Komunikacja człowiek-komputer – laboratoria blok I, wersja koocowa.
Format sprawozdania:
Sprawozdanie ma byd zrealizowane w zespole 2-osobowym, w szczególnym przypadku (nieparzysta
liczba osób w grupie) w zespole 3-osobowym.
Sprawozdanie ma 3 części (praca na kolejnych trzech zajęciach), opisane poniżej.
Analiza ma zostad przeprowadzona w środowisku Matlab. Pracę należy udokumentowad wykresami z
Matlaba.
Sprawozdanie należy zapisad do formatu PDF i wysład najpóźniej dnia poprzedzającego lab nr 5 na
adres
Format plików dźwiękowych:
Pliki mają mied format bezstratny wav oraz parametry: 16b, 44.1 kHz, MONO, czyli jeden kanał
(w przypadku nagraniu STEREO należy wykorzystad jeden, dowolny z kanałów).
Każda osoba w zespole nagrywa 2 frazy:
„Jestem studentem informatyki” oraz „Nazywam się <imię> <nazwisko>”.
Należy zwrócid uwagę na następujące problemy występujące w nagraniach głosu:
1. Dynamika sygnału (czy zakres amplitudy jest odpowiednio wykorzystany, czy nie występuje
2. Jaka jest amplituda szumu na początku i na koocu nagrania oraz czy jest on losowy czy
pseudookresowy.
Jeżeli występują problemy warto powtórzyd nagranie, zadbad o ciszę w pomieszczeniu, ewentualnie
zmieni d mikrofon. Poprawne nagranie dźwięku ułatwia też odpowiedni program, z darmowych
przykładowo
LAB 1
Automatyczne wykrywanie segmentów dźwięcznych i bezdźwięcznych:
1. Należy wczytad plik dźwiękowy za pomocą funkcji wavread zapisując wektor sygnału do
zmiennej sygnal oraz odczytad parametry nagrania.
2. Sygnał należy wyświetlid tak, aby na osi poziomej znajdowała się jednostka czasu [ms] (należy
pamiętad o znaczeniu parametru częstotliwośd próbkowania).
3. Po podzieleniu sygnału na ramki (okna) długości 10 ms obliczyd dla każdej ramki dwie
statystyki – funkcję energii E oraz funkcję przejśd przez zero Z:
gdzie:
s – wektor sygnału, j – numer ramki, n – długośd ramki w próbkach.
4. Uzyskane dwie funkcje (wektory) energii E oraz zer Z należy znormalizowad w całym zakresie,
aby dla fragmentu nagrania stanowiącego sygnał mowy mieściły się w zakresie 0:1.
5. Wykonad badania na nagranych plikach dźwiękowych w celu odpowiedzi na następujące
pytania:
a) Jaki wpływ na segmentowanie sygnału ma długośd okna?
b) Jakie elementy nagrania zostają rozdzielone przy bardzo długim, a jakie przy bardzo
krótkim oknie?
c) Jaka jest poprawnośd i precyzja automatycznego podziału na segmenty?
d) Jaka długośd okna wydaje się byd optymalna?
e) Jakie typy głosek można rozdzielid automatycznie na podstawie funkcji Z i E?
f) Czy istnieją sekwencje głosek nierozdzielnych?
g) Jaki wpływ na realizację zadania ma szum w nagraniach głosu?
h) Czy te same parametry analizy można zastosowad do badania nagrao obu osób w grupie?
Wnioski należy zilustrowad odpowiednimi wykresami z programu Matlab.
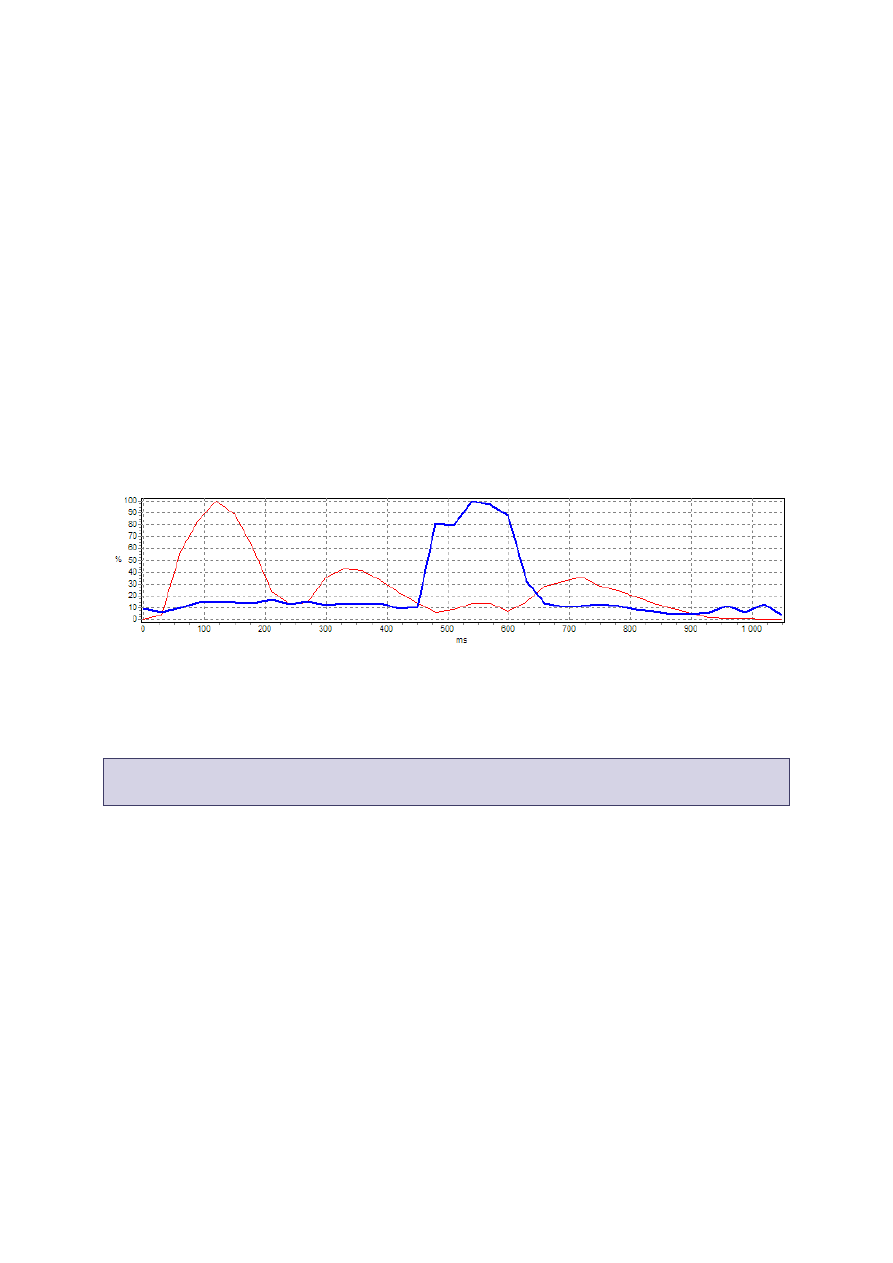
Przykład funkcji E(czerwona) i Z(niebieska) rozdzielających głoski (fonemy):
Dla chętnych: podzielid sygnał na nakładające się ramki np. w stopniu 50% i przeprowadzid powyższe
analizy. Jak wpływa nakładanie ramek na precyzję granic segmentów?
LAB 2
Analiza częstotliwościowa – widmo mowy dźwięcznej i bezdźwięcznej:
1. Za pomocą wcześniejszego skryptu należy zlokalizowad fragment nagrania stanowiący
samogłoskę ustną i skopiowad jej fragment długości 2048 próbek do zmiennej okno.
2. Obliczyd logarytmiczne widmo amplitudowe dla badanego okna (w to tzw. funkcja
okienkująca):
w=hamming(2048);
widmo=log(abs(fft(okno.*w) ) );
3. Wyświetlid widmo w taki sposób, aby na osi poziomej znajdowała się jednostka częstotliwości
*Hz+ w zakresie od 0 Hz do częstotliwości próbkowania 44100 Hz. Ze względu na symetrię
widma i na zakres istotny w analizie mowy wystarczy rozpatrywad i wyświetlad zakres 0-
10000Hz.
4. Odczytad F0, czyli częstotliwośd podstawową (częstotliwośd drgania strun głosowych) na
podstawie pierwszego dominującego maksimum w przebiegu widma (seria maksimów
występujących w równych odległościach to struktura harmoniczna, należy zatem odczytad
częstotliwośd pierwszej harmonicznej). Przykład poniżej:
P
A
R
A
S
L
<szum>
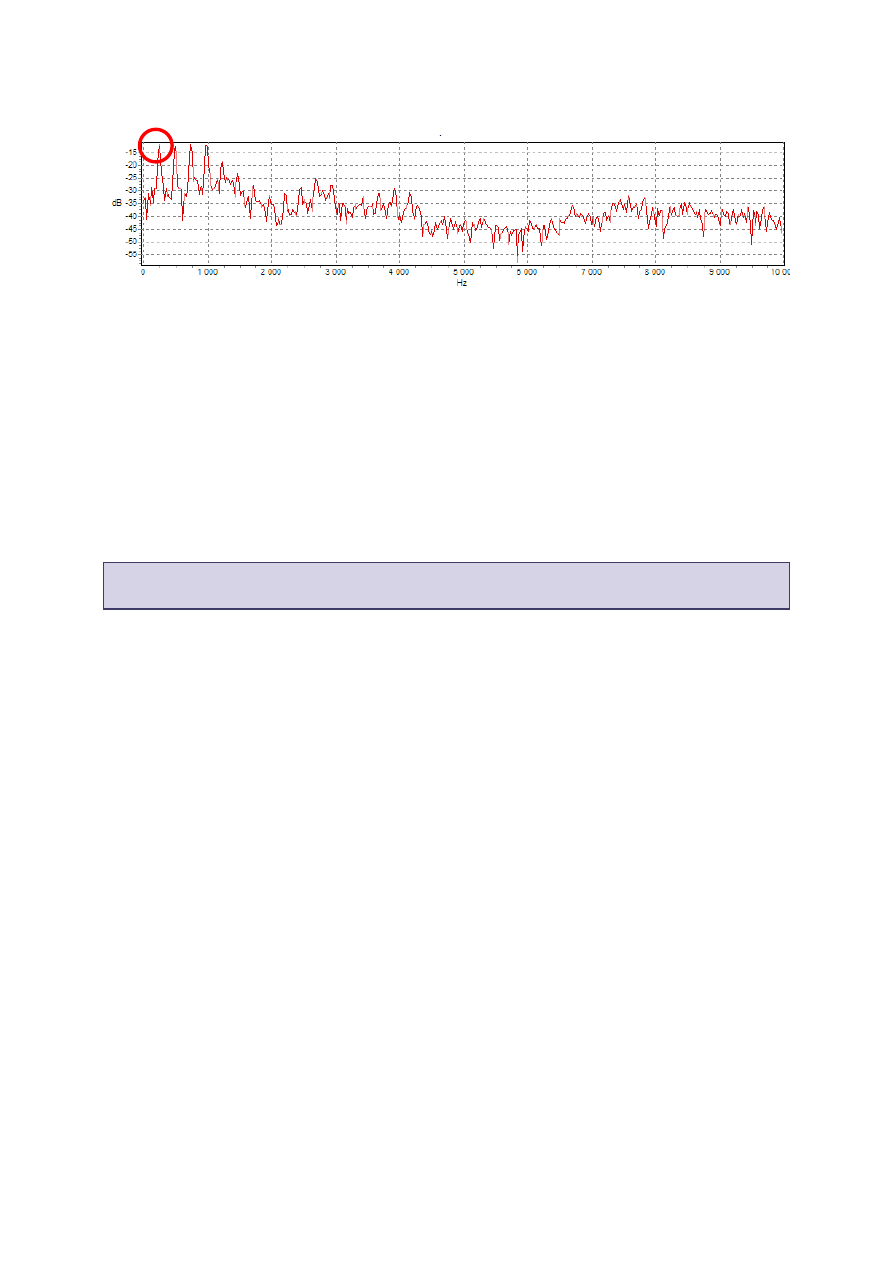
F0=250 Hz
5. Wykonad powyższe zalecenia dla kilku innych samogłosek i spółgłosek (w tym /s/). Aby
upewnid się, że poprawnie zidentyfikowano daną głoskę można zastosowad funkcję
wavplay(sygnal, fs).
6. Odpowiedzied na następujące pytania:
a) Które z badanych głosek posiadają strukturę harmoniczną i można odczytad z nich F0
(częstotliwośd drgania strun głosowych)?
b) Czym różni się wizualnie widmo głosek dźwięcznych od bezdźwięcznych?
c) Czy widma samogłosek różnią się między sobą? W jaki sposób?
d) Czy częstotliwośd F0 jest stała dla tego samego nagrania, ale różnych głosek?
e) Jaka jest średnia częstotliwośd F0 głosów osób w zespole?
Wnioski należy zilustrowad odpowiednimi wykresami z programu Matlab.
LAB 3
Automatyczne rozpoznawanie samogłosek ustnych /a, e, i, o u, y/:
1. Za pomocą wcześniejszego skryptu należy zlokalizowad fragment nagrania stanowiący
samogłoskę ustną i skopiowad jej fragment długości 2048 próbek do zmiennej okno.
2. Wyznaczyd dla tego fragmentu p=20 współczynników liniowego filtra (LPC Liniowe
Kodowanie Predykcyjne):
a=lpc(sygnal, p))
3. Uzupełnid otrzymany wektor a długości p zerami do długości okna sygnału (2048).
4. Wyznaczyd wygładzone widmo amplitudowe na bazie wektora a:
widmo_lpc=log(abs(fft(a)))
5. Odbid otrzymane wygładzone widmo w poziomie (pomnożyd przez -1), nałożyd
wykres na właściwe widmo amplitudowe fragmentu sygnału tak, aby oba znalazły się
na podobnej wysokości na osi y (prawdopodobnie będzie koniecznośd przeskalowania
lub/i przesunięcia). Należy zadbad o prawidłową oś częstotliwości [Hz]!
6. Otrzymane maksima są to FORMANTY, oznaczane kolejno F1, F2... Przeanalizowad
częstotliwości pierwszych dwóch formantów dla fragmentów samogłosek ustnych.
Przedstawid wyniki pomiarów F1 i F2 dla różnych samogłosek na wykresie (F1 w
poziomie, F2 w pionie).
7. Odpowiedzied na następujące pytania:
a)
Jak wpływa ilośd wybranych współczynników filtra p na proces rozpoznawania?
Przetestowad kilka możliwości.
b)
Jakie samogłoski udało się właściwie rozpoznad?
c)
Jak bardzo zbliżone są częstotliwości formantowe tych samych samogłosek
wypowiadanych przez osoby z zespołu?
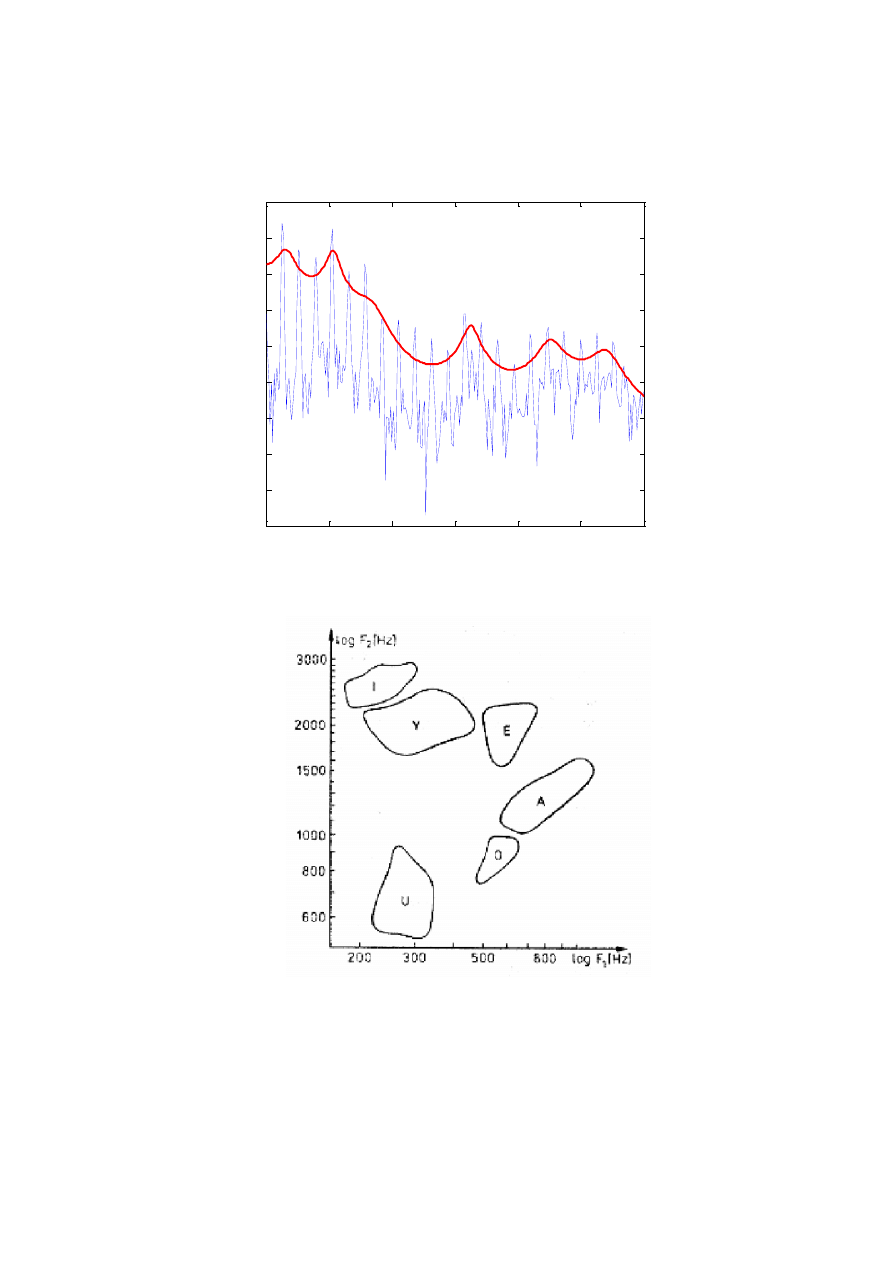
Przykład wygładzonego widma nałożonego na właściwe widmo amplitudowe (oznaczono
kolejne formanty):
Wzorcowa tablica do rozpoznawania polskich samogłosek:
W przypadku, gdy istnieje problem ekstrakcji niezakłóconych samogłosek z nagrania należy
dokonad kolejnego nagrania audio, tym razem zawierającego izolowane samogłoski:
/a,e,i,o,u,y/.
Dla chętnych – dowiedzied się i krótko opisad, co to jest i do czego służy Liniowe Kodowanie
Predykcyjne.
0
1000
2000
3000
4000
5000
6000
-1.5
-1
-0.5
0
0.5
1
1.5
2
2.5
3
F1 F2
F3
F4
F5
Wyszukiwarka
Podobne podstrony:
Seminarium-KCK, Inżynierskie, Semestr V, Komunikacja człowiek-komputer
Sprawozdanie(2), WAT, semestr VI, Komunikacja człowiek-komputer
ĆWICZENIE NR 2, WAT, semestr VI, Komunikacja człowiek-komputer
komunikacja człowiek komputer
Hubert Masiak KCK laborki 1 20, WAT, semestr VI, Komunikacja człowiek-komputer
sprawozdanie1(1), WAT, semestr VI, Komunikacja człowiek-komputer
Rzeczywistość wirtualna, Inżynieria Oprogramowania - Informatyka, Semestr V, Komunikacja Człowiek Ko
sprawdzian z acada5, studia Polibuda Informatyka, III semestr, grafika i komunikacja człowiek - kom
SprKwiatkowskiKCK2, WAT, semestr VI, Komunikacja człowiek-komputer
sprawdzian z acada7, studia Polibuda Informatyka, III semestr, grafika i komunikacja człowiek - kom
Streszczenie z wykładów, Semestr 5, Grafika komunikacja człowiek - komputer
sprawdzian z acada4, studia Polibuda Informatyka, III semestr, grafika i komunikacja człowiek - kom
Seminarium-KCK, Inżynierskie, Semestr V, Komunikacja człowiek-komputer
jarnicki,grafika komputerowa i komunikacja człowiek komputer P, Generowanie modelu góry z wykorzysta
więcej podobnych podstron