Maria Pajda
ZIP 2.1
sekcja 1

POLITECHNIKA ŚLĄSKA W GLIWICACH
WYDZIAŁ ORGANIZACJI I ZARZĄDZANIA
kierunek: Zarządzanie i Inżynieria Produkcji
MODEL
EKONOMETRYCZNY
Zabrze, 12.01.2007r.
Liczba zamachów samobójczych zarejestrowanych przez policję
w latach 1987 - 2004.
Wykonany przeze mnie model pokazuje zależności rożnych zjawisk, które wpływają na liczbę popełnianych zamachów samobójczych, jakie zostały zarejestrowane przez policję w latach 1987 - 2004r.
Dane do modelu zebrałam na podstawie danych źródłowych z Roczników Statystycznych Głównego Urzędu Statystycznego, a przy tworzeniu modelu korzystałam z programu Microsoft Excel.
Dane do modelu
t |
Y |
X1 |
X2 |
X3 |
X4 |
1987 |
4740 |
40,9 |
2235,6 |
49707 |
534882 |
1988 |
4208 |
48,1 |
1997,4 |
48211 |
549326 |
1989 |
3657 |
49,7 |
2116,4 |
47189 |
534101 |
1990 |
3841 |
56,3 |
2594,4 |
42436 |
553008 |
1991 |
4327 |
97,9 |
2726,9 |
33823 |
558761 |
1992 |
5746 |
142,83 |
2040,3 |
32024 |
565474 |
1993 |
5928 |
173,62 |
1789,3 |
27891 |
586296 |
1994 |
6004 |
230,93 |
1813,3 |
31574 |
623198 |
1995 |
5988 |
300,56 |
1887,5 |
38115 |
649494 |
1996 |
5830 |
383,43 |
1903,2 |
39449 |
658526 |
1997 |
6129 |
473,79 |
1457 |
42549 |
664140 |
1998 |
6028 |
522,93 |
1971,4 |
45230 |
705538 |
1999 |
5182 |
560,43 |
2025,8 |
42020 |
782591 |
2000 |
5621 |
610,51 |
1830,8 |
42770 |
821645 |
2001 |
5712 |
644,48 |
1836,3 |
45308 |
923489 |
2002 |
5928 |
664,21 |
1389 |
45414 |
1050771 |
2003 |
5467 |
711,96 |
1536 |
48632 |
1149959 |
2004 |
5893 |
735,4 |
1498,5 |
56332 |
1275336 |
Y - Liczba zamachów samobójczych zarejestrowanych przez policję w sztukach
X1 - Przeciętny miesięczny dochód rozporządzalny w gospodarstwach domowych na 1 osobę w zł.
X2 - Liczba osób zwolnionych z pracy w tys. sztuk
X3 - Liczba małżeństw rozwiązanych przez rozwód w sztukach
X4 - Liczba osób zarejestrowanych w poradniach zdrowia psychicznego cywilnej służby zdrowia w sztukach
Współczynniki korelacji
t |
Y |
X1 |
X2 |
X3 |
X4 |
1987 |
4740,0000 |
40,9000 |
2235,6000 |
49707,0000 |
534882,0000 |
1988 |
4208,0000 |
48,1000 |
1997,4000 |
48211,0000 |
549326,0000 |
1989 |
3657,0000 |
49,7000 |
2116,4000 |
47189,0000 |
534101,0000 |
1990 |
3841,0000 |
56,3000 |
2594,4000 |
42436,0000 |
553008,0000 |
1991 |
4327,0000 |
97,9000 |
2726,9000 |
33823,0000 |
558761,0000 |
1992 |
5746,0000 |
142,8300 |
2040,3000 |
32024,0000 |
565474,0000 |
1993 |
5928,0000 |
173,6200 |
1789,3000 |
27891,0000 |
586296,0000 |
1994 |
6004,0000 |
230,9300 |
1813,3000 |
31574,0000 |
623198,0000 |
1995 |
5988,0000 |
300,5600 |
1887,5000 |
38115,0000 |
649494,0000 |
1996 |
5830,0000 |
383,4300 |
1903,2000 |
39449,0000 |
658526,0000 |
1997 |
6129,0000 |
473,7900 |
1457,0000 |
42549,0000 |
664140,0000 |
1998 |
6028,0000 |
522,9300 |
1971,4000 |
45230,0000 |
705538,0000 |
1999 |
5182,0000 |
560,4300 |
2025,8000 |
42020,0000 |
782591,0000 |
2000 |
5621,0000 |
610,5100 |
1830,8000 |
42770,0000 |
821645,0000 |
2001 |
5712,0000 |
644,4800 |
1836,3000 |
45308,0000 |
923489,0000 |
2002 |
5928,0000 |
664,2100 |
1389,0000 |
45414,0000 |
1050771,0000 |
2003 |
5467,0000 |
711,9600 |
1536,0000 |
48632,0000 |
1149959,0000 |
2004 |
5893,0000 |
735,4000 |
1498,5000 |
56332,0000 |
1275336,0000 |
suma |
96229,0000 |
6447,9800 |
34649,1000 |
758674,0000 |
13186535,0000 |
średnia |
5346,0556 |
358,2211 |
1924,9500 |
42148,5556 |
732585,2778 |
Na podstawie danych z powyższej tabeli obliczam współczynniki korelacji pomiędzy zmienną objaśnianą Y a zmiennymi objaśniającymi X1,X2,X3,X4 korzystając ze wzoru:
r(y,x1) = |
0,6266 |
r(y,x2) = |
-0,7215 |
r(y,x3) = |
-0,2066 |
r(y,x4) = |
0,4275 |
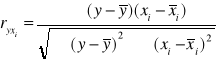
Obliczam również współczynniki korelacji pomiędzy zmiennymi objaśniającymi, korzystając ze wzoru:
r(x1,x2) = |
-0,7117 |
r(x1,x3) = |
0,3989 |
r(x1,x4) = |
0,8882 |
r(x2,x3) = |
-0,2565 |
r(x2,x4) = |
-0,6651 |
r(x3,x4) = |
0,5435 |
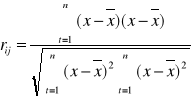
Następnie tworzę wektor korelacji R0 oraz macierz korelacji R
|
0,6266 |
|
|
|
1,0000 |
-0,7117 |
0,3989 |
0,8882 |
R0 |
-0,7215 |
|
|
R |
-0,7117 |
1,0000 |
-0,2565 |
-0,6651 |
|
-0,2066 |
|
|
|
0,3989 |
-0,2565 |
1,0000 |
0,5435 |
|
0,4275 |
|
|
|
0,8882 |
-0,6651 |
0,5435 |
1,0000 |
Metoda Hellwiga
W modelu ekonometrycznym powinny znaleźć się zmienne, które są odpowiednio silnie skorelowane ze zmienną objaśnianą Y. W celu wyeliminowania z modelu zmiennych, które mają słaby wpływ na zmienną objaśniana stosuje się metodę Hellwiga lub Metodę Grafów.
Na początku obliczam ilość kombinacji zmiennych objaśniających x1, x2, x3, x4 według wzoru L=2k-1, gdzie k to ilość zmiennych objaśniających.
L = 2k-1 = 24-1 = 15 kombinacji
Następnie obliczam pojemność indywidualną i integralną z następujących wzorów korzystając z wcześniej obliczonych współczynników korelacji:
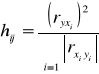
![]()
Zestaw możliwych kombinacji zmiennych objaśniających:
C1={x1} |
H= |
0,3926 |
|
|
|
|
C2={x2} |
H= |
0,5206 |
|
|
|
|
C3={x3} |
H= |
0,0427 |
|
|
|
|
C4={x4} |
H= |
0,1828 |
|
|
|
|
C5={x1x2} |
H= |
0,5335 |
|
|
|
|
C6={x1x3} |
H= |
0,3112 |
|
|
|
|
C7={x1x4} |
H= |
0,3047 |
|
|
|
|
C8={x2x3} |
H= |
0,4483 |
|
|
|
|
C9={x2x4} |
H= |
0,4224 |
|
|
|
|
C10={x3x4} |
H= |
0,1461 |
|
|
|
|
C11={x1x2x3} |
|
|
|
|
|
|
h(11,1)= 0,1860 |
h(11,2)= 0,2645 |
h(11,3)= 0,0258 |
H=0,4763 |
|
|
|
|
|
|
|
|
|
|
C12={x1x2x4} |
|
|
|
|
|
|
h(12,1)= 0,1510 |
h(12,2)= 0,2190 |
h(12,4)= 0,0716 |
H=0,4416 |
|
|
|
|
|
|
|
|
|
|
C13={x1x3x4} |
|
|
|
|
|
|
h(13,1)= 0,1717 |
h(13,3)= 0,0220 |
h(13,4)= 0,0752 |
H=0,2688 |
|
|
|
|
|
|
|
|
|
|
C14={x2x3x4} |
|
|
|
|
|
|
h(14,2)= 0,2709 |
h(14,3)= 0,0237 |
h(14,4)= 0,0827 |
H=0,3774 |
|
|
|
|
|
|
|
|
|
|
C15={x1x2x3x4} |
|
|
|
|
|
|
h(15,1)= 0,1309 |
h(15,2)= 0,1977 |
h(15,3)= 0,0194 |
h(15,4)= 0,0590 |
H=0,4070 |
|
|
Wybieram kombinację, która ma najwyższą wartość; jest to tzw. kombinacja optymalna
C MAX = |
0,5335 |
Z metody Hellwiga wynika, że do modelu wchodzą zmienne x1 i x2, ponieważ C MAX to C5={x1x2}. Oznacza to, że zmienne x1 i x2 mają duży wpływ na zmienną objaśnianą.
Równanie modelu ma postać:
y=α0+α1x1i+α2x2i+εi
Metoda analizy grafów
W metodzie tej korzystamy ze wzoru:
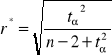
Przeprowadzam test istotności. Z tablic rozkładu t-Studenta odczytuję wartość dla:
α = 0,05 i n-2 = 16
t* = 2,1200 t*2 = 4,4944
Po podstawieniu do wzoru otrzymujemy: r* = 0,4973
Następnie konstruujemy macierz R* składającą się ze współczynników |rxixj| ≤ r* i zastępujemy je 0
|
1,0000 |
0,7117 |
0,0000 |
0,8882 |
R* |
0,7117 |
1,0000 |
0,0000 |
0,6651 |
|
0,0000 |
0,0000 |
1,0000 |
0,5435 |
|
0,8882 |
0,6651 |
0,5435 |
1,0000 |
Na podstawie macierzy R* buduję graf powiązań
Z medoty grafów wynika, że do modelu wchodzi tylko zmienna x4, ponieważ ma najwięcej powiązań - 3.
Model ma następującą postać:
y=α0+α4x4i+εi
Metoda Najmniejszych Kwadratów (MNK)
Aby oszacować parametry strukturalne korzystam ze wzoru:
Następnie tworzę macierze X i Y
|
1,0000 |
40,9000 |
2235,6000 |
|
|
1,0000 |
48,1000 |
1997,4000 |
|
|
1,0000 |
49,7000 |
2116,4000 |
|
|
1,0000 |
56,3000 |
2594,4000 |
|
|
1,0000 |
97,9000 |
2726,9000 |
|
|
1,0000 |
142,8300 |
2040,3000 |
|
|
1,0000 |
173,6200 |
1789,3000 |
|
|
1,0000 |
230,9300 |
1813,3000 |
|
X |
1,0000 |
300,5600 |
1887,5000 |
|
|
1,0000 |
383,4300 |
1903,2000 |
|
|
1,0000 |
473,7900 |
1457,0000 |
|
|
1,0000 |
522,9300 |
1971,4000 |
|
|
1,0000 |
560,4300 |
2025,8000 |
|
|
1,0000 |
610,5100 |
1830,8000 |
|
|
1,0000 |
644,4800 |
1836,3000 |
|
|
1,0000 |
664,2100 |
1389,0000 |
|
|
1,0000 |
711,9600 |
1536,0000 |
|
|
1,0000 |
735,4000 |
1498,5000 |
|
|
4740,0000 |
|
|
4208,0000 |
|
|
3657,0000 |
|
|
3841,0000 |
|
|
4327,0000 |
|
|
5746,0000 |
|
|
5928,0000 |
|
|
6004,0000 |
|
Y |
5988,0000 |
|
|
5830,0000 |
|
|
6129,0000 |
|
|
6028,0000 |
|
|
5182,0000 |
|
|
5621,0000 |
|
|
5712,0000 |
|
|
5928,0000 |
|
|
5467,0000 |
|
|
5893,0000 |
|
Obliczam kolejno:
|
18,0000 |
6447,9800 |
34649,1000 |
(XTX)= |
6447,9800 |
3449405,0568 |
11299465,7580 |
|
34649,1000 |
11299465,7580 |
68841938,1900 |
det(XTX) = |
21701931011311,2000 |
(wyznacznik jest większy od 0, dlatego mogę przeprowadzać kolejne obliczenia)
|
5,0588 |
-0,0024 |
-0,0022 |
(XTX)-1= |
-0,0024 |
0,0000 |
0,0000 |
|
-0,0022 |
0,0000 |
0,0000 |
|
96229,0000 |
XTY= |
36726069,8200 |
|
181674542,8000 |
Podstawiając do wzoru otrzymuję wektor parametrów strukturalnych:
|
7561,6387 |
a= |
0,7235 |
|
-1,2856 |
Równanie modelu ma zatem postać:
Ŷ=7561,6387 + 0,7235X1 - 1,2856X2
Następnie obliczam:
- wariancję Se2
- odchylenie standardowe reszt Se
- współczynnik zmienności resztowej We
- współczynnik determinacji R2
- współczynnik zbieżności φ2
Aby przeprowadzić zamierzone obliczenia, wykorzystuję dane z poniższej tabeli:
Ŷi |
ei |
(ei)2 |
Ŷi-Ỹi |
(Ŷi-Ỹi)2 |
Yi-Ỹi |
(Yi-Ỹi)2 |
4717,1066 |
22,8934 |
524,1085 |
-628,9490 |
395576,8102 |
-606,0556 |
367303,3364 |
5028,5492 |
-820,5492 |
673300,9804 |
-317,5064 |
100810,2894 |
-1138,0556 |
1295170,4475 |
4876,7185 |
-1219,7185 |
1487713,2131 |
-469,3371 |
220277,2741 |
-1689,0556 |
2852908,6698 |
4266,9692 |
-425,9692 |
181449,7362 |
-1079,0864 |
1164427,4214 |
-1505,0556 |
2265192,2253 |
4126,7215 |
200,2785 |
40111,4811 |
-1219,3341 |
1486775,5606 |
-1019,0556 |
1038474,2253 |
5041,9307 |
704,0693 |
495713,6355 |
-304,1249 |
92491,9521 |
399,9444 |
159955,5586 |
5386,8958 |
541,1042 |
292793,7308 |
40,8403 |
1667,9274 |
581,9444 |
338659,3364 |
5397,5032 |
606,4968 |
367838,4276 |
51,4476 |
2646,8551 |
657,9444 |
432890,8920 |
5352,4857 |
635,5143 |
403878,3778 |
6,4302 |
41,3472 |
641,9444 |
412092,6698 |
5392,2556 |
437,7444 |
191620,1734 |
46,2000 |
2134,4427 |
483,9444 |
234202,2253 |
6031,2700 |
97,7300 |
9551,1438 |
685,2145 |
469518,8989 |
782,9444 |
613002,0031 |
5405,5008 |
622,4992 |
387505,3079 |
59,4452 |
3533,7319 |
681,9444 |
465048,2253 |
5362,6934 |
-180,6934 |
32650,1119 |
16,6379 |
276,8185 |
-164,0556 |
26914,2253 |
5649,6199 |
-28,6199 |
819,0964 |
303,5643 |
92151,2869 |
274,9444 |
75594,4475 |
5667,1253 |
44,8747 |
2013,7412 |
321,0697 |
103085,7626 |
365,9444 |
133915,3364 |
6256,4552 |
-328,4552 |
107882,8057 |
910,3996 |
828827,4774 |
581,9444 |
338659,3364 |
6102,0154 |
-635,0154 |
403244,5810 |
755,9599 |
571475,3136 |
120,9444 |
14627,5586 |
6167,1842 |
-274,1842 |
75176,9494 |
821,1286 |
674252,1726 |
546,9444 |
299148,2253 |
|
|
5153787,6020 |
|
6209971,3425 |
|
11363758,9444 |
Obliczam wariancję Se2 oraz odchylenie standardowe Se ze wzorów:
Se2 = |
343585,8401 |
Se = |
586,1620 |
Współczynnik zmienności resztowej Ve. Informuje on o tym, jaką część wartości średniej Y stanowi odchylenie standardowe reszt. Ve powinno być bliskie 0, aby stwierdzić, że weielkość Se jest odpowiednio mała. Obliczamy go według wzoru:
Ve = 0,1096 Oznacza to, że dany model jest wyjaśniony w 10,96%
Ocena dopasowania modelu do danych empirycznych ma na celu sprawdzenie czy model w wystarczającym stopniu wyjaśnia kształtowanie się zmiennej objaśnianej. Dopasowanie można obliczyć za pomocą następujących współczynników, które przyjmują wartości z przedziału <0,1>.
Współczynnik determinacji R2 informuje, jaka część zmiennej objaśnianej Y została objaśniona przez zbudowany model teoretyczny. Dopasowanie modelu do danych empirycznych jest tym lepsze, im współczynnik determinacji bliższy jest wartości 1. Obliczam go korzystając ze wzoru:
R2 = 0,5465 Model jest dopasowany do danych empirycznych w ok. 55%
Współczynnik zbieżności φ2 informuje, jaka część zmienności zmiennej objaśnianej Y nie została wyjaśniona przez zbudowany model teoretyczny (jest spowodowana przez czynnik losowy). Dopasowanie modelu do danych empirycznych jest tym lepsze, im współczynnik zbieżności jest bliższy 0. Obliczam go korzystając ze wzoru:
φ 2 = 0,4535 Model jest niedopasowany do danych empirycznych w ok. 45%
TEST ISTOTNOŚCI WSPÓŁCZYNNIKA KORELACJI WIELORAKIEJ (próba Fishera)
Stawiam hipotezy:
H0 : R2 = 0
H1 : R2 ≠ 0
Obliczam F ze wzoru:
F = 9,0370
Dla α=0,05, k=2 i n-k-1=15 odczytuję F* z tablic Fishera
F* = 19,4300
F < F* nie ma podstaw do odrzucenia hipotezy H0
MACIERZ WARIANCJI I KOWARIANCJI OCEN PARAMETRÓW STRUKTURALNYCH
Z macierzy wariancji i kowariancji, wyrażonej poniższym wzorem, szacuję średnie błędy szacunku parametrów:
|
1738133,2306 |
-829,2050 |
-738,7238 |
|
D2(a) = |
-829,2050 |
0,6110 |
0,3171 |
|
|
-738,7238 |
0,3171 |
0,3248 |
|
Następnie obliczam błędy szacunku parametrów strukturalnych
D(a0) = |
1318,3828 |
D(a1) = |
0,7817 |
D(a2) = |
0,5699 |
Postać modelu w przypadku błędów strukturalnych:
Ŷ=7561,6387 + 0,7235X1 - 1,2856X2
(1318,3828) |
(0,7817) |
(0,5699) |
TEST ISTOTNOŚCI PARAMETRÓW STRUKTURALNYCH
Stawiam hipotezy:
H0 : αi = 0
H1 : αi ≠ 0
Dla 2α=0,1 oraz n-k-1=15 odczytuję wartość t* z tablic t-Studenta
t*=1,753
Obliczam wartość tαi ze wzoru:
tα0 = |
5,7355 |
> t* odrzucam hipotezę H0 na rzecz hipotezy H1. Oznacza to, że parametr ten jest istotnie różny od zera. Zmienna oddziaływuje w istotny sposób na zmienną Y. |
tα1 = |
0,9255 |
< t* nie ma podstaw do odrzucenia hipotezy H0. Parametr ten nie jest istotnie różny od zera. Zmienna nie oddziaływuje w istotny sposób na zmienną Y. |
tα2 = |
2,2558 |
> t* odrzucam hipotezę H0 na rzecz hipotezy H1. Oznacza to, że parametr ten jest istotnie różny od zera. Zmienna oddziaływuje w istotny sposób na zmienną Y. |
Weryfikacja modelu
Po oszacowaniu modelu należy zbadać, czy zbudowany model dobrze opisuje badane zależności, a dzieje się to za sprawą weryfikacji modelu.
TEST LOSOWOŚCI
Test losowości ma na celu zbadanie trafności doboru zmiennych do modelu.
Stawiam hipotezę:
H0 : rozkład jest losowy
H1 : rozkład jest nie losowy
Następnie tworzę serie, czyli przyporządkowuję każdej reszcie dodatniej literę a, zaś każdej reszcie ujemnej literę b.
ei |
|
|
22,89342 |
a |
1 |
-820,549 |
b |
|
-1219,72 |
b |
|
-425,969 |
b |
2 |
200,2785 |
a |
|
704,0693 |
a |
|
541,1042 |
a |
|
606,4968 |
a |
|
635,5143 |
a |
|
437,7444 |
a |
|
97,72995 |
a |
|
622,4992 |
a |
3 |
-180,693 |
b |
|
-28,6199 |
b |
4 |
44,87473 |
a |
5 |
-328,455 |
b |
|
-635,015 |
b |
|
-274,184 |
b |
6 |
Otrzymałam 6 serii, czyli k = 6
Następnie obliczam ilość dodatnich i ujemnych reszt:
a = 10 = n1 b = 8 = n2
Z tablic testu liczby serii odczytuję wartości krytyczne Kl (0,025) i Kl (0,975) dla:
α=0,05, n1 i n2
Kl = 5
Kp = 14
Kl ≤ K ≤ Kp Rozkład reszt jest losowy. Nie ma podstaw do odrzucenia hipotezy H0.
Postać modelu została poprawne dobrana.
TEST SYMETRII
Test ten ma na celu sprawdzenie czy rozkład reszt jest symetryczny czy też asymetryczny.
Stawiam hipotezy:
r - liczba reszt dodatnich r = 10
n - liczba wszystkich reszt n = 18
Obliczam statystykę tα według wzoru
Następnie dla poziomu istotności α oraz n-1 liczby stopni swobody odczytujemy t* z tablic t-Studenta
α = 0,05
n-1 = 17
t* = 2,110
tα < t* Nie ma podstaw do odrzucenia hipotezy H0. Rozkład reszt jest symetryczny.
TEST NORMALNOŚCI (TEST ZGODNOŚCI HELLWIGA)
Stawiamy hipotezy:
H0: F(Ei)=FN(Ei) rozkład jest normalny
H1: F(Ei)≠FN(Ei) rozkład nie jest normalny
Do obliczeń wykorzystuję poniższe dane
et |
Ui |
fi (Ui) |
cela |
|
|
22,8934 |
0,0416 |
0,5166 |
0,00 |
0,06 |
+ |
-820,5492 |
-1,4903 |
0,0681 |
0,06 |
0,11 |
+ |
-1219,7185 |
-2,2152 |
0,0134 |
0,11 |
0,17 |
+ |
-425,9692 |
-0,7736 |
0,2196 |
0,17 |
0,22 |
+ |
200,2785 |
0,3637 |
0,6420 |
0,22 |
0,28 |
+ |
704,0693 |
1,2787 |
0,8995 |
0,28 |
0,33 |
+ |
541,1042 |
0,9827 |
0,8371 |
0,33 |
0,39 |
+ |
606,4968 |
1,1015 |
0,8647 |
0,39 |
0,44 |
0 |
635,5143 |
1,1542 |
0,8758 |
0,44 |
0,50 |
+ |
437,7444 |
0,7950 |
0,7867 |
0,50 |
0,56 |
++ |
97,7300 |
0,1775 |
0,5704 |
0,56 |
0,61 |
+ |
622,4992 |
1,1306 |
0,8709 |
0,61 |
0,67 |
+ |
-180,6934 |
-0,3282 |
0,3714 |
0,67 |
0,72 |
0 |
-28,6199 |
-0,0520 |
0,4793 |
0,72 |
0,78 |
0 |
44,8747 |
0,0815 |
0,5325 |
0,78 |
0,83 |
+ |
-328,4552 |
-0,5965 |
0,2754 |
0,83 |
0,89 |
++++ |
-635,0154 |
-1,1533 |
0,1244 |
0,89 |
0,94 |
+ |
-274,1842 |
-0,4980 |
0,3093 |
0,94 |
1,00 |
0 |
długość celi = 0,0556
odchylenie standardowe Se = 550,6033
Wyznaczam liczbe pustych cel (K)
K = 4
Z tablic rozkładu Hellwiga odczytuję wartości K1 i K2 dla:
α = 0,05.
n - ilość obserwacji
K1 = 3
K2 = 9
K1 ≤ K ≤ K2 Nie ma podstaw do odrzucenia hipotezy H0. Rozkład reszt jest
zgodny z rozkładem normalnym.
TEST AUTOKORELACJI - Durbina-Watsona
(stosowany, gdy w modelu występuje wyraz wolny)
Do obliczeń potrzebne są mi następujące wartości:
Σ(et - et-1)2 = 3645742,21
Σet2 = 5153787,60
Stawiam hipotezę H0
H0 : g1 = 0 brak autokorelacji
Następnie obliczam statystykę d według wzoru:
Jeżeli
d = 2 brak autokorelacji
d < 2 => H1: g1>0
d > 2 => H1: g1<0 obliczamy statystykę d'=4-d
Statystyka d wynosi zatem:
d = 0,7074
d < 2 dlatego stawiamy hipotezę H1
H1 : g1 > 0 (podejrzewamy autokorelację dodatnią)
k' - liczba zmiennych X n - liczba obserwacji
k' = 2
n = 18
Wartości dL i dU odczytuję z tablic Durbina-Watsona
dL = 1,05
dU = 1,53
d < dL Odrzucam hipotezę H0 na rzecz hipotezy H1. Istnieje autokorelacja
dodatnia.
BADANIE AUTOKORELACJI
Stawiam hipotezy:
Obliczam statystykę t według wzoru:
Do obliczeń wykorzystuję poniższe dane
e t |
e t-1 |
e t-2 |
e t-3 |
e t-4 |
e t-5 |
e t-6 |
e t-7 |
e t2 |
22,89 |
|
|
|
|
|
|
|
524,11 |
-820,55 |
22,89 |
|
|
|
|
|
|
673300,98 |
-1219,72 |
-820,55 |
22,89 |
|
|
|
|
|
1487713,21 |
-425,97 |
-1219,72 |
-820,55 |
22,89 |
|
|
|
|
181449,74 |
200,28 |
-425,97 |
-1219,72 |
-820,55 |
22,89 |
|
|
|
40111,48 |
704,07 |
200,28 |
-425,97 |
-1219,72 |
-820,55 |
22,89 |
|
|
495713,64 |
541,10 |
704,07 |
200,28 |
-425,97 |
-1219,72 |
-820,55 |
22,89 |
|
292793,73 |
606,50 |
541,10 |
704,07 |
200,28 |
-425,97 |
-1219,72 |
-820,55 |
22,89 |
367838,43 |
635,51 |
606,50 |
541,10 |
704,07 |
200,28 |
-425,97 |
-1219,72 |
-820,55 |
403878,38 |
437,74 |
635,51 |
606,50 |
541,10 |
704,07 |
200,28 |
-425,97 |
-1219,72 |
191620,17 |
97,73 |
437,74 |
635,51 |
606,50 |
541,10 |
704,07 |
200,28 |
-425,97 |
9551,14 |
622,50 |
97,73 |
437,74 |
635,51 |
606,50 |
541,10 |
704,07 |
200,28 |
387505,31 |
-180,69 |
622,50 |
97,73 |
437,74 |
635,51 |
606,50 |
541,10 |
704,07 |
32650,11 |
-28,62 |
-180,69 |
622,50 |
97,73 |
437,74 |
635,51 |
606,50 |
541,10 |
819,10 |
44,87 |
-28,62 |
-180,69 |
622,50 |
97,73 |
437,74 |
635,51 |
606,50 |
2013,74 |
-328,46 |
44,87 |
-28,62 |
-180,69 |
622,50 |
97,73 |
437,74 |
635,51 |
107882,81 |
-635,02 |
-328,46 |
44,87 |
-28,62 |
-180,69 |
622,50 |
97,73 |
437,74 |
403244,58 |
-274,18 |
-635,02 |
-328,46 |
44,87 |
-28,62 |
-180,69 |
622,50 |
97,73 |
75176,95 |
Badam autokorelacje do rzędu 7 (1,2,3,4,5,6,7)
t1 = 2,3196
t2 = 1,0941
t3 = 0,1536
t4 = 0,9388
t5 = 1,4576
t6 = 1,4214
t7 = 1,6484
Dla poziomu istotności α=0,05 oraz n-t-1 liczby stopni swobody odczytujemy t* z tablic t-Studenta
t*0,05;16 = 2,120 t ≥ t*
t*0,05;15 = 2,131 t ≤ t*
t*0,05;14 = 2,145 t ≤ t*
t*0,05;13 = 2,160 t ≤ t*
t*0,05;12 = 2,179 t ≤ t*
t*0,05;11 = 2,201 t ≤ t*
t*0,05;10 = 2,228 t ≤ t*
t ≥ t* Odrzucam hipotezę H0 na rzecz hipotezy H1. Zachodzi autokorelacja rzędu 1.
t ≤ t* Nie ma podstaw do odrzucenia hipotezy H0.Nie zachodzi autokorelacja rzędu 2-7.
TEST STAŁOŚCI WARIANCJI
|e t| |
22,8934 |
820,5492 |
1219,7185 |
425,9692 |
200,2785 |
704,0693 |
541,1042 |
606,4968 |
635,5143 |
437,7444 |
97,7300 |
622,4992 |
180,6934 |
28,6199 |
44,8747 |
328,4552 |
635,0154 |
274,1842 |
Stawiam hipotezy:
Obliczam statystykę t korzystając z następującego wzoru:
Podstawiając odpowiednie dane otrzymuję:
t = 1,5304
Dla poziomu istotności α=0,05 oraz n-2 liczby stopni swobody odczytuję t* z tablic t-Studenta
t*0,05;16 =2,1200
t ≤ t* Nie ma podstaw do odrzucenia hipotezy H0. Wariancja jest stała w czasie.
TEST STAŁOŚCI WARIANCJI FISHERA
Stawiam hipotezy:
Następnie obliczam Se21 i Se22 według wzorów:
Do obliczeń wykorzystuję poniższe dane
|
t |
e t |
e t-ē |
(e t-ē)2 |
|
1 |
22,8934 |
22,8934 |
524,1085 |
|
2 |
-820,5492 |
-820,5492 |
673300,9804 |
|
3 |
-1219,7185 |
-1219,7185 |
1487713,2131 |
|
4 |
-425,9692 |
-425,9692 |
181449,7362 |
|
5 |
200,2785 |
200,2785 |
40111,4811 |
|
6 |
704,0693 |
704,0693 |
495713,6355 |
|
7 |
541,1042 |
541,1042 |
292793,7308 |
|
8 |
606,4968 |
606,4968 |
367838,4276 |
1 |
9 |
635,5143 |
635,5143 |
403878,3778 |
2 |
10 |
437,7444 |
437,7444 |
191620,1734 |
|
11 |
97,7300 |
97,7300 |
9551,1438 |
|
12 |
622,4992 |
622,4992 |
387505,3079 |
|
13 |
-180,6934 |
-180,6934 |
32650,1119 |
|
14 |
-28,6199 |
-28,6199 |
819,0964 |
|
15 |
44,8747 |
44,8747 |
2013,7412 |
|
16 |
-328,4552 |
-328,4552 |
107882,8057 |
|
17 |
-635,0154 |
-635,0154 |
403244,5810 |
|
18 |
-274,1842 |
-274,1842 |
75176,9494 |
|
|
-0,000000001646185 |
|
|
Obliczam wartość średnią ē
ē = -0,0000000001
Następnie dokonuję obliczeń:
Se21 = 3943323,6911
Se22 = 1210463,9108
Obliczam wartość statystyki F według wzoru:
F = 0,3070
Z tablic Fishera odczytuję wartość F* dla:
m1 = n2 - k - 1
m2 = n1 - k -1
F* = 4,28
F < F* Brak podstaw do odrzucenia hipotezy H0. Wariancja jest stała w czasie.
TEST JARQUE - BERA
Stawiam hipotezy:
rozkład jest normalny
rozkład nie jest normalny
Korzystam z danych zawartych w tabeli niżej
et |
et2 |
et3 |
et4 |
et5 |
22,8934 |
524,1085 |
11998,6355 |
274689,7674 |
6288587,4128 |
-820,5492 |
673300,9804 |
-552476577,0779 |
453334210245,3040 |
-371983021010057,0000 |
-1219,7185 |
1487713,2131 |
-1814591324,9509 |
2213290604406,7800 |
-2699591490490510,0000 |
-425,9692 |
181449,7362 |
-77291994,0418 |
32924006768,6195 |
-14024611929588,4000 |
200,2785 |
40111,4811 |
8033467,6238 |
1608930916,5753 |
322234284812,5480 |
704,0693 |
495713,6355 |
349016772,1308 |
245732008387,9630 |
173012372951946,0000 |
541,1042 |
292793,7308 |
158431910,8462 |
85728168791,2364 |
46387870253196,6000 |
606,4968 |
367838,4276 |
223092847,2324 |
135305108840,8590 |
82062122141316,7000 |
635,5143 |
403878,3778 |
256670469,4389 |
163117744092,1600 |
103663652838147,0000 |
437,7444 |
191620,1734 |
83880660,8536 |
36718290870,7857 |
16073226781378,6000 |
97,7300 |
9551,1438 |
933432,8353 |
91224347,4194 |
8915351214,7273 |
622,4992 |
387505,3079 |
241221760,9770 |
150160363681,7060 |
93474712769250,0000 |
-180,6934 |
32650,1119 |
-5899660,3602 |
1066029804,5565 |
-192624570705,8390 |
-28,6199 |
819,0964 |
-23442,4238 |
670918,8852 |
-19201604,5314 |
44,8747 |
2013,7412 |
90366,0912 |
4055153,7944 |
181973924,8818 |
-328,4552 |
107882,8057 |
-35434666,4451 |
11638699769,7275 |
-3822791235801,3300 |
-635,0154 |
403244,5810 |
-256066526,1630 |
162606192134,6920 |
-103257439059865,0000 |
-274,1842 |
75176,9494 |
-20612328,1634 |
5651573726,9123 |
-1549571952157,2000 |
|
5153787,6020 |
-1441012832,9614 |
3698978157547,7500 |
-2679416273816510,0000 |
Obliczam JB ze wzoru:
![]()
, gdzie:
Po podstawieniu odpowiednich danych otrzymuję:
B1 = 0,2730
B2 = 2,5067
JB = 1,0016
Z tablic testu X2 odczytuje statystyke X2 dla α = 0,05 i 2 stopnia swobody
X2 = 5,991
H0: JB ≤ X2
H1: JB > X2
JB ≤ X2 Przyjmujemy hipotezę H0. Rozkład jest rozkładem normalnym.
Podsumowanie
Wykonany przeze mnie model obrazujący zależności rożnych zjawisk, które wpływają na liczbę popełnianych zamachów samobójczych, jest wyjaśniony w 10,96%. Zmienna objaśniana Y została wyjaśniona przez zbudowany model w ok. 55%.
12

EMBED Word.Picture.8 
EMBED Equation.3 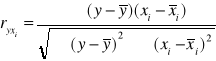
EMBED Equation.3 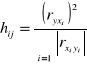
EMBED Equation.3 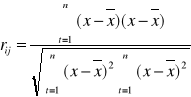
EMBED Equation.3 ![]()
EMBED Equation.3 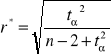
EMBED Equation.3 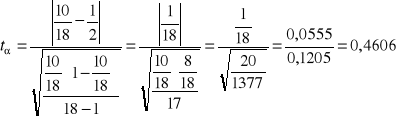
EMBED Equation.3 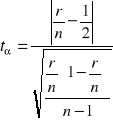
EMBED Equation.3 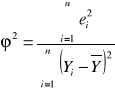
EMBED Equation.3 ![]()
EMBED Equation.3 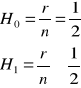
EMBED Equation.3 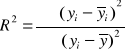
EMBED Equation.3 ![]()
EMBED Equation.3 ![]()
EMBED Equation.3 ![]()
EMBED Equation.3 ![]()
EMBED Equation.3 ![]()
EMBED Equation.3 ![]()
EMBED Equation.3
EMBED Equation.3 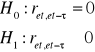
EMBED Equation.3 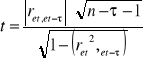
EMBED Equation.3 ![]()
EMBED Equation.3 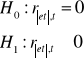
EMBED Equation.3 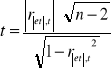
EMBED Equation.3 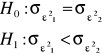
EMBED Equation.3 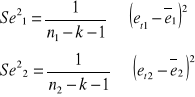
EMBED Equation.3 ![]()
EMBED Equation.3 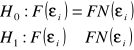
EMBED Equation.3 ![]()
EMBED Equation.3 ![]()
Wyszukiwarka
Podobne podstrony:
Model Krisa, Zarządzanie i inżynieria produkcji, Semestr 3, Ekonometria
Model 450, Zarządzanie i inżynieria produkcji, Semestr 4, Makroekonomia
Model IS, Zarządzanie i inżynieria produkcji, Semestr 4, Makroekonomia
ekonometria, Zarządzanie i inżynieria produkcji, Semestr 3, Ekonometria
zarzadzanie piatek 1 czerwca, Zarządzanie i inżynieria produkcji, Semestr 2, Podstawy Zarządzania
Tabela[2], Zarządzanie i inżynieria produkcji, Semestr 4, Mechanika Stosowana
spr z ZP, Zarządzanie i inżynieria produkcji, Semestr 4, Zarządzanie personelem
zpiu kartkowa, Zarządzanie i inżynieria produkcji, Semestr 6, Zarządzanie produkcją i usługami
Przedszkole2, Zarządzanie i inżynieria produkcji, Semestr 6, Podstawy projektowania inżynierskiego,
cwiczenie scenariusze 2, Zarządzanie i inżynieria produkcji, Semestr 5, Zarządzanie strategiczne
Sprawozdanie 2 - Parametryzacja rysunków, Zarządzanie i inżynieria produkcji, Semestr 3, Grafika inż
PA.pojazd.w.labiryncie.1, Zarządzanie i inżynieria produkcji, Semestr 5, Podstawy automatyzacji
cwiczenie 6, Zarządzanie i inżynieria produkcji, Semestr 5, Zarządzanie strategiczne
Sprawozdanie 1 - Komputerowy zapis konstrukcji, Zarządzanie i inżynieria produkcji, Semestr 3, Grafi
sprawozdanie po liftingu nr7, Zarządzanie i inżynieria produkcji, Semestr 3, Metrologia
więcej podobnych podstron