
Wprowadzenie do programowania obiektowego
Programowanie strukturalne ma niestety kilka wad. Pierwszą z nich jest to, że nie ma możliwości zabezpieczenia danych przed dostępem do nich przez funkcje, które są "nieuprawnione". W przypadku dużego projektu liczącego sobie kilkadziesiąt tysięcy wierszy kodu i tworzonego przez wielu programistów może dochodzić do takich sytuacji, że np., funkcja napisana przez jednego z nich dobrze działa tylko na tablicy zawierającej liczby całkowite wyrażające temperaturę (powiedzmy z zakresu od -30 do 40 stopni Celsjusza). Użycie tej funkcji przez drugiego programistę do przetwarzania tablicy przechowującej np., ciśnienie mierzone w hPa niestety może spowodować trudne do wychwycenia błędy. Jeśli obie funkcje miały takie same argumenty to nic nie chroni programisty przed pomyłkową ich zamianą. Programowanie strukturalne wymaga też pamiętania o wielu różnych drobnych szczegółach co w przypadku pisania dużego projektu może niestety spowodować wydłużenie czasu realizacji oraz zwiększa ryzyko wystąpienia błędów.
W wyniku poszukiwań nowych metod programowania, które pozwoliłyby wyeliminować uciążliwości języka strukturalnego stworzono programowanie obiektowe. Ogólnie można powiedzieć, że programowanie obiektowe łączy ze sobą dane i funkcje, które operowały na tych danych. Umożliwia bardziej intuicyjne programowanie bo zgodne z ludzkim widzeniem świata. Przy zastosowaniu podejścia obiektowego wydatnie skraca się czas tworzenia dużego projektu jednocześnie przy mniejszej liczbie błędów. Bardzo istotne jest także to, że program napisany obiektowo można znacznie łatwiej poprawić.
Obecnie w zasadzie już każdy z ważnych języków programowania umożliwia działanie na obiektach, aczkolwiek czasami w różnym stopniu. My w ramach tego skryptu będziemy poznawać programowanie obiektowe na przykładzie języka C++. Język ten jest bardzo elastyczny ponieważ oprócz zaimplementowanej w nim pełnej obiektowości zawiera wszystko to co daje klasyczny język C a więc możliwość programowania na niskim poziomie, pełną kontrolę nad komputerem, wydajny kod.
Ważnymi właściwościami programowania obiektowego są:
hermetyzacja danych - zapewnia możliwość ukrywania fragmentów kodu przed innymi obiektami w programie dzięki czemu istnieje mniejsze prawdopodobieństwo "nieuprawnionego" użycia metody na rzecz danych, które nie należą do tej klasy,
dziedziczenie - daje możliwość łatwego przejmowania własności już istniejących klas i tworzenia nowych klas pokrewnych wzbogaconych o nowe możliwości,
przeciążanie funkcji i operatorów - zapewnia elastyczną i zgodną w potrzebami rozbudowę klas,
polimorfizm - umożliwia napisanie klasy w ten sposób, aby później (już na etapie wykonania programu) można było zdecydować jakie wersje funkcji składowych będą wywoływane.
Zastosowanie operatorów new i delete
Jedną z nowych własności języka C++ jest możliwość "mieszania" kodu i deklaracji zmiennych. W dowolnym bloku programu programista może zadeklarować pożądane w tym miejscu zmienne (zostało to zaprezentowane w podanym niżej przykładzie).
#include <stdio.h>
#include <stdlib.h>
int a, b = 10;
main()
{
int c, d;
for( int e = 0; e < 20; e++ ) {
int x = random(10);
if( x / 2 == 0 )
printf("\nLiczba parzysta");
else
printf("\nLiczba nieparzysta");
}
}
W tym krótkim programie mamy do czynienia z dwoma rodzajami zmiennych. Jak wiemy zmienne a, b są zadeklarowane jako globalne i z tego względu są dostępne w całym naszym programie. Sposób deklaracji zmiennych c i d także nie jest dla nas czymś nowym. Są to zmienne lokalne funkcji main. Natomiast nowością jest deklaracja zmiennych e i x. Otóż jak dowiedzieliśmy się z wstępu specyfikacja języka C++ pozwala na deklarację zmiennej w wyrażeniu inicjacyjnym instrukcji for. Zmienna ta jest "widzialna" od tego miejsca do końca bloku, w którym została zadeklarowana.
Bardzo ciekawy jest sposób zadeklarowania zmiennej x. Otóż z tej zmiennej można skorzystać tylko w obrębie bloku, w którym została ona zadeklarowana tj. w bloku instrukcji wykonywanych w pętli for.
Ten rozszerzony sposób deklarowania zmiennych zapewnia dużą wygodę programiście przy pisaniu programu.
Z punktu widzenia czasu trwania zmiennych można podzielić je na: statyczne czyli takie, dla których pamięć jest wydzielana na początku programu (a, b) oraz automatyczne, których trwanie jest ograniczone do bloku, w którym zostały zadeklarowane. Dla obu rodzajów deklaracji zmiennych w momencie kompilacji musi być znany ich rozmiar.
Z punktu widzenia tworzenia programu wygodne jest planowanie wykorzystania pamięci dla zmiennych na etapie uruchomienia programu. I tak w klasycznej wersji języka C do tego celu wykorzystywane były funkcje malloc i free lub jakieś im pokrewne. W wersji obiektowej tego języka oczywiście możemy dalej korzystać z tych funkcji ale twórcy języka oddali nam do dyspozycji dwa nowe operatory new i delete. Jak się w dalszej części tego modułu przekonamy są one bardzo elastyczne i za ich pomocą można pisać naprawdę zwięzłe i efektywne programy.
W najprostszym przykładzie wykorzystanie operatora new może wyglądać następująco:
int *a;
a = new int;
W wyniku działania tego fragmentu programu został przydzielony obszar pamięci niezbędny do przechowania obiektu typu int i operator zwrócił adres tego obszaru pamięci. Jak widać operator new należy do grupy operatorów jednoargumentowych, po jego prawej stronie podajemy typ danych jakie chcemy uzyskać. Potrzebne jest to do określenia rozmiaru przydzielonej pamięci. W przypadku gdy nie uda się przydzielić żądanego obszaru pamięci operator new zwraca wartość NULL.
Jak widać nie trzeba stosować żadnych konwersji typu, tak jak to się wykonywało w przypadku korzystania z klasycznych sposobów przydzielania pamięci za pomocą funkcji malloc.
int *a;
a = (int *)malloc(sizeof(int));
Obszary pamięci przydzielone za pomocą operatora new zawierają 'śmieci'. Ten obszar pamięci istnieje od tego momentu aż do zakończenia programu lub do zwolnienia pamięci za pomocą drugiego wprowadzonego w C++ operatora delete.
delete a;
W tym przypadku jak widać wystarczy podać wskaźnik, dla którego chcemy zwolnić pamięć.
Przy alokacji obiektów możliwa jest także ich inicjalizacja:
int *a;
a = new int(1);
Teraz mamy przydzieloną pamięć dla wskaźnika a wraz z równoczesnym wpisaniem do przydzielonego obszaru wartości 1. Tego sposobu inicjalizacji niestety nie można wykorzystać do tablic.
Cała siła tych dwóch operatorów przejawia się w aspekcie takich operacji na obiektach jak tworzenie dynamicznych tablic o wymiarach podawanych na etapie uruchomienia programu oraz tworzenia list złożonych obiektów.
Operator new ma taką ciekawą właściwość, że jeśli tworzonym obiektem jest tablica to liczba jej elementów może być podana w nawiasach kwadratowych po typie.
int *a, n = 10;
a = new int[n];
W tym przypadku zostanie utworzona tablica zawierająca n elementów typu int (n może się zmieniać w trakcie wykonywania się tego programu). W przypadku alokacji pamięci dla tablic wielowymiarowych musimy pamiętać, że można przydzielać pamięć tylko dla takich tablic, dla których typ elementu jest dopuszczalny dla kompilatora, np.:
int (*a)[10] = new int[n][10];
Mamy więc do czynienia z wskaźnikiem na tablicę 10 elementową typu int, a operator new przydzieli obszar, który będzie mógł przechować n takich tablic.
Teraz typ elementu tablicy został określony jako tablica zawierająca 10 elementów typu int i taka operacja spowoduje przydzielenie obszaru pamięci zdolnego pomieścić n tablic po 10 elementów typu int każda.
Przy usuwaniu takiego obiektu należy podać po prostu:
delete a;
Więcej informacji dotyczących tych dwóch operatorów zostanie podanych w momencie omawiania funkcji operatorowych.
Standardowa biblioteka wejścia / wyjścia w C++
W przypadku programowania w języku C jak zapewne pamiętamy przy realizacji operacji wejścia / wyjścia korzystaliśmy z biblioteki stdio.h zawierającej wszystkie potrzebne nam funkcje. Teraz programowanie obiektowe nie zamyka przed nami możliwości skorzystania z tych dobrze znanych funkcji ale daje nam do dyspozycji zestaw klas realizujący operacje wejścia / wyjścia. Takie predefiniowane klasy będziemy mogli znaleźć przede wszystkim w bibliotece iostream.h.
Zacznijmy od przypomnienia sobie nazw standardowych plików już otwartych w momencie uruchomienia naszego programu. Były to stdin, stdout, stdprn, stderr, stdaux. W C++ nie będziemy operować pojęciem pliku lecz strumieniem. Mam do dyspozycji:
cin - strumień wejściowy podłączony do standardowego wejścia (w C jego odpowiednik stanowi stdin),
cout - strumień wyjściowy podłączony do konsoli (stdout),
cerr - strumień wyjściowy podłączony do niebuforowanego wejścia dla obsługi błędów (stderr),
clog - w pełni buforowany strumień o działaniu analogicznym do cerr (brak odpowiednika w C).
Operacje na tych strumieniach są realizowane przy pomocy klas istream (wejście programu) oraz ostream (wyjście programu).
Do realizacji komunikacji ze strumieniem są wykorzystywane operatory << oraz >> zamiast odpowiednich funkcji składowych. Pełnią one identyczną rolę jak funkcje: printf i scanf. Najprostszy program z użyciem tych operatorów może wyglądać następująco:
#include <iostream.h>
void main()
{
int a;
double b;
cout << "Podaj liczbę a = ";
cin >> a;
cout << "Podaj liczbę b = ";
cin >> b;
cout << endl << "Wprowadziłeś a = " << a << endl << " b = " << b;
}
Te dwa operatory tworzą zapis operacji w sposób bardzo wizualny pokazując jaki jest przepływ informacji. Jak widać operatory umożliwiają w jednym wierszu przekazywanie do strumienia i odbieranie z niego wielu informacji. Poza tym podobnie jak wspomniane funkcje scanf oraz printf "potrafią" obsługiwać tylko podstawowe typy danych.
Zwróćmy jeszcze raz uwagę na podany wyżej program. Otóż nie posiada on żadnych (na pierwszy rzut oka) określeń formatów, do których byliśmy przyzwyczajeni przy pisaniu programów w C. Chcemy wczytać liczbę całkowitą, proszę bardzo - operator >> domyśli się jaki powinien być jej format, chcemy wczytać rzeczywistą - i także nie ma z tym problemu. Nie trzeba określać przy tej operacji adresu zmiennej, do której będą wyprowadzone dane. Podobnie jest w przypadku wyprowadzania wartości do strumienia. Załóżmy, że wprowadziliśmy następujące wartości:
a = 345
b = 12.45
Na ekranie otrzymamy wydruk w postaci:
Wprowadziłeś a = 345
b = 12.45
Brak jawnie określonego jakiegokolwiek formatowania w najmniejszym stopniu nie przeszkodził w sensownym wyprowadzeniu wyników. Operacje wejścia / wyjścia z użyciem obiektowej biblioteki są jak widać bardzo łatwe. Zajmijmy się teraz trochę bardziej skomplikowanymi przypadkami.
Formatowanie wydruków
Programowanie obiektowe nie byłoby tak dobre gdyby przy tak dużej "domyślności" w działaniu nie zostawiło nam pełnej możliwości modyfikowania działania dwóch operatorów obsługujących strumienie wejściowy i wyjściowy. Otóż aby zmienić ich działanie niezbędne jest skorzystanie z manipulatorów. Są specjalne funkcje, które w odpowiedni sposób wpływają na klasy wejścia / wyjścia. Z jednym manipulatorem mieliśmy już do czynienia w naszym przykładzie - był to manipulator endl i jak zapewne się domyślamy spowodował on wyprowadzenie do strumienia wyjściowego znaku zmiany wiersza. Inne najczęściej używane manipulatory podane są w tablicy:
dec |
zmienia format wyprowadzanych liczb całkowitych na dziesiętny, |
|
hex |
wyprowadza liczby całkowite zapisane w formacie heksadecymalnym, |
|
endl |
wyprowadza znak zmiany wiersza, |
|
flush |
opróżnia bufor strumienia ostream, |
|
setbase(int) |
wybiera podstawę konwersji na podany argument typu int, możliwe są liczby 8, 10, 16, |
|
setfill(int) |
umożliwia określenie jaki będzie znak wypełnienia pola przy wyprowadzaniu wartości "mniejszych" od założonego rozmiaru tego pola, |
|
setprecision(int) |
ustawia liczbę znaków po kropce w przypadku wyprowadzania liczb rzeczywistych, |
|
setw(int) |
określa szerokość pola wydruku, |
|
setiosflags(long) |
format określony jest przez argument typu long, który może przyjmować następujące wartości: |
|
|
ios::left |
wyrównanie do lewej strony pola wydruku, |
|
ios::right |
wyrównanie do prawej strony pola wydruku, |
|
ios::fixed |
używanie notacji dziesiętnej dla wyprowadzania liczb rzeczywistych, |
|
ios::scientific |
używanie notacji wykładniczej dla wartości rzeczywistych, |
|
ios::dec |
wyprowadzanie wartości całkowitych w systemie dziesiętnym, |
|
ios::hex |
wyprowadzanie wartości całkowitych w systemie szesnastkowym. |
Przykłady wykorzystania najczęściej wykorzystywanych manipulatorów.
#include <iostream.h>
#include <iomanip.h>
main()
{
int a = 100;
long b = 123;
double r = 3.155456;
// wyprowadzenie znaku zmiany wiersza
cout << endl;
// wyprowadzenie wartości zmiennych a i b w formacie szesnastkowym
cout << endl << hex << a << b;
/*
wyprowadzenie zmiennej a w obowiązującym formacie szesnastkowym,
zmiana domyślnego sposobu wyprowadzania na system dziesiętny oraz
wyprowadzenie zmiennej b w tym systemie
*/
cout << endl << a << dec << b;
// okreslenie minimalnej szerokości pola wydruku na 8 znaków
cout << endl << a << hex << setw(8) << b;
/*
określenie szerokości pola wydruku na 10 znaków, ustalenie domyślnego
sposobu drukowania jako dziesiętnie oraz poprzedzenie kropkami znaków
z wyprowadzanej zmiennej b
*/
cout << endl << dec << a << setw(10) << setfill('.') << b;
// wyprowadzanie wartości zmiennej rzeczywistej
cout << endl << r;
/*
ustawienie domyślnego sposobu wyprowadzania wartości rzeczywistych
w postaci zapisu wykładniczego
*/
cout << endl << setiosflags(ios::scientific) << r;
/*
ustawienie szerokości pola wydruku na 7 znaków, dokładności dwóch
cyfr po kropce, zapisu stałoprzecinkowego oraz lewostronnego
wyrównania wyprowadzanego napisu
*/
cout << endl << setw(7) << setprecision(2) << setiosflags(ios::fixed)
<< setiosflags(ios::left) << r;
return 0;
}
Pełna postać przygotowanych wydruków podana jest poniżej
647b
64123
100 7b
100.......123
3.155456
3.155456e+00
3.16...
Definiowanie klas
Jak zapewne pamiętamy z modułu "Programowanie w języku C" występowało tam takie pojęcie jak struktura danych (struct). Jej cechą charakterystyczną było to, że mogła ona gromadzić dane różnych typów w przeciwieństwie do tablic. W języku C++ dodano jeszcze możliwość gromadzenia funkcji, które będą operować na polach tej struktury. Napiszmy sobie najprostszą deklarację takiej struktury:
struct Test {
int a, b;
void write();
};
W naszym przypadku mamy połączenie dwóch pól typu int oraz funkcji, która będzie wyprowadzać pola tej struktury danych na ekran. Aby zdefiniowana przez nas struktura była kompletna musimy podać także jak wygląda zapis funkcji write.
void Test::write()
{
cout << endl <<a << ' ' << b;
}
W programowaniu obiektowym zamiast słowa "struktura danych" używamy pojęcia obiekt lub klasa a funkcja zadeklarowana w tej klasie to funkcja składowa (metoda) tej klasy lub obiektu.
Ogólnie rzecz biorąc programowanie obiektowe rozszerzyło możliwości struktury o to, że:
elementami (komponentami) mogą być funkcje zapewniające dopuszczalne na niej operacje,
istnieje możliwość regulowania praw dostępu do komponentów klasy - hermetyzacja,
definiowana klasa może przejmować komponenty (własności) innych klas - dziedziczenie.
Prawa dostępu dzielą nam komponenty na: publiczne (public), prywatne (private) i zabezpieczone (protected). Istnieje zasada, że komponenty publiczne są dostępne bez żadnych ograniczeń a do komponentów prywatnych (mogą nimi być zarówno pola klasy jak i jej funkcje składowe) wolno się odwoływać tylko z wnętrza funkcji składowych tej klasy lub z funkcji zaprzyjaźnionych z tą klasą. Zabezpieczenie (protected) komponentów gra rolę dopiero w przypadku dziedziczenia i zostanie omówione w jednym z ostatnich rozdziałów tego skryptu.
Definicję klasy wolno rozpocząć słowem class lub struct. Jedyną różnicą jest fakt, że w pierwszym przypadku komponenty domyślnie są prywatne a w drugim publiczne.
class Test { int a; void write(); public: int c; int read(); protected: double x; }; |
struct Test { int a; void write(); public: int c; int read(); protected: double x; }; |
Pierwszy wariant definicji klasy Test zakłada, że pole a i funkcja składowa write są prywatne a w drugim przypadku są domyślnie publiczne. Widzialność pozostałych komponentów tej klasy jest chyba oczywista. Ponadto w obu przypadkach do obiektów typu Test nie można odwołać się do pola x ponieważ jest ono zabezpieczone.
Odwołanie do pól i metod odbywa się za pomocą operatora wyboru komponentu podobnie jak to miało miejsce w przypadku operacji na strukturach np.,
main()
{
Test s1, s2;
s1.c = s2.read();
...
}
Konstruktor bezparametrowy
Spróbujmy zadeklarować sobie zmienne tego typu obiektowego.
Test a1, *a2, a3[10], *a4[10];
Jak widać zmienna a1 to "normalna" zmienne obiektowa. Zajmuje ona w pamięci sizeof(Test) bajtów czyli w naszym przypadku (2 * sizeof(int) + sizeof(double)) bajtów. Nietrudno zgadnąć, że a2 jest wskaźnikiem na taką klasę, a3 to oczywiście znowu "normalna" tablica zawierająca 10 elementów typu Test a a4 to tablica wskaźników na typ Test. Jak widać w deklaracjach zmiennych nie ma nic nowego w stosunku do klasycznego programowania w C.
Ciekawe jest natomiast jak zmienne a1 oraz a3 są tworzone w pamięci. Otóż w momencie tworzenia zostaje wykonana specjalna funkcja składowa zwana konstruktorem o nazwie dokładnie takiej jak nazwa klasy, której zadaniem jest utworzenie i ewentualne zainicjowanie komponentów tej klasy. Cechą charakterystyczną konstruktora jest to, że nie zwraca on żadnej wartości.
W naszym przypadku (brak definicji konstruktora w napisanej przez nas klasie) taki konstruktor bezparametrowy został automatycznie dołączony do klasy przez kompilator. Jak zapewne się spodziewamy programista może oczywiście napisać swój własny konstruktor bezparametrowy i wtedy kompilator nie będzie dodawał domyślnego. Ogólnie rzecz biorąc konstruktor to jest taka specjalna funkcja, która jest wykonywana zawsze w momencie inicjacji obiektu. Nie może ona zwracać żadnej wartości nawet typu void. Co bardzo istotne dla programowania w C++ można je przeciążać tzn. tworzyć większą ich ilość dla jednej klasy. Muszą się one różnić tylko listą argumentów. Kompilator w każdym momencie przy inicjacji obiektu będzie "wiedział" o który aktualnie chodzi.
#include <iostream.h>
class Test {
int a, b;
void write() { cout << endl <<a << ' ' << b; }
public:
Test();
int c;
int read();
protected:
double x;
};
Test::Test()
{
a = 0;
}
main()
{
Test p;
// ...
}
W tym przypadku dodaliśmy własny konstruktor bezparametrowy, którego zadaniem jest zainicjowanie pola a wartością 0. Domyślny konstruktor bezparametrowy dodany zostałby natomiast w postaci:
Test::Test()
{
}
Różnica jest jak widać dosyć znacząca. Przy deklaracji obiektu lokalnego p (lokalnego bo zadeklarowany jest w funkcji main) pole a zawierałoby jakieś "śmieci".
Inicjowanie obiektów przy pomocy własnych konstruktorów
Załóżmy, że chcemy zapisać operacje tworzenia obiektów w następujący sposób:
Test a(2);
Teraz musimy zmodyfikować listę konstruktorów dostępnych w tej klasie. Wyglądać będzie ona następująco:
#include <iostream.h>
class Test {
int a, b;
void write() { cout << endl <<a << ' ' << b; }
public:
Test();
Test(int _a);
int c;
int read() { cin >> a >> b; };
protected:
double x;
};
Test::Test()
{
a = 0;
}
Test::Test(int _a)
{
a = _a;
}
main()
{
Test p;
// ...
}
Zadeklarować musimy konstruktor zawierający jeden parametr typu int. W ciele konstruktora jest przypisanie polu tego obiektu odpowiedniej wartości. Ciekawe jest to, że można definicję tej klasy zapisać także w ten sposób:
//...
class Test {
int a, b;
void write() { cout << endl <<a << ' ' << b; }
public:
Test() { a = 0; };
Test(int _a) { a = _a; };
int c;
int read() { cin >> a >> b; };
protected:
double x;
};
//...
Na pierwszy rzut oka różnica jest w tym momencie czysto "kosmetyczna". Różnica jest jednak głębsza. Przyjęto bowiem założenie, że taka deklaracja zapewnia, że jest to funkcja otwarta (inline), tj. taka, która będzie włączona bezpośrednio w kod programu bez uwzględniania np. odkładania na stos jej parametrów. Zapewnia to znacznie większą szybkość działania tego fragmentu programu. Istotne jest to aby taka funkcja nie miała w swoim kodzie instrukcji pętli, switch i goto.
Lista inicjacyjna konstruktora
W przypadku deklarowania własnych konstruktorów można posłużyć się tzw. listą inicjacyjną konstruktora. Ma ona następującą postać:
nazwa_klasy::nazwa klasy(lista argumentów) : inicjowane_pole(wartość)
Naszą klasę moglibyśmy zadeklarować następująco:
//...
class Test {
int a, b;
void write() { cout << endl <<a << ' ' << b; }
public:
Test() : a(0) {};
int c;
int ();
protected:
double x
};
//...
Taka lista inicjacyjna daje nam skrócenie zapisu a w przypadku pól referencyjnych stanowi ich jedyną możliwość inicjalizacji.
#include <iostream.h>
class Test {
int& a;
public:
int b;
Test(int &_a) : a(_a) { b = 10; };
void write() { cout << endl <<a << ' ' << b; }
};
main()
{
int a = 2;
Test x(a);
x.write();
}
Usuńmy teraz jeden znak (operator referencji) z nagłówka konstruktora klasy Test.
...
Test(int _a) : a(_a) { b = 10; };
...
Efektem działania tak napisanego programu jest drukowanie przypadkowych liczb znajdujących się w polu a.
Wyjaśnienie tego faktu jest następujące: W przypadku wykonania inicjowania pól obiektu typu klasa Test pole a staje się jest referencją do argumentu _a, który jak wiemy z przekazywania argumentów ma charakter tymczasowy tzn. po wykonaniu się tego konstruktora jest USUWANY Z PAMIĘCI. Zatem pole referencyjne a pokazuje na NIE ISTNIEJĄCY rzeczywistości obszar pamięci. Jak widać obiektowa technika pisania programów nie zabezpiecza całkowicie przed myśleniem.
Konstruktor kopiujący
Załóżmy następującą deklarację klasy Test:
class Test {
int a, b;
public:
Test() { a = b = 0; };
Test(int _a, int _b) :a(_a), b(_b) {};
};
Test p(3, 5), q;
Jak widać mamy zadeklarowane dwie zmienne typu obiektowego. Pierwszy obiekt został zainicjowany za pomocą zdefiniowanego w tej klasie konstruktora zawierającego dwa parametry typu int, a do inicjacji drugiego został wykorzystany konstruktor bezparametrowy zapewniający przypisanie komponentom a i b wartości 0.
Wykonajmy na tych zmiennych następującą operację:
q = p;
Jest to "zwyczajne" przypisanie jednego obiektu do drugiego. Otóż w tym przypadku chodzi na o to aby pola obiektu q miały takie same wartości jak pola obiektu p. Takie przypisanie jak już wcześniej sobie powiedzieliśmy jest realizowane przez domyślny operator przypisania.
Teraz spróbujmy zadeklarować zmienną r następująco:
Test p(3, 5), r(p);
Obiekt r jest inicjowany przez konstruktor kopiujący. Ponieważ nie zadeklarowaliśmy go w naszej klasie to kompilator "przeczuwając", że kiedyś może wystąpić taka operacja w programie automatycznie dodał domyślny konstruktor kopiujący, którego postać jest następująca:
class Test {
int a, b;
public:
Test() { a = b = 0; };
Test(int _a, int _b) :a(_a), b(_b) {};
// tak wyglądać może przykładowy konstruktor kopiujący
Test(Test& n) { a = n.a; b = n.b; }
};
Test p(3, 5), q;
Na liście argumentów pojawiła się referencja do typu Test (z pojęciem tym zetknęliśmy się już w trakcie nauki programowania w języku C). Jak widać sens działania tego konstruktora sprowadza się do kopiowania pól obiektu, który jest jego argumentem do drugiego właśnie tworzonego przez niego.
W takich przypadkach tworzenia prostych obiektów wystarczy nam domyślny konstruktor kopiujący. Co będzie jednak w takim przypadku?
#include <iostream.h>
#include <string.h>
class Test {
char *s;
int b;
public:
Test() { s = NULL; }
Test(int _b, char *_s);
~Test() {delete s; };
};
Test::Test(int _b, char *_s)
{
b = _b;
s = new char[strlen(_s) + 1];
strcpy(s, _s);
}
main()
{
Test *p = new Test(3, "Ala ma kotka");
Test *q = new Test(*p);
// ...
delete p;
// ...
delete q;
}
Teraz brak własnego zdefiniowanego konstruktora kopiującego może zakończyć się dla programu bardzo źle. Otóż domyślny konstruktor zaproponowany przez kompilator będzie miał postać:
Test::Test(Test& n)
{
b = n.b;
s = n.s;
}
Jego zadaniem jest skopiowanie wszystkich pól obiektów ale niestety "nie wie" on, że jedno z tych pól jest polem wskaźnikowym, które ma przydzielony odpowiedni obszar pamięci. W tym przypadku oba pola s należące do dwóch obiektów pokazują na ten sam obszar pamięci. Co więcej usunięcie obiektu p powoduje zwolnienie pamięci wskazywanej przez s (bo tak działa destruktor tej klasy). Następne wywołanie destruktora na rzecz obiektu q spowoduje niestety zwolnienie nie przydzielonej pamięci. Efekty działania takiego programu mogą być bardzo dziwne.
Spróbujmy napisać teraz poprawnie ten program. Przyczyną błędu w jego działaniu był brak konstruktora kopiującego zdefiniowanego dla tej klasy.
#include <iostream.h>
#include <string.h>
class Test {
char *s;
int b;
public:
Test() { s = NULL; }
Test(int _b, char *_s);
Test(Test& n);
~Test() {delete s; };
};
Test::Test(int _b, char *_s)
{
b = _b;
s = new char[strlen(_s) + 1];
strcpy(s, _s);
}
Test::Test(Test& n)
{
b = n.b;
s = new char[strlen(n.s) + 1];
strcpy(s, n.s);
}
main()
{
Test *p = new Test(3, "Ala ma kotka");
Test *q = new Test(*p);
// ...
delete p;
// ...
delete q;
}
Jak widać konstruktor bezparametrowy przydziela pamięć dla pola s i kopiuje do niego zawartość łańcucha znaków n.s. Tak więc po wykonaniu działania:
Test *q = new Test(*p);
mamy dwa obiekty poprawnie utworzone, których pola zawierają te same wartości ale obiekty nie posiadają wspólnych pól wskaźnikowych. Usunięcie jednego z tych obiektów nie wpływa już w żaden sposób na funkcjonowanie drugiego.
Proszę sobie zapamiętać, że brak konstruktora kopiującego może być przyczyną poważnych i niezrozumiałych błędów w programie.
Usuwanie obiektów - destruktor
Każdy obiekt utworzony w programie jest kiedyś usuwany. Obiekty globalne zdefiniowane przed funkcją main lub zadeklarowane w innych funkcjach ale z atrybutem static są usuwane na zakończenie programu. Obiekty lokalne tworzone są w momencie wejścia do bloku programu lub w wyniku wykonania operacji tworzenia za pomocą funkcji new. Usuwane są w momencie gdy sterowanie programu opuszcza ten blok lub gdy programista wykonał operację delete. Przy usuwaniu obiektu wywoływana jest specjalna funkcja zwana destruktorem. Jest to funkcja bezparametrowa, która także podobnie jak konstruktor nie zwraca żadnej wartości. Destruktor ma taką samą nazwą jak klasa oraz jest poprzedzony znakiem tyldy (~).
Zadaniem destruktora może być np., zwolnienie pamięci przydzielonej dynamicznie w konstruktorze ale nie należy liczyć na zwolnienie całego obiektu. Taka sytuacja występuje w następującym przykładzie:
class String {
char *s;
public:
String(): s(NULL) {};
String(char *_s) { s = new char[strlen(_s) + 1]; strcpy(s, _s) };
~String();
// ...
};
Zadaniem destruktora będzie zwolnienie przydzielonej pamięci dla pola s. Prawdopodobnie w pierwszej chwili napisalibyśmy destruktor w takiej oto postaci.
String::~String(char _s)
{
delete s;
}
Zastanówmy się czy zawsze będzie on działać poprawnie. Pierwsza wątpliwość dotyczy sytuacji gdy zainicjowaliśmy obiekt przy pomocy konstruktora bezparametrowego np., tak:
String *n = new Test;
...
delete n;
Jak widzimy pole s nie zawiera przydzielonej pamięci i ma wartość NULL. W przypadku usuwania obiektu destruktor wywoła operację zwalniania pamięci, która nie została przydzielona. Spowoduje to wystąpienie błędu alokacji pamięci. Aby temu zapobiec należy destruktor napisać w następującej postaci:
String::~String()
{
if( s ) {
delete s;
s = NULL;
}
}
Ustawienie pola s na wartość NULL informuje nas, że pole to nie ma przydzielonej pamięci
Ciekawa właściwość destruktora dotycząca jego możliwości wywołania na rzecz dowolnego obiektu tej klasy pokazana jest w kolejnym przykładzie.
String n;
...
n.String::~String;
To wywołanie destruktora zwolni pamięć przydzieloną dla pól obiektu ale nie zwolni obiektu.
Przykład
Napisać klasę, która umożliwi odkładanie liczb całkowitych na umownym stosie. Zdefiniować dwie operacje odłożenia i pobrania liczby ze stosu.
#include <iostream.h>
class Stack {
int buf[100];
int ptr;
public:
Stack();
int get( int &a );
int put( int a );
};
Stack::Stack()
{
ptr = -1;
}
int Stack::get( int &a )
{
if( ptr == -1 )
return 0;
else
a = buf[ptr--];
return 1;
}
int Stack::put( int a )
{
if ( ptr >= 99 )
return 0;
else
buf[++ptr] = a;
return 1;
}
void main()
{
Stack s;
int c;
cout << endl;
for( int i = 0; i < 20; i++ )
s.put( i );
for( i = 0; i < 20; i++ ) {
s.get( c );
cout << c << ' ';
}
}
Zadaniem konstruktora bezparametrowego jest ustawienie pola ptr na wartość -1, która będzie oznaczać, że stos jest pusty. Właściwy stos reprezentuje pole buf, które jest normalną tablicą. Metoda put "odkłada" na stosie liczbę, która przychodzi jako jej argument i zwiększa ptr o 1 zaś metoda get czyni dokładnie odwrotnie. Użyteczność tego programu zapewne jest niewielka ale pokazuje jak wygląda samo programowanie obiektowe.
Spróbujmy teraz nasz program trochę udoskonalić. Wadą poprzedniego rozwiązania było to, że na stałe była określona wielkość bufora imitującego stos. Teraz po zmianie deklaracji pola buf na
int *buf;
będzie można wykorzystywać już dowolny rozmiar stosu. Za tą zmianą muszą pójść także następne. Powinien pojawić się konstruktor umożliwiający inicjalizację klasy za pomocą liczby całkowitej oznaczającej maksymalną liczbę elementów na stosie oraz destruktor, który umożliwi z kolei zwolnienie pamięci przydzielonej dla buf.
#include <iostream.h>
class Stack {
int *buf;
int ptr, n;
public:
Stack();
Stack( int _n );
~Stack();
int get( int &a );
int put( int a );
};
Stack::Stack()
{
ptr = -1;
n = 100;
buf = new int[n];
}
Stack::Stack( int _n )
{
ptr = -1;
n = _n;
buf = new int[n];
}
Stack::~Stack()
{
if( buf ) delete buf;
}
int Stack::get( int &a )
{
if( ptr == -1 )
return 0;
else
a = buf[ptr--];
return 1;
}
int Stack::put( int a )
{
if ( ptr >= 99 )
return 0;
else
buf[++ptr] = a;
return 1;
}
void main()
{
Stack *s = new Stack( 100 );
int c;
cout << endl;
for( int i = 0; i < 20; i++ )
s->put( i );
for( i = 0; i < 20; i++ ) {
s->get( c );
cout << c << ' ';
}
delete s;
}
Czas życia obiektów
Jest to bardzo ciekawy aspekt związany z programowaniem obiektowym w C++. Jak już wspomniano obiekty globalne lub statyczne są tworzone przed rozpoczęciem wykonywania funkcji main i usuwane po jej zakończeniu. Obiekty lokalne czyli definiowane w blokach programu są tworzone w momencie wejścia do bloku i usuwane gdy sterowanie opuszcza ten blok. Obiekty kontrolowane powstają w momencie wywołania operatora new i są usuwane po użyciu operatora delete. Podany niżej program pokazuje kiedy są tworzone i usuwane obiekty globalne, lokalne i kontrolowane.
#include <iostream.h>
#include <string.h>
#include <stdlib.h>
class String {
char *s;
public:
String(char *_s) {
cout << endl << "Konstruktor : " << _s;
s = new char[strlen(_s) + 1];
strcpy(s, _s);
}
~String() {
cout << endl << "Destruktor:";
if (s) {
cout << s;
delete s;
s = NULL;
}
else
cout << endl << "Pusty obiekt (s == NULL)";
}
};
void f1()
{
cout << endl << "Początek func1";
String s = "Obiekt lokalny w funkcji func1";
cout << endl << "Koniec func1";
}
void f2()
{
cout << endl << "Początek func2";
String s = "Obiekt lokalny w funkcji func2";
cout << endl << "Koniec func2";
}
String sg1 = "Pierwszy globalny obiekt";
String sg2("Drugi globalny obiekt");
int main()
{
cout << endl << endl << "Początek funkcji main";
String a = "Pierwszy obiekt w funkcji main";
f1();
String b = "Drugi obiekt w funkcji main";
cout << endl << "Blok wewnętrzny funkcji main";
{
String s("Obiekt w bloku wewnętrznym main");
}
cout << endl << "Koniec bloku wewnętrznego funkcji main";
cout << endl << "Jawne wywołanie destruktora na rzecz drugiego obiektu main";
b.String::~String();
f2();
cout << endl << "Koniec main";
return 0;
}
Konstruktor : Pierwszy globalny obiekt
Konstruktor : Drugi globalny obiekt
Początek funkcji main
Konstruktor : Pierwszy obiekt w funkcji main
Początek func1
Konstruktor : Obiekt lokalny w funkcji func1
Koniec func1
Destruktor:Obiekt lokalny w funkcji func1
Konstruktor : Drugi obiekt w funkcji main
Blok wewnętrzny funkcji main
Konstruktor : Obiekt w bloku wewnętrznym main
Destruktor:Obiekt w bloku wewnętrznym main
Koniec bloku wewnętrznego funkcji main
Jawne wywołanie destruktora na rzecz drugiego obiektu main
Destruktor:Drugi obiekt w funkcji main
Początek func2
Konstruktor : Obiekt lokalny w funkcji func2
Koniec func2
Destruktor:Obiekt lokalny w funkcji func2
Koniec main
Destruktor:
Pusty obiekt (s == NULL)
Destruktor:Pierwszy obiekt w funkcji main
Destruktor:Drugi globalny obiekt
Destruktor:Pierwszy globalny obiekt
Dostęp do komponentów obiektu
Funkcje składowe klasy
W ramach funkcji składowych klasy wolno odwoływać się do wszystkich pól i metod tej klasy (także prywatnych) bez konieczności stosowania operatora wyboru komponentu. Definicja funkcji składowej może być połączona z jej deklaracją w ciele klasy i w tym przypadku funkcja będzie traktowana jako inline.
Przeanalizujmy podany niżej program. Jego działanie jest interesujące z punktu widzenia przesłaniania pól i funkcji składowych.
#include <iostream.h>
int n = 20;
void w1()
{
cout << endl << "Funkcja poza klasą " << n;
}
class Test {
int n;
public:
Test(int _n) : n(_n), b(23) {}
double b;
int getInt() { return n; }
void w1();
void w2();
};
void Test::w1()
{
cout << endl << "Funkcja w klasie " << n << ' ' << b;
}
void Test::w2()
{
cout << endl << "Funkcja w klasie " << ::n << ' ' << b;
::w1();
}
main()
{
Test a(5);
a.w1();
a.w2();
};
Jak widać funkcja w1 występuje "samotnie" jak również jest częścią klasy Test podobnie jak pole n ma także swój odpowiednik w zmiennej globalnej n. Jak już powiedzieliśmy wewnątrz dowolnej funkcji składowej mamy dostęp do wszystkich komponentów obiektu - wystarczy podać tylko jego nazwę. Inaczej jest w przypadku próby odwołania się do przesłoniętego identyfikatora. Wymagane jest wtedy poprzedzenie identyfikatora operatorem zakresu w naszym przypadku jest to ::n i ::w1().
Pola i metody statyczne
Pola statyczne są zadeklarowane z atrybutem static. Ich cechą charakterystyczną jest to, że istnieją przez cały czas działania programu nawet jeśli nie ma w pamięci utworzonych obiektów. Ponadto takie pole statyczne jest wspólne dla wszystkich obiektów tej klasy niezależnie od liczby utworzonych obiektów. Tę właściwość wykorzystuje się najczęściej do przechowywania w pamięci wspólnych danych, które mają być dostępne dla wszystkich tego typu obiektów. Do modyfikacji pól statycznych wykorzystuje się najczęściej konstruktory, destruktory i funkcje statyczne.
Pola klasy globalnej muszą być zainicjalizowane po deklaracji klasy.
Metody statyczne są zadeklarowane także z atrybutem static. Można odwoływać się do nich nawet jeśli nie ma żadnego utworzonego w pamięci obiektu. W tym przypadku należy określić klasę na rzecz, której ta funkcja ma być aktywowana.
W podanym niżej przykładzie zostały zadeklarowane dwa pola statyczne. Jedno z nich jest polem prywatnym klasy a drugie polem publicznym. Statyczna funkcja write jest także publiczna. W statycznym polu n chcemy przechowywać liczbę obiektów, które są w tej chwili utworzone w pamięci. Stąd też w konstruktorze występuje automatyczne zwiększanie tego pola o jeden. Jeśli będziemy mieć kilka konstruktorów w tej klasie to należy taką operację powtórzyć we wszystkich.
#include <iostream.h>
class Test
{
static int n;
public:
static int m;
Test() { n++; }
static void write() { cout << endl << "n = " << n << " m = " << m; }
};
Po definicji klasy następuje zainicjowanie pól statycznych wartościami początkowymi.
int Test::n = 0;
int Test::m = 1;
W funkcji main następuje utworzenie trzech obiektów klasy Test (na wydruku otrzymamy potwierdzenie tego faktu). Z poziomu funkcji main można oczywiście modyfikować tylko to pole statyczne, które jest zadeklarowane jako publiczne.
W składowych statycznych nie wolno odwoływać się do pól niestatycznych, gdyż nie w każdym momencie działania funkcji statycznej pola takie istnieją.
void main()
{
Test a, b, c;
a.write();
b.m = -1;
}
Jak już na wstępie powiedzieliśmy, że pola i metody statyczne są dostępne nawet, gdy nie ma w pamięci żadnego obiektu. W tym przypadku należy odwoływać się do pól i metod za pomocą identyfikatora klasy.
void main()
{
Test::m = -4;
Test::write();
}
Zmienna this
Wewnątrz każdej funkcji niestatycznej kompilator dodaje lokalną zmienną o nazwie this, która jest wskaźnikiem na obiekt, na rzecz którego funkcja została aktywowana. Zmienna ta jest nam potrzebna aby:
funkcja składowa mogła zwrócić wskaźnik na obiekt, na rzecz którego była aktywowana lub referencję do niego,
w funkcji składowej odwołać się do adresu obiektu, na rzecz którego została ona aktywowana.
Przyjmując deklarację klasy w postaci:
class Test {
char *ptr;
public:
...
void set();
};
odwołania w funkcji set do pola ptr można zapisać na kilka różnych sposobów:
ptr;
Test::ptr;
this->ptr
this->Test::ptr
(*this).ptr
(*this).Test::ptr
Jeden ze sposobów wykorzystania tej zmiennej można pokazać na następującym przykładzie.
#include <iostream.h>
#include <string.h>
class Test {
char *s;
int b;
public:
Test() {s = NULL;}
Test(int _b, char *_s);
~Test() {delete s; };
void fun();
};
Test::Test(int _b, char *_s)
{
b = _b;
s = new char[strlen(_s) + 1];
strcpy(s, _s);
}
void Test::fun()
{
int b = 20;
cout << b << this->b;
}
main()
{
Test p(3, "Ala ma kotka");
p.fun();
// ...
}
Wewnątrz funkcji fun mamy do czynienia z przesłonięciem pola b przez zmienną lokalną b. Wszelkie odwołania do identyfikatora b będą domyślnie dotyczyć właśnie tej zmiennej. Aby uzyskać dostęp do pola b powinniśmy wykorzystać wskaźnik this.
Funkcje zaprzyjaźnione
Funkcje zaprzyjaźnione mają z funkcjami składowymi tylko jedną wspólną cechę: otóż mogą odwoływać się do prywatnych i zabezpieczonych komponentów klasy z którą są zaprzyjaźnione. Nie są one w zakresie klasy mimo, że trzeba podać ich deklarację ze specyfikatorem friend w ciele tej klasy. To, że nie są one w klasie powoduje, że umieszczenie ich w sekcji prywatnej nie nadaje im oczywiście prawa prywatności. Funkcja zaprzyjaźniona może działać na obiektach klasy, z którą jest zaprzyjaźniona, jeśli zostaną one jej przekazane przez listę argumentów lub będą to zmienne globalne. Jedna funkcja może zostać zaprzyjaźniona z kilkoma klasami i co więcej funkcja składowa jednej klasy może być zaprzyjaźniona z inną klasą. W podanym niżej przykładzie funkcja "wolnostojąca" fun4 jest zaprzyjaźniona z obiema klasami. Funkcja fun2, która jest składową klasy AA jest zaprzyjaźniona z klasą BB. Aby taka deklaracja mogła zostać przyjęta przez kompilator konieczne jest wprowadzenie przed definicję klasy AA wiersza zapowiadającego definicję klasy BB.
#include <iostream.h>
class BB;
class AA {
int a;
void fun1() { a = 10;}
public:
int b;
int c;
AA() : a(0), b(1), c(2) {}
void fun2(BB _a) {BB a;}
void fun3() {};
private:
void write() { cout << endl << "a = " << a
<< " b = " << b << " c = " << c; }
friend void fun4(AA a, BB b);
};
class BB {
int b;
public:
BB() : b(100) {}
void write() { cout << endl << "b = " << b; }
private:
friend void AA::fun2(BB a);
friend void fun4(AA a, BB b);
};
void fun4(AA a, BB b)
{
a.write();
b.write();
}
main()
{
AA x;
BB y;
fun4( x, y );
x.fun2( y );
return 0;
}
Funkcje operatorowe
Specyfika języka C++ pozwala na przeciążanie większości operatorów, które mogą mieć nowe właściwości odnośnie operacji na obiektach. Technikę tę stosuje się w celu zapewnienia programiście większej swobody przy operowaniu obiektami. Poza tym jak zapewne Państwo zobaczycie w dalszej części tego rozdziału sprzyja to zwiększeniu czytelności programu.
Zdecydowana większość operatorów może być przeciążana za wyjątkiem następujących operatorów podanych w nawiasach: (.) (.*) (?:) (::) (sizeof) oraz symboli preprocesora (#) (##).
Przeciążanie operatorów odbywa się za pomocą funkcji operatorowych. Można podzielić je na cztery kategorie:
Funkcje operatorowe, które wymagają aby przynajmniej jeden z ich argumentów był typu obiektowego. Mogą być zdefiniowane w ramach klasy ale nie muszą.
Funkcje operatorowe zmieniające znaczenie operatorów new i delete.
Specjalne funkcje operatorowe takie jak: = () [] ->.
Konwertery czyli jednoparametrowe funkcje operatorowe, których zadaniem jest umożliwienie konwersji do typu swego argumentu. Muszą być one zadeklarowane jako niestatyczne składowe klasy i w definicji nie mogą zwracać żadnej wartości nawet typu void.
Przeciążanie symboli operatorów nie zmienia i priorytetów i wiązań i zawsze trzeba o tym pamiętać.
Przeciążanie operatorów ogólnych
Zacznijmy najpierw od sformułowania zadania. Przyjmijmy, że mamy następującą deklarację klasy LICZBY.
class LICZBY {
public:
int num;
LICZBY() { num = 0; }
LICZBY(int n): num(n) {}
...
};
LICZBY a, b(5), c(7);
Na zmiennych typu klasa LICZBY mamy wykonywać operacje dodawania rozumianego jako sumowanie zawartości pól num. Klasycznie można byłoby rozwiązać ten problem następująco:
main()
{
a.num = b.num + c.num;
...
}
Jest to poprawne rozwiązanie ale niezbyt wygodne. Ciągle musimy pamiętać o tym jak nazywają się pola przechowujące wartości liczb i ciągle nie możemy posługiwać się obiektami jako samodzielnymi jednostkami. Technika tworzenia własnych operatorów umożliwia nam zapis tego problemu w następującej i jakże eleganckiej postaci.
main()
{
a = b + c;
...
}
Teraz już można na tym etapie pisania programu zapomnieć o strukturze obiektów i posługiwać się całymi obiektami. Aby można było zapisać w tej postaci "dodawanie" obiektów konieczne jest zmodyfikowanie struktury klasy LICZBY. Jedna z możliwych implementacji może wyglądać następująco:
#include <iostream.h>
class LICZBY {
public:
int num;
LICZBY() { num = 0; }
LICZBY(int n): num(n) {}
LICZBY operator=(LICZBY x); //operator przypisania będący w klasie
LICZBY operator+(LICZBY x); //operator dodawania będący w klasie
};
LICZBY LICZBY::operator=(LICZBY x)
{
this->num = x.num;
return *this;
}
LICZBY LICZBY::operator+(LICZBY x)
{
LICZBY a;
a.num = this->num + x.num;
return a;
}
main()
{
LICZBY a, b(5), c(7);
a = b + c;
cout << a.num;
return 0;
}
Jak widać pojawiły się nowe metody tej klasy o nazwach operator= oraz operator+. Jak już zaznaczono w komentarzach w tym programie oba te operatory zdefiniowane są w ramach klasy LICZBY.
Ogólna postać funkcji operatorowej dwuargumentowej zadeklarowanej w klasie ma postać:
typ_wyniku operator$(typ_argumentu)
Za znak $ trzeba podstawić właściwy operator, w tym przypadku = oraz +. W tym przypadku lewy argument zawsze musi być typu obiektowego.
Przyjmując podane w zadaniu oznaczenia wywołanie funkcji operatorowej działającej na dwóch zmiennych obiektowych b i c można zapisać jako
b.operator+(c)
lub wersji uproszczonej
b + c
Operatory dodawania i przypisania są operatorami dwuargumentowymi. Prawy argument reprezentuje to co znajduje się w nawiasach okrągłych a lewy to domyślnie zmienna na rzecz, której została ta metoda wywołana.
Drugi argument może być typu nieobiektowego, np.; przy takiej deklaracji funkcji operatorowej
LICZBY LICZBY::operator+(int x)
{
LICZBY a;
a.num = this->num + x;
return a;
}
LICZBY a, b(5);
int x = 7;
można wykonać następujące działanie:
a = b + x;
Poza operatorami dwuargumentowymi istnieją oczywiście operatory jednoargumentowe. W tym przypadku ogólny zapis takiej funkcji operatorowej ma postać:
typ_wyniku operator$(void)
Wracając do naszego przykładu podczas operacji dodawania powstaje obiekt tymczasowy a.
LICZBY LICZBY::operator+(LICZBY x)
{
LICZBY a;
a.num = this->num + x.num;
return a;
}
Po zakończeniu działania
a = b + c;
ten obiekt tymczasowy jest usuwany. Szerzej na temat tworzenia i usuwania obiektów będzie w dalszej części tego rozdziału. Wyrażenie this->num oznacza, że odwołujemy się do pola num, które należy do tego obiektu na rzecz, którego wywołana została funkcja ta operatorowa.
Czasami wygodniej jest zadeklarować funkcję operatorową będącą poza klasą. Umożliwia to obejście dosyć mocnego ograniczenia jakim jest to aby lewy argument zawsze był typu obiektowego. W tym przypadku należy na liście argumentów tej funkcji podać już dwa argumenty.
#include <iostream.h>
class LICZBY {
public:
int num;
LICZBY() { num = 0; }
LICZBY(int n): num(n) {}
LICZBY operator=(LICZBY x); //operator przypisania będący w klasie
};
LICZBY LICZBY::operator=(LICZBY x)
{
this->num = x.num;
return *this;
}
int operator+(int x, LICZBY n) //operator poza klasą
{
return x + n.num;
}
main()
{
LICZBY a, b(5), c(7);
a = 5 + b;
cout << a.num;
cout << 5 + c;
return 0;
}
Dzięki takie deklaracji operatora dodawania można zrealizować zapis
a = 5 + b;
oraz
cout << 5 + c;
Przeciążanie operatorów ++ i --
Ciekawą sytuację mamy w przypadku przeciążania operatorów inkrementacji i dekrementacji. Otóż, jak wiemy, mogą one występować w dwóch wersjach jako przedrostkowe i przyrostkowe. Aby rozróżnić o którą wersję nam w danym momencie chodzi zastosowano pewną sztuczkę w zapisie polegającą na dodaniu jednego parametru typu int. I tak operator zdefiniowany w klasie jako bezargumentowy obsługuje wersję przedrostkową a z jednym argumentem typu int wersję przyrostkową.
class INT {
public:
int val;
INT(int n) : val(n) {}
INT operator++();
INT operator++(int);
};
INT INT::operator++()
{
val++;
}
INT INT::operator++(int)
{
val++;
}
main()
{
INT a(4), b(4);
a++; //wywołana zostanie funkcja operatorowa operator++(int)
++b; //wywołana zostanie funkcja operatorowa operator++()
}
Przykład
Korzystając z poznanych w pierwszej części tego rozdziału informacji dotyczących funkcji operatorowych należy napisać klasę String, która będzie umożliwiać takie podstawowe operacje na tekstach jak:
inicjowanie klasy: łańcuchem znaków (char *), znakiem (char), liczbą całkowita reprezentującą długość łańcucha znaków oraz innym obiektem typu String,
"dodawanie" do obiektu typu String: łańcucha znaków, pojedynczego znaku oraz innego obiektu String.
Rozwiązanie (opracowanie na podstawie Barteczko K. ''Praktyczne wprowadzenie do programowania obiektowego w języku C++").
#include <iostream.h>
#include <string.h>
#include <stdlib.h>
class String {
char *ptr;
public:
static int num;
String();
String( char *s );
String( char *s1, char *s2 );
String( char *s1, char c );
String( char c );
String( int c );
String( String &s );
~String();
char *get() { return ptr; }
int operator== ( char *s );
void operator= ( char *s );
String operator= ( String &s );
String operator+ ( char *s );
String operator+ ( char c );
String operator+ ( String &s );
};
int String::num = 0;
/*
zadaniem konstruktora bezparametrowego jest ustawienie
pola ptr na wartość NULL oraz zwiększenie licznika utworzonych
kopii obiektów
*/
String::String()
{
ptr = NULL;
num++;
}
/*
ten konstruktor ma na celu umożliwienie inicjowania obiektów
łańcuchami znaków
*/
String::String( char *s )
{
ptr = new char[ strlen( s ) + 1 ];
strcpy( ptr, s );
num++;
}
/*
ten konstruktor ma na celu umożliwienie inicjowania obiektów
pojedynczymi znakami
*/
String::String( char c )
{
ptr = new char[ 2 ];
*ptr = c;
*(ptr + 1) = '\0';
num++;
}
/*
zadaniem tego konstruktora jest utworzenie obiektu
i przydzielenie polu ptr pamięci o długości c znaków
*/
String::String( int c )
{
ptr = new char[ c ];
*ptr = '\0';
num++;
}
// konstruktor kopiujący zdefiniowany dla tej klasy
String::String( String &s )
{
ptr = new char[ strlen( s.ptr ) + 1 ];
strcpy( ptr, s.ptr );
num++;
}
/*
dwa następne zdefiniowane konstruktory mają charakter
pomocniczy, wykorzystywane są w funkcjach operatorowych
*/
String::String( char *s1, char *s2 )
{
ptr = new char[ strlen( s1 ) + strlen( s2 ) + 1 ];
strcpy( ptr, s1 );
strcat( ptr, s2 );
num++;
}
String::String( char *s1, char c )
{
ptr = new char[ strlen( s1 ) + 2 ];
strcpy( ptr, s1 );
*(ptr + strlen( ptr ) + 1) = '\0';
*(ptr + strlen( ptr )) = c;
num++;
}
/*
zadaniem destruktora klasy String jest zwolnienie pamięci
przechowywanej przez pole ptr oraz zmniejszenie
licznika obiektów num
*/
String::~String()
{
if( ptr ) delete ptr;
ptr = NULL;
num--;
}
// "porównanie" obiektu String (jego pola ptr) z łańcuchem znaków s
int String::operator== ( char *s )
{
return strcmp( ptr, s );
}
// skopiowanie obiektu s do *this
String String::operator= ( String &s )
{
if( ptr ) delete ptr;
ptr = new char[ strlen( s.ptr ) + 1 ];
strcpy( ptr, s.ptr );
return *this;
}
// skopiowanie łańcucha znaków s do pola ptr
void String::operator= ( char *s )
{
if( ptr ) delete ptr;
ptr = new char[ strlen( s ) + 1 ];
strcpy( ptr, s );
}
/*
zadaniem kolejnych trzech operatorów jest dodanie obiektu,
łańcucha znaków lub jednego znaku do aktualnego pola ptr,
w tym celu następuje "powołanie do życia" obiektu tymczasowego
"dodanie" pola ptr z obiektu s do aktualnego pola ptr, w tym celu
następuje "powołanie do życia" obiektu tymczasowego
*/
String String::operator+ ( String &s )
{
return String( ptr, s.ptr );
}
/*
"dodanie" argumentu s do aktualnego pola ptr, tworzony jest
obiekt tymczasowy
*/
String String::operator+ ( char *s )
{
return String( ptr, s );
}
String String::operator+ ( char s )
{
return String( ptr, s );
}
void main()
{
String *c = new String( "Ala " );
String *d = new String( "szkoły" );
String *e = new String( 20 );
*e = *c + "idzie do " + *d + '.';
cout << endl << String::num << ' ' << e->get();
delete c;
delete d;
delete e;
}
W wyniku działania tego programu uzyskamy napis na ekranie komputera w postaci:
3 Ala idzie do szkoły
Na podanym niżej rysunku pokazany jest schemat działania funkcji operatorowych w wierszu
*e = *c + "idzie do " + *d + '.';
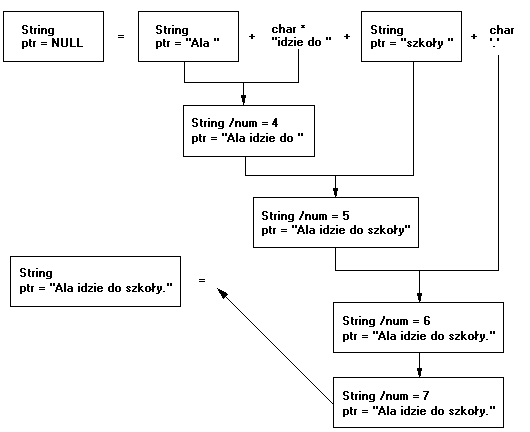
Najpierw wykonywane jest działanie *c + "idzie do " (do obiektu klasy String dodawany jest typ nieobiektowy). W jego wyniku powstaje obiekt tymczasowy, nazwijmy go sobie tmp1, przechowujący powstały napis "Ala idzie do ". Licznik utworzonych obiektów zwiększył się oczywiście o jeden i wynosi w tym momencie 4.
W drugim kroku do powstałego obiektu tymczasowego tmp1 dodawany jest obiekt *d. Powstaje kolejny obiekt (tmp2) z polem ptr zawierającym napis "Ala idzie do szkoły". Licznik obiektów wynosi w tym momencie już 5.
Następnie według tego samego schematu dodawany jest jeszcze jeden element - znak '.'. Będziemy mieć kolejny obiekt tymczasowy, pole statyczne num ma zatem wartość 6.
Przy kopiowaniu (w tym momencie wywoływany jest operator przypisania zdefiniowany dla tej klasy, który "wie" jak wykonać kopiowanie obiektów) wartości wyrażenia znajdującego się po prawej stronie tego operatora następuje utworzenie kolejnego obiektu tymczasowego (razem mamy ich już 7 w tym trzy jawnie zadeklarowane na początku programu).
Po obliczeniu wartości tego wyrażenia (przypisanie zmiennej *e) następuje automatyczne usuwanie obiektów tymczasowych. Z tego też powodu na koniec przy drukowaniu pola statycznego num nastąpiło wydrukowanie liczby 3.
Jak widać wadą tego sposobu wykonywania działań jest zwiększone zapotrzebowanie na pamięć aby pomieścić tworzone obiekty tymczasowe oraz czas wykonania tego programu.
Modyfikacja funkcji operatorowej
Zmieńmy teraz jedną funkcję operatorową na następującą postać:
String String::operator+ ( String &s )
{
String *w = new String( ptr, s.ptr );
return *w;
}
W tym momencie na ekranie zobaczymy
4 Ala idzie do szkoły
Bardzo ważna jest wyprowadzona w tym momencie liczba 4. Pojawia się ona na ekranie w wyniku wydrukowania zawartości statycznego pola num, które opisuje ile w danym momencie jest utworzonych kopii obiektu String. W momencie wykonywania się wszystkich funkcji operatorowych w wierszu
*e = *c + "idzie do " + *d + '.';
powstają jak już wiemy obiekty tymczasowe - każda z tych funkcji ma w sobie wywołanie odpowiedniego konstruktora klasy String. Są one jednak automatycznie usuwane po zakończeniu wykonywania się tego wiersza. W naszym przypadku "ręcznie" powołaliśmy do życia obiekt lokalny w. Po zakończeniu działania tej funkcji operatorowej nastąpiło usunięcie zmiennej w z pamięci tak samo jak są usuwane inne zmienne lokalne bez uwzględnienia, że jest to zmienna wskazująca na utworzony obiekt. Konsekwencją tego działania jest to, że nie mamy już dostępu do tego obiektu (zmienna w jest "zniszczona") ale pozostał zarezerwowany obszar pamięci wcześniej wskazywany przez pole ptr tego obiektu w. Poza tym program działa poprawnie.
Przykład
Zastanówmy się teraz czy nie można napisać tego programu tak aby nie tworzyło się tak dużo tymczasowych obiektów. W tym celu wykorzystamy referencje wprowadzone w programowaniu obiektowym. My zapoznaliśmy się z nim już wcześniej w ramach modułu "Programowanie w C". Wiemy już jakie znaczenie ma to pojęcie i dlaczego je wprowadzono. Otóż główną zaletą przekazywania argumentów do funkcji przez referencję było to, że następowało przekazanie jedynie adresu argumentu faktycznego zamiast kopiowania argumentu faktycznego. Podobnie było w przypadku zwracania wartości przez funkcję. Wtedy zyskiwaliśmy na czasie zwłaszcza w przypadkach gdy "kopiowane" były argumenty umieszczone w dużych obszarach danych. Teraz w przypadku programowania pojęcie nabiera znacznie większego znaczenia.
Rozwiązanie (opracowanie na podstawie Barteczko K. ''Praktyczne wprowadzenie do programowania obiektowego w języku C++").
Aby uniknąć przechowywania zbędnych kopii obiektów klasy String zmieńmy jej deklarację na następującą:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
class String {
char *ptr;
char tmp;
public:
static int num;
String();
String( char *s );
String( char c );
String( int c );
String( String &s );
~String();
char *get() { return ptr; }
void KillWhenTmp();
void Alloc( int size, char id = 0 );
int operator== ( char *s );
void operator= ( char *s );
String &operator= ( String &s );
String &operator+ ( char *s );
String &operator+ ( char c );
String &operator+ ( String &s );
};
int String::num = 0;
/*
Oprócz statycznego pola num, które jak się zapewne domyślamy ma
mieć identyczne działanie jak w poprzednim przykładzie dodaliśmy
jeszcze jedno pole już nie statyczne tmp. W to pole będą
wprowadzane dwie wartości: 0 lub 1. I tak 0 będzie oznaczało,
że obiekt ma charakter trwały a 1, że jest tymczasowy. Ponadto
operatory przypisania oraz dodawania są zmienione i zwracają
referencję. Oprócz tego zrezygnowaliśmy z jednego konstruktora
i dodaliśmy dwie funkcje Alloc oraz KillWhenTemp.
Zadaniem pierwszej z nich jest przydział pamięci dla pola ptr
w ilości size bajtów. Jak widać z deklaracji tej funkcji jest
to funkcja z parametrami domniemanymi, pojęcie to zostało
także wprowadzone w programowaniu obiektowym a my się zapoznaliśmy
z nim także przy okazji studiowania modułu "Programowanie w C".
Jeśli funkcja zostanie wywołana bez tego argumentu to przyjęta
zostanie wartość id = 0, czyli, że będzie to obiekt trwały.
*/
void String::Alloc( int size, char idtemp )
{
ptr = new char[ size + 1 ];
tmp = idtemp;
}
/*
Zadaniem funkcji KillWhenTemp jest usuwanie z pamięci wszystkich
w tym momencie dostępnych i już niepotrzebnych obiektów
tymczasowych. Działanie tej funkcji jest następujące: sprawdzamy
wartość pola tmp i jeśli zawiera ono wartość różną od 0 to
usuwany jest z pamięci ten obiekt na rzecz, którego została
wywołana ta funkcja. To usunięcie obiektu odbywa się za
pośrednictwem operatora delete, który wywoła destruktor zawarty
w tej klasie.
*/
void String::KillWhenTmp()
{
if( tmp ) delete this;
}
/*
Cechą charakterystyczną czterech konstruktorów zdefiniowanych
niżej jest to, że pole tmp jest wypełnianie wartością 0
(funkcja Alloc wywoływana jest tylko z jednym parametrem).
*/
String::String()
{
ptr = NULL;
tmp = 0;
num++;
}
String::String( char *s )
{
Alloc( strlen( s ) );
strcpy( ptr, s );
num++;
}
String::String( char c )
{
Alloc( 1 );
*ptr = c;
*(ptr + 1) = '\0';
num++;
}
String::String( int c )
{
Alloc( c );
*ptr = '\0';
num++;
}
/*
W przypadku tego konstruktora (konstruktor kopiujący) wiemy,
że jest on wywoływany w sytuacjach gdy mogą już istnieć
obiekty tymczasowe (np. obiekt s przychodzący jako argument
tego konstruktora). Dlatego też na końcu kodu tego konstruktora
następuje wywołanie metody KillWhenTemp na rzecz obiektu s.
Jeśli będzie on mieć charakter tymczasowy to zostanie on
usunięty z pamięci.
*/
String::String( String &s )
{
Alloc( strlen( s.ptr ) );
strcpy( ptr, s.ptr );
s.KillWhenTmp();
num++;
}
// Postać destruktora nie uległa jak widać żadnej zmianie.
String::~String()
{
if( ptr ) delete ptr;
ptr = NULL;
num--;
}
int String::operator== ( char *s )
{
return strcmp( ptr, s );
}
String &String::operator= ( String &s )
{
if( this != &s ) {
if( ptr ) delete ptr;
Alloc( strlen( s.ptr ) );
strcpy( ptr,s.ptr );
s.KillWhenTmp();
}
return *this;
}
void String::operator= ( char *s )
{
if( ptr ) delete ptr;
ptr = new char[ strlen( s ) + 1 ];
strcpy( ptr, s );
}
/*
Ciekawa sytuacja występuje w przypadku tej funkcji
operatorowej. Otóż wynik działania tego operatora to
utworzenie nowego obiektu t (o charakterze tymczasowym,
o którym mówi postać wywołania metody Alloc z drugim
argumentem o wartości 1) zawierającego w swoim polu ptr
odpowiedni napis. Po jego utworzeniu należy podjąć próbę
usunięcie dwóch obiektów: s oraz "samego siebie" gdyż
jest on już w tym momencie niepotrzebny. Przeoczenie tego
faktu spowoduje niestety, że po zakończeniu wszystkich
działań związanych z funkcjami operatorowymi nastąpi
pozostawienie w pamięci pewnych obiektów tymczasowych.
*/
String &String::operator+ ( String &s )
{
String *t = new String;
t->Alloc( strlen( ptr ) + strlen( s.ptr ), 1 );
strcpy( t->ptr, ptr );
strcat( t->ptr, s.ptr );
s.KillWhenTmp();
KillWhenTmp();
return *t;
}
/*
W dwóch następnych przypadkach trzeba podjąć
próbę usunięcia "samego siebie".
*/
String &String::operator+ ( char *s )
{
String *t = new String;
t->Alloc( strlen( ptr ) + strlen( s ), 1 );
strcpy( t->ptr, ptr );
strcat( t->ptr, s );
KillWhenTmp();
return *t;
}
String &String::operator+ ( char s )
{
String *t = new String;
t->Alloc( strlen( ptr ) + 1, 1 );
strcpy( t->ptr, ptr );
*( t->ptr + strlen( t->ptr ) + 1 ) = '\0';
*( t->ptr + strlen( t->ptr ) ) = s;
KillWhenTmp();
return *t;
}
void main()
{
String *c = new String( "Ala " );
String *d = new String( "szkoly" );
String *e = new String( 20 );
*e = *c + "idzie do " + *d + '.';
printf( "\n%d %s", String::num, e->get() );
delete c;
delete d;
delete e;
}
Sieć wzajemnych wywołań i usunięć obiektów jest pokazana na podanym niżej rysunku.
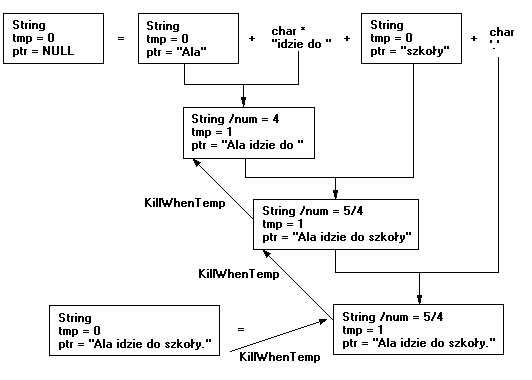
W tym przypadku dodanie do obiektu *c łańcucha znaków "idzie do " powoduje oczywiście utworzenie obiektu tymczasowego zawierającego napis "Ala idzie do ". Pole statyczne num przyjmuje wartość 4. Potem tworzony jest nowy obiekt tymczasowy, który przechowa wynik "Ala idzie do szkoły" (num wzrośnie do 5) ale funkcja KillWhenTemp usunie obiekt na rzecz, którego zostanie wywołana. Tak więc num zmniejszy swoja wartość do 4. Podobne sytuacje będą się występować w dalszej części tego wyrażenia. Maksymalnie w pamięci będzie zatem pięć obiektów tego typu (trzy trwałe oraz dwa tymczasowe). W przypadku skomplikowanych wyrażeń "zysk pamięciowy" może być wystarczającą zachętą do zastosowania tej metody postępowania.
Przeciążanie operatorów new i delete
Przeciążanie operatorów new i delete odbywa się na trochę innych zasadach. Otóż są one traktowane zawsze jako funkcje statyczne danej klasy. Konsekwencje z tego tytułu są np.: takie, że w ramach tej funkcji operatorowej nie można odwołać się do pól tej klasy dlatego, że funkcje statyczne istnieją nawet gdy nie ma żadnego obiektu tego typu.
Składnia tych operatorów jest następująca:
Funkcja operatorowa new musi zwrócić adres obszaru pamięci i przyjmować w charakterze argumentu wartość typu size_t, jest to inaczej zwany typ unsigned. Poza tym funkcja może mieć także inne parametry. W przypadku użycia większej liczby argumentów zapis przedefiniowanego operatora new jest następujący:
void *operator new(size_t, typ1, typ2, ...);
Operator delete jako argument ma wskazanie void * i zwraca typ void.
Przeciążanie tych dwóch specyficznych operatorów można wykorzystać do np. zastosowania własnego algorytmu zarządzania pamięcią przydzielaną w momencie tworzenia obiektów.
Przykład
W podanym niżej przykładzie w momencie inicjowania zmiennej typu klasa X następuje zwiększenie obszaru przydzielonej pamięci o tyle bajtów ile wynosi drugi argument funkcji operatorowej new. Ten obszar może zostać wykorzystany jako w pewnym sensie bufor tego obiektu (co ciekawe położony razem z nim a nie w jakimś innym miejscu pamięci).
#include <stdio.h>
#include <alloc.h>
#include <string.h>
#include <stdlib.h>
class X {
public:
char *s;
X() { s = new char [20]; }
~X() { delete s; }
void Set(char *ptr);
void *operator new(size_t n, int len);
void operator delete(void *a);
};
void X::Set(char *ptr)
{
strcpy(s + sizeof(*this), ptr);
}
void *X::operator new(size_t n, int len)
{
return new char[n + len];
}
void X::operator delete(void *ptr)
{
delete ptr;
}
main()
{
X *x = new (100)X;
x->Set("Ala ma kotka");
delete x;
}
Proszę zwrócić uwagę na wywołanie przeciążonego operatora new. W tym przypadku dodatkowy argument znajduje się przed nim!
Przykład
W podanym niżej przykładzie w funkcji main tworzonych jest 20 obiektów typu NN za pomocą jednego przeciążonego operatora new. Implementacja tego operatora zawiera w sobie kompleksowe utworzenie wszystkich obiektów wraz z przydziałem pamięci dla pól ptr i z ich jednoczesną inicjacją jednoznakowymi łańcuchami zaczynającymi się od litery 'B'.
#include <iostream.h>
#include <alloc.h>
#include <mem.h>
class NN {
public:
char *ptr;
int p;
static int num;
NN() {}
void *operator new(size_t m);
void *operator new(size_t m, size_t n);
void setPtr(size_t mx)
{
ptr = NULL;
ptr = new char[mx + 1];
p = num++;
*ptr = num + 'A';
*(ptr + 1) = '\0';
};
};
int NN::num = 0;
void *NN::operator new(size_t m)
{
char *p = new char[m];
((NN*)p)->setPtr(1);
return p;
}
void *NN::operator new(size_t m, size_t n)
{
char *p = new char[m * n];
for( int i = 0; i < n; i++)
((NN*)( p + i * sizeof(NN)))->setPtr(1);
return p;
}
main()
{
int n = 20;
NN *a = new (n)NN;
cout << endl;
for( int i = 0; i < n; i++ )
cout << endl << a[i].p << ' ' << a[i].ptr[0];
delete a;
return 0;
}
Deklarowanie operatorów specjalnych
Do operatorów specjalnych zaliczamy następujące cztery operatory: indeksowania [], wywołania funkcji (), pośredniego wyboru komponentu -> oraz przypisania =. Jak już na początku tego rozdziału zaznaczyliśmy muszą się one znajdować w klasie oraz nie mogą być statyczne. W ramach tego modułu internetowego głębiej zastanowimy się nad dwoma z nich: indeksowania i przypisania.
Operator indeksowania zaliczany jest do grupy operatorów dwuargumentowych. W skróconym zapisie wygląda to następująco:
x[y]
gdzie x jest jego lewym argumentem (oczywiście zawsze musi być to obiekt), a prawym dowolny typ. Najczęściej ten argument jest wykorzystywany do odwoływania się do obszaru pamięci dostępnego w ramach obiektu x.
Rozszerzmy sobie deklarację naszej klasy String o nową właściwość polegającą na tym, że chcemy mieć bezpośredni dostęp do elementów łańcucha znaków przechowywanego przez pole ptr tej klasy podobnie jak to się czyni ze zwykłymi łańcuchami znaków.
String s;
char c = s[2];
Aby takie działanie było możliwe należy zdefiniować operator indeksowania będący w klasie String.
Jego postać jest następująca:
class String {
...
char& operator[](int n) { return *(ptr + n); }
...
};
W przypadku operatora przypisania mamy
x = y
gdzie x jest jego lewym argumentem (także tylko typ obiektowy) a y dowolnym typem. Operator przypisania wykorzystywany jest do przypisywania obiektom danych różnych typów. Mieliśmy już z nim do czynienia w zaprezentowanych dotychczas dwóch przykładach dotyczący klasy String.
class String {
...
void operator= ( char *s );
String& operator= ( String &s );
...
};
Konwertery
Pozostała nam do omówienia ostatnia grupa operatorów, które można przeciążyć. Noszą one ogólną nazwę konwerterów i ich głównym zadaniem jest konwersja typu obiektowego do typu podanego przy ich deklaracji. Podobnie jak operatory należące do grupy operatorów specjalnych także konwertery muszą znajdować się w klasie i nie mogą być statyczne.
Dla takiej deklaracji zmiennej obiektowej typu String
String s;
załóżmy, że łańcuch znaków przechowywany w polu ptr obiektu x przechowuje ciąg znaków zawierających tylko cyfry czyli liczbę całkowitą zapisaną tekstowo a nie binarnie. Chcemy aby było można wykonać następujące działanie:
int i = s;
W tym przypadku chcemy uzyskać konwersję tej liczby zapisanej tekstowo na liczbę typu int. Aby takie działanie było wykonalne należy zadeklarować w klasie String konwerter z typu String do typu int.
class String {
...
operator int (void) { if (ptr) return atoi(ptr); }
...
};
Słowo int oznacza typ wyniku do jakiego jest przeprowadzana konwersja.
Zaprzyjaźnione funkcje operatorowe
Zastanówmy się nad problemem wypełnienia z klawiatury pola ptr zawartego w obiektach typu String. W jednym z wcześniejszych rozdziałów poznaliśmy już jak działa obiektowe wejście/wyjście. Powiedzieliśmy tam, że operatory >> i << są operatorowymi funkcjami składowymi klas strumieniowych istream i ostream odpowiednio dla wejścia i wyjścia. Dzięki przeciążeniu tych operatorów w klasach strumieniowych lewym ich argumentem jest referencja do strumienia, a prawym różne typy danych. Ponadto wspomniane operatory zwracają referencje do strumienia, który jest ich lewym argumentem. Z tego jednoznacznie wynika, że lewym argumentem tych operatorów nie może być typ String. Aby tę niedogodność obejść spróbujmy zadeklarować te funkcje jako zaprzyjaźnione z klasą String. W tym momencie nie są one składowymi klasy String ale umożliwiają dostęp do jej komponentów prywatnych. W tym przypadku możemy zadeklarować je w następujący sposób:
#include <iostream.h>
...
class String {
...
public:
...
friend istream& operator>>(istream& in, String &s)
{ return in >> s.ptr; }
friend ostream& operator<<(ostream& out, String &s)
{ return out << s.ptr; }
};
...
void main()
{
String *c = new String(20);
String *d = new String(20);
String *e = new String(20);
cin >> *c;
cin >> *d;
*e = *c + " idzie do " + *d + '.';
cout << *e;
delete c;
delete d;
delete e;
}
Wczytanie wartości łańcuchów znaków z klawiatury jest teraz bardzo czytelne.
Przykład 3
Napisać klasę VECTOR, która będzie wykonywać następujące operacje na tablicach jednowymiarowych (wektorach) zawierających liczby rzeczywiste:
sumowanie i odejmowanie dwóch wektorów,
obliczanie iloczynu skalarnego dwóch wektorów,
mnożenie wektora przez liczbę,
porównanie,
inicjowanie wektora tablicą,
operacje wejścia/wyjścia.
Rozwiązanie
Przykładowa realizacja jest podana poniżej.
#include <iostream.h>
#include <stdio.h>
#include <mem.h>
#include <process.h>
#include <alloc.h>
typedef enum { FALSE, TRUE } Boolean;
class VECTOR {
public:
static int num;
VECTOR( unsigned size);
VECTOR( VECTOR &v );
VECTOR( double v[], int n );
~VECTOR();
Boolean operator== ( VECTOR& v ); //porównanie
VECTOR& operator= ( VECTOR& v ); //przypisanie
VECTOR operator+ ( VECTOR& v ); //suma
VECTOR operator- ( VECTOR& v ); //różnica
double operator* ( VECTOR& v ); //iloczyn skalarny
VECTOR& operator* ( double f ); //mnożenie przez liczbę
double& operator[] ( int i ); //adres elementu [i]
VECTOR& operator() ( double f[] ); //inicjowanie obiektu tablicĄ
unsigned getSize() { return size; }; //liczba elementów
friend ostream& operator<< ( ostream& o, VECTOR& v );
friend istream& operator>> ( istream& o, VECTOR& v );
protected:
unsigned size;
VECTOR() { tab = NULL; }
unsigned min( int a, int b ) { return a < b ? a : b; };
private:
double *tab;
};
int VECTOR::num = 0;
VECTOR::VECTOR( unsigned size )
{
if( (this->tab = new double[size]) == NULL )
exit(0);
memset( this->tab, 0, size * sizeof( double ) );
this->size = size;
num++;
}
// konstruktor kopiujący
VECTOR::VECTOR( VECTOR &v )
{
this->size = v.size;
if( (this->tab = new double[size]) == NULL )
exit( 0 );
memset( this->tab, 0, size * sizeof( double ) );
memcpy( tab, v.tab, size * sizeof( double ) );
num++;
}
VECTOR::VECTOR( double v[], int n )
{
this->size = n;
if( (this->tab = new double[size]) == NULL )
exit( 0 );
memset( this->tab, 0, size * sizeof( double ) );
memcpy( tab, v, size * sizeof( double ) );
num++;
}
// destruktor
VECTOR::~VECTOR()
{
if( tab != NULL )
delete []tab;
num--;
}
// Operator porównania
Boolean VECTOR::operator== ( VECTOR &v )
{
if( memcmp(tab, v.tab, size * sizeof(double) ) )
return FALSE;
return TRUE;
}
// Operator przypisania
VECTOR& VECTOR::operator= ( VECTOR &v )
{
size = min( size, v.size );
memcpy( tab, v.tab, size * sizeof( double ) );
return *this;
}
// Operator sumy
VECTOR VECTOR::operator+ ( VECTOR &v )
{
size = min( size, v.size );
VECTOR p = VECTOR( size );
for( int i = 0; i < size; i++ )
p.tab[i] = this->tab[i] + v.tab[i];
return VECTOR(p);
}
// Operator różnicy dwóch wektorów
VECTOR VECTOR::operator- ( VECTOR &v )
{
size = min( size, v.size );
VECTOR p = VECTOR( size );
for( int i = 0; i < size; i++ )
p.tab[i] = this->tab[i] - v.tab[i];
return VECTOR(p);
}
// Operator iloczynu skalarnego dwóch wektorów
double VECTOR::operator* ( VECTOR &v )
{
double x = 0;
size = min( size, v.size );
for( int i = 0; i < size; i++ )
x += tab[i] * v.tab[i];
return x;
}
// Mnożenie przez liczbę
VECTOR &VECTOR::operator* ( double f )
{
for( int i = 0; i < size; i++ )
tab[i] *= f;
return *this;
}
// Adres i-tego elementu
double &VECTOR::operator[] ( int i )
{
if( i < size )
return tab[i];
else
return tab[size - 1];
}
// Inicjowanie obiektu tablicą
VECTOR &VECTOR::operator()(double f[])
{
memcpy( tab, f, size * sizeof( double ) );
return *this;
}
// Inicjowanie obiektu tablicą
// Drukowanie do pliku
ostream& operator<< ( ostream& o, VECTOR& v )
{
o << endl;
for( int i = 0; i < v.getSize(); o << v.tab[i++] << ' ' );
}
// Wczytanie z pliku
istream& operator>> ( istream& o, VECTOR& v )
{
for( int i = 0; i < v.getSize(); o >> v.tab[i++] );
}
main()
{
double x[5];
VECTOR *a = new VECTOR(5),
*b = new VECTOR(5),
*c = new VECTOR(5);
VECTOR *d = new VECTOR(x, 5);
(*c)(x);
cin >> *a;
cin >> *b;
*c = *b - *a;
*d = *a * 2;
cout << *c;
cout << *d;
delete a;
delete b;
delete c;
delete d;
}
Konwersje konstruktorowe
Przeanalizujmy podany niżej program.
#include <stdio.h>
#include <string.h>
#include <iostream.h>
class String {
char *ptr;
public:
String() { ptr = NULL; };
String( char *s ) { ptr = new char[ strlen( s ) + 1 ]; strcpy( ptr, s );}
String( char c ) { ptr = new char[ 2 ]; *ptr = c; *(ptr + 1) = '\0'; }
String( String &s ) { ptr = new char[strlen( s.ptr ) + 1];
strcpy( ptr, s.ptr );}
String& operator= ( String &s );
~String() { if( ptr ) delete ptr; ptr = NULL; };
friend ostream& operator<< (ostream &out,
String &s)
{
out << s.ptr;
return out;
}
};
String& String::operator= ( String &s )
{
if( ptr ) delete ptr;
ptr = new char[ strlen( s.ptr ) + 1 ];
strcpy( ptr, s.ptr );
return *this;
}
void main()
{
String a, b;
// konwersja konstruktorowa z typu char * do typu String
b = "Ala";
// konwersja konstruktorowa z typu char do typu String
a = 'a';
cout << a << b;
}
W funkcji main jak widzimy znajdują się dwa wiersze, w których następuje przypisanie do obiektów a i b odpowiednio łańcucha znaków i znaku. W tym miejscu możemy postawić sobie pytanie jak ta operacja, która nawiasem mówiąc przebiega całkowicie pomyślnie może zostać przeprowadzona przy braku zdefiniowanych operatorów przypisania w postaci:
String& String::operator= ( char *s )
{
if( ptr ) delete ptr;
ptr = new char[ strlen( s ) + 1 ];
strcpy( ptr, s );
return *this;
}
String& String::operator= ( char s )
{
if( ptr ) delete ptr;
*ptr = s;
*(ptr + 1) = '\0';
return *this;
}
Otóż w tym momencie zostały wywołane niejawnie tzw., konwersje konstruktorowe. Są one wykonywane przez jednoargumentowe konstruktory, które wyznaczają konwersję typu swego argumentu do typu klasy, do której należą.
Po wystąpieniu wiersza
b = "Ala";
następuje najpierw wywołanie konstruktora o argumencie char *. Daje on w wyniku obiekt tymczasowy zawierający łańcuch znaków "Ala". Następnie wywoływany jest operator przypisania zwracający referencję. Po przypisaniu łańcucha znaków "Ala" do obiektu b następuje usunięcie obiektu tymczasowego.
W przypadku deklaracji operatora przypisania w postaci
String String::operator= ( String &s )
{
if( ptr ) delete ptr;
ptr = new char[ strlen( s.ptr ) + 1 ];
strcpy( ptr, s.ptr );
return *this;
}
będą tworzone i potem usuwane dwa obiekty tymczasowe.
Dziedziczenie
Dziedziczenie jest bardzo ważną cechą programowania obiektowego. Ogólnie można powiedzieć, że jest to mechanizm pozwalający budować nowe klasy przez przejmowanie własności dowolnych klas bazowych. Oczywiście nowotworzone klasy mogą mieć dodawane nowe pola i funkcje składowe. Takie "przejęcie" własności wcześniej zdefiniowanej klasy umożliwia np., wydatne skrócenie czasu tworzenia całego projektu, znacząco zmniejsza możliwość popełnienia błędów w programie.
Teraz skupimy się na relacjach jakie występują między klasą bazową i pochodną. Zaprezentujemy jak można i trzeba odwoływać się do komponentów klasy bazowej oraz jak zapewnić w programie bezpieczeństwo komponentów zawartych w klasie bazowej.
Rozpoczynając nasze rozważania dotyczące dziedziczenia utwórzmy sobie nową klasę Point. Klasa ma: przechowywać informacje o współrzędnych jednego piksela na ekranie oraz "posiadać umiejętność" zapalenia tego piksela na ekranie.
#include <conio.h>
#include <graphics.h>
class Point {
int a, b;
public:
Point() : a(0), b(0) {}
Point(int _a, int _b) : a(_a), b(_b) {}
void draw() { putpixel(a, b, RED); }
};
main()
{
int d = DETECT, b;
initgraph(&d, &b,"e:\\apps-dos\\bc31\\bgi");
Point p(10, 20), q(130, 240);
p.draw();
q.draw();
getch();
closegraph();
return 0;
}
Jak widać klasa posiada dwa pola typu int zadeklarowane w części prywatnej tej klasy gdyż nie przewidujemy konieczności modyfikacji wartości tych pól przez funkcje nie należące do tej klasy. Do wyprowadzenia na ekran tak określonego punktu służy funkcja składowa draw wywołująca funkcję putpixel zawartą w bibliotece graficznej Borlanda. Myślę, że program w tej wersji jest na tyle nieskomplikowany, że nie trzeba poświęcać mu więcej czasu.
Spróbujmy teraz rozszerzyć nasze zadanie o zaprojektowanie klasy "rysującej" okrąg. Można oczywiście podejść to tego problemu klasycznie i utworzyć od podstaw nową klasę, ale my spróbujemy znaleźć cechy wspólne między tymi dwoma obiektami graficznymi. Na pierwszy rzut oka można stwierdzić, że współrzędne punktu z poprzedniego zadania mogą posłużyć jako współrzędne środka okręgu. Aby okrąg został określony jednoznacznie musi zostać dodany jeszcze jeden parametr, a mianowicie jego promień. Musimy zmienić także część wykonawczą funkcji draw. Ponadto rozszerzymy naszą klasę o możliwość wyprowadzenia tej figury geometrycznej w kolorze.
Tak więc po krótkiej analizie nowego zadania i posiadaniu klasy bazowej można stwierdzić, że nowa klasa Circle będzie dziedziczyć własności z klasy bazowej Point oraz musi dodać dwa pola przechowujące informację dotyczącą promienia okręgu oraz jego kolor.
Tworzenie klasy pochodnej
Ogólnie nagłówek klasy dziedziczącej wygląda następująco:
class nazwa_klasy : [modyfikator_praw_dostępu] nazwa_klasy_bazowej
Jako modyfikator_praw_dostępu można podać dwa słowa public lub private. Jeśli podany został modyfikator public to nowa klasa przejmuje publiczne i zabezpieczone pola z klasy bazowej i traktuje je jako publiczne i zabezpieczone. Komponenty prywatne klasy bazowej pozostają oczywiście niedostępne dla klasy pochodnej. Jeśli natomiast w schemacie dziedziczenia podalibyśmy słowo private, to ta deklaracja czyni z publicznych i zabezpieczonych pól klasy bazowej pola prywatne w klasie pochodnej. Ma to sens w przypadku dalszych dziedziczeń. Pokazane zostanie to w jednym z następnych przykładów.
W przypadku braku określenia tego modyfikatora (występuje on opcjonalnie) ważne jest jak rozpoczęliśmy definicję klasy tzn., od słowa struct czy class. Jeśli było to słowo struct to domyślnie dziedziczenie jest publiczne w przeciwnym przypadku (deklaracja rozpoczynające się od class) dziedziczenie jest prywatne.
Komponenty prywatne są niedostępne w obu przypadkach.
Przeanalizujmy teraz nasz układ dwóch klas. Dziedziczenie "robimy" jako publiczne.
#include <conio.h>
#include <graphics.h>
class Point {
int a, b;
public:
Point() : a(0), b(0) {}
Point(int _a, int _b) : a(_a), b(_b) {}
void draw() { putpixel(a, b, RED); }
};
class Circle : public Point {
int r, color;
public:
Circle() : Point(0, 0), r(0) { color = RED; }
Circle(int _a, int _b, int _r, int _color) :
Point(_a, _b), r(_r), color(_color) {}
void draw() { setcolor(color); circle(a, b, r); }
};
Funkcja draw "nie kompiluje" się z powodu niedostępności w tym miejscu pól a i b, które są w klasie bazowej zdefiniowane w zakresie deklaracji private.
Czego nie można odziedziczyć?
Nie dziedziczy się konstruktorów i destruktorów klasy bazowej mimo, że są one automatycznie wywoływane przy konstruowaniu i likwidowaniu obiektów klasy pochodnej. Ponadto nie podlega dziedziczeniu operator przypisania =. Tak więc przy konstruowaniu klasy pochodnej powinniśmy zaopatrzyć ją w odpowiednie konstruktory, destruktor oraz ewentualnie w operator =.
Komponenty zabezpieczone
Niestety tak zdefiniowana klasa Circle "nie widzi" komponentów a i b gdyż w klasie Point są one prywatne. Z drugiej strony są one nam niezbędne w nowej klasie. Przesunięcie ich do części publicznej niestety "otwiera" te pola na możliwość ich modyfikacji z zewnątrz a więc tracimy ważną cechę programowania obiektowego jaką jest hermetyzacja danych w klasach. Wyjściem z tej sytuacji jest skorzystanie z nowego słowa kluczowego protected. Otóż komponenty występujące w jego zakresie są dostępne tylko w klasie macierzystej, funkcjach składowych klasy dziedziczącej ale nie są dostępne z zewnątrz.
Nowa wersja tych klas jest podana następująco:
#include <conio.h>
#include <graphics.h>
class Point {
public:
Point() : a(0), b(0) {}
Point(int _a, int _b) : a(_a), b(_b) {}
void draw() { putpixel(a, b, RED); }
protected:
int a, b;
};
class Circle : public Point {
int r, color;
public:
Circle() : Point(), r(0) { color = RED; }
Circle(int _a, int _b, int _r, int _color) :
Point(_a, _b), r(_r), color(_color) {}
void draw() { setcolor(color); circle(a, b, r); }
};
main()
{
int d = DETECT, b;
initgraph(&d, &b, "e:\\apps-dos\\bc31\\bgi");
Point p(10, 20), q(130, 240);
p.draw();
q.draw();
Circle c(300, 200, 100, GREEN);
c.draw();
getch();
closegraph();
return 0;
}
Przeanalizujmy teraz sposób deklaracji konstruktorów w klasie Circle. Tworzeniem obiektów zajmują się konstruktory. Przyjęto, że skonstruowanie obiektu klasy pochodnej wymaga uprzedniego utworzenia obiektu klasy bazowej. Tak więc przed utworzeniem takiego obiektu zawsze wywoływany jest konstruktor klasy bazowej. Wybór tego konstruktora został scedowany na programistę. W naszym zadaniu w przypadku tworzenia klasy Circle za pomocą konstruktora bezparametrowego wywoływany jest także bezparametrowy konstruktor klasy Point.
Circle() : Point(), r(0)
{
color = RED;
}
Wywołanie konstruktora klasy bazowej zostało umieszczone na liście inicjacyjnej konstruktora klasy pochodnej. Ponadto jedno z pól jest inicjowane za pomocą tej listy a drugie "normalnie".
Tworzenie klasy pochodnej za pomocą konstruktora z czterema parametrami powoduje wywołanie innego konstruktora klasy bazowej.
Circle(int _a, int _b, int _r, int _color) :
Point(_a, _b), r(_r), color(_color) {}
Dziedziczenie publiczne i prywatne
Zastanówmy się teraz bliżej nad trzema trybami dziedziczenia z publiczną klasą bazową, z prywatną i zabezpieczoną klasą bazową. W pierwszej wersji klasa "środkowa" czyli Test2 dziedziczy publicznie po klasie bazowej Test1. Tym samym wszystkie pola publiczne i zabezpieczone będą dostępne odpowiednio jako publiczne i zabezpieczone w klasach dziedziczących po Test2.
class Test1 {
int a1;
public:
int b1;
Test1() : a1(0), b1(0), c1(0) {}
protected:
int c1;
};
class Test2 : public Test1 {
int a2;
public:
int b2;
Test2() : Test1(), a2(0), b2(20), c2(0) {}
protected:
int c2;
};
class Test3 : public Test2 {
int a3;
public:
int b3;
Test2 p;
Test3() : Test2(), a3(0), b3(20), c3(0) {}
void fun()
{
/* Pola niedostępne z uwagi na ich deklarację w sekcji prywatnej */
// a1 = 10;
// a2 = 11;
b1 = 20;
b2 = 21;
b3 = 22;
c1 = 30;
c2 = 31;
c3 = 32;
/* Pola niedostępne z uwagi na ich deklarację w sekcji prywatnej */
// p.a1 = 10;
// p.a2 = 20;
p.b1 = 10;
p.b2 = 20;
/* Pola niedostępne z uwagi na ich deklarację w sekcji zabezpieczonej */
// p.c1 = 10;
// p.c2 = 20;
}
protected:
int c3;
};
Jak widać z poziomu funkcji składowej klasy Test3 można odwoływać się do komponentów zabezpieczonych w klasach Test1, Test2 oraz Test3. Niestety próba odwołania się do komponentów zabezpieczonych pola p typu Test2 kończy się niepomyślnie:
// p.c1 = 10;
// p.c2 = 20;
Wynika to z faktu, że komponenty występujące w zakresie deklaracji protected są dostępne tylko w funkcjach składowych klasy dziedziczącej ale nie są dostępne z zewnątrz. W tym przypadku odwołania do tych pól są pośrednie bo za pośrednictwem komponentu p i są traktowane jako zewnętrzne.
W wyniku prywatnego dziedziczenia klasa Test2 zamyka dostęp do wszystkich komponentów z klasy Test1 dla klas dziedziczących po Test2.
class Test1 {
int a1;
public:
int b1;
Test1() : a1(0), b1(0), c1(0) {}
protected:
int c1;
};
class Test2 : private Test1 {
int a2;
public:
int b2;
Test2() : Test1(), a2(0), b2(20), c2(0) {}
protected:
int c2;
};
class Test3 : public Test2 {
int a3;
public:
int b3;
Test2 p;
Test3() : Test2(), a3(0), b3(20), c3(0) {}
void fun()
{
/* Pola niedostępne z uwagi na ich deklarację w sekcji prywatnej */
// a1 = 10;
// a2 = 11;
// b1 = 20;
a3 = 12;
b2 = 21;
b3 = 22;
/* Pola niedostępne gdyż przy dziedziczeniu zostały one w klasie
"uprywatnione" */
// c1 = 30;
c2 = 31;
// c3 = 32;
/* Pola niedostępne z uwagi na ich deklarację w sekcji prywatnej */
// p.a1 = 10;
// p.a2 = 20;
// p.b1 = 10;
p.b2 = 20;
/* Pola niedostępne z uwagi na ich deklarację w sekcji zabezpieczonej */
// p.c1 = 10;
// p.c2 = 20;
}
protected:
int c3;
};
Dostęp do komponentów klasy bazowej i ich przesłanianie
Często przy dziedziczeniu występują takie sytuacje, w których zarówno w klasie bazowej jak i w klasie pochodnej mamy komponenty o takich samych nazwach. Problem ten dotyczy to zarówno funkcji składowych jak i pól. Na podanym niżej przykładzie zastanówmy się co się wtedy dzieje.
#include <iostream.h>
class Test1 {
protected:
int a, b;
public:
Test1() : a(1), b(2) {}
void print() { cout << endl << "Test1" << *this; }
void p1() { cout << "Funkcja p1"; }
protected:
friend ostream& operator<< (ostream &out,
Test1 &x)
{
out << endl << "a = " << x.a << " b = " << x.b;
return out;
}
};
class Test2 : public Test1 {
int a, c;
public:
Test2() : Test1(), a(12), c(23) {}
void print()
{
cout << endl << "Test2";
Test1::print();
cout << *this;
p1();
}
protected:
friend ostream& operator<< (ostream &out, Test2 &x)
{
out << endl << "a = " << x.a << " b = " << x.c;
return out;
}
};
main()
{
Test1 m1;
Test2 m2;
cout << endl << "Test1 = " << sizeof(m1);
cout << endl << "Test2 = " << sizeof(m2);
m1.print();
m2.print();
return 0;
}
Rozmiary pamięci zajmowanej przez obiekty klas Test1 i Test2 wynoszą odpowiednio 4 i 8 bajtów. Cóż to oznacza? W przypadku obiektu klasy Test1 sprawa jest prosta, zawiera on dwa pola typu int. Natomiast otrzymanie wyniku 8 bajtów powinno nas zastanowić. Oznacza ono bowiem, że obiekt klasy Test2 zawiera zarówno pola zdefiniowane w tej klasie jak i odziedziczone z klasy bazowej Test2. Ciekawy jest sposób odwołanie się do przesłoniętych pól. Otóż powinniśmy w tym celu skorzystać z operatora wyboru komponentu obiektu ::. I tak odwołanie w ramach funkcji składowych klasy Test2 do pól odziedziczonych z klasy Test1 powinno wyglądać następująco:
Test1::a = 23;
Taki zapis oznacza, że odwołujemy się do przesłoniętego pola a znajdującego się w klasie Test1.
Podobnie wygląda sprawa z funkcjami składowymi. W każdej chwili mamy dostęp do przesłoniętych funkcji znajdujących się w klasie bazowej za pomocą tego operatora:
Test1::print();
Funkcje wirtualne
Załóżmy sobie, że będziemy dysponować dwiema klasami Circle oraz Rectangle wywodzącymi się z klasy bazowej Point. W obu klasach pochodnych powinniśmy mieć funkcje składowe do narysowania figury na ekranie oraz obliczenia pola jej powierzchni (w przypadku klasy Point powierzchnia oczywiście wynosi 0).
#define pi 3.14
#include <graphics.h>
#include <stdlib.h>
#include <iostream.h>
class Point {
protected:
int x, y;
public:
Point(int _x, int _y) : x(_x), y(_y) {}
double area() { return 0; }
void draw() { putpixel( 0, 0, RED); }
};
class Circle : public Point {
int r;
public:
Circle(int _x, int _y, int _r) : Point(_x, _y), r(_r) {}
double area() { return pi *r * r; }
void draw() { circle(x, y, r); }
};
class Rectangle : public Point {
int p, q;
public:
Rectangle(int _x, int _y, int _p, int _q) :
Point(_x, _y), p(_p), q(_q) {}
double area() { return abs((x - p) * (y - q)); }
void draw() { rectangle(x, y, p, q); }
};
main()
{
Rectangle *p = new Rectangle(10, 20, 20, 40);
Point *q = new Rectangle(10, 20, 20, 40);
cout << endl << q->area();
delete q;
delete p;
}
Funkcja main zawiera bardzo ciekawy zapis. Otóż deklarujemy w niej wskaźnik na obiekt typu Point ale inicjujemy go konstruktorem z klasy pochodnej Rectangle. Dążymy do tego, aby mieć wskaźnik umieszczony na klasę bazową, a obiekty wskazywane tworzyć za pomocą konstruktorów z klas pochodnych. Jest to dopuszczalna konstrukcja ale niewiele jak na razie mamy z niej pożytku, gdyż odwołanie się do funkcji składowej area prowadzi oczywiście do wywołania funkcji area z klasy Point.
W programowaniu obiektowym wprowadzono polimorfizm, który jest w wielu sytuacjach bardzo użyteczny. Oznacza on, że aktywowanie funkcji składowych klasy następuje nie w momencie kompilacji lecz w trakcie wykonywania się programu. Ta drobna z pozoru zmiana ma kapitalne znaczenie w programowaniu. Funkcja polimorficzna, inaczej zwana wirtualną, jest w deklaracji klasy poprzedzona słowem virtual. Jest taka zasada, że wystarczy zdefiniować w klasie bazowej dowolną niestatyczną funkcję składową jako wirtualną i od tego miejsca wszystkie funkcje o tej nazwie należące do kolejnych klas dziedziczących po klasie bazowej będą wirtualne. Ważne jest to, że wszystkie funkcje w zestawie muszą mieć taką samą nazwę jak i również takie same argumenty.
W naszym przypadku w klasie Point deklarujemy wspomniane funkcje area oraz draw jako wirtualne i wirtualny charakter tych funkcji jest przenoszony na kolejne klasy Circle i Rectangle, które dziedziczą po klasie bazowej.
class Point {
protected:
int x, y;
public:
Point(int _x, int _y) : x(_x), y(_y) {}
virtual double area() { return 0; }
virtual void draw() { putpixel( 0, 0, RED); }
};
Przy tak zdefiniowanej klasie bazowej odwołanie się do funkcji wirtualnej area aktywowanej na rzecz obiektu utworzonego przy pomocy konstruktora klasy Rectangle i wskazywanego przez wskaźnik q prowadzi do wywołania funkcji o nazwie area ale z klasy Rectangle.
main()
{
Rectangle *p = new Rectangle(10, 20, 20, 40);
Point *q = new Rectangle(10, 20, 20, 40);
cout << endl << q->area();
delete q;
delete p;
}
Oczywiście polimorfizm nie wyklucza odwoływania się do wersji z klasy bazowej. Wystarczy w tym momencie napisać:
cout << endl << q->Point::area();
aby została wywołana funkcja z klasy Point.
Przeanalizujmy kolejny program wykorzystujący funkcje wirtualne.
#include <iostream.h>
#include <constrea.h>
class A {
int i;
public:
A(int n) : i(n) { }
char *ClassName() { return "A"; }
int Val() { return i; }
};
class B : public A {
int j;
public:
B(int n) : A(0), j(n) { }
char *ClassName() { return "B"; }
int Val() { return j; }
};
class C : public B {
int k;
public:
C(int n) : B(0), k(n) { }
char *ClassName() { return "C"; }
int Val() { return k; }
};
void main()
{
constream con;
con.clrscr();
A a(1); B b(2); C c(3);
cout << endl << a.ClassName() << a.Val() << " - "
<< b.ClassName() << b.Val() << " - " << c.ClassName()
<< c.Val() << endl;
A *p;
p = &a;
cout << p->ClassName() << p->Val() << " - ";
p = &b;
cout << p->ClassName() << p->Val() << " - ";
p = &c;
cout << p->ClassName() << p->Val() << endl;
B *t;
cout << " - ";
t = &b;
cout << t->ClassName() << t->Val() << " - ";
t = &c;
cout << t->ClassName() << t->Val();
}
Działanie tego programu jest następujące:
A1 - B2 - C3
A1 - A0 - A0
- B2 - B0
Wprowadźmy teraz polimorfizm do klasy bazowej A (obie funkcje składowe w tej klasie będą wirtualne).
class A {
int i;
public:
A(int n) : i(n) { }
virtual char *ClassName() { return "A"; }
virtual int Val() { return i; }
};
Jak wiemy odpowiedniki tych funkcji znajdujące się w kolejnych klasach dziedziczących po tej klasie bazowej także będą wirtualne. Działanie programu będzie już zupełnie inne.
A1 - B2 - C3
A1 - B2 - C3
- B2 - C3
W tej wersji programu dzięki zastosowaniu funkcji wirtualnych aktywowane są zawsze funkcje składowe z klasy, do której należy obiekt.
Klasy abstrakcyjne
Często tworzy się specjalne klasy zwane abstrakcyjnymi, które mają stanowić fundament położony pod utworzoną później strukturę klas. Aby klasa została potraktowana jako klasa abstrakcyjna musi mieć przynajmniej jedną funkcję wirtualną, do której po prawej stronie za listą jej argumentów przypisujemy wartość 0.
class Point {
protected:
int x, y;
public:
Point(int _x, int _y) : x(_x), y(_y) {}
virtual double area() = 0;
virtual void draw() = 0;
};
Po takiej deklaracji nie można utworzyć jakiejkolwiek zmiennej obiektowej tego typu. Ten prosty zabieg zabezpiecza przed utworzeniem obiektu, który nie będzie w pełni funkcjonalny gdyż klasa abstrakcyjna służy jedynie do zasygnalizowania właściwości jakie będą miały klasy wywodzące się od niej. Podane niżej deklaracje nie są oczywiście akceptowane przez kompilator:
Point *p = new Point(3, 4);
Point q(30, 20);
Aby klasa pochodna od klasy abstrakcyjnej straciła "abstrakcyjność", musi mieć zdefiniowane wszystkie funkcje określone w klasie bazowej jako abstrakcyjne.
Wirtualne mogą być także destruktory. Są one niezbędne gdy w trakcie tworzenia obiektu była przydzielana pamięć.
#include <iostream.h>
#include <string.h>
class A {
char *str;
public:
A() { str = NULL; }
A(char *a) { str = new char[strlen(a) + 1]; strcpy(str, a); }
virtual ~A() { if( str ) delete str; str = NULL; }
virtual void print() { cout << str; }
};
class B : public A{
int *ptr;
int n;
public:
B(int *a, int _n) : A(), n(_n) {
ptr = new int[n];
memcpy(ptr, a, sizeof(int) * n);
}
virtual ~B() { if( ptr ) delete ptr; ptr = NULL; }
virtual void print() {
for( int i = 0; i < n; cout << ptr[i++] << ' ');
}
};
main()
{
int a[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
A *x = new B(a, 10);
x->print();
delete x;
}
Brak destruktora wirtualnego spowoduje, że przy takim zapisie (utworzony obiekt za pomocą konstruktora z klasy pochodnej) zostanie wywołany jedynie destruktor z klasy bazowej co spowoduje w przypadku usuwania obiektu typu B brak zwolnienia pamięci przydzielonej dla pola ptr.
Dziedziczenie wielobazowe
Dotychczas we wszystkich przykładach dotyczących dziedziczenia zakładaliśmy, że klasa pochodna dziedziczy własności tylko po jednej klasie bazowej. W wielu przypadkach taki sposób dziedziczenia zwany dziedziczeniem sekwencyjnym wystarcza nam w zupełności przy tworzeniu oprogramowania tym niemniej czasami znacznie wygodniej byłoby aby dziedziczyć własności więcej niż po jednej klasie bazowej jednocześnie. Taki sposób dziedziczenia nazywany jest dziedziczeniem wielobazowym.
|
|
Deklaracja klasy pochodnej z kilkoma klasami bazowymi wygląda następująco:
#include <iostream.h>
class A {
public:
int a;
A() : a(0) {}
A(int _a) : a(_a) {}
void print() { cout << endl << "Klasa A a = " << a; }
};
class B {
public:
int a, b;
B() : b(0), a(0) {}
B(int _a, int _b) : a(_a), b(_b) {}
void print() { cout << endl << "Klasa B a = " << a << " b = " << b; }
};
class C : public A, public B {
public:
int c;
C() : c(0) {}
C(int _c) : B(12, 34), c(_c) {}
void print() {
A::print();
B::print();
cout << endl << "Klasa C c = " << c;
}
};
main()
{
C c(20);
c.print();
return 0;
}
Wynik działania tego programu jest następujący:
Tworzenie obiektu klasy A
Tworzenie obiektu klasy B
Tworzenie obiektu klasy C
Klasa A a = 0
Klasa B a = 12 b = 34
Klasa C c = 20
Usuwanie obiektu klasy C
Usuwanie obiektu klasy B
Usuwanie obiektu klasy A
Mamy zadeklarowaną klasę C, która dziedziczy publicznie własności po klasach A, B. W przypadku dziedziczenia wielobazowego, kolejność aktywowania konstruktorów z klas bazowych jest taka sama jak kolejność występowania klas na liście dziedziczenia tj. w tym przypadku najpierw zostanie aktywowany konstruktor bezparametrowy z klasy bazowej A a następnie dwuargumentowy konstruktor z klasy B.
Obiekt klasy pochodnej C składa się z czterech pól: A::a, B::a, B::b oraz c. Ponadto klasa C zawiera następujące funkcje: A::print(), B::print(), print(). Dostęp do pól c oraz b nie nastręcza żadnych trudności natomiast wprowadzenie do klasy pochodnej dwóch pól a wymusza odwołania do nich za pośrednictwem klasy bazowej:
A::a = 10;
Przykład
Utworzyć klasę obsługującą listę dynamiczną zawierającą obiekty dowolnego typu. Zdefiniować następujące operatory:
dodawania do listy nowego elementu,
usuwania z listy wskazanego elementu,
wyświetlania zawartości całej listy.
#include <iostream.h>
#include <alloc.h>
// definicja klasy abstrakcyjnej
class BASIC {
public:
BASIC() {};
virtual void out() = 0;
};
class INTEGER : public BASIC {
public:
int num;
INTEGER( int num ) : num(num) {};
virtual void out() { cout << endl << num; }
};
class DOUBLE : public BASIC {
public:
double num;
DOUBLE( double num ) : num(num) {};
virtual void out() { cout << endl << num; }
};
class NODE {
public:
NODE *next;
void *ref;
NODE() { next = NULL; ref = NULL; }
};
class LIST {
NODE *head, *tail;
public:
LIST() { head = tail = NULL; }
void operator< ( void *right );
void operator> ( void *right );
void operator! ();
};
// dodawanie elementu do listy
void LIST::operator< ( void *right )
{
NODE *ptr = new NODE;
if( tail )
tail->next = ptr;
else
head = ptr;
tail = ptr;
tail->next = NULL;
tail->ref = right;
}
// usuwanie elementu z listy
void LIST::operator> ( void *right )
{
NODE *ptr = head;
if (! ptr )
return;
if( ptr->ref == right ) {
head = ptr->next;
delete ptr;
if (! head)
tail = NULL;
}
else
while( ptr ->next) {
if( ptr->next->ref == right ) {
NODE* tmp = ptr->next;
if(tmp == tail)
tail=ptr;
ptr->next=tmp->next;
delete tmp;
break;
}
ptr = ptr->next;
}
}
// drukowanie zawartości listy
void LIST::operator! ()
{
NODE *tmp = head;
cout << endl << "----";
while( tmp ) {
((BASIC*)tmp->ref)->out();
tmp = tmp->next;
}
cout << endl << "----";
}
main()
{
INTEGER a(20), b(30), c(50);
DOUBLE x(12.45), y(23.56);
LIST list;
!list;
list < &a; !list;
list < &b; !list;
list < &c; !list;
list < &x; !list;
list < &y; !list;
list > &y; !list;
list > &x; !list;
list > &c; !list;
list > &b; !list;
list > &a; !list;
return 0;
}
Dziedziczenie wielobazowe wirtualne
Dziedziczenie wielobazowe może spowodować, że do klasy pochodnej zostanie włączony kilkukrotnie ten sam obiekt z klasy bazowej. Jest to niepożądane ze względu na znaczny czasami rozrost rozmiaru klasy pochodnej. Aby tego uniknąć stosuje się dziedziczenie wielobazowe wirtualne. Taki sposób dziedziczenia oznacza się słowem virtual.
class A : public B, virtual public C {
...
}
W tym przypadku klasa C będzie dziedziczona wirtualne.
W przypadku dziedziczenia wirtualnego obowiązuje kilka reguł postępowania. Pierwsza z nich dotyczy faktu, że konstruktory klas dziedziczonych wirtualnie są aktywowane przed konstruktorami innych klas bazowych a pozostałe w kolejności ich umieszczenia na liście określającej sposób dziedziczenia. W przypadku destruktorów kolejność jest dokładnie odwrotna.
Istotę dziedziczenia wielobazowego wirtualnego prześledzimy na kilku następnych przykładach.
W każdym z nich jest zdefiniowane uniwersalne makro size(x) pozwalające wyprowadzić nazwę klasy wraz z jej rozmiarem liczonym w bajtach. Ponadto konstruktor każdego tworzonego obiektu zawiera wyprowadzenie napisu przygotowanego przez to makro. Ma to na celu pokazanie w jakiej kolejności aktywowane są konstruktory klas bazowych.
Pierwszy z przykładów zakłada "normalne" dziedziczenie wielobazowe.
#include <iostream.h>
#define size(x) " " << #x << "-" << sizeof(x)
class A {
public:
int i[100], j;
A() { cout << size(A); }
};
class B {
public:
int i, j;
B() { cout << size(B); }
};
class C : public A, public B {
public:
int j;
C() { cout << size(C); }
};
class D : public A {
public:
int j;
D() { cout << size(D); }
};
class E : public D, public C {
public:
int j;
E() { cout << size(E); }
};
void main()
{
cout << endl;
E e;
}
W tym przypadku wynik działania programu przedstawia się następująco:
// A-202 D-204 A-202 B-4 C-208 E-414
Na początku przy tworzeniu obiektu klasy E wywoływany jest konstruktor z klasy D. Ta klasa także ma swojego "rodzica" - jest nim klasa A i dlatego najpierw jest wykonany jest w całości konstruktor zdefiniowany dla klasy A bo ona nie ma już żadnego przodka. Na ekranie pokazuje się napis A-202 ponieważ w klasie A zadeklarowano jedną tablicę zawierającą 100 elementów typu int oraz jedno pole typu int, czyli razem 202 bajty (dla systemu DOS). Potem następuje dokończenie działania konstruktora D. Drukowany jest wtedy fragment D-204 ponieważ klasa D dodaje jedno pole typu int. Następnie podobnie wygląda tworzenie obiektu C, który wchodzi w skład obiektu E.
Obiekt klasy C dziedziczący wielobazowo po dwóch klasach A i B zajmuje jak widać 208 bajtów czyli sumę rozmiarów obu klas, natomiast klasa E jest jeszcze bardziej rozrzutna i zajmuje aż 416 bajtów. Poniżej pokazane jest z jakich elementów składa się klasa E.
Spróbujmy wprowadzić teraz do naszego przykładu dziedziczenie wirtualne, które w założeniu powinno zapobiec właczaniu do klasy E więcej niż jednej klasy A. Dziedziczenie wirtualne odbywa się w tylko klasie D. Wynik działania jest następujący:
// A-202 D-206 A202 B-4 C-208 E-416
Owocem tego programu jest ciągle dwukrotna obecność klasy A w ramach klasy E.
#include <iostream.h>
#define size(x) " " << #x << "-" << sizeof(x)
class A {
public:
int i[100], j;
A() { cout << size(A); }
};
class B {
public:
int i, j;
B() { cout << size(B); }
};
class C : public A, public B {
public:
int j;
C() { cout << size(C); }
};
class D : virtual public A {
public:
int j;
D() { cout << size(D); }
};
class E : public D, public C {
public:
int j;
E() { cout << size(E); }
};
void main()
{
cout << endl;
E e;
}
Jest to jak widać przykład złego zaprojektowania dziedziczenia wielobazowego. Trzecia wersja tego przykładu zawiera dziedziczenie wirtualne klasy A we wszystkich miejscach gdzie się ona znajduje.
Dopiero tak zastosowane dziedziczenie wirtualne zapewniło jednokrotne właczenie klasy A do klasy E.
// A-202 D-206 B-4 C-210 E-216
#include <iostream.h>
#define size(x) " " << #x << "-" << sizeof(x)
class A {
public:
int i[100], j;
A() { cout << size(A); }
};
class B {
public:
int i, j;
B() { cout << size(B); }
};
class C : public B, virtual public A {
public:
int j;
C() { cout << size(C); }
};
class D : virtual public A {
public:
int j;
D() { cout << size(D); }
};
class E : public D, public C {
public:
int j;
E() { cout << size(E); }
};
void main()
{
cout << endl;
E e;
}
Strumienie - operacje na plikach w ujęciu obiektowym
Język C++ dostarcza nam znacznie doskonalsze mechanizmy dostępu do plików niż te, z którymi zapoznaliśmy się w module "Programowanie w C". Jak wiemy polegały one na wykorzystaniu wielu funkcji takich jak fscanf, fgets, fgetc, fprintf, fputc, fputs. Wielość tych funkcji oraz w wielu przypadkach skomplikowany układ parametrów powodowały, że pisanie takiego programu było często dosyć niewdzięczne. Teraz w wielu przypadkach można korzystać z intuicyjnego sposobu zapisu operacji na plikach
Ogólnie można powiedzieć, że za obsługę plików odpowiedzialnych jest kilka klas. Ich definicje znajdują się w pliku "fstream.h", a istniejące między nimi powiązania pokazane są na podanym niżej schemacie.
Z tej całej struktury trzy ostatnie klasy ifstream, ofstream oraz fstream są przeznaczone do użytku przez programistów i umożliwiają wykonanie każdej dowolnej operacji na plikach.
Inicjowanie strumieni
Otwarcie strumienia do zapisu i do odczytu jest możliwe za pomocą odpowiednich konstruktorów klasy ifstream i ofstream.
ifstream in("dane1.txt");
ofstream out("dane2.txt");
W tym przypadku zostały otworzone dwa strumienie in oraz out skojarzone odpowiednio z plikami dyskowymi "dane1.txt" i "dane2.txt". Dzięki temu, że klasa ifstream obsługuje wejście nie jest konieczne określanie, że strumień in otwarty jest do zapisu. Można też wykonać tę operację następująco:
ifstream in;
ofstream out;
in.open("dane1.txt");
out.open("dane2.txt");
W tym przypadku najpierw zadeklarowaliśmy dwa strumienie podanych wyżej klas, które następnie zostały otworzone za pomocą funkcji składowej tych klas open.
Pełna postać konstruktora ma postać:
ifstream(const char *f, int c = ios::in, int d = filebuf::openprot);
Dwa ostatnie argumenty mają charakter domniemany tzn., można wywołać tego konstruktora zarówno z jednym, dwoma lub trzema parametrami.
Pierwszy z tych argumentów określa ścieżkę dostępu do pliku dyskowego, który będzie podłączony do otwartego strumienia, drugi argument stanowi o rodzaju otwarcia pliku. I tak w przypadku strumienia out mamy otwarcie podłączonego do niego pliku w trybie ios::out czyli otwarcie do pisania z utratą wcześniej zapisanych do niego danych. Inne możliwe i często stosowane typy otwarcia to:
ios::app |
dołączanie danych do pliku, |
ios::binary |
otwarcie pliku w trybie binarnym, |
ios::in |
otwarcie do odczytu, |
ios::nocreate |
jeśli plik nie istniał, to otwieranie pliku kończy się niepowodzeniem, |
ios::noreplace |
jeśli plik istnieje, to próba otwarcia go kończy się niepowodzeniem, |
ios::out |
otwarcie do zapisu z utratą poprzedniej zawartości, |
ios::trunc |
jeśli plik istnieje, to jego zawartość jest tracona. |
Trzeci argument konstruktora zapewnia możliwość ochrony pliku, który został do niego podłączony. Normalnie jest to pozwolenie za zapis i odczyt.
Odłączenie strumienia od pliku odbywa się za pomocą metody close.
in.close();
out.close();
Teraz można do strumienia podłączyć inny plik poprzez wykorzystanie to tego celu poznanej wcześniej funkcji open.
Funkcje wykonujące operacje na strumieniach
Klasa ifstream
Zapoznajmy się teraz z najczęściej wykorzystywanymi funkcjami składowymi klasy ifstream.
istream & get(char &);
Funkcja składowa get wprowadza jeden znak ze strumienia.
istream & get(char*, int, char = '\n');
Zadaniem tej metody, jest wprowadzenie ze strumienia, na rzecz którego jest aktywowana ciągu znaków do tablicy określonej przez swój pierwszy argument. Liczba wprowadzonych znaków jest ograniczona przez:
napotkanie końca pliku,
drugi argument tej funkcji może określać ile znaków ma zostać wprowadzone,
wprowadzanie kończy się po napotkaniu znaku końca określonego przez trzeci argument tej funkcji - domyślnie jest to znak zmiany wiersza - znak ten nie jest kopiowany do tablicy.
Wprowadzony do tablicy ciąg znaków jest uzupełniany znakiem końca łańcucha '\0'. Funkcja zwraca referencję do obiektu, na rzecz którego jest aktywowana.
istream & getline(char*, int, char ='\n');
Zadaniem tej metody, jest wprowadzenie ze strumienia, na rzecz którego jest aktywowana ciągu znaków do tablicy określonej przez swój pierwszy argument. Liczba wprowadzonych znaków jest ograniczona przez:
napotkanie końca pliku,
drugi argument tej funkcji może określać ile znaków ma zostać wprowadzone,
wprowadzanie kończy się po napotkaniu znaku końca określonego przez trzeci argument tej funkcji - domyślnie jest to znak zmiany wiersza - znak ten jest kopiowany do tej tablicy. Jedynie tym różni się ta funkcja od poprzednich dwóch funkcji.
Wprowadzony do tablicy ciąg znaków jest uzupełniany znakiem końca łańcucha '\0'. Funkcja zwraca referencję do obiektu, na rzecz którego jest aktywowana.
istream & read(char *, int);
Metoda wprowadza ze strumienia ciąg znaków o długości określonej przez drugi argument. Znaki są umieszczane w pamięci poczynając od miejsca wskazanego przez pierwszy argument.
istream & seekg(long);
Przesunięcie aktualnej pozycji w strumieniu na pozycję określoną przez argument tej funkcji począwszy od początku strumienia.
istream & seekg(long, int);
Przemieszczenie aktualnej pozycji w strumieniu o liczbę znaków określona przez pierwszy argument licząc od miejsca wskazanego przez drugi argument, który może przyjmować jedną z trzech wartości:
ios::beg od początku,
ios::cur od pozycji bieżącej,
ios::end od końca strumienia.
Kierunek przesuwania jest uzależniony od znaku pierwszego argumentu. Jeśli jest on dodatni to przesunięcia liczone są w kierunku końca strumienia.
long tellg();
Ta funkcja składowa zwraca aktualna pozycję w strumieniu licząc od początku.
Ponadto na strumieniu działają funkcje operatorowe umożliwiające odczyt ze strumienia wartości nastepujących typów:
istream & operator >>(short &);
istream & operator >>(int &);
istream & operator >>(long &);
istream & operator >>(float &);
istream & operator >>(double &);
istream & operator >>(unsigned char *);
Klasa ofstream
Zapoznajmy się teraz z najczęściej wykorzystywanymi funkcjami składowymi klasy ofstream.
ostream & put(char);
Funkcja składowa put wyprowadza jeden znak do strumienia.
ostream & write(char *, int);
Metoda wyprowadza do strumienia ciąg znaków (pierwszy argument) o długości określonej przez drugi argument.
ostream & seekp(long);
Przesunięcie aktualnej pozycji w strumieniu na pozycję określoną przez argument tej funkcji począwszy od początku strumienia.
ostream & seekp(long, int);
Przemieszczenie aktualnej pozycji w strumieniu o liczbę znaków określona przez pierwszy argument licząc od miejsca wskazanego przez drugi argument, który może przyjmować jedną z trzech wartości:
ios::beg od początku,
ios::cur od pozycji bieżącej,
ios::end od końca strumienia.
Kierunek przesuwania jest uzależniony od znaku pierwszego argumentu. Jeśli jest on dodatni to przesunięcia liczone są w kierunku końca strumienia.
long tellp();
Ta funkcja składowa zwraca aktualna pozycję w strumieniu licząc od jego początku.
Ponadto na strumieniu działają funkcje operatorowe umożliwiające zapis do strumienia wartości:
ostream & operator << (short);
ostream & operator << (int);
ostream & operator << (long);
ostream & operator << (unsigned short);
ostream & operator << (unsigned int);
ostream & operator << (unsigned long);
ostream & operator << (float);
ostream & operator << (double);
ostream & operator << (signed char *);
ostream & operator << (unsigned char *);
Klasa fstream jest klasą, która dziedziczy własności po dwóch klasach i najprościej mówiąc ma cechy tak jednej jaki drugiej klasy objawiające się posiadaniem określonych wcześniej funkcji składowych.
Wykrywanie błędów operacji wejścia/wyjścia dla strumienia
Jak wiemy z programowania w C w trakcie korzystania z pliku trzeba sprawdzać, czy wydane przez nas polecenie dotyczące odczytu, zapisu, przesunięcia wskaźnika pliku, itp., zostało wykonane poprawnie. W C++ do sprawdzania stanu strumienia służy funkcja składowa fail. Zwraca ona wartość 1 gdy operacja nie została wykonana poprawnie. Można jej użyć w programie w następujący sposób:
ifstream in("dane.txt");
...
if( in.fail() )
cout << "Błąd dostępu do strumienia";
else
cout << Operacja dostępu do pliku była poprawna";
Aby wykryć koniec pliku należy skorzystać z funkcji eof - przypominamy, że wskaźnik końca pliku jest ustawiony gdy została wykonana operacja np., czytania spoza pliku:
ifstream in(dane.txt");
// operacja wczytania danych spoza pliku
...
if( in.eof() )
in.clear();
/*
usunięty został wskaźnik błędu i dlatego można dalej wykonywać
operacje na strumieniu.
*/
Inne dostępne strumienie
Oprócz podanych strumieni wyżej strumieni wejścia wyjścia mamy do dyspozycji także inne strumienie takie jak: ostrstream oraz constream. Pierwszy z nich operuje na łańcuchu znaków, a drugi zapewnia dostęp do konsoli z użyciem kolorów itd. Ogólnie można powiedzieć, że pełni on rolę biblioteki conio.h.
Klasa ostrstream
Jeden z konstruktorów pierwszego strumienia ma postać:
ostrstream::ostrstream(char*, int, int=ios::out);
Jako pierwszy argument podajemy łańcuch znaków, do którego będą wyprowadzone wartości. Drugi określa ile znaków ma zostać tam wyprowadzone.
#include <iostream.h>
#include <strstrea.h>
main() {
char s[100];
double r = 3.1245;
int c = 12, d = 23;
ostrstream out(s, 100);
out << endl << r << endl << c << endl << d << '\0';
cout << s;
return 0;
}
Klasa constream
Jak już powiedzieliśmy działanie tej klasy jest funkcjonalnie dokładnie takie same jak nieobiektowej biblioteki conio.h. Poniżej jest wymieniona lista najczęściej używanych funkcji.
void clreol();
void setcursortype( int );
void highvideo();
void lowvideo();
void normvideo();
void textattr( int );
void textbackground( int );
void textcolor( int );
void gotoxy( int, int );
int wherex();
int wherey();
void delline();
void insline();
void clrscr();
void window( int, int, int, int );
static void textmode( int );
Przykładem użycia dwóch funkcji niech będzie zmiana rozdzielczości z 25 na 50 wierszy oraz wyprowadzenie na ekran napisu " Nowa rozdzielczość ekranu w trybie tekstowym" w kolorze czerwonym.
#include <constrea.h>
void main()
{
constream c;
c.clrscr();
c.textmode(C4350);
c.rdbuf()->textcolor(RED);
c << "Nowa rozdzielczość ekranu w trybie tekstowym";
}
Przykłady użycia strumieni
Napiszmy teraz krótki program kopiowania zawartości jednego pliku do drugiego.
#include <fstream.h>
void main()
{
char s[13], d[13], c;
cout << "Podaj plik wejściowy";
cin >> s;
cout << "Podaj plik wynikowy";
cin >> d;
ifstream in(s);
ofstream out(d);
while( in.get(c) && out )
out.put(c);
}
W tym programie wykorzystaliśmy dwie funkcje składowe klas ifstream oraz ofstream: get i put. Ich zadaniem jest wczytanie i wyprowadzenie jednego znaku.
Kolejnym zadaniem jest napisanie klasy COMPLEX, która posiada dwa pola całkowite typu int. Klasa powinna umożliwiać wyprowadzenie zmiennych obiektowych typu COMPELX do dowolnego pliku.
W celu realizacji tego zadania należy posłużyć się przeciążonymi operatorami skierowania do i z strumienia, zapoznaliśmy się z tą techniką przy przeciążaniu operatorów. W funkcji main otwieramy strumień skojarzony z plikiem "dane.dat" do zapisu a, "wysyłamy" tam dwie zmienne obiektowe a i b a następnie odczytujemy z tego pliku wyprowadzone tam wartości do kolejnych dwóch zmiennych c i d. Przy wyprowadzaniu wartości pól tych obiektów należy pamiętać o ich rozdzieleniu dowolnym znakiem odstępu, w naszym przypadku tę rolę pełni znak spacji.
#include <iostream.h>
#include <fstream.h>
class COMPLEX {
int a, b;
public:
COMPLEX() : a(0), b(0) {}
COMPLEX(int _a, int _b) : a(_a), b(_b) {}
friend istream& operator>>(istream& in, COMPLEX &c)
{ return in >> c.a >> c.b; }
friend ostream& operator<<(ostream& out, COMPLEX &c)
{ return out << c.a << ' ' << c.b << ' '; }
};
main()
{
COMPLEX a(3, 4), b(2, 6), c, d;
ofstream out("dane.dat");
out << a << b;
out.close();
ifstream in("dane.dat");
in >> c >> d;
return 0;
}
Drugi program został wzbogacony o prezentację jak należy zapisywać do strumienia obiekty, które mają pola zawierające wskaźniki oraz inne obiekty. Prosimy o samodzielne przestudiowanie tego zagadnienia.
#include <iostream.h>
#include <fstream.h>
class COMPLEX {
int a, b;
public:
COMPLEX() : a(0), b(0) {}
COMPLEX(int _a, int _b) : a(_a), b(_b) {}
void set(int _a, int _b) { a = _a; b = _b; }
friend istream& operator>>(istream& in, COMPLEX &c)
{ return in >> c.a >> c.b; }
friend ostream& operator<<(ostream& out, COMPLEX &c)
{ return out << c.a << ' ' << c.b << ' '; }
};
class TABLE {
int *a, n;
COMPLEX c;
public:
TABLE() : a(NULL), n(0) {}
TABLE(int *_a, int _n, COMPLEX _c);
~TABLE();
friend istream& operator>>(istream& in, TABLE &c);
friend ostream& operator<<(ostream& out, TABLE &c);
};
TABLE::TABLE( int *_a, int _n, COMPLEX _c ) : c(_c)
{
n = _n;
a = new int[n];
memcpy(a, _a, sizeof(int) * n);
}
TABLE::~TABLE()
{
if( a ) delete a;
a = NULL;
n = 0;
c.set(3, 2);
}
istream& operator>> (istream& in, TABLE &c)
{
in >> c.n;
for( int i = 0; i < c.n; i++ )
in >> c.a[i];
in >> c.c;
return in;
}
ostream& operator<< (ostream& out, TABLE &c)
{
out << c.n << endl;
for( int i = 0; i < c.n; i++ )
out << c.a[i] << ' ';
out << endl << c.c;
return out;
}
main()
{
int x[] = {1, 2, 3, 4}, y[] = {1, 3, 5, 7, 9, 11};
COMPLEX c1(311, 411), c2(211, 611), d1, d2;
TABLE a(x, 4, c1), b(y, 6, c2), c, d;
cout << endl << "Obiekt a = " << a << endl << "Obiekt b = " << b;
ofstream out("dane.dat");
out << a << b;
out.close();
ifstream in("dane.dat");
in >> c >> d;
cout << endl << "Obiekt c = " << c << endl << "Obiekt d = " << d;
return 0;
}
Sesja internetowa
Zadanie 1
Stworzyć klasę odpowiedzialną za pracę w trybie graficznym. Klasa powinna zawierać konstruktor inicjujący tryb graficzny i sprawdzający jej poprawność, destruktor kończący pracę w tym trybie oraz kilka funkcji obsługujących podstawowe zadania, np.: przejście do trybu o innej rozdzielczości, zmiana koloru tła, ustawienie okna graficznego, itp.
Zadanie 2
Stworzyć klasę implementującą liczbę wymierną o następujących polach: część całkowita, licznik, mianownik. Napisać kilka konstruktorów pozwalających na inicjowanie zmiennych tej klasy liczbami rzeczywistymi, liczbami całkowitymi, ułamkami właściwymi oraz niewłaściwymi.
Zadanie 3
Stworzyć klasę implementującą tablicę dynamiczną, o dowolnie regulowanej w dowolnym momencie liczbie elementów typu float. Wykorzystać standardowe funkcje przydzielania i zwalniania pamięci.
Zadanie 4
Na bazie klasy z zadania 3 stworzyć klasę implementującą wielomian dowolnego stopnia. Przy konstrukcji obiektu tej klasy należy podać liczbę współczynników. Klasa powinna realizować takie funkcje jak: wczytanie współczynników, wypisanie wielomianu na ekranie oraz obliczenie wartości w dowolnym punkcie.
Zadanie 5
Do klasy opisującej wielomian z zadania 4 dodać funkcje operatorowe umożliwiające dodawanie, odejmowanie i mnożenie dwóch wielomianów.
Zadanie 6
Stworzyć klasę PUNKT opisującą punkt na ekranie graficznym. Bazując na klasie punkt stworzyć klasę KOŁO, a następnie WALEC. Wyposażyć te klasy w funkcje rysujące te obiekty na ekranie.
Zadanie 7
Stworzyć klasę opisującą dwukierunkową listę dynamiczną. Lista powinna być uniwersalna tj. zamiast pól informacyjnych wstawić jedno pole wskaźnikowe (void *). Zdefiniować funkcje umożliwiające wstawienie nowego elementu do listy, usunięcie elementu, skasowanie całej listy, zmianę pozycji bieżącej wskaźnika.
Zadanie 8
Wykorzystując uniwersalną listę z zadania 7 stworzyć prostą bazę danych obsługujących trzy różne typy rekordów jednocześnie. Dla każdego typu danych (rekordów) stworzyć odpowiednie funkcje polimorficzne do wprowadzania i wyprowadzania danych. Przykład zastosowania: Baza danych obsługująca magazyn materiałów budowlanych zawiera informacje o trzech materiałach:
pręty stalowe - długość, grubość, gatunek stali, cena jednostkowa, ilość,
cement - rodzaj, producent, ilość, cena jednostkowa,
stolarka okienna - rodzaj, wymiary, cena jednostkowa, ilość.
Zadanie 9
Zdefiniować klasę DBF umożliwiającą wykonanie prostych operacji na pliku z bazą danych w formacie DBF (zakładanie bazy, przeglądanie zawartości, dodawanie i usuwanie rekordów, itp.)
Zadanie 10. Notatnik
Opracować klasę Osoba do reprezentacji nazwiska, imienia, instytucji, numeru telefonu oraz klasę SpisOsób. Korzystając z tych klas napisać program, który pozwala przeglądać i aktualizować istniejący w pliku notatnik. Czynność do wykonania powinna być wybierana z menu. Dostępne operacje:
zakładanie nowego notatnika,
otwarcie istniejącego notatnika,
wyświetlanie danych osoby, której nazwisko zostanie podane,
dodawanie danych nowej osoby,
usuwanie danych osoby o podanym nazwisku,
zachowanie otwartego notatnika w tym samym pliku,
zachowanie otwartego notatnika w pliku o podanej nazwie.
Zadanie 11. Wieloboki
Opracować klasę Wieloboki, za pomocą której można opisać proste wieloboki: trójkąt, prostokąt, kwadrat. Na obiektach klasy powinno być możliwe wykonywanie następujących operacji:
obliczanie obwodu,
obliczanie powierzchni,
skalowanie.
Zaprezentować działanie klasy w programie testującym.
Zadanie 12. Zbiory kwadratów
Opracować klasę Kwadraty do reprezentacji zbioru kwadratów, których lewy dolny wierzchołek leży w punkcie (0,0). Każdy kwadrat jest równoległy do osi układu współrzędnych i reprezentowany jest za pomocą długości boku. Na obiektach klasy powinno być możliwe wykonywanie następujących operacji:
dodawanie kwadratu do zbioru,
usuwanie kwadratu ze zbioru,
sprawdzanie, czy dany kwadrat należy do zbioru
określanie liczby elementów zbioru,
obliczanie powierzchni kwadratu,
znajdowanie kwadratu o największej powierzchni.
Zaprezentować działanie klasy w programie testującym.
Zadanie 13. Wektory
Opracować klasę Wektor do reprezentacji wektora na płaszczyźnie. Wektor jest określony przez podanie jednego punktu - czyli jest to wektor skierowany od początku układu współrzędnych do zadanego punktu. Na obiektach klasy powinno być możliwe wykonywanie następujących operacji:
obliczanie długości wektora,
dodawanie i odejmowanie pary wektorów,
mnożenie wektora przez liczbę,
iloczyn skalarny wektorów,
przesunięcie wektora.
Należy uwzględnić również operator [] udostępniający składową wektora.
Działanie klasy należy zademonstrować w programie testującym, który pozwala użytkownikowi manipulować wektorami.
Zadanie 14. Pieniądze
Opracować klasę Zloty do obliczeń złotówkowych. Należy przeciążyć operatory tak, aby obiektach klasy powinno być możliwe wykonywanie następujących czynności:
dodawanie (np. 3 zł 40 gr + 80 gr = 4 zł 20 gr) - operator +,
odejmowanie - operator -,
mnożenie i dzielenie przez liczbę całkowitą - operatory * i /,
porównywanie dwóch kwot - wszystkie operatory relacji.
Zaprezentować działanie klasy w programie testującym.
Zadanie 15. Zbiór liczb całkowitych
Opracować klasę SetInt dla obsługi zbiorów liczb całkowitych. Maksymalna liczba elementów zbioru będzie podawana jako argument konstruktora, który przydzieli odpowiednią pamięć.
Określić operacje (wybrać i przeciążyć istniejące operatory):
dodawania elementu do zbioru,
sprawdzania przynależności elementu do zbioru,
określania przynależności do zbioru,
wyprowadzania zawartości zbioru,
dodawanie zbiorów,
przecinanie zbiorów.
Zaprezentować działanie klasy w programie testującym.
Zadanie 16. Zbiór wektorów
Opracować klasę Wektory do reprezentacji zbioru wektorów na płaszczyźnie. Wektor zawsze jest określony przez podanie dwóch punktów - czyli jest to wektor skierowany od pierwszego punktu do drugiego). Na obiektach klasy powinno być możliwe wykonywanie następujących operacji:
dodawanie wektora do zbioru,
usuwanie wektora ze zbioru,
sprawdzanie przynależności wektora do zbioru,
łączenie określonej liczby zbiorów wektorów,
przeglądanie zawartości zbioru ,
Zaprezentować działanie klasy w programie testującym.
Zadanie 17. Zbiór punktów
Opracować klasę Punkty do reprezentacji zbioru punktów na płaszczyźnie. Liczba punktów podawana jest jako parametr konstruktora. Na obiektach klasy powinno być możliwe wykonywanie następujących operacji (należy przeciążyć operatory i opracować metody):
dodawanie punktu do zbioru
usuwanie punktu ze zbioru
tworzenie sumy i różnicy zbiorów punktów
przeglądanie zawartości zbioru
określanie liczby punktów w zbiorze
określanie przynależności punktu do zbioru.
Zaprezentować działanie klasy w programie testującym.
Zadanie 18. Średnia ocen
Opracować klasę Student do reprezentacji nazwiska, imienia, przedmiotów, na które uczęszcza i uzyskanych ocen oraz klasę Przedmioty do reprezentacji przedmiotów i zapisanych na nie studentów. Studenci zapisują się na przedmioty i są oceniani. Każdy obiekt klasy Student musi wiedzieć na jakie przedmioty się zapisał oraz każdy obiekt klasy Przedmiot musi znać listę studentów na niego zapisanych.
Napisać program, który oblicza średnią z każdego przedmiotu oraz średnią każdego studenta.
Zadanie 19. Macierz
Opracować klasę Macierz do reprezentacji tablic dwuwymiarowych. Na obiektach tej klasy powinna być możliwość wykonywania następujących operacji:
zwracanie referencji na element i, j (indeksowanie z kontrolą zakresu),
dodawanie i odejmowanie macierzy,
mnożenie macierzy,
generowanie wartości elementów przy pomocy funkcji fun(i, j).
Zaprezentować działanie klasy w programie testującym.
Zadanie 20. Układ słoneczny
Opracować zestaw klas umożliwiający pokazanie (animacja) istoty działania układu słonecznego złożonego ze słońca, wszystkich planet układu słonecznego oraz księżyca obiegającego Ziemię.
Wyszukiwarka
Podobne podstrony:
08 wprowadzenie do programowani Nieznany
Automatyka- Wprowadzenie do programu Matlab
001 wprowadzenie do programowania wsadowego
MWB 2 Wprowadzenie do modelowania obiektowego funkcjonowania systemów bezpieczeństwa
materiały szkoleniowe, Outlook Express 5 Pomoc, Pomoc Wprowadzenie do programu Outlook Express
Jezyk C Wprowadzenie do programowania
Jezyk C Wprowadzenie do programowania jcwpro
MudoL nr 1 wprowadzenie do programowania
Wprowadzenie do programu WMM, Multimedia i Grafika
Wprowadzenie do Programowania, listy, ĆWICZENIE 1
10 Wprowadzenie do programowania robotów przemysłowych
ImageJ wprowadzenie do programu id 210
08 wprowadzenie do programowani Nieznany
Jezyk C Wprowadzenie do programowania jcwpro
Windows Azure Wprowadzenie do programowania w chmurze winazu
Windows Azure Wprowadzenie do programowania w chmurze
więcej podobnych podstron