, tym zależność korelacyjna między badanymi zmiennymi jest silniejsza.
Orientacyjnie przyjmuje się, że korelacja jest:
niewyraźna, jeżeli rxy < 0,3;
średnia, gdy 0,3 < rxy < 0,5;
wyraźna, jeżeli rxy < 0,5.
Interpretacja ta odnosi się również do ujemnych wartości współczynnika korelacji. Jeżeli ![]()
, to zależność korelacyjna przechodzi w zależność funkcyjną. Jeżeli natomiast ![]()
, to brak jest związku korelacyjnego między badanymi zmiennymi X i Y.
Współczynnik korelacji jest określonym wskaźnikiem, a nie pomiarem na skali liniowej o jednakowych jednostkach. Oznacza to, że zależność rxy = 0,90 nie jest dwukrotnie większa od rxy = 0,45.
Kwadrat współczynnika korelacji nazywamy współczynnikiem determinacji ![]()
. Informuje on o tym, jaka część zmian zmiennej objaśniającej (skutek) jest wyjaśniona przez zmiany zmiennej objaśniającej (przyczyna).
Przykład 2
W pewnym Urzędzie Stanu Cywilnego pewnego dnia przeprowadzono badanie nowo zawartych małżeństw wg wieku żony i męża. Wyniki badania losowo pobranych par przedstawiono niżej.
Określić siłę i kierunek zależności między badanymi zmiennymi. [Sobczyk str. 209-210, wyd.1991]
Wiek żony (xi) |
18 |
19 |
20 |
21 |
23 |
24 |
26 |
27 |
27 |
30 |
Wiek męża (yi) |
19 |
21 |
23 |
21 |
20 |
23 |
26 |
25 |
26 |
34 |
Na podstawie analizy diagramu punktowego (korelacyjnego) można stwierdzić, że zależność między badanymi zmiennymi ma charakter prostoliniowy. Dlatego też siłę i kierunek zależności można ocenić przy użyciu współczynnika korelacji liniowej Pearsona.
Aby go obliczyć należy wykonać obliczenia pomocnicze:
xi |
yi |
|
|
|
|
|
18 19 20 21 23 24 26 27 27 30 |
19 21 23 21 20 23 26 25 26 34 |
-5,5 -4,5 -3,5 -2,5 -0,5 0,5 2,5 3,5 3,5 6,5 |
-4,8 -2,8 -0,8 -2,8 -3,8 -0,8 2,2 1,2 2,2 10,2 |
26,4 12,6 2,8 7,0 1,9 -0,4 5,5 4,2 7,7 66,3 |
30,25 20,25 12,25 6,25 0,25 0,25 6,25 12,25 12,25 42,25 |
23,04 7,84 0,64 7,84 14,44 0,64 4,84 1,44 4,84 104,04 |
235 |
238 |
x |
x |
134,0 |
142,5 |
169,6 |
Średni wiek kobiet zawierających w badanym dniu związek małżeński wynosi: ![]()
lat. Średni wiek mężczyzny wynosi: ![]()
lat.
W celu obliczenia współczynnika korelacji liniowej Pearsona niezbędna jest znajomość odchyleń standardowych obydwu cech:
Odchylenie standardowe wieku kobiet jest równe:
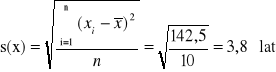
Odchylenie standardowe wieku mężczyzn jest równe:
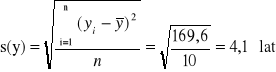
Dysponując powyższymi informacjami możemy obliczyć współczynnik korelacji liniowej Pearsona:
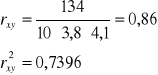
Otrzymany wynik oznacza, że między badanymi zmiennymi istnieje silna dodatnia zależność korelacyjna. W 74% przypadków zmiany jednej cechy są uwarunkowane zmianami drugiej.
Przykład 3
W 100 szkołach przeprowadzono badanie mające na celu określenie zależności między liczbą izb w szkole (Y) a liczbą uczniów (X). Wyniki prezentuje tablica.
Zbadać siłę oraz kierunek zależności między liczbą izb a liczbą uczniów w szkole. [Sobczyk str. 211-212, wyd. z 1991]
Liczba uczniów w szkole |
Liczba izb w szkole (yi) |
Razem |
||
|
4-8 |
8-12 |
12-16 |
|
60-120 120-180 180-240 240-300 300-360 |
10 - - - - |
- 10 20 - - |
- 10 20 20 10 |
10 20 40 20 10 |
Razem |
10 |
30 |
60 |
100 |
Z rozkładu liczebności tablicy można wnioskować, że korelacja ma charakter dodatni i prostoliniowy (liczebności układają się wzdłuż przekątnej biegnącej od lewego górnego do prawego dolnego rogu tablicy).
Potwierdza to również nierówność średnich warunkowych:
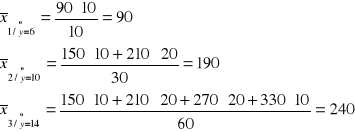
Średnie warunkowe zmiennej X rosną wraz ze wzrostem konkretnych wartości zmiennej Y. Świadczy to istnieniu dodatniego związku korelacyjnego między badanymi zmiennymi.
Z rozkładów brzegowych zmiennych X i Y obliczamy średnie arytmetyczne i odchylenia standardowe:
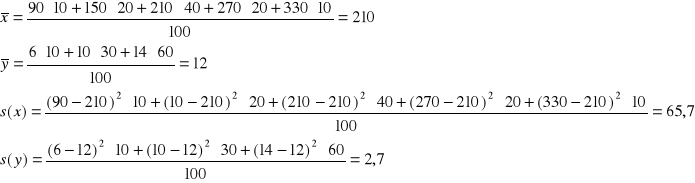
Rozrzut odchyleń indywidualnych wartości zmiennych X i Y od ich średnich wartości przedstawia tablica:
|
-6 |
-2 |
2 |
Razem |
-120 -60 6 60 120 |
10 - - - - |
- 10 20 - - |
- 10 20 20 10 |
10 20 40 20 10 |
Razem |
10 |
30 |
60 |
100 |
Suma ważonych iloczynów par odchyleń zmiennych jest równa:
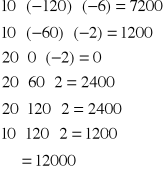
Kowariancja zmiennych X i Y wynosi: 120 (12000:100).
Zatem współczynnik korelacji liniowej Pearsona jest równy:
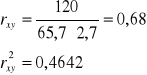
Na tej podstawie można stwierdzić, że między liczbą izb a liczbą uczniów w szkole zachodzi dosyć silna dodatnia zależność korelacyjna. Zmienność jednej cechy jest w 46,42% wyjaśniona zmiennością drugiej.
Współczynnik korelacji kolejnościowej (rang) Spearmana
Współczynnik ten służy do opisu siły korelacji dwóch cech, szczególnie wtedy, gdy mają one charakter jakościowy i istnieje możliwość uporządkowania obserwacji w określonej kolejności.
Miarę tę można stosować również do badania zależności między cechami ilościowymi w przypadku niewielkiej liczby obserwacji.
Współczynnik rang Spearmana obliczamy ze wzoru:
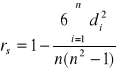
Gdzie:
di - różnice między rangami odpowiadających sobie wartości cechy xi i cechy yi (i=1, 2, ..., n).
Obliczenia rozpoczynamy zazwyczaj od uporządkowania wyjściowych informacji według rosnących (malejących) wariantów jednej z cech.
Uporządkowanym wartościom nadajemy następnie numery kolejnych liczb naturalnych. Czynność ta nosi nazwę rangowania. Rangowanie może odbywać się od najmniejszej do wartości największej do najmniejszej i odwrotnie, przy czym sposób rangowania musi być jednakowy dla obydwu zmiennych.
W przypadku, gdy występują jednakowe wartości realizacji zmiennych, przyporządkowujemy im średnią arytmetyczną obliczoną z ich kolejnych numerów. Mówi się wówczas o występowaniu węzłów.
Jednakowe rangi wartości badanych zmiennych (lub na ogół jednakowe) świadczą o istnieniu dodatniej korelacji między zmiennymi. Natomiast przeciwstawna numeracja sugeruje istnienie korelacji ujemnej.
Współczynnik rang przyjmuje wartości z przedziału -1 < rs < +1, a jego interpretacja jest identyczna jak współczynnika korelacji Pearsona.
Przykład 4
Na podstawie kontroli całokształtu pracy zawodowej i kwalifikacji nauczycieli dyrektor szkoły i wizytator wydali opinię o każdym z nauczycieli. Wyniki ujęto w punktach.
Ustalić natężenie współzależności między opiniami o nauczycielach dyrektora i wizytatora [Sobczyk str. 214, wyd. z 1991]
Nauczyciele |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
Dyrektor |
41 |
27 |
35 |
33 |
25 |
47 |
38 |
53 |
43 |
35 |
36 |
Wizytator |
38 |
24 |
34 |
29 |
27 |
47 |
43 |
52 |
39 |
31 |
29 |
Punktowym wynikom oceny nauczycieli nadajemy rangi, największej ilości punktów przypisujemy rangę 1.
Rangi ocen |
|||||||||||
Dyrektor |
4 |
10 |
7,5 |
9 |
11 |
2 |
5 |
1 |
3 |
7,5 |
6 |
Wizytator |
5 |
11 |
6 |
8,5 |
10 |
2 |
3 |
1 |
4 |
7 |
8,5 |
Różnice rang |
|||||||||||
Dyrektor |
-1 |
-1 |
1,5 |
0,5 |
1 |
0 |
2 |
0 |
-1 |
0,5 |
-2,5 |
Wizytator |
1 |
1 |
2,25 |
0,25 |
1 |
0 |
4 |
0 |
1 |
0,25 |
6,25 |
Wykorzystują wzór na współczynnik rang Spearmana otrzymujemy:
![]()
Otrzymany wynik wskazuje, że współzależność opinii dyrektora i wizytatora jest bardzo silna. Oceniający kierowali się podobnymi kryteriami. Współczynnik determinacji liniowej obydwu zmiennych wynosi 84,64% (wszak ![]()
)
Rodzaje prognoz:
W literaturze polskiej można spotkać wiele kryteriów umożliwiających dokonanie podziału prognoz:
KRYTERIA PODZIAŁU
|
RODZAJE PROGNOZ |
Horyzont czasowy |
Długoterminowe, średnioterminowe, krótkoterminowe i bezpośrednie oraz operacyjne i strategiczne
|
Charakter lub struktura |
1.Proste i złożone 2.Ilościowe i jakościowe w tym ilościowe mogą być: -punktowe i przedziałowe -skalarne i wektorowe 3.Jednorazowe i powtarzalne 4.Kompleksowe i sekwencyjne 5.Samosprawdzające się i destrukcyjne
|
Stopień szczegółowości |
Ogólne i szczegółowe
|
Zakres ujęcia |
Całościowe i częściowe (globalne i odcinkowe)
|
Zasięg terenowy |
Światowe, międzynarodowe, krajowe i regionalne
|
Metoda opracowania |
1. Minimalne, średnie, maksymalne 2.Czyste(pierwotne),weryfikowalne,modelowe 3.Nieobciążone wg największego prawdopodobieństwa, minimalizujące oczekiwaną stratę
|
Cel lub funkcja |
Badawcze w tym ostrzegawcze: - normatywne -aktywne - pasywne
|
Najważniejszą przesłanką wydaje się tzw.: horyzont prognozy czyli okres na który została ona zbudowana .
1. prognoza bezpośrednia inaczej bezzwłoczna nie przekracza 1-miesiąca;
2. prognoza krótkoterminowa obejmuje od 1-3 miesięcy;
3. prognoza średnioterminowa nie przekracza 2 lat;
4. prognoza długoterminowa przekracza 2 lata
Charakter lub struktura pozwala wyróżnić prognozy :
1. proste i złożone
- proste dotyczą pojedynczej zmiennej ekonomicznej
- złożone dotyczą złożonego zjawiska ekonomicznego opisanego przez wyróżniony zbiór zmiennych
2. ilościowe i jakościowe
- ilościowa , gdy stan zmiennej prognozowanej jest wyrażony liczbą i tak mamy:
* punktowa - gdy podaje się, że zmienna prognozowana przyjmie określoną wartość
* przedziałowa - gdy podaje się przedział liczbowy, w którym znajduje się wartość zmiennej prognozowanej
* skalarna - jeżeli podawana jest pojedyncza wartość
* wektorowa - jeżeli jako prognozę uzyskujemy wektor liczb
- jakościowa, dotyczy cechy jakościowej czyli jest to prognoza opisana słownie(stan zmiennej ilościowej)
3. prognoza jednorazowa stawiana jest jednokrotnie i najczęściej dla zmiennych strategicznych
4. prognoza strategiczna dostarcza podstaw do podejmowania długofalowych decyzji
5. prognoza powtarzalna jest ciągle poprawiana w miarę dopływu nowych rzeczywistych informacji o kształtowaniu się zmiennej prognozowanej. Prognozowaniu powtarzalnemu poddawane są głównie prognozy operacyjne .Prognozy operacyjne są wykorzystywane w planowaniu bieżącej działalności (krótkoterminowo)
6.prognozy kompleksowe to prognoza całościowa opisująca przyszłą sytuację na ogół złożonego zjawiska
7. prognozy sekwencyjne to prognoza obliczona dla badanego zjawiska ekonomicznego dla kilku okresów przy czym okresy te muszą być oddalone od siebie o ten sam odcinek czasu
8. prognozy samosprawdzające się to takie , które ogłoszone sprzyjają realizacji tego przewidywania mimo, że przed jej ogłoszeniem prawdopodobieństwo realizacji nie było zbyt duże
9. ogłoszenie prognozy destruktywnej powoduje obniżenie szans na realizację przewidywanego zdarzenia
Kolejne dwa kryteria dają takie same podziały prognoz, dotyczą one tylko pewnego aspektu badanego zjawiska tzn.: prognozy ogólne inaczej całościowe, globalne opisują stan zjawiska agregatów , zaś prognozy szczegółowe , częściowe, odcinkowe opisują stan zjawiska jednorodnego.
Zasięg terenowy determinuje nazwę prognozy.
Metoda opracowania: prognozy gospodarcze dzieli się także ze względu na zastosowaną metodę opracowania i tak przyjęcie prognozy na najmniejszym, średnim lub największym z obliczonych poziomów daje prognozę odpowiednio - minimalną, średnią lub maksymalną.
- prognozy czyste(pierwotne) są to prognozy uzyskane w wyniku ekstrapolacji zaobserwowanego trendu badanego zjawiska. Takie prognozy są najczęściej krótkoterminowe i są traktowane jako wstępne przewidywanie przyszłego rozwoju
- prognozy weryfikowalne to na ogół prognozy powtarzalne, weryfikowalne w oparciu o napływające materiały statystyczne
- prognozy modelowe to taki, które zostały uzyskane na podstawie modelu
- prognozy nieobciążone wg największego prawdopodobieństwa i minimalizujące oczekiwaną stratę to takie prognozy , które są wynikiem zastosowania odpowiedniej zasady predykcji ilościowej
Cel lub funkcja: głównym zadaniem prognoz badawczych jest wszechstronne rozpoznanie przyszłości . Wśród tych prognoz wyróżniamy:
- prognozy ostrzegawcze, których zadaniem jest przekazywanie sygnałów zwracających uwagę na niekorzystne dla odbioru kształtowanie się zjawisk
- jeżeli prognoza dotyczy pewnych norm, które będą obowiązywać w przyszłości to nazywa się prognozą normatywną
- jeśli prognoza pobudza do działania to jest to prognoza aktywna
- w przeciwieństwie do prognozy pasywnej zniechęcającej odbiorcę do podejmowania określonych działań
Dane statystyczne wykorzystywane w prognozowaniu:
Wymaga się aby dane liczbowe były (ich cechy):
- jednorodne
- rzetelne
- jednoznaczne(podawane w taki sposób aby każdy rozumiał je tak samo)
-porównywalne w czasie i przestrzeni
- kompletne
- aktualne dla przyszłości
Materiał statystyczny, który jest podstawą do wyboru klasy, modelu prognostycznego, postaci zależności oszacowań parametrów, weryfikacji prognoz wygasłych itd.. powinien być wolny od błędnych informacji.
Wyróżnia się dwa rodzaje błędów:
systematyczne(nielosowe)
przypadkowe(losowe)
Podstawowym źródłem błędów powstałych w trakcie zbierania i wstępnego opracowania danych są:
1. niedokładność i praktyczne trudności przy określaniu jednostki badania
2. opuszczenie lub wielokrotne ujęcie niektórych jednostek
3. niejasne lub ogólnikowe sformułowanie pytań w formularzu lub ich niewłaściwa interpretacja
4.świadome lub nieświadome udzielanie fałszywych informacji
5. niedokładność pomiarów lub obliczeń
6. błędy powstałe w trakcie wpisywania danych do formularza, przenoszenie ich do zbiorczego formularza lub na maszynowe nośniki informacji
7. błędy klasyfikacji i symbolizacji lub segregacji i tabulacji
Szacowanie brakujących danych
Jeżeli przy prowadzeniu badań powstaje problem niedostępności informacji statystycznej bezpośrednie wykorzystanie klastycznych metod ekonometrycznych staje się niemożliwe. W tej sytuacji można zastosować jedno z trzech rozwiązań:
ograniczyć przekroje analizy - polega to na wyeliminowaniu tych zmiennych lub obiektów dla , których brakuje danych. Usunięcie zbyt dużej liczby istotnych zmiennych objaśniających może znacznie zredukować rozmiary modelu a tym samym podwyższyć wariancję resztową modelu i w rezultacie spowodować zwiększenie błędu prognozy
wykorzystać niekompletne dane(badania bez obcej informacji) - polega na tym, iż korzysta się tylko z tych metod ekonometrycznych, które mogą być zastosowane przy posiadaniu niekompletnych danych ponadto można stosować np. procedury o charakterze jakościowym czyli metody szacunku, ekspertów, burzę mózgów , seanse delfickie, metody Peatter (nie można stosować klasycznych metod)
szacować brakujące informacje(badanie z obcą informacją) - kompromisowe rozwiązanie polega na tym, że na podstawie dostępnych danych źródłowych dokonuje się oszacowania brakujących informacji w rezultacie otrzymuje się kompletny materiał liczbowy. W ten sposób z jednej strony nie ogranicza się a priori zakresu merytorycznego analizy z powodu braku kompletnych danych a z drugiej strony umożliwia stosowanie bardziej precyzyjnych metod ekonometrycznych. Z takiego rozwiązania wynikają korzyści merytoryczne i metodologiczne. Wadą zaproponowanego podejścia jest wprowadzenie do badań informacji obarczonych pewnym błędem szacunków.
Prognozy w procesie decyzyjnym
Niemożność obliczenia bezbłędnej prognozy pasywnej lub aktywnej dotyczącej złożonych
zjawisk gospodarczych wynika przede wszystkim z faktu, że w procesach gospodarczych uczestniczy człowiek . Każdy proces, w który uczestniczy człowiek zawsze jest nie w pełni przewidywalny i stąd między innymi nie można opracować pewnej prognozy zjawisk gospodarczych. Konsekwencją jest, że rezultat decyzji podejmowanych na podstawie niepewnej prognozy jest też niepewny.
W każdej sytuacji możliwość wyznaczenia najlepszej w danych warunkach strategii posługiwania się prognozą, wiąże się z koniecznością przyjęcia odpowiedniego kryterium pozwalającego na ocenę poszczególnych strategii i wskazanie w danych warunkach najlepszej z nich. Ogólnie można powiedzieć, że kryterium tym jest korzyść. W najprostszych przypadkach korzyść ta może wyrażać się zyskiem. Jednak ze względu na niepewność prognozy w momencie podejmowania decyzji korzyść osiągana przy stosowaniu poszczególnych strategii też jest niepewna. Potrzebne więc jest jeszcze jedno kryterium przyjęcie dodatkowej zasady wyboru optymalnej strategii. Jest wiele sytuacji, w których chcąc zapewnić największą korzyść decyzję należy podjąć z pominięciem wyników jakie daje prognoza i poprzestać na posiadanej wiedzy a priori o prognozowanym zjawisku.
Zasady budowania prognoz ekonometrycznych.
Szczególna rola prognoz typu ekonometrycznego wynika z dwóch podstawowych okoliczności:
prognozy budowane na podstawie metod ekonometrycznych mają charakter ścisły
metody te pozwalają już w chwili budowania prognozy ocenić rząd jej dokładności co ma istotne znaczenie praktyczne
Obiektywność prognoz ekonometrycznych polega na tym, że gdy model został już zbudowany i oszacowany oraz została wybrana zasada i metoda predykcji(wnioskowania w przyszłość) nie można zbudowanej prognozy dowolnie interpretować.
Wybór modelu prognostycznego
(wybór modelu ekonometrycznego służącego do prognozowania)
Konstruowanie modelu prognostycznego składa się z kilku etapów:
I PIERWSZY ETAP
Na pierwszym etapie wyróżnia się zjawiska, które będą poddane badaniu oraz podejmuje się decyzje w zakresie wyboru postaci analitycznej funkcji służącej do prognozowania. Wybór ten oparty jest na:
1. analizie materiału statystycznego(analiza graficzna z wykorzystaniem różnorakich wykresów, analiza ilościowa z użyciem różnych mierników dobroci dopasowania modelu do danych statystycznych
2. oparty na teorii ekonomicznej, korzystamy ze znanych i sprawdzonych zależności między zjawiskami ekonomicznymi, ujętych w postaci zasad , reguł i twierdzeń ekonomicznych
3. doświadczeniu zdobytym w trakcie prowadzenia podobnych badań, podstawą są rozpoznawalne i empirycznie sprawdzone związki między badanymi zmiennymi wykryte podczas prac badawczych i prognostycznych.
Przyjęcie modelu prognostycznego jest uzależnione od następujących czynników:
jasnej interpretacji ekonomicznej parametrów modelu
możliwości względnie łatwej estymacji parametrów modelu
stopnia dokładności z jaką model opisuje rozwój badanego zjawiska
Na tym etapie przy wyborze modelu w zasadzie są trzy sposoby podejścia:
1.polega na odwołaniu się do istniejącej teorii
2.na analizie materiału empirycznego
3.na wyborze tych zmiennych objaśniających, które są najsilniej skorelowane ze zmienną objaśnianą czyli endogeniczną
II DRUGI ETAP
Na drugim etapie zbiera się dane statystyczne na podstawie, których szacuje się parametry strukturalne i parametry struktury stochastycznej modelu.
III TRZECI ETAP
Na etapie trzecim przeprowadza się estymację parametrów modelu. Nie istnieje uniwersalny sposób szacowania tych parametrów(modelu). Metoda najmniejszych kwadratów może być stosowana tylko w odniesieniu do pewnej określonej klasy modeli.
IV CZWARTY ETAP
Na czwartym etapie następuje weryfikacja modelu. Należy odpowiedzieć na pytanie czy otrzymane wartości ocen parametrów strukturalnych są zgodne z obserwowanymi prawidłowościami i czy model z dostateczną dokładnością ujmuje wahania badanych zmiennych endogenicznych.
V PIĄTY ETAP
Na piątym etapie praktycznie wykorzystuje się zbudowany model, który służy albo do opisu przeszłości albo do wnioskowania w przyszłość.
O wartości stosowanych w prognozowaniu modeli ekonometrycznych decydują przede wszystkim zalety prakseologiczne takie jak:
- celowość
-poprawność
- ścisłość
-znaczenie poznawcze i praktyczne
- uniwersalność i efektywność w zastosowania ich w praktyce
Podstawowe założenia wnioskowania w przyszłość(Z.Pawłowski 1973)
Klasyczne założenia teorii predykcji są następujące:
znajomość modelu kształtowania się zmiennej prognozowanej
stabilność prawidłowości ekonomicznej w czasie
stabilność rozkładu składnika losowego modelu
znajomość wartości zmiennych objaśniających modelu w okresie, na który się prognozuje
dopuszczalność ekstrapolacji modelu poza zaobserwowany w „próbie” obszar zmienności zmiennych objaśniających
Zmodyfikowane założenia teorii predykcji są następujące(prof.Zelias 1997)
znajomość modelu kształtowania się zmiennej prognozowanej, w których odzwierciedla prawidłowość rozwoju tej zmiennej także w przypadku prawie stabilności tej prawidłowości
stabilność lub prawie stabilność prawidłowości w czasie
stabilność lub prawie stabilność rozkładu składnika losowego modelu
znajomość wartości zmiennych objaśniających wartości modelu lub ich rozkładu prawdopodobieństwa w okresie na, który się prognozuje
możliwość ekstrapolacji modelu poza obszarem zmienności zaobserwowany w „próbie” z błędem nie większym od z góry zadanej liczby
Niektóre ważniejsze zasady predykcji ilościowej:
W literaturze przedmiotu wyróżnia się kilka rodzajów predykcji. Do najczęściej wymienianych należą:
- ilościowa i jakościowa
- kompleksowa i sekwencyjna
- jednorazowa i powtarzalna
Podstawowy podział predykcji to rozróżnienie predykcji ilościowej i jakościowej.
Predykcja jakościowa- służy do:
predykcji punktów zwrotnych - polega na przewidywaniu wystąpienia w pewnym okresie zmiany obecnej tendencji
predykcji przewyższaj - ma na celu zbudowanie prognozy mówiącej o tym, że w pewnym okresie zmienna prognozowana osiągnie wartość większą lub mniejszą od wyróżnionej liczby
predykcji ciągów monotonicznych - daje odpowiedź na pytanie czy w kolejnych okresach obserwowana tendencja wzrostowa lub spadkowa utrzyma się
Wymienione rodzaje predykcji jakościowej mają bardzo duże znaczenie dla działalności gospodarczej a przy ich rozwiązywaniu stosuje się najczęściej metody nie matematyczne.
Predykcja jakościowa może być traktowana jako pierwsza przymiarka do przewidywania rozwoju badanego zjawiska a uzyskane prognozy mogą być prognozami ostrzegawczymi.
Predykcja Ilościowa - kończy się obliczeniem prognozy ilościowej.
Predykcja ilościowa punktowa - polega na wyborze jednej liczby uznanej za najlepszą w danych warunkach o cenę wartości interesującej nas zmiennej w przyszłym okresie.
Predykcja przedziałowa - polega na wyznaczeniu przedziału liczbowego o takiej własności, że można mu przypisać rozsądnie bliskie jedności prawdopodobieństwo, że rzeczywista wartość zmiennej prognozowanej znajdzie się w tym przedziale. W literaturze przedmiotu przedział ten nazywa się przedziałem predykcji.
Predykcja punktowa - dominują w niej następujące zasady:
zasada predykcji nieobciążonej - polega na tym, że prognozę ustala się na poziomie nadziei matematycznej zmiennej prognozowanej w okresie na który się prognozuje
zasada predykcji według największego prawdopodobieństwa - polega na obliczeniu prognozy na poziomie wartości najbardziej prawdopodobnej. Pierwsza i druga zasada są nazywane zasadami statystycznymi
zasada minimalizacji oczekiwanej straty - nazywa się zasadą ekonomiczną w wyniku zastosowania tej zasady otrzymuje się prognozę, która nie musi być wartością oczekiwaną czy najbardziej prawdopodobną , musi zapewniać najmniejszy poziom ewentualnych strat
Gdy zmienna prognozowana ma rozkład symetryczny - zasady predykcji nieobciążonej i według największego prawdopodobieństwa dają takie same wyniki.
Gdy zmienna prognozowana ma rozkład asymetryczny bardziej uzasadniona jest predykcja według największego prawdopodobieństwa.
Dominująca zasada to zasada predykcji opartej na przedziale ufności ( predykcja przedziałowa)
Miary dokładności wnioskowania w przyszłość:
Dokładność wnioskowania w przyszłość na podstawie modelu ekonometrycznego zależy od trzech czynników:
poprawnego oszacowania parametrów modelu
zastosowania właściwej zasady wnioskowania
przyjęcia właściwych założeń wyjściowych
Rola składnika losowego w modelu, w procesie wnioskowania w przyszłość:
Składnik losowy modelu ekonometrycznego nie jest bezpośrednio obserwowalny, można jednaj otrzymać oceny jego wartości przy obliczeniu reszt modelu. Reszty modelu definiuje się jako różnice między rzeczywistymi wartościami zmiennej objaśnianej a jej wartościami teoretycznymi. Wpływ składników losowych na proces predykcji realizuje się przez powodowanie odchyleń wartości zmiennej prognozowanej od obliczonej prognozy przez fakt, że błędy szacunku parametrów strukturalnych modelu ekonometrycznego zależą wariancji składnika losowego. Wpływ jest tym większy im większa jest wariancja, gdy wariancja składnika losowego jest duża nie jest możliwe ani oszacowanie modelu z wystarczającą do celów praktycznych dokładnością, nie jest też możliwe zbudowanie prognoz dopuszczalnych. Jeżeli wariancja składnika losowego jest bardzo mała to nawet systematyczny wzrost wariancji nie musi świadczyć o niedopuszczalności prognoz. W pewnych sytuacjach można zaobserwować wzrost ocen wariancji składnika losowego w czasie - oznacza to, że w miarę wydłużania horyzontu czasowego prognozy rząd odchyleń przypadkowych wartości zmiennej prognozowanej jest coraz większy, a tym samym dokładność wnioskowania w przyszłość maleje.
Prognozowanie na podstawie klasycznych modeli trendu:
Analiza statystyczna szeregów czasowych ma na celu wykrycie prawidłowości jakim podlega badane zjawisko i jest podstawą prognozowania przebiegu tego zjawiska w przyszłości. W analizie tej wykorzystuje się aparat rachunku prawdopodobieństwa i statystyki matematycznej przyjmując, że zaobserwowany szereg czasowy jest jedną z wielu możliwych realizacji pewnego dyskretnego procesu stochastycznego {Yt} t= 1,2,…,n określanego dla wszystkich t całkowitych i dodatnich. Jeżeli ustalimy t , to Yt jest zmienną losową, której realizacją jest element yt zaobserwowanego szeregu, o procesie tym zakłada się zwykle, że jest:
stacjonarny (co najmniej w sensie szeregowym) - to założenie gwarantuje, że mechanizm generujący proces stochastyczny jest niezmienny w czasie tak, iż ani postać przyjętego modelu ani jego parametry nie podlegają zmianą w czasie
ergodyczny - to założenie gwarantuje, że wartości procesu stochastycznego stosunkowo odległe w czasie są nie skorelowane lub bardzo słabo skorelowane
Do celów prognostycznych wygodniej jest przyjąć, że proces stochastyczny, którego fragmentem realizacji dysponujemy ( w postaci zaobserwowanego szeregu czasowego) jest wypadkową działania pewnego procesu deterministycznego związanego z działaniem tzw. przyczyn głównych oraz innego - mającego pewne szczególne wartości procesu stochastycznego związanego z działaniem tzw. przyczyn przypadkowych (ubocznych)
W związku z tym w analizowanych szeregach czasowych będziemy wyróżniać dwie składowe:
1. składowo- systematyczną związaną z procesem deterministycznym
2. składową - przypadkową (zwaną też składnikiem losowym lub wahaniami przypadkowymi) związaną z procesem stochastycznym o szczególnych własnościach
Składowa systematyczna może wystąpić w postaci :
trendów - trend jest to długookresowa skłonność do jednokierunkowych zmian(wzrostu lub spadku) wartości badanej zmiennej. Jest rozpatrywana jako konsekwencja działania stałego zestawu czynników na prognozowane zjawisko
stałego(średniego) poziomu zmiennej prognozowanej - stały poziom oznacza brak trendu i oscylowanie wartości badanej zmiennej wokół pewnego stałego poziomu
składowej okresowej(periodycznej), która z kolei może wystąpić w postaci
- wahań cyklicznych; wahania cykliczne to długookresowe rytmiczne wahania wartości badanej zmiennej wokół trendu lub stałego(średniego) poziomu zmiennej . W przypadku ekonomicznych szeregów czasowych są one na ogół związane z cyklem koniunkturalnym gospodarki
- wahań sezonowych : wahania sezonowe są zmianami wartości prognozowanej zmiennej wokół trendów lub stałego(średniego) poziomu zmiennej, powtarzającymi się mniej więcej w tych samych rozmiarach co pewien okres(w przybliżeniu stały) nie przekraczający 1 roku
Proces wyodrębniania poszczególnych składowych szeregu czasowego nazywa się dekompozycją szeregu czasowego. W praktyce dekompozycję szeregu czasowego na poszczególne składowe przeprowadza się budując modele szeregu czasowego. W zależności od przyjętych założeń co do wpływu poszczególnych składowych i ich wzajemnych relacji oraz sposobu określenia parametrów modele te mogą mieć różną postać. W procesie prognozowania wykorzystywane są między innymi modele addytywne i modele multiplikatywne. Załóżmy, że dysponujemy szeregiem czasowym y1,y2,…,yn, będącym fragmentem realizacji pewnego procesu stochastycznego opisującego prognozowane zjawisko, jeżeli przyjmiemy, że każdy element yt jest sumą (wszystkich lub kilku) składowych szeregu czasowego to model nazywamy addytywnym . Przy założeniu, że jedyną zmienną objaśniającą w tym modelu jest zmienna czasowa to zapisujemy go w postaci yt = f(t) + g(t) + h(t) + ξt gdzie t= 1,2,…,n
f(t) funkcja czasu opisująca trend
g(t) funkcja czasu opisująca wahania sezonowe
h(t) funkcja czasu opisująca wahania cykliczne
ξ składnik losowy , a więc realizacja procesu opisującego składową przypadkową
W modelu tym składowa systematyczna związana z procesem deterministycznym jest opisywana sumą funkcji.
Jeżeli założymy, że każdy element yt jest iloczynem składowych szeregu czasowego to model nazywa się multiplikatywnym i przy założeniu, że jedyną zmienną objaśniającą w tym modelu jest zmienna czasowa yt = f(t) ∙ g(t) ∙ h(t) ∙ ξt gdzie t= 1,2,…,n. W modelu tym składowa systematyczna jest opisywana przez iloczyn funkcji: f(t) ∙ g(t) ∙ h(t)
Gdy w szeregu czasowym występuje składowa w postaci stałego(średniego) poziomu w obydwu modelach będziemy przyjmować, że f(t) ≡ c = const.
Horyzont prognozy
Prognozę łatwiej jest skonstruować i uzasadnić gdy horyzont czasowy prognozy jest krótki. Przyjmijmy następujące oznaczenia:
Yt zmienna czasowa opisująca badane zjawisko ekonomiczne
t(t= 1,2,…,n) zmienna czasowa
yt (t= 1,2,…,n) szereg czasowy realizacji zmiennej Yt w badanych okresach(lub momentach)
It przedział czasowy „próby” gdzie t jest numerem środkowego okresu(lub momentu) należącego do badanego przedziału czasu
Prognozy gospodarcze są obliczone z określonym wyprzedzeniem, podstawowe pojęcia z tym związane są następujące:
horyzont prognozy to przedział postaci (Z.Pawłowski 1993r.) - (tb,T ] gdzie tb - to bieżący okres, T - jest to okres dla którego sporządzamy prognozę
wyprzedzenie czasowe prognozy(w stosunku do bieżącego okresu) jest to długość horyzontu prognozy h'= T - tb
horyzont predykcji(dla bieżącego okresu) to przedział postaci (tb,tb + Δ2 ], gdzie Δ2 jest to długość horyzontu predykcji wynikająca z przyjęcia określonego modelu prognostycznego. Horyzont predykcji jest pojęciem teoretycznym ponieważ nie znamy wartości Δ2 dla modeli prognostycznych. Możemy jedynie próbować ją oszacować w drodze badania dopuszczalności prognoz uzyskiwanych dane metodą dla prognozowanego zjawiska. Jeżeli przez Δ1 oznaczymy czas niezbędny do podjęcia efektywnych kroków w celu skorygowania zarysowujących się( w świetle otrzymanej prognozy np. ostrzegawczej) niekorzystnych tendencji ekonomicznych to chcielibyśmy aby zachodziły następujące nierówności Δ1 ≤ h' ≤ Δ2 , oznacz to, że wyprzedzenie czasowe prognozy( w stosunku do bieżącego okresu) powinno zapewniać możliwość podjęcia działań zmierzających do przeciwstawienia się lub złagodzenia przyszłych niekorzystnych dla odbiorcy prognoz zdarzeń. Jednocześnie wyprzedzenie czasowe prognozy powinno być ograniczone długością horyzontu predykcji czyli „możliwościami” prognostycznymi zastosowanego modelu.
opóźnienie bieżące modelu(w stosunku do bieżącego okresu) nazywamy odległość między okresem bieżącym i okresem środkowym przedziału czasowego „próby” Δ0 = tb - t
predyktywne opóźnienie modelu nazywamy sumę opóźnienia bieżącego modelu i wyprzedzenia czasowego prognozy o postaci L = Δ0 + h' lub L = T - t , którą interpretujemy jako uprzedzenie okresu na, który się prognozuje w porównaniu ze środkiem przedziału czasowego „próby”
horyzont predykcji(dla wyjściowego okresu prognozy) to przedział postaci (tn, tn+ Δ2] gdzie tn jest to wyjściowy okres prognozy, czyli okres dla, którego dysponujemy najnowszą informacją o rzeczywistej realizacji zmiennej prognozowanej
opóźnienie w dopływie danych statystycznych to następująca równość Δ3 = tb - tn
realne wyprzedzenie czasowe prognozy to odległość okresu na, który się prognozuje od wyjściowego okresu prognozy czyli h = T - tn lub h = h' + Δ3 = T - tb + Δ3
Na podstawie powyższych definicji można zapisać następującą nierówność: h' ≤ h ≤ Δ2
Realne wyprzedzenie czasowe prognozy jest co najmniej równe wyprzedzeniu czasowemu prognozy( w stosunku do bieżącego okresu).Równość zachodzi tylko wówczas gdy nie występuje opóźnienie w dopływie danych czyli bieżący okres jest zarazem ostatnim okresem dla, którego posiadamy dane statystyczne.
Realne wyprzedzenie czasowe prognozy powinno być ograniczone ze względu na zastosowany model prognostyczny, którego własności pozwalają uznać za uzasadnione tylko prognozy charakteryzujące się realnym wyprzedzeniem czasowym nie przekraczającym długości horyzontu predykcji.
Zadanie 1
Przyjmijmy, że mamy szereg czasowy obserwacji zmiennej Yt w kolejnych miesiącach od stycznia 1997 do czerwca 2001r. Zatem yt (t= 1,…,54) jest realizacją zmiennej Yt w miesiącu t. Zakładamy, że w listopadzie 2001 r. obliczono prognozę dla stycznia 2002 r. Na podstawie przyjętych założeń można określić następujące wielkości:
tb = 59 to bieżący okres czyli listopad 2001
T = 61 to okres dla, którego obliczono prognozę czyli styczeń 2002
t = 27 to numer środkowego okresu należącego do badanego przedziału czasu czyli
marzec 1999
tn = 54 to wyjściowy okres prognozy czyli czerwiec 2001
Mając ustalone powyższe wielkości można zapisać następujące charakterystyki obliczonej prognozy:
przedział czasowy próby jest w postaci J27 = [1,54]
horyzont prognozy to przedział ( 59, 61]
opóźnienie w dopływie danych Δ3 = 59-54 =5 miesięcy
wyprzedzenie czasowe prognozy (w stosunku do bieżącego okresu) jest równe h' = 61-59 = 2 miesiące; natomiast ze względu na występujące opóźnienie w dopływie danych, realne wyprzedzenie czasowe prognozy wynosi h = 2+5 = 7 miesięcy. Brak dostępu do aktualnych danych ( Δ3 > 0 ) może spowodować, że prognoza krótkoterminowa z punktu widzenia bieżącego okresu (h'=2) może się stać prognozą średnioterminową (h= 7) taka zmiana klasyfikacyjna może doprowadzić do uznania prognozy za niedopuszczalną ze względu na zastosowany model prognostyczny tzn. może mieć miejsce następująca nierówność Δ2 < h
opóźnienie bieżące modelu ( w stosunku do bieżącego okresu) jest równe Δ0 = 59-27 = 32 miesiące
predyktywne opóźnienie modelu wynosi L = 32 + 2 = 34 miesiące
Zadanie 2
Przyjmijmy, że dysponujemy szeregiem czasowym (dane dzienne) zmiennej Yt od lipca 2000r do 15 grudnia 2001r. W dniu 28 grudnia 2001r sporządzamy prognozę dla 10 stycznia 2002r. Na podstawie tych informacji określ:
1. bieżący okres
2. wyjściowy okres prognozy
3. horyzont prognozy
4. wyprzedzenie czasowe prognozy ( w stosunku do bieżącego okresu)
5. opóźnienie bieżące modelu ( w stosunku do bieżącego okresu)
6. predyktywne opóźnienie modelu
7. opóźnienie w dopływie danych statystycznych
8. realne wyprzedzenie czasowe prognozy
Odp.:
1. bieżący okres
yt ( 1,…,533)
tb = 546 od 1 lipca 2000 do 28 grudnia 2001r
2. wyjściowy okres prognozy
tn = 533 dni
od lipca 2000 do 15 grudnia 2001r
3. horyzont prognozy
( tb,T] T = 559 dni to okres dla, którego sporządzamy prognozę 1 lipca 2000 do 10 stycznia 2002r czyli ( 546, 559]
4.wyprzedzenie czasowe prognozy ( w stosunku do bieżącego okresu) - to długość horyzontu prognozy
h' = T - tb
h' = 559-546 = 13 dni
5. opóźnienie bieżące modelu ( w stosunku do bieżącego okresu) czyli odległość między okresem bieżącym a środkowym przedziału czasowego „próby”
Δ0 = tb-t t = (tn +1):2, gdy tn jest nieparzyste
Δ0 = 546 - (533+1) : 2 t = tn : 2 , gdy tn jest parzyste
Δ0 = 546 - 267 = 279 dni
6. predyktywne opóźnienie modelu to suma opóźnienia bieżącego i wyprzedzenia czasowego prognozy
L = Δ0 +h' L = T - t
L = 279+13 = 292 dni lub L = 559 - 267 = 292 dni
7. opóźnienie w dopływie danych statystycznych
Δ3 = tb - tn
Δ3 = 546 - 533 = 13 dni
8. realne wyprzedzenie czasowe prognozy
h = T - tn
h = 559 - 533 = 26 dni
Zadanie 3
Wpływy z prywatyzacji (w mln zł) w latach 1992-1998 w Polsce (zmienna Yt) kształtowały się następująco:
ROK
|
yt |
1992 1993 1994 1995 1996 1997 1998 |
309 440 846 1722 1959 6636 7069
|
W 1999 roku podano, że prognozowana wartość wpływów z prywatyzacji w 2000 roku wyniesie 20 000 mln zł. Dla podanej prognozy określ:
1. bieżący okres
2. wyjściowy okres prognozy
3. horyzont prognozy
4. wyprzedzenie czasowe prognozy ( w stosunku do bieżącego okresu)
5. opóźnienie bieżące modelu ( w stosunku do bieżącego okresu)
6. predyktywne opóźnienie modelu
7. opóźnienie w dopływie danych statystycznych
8. realne wyprzedzenie czasowe prognozy
Odp.:
1. yt t= 1,…,7) tb = 8 lat ( od 1992 do 1999)
2. tn = 7 lat ( od 1992 do 1998)
3. (tb,T] T= 9 lat (od 1992 do 2000)
(8, 9 ]
4. h' = T - tb
h' = 9 - 8 1 rok
5. Δ0 = tb - t t = (7+1) : 2 = 4
Δ0 = 8-4 = 4 lata
6. L = Δ0 + h' lub T - t = 9 - 4 = 5 lat
L = 4+1 = 5 lat
7. Δ3 = tb - tn
Δ3 = 8 - 7 = 1 rok
8. h = T - tn
h 9 - 7 2 lata
Zadanie 4
Załóżmy, że w grudniu 2001 roku obliczono prognozę dotyczącą sytuacji finansowej Akademii Ekonomicznej w Krakowie, w marcu 2002 roku. Na prognozę tę składają się prognozy cząstkowe dotyczące różnych zagadnień wpływających na kondycję finansową uczelni np.: liczby studentów na studiach dziennych, zaocznych i wieczorowych; wysokości czesnego na różnych typach studiów; liczby pracowników dydaktycznych; naukowo- dydaktycznych i administracji; dotacji budżetowych; kosztów różnego rodzaju. Rozważając kolejno wyróżnione kryteria podziału prognoz można przyjąć, że obliczona prognoza jest:
ze względu na horyzont czasowy :
- krótkoterminowa ( stan za trzy miesiące);
- operacyjna (determinuje bieżącą działalność)
ze względu na charakter lub strukturę:
- złożona (sytuacja finansowa jest opisana przez wyróżniony zbiór zmiennych)
- ilościowa (prognozy zmiennych opisujących sytuację finansową mają charakter ilościowy , w tym wektorowa prognozy cząstkowe mogą być zapisane w postaci wektora liczb; przy czym prognozy cząstkowe mogą być punktowe lub przedziałowe
- jednorazowa ( prognoza została obliczona jednorazowo w grudniu 2001 roku)
- kompleksowa (obliczona prognoza całościowo opisuje przyszłą sytuację złożonego zjawiska jakim jest sytuacja finansowa; może ale nie musi być samosprawdzająca lub destruktywna zależy jaką reakcję spowoduje ogłoszenie prognozy
ze względu na stopień szczegółowości
- ogólna, jeżeli przedmiotem zainteresowania jest tylko Akademia Ekonomiczna w Krakowie ( prognozowana zmienna jest zmienną agregatową)
- rozważana prognoza jest szczegółowa jeżeli badanie dotyczy sytuacji finansowej wszystkich akademii ekonomicznych w Polsce
ze względu na zakres ujęcia
- całościowa, jeżeli przedmiotem zainteresowania jest tylko Akademia Ekonomiczna w Krakowie (prognozowana zmienna jest zmienną agregatową
- jest prognozą częściową w przypadku, gdy jest tylko jedną z wielu prognoz składających się na obraz sytuacji finansowej wszystkich akademii ekonomicznych w Polsce w marcu 2002 roku
ze względu na zasięg terenowy
- regionalna (prognoza ma charakter lokalny)
ze względu na metodę opracowania
- zależy od zastosowanej metody prognostycznej
ze względu na cel lub funkcję
- badawcza ( ma na celu wszechstronne rozpoznanie sytuacji finansowej uczelni)
- może być ostrzegawcza ( jeżeli wskaże na niekorzystne kształtowanie się rozważanych elementów wpływających na sytuację finansową)
-może być aktywna tzn. pobudzać do działania
Symulacja
Słowo symulacja jest używane w wielu znaczeniach, dla ustalenia przyjmujemy, że symulacja to wprawianie modelu w ruch. Modele mogą być różne w szczególności mogą zawierać elementy niepewne a więc: zmienne lub parametry, które są losowe i takie modele nazwiemy stochastycznymi lub elementów takich nie zawierać i takie modele nazywamy deterministycznymi. Modele deterministyczne są uproszczeniami modeli stochastycznych.
Symulacja - przegląd definicji:
W wielu publikacjach terminy takie jak:
- symulacja
- montecarlo
- gry(gry operacyjne)
- próbkowanie modelu
używane są zamiennie podczas gdy w innych pracach te same terminy używane są w zróżnicowanym sensie.
w/g Morgenthalera
Symulować oznacza odtworzyć istotę systemu lub jego działanie bez rzeczywistego uruchamiania samego systemu. Symulacja wykorzystuje model do przedstawienia przebiegu w czasie istotnych charakterystyk badanego systemu lub procesu.
w/g Naylora
Definiuje on symulację jako technikę numeryczną służącą do dokonywania eksperymentów na pewnych rodzajach modeli matematycznych, które opisują przy pomocy maszyny cyfrowej zachowanie się złożonego systemu w ciągu długiego okresu czasu.
w/g Kleina (laureat nagrody Nobla z ekonomi-jest nazywany ojcem symulacji w badaniach ekonometrycznych)
Symulacja to znalezienie całkowitej ścieżki rozwiązania skończonego równania różnicowego. Numeryczna symulacja jest sekwencją liczbowych obliczeń na danych gospodarczych i oszacowanych parametrach układu równań a wielkości liczbowe ze ścieżki wzrostu y1,y2,…,yt są liczbową aproksymacją wzorów na rozwiązanie końcowe.
Symulacja deterministyczna to proces numerycznego rozwiązywania modelu (równania) lub układu równań/nierówności celem wyznaczenia trajektorii zmiennych endogenicznych.
W wielu eksperymentach pojawia się konieczność uwzględnienia źródeł niepewności w zachowaniu modelowanego systemu , stwarza to zapotrzebowanie na wprowadzenie do modelu wielkości przybierających wartości losowe zgodnie z pewnym rozkładem prawdopodobieństwa.
Przez metodę Montecarlo rozumie się technikę wyboru wielkości losowych z pewnego rozkładu prawdopodobieństwa. Nazwa montrcarlo wywodzi się od kryptonimu jednego z zadań w projekcie „Manhattan” - budowy amerykańskiej bomby atomowej. Symulacje z wykorzystaniem metody montecalo nazywa się symulacją stochastyczną (lub symulacją montecarlo).
Pojęcie symulacja stochastyczna używane jest w odniesieniu do eksperymentów typu: próbkowania modelu służących badaniu właściwości modelu (lub zastosowanej do badania metody)
Symulacja stochastyczna rozumiana jako próbkowanie modelu oznacza generowanie reprezentatywnej próby zmiennych niezależnych (egzogenicznych) modelu aby następnie wyliczyć pewne sumaryczne charakterystyki trajektorii po jakiej biegną zmienne zależne (e3ndogeniczne) modelu.
Próbkowanie modelu pozwala na określenie charakteru rozkładów wynikowych tam gdzie zastosowanie technik charakterystycznych jest zawodne.
Pojęcie symulacji pojawia się także w grach kierowniczych oraz optymalizacji strategii dla graczy w sytuacjach konfliktowych. Do symulacji zaliczane są pewne metody heurystyczne naśladujące w ten czy inny sposób podejmowanie decyzji w ludzkim umyśle oraz proces rozwiązywania problemów decyzyjnych. W klasie metod naśladujących umysł wyróżniamy metody sieci neuronowych:
- w klasie metod naśladujących ewolucję - algorytmy genetyczne,
- w klasie metod naśladujących zjawiska fizyczne - symulowane wyżarzanie .
Symulacja zdarzeń dyskretnych:
To symulacja prosta - główną niedoskonałością rozwiązania praktycznego jest to, że wymaga ono fizycznego losowania składników z odpowiednich pojemników, jest to operacja kłopotliwa a przy wielokrotnym powtarzaniu pracochłonna i kosztowna - losowanie metodą odwracania dystrybuanta.
Dokładność wnioskowania z próby:
Ocena parametrów populacji generalnej wykorzystująca informacje statystyczną zawartą w próbie wiąże się z ryzykiem związanym ze zmiennością próby. O próbie , w której rozkład interesującej nas cechy odbiega od rozkładu tej cechy populacji z której pobraliśmy próbę mówimy, że jest nie reprezentatywna. Dział statystyki zwany metodą reprezentacyjną zajmuje się metodami doboru prób reprezentatywnych. Metoda reprezentacyjna zajmuje się metodami takiego generowania próby aby ta miała szansę okazać się reprezentatywną. Zmienność rezultatów wyliczanych na podstawie różnych prób jest skutkiem tego, że w wyniku losowania do prób takich trafiają różne elementy a więc wyliczanie różnych prób miary jak np.: średnia lub odchylenia standardowe przybierają odmienne wartości o miarach takich mówimy, że mają zmienność z próby tzn.: ich wartości są niepewne gdyż wyliczane są z losowo dobranej próby. Stosując odpowiednie metody statystyczne możemy zmniejszyć zmienność z próby. Jednym z głównych sposobów zmniejszania niepewności związanej ze zmiennością z próby jest powiększenie ilości wylosowanych obserwacji tzn.:zwiększanie liczebności próby.
TERMINOLOGIA MODELI ZDARZEŃ DYSKRETNYCH
Terminologia związana z symulacją zdarzeń dyskretnych jest zdecydowanie niejednoznaczna. W symulowanych systemach występują dwa rodzaje elementów(obiektów)- jednostki działające w systemie oraz zasoby.
Jednostki są indywidualnymi elementami działającymi w systemie i ich zachowanie jest przedmiotem symulacji.
Zachowanie każdej jednostki jest bezpośrednio śledzone a zmiana jej stanu rejestrowana np.: jednostka pacjent zmienia swój stan, ..
Zmiana stanu całego systemu jest owocem wzajemnych oddziaływań jednostek funkcjonujących w tym systemie.
Jednostki mogą być:
permanentne - funkcjonują w modelu od początku do końca symulacji
czasowe - pojawiają się i znikają w miarę potrzeb
Zasoby są takimi elementami systemu , które nie są modelowane indywidualnie ale zmieniają się w skutek działania jednostek np.: liczba pasażerów oczekujących na przystanku.
Elementy składowe zasobów są jednorodne i przeliczalne a wykonawca rejestruje wielkość (liczebność) zasobów.
Zaliczenie elementu systemu do grupy jednostek lub zasobów jest decyzją twórcy modelu wyznaczoną przez cel symulacji, rodzaj modelu i jego szczegółowość.
Jednostki mogą być grywane w klasy (stałe grupy identycznych jednostek); zbiory (czasowe grupy jednostek); jednostek także mogą być rozróżniane w/g atrybutów (cech).
Upływ czasu zaznaczony jest przez:
zdarzenia a więc momenty w których zaszła istotna zmiana stanu systemu gdy np.: jednostka opuszcza jakiś zbiór ; jakaś czynność rozpoczyna się lub kończy
czynności gdy jakaś jednostka przechodzi ze zbioru do zbioru dzięki operacji w której uczestniczy - czynności rozpoczynane są zdarzeniami przekształcającymi stan systemu
procesy - są to chronologicznie rozporządzane ciągi zdarzeń czynności rozpoczynanych i kończonych zdarzeniami
zegar - jest to zmienna reprezentująca moment w którym znajduje się symulowany system, zmiany zegara symulują upływ czasu.
Modele zdarzeń dyskretnych opisują procesy i systemy będące szczególnie często przedmiotem zainteresowania badań operacyjnych.
SYMULACJA MODELI CIĄGŁYCH
Symulacja modeli ekonometrycznych jest szczególnie rozwiniętą wyspecjalizowaną gałęzią symulacji.
W kontekście modeli wielorównaniowych słowo symulacja używane jest zarówno jako określenie procesu rozwiązywania modelu (symulacja deterministyczna); jak i procesu badania właściwości estymatorów, testów lub rozwiązań modelu (symulacja stochastyczna).
Rozróżniamy symulację (czynność) od rozwiązania (produktu tej czynności).Rozwiązanie
dla kilku okresów czasu daje trajektorię po której biegną zmienne endogeniczne.
Symulacja dynamiczna różni się od statycznej sposobem w jaki traktujemy opóźnione zmienne endogeniczne występujące po prawej stronie znaku równości:
w dynamicznej wstawiamy tam rozwiązanie wyliczone w poprzednich okresach
w statycznej wstawiamy tam empiryczne wartości zmiennych endogenicznych.
W modelach ciągłych zmienne endogeniczne są ciągłe, natomiast czas może być albo ciągły(głównie w modelach teoretycznych ) albo dyskretny a przynajmniej zdyskretyzowany gdy wartości zmiennych endogenicznych aktualizujemy w oddalonych od siebie momentach czasu.
Do obszernej klasy modeli ciągłych należą modele ekonomii matematycznej jak np.: modele wzrostu, modele popytu.
modele ekonomii matematycznej
modele dynamiki systemu
modele ekonometryczne - zwane modelami opisowymi, regresyjnymi, strukturalnymi.
Modele strukturalne opierają się na strukturze pewnej teorii ekonomicznej. Modele regresyjne opisują regresję albo warunkową wartość oczekiwaną zmiennej endogenicznej względem zmiennych objaśniających.
Pojęcia te różnią się nieco od siebie, a mianowicie równania modeli strukturalnych ze sprzężeniami zwrotnymi nie zawsze dadzą się zinterpretować jako równania regresji ze względu na to, że pewne zmienne objaśniające nie są niezależne od zakłóceń. Z kolei wiele równań regresji nie opiera się na teorii ekonomicznej.
Modele strukturalne stosowane są nie tylko do opisu zjawisk gospodarczych ale mogą być stosowane w:
- demografii (modele demometryczne)
- socjologii (modele socjometryczne)
- biologii (modele biometryczne)
Rozwiązania modeli tj. trajektorie po których biegną zmienne objaśniane przez równania modelu wyliczone są przy pomocy symulacji deterministycznej. W symulacji deterministycznej wprawiamy model w ruch bez uwzględnienia faktu, że pewne jego elementy są losowe..
W zależności od sposobu wyznaczenia i wykorzystania tych rozwiązań, otrzymujemy prognozy i scenariusze, jeśli analiza skupia się na przyszłych a przynajmniej możliwych zdarzeniach w świecie opisywanym przez model.
Natomiast gdy analiza skupia się na właściwościach samego modelu opisującego rzeczywistość otrzymujemy mnożniki oraz rozwiązania:
- bazowe
- kontrolne
- zaburzone
W symulacji stochastycznej uwzględniamy fakt, że pewne elementy modelu systemu są losowe i jako takie znamy jedynie w przybliżeniu. Wielokrotnie wprawiamy model w ruch wprowadzając za każdym razem pewne zaburzenia do losowych fragmentów modelu.
Zaburzeniom poddajemy takie niepewne elementy modelu jak:
- zakłócenia
- oceny parametrów
- lub zmienne
Symulacja stochastyczna pozwala na pomiar wpływu niepewności na właściwości modelu, na wyznaczenie miar dokładności szacunku parametru, wartości krytycznych testu a także charakterystyk dokładności prognoz scenariuszy czy też mnożników modeli.
Programy:
STATGRAPHICS - stary program robiący symulacje
STATISTICA wersja VI
SPSS program bardzo trudny ale bardzo dobry
NATCAD bardzo dobry program
Siła korelacji
1
METODY PROGNOSTYCZNE
Modele o równaniach współzależnych
Modele rekurencyjne
Modele proste
Modele autoregresyjne
Modele przyczynowo- opisowe
Adaptacyjne modele trendu
Klasyczne modele trendu
Wielorównaniowe modele ekonometryczne
Jednorównaniowe modele ekonometrycze
Metody oparte na modelach ekonometrycznych
Metody oparte na modelach deterministycznych
Metody:
-ankietowe
-intuicyjne
-kolejnych przybliżeń
-ekspertyz
-delficka
-refleksji
-analogowe
-inne
Metody nie matematyczne
Metody matematyczno-
statystyczne
Wyszukiwarka