
Materiały szkoleniowe
Podstawy budowy
raportów w Oracle Reports 2.5
ćwiczenia

Podstawy
Strona 2
Spis treści
Zawartość tabel wykorzystywanych na kursie __________________________________ 5
Zawartość tabeli DEPT ________________________________________________________ 6
Zawartość tabeli EMP _________________________________________________________ 6
Zawartość tabeli SALGRADE __________________________________________________ 6
Budowa tabel wykorzystywanych na kursie _______________________________________ 7
Podstawy ________________________________________________________________ 9
Zapytanie i model danych _____________________________________________________ 10
Rozkład domyślny ___________________________________________________________ 11
Modyfikacje rozkładu domyślnego _____________________________________________ 12
Uruchomienie raportu ________________________________________________________ 12
Łamanie i funkcje grupowe ________________________________________________ 15
Model danych _______________________________________________________________ 16
Dobranie rozkładu domyślnego ________________________________________________ 17
Funkcje grupowe w raportach _____________________________________________ 19
Podsumowania ______________________________________________________________ 20
Inne funkcje grupowe ________________________________________________________ 21
Rozkład ____________________________________________________________________ 21
Łączenie zapytań ________________________________________________________ 23
Raport nadrzędny-podrzędny __________________________________________________ 24
Kolumny formuł i wypełniające ____________________________________________ 27
Kolumny formuł _____________________________________________________________ 28
Kolumna wypełniająca _______________________________________________________ 28
Wyjątki ____________________________________________________________________ 29
Raport Macierzowy ______________________________________________________ 33
Raport macierzowy na trzech zapytaniach _______________________________________ 34
Problem pustych miejsc _______________________________________________________ 37
Raport o zredukowanej ilości zapytań ___________________________________________ 38

Budowa raportów
Strona 3
Programowe sterowanie wydrukiem _________________________________________ 41
Programowe wyłączenie ______________________________________________________ 42
Formatowanie warunkowe ____________________________________________________ 43
Uruchamianie raportu z parametrem ________________________________________ 45
Parametr uruchomienia raportu. ______________________________________________ 46
Zapytanie z parametrem _____________________________________________________ 46
Przekazanie fragmentu zapytania ______________________________________________ 49
Suplement ______________________________________________________________ 51
Data bieżąca ________________________________________________________________ 52
Tryb dopasowania ___________________________________________________________ 53
Rozkład listowy _____________________________________________________________ 53
Kierunek tekstu _____________________________________________________________ 54
Wyzwalacze Raportu ________________________________________________________ 54


Zawartość tabel wykorzystywanych na kursie

Podstawy
Strona 6
Zawartość tabeli DEPT
DEPTNO DNAME LOC
---------- -------------- -------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
Zawartość tabeli EMP
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
--------- ---------- --------- --------- -------- --------- --------- ---------
7839 KING PRESIDENT 81/11/17 5000 10
7698 BLAKE MANAGER 7839 81/05/01 2850 30
7782 CLARK MANAGER 7839 81/06/09 2450 10
7566 JONES MANAGER 7839 81/04/02 2975 20
7654 MARTIN SALESMAN 7698 81/09/28 1250 1400 30
7499 ALLEN SALESMAN 7698 81/02/20 1600 300 30
7844 TURNER SALESMAN 7698 81/09/08 1500 0 30
7900 JAMES CLERK 7698 81/12/03 950 30
7521 WARD SALESMAN 7698 81/02/22 1250 500 30
7902 FORD ANALYST 7566 81/12/03 3000 20
7369 SMITH CLERK 7902 80/12/17 800 20
7788 SCOTT ANALYST 7566 82/12/09 3000 20
7876 ADAMS CLERK 7788 83/01/12 1100 20
7934 MILLER CLERK 7782 82/01/23 1300 10
Zawartość tabeli SALGRADE
GRADE LOSAL HISAL
--------- --------- ---------
1 700 1200
2 1201 1400
3 1401 2000
4 2001 3000
5 3001 9999
Budowa raportów
Strona 7
Budowa tabel wykorzystywanych na kursie
Podczas kursu będziemy korzystać z uprzednio utworzonych tabel opisujących
zatrudnionych w pewnej firmie, ich wynagrodzenia i miejsca pracy. Firma dzieli się na
departamenty. Każdy pracownik należy do pewnej grupy zaszeregowania, w zależności od
wysokości pensji, którą otrzymuje.
Tabela DEPT — tabela zawierająca wszystkie departamenty
Kolumna
Opis
DEPTNO
Departament number — unikalny numer departamentu
DNAME
Nazwa departamentu — przechowywana w zapisie dużymi literami
LOC
Lokalizacja departamentu (miasto w którym znajduje się departament)
Tabela EMP
—
wykaz wszystkich pracowników
Kolumna
Opis
EMPNO
Employee number — unikalny numer pracownika
ENAME
Nazwisko pracownika — przechowywane w zapisie dużymi literami
JOB
Etat, stanowisko pracy
MGR
Identyfikator szefa (czyli EMPNO we wierszu szefa)
HIREDATE
Data zatrudnienia
SAL
Pensja
COMM
Prowizja naliczona od początku roku, dotyczy pracowników
zatrudnionych na stanowisku SALESMAN
DEPTNO
Numer departamentu w którym zatrudniony jest pracownik. Wartość
w tym polu musi odpowiadać jednemu i tylko jednemu wierszowi
w tabeli DEPT

Podstawy
Strona 8
Tabela SALGRADE — tabela „widełek” zaszeregowania
Kolumna
Opis
GRADE
Numer grupy zaszeregowania
LOSAL
LOW SALARY — dolna granica widełek płacowych dla stawki
zaszeregowania GRADE
HISAL
HIGH SALARY — górna granica widełek

Budowa raportów
Strona 9
Podstawy
Podstawy
Strona 10
Wykonanie Raportu w zaprojektowanego Reports Designerze 2.5 polega w na wykonaniu
instrukcji SELECT na serwerze. Uzyskane w wyniku tej lub tych instrukcji dane otrzymuje
klient, można zauważyć, że otrzymywane przez niego dane mają formę „tabelki” która
podlega dalszej obróbce na kliencie
1
. Oprócz szaty graficznej na komputerze-kliencie
wykonywane są niektóre operacje sumaryczne, obliczenia korzystające z wbudowanych
komponentów lub samodzielnie napisanych procedur i funkcji.
Zapytanie i model danych
Reports Designer składa się z wielu obiektów. Przyjrzymy się ich roli i własnościom
tworząc elementarny raport.
Model danych – model danych to graficzny obraz danych jako zapytania, lub zapytań
które zostaną wykonane oraz obliczeń którym te dane zostaną poddane.
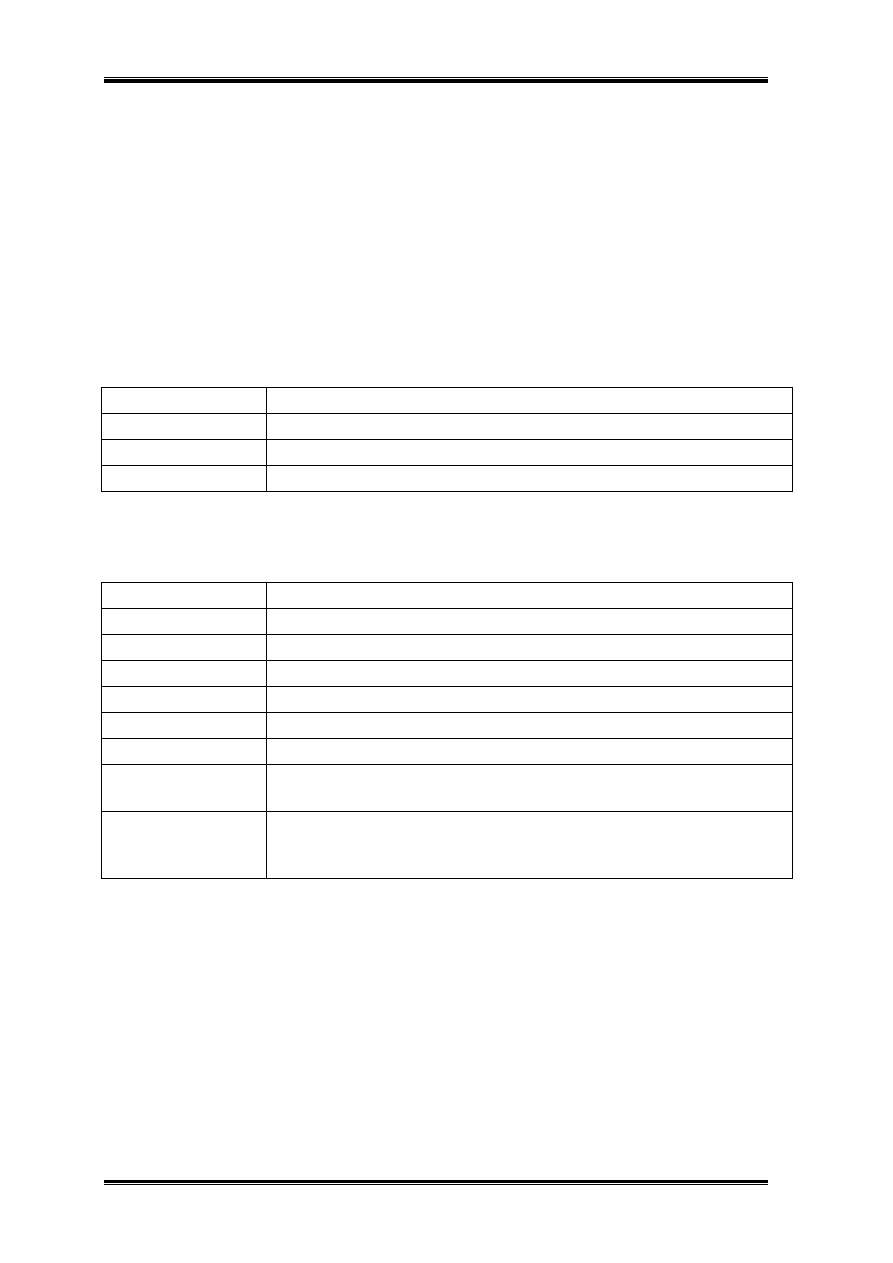
Wchodzimy do edytora modelu danych klikając na ikonę Data Model. Następnie sięgamy
po narzędzie SQL, przy jego pomocy rysujemy zaokrąglony prostokąt.
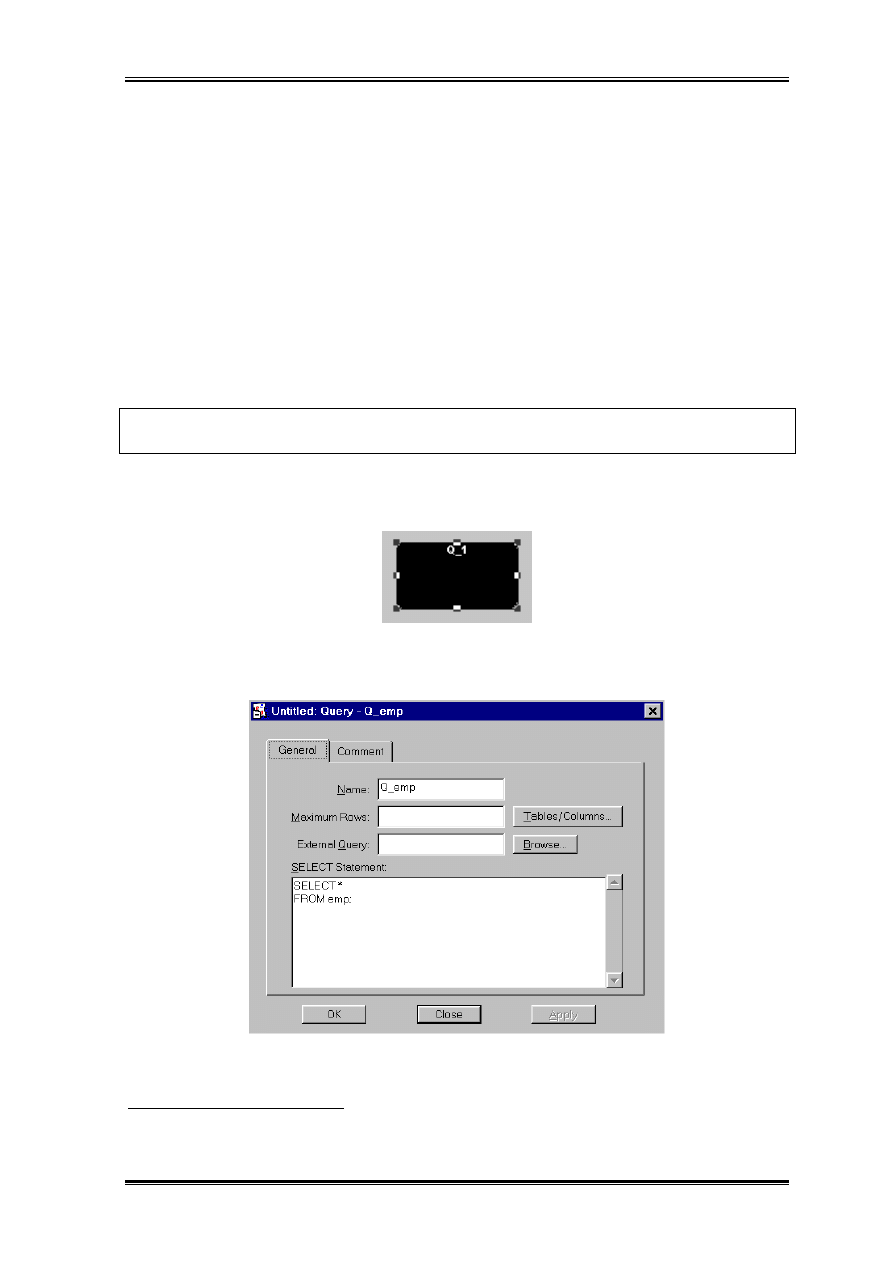
Wchodzimy do właściwości tego obiektu (prawy przycisk myszy). Przed nami ukazuje się
następujące okienko:
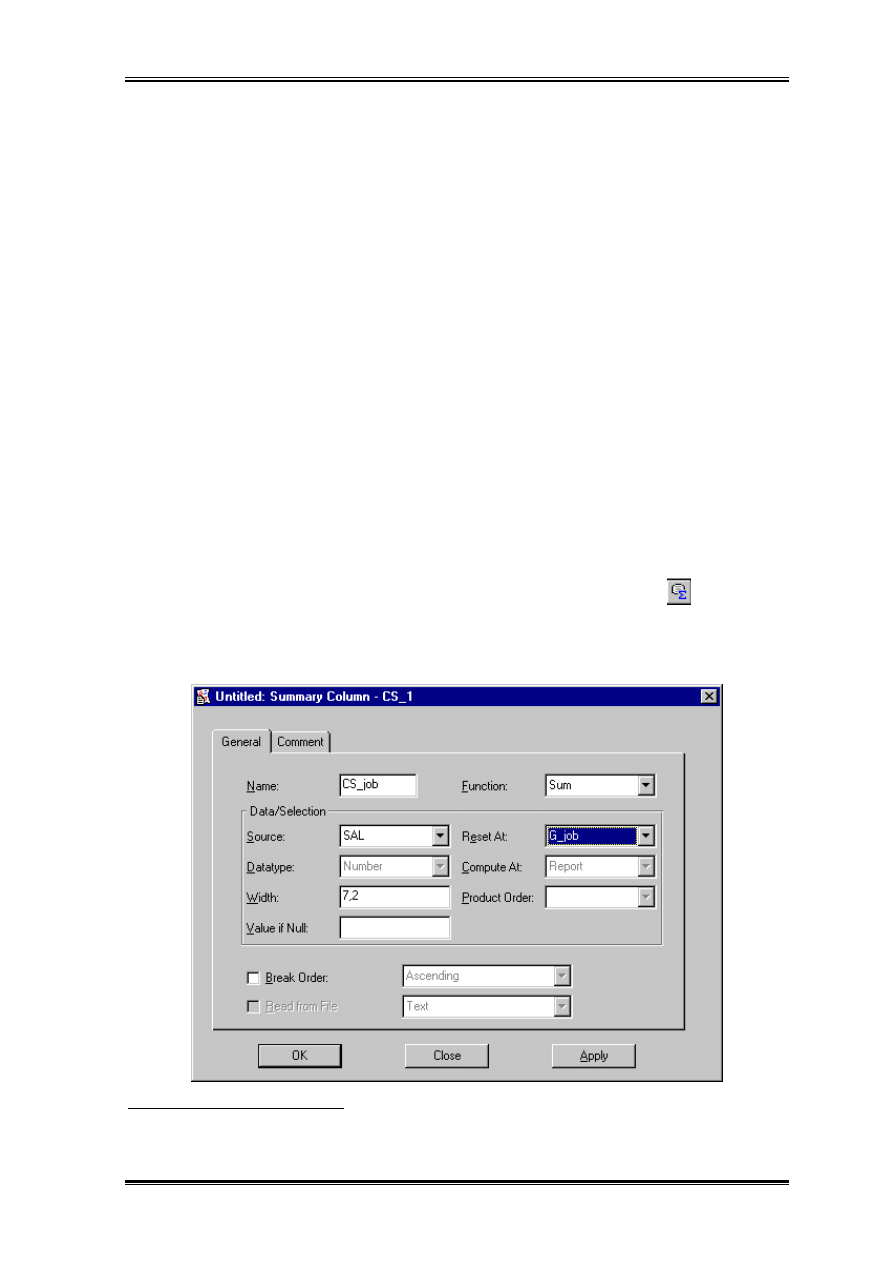
Wypełniamy je w sposób pokazany na rysunku. Poszczegolne właściwości oznaczają:
1
Wyjątkiem od tej sytuacji może być struktura klient-serwer raportów- serwer. Tego typu strukturę stosuje
się w przypadku gdy klient jest mało wydajny.

Budowa raportów
Strona 11
• Name – nazwa zapytania wykorzystywana jest dalej do nazwania grup danych.
• Maximum Rows – własność użyteczna tylko w przypadku testowania raportu na małej
ilości wierszy, w sytuacji kiedy zapytanie wykonuje się bardzo długo – należy
pamietać aby usunąć te wartość przed wysłaniem raportu do klienta.
• External Query – możliwe jest zapisanie tekstu polecenia w oddzielnym pliku.
Klikamy na Applay(Zastosuj). W modelu danych poniżej czarnego zaokrąglonego
prostokąta zapytania pojawił się prostokąt grupy. Jeżeli nazwaliśmy zapytanie Q_emp to
uzyskaliśmy grupę G_emp. Dalej konsekwetnie ta nazwa zostanie odziedziczona przez
graficzny obiekt – ramkę, będzie to ramka R_emp.
Rozkład domyślny
Rozkład raportu – jest to graficzny projekt przyszłego raportu, zawierający obiekty
określające sposób (kolor, kierunek itp) drukowania obiektów wystepujących w modelu
danych.
Tworzenie rozkładu raportu rozpoczynamy od kliknięcia na ikonę
Default Layout
(Rozkład Domyslny). Ukazuje nam się okno w którym wybieramy Tabular (Tabelaryczny)
i klikamy na przycisk OK.
Teraz pownien nam się ukazać rozkład gdzie poniżej etykiet leżą pola raportu. W
przypadku gdy danych w tabeli jest bardzo dużo lub szerokość strony jest waska może do
zawinięcia danych na rozkładzie – tzn. etykiety i pola które nie zmieściły się w pierwszym
wierszu umieszczane są w odpowiadających im ramkach rozpoczynając od lewej strony.
Podstawy
Strona 12
Modyfikacje rozkładu domyślnego
Jeżeli generator przygotował nam rozkład domyślny możemy skorzystać z narzędzi do
kolorowania obiektów. Są to po kolei wypełnianie obiektów kolorem, obrysowywanie
obiektów kolorem, kolorowanie trzcionek.
Zmiany formatów czcionki dokonujemy z menu Format/Font. Przykład zmodyfikowanego
rozkładu domyślnego znajduje się na poniższej ilustracji.
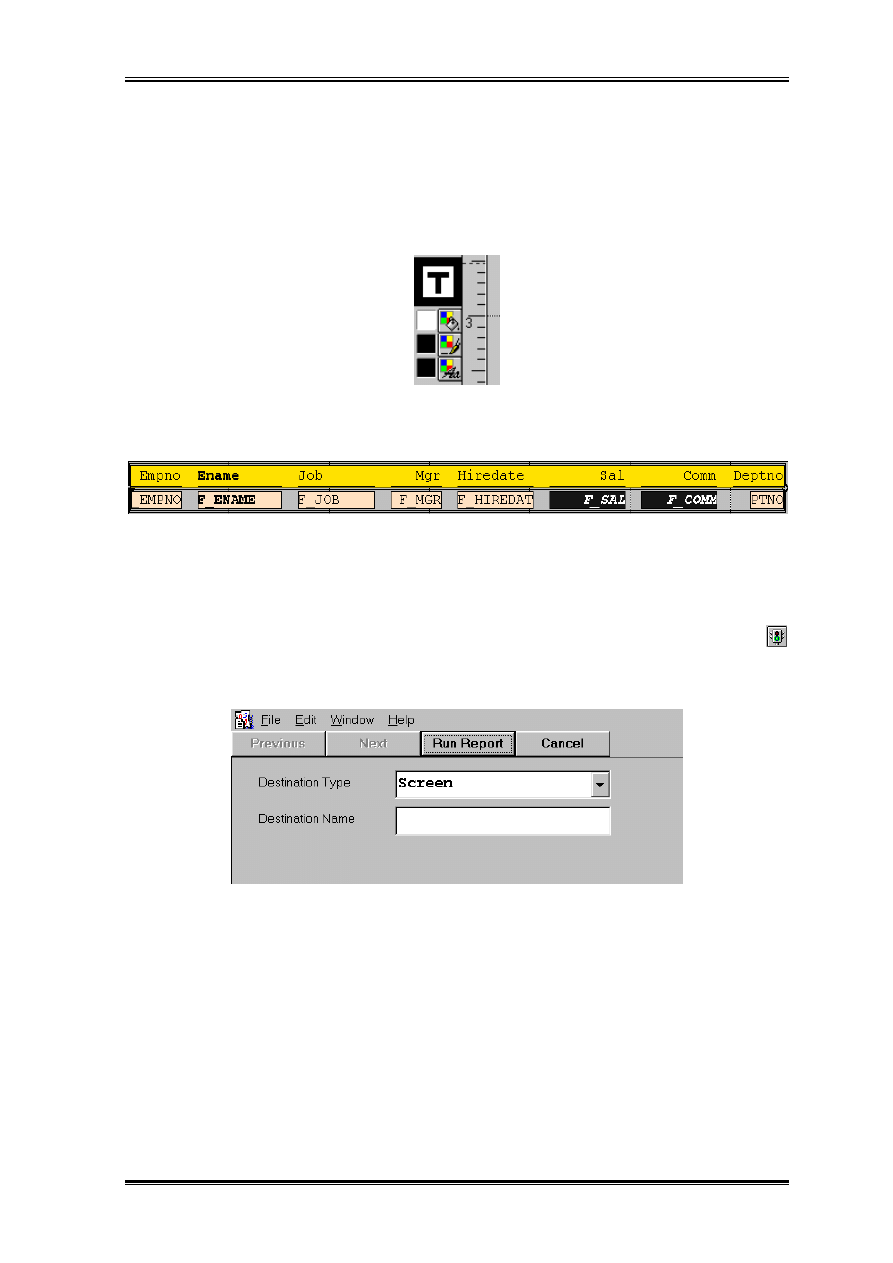
Uruchomienie raportu
Jeżeli rozkład odpowiada naszym oczekiwaniom możemy go uruchomić. Ikoną
uruchamiamy raport, pojawia się tak zwana formatka uruchomienia raportu. Na formatce
która się pojawiła klikamy na „Run Report”.
Teraz przed nami powinien pojawić się wykonany raport.

Budowa raportów
Strona 13
Widzimy że zapytanie które w SQL+ było w prostej formie tekstowej, teraz jest “ubrane”
w pewną formę graficzną. Wygenerowany “wydruk” możemy zamknąć(CLOSE) aby
przyjrzeć się strukturze ramek. Aby lepiej było ją widać rozsunąłem ramki
i pokolorowałem je nieco intensywniej:
Ramka czerwona to ramka obejmująca jej rola to pilnowanie położenia obiektów. Znaki
“dzwonek” na jej bokach to oznaczenie iż posiadaja zdolność do rozszerzania się w pionie.
Ramka koloru zielonego to ramka która drukuje się dla każdego wiersza wybranego w
zapytaniu. Ciemna strzałka na jej krawędzi ramki określa kierunek drukowania.


Łamanie i funkcje grupowe
Podstawy
Strona 16
Model danych
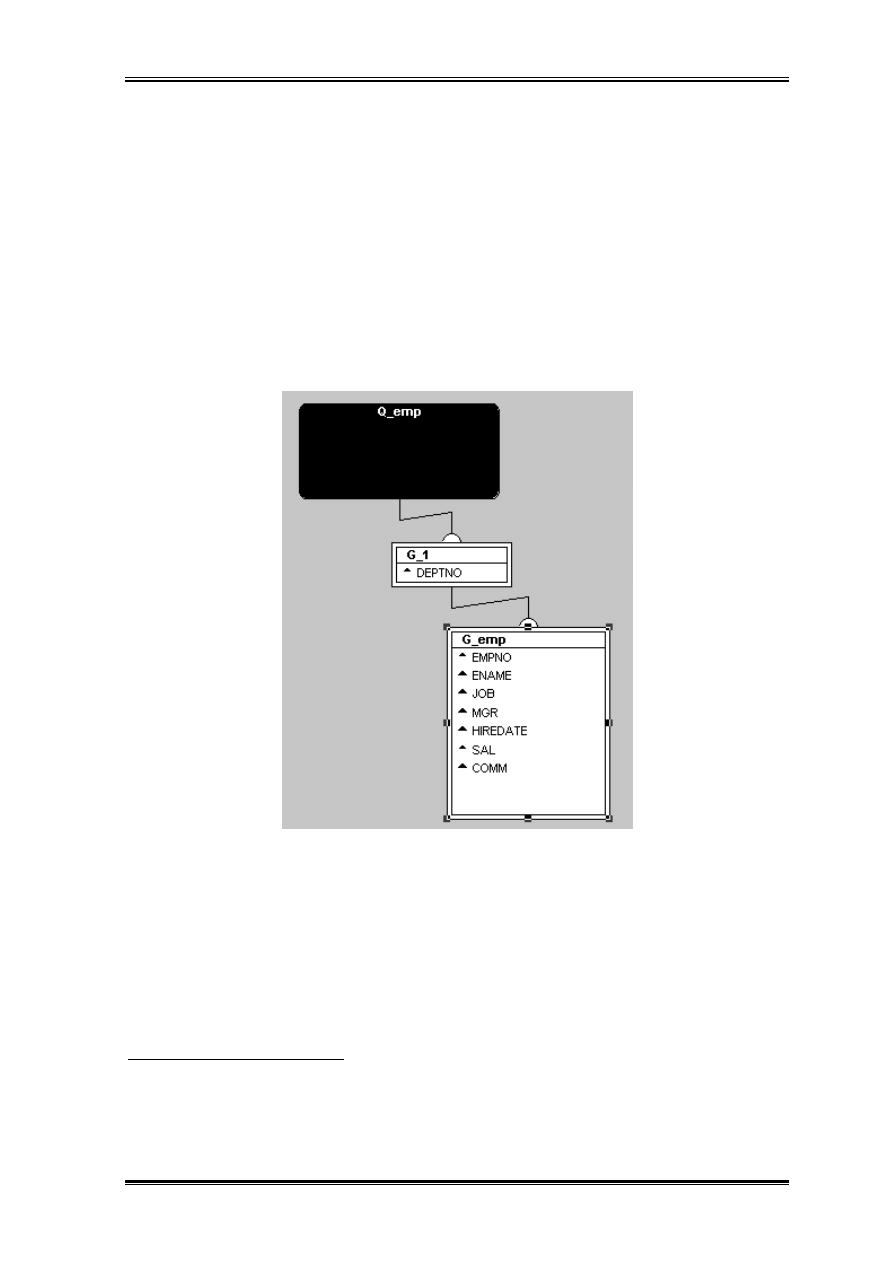
Operacja łamania może kojarzyć się z grupowaniem w SQL. Weźmy raport zbudowany
na:
SELECT *
FROM emp;
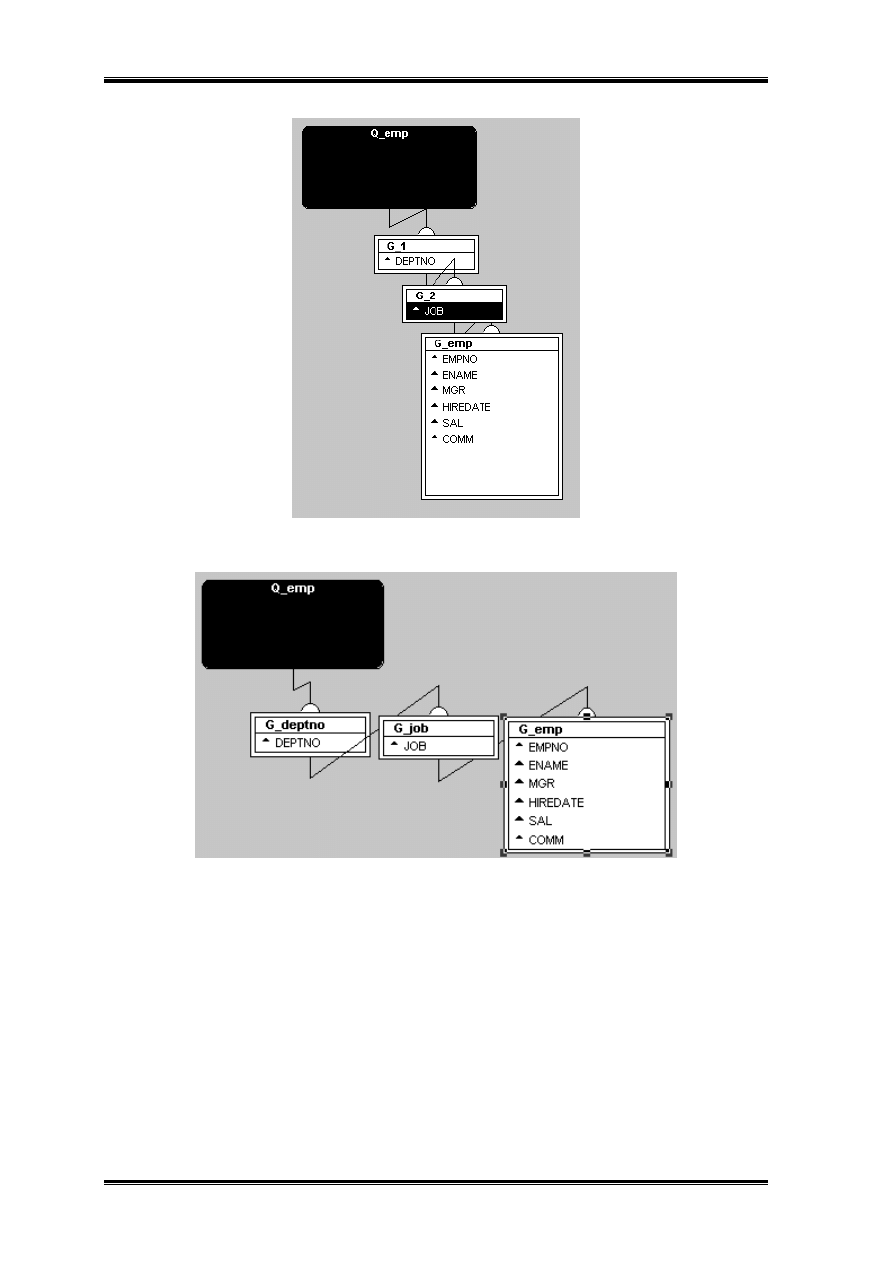
Dane pochodzące z tego raportu „połammy” ze względu na numer departamentu i zawód.
Powyższy wykres uzyskamy wyciągając z G_emp pola deptno i job.
Jednak różnica polega na tym że w odróżnieniu od grupowania łamanie nie powoduje
utraty dostępu do danych szczegółowych.
2
2
Efekt łamania i obliczania podsumowań jest dostępny w skryptach SQL+ - łamanie
instrukcją BRAKE ON, a obliczanie instrukcją COMPUTE jednak ze względu na istnienie
programów graficznych są one prawie zupełnie niewykorzystywane.
Budowa raportów
Strona 17
Teraz należy jeszcze „nazwać” grupy i uporządkować rozkład np. w następujący sposób:
Dobranie rozkładu domyślnego
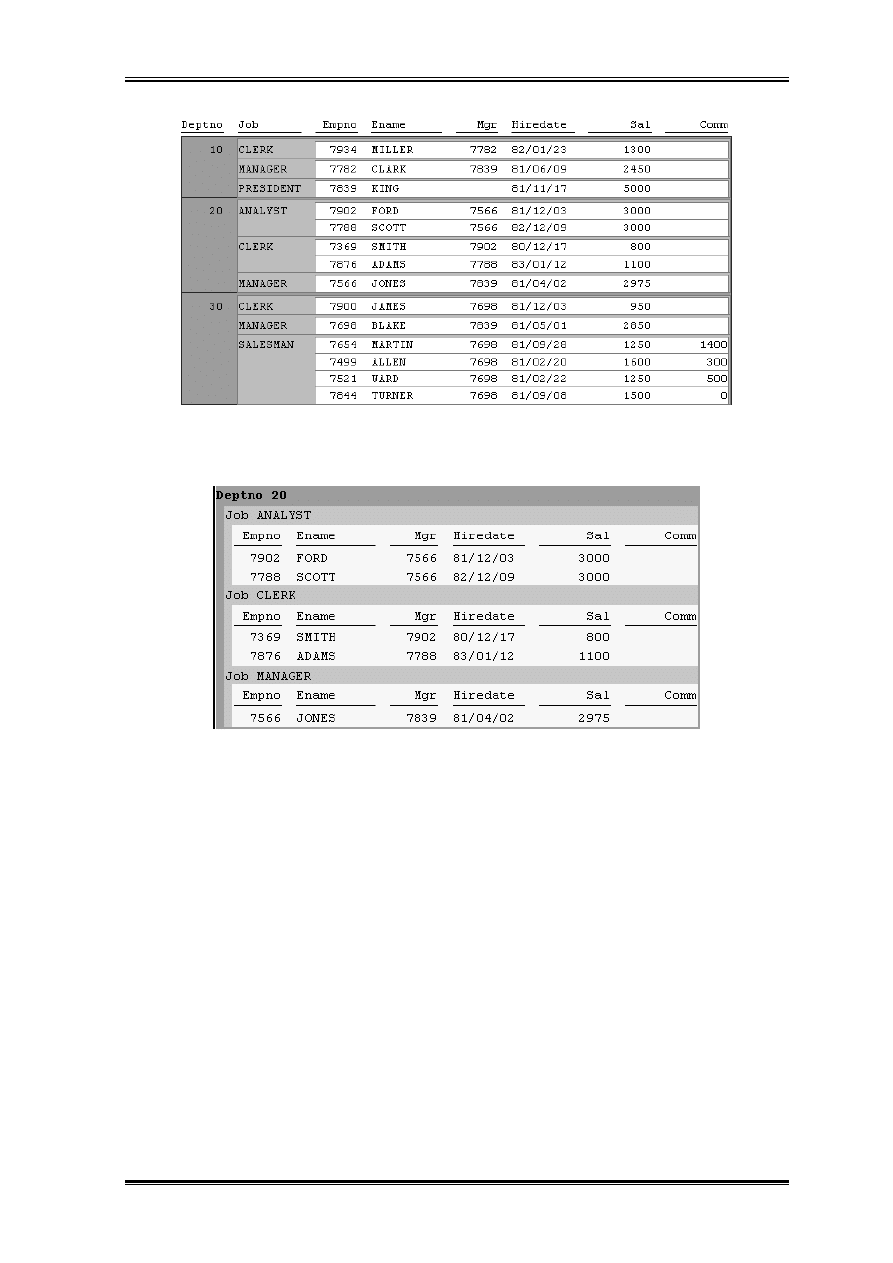
Do sporządzonego modelu danych możemy przygotować dwa rozkłady. Jeżeli wybierzemy
rozkład tabelaryczny to uzyskamy poniższy efekt: (Wartość rozpoczynająca każdą nową
grupę jest drukowana tylko raz).
Podstawy
Strona 18
Ze względu na wielkość prezentowany jest poniżej jedynie fragment rozkładu
nadrzędny-podrzędny (master-detail), rozkład wyglądający następująco:
Przygotowany w tym raporcie rozkład warto zachować do wykorzystania w następnym
rozdziale.

Budowa raportów
Strona 19
Funkcje grupowe w raportach
Podstawy
Strona 20
W tytule tego rozdziału pojawiło się hasło funkcje grupowe. Z tego typu funkcjami
mogliśmy mieć wcześniej do czynienia w SQL’u. Czy jest to więc drugi raz to samo?
Okazuje się że nie. Funkcje grupowe wykorzystywane w SQL redukowały każdą grupę do
jednego wiersza. Dane z serwera miały być zwrócone w postaci tabelki, nie mieliśmy
możliwości odniesienia się do poszczególnych elementów z grup.
3
W funkcjach
grupowych w raportach działamy na kliencie, nie tracimy informacji o elementach grup.
Podsumowania
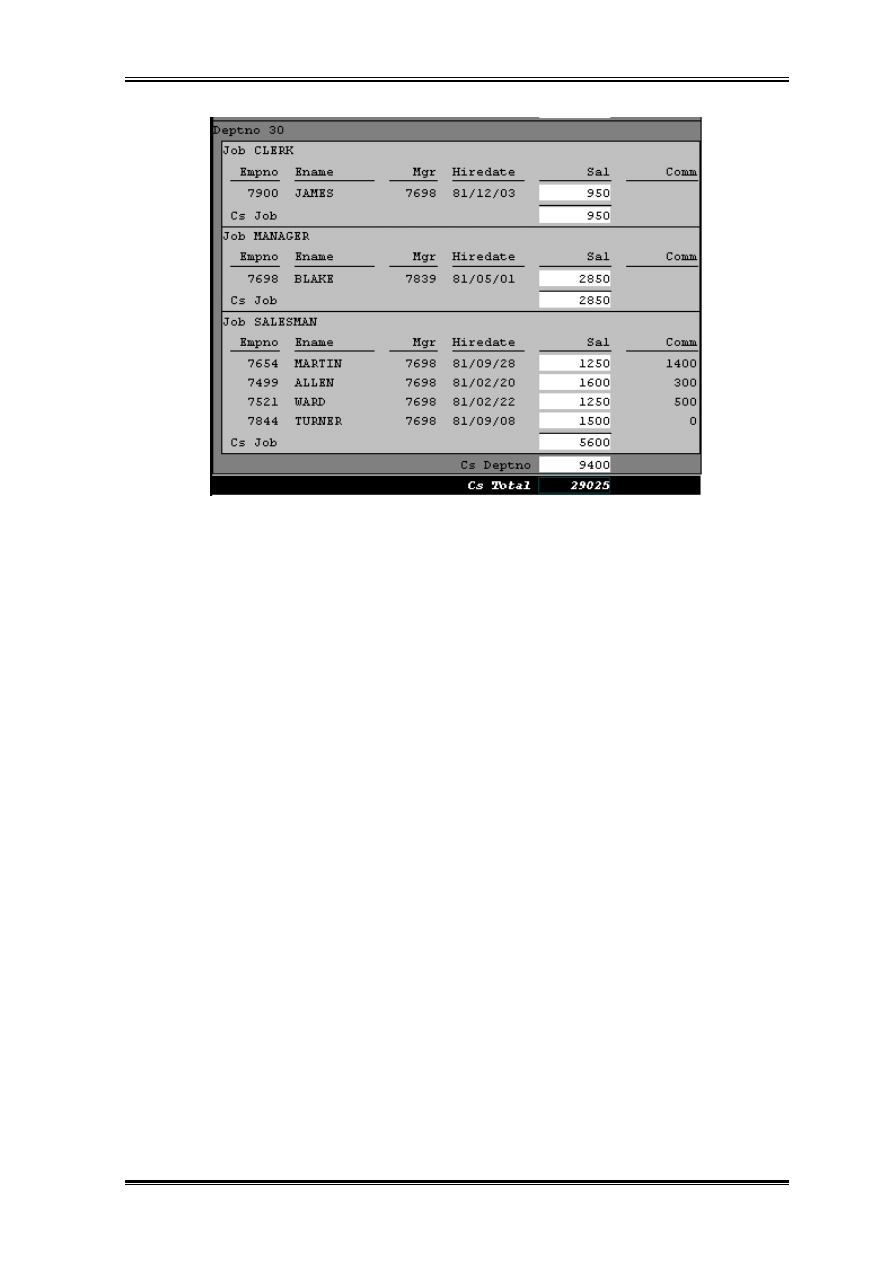
Aby zrozumieć istotę działania funkcji grupowych przeanalizujmy następujący problem.
Dla modelu danych z poprzedniego rozdziału przygotujmy raport z podsumowaniami:
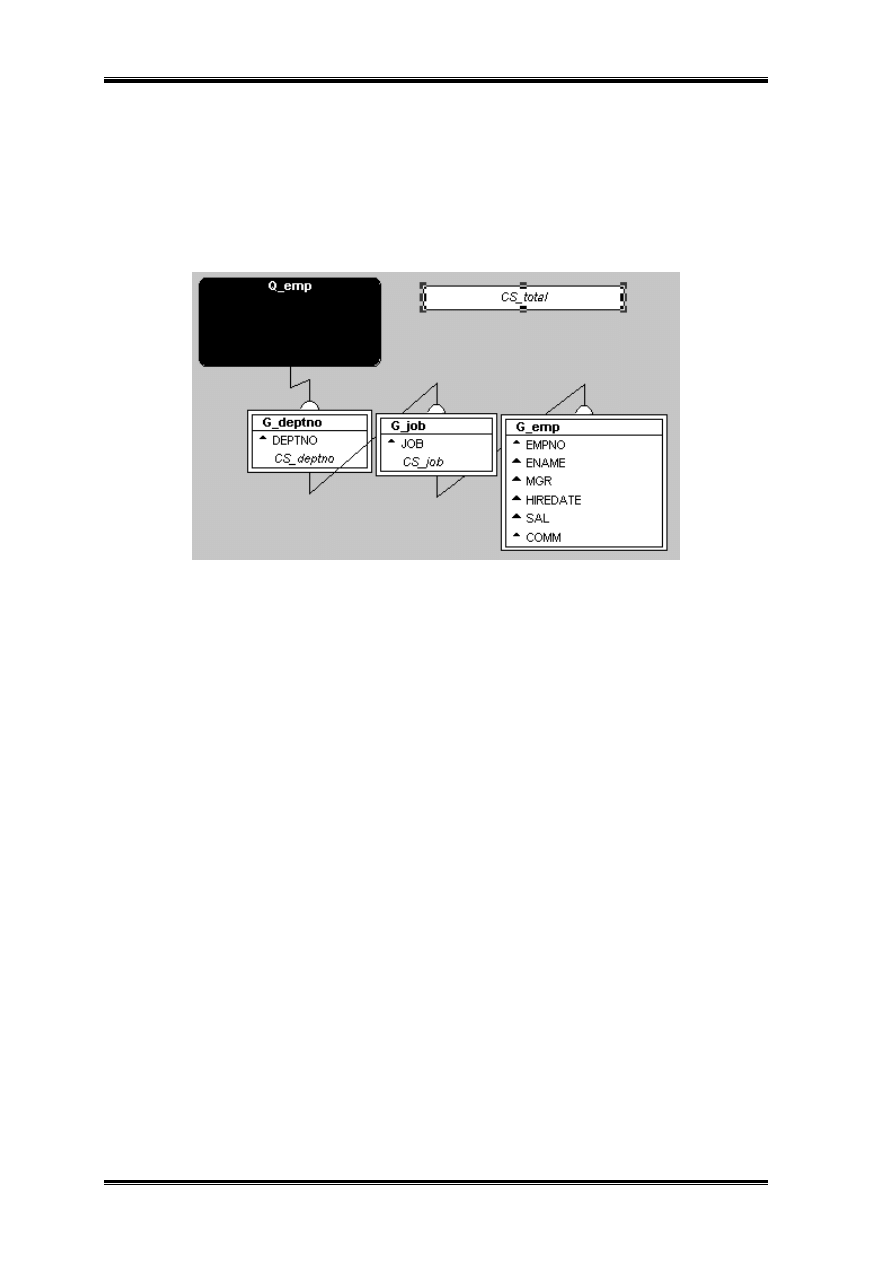
CS_total – sumaryczna kwota pensji w firmie
CS_deptno – sumaryczna kwota pensji w każdym departamencie
CS_job – sumaryczna kwota pensji w każdym departamencie przypadająca na dane
stanowisko.
śą
dane sumy musimy przygotować w Modelu Danych. W tym celu rozciągam nieco w dół
prostokąty G_deptno i G_job tak abym mógł korzystając z narzędzia
umieścić na
każdym z poziomów sumy.
Pierwsza suma CS_job niech będzie sumą SAL zerowaną co G_job.
3
NP. SELECT job, max(sal) FROM emp GROUP BY job; - nie możemy w tej instrukcji dopisać kolumny
ename po słowie SELECT .... – w koneksie grupy ta informacja jest niedostępna.
Budowa raportów
Strona 21
Kolejna suma CS_deptno niech będzie sumą w obrębie departamentu. Mogła by to być
również suma po kolumnie sal ale zredukujemy ilość obliczeń czyniąc ja sumą po CS_job
zerowaną co G_DEPTNO. Sumaryczna kwota wypłacanych pensji w firmie to oczywiście
CS_total zerowana dla raportu i sumująca sumy wyliczone w poszczególnych
departamentach.(Cechą intuicyjnie nie do końca oczywistą jest fakt iż CS_total leży
niejako poza bloczkiem zapytania.)
Inne funkcje grupowe
Inne funkcje dostępne oprócz sumy to min.:
-
średnia
-
ilość elementów
-
procent całości
-
min
-
max
-
pierwszy z grupy
-
ostatni z grupy
-
wariancja
Rozkład
Do tak przygotowanego modelu proponuje wybrać rozkład nadrzędny-podrzędny. Wydruk
raportu możemy mieć następującą formę (fragment):
Podstawy
Strona 22

Budowa raportów
Strona 23
Łączenie zapytań
Podstawy
Strona 24
Raport nadrzędny-podrzędny
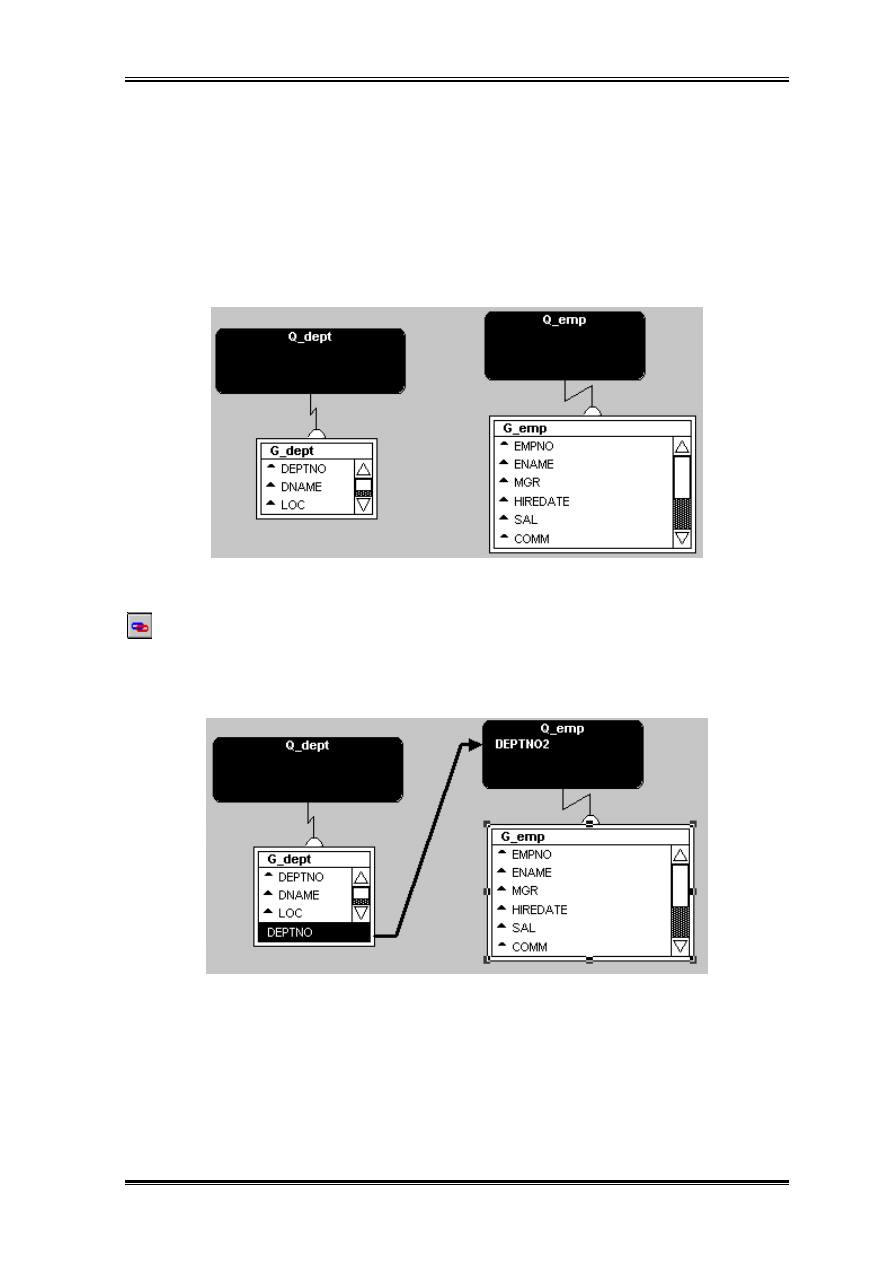
Inna metoda uzyskania raportu master-detail dla tablic Dept i Emp to połączenie dwóch
zapytań za pomocą narzędzia Link.
- narzędzie za pomocą którego łączymy zapytania
Za pomocą wspomnianego narzędzia ciągniemy linie od deptno w Q_dept do deptno w
Q_emp.
Teraz dla każdego znalezionego wiersza w pierwszym zapytaniu uruchamiane będzie
przeszukiwanie tablicy emp.
Struktura raportu jest może nieco przejrzystsza niż przy zredukowanej ilości zapytań.
Niejednokrotnie również raport działa szybciej szczególnie wtedy gdy wielkość i ilość

Budowa raportów
Strona 25
pozyskiwanych danych w zapytaniu nadrzędnym jest stosunkowo duża a w podrzędnym
mniejsza.

Podstawy
Strona 26

Budowa raportów
Strona 27
Kolumny formuł i wypełniające

Podstawy
Strona 28
W tym rozdziale zapoznamy się z dwoma obiektami modelu danych:
- kolumna formuły
- kolumna wypełniająca
Kolumny formuł
Kolumna formuły to funkcja liczona każdorazowo przy nowej instancji elementu tabeli lub
grupy łamania. Raport którego budowę prześledzimy w tym rozdziale powstał poprzez
usuniecie grupy G_job i kolumny sumującej w tej grupie.
Korzystając z ikony umieszczamy w grupie G_emp funkcje. Przyjmijmy, że jest to
funkcja obliczająca pensje pracownika brutto w ciągu całego roku. Funkcja zwraca wartość
v_brutto dla każdego nowego wiersza wybranego instrukcją SELECT.
function CF_bruttoFormula return Number is
v_annual NUMBER(9,2);
begin
v_annual := 12*:sal+nvl(:comm,0);
return v_annual;
end;
Zwróćmy uwagę że jeżeli w kodzie pojawia się odniesienie do zmiennej zewnętrznej
stosujemy notację z dwukropkiem.
Kolumna wypełniająca
Funkcja zwraca jedną wartość, przypuśćmy jednak że zależy nam aby w tej funkcji
wyliczyć dwie wartości. Można by taki efekt uzyskać gdyby na poziomie każdego wiersza
istniała zmienna której wartość mogłaby być ustawiana na poziomie każdego wiersza
pobranego w zapytaniu. Rolę takiej zmiennej może pełnić pełni kolumna wypełniająca.
Umieśmy kolumnę CP_ofe na poziomie grup G_emp. Teraz zmodyfikujmy ciało funkcji
tak aby CP_ofe stanowiło 40 % kwoty zarobków pracownika.
function CF_bruttoFormula return Number is
v_annual NUMBER(9,2);
begin
v_annual := 12*:sal+nvl(:comm,0);
:CP_ofe := 0.4*v_annual;
return v_annual;
end;
Skoro raport dotyczy zarobków rocznych logicznym jest aby zmienić źródło sumowania
CS_deptno z sal na CF_brutto.

Budowa raportów
Strona 29
Ponieważ nastąpiło wiele zmian w modelu danych najłatwiej będzie przygotować nowy
rozkład korzystając z rozkładu domyślnego.
Wyjątki
Przyjrzyjmy się następującej sytuacji. Niech będzie dany raport wybierający wszystkie
dane wiersze z tablicy emp. W procedurze CF_mgr_name chcielibyśmy obliczać nazwiska
wybranych pracowników.
Raport składa się z jednej grupy w której umieszczamy procedurę następującej treści:
function CF_mgr_nameFormula return Char is
v_mgr_ename emp.ename%TYPE;
begin
SELECT ename
INTO v_mgr_ename
FROM emp
WHERE empno = :mgr;
return v_mgr_ename;
end;
Czytelnika nie znającego PL/SQL zastanowiać może deklaracje v_mgr_name. Ten rodzaj
deklaracji to chrakterystyczny właśnie dla PL/SQL, zmienna będzie takiego typu jak
kolumna ename w tablicy emp.
Procedura kompiluje się tak jak i cały raport. Przygotowujemy rozkład domyślny i
uruchamiamy raport i ... dostajemy informację o wystąpieniu sytuacji wyjątkowej.

Podstawy
Strona 30
Jaka to sytuacja wyjątkowa? Oczywiście KING pracownik który nie posiada szefa. Tę
sytuację należy w jakiś sposób obsłużyć, dokonujemy tego w bloku obsługi wyjątków.
Sytuacja wyjątkowa pojawia się w instrukcji SELECT ...INTO..., następnie sterowanie
przechodzi do bloku obsługi wyjatków.
function CF_mgr_nameFormula return Char is
v_mgr_ename emp.ename%TYPE;
begin
SELECT ename
INTO v_mgr_ename
FROM emp
WHERE empno = :mgr;
return v_mgr_ename;
exception
when NO_DATA_FOUND then
v_mgr_ename := 'THE BOSS';
return v_mgr_ename;
end;
Zapobiegliwy programisty mógłby jeszcze dodać obsługę wszystkich innych wyjątków:
function CF_mgr_nameFormula return Char is
v_mgr_ename emp.ename%TYPE;
begin
SELECT ename
INTO v_mgr_ename
FROM emp
WHERE empno = :mgr;
return v_mgr_ename;
exception
when NO_DATA_FOUND then
v_mgr_ename := 'THE BOSS';
return v_mgr_ename;
when OTHERS then
v_mgr_ename := 'STRANGE !!!';
return v_mgr_ename;
end;

Budowa raportów
Strona 31
Ostatecznie interesujący nas raport będzie miał formę jak na poniższym
rysunku(fragment):

Podstawy
Strona 32

Budowa raportów
Strona 33
Raport Macierzowy
Podstawy
Strona 34
Raport macierzowy na trzech zapytaniach
Raport macierzowy to rodzaj raportu w którym dla pewnych dwóch
4
wymiarów
drukowanych jeden w poziomie, drugi w pionie na ich przecięciu umieszczane są wartości
przecięcia.
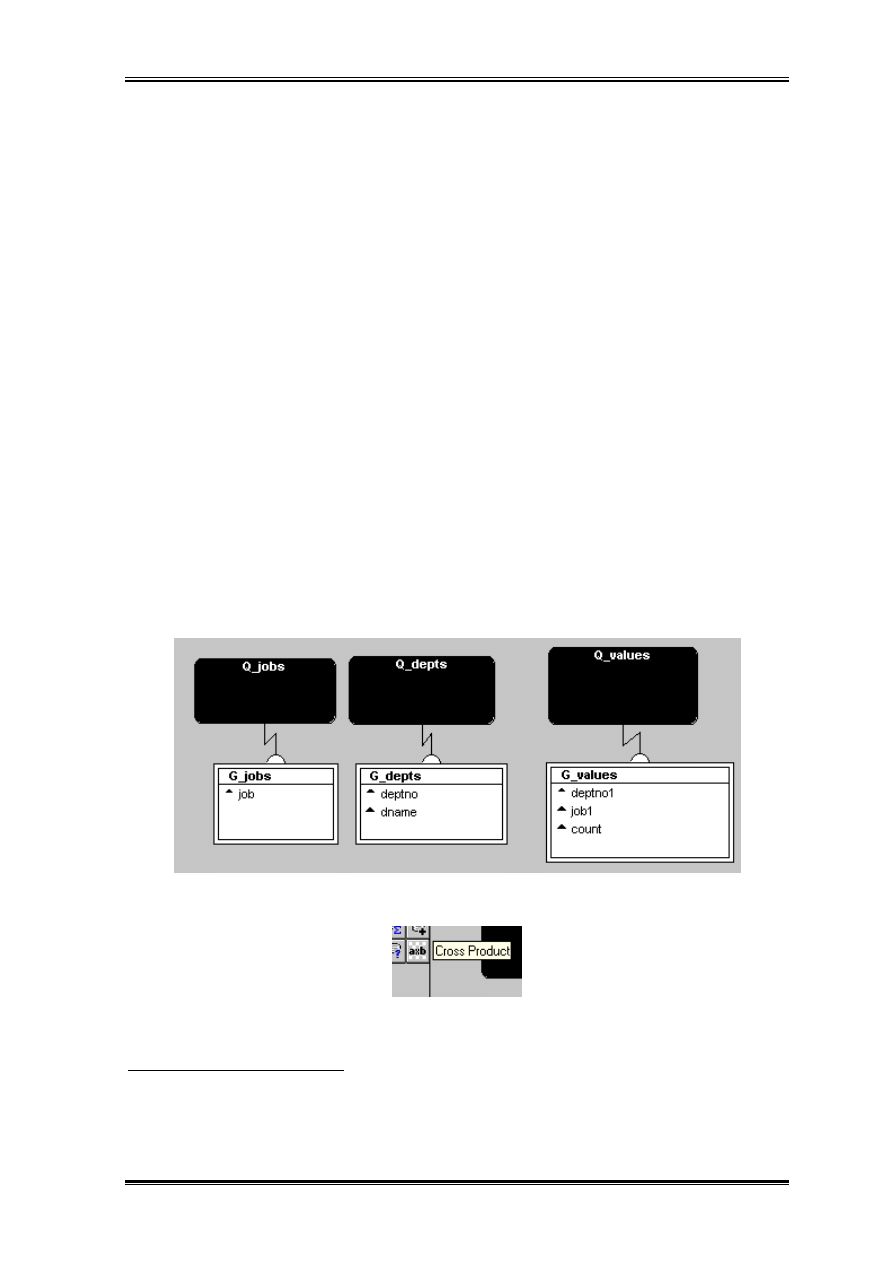
Przygotowanie raportu rozpocznijmy od skonstruowania zapytań wybierających wymiary
przyszłego raportu. Niech Q_jobs wybiera wszystkie zawody w firmie, a Q_depts
wszystkie numery i nazwy departamentów.
Zapytania będą miały postać:
SELECT DISTINCT job
FROM emp;
SELECT deptno, dname
FROM dept;
Trzecie zapytanie Q_values musi przygotowywać trójki
5
x,y, f(x,y). Wartość f(x,y) będzie
to w naszym przypadku ilość osób w danym departamencie na danym stanowisku, równie
dobrze mogła by to być sumaryczna czy średnia wartość zarobków itp.
SELECT deptno, job, count(*)
FROM emp
GROUP BY deptno, job;
Teraz dwa pierwsze zapytania należy przykryć obiektem zwanym produktem krzyżowym.
Teraz rozciągamy prostokąt produktu krzyżowego tak aby przykryć grupy G_jobs i
G_depts. Tak utworzoną nową grupę nazywam G_matrix.
4
Można wyobrazić sobie raport macierzowy dla trzech i więcej wymiarów jednak ze względu na
dwuwymiarowość papieru może być to tylko np. raport gdzie każdy nowa wartość zmiennej Z spowoduje
np. otwarcie nowej strony raportu.
5
Na następnych stronach będzie opisana konstrukcja raportu macierzowego wyłącznie na jednym zapytaniu.
Budowa raportów
Strona 35
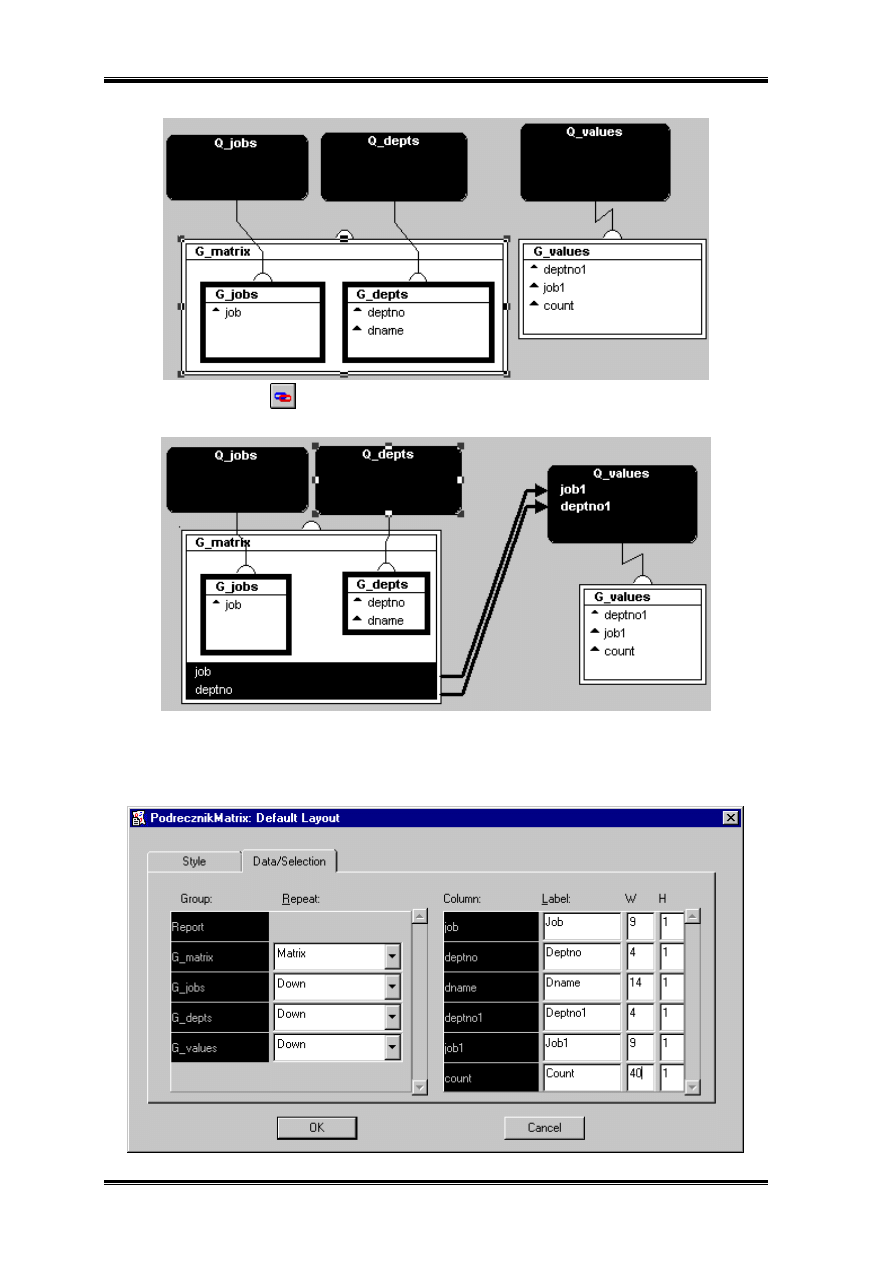
Teraz przy pomocy
łączę odpowiednie pola z G_matrix do odpowiednich pól
G_values.
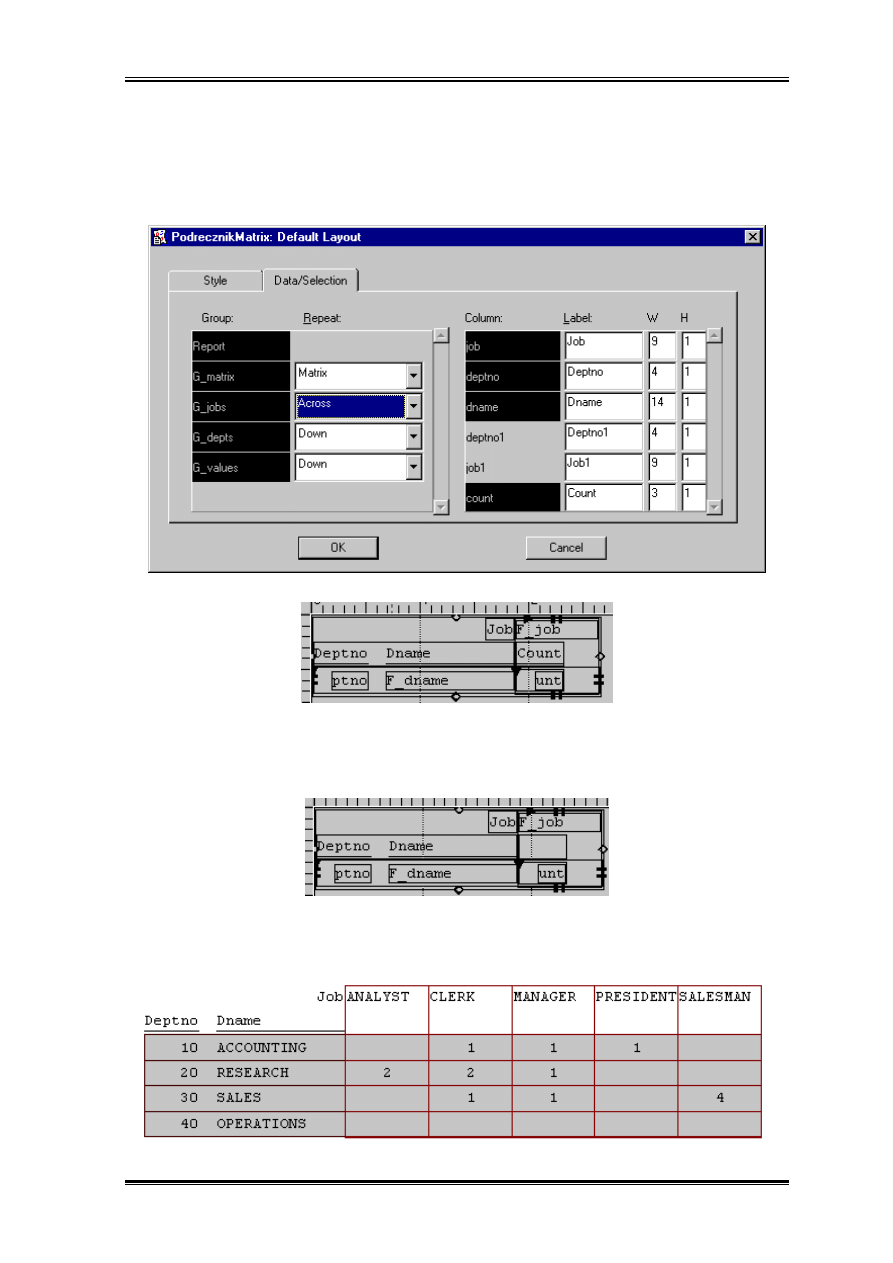
Teraz możemy przystąpić do generacji domyślnego rozkładu – będzie to oczywiście
rozkład macierzowy(matrix). Warto zwrócić uwagę, że pozostałe domyślne ustawienia
wymagają przestawienia.
Podstawy
Strona 36
Na drugiej zakładce musimy wybrać która grupa będzie drukowana wszerz. W rozkładzie
domyślnym na przecięciu deptno i job wpisywane są zarówno deptno, job, count(*) z
dwóch pierwszych wartości warto zrezygnować – raport stanie się czytelniejszy. Również
przestrzeń rezerwowana na wyniki obliczeń count(*), 40 znaków jest stanowczo za duża,
nawet gdyby w emp było do 1000 rekordów wystarczyły by 3 znaki.
Bo dokonaniu tych zmian wygenerujmy rozkład.
W rozkładzie tym również dokonuję kilku zmian, o znaczeniu raczej kosmetycznym dzięki
czemu raport stanie się czytelniejszy. Przede wszystkim należy wprowadzić ramki dzięki
czemu wyraźnie widać kolumny i wiersze. Usuwam również szablon tekstowy count.
W wyniku tych zmian ostatecznie otrzymuję.

Budowa raportów
Strona 37
Problem pustych miejsc
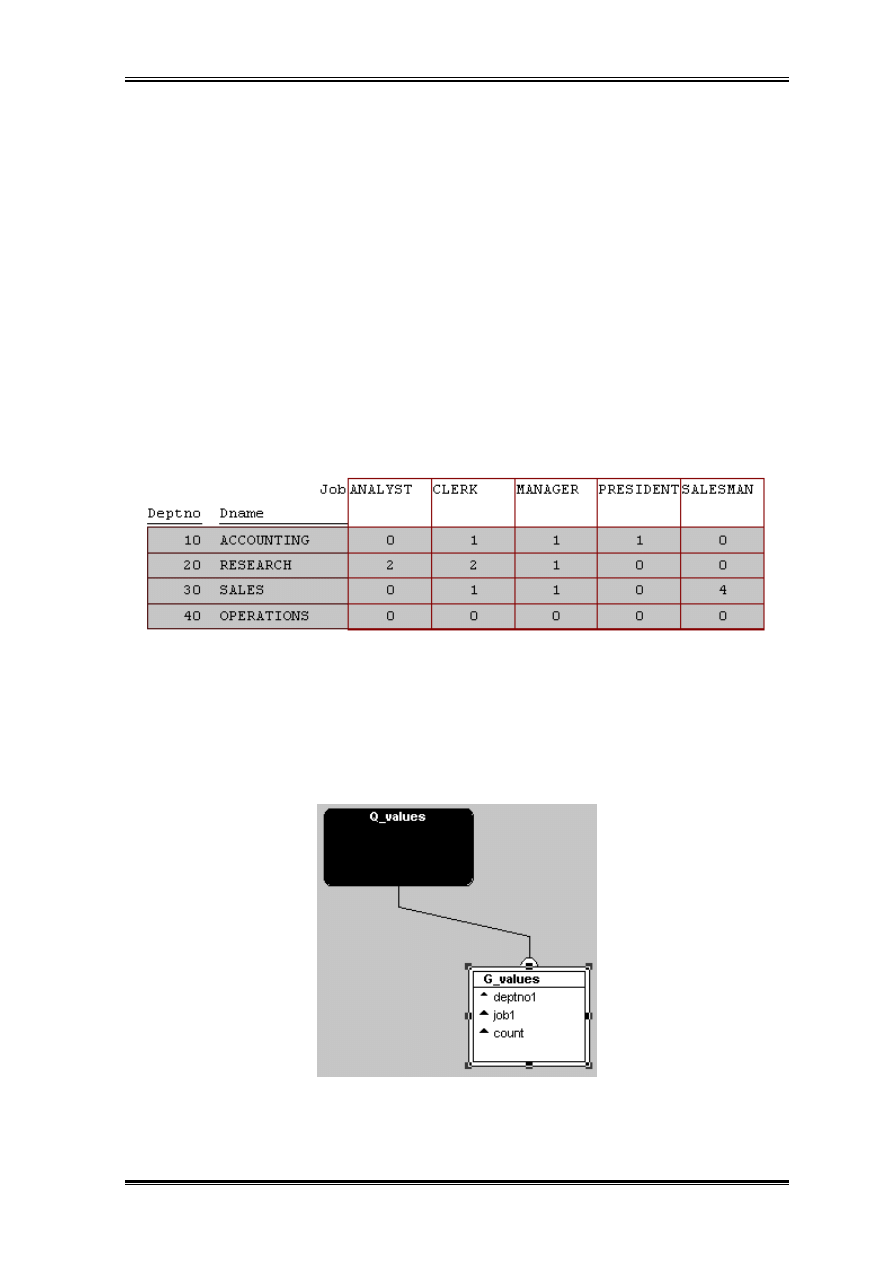
Jednym z problemów w raportach Developera 2000 który często pojawia się na listach
dyskusyjnych są puste miejsca. Wynikają one z tego, iż wartości raportów ustalone są
tylko tam gdzie dla x i y istnieje pewna wartość f(x,y). Jak jeżeli przyjrzymy się
poniższemu zapytaniu widzimy, że wyznacza ono tylko 9 wartości. Oznacza to że 11
komórek raportu pozostanie pustych.
SQLWKS> SELECT deptno, job, count(*)
2> FROM emp
3> GROUP BY deptno, job;
DEPTNO JOB COUNT(*)
---------- --------- ----------
10 CLERK 1
10 MANAGER 1
10 PRESIDENT 1
20 ANALYST 2
20 CLERK 2
20 MANAGER 1
30 CLERK 1
30 MANAGER 1
30 SALESMAN 4
9 wierszy wybranych.
Istnieją sztuczki graficzne typu graficzne zero które pokazuje się we wszystkich nie
zadrukowanych komórkach. Sztuczka ta czasem się udaje ale jest to uzależnione np. od
sterowników drukarki. Formalne rozwiązanie tego problemu polega jednak na takim
zmodyfikowaniu zapytania aby wybierało te dodatkowe zera dla tych przecięć deptno i job
dla których nie ma żadnej danej.
SELECT deptno, job, count(*)
FROM emp
GROUP BY deptno, job
UNION
SELECT D.deptno, E.job, 0
FROM dept D, emp E
WHERE (D.deptno,E.job) NOT IN (SELECT deptno, job
FROM emp
GROUP BY deptno, job);
Powyższe zapytanie sumuje poprzez UNION [DISTINCT] te przecięcia dla których są
dane z zapytaniem, w którym uzyskano iloczyn kartezjański kolumny job i wszystkich
numerów departamentów eliminując zbędne zestawienia poprzez umieszczenie nieco
zmodyfikowanego pierwszego zapytania w klazuli WHERE zapytania drugiego. Duplikaty
zwracane przez drugie zapytanie zostały wyeliminowane przez UNION
6
.
Zmodyfikowane zapytanie wybiera.
DEPTNO JOB COUNT(*)
---------- --------- ----------
10 ANALYST 0
10 CLERK 1
10 MANAGER 1
6
UNION – domyślnie UNION jest to UNION DISTINCT czyli suma zbiorów w sensie znanym na z
matematyki, nie domyślne zachowanie UNION można by uzyskać poprzez zastosowanie UNION ALL
wtedy w sumie elementy powtarzające się pozostałyby.
Podstawy
Strona 38
10 PRESIDENT 1
10 SALESMAN 0
20 ANALYST 2
20 CLERK 2
20 MANAGER 1
20 PRESIDENT 0
20 SALESMAN 0
30 ANALYST 0
30 CLERK 1
30 MANAGER 1
30 PRESIDENT 0
30 SALESMAN 4
40 ANALYST 0
40 CLERK 0
40 MANAGER 0
40 PRESIDENT 0
40 SALESMAN 0
Modyfikacja zapytania nie spowoduje zmiany działania raportu i konieczności
modyfikowania raportu. Po rozbudowaniu zapytania możemy od razu obejrzeć oczekiwane
zera na ekranie.
Raport o zredukowanej ilości zapytań
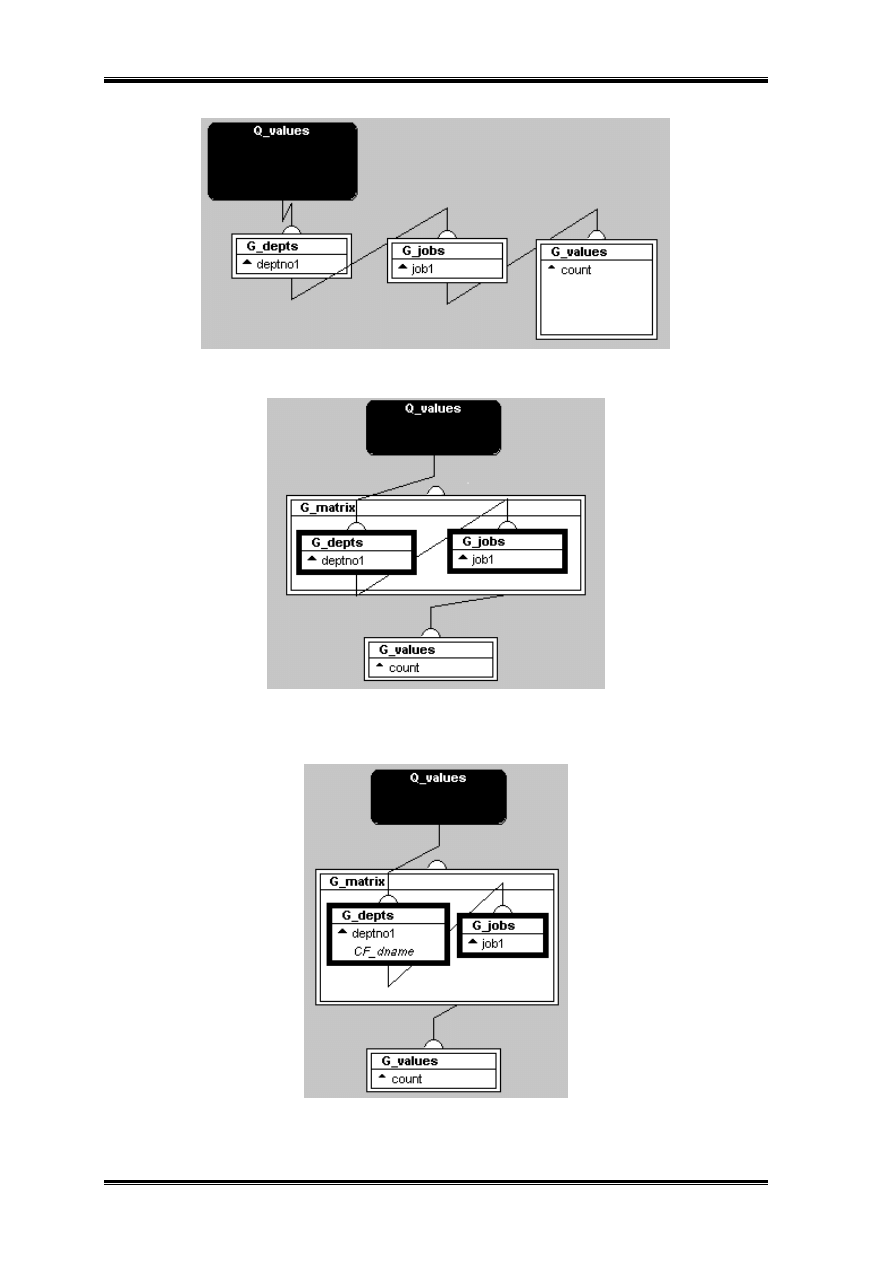
Spróbujmy stworzyć ten sam raport na mniejszej ilości zapytań. Zatem jedno zapytanie
musi zwracać trójki.
Z bloczek zwracający trójki musimy połamać.
Budowa raportów
Strona 39
Teraz na dwie pierwsze grupy nakładamy produkt krzyżowy. Po uporządkowaniu
uzyskuję:
Funkcjonalnie raport nie różni się od poprzedniego. Problemem może być ujedynie
uzyskanie deptno za pomocą kolumny formuły.
Gdzie ciało funkcji:
function CF_dnameFormula return Char is

Podstawy
Strona 40
v_dname varchar2(20);
begin
SELECT dname
INTO v_dname
FROM dept
WHERE deptno = :deptno1;
return v_dname;
end;
Druga możliwość to modyfikacja zapytania na przykład do postaci:
SELECT dname, job, count(*)
FROM emp E, dept D
WHERE E.deptno=D.deptno
GROUP BY dname, job
UNION
SELECT D.dname, E.job, 0
FROM dept D, emp E
WHERE (D.deptno,E.job) NOT IN (SELECT deptno, job
FROM emp
GROUP BY deptno, job);

Budowa raportów
Strona 41
Programowe sterowanie wydrukiem
Podstawy
Strona 42
Programowe wyłączenie
Zdarza się że dopiero w czasie drukowania raportu pewne ramki dla pewnych danych nie
muszą być w ogóle drukowane. Może to być np. raport opisujący korzystanie z pewnych
usług. W sumie ukazuje się, że osoby korzystające z tych usług mogły to robić, za darmo i
nie są nam na wydruku potrzebne.
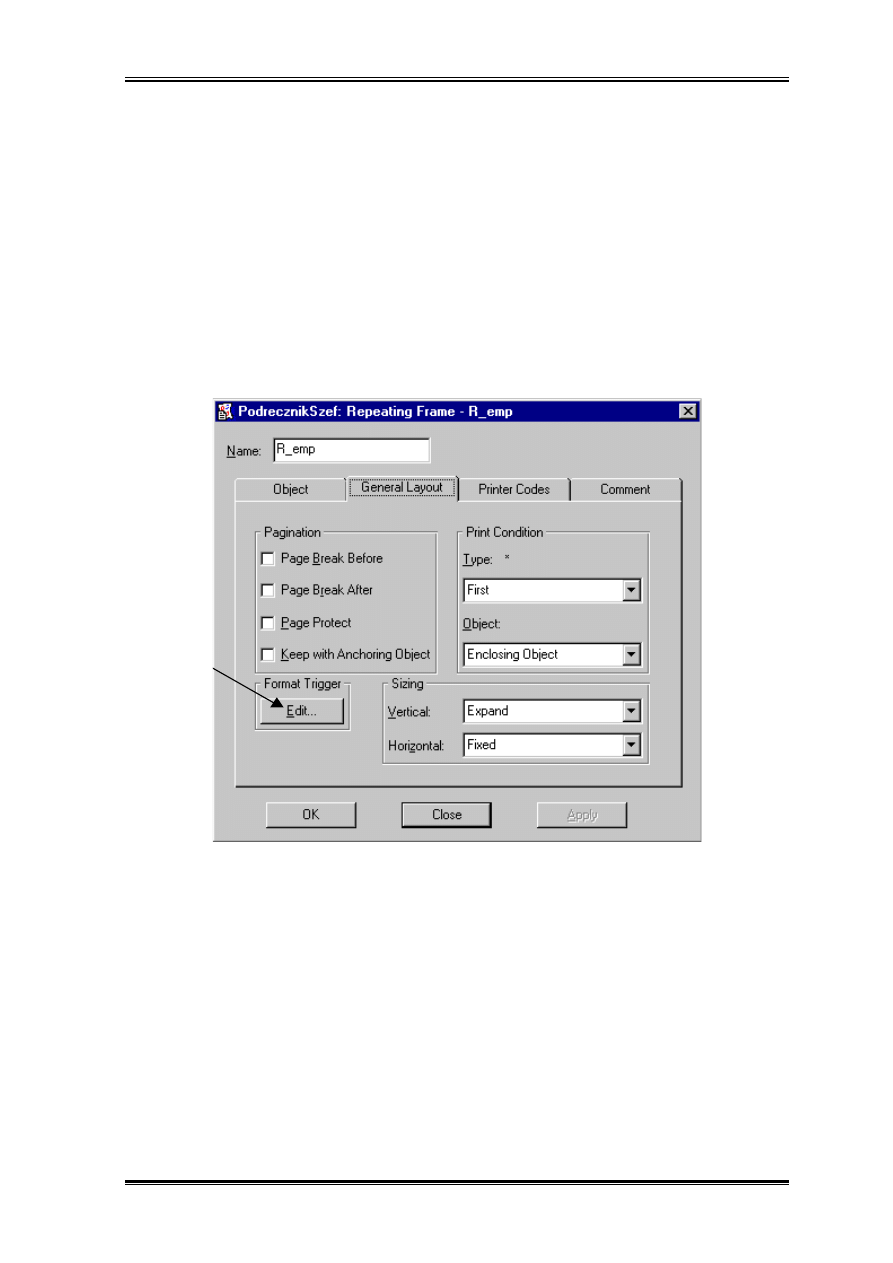
Dla przykładu spróbujmy wyeliminować KINGA z wydruku. W tym celu w możemy
przerobić raport w którym w funkcji znajdowaliśmy nazwisko szefa. Stajemy na ramce
R_emp i wyświetlamy jej właściwości. Przechodzimy na drugą zakładkę.
Następnie klikamy na w bloku Foramat Trigger na przycisk Edit. Pokazuje się nam
okienko do wpisywania kodu PL/SQL. Wpisujemy:
function R_empFormatTrigger return boolean is
begin
if :mgr is null then
return (FALSE);
else
return (TRUE);
end if;
end;
Aby przekonać się że wyzwalacz faktycznie jedynie ukrywa (usuwa z drukowani) ramki
R_emp warto umieścić sumę pensji wszystkich pracowników. Wtedy wyraźnie widać, że
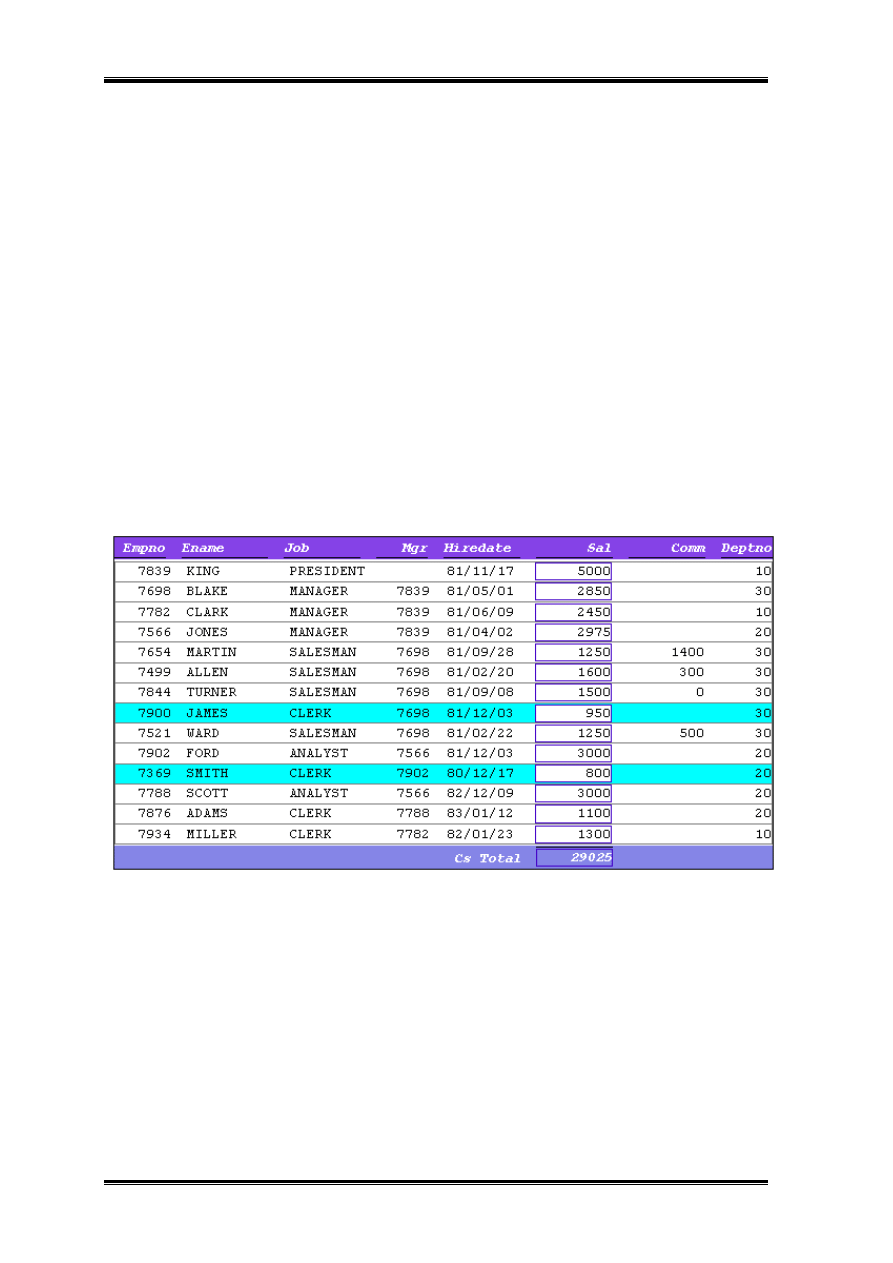
Budowa raportów
Strona 43
pensja KINGA, 5000 jest brana pod uwagę w obliczeniach, ale sam wiersz KINGA nie jest
drukowany.
Formatowanie warunkowe
Jeżeli chcielibyśmy pewne rekordy wyróżnić na wydruku np. pracownicy o dochodach
poniżej tysiąca byli drukowani innym atrybutem wizualnym korzystamy z funkcji z
wbudowanego pakietu SRW.
W wymienionym na poprzedniej stronie wyzwalaczu umieszczamy kod który zmieni kolor
drukowania wszystkich tych ramek wewnątrz których pensja jest mniejsza od 1000.
function R_empFormatTrigger return boolean is
begin
if :sal < 1000 then
srw.attr.bfcolor := 'cyan';
srw.set_attr(0, srw.attr);
end if;
return (TRUE);
end;
Warto zaglądnąć do pakiety SRW nie tylko wtedy kiedy programowo zmieniamy kolory
czy czcionkę ale również wtedy kiedy chcemy wyświetlić w czasie wykonywania raportu
wiadomość czy wykonać w bazie instrukcje DML (np. po to aby odnotować w jakiejś
tablicy fakt uruchomienia raportu).

Podstawy
Strona 44

Budowa raportów
Strona 45
Uruchamianie raportu z parametrem
Podstawy
Strona 46
Parametr uruchomienia raportu.
Raport może sam pobierać swoje parametry z formatki wywołania raportu lub może je
otrzymać z .zewnętrznego uruchamiającego go programu. Wtedy formatka parametrów nie
jest pokazywana.
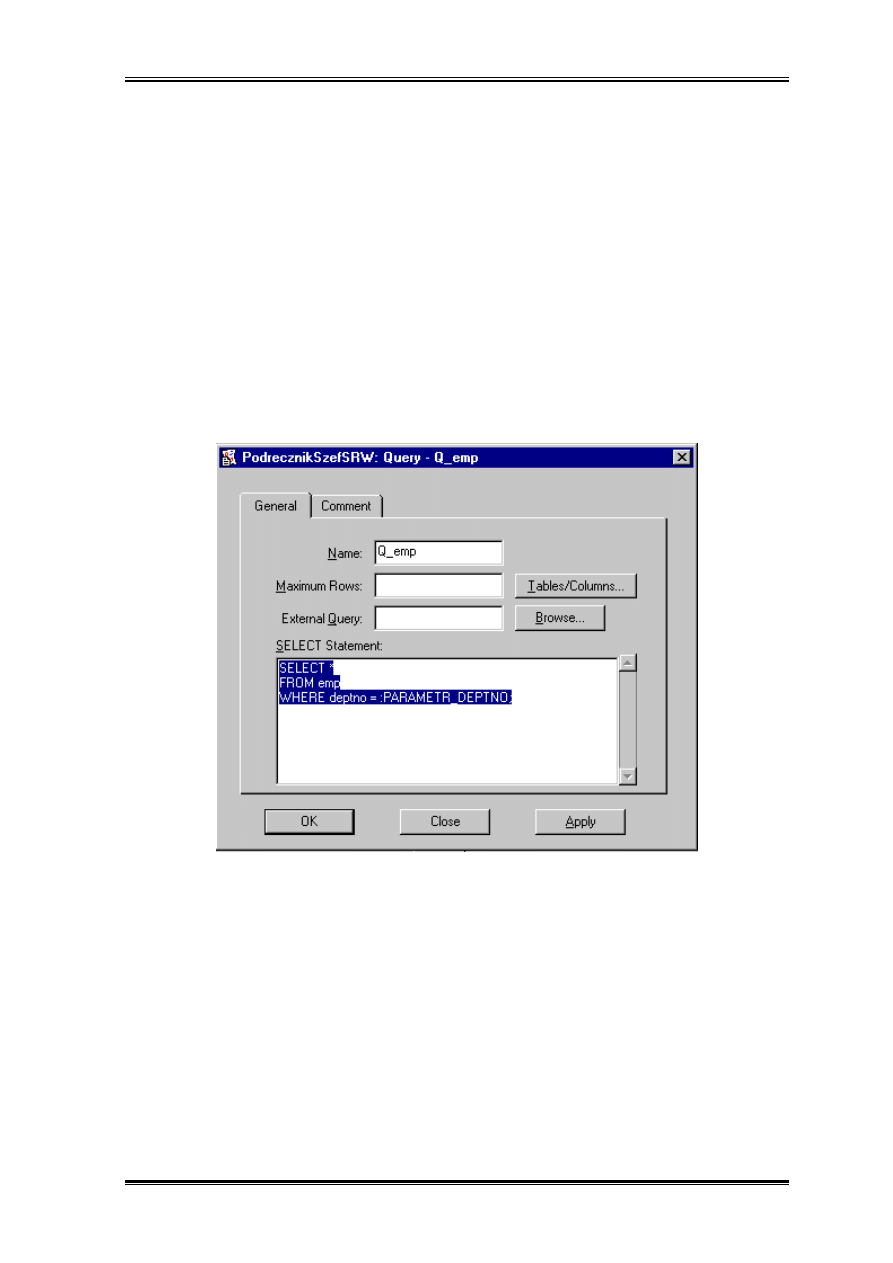
Zapytanie z parametrem
Nowy parametr użytkownika możemy utworzyć w nawigatorze obiektów lub podać w
zapytaniu.
Warto zwrócić uwagę, że przed PARAMETR_DEPTNO występuje dwukropek.
SELECT *
FROM emp
WHERE deptno = :PARAMETR_DEPTNO;
Jeżeli podaliśmy parametr bezpośrednio w zapytaniu Raports_Designer stworzy go
automatycznie. Trzeba jedynie zwrócić uwagę czy jest on oczekiwanego przez nas typu.
Budowa raportów
Strona 47
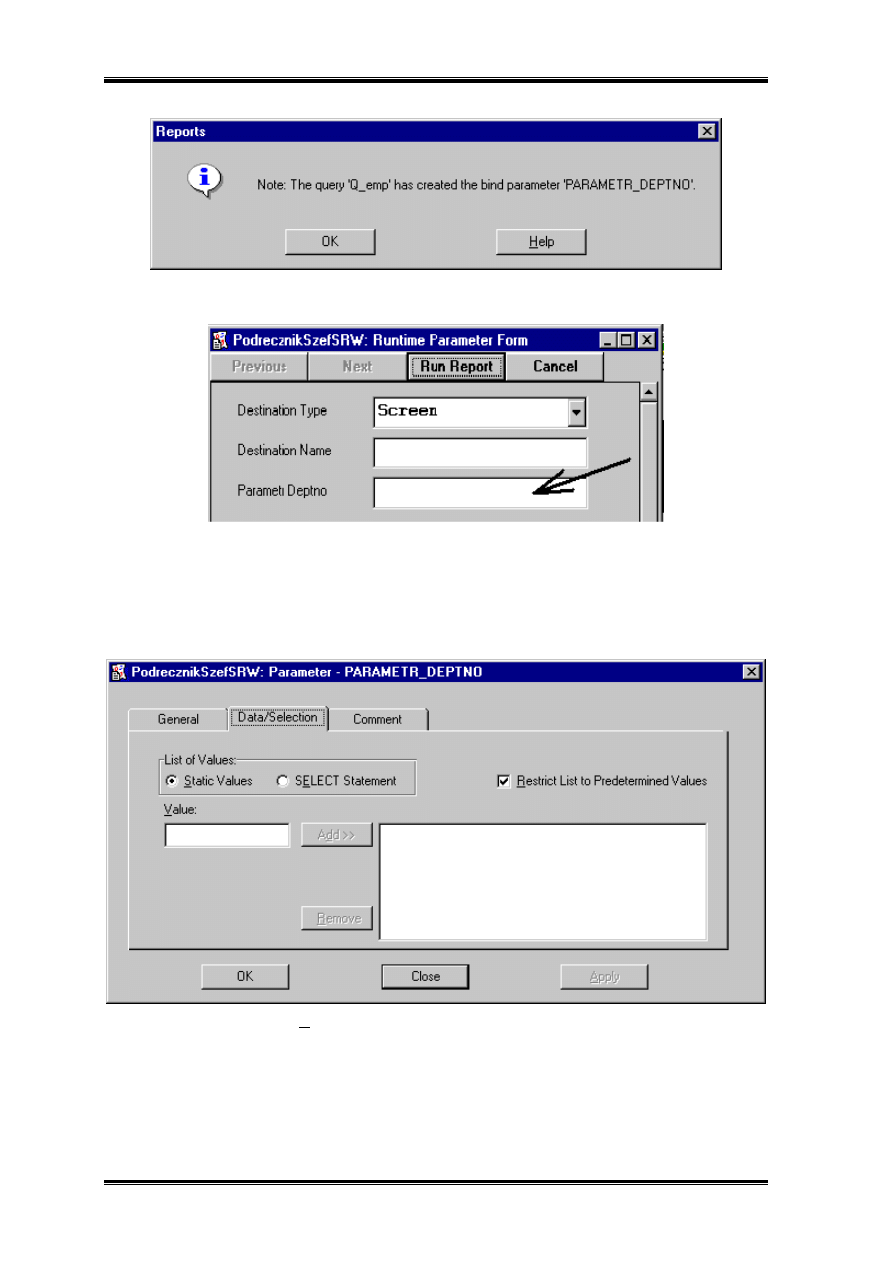
Tak utworzony parametr pojawia się na formatce uruchomienia raportu.
To rozwiązanie w zupełności wystarcza jeżeli raport jest gdzieś indziej podpinany. Jeżeli
jednak raport funkcjonuje jako samodzielny program. Warto byłoby dołożyć do niego
rozwijaną listę z której użytkownik wybierałby departament dla którego chce uruchomić
raport. W tym celu musimy wrócić do parametrów uruchomienia raportów i wejść w jego
właściwości.
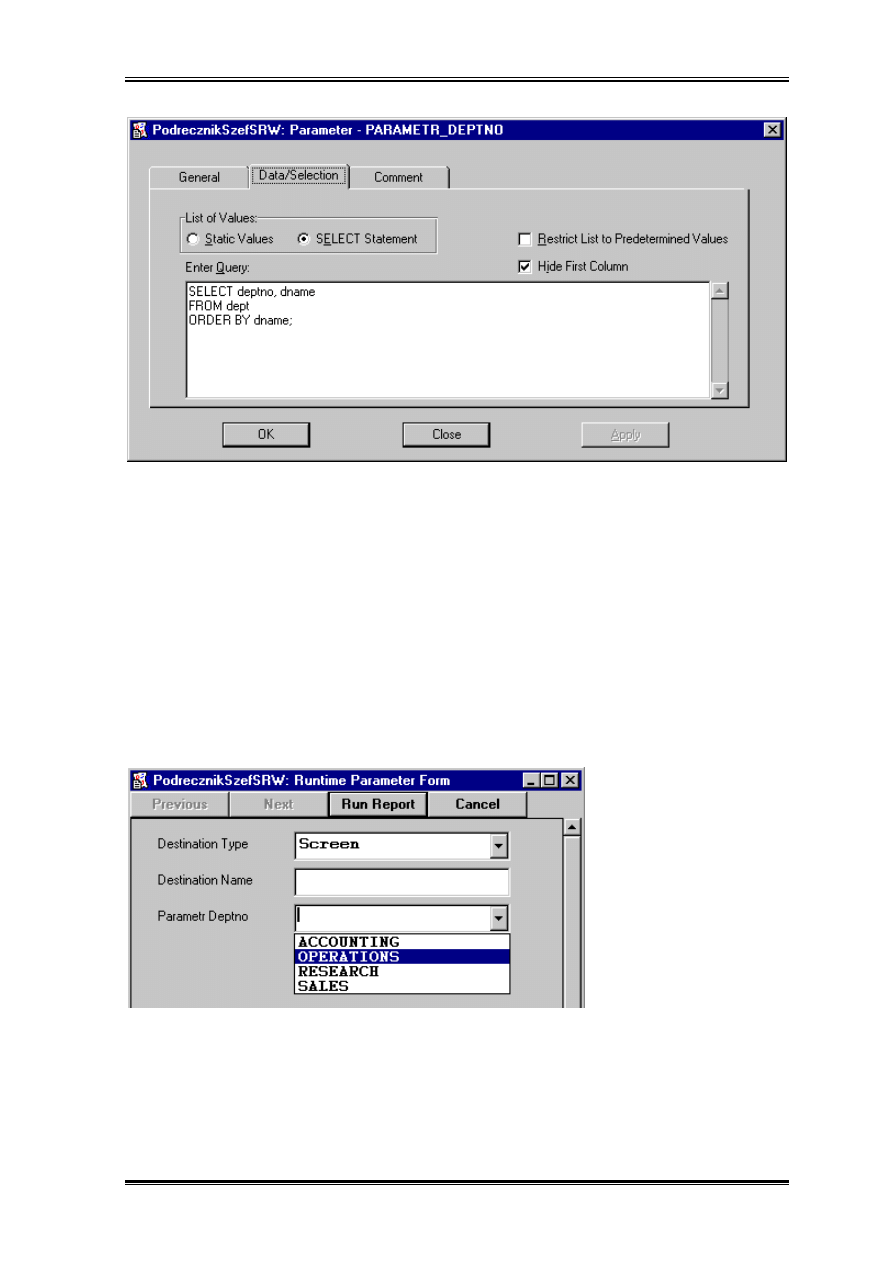
Jeżeli zaznaczymy opcję SELECT okienko zmieni swoja postać.
Podstawy
Strona 48
Teraz mamy możliwość wpisania zapytania. Oraz dwie opcje do wyboru. Możliwości
użytkownika są ograniczone jedynie do tego co wybiera lista (Restrict List to
Predetermined Values) i Hide First Column jeżeli nie chcemy pokazywać użytkownikowi
kluczy. Jeżeli chcemy aby użytkownik miał możliwość pominąć ten parametr i uruchamiać
raport dla wszystkich departametów musimy odznaczyć Restrict List to Predetermined
Values i zmodyfikować główne zapytanie raportu:
SELECT *
FROM emp
WHERE
(deptno = :PARAMETR_DEPTNO OR :PARAMETR_DEPTNO is null);
Teraz z okienka parametrów można skasować wartość w polu DEPTNO i raport uruchomi
się dla wszystkich.
Druga możliwość to zmodyfikowanie listy przy użyciu UNION tak aby pojawiała się
dodatkowa pusta wartość.
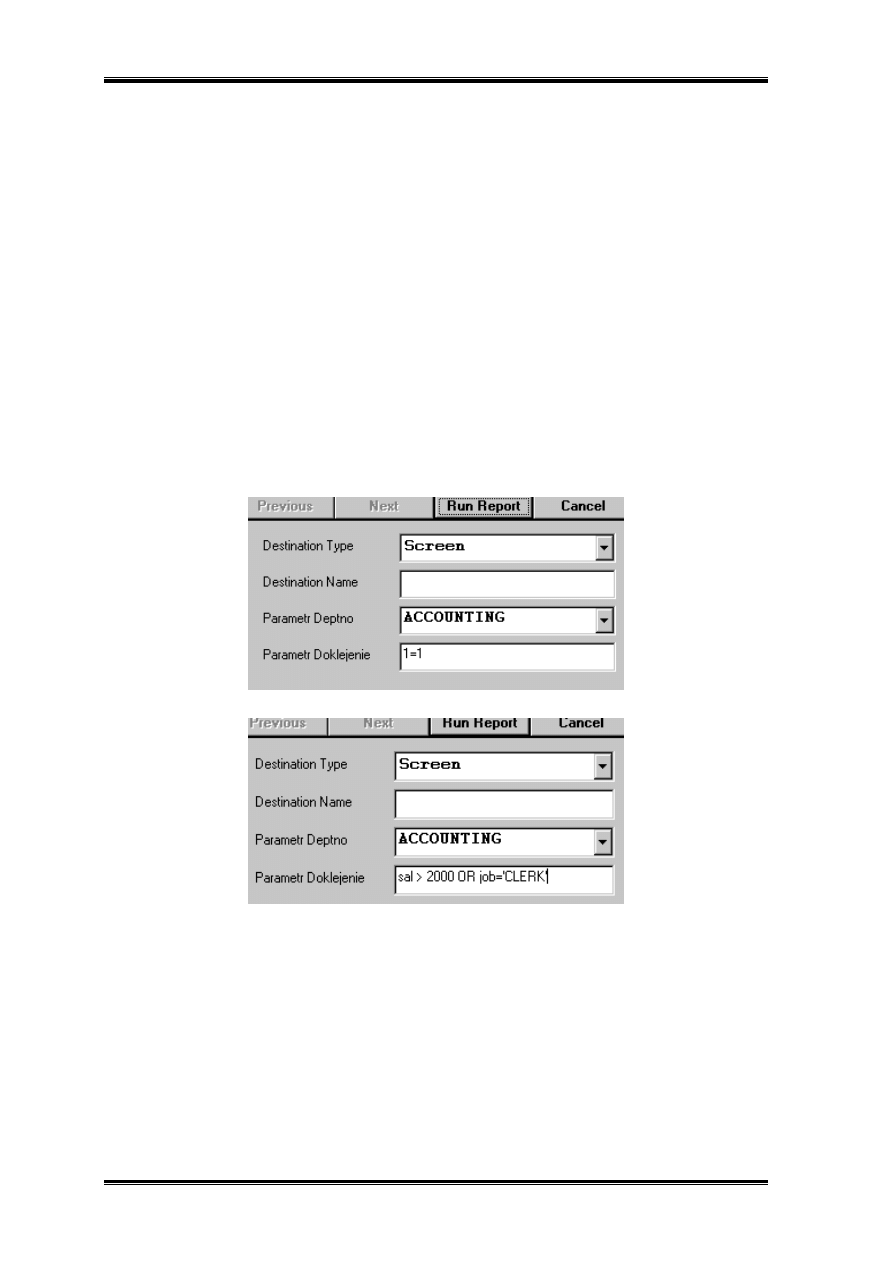
Budowa raportów
Strona 49
Przekazanie fragmentu zapytania
Druga możliwość przekazania sparametryzowania raportu to przekazywanie fragmentu
zapytania. Tym razem trzeba obowiązkowo rozpocząć od nawigatora obiektów. Dodajemy
nowy parametr np. o nazwie PARMETR_DOKLEJENIE typu znakowego od razu
ustawiając jego wartość np. na 1=1.
Teraz możemy rozbudować raport z poprzednich stron. W zapytaniu dodajemy:
SELECT *
FROM emp
WHERE
(deptno = :PARAMETR_DEPTNO OR :PARAMETR_DEPTNO is null) and
(&PARAMETR_DOKLEJENIE);
Wartość domyślna(1=1) używana jest na etapie parsowania i sprawdzania poprawności
instrukcji SELECT.
W czasie uruchamiania raportu, zawsze poprawną wartość domyślną zamieniamy na
interesujący nas warunek.
Ten sposób jest czasem wykorzystywane przez programistów przy czym użytkownik widzi
np. pewne grup klasyfikacji klientów, wybiera je z listy, a jest to równoznaczne z
wykonaniem pewnego zapytania do tablicy w której trzymane są fragmenty zapytań.
Oczywiście należy jeszcze zadbać o używanie tych samych aliasów i o to aby grupy
klasyfikacji itp. pokazywały się odpowiednio do treści zapytania zawartego w raporcie.

Podstawy
Strona 50

Budowa raportów
Strona 51
Suplement
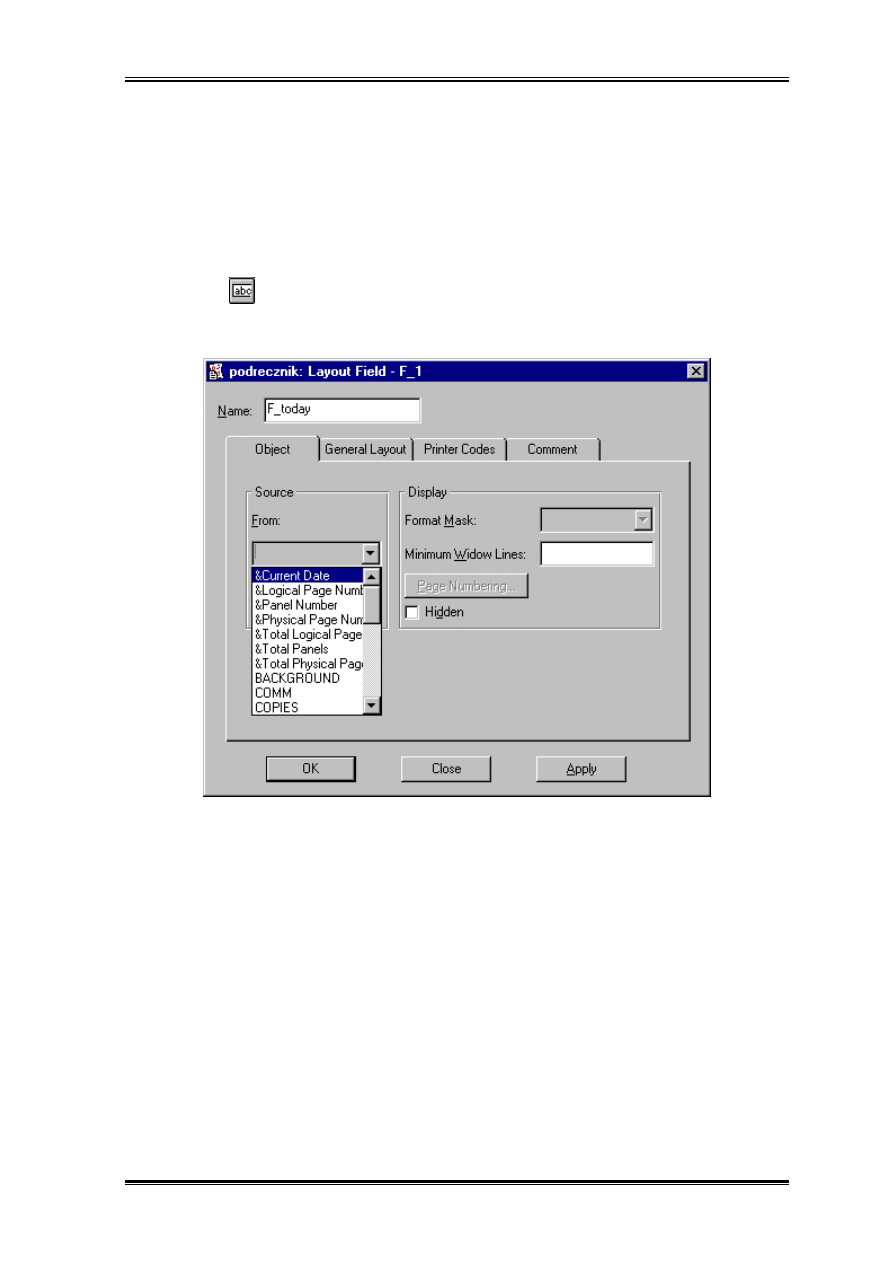
Podstawy
Strona 52
W tym rozdziale przedstawione zostaną zagadnienia które nie zmieściły się poprzednich
rozdziałach.
Data bieżąca
Ź
ródłem częstego zaskoczenia programisty jest wbudowana data bieżąca. Jeżeli sięgniemy
po pole typu
w edytorze rozkładu, to w polu tym jako źródło wypełniania możemy
podać &Current Date.
Jeżeli zarówno nasz serwer jak i komputer mają zgodnie i prawidłowo ustawiony czas
nigdy nie zauważymy, że nie jest to niestety data z serwera ale data z systemu
operacyjnego. Jeżeli użytkownik z jakiś względów utrzymuje na komputerze niewłaściwą
datę (np. ze względu na pirackie oprogramowanie) to drukuje raporty ze złą datą. Zdarzają
się też przypadki, że użytkownicy którzy posługiwali się takimi raportami celowo cofali
datę aby przygotować raporty które powinny być wydrukowane wcześniej.
Aby zmusić raport do pisania właściwej daty z serwera należy napisać samodzielnie
funkcję (kolumnę formuły), która wykorzysta:
select sysdate
into ....
from dual;

Budowa raportów
Strona 53
Tryb dopasowania
W czasie dostosowywania rozkładu domyślnego do naszych potrzeb tracimy wiele czasu
na rozciąganie ramek. Pracę z ramkami możemy jednak znacznie uprościć, jeżeli
skorzystamy z Trybu Dopasowania. Ikonka odpowiedzialna za ten tryb ma dwie postaci:
- włączony tryb dopasowania
- wyłączony tryb dopasowania.
Zanim projektant raportu zapozna się z tymi dwoma ikonkami (czasami nie następuje to
nigdy) rozciąga ramki aby zrobić miejsce na nowy obiekt. Okazuje się, że jeżeli tryb
dopasowania jest włączony, przesuwany obiekt sam toruje sobie drogę spychając lub
powiększając obiekty które stoją na jego drodze. Obiekt cofając się działa w sposób
odwrotny.
W domyślnym, a więc wyłączonym trybie dopasowania przesuwane pole tekstowe dosuwa
się do ograniczającej jego grupę ramki i dalej nie może się przesunąć.
Rozkład listowy
Rozkład listowy do taki w którym występuje pewien tekst w którym pojawiają się nazwy
pól poprzedzone znakiem &. W czasie wykonywania raportu pola te wypełniają się za
pomocą pól, które są poziomo zmienne i ukryte. Najczęściej element ten stosowany jest
do drukowania nagłówków i stopek raportów.
Na poniższym rysunku znajduje się pewien tekst a obok niego trzy ukryte, poziomo
zmienne pola.
Warto zwrócić uwagę że fragmenty tekstu wklejanego „dziedziczą” własności z obiektów
ukrytych, nazwisko pojawia się pogrubione, a job i hiredate – kursywą.

Podstawy
Strona 54
Kierunek tekstu
Ponieważ pola
nie chcą się obracać (rotate), a czasem chcielibyśmy wydrukować je w
pionie , można wykorzystać w tym celu pola tekstowe(T) które pozwalają się obracać.
Wyzwalacze Raportu
Istnieje pięć sytuacji które możemy obsłużyć w czasie wykonywania raportu. Są to po
kolei:
Before Parameter Form
After Parameter Form
Before Report
Between Pages
After Report
Dzięki tym wyzwalaczom możemy kontrolować kiedy z jakiego komputera były
uruchamiane raporty. W wyzwalaczach tych możemy stosować instrukcje DML,
wykonanie instrukcji DDL wymaga użycia pakietu.
function BeforeReport return boolean is
V_instrukcja varchar2(150);
V_numer varchar2(5);
begin
SELECT to_char(dziennik_seq.nextval)
INTO V_numer
FROM dual;
V_instrukcja := 'CREATE table dziennik'||V_numer||'(dzi_id NUMBER,kto
VARCHAR2(40),kiedy DATE)';
--Ponizej wykonuje instrukcje na serwerze tworzac tymczasowa tabele ...
SRW.do_sql(V_instrukcja);
--Ponizej bezposrednio wykonuje instrukcje DDL(insert,commit)

Budowa raportów
Strona 55
INSERT INTO dziennik values(dziennik_seq.nextval,' PRZED RAPORTEM',SYSDATE);
commit;
return (TRUE);
end;
Wyszukiwarka
Podobne podstrony:
Niebieski kontra Czerwony - ćwiczenia, Materiały szkoleniowe
Mediacje i negocjacje społ. -ćwiczenia, Materiały szkoleniowe
Materialy szkoleniowe cwiczenia z HPLC poziom podstawowy
Materialy szkoleniowe podstawowe wiadomosci o zagroze
Materialy szkoleniowe cwiczenia z HPLC poziom zaawansowany
Materialy szkoleniowe cwiczenia z HPLC
PODSTAWOWE ZASADY NAUCZANIA, Materiały szkoleniowe piłka nożna, materiały z kursów
nauczanie podstawowych elementów technicznych, Piłka nożna, Materiały szkoleniowe, KONSPEKTY
Ratownictwo śródlądowe - podstawowe zasady, Żeglarstwo, Materiały Szkoleniowe
Porównanie budowy oka ludzkiego i krowiego na podstawie analizy świeżego oka krowy, referaty i mater
Materialy szkoleniowe podstawowe wiadomosci o zagroze
Materiały szkoleniowe Podstawy psychologii ogólnej
więcej podobnych podstron