
Techniki
PHP Solutions Nr 5/2005
www.phpsolmag.org
60
J
ęzyk PHP5 przyniósł wiele zmian,
które odróżniają go od wcześniej-
szych wersji. W większości wypad-
ków nowa funkcjonalność czy zwiększo-
na wydajność nie wpłynęły na kompatybil-
ność wstecz. Najistotniejsze wyjątki psują-
ce zgodność z poprzednimi wydaniami do-
tyczą funkcji związanych z programowa-
niem zorientowanym obiektowo (OO, ang.
object-oriented) – tutaj twórcy PHP wywo-
łali prawdziwą rewolucję w języku. W tym
artykule pokażemy, że nowe, obiektowe
możliwości PHP5 są na tyle istotną zmia-
ną w języku, iż każdy powinien je przyjąć
oraz że nie warto rozpoczynać projektów
w PHP4.
Powyższa teza ma dwa argumenty
na swoje poparcie: pierwszy jest taki, że
nowe możliwości pozwolą programistom
PHP na zgodne ze standardami techniki
programowania i projektowania aplikacji.
Podejście obiektowe ma znaczną przewa-
gę nad proceduralnym – pokażemy te za-
lety na przykładzie.
Masz dość żmudnego i podatnego na błędy
programowania proceduralnego w PHP? PHP5
posiada świetny model OOP oraz silnik, o jakim
programiści PHP4 mogą tylko marzyć i który
sprawia, że użytkownicy Javy płoną z zazdrości.
Drugim argumentem jest to, że do PHP
dodano potężną (i, biorąc pod uwagę np.
metody magiczne, nieortodoksyjną) funkcjo-
nalność OO, dzięki której język ten wyraź-
nie różni się od innych. W kolejnym artykule
przyjrzymy się tym specjalnym możliwościom
i pokażemy, na jak wiele one pozwalają.
Dlaczego obiekty?
Powszechnym zarzutem przeciwko
obiektom, wysuwanym przez programi-
stów, którzy ich nie stosują jest to, że
gdy patrzą na kod OO, mówią: Mógłbym
zrobić to samo bez obiektów. Z technicz-
Po co nam PHP5?
Erik Zoltán
W SIECI
1. http://php.net – ofi cjalna
strona PHP
2. http://www.eventhelix.com/
RealtimeMantra/Object_
Oriented/ – Object Oriented
Design and Principles, witry-
na poświęcona OOP
3. http://www.objectfaq.com/
oofaq2/ – Object Orien-
ted FAQ
4. http://www.agilemodeling
.com/artifacts/
sequenceDiagram.htm – wy-
jaśnienie diagramów se-
kwencyjnych
Co powinieneś
wiedzieć...
Pownieneś znać programowanie proce-
duralne (PP) w PHP.
Co obiecujemy...
Po przeczytaniu artykułu będziesz wie-
dział jak modelować zorientowane obiek-
towo aplikacje w PHP5.
60_61_62_63_64_65_66_67____php5_zoltan.indd 60
2005-09-12, 10:52:03
Techniki
PHP5
PHP Solutions Nr 5/2005
www.phpsolmag.org
61
nego punktu widzenia mają rację – osta-
tecznie programy OO można zreduko-
wać do zestawu kroków wykonywanych
przez komputer, więc takie same rezul-
taty da się uzyskać metodą procedural-
ną. Oczywiście w praktyce nie jest to aż
takie proste.
Programy składają się z dwóch ele-
mentów: kodu i danych. Tradycyjne pro-
gramowanie proceduralne koncentru-
je się przede wszystkim na kodzie, pod-
czas gdy struktura danych w naturalny
sposób wynika z funkcjonalności. Pro-
gramowanie obiektowe skupia się nato-
miast głównie na strukturze danych, zaś
określone oddziaływania funkcjonalne w
naturalny sposób wynikają ze struktury
obiektów.
Spójrzmy na przykład ilustrujący różni-
cę między podejścierm obiektowym a tra-
dycyjnym. Wyobraźmy sobie dobrze zna-
ną aplikację, na przykład generator parse-
rów czytający instrukcje w jednym forma-
cie i generujący dane wyjściowe w innym.
Charakterystyczna dla PHP dobra obsłu-
ga łańcuchów i tablic sprawia, że język ten
jest doskonałym wyborem przy tworzeniu
tego typu aplikacji.
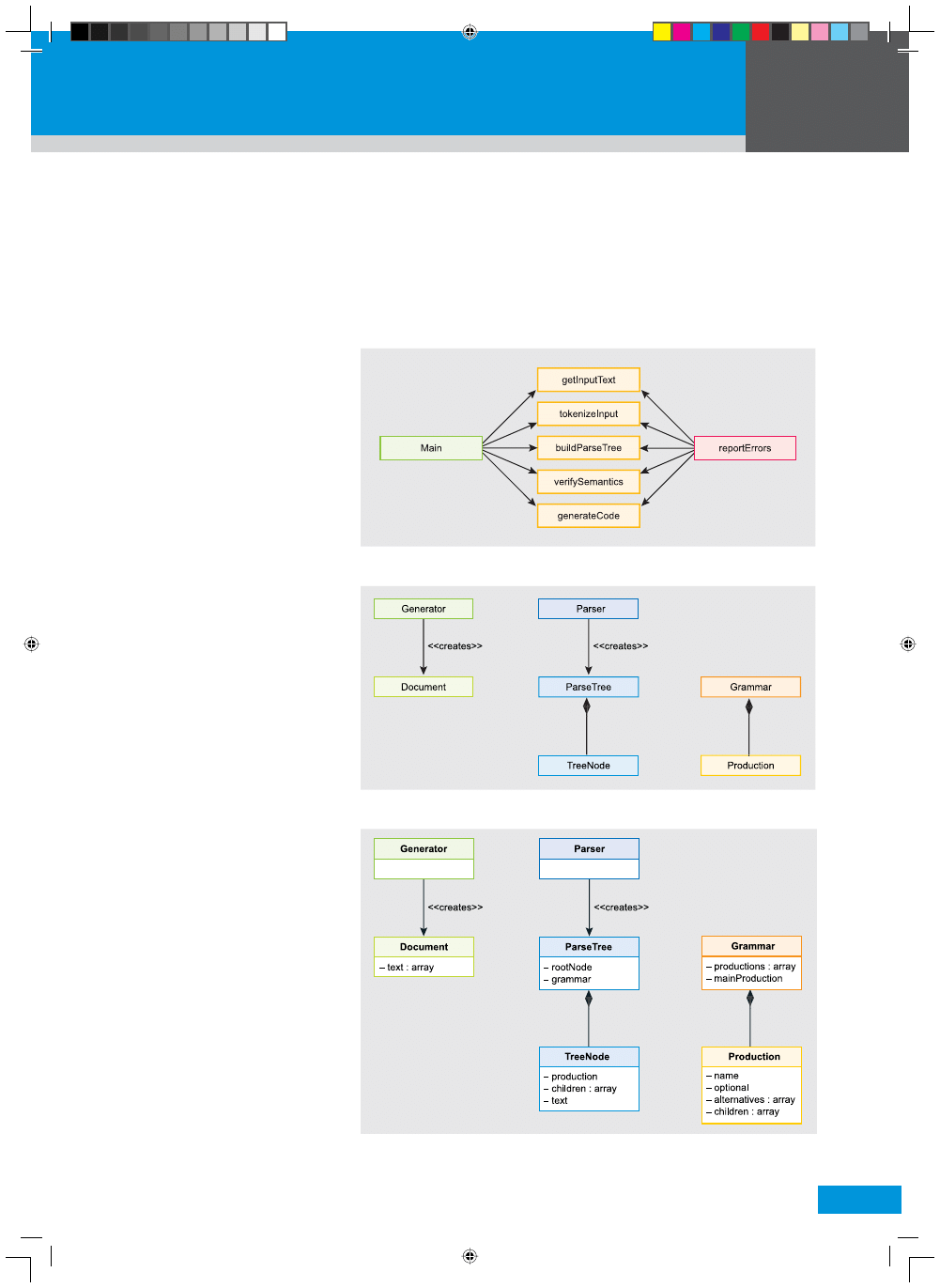
Projekt proceduralny
Przy korzystaniu z pionowego (ang
top-down) projektowania proceduralne-
go można zacząć od procedury głów-
nej, a następnie rozbić ją na podproce-
dury. Może to wyglądać tak, jak na Ry-
sunku 1.
Strzałki na tym schemacie przedsta-
wiają przepływ kontroli. Zauważmy, że
myślimy tu w kategoriach czasowników
(lub raczej zdań). Program główny wywo-
łuje każdą z podfunkcji, na którą wskazu-
je, a z kolei każda z tych podfunkcji może
wywołać funkcję
reportErrors
. Pamiętaj-
my, że aplikacja tłumaczy dane wejściowe
w języku źródłowym na dane wyjściowe
w docelowym. W przypadku tego sche-
matu można sobie wyobrazić, że funk-
cja
getInputText
wczyta zawartość pliku,
zaś
tokenizeInput
podzieli ją na kawał-
ki (tokeny), aby parsowanie było łatwiej-
sze. Z kolei funkcja
buildParseTree
zor-
ganizuje program wejściowy w drzewia-
stą strukturę zgodnie z regułami języka
źródłowego, natomiast
verifySemantics
sprawdzi drzewo, by upewnić się, czy nie
pojawią się określone błędy oraz dokona
odpowiednich transformacji. Wreszcie,
Rysunek 1.
Pionowy projekt proceduralny parsera
Rysunek 2.
Najwyższego poziomu obiektowy projekt parsera
Rysunek 3.
Dodawanie właściwości do obiektów
generateCode
użyje informacji z drzewa
parsowania, by wygenerować program
wyjściowy w języku docelowym. Takie po-
dejście wygląda klarownie i z pewnością
jest łatwe w zaprojektowaniu oraz imple-
mentacji. Może natomiast być niezbyt wy-
godne przy jakichkolwiek zmianach, czym
zajmiemy się później.
Projekt OO
najwyższego poziomu
Przyjrzyjmy się projektowi obiektowemu
najwyższego poziomu (ang top-level) dla
aplikacji tego samego typu co poprzednio
(Rysunek 2).
W projektowaniu OO najwyższe-
go poziomu nie zajmujemy się tym, jak
60_61_62_63_64_65_66_67____php5_zoltan.indd 61
2005-09-12, 10:52:11
PHP5
Techniki
PHP Solutions Nr 5/2005
www.phpsolmag.org
62
Rysunek 4.
Diagram parsowania
Rysunek 5.
Diagram sekwencyjny procesu generowania kodu wyjściowego
60_61_62_63_64_65_66_67____php5_zoltan.indd 62
2005-09-12, 10:52:18
Techniki
PHP5
PHP Solutions Nr 5/2005
www.phpsolmag.org
63
działa aplikacja. Zamiast o czasowni-
kach, myślimy o rzeczownikach. Każ-
dy z prostokątów na tym schemacie re-
prezentuje pojedynczą klasę (typ obiek-
tu).
Document
przedstawia informacje za-
warte w pliku wejściowym lub wyjścio-
wym. Klasa
Grammar
reprezentuje skład-
nię i semantykę docelowego języka,
zaś
Production
pojedynczy element ję-
zyka. Zwróćmy uwagę na romb łączą-
cy klasy
Grammar
i
Production
– świad-
czy on o tym, że
Grammar
może zawie-
rać wiele klas
Production
. Z kolei kla-
sa
ParseTree
zawiera te same informa-
cje, co
Document
, ale jest zorganizowa-
na w hierarchiczną strukturę zdefi niowa-
ną przez
Grammar
. Klasa
TreeNode
jest tą
częścią drzewa parsowania, która repre-
zentuje pojedynczy element języka (czyli
pojedynczą klasę
Production
zawartą w
Grammar
). Natomiast
Parser
odpowiada
za dane wejściowe, co sprowadza się
do przekształcania dokumentu wejścio-
wego w drzewo parsowania. Z kolei kla-
sa
Generator
ma za zadanie przekształ-
cić drzewo parsowania w dokument wyj-
ściowy.
Dodawanie właściwości
Gdy już mamy projekt najwyższego po-
ziomu, przyjrzyjmy się dokładniej da-
nym. Określimy wewnętrzne zmienne,
których będzie potrzebował każdy obiekt
– zarówno informacje zawarte w obiek-
tach, jak i te, które łączą ze sobą obiekty
(można je porównać do kleju). Rysunek
Rysunek 6.
Klasy zawierające pola i metody
3 przedstawia zmodyfi kowany schemat,
pokazujący zmienne wewnętrzne (pola)
każdego z obiektów.
Omówmy pokrótce zmienne, które do-
daliśmy do każdej klasy.
• Dokument musi zawierać jakiś tekst
– zdecydowaliśmy się stworzyć tabli-
cę reprezentującą fragmenty doku-
mentu (tokeny). Możemy podzielić do-
kument na tokeny w dowolny, dosto-
sowany do parsowanego języka spo-
sób.
• Drzewo parsowania musi znać głów-
ny węzeł (ang. root node) drzewa i
skojarzoną z nim klasę
Gram mar
.
• Każdy węzeł drzewa musi być po-
łączony z klasą
Production
w doce-
lowym języku i może zawierać tekst
zawarty w pojedynczym tokenie.
Może też mieć potomków będących
dodatkowymi węzłami drzewa.
•
Grammar
może posiadać macierz
wszystkich swoich elementów ty-
pu
Production
, ale musi znać głów-
ny element
Production
lub element ję-
zyka dla docelowego pliku. Aby klasa
Grammar
reprezentowała PHP, możemy
jej nadać nazwę, na przykład program.
• Każda klasa
Production
ma indy-
widualną nazwę. Reprezentowa-
ny przez nią element języka mo-
że być opcjonalny lub wymaga-
ny. Może istnieć kilka alternatyw-
nych defi nicji, z których każda bę-
dzie klasą
Production
. ( przykład: w
PHP istnieje kilka różnych zasadni-
czych funkcji, więc klasa
Production
o nazwie function może wymie-
niać je wszystkie jako alternatyw-
ne). Wreszcie, element języka może
zwierać pewną liczbę komponentów
potomnych, które muszą być obec-
ne w stałym porządku (przykład:
przypisanie zmiennej wymaga jej
nazwy, znaku równości i wyrażenia
reprezentującego wartość przecho-
wywaną w zmiennej).
Przedstawiliśmy tylko ogólny szkic: do-
dawanie do projektów nowych atrybu-
tów w czasie projektowania i późniejsze-
go kodowania jest powszechne. Typowe
jest także wstawianie do projektu nowych
klas, w miarę jak określamy atrybuty każ-
dej z nich.
Diagramy sekwencji
Następna faza projektu obiektowego jest
taka sama, jak pierwsza faza przy pro-
jektowaniu proceduralnym. Aby stwo-
rzyć aplikację, musimy stworzyć meto-
dy (lub funkcje) dla każdej klasy i spraw-
dzić, jak łączą się one i współpracują ze
sobą. Diagram sekwencji lub diagram in-
terakcji to dobry sposób, gdyż pokazu-
je, jak obiekty wywołują się wzajemnie
w czasie typowej interakcji. W przypad-
ku generatora parserów typową interak-
cją może być parsowanie i generowa-
nie kodu. Spójrzmy na schematy tych
dwóch sytuacji.
60_61_62_63_64_65_66_67____php5_zoltan.indd 63
2005-09-12, 10:52:23
PHP5
Techniki
PHP Solutions Nr 5/2005
www.phpsolmag.org
64
Weźmy najpierw schemat parsowa-
nia (Rysunek 4). Na tym diagramie apli-
kacja przeprowadza proces parsowa-
nia dokumentu wejściowego. Jego ce-
lem jest stworzenie drzewa parsowa-
nia, które będzie reprezentować instruk-
cje zawarte w dokumencie wejściowym.
Każda strzałka reprezentuje wywoła-
nie funkcji lub pewnego rodzaju opera-
cję wewnętrzną. Najpierw
Application
nakazuje klasie
Document
, by załado-
wała (
Load
) plik wejściowy i jako argu-
ment podaje jego nazwę. Następnie
Application
nakazuje parserowi (
Par-
ser
), by przetworzył (
Parse
) dokument
wejściowy (argumentem jest obiekt kla-
sy
Document
).
Parser
zapytuje
Grammar
w celu okre-
ślenia głównego obiektu
Production
(w
przypadku języka PHP zapewne nazywał-
by się on program). Następnie otwiera w
pętlę, w której powtarza następujące ope-
racje aż do końca pliku:
1.
GetToken
: pobiera natępny token z do-
kumentu.
2.
TokenDivider
: klasa
Document
py-
ta
Gram mar
, czy każdy znak jest se-
paratorem tokenów. W PHP sepa-
ratorami byłyby znaki przestankowe
(takie jak nawiasy, przecinki czy cu-
dzysłowy), a litery, cyfry i spacje już
nie.
3.
IsValid
: sprawdza poprawność toke-
na względem aktualnej
Production
.
4.
AddNode
: dodaje nowy węzeł do drze-
wa parsowania. Drzewo to jest two-
rzone wewnętrznie przez
AddNode
.
Po zakończeniu tych działań możemy się
spodziewać, że drzewo parsowania zosta-
ło poprawnie stworzone. Spójrzmy więc
na diagram sekwencyjny procesu tworze-
nia kodu wyjściowego w języku docelo-
wym (Rysunek 5).
Po zakończeniu parsowania doku-
mentu wejściowego, aplikacja powinna
wygenerować dokument wyjściowy w ję-
zyku docelowym. W tym celu
Application
wywołuje klasę
Generator
. Ten obiekt po
prostu pobiera główny węzeł z
ParseTree
i nakazuje mu, aby wygenerował (
Genera-
te
) się sam.
Podczas generowania samego siebie,
węzeł drzewa parsowania prosi powią-
zaną z nim klasę
Production
o wykona-
nie wszystkich przekształceń wyjściowych
na nim i jego potomkach (przykładowo,
Production
mogłaby przetłumaczyć słowo
kluczowe lub operator na język docelowy
lub posortować węzły potomne w nowym
porządku; jest to rodzaj operacji seman-
tycznej, którą w projekcie proceduralnym
wykonałaby funkcja
verifySemantics
). Je-
śli drzewo parsowania ma potomków, to
zaczyna pętlę, w której wywołuje ich re-
kursywnie z żądaniem, aby sami się wy-
generowali. Jeśli węzeł drzewa parsowa-
nia zawiera token tekstu wejściowego, do-
daje go do dokumentu wyjściowego. Nie-
które węzły drzewa będą miały potomków
i nie będą zawierać tekstu, inne odwrot-
nie – będą zawierać tekst bez potomków.
Jeszcze inne będą miały jedno i drugie.
Dodawanie metod
do diagramów klas
Opierając się na tych diagramach sekwen-
cyjnych, możemy powrócić do stworzone-
go już projektu bazującego na klasach i
dodać metody potrzebne w tych sekwen-
cjach (zwykle używa się łatwo dostępnych
na rynku narzędzi, które robią to automa-
tycznie).
Patrząc na diagramy klas i diagramy
sekwencyjne, zauważymy pewne luki w
projekcie – możemy potrzebować bardziej
szczegółowych schematów, aby dokład-
niej prześledzić część procesu. Dokład-
ność w fazie projektu zwykle się opłaca,
bo to najlepszy sposób na jak najwcze-
śniejsze zidentyfi
kowanie i poprawienie
błędów.
W tym miejscu możemy przystąpić
do właściwego kodowania. Jeśli mamy
zespół programistów, każdy z nich mo-
że zająć się daną klasą lub grupą klas.
Czasem część klas współpracuje ze so-
bą tak ściśle, że programiści i tak muszą
Rysunek 7.
Diagram sekwencyjny planu testowania klasy Document za pomocą naszej
procedury testującej
60_61_62_63_64_65_66_67____php5_zoltan.indd 64
2005-09-12, 10:52:28

Techniki
PHP5
PHP Solutions Nr 5/2005
www.phpsolmag.org
65
działać wspólnie. W tym projekcie sku-
pimy się głównie na klasach
TreeNode
i
Production
, które są ze sobą bardzo bli-
sko związane. W innych przypadkach
klasy są bardziej odizolowane (na przy-
kład
Document
) i można je tworzyć nieza-
leżnie.
Programowanie
sterowane testami
Ważną zaletą OO jest to, że każdy
obiekt jest jednostką, którą można od-
dzielnie testować. Podejście oparte
na testach, zwane również TDP (ang.
test-driven programming) lub TDD (ang.
test-driven development) zakłada rygo-
rystyczne testowanie każdego kompo-
nentu zanim zostanie on włączony do
gotowej aplikacji. W ten sposób pro-
ces testów właściwie steruje tworzeniem
programu, skąd pochodzi nazwa tej me-
tody. Opisujemy ją szczegółowo w arty-
kule Testowanie modułów z użyciem fra-
meworka SimpleTest.
Opierając się na naszym przykładzie
wyobraźmy sobie, że stworzyliśmy pełną
implementację klasy
Document
(Listing
1). Zwróćmy uwagę na tekstową wesję
diagramu klasy umieszczoną w kodzie
przed deklaracją klasy. Jest to pomoc-
ne, bo pozwala zobaczyć interfejs ze-
wnętrzny bez konieczności przewijania
całego listingu. Warto też modyfi kować
ten diagram zgodnie ze zmianami w kla-
sie – ułatwia to porównanie kodu źródło-
wego do projektu w celu sprawdzenia,
czy zgadzają się ze sobą.
Dla zilustrowania procedury testowa-
nia, w powyższym kodzie umieszczono
celowo dwa błędy – w celu ułatwienia ich
odnalezienia zostały one oznaczone. Od-
kryjemy i naprawimy je później.
Istotną rzeczą w tej implementacji jest
fakt, że zawartość klasy jest oparta na
założeniach zupełnie innych, niż te uży-
te w intefejsie zewnętrznym. Użytkownik
tej klasy poczyniłby zapewne następują-
ce założenia:
• Kiedy wywoływana jest metoda
Load
,
obiekt
Document
odczyta całą zawar-
tosć pliku.
• Za każdym wywołaniem metody
GetToken
obiekt
Document
przeskanu-
je jeden token w przód i zwróci war-
tość następnego.
Takie zachowanie obiektu
Document
nie by-
łoby jednak zbyt wydajnie, gdyż musiałby
Listing 1.
Klasa Document
<?
php
/*
+--------------------------+
| Document |
+--------------------------+
|-fi leName |
|-text: array |
+--------------------------+
|+Load($fi leName) |
|+GetToken($grammar, $pos) |
|+AddToken($token) |
|+Write($fi leName) |
+--------------------------+
*/
class
Document
{
private
$text
=
array
()
;
private
$loaded
= false;
function
Load
(
$fi leName
){
$this
-
>
fi leName =
$fi leName
;
}
function
GetToken
(
$grammar
,
$pos
){
if
(
!
$this
-
>
loaded
){
$handle
=
fopen
(
$this
-
>
fi leName,
"r"
)
;
$accum
=
""
;
while
((
$c
=
fgetc
(
$handle
))
!== false
){
if
(
$grammar
-
>
TokenDivider
(
$c
)){
if
(
$accum
!=
""
){
$this
-
>
text
[]
=
$accum
;
$accum
=
""
;
}
$this
-
>
text
[]
=
$c
;
}
else
$accum
.=
$c
;
}
fclose
(
$handle
)
;
//if ($accum != "")
//$this->text[] = $accum;
$this
-
>
loaded = true;
}
if
(
count
(
$this
-
>
text
)
>
$pos
)
return
$this
-
>
text
[
$pos
]
;
return
null;
}
function
AddToken
(
$token
){
$this
-
>
text
[]
=
$token
;
}
function
Write
(
$fi leName
){
$this
-
>
fi leName =
$fi leName
;
$handle
=
fopen
(
$fi leName
,
"w"
)
;
$tokens
=
count
(
$this
-
>
text
)
;
for
(
$i
=1;
$i
<
$tokens; $i++
)
fwrite
(
$handle, $this-
>
text
[
$i
])
;
fclose
(
$handle
)
;
}
}
?>
60_61_62_63_64_65_66_67____php5_zoltan.indd 65
2005-09-12, 10:52:34
PHP5
Techniki
PHP Solutions Nr 5/2005
www.phpsolmag.org
66
on przechowywać całą zawartość pliku w
pamięci. Pociągałoby ono za sobą rów-
nież wielokrotne wewnętrzne kopiowanie
długich łańcuchów. Zamiast tego użyliśmy
więc następującej implementacji:
• Kiedy wywoływana jest metoda
Load
,
obiekt
Document
zapamiętuje nazwę
określonego pliku i nie robi nic więcej.
• Za pierwszym wywołaniem
GetToken
obiekt
Document
czyta całą zawartość
pliku i dzieli go na fragmenty, umiesz-
czając je w wewnętrznej tablicy, zgod-
nie z tokenami zdefi niowanymi przez
Grammar
.
• W kolejnych wywołaniach
GetToken
obiekt
Document
po prostu wyszukuje
odpowiedni numer tokena i zwraca go
wywołującemu obiektowi.
Stanowi to odejście od oryginalnego dia-
gramu sekwencyjnego. Nie jest to pro-
blemem, ponieważ taka implementacja
jest bardziej wydajna i wciąż zgodna z
duchem projektu opartego na klasach.
W rzeczywistości nasz projektant mógł-
by zechcieć cofnąć się i zmodyfi kować
diagram sekwencyjny, podczas gdy pro-
gramiści kontynuowaliby pracę.
Aby tak się stało, musimy mieć
przynajmniej częściowo sprawną klasę
Grammar
. Na raie zadowolimy się protezą,
która po prostu dostarczy listę tokenów
klasie wywołującej (Listing 2).
Obiekt wywołujący, który tworzy no-
wą instancję klasy
Grammar
, przekazuje po
prostu tablicę zawierającą tokeny
Grammar
.
Używa jej wewnętrznie aby określić, czy da-
ny znak jest tokenem w języku. Możemy się
spodziewać dodania do tej klasy pozostałej
funkcjonalności później.
Zautomatyzowana
procedura testująca
Aby to przetestować, musimy stworzyć
procedurę, która każe wykonać klasie
Document
jej wszystkie kroki i porówna
spodziewane rezultaty do rzeczywistych.
Taka procedura musi być powtarzal-
na, tzn. ma się zachowywać poprawnie
podczas setek wywołań w trakcie proce-
su debugowania. W dodatku procedura
testująca musi być w przyszłości utrzy-
mywana równolegle z klasą
Document
– jeśli zmodyfi kujemy lub rozubuduje-
my
Document
, będziemy musieli uaktu-
alnić procedurę testującą i upewnić się,
że wykonuje ona stare testy. Nie chce-
my przecież dodawać nowej funkcjonal-
ności, która zepsuje stary kod. Naszym
zamiarem jest również wprowadzanie
nowych testów dla nowo dodawanych
możliwości klasy.
Na Rysunku 7 przedstawiamy prosty
diagram sekwencyjny pokazujący, w jaki
sposób planujemy testować obiekt
Document
korzystając z naszej procedury.
Musimy stworzyć dwa oddzielne obiek-
ty
Document
– jeden do testowania wejścia,
a drugi do sprawdzania wyjścia. Procedu-
ra testująca po prostu stworzy dokument
wejściowy i pobierze wszystkie jego toke-
ny, porównując je z oczekiwaniami i rapor-
tując każde odstępstwo. Następnie stworzy
dokument wyjściowy, doda do niego toke-
ny i zapisze jego zwartość do pliku. Rezulta-
tem tej operacji również będzie porównanie
do oczekiwań i zgłoszenie wszystkich różnic
jako błędów.
Trzeba pamiętać, że podczas automa-
tycznego testowania jedna połowa otrzy-
manych błędów będzie dotyczyć testowa-
nego kodu, a druga samej procedury testu-
jącej. Czy warto włożyć dodatkowy wysi-
łek w pisanie, utrzymywanie i debugowanie
nadprogramowego kodu? Tak, gdyż efek-
tem będzie zwiększona niezawodność klas,
które próbujemy zintegrować do stworzenia
większej aplikacji. Każdy, kto miał kiedykol-
wiek problemy z nieprawidłowym zachowa-
niem dużego programu i nie mógł określić
przyczyn błędów, z pewnością od razu do-
ceni takie podejście. Listing 3 przedstawia
kod testujący, który spełnia powyższe wy-
magania.
Pętla testująco-debugująca
Chociaż zaimplementowaliśmy w pełni tylko
jedną klasę (i częściowo drugą), jesteśmy
gotowi do rozpoczęcia testowania i debugo-
wania. W rezultacie będziemy mogli zidenty-
fi kować problemy, które mogłyby prowadzić
do poprawek w kodzie czy zmian projek-
tu. Jak najwcześniejsze rozpoznanie takich
zmian jest bardzo pomocne. Uruchomienie
naszego kodu testowego daje w efekcie ra-
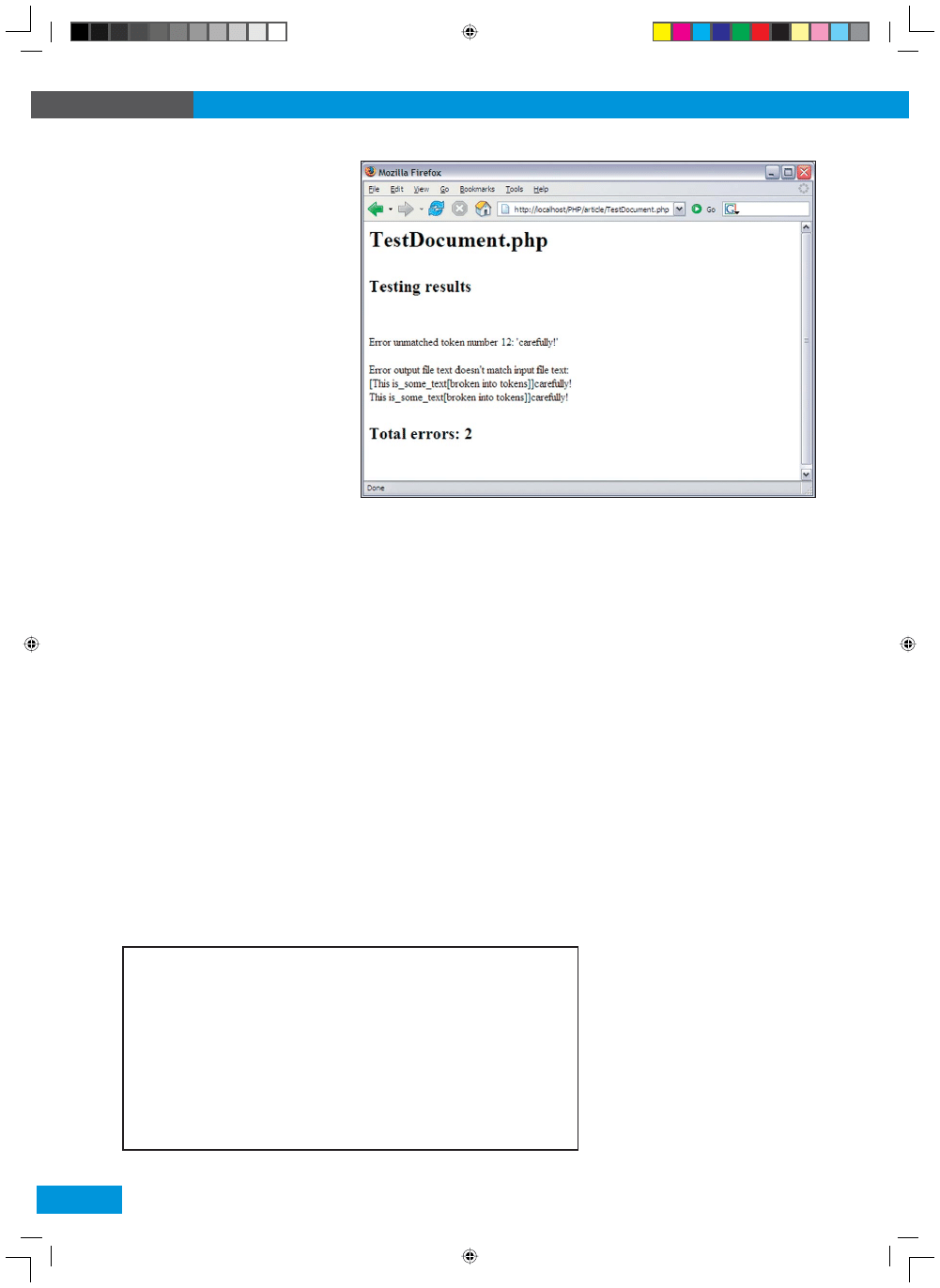
port o błędach przedstawiony na Rysunku 8.
Listing 2.
Protezowa implementacja klasy Grammar
<?
php
class
Grammar
public
$Tokens
;
function
__construct
(
$tokenArr
){
$this
-
>
Tokens =
$tokenArr
;
}
function
TokenDivider
(
$token
){
return
array_key_exists
(
$token
,
$this
-
>
Tokens
)
;
}
}
?>
Rysunek 8.
Raport o błędach
60_61_62_63_64_65_66_67____php5_zoltan.indd 66
2005-09-12, 12:37:09

Techniki
PHP5
PHP Solutions Nr 5/2005
www.phpsolmag.org
67
W naszym kodzie są dwa błędy. Po
pierwsze, gubimy część tekstu przetwa-
rzanego przez naszą pętlę tokenizują-
cą. W celu wyeliminowania tego proble-
mu musimy wstawić dodatkowe wyraże-
nie uniemożliwiające pominięcie tekstu,
przed którym nie ma żadnego tokena
(tak jak tekst
ostroznie!
w naszym pli-
ku testującym). Po drugie, zmienna in-
deksu pętli zaczyna się od 1 zamiast od
0. To sprawia, że gubimy pierwsze
[
to-
kena na wyjściu.
Aby naprawić te błędy, wprowadzi-
my w kodzie klasy
Document
następujące
zmiany w zaznaczonych wcześniej miej-
scach.
Po pierwsze, te linie pownny być od-
komentowane w następujący sposób:
if ($accum != "")
$this->text[] = $accum;
W tych liniach
1
wewnątrz polecenia
for
zostało zastąpione przez
0
:
for ($i=0; $i<$tokens; $i++)
fwrite($handle, $this->text[$i]);
Te poprawki zlikwidują błędy w kodzie.
Podsumowanie
Nie musimy pokazywać całej implemen-
tacji przykładowej aplikacji, jest nam ona
bowiem potrzebna wyłącznie jako ilustra-
cja wdrożenia spełniającego standar-
dy przemysłowe projektowania, tworze-
nia i testowania oprogramowania zorien-
towanego obiektowo w PHP5. Proces
ten różni się od podejścia stosowane-
go w PHP w przeszłości. Mamy nadzie-
ję, że posłużyło to za przekonujący argu-
ment za szybkim zaadoptowaniem PHP5
przez fi rmy i organizacje korzystające z
PHP lub rozważające jego stosowanie.
Listing 3.
Kod testujący
<
html
>
<
body
>
<
h1
>
TestDocument.php
<
/h1
>
<
h2
>
Wyniki testów
<
/h1
>
<?
php
// Funkcja autoload dynamiczie zaimportuje wszystkie potrzebne do testowania
// klasy
require_once
"autoload.phpf"
;
$errors
= 0;
// Tworzymy plik do testowania wejścia
$testFileName
=
"testDocument.txt"
;
$testText
=
"[To jest_jakis_tekst[rozbity na tokeny]]ostroznie!"
;
$handle
=
fopen
(
$testFileName
,
'w'
)
;
fwrite
(
$handle
,
$testText
)
;
fclose
(
$handle
)
;
// Stwórz obiekt Grammar i zdefi niuj tokeny, które należy użyć.
$tokens
=
array
()
;
$tokenChars
=
array
(
" "
=
>
true,
"["
=
>
true,
"]"
=
>
true
)
;
$grammar
=
new
Grammar
(
$tokenChars
)
;
// To są tokeny spodziwane w oparciu o Grammar
$expectedTokens
=
array
(
"["
,
"To"
,
" "
,
"jest_jakis_tekst"
,
"["
,
"rozbity "
,
"
"
,
"na"
,
" "
,
"tokeny"
,
"]"
,
"]"
,
"ostroznie!"
)
;
// Stwórz nowy obiekt wejściowy Document
$doc
=
new
Document
()
;
$doc
-
>
Load
(
$testFileName
)
;
// Get the tokens from the input document (based on our grammar)
for
(
$position
=0;
$position
<
100; $position++){
$thisToken = $doc-
>
GetToken
(
$grammar
,
$position
)
;
if
(
$thisToken
== null
)
break
;
$tokens
[]
=
$thisToken
;
}
// Porównaj prawdziwe tokeny ze spodziewanymi
for
(
$i
=0;
$i
<
count($expectedTokens); $i++){
if ($i
>
=
count
(
$tokens
)){
$errors
++;
echo
"<br>Błąd: niepasująca liczba tokenów $i: '$expectedTokens[$i]'"
;
break
;
}
if
(
$tokens
[
$i
]
!=
$expectedTokens
[
$i
]){
$errors
++;
echo
"<br>Błąd: niepasująca liczba tokenów $i: spodziewana
'$expectedTokens[$i]'ale otrzymano '$tokens[$i]'."
;
}
}
// Teraz stwórz dokument wyjściowy i wyeksportuj jego zwartość do zewnętrznego
// pliku
$outDoc
=
new
Document
()
;
for
(
$i
=0;
$i
<
count
(
$expectedTokens); $i++
)
$outDoc-
>
AddToken
(
$expectedTokens
[
$i
])
;
$outDoc
-
>
Write
(
$testFileName
)
;
$outputResult
= fi le_get_contents
(
$testFileName
)
;
// Porównaj tekst pliku wyjściowego do spodziewanego tekstu wyjściowego
if
(
$testText
!=
$outputResult
){
$errors
++;
echo
"<p>Błąd: tekst pliku wyjściowego nie pasuje do tekstu wejściowego
pliku:<br>$testText<br>$outputResult</p>"
;
}
// Na koniec zaraportuj liczbę błędów użytkownikowi
echo
"<h2>W sumie błędów: $errors</h2>"
;
?>
<
/body
>
<
/html
>
Erik Zoltán wykorzystuje PHP od 2000 r.
i używa go do tworzenia stron WWW
oraz do backendowych (szkieletowych)
systemów tłumaczenia i authoringu.
Posiada 15 lad doświadczenia
w programowaniu obiektowym,
tworzył narzędzia projektowe i języki
OO. Prowadził wykłady dla setek
profesjonalnych programistów. Mieszka
w Massachusetts, USA, gdzie obecnie
pracuje jako wolny strzelec.
Kontakt z autorem: erik@zoltan.org
O autorze
60_61_62_63_64_65_66_67____php5_zoltan.indd 67
2005-09-12, 10:52:47
Wyszukiwarka
Podobne podstrony:
Po co nam socjologia
9 3 Po co nam sen,?za REM imarzenia senne
Jablecki Po co nam rynek miedzybankowy
Po co nam reakcja stresowa
Po co nam uklad krazenia, Dietetyka, Anatomia i fizjologia człowieka, Fizjologia wykłady
Po co nam układ krążenia
Po co nam suwerenność (rp.pl), ciekawe teksty
Po co nam wybory w szkole
Po co nam to było
trzustka, Po co nam trzustka, Po co nam trzustka
Stres – po co nam reakcja stresowa,
Po co nam socjologia
po co nam psychologia
Leszek Kolakowski po co nam pojecie sprawiedl spol
PO CO NAM TO BYŁO
Po co nam węgiel scenariusz
więcej podobnych podstron