Podstawowe pojęcia, wykrywanie błędów
Współczynnik informacji = log|k|*(1/n)
Odległość Hamminga - d(a,b)=
.
Minimalna odległość Hamminga = d => kod wykrywa d-1
błędów i koryguje
.
Minimalna waga d (dla pewnego a
0
: d = d(a
0
,0)) = minimalna
odległość d(a,b).
Kod Hamminga: n=2
m
-1, k=2
m
-m-1, d=3.
Kod cykliczny (n,k) (n = stopień g(x) musi być dzielnikiem x
n
-1,
Wielomian parzystości h(x) =
.
Kompresja bezstratna
Miara informacji - i(A)= .
Entropia (średnia informacja) H=
.
Kod jednoznacznie dekodowalny, spełnia: L >= H, L – średnia
długość kodu (podstawowe twierdzenie Shannona).
Test na jednoznaczną dekodowalność:
1. lista słów kodowych,
2. sprawdzać pary aż znajdzie się prefiks, wtedy sufiks dodać do
listy,
3. gdy słowo (sufiks) już jest na liście – kod niejednoznaczny,
4. osiągnięcie końca listy - kod jednoznaczny.
Nierówność Krafta-McMillana
.
Kody Shannon-Fano: długość kodu l
i
=
, średnia długość
≤ H+1.
Konstrukcja kodu Shannon-Hano:
- niech l
1
≤ l
2
≤ … ≤ l
N
,
- definiujemy pomocnicze w
1
, w
2
, …, w
N
jako w
1
=0,
,
- binarna reprezentacja w
j
dla j > 1 zajmuje
bitów,
- liczba bitów w
j
jest mniejsza lub równa l
j
, dla w
1
to oczywiste,
-
Kodowanie:
Kody Huffmana: wszystkie mają taką samą średnią długość dla
danego ciągu, kodowanie w czasie liniowym, optymalne kody
prefiksowe, możliwość implementacji dynamicznej.
Kody Tunstalla: znak z największym prawdopodobieństwem np.
‘a’ zastepujemy aa,ab,ac
Średnia długość =
, e
i
– słowo kodowe
odpowiadające i-temu kodowi.
Kodowanie arytmetyczne: elementom przyporządkujemy
przedział [F(i),F(i+1)), F(i) =
.
Kodowanie:
- d <- p-l, p <- l+F(j+1)d, l <- l+F(j)d,
znacznik – liczba z przedziału [l,p) np.
.
Skalowanie:
1. jeśli [l,p) ⊆ [0;0,5):
- [l,p) -> [2l,2p),
- dołącz do kodu 01
licznik
,
- wyzeruj licznik,
2. jeśli [l,p) ⊆ [05;1):
- [l,p) -> [2l-1,2p-1),
- dołącz do kodu 10
licznik
,
- wyzeruj licznik,
3. jeśli l<0.5<p oraz [l,p) ⊆ [0,25;0,75):
- [l,p) <- [2l-0,5;2p-0,5),
- licznik <- licznik+1.
Możliwe usprawnienia: przejście na arytmetykę liczb
całkowitych: [0,1) -> [0,2
m
-1).
Kodowanie słownikowe: słowniki statyczne – tekst kodujemy
jako całe słowa ze słownika, słowa których nie ma można
umieszczać jako 1-literowe słowa, wrażliwe na zmianę char.
danych.
kodowanie LZ77:
Wysylamy(w lewo, copy, nowy znak)
kodowanie LZ78:
(nr slowa, nowy znak)
LZW: słownik zawiera na starcie wszystkie poj. Liter
(nr slowa) parujemy nowe slowa
PPM (Prediction by Partial Matching):
1. dla bieżącej pozycji znajdź aktualny kontekst maks rzędu,
2. jeśli znak występował już w tym kontekście to zakoduj go z
prawdopodobieństwem wyznaczonym na podstawie statystyk tego
kontekstu,
3. w.p.p. zakoduj <esc> z prawdopodobieństwem wyznaczonym
na podstawie statystyk oraz:
- zakoduj kodowany symbol w kontekście o 1 krótszym (rząd
kontekstu > -1),
- zakończ kodowanie symbolu (rząd = -1),
4. zaktualizuj statystyki wystąpień symboli.
rząd -1 wprowadzony, aby każdy symbol dało się zakodować
(rozkład równy dla każdej litery).
dla kontekstów można utworzyć dynamicznie kod Huffmana lub
kod arytmetyczny.
Zazwyczaj maksymalna dł. kontekstu to 5.
CALIC (Context Adaptive Lossless Image Compression):
d
h
=|W-WW|+|N-NW|+|NE-N|
d
v
=|W-NW|+|N-NN|+|NE-NNE|
Pseudokod:
1. jeżeli d
h
-d
v
> 80, to X’ <- N,
2. w.p.p., jeżeli d
v
-d
h
> 80, to X’ <- W,
3. w.p.p.:
- X’ <-
- jeżeli d
h
-d
v
> 32, to X’ <-
,
- w.p.p., jeżeli d
v
-d
h
> 32, to X’ <-
,
- w.p.p., jeżeli d
h
-d
v
> 8, to X’ <-
,
- w.p.p., jeżeli d
v
-d
h
> 8, to X’ <-
.
Kodujemy ciąg różnic X-X’.
JPEG-LS: 7 schematów predykcji: X’=W, X’=N, X’=NW, X’=N+W-
NW, X’=
, X’=
, X’=
.
Nowy standard:
1. jeżeli NW≥max(W,N), to X’<-max(N,W),
2. w.p.p. jeżeli NW≤max(W,N), to X’<-min(N,W),
3. w.p.p. X’<-W+N-NW.
Poziomy rozdzielczości:
1. kodujemy najpierw średni kolor kw. 2
k
x2
k
, a nast. różnicę
między tą średnią a kw. 2
k-1
x2
k-1
,
2. kończymy na pikselach (2
0
x2
0
),
3. różnice nie są duże i łatwo się kompresują.
Obrazy czarno-białe (faksy): linie obrazów zaw. na przemian
bloki białe i czarne, można więc przesyłać tylko ich długości
Kompresja stratna
Kryteria oceny zniekształceń:
- czynnik ludzki,
- kwadratowa miara błędu: d(x,y)=
,
- bezwzględna miara błędu: d(x,y)=
.
- błąd średniokwadratowy (mean squared error - mse):
,
- SNR =
, SNR (dB) = 10 log
10
SNR.
Miary kwantyzacji:
- średniokwadratowy błąd kwantyzacji: kwantyzacja Q(x)=y
b
i-1
<x≤b
i
,
wówczas
,
- średnia bitowa kwantyzatora: średnia liczba bitów do
zapisania
jednej
wynikowej
kwantyzatora.
Poziom reprezentacji: inaczej wartość, jaką przypisujemy
wszystkim kwantyzowanym liczbom w danym przedziale.
Poziom decyzyjny: kraniec przedziału kwantyzatora, poziomów
tych jest o 1 mniej niż poziomów decyzyjnych.
Kwantyzacja adaptacyjna w przód: zakładamy, że wartość
średnia wejścia jest równa 0, na podst. bloku N kolejnych próbek
(w chwili t) szacujemy wariancję źródła:
,
przesyłamy (skwantowaną) informację o wariancji do dekodera.
Kwantyzacja adaptacyjna wstecz (kwantyzator Jayanta):
do zmiany wykorzystujemy wcześniejsze dane (w postaci
skwantyzowanej), każdy przedział ma przypisany mnożnik M
k
,
mnożniki przedziałów wew. < 1, a zewnętrznych > 1, jeżeli w
kroku n-1 próbka wpadła do przedziału l(n-a) to parametr Δ dla
następnego kroku:
, jeśli wejście jest dobrze
dopasowane to iloczyn kolejnych wsp. = 0.
Kwantyzacja
z
kompanderem:
przed
kwantyzacją
przekształcamy dane za pomocą jakiejś funkcji(kompander), po
rekonstrukcji przekształcamy za pomocą funkcji odwrotnej.
Kwantyzacja wektorowa: zamiast pojedynczych elementów
kwantyzujemy całe bloki,
Średniokwadratowy błąd kwantyzacji: Q(X) = Yi ∀Y
i
∈ C
||X − Y
j
|| ≤ ||X − Y
i
||, C – słownik kwantyzatora,
(zniekształcenie liczymy po próbkach),
Poziom kompresji: słownik zawiera K elementów, wektor
wejścia ma wymiar L:
- zakodowanie numeru wektora - bitów,
- wektor zaw. rekonstruowane wartości z L próbek,
- liczba bitów na próbkę:
.
Algorytm Linndego-Buza-Graya:
1. wybierz dowolny zbiór rekonstruowalnych wartości
,
ustal k=0, D
(-1)
=0, wybierz próg ε,
2. znajdź
obszary
kwantyzacji
∀
,
3. oblicz
zniekształcenie
,
4. jeśli
zakończ obliczenia,
5. przyjmij k<-k+1, za nowe
przyjmij środki ciężkości
, wróć do korku 2.
Inicjalizacja LBG – metoda podziałów:
- rozpoczynamy z jednym punktem (rozmiar słownika 1),
będącym średnią z całego zbioru uczącego,
- dodajemy pewien ustalony wektor perturbacji e do każdego
punktu słownika i wykonujemy LBG,
- kontynuujemy aż do uzyskania zakładanej liczby poziomów
(jeżeli nie jest potęgą 2, to w ostatnim kroku nie wszystkie
podwajamy).
Kwantyzatory o strukturze drzewiastej:
- dzielimy przestrzeń na dwie części i uzyskujemy dla nich
wektory reprezentacji,
- powtarzamy aż uzyskamy pewne drzewo binarne o wysokości k,
- jeśli zmniejszy to zniekształcenie przycinamy niektóre
poddrzewa,
- optymalne zwykle tylko dla kw. symetrycznych.
Kratowa kwantyzacja wektorowa:
Krata – {a
1
, a
2
, …, a
L
} – L niezależnych wektorów o L wymiarach,
jest kratą jeśli wszystkie u
i
są liczbami
całkowitymi.
Inne kwantyzacje wektorowe: piramidalne, sferyczne i
biegunowe, skala-kształt, z usuniętą średnią, klasyfikowane,
wieloetapowe, adaptacyjne.
Kodowanie różnicowe: obliczamy kwantyzacje nie elementów
ale ich kolejnych różnic:
1. mamy ciąg {x
n
}, ciąg różnic {d
n
} generujemy biorąc d
n
=x
n
-x
n-1
,
kwantyzujemy d’
n
=Q[d
n
]=d
n
+q
n
otrzymując {d’
n
} (q
n
- błąd
kwantyzacji),
2. u odbiorcy odtwarzamy {x’
n
}: x’
n
=x’
n
+d’
n
,
3. stąd:
,
błąd akumuluje się z czasem – zapobieganie:
używamy d
n
=x
n
-x’
n-1
, wtedy x’
n
=x
n
+q
n
.
Predykcja DPCM (Diffirential Pulse Code Modulation): zamiast
różnicy między kolejnymi elementami mamy funkcję predykcyjną
generującą {p
n
}, p
n
=f(x’
n-1
, …, x’
0
), kodujemy x
n
-p
n
, szukamy
takiego f aby
jak najmniejsze.
Zakładamy, że
(N -rząd predyktora).
Zamiast x’
n
używamy x
n
(zał. błędy kw. małe).
Szukamy {a
i
}, aby
jak najmniejsze. W
tym celu:
1. obliczamy wartości oczekiwane N równań postaci:
, otrzymując układ
, gdzie R
xx
(k)=E[x
n
x
n+k
] funkcja autokorelacji zmiennej x
n
.
2. jeśli znamy wartości autokorelacji możemy obliczyć wartości a
i
.
Odmiany DPCM:
- adaptacyjne DPCM (w przód i w tył),
- modulacja delta: dwustopniowy kwantyzator i odp. częstość
próbkowania (2 razy większa niż największa częstotliwość).
Zastosowanie: kodowanie mowy, obrazów.
Kodowanie transformujące: przekształca informację tak, aby
można było zrezygnować z części elementów:
1. podziel sygnał na bloki,
2. oblicz przekształcenie każdego bloku,
3. skwantuj współczynniki,
4. skompresuj skwantowane współ. bezstratnie.
Odkodowanie odwrotnie.
Przekształcenia liniowe:
1. ciąg
{x
0
,…,x
N-1
}
przekształcamy
na
{θ
0
,…,θ
N-1
}:
,
2. oryginalny ciąg odtwarzamy:
,
3. można poszerzyć przekształcenia jednowymiarowe (dźwięk) na
dwuwymiarowe (obrazy),
4. wszystkie przekształcenia są ortonormalne.
Dyskretne przekształcenia kosinusowe (DCT):
macierz przekształcenia NxN:
,
- łatwiejsza do policzenia i lepiej się sprawdza niż transformata
Fouriera (DFT),
- używana do obrazów i dźwięków.
Dyskretne przekształcenie sinusowe:
macierz przekształcenia NxN:
,
- lepsze niż kosinusowe gdy współczynnik korelacji
jest
mały,
- uzupełnia przekształcenie kosinusowe.
Dyskretne przekształcenie Walsha-Hadamarda:
macierz przekształcenia NxN:
, dla potęg dwójki:
, macierz przekształcenia uzyskujemy przez
normalizację i ustawienie kolumn w porządku ilości zmian znaków
(+ na – i odwrotnie).
- proste do uzyskania i implementacji,
- minimalizuje ilość obliczeń.
Kodowanie podpasmowe: rozłożenie informacji na części
(pasma) i kodowanie ich oddzielnie:
1. wybierz zbiór filtrów do rozkładu źródła {x
n
},
2. używając filtrów oblicz sygnały podpasm {y
k,n
},
3. zdziesiątkuj wyjście filtra,
4. zakoduj zdziesiątkowane wyjście.
Odkodowanie jest odwrotnością kodowania.
Filtry rzeczywiste mają nieostre granice przejścia (odcięcia).
Reguła
Nyquista:
jeśli
sygnały
mają
składowe
o
częstotliwościach pomiędzy f
1
a f
2
to, aby odtworzyć dokładnie
sygnał, musimy próbkować z częstością co najmniej 2(f
2
-f
1
)
próbek na sekundę.
Filtrowanie cyfrowe: suma ważona bieżącego i poprzednich
wejść filtra i ew. także wyjść filtra:
,
wartości {a
i
} i {b
j
} nazywamy współczynnikami filtra.
Reakcja impulsowa: niezerowy ciąg współczynników na wyjściu
filtra (zazwyczaj dla ciągu wejściowego: 1, 0, 0, …).
Filtry dzielimy na te o skończonej i nieskończonej reakcji.
Filtry często łączy się kaskady (str. drzewiaste), dobierane są do
sygnału, pasma mogą się nakładać lub nie, redukcja próbek na
wyjściu odpowiada redukcji rozmiaru częstotliwości.
Zastosowania:
- kodowanie mowy G.722: tryby 64, 56 i 48 kbps, filtr 7kHz
jako ochrona przed aliasingiem przy próbkowaniu 16000/s, każda
próbka kodowana przy pomocy 14 bitowego jednolitego
kwantyzatora i przepuszczana przez bank 24-rzędowych filtrów
FIR, ich wynik jest redukowany o współczynnik 2 i kodowany
ADPCM (6 bitów na próbkę z możliwością odrzucenia 1 lub 2
niższe pasmo i 2 bity wyższe),
- kodowanie dźwięku MPEG: schematy kodowania Layer 1, 2,
3, każdy kolejny bardziej skomplikowany i dający lepszą
kompresję, kodery zgodne w górę, Layer 1 i 2 używają banku 32
filtrów (32 podpasma o szerokości f
s
/64, f
s
– cz. próbkowania
równa 32k, 44,1k lub 48k), wyjście kwantyzowane przy użyciu
równomiernego kwantyzatora ze zmienną liczbą bitów (model
psychoakustyczny – własności ludzkiego ucha), w Layer 1 i 2
ramki zawierają 384 i 1152 próbki (ma to wady przy dużej
zmienności sygnału i zostało poprawione w 3),
- kodowanie obrazów: obraz dzielimy za pomocą filtrów
(najlepiej separowanych, aby można było je stosować oddzielnie
w każdym z wymiarów), górno i dolno przepustowych, a następnie
dziesiątkujemy wyjście o czynnik 2, w każdym kroku rozkładamy
tylko 1 z 4 podobrazów (podobrazi o wysokiej częstotliwości mają
większość współczynników bliską 0),
- kompresja wideo: często klatki niewiele się różnią, pewne
zniekształcenia są słabo widoczne (niewyraźnie krawędzie),
niektóre bardzo (zmiany jasności pow. migotanie), w predykcji
następnych klatek można wykorzystywać poprzednie, predykcja
musi uwzględniać ruch obiektów, aby uniknąć błędów, co jakiś
czas rezygnujemy z predykcji (co kilka klatek, albo gdy zmiany są
zbyt duże), kompresja klatek opiera się na algorytmach kompresji
obrazu,
- kompresja ruchu: obraz dzielimy na kratki, szukamy
podobnych, po czym przypisujemy im wektor przesunięcia.
W wideo klatki dzielimy na grupy obrazów (GOP):
- co najmniej 1 ramka typu I (obraz podobny do JPEGa,
wymagane do rozpoczęcia [de]kodowania),
- kilka klatek typu P (różnica pomiędzy poprzednią ramką typu P
lub I a bieżącą),
- opcjonalne ramki typu B (obraz zakodowany z wykorzystaniem
OBY sąsiednich klatek typu P lub I, najcięższe obliczeniowo, błędy
nie propagują się).
Przykład: I B B B P B B B P B B B P.
Algorytmy symetryczne: wideokonferencji – kompresja i
dekompresja muszą być szybkie.
Algorytmy asymetryczne: kompresja może być czaso- i
zasobożerna, ale dekompresja musi być szybka (MPEG-1, MPEG-
2, MPEG-4).
Kryptografia
Szyfry strumieniowe – na podstawie klucza tworzymy ciąg
bitów (potencjalnie nieskończony) za pomocą którego szyfrujemy
tekst jawny – np. przy pomocy XORa.
Efekt lawinowy – zmiana jednego bitu szyfrogramu powoduje
zmianę wielu bitów kryptogramu.
Szyfr Cezara: kluczem jest s, szyfrowanie c=(p+s) mod 26,
deszyfrowanie p=(c+26-s) mod 26.
Szyfr Viginiére’a – hasło (klucz) dodajemy modulo do blokow
tekstu (można też XORem) uogólnienie szyfru Cezara.
System Playfair: klucz to kwadrat 5x5 zawierający 25 różnych
liter (np. hasło i ciąg kolejnych liter alfabetu w nim
niewystępujących), w haśle znaki (występujące w kluczu) nie
mogą się powtarzać
Szyfrowanie:
1. tekst jawny dzielimy na pary: dla każdej wyznaczamy w
kwadracie-kluczu prostokąt,
2. dla prostokątów 1-wymiarowych bierzemy litery na prawo
(wspólny rząd)/poniżej (wspólna kolumna) nich,
3. w.p.p. wybieramy przeciwne rogi prostokąta.
One-time pad: jednorazowo wylosowany klucz XORujemy z
tekstem jawnym, wymaga osobnego przesyłu klucza.
ECB – Electronic Codebook: tekst jawny dzielony na bloki
długości n, każdy szyfrowany za pomocą tego samego klucza K.
uszkodzenie/utrata bloku nie wpływa na resztę, ale możliwa jest
też podmiana bloków.
CBC – Cipher Block Chaining: C
1
=E
k
(P
1
XOR IV), C
i
=E
k
(P
i
XOR
C
i-1
), P
1
=D
K
(C
1
) XOR IV, P
i
=D
K
(C
i
) XOR C
i-1
. Przekłamania 1 bloku
zmieniają tylko 2 bloki po deszyfracji, takie same bloki mają
zazwyczaj różne kryptogramy, ten sam tekst jawny dla tego
samego klucza może mieć różne kryptogramy dla różnych
wektorów inicjujących.
CFB – Cipher Feedback: C
0
=IV, C
i
=E
K
(C
i-1
) XOR P
i
, P
i
=C
i
XOR
E
K
(C
i-1
). Wady i zalety jak w CBC.
OFB – Output Feedback: S
0
=IV, S
i
=E
K
(S
i-1
), C
i
=S
i
XOR P
i
, P
i
=S
i
XOR C
i
. Można wysyłać nawet pojedyncze bity, proces
generowania ciągu szyfrującego zależy tylko od ciągu
początkowego i nie zależy od tekstu jawnego, niebezpiecznie jest
używać tego samego klucza i ciągu inicjującego.
Szyfrowanie symetryczne
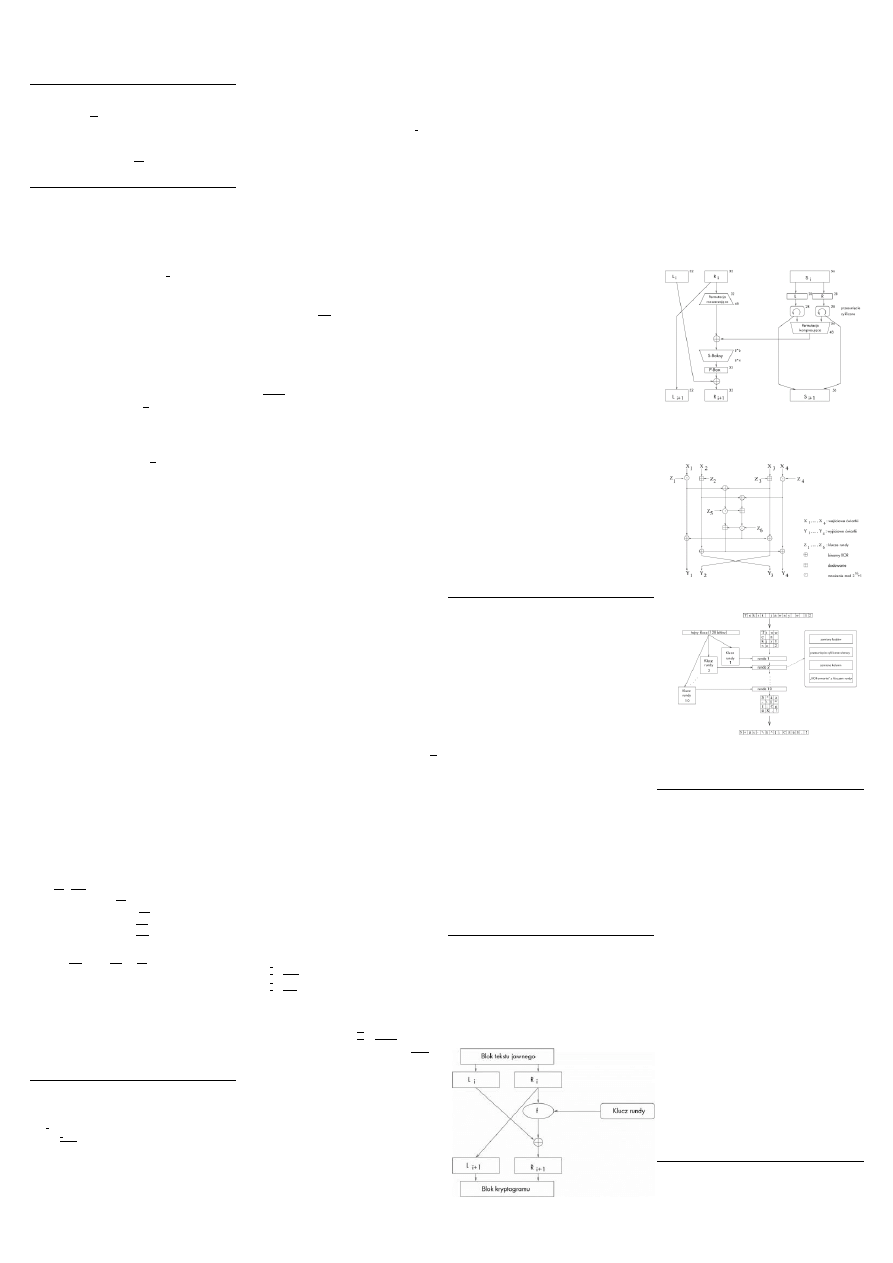
Schemat Feistela:
Sieć Feistela pozwala na szyfrowanie i deszyfrowanie
informacji tym samym algorytmem, mimo iż funkcja f nie
jest odwracalna. Sieć Feistela generuje z tekstu jawnego
szyfrogram, a z szyfrogramu tekst jawny. W ten sposób
konstruowanie algorytmów szyfrujących znacznie się uprościło,
ponieważ nie trzeba się troszczyć o odwracalność funkcji f.
Tekst jawny dzieli się na dwa równe bloki L
i
, R
i
. Funkcja f jest
właściwym algorytmem szyfrującym. Jako wynik otrzymuje
się szyfrogram. Numer kolejnej rundy oznaczany jest indeksem i;
to oznacza iż wynik szyfrowania jest ponownie i-krotnie
szyfrowany, co polepsza jakość szyfrowania.
Wykorzystanie: DES, 3DES, Twofish, FEAL.
Szyfrowanie: L
i
=R
i-1
, R
i
=L
i-1
XOR f(R
i-1
,K
i
).
Deszyfrowanie: R
i-1
=L
i
, L
i-1
=R
i
XOR f(L
i
,K
i
).
DES – Data Encryption Standard: symetryczny, opis
opublikowany, zaprojektowane do działania jako hardware,
szyfruje bloki 64 bitów, 56 bitowy klucz, działa tylko brute force:
- szyfrowanie i deszyfrowanie składa się z 16 rund,
- każda zawiera te same obliczenia na wyniku poprzedniej rundy i
z innym podkluczem,
- podklucze generowane są z klucza głównego za pomocą
przesunięć cyklicznych,
- blok tekstu jawnego jest permutowany na początku i końcu
algorytmu (łatwe hardwarowo, trudne softwarowo),
- dzięki wykorzystaniu sieci Feistela, deszyfrowanie przebiega
niemal identycznie jak szyfrowanie (tak sama funkcja f),
deszyfrowania można więc użuć do zaszyfrowania wiadomości,
wówczas odszyfrowuje się ją funkcją szyfrującą (wykorzystane
jest to np. w algorytmie 3DES).
Niektóre rozwiązania wprowadzone w DESie:
- permutacja rozszerzająca: permutuje wszystkie i dubluje
niektóre bity,
- S-Boksy: dzielą blok na ciągi 6 bitowe i zastępują każde 6 bitów
4 wg. z góry określonego schematu,
- P-Boksy: perutacja bitów wg. określonego schematu
Żadne z tych operacji nie są wyliczane, ale zamiast tego są one
przypisane na stałe do określonych ciągów bitów/ich pozycji.
Rozszerzenia DESa:
- DESX – dodanie whiteningu, dwa dodatkowe klucze utrudniające
przeszukiwanie: C = K
EXT
XOR DES
K
(P XOR K
INT
).
- 3DES – używamy dwa 56 bitowe klucze K
1
i K
2
oraz trzykrotnie
algorytm DES: C = DES
K1
-1
(DES
K2
(DES
K1
-1
(P))).
IDEA: opatentowany, ale bezpłatny do celów niekomercyjnych,
klucze 128 bitowe, bloki są 64 bitowe, algorytm ma 8 rund.
AES – Advanced Encryption Standard (Rinjadael): następca
DESa, klucze w zależności od potrzeb 128, 192 lub 256, długość
bloku to 128 (można zwiększyć do 129 lub 256 bitów), 10 rund
(lub 12, lub 14), szybki w implementacji programowej.
RC4: szyfr strumieniowy, opracowany do celów komercyjnych,
implementacja ujawniona anonimowo na listach dyskusyjnych w
’94, na podstawie klucza generuje ciąg bitów XORowany z
tekstem jawnym.
Szyfrowanie asymetryczne
Klucze występują w parach: 1 do szyfrowania 1 do deszyfrowania
(czasem nierozróżnialne). Opublikowanie klucza szyfrującego
(publicznego) nie zdradza drugiego z kluczy (prywatnego)
(obliczenia zbyt kosztowne).
Twierdzenie Eulera: a
Ф(n)
mod n = 1, dla a względnie
pierwszego z n.
Faktoryzacja liczb jest NP-trudna.
RSA:
Generowanie kluczy:
- losowo wybieramy 2 duże liczby pierwsze p i q (512, 1024 lub
2048 bitów),
- losowo wybieramy e takie, że e i (p-1)(q-1) względnie pierwsze,
- znajdujemy d takie, że ed mod (p-1)(q-1) = 1,
- obliczamy n=pq i zapominamy liczby p i q,
- para [e,n] jest kluczem publicznym a [d,n] kluczem prywatnym,
- bez p i q nie można obliczyć d na podstawie e i n, a rozkład n na
p i q jest bardzo trudny obliczeniowo.
Szyfrowanie:
C=E
[e,n]
(m)=m
e
mod n (m < n).
Deszyfrowanie:
m=D
[d,n]
(C)=C
d
mod n.
Poprawność wynika z Twierdzenia Eulera i Chińskiego
Twierdzenia o Resztach. Szyfrowanie i deszyfrowanie są
symetryczne i można je stosować zamiennie.
Algorytm ElGamala: każdorazowe szyfrowanie wykorzystuje
losowo wybraną liczbę, różne szyfrogramy przy tym samym
kluczu, klucz publiczny tylko szyfruj, prywatny tylko deszyfruje,
algorytm bazuje na trudności obliczenia logarytmu dyskretnego
tzn. znalezienia takiego x, że g
x
mod p = y na liczbach
naturalnych.
Generowanie kluczy:
- wybieramy liczbę pierwszą p (512 bitów) i liczbę g będącą
generatorem grupy Z
p
,
- dla danego użytkownika wybieramy losowo liczbę x < p – 1 oraz
obliczamy y = g
x
mod p,
- kluczem publicznym jest [y,p,g] a kluczem prywatnym [x,p,g].
Szyfrowanie:
Szyfrujemy m < p, wybieramy losowo i tajnie k < p, obliczamy: a
= g
x
mod p, b = m y
k
mod p.
Para liczb [a,b] jest kryptogramem dla m.
Deszyfrowanie:
b(a
x
)
-1
=m y
k
g
-kx
= m mod p.
Funkcje hashujące i podpisy cyfrowe
MD5: skonstruowana przez Rivesta w 1991, 128 bitowe wartości,
łatwo implementowana na komputerach 32 bitowych, brak
matematycznych podstaw poprawności.
SHA-1 (Secure Hash Algorithm): opublikowana w USA w 1994,
powstała przy współpracy z NSA, daje 160 bitowe wartości, jest
częścią DSA (Digital Signature Algorithms), który jest
amerykańskim standardem podpisów cyfrowych, brak podstaw
matematycznych.
Użycie symetrycznych algorytmów szyfrujących:
- Schemat Rabina: zakładamy, że mamy algorytm szyfrujący z
kluczem tej samej długości co szyfrowany blok, dzielimy tekst M
na bloki M
1
, M
2
, …, M
t
: H
0
=IV, H
i
=E
Mi
(H
i-1
), H
t
– wartość funkcji
haszującej dla M.
- Schemat Daviesa: H
0
=IV, H
i
=E
Mi
(H
i-1
) XOR H
i-1
, H
t
– wartość
funkcji hashującej dla M.
- Schemat Matyas-Meyer-Oseasa: s – funkcja, która z
kryptogramu generuje klucz (może usuwać różnicę w
długościach): H
0
=IV,
, H
t
– wartość funkcji
haszującej dla M.
Podpis RSA: podpisujemy nie sam dokument, a wartość jego
funkcji skrótu.
Podpis: S=RSA
Kpriv
(h(M))=(h(M))
d
mod n.
Weryfikacja: RSA
Kpub
(S)=S
e
mod n=(h(M))
de
mod n =h(M),
podpis pod tym samym dokumentem jest zawsze taki sam.
Podpis ElGamal: p – duża liczba pierwsza, g – generator Z
p
,
wybieramy x<p-1 i obliczamy y=g
x
mod p, klucz publiczny
[x,p,g], prywatny [y,p,g].
Podpis: wybieramy losowe k wzg. pierwsze z p-1, obliczamy:
- a = g
k
mod p,
- t = k
-1
mod (p-1),
- b = t(h(M)-xa) mod (p-1).
Podpisem jest para (a,b).
Weryfikacja: y
a
a
b
= g
ax
g
kb
= g
ax+k t(h(M)-xa)
= g
h(M)
mod p.
Podpisy pod tym samym dokumentem mogą być różne.
DSA (Digital Signature Algorithm): standard przyjęty w USA,
oparty na ElGamalu, zmieniony tak, aby podpisy były krótkie,
podpisujemy wartość funkcji SHA, długość podpisu to 320 bitów,
tylko do podpisów, nie ma jego modyfikacji do szyfrowania.
Administracja kluczami i dzielenie sekretów
Uzgadnianie kluczy sesyjnych: tak aby niemożliwy była atak
np. man-in-the-middle:
- A i B mają wspólny klucz symetryczny k,
- A wybiera losowe r
A
i wysyła do B E
K
(r
A
,t,n), gdzie t aktualny
czas, a numer uzgadnianego klucza,
- B odbiera E
K
(r
A
,t,n), losuje r
B
i wysyła do A E
K
(r
B
,t’,n), t’
aktualny czas,
- kluczem sesyjnym jest f(r
A
,r
B
,k,n).
Podobnie dla szyfrowania asymetrycznego.
Certyfikat: podpisany elektronicznie przez zaufaną stronę trzecią
(CA – Certificate Authority) klucz publiczny z danymi właściciela i
czasem ważności klucza, weryfikacja przez serwery zawierające
klucz publiczny zaufanej strony.
Protokół Diffie-Helmana: jak uzgodnić wspólny klucz przy
braku szyfrowanego kanału:
- publicznie znane są p – duża liczba pierwsza i g – generator
ciała Z
p
,
- A wybiera r
A
<p-1 i wysyła do B s
A
=g
ra
mod p,
- B wybiera r
B
<p-1 i wysyła do A s
B
=g
rb
mod p,
- kluczem jest g
rarb
= s
A
rb
= s
B
ra
mod p.
Złamanie klucza wymaga umiejętności liczenia logarytmu
dyskretnego.
Protokół interlock:
1. B przesyła A swój klucz publiczny,
2. A przesyła B swój klucz publiczny,
3. B szyfruje swoją pierwszą wiadomość i przesyła do A jej
pierwszą połowę,
4. A po otrzymaniu pierwszej połowy wiadomości od B szyfruje
swoją wiadomość i wysyła do B jej pierwszą połowę,
5. B po otrzymaniu pierwszej połowy wiadomości od A przesyła do
A drugą połowę,
6. A po otrzymaniu drugiej połowy wiadomości od B odszyfrowuje
są i sprawdza jej poprawność, jeśli wszystko w porządku to
przesyła drugą połowę swojej wiadomości do B,
7. B, po otrzymaniu drugiej połowy wiadomości od A,
odszyfrowuje ją i sprawdza jej poprawność.
Osoba podszywająca się nie może odszyfrować wiadomości przed
przesłaniem jej drugiej połowy.
Dzielenie tajemnic przy pomocy XOR:
1. wybieramy losowo dla R
i
dla i=1, …, n-1, że |M|=|R
i
|,
2. obliczamy R
n
=M XOR R
1
XOR … XOR R
n-1
,
3. dla i=1, …, n osoba otrzymuje R
i
.
Dzielenie tajemnic z progiem k:
1. wybieramy odpowiednio dużą liczbę pierwszą p, p>M, p>m,
2. wybieramy losowo w
1
, …, w
k-1
liczb mniejszych od p,
3. konstruujemy wielomian
,
4. dla i=1, …, n osoba A
i
otrzymuje w(i).
k osób jest w stanie odtworzyć w(x) (interpolacja) i obliczyć
w(0)=M.
Uwierzytelnianie
Hasła jednorazowe – schemat Lamporta:
Przygotowanie:
- A bierze funkcję hashującą h, ilość haseł t i sekret w,
- do B dostarczamy w
0
=h
t
(w).
Uwierzytelnianie: przy k-atym uwierzytelnieniu A przesyła do B
(A,k,w
k
,h
t-k
(w)).
Weryfikacja: B sprawdza czy h(w
k
)=w
k-1
, gdzie w
k-1
było
dostarczone w poprzednim uwierzytelnianiu.
Protokół „challange and response” – silne uwierzytelnianie,
niemożliwy atak man-in-the-middle, praktycznie niemożliwy atak
powtórzeniowy, ale administratorzy po stronie B mogą mieć
dostęp do k i umożliwić podszycie się za Z: A i B znają wspólny
sekret k i funkcję f mającą własności funkcji hashującej.
Uwierzytelnianie:
1. A przesyła do B swój identyfikator,
2. B losuje losowy ciąg r i przesyła do A,
3. A przesyła do B f(k,r),
4. B także oblicza f(k,r) i sprawdza, czy jest równy przesłanemu
przez A.
Dowody z wiedzą zerową: A przekonuje B, że zna pewien
sekret tak, aby go nie zdradzić.
TA – Trusted Authority: zaufana osoba/instytucja potrzebna w
trakcie tworzenia kluczy.
Protokół Fiata-Shamira:
Przygotowanie:
1. TA losowo wybiera dwie liczby pierwsze p i q (n=pq),
2. A otrzymuje od TA sekret s względnie pierwszy z n,
3. TA oblicza v=s
2
mod n i publikuje parę (v,n) jako identyfikator
A.
Uwierzytelnianie:
1. A wybiera losowe r względnie pierwsze z n, oblicza x=r
2
mod n
i przesyła x do B,
2. B wybiera losowo b ∊ {0,1} i przesyła je do A,
3. A oblicza y=rs
b
mod n i przesyła y do B,
4. sprawcza czy y
2
=xv
b
mod n.
Osoba trzecia może się podszyć prawd. ½: ma nadzieję, że b=0 i
s nie będzie potrzebne, wysyła x=y
2
/v mod n dla wcześniej
wybranego y i ma nadzieję, że b=1. Dlatego protokół powtarzamy
ok. 10 razy.
Zabezpieczenie komunikacji komputerowej
Kerberos: cała komunikacja szyfrowana, dostęp do każdego
elementu systemu tylko za pomocą biletu, krytyczne części
systemu na specjalnie chronionych serwerach, zabezpieczenie
przed atakami przez podsłuchanie i przechwytywanie komunikacji.
Serwer Kerberosa – weryfikuje uprawnienia i przyznaje bilet
potwierdzający autentyczność klienta, który jest okazywany
Serwerowi Przyznającemu Bilety.
Serwer Przyznający Bilety (TGS) – przyznaje bilety niezbędne
do komunikacji z innymi klientami i urządzeniami.
- wszystkie czynności poza logowaniem się do systemu
wykonywane są automatycznie,
- własnych kluczy używamy tylko do komunikacji z Serwerem
Kerberosa, a poza nim tylko kluczy sesyjnych,
- bilety mają okresy ważności, więc dostęp do usług kończy się po
pewnym czasie (system jest czuły na zakłócenia zegarów).
Protokół SSH: pakiet zaprojektowany, jako bezpieczne zdalne
logowanie, oparty na kryptografii asymetrycznej i świadomej
decyzji użytkownika akceptującej klucze publiczne serwera, z
którym się łączy.
Przygotowania:
- każdy komputer w momencie zostania serwerem SSH otrzymuje
parę kluczy (host keys): prywatny (mocno chroniony) i publiczny,
- serwer co jakiś czas tworzy dodatkową parę kluczy (server
keys), z których prywatny jest trzymany tylko w pamięci
komputera,
- użytkownik również używa pary kluczy – często ich generacją,
obsługą zajmuje się program klienta.
Przebieg logowania:
1. klient t łaczy się z serwerem i pobiera jego publiczne host key i
server key, w przypadku pierwszego logowania klient musi
zaakceptować klucze, a w przypadku kolejnych logowań porównać
klucze z zapamiętanymi. Dodatkowo Klient otrzymuje losowy
identyfikator sesji (cookie),
2. obie strony tworzą ciąg składający się z cookie, host key i
server key i za pomocą funkcji hashującej tworzą session-id,
3. klient tworzy losowy klucz sesyjny, wykonuje XOR klucza i
session-id i przesyła do serwera zaszyfrowane oboma kluczami
serwera,
4. serwer odszyfrowuje klucz sesyjny i używa go do dalszej
komunikacji,
5. klient uwierzytelnia się teraz identyfikatorem i hasłem lub za
pomocą własnej pary kluczy,
Protokół
SSL:
protokół
zawierający bezpieczny
kanał
komunikacji oparty na szyfrowaniu asymetrycznym i certyfikatach
wiążących klucz publiczny z usługodawcą.
Budowanie połączenia w SSL:
- Client Hello – prośba do serwera zawierająca dane na temat
używanych protokołów i algorytmów szyfrowania oraz wartość
losową CH.random.
- Server Hello – odpowiedź serwera zawierająca podobne dane i
losową wartość SH.random, możliwe jest także przesłanie
Certyfikatu serwera.
- Certificate Request – czasami serwer może zażądać
certyfikatu klienta.
- Server/Client Key Exchange – klient i serwer uzgadniają
klucz sesyjny wykorzystując klucze publiczne lub inny protokół
uzgadniania kluczy, oraz losowe wartości otrzymane od siebie.
- Certyficate Verify – sprawdzanie poprawności certyfikatów.
Inne metody zabezpieczania komunikacji – PGP
Kodowanie uniwersalne, bzip2
Kodowanie liczby naturalnej powinno być asymptotycznie
proporcjonalne do kodowanej wartości θ(log
2
n).
Zastosowanie: czasami konieczne jest przesłanie kilku liczb,
których wielkość ciężko oszacować (wykorzystanie np. przez
niektóre odmiany LZ77 do kodowania przesunięć).
Kodowanie Eliasa (lata ‘70) – wyróżniamy 3 rodzaje kodów
Eliasa (co najmniej 3) różniące się konstrukcją γ, δ, ω, ogólna
idea jest następująca:
- kodujemy zadaną liczbę binarnie,
- doklejamy informację o długości tak, by powstał kod
jednoznacznie dekodowalny.
Kodowanie γ: kodowanie liczba x jest zapisana w kodzie
binarnym, niech n oznacza liczbę cyfr w zapisie binarnym, słowo
składa się z (n-1) bitów o wartości 0, liczby x zapisanej binarnie.
Kodowanie δ: liczba x jest zapisywana binarnie, liczba n oznacza
liczbę bitów binarnej reprezentacji x, liczbę n przedstawiamy w
kodzie γ, z binarnej reprezentacji liczby x usuwamy najbardziej
znaczącą cyfrę, niech k oznacza liczbę bitów znaczących n,
wynikiem jest: k-1 zer, binarna reprezentacja liczby n, binarna
reprezentacja liczby x bez pierwszej jedynki.
Kodowanie ω:
1. zapisz bit 0 (znacznik końca),
2. k<-x,
3. while k>1:
- zapisz dwójkowo liczbę k,
- nowe k, to liczba bitów z poprzedniego kroku pomniejszona o 1.
Liczba bitów wynosi:
(
, n – liczba kroków).
Dekodowanie ω:
1. n<-1,
2. while kolejny bit nie ma wartości 0
- n <- wartość zapisana na kolejnych n+1 bitach,
3. x<-n.
Właściwości liczb Fibonacciego: każda liczba całkowita
dodatnia k może być przedstawiona jednoznacznie jako:
, gdzie a
i
jest równe 0 lub 1. Zawsze możemy zapisać ten
ciąg w taki sposób, że nie wystąpią obok siebie dwie jedynki!
Kody Fibonacciego:
- znajdujemy współczynniki a
i
,
- zapisujemy w kolejności od najmniej znaczącego,
- za końcu dopisujemy jedynkę.
Za końcu zawsze wystąpią 2 jedynki!
bzip2: algorytm kompresji popularny w systemach Linuksowych,
standardowa implementacja kompresuje bloki danych o
rozmiarach od 100 do 900 kb, blok jest przekształcany
transformatą
Burrowsa-Wheelera,
następnie
kodowany
algorytmem Move-To-Front i kompresowany algorytmem
Huffmana, osiąga o 10-20% lepsze rezultaty niż algorytmy
strumieniowe, ale nie może być używany do kodowania strumieni.
Transformata Burrowsa-Wheelera:
- przygotowujemy listę wszystkich przesunięć cyklicznych
(rotacje) łańcucha wejściowego,
- sortujemy je leksykograficznie,
- zwracamy: numer wiersza z pierwotnym tekstem i ostatnią
kolumnę tabeli.
Odwracanie transformacji:
- mamy numer wiersza k i tekst,
- dopisujemy do tekstu indeksy,
- sortujemy tekst (stabilnie),
- zaczynając od pozycji k wypisujemy kolejno znaki zgodnie z
indeksami:
posortowany
[k]->litera
i
indexPierwotny
0
,
posortowany [indeksPierwotny
0
]->litera i indexPierwotny
1
, …
Move-To-Front:
transformacja
mogąca
spowodować
zmniejszenie entropii, zyski, gdy symbole wykazują tendencję do
lokalnego grupowania się, dane o takiej charakterystyce są często
wynikiem transformaty Burrowsa-Wheelera.
Transformacja:
- na początku mamy tablicę N posortowanych symboli, kodem
symbolu jest numer pozycji w tablicy (numery od 0 do N-1),
- w każdym kroku bierzemy pojedynczy symbol, wypisujemy jego
numer z tablicy i modyfikujemy tablicę przesuwając rozpatrywany
symbol na początek tablicy,
- jeśli symbole są lokalnie pogrupowane to są przesuwane na
początek tablicy i w kodzie wynikowym pojawiają się częściej
małe liczby,
- odwrócenie transformacji jest praktycznie identyczne jak
algorytm transformacji.
ile bitów informacji może mieć n-bitowy kod korygujący t-
błedy
szukamy k!
skonstruuj
kompresję
stratną
z
sześciostopniowym
jednostajnym kwantyzatorem skalarnym.
- dopasowujemy współczynniki przy x do siebie(kompredator?),
tak żeby jedno nadal było przedluzeniem drugiego
- tworzymy funkcje odwrotna
W systemie Kerberos przesunieto zegar: to serwer będzie nadal
wydawał bilety, ale będą one miały krótszą ważność. Może się
zdarzyć, że bilety będą nieważne zaraz po ich wydaniu (zależy jak
bardzo był cofnięty zegar), co uniemożliwi dostęp. Ponadto, kiedy
użytkownik wyśle prośbę o bilet, to będą one dochodziły tak jakby
z przyszłości, a że serwer ma określony czas na wydanie biletu, to
zaburzony zostanie czas ich wydania, przez co użytkownik
otrzyma go później.
Czy dla połączenia SSH jest możliwy atak man-in-the-middle:
Połączenia SSH opierają się na przekazywaniu kluczy. Nieznany
klucz publiczny musi być zaakceptowany przez użytkownika. Z
tego powodu atak man-in-the-middle nie jest możliwy, ponieważ
użytkownik powinien mieć świadomość akceptacji nieznanego
klucza publicznego (może mieć pewne podejrzenia co do
autentyczności). Ale z tego samego powodu atak jest
prawdopodobny, gdyż użytkownik może nie zauważyć, że klucz
jest podłożony i atak dojdzie do skutku.
czy schemat elGamala będzie skuteczny gdy zastąpimy
losowe wartości kolejnymi liczbami naturalnymi, tj. k, k+1, k+2,
itd. – nie będzie . Z kolejnych iteracji k będzie można wyciągnąć
wnioski, które mogą prowadzić, do złamania klucza.
Policzmy b1 i b2 generowane kolejno z k i k+1.
B1 = m1*y
k
B2 = m2*y
k+1
Zauważmy, że kiedy zrobimy b1/b2 , to będziemy mogli policzyć z
tego: b1/b2 = m1/(m2*y). Rozszyfrowaliśmy klucz.
Wyszukiwarka
Podobne podstrony:
Mechanika płynów na kolosa z wykładów
pkm rozwiazania na kolosa
NA kolosa Z IM
Ćwiczenia teatralne, Teatr, Pomoce na zajęcia teatralne
ORZECZENIA NA KOLOSA
materiały na kolosa, LEŚNICTWO SGGW, MATERIAŁY LEŚNICTWO SGGW, Hodowla
geologia górnicza teoria na kolosa ŚCIĄGA
II ZESTAW I pytania na kolosa poprawkowego z chemii
Napędy Robotów Pytania na KOLosa I
dała wam pytania na kolosa Kaśka
sciaga, Pomoce na wyklad
pytania na kolosa z polityki tur, II rok II semestr, BWC, Polityka
NA KOLOSA-sciaga, elektronika i telekomunikacja
MNS -zebranie informacji do egzaminu, POMOCE NA STUDIA, METODOLOGIA NAUK SPOŁECZNYCH - MNS
WZORY-~1(1), (PCz) POLITECHNIKA CZĘSTOCHOWSKA, Grunty, Materiały na kolosa
zagadnienia na kolosa (2)
więcej podobnych podstron