METODY MODELOWANIA
PROCESÓW
cz. III
Dodatkowe narzędzia modelowania
Narzędzia do tej pory opisane powinny
wystarczyć do wykonania dowolnego
projektu. Istnieje jednak szereg dodatkowych
narzędzi:
diagramy przepływu sterowania i ich odmiany
systemowe diagramy przepływu
diagramy HIPO (Hierarchy Input Process Output) i
diagramy struktury
odmiany diagramów przepływu danych
odmiany diagramów związków encji
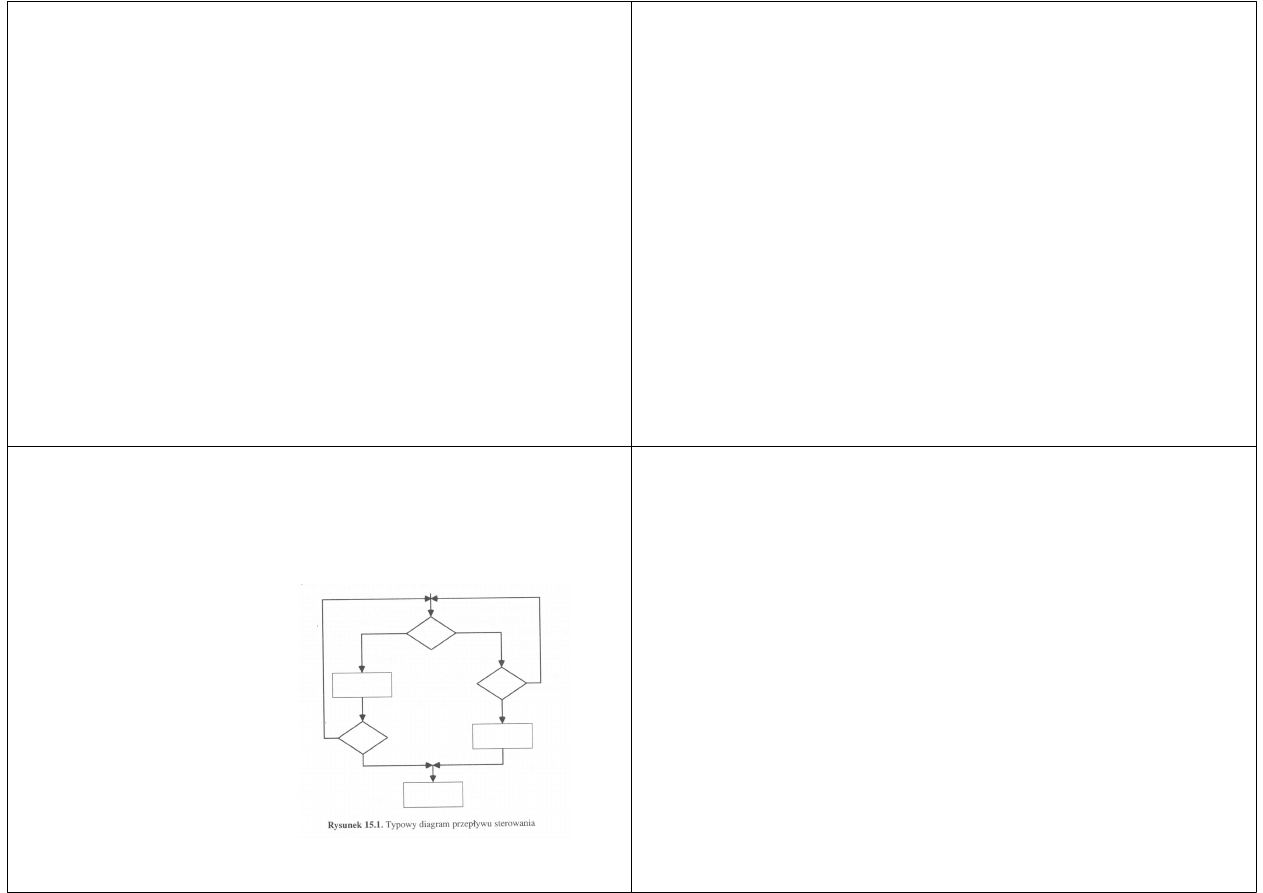
Klasyczny diagram przepływu
sterowania
Jednym z
najstarszych i
najlepiej znanych
narzędzi
modelowania jest
klasyczny diagram
przepływu
sterowania
Klasyczny diagram przepływu
sterowania
Stosowany przy programowaniu lub przetwarzaniu danych.
Notacja ma tylko trzy składniki:
Prostokąty, które reprezentują wykonywane instrukcje
komputera lub ciągłe sekwencje instrukcji
Romby, które reprezentują decyzje
Strzałki łączące czworokąty reprezentują przepływ
sterowania. Z prostokąta może wychodzić tylko jedna strzałka,
tzn. kiedy zakończy się wykonanie instrukcji komputera,
można przejść tylko do pojedynczej następnej instrukcji lub
decyzji. Z decyzji zaś mogą wychodzić tylko dwie strzałki

Klasyczny diagram przepływu
sterowania
Diagramy przepływu sterowania pozwalają
przedstawić proceduralną logikę programu
Diagramy przepływu sterowania są narzędziami
programowania lecz niektórzy analitycy używają ich
do dokumentowania specyfikacji procesów, jako
alternatywy dla strukturalnego języka polskiego
Jakakolwiek technika dokumentacji, która poprawnie
opisuje wymagania użytkownika i umożliwia
efektywną komunikację jest zadawalająca
Prosty przykład
Obliczyć średnią arytmetyczną z N wartości
Wartości zapisane są w wektorze A
Oznaczenia:
N – liczba wartości
i – indeks
A[i] – i-ty element wektora
Suma – zmienna pomocnicza
Średnia – wynik
SEKWENCJA
PĘTLA Z LICZNIKIEM
DECYZJA
Odmiany diagramu przepływu
sterowania
Istnieje kilka odmian diagramów, z których
cztery są najczęściej wykorzystywane. Są to
diagramy :
Nassi-Shneidermana
Ferstla
Hamiltona-Zeldina
Analizy problemu
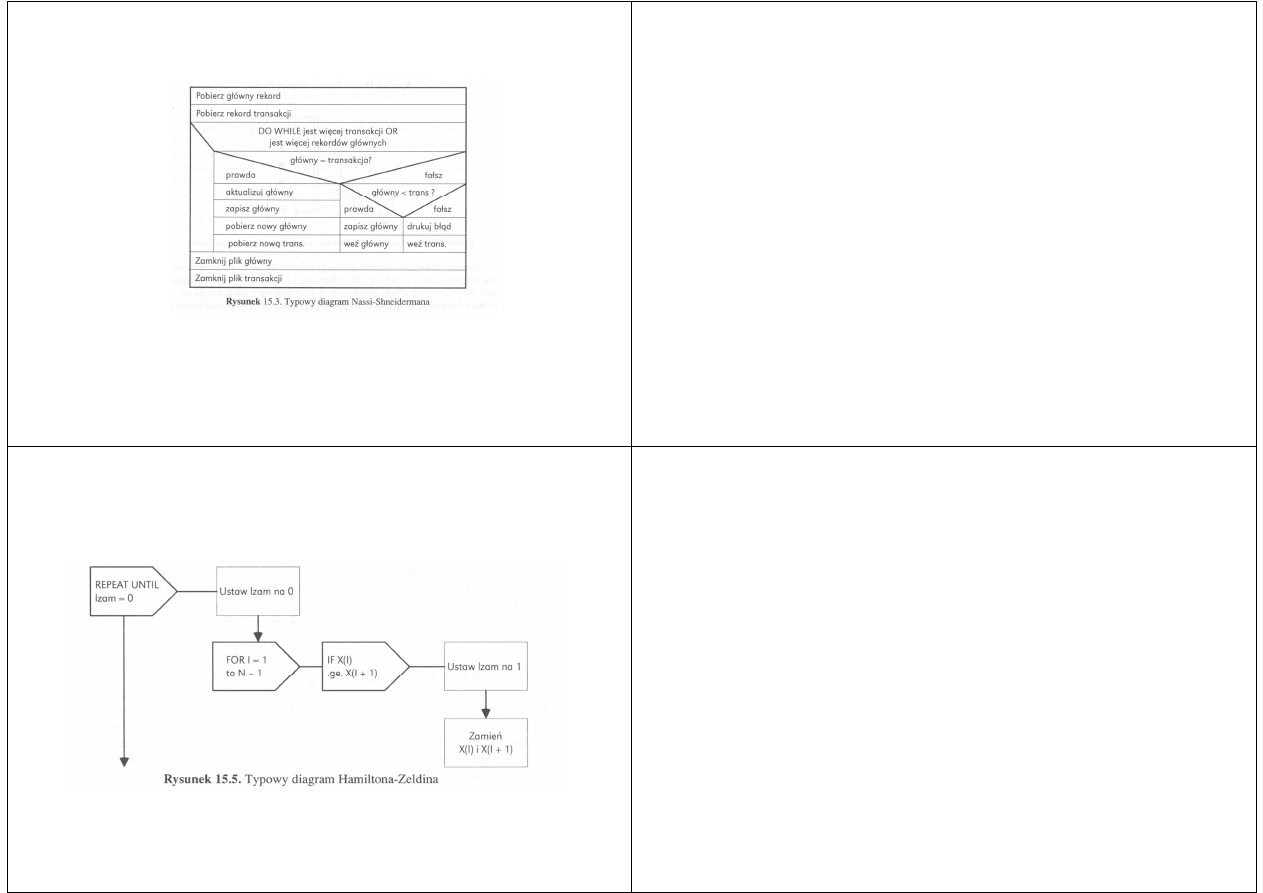
Diagram Nassi-Shneidermana
Diagramy Nassi-Shneidermana wprowadzono w latach 70-tych jako sposób
wymuszenia strukturalnego podejścia do programowania
Niektórzy twierdzą jednak, że diagramy Nassi-Shneidermana to po prostu
strukturalny język naturalny z dorysowanymi wokoło prostokątami
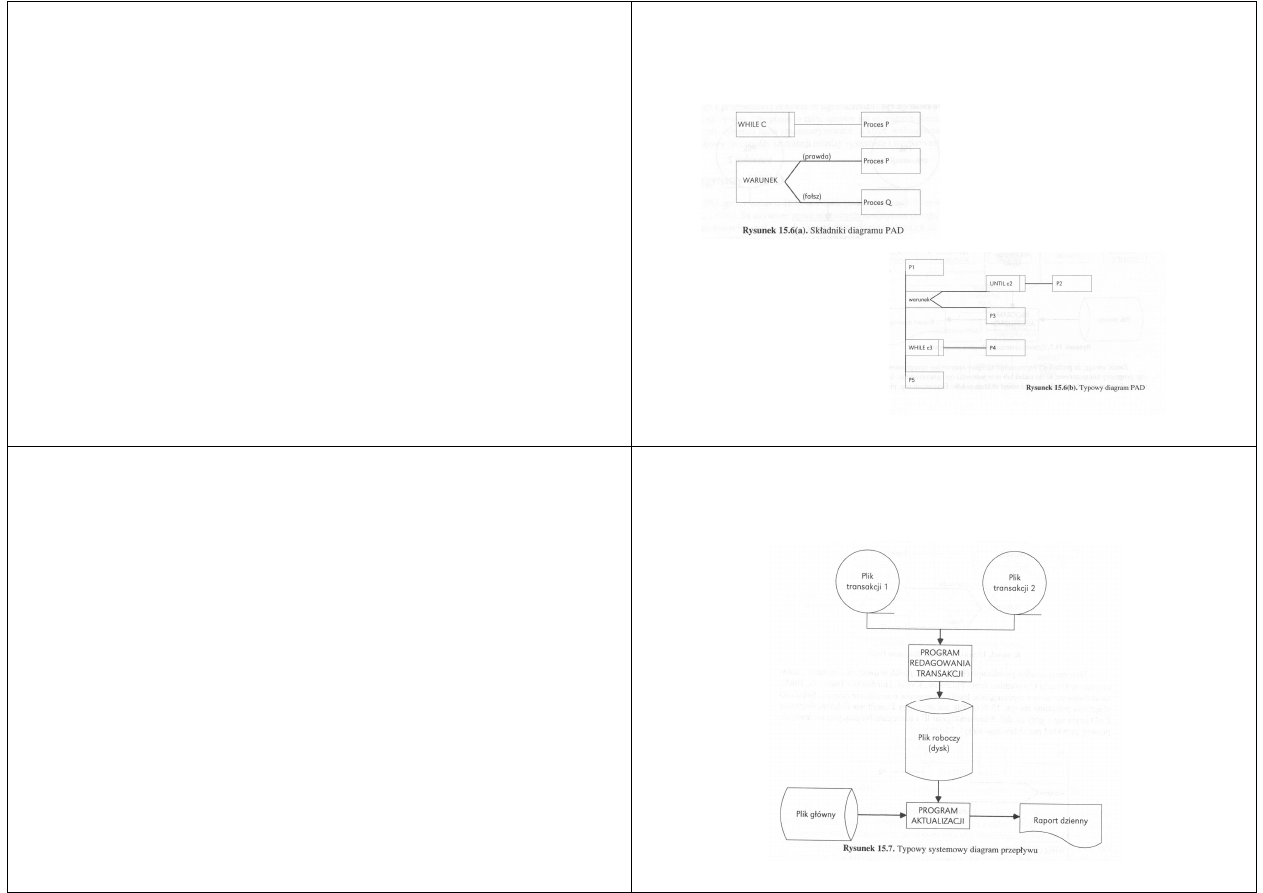
Diagramy Hamiltona-Zeldina
Diagramy Hamiltona-Zeldina powstały
podczas budowy oprogramowania dla
projektu Space Shuttle w NASA
Typowy diagram, czasem nazywany
diagramem projektowania strukturalnego,
pokazano na kolejnym rysunku
Diagramy Hamiltona-Zeldina
Diagramy Hamiltona-Zeldina
Prostokąty mają takie samo znaczenie jak w
diagramach przepływu sterowania, czyli reprezentują
wykonywalną instrukcję lub ciąg wykonywalnych
instrukcji
Wydłużony pięciokąt służy zarówno do pokazania
instrukcji IF, jak i do iteracji DO-WHILE/REPEAT
UNTIL
Sterowanie zwykle przepływa z góry na dół
diagramu, z wyjątkiem testów IF i iteracji (DO i
REPEAT), kiedy biegnie od lewej do prawej
Diagramy analizy problemów PAD
Diagramy analizy problemów (PAD – problem analysis
diagrams), opracowane w Hitachi Corporation, są to
dwuwymiarowe reprezentacje logiki programów o
strukturze drzewa
Składniki diagramu pokazano na rysunku a
Diagramy te czyta się z góry na dół, z konstrukcjami IF i
iteracjami biegnącymi od lewej do prawej, przykład na
rysunku b
Diagramy analizy problemów PAD
Systemowe diagramy przepływu
Omówione przykłady przydają się do
pokazania szczegółów sterowania, czy to
wewnątrz programu komputerowego czy też
wewnątrz specyfikacji dla pojedynczego
procesu na DFD
Natomiast ogólne spojrzenie na organizację
systemu można przedstawić za pomocą
innego rodzaju diagramu przepływu
sterowania nazwanym systemowym
diagramem przepływu co ilustruje kolejny
rysunek
Systemowe diagramy przepływu
Systemowe diagramy przepływu
Prostokąty reprezentują agregaty operacyjne
oprogramowania (np. programy
komputerowe, kroki zadań lub inne jednostki
oprogramowania)
Systemowy diagram przepływu pokazuje też
różne rodzaje plików fizycznych (np. plików na
różnych nośnikach)
Może też przedstawiać obecność terminali
interakcyjnych i linii telekomunikacyjnych
Systemowe diagramy przepływu
Systemowy diagram przepływu przydaje się często projektantom
systemu, którzy muszą opracować ogólną architekturę sprzętu i
oprogramowania, implementującą wymagania użytkownika
Nie jest to jednak odpowiednie narzędzie modelowania dla
analizy systemów, ponieważ kładzie nacisk na szczegóły
implementacji fizycznej, których analityk i użytkownik nie powinni
omawiać
Zamiast zajmować się plikiem dyskowym, użytkownik i analityk
powinni przedyskutować zawartość tego pliku; zamiast mówić o
poszczególnych programach komputerowych, powinni zajmować
się funkcjami, które trzeba zrealizować
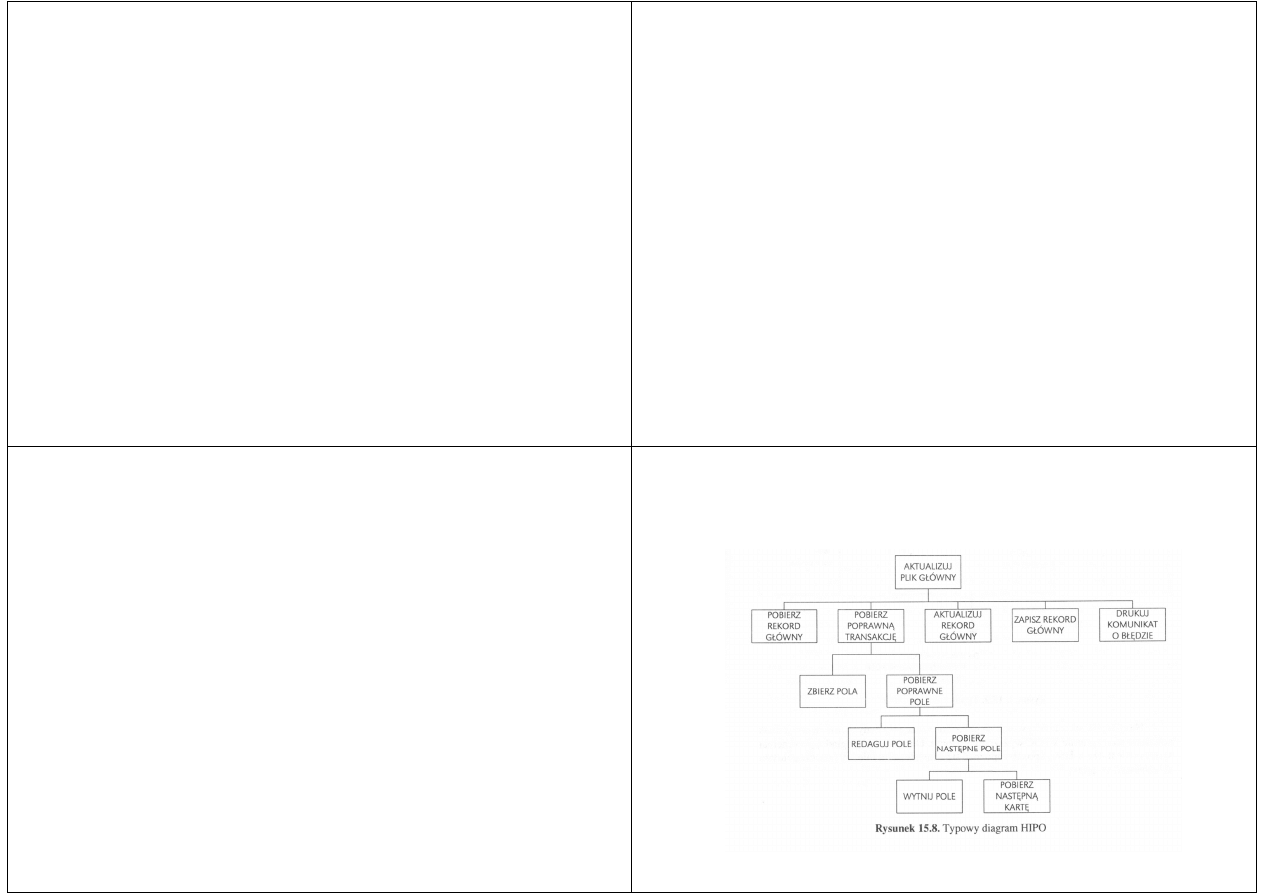
Diagramy HIPO
Diagramy HIPO opracowano w IBM w latach
70-tych
Są używane przez niektórych analityków do
ogólnej prezentacji funkcji realizowanych
przez system, jak też dekompozycji funkcji na
podfunkcje itd.
Typowy diagram jest na rysunku
Diagramy HIPO
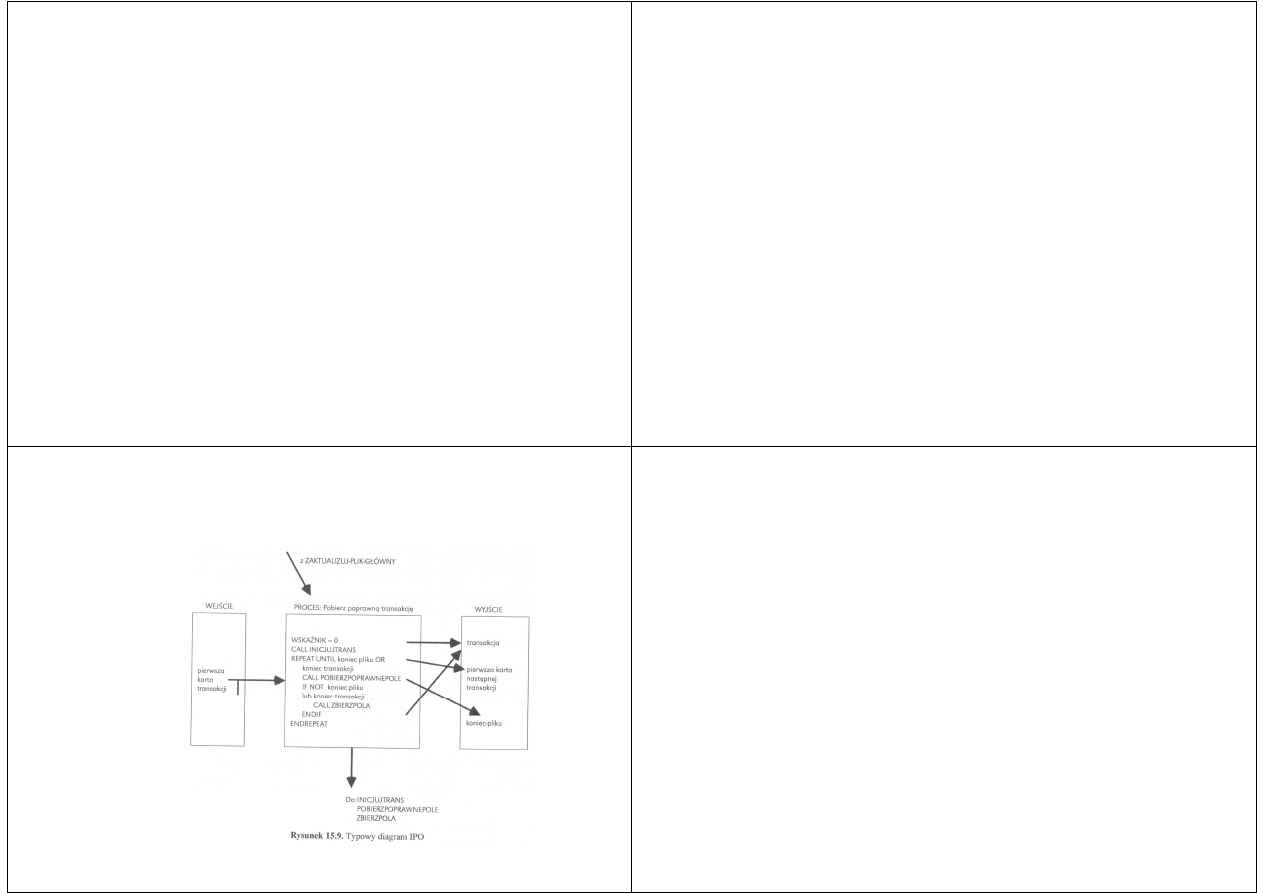
Diagramy HIPO
W niektórych kręgach użytkowników diagramy HIPO
mogą stanowić pożyteczne narzędzia modelowania,
ponieważ przypominają znane diagramy
organizacyjne, opisujące hierarchię kierownictwa
Nie pokazują one jednak danych używanych lub
wytwarzanych przez system
Chociaż może być zrozumiałe dążenie do
zmniejszenia nacisku na dane w pewnych sytuacjach,
jednakże nie jest pożyteczna całkowita ich eliminacja
Diagramy HIPO
W rzeczywistości istnieje drugi składnik diagramu
HIPO ujawniający dane
Diagram z kolejnego rysunku nosi nazwę VTOC, czyli
wizualny spis treści (ang. visual table of contents)
Każda funkcja reprezentowana prostokątem może
być opisana w szczegółach na diagramie IPO (ang.
input-process-output - wejście-proces-wyjście).
Diagramy HIPO
Diagramy struktury
Szeroko używaną odmianą diagramów HIPO
są diagramy struktury
Typowy diagram struktury jest pokazany na
kolejnym rysunku
Oprócz hierarchii funkcyjnej przedstawia on
również interfejs danych między składowymi
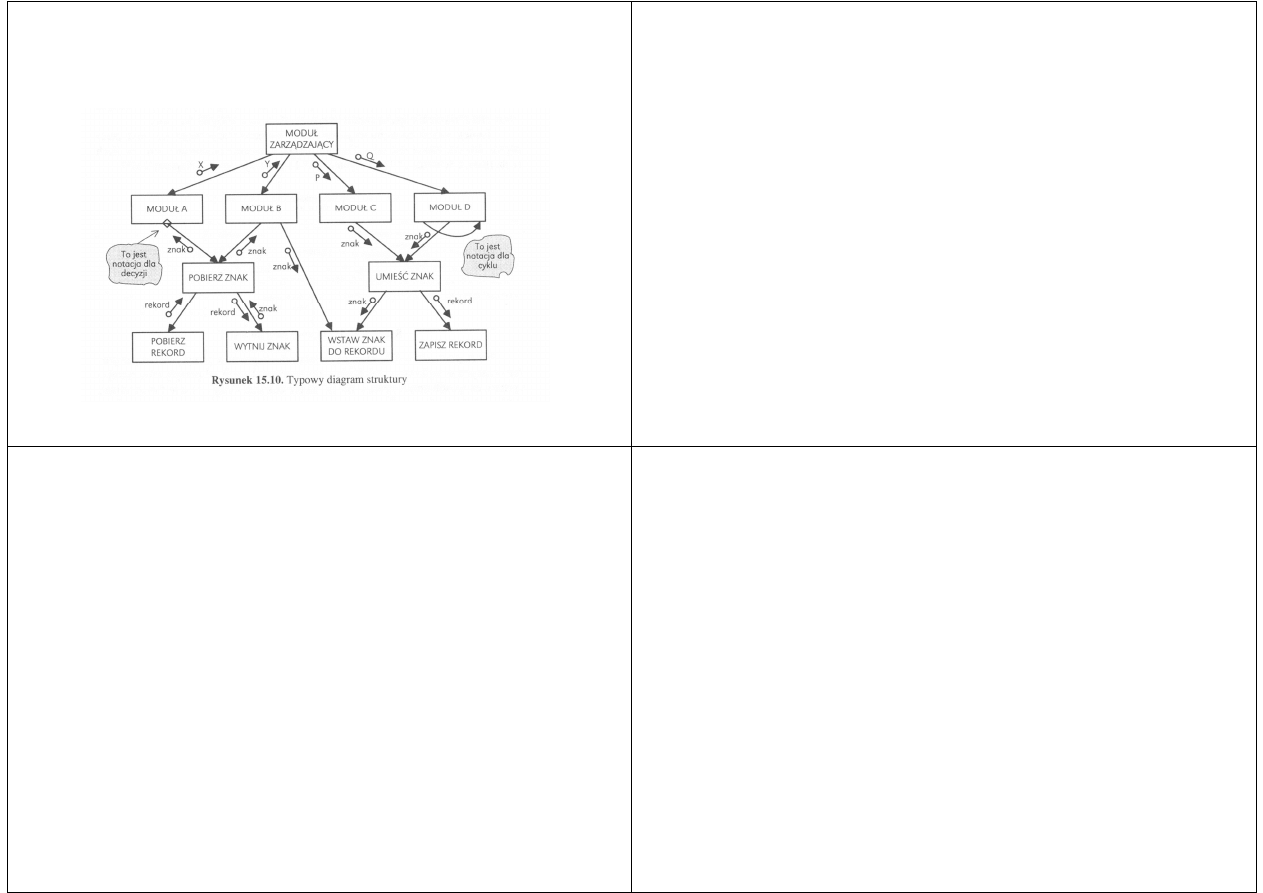
Diagramy struktury
Diagramy struktury
W przeciwieństwie do poprzednich diagramów
prostokąt na diagramie struktury nie reprezentuje
pojedynczej instrukcji obliczalnej albo ciągu
instrukcji, lecz moduł
Typowe przykłady modułów np. procedury w Pascalu
Strzałki łączące moduły nie przedstawiają instrukcji
GOTO, lecz wywołania procedur
W tej notacji zakłada się, że procedura po
zakończeniu pracy zwróci sterowanie do modułu,
który ją wywołał
Odmiany diagramów związków encji
Omówione diagramy związków encji,
większość analityków uznaje za najbardziej
ogólny, abstrakcyjny sposób reprezentowania
związków między danymi
Są jednak również inne popularne notacje do
struktur danych. Są nimi diagramy:
Bachmana
struktury danych DeMarco
Diagram Bachmana
Jedną z najpopularniejszych form modeli danych jest
diagram Bachmana
Typowy diagram pokazano na rysunku
Jest on bardzo podobny do diagramu związków encji,
omawianego poprzednio, lecz nie pokazuje jawnie
związków między obiektami
Strzałki z podwójnym grotem oznaczają związki
jeden-do-wielu
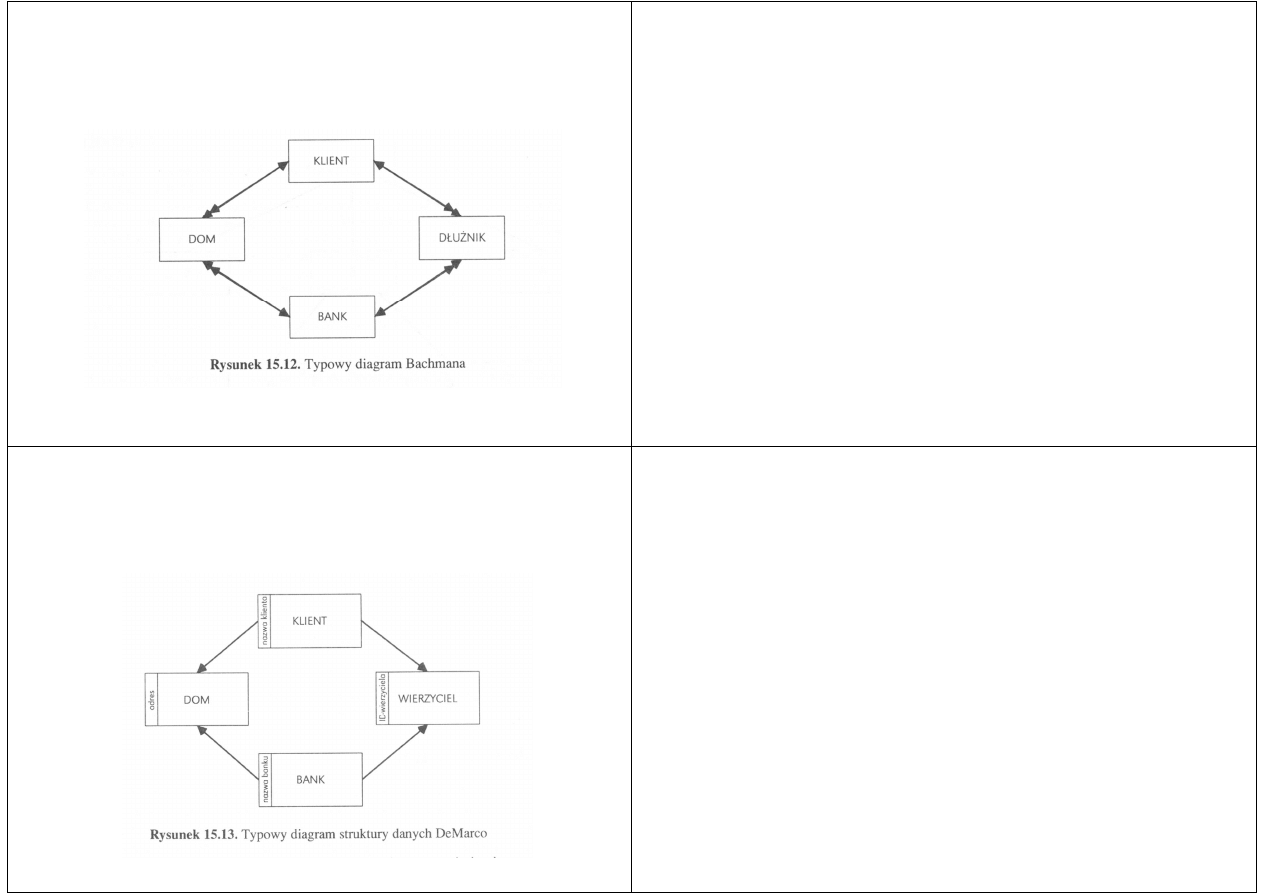
Diagram Bachmana
Diagramy struktury danych DeMarco
Diagramy struktury danych DeMarco zdobyły
popularność w latach 80-90
Typowy diagram znajduje się na kolejnym rysunku
Oprócz pokazania każdego obiektu z modelu danych,
diagram przedstawia też pola kluczowe
W prezentowanym sposobie podejścia używamy
konwencji pokazywania pól kluczowych w słowniku
danych
Diagramy struktury danych DeMarco
Analiza obiektowa
i projektowanie

Wprowadzenie
Rodowód w dziedzinie inżynierii
oprogramowania
W latach pięćdziesiątych XX wieku, kiedy
zaczęto stosować komputery, programy były
tworzone ad hoc
Każdy system stanowił unikatowy,
dostosowany do potrzeb danego użytkownika
produkt intelektualny
Nie istniały metody formalnego projektowania
Wprowadzenie
Utrzymanie poprawności działania czy
wprowadzanie udoskonaleń w tego typu
systemach było niezwykle trudne
Każda zmiana w systemie powodowała
powstanie systemu jeszcze trudniejszego do
pielęgnowania i poprawiania
Wprowadzenie
Lata sześćdziesiąte to wprowadzenie bardziej
metodycznego podejścia do projektowania
systemów informacyjnych
Podejście to, zwane powszechnie
kaskadowym, wymagało, aby w procesie
tworzenia systemu zostało zrealizowanych
kilka formalnych etapów
Wprowadzenie
Każdy z etapów, takich jak analiza wymagań,
modelowanie, projektowanie szczegółowe itd.,
musiał być zakończony, aby mógł się rozpocząć etap
następny
Zakończenie każdego etapu oznaczało dostarczenie
jednego lub kilku kluczowych dokumentów
Dlatego też podejście kaskadowe do opracowania
systemu często charakteryzowało się produkcją
olbrzymiej ilości dokumentacji

Wprowadzenie
Nadal jednak, pomimo tych innowacji, duże,
złożone systemy informatyczne przekraczały
budżet, harmonogram i nie spełniały
wymagań użytkowników
Wprowadzenie
Etapy procesu kaskadowego
analiza potrzeb
specyfikacja systemu
projektowanie
programowanie
testowanie
integracja
adaptacja i modyfikacja
eksploatacja
dezaktualizacja
Wprowadzenie
W latach siedemdziesiątych nastąpiła duża zmiana w
filozofii tworzenia systemów
Tom DeMarco wprowadził pojęcie inżynieria
systemowa, która oparta jest na modelu
Twierdził, że złożone systemy informatyczne
powinny być budowane podobnie jak duży, złożony
system inżynierski
Jego zdaniem, najpierw powinny powstać modele
systemu „działające” na papierze, a dopiero potem
powinny być zatwierdzone środki na ich praktyczną
realizację
Wprowadzenie
U podstaw tej filozofii leżało stwierdzenie, że
użytkownicy powinni mieć możliwość zobaczenia, jak
będzie działał ich przyszły system, zanim rzeczywiście
dojdzie
do tworzenia go!
W latach siedemdziesiątych było to radykalne
odejście od prostego "przywiązania do kodu" i oceny
produktu, jeśli powstały kod stwarzał pewne pozory
poprawnego działania

Wprowadzenie
Panował pogląd, że jeśli kod nie zadziała, to
trudno
Nie należy się tym przejmować, dopóki system
nie zostanie wdrożony, a to może nastąpić za
kilka miesięcy, jeśli nie lat!
Wprowadzenie
Podejście oparte na modelu jest takie samo jak
podejście stosowane przez architektów przy określaniu i
projektowaniu dużych złożonych budynków
Architekci budują modele domów w odpowiedniej skali,
tak żeby użytkownicy mogli wyobrazić sobie, jak ich
domy będą wyglądać w przyszłości
Modele te ułatwiają porozumienie i negocjacje między
użytkownikami, projektantami, budowniczymi itp.
Wprowadzenie
Budowa
systemu na
podstawie
modelu
Wprowadzenie
Filozofia oparta na modelu została w zasadzie
przyjęta we wszystkich nowoczesnych
metodykach inżynierii oprogramowania
Różnice między poszczególnymi podejściami
dotyczą określenia, jakie modele powinny być
budowane,
w jaki sposób powinny być budowane i kto
powinien je budować
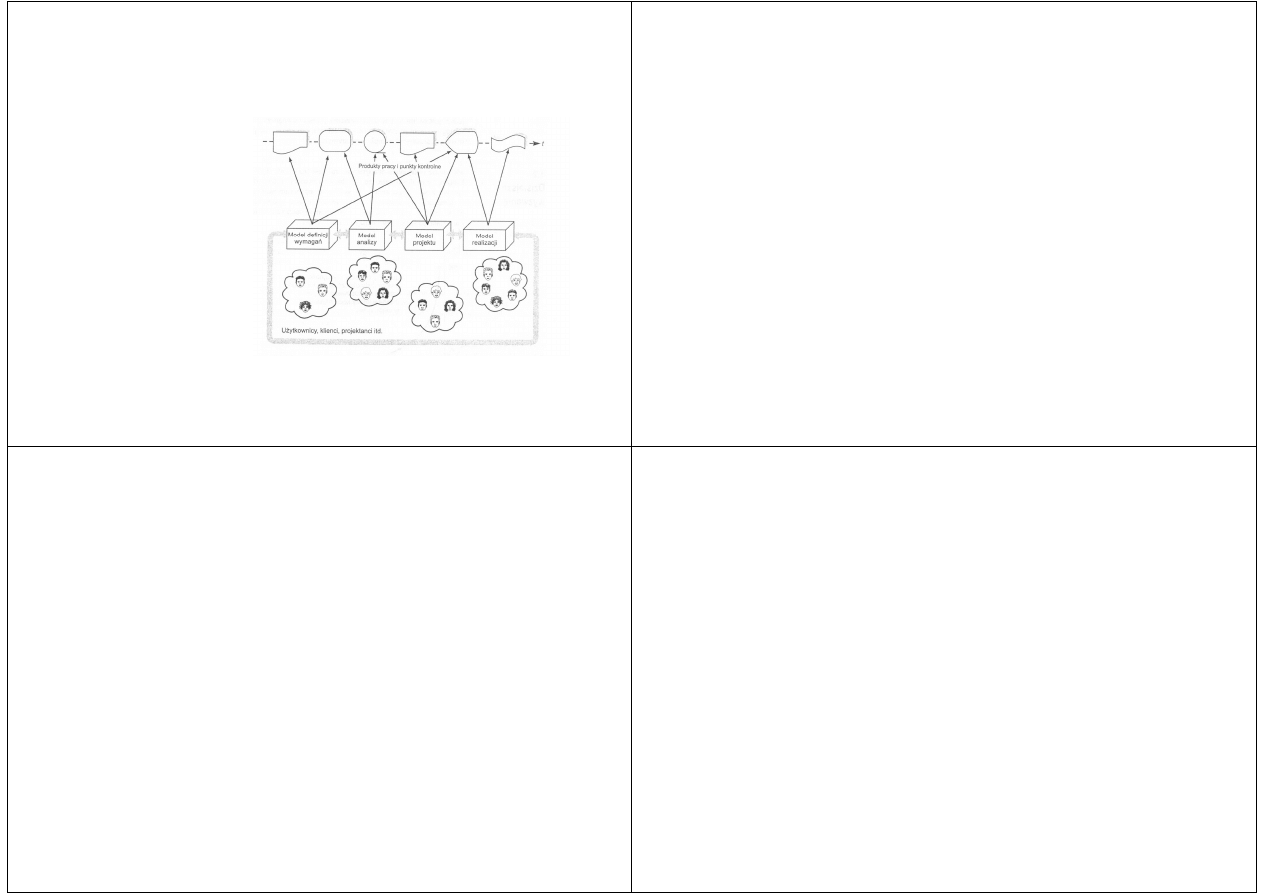
Wprowadzenie
Na rysunku jest
przedstawiony cykl
życia
oprogramowania
bazujący na modelu
Są tu różne modele
tworzone przez różne
grupy użytkowników
do różnych celów
Wprowadzenie
Model definiowania wymagań może
powstawać w celu uchwycenia
i wynegocjowania całościowych wymagań
dotyczących systemu
Może być tworzony zarówno przez
przedstawicieli działu marketingu, jak
i przez analityków systemów i analityków
oprogramowania
Wprowadzenie
Ważnym pojęciem stosowanym w większości metod
inżynierii oprogramowania opartych na modelach
jest zasada oddzielenia pojęć
Wyraża się ona zwykle w konstruowaniu modelu
analizy rozłącznego z modelem projektu
W modelach analizy są uwzględnione zasadnicze lub
"logiczne" wymagania dotyczące systemu w
przeciwieństwie do wymagań realizacyjnych lub
"fizycznych"
Wprowadzenie
Modele analizy opisują, co system będzie robił -
niezależnie od poszczególnych implementacji lub
zastosowanych technik
Modele projektu określają, jak poszczególne systemy
będą zbudowane w kontekście danego środowiska
implementacyjnego (platforma, sieć, system operacyjny,
baza danych, interfejs użytkownika itd.)
Modele analizy są zwykle budowane przez osoby z
szeroką wiedzą w zakresie danej aplikacji; mogą służyć
jako "środek" komunikowania się między klientami,
użytkownikami i projektantami

Wprowadzenie
Modele projektu natomiast są budowane
przez osoby z dużą wiedzą na temat
środowiska implementacyjnego
Służą jako "środek" komunikowania się
między projektantami, wdrożeniowcami,
osobami zajmującymi się testowaniem itp.
Zasada oddzielenia pojęć stanowi zasadniczą
siłę napędową metodyki obiektowej
Wprowadzenie
Prezentowane podejście, podobnie jak w
przypadku innych dyscyplin inżynierskich,
opiera się w dużym stopniu na zrozumieniu
problemu i ustaleniu wymagań przez
budowanie odpowiednich modeli
proponowanych systemów
Wprowadzenie
Podobnie jak to się robi w innych dziedzinach
inżynierskich, tworzy się jeden zestaw modeli
w celu ustalenia podstawowego zachowania
się proponowanego systemu i drugi w celu
określenia, jak zbudować proponowany
system w danym środowisku
implementacyjnym
Wprowadzenie
Programy w dostarczanych systemach
informatycznych niekoniecznie muszą być
najdroższym elementem, ale są zwykle ściśle związane
ze sprzętem
Oznacza to, że jeśli oprogramowanie nie działa, to
sprzęt jest bezużyteczny
Od twórców oprogramowania oczekuje się
jednocześnie dotrzymania budżetu
i harmonogramu prac oraz spełnienia wymagań
i oczekiwań użytkowników
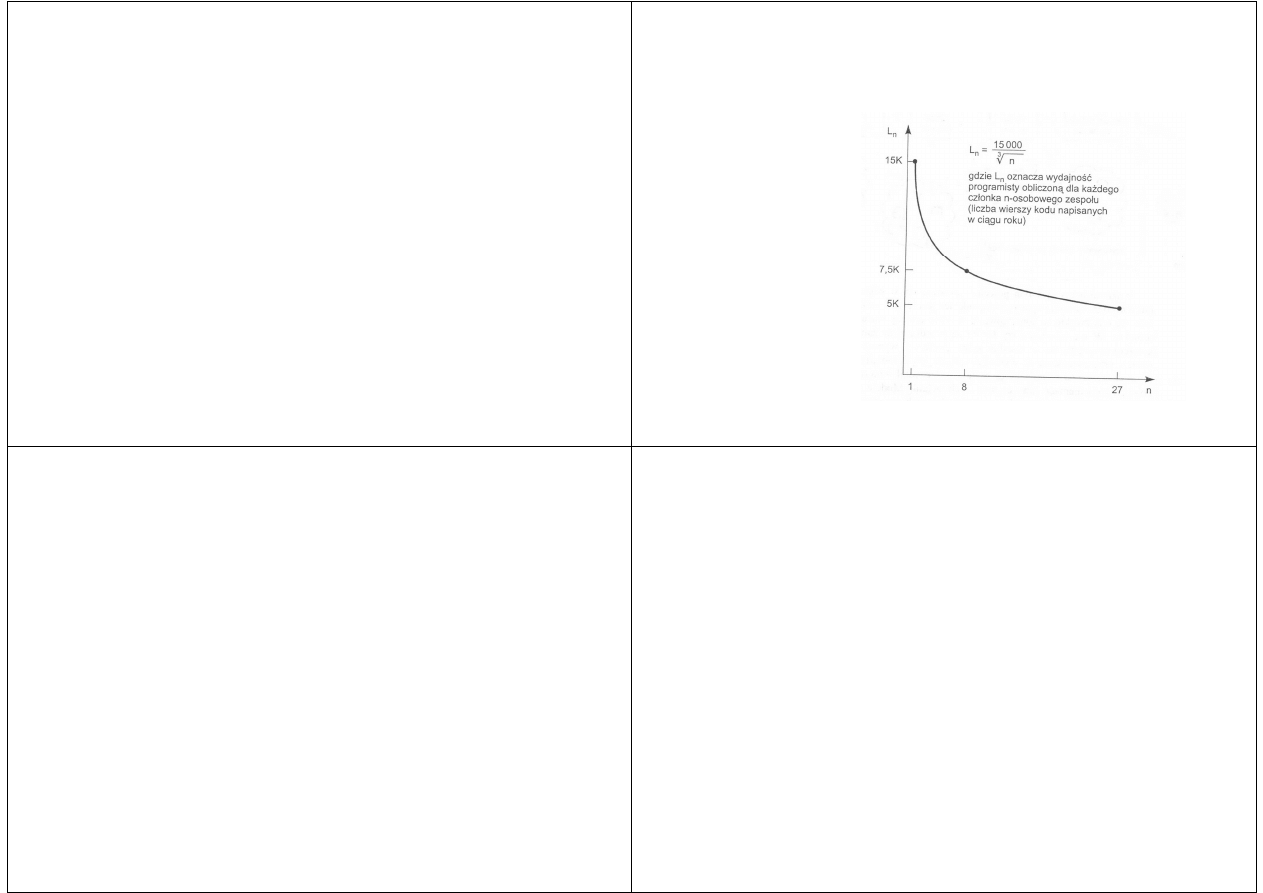
Prawo Philippe'a
Chcąc pokazać, jak bardzo trudne jest to zadanie,
Philippe Kahn, założyciel firmy Borland International,
w 1992 roku zaprezentował coś, co nazwał „prawem
Philippe'a”
Jak wynika z kolejnego rysunku, im większy jest
zespół tworzący oprogramowanie, tym mniejsza jest
wydajność każdego z członków tego zespołu
Prawo Philippe'a
gdzie Ln oznacza
wydajność
programisty
obliczoną dla
każdego członka
n-osobowego
zespołu (liczba
wierszy kodu
napisanych
w ciągu roku)
Wprowadzenie
Jest to sprzeczne z jedną z podstawowych zasad
industrializacji, która głosi, że wraz ze zwiększeniem
skali produkcji wzrasta wydajność każdego członka
zespołu produkcyjnego
Konwencjonalne metody tworzenia
oprogramowania, które zależą od ludzi piszących
kod, są z natury wadliwe
Po prostu nie ma wystarczającej liczby ludzi ani
pieniędzy, aby za pomocą konwencjonalnych
narzędzi budować olbrzymie, złożone aplikacje
Wprowadzenie
Obecnie większość programów mogłaby ewentualnie
być opracowana w krajach trzeciego świata, gdzie
robocizna jest bardzo tania
Jednakże, jeśli Stany Zjednoczone czy Europa chcą
nadal przodować w tym przemyśle, muszą stosować
inne techniki tworzenia oprogramowania
Częściowym rozwiązaniem tego problemu są metody
obiektowe

Pojęcie obiektowości
W latach pięćdziesiątych i sześćdziesiątych XX
wieku wykonanie czegokolwiek za pomocą
komputerów wymagało wyciśnięcia każdego
"bitu" efektywności z dostępnego sprzętu
Kontrolowano i wydzielano oszczędnie każde
niemal słowo
Programy komputerowe były duże,
monolityczne i trudne do pielęgnowania
Pojęcie obiektowości
W latach sześćdziesiątych, wyłoniła się nowa
szkoła myślenia głosząca, iż wielkie,
monolityczne programy komputerowe,
będące bez wątpienia najbardziej efektywnym
rozwiązaniem problemu, nie są rozwiązaniem
najlepszym
Lepszym programem komputerowym jest
program zrozumiały
Pojęcie obiektowości
Dlaczego zrozumiały?
Ponieważ taki program komputerowy może
być rzeczywiście pielęgnowany i
rozbudowywany!
W pewnych firmach takie podejście było
uznawane za zbyt radykalne
"Jeśli mamy najlepszy program na rozwiązanie
określonego problemu, to po co go zmieniać?"
Pojęcie obiektowości
W miarę jak technika komputerowa zaczęła
docierać do różnych dziedzin, argumenty te
straciły sens
Uwagi typu: "Jeśli mamy już najlepszy
program do zarządzania płacami, to po co go
zmieniać?" nie brzmią dzisiaj zbyt
przekonywająco

Pojęcie obiektowości
Modułowe programy komputerowe są, być może,
mniej efektywne, ale bardziej zrozumiałe, elastyczne
i lepiej można je pielęgnować niż duże, monolityczne
Ponieważ wydajność sprzętu komputerowego z
biegiem lat się zwiększała, podejście to było coraz
szerzej akceptowane w społeczności zajmującej się
inżynierią oprogramowania
Pojęcie obiektowości
Gdy już wszyscy zgodzili się, że modułowe programy
komputerowe są lepsze niż programy monolityczne,
projektanci systemowi zaczęli się spierać o to, jak
owe moduły powinny być tworzone
Przedstawiciele jednej szkoły twierdzili, że
najlepszym sposobem jest "krojenie" na moduły
według funkcji
„Każdy moduł wykonuje jedną i tylko jedną rzecz”
Inna szkoła głosiła: „Każdy moduł powinien zawierać
jedną strukturę danych”
Pojęcie obiektowości
Ludzie zajmujący się systemami czasu
rzeczywistego uważali z kolei, że moduły
powinny być dzielone według zdarzeń
"Każdy moduł powinien rozpoznawać i
odpowiadać na jedno i tylko jedno zdarzenie"
Pojęcie obiektowości
Gdy te trzy obozy toczyły ze sobą wojnę,
wyłonił się czwarty
To jasne, głosili jego przedstawiciele, że
najlepszym sposobem modularyzacji
programów komputerowych jest taki podział,
że
„Każdy moduł odpowiada jednej i tylko jednej
rzeczy ze świata rzeczywistego”

Pojęcie obiektowości
Zamiast dzielić programy komputerowe
zgodnie z pewnym podejściem analitycznym,
zwolennicy obiektowości twierdzili, że należy
tworzyć strukturę programu zgodnie z
problemem, który ma być rozwiązany
To była zasadnicza zmiana
Pojęcie obiektowości
Chociaż termin "obiektowy" jest używany w różny
sposób, powinien zawsze sugerować związek między
rzeczami w świecie rzeczywistym a częściami
programu komputerowego
Czym więc jest obiekt? Nieformalnie jest niezależną,
asynchroniczną, współbieżną jednostką, która "wie,
o co chodzi" (tzn. przechowuje dane), "działa" (tzn.
wykonuje usługi) i "współpracuje z innymi
obiektami" (przez wymianę komunikatów) w celu
realizacji wszelkich funkcji (modelowanego) systemu
Pojęcie obiektowości
Dlaczego właściwie zajmować się obiektami?
Odpowiedź jest prosta: wielokrotne użycie
Chociaż od zarania komputerów kod był wielokrotnie
wykorzystywany, techniki obiektowe pozwalają na
ponowne użycie czegoś więcej niż kodu
Można wielokrotnie wykorzystywać wymagania,
analizy, plany testów, interfejsy użytkownika i
architektury
W rzeczywistości właściwie każdy składnik cyklu życia
oprogramowania może być potraktowany jako
obiekt nadający się do powtórnego użycia
Analiza obiektowa
Celem jest skonstruowanie formalnych modeli
proponowanego systemu informatycznego
(jak skonstruowanie modelu budynku
tworzonego przez architekta), dzięki czemu
możliwe będzie wychwycenie zasadniczych
wymagań systemu
Analiza obiektowa
Model Analizy Obiektowej (AO) opisuje obiekty
reprezentujące określoną dziedzinę zastosowania,
łącznie z różnymi związkami strukturalnymi i
komunikacyjnymi
Model AO służy do dwóch celów
Pierwszy to sformalizowanie spojrzenia na rzeczywistość, w
ramach której będzie zbudowany system informatyczny.
Model określa obiekty, które posłużą jako zasadnicze
struktury organizacyjne danego systemu informatycznego,
oraz reguły lub ograniczenia, jakie świat rzeczywisty
nakłada na każdy system informatyczny
Analiza obiektowa
Drugi cel to ustalenie, jak zbiór obiektów
współdziała, żeby wykonać pracę analizowanego
systemu informatycznego
Owo współdziałanie jest reprezentowane w modelu
przez zbiór komunikatów pokazujących, jak
poszczególne obiekty komunikują się z innymi
obiektami
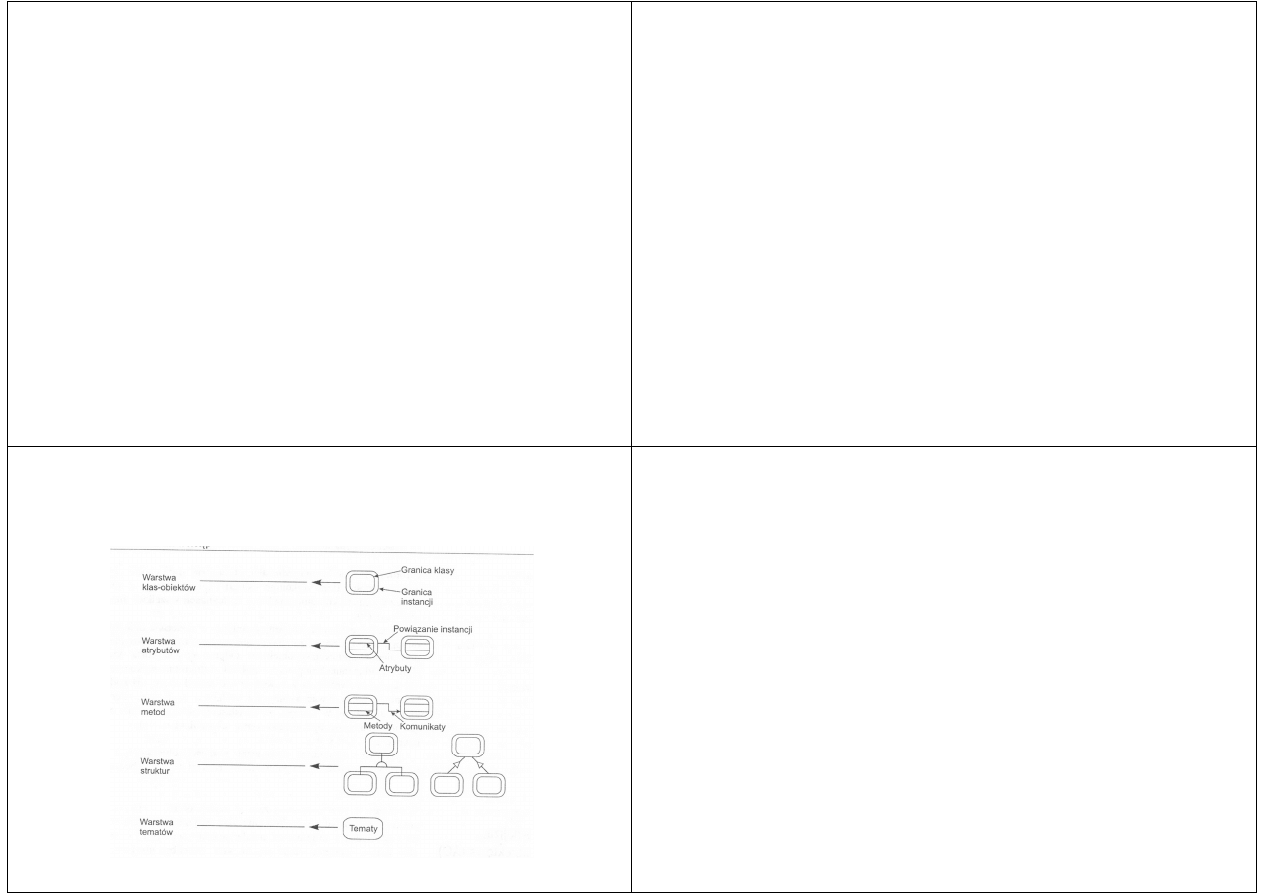
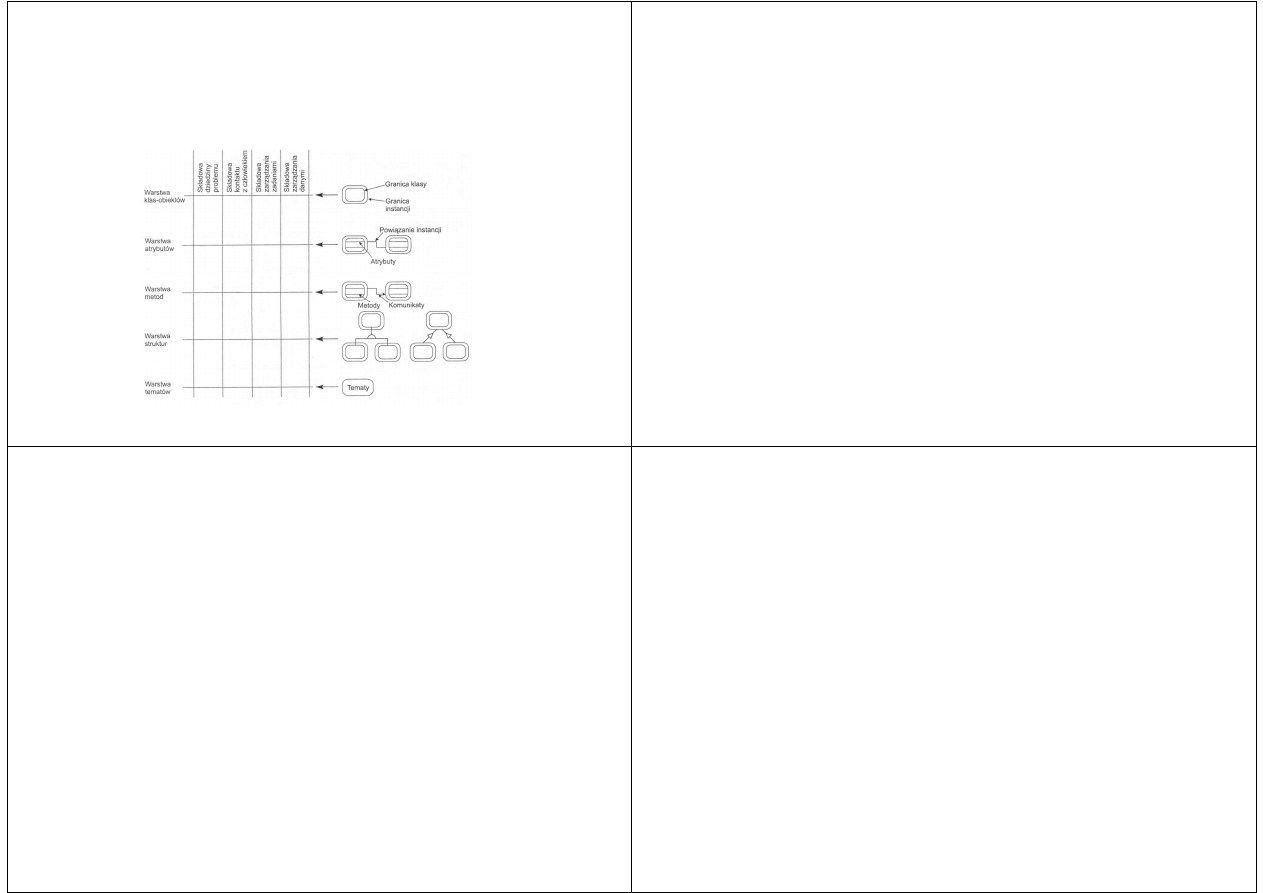
Model AO jest zbudowany z pięciu warstw lub
perspektyw
Warstwy modelu
Warstwy modelu
Dzięki warstwom możemy badać model AO z różnych
punktów widzenia
Taka struktura umożliwia również radzenie sobie w
efektywny sposób z dużymi modelami AO
Model AO składa się z pięciu warstw:
warstwa klas-obiektów
warstwa atrybutów
warstwa metod (usług)
warstwa struktur
warstwa tematów
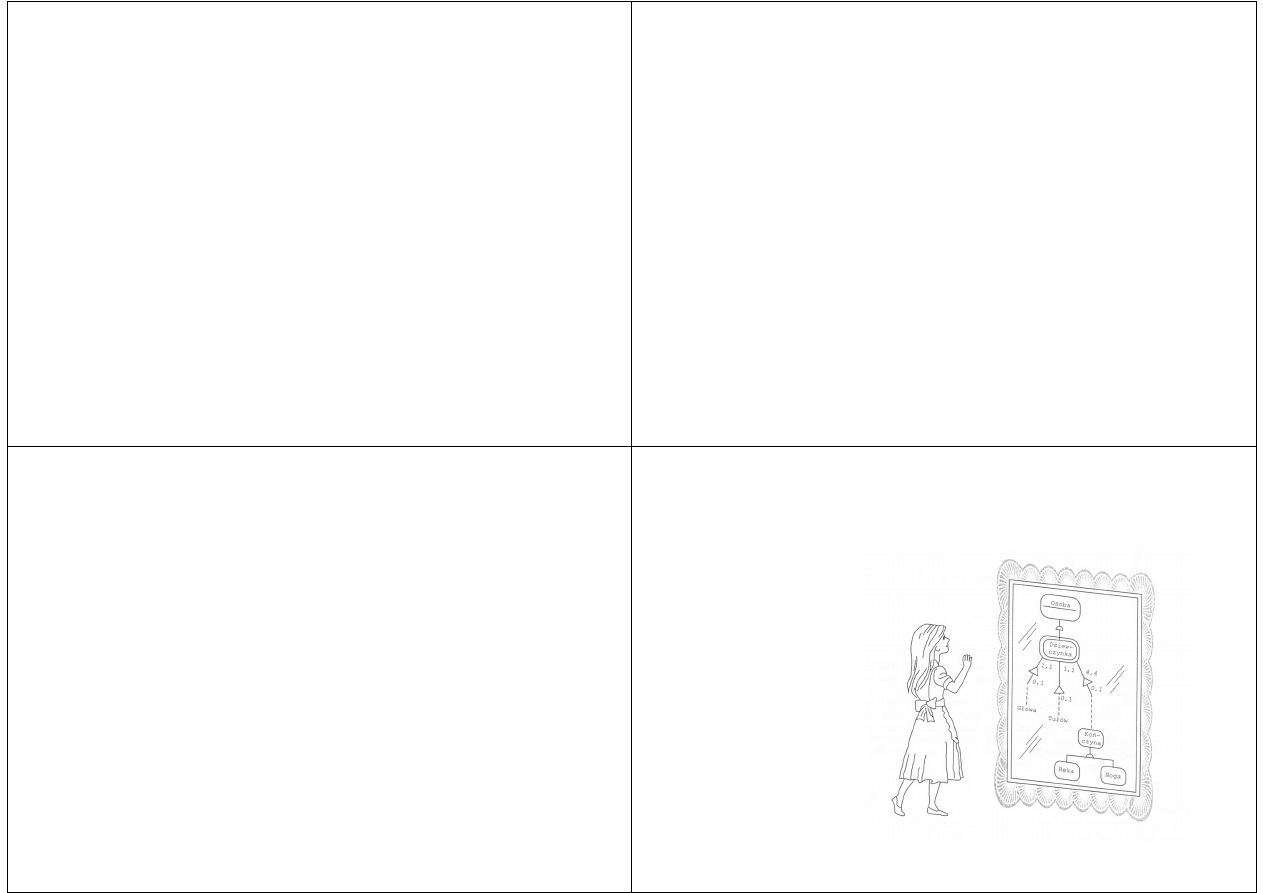
Warstwy modelu
Pierwsza warstwa klas-obiektów, przedstawia
podstawowe bloki tworzące proponowany
system
Obiekty są odbiciem rzeczywistych pojęć
danej dziedziny zastosowania
Warstwa ta stanowi podstawę całego modelu
AO
Prawdziwym rdzeniem każdej analizy
obiektowej jest proces, który nazywamy
modelowaniem informacji
Warstwy modelu
W AO trudną sprawą jest określenie, co to są te
rzeczy ze świata rzeczywistego, o których
wspominaliśmy wyżej
Będą one tworzyły podstawowe bloki, z których
zostanie zbudowany system
Modelowanie informacji jest procedurą
umożliwiającą wyodrębnienie ze świata
rzeczywistego podstawowej struktury danej
dziedziny
Jest to jedno z najbardziej elementarnych, a zarazem
najbardziej krytycznych działań procesu analizy
obiektowej
Warstwy modelu
Do zbudowania systemu informatycznego
było potrzebne pewne zrozumienie danej
dziedziny zastosowania
Natomiast w wypadku metod obiektowych
większy nacisk kładzie się na modelowanie
informacji jako na formalną procedurę w
ramach procesu inżynierii oprogramowania
Warstwy modelu
Koncepcja ta jest
pokazana na
rysunku
Alicja jest realną
osobą w realnym
świecie
Odbita w lustrze
obiektowym
może być jednak
postrzegana w
bardzo
specyficzny,
uproszczony
sposób
Warstwy modelu
W kontekście danej dziedziny, w naszym przypadku
anatomii człowieka, może być wyodrębniona jako
podstawowy zbiór pojęć
W tej dziedzinie Alicja jest "rozpatrywana" jako
kolekcja poszczególnych części ciała
W innej dziedzinie może być postrzegana jako zestaw
możliwości ekonomicznych; jej częściami składowymi
mogłyby być: historia kredytu, profil konsumpcji,
miejsce zamieszkania itp.
Warstwy modelu
W jeszcze innej dziedzinie Alicja może być widziana
na przykład jako prowadzący pojazd - z historią
wypadków, wykroczeń i stawką ubezpieczeniową
Obiektami nazywamy rzeczy ze świata rzeczywistego
Ponieważ obiekty to kawałki programów
komputerowych, a programy przechowują dane i
wykonują pracę, będzie wygodniej traktować obiekty
po prostu jako agentów, którzy przechowują dane
i/lub wykonują pewną pracę
Warstwy modelu
Dalej, obiekty mogą być traktowane jako kilku
podobnych agentów, różniących się
charakterystyką
W razie konieczności będziemy odwoływać się
do każdego z tych agentów jako do instancji -
angielska nazwa instance jest tłumaczona
jako: instancja, konkret, egzemplarz,
wystąpienie
Warstwy modelu
Jeżeli konieczne jest odwołanie się do
zbioru wielu podobnych obiektów, używa
się dla nich terminu klasa
Sposób przedstawiania klasy/ obiektu
Wewnętrzną granicą ikony jest narysowana
granica klasy
Taka notacja jest bardzo przydatna, gdyż
można wyróżnić klasę jako całość jak i jej
poszczególne elementy, czyli obiekty

Warstwy modelu
Dane przechowywane (lub zamknięte) w obiekcie
będziemy nazywać atrybutami danego obiektu,
natomiast prace, które obiekt wykonuje - metodami
(usługami)
W przyjętej notacji atrybuty obiektu i metody
przedstawia się jak na rysunku
Warstwy modelu
Często zdarza się, że pary instancji klas są ograniczone, to
znaczy zmuszone do spełnienia pewnych warunków lub
podporządkowania się pewnym regułom obowiązującym w
danej dziedzinie zastosowania
Może być np. wymagane, aby wraz z usuwaniem subskrypcji
usuwać też związanego z nią subskrebenta
Atrybuty obiektu wraz z powiązaniem instancji tworzą
warstwę atrybutów modelu AO
Warstwy modelu
W dziedzinie, w której system jest modelowany,
SUBSKRYPCJA ma różne atrybuty lub charakterystyki,
np. takie jak status
Również oczywiste są ograniczenia, czy też
obowiązujące reguły działania
W konkretnej sytuacji SUBSKRYPCJA musi być
powiązana dokładnie z jednym SUBSKRYBENTEM
bez względu na sposób budowy systemu, na sposób
jego realizacji lub też osobę subskrybujacą
Warstwy modelu
Metody (usługi) obiektu wraz z komunikatami przesyłanymi
między instacjami tych obiektów tworzą warstwę metod AO
Na rysunku można zauważyć, że zarówno SUBSKRYPCJA, jak i
SUBSKRYBENT wykonują pewne prace lub funkcje
Komunikują się również
między sobą,
czyli współpracują,
na co wskazuje strzałka

Warstwy modelu
Powiązanie przez komunikaty pokazane na poprzednim
rysunku dowodzi, że jedna z metod SUBSKRYPCJI
komunikuje się z jedną z metod SUBSKRYBENTA
Kolejną warstwą modelu AO jest warstwa struktur
Warstwa ta wychwytuje pewne związki strukturalne w
danej dziedzinie zastosowania
Przykładowy typ warstwy struktur pokazany jest na
kolejnym rysunku
Warstwy modelu
Istnieje pewien rodzaj relacji
między obiektami SILNIK WINDY,
CZUJNIK PRZECIĄŻENIA, PANEL
PRZYJAZDU i PANEL DYSPOZYCJI
Przedstawiona jest struktura
całość-część, wskazująca, że
WINDA jako „całość” musi składać
się z „części”
Widać też, że winda musi mieć
jeden silnik, który musi być częścią
windy – podobnie inne
Liczebność, uczestnictwo
Związki całość część zachodzą wtedy, kiedy
obiekt rodzic jest złożony z kilku obiektów
dzieci.
Zwykle określamy je na podstawie złożoności
fizycznej. Możliwe są jednak inne typy
złożoności.
Chociaż związki całość-część nie wykazują
dziedziczenia, jak związki generalizacja-
specjalizacja, mają cechy liczebności i
uczestnictwa
Liczebność, uczestnictwo
Liczebność odnosi się do liczby obiektów
dzieci, z których może składać się rodzic (np.
samochód ma cztery koła).
Uczestnictwo mówi o tym, czy obiekt rodzic
lub dziecko musi brać udział w związku całość-
część.
Samochód musi mieć cztery koła, chociaż koło
niekoniecznie musi być częścią samochodu.
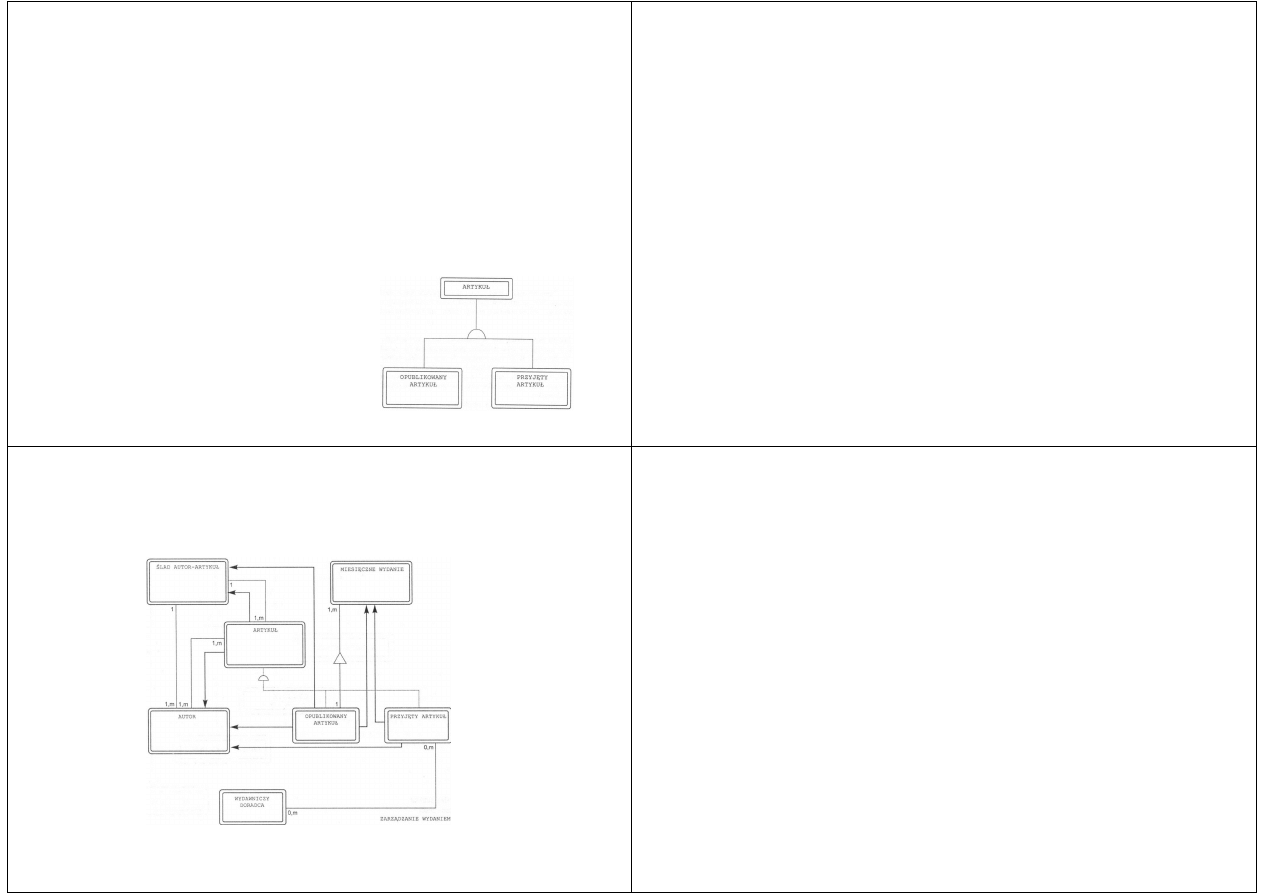
Warstwy modelu
Inny typ warstw struktur to struktura uogólnienie-
uszczegółowienie (generalizacja-specjalizacja)
Struktura ta jest zupełnie inna niż struktura całość-część
Na rysunku określono OPUBLIKOWANY ARTYKUŁ I
PRZYJĘTY ARTYKUŁ jako specjalizacje ARTYKUŁU
(uogólnienie)
Struktura ta wskazuje na
własność dziedziczenia, to znaczy
atrybuty lub metody klasy
uogólnienia są wspólne (dziedziczone)
dla klas będących specjalizacjami
Warstwy modelu
Ponieważ modele AO są duże, o płaskiej strukturze, liczba
obiektów może okazać się pokaźna
Obiekty mogą być łączone w tematy
Odbywa się to przez zamknięcie powiązanych ze sobą
obiektów w granicę tematu
Tematy można sobie wyobrazić jako modele podrzędne lub
nawet subsystemy
Tematy są zawarte w warstwie tematów
Kolejny rysunek przedstawia przykład jednego tematu w
ramach warstwy
Temat „zarządzanie wydaniem” obejmuje te obiekty, które
realizują funkcje systemowe związane z „zarządzaniem
wydaniem”.
Warstwy modelu
Projektowanie obiektowe
W kontekście inżynierii oprogramowania proces analizy
traktowany jest jako ustalenie podstawowego zachowania
się systemu
Natomiast projektowanie uważane jest za proces
określania elementów służących do konstrukcji – czyli
instrukcji, wskazówek, wytycznych, zaleceń, reguł itp., za
pomocą których dany system informatyczny powinien być
realizowany w konkretnym środowisku
Model projektowania obiektowego jest konstruowany jako
rozszerzenie modelu analizy obiektowej
Model projektowania zawiera pięć tych samych warstw co
model analizy i stosuje się w nim tę samą notację
Projektowanie obiektowe
Model projektowania zawiera poza tym dodatkowe cztery
składowe
Projektowanie obiektowe
Składowa dziedziny problemu (SDP)
Składowa kontaktu z człowiekiem (SKC)
Składowa zarządzania zadaniami (SZZ)
Składowa zarządzania danymi (SZD)
Projektowanie obiektowe
Składowa dziedziny problemu, wskazuje te obiekty, które
realizują podstawowe funkcje danej dziedziny
zastosowania
Model analizy obiektowej może stać się wstępną wersją
składowej dziedziny problemu
Modele składowej kontaktu z człowiekiem wskazują na
sposób tworzenia interfejsów, które zostaną użyte do
konkretnej realizacji systemu – jest to przykład zasady
oddzielania pojęć. Szczegóły dotyczące sposobu realizacji są
odizolowane od pracy wykonywanej przez dany system
Projektowanie obiektowe
Składowa zarządzania zadaniami modelu projektowania
obiektowego określa składniki systemu, które umożliwią
realizację danego systemu
Składowa zarządzania danymi definiuje te obiekty, które
są niezbędne w celu współdziałania ze stosowaną bazą
danych
Podobnie jak składowa kontaktu z człowiekiem, składowe
te są przykładem zasady oddzielania pojęć
Szczegóły techniczne bazy danych są odseparowane od
podstawowych funkcji systemu

Projektowanie obiektowe
Podejście bazujące na zastosowaniu zasady oddzielania
pojęć pozwala na zbudowanie modelu niezależnego od
techniki, co z kolei daje możliwość wielokrotnego
wykorzystania systemu
Np. gdy zmienia się rodzaj interfejsu z graficznego na
głosowy, jedynym elementem do zmiany jest składowa
kontaktu z człowiekiem – reszta systemu pozostaje bez
zmian
Oznacza to, że reszta systemu powinna być odporna na
zmiany dotyczące interfejsu użytkownika
Projektowanie obiektowe -
Kluczowe zagadnienia
Zasada oddzielenia pojęć polega na odizolowaniu
zasadniczych wymagań dotyczących pracy systemu od
wymagań dotyczących jego realizacji
Pojęcie obiektowości różni się od tradycyjnego podejścia
opartego na dekompozycji funkcji „od góry do dołu”
Techniki obiektowe umożliwiają powtórne użycie pełnego
cyklu życia oprogramowania
Obiekt to niezależna, asynchroniczna, współbieżna
jednostka, która wie o co chodzi, działa i współpracuje z
innymi obiektami w celu realizacji funkcji systemu
Notacja UML
Wprowadzenie
UML (ang. Unified Modeling Language)
UML to język służący do komunikowania się w
dziedzinie systemów: ewolucyjny,
wszechstronny, obsługiwany przez różne
narzędzia i znormalizowany branżowo język
specyfikowania, wizualizacji, konstruowania i
dokumentowania procesu

Wprowadzenie
Język UML można stosować do różnych typów
systemów (oprogramowania i innych), domen
(biznes lub oprogramowanie), metod i procesów
UML umożliwia i promuje (lecz nie wymaga ani nie
nakazuje) procesy sterowane przypadkami użycia,
iteracyjne i przyrostowe, zorientowane na technikę
obiektową
Wprowadzenie
UML został pierwotnie utworzony przez Rational
Software Corporation i trzech z najbardziej liczących
się metodologów tej firmy: Grady'ego Boocha,
Jamesa Rumbaugha i Ivara Jacobsona
UML stał się standardem dzięki wysiłkom Object
Management Group (OMG) i Rational Software
Corporation, mającym na celu połączenie najlepszych
rozwiązań inżynierskich z systemów informatycznych
i technicznych branż przemysłu w zbiór technik
modelowania
Wprowadzenie
Język UML jest czymś znacznie więcej niż
standardem, czy też kolejnym językiem modelowania
UML to "paradygmat", "filozofia", "rewolucja" i
"ewolucja" metod podejścia do rozwiązywania
problemów i do systemów
Często mówi się, że język angielski jest światowym
"językiem uniwersalnym"; dzisiaj jest niemal pewne,
że UML stanie się "językiem uniwersalnym" świata
systemów informatycznych i technologii
Wprowadzenie
Bardziej formalnie, UML jest językiem
ogólnego zastosowania, a zarazem
standardem branżowym o szerokich
zastosowaniach, powszechnie obsługiwanym
przez narzędzia obecne na rynku

Wprowadzenie
Konstruowanie systemów polega na tworzeniu ich
zgodnie z wymaganiami, z zastosowaniem przy ich
rozwoju procesu cyklu życia
Wymagania są zasadniczo problemami do
rozwiązania, system jest rozwiązaniem tych
problemów, zaś konstruowanie systemu jest
procesem rozwiązywania problemów, w skład
którego wchodzą:
rozpoznanie problemu
rozwiązanie problemu
implementacja rozwiązania
Wprowadzenie
Do opisywania wymogów służą języki naturalne
Języki programowania służą do przekazywania
(opisywania) szczegółów systemu
Ponieważ języki naturalne są mniej precyzyjne od
języków programowania, w procesie rozwiązywania
problemów do przekraczania przepaści pomiędzy
wymogami i systemem służą języki modelowania,
takie jak UML
Wprowadzenie
UML, może być stosowany w całym procesie tworzenia
systemu, od gromadzenia wymogów, aż po
implementację systemu
Ponieważ UML jest językiem o szerokim zakresie
zastosowań, można go używać w różnych typach
systemów, dziedzin i procesów
Możemy dzięki temu użyć UML-a do opisu systemów
programowych i nieprogramowych (tzw. systemów
biznesowych) w różnych dziedzinach i branżach, np. w
produkcji, bankowości, handlu elektronicznym itd.
Co to jest UML?
UML jest po prostu językiem wizualnym,
służącym do modelowania i opisywania
systemów za pomocą diagramów i
dodatkowego tekstu
Przykład przedstawiony jest na rysunku
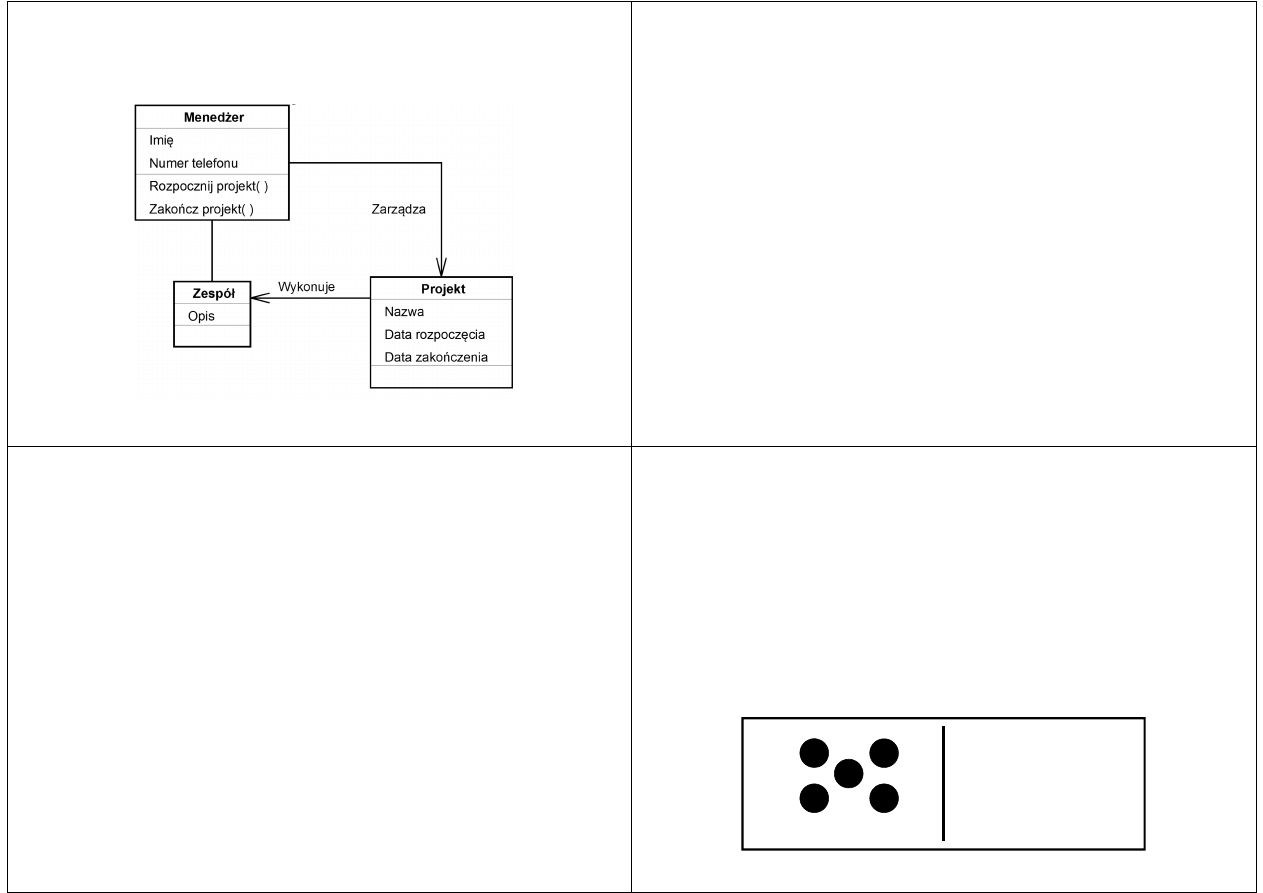
Co to jest UML?
Co to jest UML?
Rysunek przekazuje następujące informacje:
Menedżer przewodzi zespołowi, który wykonuje
projekt
Każdy menedżer ma imię i numer telefonu, i może
zainicjować lub zakończyć (przerwać) projekt
Każdy projekt ma nazwę, datę rozpoczęcia i datę
ukończenia
Każdy zespół ma opis, i tylko to nas w nim
interesuje
Trzy aspekty UML-a
Każde z tych trzech słów „Unified Modeling
Language” mówi o innym ważnym aspekcie UML-a
Language (język)
Język pozwala nam porozumiewać się na temat
danego podmiotu
W konstruowaniu systemu podmiotem może być
wymóg lub system
Bez języka trudno o komunikację pomiędzy
członkami zespołu i o współpracę, pozwalającą z
powodzeniem opracować system
Trzy aspekty UML-a
Języki w ogólnym znaczeniu nie zawsze składają się z
zapisanych wyrazów
Na przykład, powszechnie używamy "języka
rachunkowego", aby uczyć dzieci liczenia i arytmetyki
5
Język rachunkowy
Język arytmetyczny

Trzy aspekty UML-a
Działania dodawania i odejmowania w języku
rachunkowym są reprezentowane przez fizyczną
czynność dodawania lub zabierania obiektów ze
zbioru
W języku arytmetyki, w którym określoną liczbę
reprezentuje łańcuch cyfr arabskich, dodawanie i
odejmowanie reprezentowane są przez operatory + i
-
Trzy aspekty UML-a
Rozważmy możliwość przedstawienia w tych dwóch
językach określonej liczby dni w projekcie
Do zamodelowania i wyrażenia wartości "pięć" język
rachunkowy używa pięciu obiektów, zaś język
arytmetyczny łańcucha „5”
Do modelowania i wyrażania większych wartości, np.
365, język rachunkowy wymaga 365 obiektów (co
może być niepraktyczne), zaś język arytmetyczny
stosuje ciąg ,,365"
Trzy aspekty UML-a
Aby zamodelować i wyrazić wartość cztery i pół język
rachunkowy wymaga czterech i pół obiektu (pół
obiektu niekoniecznie jest praktycznym
rozwiązaniem), zaś arytmetyczny używa łańcucha
„4,5”
Ponieważ arytmetyka pozwala łatwiej i bardziej
praktycznie niż język rachunkowy przedstawiać
wartości z szerszego zakresu, mówimy, że język
arytmetyczny jest bardziej ekspresywny od
rachunkowego
Trzy aspekty UML-a
Oprócz tego liczbę możemy wyrazić za
pomocą arytmetyki bardziej ściśle niż w języku
rachunkowym
Stosując bardziej ekspresywne języki,
możemy przekazywać w sposób bardziej
zwięzły złożone informacje o złożonych
podmiotach

Trzy aspekty UML-a
UML jest językiem służącym do specyfikacji,
wizualizacji, konstrukcji i dokumentacji artefaktów
(wytworów) procesu zorientowanego na system
Proces zorientowany na system oznacza podejście
koncentrujące się na systemie, łącznie z etapami
tworzenia i utrzymania systemu, zgodnie z
wymogami, jakie ten system musi spełnić
Specyfikacja obejmuje tworzenie modelu
opisującego system
Trzy aspekty UML-a
W procesie wizualizacji model jest tworzony i
opisywany za pomocą diagramów (model jest ideą, a
diagramy wyrażeniem tej idei)
Konstrukcja oznacza wykorzystanie tego wizualnego
obrazu do zbudowania systemu, podobnie jak plany
techniczne są używane przy wznoszeniu budynku
Dokumentacja wykorzystuje modele i diagramy do
zarejestrowania naszej wiedzy o wymogach i
systemie w obrębie całego procesu
Trzy aspekty UML-a
UML sam w sobie nie jest procesem
Proces polega na zastosowaniu zbioru kroków,
opisanych przez metodologię, do rozwiązania
problemu i stworzenia systemu spełniającego
wymogi użytkownika
Metoda zajmuje się jedynie częścią procesu
tworzenia systemu, na przykład gromadzeniem
wymogów, analizą, projektowaniem itp., natomiast
metodologia dotyczy całego procesu, od
gromadzenia wymogów aż do udostępnienia
systemu użytkownikom
Trzy aspekty UML-a
Różnorodne metody gromadzenia i wykorzystywania
wymogów, analizowania wymogów, projektowania
systemu itp. noszą nazwę technik
Artefakty (wytwory) są produktami pracy,
tworzonymi i wykorzystywanymi w procesie; należy
do nich również dokumentacja służąca do
komunikacji pomiędzy stronami pracującymi nad
systemem i samym fizycznym systemem
Wszystkie typy diagramów UML nazywane są
również technikami modelowania

Trzy aspekty UML-a
Model
Model jest reprezentacją podmiotu
Na przykład do modelowania i wyrażenia wartości
"pięć" język rachunkowy używa pięciu obiektów, zaś
język arytmetyczny ciągu „5”
Model rejestruje zbiór związanych z podmiotem idei,
zwanych abstrakcjami
Bez modelu bardzo trudno jest osiągnąć
porozumienie pomiędzy członkami zespołu na temat
wymogów i systemu oraz analizować wpływ zmian
wprowadzanych podczas tworzenia systemu
Trzy aspekty UML-a
Model
Model jest reprezentacją podmiotu
Model rejestruje zbiór związanych z podmiotem idei,
zwanych abstrakcjami
Bez modelu bardzo trudno jest osiągnąć
porozumienie pomiędzy członkami zespołu na temat
wymogów i systemu oraz analizować wpływ zmian
wprowadzanych podczas tworzenia systemu
Trzy aspekty UML-a
Jeśli przy tworzeniu modelu będziemy próbowali
przedstawić jednocześnie wszystkie informacje o danym
podmiocie, z łatwością przytłoczy nas objętość informacji
Ważne jest więc skoncentrowanie się na rejestrowaniu
liczących się informacji, niezbędnych do zrozumienia
danego problemu, znalezienia rozwiązania tego
problemu i zaimplementowania rozwiązania, a zarazem
wykluczaniu wszelkich nieistotnych informacji, które
mogą spowolnić dochodzenie do rozwiązania
Trzy aspekty UML-a
Decydując, które abstrakcje składają się na
model, ustalając poziom ich szczegółowości i
etapy, na których będą rejestrowane w
procesie konstruowania systemu, możemy
lepiej zapanować nad ogólną złożonością
tworzenia systemu

Trzy aspekty UML-a
Unified (ujednolicony)
Pojęcie "ujednolicony" bierze się z faktu, iż
Object Management Group (OMG) -
organizacja tworząca standardy powszechnie
przyjmowane w przemyśle - razem z Rational
Software Corporation stworzyły UML w celu
połączenia ze sobą najlepszych metod
stosowanych w systemach informacyjnych i w
branży technologicznej
Trzy aspekty UML-a
Do praktyk tych zalicza się stosowanie technik,
które pozwalają z większym powodzeniem
konstruować systemy
Bez wspólnego języka, nowym członkom
zespołów trudno jest szybko osiągać
produktywność i wnosić swój wkład do
tworzenia systemu
Zadania i zakres
Według założeń OMG, UML ma być:
gotowy do użytku
ekspresywny
prosty
precyzyjny
rozszerzalny
niezależny od implementacji
niezależny od procesu
Zadania i zakres
Ponieważ UML jest gotowy do użytku, ekspresywny,
prosty i precyzyjny, język ten można od razu
zastosować w projekcie rozwojowym
Język rozszerzalny pozwala definiować nowe pojęcia,
co przypomina wprowadzanie nowych słów i
rozszerzanie słownictwa języka naturalnego
Język niezależny od implementacji może być
używany niezależnie od konkretnej technologii
implementacji
Język niezależny od procesu może być stosowany do
różnych typów procesów

Historia
W historii UML-a możemy wyróżnić pięć
okresów
Poznanie tych okresów pozwala zrozumieć, z
jakich powodów powstał UML i jak wciąż
ewoluuje
Historia
Okres fragmentacji
Od połowy lat 70. do połowy lat 90. organizacje
zaczęły zdawać sobie sprawę z tego, jak cenne jest
oprogramowanie dla biznesu, lecz dysponowały tylko
niepełnymi zbiorami technik tworzenia i utrzymania
oprogramowania
Było wówczas kilka różnych technik i metod,
koncentrujących się na bardziej wydajnym tworzeniu
i utrzymaniu oprogramowania (każda miała własne
języki modelowania)
Historia
W miarę ewoluowania metod strukturalnych w
kierunku metod obiektowych branża podzieliła się,
na zwolenników różnych metod
Wyznawcy jednej metody mieli kłopoty ze
zrozumieniem produktów entuzjastów innych metod
Oprócz tego mieli problemy z przenoszeniem się z
jednej organizacji do drugiej, ponieważ taki ruch
często oznaczał konieczność nauczenia się nowej
metody
Historia
Okres jednoczenia
Od połowy lat 90. do roku 1997 wyłonił się język
UML 1.0. w firmie Rational Software Corporation,
aby połączyć swoje metody podejścia
Okres standaryzacji
W drugiej połowie 1997 roku pojawił się UML 1.1.
W listopadzie 1997 organizacja OMG (Object
Management Group) zaadoptowała UML i wzięła na
siebie odpowiedzialność za dalszy rozwój standardu

Historia
Okres korekt
Pojawiły się różne wersję języka UML
OMG wyznaczyła grupę zajmującą się korektami (RTF
- ang. revision task force), której zadaniem było
przyjmowanie publicznych komentarzy dotyczących
UML-a i dokonywanie pomniejszych zmian
redakcyjnych i technicznych w standardzie
Wielu różnych dostawców produktów i usług zaczęło
wspierać i promować UML poprzez narzędzia, usługi
doradcze, książki itp.
Historia
Okres wdrożenia
Równolegle z korektami OMG zgłasza
standard UML do przyjęcia jako standard
międzynarodowy poprzez organizację ISO
(ang. Organization for Standardization) w
formie dostępnej publicznie specyfikacji - PAS
(ang. Publicly Available Specification).
Najbardziej aktualna wersja specyfikacji UML
jest dostępna w serwisie OMG
http://www.omg.org.
UML i proces
Mimo że UML jest niezależny od procesu, jego
autorzy promują proces, który jest sterowany
przypadkami użycia, skoncentrowany na
architekturze, iteracyjny i przyrostowy
Mimo to z języka UML może korzystać proces
dowolnego typu, nawet nie posiadający tych
cech
UML i proces
Proces cyklu życia rozwoju każdego systemu
obejmuje następujące czynności:
Gromadzenie wymogów definiujących, co system
powinien robić
Analizę pozwalającą zrozumieć wymogi
Projektowanie - ustalenie, w jaki sposób system będzie
spełniał narzucone wymogi
Implementację - budowanie systemu
Testowanie - weryfikacja, czy system spełnia wymogi
Wdrożenie, udostępniające system użytkownikom

UML i proces
Do wykonania tych czynności w celu
stworzenia systemu można podchodzić na
wiele sposobów
Tradycyjnie stosowana była metoda
kaskadowa
W chwili obecnej częściej spotyka się
podejście iteracyjne
UML i proces
Przy stosowaniu metody kaskadowej czynności
związane z cyklem życia systemu wykonywane są w
pojedynczej, liniowej sekwencji dla wszystkich
wymogów
Prowadzi to często do odkrywania podczas testów,
gdy integrowane są poszczególne fragmenty
systemu, problemów związanych z jakością, które
pozostawały w ukryciu podczas czynności
projektowania i implementacji
UML i proces
Ponieważ problemy takie są odkrywane na
późnych etapach procesu rozwoju, może być za
późno na ich rozwiązanie lub koszty rozwiązania
mogą być zbyt wysokie
Na przykład odkrycie, iż dany system zarządzania
bazą danych ma za małą wydajność dla
korzystających z niego aplikacji, gdy aplikacje
zostały już opracowane, stanowi kolosalny
problem
UML i proces
Przy podejściu kaskadowym wszystkie wymogi są
rejestrowane i analizowane, a cały system jest
projektowany, implementowany, testowany i
wdrażany w jednej liniowej sekwencji

UML i proces
W takim przypadku UML może z łatwością posłużyć do
przekazywania wymogów i opisu systemu
Ponieważ jednak czynności wykonywane są dla wszystkich
wymogów w jednej liniowej sekwencji, modele UML na każdym
kolejnym kroku muszą być dość kompletne
Taki poziom kompletności często trudno jest zmierzyć lub
osiągnąć, ponieważ wprawdzie UML jest bardziej precyzyjny od
języków naturalnych, lecz zarazem mniej precyzyjny od języków
programowania
Zamiast więc koncentrować się na systemie, zespoły
korzystające z UML-a przy podejściu kaskadowym poświęcają
swój czas na ustalenie, czy ich modele UML są wystarczająco
kompletne
UML i proces
Gdy stosujemy metodę iteracyjną, wszystkie podzbiory
czynności w cyklu życia są wykonywane kilkakrotnie, aby
lepiej zrozumieć wymogi i stopniowo opracować bardziej
niezawodny system
Każde przejście cyklu tych działań lub ich podzbioru nosi
nazwę iteracji, a seria iteracji w końcu krok po kroku
doprowadza do ostatecznego systemu
Pozwala to lepiej zrozumieć wymogi i stopniowo
stworzyć bardziej odpowiedni system przez kolejne
ulepszenia i przyrostowe zwiększanie szczegółowości w
miarę kolejnych iteracji
UML i proces
Na przykład, możemy zbadać wydajność określonego
systemu zarządzania bazami danych i odkryć, iż
będzie niewystarczająca dla korzystających z niego
aplikacji, jeszcze zanim aplikacje te zostaną w pełni
skonstruowane
Pozwoli to wprowadzić odpowiednie zmiany w
aplikacjach lub zbadać inny system zarządzania bazą
danych, zanim będzie na to za późno lub stanie się to
zbyt kosztowne
UML i proces
Rozważmy projekt, który obejmuje
generowanie 10 różnych typów raportów
W podejściu iteracyjnym możliwy jest
następujący ciąg iteracji:
1.
Identyfikujemy pięć wymogów (nazwanych od
W1 do W5) i analizujemy trzy z nich (np. W1, W3
i W5)

UML i proces
2. Rejestrujemy pięć kolejnych wymogów
(nazwanych od W6 do W1O), analizujemy
dwa nie przeanalizowane w poprzedniej
iteracji (W2 i W 4) oraz projektujemy,
implementujemy i testujemy system, który
spełnia trzy wymagania przeanalizowane w
poprzedniej iteracji (Wl, W3 i W5) oraz dwa
przeanalizowane w tej iteracji (W2 i W4),
lecz nie wdrażamy systemu
UML i proces
3. Wdrażamy system spełniający pięć wymogów
przetestowanych w poprzedniej iteracji (od W1 do
W5) i kontynuujemy pracę nad pozostałymi (od W6
do W1O)
4. Dalej pracujemy nad systemem, lecz musimy zająć
się zmianami w jednym z wdrożonych już
wymogów (np. W3), zmianami w innych
wymogach, które nie zostały jeszcze wdrożone (np.
W6 i W1O) oraz innymi technicznymi zmianami w
systemie
UML i proces
Podejście iteracyjne do konstruowania systemu
przynosi następujące korzyści:
Możemy lepiej radzić sobie ze złożonością,
budując system małymi przyrostowymi porcjami,
a nie cały od razu
Możemy lepiej radzić sobie ze zmianami w
wymogach, rozkładając zmiany na cały proces, a
nie usiłując zarejestrować i wprowadzić wszystkie
zmiany na raz
UML i proces
Możemy udostępniać użytkownikom
fragmentaryczne rozwiązania w trakcie procesu, a
nie kazać im czekać na ukończenie procesu, kiedy
otrzymaliby kompletny system i być może
stwierdzili, że nie tego oczekiwali
Możemy zwrócić się do użytkowników z prośbą o
uwagi dotyczące opracowanych już części
systemu, co pozwoli wprowadzać zmiany i tak
kierować postępami w pracach, by stworzyć
bardziej solidny system spełniający potrzeby
użytkowników

UML i proces
Proces iteracyjny jest przyrostowy, ponieważ nie
przerabiamy jedynie raz za razem tych samych
wymogów w kolejnych iteracjach, lecz zajmujemy się
w nich coraz większą liczbą wymogów
Oprócz tego w jednej iteracji mogą odbywać się
równolegle czynności, jeśli koncentrują się na
różnych częściach systemu i nie kolidują ze sobą
Wobec tego, chociaż podejście to określane jest
często iteracyjnym i przyrostowym, w rzeczywistości
jest iteracyjne, przyrostowe i równoległe
UML i proces
Jak można organizować i motywować działania w
celu spełnienia wymogów przy takim dynamicznym
podejściu, w którym iteracje odbywają się
równolegle a system jest tworzony przyrostowo?
Jak skupić się na systemie i uniknąć tworzenia
systemu, który będzie trudny do utrzymania i
rozbudowy, ponieważ będzie jedynie zbiorem
elementów posklejanych ze sobą bez obejmującego
je schematu?
Którymi wymogami mamy zająć się na początku, i
które części systemu implementować w pierwszej
kolejności?
UML i proces
Odpowiedzi na te pytania są elementami
podejścia iteracyjnego, w których przypadki
użycia, architektura i zarządzanie ryzykiem są
krytyczne
Przypadki użycia
Przypadek użycia (use case) jest wymogiem
opisanym z perspektywy użytkowników
systemu
Np. do wymogów funkcjonalnych w
większości systemów zalicza się
funkcjonalność zabezpieczeń, pozwalającą
użytkownikom logować się do systemu i
wylogować, wprowadzać i przetwarzać dane,
generować raporty itp.
Przypadki użycia
Proces kierowany przypadkami użycia to taki proces, w
którym możemy wykorzystać przypadki użycia do planowania
i przeprowadzania iteracji
Pozwala nam to zorganizować działania i skoncentrować się
na implementowaniu wymogów wobec systemu
Inaczej mówiąc, rejestrujemy i analizujemy przypadki użycia,
projektujemy system spełniający ich potrzeby, testujemy i
wdrażamy system oraz planujemy następne iteracje
Przypadki użycia wiążą ze sobą wszystkie czynności w danej
iteracji
Przypadki użycia
Przykład diagramu
Przypadek użycia definiuje wymóg funkcjonalny, opisany w
postaci szeregu kroków, do których należą działania
wykonywane przez system i interakcje pomiędzy systemem a
aktorami (reprezentują użytkowników)
Przypadki użycia odpowiadają na pytania jak aktorzy wchodzą
w interakcje z systemem i opisują działania wykonywane
przez system
Składowe diagramu
Przykład - diagram
dla strony
internetowej

Architektura
Architektura obejmuje elementy składające się na system i
sposób, w jaki współpracują one ze sobą w celu zapewnienia
wymaganej funkcjonalności systemu
Np. większość systemów zawiera elementy obsługujące
funkcjonalność zabezpieczeń, wprowadzania i przetwarzania
danych itp.
Elementy i relacje pomiędzy nimi stanowią struktury systemu
– a ich modelowanie nosi nazwę modelowania strukturalnego
Elementy, ich interakcje i współpraca noszą nazwę
zachowania systemu – a ich modelowanie nosi nazwę
modelowania behawioralnego
Architektura
Każdy przypadek użycia można rozwinąć
opisując kolejne kroki jego wykonania
Zapis taki nosi nazwę sekwencji behawioralnej
i może zostać zapisany w postaci tekstu lub
diagramów
Zapis tekstowy sekwencji behawioralnej ma
postać kolejnych punktów opisujących
następujące po sobie działania, natomiast
przykładem modelowania behawioralnego
może być „Diagram aktywności”
Architektura
Techniki języka UML pozwalają na
uszczegółowienie przypadków użycia
Prezentacja sekwencji behawioralnej opisuje
zapis dotyczący przykładowej funkcjonalności
strony internetowej - głosowania w mini-
ankiecie
Kolejno pokazane są: tabela przedstawiająca
zapis tekstowy oraz diagram aktywności
Architektura
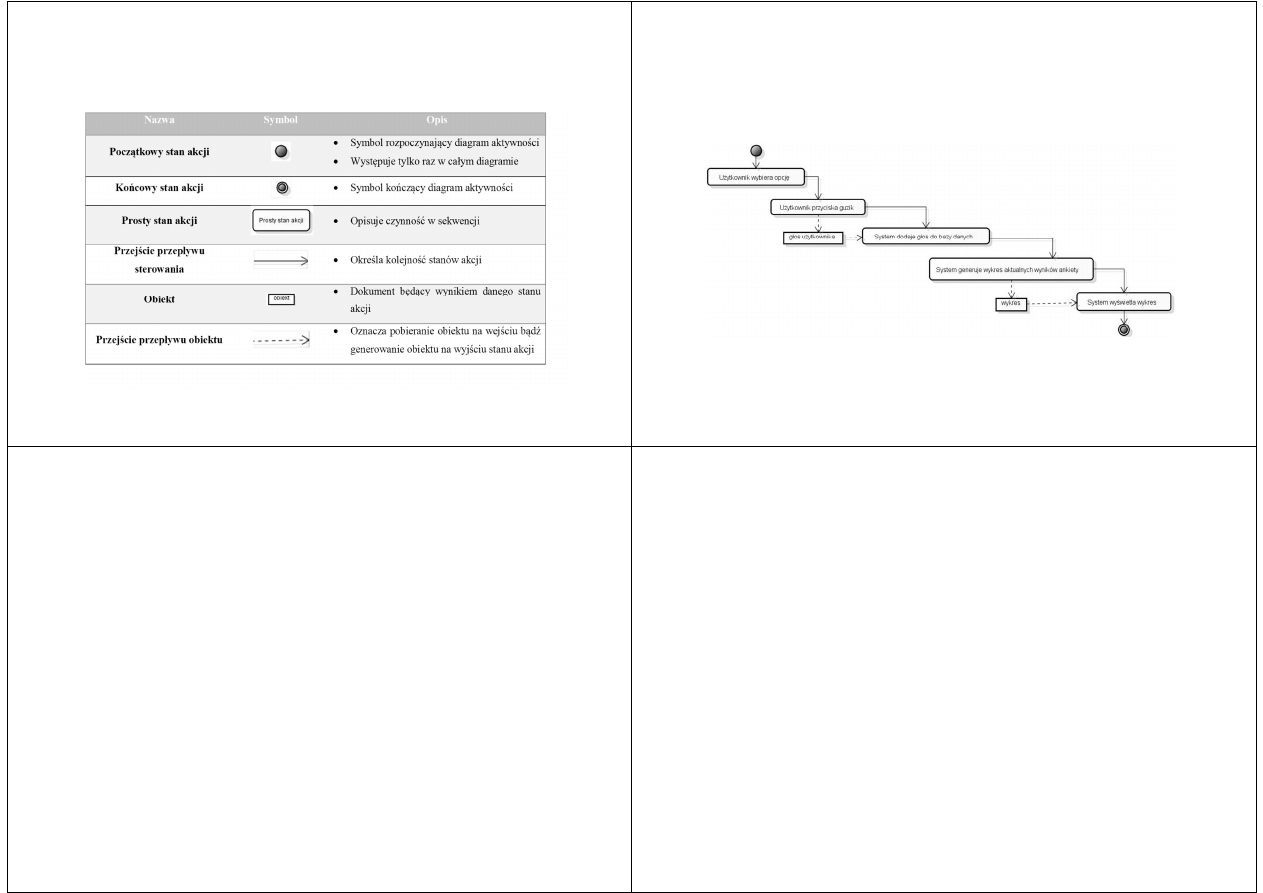
Architektura
Architektura
Ryzyko
Ryzykiem przy konstruowaniu systemu mogą być
niewystarczające fundusze, nieprzeszkoleni członkowie
zespołu lub niestabilne technologie
Aby ustalić, jakie przypadki użycia powinny motywować daną
iterację, najpierw identyfikujemy zagrożenia dotyczące
projektu
Następnie zajmujemy się tymi przypadkami użycia, które
związane są z największym ryzykiem i tymi elementami
architektury, które po skonstruowaniu rozwiążą
najpoważniejsze zagrożenia
Ryzyko
W przykładzie, w którym generowanych jest 10
raportów, trzy z nich (W1, W3 i W5) wymagają
znacznego dostępu do bazy danych, a cztery (W3,
W6, W8 i W10) wymagają znaczącego wkładu
użytkownika
Ryzyka mogą być dwa: brak wystarczająco
intuicyjnego interfejsu użytkownika (o nazwie R1) i
niewystarczająco wydajny system zarządzania bazą
danych (nazwane R2)
Z powyższego opisu wiemy, że W1, W3 i W5 są
związane z ryzykiem R2, a W3, W6, W8 i W10 z
ryzykiem R2

Ryzyko
W zależności od tego, które ryzyko jest bardziej
krytyczne i ma większe prawdopodobieństwo
wystąpienia lub poważniejszy wpływ na projekt
wybiera się pierwszą lub drugą grupę wymogów
Bezwzględnie w obu przypadkach powinno się zacząć
od W3, ponieważ wiąże się z obydwoma ryzykami
WYBRANE ZAGADNIENIA
SYSTEMÓW KOLEJKOWYCH
Systemy kolejkowe
Teoria kolejek, nazywana również teorią masowej obsługi,
jest gałęzią badań operacyjnych
Metody analizy systemów kolejkowych:
Analityczne, których istota sprowadza się do ułożenia i rozwiązania
układów równań różniczkowych wiążących ze sobą
prawdopodobieństwa zdarzeń występujących w procesie obsługi
Symulacyjne, polegające na syntezie algorytmu symulującego
funkcjonowanie danego systemu przy obsłudze strumienia
zgłoszeń. Wielokrotna komputerowa realizacja procesu obsługi przy
użyciu tego algorytmu, a następnie opracowanie statystyczne
otrzymanych rezultatów, umożliwiają znalezienie interesujących
nas współzależności oraz wartości wskaźników jakości badanego
systemu kolejkowego
Systemy kolejkowe
Przykładami prostych systemów obsługi mogą być:
zagadnienie oczekiwania na połączenie telefoniczne
obsługa klientów w urzędach, bankach, sklepach itp.
W odróżnieniu od tych prostych systemów, systemy
wielokanałowe i wielofazowe wymagają realizacji wielu
czynności obsługi (np. złożonych operacji technologicznych)
jednocześnie lub w określonej kolejności. Przykładem może
być:
ciąg operacji technologicznych wykonywanych w procesie produkcji
traktowany jako wielofazowy system kolejkowy
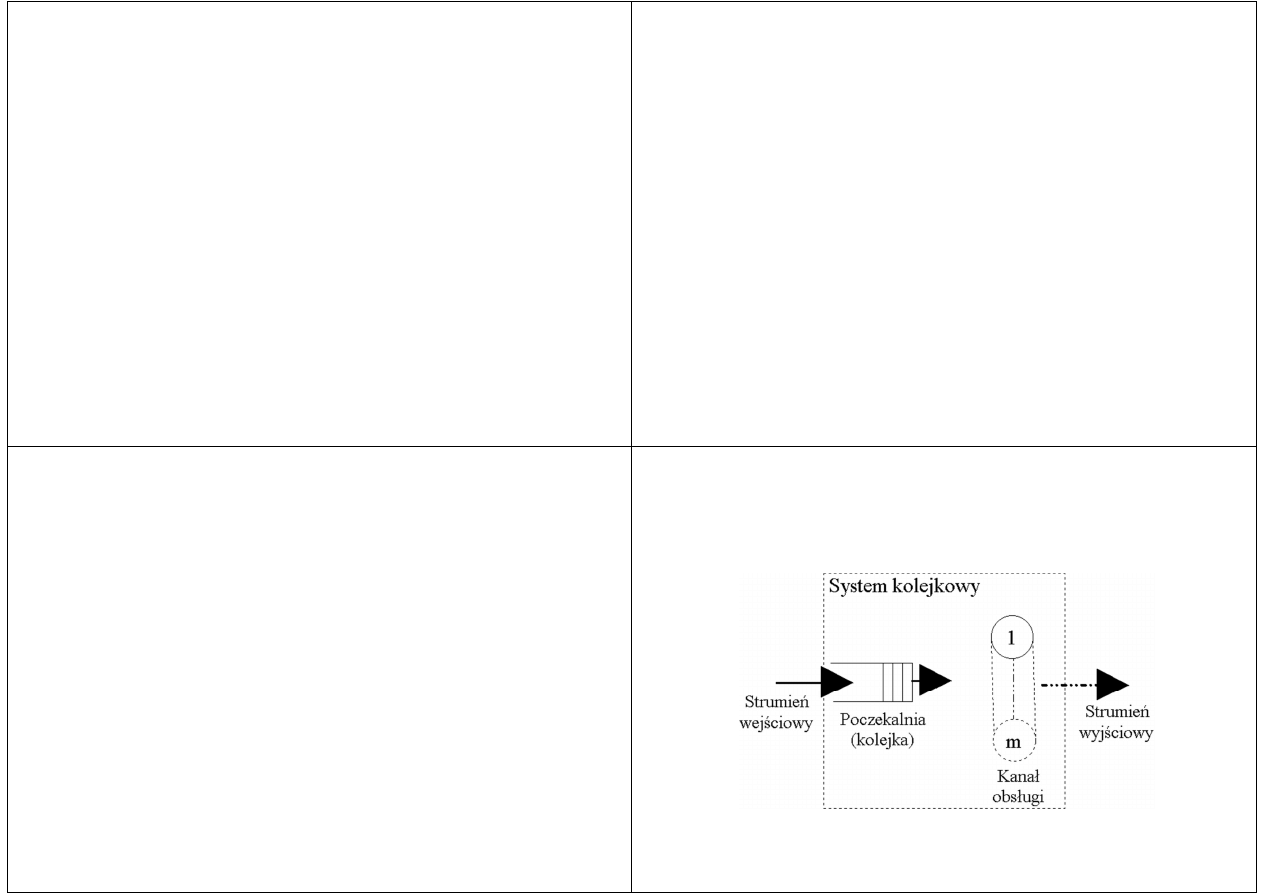
Systemy kolejkowe
Metoda symulacji stanowi jedyną efektywną metodę
analizy złożonych wielokanałowych i wielofazowych
systemów obsługi przy dowolnych strumieniach
wejściowych zgłoszeń i funkcjach rozkładów czasów
obsługi
Zasadniczym celem teorii kolejek jest opracowanie
ogólnych metod umożliwiających wyznaczenie
wartości podstawowych wskaźników
charakteryzujących proces obsługi i ocenę jakości
pracy systemu kolejkowego oraz wybór optymalnej
struktury i organizacji obsługi
Systemy kolejkowe
Z punktu widzenia użytkownika należy wypracować
wskazania do podjęcia decyzji o sposobie
użytkowania systemu, natomiast z punktu widzenia
zarządzającego systemem należy określić warunki
najbardziej efektywnego jego wykorzystania
Podstawowe pojęcia
Zgłoszenie. Przez zgłoszenie rozumie się żądanie spełnienia
przez system określonej czynności, przy czym zgłoszenie jest
utożsamiane z jego nośnikiem. Zamiast mówić: klient,
pasażer, abonent stoi w kolejce lub oczekuje na obsługę,
mówimy: zgłoszenie stoi w kolejce lub oczekuje na obsługę
Obsługa. Spełnienie określonej potrzeby, w szerokim sensie
tego słowa. Środki, które umożliwiają obsługę zgłoszeń
(człowiek, urządzenie, automat), nazywamy urządzeniami
obsługującymi, stanowiskami obsługi lub kanałami obsługi, a
zbiór takich identycznych urządzeń obsługujących systemem
obsługi
Podstawowe pojęcia

Podstawowe pojęcia
Strumień zdarzeń. Ciąg zdarzeń losowych jest nazywamy
strumieniem zdarzeń. Dotyczy to zdarzeń losowych
związanych z procesem przybywania zgłoszeń do systemu lub
też z procesem obsługi
Strumień wejściowy. Ciąg zgłoszeń wymagających obsługi.
Zgłoszenia pojawiające się w systemie są kierowane
bezpośrednio do obsługi w przypadku wolnych kanałów lub
też gromadzone w poczekalni, gdzie oczekują na zwolnienie
kanału obsługi
Strumień wyjściowy. Może zawierać zgłoszenia zarówno
obsłużone, jak też i nie obsłużone, tzn. takie, które
zrezygnowały z obsługi w systemie
Podstawowe pojęcia
Opis strumieni wejściowych i wyjściowych. Momenty
określające wejścia zgłoszeń do systemu oraz momenty ich
wyjścia są wielkościami losowymi opisywanymi przez dwa
rozkłady statystyczne:
rozkład opisujący rodzaj strumienia wejściowego zgłoszeń,
tzn. rozkład przedziałów czasowych pomiędzy chwilami
t
1
,...,t
n
, w których przybywają do systemu kolejne
zgłoszenia x
1
,...x
n
,
rozkład czasów obsługi opisujący typ obsługi, tzn. rozkład
czasów wymaganych dla zapewnienia obsługi kolejnym
zgłoszeniom na stanowiskach obsługi.
Podstawowe pojęcia
Wieloetapowy (wielofazowy) proces obsługi. W praktyce
często obsługa jednego zgłoszenia jest realizowana przez kilka
aparatów obsługi, z reguły kolejny aparat obsługi rozpoczyna
swą pracę po jej zakończeniu przez aparat poprzedzający go
Prosty (jednofazowy) proces obsługi. Polega na realizacji
pojedynczej operacji.
Typowe postacie systemów kolejkowych:
wszystkie aparaty obsługi są równouprawnione i mają identyczne
charakterystyki
aparaty obsługi tworzące dany system nie są równouprawnione, tzn.
mają indywidualne charakterystyki
Podstawowe pojęcia
W zależności od liczby kanałów systemy kolejkowe dzieli się
na: jednokanałowe i wielokanałowe
Podział ze względu na sposób zachowania się zgłoszenia,
nadchodzącego w chwili, gdy wszystkie kanały obsługi są
zajęte:
System ze stratami. Zgłoszenie nie może czekać na początek obsługi w
systemie lub system obsługi odmawia przyjęcia zgłoszenia w chwili. W
systemie nie istnieją warunki do utworzenia kolejki
System z oczekiwaniem (bez strat). Zgłoszenia nadchodzące do systemu mogą
go opuścić tylko wtedy, kiedy zostaną całkowicie obsłużone. W razie braku
wolnych kanałów obsługi zbiór zgłoszeń tworzy kolejkę w poczekalni o
nieograniczonej pojemności
Mieszane systemy obsługi. Istnieje obecność pewnych warunków pośrednich,
np. ograniczony czas przebywania zgłoszenia w systemie, czy też czas
oczekiwania w kolejce na rozpoczęcie obsługi

Podstawowe pojęcia
Rozmiar systemu. Rozważane są dwa typy
systemów: z ograniczonym lub nieograniczonym
rozmiarem, przy czym przez rozmiar systemu
rozumie się sumaryczną liczbę kanałów obsługi i
miejsc w poczekalni.
Innym kryterium klasyfikacji systemów kolejkowych
może być liczba źródeł zgłoszeń. Systemy kolejkowe
dzielą się na:
systemy otwarte, które mogą mieć nieskończenie wielką
liczbę zgłoszeń przychodzących do systemu
systemy zamknięte, w których maksymalna liczba zgłoszeń
do obsługi jest ustalona i stała w czasie.
Podstawowe pojęcia
System kolejkowy, powinien obsługiwać zgłaszające się
obiekty z prędkością większą niż ich przybywanie
Jednakże, natężenie strumienia zgłoszeń, jak i prędkość
obsługi podlegają przypadkowym wahaniom. Stąd część
zgłoszeń czeka w kolejce
Nasycenie systemu kolejkowego można opisać za pomocą
trzech charakterystyk:
strumienia zgłoszeń - będącego statystycznym opisem procesu
przybywających do systemu zgłoszeń
procesu obsługi – opisującego proces realizacji obsługi
regulaminu (dyscypliny) kolejki - określającego metodę wybierania
następnego zgłoszenia do obsługi w przypadku istnienia kolejki
Podstawowe pojęcia
Proces obsługi jest określany przez dwa parametry:
Czas obsługi jest to czas wymagany do obsługi jednego zgłoszenia
Krotność systemu obsługi jest liczbą zgłoszeń, które mogą być
jednocześnie obsługiwane. System obsługi o krotności m nazywa się
m-kanałowym systemem obsługi
W prostych przypadkach statystyczne własności strumienia
zgłoszeń i procesu obsługi są stacjonarne (niezależne od
czasu). Często jednak mamy do czynienia z procesami
niestacjonarnymi. Na przykład natężenie strumienia zgłoszeń
może zależeć od pory dnia lub też prędkość obsługi może być
funkcją długości kolejki itp.
Podstawowe pojęcia
Strumień zgłoszeń jest statystycznym opisem procesu
przybywania zgłoszeń do systemu obsługi. Jest on zazwyczaj
opisywany za pomocą funkcji rozkładu odstępów czasu
(interwałów) między kolejnymi zgłoszeniami
Strumień zgłoszeń może być:
deterministyczny, interwał ten jest stały
losowy, gdy zgłoszenia są losowe, interwał jest wtedy zmienną losową
i należy określić jego funkcję rozkładu
Czas obsługi zgłoszenia może nie być stały. Jeżeli podlega on
stochastycznym wahaniom, to musi być opisany za pomocą
odpowiedniej funkcji rozkładu

Podstawowe pojęcia
Regulamin (dyscyplina) obsługi kolejki określa kolejność
wybierania zgłoszeń z kolejki
Podstawowe sposoby to:
Dyscyplina FIFO (ang. First-In, First-Out). Jako pierwsze do
obsługi kieruje się zgłoszenie najdłużej oczekujące w kolejce
Dyscyplina LIFO (ang. Last-In, First-Out). Jako pierwsze do
obsługi kieruje się zgłoszenie, które przybyło jako ostatnie. -
Dyscyplina RSS (ang. Random Selection for Service). Jako
następne do obsługi wybiera się zgłoszenie w drodze
losowania (uporządkowanie przypadkowe)
Podstawowe pojęcia
System z niecierpliwymi klientami, może się zdarzyć
opuszczenie kolejki przez zgłoszenie. Reguła odstępowania
(rezygnacji) może zależeć od długości kolejki lub czasu
oczekiwania w kolejce
Priorytet - niektóre zgłoszenia z kolejki mogą mieć prawo
pierwszeństwa obsługi przed zgłoszeniem o niższym
priorytecie
Priorytet rugujący. Zgłoszenie jednostki o wyższym
priorytecie powoduje przerwanie obsługi.
Priorytet nierugujący. Obsługa jednostki o niższej klasie
priorytetu jest kontynuowana
Podstawowe pojęcia
W zależności od tego, co dzieje się z wyrugowaną jednostką
są trzy rodzaje priorytetu absolutnego:
priorytet absolutny z doobsługiwaniem
priorytet absolutny z identyczną obsługą od nowa
priorytet absolutny z inną obsługą od nowa
Klasyfikacja systemów kolejkowych według różnych wielkości
określających system obsługi:
dyscyplina kolejki
typ rozkładu wejściowego strumienia zgłoszeń
typ rozkładu czasów obsługi
liczba kanałów obsługi
liczba faz obsługi itp.
Analiza systemów kolejkowych
Jeżeli w systemie obsługi:
strumień zgłoszeń wchodzących do systemu nie jest stacjonarny
nie ma własności jednorodności
organizacja obsługi jest wielofazowa rozwiązanie analityczne
zagadnienia praktycznie nie jest możliwe
Rozwiązanie w takim przypadku można otrzymać jedynie na
drodze symulacji
Wielokrotna realizacja procesu obsługi, a następnie
statystyczne opracowanie otrzymanych rezultatów pozwalają
znaleźć interesujące badającego wskaźniki jakości procesu
obsługi w systemie.

Analiza systemów kolejkowych
System dyskretny - złożone kompleksy operacji związanych ze
sterowaniem pojedynczych obiektów lub całych procesów np.
technologicznych, w których zachodzące zmiany mają
charakter nieciągły
Mogą to być procesy:
produkcyjne
kierowania złożonym systemem transportowym
zarządzania przedsiębiorstwem
Ze względu na przyjmowaną z założenia nieciągłość zmian,
operuje się często pojęciami zdarzeń, pod którymi jest
rozumiana zmiana stanu zachodząca w systemie
Analiza systemów kolejkowych
Wynikiem symulacji jest ciąg zdarzeń, które wystąpiły w
systemie. Dla uzyskania pełnego obrazu zachowania się
systemu w określonym przedziale czasu należy prowadzić
rejestrację czasu zdarzeń oraz obiektów, których te zdarzenia
dotyczą
Przy realizacji dyskretnych modeli symulacyjnych ważne jest
przedstawienie czasu. Czas jest tu pojęciem umownym, gdyż
nie ma on bezpośredniego związku z rzeczywistym czasem, w
którym odbywają się zdarzenia (stanowi jedynie jego
odwzorowanie), ani też z czasem wykonywania obliczeń przez
komputer (który zależy wyłącznie od złożoności obliczeń i
własności komputera)
Analiza systemów kolejkowych
W modelu symulacyjnym czas jest realizowany jako zmienna
nazywana czasem zegarowym. Na początku procesu symulacji
czas zegarowy jest nastawiany na wartość zero, potem
wskazuje liczbę umownych jednostek czasu, które upłynęły od
chwili początkowej. Wszystkie zdarzenia zachodzące w
systemie zostają usytuowane w czasie z dokładnością do
przyjętej jednostki czasu zegarowego.
Mając sformalizowany opis modelowanego systemu,
przygotowanie komputerowego programu symulacyjnego
można ogólnie podzielić na trzy zasadnicze etapy
Analiza systemów kolejkowych
Pierwszy etap: generowanie oraz inicjowanie modeli. Na
podstawie posiadanego opisu systemu należy określić zbiór
wielkości, które w modelu będą reprezentować jego stan.
Zbiór ten stanowi w modelu odwzorowanie systemu,
określając jego stany w kolejnych chwilach czasu
Etap drugi: zaprogramowanie procedury obejmującej cykl
operacji związanych z samym przebiegiem symulacji.
Procedura ta jest nazywana algorytmem symulacji, lub
procedurą upływu czasu, która zwykle jest realizowana w
sposób iteracyjny i składa się z następujących kroków:
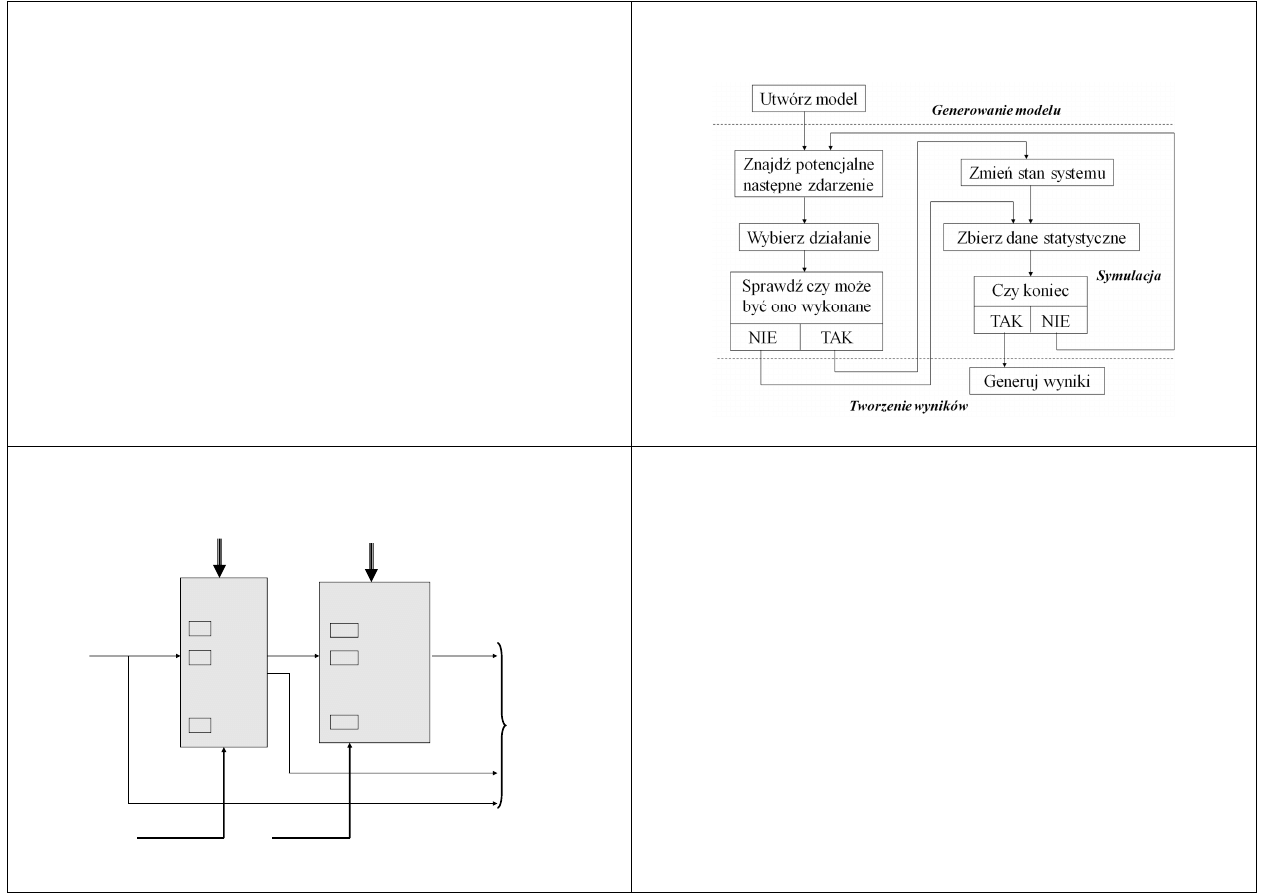
Analiza systemów kolejkowych
Kolejne kroki algorytmu symulacji:
wyszukiwanie potencjalnego następnego zdarzenia
wybór działania
sprawdzenie czy dane zdarzenie może być realizowane
zmiana stanu systemu wynikająca z zaistniałych zdarzeń
gromadzenie danych otrzymanych w wyniku symulacji (często są to
dane o charakterze statystycznym)
Etap trzeci: opracowanie formy wyprowadzania wyników
symulacji. Wyniki mogą być przedstawione w formie
tekstowej lub graficznej. Wyniki końcowe mogą być wstępnie
opracowane statystycznie
Zasady konstrukcji dyskretnych modeli symulacyjnych
Model symulacyjny jednofazowego systemu kolejkowego
Poczekalnia
.
.
.
1
2
N
Kanały obsługi
.
.
.
1
2
m
Strumień
wejściowy
Klienci
obsłużeni
Dyscyplina kolejki
Zbiór reguł
przydziału kanałów
Klienci opuszczający
poczekalnię
Klienci rezygnujący
z oczekiwania
Strumień
wyjściowy
Czas obsługi
Max czas
oczekiwania
Model przedstawia jednofazowy system kolejkowy
Dla otrzymania odpowiednich charakterystyk systemu po
każdej realizacji eksperymentu symulacyjnego są
wyprowadzane następujące dane dotyczące tej realizacji:
ogólna liczba zgłoszeń, które przybyły do systemu
liczba zgłoszeń obsłużonych
ogólna liczba odmów obsługi (zawierająca odmowy z
powodu przepełnienia miejsc w poczekalni, z powodu
zakończenia pracy systemu oraz z powodu ewentualnego
opuszczenia kolejki przez niecierpliwe zgłoszenie)
średnia długość kolejki, liczona jako średnia po czasie z
długości kolejki zgłoszeń
Model symulacyjny jednofazowego systemu kolejkowego
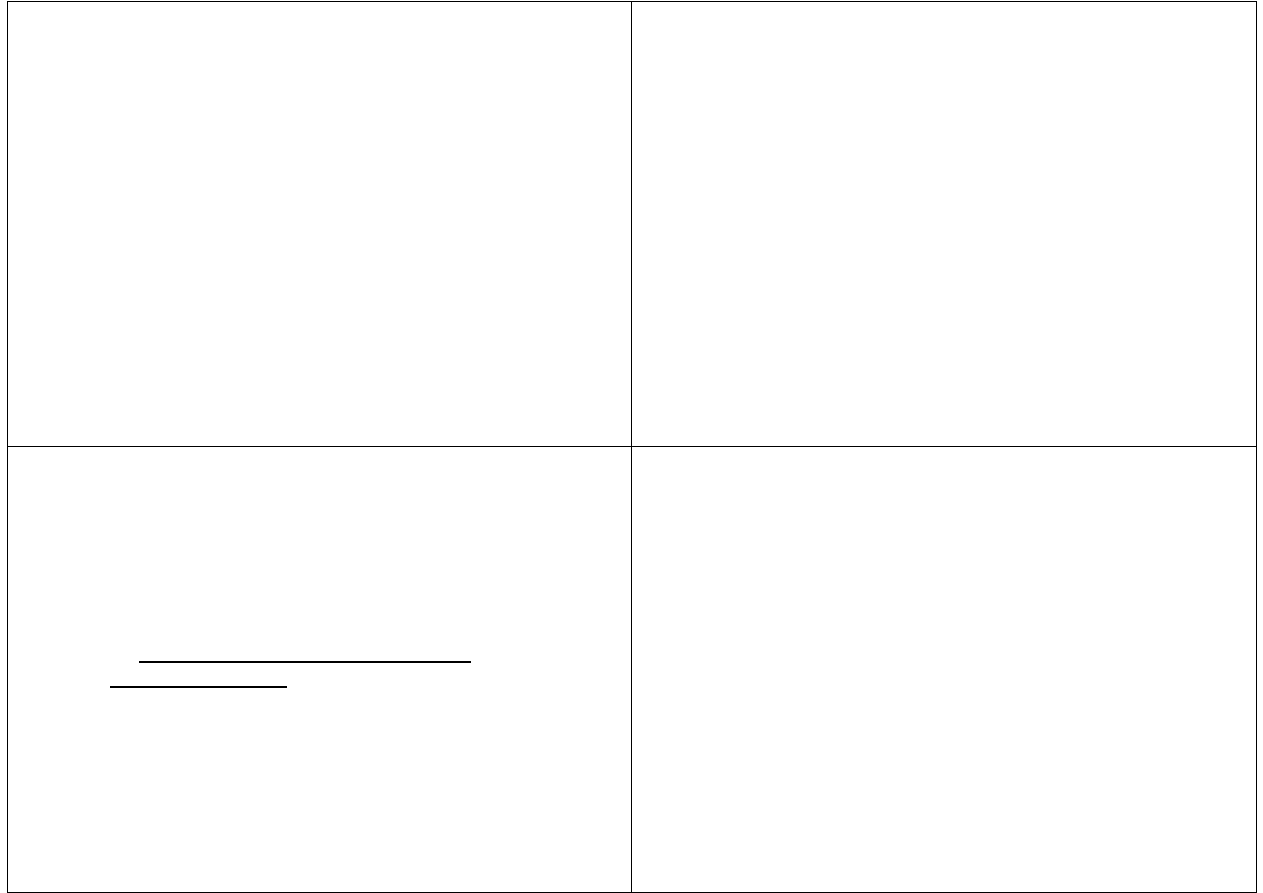
zajętość systemu, określająca przeciętną liczbę
jednocześnie używanych kanałów obsługi,
obciążenie dla każdego z kanałów obsługi, które podaje w
procentach zajętość kanału w rozważanym przedziale
czasu,
średni czas oczekiwania na obsługę liczony tylko dla
zgłoszeń obsłużonych
Wynikami końcowymi są analogiczne wielkości
liczone jako średnie po założonej ilości realizacji
eksperymentu symulacyjnego. Przedstawiony model
może być wykorzystany w fazie projektowania do
wyboru optymalnej struktury i organizacji systemu
kolejkowego lub do doskonalenia już istniejących
systemów
Model symulacyjny jednofazowego systemu kolejkowego
Podstawowe wiadomości
o algorytmach
Algorytm
Algorytmem nazywa się przepis
postępowania, którego wykonanie prowadzi
do rozwiązania określonego zadania w
skończonym czasie
Algorytm jest zbiorem pewnych reguł (zasad)
określających rodzaj czynności, które należy
wykonać
Algorytm
W algorytmie muszą być wyszczególnione
wszystkie niezbędne czynności, potrzebne do
rozwiązania postawionego zadania, oraz ściśle
sprecyzowana kolejność ich wykonania
Przepis postępowania powinien być na tyle
przejrzysty, aby posługiwanie się nim polegało
tylko na automatycznym wykonaniu czynności
Algorytm
Obiekty podlegające przekształcaniu
(przetworzeniu) podczas wykonywania
algorytmu nazywa się danymi
Ostateczne rezultaty wykonania algorytmu
nazywa się wynikami
ALGORYTM
DANE
WYNIKI
Algorytm
Realizacja algorytmu nie wymaga znajomości
problemu, który ten algorytm rozwiązuje
Sprowadza się do czysto mechanicznego
wykonania reguł
Zatem wykonawcą algorytmu nie musi być
człowiek
Algorytm musi być opisany w języku
zrozumiałym dla maszyny cyfrowej
Podstawowe własności algorytmu
Masowość: zastosowanie oznaczeń symbolicznych
umożliwia otrzymanie takiego opisu algorytmu,
dzięki któremu możemy go zrealizować dla
dowolnego zestawu danych
Ogólność: Opis algorytmu powinien zawierać obok
listy czynności również dziedzinę danych i postać
wyników (np. pierwiastki równania kwadratowego –
zespolone, rzeczywiste)
Podstawowe własności algorytmu
Skończoność wykonania: Wyniki powinno się
uzyskać po wykonaniu skończonej liczby
operacji
Jednoznaczność zapisu: poprawny zapis
algorytmu powinien gwarantować, że
każdorazowe jego wykonanie – dla tego
samego zestawu danych – daje te same wyniki
pośrednie i końcowe

Podstawowe własności algorytmu
Niezawodność: jest prawdopodobieństwem
tego, że algorytm będzie prawidłowo
realizował dane zadanie dla dowolnego
zestawu danych
Niezawodność jest związana z jego
poprawnością
Konwencje notacyjne algorytmów
Istnieją dwa zasadnicze kierunki formalizacji
algorytmów: algebraiczny i graficzny
Sieci działań algorytmów (flow charts)
Ich autorem jest słynny amerykański
matematyk John von Neumann, który
zaproponował formalizację algorytmów za
pomocą sieci działań
Konwencje notacyjne algorytmów
Sieci działań należą do klasy graficznego
sposobu zapisów algorytmów
Podstawą tej koncepcji jest podzielenie
procesu rozwiązywania zadania na odrębne
etapy, które w sieci działań przedstawia się w
postaci bloków
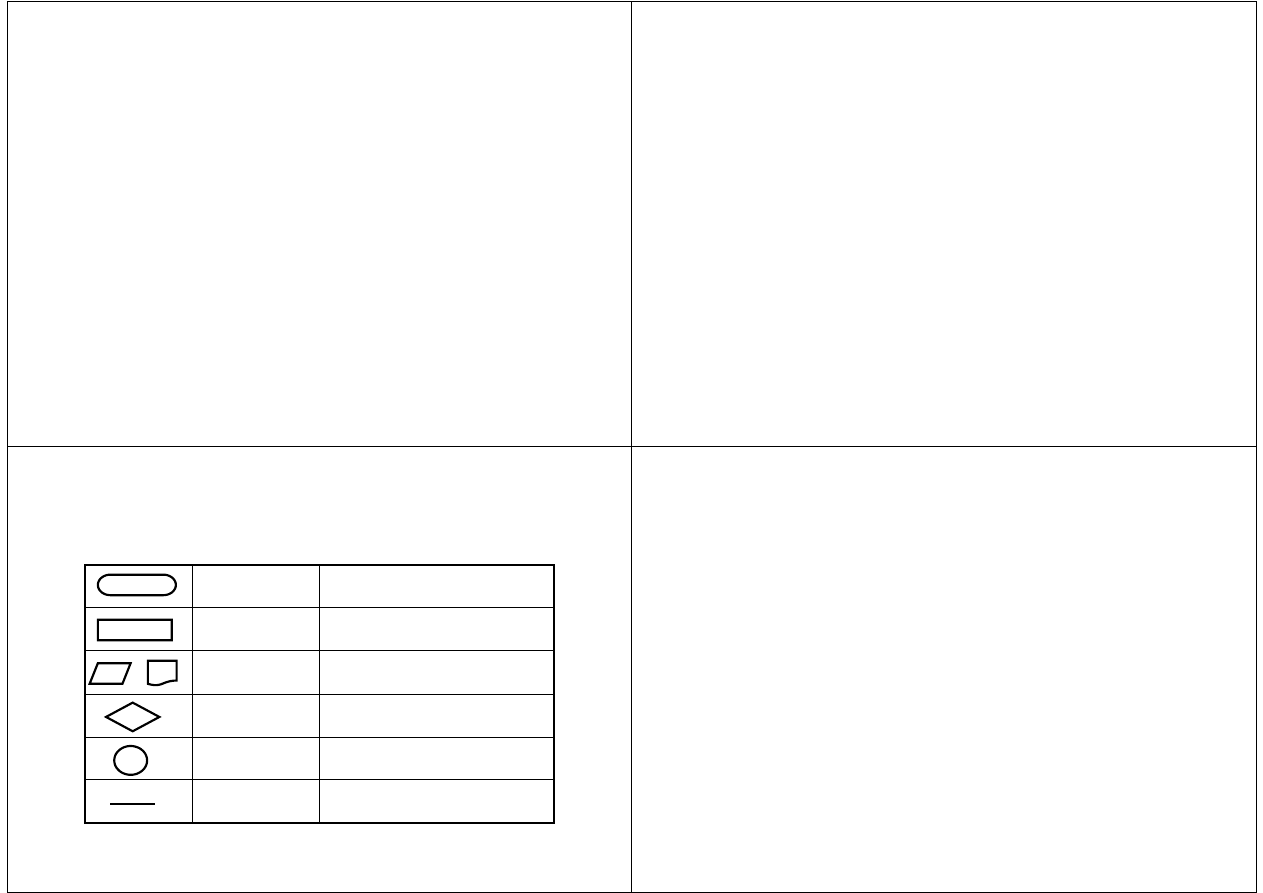
Konwencje notacyjne algorytmów
Bloki są figurami graficznymi, posiadającymi
pewną cechę znaczeniową
Wewnątrz nich wpisuje się rodzaj czynności,
która ma być wykonana
Bloki łączy się liniami, które ukazują ich
powiązania logiczne, a strzałki wskazują na
kolejność wykonywania poszczególnych
czynności algorytmu
Konwencje notacyjne algorytmów
Algorytm przedstawiony jako sieć działań jest
niezależny od języka, w jakim będzie napisany
program
Zaletą sieci działań jest to, że tak
przedstawiony algorytm jest bardziej
przejrzysty i czytelny niż program
Cecha ta staje się tym bardziej wyraźna, im
bardziej skomplikowany jest algorytm
Konwencje notacyjne algorytmów
Mając sieć działań, można sprawdzić poprawność
algorytmu oraz przeprowadzić korektę wynikającą z
jego logicznej niepoprawności
Każdy algorytm winien być przedstawiony w postaci
działań na takim poziomie szczegółowości, aby po
dokonaniu wyboru języka programowania
przekształcenia sieci działań w program było
odwzorowaniem w stosunku 1:1
Stosowane symbole graficzne
Początek,
koniec
Oznaczenie miejsca rozpoczęcia
lub zakończenia algorytmu
Operator
Działanie (operacja) do
wykonania
Operator
wejścia/wyjścia
Wprowadzanie danych do pamięci
lub wyprowadzanie wyników
Element
decyzyjny
Operacja określająca wybór
jednej z dróg działania
Łącznik
Symbol łączenia dwóch
fragmentów sieci działań
Linia
Połączenie poszczególnych
symboli sieci działań
Typowe struktury sieci działań
W sieciach działań można wyróżnić pewne typowe
struktury graficzne, do których należą:
sekwencja
rozwidlenie
decyzja
pętla z licznikiem (gdy wiadomo, ile będzie dokładnie
powtórzeń w pętli)
pętla z warunkiem (gdy ilość powtórzeń zależy od
spełnienia pewnych warunków)

Modelowanie procesów
obliczeniowych
Przykład algorytmu
Przykład algorytmu badającego czy liczba N
jest liczbą pierwszą
Liczba jest pierwsza, gdy dzieli się tylko przez 1
i przez siebie
Np. 3, 5, 7, 11, 13, 17 są liczbami pierwszymi
Na rysunku
przedstawiony jest
algorytm
sprawdzania, czy
liczba N (N>=3) jest
pierwsza.
Algorytm ten polega
na dzieleniu N przez
2, 3, 4, ..., N-1 aż do
osiągnięcia N lub
znalezienia
podzielnika
DECYZJA
ROZWIDLENIE
P
Ę
T
L
A
Z
W
A
R
U
N
K
IE
M
Analiza pozwala stwierdzić,
że nie trzeba sprawdzać
podzielności N przez
wszystkie liczby parzyste
mniejsze od N. Wystarczy
zbadać podzielność przez 2,
ponieważ liczba podzielna
przez dowolną liczbę
parzystą dzieli się przez dwa.
Teraz trzeba tylko zbadać
podzielność przez liczby
nieparzyste 3, 5, 7 itd.

Następny krok to stwierdzenie, iż
musimy badać jedynie podzielniki
nie większe niż pierwiastek z N.
Jeżeli liczba ma podzielnik większy
od pierwiastka z N, to ma też
podzielnik mniejszy od pierwiastka
z N.
Np. liczba 792 – pierwiastek 27;
dzieli się przez 81 ale również
przez 3 i 9
Algorytm polega na dzieleniu N
przez 2, a następnie przez liczby
nieparzyste nie większe niż
pierwiastek z N, aż do znalezienia
podzielnika lub do osiągnięcia
pierwiastka z N
Podsumowanie przykładu
Wszystkie trzy sposoby prowadzą do celu
Zbadajmy liczbę podzielników, które musimy
sprawdzić w każdym z trzech przypadków, dla trzech
różnych N
N
Algorytm
1
Algorytm
2
Algorytm
3
10
8
5
2
100
98
50
5
1000
998
500
50
Wyszukiwarka
Podobne podstrony:
Metody modelowania procesow 2012 cz III
Metody modelowania procesow 2012 cz II
Metody modelowania procesow 2012 cz I (1)
Metody modelowania procesow 2012 cz II
Proces Templariuszy Cz III
Polskie wytyczne profilaktyki i leczenia żylnej choroby zakrzepowo zatorowej aktualizacja 2012 (cz
03 01 2012 Kinezyterapia cz III
Modelowanie, Semestr III PK, Semestr Zimowy 2012-2013 (III), Sprawozdania odlewnictwo moje
Procesy poznawcze cz I Psychologia N 2012 2013
Procesy poznawcze cz I Psychologia N 2012 2013
Prawo cywilne Wykład XII 11 12 2012 Delikty cz III
modelowanie procesˇw transportowych
Cz III Ubezpieczenia osobowe i majątkowe
Dziady cz III
Procesy Poznawcze cz
dziady cz III salon
więcej podobnych podstron