1
Prof. dr hab. inż. Jan T.Duda
Kraków, grudzien 2004
Katedra Analizy Systemowej i Modelowania Cyfrowego
AGH, tel. 617-45-06
Ekonometria – repetytorium
1. Przedmiot i narz
ę
dzia ekonometrii
Ekonometria – nauka o metodach badania ilościowych prawidłowości występujących w
zjawiskach ekonomicznych. Wykorzystuje do tego aparat rachunku prawdopodobieństwa i
statystyki matematycznej oraz algebrę liniową (rachunek macierzowy)
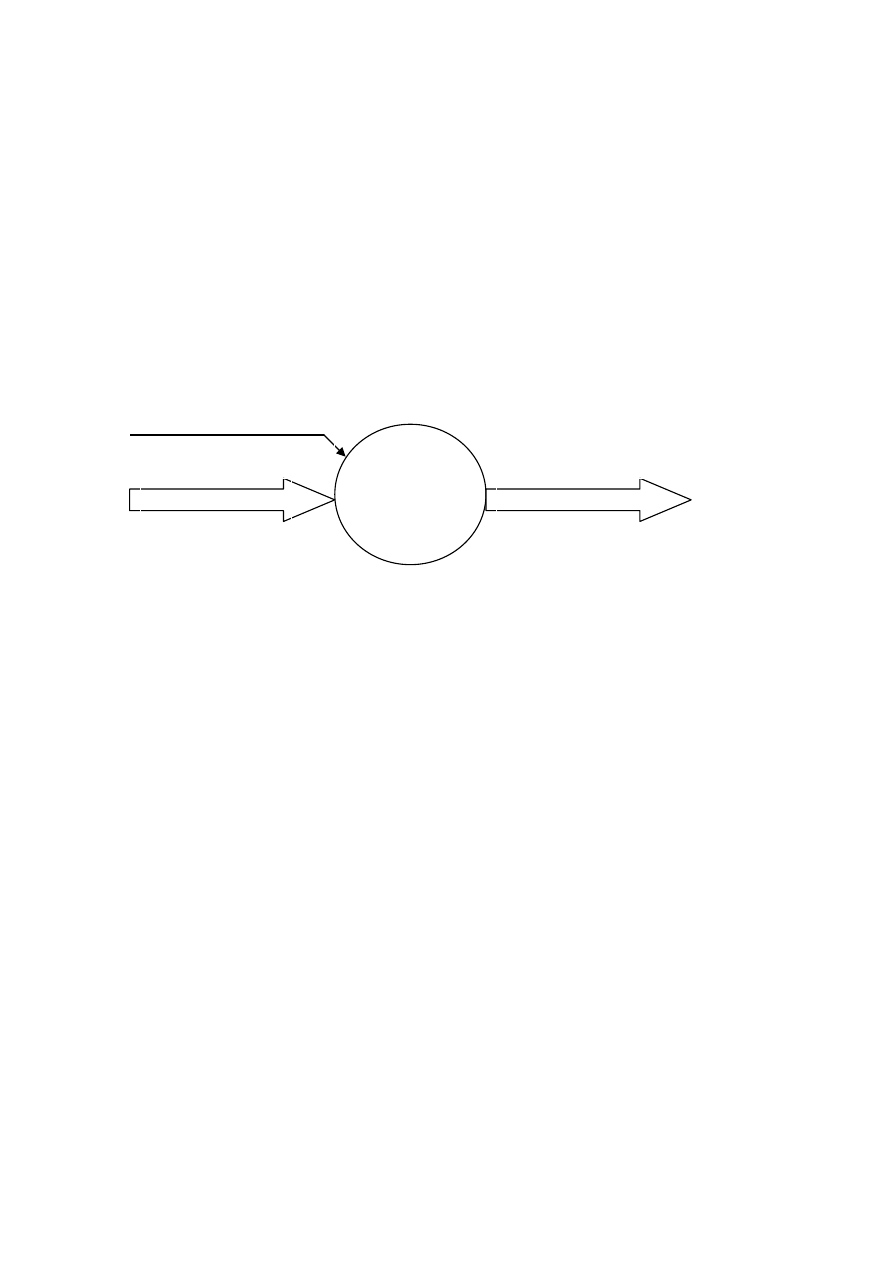
Rys.1. Ekonometryczne ujęcie zjawisk ekonomicznych
Ekonometria zajmuje się poszukiwaniem zależności ekonometrycznych f(X) (tj.
deterministycznych powiązań ilościowych pomiędzy zmiennymi objaśniającymi i
objaśnianymi) oraz analizą probabilistyczną składowej losowej e zmiennych objaśnianych.
Literatura:
1.
Henry Theil: Zasady ekonometrii, PWN, Warszawa, 1979
2.
Zbigniew Pawłowski: Ekonometria, PWN, Warszawa 1969
3.
Edward Nowak: Zarys metod ekonometrii – zbiór zadań, PWN, Warszawa 1994
4.
John Freund Podstawy nowoczesnej statystyki, PWE, Warszawa 1968
5.
G.E.P.Box, G.M.Jenkins: Analiza szeregów czasowych, PWN, Warszawa, 1983
2. Podstawowe poj
ę
cia rachunku prawdopodobie
ń
stwa
Literatura:
1.
I.E. Brontsztejn, K.A.Siemeindiajew: Matematyka – poradnik encyklopedyczny. Część
szósta – Opracowanie danych doświadczalnych,. PWN, Warszawa 1986
2.
Poradnik inżyniera – Matematyka – Rozdziały XXXII i XXXIII
3.
J.Greń: Statystyka matematyczna – modele i zadania, PWN, Warszawa 1982
Definicje intuicyjne: (Foralnie definicje można znależć np. w Poradniku 2)
Badane
zjawiska
ekonomiczne
Zm.egzogeniczne X
Wpływ otoczenia na proces
opisują zmienne objaśniające
(egzogeniczne) X
Wpływ procesu na otoczenie
opisują zmienne objaśniane
(endogeniczne) Y: Y=f(X)+e
e – reprezentacja losowości opisu
Zm.endogeniczne: Y=f(X)+e
Nieznane czynniki losowe v
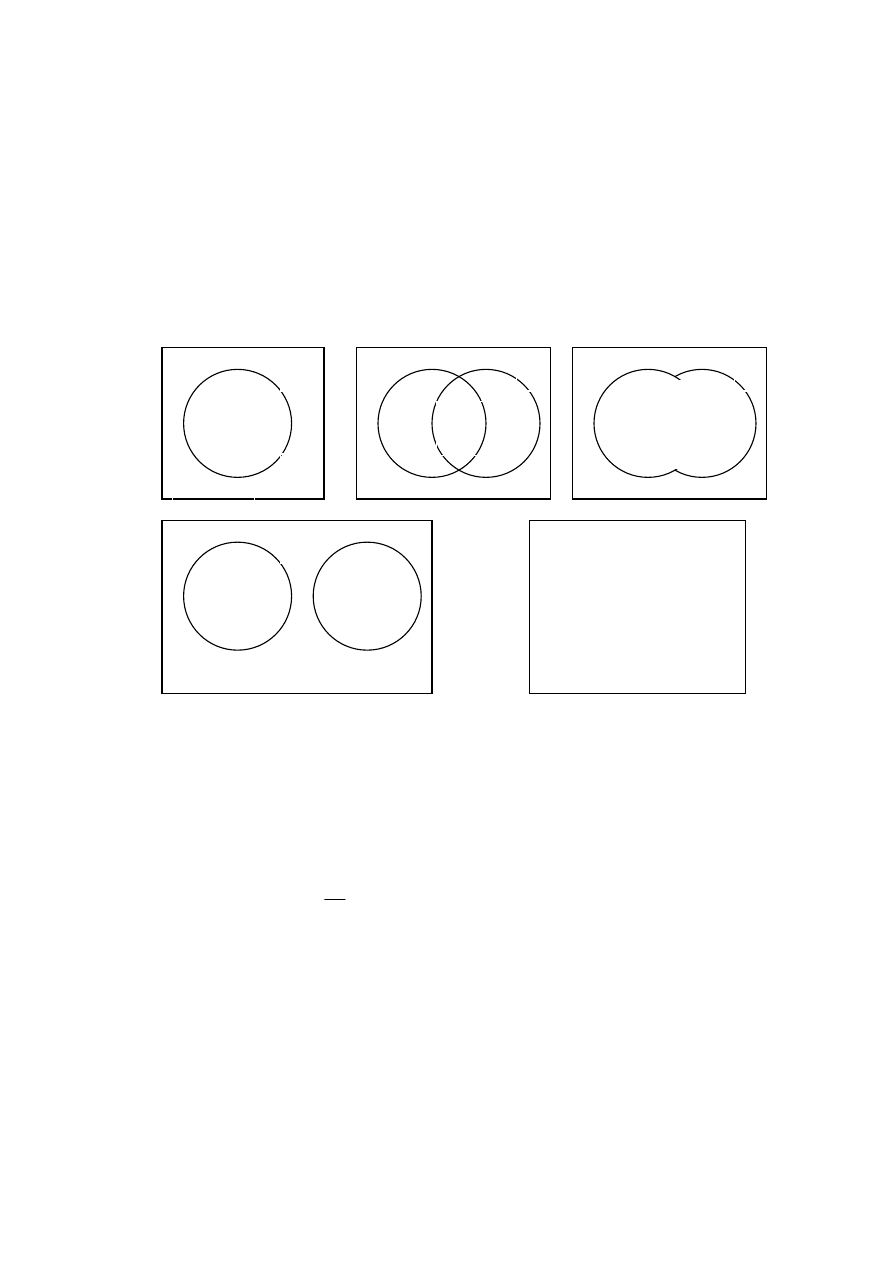
2
Zdarzenie losowe: zdarzenie, którego zajście leży całkowicie lub częściowo poza zasięgiem
kontroli.
Definuje się:
iloczyn zdarzeń A i B jako równoczesne wystąpienie zdarzenia A i zdarzenia B; (A*B)
sumę (alternatywę) zdarzeń A, B, jako wystąpienie zdarzenia A lub zdarzenia B. (A+B)
zdarzenie przeciwne do A – zdarzenie zachodzące wtedy gdy A nie zachodzi (
~
A)
zdarzenie pewne – zachodzi zawsze (np. A+(
~
A));
zdarzenie niemożliwe – nie zachodzi nigdy (np. A*(
~
A)); oznaczamy go symbolem
∅
zdarzenia rozłączne A, B – takie, że A*B jest zdarzeniem niemożliwym
Rys.2. Graficzna ilustracja zdarzeń elementarnych i złożonych:
koła- elementarne zdarzenia losowe, całe ramki – wszystkie zdarzenia możliwe
Prawdopodobieństwo zdarzenia – liczba wyrażająca stopień możliwości zachodzenia
zdarzenia. Prawdopodobieństwo zdarzenia A czyli P(A) jest równe stosunkowi liczby
przypadków sprzyjających zdarzeniu A (n
A
) do wszystkich przypadków możliwych (n):
n
n
A
P
A
=
)
(
Wartość tak zdefiniowanego prawdopodobieństwa ilustrują stosunki pól figur (kół)
reprezentujących zdarzenia A, B na rysunkach powyżej, do pola całej ramki E.
Właściwości prawdopodobieństwa:
1.
Jeśli A, B, .. są zdarzeniami rozłącznymi (wykluczają się wzajemnie) to
P(A lub B lub ..)=P(A)+P(B)+..
(patrz rysunek d)
2.
Jeśli E jest zdarzeniem pewnym to
P(E)=1
(patrz rysunek e)
Stąd wynika, że dla dowolnego zdarzenia A
0
≤
P(A)
≤
1
A
~
A
nieA
A
B
A i B
A*B
A
B
Zdarzenia rozłączne A, B
E
Zdarzenie pewne E
(suma wszystkich zdarzeń
możliwych)
(a)
(b)
A lub B
(A+B)
(c)
(d)
(e)
A+(
~
A)=E

3
P(nieA)=1-P(A)
(patrz rysunek a)
Dla dowolnych zdarzeń A i B
P(A lub B)=P(A)+P(B)-P(A i B)
(patrz rysunki b, c)
Prawdopodobieństwo warunkowe i prawdopodobieństwo całkowite:
Mamy dwa zdarzenia losowe A i B. Niech P(B)>0. Jeśli zdarzenia A i B mogą występować
równocześnie to można mówić o prawdopodobieństwie zajścia zdarzenia A pod warunkiem,
ż
e zaszło zdarzenie B, co oznacza się symbolem P(A|B). W tym przypadku zbiór zdarzeń
możliwych redukuje się do zdarzenia B, zatem (zgodnie z rys.2b) mamy:
)
(
)
(
1
)
(
B
P
B
i
A
P
n
n
n
n
B
A
P
n
n
iB
A
B
iB
A
B
=
⋅
=
=
gdzie
n
n
B
P
n
n
B
i
A
P
B
AiB
=
=
)
(
;
)
(
Prawdopodobieństwo warunkowe nazywane jest prawdopodobieństwem a posteriori (po
uzyskaniu dodatkowej informacji) i na ogół różni się od P(A) zwanego prawdopodobieństwem
a priori (określonym dla dowolnych warunków przy których zachodzi A).
Jeśli w wyniku pewnego doświadczenia losowego realizuje się zawsze jedno z wzajemnie
wykluczających się zdarzeń B
1
, B
2
, .. B
N
(tzn. B
1
+ B
2
+.. B
N
=E oraz B
1
*B
2
=
∅
, B
i
*B
k
=
∅
dla
każdej pary zdarzeń B
i
, B
k
i
≠
k) to dla dowolnego zdarzenia A zachodzi równość:
∑
=
=
⋅
+
⋅
+
⋅
=
N
n
n
N
N
B
i
A
P
B
P
B
A
P
B
P
B
A
P
B
P
B
A
P
A
P
1
2
2
1
1
)
(
)
(
)
(
...
)
(
)
(
)
(
)
(
)
(
Jest to wzór na
prawdopodobieństwo całkowite.
Stosuje się go, gdy prawdopodobieństwa warunkowe P(A|B
n
) oraz prawdopodobieństwa P(A)
albo P(B
n
) są łatwe do oszacowania lub znane. Prawdopodobieństwo wystąpienia zdarzenia B
n
gdy zaszło zdarzenie A liczy się ze wzoru Bayesa:
;
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
)
(
1
A
P
AiB
P
A
P
B
P
B
A
P
B
P
B
A
P
B
P
B
A
P
A
B
P
n
n
n
N
i
i
i
n
n
n
=
⋅
=
⋅
⋅
=
∑
=
Jeśli zdarzenie B nie wpływa na prawdopodobieństwo zdarzenia A to zdarzenia A, B są
zdarzeniami niezależnymi. Wówczas obowiązuje zależność:
);
(
)
(
A
P
B
A
P
=
zatem
)
(
)
(
)
(
B
P
A
P
B
i
A
P
⋅
=
Zdarzenia A, B są zatem niezależne, gdy mogą występować w różnych okolicznościach, a ich
łączne wystąpienie jest tylko całkowicie przypadkowe.
Założenie niezależności zdarzeń jest
często wykorzystywane w obliczeniach probabilistycznych. W ekonometrii mamy na ogół
do czynienia ze zdarzeniami współzależnymi, ale założenie niezależności pozwala dokonać
zgrubnych oszacowań prawdopodobieństw iloczynu zdarzeń.
Zmienne losowe: liczby charakteryzujące rezultat zjawiska losowego
Zmienne losowe dyskretne – liczby losowe ze skończonego lub przeliczalnego zbioru
wartości. Na ogół są to liczby całkowite symbolizujące rozważane zdarzenia losowe,
zliczające ich krotność itp.
Zmienne losowe ciągłe: liczby rzeczywiste o losowej wartości, charakteryzujące ilościowo
zjawiska losowe:

4
Zdarzenia losowe odniesione do liczb losowych dotyczą wystąpienia określonych wartości
zmiennych dyskretnych oraz wystąpienia wartości zmiennych ciągłych w określonych
przedziałach.
Prawdopodobieństwa takich zdarzeń charakteryzują rozkłady prawdopodobieństwa
zmiennych losowych:
Dystrybuantą rozkładu zmiennej losowej x nazywamy prawdopodobieństwo wystąpienia
wartości x mniejszej niż argument dystrybuanty (założona wartość zmiennej) X.
F(X) = P(x < X)
Dystrybuanta posiada następujące cechy:
1.
F(-
∞
)=0;
2.
F(
∞
)=1;
3.
jest funkcją lewostronnie ciągłą i niemalejącą, tzn., jeśli X
1
<X
2
to F(X
1
)
≤
F(X
2
)
Dystrybuanta zmiennej losowej dyskretnej zmienia się skokowo w punktach
odpowiadających kolejnym wartościom zmiennej.
Rozkład prawdopodobieństwa takich zmiennych wygodniej jest charakteryzować podając
wprost prawdopodobieństwa wystąpienia poszczególnych wartości p(x
i
). Nazywa się to
krótko rozkładem prawdopodobieństwa zmiennych dyskretnych:
f(x)={p(x
i
); i=1,2, ...,N}, gdzie N oznacza liczbę możliwych wartości zmiennej x
W przypadku zmiennych losowych ciągłych (dokładnie – absolutnie ciągłych – patrz
Poradnik [2]) rozkład opisuje się tzw. funkcją gęstości prawdopodobieństwa f(x), którą
definiuje się jako pochodną dystrybuanty względem zmiennej x, tzn. w następujący sposób:
)
(
)
(
)
(
lim
)
(
2
2
x
F
dx
d
x
x
F
x
F
x
f
x
x
o
x
=
∆
−
−
+
=
∆
∆
→
∆
Zgodnie z własnością (3) dystrybuanty funkcja f(x) jest nieujemna
Uwaga !! Funkcja gęstości prawdopodobieństwa nie jest prawdopodobieństwem, ale pozwala
obliczyć prawdopodobieństwo wystąpienia wartości X w zadanym przedziale x
1
, x
2
z wzoru:
∫
⋅
=
≤
≤
2
1
)
(
)
(
2
1
x
x
dx
x
f
x
X
x
P
Wynika stąd, że
∫
∞
−
⋅
=
X
dx
x
f
X
F
)
(
)
(
oraz
∫
∞
∞
−
=
⋅
1
)
(
dx
x
f
Parametry rozkładu prawdopodobieństwa jednowymiarowych zmiennych losowych:
Rozkład prawdopodobieństwa zmiennej ciągłej charakteryzuje się przy pomocy parametrów
zwanych momentami. Moment i-tego rzędu m
i
(x) definiuje się następująco:
dx
x
f
x
x
m
i
i
⋅
⋅
=
∫
∞
∞
−
)
(
)
(
Moment rzędu zerowego jest zawsze równy 1.
Moment rzędu pierwszego zmiennej X nazywa się
wartością oczekiwaną zmiennej losowej
X, a operację jego obliczania oznacza się symbolem E(X).

5
Wartość oczekiwana jest też nazywana wartością przeciętną zmiennej losowej lub nadzieją
matematyczną.
Dla zmiennej losowej ciągłej wartość oczekiwaną wyraża wzór:
dX
X
f
X
X
E
X
m
def
⋅
⋅
=
=
∫
∞
∞
−
)
(
)
(
)
(
1
Dla zmiennej dyskretnej przyjmującej wartości x
i
z prawdopodobieństwem p
i
wartość
oczekiwaną oblicza się ze wzoru:
∑
∞
=
⋅
=
1
)
(
i
i
i
x
p
x
E
Właściwości wartości oczekiwanej:
1.
Każda ograniczona zmienna losowa ma wartość oczekiwaną.
2.
Wartość oczekiwana kombinacji liniowej zmiennych losowych jest kombinacją liniową
ich wartości oczekiwanych
)
(
...
)
(
)
(
)
...
(
2
2
1
1
2
2
1
1
N
N
N
N
x
E
a
x
E
a
x
E
a
x
a
x
a
x
a
E
⋅
+
+
⋅
+
⋅
=
+
+
+
3.
Jeśli
x
1
i
x
2
są niezależnymi zmiennymi losowymi to
)
(
)
(
)
(
2
1
2
1
x
E
x
E
x
x
E
⋅
=
⋅
Zmienna losowa ciągła
x będąca odchyłką zmiennej losowej oryginalnej X od jej wartości
oczekiwanej
m
1
(
X) nazywa się zmienną losową scentrowaną:
);
(
1
X
m
X
x
def
−
=
Oczywiście E(
x)=0
Momenty wyższego rzędu można obliczać dla oryginalnych zmiennych lub scentrowanych.
Momenty dla zmiennych scentrowanych nazywa się momentami centralnymi.
Centralny moment rzędu drugiego zmiennej nazywa się wariancją zmiennej
2
x
σ
∫
∫
∞
∞
−
∞
∞
−
=
−
=
=
=
−
=
σ
dx
x
f
x
dX
X
f
X
E
X
x
E
x
m
X
E
X
m
X
)
(
)
(
)]
(
[
)
(
)
(
)]
(
[
2
2
2
2
2
2
Właściwości wariancji:
1.
Znając pierwszy i drugi moment oryginalnej zmiennej losowej X można obliczyć jej
wariancję:
)
(
)
(
)
(
)
(
2
1
2
2
2
2
X
m
X
m
X
E
X
E
X
−
=
−
=
σ
bo:
)
(
)
(
)
(
)
(
2
)
(
)
(
)
(
)
(
)
(
2
)
(
)
(
)]
(
[
2
2
2
2
2
2
2
2
X
E
X
m
X
E
X
E
X
m
dX
X
f
X
E
dX
X
f
X
X
E
dX
X
f
X
dX
X
f
X
E
X
−
=
+
⋅
−
=
=
+
⋅
−
=
−
∫
∫
∫
∫
∞
∞
−
∞
∞
−
∞
∞
−
∞
∞
−
2.
Jeśli
x
1
,
x
2
...
x
N
są niezależnymi zmiennymi losowymi to
2
2
2
2
2
2
2
1
2
1
2
2
2
1
1
]
)
[(
xN
N
x
x
N
N
a
a
a
x
a
x
a
x
a
E
σ
+
+
σ
+
σ
=
+
+
+
Κ
Κ
Odchyleniem średnim (standardowym) lub
dyspersją
σσσσ
zmiennej losowej nazywamy
pierwiastek arytmetyczny z jej wariancji
.
Odchyleniem przeciętnym
β
X
zmiennej losowej X nazywamy wartość oczekiwaną modułu
scentrowanej zmiennej
x
β
X
=E(|X-E(X)|)

6
Parametry pozycyjne rozkładu – kwantyle
Kwantylem rzędu p zmiennej losowej x nazywamy taką wartość
λ
p
zmiennej, że
P(x
≤
λ
p
)
≥
p
P(x
≥
λ
p
)
≥
1-p
Kwantyl rzędu p=1/2 nazywa się medianą (jest to wartość zmiennej losowej rozdzielająca jej
zakres na dwie części o jednakowym prawdopodobieństwie wystąpienia p=0.5.
Kwantyle rzędu p=1/4 i ¾ nazywają się odpowiednio kwantylem górnym i dolnym.
Kwantyle rzędu p=0.1, 0.2 ....0.9 nazywa się decylami.
Zmienną losową o wartości oczekiwanej 0 i wariancji 1 nazywamy zmienną losową
standaryzowaną.
Jeśli mamy zmienną losową X o wartości oczekiwanej E(X) i dyspersji
σ
X
to odpowiadającą
jej zmienną standaryzowaną x uzyskuje się przez przekształcenie
X
X
E
X
x
σ
−
=
)
(
i odwrotnie, mając
zmienną standaryzowaną x, np. odczytaną z tablic rozkładu, uzyskuje się
zmienną X o zadanej :
)
( X
E
x
X
X
+
σ
⋅
=
Zmienne losowe wielowymiarowe
Jeśli rozważamy kilka zbiorów liczb losowych to mówimy o
zmiennej losowej wielowymiarowej.
Dystrybuantę zmiennej wielowymiarowej X=[X
1,
X
2,
... X
N
] definiuje się jako
prawdopodobieństwo zdarzenia polegającego na równoczesnym wystąpieniu wszystkich
rozważanych liczb losowych mniejszych od zadanych argumentów dystrybuanty [X
1,
X
2,
. X
N
]
F(X
1,
X
2,
... X
N
)=P[(x
1
<X
1
) i (x
2
<X
2,
) ...i (x
N
<X
N
)]
Wielowymiarowa zmienna losowa ma rozkład absolutnie ciągły jeśli istnieje taka funkcja
f(x
1,
x
2,
... x
N
) zwana
wielowymiarową gęstością prawdopodobieństwa, że
∫ ∫ ∫
∞
−
∞
−
∞
−
=
1
2
2
1
2
1
2
1
.
)
,
,.
(
)
,
,
(
x x
x
N
N
N
N
dx
dx
dx
x
x
x
f
X
X
X
F
Κ
Κ
Λ
Κ
Zmienne losowe X
1,
X
2,
... X
N
są niezależne, jeśli ich łączna dystrybuanta jest iloczynem
dystrybuant poszczególnych zmiennych:
F(X
1,
X
2,
... X
N
)=F(x
1
<X
1
)*F(x
2
<X
2,
)*...*F(x
N
<X
N
)
Zmienne losowe absolutnie ciągłe są niezależne, jeśli ich wielowymiarowa funkcja gęstości
prawdopodobieństwa jest iloczynem funkcji gęstości dla poszczególnych zmiennych:
Rozkłady brzegowe i warunkowe zmiennych losowych wielowymiarowych
Niech f(x
,
y) oznacza dwuwymiarowy rozkład zmiennych x, y.
Rozkładami brzegowymi są funkcje:

7
∫
∞
∞
−
=
.
)
,
(
)
(
dy
y
x
f
x
f
x
∫
∞
∞
−
=
dx
y
x
f
y
f
y
)
,
(
)
(
Oczywiście, obie spełniają warunek podstawowy:
∫
∞
∞
−
=
1
dx
x
f
x
)
(
i
∫
∞
∞
−
=
1
)
(
dy
y
f
y
Rozkładami warunkowymi są natomiast funkcje:
∫
∞
∞
−
=
=
=
dx
y
x
f
y
x
f
y
f
y
x
f
y
Y
x
f
y
x
)
,
(
)
,
(
)
(
)
,
(
)
(
0
0
0
0
0
oraz
∫
∞
∞
−
=
=
=
dy
y
x
f
y
x
f
x
f
y
x
f
x
X
y
f
x
y
)
,
(
)
,
(
)
(
)
,
(
)
(
0
0
0
0
0
Kowariancja zmiennych losowych X, Y – wartość oczekiwana iloczynu scentrowanych
zmiennych x, y:
cov(
X,Y)=E(x
⋅
y)=
)
(
)
(
)
(
)
,
(
)]
(
[
)]
(
[
Y
E
X
E
Y
X
E
dY
dX
Y
X
f
Y
E
Y
X
E
X
⋅
−
⋅
=
⋅
⋅
⋅
−
⋅
−
∫ ∫
∞
∞
−
∞
∞
−
Współczynnik korelacji
ρρρρ
XY
zmiennych X i Y to ich kowariancja przeliczona do zakr. [–1, 1]
ρ
XY
=cov(X,Y)/(
σ
x
⋅σ
y
)
Współczynnik korelacji przyjmuje wartość 0 gdy zmienne X, Y są niezależne i wartość
±
1
gdy są one
zależne liniowo (ale tylko liniowo np. X=a+bY, a, b stałe);
Wynika to z następujących rachunków:
cov(X
⋅
Y)=E(a
⋅
Y+b
⋅
Y
2
)-E(Y)
⋅
E(X)=a
⋅
E(Y)+b
⋅
E(Y
2
)-E(Y)
⋅
[a+b
⋅
E(Y)]=
=b
⋅
{E(Y
2
)-[E(Y)]
2
}=b
⋅σ
2
Y
σ
2
X
=E[(a+b
⋅
Y)
2
]-[E(a+b
⋅
Y)]
2
=E(a
2
+2a
⋅
bY+b
2
⋅
Y
2
)-[a+b
⋅
E(Y)]
2
=
=a
2
+2a
⋅
b
⋅
E(Y)+b
2
⋅
E(Y
2
)-a
2
-2a
⋅
b
⋅
E(Y)-b
2
⋅
[E(Y)]
2
=b
2
⋅
{E(Y
2
)-[E(Y)]
2
}=b
2
⋅σ
Y
2
Zatem
σ
X
⋅σ
Y
=|b|
⋅σ
Y
, czyli
ρ
XY
=cov(X
⋅
Y)/(
σ
X
⋅σ
Y)
=b/|b|=
±
1
UWAGA !!
Niezerowe, a nawet wysokie wartości współczynnika korelacji dwóch zmiennych
losowych nie oznaczają związku przyczynowo-skutkowego między nimi, a jedynie
współzależność stochastyczną, czyli istnienie wspólnych przyczyn dla obu zjawisk
Procesy stochastyczne
Procesem stochastycznym nazywa się zmienną losową sparametryzowaną czasem (ogólnie –
dowolną zmienną skalarną).
Z=(X,t)=X
t
Oznacza to, że
każdej chwili czasu t
o
przypisuje się zbiór zmiennych losowych X
to
(zwany
zbiorem możliwych realizacji procesu Z w chwili
t
o
), z jego wartością oczekiwaną E(
X
to
) i
rozkładem prawdopodobieństwa f(
X
to
).

8
Proces stochastyczny jest zatem szczególnym przypadkiem wielowymiarowej zmiennej
losowej i można dla niego definiować wielowymiarowe rozkłady prawdopodobieństwa
f(X
to
, X
t1
, .. , X
tN
), a także kowariancje cov(X
to
, X
t1
) odpowiadające różnym t
o
, t
1
(zwane
autokowariancjami lub funkcjami korelacyjnymi). Określa się je identycznie jak dla
wielowymiarowych zmiennych losowych. Współczynnik korelacji odpowiadający dwóm
różnym wartościom t, nazywa się współczynnikiem autokorelacji procesu.
Ważną klasą procesów stochastycznych są procesy stacjonarne.
Proces stochastyczny jest stacjonarny w węższym sensie jeśli wszystkie jego rozkłady
prawdopodobieństwa nie zależą od czasu, a jedynie od różnic wartości t
o
, t
1
, .. , t
N
dla
których są definiowane.
Zatem jednowymiarowe rozkłady prawdopodobieństwa zmiennych X
t
dla kolejnych t są
identyczne, czyli f(X
t
)=f(X), a rozkłady dwuwymiarowe f(X
t1
, X
t2
) zależą tylko od różnicy
czasów
τ
=t
2
-t
1
, tzn. f(X
t1
, X
t2
) = f(X,
τ
).
Także autokowariancja i współczynnik autokorelacji zależą tylko od
τ
. Nazywa się je funkcją
korelacyjną K
X
(
τ
) i funkcją autokorelacji r(
τ
)
)
(
))
(
(
)
(
)
(
2
τ
−
τ
−
⋅
=
−
⋅
=
τ
t
t
t
t
def
X
x
x
E
X
E
X
X
E
K
2
2
2
)
(
))
(
(
)
(
)
(
σ
⋅
=
σ
−
⋅
=
τ
τ
−
τ
−
t
t
t
t
def
X
x
x
E
X
E
X
X
E
r
czyli
2
)
(
)
(
σ
τ
=
τ
X
def
X
K
r
gdzie x
t
oznacza proces scentrowany (tj. E(x)=0).
Wartość funkcji autokorelacji w zerze wynosi zawsze 1, r(0)=1
Proces stochastyczny jest stacjonarny w szerszym sensie jeśli istnieje jego wartość
oczekiwana i jest ona stała w czasie, a funkcje korelacyjne zależą tylko od przesunięcia
czasu
ττττ
(nie zależą od wartości t
o
, t
1
):
m
X
(t)=E(X
t
)=m
X
=const
K
X
(t
1
, t
2
)=E(x
t1
⋅
x
t2
)=K
X
(
τ
)
Zatem procesy stochastyczne stacjonarne mają stałą wartość oczekiwaną, a relacje
probabilistyczne między ich wartościami w różnych chwilach czasu są określone
(deterministycznie) przez funkcję autokorelacji r(
τ
).
Mówimy, że funkcja autokorelacji opisuje właściwości dynamiczne procesu
stochastycznego stacjonarnego, natomiast jego właściwości chwilowe (statyczne)
charakteryzuje funkcja gęstości prawdopodobieństwa, czyli rozkład prawdopodobieństwa
Im wolniej maleje funkcja autokorelacji, tym mniej losowe są zmiany w czasie procesu, tzn.
zmiany te są powodowane głównie wewnętrzną inercją procesu, a nie czynnikami losowymi.
Transformata Fouriera funkcji autokorelacji nazywa się funkcją gęstości widmowej mocy
procesu lub spektrum procesu
UWAGA:
Funkcje analogiczne jak funkcja korelacyjna mogą być definiowane dla dwu różnych
procesów stochastycznych stacjonarnych przesuniętych względem siebie w czasie.

9
Modelowe rozkłady prawdopodobieństwa
Szereg zjawisk losowych można opisać rozkładami prawdopodobieństwa, których gęstości są
stosunkowo prostymi funkcjami analitycznymi zmiennej losowej.
Modelowe rozkłady prawdopodobieństwa dla zmiennych dyskretnych (I.E. Brontsztejn,
K.A.Siemeindiajew: Matematyka – poradnik encyklopedyczny. Część szósta –
Opracowanie danych doświadczalnych,. PWN, Warszawa 1986, str.782)
1.
Rozważmy zdarzenie losowe (zwane sukcesem) występujące w pewnym procesie
losowym ze stałym prawdopodobieństwem p>0. Prawdopodobieństwo nie wystąpienia
sukcesu wynosi (1-p).
Jeśli przeprowadzimy n niezależnych doświadczeń, to liczba sukcesów S
n
jest liczbą
losową o rozkładzie dwumianowym:
k
n
k
n
p
p
k
n
k
S
P
−
−
⋅
⋅
=
=
)
1
(
)
(
wartość oczekiwana E(S
n
)=n
⋅
p;
wariancja
2
Sn
σ
=n
⋅
p
⋅
(1-p)
2.
Prawdopodobieństwo łącznej liczby wystąpień X pewnego rzadkiego zdarzenia (o
małym prawdopodobieństwie) oblicza się z rozkładu Poissona, który jest przybliżeniem
rozkładu dwumianowego dla
∞
→
n
i
0
→
p
ale tak, że
0
>
λ
→
⋅
p
n
.
λ
−
λ
=
=
e
k
k
X
P
k
!
)
(
wartość oczekiwana E(X)=
λ
;
wariancja
λ
=
σ
2
X
Rozkład ten jest w praktyce stosowalny już dla n rzędu kilkudziesięciu, przy
λ
<10.
Przykładem zmiennej X może być liczba klientów zainteresowanych - w pewnym
przedziale czasu - luksusowym artykułem w sklepie odwiedzanym przez wielu klientów
zainteresowanych na ogół innymi artykułami (np. w kiosku). Można go wykorzystać do
oceny opłacalności zamawiania takich artykułów.
3.
Rozważmy sytuację jak w (1), ale gdy interesuje nas prawdopodobieństwo zdarzenia
polegającego na wystąpieniu
serii k sukcesów, po których następuje brak sukcesu.
Zakładając niezależność kolejnych prób uzyskuje się wyrażenie zwane
rozkładem
geometrycznym dyskretnej zmiennej losowej X wyrażającej długość serii niezależnych
sukcesów o jednakowym prawdopodobieństwie wystąpienia:
)
1
(
)
(
p
p
k
X
P
k
−
⋅
=
=
wartość oczekiwana
p
p
S
E
n
−
=
1
)
(
;
wariancja
2
2
)
1
(
p
p
X
−
=
σ
Modelowe rozkłady prawdopodobieństwa dla zmiennych ciągłych (I.E. Brontsztejn,
K.A.Siemeindiajew: Matematyka – poradnik encyklopedyczny. Część szósta –
Opracowanie danych doświadczalnych,. PWN, Warszawa 1986, str.783 i dalsze)
1.
Rozkład wykładniczy określa rozstęp czasowy x pomiędzy wystąpieniami zdarzenia
którego prawdopodobieństwo zależy tylko od przedziału czasu w którym się go oczekuje,
a nie zależy od czasu trwania procesu losowego (np. czas pomiędzy nadejściem dwu
kolejnych klientów, czas pomiędzy awariami urządzenia)
10
<
≥
⋅
=
−
0
0
0
)
(
x
gdy
x
gdy
e
a
x
f
ax
≥
−
<
=
−
0
1
0
0
)
(
x
dla
e
x
dla
x
F
ax
wartość oczekiwana E(x)=1/a; wariancja
2
2
1
a
X
=
σ
Jest to ciągły odpowiednik rozkładu geometrycznego, gdy x=k
⋅δ
t, a=(1-p)/
δ
t, 1-p=a
⋅δ
t,
δ
t
≅
0. (1-p) – prawdopodobieństwo wystąpienia zdarzenia
2.
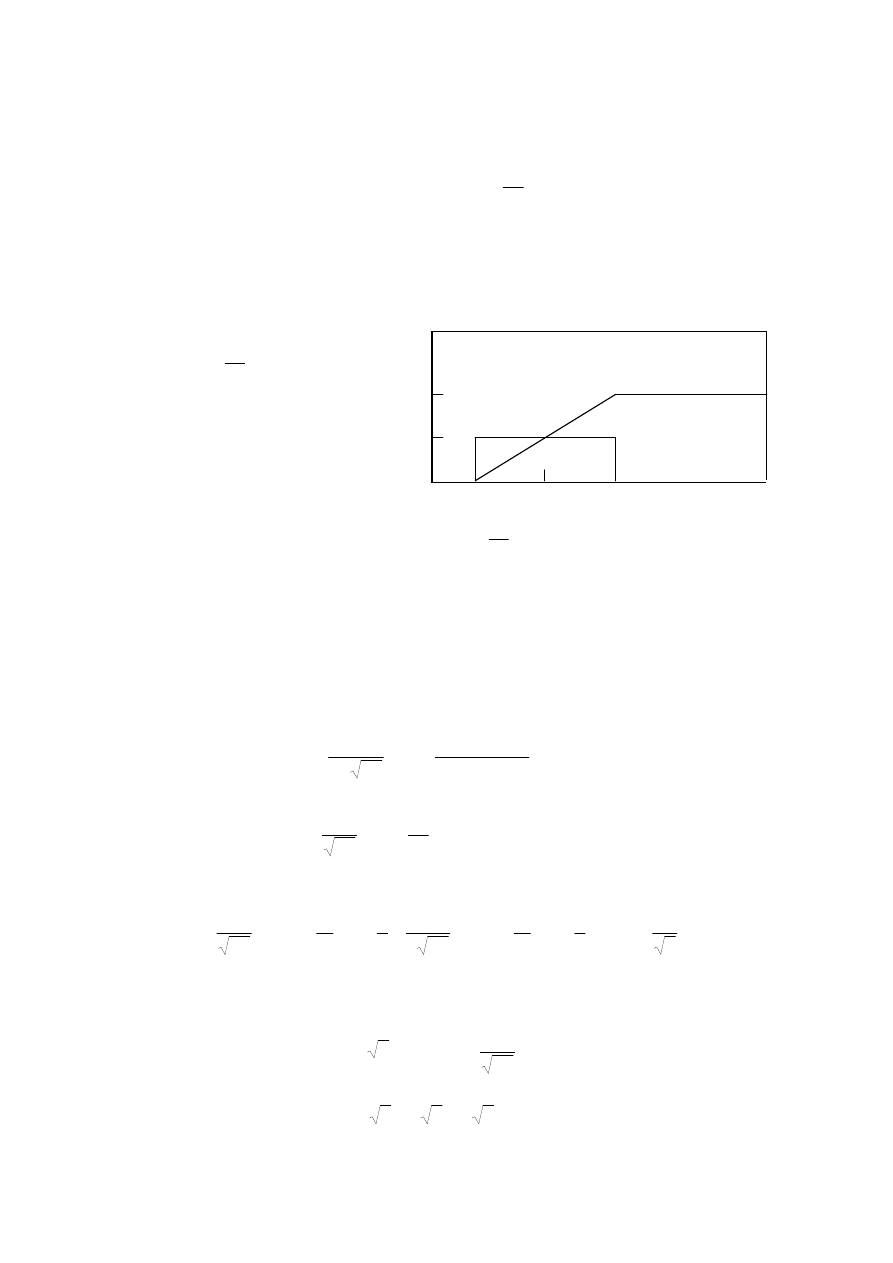
Rozkład równomierny ma zmienna losowa x, gdy może przyjmować z tym samym
prawdopodobieństwem dowolną wartość z przedziału [a-b, a+b], b>0 i nie występuje poza
tym przedziałem:
+
−
∉
+
−
∈
=
]
,
[
0
]
,
[
2
1
)
(
b
a
b
a
x
gdy
b
a
b
a
x
gdy
b
x
f
wartość oczekiwana E(x)=a; wariancja
3
2
2
b
X
=
σ
Rozkład równomierny przypisuje się zmiennym losowym, których wartości są naturalnie
ograniczone i wynikają z oddziaływania pewnego czynnika o czysto losowym charakterze
i ograniczonej „sile”. Przykładowo, taki rozkład może mieć kwota wydawana przez
jednego klienta w małym sklepie spożywczym lub kiosku.
3.
Rozkład normalny czyli rozkład Gaussa: dla zmiennej X o wartości oczekiwanej m=E(X)
i dyspersji
σ
(oznaczany symbolem
N(m,
σσσσ
)):
σ
⋅
−
−
π
⋅
σ
=
2
2
2
)]
(
[
exp
2
1
)
(
X
E
X
X
f
Dla zmiennej standaryzowanej x rozkład Gaussa N(0, 1) ma postać
−
π
=
2
exp
2
1
)
(
2
x
x
f
i w tej postaci jest on dostępny w tablicach i generatorach liczb
Dystrybuanta rozkładu Gaussa jest funkcją nieanalityczną zapisywaną w postaci:
∫
∫
−
∞
−
+
=
−
π
+
=
−
π
=
x
x
x
x
erf
dt
t
dt
t
x
F
2
1
2
1
2
exp
2
2
1
2
1
2
exp
2
1
)
(
2
2
gdzie
erf(x) (error function – funkcja błędu) jest definiowana jako
( )
∫
−
−
π
=
−
∈
⋅
=
x
x
dt
t
x
x
t
P
x
erf
2
exp
2
1
])
,
[
2
(
)
(
Wartości funkcji
erf(x) dla x=1/
2
, 2/
2
, 3/
2
(czyli w otoczeniu wartości
oczekiwanej o szerokości
σσσσ
, 2
⋅⋅⋅⋅σσσσ
, 3
⋅⋅⋅⋅σσσσ
), wynoszą:
F(x)
0
f(x)
Dystrybuanta i gęstość rozkładu równomiernego
a+b
a-b
x
1
x=a
11
erf(1/
2
)=0.6827=68.3%
erf(2/
2
)=0.9545=95.5%
erf(3/
2
)=0.9973=99.7%
erf(4/
2
)=0.9999=99.99%
Jak widać, zmienne losowe o rozkładzie normalnym praktycznie mieszczą się w zakresie (m-
3
⋅⋅⋅⋅σσσσ
, m+3
⋅⋅⋅⋅σσσσ
) (z prawdopodobieństwem 99.7%). Jest to tzw. zasada trzech sigm.
UWAGA !!! Wartość erf(x) wylicza w MATLABie funkcja o nazwie erf()
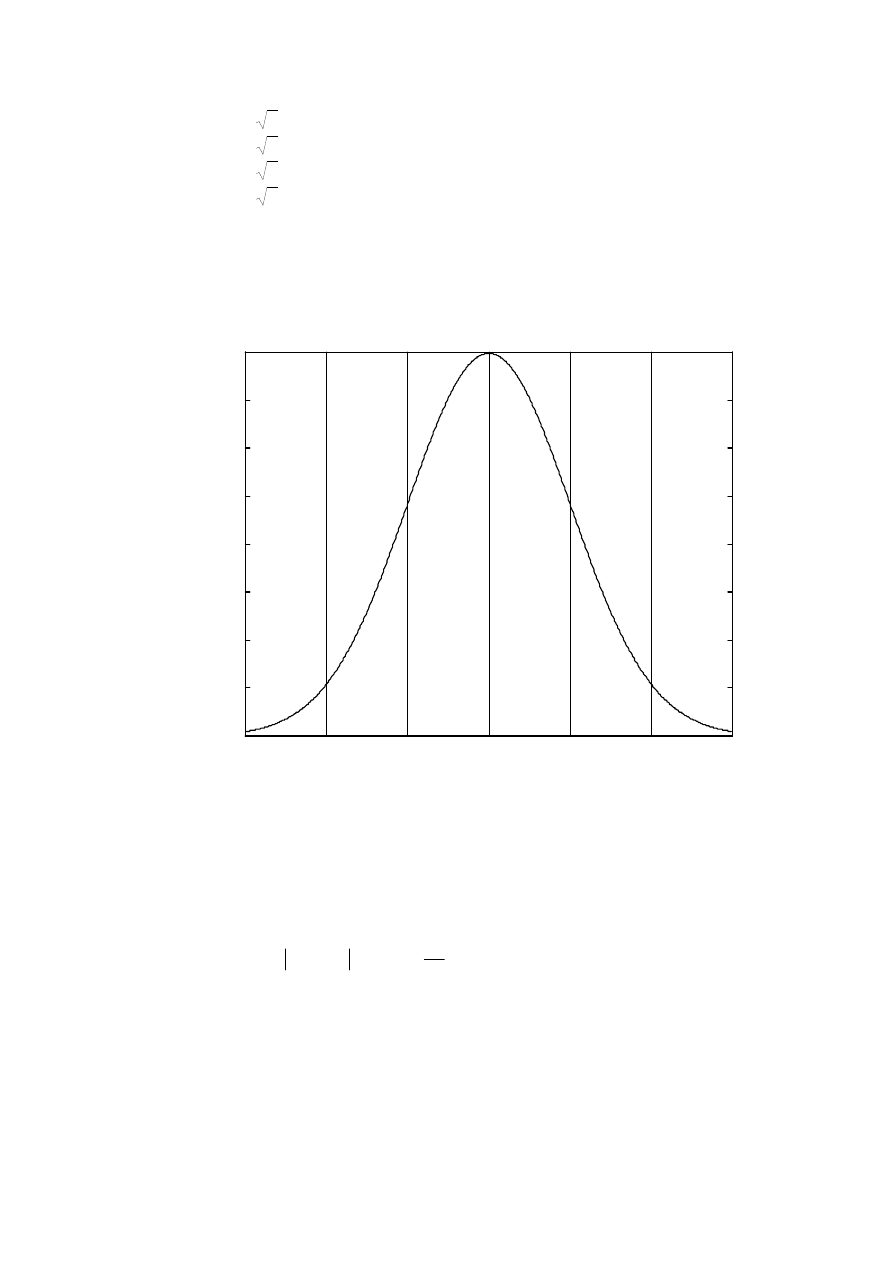
Rys. 3. Rozkład Gaussa N(0,1) dla standaryzowanej zmiennej losowej x
UZUPEŁNIENIE: Zasada trzech sigm stosuje się dla liczb losowych o dowolnym
rozkładzie.
Ujmuje to ogólnie nierówność Czebyszewa. Niech x oznacza zmienną losową o dowolnym
rozkładzie z ograniczoną wartością oczekiwaną E(x) i ograniczoną wariancją
σ
2
. Wówczas
(
)
2
1
)
(
k
k
x
E
x
P
≤
σ
⋅
>
−
Zatem, dowolna zmienna losowa mieści się w zakresie trzech sigm z prawdopodobieństwem
co najmniej 90%.
Rozkład normalny mają zmienne losowe, których wartości są zależne od wielu czynników,
przy czym każdy z nich indywidualnie ma mały wpływ na tę wartość. Z taką sytuacją mamy
bardzo często do czynienia w praktyce, w tym również w ekonometrii, dlatego rozkład
normalny odgrywa bardzo ważną rolę w zastosowaniach rachunku prawdopodobieństwa i w
statystyce matematycznej.
-3
-2
-1
0
1
2
3
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
x
f(x)

12
Formalnie ujmują to tzw. twierdzenia graniczne (patrz I.E. Brontsztejn, K.A.Siemeindiajew:
Matematyka – poradnik encyklopedyczny. Część szósta – Opracowanie danych
doświadczalnych,. PWN, Warszawa 1986, Poradnik inżyniera – Matematyka – Rozdział
XXXII).
1. Twierdzenie Lindberga-Leviego: Niech x
1,
x
2,
x
3,
... x
n,
będzie ciągiem niezależnych
zmiennych losowych, o jednakowym rozkładzie, posiadających wartość oczekiwaną m i
wariancję
σ
2
. Wtedy dla każdego rzeczywistego X spełniona jest relacja:
dy
y
X
n
m
n
x
P
X
n
k
k
n
⋅
−
π
=
<
⋅
σ
⋅
−
∫
∑
∞
−
=
∞
→
2
exp
2
1
lim
2
1
Oznacza to, że suma n takich zmiennych przy dużej liczbie składników n ma rozkład zbliżony
do normalnego z
wariancją równą n
⋅⋅⋅⋅σσσσ
2
i wartością oczekiwaną równą
n
⋅⋅⋅⋅
m.
Można pokazać, że jeśli liczby x
1,
x
2,
x
3,
... x
n
mają rozkład równomierny to już dla n
zbliżonych do 10 uzyskuje się praktycznie rozkład normalny.
2. Twierdzenie Lapunowa mówi, że
suma zmiennych x
1,
x
2,
x
3,
... x
n
zmierza do rozkładu
normalnego także wówczas, gdy mają one różne rozkłady, różne wartości oczekiwane m
k
i
wariancje
2
k
σ
, ale muszą mieć odpowiednio silnie ograniczone momenty centralne rzędu
trzeciego b
k
=E(|x
k
–m
k
|
3
), tak aby spełniony był następujący warunek:
0
lim
3
1
=
σ
∑
=
∞
→
n
k
k
n
b
;
gdzie
∑
=
σ
=
σ
n
k
k
1
2
jest dyspersją sumy zmiennych.
Wartość oczekiwana m rozkładu sumy takich liczb jest oczywiście sumą m
k
dla k=1, 2, ..n.
Z powyższego wynika, że
suma niezależnych zmiennych losowych o dowolnych
symetrycznych rozkładach (czyli o zerowych b
k
, ale posiadających ograniczone wartości
oczekiwane i ograniczone wariancje),
zmierza do rozkładu normalnego. Oczywiście,
zbieżność jest w tym przypadku wolniejsza niż dla liczb z Twierdzenia Lindberga-Leviego.
3.Lokalne twierdzenie graniczne Moivre’a-Laplace’a:
Rozkład dwumianowy o ustalonym
prawdopodobieństwie sukcesu p
zmierza do rozkładu normalnego, gdy liczba prób n
rośnie do nieskończoności.
Liczbę sukcesów S
n
w takiej sytuacji można obliczać jako zmienną losową (ciągłą) o
rozkładzie normalnym z wartością oczekiwaną m=n
⋅
p i wariancją
σ
2
= n
⋅
p
⋅
(1-p). Formalnie
zapisuje się to w postaci:
dy
y
b
p
p
n
p
n
S
a
P
b
a
n
n
⋅
−
π
=
≤
−
⋅
⋅
⋅
−
≤
∫
∞
→
2
2
1
1
2
exp
)
(
lim

13
Twierdzenie to stosuje się już dla n rzędu kilkudziesięciu. Pozwala ono oszacować przedziały
np. liczby sztuk S
n
pewnego artykułu (o stałym popycie) sprzedanych w ciągu dnia, z
wykorzystaniem tablic funkcji błędu erf(x) pakietu MATLAB,
gdzie
)
1
(
2
p
p
n
d
x
−
⋅
⋅
⋅
=
; d - promień przedziału S
n
wokół wartości oczekiwanej m=n
⋅
p.
Przykładowo, dla p=0.02 i n=50 (jeden dzień) mamy E(S
n
)=1,
σ
Sn
=0.99, co daje
P(S
n
∈
[0,2])
≅
0.68.
Dla n=300 (tydzień) mamy E(S
n
)=6,
σ
Sn
=2.43, co daje P(S
n
∈
[4,8])
≅
0.59 oraz
P(S
n
∈
[0,12])
≅
0.986, czyli, że sprzedaż tygodniowa praktycznie nie przekroczy 12 sztuk.
W analizie danych wykorzystuje się prawa wielkich liczb.
P
RAWO WIELKICH LICZB
Chinczyna (Poradnik inżyniera – Matematyka str.1072)
Niech x
1,
x
2,
x
3,
... x
n
oznacza ciąg niezależnych liczb losowych o jednakowym rozkładzie i
ograniczonej wartości oczekiwanej E(x)=m. Wtedy dla dowolnej liczby dodatniej
ε
zachodzi
równość:
0
1
lim
1
=
ε
≥
−
∑
=
∞
→
m
x
n
P
n
k
k
n
Jeśli dodatkowo niezależne liczby losowe x mają skończoną wariancję to słuszne jest
MOCNE PRAWO WIELKICH LICZB
, które mówi, że średnia arytmetyczna ciągu niezależnych
liczb losowych o ograniczonej wartości oczekiwanej i wariancji zmierza z
prawdopodobieństwem 1 do ich wartości oczekiwanej.
1
)
(
1
lim
1
=
=
∑
=
∞
→
x
E
x
n
P
n
k
k
n
4. ELEMENTY STATYSTYKI MATEMATYCZNEJ
Literatura:
1.
J.Greń: Statystyka matematyczna – modele i zadania, PWN, Warszawa 1982
2.
"Ekonometria. Metody i analiza problemów ekonomicznych". Pod red. K. Jajugi; Wydawnictwo
AE we Wrocławiu, Wrocław 1999.
3.
I.E. Brontsztejn, K.A.Siemeindiajew: Matematyka – poradnik encyklopedyczny. Część
szósta – Opracowanie danych doświadczalnych,. PWN, Warszawa 1986
4.
Poradnik inżyniera – Matematyka – Rozdział XXXIII
5.
Edward Nowak: Zarys metod ekonometrii – zbiór zadań, PWN, Warszawa 1994
6.
John Freund Podstawy nowoczesnej statystyki, PWE, Warszawa 1968
Pojęcia podstawowe statystyki (wg J.Greń: Statystyka matematyczna)
Metody statystyki stosuje się w ekonometrii w celu badania właściwości probabilistycznych
zmiennych ekonometrycznych. Zmienne te reprezentują pewne cechy badanej zbiorowości,
czyli populacji generalnej. Poddawane analizie dane (liczby losowe) są widziane jako losowa
próba populacji generalnej. Aby wynik badania był miarodajny, należy zadbać o

14
reprezentatywność próby. Uzyskuje się ją przez odpowiedni dobór (losowanie, rejestrację)
elementów próby z populacji generalnej.
Losowe wartości cechy w próbie o liczności n traktuje się jako jedną wartość n-wymiarowego
wektora losowego. Zbiór wszystkich możliwych wartości tej cechy w próbie o liczności n
nazywa się przestrzenią próby.
Rozkład populacji, to rozkład wartości badanej cechy w populacji generalnej. Zwykle zakłada
się, że rozkład populacji jest zbliżony do pewnego rozkładu modelowego (patrz poprzedni
rozdział).
Na podstawie zebranych danych losowych można obliczać statystyki z próby, czyli dowolne
funkcje zebranych zmiennych losowych. Statystyki są także zmiennymi losowymi.
Takimi statystykami mogą być zależności pozwalające na oszacowanie parametrów
rozkładów prawdopodobieństwa badanych cech populacji generalnej. Nazywa się je
estymatorami parametrów rozkładów. Wynikiem zastosowania estymatora jest estymata
poszukiwanego parametru rozkładu.
Estymator nieobciążony – estymator a pewnego parametru
α
spełniający równość E(a)=
α
,
co oznacza, że estymator szacuje wartość
α
bez błędu systematycznego, a więc pozwala
znaleźć faktyczną wartość parametru.
Estymator zgodny – estymator a pewnego parametru
α
spełniający warunek:
1
)
(
lim
=
ε
<
α
−
∞
→
n
n
a
P
tzn, estymator, który jest stochastycznie zbieżny do wartości parametru. Gdy używa się
estymatora zgodnego, to zwiększanie liczności próby zmniejsza błąd estymacji.
Ogólnie, estymator zgodny może być obciążony, a estymator nieobciążony może nie być
zgodny.
Estymator efektywny – estymator o możliwie małej wariancji.
Badania statystyczne zmiennych ekonometrycznych obejmują:
1.
analizę losowości zmiennych i określenie ich rozkładu prawdopodobieństwa;
2.
obliczanie czyli estymację parametrów tych rozkładów;
3.
weryfikację hipotez statystycznych dotyczących rozkładów populacji generalnej
Analiza losowości zmiennych i określenie ich rozkładu prawdopodobieństwa
Podstawowe estymatory rozkładów zmiennych losowych
1. Zgodnie z prawem wielkich liczb, jeśli cecha x populacji generalnej jest zmienną losową o
ograniczonej wariancji
σσσσ
2
i ograniczonej wartości oczekiwanej m, a ciąg wartości x
1,
x
2, ...
x
n
tej cechy w próbie jest ciągiem niezależnych liczb losowych, to estymatorem zgodnym,
nieobciążonym i najefektywniejszym wartości m=E(x) jest jej
średnia arytetyczna:
E(x)=m
≅
∑
=
−
=
n
k
k
x
n
x
1
1
Ś
rednia arytmetyczna liczb o rozkładzie normalnym ma rozkład normalny o wartości
oczekiwanej m (takiej jak liczby uśredniane) i wariancji
n
xs
σ
=
σ
2
Jeśli uśredniane liczby mają rozkład inny niż normalny to rozkład średniej arytmetycznej
zmierza (dla n zmierzającego do nieskończoności) do rozkładu normalnego
)
,
(
n
m
N
σ
(patrz Twierdzenie Lindberga-Leviego)
15
1. Zgodnie z prawem wielkich liczb, jeśli cecha x populacji generalnej jest zmienną losową o
ograniczonej wariancji
σσσσ
2
i ograniczonej wartości oczekiwanej m, a ciąg wartości x
1,
x
2, ...
x
n
tej cechy w próbie jest ciągiem niezależnych liczb losowych, to estymatorem zgodnym,
nieobciążonym i najefektywniejszym wartości m=E(x) jest jej
średnia arytetyczna:
E(x)=m
≅
∑
=
−
=
n
k
k
x
n
x
1
1
Ś
rednia arytmetyczna liczb o rozkładzie normalnym ma rozkład normalny o wartości
oczekiwanej m (takiej jak liczby uśredniane) i wariancji
n
xs
σ
=
σ
2
2.
Estymatorem zgodnym, nieobciążonym i najefektywniejszym wariancji cechy x na
podstawie ciągu wartości x
1,
x
2, ...
x
n
tej cechy w próbie o własnościach jak wyżej, jest
ś
redniokwadratowa odchyłka od wartości średniej obliczana wg wzoru
:
∑
∑
=
−
=
−
−
−
−
=
−
−
=
≅
σ
=
−
n
k
k
n
k
k
x
n
n
x
n
x
x
n
s
m
x
E
1
2
2
1
2
2
2
2
1
1
1
1
1
)
(
)
(
]
)
[(
Występująca w mianowniku różnica (n-1) powoduje, że estymator jest nieobciążony. Wynika
ona z faktu, że dane w liczbie n zostały już wykorzystane do obliczenia wartości średniej.
Zatem liczba jeszcze nie wykorzystanych danych wynosi (n-1).
Formalnie można to wykazać wychodząc z zależności:
∑
∑
=
−
=
−
−
=
−
=
−
n
k
k
n
k
k
x
E
M
n
x
E
M
x
x
E
M
m
x
E
1
2
2
1
2
2
}
)
{(
}
{
1
}
)
(
{
1
]
)
[(
gdzie M jest nieznanym jeszcze dzielnikiem estymatora.
Ze wzorów podanych w poprzednim rozdziale wynika, że:
2
2
2
}
{
m
x
E
x
k
+
=
σ
,
2
2
2
2
2
}
{
m
n
m
x
E
x
xs
+
=
+
=
σ
σ
Po podstawieniu do wzoru wyżej mamy:
2
2
1
2
2
2
2
2
2
)
1
(
)
1
(
1
]
)
[(
x
x
n
k
x
x
m
n
n
n
M
n
m
n
m
M
m
x
E
σ
σ
σ
σ
σ
⋅
−
=
⋅
−
=
−
−
+
=
−
=
∑
=
Wynika stąd, że aby uzyskać tożsamość, M powinno być równe (n-1).
Dzielenie przez n daje zatem błąd estymatora (obciążenie) jakkolwiek pozostaje on zgodny.
Dla dużych n można ten błąd zaniedbać i dzielić przez n.
∑
∑
=
−
=
−
−
=
−
≅
n
k
k
n
k
k
x
x
n
x
x
n
s
1
2
2
1
2
2
1
1
)
(
)
(
Estymata wariancji obliczona jak wyżej dla liczb o rozkładzie normalnym ma rozkład
χ
2
(chi-kwadrat) – patrz I.E. Brontsztejn, K.A.Siemeindiajew: Matematyka – poradnik
encyklopedyczny. Część szósta.
Zmienna losowa
η
ma rozkład
χ
2
o k stopniach swobody, gdy gęstość
)
(
)
(
χ
η
n
p
wyraża
się wzorem
1
2
2
2
)
(
2
2
2
)
(
−
−
Γ
=
k
k
k
k
k
e
p
χ
χ
η
Suma kwadratów N niezależnych liczb losowych o rozkładzie normalnym N(0,1) ma rozkład
χ
2
o N-1 stopniach swobody. Zatem

16
α
χ
χ
σ
η
=
=
−
<
<
−
∫
−
b
a
N
d
p
a
s
N
b
s
N
P
)
(
)
1
(
)
1
(
)
1
(
2
2
2
4.Estymatorem kowariancji dwóch zmiennych losowych x, y jest wyrażenie
:
∑
=
−
−
−
⋅
−
−
=
≅
=
−
⋅
−
n
k
k
k
xy
y
x
y
y
x
x
n
K
y
x
m
y
m
x
E
1
1
1
)
(
)
(
)
,
cov(
)]
(
)
[(
lub w przybliżeniu (dla dużych n)
∑
∑
=
−
−
=
−
−
⋅
−
⋅
=
−
⋅
−
≅
n
k
k
k
n
k
k
k
xy
y
x
y
x
n
y
y
x
x
n
K
1
1
1
1
)
(
)
(
Zachodzi równość: K
xy
=K
yx
Analogicznie, dla wielowymiarowych zmiennych losowych X=[X
1
, X
2
, .. X
M
], gdzie X
1
, X
2
, ..
X
M
są wektorami kolumnowymi (o jednakowej długości) losowych wartości kolejnych cech w
próbie, liczy się macierz kowariancji K wg wzoru macierzowego:
−
−
⋅
−
⋅
=
X
X
X
X
n
K
T
T
1
gdzie
T
oznacza transpozycję macierzy,
−
X jest wektorem wierszowym wartości średnich
kolejnych wektorów X
1
, X
2
, .. X
M,
, zatem
−
X
T
(wektor kolumnowy) pomnożony przez
−
X
(wektor wierszowy) daje macierz kwadratową o wymiarze MxM, czyli taką jak macierz K.
Jeśli wektory X
1
, X
2
, .. X
M
są wektorami wierszowymi (takie są na ogół produkowane przez
procedury pakietu MATLAB), to macierz kowariancji K liczy się wg wzoru:
T
T
X
X
X
X
n
K
−
−
⋅
−
⋅
=
1
Macierz kowariancji K jest symetryczna, tzn K
T
=K
5.
Estymator funkcji autokowariancji i autokorelacji
Jeśli ciąg liczb losowych jest uporządkowany wg czasu ich rejestracji, z jednakowym
rozstępem czasowym
∆∆∆∆
t między próbkami, czyli do kolejnych próbek można przypisać
czas liczony numerem kolejnym próbki
, to ciąg jest reprezentacją dyskretną procesu
stochastycznego (albo inaczej – zdyskretyzowanym procesem stochastycznym).
Jeśli badany proces stochastyczny jest stacjonarny, to estymatorem jego funkcji
autokowariancji z rozstępem m (czyli z rozstępem czasowym
ττττ
=m
⋅⋅⋅⋅∆∆∆∆
t) ma postać
∑
+
=
−
−
−
−
⋅
−
−
−
=
n
m
k
m
k
k
xn
x
x
x
x
m
n
m
R
1
1
1
)
(
)
(
)
(
Funkcję autokowariancji liczy się na ogół dla wystarczająco długich ciągów, aby można było
zastosować wzór:
∑
∑
+
=
−
−
+
=
−
−
−
−
⋅
−
=
−
⋅
−
−
≅
n
m
k
m
k
k
n
m
k
m
k
k
xn
x
x
x
m
n
x
x
x
x
m
n
m
R
1
2
1
1
1
)
(
)
(
)
(
Jeśli ciąg
x
1,
x
2, ...
x
n
jest ciągiem niezależnych liczb losowych reprezentujących stacjonarny
proces stochastyczny, to
>
=
σ
=
∞
−
0
0
0
2
m
dla
m
dla
m
R
x
xn
n
)
(
lim

17
Estymatorem unormowanej funkcji autokowariancji (czyli autokorelacji) r
xn
(m) jest
wyrażenie
2
x
xn
xn
s
m
R
m
r
)
(
)
(
=
Dyskusje ocen autokowariancji ciągu r
nm
dla kolejnych m zawiera podręcznik
[Mańczak Nahorski] str.66. Dla dużych n i dużych m mamy:
∑
∞
−∞
=
+
+
=
k
k
k
m
m
n
r
r
1
1
1
)
,
cov(
ρ
ρ
ρ
m
– prawdziwa wartość funkcji
Stąd wynika oszacowanie wariancji r
m
+
=
∑
∞
=
1
2
2
1
1
)
var(
k
k
m
n
r
ρ
(i)
Jeśli proces x
i
jest liniowy i spełnia warunki:
∑
∞
−∞
=
−
=
k
k
n
k
n
a
x
ξ
∑
∞
−∞
=
∞
<
k
k
a
2
∑
∞
−∞
=
∞
<
k
k
a |
|
∑
∞
−∞
=
∞
<
k
k
a
k
2
|
|
to wielowymiarowy rozkład zmiennych
)
,
0
(
)
(
W
N
r
n
n
m
m
∞
→
→
−
ρ
.
Dla dużych n istotność funkcji autokorelacji można badać metodą Boxa:
1.
Zakładamy, że
ρ
1
, ...,
ρ
k
są zerowe
2.
obliczamy wariancje r
m
ze wzoru (i) i sprawdzamy hipotezę j.w. dla m=1
3.
jeśli należy ją odrzucić przyjmujemy
ρ
1
=r
1
i sprawdzamy hipotezę dla m=2
4.
w taki sam sposób sprawdzamy dla dalszych m
Szeregi rozdzielcze i estymacja rozkładu prawdopodobieństwa
Histogram
a)
dzielimy przedział zmienności zbioru liczb x na pewną liczbę m podprzedziałów o
szerokości
∆
x
i
. i grupujemy liczby w klasy takie, aby w i-tej klasie znalazły się wszystkie
liczby x
k
∈
(
]
.
,
.
i
i
i
i
x
x
x
x
∆
+
∆
−
−
−
5
0
5
0
Należy przy tym tak dobrać liczbę klas lub ich
szerokości, aby w każdej klasie znalazło się co najmniej 10 liczb Uzyskuje się w ten
sposób
szereg rozdzielczy zmiennej x.
b)
dla każdego przedziału liczymy wysokość słupka histogramu p
i
wg wzoru:
i
i
i
x
n
n
p
∆
=
1
Wartość p
i
jest estymatą prawdopodobieństwa P
i
{x
∈
(
]
.
,
.
i
i
i
i
x
x
x
x
∆
+
∆
−
−
−
5
0
5
0
}
c)
robimy wykres słupkowy wartości p
i
względem
i
x
−
i uzyskujemy histogram.
Na tle histogramu wskazane jest wykreślenie przypuszczalnego rozkładu teoretycznego (lub
zestawu rozkładów) populacji generalnej, z parametrami E(x) oraz s
2
obliczonymi jak wyżej.
Jeśli danych jest wystarczająco dużo, najwygodniej jest przyjąć stałą szerokość klas szeregu
rozdzielczego. Można do tego wykorzystać
funkcję hist(x,k) z pakietu MATLAB. Tworzy
ona szereg rozdzielczy wektora x z liczbą przedziałów k, a następnie wykreśla histogram dla
liczności n
i
próbek w podprzedziałach (a nie dla p
i
jak zalecono w punkcie b)
Histogram można wykonać dla dowolnego zbioru liczb, ale ma on sens, gdy liczby te są
liczbami losowymi. Sam kształt histogramu nie rozstrzyga kwestii losowości danych,

18
jakkolwiek może sugerować, że są lub nie są one losowe. Hipotezę losowości należy przyjąć
wcześniej na podstawie analizy przyczyn losowości danych, obecności pewnych oddziaływań
deterministycznych, czy wreszcie przypuszczalnego rozkładu prawdopodobieństwa danych.
Na ogół dla zmiennych ciągłych rozkład ten winien być zbliżony do normalnego, w pewnych
przypadkach – do równomiernego. Stwierdzenie dużych rozbieżności histogramu od takiej
hipotezy może być spowodowane:
a)
niejednorodnością próbki, tzn. występowaniem kilku (np. dwóch) klas danych o różnych
rozkładach;
b)
zależnością parametrów rozkładu (głównie wartości oczekiwanej) od pewnych czynników
nielosowych (np. czasu lub zmiennych egzogenicznych)
W przypadku (a) zbiór danych należy rozdzielić na podzbiory jednorodne statystycznie.
W przypadku (b) należy znaleźć najpierw odpowiednie zależności ekonometryczne badanej
zmiennej (endogenicznej) od znanych czynników egzogenicznych, a następnie poddać
analizie probabilistycznej odchyłki losowe danych od tych zależności. Będzie to przedmiotem
następnego rozdziału opracowania.
Estymacja przedziałowa
Jak, wspomniano, estymaty są liczbami losowymi o określonym rozkładzie
scharakteryzowanym dyspersją i wartością oczekiwaną. W związku z tym wynik estymacji
można przedstawić jako estymatę wartości oczekiwanej parametru oraz przedział, w którym
z zadanym prawdopodobieństwem – zwanym poziomem ufności – mieści się prawdziwa
wartość parametru. Przedział taki nazywa się przedziałem ufności, sam sposób postępowania
– estymacją przedziałową.
Zwykle podaje się przedział ufności o szerokości 1
⋅σ
, 2
⋅σ
lub 3
⋅σ
. Dla rozkładu normalnego
estymatora odpowiada to poziomowi ufności odpowiednio: 68.3%, 95.5% i 99.7%
Zgodność histogramu z założonym rozkładem prawdopodobieństwa testuje się m.in.
przy pomocy statystyki
χ
2
(kryterium
χ
2
Pearsona).
Niech F(x) oznacza założoną (teoretyczną) dystrybuantę zmiennej losowej x, f(x) – funkcję
gęstości prawdopodobieństwa,
∆
1
,
∆
1
, ...,
∆
j
, ...,
∆
L
ciąg rozłącznych przedziałów histogramu
o wartości średniej x
j
, n
j
- liczbę danych w j-tym przedziale. Wówczas, dla N
→∞
statystyka
(
)
∑
∑
∫
∫
=
=
∆
∆
∆
⋅
−
∆
⋅
≅
−
=
L
j
L
j
j
j
j
j
j
j
j
j
x
f
N
n
x
f
N
x
dF
N
n
x
dF
N
1
1
2
2
2
)
(
)
(
)
(
)
(
χ
ma rozkład
χ
2
o L-1
stopniach swobody. W praktyce wystarcza, aby min
j
N
f(x)
∆
j
>10.
5. Modele ekonometryczne
Literatura:
1.
Manikowski A., Tarapata Z.: Prognozowanie i symulacja rozwoju przedsiębiorstwa.
WSE Warszawa 2002
2.
Pawłowski Z. " Zasady predykcji ekonometrycznej" PWN, Warszawa 1982.
3.
Zeliaś A. "Teoria prognozy" PWE, Warszawa 1997.
4.
Dittmann P., Metody prognozowania sprzedaży w przedsiębiorstwie, wyd. 6, Wyd. AE
Wrocław, 2002.

19
5.
Gajda J.B., Prognozowanie i symulacja a decyzje gospodarcze, C.H.Beck Warszawa,
2001.
6.
Radzikowska B. (red.), Metody prognozowania. Zbiór zadań, wyd. 3, Wyd. AE Wrocław,
2001.
7.
Zeigler B.P, Teoria modelowania i symulacji, PWN Warszawa, 1984.
8.
K. Molenda, M. Molenda, Analiza i prognozowanie szeregów czasowych, Placet,
Warszawa 1999
9.
E. Nowak. (red.) Prognozowanie gospodarcze. Metody, modele, zastosowania,
przykłady. Placet 1998
10.
Cieślak M. Prognozowanie gospodarcze. Wydawnictwo AE Wrocław, 1998.
11.
Henry Theil: Zasady ekonometrii, PWN, Warszawa, 1979
12.
Zbigniew Pawłowski: Ekonometria, PWN, Warszawa 1969
6.
G.E.P.Box, G.M.Jenkins: Analiza szeregów czasowych, PWN, Warszawa, 1983
Modelem ekonometrycznym nazywa się zależność stochastyczną wartości oczekiwanych
zmiennych endogenicznych od deterministycznych zmiennych egzogenicznych.
Schemat ujęcia zagadnienia zilustrowano na Rys.1.
Model ekonometryczny zapisuje się ogólnie w postaci:
)
(
^
X
f
y
=
;
gdzie X jest wektorem wartości zmiennych, przyjętych jako istotnie oddziałujące na zmienną
objaśnianą y. Zmienna objaśniająca y ma wartość:
e
y
y
+
=
^
gdzie e jest błędem modelu spowodowanym z założenia tylko czynnikami losowymi.
Jeśli wektor X zawiera tylko zmienne egzogeniczne (zewnętrzne) przypisane do tej samej
chwili czasu co zmienna endogeniczna, to model jest równaniem algebraicznym opisującym
proces ekonomiczny w stanie wewnętrznej równowagi, a model nazywa się zależnością
statyczną.
Modele statyczne buduje się w celu znalezienia ilościowych i stałych w czasie powiązań
zmiennych egzogenicznych z endogenicznymi.
Jeśli co najmniej jedna spośród zmiennych X jest zmienną endogeniczną zarejestrowaną w
poprzednich chwilach czasu, lub zmienne egzogeniczne brane są z wcześniejszych chwil
czasu niż y, to model jest dyskretnym zapisem równania różniczkowego (czyli równaniem
różnicowy) i opisuje przebieg zjawiska dynamicznego (uwarunkowanego wewnętrzną
dynamiką badanego procesu ekonomicznego). Taki model nazywa się modelem dynamiki
zjawiska. Modele takie wykorzystuje się w ekonometrii głównie do prognozowania przebiegu
zjawiska w przyszłości (matematyczne prognozowanie procesów ekonomicznych, np. cen,
zapotzrzebowania itp.)
W ekonometrii czynniki losowe odgrywają zwykle dużą rolę, stąd konieczność poszukiwania
raczej prostych zależności f(X).
W praktyce najczęściej stosuje się modele jednoczynnikowe, gdzie mamy tylko jedną
zmienną objaśniającą. Opracowanie wiarygodnych modeli wieloczynnikowych jest zadaniem
bardzo trudnym i wymaga często długotrwałych badań.

20
Szczególnym przypadkiem modeli jednoczynnikowych są takie, gdzie jedyną zmienną
objaśniającą jest czas t. Zależność ekonometryczną tego typu nazywa się często trendem, a
wyliczanie odchyłek danych od takiej zależności – ekstrakcją trendu. Formalnie, zależność
taka jest zależnością statyczną, niemniej może być (i często jest) wykorzystywana do analizy
dynamicznego przebiegu zjawiska. W szczególności stosuje się takie modele do
prognozowania zjawisk (tzw. modele Browna).
Modele regresyjne, liniowe
Bardzo ważną grupę modeli ekonometrycznych stanowią modele liniowe o ogólnej postaci:
A
U
X
u
a
y
n
K
k
kn
k
n
⋅
=
⋅
=
∑
=
0
^
)
(
gdzie
U
n
jest wektorem wierszowym tzw. wejść uogólnionych [
u
0n
,
u
1n
, ...,
u
Kn
],
A –
wektorem kolumnowym nieznanych współczynników modelu
A=[a
0
,
a
1
, ...,
a
K
].
Wejścia uogólnione są to funkcje algebraiczne zmiennych objaśniających, zadane wraz ze
wszystkimi koniecznymi współczynnikami, tak aby mając wartości zmiennych X
n
w
kolejnych próbkach
n=1..N, można było obliczyć wszystkie wartości U
n
dla
n=1, ..N.
Zatem, dane o wejściach X pozwalają obliczyć całą macierz
U złożoną z wierszy U
n
.
Niech
^
,
Y
Y
oznaczają wektory kolumnowe wartości
^
,
n
n
y
y
dla n=1, .. N; E – wektor
kolumnowy kolejnych wartości zakłóceń e
1
,
e
2
, ..., e
N
. Można ogólnie zapisać formuły:
E
A
U
Y
+
⋅
=
; lub
E
Y
Y
+
=
^
gdzie
A
U
Y
⋅
=
^
W ekonometrii najczęściej wykorzystuje się takie modele bądź jako
modele wieloczynnikowe
liniowe, tj. biorąc U
n
≡
X
n
, lub jako
modele jednoczynnikowe, w których wejścia u(x) są
prostymi funkcjami, przeważnie jednomianami. W ostatnim przypadku mamy modele
wielomianowe (najpopularniejsze).
Postać wejść U oraz ich liczba to
struktura modelu regresyjnego. Struktura modelu
regresyjnego musi być ustalona arbitralnie. Mając tę strukturę należy obliczyć parametry A.
Wyznaczanie parametrów A nazywa się identyfikacją modelu. Realizuje się ją w następujący
sposób:
a)
Dokonuje się pomiarów w liczbie N>K+1, tak aby nadmiar danych w stosunku do liczby
nieznanych współczynników pozwolił dobrać optymalne współczynniki
b)
Definiuje się kryterium jakości modelu
c)
Oblicza się wartości współczynników rozwiązując zadanie optymalizacji polegające na
minimalizacji kryterium (b)
Najprostszy algorytm uzyskuje się przyjmując jako kryterium (b) sumę kwadratów błędów
modelu. Nazywa się to
metodą najmniejszych kwadratów MNK.
Takie zadanie ma rozwiązanie analityczne, tzn. optymalny wektor współczynników modelu
wyraża się wzorem macierzowym:
[
]
Y
U
U
U
A
T
T
⋅
⋅
⋅
=
−
1
UWAGA !!!
Wyznaczone w powyższy sposób
parametry A mają sens tylko wówczas, gdy macierz U jest
dobrze uwarunkowana, tzn. wynik jej odwracania jest słabo zależny od błędów
numerycznych.
Sprawdza się to procedurą svd() z biblioteki MATLAB. Uwarunkowanie nie
zależy od wartości wyjść procesu (i ich składnika losowego) ale tylko od struktury funkcji

21
regresji i zmienności wejść (im mniejsza zmienność tym gorsze uwarunkowanie).
Uwarunkowanie można zatem poprawić tylko przez zmianę struktury modelu lub zebranie
bardziej zróżnicowanych danych wejściowych.
Warto podkreślić, że taki sam wzór określa współczynniki optymalnej aproksymacji dowolnej
funkcji y(u) zadanej w N punktach. Model ekonometryczny ma być jednak zależnością
stochastyczną, a nie aproksymatą pewnej funkcji deterministycznej. Oznacza to, że błedy
modelu chcemy interpretować jako spowodowane tylko czynnikami losowymi, a nie
wynikające z arbitralnego doboru wartości funkcji.
Aby uzyskany model mógł być interpretowany jako zależność stochastyczna winny być
spełnione następujące warunki (podane przez Gaussa) (patrz Z.Pawłowski: Ekonometria):
a)
zmienne objaśniające X, a więc także U winny być nielosowe (czyli dokładnie znane), i U
nie mogą być liniowo współzależne (ogólnie – macierz U musi być dobrze
uwarunkowana, co jest konieczne, aby obliczenia dawały sensowne rezultaty)
b)
składnik losowy e zmiennej objaśnianej musi mieć zerową wartość oczekiwaną E(e)=0, i
skończoną oraz stałą wariancję (niezależną od czasu przypisanego do kolejnych danych)
c)
ciąg {e
n
, n=1,2, ..N}musi być ciągiem niezależnych liczb losowych
d)
składnik losowy e nie może być skorelowany ze zmiennymi objaśniającymi
uwzględnionymi w modelu.
Jeśli te założenia są spełnione to estymatory A współczynników modelu są zgodne i
nieobciążone, a ich macierz kowariancji wyraża się prostym wzorem:
2
1
]
[
r
T
A
s
U
U
K
⋅
⋅
=
−
gdzie
2
r
s oznacza estymatę wariancji reszt modelu.
Pozwala to wyznaczać nie tylko samą funkcję regresji, ale także przedziały ufności dla tej
funkcji oraz prognoz zmiennej y, regresji w oparciu o oceny wariancji funkcji regresji
2
ym
s
i
wariancji przewidywanej zmiennej objaśnianej
2
y
s
, które oblicza się ze wzorów:
T
n
A
n
ym
u
K
u
s
⋅
⋅
=
2
;
2
2
2
r
ym
y
s
s
s
+
=
Model jednoczynnikowe wielomianowe mają wejścia uogólnione o postaci:
u
0n
≡≡≡≡
1; (stała modelu)
u
1n
= x
n
u
2n
= (x
n
)
2
.........
u
Kn
= (x
n
)
K
Model z ograniczeniami równościowymi [Pawłowski str.120]
BA=C
B – znana macierz, C – znany wektor, A – wektor współczynników oryginalnych.
Zmodyfikowany wektor parametrów wyraża się wzorem:
[
]
C
H
A
HB
I
A
⋅
+
−
=
*
gdzie
1
1
1
]
)
(
[
]
[
−
−
−
⋅
⋅
⋅
=
T
T
T
T
B
U
U
B
B
U
U
H
Macierz kowariancji ma postać:
[
]
[
]
2
1
]
[
*
r
T
T
A
s
HB
I
U
U
HB
I
K
⋅
−
⋅
−
=
−
22
Funkcje korelacyjne a zależności regresyjne
W przypadku szeregów czasowych, stosowaną powszechnie analizę współczynnika
korelacji zmiennych losowych można łatwo rozszerzyć, badając korelacje szeregów
przesuniętych względem siebie w czasie, czyli funkcje korelacyjne. Dla szeregów X
Nd
={x
1
, ..
x
N-d
}, Y
N
={y
d+1
, .. y
N
}przesuniętych o d próbek definiuje je formuła:
∑
+
=
−
−
−
−
−
−
=
≅
−
−
−
−
=
N
d
n
sr
d
n
sr
n
x
y
def
yxd
d
N
N
sr
d
N
sr
N
def
yxd
x
x
y
y
s
s
d
N
R
x
X
E
y
Y
E
x
X
y
Y
E
R
1
*
2
2
)
)(
(
1
1
}
)
{(
}
)
{(
)}
)(
{(
(1)
∑
+
=
−
−
−
=
N
d
n
sr
d
n
x
x
x
d
N
s
1
2
)
(
1
,
∑
+
=
−
−
=
N
d
n
sr
n
y
y
y
d
N
s
1
2
)
(
1
(2)
gdzie s
x
, s
y
,
y
,
x
, y
sr
, x
sr
oznaczają dyspersje, wartości oczekiwane i średnie ciągów X
Nd
i Y
N
.
Wzór (1) można zastosować dla dowolnych ciągów, ale funkcja R
yxd
jest miarodajna, gdy
są one stacjonarnymi szeregami czasowymi [6].
Przyjmijmy, że szeregi Y
N
, X
Nd
mają zerowe wartości średnie (y
sr
=0, x
sr
=0) (co można
zawsze uzyskać prowadząc analizy dla szeregów scentrowanych) i są powiązane liniową
funkcją regresji:
n
d
n
n
z
ax
y
+
=
−
,
d
n
n
ax
y
−
=
ˆ
(3)
gdzie z
n
są próbkami zakłócenia,
n
yˆ
- wartością oczekiwaną E{y
n
} (zależną liniowo od x
n-d
).
Jeśli zakłócenia z
n
mają rozkład normalny z zerową wartością oczekiwaną oraz stałą wariancją
(niezależną od n), i nie są skorelowane z poprzednimi wartościami (E{z
n
z
n
−
m
}=0 dla m
>0) i ze
zmienną x (E{z
n
x
n
−
d
}=0), to optymalny, zgodny i nieobciążony estymator współczynnika a
wyraża się wzorem wynikającym z metody najmniejszych kwadratów [Paw]:
*
*
2
1
1
2
1
yxd
x
y
yxd
x
y
s
N
d
n
d
n
n
N
d
n
d
n
R
s
s
R
s
s
s
x
y
x
a
⋅
=
=
=
∑
∑
+
=
−
+
=
−
(4)
Dyspersję s
e
błędów zależności (3) wyraża wzór:
2
*
1
2
*
1
2
)
(
1
)
(
1
)
(
1
yxd
y
N
d
n
d
n
yxd
x
y
n
N
d
n
d
n
n
def
e
R
s
x
R
s
s
y
d
N
ax
y
d
N
s
−
=
⋅
−
−
=
−
−
=
∑
∑
+
=
−
+
=
−
(5)
a dyspersja współczynnika a obliczonego ze wzoru (4) wynosi:
d
N
R
s
s
d
N
s
s
s
x
s
yxd
x
y
x
e
e
N
d
n
d
n
a
−
−
=
−
=
=
∑
+
=
−
2
*
1
2
)
(
1
1
1
(6)
Miarą zasadności stosowania modelu regresyjnego (3) jest statystyka Studenta (t) jego
współczynnika a:
2
*
*
)
(
1
yxd
yxd
a
def
a
R
d
N
R
s
a
t
−
−
=
=
(7)
Wynika stąd też zależność między statystyką Studenta i współczynnikiem korelacji, którą
wykorzystuje się do testowania istotności korelacji [A.Manikowski, Z.Tarapata:
Prognozowanie i symulacja rozwoju przedsiębiorstwa. WSE Warszawa 2002 (str. 172)]:
2
2
*
2
a
a
yxd
t
d
N
t
R
+
−
−
=
(7a)

23
Dla odpowiednio długich, nieskorelowanych ciągów (N-d
>30) statystyka t
a
ma rozkład
Gaussa N(0,1) [Pa]. Uzyskanie wartości t
a
>3 oznacza zatem, że zależność (3) jest istotna na
poziomie istotności 0.3%. Zatem, jeśli R
yxd
≠
0, to wykazanie tego wymaga ciągu o długości
(
)
1
)
(
9
2
*
−
>
−
−
yxd
R
d
N
(8)
Bardziej praktyczną miarą przydatności modelu jest jednak stopień redukcji niepewności
informacji o wartościach y
n
uzyskiwanych wg wzoru (3) względem oceny trywialnej, jaką
daje średnia wartość y
sr
szeregu Y
N
. Zgodnie ze wzorem (5) miarę tę wyraża formuła:
2
*
)
(
1
yxd
y
e
R
s
s
−
=
(9)
Jeśli szeregi Y
N
, X
N-d
są stacjonarne, to dla odpowiednio dużych wartości N, np.
spełniających relację (8), uzyskuje się
*
yxd
R
≅
R
yxd
=const, s
y
≅
σ
y
, s
x
≅
σ
x
, s
e
≅
σ
e
oraz:
2
1
/
yxd
y
e
R
−
=
σ
σ
,
(10)
gdzie
σ
x
,
σ
y
,
σ
e
są stałymi odchyleniami standardowymi zmiennych x, y i błędów modelu (3),
Wówczas właściwości prognoz uzyskiwanych przez zastosowanie modelu (3), t.j.
n
d
n
ax
y
=
+
ˆ
(11)
można miarodajnie ocenić wg wzoru (9), a istotność zależności (3) – wg. wzoru (8).
W przeciwnym wypadku ekstrapolacja zawarta w formule predyktora (11) może wprowadzać
znaczący błąd, większy niż wynikałoby to ze wzoru (9), szczególnie dla małych N.
Modele regresyjne dynamiki procesów (modele ARMAX)
Ważną rolę odgrywają regresyjne, liniowe modele dynamiki procesów wynikające z równań
różnicowych opisujących przebieg procesu w dyskretnych chwilach czasu:
n
K
k
k
n
j
J
j
m
j
n
j
I
i
i
n
i
n
z
z
x
y
y
+
⋅
γ
+
⋅
β
+
⋅
α
=
∑
∑
∑
=
−
=
−
−
=
−
1
1
1
gdzie pierwszą sumę nazywa się członem autoregresyjnym (AR), a sumy druga i trzecia są
ś
rednimi ruchowymi (moving average MA) dla zmiennych egzogenicznych X (np. sterowań
branych z zadanym opóźnieniem m próbek) oraz zakłóceń z (zakłocenia z są z założenia
ciągiem niezależnych liczb losowych o zerowej wartości oczekiwanej) .
Modele takie omawia obszernie monografia G.E.P.Box, G.M.Jenkins: Analiza szeregów
czasowych, PWN, Warszawa, 1983.
W pakiecie MATLAB są procedury do identyfikacji współczynników modeli ARMAX.
W przypadku, gdy wejścia są nieznane (np. gdy interesują nas przebiegi wejść zakłócających
widzianych jako efekt czynników wyłącznie losowych), stosuje się model ARMA:
n
K
k
k
n
j
I
i
i
n
i
n
z
z
y
y
+
⋅
γ
+
⋅
α
=
∑
∑
=
−
=
−
1
1
Jest on często stosowany do prognozowania takich zakłóceń (jako alternatywa dla model
Browna).
UWAGA !!! W modelu ARMA (a tak
ż
e ARMAX) zakłada si
ę
,
ż
e zakłócenia z maj
ą
warto
ść
oczekiwan
ą
zerow
ą
. Je
ś
li nie jest to spełnione, a w szczególno
ś
ci, gdy
warto
ść
ta jest zmienna, lepiej zastosowa
ć
model ARMA dla ró
ż
nic wyj
ść
y i
zakłóce
ń
. Taki model nazywa si
ę
modelem ARIMA (scałkowany model ARMA)

24
Z drugiej strony, pomijając drugą sumę modelu ARMAX uzyskuje się model dynamiki
procesu dla przypadku, gdy mamy słabe zakłócenia zewnętrzne, a z reprezentuje szumy
pomiarowe. Taki model identyfikuje się metodą analizy regresji, biorąc jako wejścia
uogólnione u wektor:
u
n
=[y
n-1,
y
n-2
, ... y
n-I
, x
n-1-m
, x
n-2-m
, ... x
n-J-m
]
oraz jako wejście ciąg:
y
n
=[y
n,
y
n-1
, ... y
n-I+1
].
Wektor współczynników:
A=[
α
1
,
α
2
, ...
α
I
,
β
1
,
β
2
, ...
β
J
];
Procedura identyfikacji może dalej przebiegać jak dla modeli statycznych, jakkolwiek lepsze
rezultaty daje metoda zmodyfikowana, zwana metodą zmiennych instrumentalnych (IV). Jest
ona omówiona np. w podręczniku: A.Niederliński: Komputerowe systemy sterowania.
W pakiecie MATLAB jest procedura do identyfikacji współczynników modelu tą metodą
(funkcja iv()).
Modelowanie charakterystyk statycznych metodą analizy regresji
(Uzupełnienie [Duda 2003])
Modele statyczne buduje się w celu znalezienia ilościowych i stałych w czasie powiązań
zmiennych wejściowych z wyjściowymi. Jeśli czynniki losowe odgrywają dużą rolę, zaleca
się poszukiwanie raczej prostych zależności f(U).
Bardzo ważną grupę modeli statystycznych procesów stanowią zależności liniowe (ze
względu na nieznane parametry) o ogólnej postaci:
A
U
a
y
n
K
k
n
kn
k
n
Φ
=
ϕ
=
∑
=
0
^
)
(
(1.6.3)
gdzie
ϕ
n
jest wektorem wierszowym tzw. wejść uogólnionych [
ϕ
0n
,
ϕ
1n
, ...,
ϕ
Kn
], A –
wektorem kolumnowym nieznanych współczynników modelu A=[a
0
, a
1
, ..., a
K
].
Wejścia uogólnione są to funkcje algebraiczne zmiennych objaśniających, zadane wraz ze
wszystkimi koniecznymi współczynnikami, tak aby mając wartości zmiennych U
n
w
kolejnych próbkach n=1..N, można było obliczyć wszystkie wartości
ϕ
n
dla n=1, ..N. Zatem,
dane o wejściach U pozwalają obliczyć całą macierz
Φ
złożoną z wierszy
ϕ
n
. Zakres
zmienności poszczególnych kolumn macierzy
Φ
wyznacza N-wymiarowe pole korelacji
modelu.
Niech
^
, Y
Y
oznaczają wektory kolumnowe wartości
^
,
n
n
y
y
dla n=1, .. N; Z – wektor
kolumnowy kolejnych wartości zakłóceń z
1
,
z
2
, ..., z
N
:
Z
A
Y
+
⋅
Φ
=
; lub
Z
Y
Y
+
=
^
gdzie
A
Y
⋅
Φ
=
^
(1.6.4)
W sterowaniu najczęściej wykorzystuje się takie modele bądź jako modele wieloczynnikowe
liniowe, tj. biorąc
ϕ
n
=f(U
n
), lub jako modele jednoczynnikowe, w których wejścia
ϕ
n
(u) są
prostymi funkcjami (przeważnie jednomianami) jednej zmiennej wejściowej.
Postać wejść
Φ
oraz ich liczba to struktura modelu regresyjnego, która musi być
ustalona arbitralnie
. Mając tę strukturę należy obliczyć parametry A. Wyznaczanie
parametrów A nazywa się identyfikacją modelu. Jest ona realizowana w następujący sposób:
d)
rejestruje się pomiary wejść i wyjść w liczbie N>K+1, tak aby nadmiar danych w stosunku
do liczby nieznanych współczynników pozwolił dobrać optymalne współczynniki A
e)
definiuje się kryterium jakości modelu
f)
oblicza się wartości współczynników rozwiązując zadanie optymalizacji polegające na
minimalizacji kryterium (b),
g)
przy pomocy testów statystycznych usuwa się z modelu mało istotne składniki.

25
Najprostszy algorytm identyfikacji uzyskuje się przyjmując jako kryterium (b) sumę
kwadratów błędów modelu. Nazywa się to metodą najmniejszych kwadratów MNK. Takie
zadanie ma rozwiązanie analityczne, tzn. optymalny wektor współczynników modelu wyraża
się wzorem macierzowym ([Mań79], [MaN81], [Gór97]):
[ ]
Y
A
T
T
Φ
Φ
Φ
=
−
1
(1.6.5)
Wzór ten można zapisać w postaci splotowej:
GY
A
=
(1.6.5a)
gdzie
[ ]
T
T
def
G
Φ
Φ
Φ
=
−
1
jest macierzą, której wiersze są odpowiedziami impulsowymi filtru
przekształcającego ciąg Y na współczynniki jego aproksymaty minimalnokwadratowej.
Zostanie wykazane w dalszej części tego rozdziału, że suma elementów wierszy k=0, 1, ....K
macierzy G spełnia równości:
∑
=
=
N
n
on
g
1
1 oraz
∑
=
=
N
n
kn
g
1
0 dla k=1, ...K
(1.6.5b)
Należy zwrócić uwagę, że wyznaczone wg wzoru (1.6.5) parametry A mają sens tylko
wówczas, gdy macierz
Φ
jest dobrze uwarunkowana, tzn. wynik jej odwracania jest słabo
zależny od błędów numerycznych (patrz rozdz.3.2). Uwarunkowanie nie zależy od wartości
wyjść procesu (i zakłóceń) ale tylko od struktury funkcji regresji i zmienności wejść (im
mniejsza zmienność tym gorsze uwarunkowanie). Można je zatem poprawić tylko przez
przeskalowanie (normalizację) wejść uogólnionych lub zmianę struktury modelu, lub zebranie
bardziej zróżnicowanych danych wejściowych. Dokładność obliczeń można również
zwiększyć stosując tzw. faktoryzację pierwiastkową i przekształcenie Hausholdera [Nied85].
Wzór (1.6.5) jest ogólną formułą minimalno-kwadratowego dopasowania danych do
założonego modelu, a więc nie zawsze daje wyniki będące estymatami w sensie
statystycznym. Określa bowiem również współczynniki optymalnej aproksymacji dowolnej
funkcji y(u) zadanej w N punktach. Dla niektórych zastosowań poszukiwana zależność (1.6.3)
może spełniać jedynie rolę aproksymaty pewnej złożonej funkcji w polu korelacji.
Przykładem są zależności wykorzystywane do iteracyjnej optymalizacji on-line omawiane w
rozdz.3.5.3.2. W wielu przypadkach wymaga się jednak, aby model był adekwatny również w
pewnym otoczeniu pola korelacji. Funkcja (1.6.4) musi być wówczas zależnością
stochastyczną co oznacza, że błędy modelu winny być powodowane tylko czynnikami
losowymi, bez znaczącego wpływu arbitralnego doboru struktury modelu.
Model (1.6.3) o współczynnikach obliczonych wg wzoru (1.6.5) jest zależnością
stochastyczną, jeśli spełnione są następujące warunki podane przez Gaussa (patrz [Paw69]):
a)
zmienne wejściowe U, a więc także
Φ
muszą być nielosowe (czyli dokładnie
znane), a macierz
Φ
musi być dobrze uwarunkowana,
b)
składnik losowy z zmiennej wyjściowej musi mieć zerową wartość oczekiwaną
E{z}=0, i skończoną oraz stałą wariancję (niezależną od czasu przypisanego
do kolejnych danych)
c)
ciąg {z
n
, n=1,2, ..N} musi być ciągiem niezależnych liczb losowych
d)
składnik losowy z nie może być skorelowany ze zmiennymi wejściowymi
uwzględnionymi w modelu, tzn.
0
}
{
=
Φ
Z
E
T
.
Jeśli spełnione jest założenie (a), to błąd losowy współczynników wyraża się wzorem:
Z
A
T
T
Φ
Φ
Φ
=
δ
−
1
]
[
(1.6.6)
Wynika stąd, że przy spełnionym założeniu (d) estymator (1.6.5) jest nieobciążony, tzn.:
E{
δ
A}=
0, a macierz kowariancji współczynników modelu wyraża ogólnie wzór:
1
1
1
1
]
[
]
[
]
[
}
{
]
[
}
)
(
{
−
−
−
−
Φ
Φ
Φ
Φ
Φ
Φ
=
Φ
Φ
Φ
Φ
Φ
Φ
=
δ
δ
=
T
Z
T
T
T
T
T
T
T
def
A
K
Z
Z
E
A
A
E
K
(1.6.7)
26
gdzie K
Z
oznacza macierz autokowariancji zakłóceń, która przy założeniach (b) i (c) wynosi
2
z
I
σ
. Estymatę zgodną
2
r
s wariancji
2
z
σ
zakłóceń (wariancji reszt modelu) wyraża wzór:
∑
=
−
−
−
=
N
n
n
n
r
y
y
K
N
s
1
2
^
2
1
1
(1.6.8)
Zatem, jeśli spełnione są założenia (a-d), to estymator (1.6.5) współczynników modelu jest
zgodny i nieobciążony, a macierz kowariancji współczynników wyraża się prostym wzorem:
2
1
]
[
r
T
A
s
K
−
Φ
Φ
=
(1.6.9)
Jeśli dodatkowo zakłócenia losowe mają rozkład Gaussa, to wzór (1.6.5) daje
najefektywniejsze estymaty współczynników modelu o przyjętej strukturze [Mań79].
Wzór (1.6.8) daje estymator zgodny wariancji resztowej. Można to wykazać, podobnie
jak dla estymatora wariancji, wychodząc z zależności:
(
)
∑
∑
=
=
−
=
−
=
N
n
n
n
N
n
n
n
r
y
E
y
E
M
y
y
E
M
s
E
1
2
2
1
2
2
}
ˆ
{
}
{
1
}
)
ˆ
(
{
1
}
{
(1.6.9a)
gdzie M jest nieznanym jeszcze dzielnikiem estymatora.
Ze wzorów podanych w rozdziale o rachunku prawdopodobieństwa wynika, że:
2
2
2
~
}
{
n
z
n
y
y
E
+
=
σ
(1.6.9b)
2
2
2
~
}
ˆ
{
n
yn
n
y
y
E
+
=
σ
(1.6.9c)
gdzie
}
{
~
n
n
y
E
y
=
.
2
yn
σ
oznacza wariancję modelu
.
Pierwszy składnik po prawej stronie wzoru (1.6.9c) jest wartością oczekiwaną estymaty
wariancji modelu. Błąd modelu dla n-tej obserwacji wejść uogólnionych
ϕ
n
wynosi (zgodnie z
1.6.5b i 1.6.6):
∑
∑∑
=
=
=
−
=
=
Φ
Φ
Φ
=
N
i
i
ni
N
i
K
k
i
ki
nk
T
T
n
n
z
c
z
g
Z
y
1
1
0
1
]
[
ˆ
ϕ
ϕ
δ
(1.6.9d)
Estymatę
)
(
2
n
y
U
s
wariancji modelu
2
yn
σ
dla obserwacji U
n
można obliczyć na dwa sposoby.
Pierwszy, to wykorzystanie macierzy kowariancji współczynników (1.6.9):
)
(
)
(
)
(
2
n
T
n
A
n
n
n
y
U
K
U
U
s
ϕ
ϕ
=
(1.6.9e)
Jeśli K
Z
=
2
z
I
σ
, to jej wartość oczekiwana wynosi:
{
}
2
2
1
2
2
]
[
}
{
z
n
z
T
n
T
n
yn
yn
s
E
σ
γ
σ
ϕ
ϕ
σ
=
Φ
Φ
=
=
−
(1.6.9f)
gdzie
T
n
T
n
def
n
ϕ
ϕ
γ
1
]
[
−
Φ
Φ
=
są współczynnikami rozkładu błędu generowanego przez
zakłócenia dla poszczególnych obserwacji
ϕ
n
będących wierszami macierzy
Φ
.
Przykładowe wartości współczynników filtrujących g
kn
i rozkładu g
n
dla 100 obserwacji
modelu wielomianowego 3. stopnia pokazano na rys.1.
Wykażemy, że
∑
=
+
=
N
n
n
K
1
1
γ
(1.6.9g)
Niech f
ij
oznacza ij-ty element macierzy F=[
Φ
T
Φ
]
-1
. Współczynnik
γ
n
wyraża wzór:

27
[
]
[
]
[
]
[
]
[
]
[
]
+
+
+
=
=
+
+
+
=
KK
K
K
nK
nK
nK
n
K
n
nK
n
n
K
n
nK
n
n
n
n
nK
KK
K
K
nK
n
n
n
K
nK
n
n
n
K
nK
n
n
n
f
f
f
f
f
f
f
f
f
f
f
f
f
f
f
f
f
f
:
,
.
,
...
:
,
..
,
:
,
....
,
,
:
,
..
,
,
...
:
,
..
,
,
:
,
..
,
,
1
0
0
1
11
01
1
1
0
0
10
00
0
0
1
0
0
1
0
1
0
1
1
11
01
1
0
0
0
10
00
1
0
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
γ
co można zapisać w skrócie:
[
]
∑
=
=
K
k
Kk
k
k
nk
nK
nk
n
nk
n
n
f
f
f
0
1
0
1
0
:
,
,..
...,
,
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
γ
(1.6.9g0)
Zsumowanie elementów
γ
n
daje:
∑
∑
∑
∑
∑
=
=
=
=
=
=
K
k
Kk
k
k
N
n
nk
nK
N
n
nk
n
N
n
nk
n
N
n
n
f
f
f
0
1
0
1
1
1
1
0
1
:
,
,..
...,
,
ϕ
ϕ
ϕ
ϕ
ϕ
ϕ
γ
(1.6.9g1)
Zwróćmy uwagę, że wektor wierszowy jest tu
k-tym wierszem macierzy
Φ
T
Φ
, natomiast
wektor kolumnowy – to
k-ta kolumna macierzy odwrotnej F, tj. [
Φ
T
Φ
]
-1
. Iloczyn skalarny
takich wektorów
musi być zawsze równy 1, co wynika z oczywistej relacji [
Φ
T
Φ
][
Φ
T
Φ
]
-1
=I.
Zatem powyższa suma wynosi zawsze
K+1, co jest wykazaniem zależności (1.6.9g) !!!!.
Wynika stąd ogólne twierdzenie algebry macierzowej:
Ślad macierzy U*[U
T
U]
-1
U
T
jest zasze równy rzędowi macierzy U
W taki sam sposób wykazuje się zależność (1.6.5b).
Sposób drugi, to zastosowanie wzoru (1.6.9d).
∑
∑∑
=
=
=
−
=
=
Φ
Φ
Φ
=
N
i
i
ni
N
i
K
k
i
ki
nk
T
T
n
n
z
c
z
g
Z
y
1
1
0
1
]
[
ˆ
ϕ
ϕ
δ
Po podstawieniu wzorów (1.6.9b) i (1.6.9cb) do wzoru (1.6.9a) i uwzględnieniu (1.6.9f) oraz
(1.6.9g) mamy:
(
)
2
1
2
1
2
2
1
2
2
2
2
2
)
1
(
1
~
~
1
}
{
z
N
n
n
z
N
n
yn
z
N
n
n
yn
n
z
r
M
K
N
N
M
N
M
y
y
M
s
E
σ
γ
σ
σ
σ
σ
σ
−
−
=
−
=
−
=
−
−
+
=
∑
∑
∑
=
=
=
Wynika stąd, że aby uzyskać estymator nieobciążony, M powinno być równe (N-K-1).
Wzór (1.6.9) pozwala wyznaczyć przedziały ufności dla funkcji regresji oraz prognoz
zmiennej y, w oparciu o oceny wariancji funkcji regresji
2
ym
s
i wariancji przewidywanej
zmiennej objaśnianej
2
y
s
, które oblicza się ze wzorów:
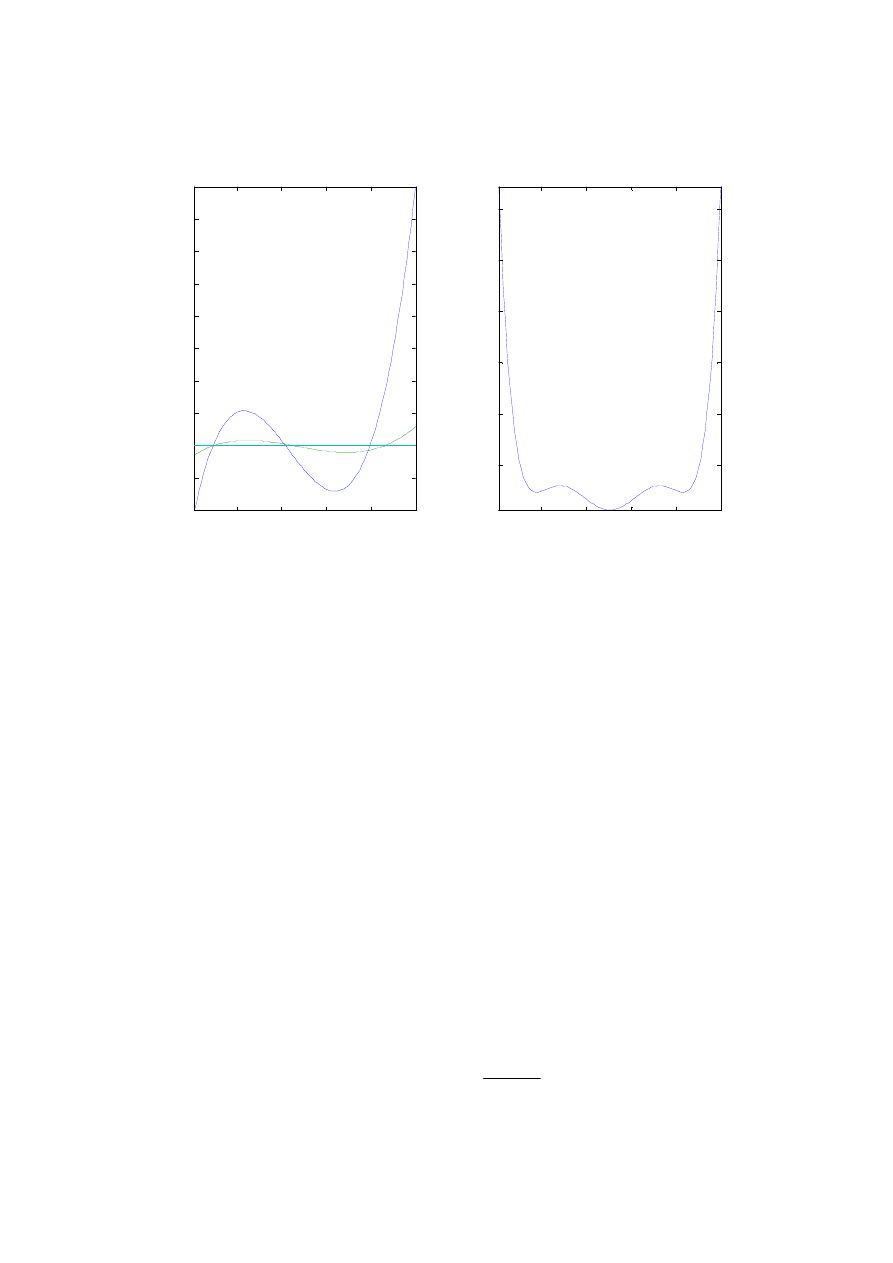
28
2
2
2
r
ym
y
s
s
s
+
=
(1.6.10)
20
40
60
80
100
0.04
0.06
0.08
0.1
0.12
0.14
n=1, ..., 100
γ
n
Rozklad bledow modelu w polu korelacji
γ
n
(n)
20
40
60
80
100
-0.04
-0.02
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
n=1, ..., 100
g
k
,n
Odpowiedzi impulsowe MNK dla K=3, W =I
Uzyskanie dobrych wyników modelowania, szczególnie poza polem korelacji,
wymaga trafnego doboru funkcji regresji, tj. przekształceń
ϕ
n
(U) generujących wejścia
uogólnione, a także przyjęcia odpowiedniej liczby członów (K+1) modelu (1.6.3). Dla
procesów wielowejściowych dobór przekształceń
ϕ
jest na ogół trudnym problemem,
wymagającym dużego doświadczenia, intuicji i wiedzy technologicznej. Jeśli rozbieżności
między funkcją regresji pierwszego rodzaju a modelem są duże, to formuła (1.6.9) jest
nieadekwatna, a co za tym idzie oszacowania przedziałów ufności są niemiarodajne (na ogół
zbyt optymistyczne). Z drugiej strony, zastosowanie zbyt złożonej funkcji regresji prowadzi
często do złego uwarunkowania zadania identyfikacji, lub powoduje bardzo niekorzystne
właściwości modelu poza polem korelacji, ujawniające się zwykle szybkim wzrostem
wariancji modelu obliczanej wg (1.6.10). Jest to typowy efekt nadparametryzacji modelu,
której skutkiem jest nadmierna wrażliwość wyniku estymacji na zakłócenia.
Podobne zależności można uzyskać dla uogólnionej MNK.
WY
W
A
T
T
Φ
Φ
Φ
=
−
1
]
[
(1.6.7)
1
1
1
1
]
[
]
[
]
[
}
{
]
[
}
)
(
{
−
−
−
−
Φ
Φ
Φ
Φ
Φ
Φ
=
Φ
Φ
Φ
Φ
Φ
Φ
=
=
W
W
WK
W
W
W
Z
Z
WE
W
A
A
E
K
T
T
Z
T
T
T
T
T
T
T
T
def
A
δ
δ
(1.6.7)
Jeśli jako macierz wagową przyjmiemy W
T
=a
⋅
(K
Z
)
-1
, gdzie a jest dowolną stałą, to
współczynniki A nie zależą od a, natomiast macierz K
A
wyraża się wzorem:
1
]
[
−
Φ
Φ
=
W
a
K
T
A
(1.6.9h)
W przypadku, gdy K
Z
jest diagonalna macierz W=diag(
)
/
2
zn
a
σ
. Obliczymy sumę ważonych
kwadratów błędów modelu:
∑
∑
=
=
−
=
−
=
N
n
zn
n
n
N
n
n
n
n
T
y
y
a
y
y
w
WE
E
1
2
^
1
2
^
σ
(1.6.8h)
Podobnie jak we wzorach (1.6.8-1.6.9f) obliczymy wartość oczekiwaną tej sumy:
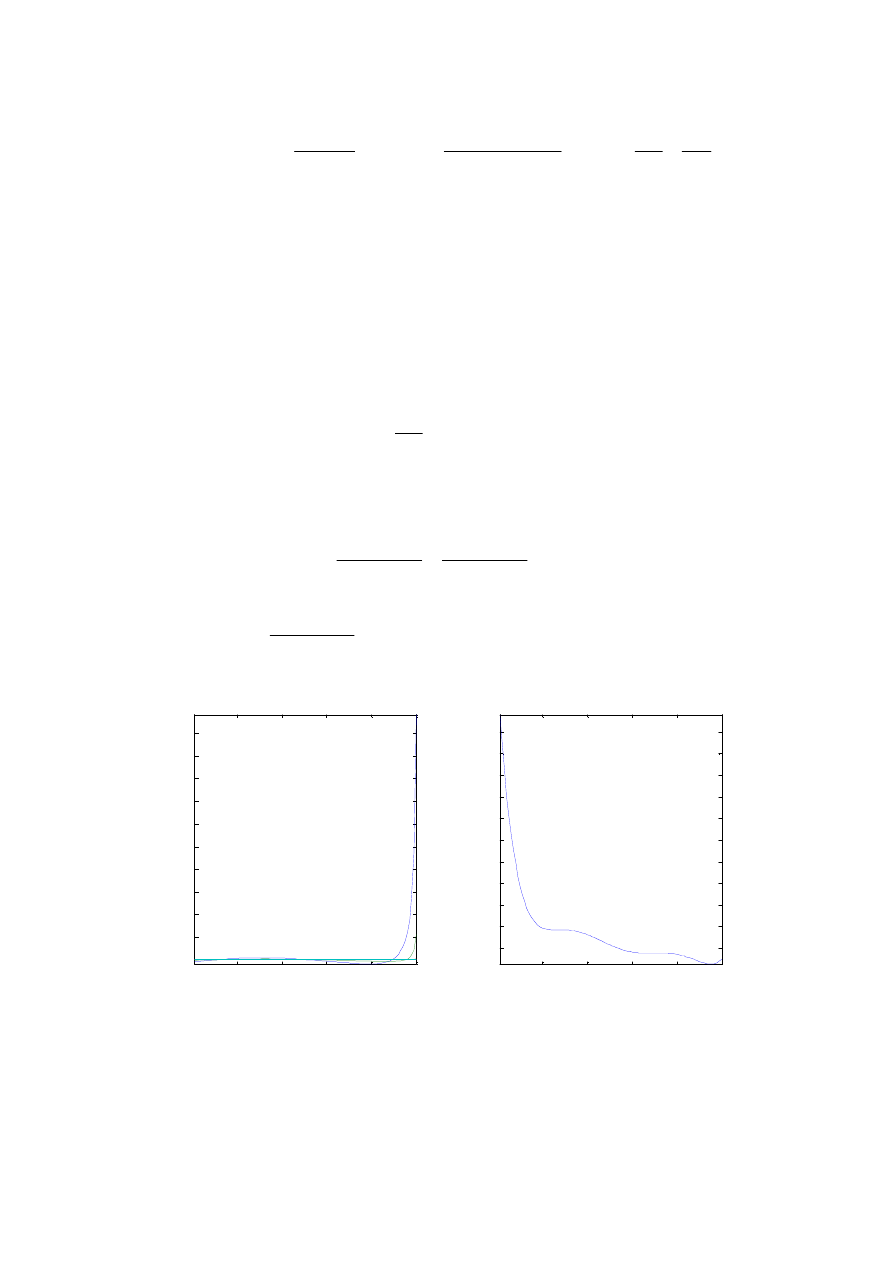
29
∑
∑
∑
=
=
=
−
=
−
=
−
=
N
n
zn
yn
zn
zn
N
n
zn
n
n
N
n
zn
n
n
T
a
y
E
y
E
a
y
y
a
WE
E
E
1
2
2
2
2
1
2
2
2
1
2
2
^
}
ˆ
{
}
{
}
}
{
σ
σ
σ
σ
σ
σ
(1.6.9i)
Estymatę
)
(
2
n
y
U
s
wariancji modelu
2
yn
σ
dla obserwacji U
n
można obliczyć wg macierzy
kowariancji współczynników (1.6.9h):
)
(
)
(
)
(
2
n
T
n
A
n
n
n
y
U
K
U
U
s
ϕ
ϕ
=
(1.6.9j)
W rozważanym przypadku jej wartość oczekiwana wynosi:
{
}
2
1
1
1
2
2
]
[
]
[
}
{
zn
n
T
n
Z
T
n
T
n
T
n
yn
yn
K
W
a
s
E
σ
γ
ϕ
ϕ
ϕ
ϕ
σ
=
Φ
Φ
=
Φ
Φ
=
=
−
−
−
(1.6.9k)
gdzie
T
n
T
n
def
n
ϕ
ϕ
γ
1
]
[
−
Φ
Φ
=
są współczynnikami rozkładu błędu generowanego przez
zakłócenia dla poszczególnych obserwacji
ϕ
n
, takimi samymi jak dla MNK – wzór (1.6.9f).
Zatem, zgodnie ze wzorem (1.6.9g) mamy
∑
∑
=
=
+
=
=
N
n
n
N
n
zn
yn
K
1
1
2
2
)
1
(
γ
σ
σ
(1.6.9l)
Zatem
)
1
(
}
{
−
−
=
K
N
a
WE
E
E
T
(1.6.9m)
a więc estymatorem zgodnym stałej a jest
∑
=
−
−
−
=
−
−
=
N
n
n
n
n
T
y
y
w
K
N
K
N
WE
E
a
1
2
^
)
1
(
1
)
1
(
(1.6.9n)
Macierz kowariancji zakłóceń należy obliczać ze wzoru:
∑
=
−
−
−
−
Φ
Φ
=
N
n
n
n
n
T
A
y
y
w
K
N
W
K
1
2
^
1
)
1
(
1
]
[
(1.6.9o)
Przykładowe współczynniki g
kn
i rozkład błędów dla K=3 i N=100 pokazano na rysunku.
2 0
4 0
6 0
8 0
1 0 0
1
2
3
4
5
6
7
8
9
1 0
1 1
n= 1 , ..., 1 0 0
γ
n
/w
n
R o zk la d b le d o w m o d e lu w p o lu k o re la c ji
γ
n
(n)/w
n
2 0
4 0
6 0
8 0
1 0 0
0
0 .0 5
0 .1
0 .1 5
0 .2
0 .2 5
0 .3
0 .3 5
0 .4
0 .4 5
0 .5
n = 1 , ..., 1 0 0
g
k
,n
O d p o w i e d zi im p uls o w e M N K d la K = 3 , W = I* 1 /n
W celu uzyskania modelu o najkorzystniejszych właściwościach należy
wyspecyfikować w miarę liczny zbiór wejść uogólnionych, a następnie wybrać z niego
możliwie mało liczny podzbiór wejść istotnych w sensie statystycznym. Suboptymalne
procedury wyboru zwane regresją krokową [MaN81] (ang. step-wize regression) są
stosunkowo łatwe do algorytmizacji. Najprostsza i zwykle wystarczająco skuteczna jest
procedura odrzucania [MaN81], oparta na iteracyjnym testowaniu hipotezy H
o
o nieistotności
kolejnych współczynników a
j
modelu:

30
H
o
:
E{a
j
}=0;
H
1
:
E{a
j
}
≠
0;
W typowym przypadku, gdy zakłócenia z mają rozkład normalny, testowanie hipotezy H
o
opiera się na statystyce t Studenta [Mań79], z założonym poziomem istotności testu
α
.
Funkcja gęstości prawdopodobieństawa rozkładu Studenta i związek poziomu istotności
α
z
wartością krytyczną t
kr
statyki mają postać [Gór97]:
2
1
2
1
1
2
2
1
1
)
,
(
+
+
Γ
+
Γ
π
=
l
l
t
l
l
l
l
t
f
α
=
−
∫
−
kr
kr
t
t
dt
l
t
f
)
,
(
1
(1.6.11)
gdzie l>0 jest parametrem całkowitym (liczbą stopni swobody),
Γ()
- funkcją gamma Eulera.
Niech s
aj
oznacza estymatę dyspersji współczynnika a
j
, obliczonego w m-tej iteracji, w
której model (1.6.3) zawierał (K
m
+1) członów (s
aj
.=
Ajj
K
). Jeśli hipoteza H
o
jest prawdziwa,
to iloraz t
j
= a
j
/s
aj
ma rozkład Studenta t o liczbie stopni swobody l=N-K
m
-1 [Mań79]. Zatem,
rozpoczynając od nadmiarowego (ale zapewniającego dobre uwarunkowanie zadania)
zestawu członów równania (1.6.3), w kolejnej iteracji oblicza się współczynniki A według
wzoru (1.6.5) oraz wartości statystyki t
j
= a
j
/s
aj
dla każdego członu obecnego w modelu. Jeśli
spełniona jest relacja:
kr
i
i
j
t
t
t
<
=
|
|
min
|
|
(1.6.12)
to przyjmuje się hipotezę H
o
dla j-tego członu równania, bo nie ma podstaw do jej odrzucenia
(oznacza to założenie a
j
=0, a więc usunięcie j-tego członu z równania), po czym rozpoczyna
się następna iteracja. Procedura kończy się, gdy relacja (1.6.12) nie jest spełniona, co oznacza,
ż
e wszystkie składniki modelu są istotne na poziomie istotności
α
.
1.6.3. Modele regresyjne dynamiki procesów
W klasycznym ujęciu punktem wyjścia do identyfikacji dynamiki procesu SISO jest model
dyskretny w postaci ARMAX (CARMA):
n
K
k
k
n
j
J
j
m
j
n
j
I
i
i
n
i
n
z
z
u
y
y
+
γ
+
β
+
α
=
∑
∑
∑
=
−
=
−
−
=
−
1
1
1
(1.6.13)
gdzie zakłócenia z są z założenia ciągiem niezależnych liczb losowych o zerowej wartości
oczekiwanej.
Modele takie omawiają obszernie monografie [BoJ83], [MaN81] i [Nied85]. Procedury ich
identyfikacji zawarte są w pakietach wspomagania projektowania układów automatyki (np.
MATLAB).
W przypadku, gdy wejścia są nieznane (np. gdy interesują nas przebiegi wejść zakłócających
widzianych jako efekt czynników wyłącznie losowych), stosuje się model ARMA:
n
K
k
k
n
j
I
i
i
n
i
n
z
z
y
y
+
⋅
γ
+
⋅
α
=
∑
∑
=
−
=
−
1
1
(1.6.14)
Jest on często stosowany do prognozowania zakłóceń.
Należy zaznaczyć, że w modelu ARMA (a także CARMA) zakłócenia
z mają z założenia
wartość oczekiwaną zerową. Jeśli nie jest to spełnione, a w szczególności, gdy wartość ta jest
zmienna, lepiej zastosować model ARMA dla różnic wyjść
y i zakłóceń. Taki model nazywa
się modelem ARIMA (scałkowany model ARMA)
Z kolei, pomijając drugą sumę modelu ARMAX uzyskuje się model dynamiki procesu
dla przypadku, gdy mamy słabe zakłócenia zewnętrzne, a
z reprezentuje szumy pomiarowe.
Taki model może uwzględniać także opóźnienie
d. Identyfikuje się je metodą analizy regresji,
biorąc jako wejścia uogólnione
ϕ
wektor:
31
ϕ
n
=[y
n-1,
y
n-2
, ... y
n-I
, u
n-1-m-d
, u
n-2-m-d
, ... u
n-J-m-d
]
(1.6.15)
oraz jako wyjście ciąg:
y
n
=[y
n,
y
n-1
, ... y
n-I+1
].
(1.6.16)
Wektor współczynników ma postać:
A=[
α
1
,
α
2
, ...
α
I
,
β
1
,
β
2
, ...
β
J
]
(1.6.17)
Procedura identyfikacji może dalej przebiegać jak dla modeli statycznych, z macierzą
Φ
zbudowaną z wierszy (1.6.15), ale wzór (1.6.5) daje obciążone estymaty współczynników A,
gdyż zakłócenia z
n
modelu (1.6.14) są skorelowane ze zmiennymi wejściowymi y
n-i
.
Lepsze rezultaty można uzyskać przez zastosowanie zmodyfikowanej procedury identyfikacji,
zwanej metodą zmiennych instrumentalnych (IV) [Nied85]. W celu wyznaczenia
nieobciążonej estymaty współczynników A modelu dynamicznego definiuje się macierz W
zmiennych instrumentalnych, taką aby W nie była skorelowana z zakłóceniami z
n
, a
równocześnie była silnie skorelowana z wejściami uogólnionymi
ϕ
, tj. :
0
1
1
lim
=
+
∞
→
Z
W
N
T
N
,
0
1
1
lim
≠
Φ
+
∞
→
T
N
W
N
(1.6.18)
Symbol lim oznacza tu granice stochastyczne [Nied85], a druga macierz musi istnieć i być
dobrze uwarunkowana. Jeśli znana jest taka macierz W, to nieobciążonym i zgodnym
estymatorem współczynników A jest formuła:
Y
W
W
A
T
T
1
]
[
−
Φ
=
(1.6.19)
Macierz W konstruuje się iteracyjnie, wychodząc od macierzy
Φ
i zamieniając występujące w
niej wartości zakłócone y
n-i
ich estymatami uzyskanymi w poprzedniej iteracji. Można
wykazać, że jeśli zakłócenia wyjścia obiektu są szumem białym, to procedura taka jest
zbieżna [Nied85].
Dla obiektów z opóźnieniem wartość d dobiera się metodą prób tak, aby zminimalizować
wariancję resztową modelu.
Model dyskretny (1.6.14) winien być przekształcony do postaci ciągłej. Jest to możliwe,
jeśli wszystkie pierwiastki rzeczywiste wielomianu o współczynnikach (1,
α
1
,
α
2
, ...
α
I
) są
dodatnie. Jeśli występują pierwiastki ujemne, to model nie ma odpowiednika ciągłego, co
może być spowodowane zbyt małą częstotliwością próbkowania, pominiętą nieliniowością,
lub zbyt słabym pobudzeniem u obiektu w stosunku do zakłóceń.
Od lat 70. rozwijane są także metody identyfikacji modeli ciągłych ([UnR87],
[FBy84]). Punktem wyjścia jest równanie różniczkowe zwyczajne o postaci:
z
z
u
y
y
K
k
k
n
j
J
j
j
j
I
i
i
i
+
γ
+
β
+
α
=
∑
∑
∑
=
+
=
=
1
)
(
0
)
(
1
)
(
(1.6.20)
które splata się obustronnie z odpowiedzią impulsową g(t) pewnego filtru określonego na
nośniku zwartym [0, T], tj. g(t)
≠
0 dla t
∈
[0, T] oraz g(t)= 0 dla t
∉
[0, T].
Jeśli funkcja g(t) posiada ciągłe pochodne do J-tej włącznie dla t
∈
[0, T], to wykorzystując
właściwości splotu uzyskuje się model regresyjny w postaci:
∑
∑
∑
=
+
+
+
=
+
+
=
ϕ
γ
+
ϕ
β
+
ϕ
α
=
K
k
k
J
I
k
J
j
I
j
j
I
i
i
i
Y
1
1
0
1
1
^
(1.6.21)
gdzie
∫
τ
τ
−
τ
=
T
def
d
t
y
g
Y
0
^
)
(
)
(
;
∫
τ
τ
−
τ
=
ϕ
T
i
def
i
d
t
y
g
0
)
(
)
(
)
(
; dla i=1,...., I;
(1.6.22)
∫
τ
τ
−
τ
=
ϕ
+
+
T
j
def
I
j
d
t
u
g
0
)
(
1
)
(
)
(
dla j=0, .....J;
∫
τ
τ
−
τ
=
ϕ
+
+
+
T
k
def
k
J
I
d
t
z
g
0
)
(
1
)
(
)
(
(1.6.23)

32
Obliczając numerycznie wartości powyższych splotów dla odpowiednio długiego ciągu
dyskretnych wartości t, uzyskuje się wektor Y i macierz
Φ
pozwalające obliczyć
współczynniki modelu ciągłego przy pomocy wzoru (1.6.5). Udoskonalone wersje tej metody
omawiają prace [FBy84], [ByF92].
W prognozowaniu zakłóceń stochastycznych, jako alternatywę dla modeli ARMA
można wykorzystać jednoczynnikowe modele statyczne, w których jedyną zmienną
wejściową jest czas t (tzw. modele Browna). Zależność tego typu nazywa się często trendem,
a wyliczanie odchyłek danych od takiej zależności – ekstrakcją trendu [DuK99a].
Szczególne znaczenie dla syntezy klasycznych układów regulacji mają proste modele
niskiego rzędu z opóźnieniem. Są one wyznaczane przez aproksymację odpowiedzi obiektu
na wymuszenie skokowe, modelem liniowym o wymaganej strukturze. Identyfikacja takich
modeli może być realizowana technikami regresji statycznej. Jako model procesu przyjmuje
się teoretyczną odpowiedź układu, a zmienną niezależną jest czas. Formalnie, prowadzi to do
nieliniowego zadania optymalizacji. Jednakże w szczególnie interesującym przypadku, gdy
poszukuje się optymalnego modelu pierwszego rzędu z opóźnieniem, problem można
sprowadzić do zadania liniowo-kwadratowego poprzez przekształcenie logarytmiczne
wyjścia. Odpowiedź skokowa takiego obiektu ma bowiem postać:
−
−
−
=
T
d
t
K
t
y
)
(
exp
1
(
)
(
ˆ
(1.6.24)
gdzie K oznacza wzmocnienie, T – stałą czasową, d - opóźnienie.
Stosując przekształcenie logarytmiczne, wzór (1.6.24) sprowadzamy do postaci:
(
)
T
d
t
K
t
y
K
)
(
)
ln(
)
(
ˆ
ln
−
−
=
−
(1.6.25)
W wyniku eksperymentu uzyskujemy ciąg Y={y
1
, y
2
, y
p
, ......, y
N
, ....., y
ε
, ....., y
f
} wartości
wyjść zarejestrowanych w chwilach czasu U
= {t
1
, t
2
, t
p
, ..., t
N
, .., t
ε
, .., t
f
} (niekoniecznie z
jednakowym rozstępem). Wartość t
ε
jest czasem po którym wyjście nie wykracza poza
przedział K(1
±
ε
) do końca okresu obserwacji t
f
, gdzie
ε
jest odpowiednio małą liczbą
dodatnią (np. 0.02). Wartość t
f
winna być istotnie większa niż t
ε
(około 5 krotna wartość
przewidywanej stałej czasowej). Jeśli wyjście jest silnie zakłócone, to jako
ε
można przyjąć
oszacowanie błędu standardowego zakłócenia, w przedziale (t
ε
, t
f
) przekroczenia zakresu
K(1
±
ε
) winny być tylko losowe, a ich liczba – rzędu 1/3 liczby danych w tym przedziale.
Uśredniając dane {y
ε
, ....., y
f
} oblicza się wzmocnienie K, a następnie wektor wyjść
Γ
pN
modelu dla chwil t
n
z zakresu [t
p
t
N
]:
(
)
}
,....
:
)
(
{ln
N
p
n
t
y
K
n
def
pN
=
−
=
Γ
(1.6.26)
Oczywiście, przekształcenie obejmuje również zakłócenia z
n
, będące różnicą między błędem
estymacji K i zakłóceniami chwilowymi wyjścia. W związku z tym wartość t
N
musi być
odpowiednio mniejsza niż t
ε
. Zgodnie ze wzorem (1.6.25) elementy
γ
n
ciągu
Γ
pN
można
wyrazić zależnością liniową:
γ
n
=a+b
u
n
+ z
n
(1.6.27)
gdzie
T
d
K
a
def
+
=
)
ln(
,
T
b
def
1
−
=
(1.6.28)
Wartości współczynników a i b uzyskuje się metodą analizy regresji liniowej ze wzoru
(1.6.27), a następnie oblicza się parametry d i T ze wzoru (1.6.28).
Czas t
ε
, jak również czas początkowy t
p
należy dobrać tak, aby błędy liniowej aproksymacji
ciągu
Γ
pN
nie były duże, np. tak aby zminimalizować wariancję resztową modelu, a
zakłócenia resztowe z
n
nie wykazywały istotnego spadku ze wzrostem t
n
.

33
ZESTAWIENIE FUNKCJI PAKIETU MATLAB, U
ś
YTECZNYCH W EKONOMETRII
abs(x) – wartość bezwzględna zmiennej x lub długość wektora x
arx([y u],[na nb nd]) – identyfikacja wg.najmniejszych kwadratów modelu ARX ciągu y z
wejsciem x; na – rząd mianownika, nb – rząd licznika, nd - opóźnienie
arxmax([y u],[na nb nc nd]) – identyfikacja wg.najmniejszych kwadratów modelu ARMAX
ciągu y z wejsciem x; na – rząd mianownika, nb – rząd licznika, nc – rząd modelu
MA zakłócenia losowego, nd - opóźnienie
bar(x,y) – rysowanie wykresu słupkowego (histogramu) elementów wektora y na pozycjach
wskazanych przez wartości wektora x.
chi2inv(p, lst_swob) – wartość chi2 na poziomie istotnosci p przy lst_swob stopni swobody
cdf() - różne funkcje rozkładu.
cov(x) – wariancja wektora x; macierz kowariancji, gdy x jest macierzą, której wiersze są
wektorami zmiennych losowych
erf(x) - funkcja błędu, tj. prawdopodobieństwo wystąpienia zmiennej losowej o rozkładzie
normalnym w przedziale E(x)
±
x
⋅√
2
floor(x) – obcięcie liczy x do wartości całkowitej
hist(y,n) – rysowanie histogramu szeregu rozdzielczego elementów wektora y w n
jednakowych przedziałach; wywołanie: [y,x]=hist(y,n); powoduje tylko policzenie
wektorów histogramu do narysowania funkcją bar(x,y);
inv(A) – odwrócenie macierzy A (kwadratowej)
iv([y u],[na nb nd],nf,mf) – identyfikacja morelu ARX metodą zmiennych instrumentalnych
mean(x) – wartość średnia wektora x
median(x) – mediana wektora x
a=polyfit(x,y,n) – obliczenie współczynników wielomianu przybliżającego
minimalnokwadratowo zależność wektora y od x; n – rząd wielomianu; a(1), a(2),
... współczynniki wielomianu od najwyższej potęgi a(1) do stałej zapisanej jako a(n)
rand – generator liczb losowych (niezależnych) o rozkładzie równomiernym z zakresu [0, 1]
randn - generator liczb losowych (niezależnych) o rozkładzie normalnym standaryzowanym,
czyli N(0,1)
std(x) – odchylenie standardowe (dyspersja) elementów wektora x
svd(A) – dekompozycja singularna macierzy A (sprawdzanie dopuszczalności odwracania
macierzy)
xcorr(x) – podaje (m.innymi) funkcje autokorelacji wektora x (nieunormowaną)
Dodatkowe informacje o funkcji uzyskuje się komendą MATLABa:
help nazwa

34
Teskt programu do badania rozkładów zmiennych (Rys.3-6)
% ============= Przetwarzanie danych
ekonometrycznych==============
clear min t tt syg ws hsyg wsyg wsred wsred2 wfilt wfilt2 wsred2sh
wfilt2sh aa okno;
Tf=10; Tsr=2*Tf; Tsrd=Tsr; dt=1;
ldan=256; ldan=ldan*2+Tsrd; Sig=1;
normalny=1;
% -------- generowanie sygnalu o rozkl.rownomiernym ----------
if(normalny==0)
for(i=1:ldan) syg(i)=Sig*(rand-0.5)*sqrt(12); end
else
% ------ generowanie sygnalu o rozkl.normalny ---------------
for(i=1:ldan) syg(i)=Sig*randn; end
end
% =============== Koniec przygotowania danych ===============
% ============== Przetwarzanie wlasciwe
=============================
% ----- Symulacja sygnalow niskoczestotliwosciowych wsred ---
Tsr=Tsrd,; Sum=0; ld=1; sygf=syg(1); clear okno;
for(i=1:ldan)
Sum=Sum+syg(i);
if(i>Tsr) Sum=Sum-okno(ld); ldusr=Tsr; else ldusr=ld; end;
okno(ld)=syg(i);
if(ld==Tsr) ld=0; end;
ld=ld+1;
wsred(i)=Sum/ldusr;
end
Ldan=ldan;
ww=syg(Tsr:Ldan); clear syg; syg=ww; ldan=length(syg); clear ww;
ww=wsred(Tsr:Ldan); clear wsred; wsred=ww; clear ww;
% ============ rysunki ===================
for(niejednor=0:1)
if(niejednor==1)
for(i=1:ldan) wsred(i)=1+10*i/ldan+syg(i); end
syg(ldan/2:ldan)=3*syg(ldan/2:ldan);
end
% ------- Normalizacja i centrowanie sygnalu ---------------
sum=0; Sum=0; for(i=1:ldan) sum=sum+wsred(i); Sum=Sum+syg(i); end;
sred=sum/ldan; Srsyg=Sum/ldan;
for(i=1:ldan) t(i)=i-1; wsred(i)=wsred(i)-sred; syg(i)=syg(i)-
Srsyg; end;
Sig=std(syg); Sigs=std(wsred);
% ----------------------------------------------------------
figure; subplot(2,1,1)
plot(t,syg,'y',t,wsred,'b')
axis([0 max(t) min([min(syg) min(wsred)]) max([max(syg)
max(wsred)])])
subplot(2,1,2)
plot(t,wsred,'b')
axis([0 max(t) min(wsred) max(wsred)]);
xlabel(sprintf('Usrednianie'))

35
% ======= histogram =====================
podpis='abcd'; kk=1;
figure;
for(typ=0:1)
if(typ==0) hsyg=syg; Sigm=Sig; else hsyg=wsred; Sigm=Sigs; end
clear ws nbar x dbar;
for(hist_rownom=0:1)
if(hist_rownom==1)
lbsr=lbar/2; smax=max(hsyg); smin=min(hsyg);
ds=(smax-smin)/(lbar+1);
s=smin+ds/2; smax=smax-ds/2;
for(i=1:lbar) ws(i)=s; s=s+ds; end
[nbar,x]=hist(hsyg,lbar); %<=== nbar liczba wart. x w przedz.ds
nbar=nbar/ldan/ds; %<=== przelicz.czestosci na rozklad
else
lbmin=30; km=lbmin-2;
for(k=1:km) lbar=ldan/lbmin; if(lbar>=20) break; end;
lbmin=lbmin-1;
end
[nbar,x]=hist(hsyg,lbar); %<=== nbar l.wart. x w przedz.ds
k=0; s=0; xp=min(x);
for(i=1:lbar)
s=s+nbar(i);
if(s>=lbmin)
k=k+1; dbar(k)=s/ldan/(x(i)-xp); s=0;
ws(k)=(xp+x(i))/2; xp=x(i);
end
end
lbar=k; nbar=dbar; clear dbar;
end
for(i=1:lbar) fg(i)=exp(-((ws(i)/Sigm)^2)/2); end
fg=fg/Sigm/sqrt(2*pi);
subplot(2,2,hist_rownom+1+2*typ);
bar(ws,nbar);
hold on
plot(ws,fg,'r')
axis([min(ws)*1.05 max(ws)*1.05 0 max([max(fg) max(nbar)])]);
xlabel(sprintf('Rysunek %c',podpis(kk))); kk=kk+1;
clear x xs ws nbar fg;
end
end
end
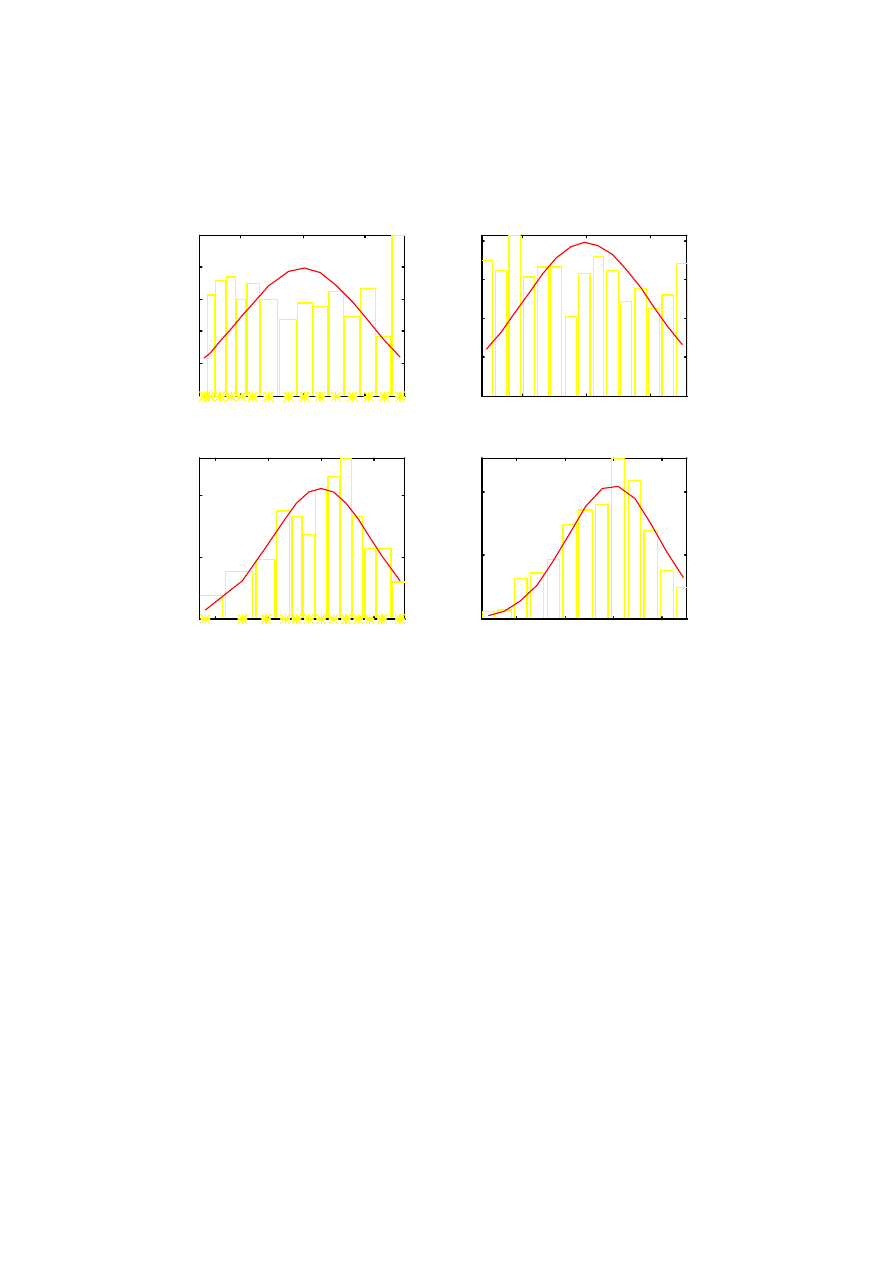
36
Rys. 3 – 4 pokazują histogramy przykładowych danych losowych różnego typu.
Rys.3. Histogramy 512 liczb losowych o rozkładzie równomiernym
a) histogram z nierównymi przedziałami; b) histogram z przedziałami równymi
c) histogram średnich z 20 próbek jak (a); d) histogram z przedziałami równymi jak (c)
-1
0
1
0
0.1
0.2
0.3
0.4
Rysunek a
-1
0
1
0
0.1
0.2
0.3
0.4
Rysunek b
-0.4
-0.2
0
0.2
0
1
2
Rysunek c
-0.4
-0.2
0
0.2
0
1
2
Rysunek d
37
Rys.4. Histogramy 512 liczb niejednorodnych losowych o rozkładzie równomiernym
a)
histogram danych z dwiema różnymi wariancjami z nierównymi przedziałami;
b)
jak (a) z przedziałami równymi; c) histogram danych z linioym wzrostem średniej –
histogram nierównomierny jak (a); d) histogram danych jak (c)z przedziałami (b)
Rys.5. Histogramy danych o rozkładzie normalnym jak na Rys.3.
-4
-2
0
2
4
0
0.05
0.1
0.15
0.2
Rysunek a
-4
-2
0
2
4
0
0.05
0.1
0.15
0.2
Rysunek b
-5
0
5
0
0.05
0.1
Rysunek c
-5
0
5
0
0.05
0.1
Rysunek d
-2
-1
0
1
0
0.1
0.2
0.3
0.4
Rysunek a
-2
0
2
0
0.1
0.2
0.3
0.4
Rysunek b
-0.4 -0.2
0
0.2 0.4
0
0.5
1
1.5
2
Rysunek c
-0.5
0
0.5
0
0.5
1
1.5
2
Rysunek d
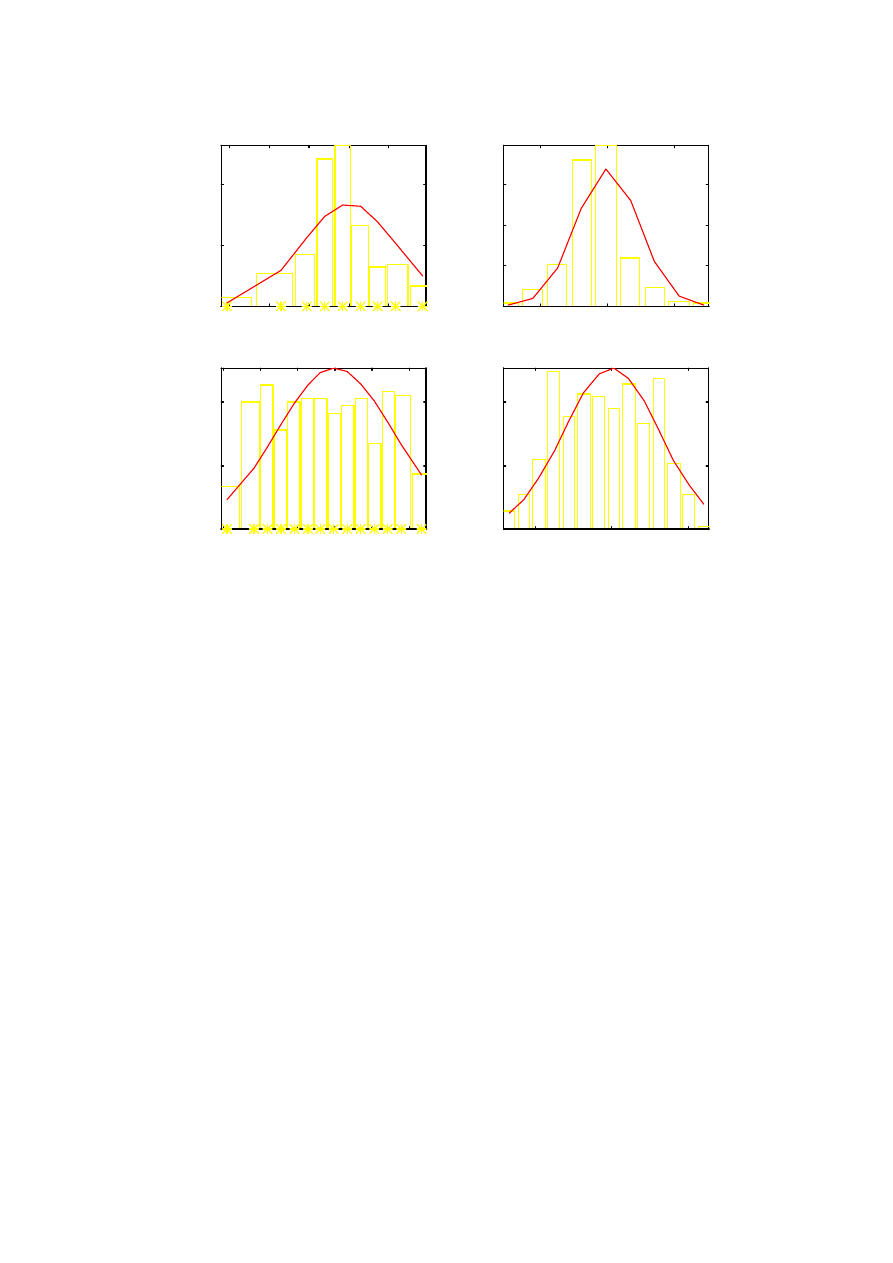
38
Rys.6. Histogramy danych o rozkładzie normalnym jak na Rys.4.
-6
-4
-2
0
2
0
0.1
0.2
Rysunek a
-5
0
5
0
0.05
0.1
0.15
Rysunek b
-6
-4
-2
0
2
4
0
0.05
0.1
Rysunek c
-5
0
5
0
0.05
0.1
Rysunek d
Wyszukiwarka
Podobne podstrony:
EKONOMETRIA1 prezentacja id 155 Nieznany
ekonomia srodowiska id 155757 Nieznany
Ekonomia Pracy id 156008 Nieznany
Ekonomia w CSGO id 156159 Nieznany
ekonometria test id 155376 Nieznany
4 Ekonomika MiR id 37568 Nieznany
Ekonomia kapitalu id 155856 Nieznany
Ekonomia wykresy id 156259 Nieznany
ekonomia 3a id 155736 Nieznany
3 ekonomia menedzerska id 33642 Nieznany
Ekonomia stud id 283921 Nieznany
EKONOMIA CW2 id 155753 Nieznany
Ekonomia wyklad 2 3 id 156193 Nieznany
Ekonomia skrypt id 156120 Nieznany
analiza ekonomiczna firm id 601 Nieznany
EKONOMIKA LE id 156570 Nieznany
Ekonomiczne czynniki id 156433 Nieznany
Ekonomia cz 2 id 155768 Nieznany
Ekonomia kryzysu id 155724 Nieznany
więcej podobnych podstron